基于异质节点的无线认知传感器网络低能量适应性分簇方法与流程
本发明属于无线传感器技术领域,涉及基于异质节点的无线认知传感器网络低能量适应性分簇方法。
背景技术
在这种异构型认知无线传感器网络中,簇首从所有的认知节点中选择出来的,认知节点只负责承担频谱感知和汇聚中继功能,不需要进行数据感知。通过均衡簇中认知节点的分布可以在保证信道感知准确率的同时减少了认知节点部署数量,进而极大降低了网络的部署成本(认知节点成本比数据节点成本昂贵)。
在hcrsn中,认知节点和传感器节点相互分离且承担不同功能,但同时又必须紧密协调共同完成数据传输工作。特别地,为了提高频谱感知性能,网络中需要多个节点对信道进行协作频谱感知,将认知节点和传感器节点组成分簇拓扑结构,以两级层次结构进行工作是实现hcrsn正常工作的前提和基础。因此,分簇路由算法是实现hcrsn的关键技术之一,对于hcrsn部署具有极其重要的现实意义。
目前基于同质节点的wsn和crsn中的分簇算法都无法适用于hcrsn。因此,设计一种能够适用于hcrsn的分簇路由协议,在保证各簇中的信道探测率,降低潜在冲突导致的能耗的同时降级网络部署成本,优化网络,具有现实意义。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于异质节点的无线认知传感器网络低能量适应性分簇方法,以解决异质节点的无线认知传感器网络分簇算法问题。
为达到上述目的,本发明提供如下技术方案:
基于异质节点的无线认知传感器网络低能量适应性分簇方法,包括以下步骤:
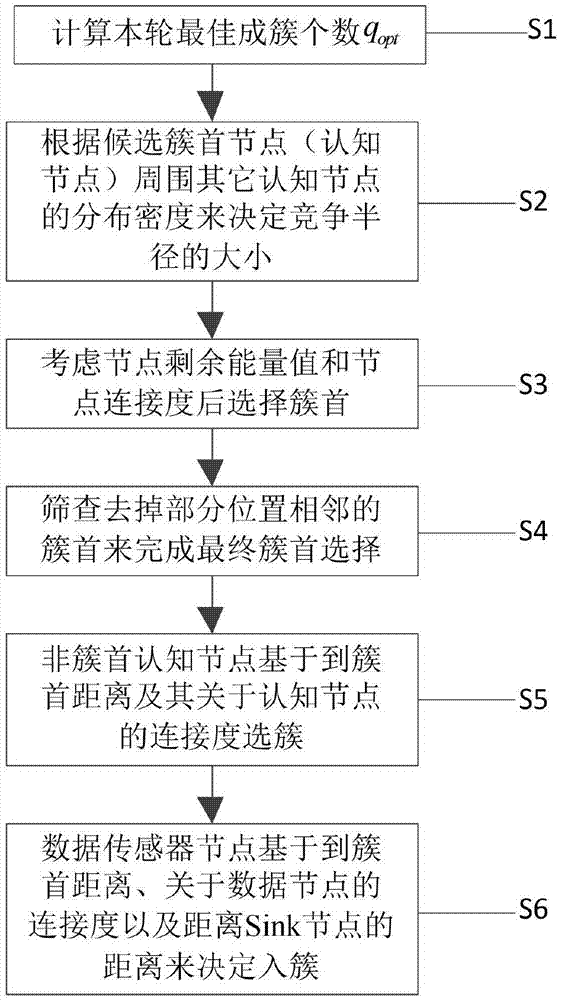
s1:计算本轮最佳成簇个数qopt;
s2:根据候选簇首,即认知节点周围其它认知节点的分布密度来决定竞争半径的大小;
s3:考虑节点剩余能量值和节点连接度后选择簇首;
s4:筛查去掉部分位置相邻的簇首来完成最终簇首选择;
s5:非簇首认知节点基于到簇首距离及其关于认知节点的连接度选簇;
s6:数据传感器节点基于到簇首距离、关于数据节点的连接度以及距离sink节点的距离来决定入簇。
进一步,在步骤s1中,建立不同类型节点的能量消耗模型;其中簇首工作从协作频谱感知开始,其工作时序依次为接收非簇首认知节点协作频谱感知信息,频谱感知结果决策并广播,接收数据节点收集的数据,融合数据,然后发送和中继数据;簇首在一轮中的能耗公式为:
其中,m表示平均每个簇中数据节点个数,l1表示数据节点事件感知数据包大小,n表示平均每个簇中非簇首认知节点个数,l2表示认知节点频谱感知结果和控制信息数据包大小,eda为融合1bit数据消耗的能量,dtonext表示簇首节点到下一跳节点的平均距离,dtoch表示簇内节点到簇首的平均距离;esense为单个认知节点频谱感知消耗的能量,l3表示为本簇事件感知数据包大小和中继转发其他簇数据的和,即簇首的平均传输的数据量,l4表示为簇首平均接收数据量,即中继簇首的平均接收数据;
非簇首认知节点能量消耗模型:
数据节点能量消耗模型:
第r轮要选取q个簇首,平均每个簇中数据节点个数为k(1-m)/q,每个簇中非簇首认知节点个数为(k·m/q)-1;
一个簇在一轮中的平均能量消耗为:
进而得到整个网络在一轮中的能量消耗总量:
eround=q·ecluster
对eround求关于q的偏导,并令该偏导数等于0,得到最优成簇个数:
进一步,在步骤s2中,候选簇首,即认知节点采用不均匀竞争半径,将距离认知节点si最近的第y个认知节点到si的距离记为si的竞争半径,记为
进一步,在步骤s3中,认知节点与其竞争半径范围内的点构建其邻簇首集合,集合构建完成后,认知节点根据自身剩余能量和周围节点个数,即连接度做出其是否担任簇首的决策。
