用于调整助听器装置的方法、设备及计算机程序与流程
本发明总体上涉及助听器装置,尤其涉及根据用户具体需要调整或校准助听器装置。
背景技术:
现代助听器需要与佩戴者的具体听力损失、身体特征和生活方式匹配的配置。该过程称为“验配”且通常由听觉病矫治专家进行,其治疗具有听力损失的人并以经验防止有关伤害。助听器的验配和细调目前并不基于证据,因为现今使用的听力测试实质上基于自我报告的数据。对于助听器满意的结果数据也是如此,因为它们基于自我报告的调查表。自我报告的数据易遭受几个偏差,如记忆偏差、威信偏差及错误分类偏差,这些均可使结果测量的可靠性和有效性变模糊因而可妨碍基于证据的临床决策支持。此外,目前临床中使用的传统听力测试具有限制,因为大脑中的单音检测不唯一地反映语音被怎样好地感知,及语音感知需要怎样的听音付出(listeningeffort)。根据听力测试进行验配还未考虑个人的认知付出及在处理声音时遇到的问题。
传统上,几乎所有听觉健康护理服务均通过助听器用户与听觉病矫治专家之间的实际会见提供,这对于各方均存在时间消耗、交通消耗和资源消耗的问题。此外,人们趋于遗忘在健康访问期间给出的信息的40-80%。“e健康(ehealth)”是通过电子处理和通信支持的健康护理实践的术语。这样的e健康解决方案目标在于准许需要健康护理的人用通过e健康解决方案从他们的听觉病矫治专家或云计算服务获得的支持进行自我管理。此外,e健康解决方案通过使信息可始终并以用户自己的节奏访问而鼓励健康护理自我管理。
现今的助听器的验配和细调并未通过来自用户的验配前/细调信息而个性化,也没有使听觉病矫治专家在验配前和验配后访问基于证据的及个性化的客观结果测量数据,其可使能对验配过程的个性化预先计划和按需支持及解决验配后问题的临床决策支持,后者对于前2-4周的适应阶段尤为重要。
用户对用户出行、对助听器的个人预期及重要的听音情形、听音偏好等具有非常少的了解,否则,这可准许他们参与康复过程并减少临床时间。缺乏用户与听觉病矫治专家之间的信息、学习和通信共享,在用户出行过程中引起一些问题:听觉病矫治专家在用户进入诊所进行验配之前不知道他们的任何东西因而没有支持个性化验配处理的计划和准备的数据。目前,用户对听音偏好、重要的听音情形等的信息和数据通过临床中短的面对面访问获得。该信息可在验配之前提供给听觉病矫治专家从而使能个性化验配。所有这些均可贡献于助听器的24%的未使用(8%的助听器用户根本不使用他们的助听器,另外16%一天使用助听器少于一小时)、高退货率及太多临床再次访问,所有这些均使得临床成本效率和用户满意度达不到预期目标。
当用户走出临床中的受控设置并回到用户现实生活听音情形时,许多用户体验到临床设置听音情形测试与现实生活体验听音情形之间的失配,从而产生对助听器的不满意,甚至可能不使用助听器。
因而在助听器验配/调整技术领域需要改进。
技术实现要素:
前述需要由根据本发明的方法、设备和计算机程序满足。另外的有利例子由从属权利要求限定的技术方案给出。
根据第一方面,本发明提供一种用于调整助听器装置/仪器的方法。从而助听器装置可被理解为根据听力测定和认知规则对环境声音(包括讲话)进行变换以使其更可懂或对用户更舒适的电声装置。所提出的方法包括向佩戴根据当前助听器设置进行配置的助听器装置的人提供声音模式。所述方法还包括响应于经助听器装置感知的声音模式评估该人的瞳孔以获得瞳孔(或瞳孔测定)信息,及基于瞳孔信息调整当前助听器设置。
人瞳孔的评估包括记录瞳孔大小、所记录的数据的后处理/清除、及所记录的瞳孔曲线的分析以估计听音付出的值即认知负荷。
受益于本发明的本领域技术人员将意识到,助听器设置可包括用于环境声音变换的音频滤波器设置。也就是说,第一助听器设置导致助听器装置的第一(频率)传递函数,而不同的第二助听器设置导致助听器装置的不同的第二(频率)传递函数。所提出的概念可用于客观地调整助听器设置因而助听器装置的传递特性,以使用户听所述声音模式并避免助听器设置因而传递特性的调整的主观评价的认知负荷最小化。
在一些例子中,声音模式可通过助听器装置的制造预先定义,这意味着声音模式不是任意的或随机的声音模式,而是经选择的和/或预先记录的声音模式。这可增加所提出的瞳孔测定助听器验配概念的可靠性和/或客观性。
在一些例子中,提供声音模式可包括向佩戴助听器装置的人播放(预定)语音样本。非必须地,对应于给定(周围)声音环境的预定背景声音可在助听器装置中播放以进行佩戴助听器装置的人的瞳孔放大的基线测量。预定的语音样本可连同预定的背景声音一起播放。人的瞳孔放大将在听语音样本连同背景声音时使用眼睛跟踪照相机进行跟踪/记录。所记录的瞳孔放大之后将被后处理,例如包括眨眼去除和测得的瞳孔信息如瞳孔大小和/或瞳孔放大的归一化,数据插值,及进行分析以获得个人的听音付出的度量。具体地,困难的和/或个别重要的听觉情形可通过预定语音样本和/或预定背景声音/噪声模拟。
在一些例子中,提供声音模式包括将指明(预定)声音模式和/或背景声音的数据从远程装置传到与佩戴助听器装置的人相关联的移动设备。这样,可支持远程验配。例如,该移动设备可以是膝上型计算机、智能电话或者配置成将预定声音模式和/或背景声音/噪声播放给佩戴助听器装置的人的任何其他设备。在一些例子中,指明(预定)声音模式和/或背景声音的数据甚至可直接传给助听器装置自身。本领域技术人员将意识到,助听器装置则将必须包括胜任的收发器电路以接收和播放数据。远程装置例如可以是远程服务器,例如存储一个或多个(预定)声音模式的云服务器。
在一些例子中,声音模式可能已由该人自己经移动设备如智能电话、平板电脑或摄像机产生和/或存储。声音模式则也可经用户的移动设备进行播放。
