小区分簇方法及基于该小区分簇方法的频谱交叠复用方法与流程
本发明涉及一种小区分簇方法及基于该小区分簇方法的频谱交叠复用方法,属于无线通信技术领域。
背景技术:
目前,常见的小区分簇方法参见如下示例:
方法1:基于图论的分簇方法
该方法主要是把节点之间的边用来表示干扰,把干扰值抽象为干扰权重,然后根据使用不同的方法画出干扰图然后来进行分簇,有些方法是用k-means来分解子图,每个子图作为一簇,有的是基于相似度,可以把小区距离、信道增益等设置为相似度,使相似度大的小区分到一个簇,然后再进行簇间的干扰管理以及簇内的资源调度。
方法2:基于干扰最小分簇方法
首先确定分簇数目n,起初把每个小基站都当做一个簇,然后根据如下公式来计算簇与簇之间的干扰,之后找到簇间干扰最小的2个簇合并成一个大簇,然后一直循环迭代,直到簇的个数达到预设的分簇数目n而且所有的小基站都加入到不同的簇中。
其中,i(ck,cv)是簇k和簇v之间的干扰值;|ck|,|cv|分别是簇k和簇v内小区数;pi,j是簇k和簇v内cellj对celli的干扰接收功率(rsrp值)。
方法3:基于干扰降低分簇方法(简称为ccir方法)
首先确定分簇数目n,然后把受到干扰最大的小区放入第1个簇中,完成第1簇的初始化,之后依次找到与已有簇干扰最大的n-1个小区完成n个簇的初始化过程;然后找到与所有已有簇干扰最大的小区,将它加入到与之干扰最小的已有簇中,一直循环迭代直到所有小区都加入到这n个簇中结束。
其中,小区对簇的干扰计算公式如下:
其中,i(celli,ck)是小区i对簇k的干扰值,pj,i是celli对簇k中的元素cellj的干扰接收功率(rsrp值),cellj是celli的干扰邻区。
以上各小区分簇方法在超密集组网条件下,当干扰小区增多、簇合并后期簇内小区数目较多时,缺点开始体现出来,例如簇合并的粒度太大,再加上只考虑了簇与簇之间的平均干扰,并不能消除和减少簇内小基站之间的强干扰,ccir方法中也仅考虑到小区之间的干扰,还是无法保证可以提升网络容量和网络覆盖水平。
技术实现要素:
本发明所要解决的技术问题在于提供一种小区分簇方法,同时还提供一种基于该小区分簇方法的频谱交叠复用方法。
为实现上述发明目的,本发明采用下述的技术方案:
根据本发明实施例的第一方面,提供一种小区分簇方法,用于将多个小区分到n个簇中,包括以下步骤:
基于吞吐量,将受干扰最小的小区放入第一个簇后,将n-1个受已有簇干扰最大的小区分别放到n-1个簇中,作为所述n个簇的初始化;
将受所述簇的干扰最小的小区加入到所述簇中,直至所有小区被分配到所述簇中;其中,所述n为正整数。
其中较优地,所述各个簇的初始化步骤中,包括以下步骤:
遍历所有小区,找到吞吐量最大的小区,放入第一簇;
遍历已有簇,将所述已有簇作为干扰小区,找到与所述已有簇的吞吐量最小的小区,加入到新的簇中;重复此步骤,直到所述簇都有小区加入。
其中较优地,所述吞吐量最大的小区,是根据用户级信息计算得到;
所述用户级信息包括小小区发射功率、小小区噪声、用户分配带宽、用户公平性系数和用户信道增益。
其中较优地,所述用户级信息是由小小区通过物理下行控制信道发送给宏小区。
