一种用于压缩视频通信中人脸视频的方法及系统与流程
本发明涉及一种人脸视频处理领域,特别涉及一种用于压缩视频通信中人脸视频的方法及方法。
背景技术:
视频是由多个视频帧组成的,每个视频帧又包括:
i帧:是一个全帧压缩编码帧,也叫帧内编码帧,因此i帧的数据量一般比较大,i帧不需要参考其他帧而生成,它是p帧或是b帧的参考帧,解码时仅用i帧就可以重构一个完整的图像。
p帧:是一个前向预测编码帧,也称为帧间编码帧,p帧需要参考前面的与其相邻的i帧或p帧而生成,同时它也是其他p帧或者b帧的参考帧,解码时必须依赖其前面的i帧或p帧才可以重构出完整的图像。
b帧:是一个双向预测编码帧,它也是一个帧间编码帧,b帧需要参考前面的i帧或p帧或后面的p帧生成,b帧不作为其它帧的参考帧,因此它的解码错误不会造成错误扩散,但是b帧解码时必须依赖i帧或p帧才可重构出完整的图像。
多媒体通信是当前通信领域中最具挑战性、发展最快、研究最活跃的领域之一。随着智能手机的快速发展,移动终端上例如facetime和微信等的应用使多媒体通信在移动网络上普及,用户越来越多地期望得到方便、快捷、无所不在的多媒体通信服务。
人脸视频(如视频通话、会议等)具有明显的特征,且人们对人脸有着丰富的先验知识。传统视频编码方法将所有信息均进行编码传输,其中很多关于人脸的共性冗余信息被视为新信息重复传递,浪费了大量网络带宽资源。为了提高传输质量,降低传输过程的中带宽,人们一般会将人脸进行压缩后,然后再进行传输;基于此,现有人员提出了一系列基于模型的视频编码方法,该类方法通过对人脸建模,实现对视频中人脸的参数化表征,使得在传输视频时只需要传输模型的一些参数就可以在接收端利用人脸模型重建出目标。例如cn104023216公开了一种人脸视频压缩方法,该方法利用人脸模型进行视频中人脸的定位和参数化表征,得到一系列保证人脸的参数向量,然后进行比对处理,将最优自适应帧间压缩后的人脸模型参数向量发送给接收端再利用独立分片线性插值方法进行人脸模型参数向量的恢复,经过人脸形状计算和经过恢复的人脸外观,得到原图像,该方法大大提高了人脸视频压缩比的同时保证了最优重建质量;但是该方法在进行人脸建模和人脸重构的过程中需要经过大量的计算,因此也需要占用大量的带宽资源,并且当两个长相比较相似的人进行人脸重构时,建立的人脸模型不易区分两个人真实的面部信息;并且再进行人脸重构的过程中,也存在着面部一些冗余信息的重复传输,造成传输质量下降。
技术实现要素:
为了解决现有技术中的问题,本发明提供一种用于压缩视频通信中人脸视频的方法及系统,该用于压缩视频通信中人脸视频的方法根据每一视频帧内的i帧情况来判断是否需要进行视频帧的传输,进而解决了现有技术中存在的视频压缩过程中的冗余了,大大降低了视频压缩的空间,并且经过传输后的各视频帧能够在接收端或发送端很清晰地呈现出人脸视频。
本发明具体技术方案如下:
本发明提供一种用于压缩视频通信中人脸视频的方法,该方法包括如下步骤:
s1:捕捉视频通信中的人脸视频,并进行解析,获取组成人脸视频的各视频帧,并按时间顺序为各视频帧进行编号;
s2:抽取各视频帧内的i祯、p帧和b帧;
s3:判断第n个i帧和第n+1个i帧是否相似,n≥1,如果相似,将第n个i帧和第n+1个i帧放入相同的存储区内,否则,将第n个i帧和第n+1个i帧分别放入不同的存储区内,并对各存储区进行编号;
s4:对存储区内的各i帧进行分析,根据分析结果将i祯和部分p帧压缩后传输给相应的发射端或接收端。
