基于数据去重的移动Web请求处理方法、设备及系统与流程
本发明属于移动web应用和数据处理技术领域,更具体地,涉及一种基于数据去重的移动web请求处理方法、设备及系统。
背景技术:
互联网是当今最重要的信息传播及通讯平台,而万维网web是互联网中最重要的平台之一,随着进入web2.0时代,页面内容逐渐多样化和复杂化,如何获得较好的web性能成为了研究热点。
随着移动设备的普及和移动互联网的快速发展,很多传统互联网应用正在向移动互联网方向转变。由于移动端的系统资源相对较缺乏,如较小的内存和存储容量、较弱的处理能力、较差的网络和连接性,请求呈现一个页面的速度要比pc端慢几秒到十几秒,所以针对移动端的优化更值得重视。
在信息爆炸时代,资源有限的移动设备对过多信息的处理能力明显不足。有相关研究表明,互联网应用里大量的数据信息存在很多冗余数据,去除冗余数据、减少数据传输量可以节约有限的存储空间、减少网络传输时间、节约用户的时间和成本,对移动互联网有重要的意义。
目前主要采用两种方法减少数据传输量:压缩技术和缓存技术。压缩技术针对每个原始文件进行压缩,减少文件传输体积,但是不能压缩文件之间的冗余,对两个相似文件分别压缩之后得到的压缩文件仍然有很多冗余数据。缓存技术可以有效减少网络请求数量,但缓存容量有限,且无法消除数据冗余问题。在文件系统及备份系统中,数据去重技术被采用来大规模识别和消除冗余数据,降低数据存储成本。但将传统领域的冗余消除技术直接应用到移动web中,会增加额外的运算来进行计算和恢复,对于处理能力较弱的移动端,可能会影响整体web性能,因此,针对移动web应用,要实现一个有效的方法,既能消除冗余数据,又能提升整体web性能。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种基于数据去重的移动web请求处理方法、设备及系统,其目的在于减少移动web请求处理过程中传输大量不必要的冗余数据降低web性能的问题,既能有效消除冗余数据,又能提升整体web性能。
为实现上述目的,按照本发明的一个方面,提供了一种基于数据去重的移动web请求处理方法,包括:
s1、客户端向服务端发送页面请求,以使所述服务端向通用网关接口cgi请求动态数据并填充,渲染页面文件,其中,所述页面请求中包括页面文件;
s2、所述客户端接收所述服务端发送的渲染好的页面文件;
s3、所述客户端提取接收到的页面文件中的文件版本号信息,与缓存中的旧版本文件的版本号对比,若发现文件发生更新,则执行步骤s4;若文件没有更新,直接使用缓存中的旧版本文件;
s4、所述客户端向所述服务端发送差量文件请求,所述差量文件请求用于请求差量文件,所述差量文件由所述服务端在文件更新时离线生成,且在所述差量文件中包括新增的数据和未变数据内容对应的块号;
s5、所述客户端接收所述服务端发送的差量文件,并由所述差量文件中新增的数据和未变数据内容对应的块号将差量文件与缓存中的旧版本文件合并恢复新版本文件。
优选地,所述步骤s5包括以下步骤:
s51、初始化空字符串变量strresult表示计算得到的新文件;
s52、扫描差量文件中的数组;
s53、若当前扫描的数组项内容是字符串,则表示是新增的数据,将该新增的数据添加到strresult中;若当前扫描的数组项内容不是字符串,则表示是记录未变数据内容的块号,根据块号对应的块大小和描述规则计算该块号对应的内容在旧版本文件里的起始和结束位置,用截取字符串方法从旧版本文件获得该描述规则对应的内容,并将该内容添加到strresult中;
s54、判断扫描是否结束,若是则执行步骤s55,否则转到s52;
s55、返回变量strresult作为新版本文件,结束。
为实现上述目的,按照本发明的另一个方面,提供了一种基于数据去重的移动web请求处理方法,包括:
a1、服务端接收客户端发送的页面请求,向通用网关接口cgi请求动态数据并填充,渲染页面文件,其中,所述页面请求中包括页面文件;
