一种低时延低复杂度的极化码译码方法与流程
本发明涉及无线通信中信道译码技术领域,尤其涉及一种低时延低复杂度的极化码译码方法。
背景技术:
极化码(polarcodes)是一种新型信道编码技术,它是第一类可以被严格证明达到二进制对称输入离散无记忆信道的信道容量的信道编码技术。极化码的主流译码方法是串行抵消列表(successivecancellationlist,scl)译码和置信传播译码。与置信传播译码方法相比,scl译码方法虽然误码率性能更好,但其缺陷也很明显:译码时延大且复杂度高,这是因为scl译码是序贯译码且需要进行大量存储。本发明针对scl译码方法的上述缺点,提出了一种低时延时延、低复杂度的scl译码方法。
技术实现要素:
发明目的:本发明针对现有技术存在的问题,提供一种低时延低复杂度的极化码译码方法。
技术方案:本发明所述的低时延低复杂度的极化码译码方法包括:
(1)在译码时,从待编码比特序列中选出fcr0节点和msr1节点;其中,fcr0节点是待编码比特序列中从第一位开始连续的冻结比特构成的节点,msr1节点是待编码比特序列中最后的连续的个数为2的幂的信息比特构成的节点;
(2)对fcr0节点的比特序列,根据接收机存储的冻结比特位的值直接获取译码结果,译码路径度量为初始值0;
(3)对fcr0节点和msr1节点之间的比特序列,若为冻结比特,则连接步骤(2)中的路径,直接根据接收机存储的冻结比特位的值获取译码结果;若为信息比特,则连接冻结比特译码路径,通过路径分裂和简化路径度量排序保留路径度量较小的路径;
(4)对msr1节点的比特序列,采用信道接收的llr进行直接判决译码,得到msr1节点译码结果,并连接在步骤(3)中保留的所有路径上;
(5)对于步骤(4)中的路径,选择一条路径度量最小的路径对应的译码序列作为译码输出。
进一步的,步骤(1)中fcr0节点的选择方法为:从待编码比特序列
进一步的,所述步骤(3)具体包括:
对于fcr0节点和msr1节点之间的比特序列,按照下面方法从前到后依次处理:
(3-1)判断当前待译码比特ui为冻结比特还是信息比特;若为冻结比特,执行(3-2),否则执行(3-3);
(3-2)对于当前待译码比特ui,连接步骤(2)中的路径,直接根据接收机存储的冻结比特位的值获取译码结果,并将译码路径进行存储,将i=i+1,返回(3-1);
(3-2)对于当前待译码比特ui,将已经存储的路径进行路径分裂,得到2l个度量值,存储在如下的矩阵中:
式中,l是已经存储的路径数,1≤l≤l,l为scl译码器的列表最大规模,pmj和
之后通过进行2l次比较,选出矩阵中的最小值和次小值,并选择剩余的尽可能小的l-2个值,从而得到l个路径并进行存储路径。
其中,2l次比较具体方法为:
第一次排序:比较同一列的两个元素pmj和
式中,
第二次排序:针对新的矩阵,比较
进一步的,所述步骤(4)具体包括:
(4-1)对msr1节点的比特序列,采用信道接收的llr进行直接判决译码,得到判决结果a|msr1|={a1,a2,...,a|msr1|};其中|msr1|为msr1节点包含信息比特的数量,a*为msr1节点的第*个比特的判决结果;
(4-2)根据判决结果计算得到msr1节点译码结果:
vn-|msr1|+1={vn-|msr1|+1,...,vn}=a|msr1|g|msr1|
其中
(4-3)将msr1节点译码结果连接在步骤(3)保留的所有的路径上,得到
式中,
进一步的,所述步骤(5)具体包括:
(5-1)计算步骤(4)中保留的所有路径的路径度量值:
式中,pmm表示msr1节点译码后第m条路径的路径度量值,pmk,m表示第m条路径在译码msr1节点前,已经具有的度量值,
(5-2)从所有路径中,选择一条路径度量最小的路径对应的译码序列作为译码输出。
有益效果:本发明与现有技术相比,其显著优点是:本发明通过简化fcr0和msr1节点的译码计算,以及简化译码过程中的排序过程,降低了极化码scl译码方法的译码延时和复杂度。
附图说明
图1是本发明提供的低时延低复杂度的极化码译码方法的流程示意图;
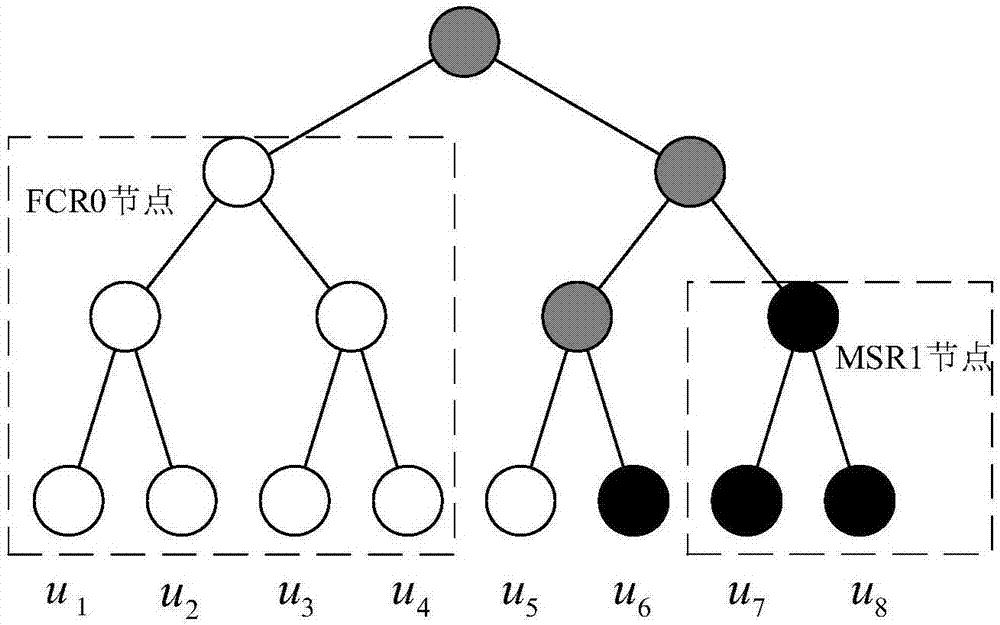