进一步的改进,步骤s4包括如下步骤:
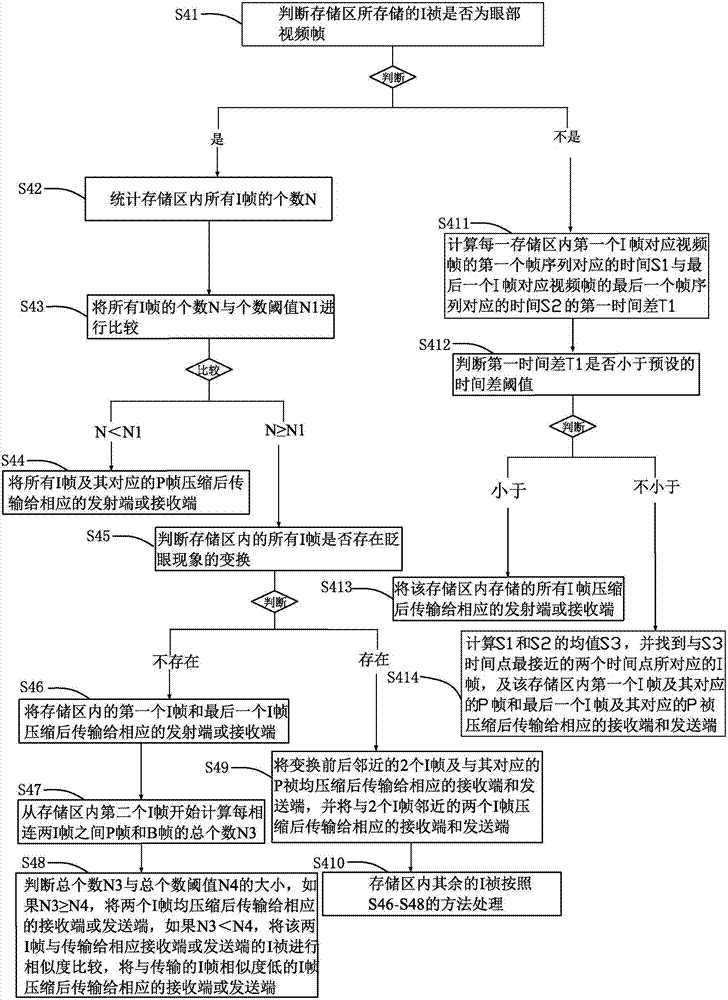
s41:判断存储区所存储的i祯是否为眼部视频帧,如果是,进行步骤s42;
s42:统计存储区内所有i帧的个数n;
s43:将所有i帧的个数n与个数阈值n1进行比较,如果n<n1,进行步骤s44;
s44:将所有i帧及其对应的p帧压缩后传输给相应的发射端或接收端。
进一步的改进,步骤s4还包括如下步骤:
s45:当步骤s43判断出n≥n1时,判断存储区内的所有i帧是否存在眨眼现象的变换,如果不存在,进行步骤s46;
s46:将存储区内的第一个i帧和最后一个i帧压缩后传输给相应的发射端或接收端。
进一步的改进,步骤s4还包括如下步骤:
s47:从存储区内第二个i帧开始计算每相邻两i帧之间p帧和b帧的总个数n3;
s48:判断总个数n3与总个数阈值n4的大小,如果n3≥n4,将两个i帧均压缩后传输给相应的发射端或接收端,如果n3<n4,将该两i帧与传输给相应发射端或接收端的i祯进行相似度比较,将与传输的i帧相似度低的i帧压缩后传输给相应的发射端或接收端。
进一步的改进,步骤s4还包括如下步骤:
s49:当步骤s45判断存在眨眼现象的变换时,将变换前后邻近的2个i帧及与其对应的p祯均压缩后传输给相应的发射端或接收端,并将与2个i帧邻近的两个i帧压缩后传输给相应的发射端或接收端;
s410:存储区内其余的i祯按照s46-s48的方法处理。
进一步的改进,步骤s4还包括如下步骤:
s411:当步骤s41判断存储区所存储的i祯不是眼部视频帧,计算每一存储区内第一个i帧对应视频帧的第一个帧序列对应的时间s1与最后一个i帧对应视频帧的最后一个帧序列对应的时间s2的第一时间差t1;
s412:判断第一时间差t1是否小于预设的时间差阈值,如果小于,进行步骤s413;
s413:将该存储区内存储的所有i帧压缩后传输给相应的发射端或接收端。
进一步的改进,步骤s4还包括如下步骤:
s414:当步骤s412判断第一时间差t1不小于预设的时间差阈值时,计算s1和s2的均值s3,并找到与s3时间点最接近的两个时间点所对应的i帧,及该存储区内第一个i帧及其对应的p帧和最后一个i帧及其对应的p祯压缩后传输给相应的发射端或接收端。
进一步的改进,步骤s3包括如下步骤:
s31:计算第n个i帧和第n+1个i帧的比值x,并与比值阈值进行比较,如果比值x大于比值阈值,进行步骤s32,否则进行步骤s33,比值x按下式计算:
hn和hn+1分别表示第n个i帧和第n+1个i帧的dc图像的直方图;
s32:将第n个i帧和第n+1个i帧分别放入不同的存储区内;
s33:计算第n个i帧、第n+1和第n+2个i帧内每相邻两i帧之间的差值,并进行处理,进而判断出第n个i帧和第n+1个i帧是否相似。
进一步的改进,步骤s33的具体方法为:
s331:分别计算第n个i帧和第n+1个i帧的差值a1,及第n+1个i帧和第n+2个i帧的差值a2;
s332:将差值a1和差值a2分别做求和及求差处理,分别得a和及a差;
s333:判断a和与阈值t1的大小,并判断a差与阈值t2的大小,如果a和>阈值t1,且a差<阈值t2,进行步骤s32,如果阈值t2<a和、a差<阈值t1,t1>(阈值t2+差值a1),进行步骤s334;
s334:将第n个i帧和第n+1个i帧分别放入相同的存储区内。