在一些例子中,人的瞳孔可被自动评估,例如通过使用自动眼睛跟踪装置和/或瞳孔计将人的瞳孔放大测量为他们的认知负荷的标示参数。眼睛跟踪装置可包括用于聚焦于一只或两只眼睛的红外照相机并在用户听声音模式时记录其瞳孔放大的运动和/或变化。眼睛跟踪装置可使用瞳孔的中心及红外/近红外非平行光产生角膜反射(cr)。另外的或者作为备选的自动化瞳孔计可以是便携、手持红外装置,其通过瞳孔放大的测量可提供瞳孔大小及反应性的可靠且客观的测量。
为了经红外照相机进行瞳孔放大的测量,人眼周围的光条件必须已知。这可通过经同样的红外照相机测量眼睛周围的光强度或者通过使人处于黑屋中完成。眼睛跟踪装置或瞳孔计可包括瞳孔测定护目镜或其它装置。护目镜或类似装置可包括一个或多个照相机及一个或多个ir辐射源。
在一些例子中,调整当前助听器设置包括响应于(预定)声音模式和/或背景声音/噪声改变当前助听器设置以减小测得的瞳孔放大。也就是说,助听器被调整使得瞳孔放大峰值减小,从而表明该人正付出努力处理声音刺激。对于远程验配,助听器设置可通过远程处理器调整或选择。
在一些例子中,调整当前助听器设置包括响应于(预定)声音模式从多个不同的预定助听器设置选择当前助听器设置及选择导致最小瞳孔放大的助听器设置。
在上面的方法也可至少部分手动执行的同时,一些例子还提出完全自动化及可能远程的实施方式。为此,该方法还可包括将测得的瞳孔放大传给处理器,其中处理器配置成对瞳孔放大进行后处理以去除眨眼、去除非自然信号、数据插值和瞳孔放大的归一化。处理器之后基于后处理的瞳孔放大提供调整的助听器设置。处理器可实施在助听器装置自身中或者其可远离助听器装置定位,例如远程(云)服务器或与听力受损用户相关联的移动设备(如智能电话)。在后一情形下,提供调整的助听器设置可包括将调整的助听器设置从远程处理器传到助听器装置。因而,云服务也可被采用用于助听器的验配。
根据另一方面,本发明还提供用于执行上面提及的方法的实施的计算机程序,当该计算机程序在可编程硬件装置如计算机、现场可编程门阵列(fpga)或专用集成电路(asic)上执行时。
根据又一方面,本发明还提供用于调整助听器装置的设备。该设备包括接收器电路,其配置成接收佩戴根据当前助听器设置配置的助听器装置的人的瞳孔信息。该设备还包括处理器电路,其配置成基于瞳孔信息产生调整的助听器设置。受益于本发明的本领域技术人员将意识到,这样的设备可集成在助听器装置自身中或者远离助听器装置定位。在一些例子中,其可以是可用于验配目的的计算机或智能电话。
根据再一方面,本发明还提供用于调整助听器装置的系统。该系统包括用于向佩戴根据当前助听器设置配置的助听器装置的人提供(预定)声音模式的装置、用于响应于经助听器装置感知的(预定)声音模式评估人的瞳孔以获得瞳孔信息的装置、及基于瞳孔信息调整当前助听器设置的装置。
在一些例子中,该系统可包括移动设备(如智能电话),其包括配置成向助听器装置或头戴式耳机或用于评估人的瞳孔的装置提供(预定)声音模式的应用软件。在一些例子中,瞳孔信息可经移动设备或服务器/云传给助听器装置或远程装置。在瞳孔信息被传给助听器装置的情形下,助听器装置可配置成基于瞳孔信息及通过云/服务器发送的预定背景声音基于检测到的声音环境(经助听器装置内的传声器)选择适当的助听器设置。
在远程装置接收瞳孔信息的情形下,听觉病矫治专家可经助听器装置与远程装置之间建立的通信链路进行助听器设置的远程细调/远程验配。通信链路例如可以是蓝牙链路,或移动电话通信链路,或因特网通信链路,或其组合。
本发明的例子通过临床或家中的瞳孔测定和e健康提出基于证据且个性化的超越听力图的验配和/或细调。瞳孔测定可用作测量人的瞳孔放大的诊断工具并解释测得的瞳孔放大的数据以确定影响助听器装置的听力曲线的助听器设置。人的瞳孔放大的基线测量可刚好在播放声音模式期间进行瞳孔放大的实际测量之前进行。
附图说明
本发明的多个方面将从下面结合附图进行的详细描述得以最佳地理解。为清晰起见,这些附图均为示意性及简化的图,它们只给出了对于理解本发明所必要的细节,而省略其他细节。在所有附图中,同样的附图标记用于同样或对应的部分。每一方面的各个特征可与其他方面的任何或所有特征组合。这些及其他方面、特征和/或技术效果将从下面的图示明显看出并结合其阐明,其中:
图1a-1d示出了基于瞳孔测定的助听器验配的不同设置。
图1e示出了调整助听器装置的方法的流程图。
图2a和2b示出了根据不同实施例的消息序图。
图3示出了基于瞳孔测定的用于助听器验配的e健康系统。
图4示出了归一化的瞳孔放大。
图5示出了仿真听力损失的方法的流程图。
图6示出了根据本发明的助听器系统的实施例,包括左和右听力装置及安装在眼镜架上的多个传感器。
具体实施方式
下面结合附图提出的具体描述用作多种不同配置的描述。具体描述包括用于提供多个不同概念的彻底理解的具体细节。然而,对本领域技术人员显而易见的是,这些概念可在没有这些具体细节的情形下实施。装置和方法的几个方面通过多个不同的块、功能单元、模块、元件、电路、步骤、处理、算法等(统称为“元素”)进行描述。根据具体应用、设计限制或其它原因,这些元素可使用电子硬件、计算机程序或其任何组合实施。
助听器装置可包括适于通过接收来自用户周围的声学信号、生成对应的音频信号、可能对音频信号进行修正、并且将可能修正后的音频信号作为可听信号提供给用户耳朵中的至少一个来改善或加强用户的听觉能力的助听器。“助听器装置”还可指适于以电子方式接收音频信号、可能修改该音频信号、及将可能已修改的音频信号作为听得见的信号提供给用户的至少一只耳朵的装置如头戴式耳机或耳麦。前述听得见的信号例如可以下述形式提供:辐射到用户外耳内的声信号、作为机械振动通过用户头部的骨结构和/或通过中耳的部分传到用户内耳的声信号、及直接或间接传到用户耳蜗神经和/或听觉皮层的电信号。