a2、所述服务端将渲染好数据的页面文件发送给所述客户端,以使所述客户端提取接收到的页面文件中的文件版本号信息,与缓存中的旧版本文件的版本号对比,并在文件发生更新时,向所述服务端发送差量文件请求,其中,所述差量文件请求用于请求差量文件,所述差量文件由所述服务端在文件更新时离线生成,且在所述差量文件中包括新增的数据和未变数据内容对应的块号;
a3、所述服务端接收来自所述客户端的差量文件请求,向所述客户端发送差量文件,以使所述客户端由所述差量文件中新增的数据和未变数据内容对应的块号将接收到的差量文件与缓存中的旧版本文件合并恢复新版本文件。
优选地,所述差量文件的生成步骤为:
t1、将旧版本文件按固定长度分块,计算每个块的哈希校验码值作为块标识对每个块编号;
t2、在新版本文件里进行滚动查找,依次比对新版文件块内容的哈希校验码值是否和旧版本文件的块标识相对应;如果对应,记录对应的块号,滚动下标一个块长度距离;否则将数据压入新数据缓冲区,滚动下标一个字符长度距离;
t3、判断新版本文件中的内容是否滚动查找结束,若是则执行步骤t4,否则转到步骤t2;
t4、合成新数据缓冲区中的新数据并生成差量文件。
为实现上述目的,按照本发明的另一个方面,提供了一种客户端,包括:
第一发送模块,用于向服务端发送页面请求,以使所述服务端向通用网关接口cgi请求动态数据并填充,渲染页面文件,其中,所述页面请求中包括页面文件;
接收模块,用于接收所述服务端发送的渲染好的页面文件;
比对判断模块,用于提取接收到的页面文件中的文件版本号信息,与缓存中的旧版本文件的版本号对比,判断文件是否发生更新;
第二发送模块,用于在文件发生更新时,向所述服务端发送差量文件请求,所述差量文件请求用于请求差量文件,所述差量文件由所述服务端在文件更新时离线生成,且在所述差量文件中包括新增的数据和未变数据内容对应的块号;
更新模块,用于接收所述服务端发送的差量文件,并由所述差量文件中新增的数据和未变数据内容对应的块号将差量文件与缓存中的旧版本文件合并恢复新版本文件。
优选地,所述更新模块包括:
初始化模块,用于初始化空字符串变量strresult表示计算得到的新文件;
扫描模块,用于扫描差量文件中的数组;
扫描处理模块,用于在当前扫描的数组项内容是字符串时,表示是新增的数据,将该新增的数据添加到strresult中;在当前扫描的数组项内容不是字符串时,表示是记录未变数据内容的块号,根据块号对应的块大小和描述规则计算该块号对应的内容在旧版本文件里的起始和结束位置,用截取字符串方法从旧版本文件获得该描述规则对应的内容,并将该内容添加到strresult中;
判断处理模块,用于在扫描结束时,返回变量strresult作为新版本文件;在扫描未结束时,返回执行所述扫描模块的操作。
为实现上述目的,按照本发明的另一个方面,提供了一种服务端,包括:
第一接收模块,用于接收客户端发送的页面请求,向通用网关接口cgi请求动态数据并填充,渲染页面文件,其中,所述页面请求中包括页面文件;
第一发送模块,用于将渲染好数据的页面文件发送给所述客户端,以使所述客户端提取接收到的页面文件中的文件版本号信息,与缓存中的旧版本文件的版本号对比,并在文件发生更新时,向所述服务端发送差量文件请求,其中,所述差量文件请求用于请求差量文件;
差量文件生成模块,用于在文件更新时离线生成差量文件,且在所述差量文件中包括新增的数据和未变数据内容对应的块号;
第二接收模块,用于接收来自所述客户端的差量文件请求;
第二发送模块,用于向所述客户端发送差量文件,以使所述客户端由所述差量文件中新增的数据和未变数据内容对应的块号将接收到的差量文件与缓存中的旧版本文件合并恢复新版本文件。
优选地,所述差量文件生成模块包括:
分块模块,用于将旧版本文件按固定长度分块,计算每个块的哈希校验码值作为块标识对每个块编号;