进一步,在步骤s4中,检查已选簇首集合中是否存在相邻近的节点,即检查节点是否满足条件
其中
遍筛查后将剩余簇首个数与预期最佳成簇个数qopt对比
如果剩余簇首个数仍大于qopt,将筛查距离扩大为
如果剩余簇首个数等于qopt,将剩余的簇首作为本轮簇首;
特殊情况如果在经过一次筛查后剩余簇首个数小于qopt,将从未被包含于簇首范围内的认知节点中选择满足簇首条件的点,如果都不满足则以当前簇首作为本轮簇首。
进一步,在步骤s5中,非簇首认知节点选簇过程中,考虑到簇首的距离和簇首平均半径范围内的认知节点个数两个因素,并且提出一个综合考虑这两个因素的选簇规则,即赋予两个因素不同权重进行叠加计算其综合值,选择综合值小的簇首加入,其计算公式如下:
f1=w1p1d1+w2p2ccn
其中w1,w2为权重系数,d1为非簇首的认知节点si到簇首的距离,ccn为簇首平均半径范围内认知节点的个数;由于d1的值要远大于ccn,为使两个因素能够对选择发挥同等影响力,增加p1,p2平衡因子。
进一步,在步骤s6中,数据节点选择簇首考虑三个因素:数据节点到簇首的距离、簇首周围数据节点个数以及簇首到sink节点的距离;分别赋予三个因素不同权重计算其综合值,数据节点选择最小值相关的簇首加入;计算公式如下:
其中w3,w4,w5为权重系数,d2为数据节点到簇首的距离,d3为数据节点到sink节点的距离,csn为簇首平均半径范围内数据节点的个数,dtobs为簇首到sink节点的距离;同样为了使各个参数能够处于同一量级,对值计算有同样的重要性,引入平衡因子p3、p4、p5。
本发明的有益效果在于:本发明与wsn和crsn分簇算法相比,本发明中基于异质节点的低能量适应性分簇方法能够适用于异构型认知无线传感器网络。通过计算网络每轮最佳成簇个数,得出认知节点竞争半径后开始构建邻簇首集合,在邻簇首集合中竞选簇首,其过程如图2所示。从簇首集合中通过筛查去掉部分位置相邻近的点,如图3所示。使网络中簇首个数达到最佳成簇个数,减少网络能耗。
非簇首认知节点通过计算簇首的综合值来加入簇,考虑到簇首的距离和簇首平均半径范围内的认知节点个数两个因素,使得各个簇中认知节点的分布较为均衡。数据传感器节点通过计算簇首的综合值来加入簇,考虑了数据节点到簇首的距离、簇首周围数据节点个数以及簇首到sink节点的距离三个因素,使得靠近sink节点的簇首簇内数据节点较少,远离sink节点的簇首簇内数据节点较多,均衡簇首的中继能耗,防止靠近sink节点的簇首因中继转发消耗过多能量而提早死亡。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为本发明实施例的流程示意图;
图2为异构认知无线传感器网络模型图;
图3为本发明实施例的簇首确定流程图;
图4为本发明实施例的簇首集合中位置邻近节点示意图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
本发明针对异构型认知无线传感器网络分簇问题,提出一种基于异质节点的认知无线传感器网络低能量适应性分簇方法。与传统同构型网络相比,异构型网络可以节约网络部署成本。普通传感器节点不用参与频谱感知,极大地节省了能耗延长工作寿命。认知节点和数据节点异质的网络模型如图2所示。
本发明基于异质节点的低能量适应性分簇方法过程如图1所示。考虑两类节点共存的网络场景,簇首从认知节点中选择,首先计算本轮最佳成簇个数,得到每个认知节点的竞争半径。认知节点与其竞争半径范围内的其它认知节点构建其邻簇首集合,在邻簇首集合中认知节点根据自身剩余能量和周围节点个数(连接度)选择出簇首。然后通过筛查去掉部分位置相邻的簇首完成簇首最终选择。非簇首认知节点和数据传感器节点通过计算簇首的综合值选择簇加入。
如图1所示,基于异质节点的低能量适应性分簇方法,该方法包括以下步骤:
s1:计算本轮最佳成簇个数qopt;
s2:根据候选簇首(认知节点)周围其它认知节点的分布密度来决定竞争半径的大小;
s3:考虑节点剩余能量值和节点连接度后选择簇首;
s4:筛查去掉部分位置相邻的簇首来完成最终簇首选择;
s5:非簇首认知节点基于到簇首距离及其关于认知节点的连接度选簇;
s6:数据传感器节点基于到簇首距离、关于数据节点的连接度以及距离sink节点的距离来决定入簇。
为了确定最佳成簇个数,建立不同类型节点的能量消耗模型。其中簇首工作从协作频谱感知开始,其工作时序依次为接收非簇首认知节点协作频谱感知信息,频谱感知结果决策并广播,接收数据节点收集的数据,融合数据,然后发送和中继数据。簇首在一轮中的能耗公式为:
其中,m表示平均每个簇中数据节点个数,l1表示数据节点事件感知数据包大小,n表示平均每个簇中非簇首认知节点个数,l2表示认知节点频谱感知结果和控制信息数据包大小,eda为融合1bit数据消耗的能量,dtonext表示簇首节点到下一跳节点的平均距离,dtoch表示簇内节点到簇首的平均距离。esense为单个认知节点频谱感知消耗的能量,l3表示为本簇事件感知数据包大小和中继转发其他簇数据的和,即簇首的平均传输的数据量,l4表示为簇首平均接收数据量,即中继簇首的平均接收数据。
非簇首认知节点能量消耗模型:
数据节点能量消耗模型:
第r轮要选取q个簇首,平均每个簇中数据节点个数为k(1-m)/q,每个簇中非簇首认知节点个数为(k·m/q)-1。
一个簇在一轮中的平均能量消耗为:
进而得到整个网络在一轮中的能量消耗总量:
eround=q·ecluster
对eround求关于q的偏导,并令该偏导数等于0,得到最优成簇个数:
得到最佳成簇个数后进一步得到认知节点的竞争半径,将距离认知节点si最近的第y个认知节点到si的距离记为si的竞争半径,记为
认知节点与其竞争半径范围内的点构建其邻簇首集合,集合构建完成后,认知节点根据自身剩余能量和周围节点个数(连接度)做出其是否担任簇首的决策,过程如图3所示。
得到簇首集合后检查簇首集合中是否存在位置相邻近的节点,即检查节点是否满足条件
其中
如果剩余簇首个数仍大于qopt,将筛查距离扩大为
如果剩余簇首个数等于qopt,将剩余的簇首作为本轮簇首;
特殊情况如果在经过一次筛查后剩余簇首个数小于qopt,将从未被包含于簇首范围内的认知节点中选择满足簇首条件的点,如果都不满足则以当前簇首作为最终簇首。
簇首确定后,非簇首认知节点选择簇加入。非簇首认知节点选簇过程中,我们考虑到簇首的距离和簇首平均半径范围内的认知节点个数两个因素,并且提出一个综合考虑这两个因素的选簇规则,即赋予两个因素不同权重进行叠加计算其综合值,选择综合值小的簇首加入,其计算公式如下:
f1=w1p1d1+w2p2ccn
其中w1,w2为权重系数,d1为非簇首的认知节点si到簇首的距离,ccn为簇首平均半径范围内认知节点的个数。由于d1的值要远大于ccn,为使两个因素能够对选择发挥同等影响力,我们增加p1,p2平衡因子。
簇首确定后,数据节点选择簇首加入。数据节点选择簇首我们选择三个因素:数据节点到簇首的距离、簇首周围数据节点个数以及簇首到sink节点的距离。分别赋予三个因素不同权重计算其综合值,数据节点选择最小值相关的簇首加入。计算公式如下:
其中w3,w4,w5为权重系数,d2为数据节点到簇首的距离,d3为数据节点到sink节点的距离,csn为簇首平均半径范围内数据节点的个数,dtobs为簇首到sink节点的距离。同样为了使各个参数能够处于同一量级,对值计算有同样的重要性,我们引入平衡因子p3、p4、p5。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!