一种基于连续时序马尔科夫模型的地理位置预测方法与流程
本发明属于基于地理位置服务的数据挖掘领域,具体涉及一种基于连续时序马尔科夫模型的地理位置预测方法。
背景技术:
随着当今互联网移动化的潮流推进,类似导航,交通管理等基于位置的服务发展迅速。为了提供更好的服务体验,越来越多的基于位置的服务系统需要提前预知用户的位置。例如:个性化位置引导,基于位置的提醒服务,基于位置的广告投放等等。假设用户在下午5点位于位置a,如果我们能够预测到用户在下午8点位于位置b,那么基于位置的服务提供商就可以提前对用户提供位置b相关的广告信息由此可见,位置预测技术具有很高的实际应用价值。随着基于地理位置服务的迅速发展,能够准确地对用户在特定时间下的位置进行预测变的尤为重要。
目前,采用基于马尔科夫模型在真实时间上进行位置预测时,需要通过对时间进行等值划分来确定位置转移时间点,从而导致预测结果粗糙的问题。
技术实现要素:
本发明要解决的技术问题是,提供一种基于连续时序马尔科夫模型的地理位置预测方法,在传统马尔科夫模型的基础上,引入连续时序的信息,在利用马尔科夫过程进行位置预测时,将离散的状态序列与连续的时间变化相结合,提高了预测准确率的同时,使得马尔科夫模型可以对连续时序进行建模。
为实现上述目的,本发明采用如下的技术方案:
一种基于连续时序马尔科夫模型的地理位置预测包括以下步骤。
步骤1、对原始的用户轨迹数据进行过滤和聚类,产生一系列的候选地点;
步骤2、根据候选地点信息,将用户的轨迹数据转化为[时间t,地点l]序列;
步骤3、对每个位置的序列密度进行高斯混合建模,结合转移概率矩阵、序列点概率等信息,对原始的马尔科夫模型进行改进,建立基于连续时序的马尔科夫模型;
步骤4、利用基于连续时序的马尔科夫模型对目标时间点的地理位置预测。
作为优选,建立基于连续时序的马尔科夫模型以及进行地理位置预测包括以下步骤:
步骤1:对于某一个用户,选择其所有移动轨迹数据
步骤2:将提取出来的数据根据转移前位置进行归类划分:
γ=(γ(0),γ(1),...,γ(m))
步骤3:利用每一个用户的每一个位置转移时间点集合作为输入数据,建立高斯混合模型,具体步骤如下:
步骤3.1:设置参数d为初始高斯混合个数d、高斯混合系数最小阈值p_threhold;
步骤3.2:如果仍有未建模的位置,则选取一个未建模的位置,进入步骤3.3,否则进入步骤4;
步骤3.3:建立由步骤3.1中设置的d个高斯分布混合而成的高斯混合模型,并且d减一;
步骤3.4:如果高斯混合个数大于1并且最小的高斯混合系数大于步骤3.1中设置的阈值,则记录每个高斯分布的均值及概率,作为该位置的转移时间点,并中进入步骤3.2,否则进入步骤3.3;
步骤4:对于每一个位置,计算每一个转移时间点所占概率的比重,作为这个位置在该转移时间点下的转移概率;
步骤5:设置当前位置和当前时间分别为起始位置la与起始时间tnow,设置结束时间tend;设置位置概率全局变量
步骤6.1:对于每一个位置k,进行如下操作:寻找当前位置a中,距离当前时间最近的转移时间点
步骤6.2:对应位置的位置概率全局变量
步骤6.3:当前概率pcur按照下式计算得出:
步骤6.4:设置当前位置为lk,当前时间为
步骤7:当全局变量
作为优选,步骤4的具体位置预测为:
已知用户在t时刻对li进行了访问,要预测在经过δt时间后用户的位置,求解下式:
其中,lr表示位置预测的结果,
采用基于连续时序的马尔科夫模型cts-mm对用户访问序列进行建模,p(lk|li,t,δt)表示给定当前地点li和当前时间t,在经过时间δt后,用户停留在地点lk的概率,其概率值可由直接计算求出,如下式:
对于求和项
乘积的第一项是递归项,初值为1,第二项是la到lk的转移概率,第三项是由下式给出的条件概率,
当下一个转移时间点大于结束时间时,停止递归迭代,并将最终概率加入该位置的结果概率中;
从所有位置的结果概率中,选择最大的概率值所对应的地点作为最终位置预测结果。