其中较优地,所述用户级信息在用户地理位置改变时触发。
其中较优地,所述将与所述簇的干扰最小的小区分别入到该簇中的步骤,包括以下步骤:
在剩余的所述小区中,找到与所有所述簇的吞吐量最大的小区,以及对应的所述簇;
将所述吞吐量最大的小区加入到所述簇中;
重复前述步骤,直到将所有所述小区加到所述簇中。
根据本发明实施例的第二方面,提供一种基于上述小区分簇方法的频谱交叠复用方法,包括以下步骤:
确定所述各个簇的所述小区能使用的频谱中的交叠部分和非交叠部分;
判断所述小区中吞吐量大的用户和吞吐量小的用户;
将所述吞吐量小的用户分配到所述非交叠部分。
其中较优地,所述频谱交叠复用方法进一步包括以下步骤:
将所述吞吐量大的用户分配到所述交叠部分。
其中较优地,所述频谱交叠复用方法进一步包括以下步骤:
将所述吞吐量大的用户分配到所述非交叠部分。
其中较优地,所述频谱交叠复用方法进一步包括以下步骤:
将吞吐量最高的用户分配到所有簇共用的频段;将吞吐量次高的用户分配到部分簇共用的频段。
与现有技术相比较,本发明所提供的小区分簇方法及基于该小区分簇方法的频谱交叠复用方法兼顾吞吐量和用户公平性,可以提升超密集网络中小区系统平均频谱效率和小区边缘频谱效率。
附图说明
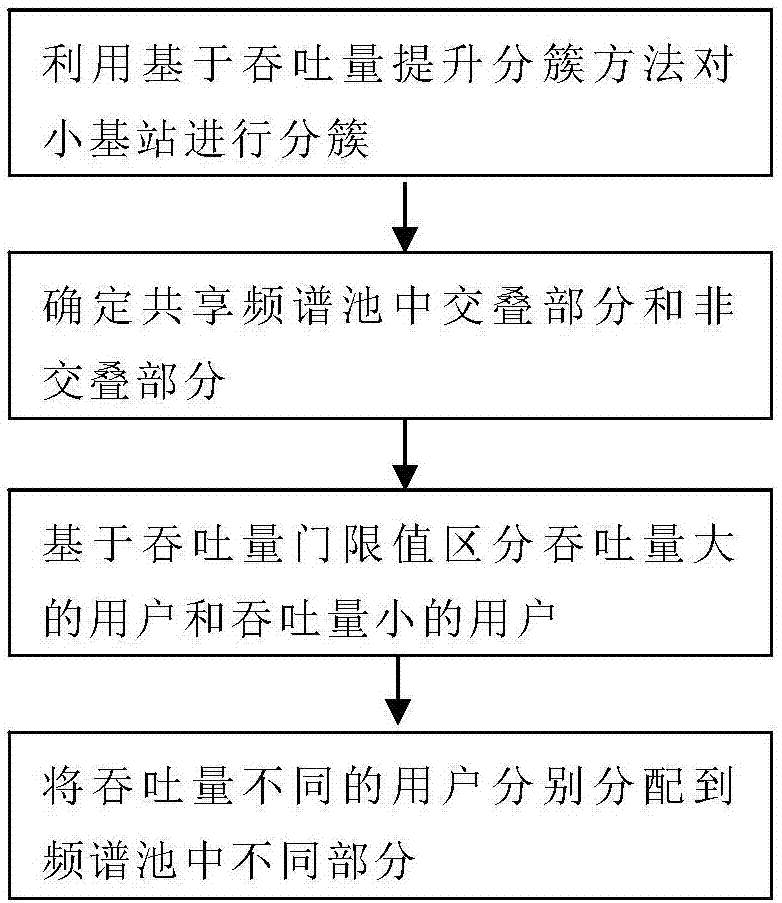
图1为本发明的第一实施例中,利用ccti方法进行分簇的流程图;
图2为本发明的第二实施例中,基于小区分簇的频谱交叠复用方法的流程图;
图3为本发明的第二实施例中,对吞吐量大和吞吐量小的用户分配频谱不同部分的示意图;
图4为本发明的第三实施例的流程示意图;
图5为本发明的第四实施例中,频谱分配的示意图。
具体实施方式
下面结合附图和具体实施例对本发明的技术内容进行详细具体的说明。
本发明针对超密集网络的技术特点,提出了一种基于小区分簇的频谱交叠复用方法。它首先对超密集网络中的小基站进行分簇,然后再进行频谱交叠,能够兼得系统容量的增加和覆盖指标的有效提升两个技术效果,是无线通信网络优化的优选方案。本发明所提供的小区分簇方法(简称为ccti方法)及基于该小区分簇方法的频谱交叠复用方法尤其适合应用于超密集网络的组网场景。
本发明所提供的频谱交叠复用方法可以在现有的ccir方法的基础上进行频谱交叠复用,也可以在本发明所提供的小区分簇方法(简称为ccti方法)基础上进行频谱交叠复用,由此可以获得两种频率交叠方法:频谱交叠干扰降低频率规划方法(frequencyoverlappingbasedontheinterferencereduction,简称为foir方法)和频谱交叠吞吐量提升频率规划方法(frequencyoverlappingbasedonthethroughputimprovement,简称为foti方法)。下面对此展开详细具体的说明。
本发明的整体思路在于对簇间吞吐量大的用户和吞吐量小的用户采用不同的频率分配方案,从而提高系统容量。如图1所示,本发明的主要步骤是将一个虚拟小区中的所有小基站分为多个簇(在图1中以2个簇为例进行说明);设置这些簇可以交叠使用的频率的比例,即频率交叠比例;再设置干扰门限值,判断吞吐量大的用户和吞吐量小的用户,最后根据各用户的吞吐量值,将每个簇中的用户分配到频率交叠部分或者非交叠部分。