助听器装置适于以任意已知的方式佩戴。这可以包括i)将助听器装置的、具有引导空传声学信号的管和/或设置成靠近耳道或位于耳道中的接收器/扬声器的单元布置在耳后,例如在耳后型助听器或耳内接收器式助听器中;和/或ii)将助听器整个或部分设置在用户的耳廓中和/或耳道中,例如在耳内式助听器或者耳道式/深耳道式助听器中;或者iii)将助听器装置的单元设置成连接到植入到颅骨内的固定结构,例如在骨锚式助听器或者耳蜗植入件中;或者iv)将助听器装置的单元设置成整个或部分植入的单元,例如在骨锚式助听器或者耳蜗植入件中。
助听器装置可以是包括一个或两个本说明书中公开的助听器装置的“听力系统”或者包括两个助听器装置(其中这些装置适于以协作的方式向用户的两个耳朵提供音频信号)的“双耳听力系统”的一部分。听力系统或双耳听力系统还可以包括与至少一个助听器装置进行通信的辅助设备,辅助设备影响助听器装置的操作和/或从助听器装置的工作中受益。在至少一个助听器装置和辅助设备之间建立有线或无线通信链路,使得能够在至少一个助听器装置和辅助设备之间交换信息(例如控制和状态信号、可能有音频信号)。辅助设备可以包括遥控器、遥控麦克风、音频网关设备、移动电话、公共广播系统、汽车音频系统或音乐播放器中的至少一个或其组合。音频网关适于诸如从像电视或音乐播放器的娱乐设备、像移动电话的电话装置或者计算机、pc接收大量音频信号。音频网关还适于选择和/或组合接收到的音频信号中的合适的一个(或信号的组合),用于传输到至少一个助听器装置。遥控器可适于对至少一个助听器装置的功能和操作进行控制。遥控器的功能可以在智能电话或其它电子设备中实现,智能电话/电子设备可能运行对至少一个助听器装置的功能进行控制的应用。
一般地,助听器装置包括i)诸如麦克风的输入单元,用于接收来自用户周围的声学信号,并且提供对应的输入音频信号,和/或ii)接收单元,用于电子地接收输入音频信号。助听器装置还包括用于对输入音频信号进行处理的信号处理单元和用于依据处理后的音频信号向用户提供可听信号的输出单元。
输入单元可以包括多个输入麦克风,例如用于提供依赖于方向的音频信号处理。这种定向麦克风系统适于增强用户环境中的大量声学源中的目标声学源。在一个方面,定向系统适于检测(例如自适应地检测)麦克风信号的特定部分源自哪个方向。这可以通过使用传统上已知的方法来实现。信号处理单元可以包括放大器,放大器适于对输入音频信号施加依赖于频率的增益。信号处理单元还可以适于提供诸如压缩、噪声降低等其它相关功能。输出单元可包括用于透皮或经皮向颅骨提供空气传播声学信号的诸如扬声器/接收器的输出转换器,或者用于提供结构传播或液体传播的声学信号的振动器。在一些助听器装置中,输出单元可包括诸如耳蜗植入件中的用于提供电信号的一个或多个输出电极。
应意识到,本说明书中提及“一实施例”或“实施例”或“方面”或者“可”包括的特征意为结合该实施例描述的特定特征、结构或特性包括在本发明的至少一实施方式中。此外,特定特征、结构或特性可在本发明的一个或多个实施方式中适当组合。提供前面的描述是为了使本领域技术人员能够实施在此描述的各个方面。各种修改对本领域技术人员将显而易见,及在此定义的一般原理可应用于其他方面。
权利要求不限于在此所示的各个方面,而是包含与权利要求语言一致的全部范围,其中除非明确指出,以单数形式提及的元件不意指“一个及只有一个”,而是指“一个或多个”。除非明确指出,术语“一些”指一个或多个。
因而,本发明的范围应依据权利要求进行判断。
多个不同的例子现在将结合附图进行更完全地描述,附图示出了一些例子。在图中,为了清晰起见,线条、层和/或区域的厚度可能被夸大。
因而,在另外的例子能够进行多种不同的修改和成为备选形式的同时,其一些特定例子在图中示出并将在随后详细描述。然而,这些详细描述不将另外的例子限于所描述的特定形式。另外的例子可覆盖落入本发明范围内的所有修改、等同和备选方案。在这些图的描述中,同样的附图标记指同样或类似的元件,在提供同样或类似功能的同时,其可被同样地或者以相较于另一形式修改的形式实施。应当理解,当元件被称为“连接”或“耦合”到另一元件时,这些元件可以是直接连接或耦合或者经一个或多个插入元件连接或耦合。如果两个元件a和b使用“或”组合,这应当理解为公开了所有可能的组合,即仅a、仅b及a和b。用于同样组合的备选用语为“a和b中的至少一个”。这同样适用于两个以上元件的组合。
在此用于描述特定例子的术语不用于限制另外的例子。无论何时使用单数形式“一”和“该”,仅使用单一元件既不明确地也不暗示地定义为强制性的,另外的例子也可使用多个元件实施同样的功能。同样,当一功能随后被描述为使用多个元件实施时,另外的例子可使用单一元件或处理实体实施同样的功能。应当进一步理解,使用的术语“包括”和/或“包含”表明存在所陈述的特征、整数、步骤、操作、处理、行为、元件和/或部件,但不排除存在或增加一个或多个其他特征、整数、步骤、操作、处理、行为、元件、部件和/或其组合。
除非明确定义,所有术语(包括技术和科学术语)在此均按其在实施例所属领域的一般含义进行使用。
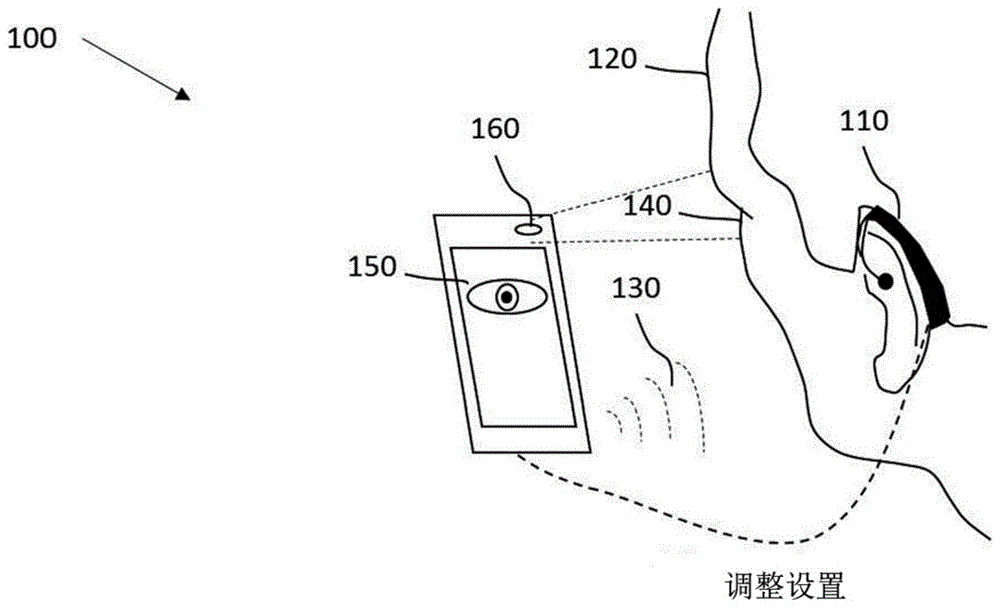
图1a-1d示出了基于瞳孔测定的助听器验配的不同设置。图1a示出了基本设置100,其可用于调整听力受损人员120佩戴的电声助听器装置110的设置。
在图1a中,用户120或接受测试的人120佩戴助听器装置110并看向瞳孔计或眼睛跟踪照相机160,其在该具体例子中为包括用于显示瞳孔信息150即瞳孔大小或瞳孔放大的图形显示器的智能电话的一部分。助听器装置110之后可基于测得的瞳孔信息即瞳孔大小和/或瞳孔放大进行修正/调整。
在图1b中,用户120佩戴从例如智能电话接收声音模式的头戴式耳机110a,及助听器装置110配置成经数字音频播放设备如智能电话接收修正/调整的助听器设置。