作为优选,每个地点的转移时间点计算过程为:转移时间点γ(i)={t1,t2,...,tn}表示一个地点li的转移时间序列;其中,首先,需要从训练数据中挖掘发生位置转移的时间点,当用户在某一条轨迹中的前一个时刻的位置与下一个时刻的位置发生变化时,则记录该时刻为一个边缘轨迹时间点;然后,对所有边缘轨迹时间点进行高斯混合建模,选取每个高斯模型的均值点作为转移时间点t1,t2,...,tn即可。
在本发明中预测用户下一个位置包含了两个任务。其一是已知用户的前一位置,预测用户的下一个位置,其二是用户需要经过多久到达下一个位置。对于第一个任务,利用传统的一阶马尔科夫模型,就可以对该问题进行较为精准的预测和解决。对于第二个任务,通过收集用户位置转移时间点,然后利用传统的高斯混合模型对用户位置转移时间的分布进行拟合,从而确定用户在位置停留的时间和转移的时间,进一步判定用户何时到达下一个位置。但要同时解决这两个问题,需要把马尔科夫模型和高斯混合模型结合起来,这也是本发明的重点。本发明在前人工作的基础上对马尔科夫模型进行了改进主要体现在两个方面:其一是取消了状态对齐的约束,其二是将离散时序改为连续的时序。由此我们将可以预测连续的真实时间条件下的用户位置。
本发明方法首先利用高斯混合模型拟合连续时间下地点之间的转移概率,从而发现可能的位置转移时间点,并将这些时间点作为马尔科夫模型的状态转移点,建立马尔科夫模型,然后,通过用户在这些时间点的转移概率流向,计算用户位于某一位置的概率值,从而得到最终的位置预测结果。在数据集geolife上的实验结果表明,该方法相对于传统模型的预测准确率提升了约10%,具有更好的应用价值和实际意义。
附图说明
图1是本发明的地理位置预测流程图;
图2是本发明的地理位置预测模型示意图;
图3是本发明实验轨迹点数据统计分布图;
图4(a)是本发明实验中在δt∈(0,1)时间间隔的位置预测性能;
图4(b)是本发明实验中在δt∈(1,10)时间间隔的位置预测性能;
图4(c)是本发明实验中在δt∈(10,30)时间间隔的位置预测性能;
图4(d)是本发明实验中在δt∈(30,60)时间间隔的位置预测性能;
图4(e)是本发明实验中在δt∈(60,+∞)时间间隔的位置预测性能。
具体实施例
如图1所示,本发明提供一种基于连续时序马尔科夫模型的地理位置预测包括以下步骤。
步骤1、对原始的用户轨迹数据进行过滤和聚类,产生一系列的候选地点;
步骤2、根据候选地点信息,将用户的轨迹数据转化为[时间t,地点l]序列;
步骤3、对每个位置的序列密度进行高斯混合建模,结合转移概率矩阵、序列点概率等信息,对原始的马尔科夫模型进行改进,提出基于连续时序的马尔科夫模型;
步骤4、利用基于连续时序的马尔科夫模型对目标时间点的地理位置预测。
步骤4的具体位置预测为:
已知用户在t时刻对li进行了访问,要预测在经过δt时间后用户的位置,求解下式:
其中,lr表示位置预测的结果,
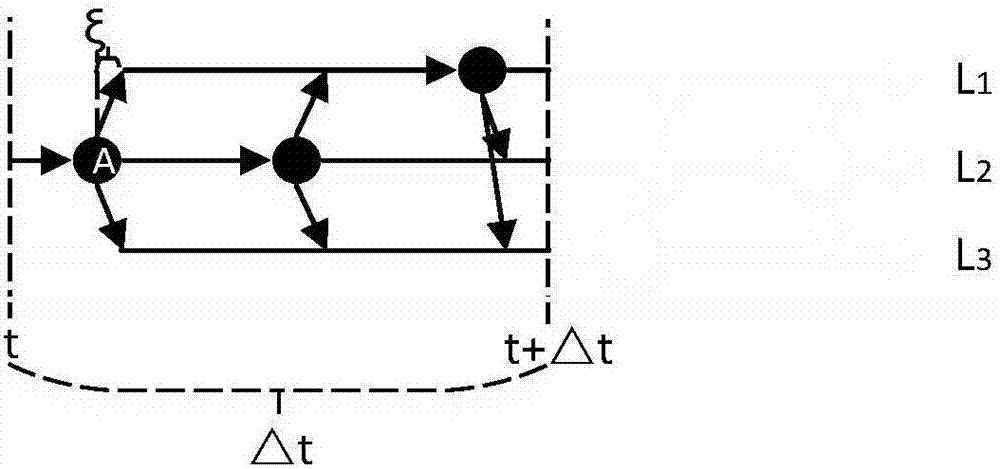
采用基于连续时序的马尔科夫模型cts-mm对用户访问序列进行建模,如图2所示。图2表示的是一个只包含3个地点:l1,l2,l3的状态转移示意图,节点表示可能发生状态转移的时刻,箭头流向表示地点转移方向,水平线表示不发生转移。
例如:节点a表示l2的一个状态转移点,经过ξ的时间可能会转移到l1或l3。
图2中,当指定t时刻用户位于位置l2时,在δt时间内的状态转移由图中黑色箭头和节点给出。
其中,p(lk|li,t,δt)表示给定当前地点li和当前时间t,在经过时间δt后,用户停留在地点lk的概率,其概率值可由直接计算求出,如下式:
对于求和项
乘积的第一项是递归项,初值为1,第二项是la到lk的转移概率,第三项是由下式给出的条件概率,
当下一个转移时间点大于结束时间时,停止递归迭代,并将最终概率加入该位置的结果概率中;
从所有位置的结果概率中,选择最大的概率值所对应的地点作为最终位置预测结果。
在计算过程中,需要用到每个地点的转移时间点,下面介绍一下转移时间点如何求出。转移时间点γ(i)={t1,t2,...,tn}表示一个地点li的转移时间序列,也就是图2中的节点。