查找处理模块,用于在新版本文件里进行滚动查找,依次比对新版文件块内容的哈希校验码值是否和旧版本文件的块标识相对应;如果对应,记录对应的块号,滚动下标一个块长度距离;否则将数据压入新数据缓冲区,滚动下标一个字符长度距离;
判断处理模块,用于在新版本文件中的内容滚动查找结束时,合成新数据缓冲区中的新数据并生成差量文件;在新版本文件中的内容滚动查找未结束时,返回执行所述查找处理模块的操作。
为实现上述目的,按照本发明的另一个方面,提供了一种基于数据去重的移动web请求处理系统,包括客户端和服务端,其中:
所述客户端,用于向服务端发送页面请求,其中,所述页面请求中包括页面文件;
所述服务端,用于接收所述页面请求,向通用网关接口cgi请求动态数据并填充,渲染页面文件;将渲染好数据的页面文件发送给客户端;
所述客户端,还用于提取接收到的页面文件中的文件版本号信息,与缓存中的旧版本文件的版本号对比,若发现文件发生更新,则向服务端发送差量文件请求,所述差量文件请求用于请求差量文件,所述差量文件由服务端在文件更新时离线生成;若文件没有更新,直接使用缓存中的旧版本文件;
所述服务端,还用于接收来自客户端的差量文件请求,向客户端发送差量文件,在所述差量文件中包括新增的数据和未变数据内容对应的块号;
所述客户端,还用于由所述差量文件中新增的数据和未变数据内容对应的块号将接收到的差量文件与缓存中的旧版本文件合并恢复新版本文件。
优选地,所述服务端,还用于将旧版本文件按固定长度分块,计算每个块的哈希校验码值作为块标识对每个块编号;在新版本文件里进行滚动查找,依次比对新版文件块内容的哈希校验码值是否和旧版本文件的块标识相对应;如果对应,记录对应的块号,滚动下标一个块长度距离;否则将数据压入新数据缓冲区,滚动下标一个字符长度距离;判断新版本文件中的内容是否滚动查找结束,若是则合成新数据缓冲区中的新数据并生成差量文件,否则在新版本文件里继续进行滚动查找;
所述客户端,还用于初始化空字符串变量strresult表示计算得到的新文件;扫描差量文件中的数组;若当前扫描的数组项内容是字符串,则表示是新增的数据,将该新增的数据添加到strresult中;若当前扫描的数组项内容不是字符串,则表示是记录未变数据内容的块号,根据块号对应的块大小和描述规则计算该块号对应的内容在旧版本文件里的起始和结束位置,用截取字符串方法从旧版本文件获得该描述规则对应的内容,并将该内容添加到strresult中;判断是否扫描结束,若是则返回变量strresult作为新版本文件,否则继续扫描差量文件中的数组。
以上的基于数据去重的移动web请求处理方法、设备及系统,简称为dwpf(deduplication-basedweb-requestprocessingframework),有别于现有技术方案:基于缓存技术和基于压缩技术。总体而言,本发明方法与现有技术方案相比,能够取得下列有益效果:
1、本发明与现有缓存技术相比,考虑文件中冗余数据的消除以及缓存容量的有限性,有效消除冗余数据,减少数据传输量以及缓存大小。
2、本发明与现有压缩技术相比,考虑相似文件之间的冗余数据消除,更进一步消除文件中的冗余,减少数据传输量。
附图说明
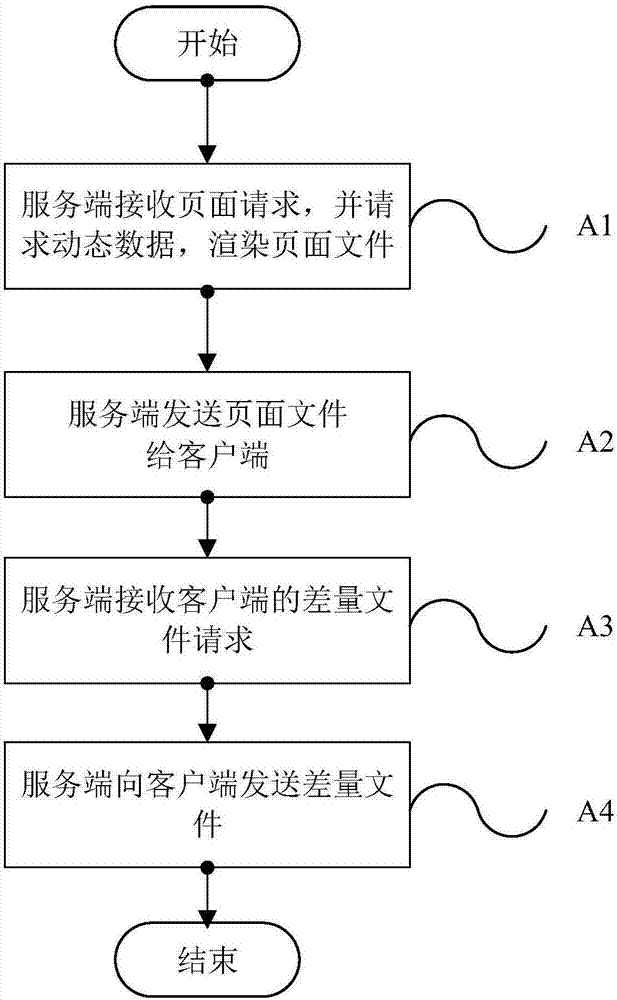
图1为本发明实施例公开的一种基于数据去重的web请求处理方法的流程示意图;
图2为本发明实施例公开的另一种基于数据去重的web请求处理方法的流程示意图;
图3为本发明实施例公开的一种基于数据去重的web请求处理系统的结构示意图;
图4为本发明实施例公开的一种差量文件生成方法的流程示意图;
图5为本发明实施例公开的一种合并差量文件和旧版文件为新版文件的方法流程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明提供一种基于数据去重的移动web请求处理方法,包括如下机制:
1、移动web请求数据去重机制
