一种基于流式数据处理架构的天文元数据归档方法及系统与流程
本发明属于天文数据处理领域,具体涉及基于流式处理架构的实时天文数据归档系统。
背景技术:
随着各地天文观测站的建成和各种高精度观测仪器的使用,天文观测数据呈现了爆发增长的趋势。面对庞大的数据集,如何实现有效管理和检索是提高科研产出的关键问题之一。在实际的天文观测中,fits文件是天文观测数据的最主要存储格式。fits包括数据头和数据体。在fits头中包含着丰富的描述性元数据信息,以基本的key/value形式存储。相对于庞大的原始fits数据集来说,fits元数据不仅具有丰富的语义信息,同时在数据量级上要小得多。天文工作者可以通过查看元数据的方式来定位数据集。所以在天文学领域中也常常通过存储元数据的方式,来实现对数据资源的管理。天文数据归档是天文数据存储和检索的重要步骤,其主要思想是基于检索天文元数据信息来定位符合用户限定条件的天文观测数据集,从而达到观测数据共享、减少数据集检索消耗的时间成本的目的。而当前的天文观测数据归档方法特别是远程数据归档往往需要用户上传原始数据集,或者归档平台以周期性扫描数据源的方式进行离线归档,从而导致了大量的观测数据占用过多的网络带宽,占用较大的缓存空间,以及对一些实时性要求比较高的应用来说数据发布的时延过大的问题。而本发明采用数据源先抽取元数据的方式,再将元数据通过网络传输到归档平台进行数据处理。而元数据的数据量级相比原始数据要小的多,因此本发明节约了大量的网络带宽,也降低了时延,提高了实时性,同时减少了归档平台所需要的缓存成本。
流式数据处理平台storm属于apache旗下的一个开源项目,是一款高性能的分布式实时流式数据处理平台,近年来已经被应用到许多实时数据处理的场景。通过搭建storm分布式集群以及设计流数据处理逻辑拓扑,实现海量数据的实时高效处理。同时基于flume+kafka+storm分布式流式数据处理架构近年来已经被应用于许多海量数据处理的场所。其中apachekafka是一款高性能消息缓存队列,apacheflume是一款实时日志采集系统。流式数据处理架构的出现也给天文元数据的归档设计带来了新的契机,可以通过流式数据处理架构来提升归档系统的数据处理能力和实时性。相比传统归档系统中先传输原始数据,然后再采用脚本处理元数据,本发明采用的基于流式数据处理架构的归档方式可提高系统吞吐量同时又可以减少数据处理时延。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种减少了离线归档所占用的临时缓存空间,同时提高了观测数据发布的实时性、使得系统的实时性大大提高,对提高天文数据的应用效率具有较大意义的方法。本发明的技术方案如下:
一种基于流式数据处理架构的天文元数据归档方法,其包括以下步骤:
101、在不同的数据源部署agent代理,agent实时监控数据源,一旦有新的原始观测数据产生,agent的监控模块会立即解析新的原始观测数据并生成相应的元数据;
102、agent的数据采集模块会实时采集监控模块生成的元数据,并通过网络传输到指定元数据归档平台;元数据归档平台的缓存模块会实时接收数据源发送过来的元数据,并将元数据写入分布式缓存队列中;
103、归档平台的流式数据处理组件实时从缓存队列中读取元数据,并处理成时空维度的关联子图写入到图形数据库中,完成天文元数据归档。
进一步的,所述步骤101在数据源部署agent,实时监控数据源变化并生成元数据信息,包括:
agent通过实时识别数据源文件存储目录md5码的方式来获取数据源动态信息,并通过实时解析观测数据文件的方式来生成相应的元数据信息。
进一步的,所述agent通过实时识别数据源文件存储目录md5码的方式来获取数据源动态信息,具体实现方法为:
agent通过设定一个文件目录md5码观察器,以5s为周期扫描数据源所在文件目录的动态变化,如果数据源向文件目录写入新的观测数据,那么该文件目录的md5码会发生变化,这时候观察器会依据md5码的变化获取到新的观测数据文件信息,而后agent数据解析器会从观测数据中提取元数据信息并按照预定的格式写入文本文件中。
进一步的,所述的102步骤agent的数据采集模块会实时采集监控模块生成的元数据,并通过网络传输到指定元数据归档平台的消息缓存队列具体包括:数据源通过flume实时采集agent生成的元数据信息,同时flume采用execsource的方式实时地将采集到的元数据信息发送到归档平台的消息队列,
进一步的,所述归档平台的消息队列采用kafka分布存储,所以数据源和归档平台之间的元数据传输采用kafkaproducer标准。
进一步的,所述步骤103归档平台的流式数据处理组件实时从缓存队列中读取元数据,并处理成时空维度的关联子图写入到图形数据库中具体包括步骤:
设计stormtopology流式数据处理拓扑实时从缓存消息队列中读取元数据信息,并对每一条元数据信息进行关联性处理而后生成和neo4j的cypher交互语句。
进一步的,所述对每一条元数据信息进行关联性处理具体包括:
stormtopology流式数据处理拓扑对每条观测数据的元数据信息抽取空间维度上的二维赤经ra和赤纬dec坐标信息、所属天区信息,以及时间维度上的具体观测时间,依据不同观测数据元数据在时空维度上的关联特性建立数据模型,处理成一张具有时空维度关联特性的子图。
一种基于流式数据处理架构的天文元数据归档系统,其包括:
采集模块、缓存模块、数据处理模块及数据库模块,其中所述采集模块部署在不同的数据源,实时监控数据源是否有新的观测数据产生,一旦检测有新的原始观测数据产生,采集模块会实时解析原始观测数据并抽取元数据并发送到归档平台的缓存模块;所述缓存模块用于缓存采集模块发送来的元数据,并采用分布式消息缓存队列;所述数据处理模块的流式数据处理组件会实时从缓存模块实时读取元数据并进行数据处理,最终生成时空维度相关联的子图,并转发给数据库模块;数据库模块,用于存储数据处理模块发送来的生成时空维度相关联的子图。
进一步的,所述数据源部署的采集模块为agent,agent包括元数据生产模块metaproudcer和元数据采集模块flume,agent的元数据生产模块metaproudcer负责实时监控数据源,一旦有新的数据产生,则立即解析新的观测数据并生成相应的元数据,而元数据采集模块flume采用execsource的方式实时地将采集到的元数据信息发送到归档平台的消息队列,其中归档平台的元数据缓存采用kafka分布式消息队列系统。
进一步的,所述agent的元数据生产模块metaproudcer首先开启md5码观
察器,以5s为周期扫描数据源所在文件目录的动态变化,如果数据源往文件
目录写入新的观测数据,那么该文件目录的md5码会发生变化,
metaproudcer的数据解析器同时实时识别数据源存储的文件目录md5码的
方式来获取数据源动态信息,而后通过i/o流的方式读取原始观测数据并过
滤掉无用信息,最后按照预定格式将元数据信息写入到指定文本。
本发明的优点及有益效果如下:
本发明基于流式数据处理架构的天文元数据归档方法,摈弃了离线的归档模式,采用了实时归档的方式,适用于对实时性要求较高的天文元数据归档场景,提高了系统的实时性,减少了网络带宽的占用以及物理缓存的消耗。系统实现方法为在数据源部署agent,由agent实时监控原始数据的产生以及元数据的抽取和预处理,因此减少了网络传输过程中大量无用冗余信息所消耗的带宽;归档平台采用了流式数据处理组件对元数据进行实时处理,避免了离线归档模式先存储再处理时需要占用大量物理缓存的问题。
附图说明
图1是本发明提供优选实施例实时天文元数据归档流程图;
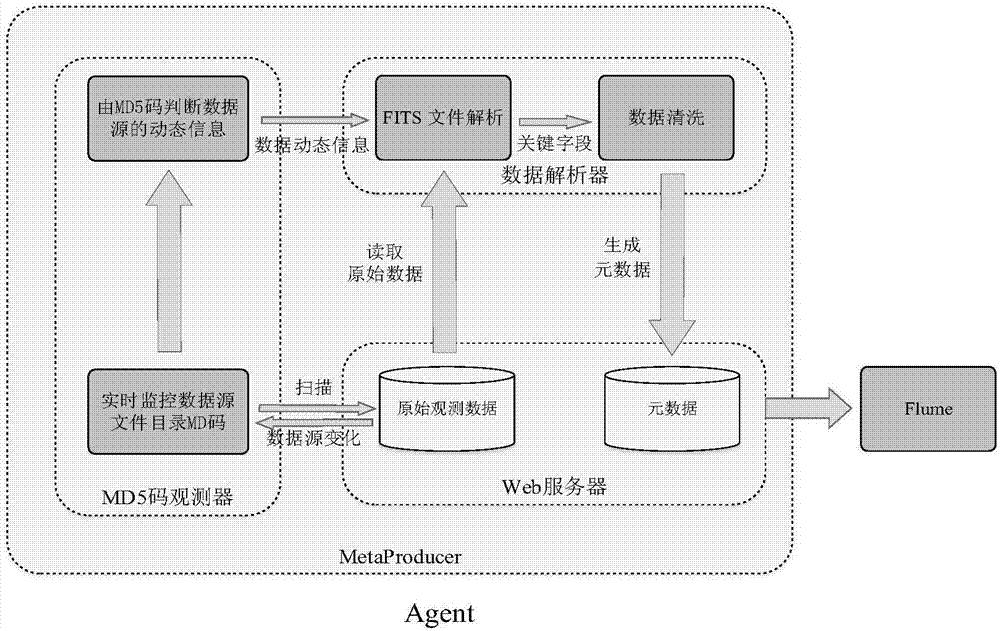
图2数据源代理agent模块示意图;
图3stormtopology示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
为了对本发明实施例进行清楚详细的介绍,此处结合图1来简要介绍本发明的步骤。基于流式数据处理架构的天文元数据归档方法大体包括4个模块:采集模块、缓存模块、数据处理模块、数据库模块。
采集模块部署在数据源,实时监控数据源是否有新的观测数据产生。一旦检测有新的原始观测数据产生,采集模块会实时解析原始观测数据并抽取元数据并发送到归档平台的缓存模块。而后数据处理模块的流式数据处理组件会实时从缓存模块实时读取元数据并进行数据处理,最终生成时空维度相关联的子图存进数据库模块中。
如图2所示,首先,在不同的数据源部署agent。agent包括元数据生产模块metaproudcer和元数据采集模块flume。agent的元数据生产模块metaproudcer负责实时监控数据源,一旦有新的数据产生,则立即解析新的观测数据并生成相应的元数据。agent的metaproudcer首先开启md5码观察器,以5s为周期扫描数据源所在文件目录的动态变化。如果数据源往文件目录写入新的观测数据,那么该文件目录的md5码会发生变化。metaproudcer的数据解析器同时实时识别数据源存储的文件目录md5码的方式来获取数据源动态信息,而后通过i/o流的方式读取原始观测数据并过滤掉无用信息,最后按照预定格式将元数据信息写入到指定文本。而元数据采集模块flume采用execsource的方式实时地将采集到的元数据信息发送到归档平台的消息队列。其中归档平台的元数据缓存采用kafka分布式消息队列系统。
如图1中所示数据处理模块采用storm分布式流式数据处理组件。需要设计stormtopology流式数据处理拓扑中每个spout、bolt在数据处理中的作用,具体topology设计如图3所示。spout负责从缓存模块kafka中实时读取消息,而后通过shufflegrouping(随机分组)的流分组方式发送到bolt1进行数据过滤。而后bolt2(负责从时间维度建模)和bolt3(负责从空间维度建模)分别以fieldgrouping(字段分组)的流分组方式订阅bolt1过滤后的数据,分别从时间维度和空间维度进行数据关联。其中bolt2抽取观测时间元数据信息,把属于同一个观测时间的不同元数据进行关联。而bolt3对每条元数据信息抽取空间维度上的二维赤经(ra)赤纬(dec)坐标信息、所属天区信息,并把属于相同空间坐标、相同天区的元数据进行数据关联。最后bolt4(负责jdbc数据库交互)同时订阅来自bolt2和bolt3的数据流,生成和neo4j数据库交互的cypher语句,完成天文元数据的实时归档。
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!