一种基于数字口令与声纹联合确认的用户身份验证方法与流程
本发明属于身份验证技术领域,尤其是涉及一种基于数字口令与声纹联合确认的用户身份验证方法。
背景技术:
传统基于口令的身份验证方法,往往采用密码或者动态验证码的形式。密码广泛应用于生产生活的各个方面。但是单一的密码可能被盗取,密码一旦丢失,将给账户安全造成极大的威胁。而随着电子技术以及移动通信工具的普及,动态验证码也开始流行。在服务终端、网页或手机客户端登录账户时,用户常常被要求输入手机接收到的短信验证码;在使用网上银行进行交易时,可采用电子口令卡(又被称为e-token)随机生成的动态数字验证码。动态验证码由于每次更换、有效时间短,相较密码增大了窃取的难度,且往往需要相应的硬件支持(手机、电子口令卡等)。但是不法分子仍可以通过硬件克隆等手段截取到动态码,账户安全风险依然存在。
随着模式识别和人工智能的发展,语音技术、特别是语音识别和声纹识别技术,得到了长足的进步并开始在实际生活中发挥着越来越重要的作用。
语音识别指的是将语音转化为文本的技术,通过语音识别,计算机能够知道用户口述的文本内容。语音识别的分类,从词汇量多少上,可分为大、中、小规模;从形式上,可分为孤立词和连续语音识别。语音识别技术自20世纪80年代发展到现在,随着语料积累以及算法进步,在识别能力上有了极大的提高。识别对象从最初的小词汇量朗读语音,逐渐扩展为几十万乃至上百万词的大词汇量口语对话。从2012年至今,随着深度学习的推广,基于深度神经网络的语音识别方法再一次大幅度提升了语音识别性能,推动语音识别进入大规模实用阶段。现有技术已经可以在大多数情况下准确识别朗读的数字口令。
同语音识别从声音到文字的过程不同,声纹识别又称为说话人识别,实现的是从声音到说话人身份的转换。声音作为人固有的生物信息,有着难以冒充的特点。根据语音内容的限制范围,声纹识别可以分为文本相关与文本无关两大类。文本无关的声纹识别不依赖于特定的语音内容,而文本相关的技术则需要对训练和测试的语音内容进行相应的限制。声纹识别的相关研究从20世纪60年代就已经开始。2000年左右麻省理工学院林肯实验室的douglasa.reynolds提出了通用背景模型,奠定了现代声纹识别技术的基础。之后,w.m.campbell、patrickj.kenny、najimdehak等人逐步提出了基于支持向量机(supportvectormachine,svm)、联合因子分析(jointfactoranalysis,jfa)、鉴别向量(identityvector,i-vector)等声纹识别方法,综合考虑了由信道和背景噪声产生的干扰,保证了在实际情况中的识别效果。目前,声纹识别已经在军事、司法刑侦、电子商务等领域得到了广泛的应用。虽然文本无关的声纹识别在应用中更为灵活方便,但在语音时长受限的情况下,识别准确率并不理想;而文本相关的声纹识别技术由于利用了语音结构信息,能够保证短语音下的识别效果,更适合在基于语音口令的身份认证中使用。
将语音技术应用于身份验证已有一些先例。中国专利公开号cn106302339a,公开日2017.01.04,公开了一种登录验证方法和装置、登录方法和装置,联合用户语音声纹以及验证文本提升用户登录账户的安全性。该发明所述的方法包括以下步骤:步骤一,根据用户登录请求生成验证文本返回给用户终端;步骤二,接收用户终端上传的待验证语音;步骤三,采用文本无关的语音识别算法对待验证语音进行语音声纹验证;步骤四,语音声纹验证通过后,将待验证语音转化为文本;步骤五,比较待验证语音文本与步骤一生成的验证文本内容是否相同,从而判断是否允许登录。该发明通过结合语音验证与文本内容验证的双重验证,避免了用户被钓鱼网站窃取账号、密码以及语音后被冒充身份的可能。该发明的主要缺陷在于:(1)实际应用中用户验证语音长度短、环境复杂,采用文本无关的语音验证算法无法利用验证码的文本结构信息,难以达到准确的验证效果;(2)在验证时,采用语音声纹与文本内容验证分步进行的做法,可能由于文本内容识别的微小错误造成拒识。