图1c示出了用户120佩戴助听器装置110和护目镜318的例子,也在图6中示出,包括瞳孔计或眼睛跟踪传感器160。在该例子中,声音模式来自外部扬声器。在另一例子中,扬声器可内置在护目镜内,或者助听器装置110可包括信号发生器或者可配置成从数字音频播放设备接收声音模式130。
图1d示出了用户120佩戴头戴式耳机110a和护目镜318,也在图6中示出,包括瞳孔计或眼睛跟踪传感器160。在该例子中,头戴式耳机110a从数字音频播放设备接收声音模式130。
助听器装置110根据当前助听器设置进行配置,从而影响助听器装置110的听力曲线。如图1e的流程图中所示,背景声音被提供给人,及响应于背景声音进行人瞳孔的基线测量(参见步骤s0)。之后,声音模式130可被提供给佩戴助听器装置110的人120(参见步骤s1)。之后,人120的瞳孔140可响应于经根据当前助听器设置配置的助听器装置110感知的声音模式130与背景声音的混合进行评估以获得瞳孔(或瞳孔测定)信息150(参见步骤s2)。基于瞳孔信息150,当前助听器设置可被修正/调整(参见步骤s3)。步骤s0到s3可重复,不同的声音模式130和助听器设置的另一调整可能必要。
本发明的基本想法是将瞳孔信息150用作听力受损人员120识别在助听器装置110的帮助下感知的声音模式130的内容的认知负荷的客观标示参数。在此,声音模式130可被视为音频刺激,及测得的瞳孔信息150包括人120因理解/处理音频刺激引起的瞳孔反应。目标在于调整助听器设置使得瞳孔信息150标示可能低的、识别声音模式130的认知负荷。
在一些例子中,声音模式130可包括一个或多个语音模式和/或周围声音环境。在声音模式130不必然必须预先确定或预定的同时,当使用预定声音或语音模式时,可获得更好的调整结果。这样的预定声音或语音模式可能已在早前记录和存储,例如在给定声音环境中,并可在随后播放给听力受损人员120及可能播放多次以验配助听器装置110。为了播放目的,邻近听力受损人员120可使用多种电声变换器,如扬声器或头戴式耳机。这样的电声变换器可耦合到模拟或数字音频播放设备,如台式计算机、膝上型计算机、智能电话或任何其它适当的设备。
瞳孔信息150如瞳孔放大可通过用眼睛跟踪装置或专用瞳孔计160测量瞳孔的放大或收缩进行确定。因而,人的瞳孔140可通过响应于试图识别声音模式130自动测量瞳孔放大进行评估。眼睛跟踪装置或瞳孔计160可以固定不动(例如在临床中)或者便携和/或可佩戴。在一些例子中,眼睛跟踪装置或瞳孔计160可集成到包括照相机和用于播放声音模式130的扬声器的智能电话内。在其它例子中,眼睛跟踪装置或瞳孔计160可集成到虚拟现实头戴式耳机内,其包括护目镜和/或用于播放声音模式130的耳机或其它装置。这样,人120在验配程序期间可被置于精确预先确定且可控的视听环境中。
测得的瞳孔信息150可被传给信号处理器进行进一步的处理。该信号处理器之后可基于测得的瞳孔信息150产生调整的助听器设置。为了应用调整的助听器设置,处理器可经有线或无线通信链路耦合到助听器装置110。为使得验配程序尽可能舒适和/或灵活,优选无线通信链路。无线技术的例子为蓝牙或ieee802.11(wlan)。在一些例子中,用于调整助听器设置的处理器可集成在助听器装置110自身中或者可远离助听器装置定位。例如,用于调整助听器设置的处理器可集成在与眼睛跟踪器或瞳孔计160同样的设备中,或者该处理器可集成在智能电话或虚拟现实头戴式耳机中。在其它例子中,处理器可以是远程处理器,例如云服务的远程服务器。因而,本发明的一些例子可使能远程验配助听器装置110。这样的例子将在下面进一步描述。
助听器设置可通过响应于识别(预定)声音模式130改变当前应用的助听器设置进行调整以减小测得的瞳孔放大。也就是说,(预定)声音或语音模式130可被播放给佩戴具有当前设定的第一助听器设置的助听器装置110的听力受损人员120。这些第一助听器设置导致助听器110的第一(频率)传递函数,从而导致第一听音体验和瞳孔放大(给出听力受损人员120的认知负荷的标示参数)。该第一认知负荷翻译为在听预定声音或语音模式130时的第一瞳孔反应。该第一瞳孔反应经眼睛跟踪装置或瞳孔计160进行测量。之后,第二助听器设置可被应用于助听器110,导致助听器110的第二(频率)传递函数。用第二助听器设置听预定声音或语音模式130将导致听力受损人员120的第二听音体验和认知负荷,其之后翻译为响应于预定声音或语音模式130的第二瞳孔反应。该第二瞳孔反应可经眼睛跟踪装置或瞳孔计160进行测量并与第一瞳孔反应比较。在已应用多个不同的助听器设置之后,那些导致标示最小认知负荷的瞳孔信息150的助听器设置可被选择。因而,调整当前助听器设置可包括从多个不同的预定助听器设置选择当前助听器设置并选择那些响应于(预定)声音模式130导致最小瞳孔放大的助听器设置。
瞳孔反应即瞳孔大小或瞳孔放大在两个(以上)不同的条件下进行测量,其意味着不同的声学场合或者具有不同的助听器设置等。不同条件下的瞳孔反应之后用作用户为识别声音模式即声音或语音刺激所花费的听音付出即认知负荷的标示参数。
图2a和2b示出了不同的实施例,其中助听器装置110的调整/验配可远程或非远程地进行。远程调整或验配定义为其中声音模式及助听器装置的调整或验配经基于云的服务器和/或经长程通信网络如电话网络、因特网、wifi等通信的助听器装置的调整或验配。
受益于本发明的本领域技术人员将意识到,所提出的概念可适合于远程验配概念,其中听觉病矫治专家可处于不同的、远程位置或者甚至根本不必被涉及。图2a示意性地示出了用于远程验配助听器装置110的示例序图200。
