一种基于可变临界距离的LTE传播模型校正方法与流程
本发明属于移动通信技术领域,还涉及一种基于可变临界距离的lte传播模型校正方法。
背景技术:
移动通信网络规划中的传播模型是预测基站无线电波传播路径损耗的模型。传播模型是移动通信小区规划的基础,其准确与否关系到小区规划是否合理。基站无线传播环境对传播模型的建立起关键作用。目前,移动通信小区规划使用的传播模型主要有okumura-hata模型、cost231-hata模型、spm模型等。
1、okumura-hata模型及其修正
hata模型是根据okumura曲线图所做的经验公式,频率范围是150~1500mhz,基站有效天线高度为30~300m,移动台天线高度为1~10m。hata模型以市区传播损耗为标准,其他地区的传播损耗在此基础上进行修正。在发射机和接收机之间的距离超过1km情况下,hata模型的预测结果与原始okumura模型非常接近。
okumuru-hata模型以城市市区的传播损耗为标准,其他地区采用修正因子进行修正。okumura-hata模型的市区传播路径损耗公式如下:
l=69.55+26.16*log10f-13.82*log10hb-a(hm)+(44.9-6.55*log10hb)*(log10d)(1)
其中,l代表路径损耗值,a(hm)为移动台天线高度校正(db);hb和hm分别为基站天线有效高度、移动台天线有效高度(m);d表示距离(km);f表示中心频率(mhz);
移动台天线高度的校正公式由下式计算。
对于中小城市:
a(hm)=(1.1*log10(f)`0.7)*hm-(1.56*log10(f)-0.8)(2)
对于大城市:
a(hm)=8.29*(log10(1.54*hm))2-1.1f≤200mhz(3)
a(hm)=3.2*(log10(11.75*hm))2-4.97f≥400mhz(4)
在郊区,okumura-hata经验公式中的路径损耗l修正为lm:
lm=l(市区)-2*log10(f/28)2-5.4(5)
在农村,路径损耗l修正为:
lm=l(市区)-4.78*(log10f)2-18.33*log10f-40.98(6)
2、cost231-hata模型及其修正
cost231-hata是hata模型的扩展版本,它以okumura的测试数据为依据,通过对较高频段的okumura传播曲线进行分析,得到了cost231-hata模型。cost231-hata模型的传播损耗值lb如下式所示:
lb=46.3+33.9*log10f-13.82*log10hb-a(hm)+(44.9-6.55*log10hb)*(log10d)+cm(7)
与okumuru-hata模型相比,cost231-hata模型主要增加了一个校正因子cm,对于树木密度适中的中等城市和郊区的中心,cm为0db,对于大城市中心,cm为3db。
cost231-hata模型的移动台天线高度修正因子根据下式进行调整。
cost231-hata模型的其他修正因子与okumuru-hata模型一致。
3、spm模型及其修正
在计算机辅助场强预测中,一般以修正的okumura-hata模型为基础,再利用针对当地的实际无线环境进行连续波(continuouswave,cw)测试所得的测试数据进行修正,最常用的是标准传播模型(spm,standardpropagationmodel)。spm模型采用了可调系数的表达式,增强了模型的灵活性和精确性,模型适用于150mhz到2ghz的频率范围,模型表达如下。
ploss=k1+k2log(d)+k3(hms)+k4log(hms)+k5log(heff)+k6log(heff)log(d)+k7diffn+kclutter
(9)
其中:ploss为路径损耗;d是基站到移动台之间的距离;hms是移动台相对地面的高度;heff是基站天线的有效高度;
diffn是使用等效刃形衍射方法计算的衍射损耗;
k1&k2是截距和斜率,这些因数对应于一个固定偏移量和基站与移动台之间距离对数值的系数;