本发明另一方面提供一种用于压缩视频通信中人脸视频的系统,包括用于相互通信的接收端和发射端,其中,发射端和接收端均包括:
视频帧解析模块,用于捕捉视频通信中的人脸视频,并进行解析,获取组成人脸视频的各视频帧,并按时间顺序为各视频帧进行编号;
视频帧抽取模块,用于抽取各视频帧内的i祯、p帧和b帧;
相似判断模块,用于判断第n个i帧和第n+1个i帧是否相似,n≥1,如果相似,将第n个i帧和第n+1个i帧放入相同的存储区内,否则,将第n个i帧和第n+1个i帧分别放入不同的存储区内,并对各存储区进行编号;
处理模块,用于对存储区内的各i帧进行处理,将经过处理后的i祯和部分p帧发送给传输模块;
传输模块,用于实现发射端和接收端之间数据的传输
本发明的有益效果如下:本发明提供一种用于压缩视频通信中人脸视频的方法及系统,该用于压缩视频通信中人脸视频的方法及系统首先在进行视频通过的发射端和接收端上分别截取人脸视频,并获取人脸视频内的各视频帧,然后抽取视频帧内的i帧、p帧和b帧,然后再对视频内的关键帧i帧进行判断和处理,进而将处理后的i帧和部分p帧传输给发射端或接收端,该方法不但降低了冗余视频帧的发送率,进而提高了视频通信的质量,提高了通信资源的利用效率。
附图说明
图1为实施例1用于压缩视频通信中人脸视频的方法的流程图;
图2为实施例2步骤s4的流程图;
图3为实施例3步骤s3的流程图;
图4为实施例3步骤s33的流程图;
图5为实施例4用于压缩视频通信中人脸视频的系统的结构框图。
具体实施方式
实施例1
本发明提供一种用于压缩视频通信中人脸视频的方法,如图1所示,该方法包括:
s1:捕捉视频通信中的人脸视频,并进行解析,获取组成人脸视频的各视频帧,并按时间顺序为各视频帧进行编号;
s2:抽取各视频帧内的i祯、p帧和b帧;
s3:判断第n个i帧和第n+1个i帧是否相似,n≥1,如果相似,将第n个i帧和第n+1个i帧放入相同的存储区内,否则,将第n个i帧和第n+1个i帧分别放入不同的存储区内,并对各存储区进行编号;
s4:对存储区内的各i帧进行分析,根据分析结果将i祯和部分p帧压缩后传输给相应的发射端或接收端。
本发明提供一种用于压缩视频通信中人脸视频的方法,该用于压缩视频通信中人脸视频的方法首先在进行视频通过的发射端和接收端上分别截取人脸视频,该截取人脸视频的方法属于现有技术,本发明不做进一步限定;然后获取人脸视频内的各视频帧,然后抽取视频帧内的i帧、p帧和b帧,然后再对视频内的关键帧i帧进行判断和处理,进而将处理后的i帧和部分p帧传输给发射端或接收端,该方法不但降低了冗余视频帧的发送率,进而提高了视频通信的质量,提高了通信资源的利用效率。
实施例2
本发明实施例2提供的用于压缩视频通信中人脸视频的方法与实施例1不同的是,参考图2所示,步骤s4包括如下步骤:
s41:判断存储区所存储的i祯是否为眼部视频帧,如果是,进行步骤s42;
s42:统计存储区内所有i帧的个数n;
s43:将所有i帧的个数n与个数阈值n1进行比较,如果n<n1,进行步骤s44;
s44:将所有i帧及其对应的p帧压缩后传输给相应的发射端或接收端;
s45:当步骤s43判断出n≥n1时,判断存储区内的所有i帧是否存在眨眼现象的变换,如果不存在,进行步骤s46;
s46:将存储区内的第一个i帧和最后一个i帧压缩后传输给相应的发射端或接收端;
s47:从存储区内第二个i帧开始计算每相邻两i帧之间p帧和b帧的总个数n3;