作为第一行动,听力受损用户120从远程站点210接收消息212以应用第一助听器设置。消息212例如可通过与用户120相关联的移动设备接收,如用户的智能电话或者助听器装置自身。消息212可包括应用存储在用户侧的第一助听器设置的指令,例如存储在用户的智能电话或助听器中,或者消息202本身可包含第一助听器设置。远程站点210可以是由听觉病矫治专家控制的远程听力学实验室的计算机/服务器。远程站点和用户120可经因特网连接。为此,能够因特网的用户设备如智能电话、计算机或虚拟现实头戴式耳机可与听力受损用户120相关联。用户设备则能根据第一助听器设置调整当前助听器设置。这可经用户设备与助听器110之间的有线或无线通信链路进行。
之后,在已将第一助听器设置应用于用户的助听器之后,用户设备可经消息214进行指令以播放一个或多个预定声音模式。播放可经智能电话、膝上型或台式计算机等进行。消息214可包括播放存储在用户侧的一个或多个预定声音模式的指令,或者消息202本身可包含一个或多个预定的数字声音模式。
瞳孔测量(如瞳孔放大)之后在用户侧进行以测量用户以第一助听器设置听及识别一个或多个预定声音模式的认知负荷。如上面提及的,瞳孔测量可使用眼睛跟踪器或瞳孔计160进行,其可被集成在智能电话、pc、平板电脑或用户120佩戴的虚拟现实头戴式耳机内。瞳孔测量结果之后可被后处理,包括眨眼去除和测得的瞳孔信息如瞳孔大小和/或瞳孔放大的归一化、数据插值,及进行分析以获得个人的听音付出的度量。针对第一助听器设置的瞳孔测量结果之后可经消息216发送回到远程站点。
接下来,听力受损用户120可从远程站点210接收另一消息218以应用不同的第二助听器设置。当前助听器设置则可根据第二助听器设置进行调整。在已应用第二助听器设置之后,用户设备可经消息220进行指令以播放一个或多个预定声音模式。之后,瞳孔测量被再次进行以测量用户以第二助听器设置听及识别一个或多个预定声音模式的认知负荷。针对第二助听器设置的瞳孔测量结果在测得的瞳孔信息的后处理之后可经消息222发送回到远程站点。
该过程可针对不同的可能助听器设置重复多次。在针对所有可能的助听器设置的瞳孔测量结果已被收集之后,远程站点210可评估瞳孔测量结果并选择导致标示听及识别一个或多个预定声音模式时具有最小认知负荷的瞳孔测量结果的最佳助听器设置。这些最佳助听器设置之后可被应用。
图2b示意性地示出了用于远程验配助听器装置110的序图200的类似例子。在图2b中,佩戴助听器装置110或头戴式耳机110a的用户接收预定背景声音213,其之后在助听器装置110或头戴式耳机110a中播放。瞳孔放大即瞳孔信息的基线测量基于背景声音提供。用户120接收声音模式214,及瞳孔测量基于所接收的声音模式与背景声音的结合进行。
测得的瞳孔测定信息被传送回给听觉病矫治专家(210、216)。基线测量刚好在每一瞳孔(测定)测量之前进行。
受益于本发明的本领域技术人员将意识到,图2a和2b的远程站点也可用与听力受损用户相关联的智能电话、平板电脑或pc代替。该智能电话、平板电脑或pc可建立与用户的助听器装置的无线连接并通过应用不同的助听器设置、播放声音模式及进行瞳孔测量控制验配过程。在这样的例子中,智能电话或pc或平板电脑可执行相应的验配app。
目前因非个性化听力损失康复及缺乏信息和通信共享引起的问题也可通过e健康生态系统300解决,如图3中所示,其中信息、通信和学习即e健康在用户和他们的助听器与云服务及听觉病矫治专家之间流动。
图3的示例性e健康生态系统300包括助听器用户域310、听觉护理专家域320、及云服务提供商域330。助听器用户域310包括助听器用户312、助听器装置314或头戴式耳机314a、智能电话、pc或平板电脑形式的便携用户设备316、及包括护目镜318或pc或平板电脑或智能电话的瞳孔测量装置。听觉护理专家域320包括听觉病矫治专家322、听觉护理计算机324、及包括护目镜326的用于在临床验配的瞳孔测量装置。云服务提供商域330包括数据服务器/中心332。
图6示出了根据本发明的(双耳)听力系统700的例子,至少包括左和/或右听力装置、安装在一对助听器眼镜318的眼镜架710上的多个传感器。该助听器系统包括与左和右助听装置310、314相关联(例如形成其一部分或者与其连接)的多个传感器s1i,s2i(i=1,…,ns)。在一实施例中,如图6中所示,第一、第二及第三对传感器s11,s12,s13和s21,s22,s23均安装在眼镜的眼镜架710上。在图6的实施例中,传感器s11,s12和s21,s22安装在相应的侧杆711a,711b上,而传感器s13和s23安装在具有到右和左侧杆711a,711b的铰链连接的横撑件713上。眼镜的透镜714安装在横撑件713上。至少一听力装置310、314包括相应的bte(耳后)部分712a、712b。在一方面,眼镜包括相应的ite(耳内)部分712a、712b。在一方面,ite部分包括用于从用户拾取身体信号的电极,例如形成用于监测用户的生理功能如脑活动或眼球运动活动或温度的传感器s1i,s2i(i=1,…,ns)的一部分。安装在眼镜架710上的传感器例如可包括眼睛照相机(例如用于监测瞳孔测定)、用于测量血氧的血液传感器、用于监测颞下颌关节(tmj)运动和/或颈部肌肉(胸锁乳突肌)活动的传感器(如雷达传感器)中的一个或多个。
便携用户设备316与云服务330通信地接口连接以将数据(如测量结果、gps数据、调查表等)从用户域310提供到云域330及从云域330接收数据(音频数据、视频数据、指令等)。听觉护理计算机324也与云服务330接口连接以上传用户312的数据及从用户312下载数据。因此,助听器用户域310经云服务330耦合到听觉护理专家域320。