中国专利公开号cn104951930a,公开日2015.09.30,公开了一种基于生物信息身份验证的电子密码票据方法及系统,采用声纹识别算法判断客户身份,减少由用户手持票据造成的丢失以及冒认。该技术主要步骤为:
1)以用户唯一的身份识别号码为索引建立用户数据库,当服务器收到用户端购票信息时,返回固定一次性秘钥或多次使用的小范围字典。所述固定一次性秘钥为由常用字字典生成的包含5个常用字的字符串文本。其中,所述常用字字典是指《现代汉语常用字表》(1988年版)所规定的2500个常用字。所述多次使用的小范围字典为从{0,1,2,3,4,5,6,7,8,9}中随机生成的6位数字。
2)用户根据收到的固定一次性秘钥或小范围字典进行朗读,相应的音频文件被反馈至服务器。服务器根据文本相关说话人模型训练算法建立声纹票据对应的说话人模型,具体方法为:
2.1)建立说话人识别通用背景模型(universalbackgroundmodel,ubm)。所述通用背景模型的训练数据为各种型号的手机录制的中文语音数据,用于训练的数据可达几百小时,每句话的长度从1s到9s不等,男女数据都有,每个人都有几十句甚至上百句的话可供选择。训练过程为:首先提取原始语音的感知线性预测系数(perceptuallinearpredictive,plp)作为特征,之后采用最大期望算法(expectationmaximization,em)算法训练1024个高斯分布的高斯混合模型,表示为表达式如式(0-1)所示:
式中,λ表示高斯混合模型参数,cm表示第m个高斯的权重,μm、σm分别为第m个高斯的均值与方差,m表示该高斯混合模型中含有的高斯分布数量,p(x|λ)表示特征数据x在该高斯混合模型中的整体似然概率。
所述最大期望算法表达式如下:
式中,γm(n)代表第n个特征xn在第m个高斯分布中的似然概率,n为所有特征的数量。μm、σm、cm分别为第m个高斯的均值、方差和权重。
2.2)将用户所读入的单子音频拼接为连续语句。所述的拼接的顺序按照固定一次性密钥或小范围字典决定。
2.3)对通用背景模型进行最大后验概率(maximumaposteriori,map)注册并生成说话人模型。所述注册数据为拼接后的用户音频,说话人模型估计的表达式如式(0-6)所示:
其中,λ为高斯混合模型的模型参数,包括高斯分布数量m、每个高斯分布上的均值μm、方差σm以及权重cm;p(λ)为参数λ的先验分布。x为注册音频特征集合{x1,x2,...,xn},n为注册音频特征数量。p(x|λ)为在模型λ条件下特征集合x的似然概率。
3)当用户发出验证请求时,服务器通过文本相关说话人验证算法比较待测音频和说话人模型是否为同一说话人,并输出认证结果。
所述文本相关说话人验证算法是指:分别计算测试音频在通用背景模型和说话人模型的似然分数。对某段测试音频y,h0表示y来自目标说话人s,h1表示y不是来自目标说话人s。评分
在该发明中,一次性和多次使用电子票据在完全使用之后一段时间内自动失效,语音经用户同意后作为训练数据进入系统训练数据库。
