一种音视频联动的远程集音器的制作方法
本实用新型涉及音视频联动的远程集音器。
背景技术:
在安保、安防,采访等领域,各类视频监控或视频采集系统已经得到广泛应用。依托各类视频监控或视频采集系统,可以对远距离视频中相关人员进行准确拍摄,但在利用视频监控系统进行远距离拍摄时很难进行远距离语音采集,如能通过远距离语音采集,视频监控系统即可利用语言、对话信息分析嫌疑人,将可大大提高工作效率。但在实际环境背景噪声条件下进行远距离语音采集可以实现,且清晰度仍然较低且语音采集巨大难以方便使用。
技术实现要素:
本实用新型要解决的技术问题是,提供一种音视频联动的远程集音器,音视频联动的远程集音器可以远距离进行清晰的语音采集且体积小。
本实用新型的技术解决方案是,提供一种具有以下结构的音视频联动的远程集音器,包括壳体、摄像组件以及至少两个拾音单体,所述的拾音单体包括麦克风以及与麦克风相配的反射面,所述的壳体包括用于容纳拾音单体和摄像组件的槽体以及配合在槽体开口上的罩体,所述的壳体内设有用于固定拾音单体和摄像组件的固定结构。
优选的,还包括单通道降噪处理模块、麦克风阵列处理模块、指向性处理模块;麦克风分别接入与之对应的单通道降噪处理模块输入端,单通道降噪处理模块输出端接入麦克风阵列处理模块的输入端,麦克风阵列处理模块的输出端接入指向性处理模块的输出端。
优选的,还包括音视频联动模块,音视频联动模块接收指向性处理模块上产生的波束方向参数和摄像机变倍参数建立音视频同步放缩参数映射表,音视频联动模块根据音视频同步放缩参数映射表和摄像机变倍参数输出音视频联动混合信号。
优选的,所述的拾音单体可拆式连接在壳体内。
优选的,所述的拾音单体呈线性阵列,所述的摄像组件设置在壳体端部或中部。
优选的,所述的拾音单体呈环形阵列,所述的摄像组件中部。
优选的,所述的拾音单体排列成两排或两列,所述的两排或两列拾音单体呈交错排布以使麦克风呈波浪状排布。
优选的,所述的拾音单体还包括环状固定片,所述的环状固定片中部设有用于容纳麦克风的槽体,所述的环状固定片外沿设有环形槽,所述的反射面连接在环形槽。
优选的,所述的固定结构包括用于支撑反射面和摄像组件的凸块,所述的反射面外沿与罩体抵触,所述的罩体设有供摄像组件穿过的通孔。
优选的,所述的罩体还包括结构层以及防护层,所述的防护层包括防风层和防水层。
优选的,所述的壳体向内翻转有折边,所述的罩体与折边抵触。
优选的,所述的壳体内侧壁附有减震吸音棉。
采用以上结构后,本实用新型的音视频联动的远程集音器,与现有技术相比,具有以下优点:通过直接排布多个拾音单元能大大提高远距离语音采集的清晰度,且与摄像组件配合能做到视频与声音同步,所述的摄像组件体积小不会干涉拾音单元的排布,另外壳体直接包覆在拾音单元上,保证较小的体积具有较好的防护力度,另外通过固定结构来固定拾音单体,整体结构稳定且体积小,反射面能加强拾音效果且拾音单元通过上述方式固定,实现可拆式的结构,即可以在壳体内设置不同性能的拾音单元,大大提高了产品的适用性。
附图说明
图1是本实用新型的音视频联动的远程集音器的结构示意图。