现有提升web性能的方法或通过压缩技术减少数据传输量或通过缓存技术增加缓存减少访问请求次数,但是这两种技术在已缓存的旧版本文件发生少量更新的情况无法有效提升web性能。本发明提出移动web请求数据去重机制,当缓存有旧版本文件的客户端向服务端请求新版本文件内容时,服务端根据新旧版本文件的版本号,消除冗余数据,生成新旧版本文件之间的差量文件,并发送给客户端,而不发送完整文件或压缩文件,以此有效减少文件冗余数据,减少数据传输量,提升web页面请求的性能。
2、异步去重与渲染机制
移动web请求数据去重机制的使用可以有效减少数据传输量,但是客户端必须将差量文件与旧版文件合并恢复新版文件,同时客户端需要进行动态数据请求和渲染页面的过程,这会增大处理能力较弱的客户端的计算压力。本发明提出异步去重与渲染机制,使服务端动态数据请求及渲染页面与客户端差量文件解析异步进行,这种机制可以减少动态数据的网络请求次数,平衡服务端和客户端的负载,有效提升整体web性能。
本发明提供一个实施例说明本发明方法的实施过程。本实例中假设客户端缓存的旧版本文件内容为chunk1-chunk2-chunk3-chunk4-chunk5(每个chunk代表按照固定长度分割的不同字符串),新版本文件内容为chunk1-“hdfjkhlf”-chunk2-chunk3-“uygfiuy”-chunk5。
如图1所示为本发明实施例公开的一种基于数据去重的移动web请求处理方法的流程示意图,包括如下步骤:
s1、客户端向服务端发送页面请求,以使所述服务端向通用网关接口(commongatewayinterface,cgi)请求动态数据并填充,渲染页面文件,其中,所述页面请求中包括页面文件;
其中,将页面渲染过程转移到服务端可以减少客户端后续对差量文件解析与恢复的计算压力。
s2、所述客户端接收所述服务端发送的渲染好的页面文件;
s3、所述客户端提取接收到的页面文件中的文件版本号信息,与缓存中的旧版本文件的版本号对比,若发现文件发生更新,则执行步骤s4;若文件没有更新,直接使用缓存中的旧版本文件;
s4、所述客户端向所述服务端发送差量文件请求,所述差量文件请求用于请求差量文件,所述差量文件由所述服务端在文件更新时离线生成,且在所述差量文件中包括新增的数据和未变数据内容对应的块号;
s5、所述客户端接收所述服务端发送的差量文件,并由所述差量文件中新增的数据和未变数据内容对应的块号将差量文件与缓存中的旧版本文件合并恢复新版本文件,差量文件解析过程与服务端渲染过程异步进行,解析完成则处理结束。
如图2所示为本发明实施例公开的另一种基于数据去重的移动web请求处理方法的流程示意图,包括如下步骤:
a1、服务端接收客户端发送的页面请求,向通用网关接口cgi请求动态数据并填充,渲染页面文件,其中,所述页面请求中包括页面文件;
a2、所述服务端将渲染好数据的页面文件发送给所述客户端,以使所述客户端提取接收到的页面文件中的文件版本号信息,与缓存中的旧版本文件的版本号对比,并在文件发生更新时,向所述服务端发送差量文件请求,其中,所述差量文件请求用于请求差量文件,所述差量文件由所述服务端在文件更新时离线生成,且在所述差量文件中包括新增的数据和未变数据内容对应的块号;
a3、所述服务端接收来自所述客户端的差量文件请求,向所述客户端发送差量文件,以使所述客户端由所述差量文件中新增的数据和未变数据内容对应的块号将接收到的差量文件与缓存中的旧版本文件合并恢复新版本文件。
本发明实施例还提供了一种客户端,包括:
第一发送模块,用于向服务端发送页面请求,以使所述服务端向通用网关接口cgi请求动态数据并填充,渲染页面文件,其中,所述页面请求中包括页面文件;
接收模块,用于接收所述服务端发送的渲染好的页面文件;
比对判断模块,用于提取接收到的页面文件中的文件版本号信息,与缓存中的旧版本文件的版本号对比,判断文件是否发生更新;