该发明为声纹识别技术找到了合适的应用场景,同时采用文本相关声纹识别技术提高识别效果。但该技术的主要缺陷在于:(1)发明中虽提及文本相关的声纹识别技术,但在具体叙述用户的注册与验证过程时,并没有对用户语音中已知的文本结构信息加以利用;(2)发明仅仅考虑了用户语音的声纹信息,没有考虑验证文本的内容,不法分子有可能盗取用户录音欺骗验证系统。
此外,中国专利公开号cn105069872a(公开日2015.11.18),以及中国专利公开号cn104392353a(公开日2015.03.04),
技术实现要素:
中都涉及使用用户语音进行声纹及动态验证码进行内容验证,但均未指明所使用的具体技术方法,对其他试图采用语音技术进行身份验证的实施者不具有足够的借鉴作用。
发明内容
本发明的目的是为克服已有技术的不足之处,提出一种基于数字口令与声纹联合确认的用户身份验证方法。本发明在传统口令验证的基础上,结合数字口令确认和声纹确认,增强了身份验证的安全性。
本发明提出的一种基于数字口令与声纹联合确认的用户身份验证方法,其特征在于,分为初始化阶段、注册阶段和验证阶段三个阶段,包括以下步骤:
1)初始化阶段;具体包括以下步骤:
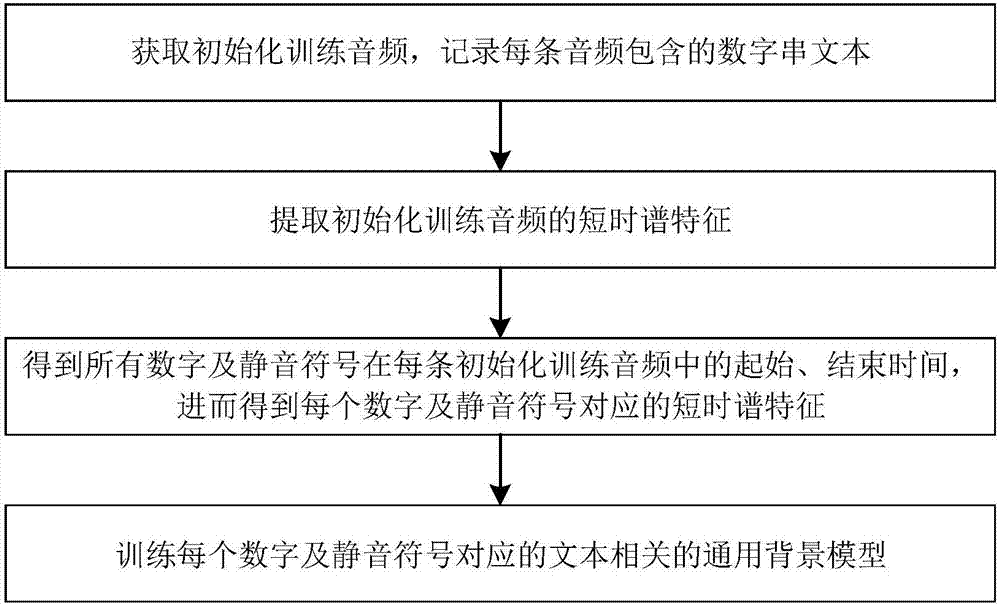
1-1)获取初始化训练音频;所述初始化训练音频为在实际信道条件下录制的中文数字串朗读语音;由人工听过后,对每一条初始化训练音频所包含的数字串文本进行记录;
1-2)建立文本相关的通用背景模型;具体步骤如下:
1-2-1)提取步骤1-1)得到的初始化训练音频的短时谱特征;所述短时谱特征指从语音的0时刻开始,起始位置每次向后移动10ms,选取长度为25ms的片段,利用特征提取算法得到的特征系数;
1-2-2)根据步骤1-2-1)得到的初始化训练音频的短时谱特征,通过语音识别技术将初始化训练音频转化为数字串文本,并得到0到9十个数字及静音符号sil在每条初始化训练音频中的起始、结束时间;若通过语音识别技术得到的数字串文本与步骤1-1)标注的数字串文本比对后不相符,则该条初始化训练音频无效,不参与后续训练;
1-2-3)除去无效音频后,将步骤1-2-1)中得到的初始化训练音频的短时谱特征按照步骤1-2-2)得到的所有数字以及静音符号在每条初始化训练音频中的起始、结束时间,划分到每个数字和静音符号,得到每个数字以及静音符号对应的短时谱特征;利用每个数字以及静音符号对应的短时谱特征,训练得到每个数字以及静音符号对应的文本相关的通用背景模型;
2)注册阶段;具体包括以下步骤:
2-1)记录用户信息;
当任意用户要求注册时,用户端向服务器发送注册请求,服务器为该用户分配唯一的标识号码作为索引并要求用户输入长度为6-12位数字的个人密码,服务器在用户数据库中记录该用户的身份信息以及个人密码;
2-2)建立文本相关的用户模型;具体步骤如下:
2-2-1)服务器生成数字串动态验证码发送给用户;所述数字串动态验证码长度为6到12位,用户根据收到的数字串动态验证码进行朗读并录制成音频,所生成的音频被发送给服务器;
2-2-2)当服务器收到用户朗读音频后,提取步骤2-2-1)录制的用户朗读音频的短时谱特征;
2-2-3)根据步骤2-2-2)得到的用户朗读音频的短时谱特征,通过语音识别技术将用户朗读音频转化为数字串文本,并得到0到9十个数字及静音符号在该段用户朗读音频上的起始、结束时间;若语音识别技术得到的数字串文本与步骤2-2-1)生成的动态验证码内容相同,则将该段用户朗读音频标记为一段有效用户注册音频;若语音识别技术得到的数字串文本与动态验证码内容不同,则将该段用户朗读音频标记为无效音频;
2-2-4)重复步骤2-2-1)到步骤2-2-3),连续录制若干段用户朗读音频并得到k段用户有效注册音频,k≥5;