在一些例子中,所提出的概念可包括如下的、e健康测得的、用户自我报告的验配前数据:在对听力损失康复的个性化预期、个性化重要听音情形、对声音的个性化偏好等方面自我报告的用户信息。这些数据可由用户312通过云验配前和/或通过如图3中所示的e健康生态系统300的细调报告给听觉病矫治专家/云服务,例如使用在验配之前下载的app获得重要听音情形等的报告。护目镜或其它眼睛跟踪装置318、326可通过临床提供。此外,准许康复信息、学习等可在验配前通过app从听觉病矫治专家/云发送给用户312,因而使用户准备好验配。在验配之后及在重要的2-4周适应时间段中,云330可向听觉病矫治专家322提供通过用户家中的护目镜或其它装置318测得的瞳孔测定、助听器使用、助听器满意度、康复问题的客观用户数据并使能快速的按需解决用户的问题。
在语音样本期间即在助听器装置314或头戴式耳机314a中播放声音模式期间,在进行瞳孔测量之前,必须进行基线测量。基线测量是在不播放声音模式的情形下受测人员的瞳孔信息即瞳孔大小和/或瞳孔放大的测量。基线测量可在每一声音模式之后进行。
作为备选,基线测量是环境中的人未变化的瞳孔信息即瞳孔大小和/或瞳孔放大的测量。环境为受测人员周围的空间,例如该空间可以在所述人员在实际测量期间所处的房间内。
作为备选,基线测量为受测人员的瞳孔信息即瞳孔大小和/或瞳孔放大的测量,其中用户经助听器装置314、110或头戴式耳机314a、110a接收背景声音。背景声音可以是白噪声信号或任何类型的预定背景声音模式。在播放背景声音的同时,照相机测量人的瞳孔信息,及该瞳孔信息的测量为基线测量。
瞳孔信息即瞳孔大小和/或瞳孔放大的基线测量用于在播放包括背景声音的声音模式期间测得的瞳孔放大的归一化。
一个例子从用户角度逐步描述如下:
1)基线测量
a、用户312可用连接的云服务(后端)接收app(前端),例如具有例如在四个不同的助听器设置下的25个听音付出句子、背景声音、报告重要听音情形的可能性等;
b、在家中,用户312可接收护目镜318或类似装置并通过经用户佩戴的头戴式耳机连同护目镜一起播放背景声音进行基线测量,同时经护目镜318测量人的瞳孔放大。基线测量则为播放背景声音时的瞳孔放大的测量;
c、步骤b将在每一播放的声音模式之后进行。
2)验配
a、瞳孔测定护目镜318可通过例如在四个不同的助听器设置下的25个听音付出句子测试用户,同时播放背景声音。这些设置下的瞳孔放大可通过具有眼睛跟踪器的护目镜或其它装置318进行测量并进行后处理。在每一听音付出句子之后,必须进行基线测量。对于四个设置中的每一设置,可测量作为处理付出的标示参数的平均瞳孔放大。
3)后续
a、在适应时间段(例如2-4周),用户312可使用护目镜或其它装置318测量其瞳孔测定反应,作为其用验配的助听器进行正确的语音识别所需的付出(努力)的标示参数。e健康解决方案可通过云330向用户312提供听音测试,参见图3。
b、助听器314可使用不同的测试即瞳孔测定的测试结果自动设置,针对他们在受助听音情形下进行语音识别所需的付出进行调整。助听器314的该自动设置可在验配期间在临床发生或者在家中通过e健康生态系统300经云330发送的设置发生。算法可使用瞳孔测定等结果设置助听器。这些数据计算和自动调整均可通过e健康生态系统300进行。
c、为进一步使助听器314针对用户现实生活体验的重要听音情形个性化,使用用户自己上传的音频文件(通过e健康生态系统发送,图3从用户域发送)的另一瞳孔测定测试可用作听音测试,及助听器314也可根据这些测试自动设置。
通过自动化的瞳孔测定而个性化的助听器验配可通过经智能电话app和/或助听器314发送的听音测试及用通过护目镜或其它装置318、326得到的瞳孔反应测量结果进行。为改善测量结果,用户312在临床中在验配期间可针对瞳孔测定测试校准,在2-4周的适应时间段在在家中使用该系统之前。这样,首先可进行个人的基线测试,因为瞳孔放大通常非常独特(参见图4)。
对于一些验配场合,例如其中我们没有预定的环境条件,知道眼睛处的光强度是有利的。因而,在使用瞳孔测定进行助听器验配时可进行下面的行动:
-例如经传统的眼睛跟踪方案检测眼睛;
-测量眼睛处的第一平均光强度;
-测量第一瞳孔放大;
-测量眼睛处的第二平均光强度;
-测量第二瞳孔放大;
-基于第一平均光强度与第二平均光强度之间的差校正第二瞳孔放大。
此外,为解决临床设置与现实生活体验之间的失配问题,来自用户现实生活体验的ema(生态瞬时评价)数据可通过e健康生态系统300作为音频文件上传到临床/云,并作为使用瞳孔测定技术通过助听器进行的个性化听音测试发送。从而,用户312可真实地从用户重要的听音情形体验个性化验配/细调。
使用护目镜160、318、326或者上面针对瞳孔测定测试提及的光强度的调整的想法可使该技术能用在非受控环境中,例如不同的临床、家中等,但仍然具有同样的测量准确度。关于用于通过助听器的测试的音频,这可被控制已使所有用户具有同样的音频测试。从而,我们最终可使人群数据用于基于人群的临床证据从而精细化用于临床决策的证据及用于年龄组之间的比较等。
结合瞳孔测定及e健康可在临床及用户家中针对验配过程传递基于证据的、个性化的及客观的结果测量。瞳孔测定可用作用于客观地测量听力损失的临床诊断工具。e健康可支持该临床工具在多周的适应时间段后验配期间在用户家中同样使用。听觉病矫治专家与他们的用户之间的e健康信息和通信共享还用于听力损失康复处理的个性化。
代替仅依赖于主观数据,可使用例如来自瞳孔测定或助听器的客观数据(使用、音量控制等),没有自我报告的数据易遭受的偏差,因而提供数据用于基于证据的临床决策支持。