第二发送模块,用于在文件发生更新时,向所述服务端发送差量文件请求,所述差量文件请求用于请求差量文件,所述差量文件由所述服务端在文件更新时离线生成,且在所述差量文件中包括新增的数据和未变数据内容对应的块号;
更新模块,用于接收所述服务端发送的差量文件,并由所述差量文件中新增的数据和未变数据内容对应的块号将差量文件与缓存中的旧版本文件合并恢复新版本文件。
本发明实施例还提供了一种服务端,包括:
第一接收模块,用于接收客户端发送的页面请求,向通用网关接口cgi请求动态数据并填充,渲染页面文件,其中,所述页面请求中包括页面文件;
第一发送模块,用于将渲染好数据的页面文件发送给所述客户端,以使所述客户端提取接收到的页面文件中的文件版本号信息,与缓存中的旧版本文件的版本号对比,并在文件发生更新时,向所述服务端发送差量文件请求,其中,所述差量文件请求用于请求差量文件;
差量文件生成模块,用于在文件更新时离线生成差量文件,且在所述差量文件中包括新增的数据和未变数据内容对应的块号;
第二接收模块,用于接收来自所述客户端的差量文件请求;
第二发送模块,用于向所述客户端发送差量文件,以使所述客户端由所述差量文件中新增的数据和未变数据内容对应的块号将接收到的差量文件与缓存中的旧版本文件合并恢复新版本文件。
如图3所示为本发明实施例公开的一种基于数据去重的移动web请求处理系统的结构示意图,在图3所示的系统中包括客户端和服务端,其中:
客户端:缓存有旧版本文件,用于向服务端发出web请求,以及后续对不同版本文件间差量文件的请求和解析过程。
服务端:包含差量文件生成器和页面解析器,用于处理来自客户端的web请求。差量文件生成器用于文件发生更新时离线生成不同版本文件间的差量文件,页面解析器用于请求动态数据并渲染页面。
如图4所示为本发明实施例公开的一种生成差量文件的方法流程示意图,包括以下操作:
t1、根据配置将旧版本文件按固定长度分块,并计算每个块的哈希校验码值并将其作为块标识并对每个块编号,分块后的内容为chunk1、chunk2、chunk3、chunk4、chunk5连续的5块,块号分别为1、2、3、4、5;
t2、在新版本文件里进行滚动查找,依次比对新版本文件块内容的哈希校验码值是否和旧版本文件的块标识相对应;如果对应,记录对应的块号,滚动下标一个块长度距离;否则将数据压入新数据缓冲区,滚动下标一个字符长度距离;在本实施例中,经过滚动查找,chunk1的内容与旧版本是对应的,记录1到差量文件;“hdfjkhlf”与旧版内容不对应,记录到差量文件;以此类推,分别写2、3、“uygfiuy”、5到差量文件;
t3、最终得到差量文件内容为{1,“hdfjkhlf”,2,3,“uygfiuy”,5}。
如图5所示为本发明实施例公开的一种合并差量文件与旧版本文件为新版文件的方法流程示意图,包括以下操作:
s51、用变量strresult表示计算得到的新文件,并初始化为空字符串“”;
s52、扫描差量文件数组s={1,“hdfjkhlf”,2,3,“uygfiuy”,5};
s53、当前的数组项内容如果是字符串,则表示是新增的数据,直接添加到strresult里;如果不是字符串,则表示是记录未变内容的块号,根据块大小和描述规则来计算这部分内容在原文件里的起始和结束位置,用截取字串方法从原文件获得该描述规则对应的真正内容,并将内容添加到strresult里;在本实施例中,经过扫描,发现s[0]=1,不是字符串,在旧版文件中找到对应的块内容,写chunk1的内容到strresult;s[1]=“hdfjkhlf”,是字符串,直接添加到strresult;以此类推,继续添加chunk2、chunk3、“uygfiuy”、chunk5到strresult;
s54、新版本文件为chunk1-“hdfjkhlf”-chunk2-chunk3-“uygfiuy”-chunk5。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!