2-2-5)将步骤2-2-2)中得到的用户有效注册音频的短时谱特征,按照步骤2-2-3)生成的十个数字及静音符号在每段有效注册音频上的起始、结束时间,划分到每个数字和静音符号后,得到每个数字以及静音符号对应的短时谱特征;利用用户有效注册音频中每个数字以及静音符号对应的短时谱特征,采用最大后验概率方法更新步骤1)得到文本相关的通用背景模型,生成该用户的文本相关的用户模型;
3)验证阶段;具体包括以下步骤:
3-1)当用户发出验证请求时,服务器首先寻找到步骤2-1)分配的该用户唯一的标识号码并读取该用户的身份信息、个人密码以及步骤2-2)得到的文本相关的用户模型;服务器生成数字串动态验证码发送给用户,所述数字串动态验证码长度为6到12位,用户将收到的数字串动态验证码以及个人密码按照服务器指定的顺序整合后进行朗读并录制成用户验证音频,所生成的用户验证音频被发送给服务器;若用户在一定持续时间内未能录入语音,则当前动态验证码失效,用户验证失败;
3-2)服务器收到用户验证音频后,提取步骤3-1)录制的用户验证音频的短时谱特征;
3-3)根据步骤3-2)得到的用户验证音频的短时谱特征以及步骤2)得到的文本相关的用户模型与步骤1)得到的文本相关的通用背景模型,验证该用户验证音频的声纹是否属于目标用户且内容与正确数字串文本是否相符,分别得到声纹验证分数s1和文本验证分数s2;所述正确数字串文本指按照服务器要求在数字串动态验证码指定位置插入用户个人密码后的合成数字串;
3-4)将步骤3-3)得到的声纹验证分数s1与文本验证分数s2加权求和后得到最终验证分数,与设定阈值比较并进行判定:当最终验证分数超过设定阈值时,则认为用户验证音频由验证用户所说且文本内容正确,验证通过;否则验证失败;所述设定阈值为使得验证集上的验证结果错误最少的值;
最终验证分数的计算表达式如式(14)所示:
s=ws1+(1-w)s2(14)
式中,s为最终验证分数,w为权重,0<w<1,权重w决定声纹验证结果与文本验证结果的相对重要程度。
本发明的特点及有益效果在于:
(1)本发明在传统口令验证的基础上,结合数字口令确认和声纹确认,增强了身份验证的安全性。
(2)本发明中,声纹验证和口令验证结果均使用分数表示,避免单一步骤的微小错误对最终验证结果的影响。
(3)本发明采用文本相关的声纹识别技术,利用验证文本的结构信息,更适合用户主动验证的场景,能够以较短的录音时间保证验证准确率。
(4)针对语音验证易受窃听、盗录、合成等攻击威胁的特点,本发明使用用户密码与动态验证码相结合的口令形式,进一步保证身份验证的安全性。动态验证码使得非法的录音回放变得困难;而用户密码则使得他人难以通过语音合成、音色转换等语音处理技术合成目标用户的语音口令。
(5)本发明可用于如电子门禁、金融交易、电话客服、网上银行等能够使用动态验证码的场合。
附图说明
图1是本发明的整体流程框图。
图2是本发明的初始化阶段流程框图。
图3是本发明的注册阶段流程框图。
图4是本发明的验证阶段流程框图。
图5是依照正确数字串文本的顺序,且数字串文本长度为6位时,文本相关的通用背景模型构成的第一个隐马尔可夫模型示意图。
具体实施方式
本发明提出的一种基于数字口令与声纹联合确认的用户身份验证方法,下面结合附图和具体实施例对本发明进一步详细说明如下。
本发明提出的一种基于数字口令与声纹联合确认的用户身份验证方法,所述数字口令为由0到9共十个数字组成的数字串,数字串长度为6到24位,长度根据需要的安全等级选择。