在上面提及的方面解决客观助听器验配并提供客观远程助听器验配的解决方案的同时,仍然非常难理解听力受损人员的日常世界及听力受损人员非常难向他人解释。重要的他人(如妻子、丈夫、父母、孩子、朋友等)对大多数听力受损人员而言为最重要的通信伙伴及在助听器验配之后为最重要的康复伙伴。这在听力损失康复及他们的具有听力损失的配偶的日常生活中对重要的他人赋予高度的责任性。然而,研究已表明,他们并未获得履行这些挑战所需要的信息或学习。
此外,听力损失是非常个人的体验。二者均关于个人重要的听音情形及感知的听力损失。已知有大多数听力受损人员愿意通过他们的听力损失和通信策略受到帮助的共同重要的听音情形,例如餐厅情形。但是还已知现今的听力损失康复需要个性化。因此,通信工具不仅可针对听力学测试个性化而且可针对个人的最重要的听音情形或当前现实世界通信情形个性化很重要,在此e健康可以是一个解决方案。
现今听力康复中的关键参与者即听觉病矫治专家、重要的他人及听力受损人员均无权使用使用来自虚拟现实或真实世界“实验室”的关于重要听音情形的数据的公共或个性化数据用于通信训练工具。因此,听觉病矫治专家没有任何从这些类型的体验的真实世界或虚拟现实数据对助听器细调或者对通信问题和策略提出建议的可能性。
为克服这些及其它问题,本发明还提供用于仿真听力损失的概念,其可独立或与上面描述的瞳孔测定概念结合。图5示出了对应的听力损失仿真方法600的流程图。
方法600包括根据反映第一人的听力损失的听力测定数据操控(610)音频数据、及将操控的音频数据播放(620)给第二人(例如重要的他人)。也就是说,所有类型的音频数据均可根据具有听力损失的人的听力测定数据进行操控以向他人提供听力损失体验。例如,音频文件可被分离为不同的频率范围,及每一频率范围可根据听力测定数据进行滤波/操控。
因而,在一些例子中,操控音频数据(610)可包括用具有反映听力损失的传递函数的滤波器对音频数据进行滤波。滤波可用数字信号处理器(dsp)进行。
一些例子在下表中示出,其分别示出了三个人的左和右耳的听力损失。可以看出,人2在整个频率范围具有最强的听力损失。
在一些例子中,操控音频数据(610)可包括操控预定音频数据并存储操控后的音频数据用于随后播放。例如,操控后的音频数据可存储在数字硬件设备如智能电话或虚拟现实头戴式耳机的计算机存储器中。
代替存储预定音频数据,作为备选,操控音频数据(610)可包括实时操控当前听音情形的音频数据。在计算机科学中,实时计算描述硬件和软件系统遭受“实时限制”,例如从事件到系统响应。实时程序必须保证在指定时间限制内响应,通常称为“绝限”。也就是说,操控音频数据可在少于500ms、少于200ms、甚至少于50ms的时间内发生。
在一些例子中,操控音频数据(610)及播放操控后的音频数据(620)可使用噪声抵消型耳机进行。这样的耳机可配置成使用有效声音控制操控周围声音。其可包括一个或多个传声器(用于方向性)及用于产生对应于环境声音的音频数据的电路。耳机的数字信号处理器可配置成根据反映听力损失的传递函数操控/滤波音频数据。在一些例子中,音频数据根据对应于第二人的当前运动和/或头部定向和/或距离的方向数据和/或距离数据进行操控。因而,db输出可根据方向数据和/或距离数据减小。真实世界情形因而可通过多传声器头戴式耳机呈现给重要的他人,其也可在家庭外面例如在餐厅中由重要的他人佩戴以从听力受损配偶的角度体验该通常非常困难的听音情形。
在一些例子中,操控后的音频数据可经虚拟现实头戴式耳机播放给第二人。在一些例子中,播放操控后的音频信号(620)还可包括连同音频数据一起和/或对应于音频数据显示视频数据。因而,虚拟现实场景可针对第二人产生。用操控的声音反映他们配偶的听力损失的共同或个人重要的听音情形因而可通过虚拟现实头戴式耳机展现给重要的他人。
在一些例子中,方法600还可包括将对应于第一人的真实生活体验的视听数据传给远程服务器,并在远程服务器处根据第一人的听力测定数据操控视听数据的音频部分。例如,听力受损人员可使用app或者智能电话将个人重要听音情形的视频上传到云/听觉病矫治专家。
在一些例子中,方法600还可包括将操控的视听数据从远程服务器传给第二人的移动显示装置。移动显示装置可以是智能电话、计算机、虚拟现实头戴式耳机等。
根据另一方面,本发明还提供计算机程序,当该计算机程序在可编程硬件设备上运行时,用于执行仿真听力损失的方法600。
根据另一方面,本发明还提供用于仿真听力损失的设备。该设备包括配置成根据遭受听力损失的第一人的听力测定数据操控音频数据的处理器,及配置成将操控的音频数据播放给第二人的播放设备。受益于本发明的本领域技术人员将意识到,该设备可包括计算机、智能电话、虚拟现实头戴式耳机、多传声器头戴式耳机等。
所提出的概念的更详细的例子可按三个步骤得到:
1)首先,可使用虚拟现实头戴式耳机,具有通过所选听觉条件例如共同重要的听音情形的声音操控复制个性化听力受损的能力,及在人/物相对于声源不同地定位时反映操控的声音。
可进行声音操控以根据听力受损用户312被验配助听器时进行的听力测定测试(听力图结果)反映听力受损用户312的听力损失,例如声音被降级以反映听力损失(例如对于2000hz的频率降低40db,对于4000hz的频率降低60db等,及具有特定响度)。
此外,声音也可根据观看重要听音情形的视频时体验的运动/位置进行降级,例如在某人以其背部朝向听力受损人员的状况讲话时或者从另一房间讲话时降级声音。这可在最常见的重要听音情形中针对听力受损人员尤其针对重要的他人训练通信策略,并用作听觉病矫治专家的基于证据的决策支持工具,因为所有客户和重要的他人在该第一通信策略训练步骤均可使用同样的常见听音情形。
2)其次,我们可追求通信策略训练的个性化。听力受损人员可使用app或智能电话将个人重要听音情形的视频上传到云/听觉病矫治专家(参见图3中的助听器用户域)。