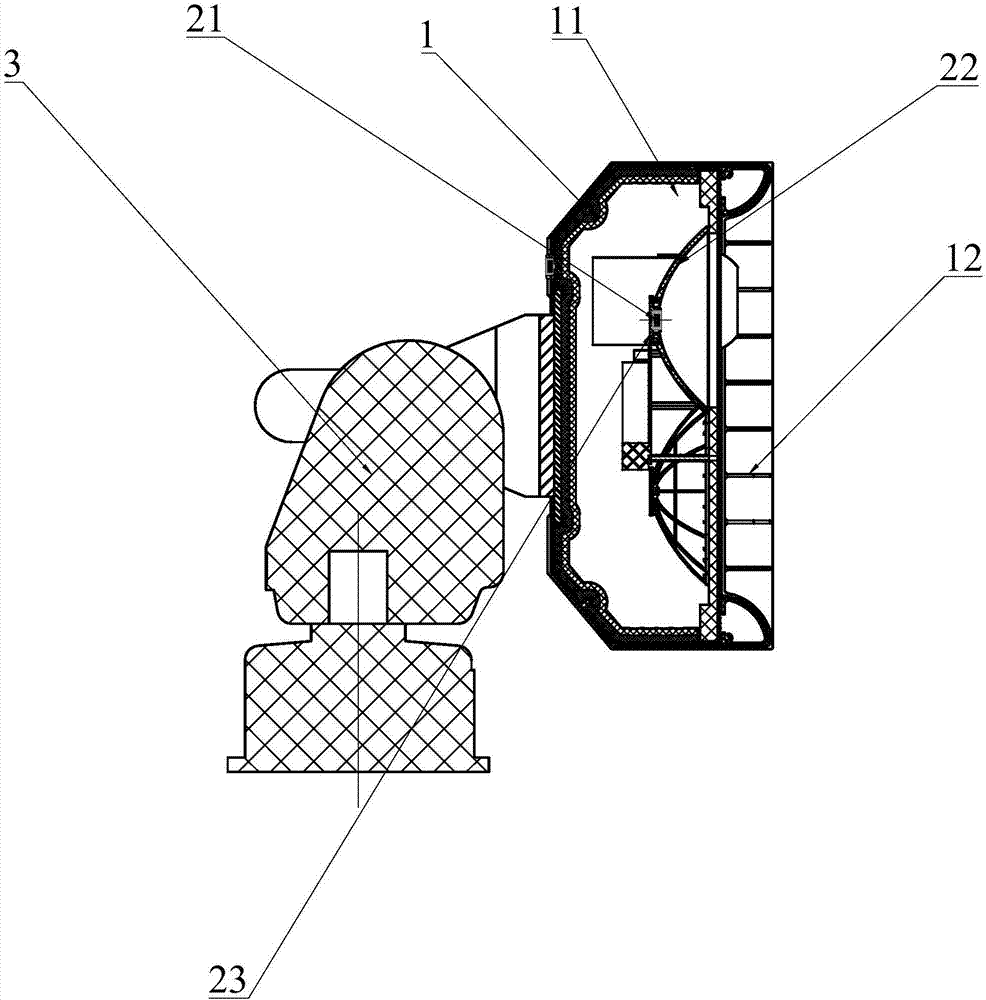
图2是本实用新型的音视频联动的远程集音器的剖面示意图。
图中所示:1、壳体;11、槽体;12、罩体;2、拾音单体;21、麦克风;22、反射面;23、环状固定片;3、云台;4、摄像组件。
具体实施方式
下面结合附图和具体实施例对本实用新型作进一步说明。
请参阅图1及图2所示,本实用新型的本实用新型要解决的技术问题是,提供一种具有以下结构的音视频联动的远程集音器,包括壳体1、摄像组件4以及至少两个拾音单体2,所述的拾音单体2包括麦克风21以及与麦克风21相配的反射面22,所述的壳体1包括用于容纳拾音单体2和摄像组件4的槽体11以及配合在槽体11开口上的罩体12,所述的壳体1内设有用于固定拾音单体2和摄像组件4的固定结构,通过直接排布多个拾音单元能大大提高远距离语音采集的清晰度,且与摄像组件4配合能做到视频与声音同步,所述的摄像组件4体积小不会干涉拾音单元的排布,另外壳体1直接包覆在拾音单元上,保证较小的体积具有较好的防护力度,另外通过固定结构来固定拾音单体2,整体结构稳定且体积小,反射面22能加强拾音效果且拾音单元通过上述方式固定,实现可拆式的结构,即可以在壳体1内设置不同性能的拾音单元,大大提高了产品的适用性,所述的拾音单体2可拆式连接在壳体1内,通过抵触或者卡扣等方式固定拾音单体2,实现可拆式的结构,即可以在壳体1内设置不同性能的拾音单元,大大提高了产品的适用性。
音视频联动的远程集音器还包括单通道降噪处理模块、麦克风21阵列处理模块、指向性处理模块;麦克风21分别接入与之对应的单通道降噪处理模块输入端,单通道降噪处理模块输出端接入麦克风21阵列处理模块的输入端,麦克风21阵列处理模块的输出端接入指向性处理模块的输出端。
音视频联动的远程集音器的远程集音方法包括以下步骤:
S1、多个拾音单元均沿一个方向进行声音拾取形成带噪语音并将带噪语音输入单通道降噪处理模块;
S2、单通道降噪处理模块首先对带噪语音进行成帧,然后对语音频谱进行估计和平滑并识别噪声类型,之后选取与噪声类型对应的滤波模型进行噪声消除,将降噪后的语音信号输入至阵列处理模块;
S3、阵列处理模块采用延迟求和波束形成算法处理降噪后的语音信号提升阵列增益并将信号输入至指向性处理模块;
S4、指向性处理模块采用基于人耳的听感知特性的计算机听觉场景分析技术建立心型或超心型拾音模型。
单通道降噪处理模块设计不同统计特性噪声所对应的滤波模型,以达到针对多种类型的噪声分别建模、分别予以消除的目标。由于针对性强且可以达到较强的降噪效果,由于先进行降噪再进行阵列增益,能大大提高阵列的准确性,使增益效果更佳,并最后通过人耳的听感知特性的计算机听觉场景分析技术建立心型或高心型或超心型拾音模型输出,使声音的指向型达到最优。
所述的步骤S2中滤波模型进行噪声消除的方法如下,利用端点检测的结果对噪声的频谱进行估计,频域维纳滤波系数通过Mel滤波器组转化为Mel域的维纳滤波系数,接着采用Mel IDCT得到滤波器的时域冲激响应,最终使用卷积得到增强后的时域语音信号用于后端的模型匹配。