本发明提出的一种基于数字口令与声纹联合确认的用户身份验证方法,分为初始化阶段、注册阶段和验证阶段三个阶段,整体流程如图1所示,包括以下步骤:
1)初始化阶段;流程如图2所示,具体包括以下步骤:
1-1)获取初始化训练音频;所述初始化训练音频为在实际信道条件下录制的中文数字串朗读语音。训练音频可达几百小时,每句话的长度从1s到9s不等,男女数据都有,每个人都有几十句甚至上百句的话可供选择。例如:在手机网上银行的应用中,需要符合时间与数量要求的各种型号的手机录制的中文数字串朗读语音。
由人工听过后,将每一条初始化训练音频所包含的数字串文本记录在标注文件中。
1-2)建立文本相关的通用背景模型;具体步骤如下:
1-2-1)提取步骤1-1)得到的初始化训练音频的短时谱特征。所述短时谱特征指从语音的0时刻开始,起始位置每次向后移动10ms,选取长度为25ms的片段,利用特征提取算法得到的特征系数,例如感知线性预测系数。
1-2-2)文本相关的发音单元由0到9十个数字及静音符号sil组成。根据步骤1-2-1)得到的初始化训练音频的短时谱特征,通过语音识别技术(此处所述语音识别技术为常用的商用语音识别技术),将初始化训练音频转化为数字串文本,并得到所有数字以及静音符号在每条初始化训练音频中的起始、结束时间;若通过语音识别技术得到的数字串文本与步骤1-1)标注的数字串文本比对后不相符,则该条初始化训练音频无效,不参与后续训练;
1-2-3)除去无效音频后,将步骤1-2-1)中得到的初始化训练音频的短时谱特征按照步骤1-2-2)得到的所有数字以及静音符号在每条初始化训练音频中的起始、结束时间,划分到每个数字和静音符号,得到每个数字以及静音符号对应的短时谱特征;利用每个数字以及静音符号对应的短时谱特征,训练得到每个数字以及静音符号对应的文本相关的通用背景模型。
所述训练过程为:对每个数字和静音符号的短时谱特征,分别采用最大期望算法(expectationmaximization,em)训练高斯混合模型。将某一数字或静音符号记为d,其高斯混合模型表达式如式(1)所示:
式中,λd代表某一数字或静音符号d对应的高斯混合模型,由参数
所述最大期望算法为,首先计算初始化训练音频中某一数字或静音符号d对应的第n帧短时谱特征在该数字或静音符号的高斯混合模型中第m个高斯分布上的后验概率
然后根据表达式如式(3)-式(6)更新权重
式中,
所述高斯混合模型的高斯分布数目md,可以根据训练音频的多少,从8到2048之间依照2的幂次递增,选择在验证集上效果最好的高斯分布数目。所述验证集为依照实际情况采集的注册与验证语音,可以用来模拟该方法的实际使用效果。例如:在手机网上银行的应用中,验证集由使用不同手机的用户分别录制的注册与验证音频构成。
2)注册阶段;流程如图3所示,具体包括以下步骤:
2-1)记录用户信息;
当任意用户要求注册时,用户端向服务器发送注册请求,服务器为该用户分配唯一的标识号码作为索引并要求用户输入长度为6-12位数字的个人密码,本实施例中用户输入的个人密码长度为6位。服务器在用户数据库中记录该用户的身份信息以及个人密码。
2-2)建立文本相关的用户模型;具体步骤如下:
2-2-1)服务器生成数字串动态验证码发送给用户。所述数字串动态验证码长度为6到12位,该长度根据实际需要设定,长度越长验证准确度越高。用户根据收到的数字串动态验证码进行朗读并录制成音频,所生成的音频被发送给服务器。
2-2-2)当服务器收到用户朗读音频后,提取步骤2-2-1)录制的用户朗读音频的短时谱特征。