<第一实施例>
下面结合图1,对第一实施例进行详细说明。
步骤1:对小基站进行分簇
在这一步骤中,将一个虚拟小区中的所有小基站分到不同簇。
首先,获得对小基站分簇的簇数。在本实施例中,根据ccir方法或者本发明提出的ccti方法(后文详述),通过仿真的方式确定ccir方法或者ccti方法中的最佳簇数。
本发明所述的最佳簇数是指,系统容量和覆盖性能相比分为其他分簇数时达到最优的簇数。换言之,将小基站分为最佳簇数时,得到的系统容量和覆盖性能综合性能最好。该最佳簇数是这样得到的:先假定分n(n为正整数,下同)个簇,然后仿真计算n为不同值时的系统容量和覆盖性能,比较n为不同值时的这两个性能指标,哪一组性能最优则对应的簇数n即为最佳簇数。所谓最优是指,在提高覆盖性能的同时提高系统容量,两个指标均达到最优。若没有覆盖性能与系统容量均达到最优的情况,则选择覆盖性能最优且系统容量次优的这组性能指标所对应的簇数。
假设通过仿真或者测试仪器得知,根据ccti方法得到的最佳簇数是2簇。在本实施例中就以2簇(即,分簇数目n=2)为例进行说明。这2个簇使用的频率之间并不是完全异频,2簇之间可以交叠复用部分频率,让吞吐量好的用户使用交叠的部分频率,提高频谱利用率。
其次,在确定了分簇数目之后,把虚拟小区中所有的小基站分配到各个簇中。在本实施例中,是将所有小基站分配到2个簇中。
下面结合图1详细说明通过本发明提出的ccti方法得到最佳簇数的过程。
ccti方法是基于现有ccir方法的改进方法,不仅考虑到小区之间的干扰,而且增加用户级信息为一条新信令作为判断依据,进行优化分簇,使用容量公式作为吞吐量的估算,以用户吞吐量作为改进目标。
ccti方法的目标是将小区加入簇中后,所有簇的吞吐量最大,主要思想是首先确定分簇数目n,然后把与其他小区之间的吞吐量最大的小区作为第1簇的初始化,然后依次找到与已有簇吞吐量最小的n-1个小区完成初始化;然后找到与已有簇吞吐量最大的小区,将它加入到与之吞吐量最大的簇中,一直迭代直到所有小区都加入到这n个簇中结束。具体的步骤如下:
1.初始阶段:目标n个簇的初始化。换言之,就是基于吞吐量,将受干扰最小的小区放入第一个簇后,将n-1个受已有簇干扰最大的小区分别放到n-1个簇中,作为各个簇的初始化。
11)遍历所有小区,根据用户级信息,找到吞吐量最大的小区,加入簇0;
本发明所提供的ccti方法中,用户级信息是由小小区通过pdsch信道(物理下行控制信道)发送给宏小区,该信息包括小小区发射功率(8比特)、小小区噪声(8比特,可以增加1比特的效验位)、用户分配带宽(8比特)、用户公平性系数(8比特)和用户信道增益(8比特,也可以增加1比特的校验位)等。
用户级信息是事件触发。在初始化布置好用户,确定用户位置后就可以触发这个消息的发出,后续用户有移动切换的话,待用户位置切换完成后就触发消息发出,也就是说,用户地理位置改变就触发该消息的发送。
宏小区接收到用户级信息,根据以下小区吞吐量计算公式,找到吞吐量最大的小区,
