基于多层分类器的移动应用流量识别方法与流程
本发明属于网络流量分析领域,涉及一种基于机器学习的网络流量识别方法,具体涉及基于多层分类器的移动应用流量识别方法。
背景技术:
随着移动设备的普及和移动应用的繁荣发展,移动应用已成为人们当前最常用的上网方式。截止2018年第一季度,谷歌应用市场有380万款应用可供用户下载,并且平均每天上新6,140个新应用。至2017年,有57%的网络流量都来自于移动设备。因此,移动网络流量已经超过传统工作站流量成为网络流量的主要组成部分。研究关注的热点也从传统工作站流量识别转向移动网络流量识别。
移动网络流量识别技术的目标是识别移动流量的应用来源。这项技术在网络管理与安全,市场调研,用户分析等领域有重要的作用。例如,基于这项技术,服务提供商可以掌握网络中的移动应用流量分布情况;网络管理员可以获取园区内流行的网络应用并优化相关网络资源分配以提高用户体验;广告提供商可以了解某一应用在何时何地更受用户欢迎从而制定更合理的广告投放策略等。
移动网络流量识别虽然与传统桌面流量识别过程类似,但移动流量的特殊性给传统流量识别技术带来了巨大的挑战:
1)移动应用流量多采用http/https协议传输,这使得基于端口的流量识别技术只能将这类移动应用流量识别为web。其他传输端口则多为随机端口号,使得这一技术完全失效。
2)为了保护用户隐私,移动流量多采用加密协议传输,降低了基于深度包检测dpi(deeppacketinspection)的流量识别技术的有效性。
3)移动应用多使用第三方库,导致不同的应用会产生相似的流量,这些流量难以使用dpi技术及ip地址进行识别。
4)cdn(contentdistributionnetwork,内容分发网络)是移动应用普遍使用的技术。这一技术导致一个服务器的ip的地址可能同时为不同的应用服务。因此降低了基于dns(domainnamingsystem,域名服务系统)的流量识别技术的有效性。除此外,一些应用可能不使用dns获取服务器地址,进一步缩小了基于dns流量识别技术的适用范围。
5)移动应用数量巨大,更新快,新兴应用层出不穷,识别技术需不断的更新,如dpi技术需持续更新负载特征库等。
鉴于以上原因,传统的流量识别方法已不能有效的处理移动流量。近年来基于机器学习的流量识别技术在传统桌面网络流量识别中表现出良好的分类性能,因此已有工作也将其应用于移动应用流量识别任务中。
wang等人(wang等,iknowwhatyoudidonyoursmartphone:inferringappusageoverencrypteddatatraffic(我知道你的手机在做什么:通过加密流量推测移动应用使用情况).ieeeconferenceoncommunicationsandnetworksecurity(ieee通信与网络安全会议),2015,433-441)人工收集13种ios系统下的应用各自运行5分钟的流量,并训练随机森林分类器。但这一工作使用的样本数量过少,因此难以评估该方法的有效性。appscanner(vincent等,robustsmartphoneappidentificationviaencryptednetworktrafficanalysis(基于加密网络流量分析的鲁棒性移动应用识别方法),ieeetransactionsoninformationforensics&security(ieee信息取证与安全期刊),2017,13(1):63–78)采用随机森林算法提取应用的指纹并识别流量。其使用的数据集来自两台不同的安卓设备上的110种应用产生的流量。但该工作采用“突发”(即一定时间内间隔时间小于某一阈值的一组包)作为流量识别的基本对象,导致这一方法只适用于简单网络的流量识别工作。wang等人(wang等,end-to-endencryptedtrafficclassificationwithone-dimensionalconvolutionneuralnetworks(基于一维卷积神经网络的端到端加密流量识别方法),ieeeinternationalconferenceonintelligenceandsecurityinformatics(ieee情报与安全信息会议),2017,43-48)采用一维卷积神经网络模型识别流量,在细粒度上对流量进行分类时,其确率达86.6%。deeppacket(mohammad等,deeppacket:anovelapproachforencryptedtrafficclassificationusingdeeplearning(deeppacket:一种基于深度学习的加密流量分类方法),arxiv,2017)基于一维卷积神经网络和栈式自动编码器对移动应用流量进行分类。giuseppe等人(giuseppe等,mobileencryptedtrafficclassificationusingdeeplearning(基于深度学习的移动加密流量分类),2018)对四种基于神经网络的识别方法比较后指出,wang等人(wang等,end-to-endencryptedtrafficclassificationwithone-dimensionalconvolutionneuralnetworks(基于一维卷积神经网络的端到端加密流量识别方法),ieeeinternationalconferenceonintelligenceandsecurityinformatics(ieee情报与安全信息会议),2017,43-48)提出的分类器具有最优的移动应用流量识别性能。