2-2-3)根据步骤2-2-2)得到的用户朗读音频的短时谱特征,通过语音识别技术将用户朗读音频转化为数字串文本,并得到0到9十个数字及静音符号在该段用户朗读音频上的起始、结束时间。若语音识别技术得到的数字串文本与步骤2-2-1)生成的动态验证码内容相同,则将该段用户朗读音频标记为一段有效用户注册音频;若语音识别技术得到的数字串文本与动态验证码内容不同,则将该段用户朗读音频标记为无效音频;
2-2-4)重复步骤2-2-1)到步骤2-2-3),连续录制若干段用户朗读音频。当得到的用户有效注册音频段数到达5段后,用户可停止录制;也可以选择继续录制更多有效注册音频以提高验证准确度。
2-2-5)将步骤2-2-2)中得到的用户有效注册音频的短时谱特征,按照步骤2-2-3)生成的十个数字及静音符号在每段有效注册音频上的起始、结束时间,划分到每个数字和静音符号后,得到每个数字以及静音符号对应的短时谱特征;利用用户有效注册音频中每个数字以及静音符号对应的短时谱特征,采用最大后验概率(map)方法更新步骤1)得到文本相关的通用背景模型,生成该用户的文本相关的用户模型。
所述最大后验概率方法为:针对每个数字以及静音符号,更新步骤1)得到的文本相关的通用背景模型中高斯分布的均值。对某一数字或静音符号d,所述更新过程如式(7)所示:
式中,
式中,
3)验证阶段;流程如图4所示,具体包括以下步骤:
3-1)当用户发出验证请求时,服务器首先寻找到步骤2-1)分配的该用户唯一的标识号码并读取该用户的身份信息、个人密码以及步骤2-2)得到的文本相关的用户模型。服务器生成数字串动态验证码发送给用户。所述数字串动态验证码长度为6到12位,长度根据实际需要设定,长度越长验证准确度越高。可选地,服务器能够告知用户在数字串动态验证码指定位置插入在注册时设定的个人密码。用户将收到的数字串动态验证码以及个人密码按照服务器指定的顺序整合后进行朗读并录制成用户验证音频,所生成的用户验证音频被发送给服务器。若用户在一定持续时间内未能录入语音,则当前动态验证码失效,用户验证失败。所述持续时间根据具体使用情况在几分钟到几十分钟的范围内设定,时间越短安全性越高。
3-2)服务器收到用户验证音频后,提取步骤3-1)录制的用户验证音频的短时谱特征。
3-3)根据步骤3-2)得到的用户验证音频的短时谱特征以及步骤2)得到的文本相关的用户模型与步骤1)得到的文本相关的通用背景模型,验证该用户验证音频的声纹是否属于目标用户且内容与正确数字串文本是否相符,分别得到声纹验证分数s1和文本验证分数s2。所述正确数字串文本指按照服务器要求在数字串动态验证码指定位置插入用户个人密码后的合成数字串。所述验证方法为:
3-3-1)依照正确数字串文本的顺序,使用步骤1)得到的文本相关的通用背景模型构建第一个隐马尔可夫模型(hiddenmarkovmodel,hmm)。所述隐马尔可夫模型为语音识别中的常用技术,每个状态具有一定的概率密度分布,各状态之间具有一定的转移概率。在本实施例中,每一状态的概率密度分布对应一个数字或静音符号的高斯混合模型,即该数字或静音符号的文本相关的通用背景模型。
所述依照正确数字串文本的顺序构建第一个隐马尔可夫模型的方法为:首先在正确数字串文本前后添加静音符号。例如:用英文字母a-f代表0到9中的任意数字,当数字串文本为a-b-c-d-e-f时,添加静音符号后的文本为sil-a-b-c-d-e-f-sil。然后使用文本相关的通用背景模型中数字以及静音符号对应的高斯混合模型依照图4的方式构成第一个隐马尔可夫模型。图4展示了当数字串长度为6时,文本相关的通用背景模型构成的第一个隐马尔可夫模型。状态转移关系用有向箭头表示,a-b-c-d-e-f表示数字串6位数字,sil表示静音符号,每个状态对应的高斯混合模型即步骤1)得到的该数字或静音符号对应的文本相关的通用背景模型。其中,第一个状态为静音符号sil,可以转移到其本身或下一个数字a;数字a-e都能转移到其自身或下一个数字;数字f可以转移到其自身或最后一个静音符号sil;最终的静音符号sil只能转移到其自身。除了最后一个静音符号转移到其自身的概率为1外,其余状态间的转移概率均为0.5。