其中,rk是小区k所有用户的吞吐量,nue为每个小区用户数,ncell为干扰小区数,同时考虑每个用户的公平性,αi为每个用户对应的公平性系数,bi是每个用户分配的带宽,pk是k小区的发射功率,h是信道增益,σ2是噪声。
公式2使用容量公式作为吞吐量的估算,增加了用户级相关信息作为判断依据,将吞吐量作为改进目标,比只考虑小区级干扰(公式1)更为精确。
在此假设小区cellk是吞吐量最大的小区,将cellk放入簇0。
12)遍历已有簇,将已有簇作为干扰小区,对每个簇都找到一个对应的吞吐量最小的小区celln,n=1,...n;
将簇0作为干扰小区,即,将cellk(其中k∈n且k≠n)作为干扰小区,对所有的已有簇(在本实施例中为簇0)找到吞吐量最小的小区。假设对簇0(小区cellk)找到对应的吞吐量最小的小区,也就是将cellk作为干扰小区,找到吞吐量最小的小区(假设为cellk+1)。
13)在这n个小区中找到吞吐量最小的小区cellmin;
本实施例中,只有簇0对应的最小吞吐量的小区cellk+1,因此,将cellk+1作为所有小区中吞吐量最小的小区cellmin。
14)将cellmin加入到新的簇中,比如簇1。直到目标n个簇都有小区加入。
由于小区cellk+1是吞吐量最小的小区cellmin,将cellk+1放入簇1。这样所有的簇(本实施例中为簇0和簇1)都有小区加入,进入下一步骤。
2.迭代阶段:将与已有簇吞吐量最大的小区,加入到对应的簇中,所述小区与该簇的吞吐量最大,换言之,即将受各个簇干扰最小的小区分别加入到该簇中,直至所有小区被分配到各个簇中。
21)遍历n个簇,在剩余的小区中找到和所有簇吞吐量最大的小区cellmax;
在前述步骤中,小区cellk和cellk+1已分别分配到簇0和簇1。针对剩余的小区,cell1,cell2,cell3……cellk-1,cellk+2……celln,分别以簇0和簇1作为干扰小区,计算吞吐量。
在本实施例中,计算cell1与簇0(cellk)的吞吐量,就是根据公式2,以cellk作为干扰小区,计算cell1的吞吐量r10。同理,计算cell1与簇1(cellk+1)的吞吐量,就是根据公式2,以cellk+1作为干扰小区,计算cell1的吞吐量r11。
类似的,计算cell2与簇0(cellk)的吞吐量r20,以及cell1与簇1(cellk+1)的吞吐量r21。
如此计算得到所有小区分别与所有簇的吞吐量r10,r11,r20,r21……rn0,rn1。从这些吞吐量中找到最大值,在此假设为r20。因为r20是最大吞吐量,那么对应的吞吐量最大的小区是cell2,作为cellmax。
22)找到和cellmax吞吐量最大的对应已有簇,作为吞吐量最大簇ci;
由于在前述步骤中,已获知与所有簇的吞吐量,所以在此步骤中可以选择出吞吐量最大值是r20,对应的小区是cell2,对应的簇是簇0,即吞吐量最大簇ci为簇0。
23)把cellmax小区加入到簇ci;