首先,需要从训练数据中挖掘发生位置转移的时间点。当用户在某一条轨迹中的前一个时刻的位置与下一个时刻的位置发生变化时,则记录该时刻为一个边缘轨迹时间点。
然后对所有边缘轨迹时间点进行高斯混合建模,选取每个高斯模型的均值点作为转移时间点t1,t2,...,tn即可。
实施例1
本发明具体实施步骤分为两部分,第一部分为数据预处理,第二部分为模型训练与预测。
为了后文更好的进行说明,现定义符号表如下:
对于数据预处理部分,按以下步骤进行:
步骤1:取所有轨迹,首先对于某一轨迹中的任意轨迹点
步骤2:对于步骤1中过滤后,剩余的轨迹和轨迹点,计算每个轨迹点的速度vj,如果某个轨迹点的速度vj大于某一阈值η,则删除该轨迹
其中,η代表用户的移动速度,η值设置为1.5m/s。其中vj通过下式进行计算。
步骤3:对于步骤2中过滤后,剩余的轨迹,计算该轨迹的持续时间δto,n,如果第i条轨迹的持续时间
其中,n代表轨迹
将剩余所有轨迹点,利用dbscan聚类算法进行聚类,其中密度设置为0.0001,类内数量与之设置为10。
将轨迹点信息从<时间,经度,纬度>更改为<时间,类别号>,其中类别号是通过聚类之后得到的一个类内的编号,它代表了一个位置。
对于模型训练和预测部分按照以下步骤进行:
步骤1:对于某一个用户,选择其所有移动轨迹数据
步骤2:将提取出来的数据根据转移前位置进行归类划分:
γ=(γ(0),γ(1),...,γ(m))
步骤3:利用每一个用户的每一个位置转移时间点集合作为输入数据,建立高斯混合模型。具体步骤如下。
步骤3.1:设置参数d为初始高斯混合个数d、高斯混合系数最小阈值p_threhold。
步骤3.2:如果仍有未建模的位置,则选取一个未建模的位置,进入步骤3.3,否则进入步骤4。
步骤3.3:建立由步骤3.1中设置的d个高斯分布混合而成的高斯混合模型,并且d减一。
步骤3.4:如果高斯混合个数大于1并且最小的高斯混合系数大于步骤3.1中设置的阈值,则记录每个高斯分布的均值及概率,作为该位置的转移时间点,并中进入步骤3.2,否则进入步骤3.3。
步骤4:对于每一个位置,计算每一个转移时间点所占概率的比重,作为这个位置在该转移时间点下的转移概率。
步骤5:设置当前位置和当前时间分别为起始位置la与起始时间tnow,设置结束时间tend。设置位置概率全局变量
步骤6.1:对于每一个位置k,进行如下操作:寻找当前位置a中,距离当前时间最近的转移时间点
步骤6.2:对应位置的位置概率全局变量
步骤6.3:当前概率pcur按照下式计算得出。
步骤6.4:设置当前位置为lk,当前时间为
步骤7:运行结束后,全局变量
利用geolife数据集,进行了实验。geolife是由微软亚洲研究院提供的一份中国用户户外活动数据集,该数据集中包含了182名用户在5年间的出行记录,共有17621条轨迹,总里程超过1292951公里。
此数据集包含了用户的户外活动、上班、回家等日常生活轨迹,还包含了以游客身份进行旅游、运动等活动的轨迹。
考虑到该数据集绝大多数轨迹点位于北京,故在实验中只针对北京的轨迹点进行预测与分析。
经过数据预处理工作,包括数据过滤与聚类,得到如图3所示的地点统计数据分布,其中dbscan参数设置为:类簇内点数量最小阈值=20,最大密度=0.0005。
本发明从中选取160名用户中的相邻20天的轨迹数据作为训练集,与其时间相邻的5天的轨迹数据作为测试集,分别对不同时间段以及不同用户的预测性能进行了评价,如图4(a)-图4(e)所示,
其中,对于轨迹天数低于25天的用户按其所有轨迹数据4:1进行划分,其中有22个用户由于轨迹数量过少被过滤掉。
本发明采用准确率(precision)来对预测结果进行评价。
该模型通过高斯混合模型拟合连续时间下地点轨迹的转移概率,发现位置转移节点,然后通过对马尔科夫过程求取最终的位置预测概率,预测准确率相比传统算法平均提高了10%左右。
- 还没有人留言评论。精彩留言会获得点赞!