频域滤波器系数H(k)经过Mel滤波器组的计算公式推导如下所示。语音采样率为8000Hz。Mel滤波器组数目为23。则每一个Mel滤波器的中心Mel值为
其中,算子MEL是将频率值转为Mel值,转换公式为
根据每一个Mel滤波器的中心Mel可以求得对应的中心频率
同时设定系统采用256点FFT,根据实数FFT的对称性质,只需要计算前128点的滤波器系数。各个Mel滤波器中心频率对应的FFT序号为
算子int用于将浮点数取整。利用三角窗滤波器可以将频域维纳滤波系数H(k)转化为Mel域维纳滤波器。
根据上式,可以得到Mel域维纳滤波系数完成了从频域到Mel域的转化。另外,由于从Mel域到时域是实数到实数的转化,所以采用了逆离散余弦变换(Inverse Discrete Cosine Transform IDCT)。另外由于每个Mel滤波器覆盖的频段长度不同,因此要附加不同的权重。Mel IDCT的计算公式如下。
是Mel IDCT的系数,其中
最终的维纳滤波器的时域冲激响应为
所述的步骤S3中采用延迟求和波束形成算法如下,各通道接收到的单路降噪信号经过时延τi补偿后,使得各路输出信号xi(n)在目标信号方向上同步,采用可调波束形成器对xi(n)进行滤波,并将滤波后各路信号相加,实现目标语音的初步增强。具体方法如下:(1)均匀线列阵,阵列孔径为d,目标语音信号源s(n),其入射角估计值为ak。设声场为远场传播模型,声波以平行波方式传播,则ak可表示为:
式中:N是扫描精度
(2)取阵列几何中心为参考阵元,对各通道语音信号进行时延补偿得:
式中:xi是第i个阵元的接收信号;
τi(ak)是第i个阵元以ak作为期望语音输入方向,与参考元之间的时延差。
(3)在可调波束形成器这一路,有:
X(ak,n)=[x'1(ak,n),x'2(ak,n),...x'M(ak,n)]T
Ws(ak,n)=[w1(ak,n),w2(ak,n),...wM(ak,n)]T
式中:ys(ak,n)是接收信号经过固定波束形成器得到的信号;
Ws(ak,n)是权向量。
(4)在阻塞矩阵这一路,有:
N(ak,n)=BX(ak,n)
式中:N(ak,n)是某通道接收信号经过阻塞矩阵B滤除期望信号后得到的噪声信号;
y(ak,n)是增强后的语音信号。
所述的步骤S4中采用基于人耳的听感知特性的计算机听觉场景分析技术建立心型或超心型拾音模型的方法如下:
(1)、指向性处理模块对获取阵列增强输出信号和残留噪声经过模拟人耳频率分解特性的gammatone滤波器组进行多子带滤波,得到多子带时域信号。
(2)、对所有子带信号进行加窗分帧,得到时频单元序列,计算可得阵列增强输出信号与残留噪声时频单元的能量;
(3)、将阵列增强输出信号与残留噪声时频单元的能量对比平滑后,作为线索,得到二值掩蔽模板;
(4)、将掩蔽模板作用于阵列输出的混合信号,提取出目标语音占优的时频单元,最终构建心形或超心型拾音模式,实现语音增强。