于是吞吐量最大值对应的小区,加入到对应的簇。本实施例中,吞吐量最大值是r20,对应的小区是cell2,对应的簇是簇0,于是将cell2作为cellmax加入到簇0(簇ci)。
24)遍历剩余所有的小区,重复步骤21~步骤23,直到将小区全部加到n个簇中。
重复步骤21~步骤23,根据吞吐量,将各个小区分别加入到所有簇中。
本发明利用用户级吞吐量或者容量作为分簇判决的输入信息,以吞吐量最大为原则将小区分配到对应的簇,既以吞吐量作为优化目标也考虑到了用户公平性。
此外,本发明增加用户信道信息,使宏小区从小小区收集到计算吞吐量所需信息,根据公式2计算吞吐量,并将吞吐量作为判断依据进行优化分簇,能更为精确的进行分簇规划,有利于同时提升容量和覆盖性能指标。
<第二实施例>
在利用本发明所提供的ccti方法,基于吞吐量(sinr)和公平性进行小区分簇后,基于此分簇结果,可以进行lte公平性调度、软切换等,也可以进行频谱复用等多种方案。
例如基于吞吐量进行小区分簇后进行用户调度的方法,可以在基于吞吐量进行小区分簇后,由各小小区根据比例公平原则各自调度小区内用户。也可以轮询和最大载干比等方式进行调度。
第二实施例中,结合图2和图3介绍基于吞吐量进行小区分簇后的频谱交叠复用方法。包括以下步骤:
确定各个簇的小区能使用的频谱中的交叠部分和非交叠部分;
判断小区中干扰大的用户和干扰小的用户,并且将干扰大的用户分配到所述非交叠部分。
其中,所述干扰大的用户是指小区中吞吐量小的用户;所述干扰小的用户是指小区中吞吐量大的用户。
基于本发明所提供的ccti方法进行小区分簇后(这步骤与第一实施例相同,在此不累述),各个簇小区使用的频率之间存在交叠复用的部分。
首先,确定各个簇小区使用频谱的交叠部分和非交叠部分。如图3所示,中间的频段(图3中深色)为共用频段,即交叠部分;两侧的频段为两个簇单独使用频段,即非交叠部分。
其次,判断吞吐量大的用户和吞吐量小的用户
在本实施例中,通过设定判断吞吐量优劣的干扰门限值来判断吞吐量大的用户和吞吐量小的用户。吞吐量低于该干扰门限的用户,即属于吞吐量小的用户;吞吐量大于该干扰门限值的用户,即属于吞吐量大的用户。
再次,对同一簇的吞吐量大的用户和吞吐量小的用户,分别分配到频谱不同部分。
参考图3,将吞吐量不同的用户分配到频谱池中的不同部分,这个频谱池是不同簇的小区共用的。分配原则是:吞吐量小的用户使用非交叠部分,吞吐量大的用户使用交叠部分或者全部频段。
本实施例中,最佳簇数为2,因此将频谱池分为三个部分:第一个簇小区单独使用的频谱部分;第二个簇小区单独使用的频谱部分;以及两个簇小区共用的频谱部分。其中,前两个单独使用的频谱部分,统一定义为:非交叠部分;相应的,将两个簇小区共用的频谱部分,定义为:交叠部分。
针对吞吐量大于该干扰门限值的用户,即属于吞吐量大的用户,由于其较少受到别的小基站影响,可以使用两个簇中频率交叠的部分,所以可以使用其所在簇的小区能够使用的全部频段。
以图3为例,a簇小区的用户中,吞吐量大的用户可以使用图3左侧频段(左侧白色区域,非交叠部分)和中间共用频段(深色区域,交叠部分),即a簇小区吞吐量大的用户可以使用a簇小区所能使用的全部频段。a簇小区的用户中,吞吐量小的用户被分配到图3所示a簇小区单独使用的频段(左侧白色区域)。