这些个人重要听音情形可用于通过虚拟现实头戴式耳机进行个性化通信训练策略。为此,云/听觉病矫治专家可将视频上传到虚拟现实系统,及这些视频可被声音操控以根据用户312被验配助听器时进行的听力测定测试(听力图结果)反映听力受损用户312的听力损失。
3)在该第三步骤中,听力受损用户312及重要的他人已在步骤1和2中训练常见及个性化重要听音情形并已通过虚拟现实体验在相对于想要听的声音位于不同位置时声音及通信情形发生了什么。但该训练迄今均是通过虚拟现实,现在是时间回到真实世界并学习更多。
这可经噪声抵消型头戴式耳机实现,这样,外部声音可被抑制,为方向性目的在每一耳机上具有至少两个传声器及在耳机中具有至少一个接收器。一旦我们已抑制外部声音,系统可放大从每一耳朵中的传声器听到的声音,而且这样做根据配偶被验配助听器时进行的听力测定测试(听力图结果)反映听力受损配偶的听力损失。
现在,重要的他人可参与他们的听力受损配偶的真实世界通信情形或其他情形,从而体验他们的配偶的听力损失并从自己的体验学习怎样与听力受损人员交流。
在一些例子中,虚拟现实头戴式耳机和多传声器头戴式耳机均可在基于云的e健康生态系统300中运行,从而使能集成三个功能域:1)助听器用户域310;2)听觉病矫治专家/健康护理专家域320;及3)云服务提供商域330。虚拟现实头戴式耳机可从云服务提供商域330获得常见及个人重要听音情形的视频。常见重要听音情形视频例如可从视频库上传。在云330中,所有类型的视频均可根据个人听力受损用户312的听力测定测试进行声音操控。个人重要听音情形可从听力受损用户经智能电话316上传到云/听觉病矫治专家。在一方面,多传声器头戴式耳机的声音操控可通过云330和/或重要的他人的智能电话进行。
重要的他人可在家中使用虚拟现实头戴式耳机。具有操控的声音反映他们配偶的听力损失的常见或个人重要听音情形可经虚拟现实头戴式耳机展现给重要的他人。真实世界情形经多传声器头戴式耳机呈现给重要的他人,其也可在家外面例如餐厅中由重要的他人佩戴以从听力受损配偶的角度体验该通常非常困难的听音情形。这些工具也可解决听力受损人员在说明其听力损失及其与世界沟通时具有非常大困难的问题。听觉病矫治专家可用这些工具具有虚拟世界“实验室”测试池,从而用于他们的临床决策支持和对通信策略的咨询服务的场合池,进而使能对听力受损人员及他们的重要的他人提供基于证据的和一致的临床服务及支持。此外,听觉病矫治专家可使用个人重要听音情形细调通信策略训练及理解和观察客户的个人问题。
该解决方案使听力受损人员及重要的他人均可参与个性化康复过程并准许重要的他人作为康复过程中的重要伙伴。
连同一个或多个先前详细描述的例子及附图提及和描述的方面和特征也可与一个或多个其它例子组合以代替其它例子的类似特征或者另外将特征引入到其它例子。
例子还可以是具有程序代码的计算机程序或者与该计算机程序有关,当计算机程序在计算机或处理器上运行时,用于执行一个或多个上面的方法。多个不同的上面描述的方法的步骤、操作或处理可通过编程的计算机或处理器执行。例子还可覆盖程序存储装置如数字数据存储介质,其为机器、处理器或计算机可读并编码指令的机器可执行、处理器可执行或计算机可执行的程序。指令执行或导致执行上面描述的方法的部分或所有行动。程序存储装置可包括或者可以是例如数字存储器、磁性存储介质如磁盘和磁带、硬盘、或光学可读数字数据存储介质。另外的例子还可覆盖计算机、处理器或控制单元,其被编程以执行上面描述的方法的行动;或者(现场)可编程逻辑阵列((f)pla)或(现场)可编程门阵列((f)pga),其被编程以执行上面描述的方法的行动。
描述及附图仅说明本发明的原理。此外,在此给出的所有例子均进行原理性地表达,仅用于示范目的以帮助读者理解本发明的原理及发明人相对于现有技术贡献的概念。在此对本发明的原理、方面和例子进行的所有陈述及其具体例子均包括其等同方案。
记为“用于……的装置”的执行某一功能的功能模块可指配置成执行某一功能的电路。因此,“用于……的装置”可实施为“配置成或适合……的装置”,如针对相应任务配置或适合相应任务的装置或电路。
图中所示的多个不同元件的功能,包括记为“装置”、“用于提供传感器信号的装置”、“用于产生传输信号的装置”等的任何功能模块,可以专用硬件的形式实施,如“信号提供者”、“信号处理单元”、“处理器”、“控制器”等,以及能够运行与适当软件相关联的软件的硬件。当由处理器提供时,这些功能可由单一专用处理器提供、由单一共享处理器提供、或由多个个别处理器提供,其部分或全部可共享。然而,术语“处理器”或“控制器”不排他地限于能够执行软件的硬件,而是可包括数字信号处理器(dsp)硬件、网络处理器、专用集成电路(asic)、现场可编程门阵列(fpga)、用于存储软件的只读存储器(rom)、随机访问存储器(ram)及非易失性存储器。也可包括其它硬件,传统的和/或定制的。
框图例如可图示实施本发明原理的高级电路图。类似地,流程图、状态转变图、伪码等可表示多个不同的处理、操作或步骤,其例如可实质上被表示在计算机可读介质中并由计算机或处理器执行,无论这样的计算机或处理器是否被明确示出。说明书或权利要求中公开的方法可通过具有用于执行这些方法的每一相应行动的装置的设备实施。
应当理解,除非明确或隐含地说明,例如因技术原因,说明书或权利要求中公开的多个行动、处理、操作、步骤或功能不可解释为必须按特定顺序。因此,多个行动或功能将不限于特定顺序,除非这样的行动或功能因技术原因不可互换。此外,在一些例子中,单一行动、功能、处理、操作或步骤可分别包括或可分解为多个子行动、子功能、子处理、子操作或子步骤。这样的子行动可被包括并作为该单一行动的部分,除非被明确排除。
- 还没有人留言评论。精彩留言会获得点赞!