采用以上述建立拾音模型的方法后,进行加窗分帧,即可以得到可以处理的单元,根据单元能量得到的可以有效需求需要的时频单元,即能得到与目标语音更接近的时频单元,最后建立的拾音模式与目标语音更加接近。
音视频联动的远程集音器还包括音视频联动模块,音视频联动模块接收指向性处理模块上产生的波束方向参数和摄像机变倍参数建立音视频同步放缩参数映射表,音视频联动模块根据音视频同步放缩参数映射表和摄像机变倍参数输出音视频联动混合信号,实现图像定位、图像放大声音放大、噪声压制,即通过音视频联动模块实现声音的放大和缩小,简化了人工调节的工作量,使声音和影响更加同步,监控效果更好。
所述的拾音单体2呈线性阵列,可以远距离采集语音,能较大程度的去除噪声,所述的拾音单体2呈环形阵列,可以大大提高对固定区域的指向形,能稳定的接收固定区域的噪声,能较大程度的减少固定区域之外的噪声,摄像组件4可以多个摄像头或者单个摄像头,摄像头设置在中部能有良好图像和音频配合,摄像头设置在两端有更大的成像范围。
所述的拾音单体2排列成两排或两列,所述的两排或两列拾音单体2呈交错排布以使麦克风21呈波浪状排布,即可以远距离采集语音,能较大程度的去除噪声,并能保证对固定区域的指向形,且体积小,摄像头设置在中部能有良好图像和音频配合。
所述的拾音单体2还包括环状固定片23,所述的环状固定片23中部设有用于容纳麦克风21的槽体11,所述的环状固定片23外沿设有环形槽,所述的反射面22连接在环形槽,通过环状固定片23连接麦克风21和反射面22,结构稳定,安装方便,且可以通过槽体11直接更换麦克风21,或者是直接更换环状固定片23和麦克风21,进一步提高产品适用性。
所述的固定结构包括用于支撑反射面22和摄像组件4的凸块,所述的反射面22外沿与罩体12抵触,即拾音单体2直接通过凸块和罩体12抵触固定,减少了安装元件并大大提高了安装效率。摄像组件4通过凸块和罩体12上通孔固定,结构简单可靠,所述的罩体12还包括结构层以及防护层,所述的防护层包括防风层和防水层,能提高户外使用,且罩体12可以更换以适配不同环境。所述的壳体1向内翻转有折边,所述的罩体12与折边抵触。通过壳体1向内翻转的折边来固定,进一步减少了安装元件并大大提高了安装效率,折边可为弧形或者多边形。所述的壳体1内侧壁附有减震吸音棉,能大大降低噪声,所述的壳体1内连接有用于转动壳体1的云台3,便于音视频联动的远程集音器多角度采集。
音视频联动的远程集音器内摄像组件4为网络摄像机、数字摄像机或模拟摄像机其中的一种,即网络摄像机、数字摄像机或模拟摄像机都可以和本申请的音视频联动的远程集音器配合。
以上所述仅是本实用新型的优选实施方式,本实用新型的保护范围并不仅局限于上述实施例,凡属于本实用新型思路下的技术方案均属于本实用新型的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本实用新型原理前提下的若干改进和润饰,这些改进和润饰也应视为本实用新型的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!