k3&k4是移动台天线的高度系数因子,系数用来修正移动台有效天线高度的影响;
k5是基站有效天线高度系数因子,用来修正基站天线有效高度的影响;
k6是log(heff)log(d)的系数因子;
k7是衍射系数;
kclutter是地物类型附加损耗。
利用用户可定义的系数,传播模型可以进行定制。以上8个参数中,k2值的取定对模型影响最为重要,他反映了信号传播随距离增大而衰减的程度,称之为斜率。
在spm传播模型应用中,k3~k7,kclutter参数一般采用默认值,仅校正k1与k2这两个参数。
现有技术的缺点及技术问题:
lte(longtermevolution,长期演进)网络部署在800m至2600mhz的不同频段上。尤其是部署在2000mhz以上的高频段时,小区覆盖距离较小,信号传播受基站周围环境影响更大。传统的应用于宏小区规划的单斜率spm模型在应用于高频段的lte网络规划时,误差较大。
移动通信基站小区无线信号覆盖离基站较近时,信号随距离的衰减规律与离基站较远区域的衰减规律不一致,可将之分为“近场”和“远场”。在3g及以前网络的规划中,由于规划小区的边缘一般都是在远场中,且离近场与远场的分界(临界距离点)较远,一般可以忽略近场的影响,选用适合远场的单斜率spm模型即可。但是在lte规划中,规划小区半径与临界距离可比拟,甚至基站覆盖区大部分都是在无线覆盖的近场区,必须考虑近场区的影响并对近场区进行良好的预测拟合。
在一些规划软件中,支持双斜率spm模型。双斜率spm模型支持两个k1、k2系数和用户定义的临界距离变换点。即近场区采用一套k1~k7参数,远场区采取另一套k1~k7参数,从模型拟合的效果看,信号衰减预测体现为两条不同斜率的曲线。但是临界距离值并未给出,由规划人员根据经验设定的分界点往往难以真实反映实际无线信号分布特点。因此需要实现在合理复杂度的前提下,提出具有更好拟合无线信号空间分布特征的传播模型参数校正方法。
技术实现要素:
本发明涉及一种基于可变临界距离的lte传播模型校正方法。该方法对连续波测试数据进行优化处理,提取包括临界距离在内的双斜率spm模型的设置参数,提升模型预测的准确性。
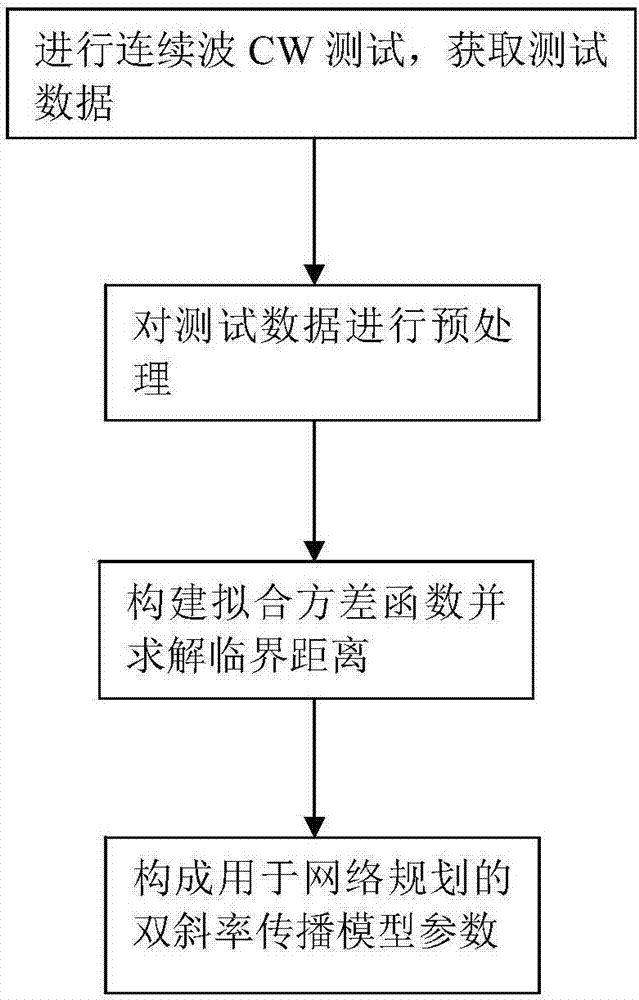
本发明包括如下步骤:
步骤1,进行连续波cw测试,获取测试数据;
步骤2,对测试数据进行预处理;
步骤3,构建拟合方差函数并求解临界距离;
步骤4,以求得的临界距离作为近场、远场分界,构成用于网络规划的双斜率传播模型参数。
步骤1包括:进行连续波测试,得到本地均值作为测试数据。连续波测试是现有技术。连续波测试时,射频信号源将特定频点上的连续波信号按照某一功率通过天馈部分发射出去,通过满足一定要求的路测方式,在接收端通过接收平台采集路测数据。根据无线电波的传播理论,信号在几十个波长的距离上经历慢的随机变化,其统计规律服从对数正态分布。当在40个波长的空间距离上取平均,就可以得到其均值包络,这个量通常称作本地均值,其和特定地点上的平均值相对应。连续波测试就是要取得特定长度上的本地均值,从而利用这些本地均值来对该区域的传播模型进行校正。
步骤2包括:
步骤2-1,过滤掉因测试路线选择明显不当所对应的测试数据记录,通过将原始测试数据展现在数字地图上对明显不当的测试点记录进行删除;
步骤2-2,对过滤后的测试数据做地理化的平均处理,以40倍测试信号波长为1个区间长度,对每个区间长度上的多个接收信号电平值进行平均得到1个均值,作为一个有效测试数据点;
步骤2-3,按步骤2-2最终得到n个有效测试数据点,n取值为自然数,将第i个有效测试数据点记为(ploss-i,di),其中i取值范围为1~n,ploss-i表示第i个有效测试数据点的路径损耗,di表示第i个有效测试数据点与基站的距离。
步骤3包括:
步骤3-1,确定临界距离d的取值范围[dmin,dmax],dmin表示临界距离d的最小值,dmax表示临界距离d的最大值;