类似的,b簇小区的用户中,吞吐量大的用户可以使用b簇小区单独使用的频段(右侧白色区域,非交叠部分)和中间共用频段(深色区域,交叠部分),即b簇小区吞吐量大的用户可以使用b簇小区所能使用的全部频段。b簇小区的用户中,吞吐量小的用户被分配到图3所示b簇小区单独使用的频段(右侧白色区域)。
<第三实施例>
第三实施例与第一实施例的不同点在于,是根据现有ccir方法得到最佳簇数,并且是基于信干噪比(sinr)大小来区分不同用户,然后分配到频谱中交叠或非交叠部分。该方法包括以下步骤:
确定各个簇的小区能使用的频谱中的交叠部分和非交叠部分;
判断小区中干扰大的用户和干扰小的用户,并且将干扰大的用户分配到所述非交叠部分。
其中,所述干扰大的用户是指小区中sinr差的用户;所述干扰小的用户是指小区中sinr高的用户。
参考图4,首先根据现有ccir方法得到最佳簇数,在本实施例中最佳簇数是2。
其次,再确定两个簇的频谱池中的频谱交叠部分和非交叠部分。
然后,设置干扰门限值(即sinr门限值),区分出每个小区的sinr高的用户和sinr差的用户。
最后,将每个簇中的小区的用户中,sinr差的用户优先分配到该簇所占用的非交叠部分的频段;sinr高的用户优先分配到两簇共用的频段,既可以分配到该簇单独占用的非交叠部分的频段,也可以分配到该簇与其他簇共用的交叠部分。即,sinr高的用户可以分配到其所在簇可以使用的全部频段。
<第四实施例>
与第二实施例或第三实施例不同,第四实施例讨论分簇数目n大于2的情况。
首先,基于ccir方法和ccti方法,将小区分簇,簇数大于2,例如为3。
其次,将3个簇小区共享的频谱池划分为图5所示七个部分。其中,标有a\b\c的三个频段分别是a簇、b簇和c簇单独使用的频段,即非交叠部分。标有a+b频段是a簇和b簇共用频段,c簇不可用;a+c频段是a簇与c簇共用频段,b簇不可用;b+c频段是b簇与c簇共用频段,a簇不可用。标有a+b+c的频段是a簇、b簇与c簇三个簇共用的频段。
再次,将各簇小区的各个用户分配到所有簇共享的频谱池。分配原则是:每一个簇将该簇内吞吐量小的用户分配到非交叠部分的频段,该簇其他用户可以使用的该簇能够使用的全部频段。
具体而言,结合图5所示,a簇小区的用户中,吞吐量大的用户被分配到a+b\a+c\a+b+c频段或者a频段(即a簇可以使用的全部频段),吞吐量小的用户被分配到a频段。优选的是,吞吐量最高的用户被分配到a+b+c频段(所有簇共用频段);吞吐量次高的用户被分配到a+b或a+c频段(部分簇共用频段)。
下面通过仿真数据来介绍本发明的技术效果。关键的仿真参数如下表1所示:
表1仿真参数设置
1.用户边缘分布时的仿真结果
在本发明实施例中需要设置判断吞吐量大小的干扰门限值,单位为db。如果用户的吞吐量大于该干扰门限值,就判断为吞吐量大的用户,这些用户可以使用虚拟小区的全部频段;如果用户的吞吐量低于该干扰门限值,那么这些用户使用属于该簇的频率非交叠的部分频率。所以理论上来讲会有一个最合适的值使系统性能最好。以下是通过多组仿真实验来寻找最优的判断吞吐量大小的干扰门限值的结果。