3-3-2)根据步骤3-2)得到的验证音频的短时谱特征以及步骤3-3-1)得到的第一个隐马尔可夫模型,采用维特比(viterbi)算法得到用户验证音频的短时谱特征与第一个隐马尔可夫模型状态之间的对应关系,所述维特比算法为语音识别中的常用技术,用于在给定语音短时谱特征以及隐马尔可夫模型时找到每帧短时谱特征与隐马尔可夫模型状态之间的对应关系,使得:
式中,xt为用户验证音频的短时谱特征集合{xt(1),xt(2),...,xt(nt)},nt为验证音频特征总数量,下标t代表验证音频。h为隐马尔可夫模型,此处为步骤3-3-1)构建的第一个隐马尔可夫模型,φt为一种可能的用户验证音频短时谱特征与隐马尔可夫模型状态的对应关系,p(xt|h,φt)表示用户验证音频短时谱特征集合xt在第一个隐马尔可夫模型h以及状态对应方式φt下的整体似然概率。
3-3-3)根据步骤3-3-2)得到的用户验证音频的短时谱特征与第一个隐马尔可夫模型状态之间的对应关系,进而得到在正确数字串文本条件下用户验证音频短时谱特征与各个数字以及静音符号的对应关系。隐马尔可夫模型每个状态代表一个数字或静音符号;而状态的概率密度分布,由该数字或静音符号的在通用背景模型中的高斯混合模型表示。计算用户验证音频在步骤2)得到的文本相关的用户模型以及步骤1)得到的文本相关的通用背景模型上的对数似然比,作为声纹验证分数s1。所述声纹验证分数s1的计算表达式表达式如式(12)所示:
式中,xt(n)为用户验证音频的第n帧短时谱特征,
3-3-4)采用语音识别技术识别用户验证音频的数字串内容,将验证得到的数字串内容作为最优数字串序列。依照最优数字串序列,使用步骤1)得到的文本相关的通用背景模型构建第二个隐马尔可夫模型。所述使用文本相关的通用背景模型构建第二个隐马尔可夫模型的方法与步骤3-3-1)相同,但将正确数字串文本更换为最优数字串序列。
3-3-5)在最优数字串序列条件下,重复步骤3-3-2),采用维特比算法得到用户验证音频的短时谱特征与第二个隐马尔可夫模型状态之间的对应关系,进而得到在最优数字串序列条件下用户验证音频短时谱特征与各个数字以及静音符号的对应关系。
3-3-6)根据步骤3-3-2)以及步骤3-3-5)分别得到的在正确数字串文本以及最优数字串序列下用户验证音频短时谱特征与各个数字以及静音符号的对应关系,计算用户验证音频在文本相关的用户模型与文本相关的通用背景模型上的对数似然比,作为文本验证分数s2。所述文本验证分数s2的计算表达式如式(13)所示:
式中,
3-4)将步骤3-3)得到的声纹验证分数s1与文本验证分数s2加权求和后得到最终验证分数,与设定阈值比较并进行判定:当最终验证分数超过设定阈值时,则认为用户验证音频由验证用户所说且文本内容正确,验证通过;否则验证失败。所述设定阈值为使得验证集上的验证结果错误最少的值,一般取值在-1到1之间,本实施例中取0.5。所述最终验证分数的计算表达式如式(14)所示:
s=ws1+(1-w)s2(14)
式中,s为最终验证分数,w为权重,0<w<1,权重w决定声纹验证结果与文本验证结果的相对重要程度,一般取值为0.5,代表两者相同重要。
- 还没有人留言评论。精彩留言会获得点赞!