步骤3-2,对于每个临界距离d∈[dmin,dmax],筛选出与基站距离小于d的测试数据点对有m个,与基站距离大于等于d的测试数据点对有n-m个;
步骤3-3,标准传播模型spm如下:
ploss=k1+k2log(d)+k3(hms)+k4log(hms)+k5log(heff)+k6log(heff)log(d)+k7diffn+kclutter
(1)
其中,ploss为路径损耗;d是基站到移动台之间的距离;hms是移动台相对地面的高度;heff是基站天线的有效高度,k1表示截距,k2表示斜率,k3和k4分别是移动台天线的高度系数因子和对数高度系数因子,k5是基站有效天线高度系数因子,k6是log(heff)log(d)的系数因子,k7是衍射系数;kclutter是地物类型附加损耗;diffn是使用epstein,peterson、deygout或bullington的等效刃形衍射方法计算的衍射损耗;
对于与基站距离小于d的m个测试数据点对,根据公式(1),当k3~k7以及kclutter参数采用默认值后,公式(1)变形为:
ploss-k3(hms)-k4log(hms)-k5log(heff)-k6log(heff)log(d)-k7diffn-kclutter=k1+k2log(d)
(2)
对于每一个测试数据点,公式(2)中等号左边构成定值,令:
x=ploss-k3(hms)-k4log(hms)-k5log(heff)-k6log(heff)log(d)-k7diffn-kclutter(3)
则有:
x=k1+k2log(d)(4)
由式(4)看出,变量x与变量log(d)构成线性关系,其中k1和k2是该线性方程的系数,根据m个有效测试数据点对,通过线性最小二乘法求出近场的k1和k2的值。最小二乘法是一种数学优化技术,最早由高斯发表于1809年他的著作《天体运动论》中,它通过最小化误差的平方和寻找数据的最佳函数匹配,利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小;
步骤3-4,对于与基站距离大于等于d的(n-m)个测试数据点对,通过线性最小二乘法求出远场的k1和k2的值;
步骤3-5,以求得的近场与远场两组k1和k2的值作为spm模型参数,计算以该模型预测的拟合方差,在临界距离d可能的取值范围[dmin,dmax]内,以临界距离d为自变量,计算不同d值下的拟合方差,构建如下拟合方差函数σ2(d):
其中xi为根据公式(3)推导出的第i个有效测试数据点电平值的实际测试记录值;根据公式(4)计算出的对应于第i个有效测试数据点电平值xi的预测值,记做xi';
步骤3-6,取拟合方差函数σ2(d)最小值对应的自变量dcritical,作为临界距离。
步骤4包括:以求得的临界距离dcritical作为近场、远场分界,结合求得的近场与远场两组k1和k2的值,构成用于网络规划的双斜率传播模型参数。
有益效果:本发明具有以下技术优点:
1、提高传播模型拟合准确度
本方案采取自适应调整的临界距离,可以根据连续波测试数据动态修正模型拟合参数,使得对实际电波传播特征的拟合更为精确。
2、与现有规划软件兼容
现有网络规划软件一般支持双折线spm传播模型。依据本方案获取的模型参数,可直接应用于现有软件规划中,不需要其他任何修改,应用方便。
附图说明
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述或其他方面的优点将会变得更加清楚。
图1为本发明流程图。
图2是原始测试数据图。
图3是过滤后的测试数据图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
如图1所示,本发明具体实施方案如下:
步骤一、cw测试
cw测试包括站点选定、设备连接与运行、测试数据采集。
(1)站点选定。选择的站点用于测试时架设连续波信号发射设备。选择站点时注意所选择的建筑高度与未来4g站点架设高度相近,建筑楼顶周围无明显高大遮挡物。