表2不同干扰门限值值频谱效率的增益
表2中清晰表示频谱交叠比例一定的情况下不同干扰门限值以0db为基准时的系统和边缘性能增益,干扰门限值为1db时的系统性能和边缘性能相对是最好的,所以当用户边缘分布时,仿真中把干扰门限值设为1db以获得最优的仿真效果。综上,用户边缘分布时干扰门限值为1db是最优值。
2.用户均匀分布时的仿真结果
表3中清晰地显示出频谱交叠比例一定的情况下以干扰门限值0db时为基准时,不同干扰门限仿真对应的总体系统性能和边缘性能增益表,干扰门限值为2db时性能更好,仿真中把干扰门限值设为2db以获得更优的仿真效果。综上,小区内用户均匀分布时,最合适的干扰门限值是2db。
表3不同干扰门限值频谱效率的增益
表4和表5中所示的是频谱交叠复用的两种方法相对基准(不分簇)频谱效率的相应增益。同时表中也列出了已有的ccir方案和基于用户级信息,以吞吐量为改进目标的ccti方案对应的仿真结果进行对比分析。数据显示,分别考虑两种用户分布场景时,四种方案对比基准(不分簇)都有明显增益,其中ccti方法性能增益优于ccir,foti方法优于foir,表明增加用户级信息,考虑吞吐量作为改进目标并考虑用户公平性进行分簇比只考虑小区级干扰有明显优势。同样地,foir方法性能增益优于ccir,foti方法优于ccti,表明设置频谱交叠比例,采用判断吞吐量大小的干扰门限这个参数进行频谱交叠复用方法有明显的增益提升。
表4四种方法中相对基线的增益对比
表5相对基于干扰降低分簇方案的增益对比
根据表中数据显示又可知,当用户边缘分布时,ccir方法是增益最小的,系统增益为6.68%,但是边缘性能又略微下降约4%;其次是foir方法系统增益是6.44%,边缘基本没有提升;第三是ccti方法,系统增益为6.78%,边缘的增益为13.50%;foti方法是提升最大的,无论系统性能还是边缘性能都提升了30%多。当用户均匀分布时,ccir、ccti、foir方案这三种方法的系统性能相对于基准都剧烈下降,所以不适合在用户均匀分布的时候采用;只有foti方法(基于ccti方法进行分簇的频谱交叠复用方法)性能有大幅提升,虽然系统性能下降了约4%,但是边缘的性能提升高达33%,是一个在用户均匀分布时仍然有效的方法。
综上所述,基于吞吐量提升分簇的频谱交叠复用方法(即foti方法)效果是最优的:在用户均匀分布场景能够大幅提升覆盖性能;在用户边缘分布时,同时提升容量和覆盖性能。
本发明利用用户级的吞吐量作为分簇判决的输入信息,以吞吐量作为优化目标并考虑用户公平性,增加用户级信息为新信令并将此作为判断依据进行优化分簇,并通过配置频谱交叠的比例和判断吞吐量大小的干扰门限参数,可以提升超密集网络中小区系统平均频谱效率和小区边缘频谱效率,实现吞吐量和公平性的均衡。
上面对本发明所提供的小区分簇方法及基于该小区分簇方法的频谱交叠复用方法进行了详细的说明。对本领域的一般技术人员而言,在不背离本发明实质精神的前提下对它所做的任何显而易见的改动,都将构成对本发明专利权的侵犯,将承担相应的法律责任。
- 还没有人留言评论。精彩留言会获得点赞!