图2是frc0和msr1节点示意图。
具体实施方式
本实施例提供了一种低时延低复杂度的极化码译码方法,如图1所示,包括如下步骤:
(1)在译码时,从待编码比特序列中选出fcr0节点和msr1节点;其中,fcr0节点是待编码比特序列中从第一位开始连续的冻结比特构成的节点,msr1节点是待编码比特序列中最后的连续的个数为2的幂的信息比特构成的节点。
其中,fcr0节点的选择方法为:从待编码比特序列
(2)对fcr0节点的比特序列,根据接收机存储的冻结比特位的值直接获取译码结果,译码路径度量为初始值0。
其中,对fcr0节点进行译码的原理有以下两点:第一,fcr0所包含的冻结比特的值对于发射机和接收机都是已知的,因此这些冻结比特对应的对数似然比(log-likelihoodratio,llr)不必计算;第二,由于fcr0节点中的冻结比特位于待编码比特序列
(3)对fcr0节点和msr1节点之间的比特序列,若为冻结比特,则连接步骤(2)中的路径,直接根据接收机存储的冻结比特位的值获取译码结果;若为信息比特,则连接冻结比特译码路径,通过路径分裂和简化路径度量排序保留路径度量较小的路径。
该步骤具体包括:
对于fcr0节点和msr1节点之间的比特序列(如图2中的u5和u6),按照下面方法从前到后依次处理:
(3-1)判断当前待译码比特ui为冻结比特还是信息比特;若为冻结比特,执行(3-2),否则执行(3-3)。
(3-2)对于当前待译码比特ui,连接步骤(2)中的路径,直接根据接收机存储的冻结比特位的值获取译码结果,并将译码路径进行存储,将i=i+1,返回(3-1)。同fcr0节点原理一致。
(3-2)对于当前待译码比特ui,将已经存储的路径进行路径分裂,得到2l个度量值,存储在如下的矩阵中:
式中,l是已经存储的路径数,1≤l≤l,l为scl译码器的列表最大规模,pmj和
其中,路径度量的数值越小越好,即具有最小度量的路径是最优路径。常规的scl译码器选择这2l个值中最小的l个值。但是在允许一定程度上损失误码率性能的场合,并不要求严格选出最小的l个值。本实施例中的排序方法通过进行2l次比较,选出矩阵(1)中的最小值和次小值,同时使得剩余的l-2个值尽可能小,尽可能小是指本实施例中的排序方法总是选择某两个数中的较小者,排序方法具体为:
第一次排序:比较同一列的两个元素pmj和
式中,
第二次排序:针对新的矩阵,比较
(4)对msr1节点的比特序列,采用信道接收的llr进行直接判决译码,得到msr1节点译码结果,并连接在步骤(3)中保留的所有路径上。
由信道编码理论可知,对于码率为1的线性分组码(即msr1节点对应的情况),直接判决从信道接收的对数似然比所得到的译码序列,等价于最大似然译码序列。因此,对于msr1节点,可以对llr进行直接判决,得到译码结果,不必进行递归的串行抵消译码计算,由此简化了译码过程,降低了译码时延。因此,步骤(4)具体包括:
(4-1)对msr1节点的比特序列,采用信道接收的llr进行直接判决译码,得到判决结果a|msr1|={a1,a2,...,a|msr1|};其中|msr1|为msr1节点包含信息比特的数量,a*为msr1节点的第*个比特的判决结果;
(4-2)根据判决结果计算得到msr1节点译码结果:
vn-|msr1|+1={vn-|msr1|+1,...,vn}=a|msr1|g|msr1|
其中
(4-3)将msr1节点译码结果连接在步骤(3)保留的所有的路径上,得到
式中,
(5)对于步骤(4)中的路径,选择一条路径度量最小的路径对应的译码序列作为译码输出。具体包括:
(5-1)计算步骤(4)中保留的所有路径的路径度量值:
式中,pmm表示msr1节点译码后第m条路径的路径度量值,pmk,m表示第m条路径在译码msr1节点前,已经具有的度量值,
(5-2)从所有路径中,选择一条路径度量最小的路径对应的译码序列作为译码输出。
本发明通过简化fcr0和msr1节点的译码计算,以及简化译码过程中的排序问题,降低了极化码scl译码方法的译码延时和复杂度。
以上所揭露的仅为本发明一种较佳实施例而已,不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!