(2)设备连接与运行。在所选择的站点建筑楼顶架设连续波信号发射机及发射天线,接通电源,发送lte频段的连续波信号。在测试车上连接信号接收设备,做好记录准备。
(3)测试数据采集。测试路线注意横向、纵向均匀分布;测试半径不能太小,也不能太大,通常取将来小区半径的三倍;测试时车速保持均匀,最高速度不能超过根据李氏定律计算出的速度,即40个波长距离内采样点保持在36~50个。对于lte常用的2ghz频段,在测试采样频率为100次/秒时,车速建议为43.2~60公里/小时。测试时采样车在道路上行驶,以采样频率连续记录数据。每条采样数据记录两个值:采样点经纬度、采样点接收信号强度值。
步骤二、数据预处理
测试得到的数据,需要一定处理之后才能用于模型校正。数据预处理最主要的目的是将测试中带入的不合理数据进行滤除,完成地理化平均处理操作,然后转换成模型校正所需要的文件格式。数据预处理由过滤预处理和地理平均两步组成。过滤预处理是完成不合理数据的过滤操作,如图2所示为原始测试数据,其中上方部分测试路线因受到高大建筑物遮挡导致接收信号明显偏弱,在图中显示为灰色测试点部分,需要删除这部分测试数据,删除后的测试数据见图3;地理平均是对数据做地理化的平均处理,以求得特定长度上的区域均值。
数据预处理后,获得n个有效测试数据点对(ploss-i,di),其中i∈(1,2,......n)。
步骤三、构建拟合方差函数并求解临界距离
(1)、确定临界距离d的取值范围[dmin,dmax]。对于lte网络,dmin可以取30米,dmax取2倍的预规划小区半径。
(2)、对于每个d∈[dmin,dmax],筛选出测试点与基站距离小于d的数据点有m个,测试点与基站距离大于等于d的数据点有n-m个。
(3)对于与基站距离小于d的m个测试数据点对(ploss-i,di),根据公式(9),当k3~k7以及kclutter参数采用默认值后,公式可变形为:
ploss-k3(hms)-k4log(hms)-k5log(heff)-k6log(heff)log(d)-k7diffn-kclutter=k1+k2log(d)
(10)
对于每一个测试数据点,公式(10)左边构成定值,令:
x=ploss-k3(hms)-k4log(hms)-k5log(heff)-k6log(heff)log(d)-k7diffn-kclutter(11)
则有:
x=k1+k2log(d)(12)
由式(12)看出,变量x与变量log(d)构成线性关系,其中k1和k2是该线性方程的系数。根据m个实测值xi与log(di),通过线性最小二乘法可求出近场的k1和k2。
(4)对于与基站距离大于等于d的(n-m)个测试数据点对(ploss-i,di),通过线性最小二乘法可求出远场的k1和k2。
(5)、以求得的近场与远场两组k1和k2作为spm模型参数,计算以该模型预测的拟合方差。在临界距离d可能的取值范围[dmin,dmax]内,以临界距离d为自变量,计算不同d值下的拟合方差,构建拟合方差函数:
其中xi为根据公式(11)推导出的第i个有效测试点的实测值,xi'为根据公式(12)计算出的对应于第i个有效测试点的预测理论值。
(6)、取拟合方差函数σ2(d)最小值对应的自变量dcritical,作为临界距离。
步骤四、以求得的临界距离dcritical作为近场、远场分界,结合对应的两组k值参数,构成用于网络规划的双斜率传播模型参数。
本发明采取自适应调整的临界距离,可以根据连续波测试数据动态修正模型拟合参数,使得对实际电波传播特征的拟合更为精确,降低拟合预测方差。下面给出一个依据本发明方案的实例。依据本发明方法校正出的双斜率传播模型,对测试数据的拟合预测方差为7.7db,而按照标准spm方法校正出来的模型对数据的拟合预测方差为8.2db,本发明的拟合方差优于标准方案0.5db,拟合精度更为准确。
表1模型校正结果表
本发明提供了一种基于可变临界距离的lte传播模型校正方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
- 还没有人留言评论。精彩留言会获得点赞!