s48:判断总个数n3与总个数阈值n4的大小,如果n3≥n4,将两个i帧均压缩后传输给相应的发射端或接收端,如果n3<n4,将该两i帧与传输给相应发射端或接收端的i祯进行相似度比较,将与传输的i帧相似度低的i帧压缩后传输给相应的发射端或接收端;
s49:当步骤s45判断存在眨眼现象的变换时,将变换前后邻近的2个i帧及与其对应的p祯均压缩后传输给相应的发射端或接收端,并将与2个i帧邻近的两个i帧压缩后传输给相应的发射端或接收端;
s410:存储区内其余的i祯按照s46-s48的方法处理;
s411:当步骤s41判断存储区所存储的i祯不是眼部视频帧,计算每一存储区内第一个i帧对应视频帧的第一个帧序列对应的时间s1与最后一个i帧对应视频帧的最后一个帧序列对应的时间s2的第一时间差t1;
s412:判断第一时间差t1是否小于预设的时间差阈值,如果小于,进行步骤s413;
s413:将该存储区内存储的所有i帧压缩后传输给相应的发射端或接收端;
s414:当步骤s412判断第一时间差t1不小于预设的时间差阈值时,计算s1和s2的均值s3,并找到与s3时间点最接近的两个时间点所对应的i帧,及该存储区内第一个i帧及其对应的p帧和最后一个i帧及其对应的p祯压缩后传输给相应的发射端或接收端。
本发明提供的方法首先判断相邻两个i帧是否相似,如果相似,将两个i帧放入相同的存储区,然后再继续判断每个存储区内的i帧具体的部位,如果存储区内的i帧属于眼部视频帧,那么再进一步判断组成眼部视频帧内i帧的个数,如果i帧的个数少,那么直接将i帧和其对应的p帧发送给发射端或接收端,如果i真的个数多,那么再继续判断存储内的所有的i帧是否存在眨眼现象的变换,本发明所提供的眨眼现象的变换可以参考现有技术,例如可以参考cn105286802内公开的判断人眼闭合状态和完全睁开状态判断是否是眨眼现象的变换;如果不存在眨眼现象的变换,先将存储区内的第一个i帧和最后一个i帧压缩传输给相应的发射端或接收端,然后存储区内其余的i帧进行如下处理,首先从第二个i帧开始计算每相邻两i帧之间p帧和b帧的总个数,如果总个数较多,说明两个之间存在着一定的变换,那么将两个i帧均进行压缩,然后传输给相应的发射端或接收端,如果总个数较小,以第二个i帧和第三个i帧为例说明,继续判断第二个i帧和第三个i帧与第一个i帧相似度,如果第一个i帧与第二i帧的相似度达于第一个i帧与第三个i帧的相似度,那么将第三个i帧进行压缩传输给相应的接收端或发射端;然后再以此类推判断第四个i帧和第五个i帧,直至判断到倒数第二个i帧;当判断存储区内存在眨眼现象变换时,先将眨眼突变点前后对应的两个i帧及其p帧压缩传输,然后再将与两个i帧邻近的i帧进行压缩,其余的i帧进行如下的压缩处理,首先将存储区内的第一个i帧和最后一个i帧压缩传输给相应的发射端或接收端,然后存储区内其余的i帧进行如下处理,首先从第二个i帧开始计算每相邻两i帧之间p帧和b帧的总个数,如果总个数较多,说明两个之间存在着一定的变换,那么将两个i帧均进行压缩,然后传输给相应的发射端或接收端,如果总个数较小,以第二个i帧和第三个i帧为例说明,继续判断第二个i帧和第三个i帧与第一个i帧相似度,如果第一个i帧与第二i帧的相似度达于第一个i帧与第三个i帧的相似度,那么将第三个i帧进行压缩传输给相应的接收端或发射端。当判断存储区内的视频帧不是眼部视频帧时,计算存储区内第一个i帧和最后一个i帧对应的时间点的差值,如果两个时间点的差值不大,那么就存储区内所有i帧都进行压缩,如果两个i帧时间点的差值过大,找到两i帧对应时间点的中间时间点最接近的两个时间点所对应的i帧,及该存储区内第一个i帧及其对应的p帧和最后一个i帧及其对应的p祯压缩后传输给相应的发射端或接收端。本发明通过对各存储区内的i帧进行分析,分析出是否属于眼部的视频帧,因为人的眼部视频帧是人面部最突出最具特征的视频帧,所以本发明主要对眼部视频帧分析,并根据存储区内i帧的个数、相邻两i帧之间p帧和b帧的个数等因素从存储区内挑选需要压缩的i帧进行传输,不但避免了冗余视频帧的传输,并且能够保证接收双方都能够看清楚通信人的脸部信息,保证了传输质量,节省了带宽的同时,提高了通信效率。
实施例3
本发明实施例3提供的用于压缩视频通信中人脸视频的方法与实施例1不同的是,如图3所示,步骤s3包括如下步骤:
s31:计算第n个i帧和第n+1个i帧的比值x,并与比值阈值进行比较,如果比值x大于比值阈值,进行步骤s32,否则进行步骤s33,比值x按下式计算:
hn和hn+1分别表示第n个i帧和第n+1个i帧的dc图像的直方图;
s32:将第n个i帧和第n+1个i帧分别放入不同的存储区内;
s33:计算第n个i帧、第n+1和第n+2个i帧内每相邻两i帧之间的差值,并进行处理,进而判断出第n个i帧和第n+1个i帧是否相似。
如图4所示,步骤s33的具体方法为:
s331:分别计算第n个i帧和第n+1个i帧的差值a1,及第n+1个i帧和第n+2个i帧的差值a2;
s332:将差值a1和差值a2分别做求和及求差处理,分别得a和及a差;
s333:判断a和与阈值t1的大小,并判断a差与阈值t2的大小,如果a和>阈值t1,且a差<阈值t2,进行步骤s32,如果阈值t2<a和、a差<阈值t1,t1>(阈值t2+差值a1),进行步骤s334;
s334:将第n个i帧和第n+1个i帧分别放入相同的存储区内。
本发明通过以上方法判断两个i帧的相似度,提高了判断的精度和准度,方便后续进一步判断。
实施例4
本发明实施例4提供的一种用于压缩视频通信中人脸视频的系统如图5所示,该系统包括用于相互通信的接收端和发射端
其中,发射端和接收端均包括:
视频帧解析模块1,用于捕捉视频通信中的人脸视频,并进行解析,获取组成人脸视频的各视频帧,并按时间顺序为各视频帧进行编号;
视频帧抽取模块2,用于抽取各视频帧内的i祯、p帧和b帧;
相似判断模块3,用于判断第n个i帧和第n+1个i帧是否相似,n≥1,如果相似,将第n个i帧和第n+1个i帧放入相同的存储区内,否则,将第n个i帧和第n+1个i帧分别放入不同的存储区内,并对各存储区进行编号;
处理模块4,用于对存储区内的各i帧进行处理,将经过处理后的i祯和部分p帧发送给传输模块;
传输模块5,用于实现发射端和接收端之间数据的传输。
本发明提供一种用于压缩视频通信中人脸视频的系统,该用于压缩视频通信中人脸视频的系统首先在进行视频通过的发射端和接收端上分别截取人脸视频,并获取人脸视频内的各视频帧,然后抽取视频帧内的i帧、p帧和b帧,然后再对视频内的关键帧i帧进行判断和处理,进而将处理后的i帧和部分p帧传输给发射端或接收端,该方法不但降低了冗余视频帧的发送率,进而提高了视频通信的质量,提高了通信资源的利用效率。
本发明不局限于上述最佳实施方式,任何人在本发明的启示下都可得出其他各种形式的产品,但不论在其形状或结构上作任何变化,凡是具有与本申请相同或相近似的技术方案,均落在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!