综上所述,尽管上述提出的移动应用流量识别方法都表现出优秀的识别结果,但这些方法均未考虑未知背景流量给分类器性能带来的影响,仅在封闭环境中测试分类器,即测试集流量都来自训练集中涉及的应用。而真实网络中,除了目标应用流量外,未知应用成千上万及新兴应用层出不穷,这些非目标应用产生的背景流量会对分类器带来极大的挑战。而上述方法的测试环境均未考虑这一问题,导致这些方法无法部署于真实网络环境。
技术实现要素:
本发明针对现有基于机器学习的移动应用流量识别方法不能检测和处理背景流量的问题,提供一种基于多层分类器的移动应用流量识别方法,逐层学习目标流量样本特征,从而使分类器在识别目标流量的同时也能排除背景流量,降低分类器的伪正数。
技术方案如下:
第一步,提取流量训练集的特征,得到流量样本的特征表示。每个流量样本记为流。
第二步,训练第一层分类器,将待检测样本初步检测为目标流量或背景流量。记目标流量为target类,背景流量为other类。
第三步,提取模糊流,构造第二层分类器的训练集,然后训练第二层分类器,对目标流量进行细粒度识别。模糊流是指同时被多个应用产生的相似流量,如第三方库或广告流量。记第i个目标应用为appi。目标应用的个数为n,n为自然数。
第四步,重新提取背景流量样本,构造第三层分类器的训练集,然后训练第三层分类器。
第五步,使用训练好的多层分类器对待检测样本进行移动应用流量识别。方法是:首先,使用第一层分类器将待检测流样本识别为target类或other类,识别为target类的流量样本进入第二层分类器继续检测;然后,第二层分类器再细粒度地将target类识别为某一目标应用或者模糊流,若某一样本被识别为目标应用appi,则进入第三层分类器,由相关的分类器继续进行识别;当第三层分类器给出一致的识别结果时,则给出最终的识别结果,否则拒绝判断。
作为本发明技术方案的进一步改进,所述第一步提取流量训练集的特征,具体方法为:首先对原始流量根据五元组<源ip,目的ip,源端口,目的端口,协议>进行分组,构成流。如果一条流包含的负载不为0的报文数小于等于五,则依据整条流提取对应的29种流量特征;如果一条流包含的负载不为0的报文数大于五,则只取前五个负载不为0的报文提取对应的29种流量特征,并舍弃第五个负载不为0的报文后的其他报文。
作为本发明技术方案的进一步改进,所述29种流量特征分别包括目的端口、流的前16个负载字节、及12种统计特征。12种统计特征分别为客户端至服务器端的报文大小的最大值、最小值,服务器端至客户端的报文大小的最大值、最小值、平均值、方差值,客户端至服务器端的前3个具有非0负载的报文的负载大小,服务器端至客户端的第1个与第3个具有非0负载的报文的负载大小,流的最小包大小。
作为本发明技术方案的进一步改进,所述第二步第一层分类器训练具体方法为:将训练集样本的标签分为target类及other类,并训练随机森林二元分类器。在训练时,增加目标流量样本的权值使得分类器优先学习目标样本的特征。
作为本发明技术方案的进一步改进,所述第二步中的训练集样本的特征为端口及12种统计特征。
作为本发明技术方案的进一步改进,所述第三步第二层分类器训练具体方法如下:
步骤3.1提取模糊流,具体方法为:首先,流量样本集按照二元组<服务器ip,服务器端口>进行分组。对于每一个分组,如果分组中的流量样本有多个应用标签,并且没有某一类应用样本占主导地位,那么该组中的流量为模糊流。在本发明中,当一类应用的样本个数占分组样本个数的90%以上时,认为其占据主导地位。
步骤3.2构造训练样本集,具体方法为:提取原训练集中提取模糊流后剩下的各个目标应用的流量样本,结合步骤3.1中提取出的模糊流样本,构成第二层分类器的训练样本集,共包含n+1类样本。
步骤3.3训练第二层n+1元随机森林分类器。
作为本发明技术方案的进一步改进,所述步骤3.3中的训练集样本的特征为端口及12种统计特征。
作为本发明技术方案的进一步改进,所述第四步第三层分类器训练具体方法如下:
步骤4.1提取other类样本,具体方法为:使用第二步训练的第一层分类器对原训练集进行分类,提取其中被误分为target类的other类样本,构成新的other类数据集。
步骤4.2构造训练样本集,具体方法为:将步骤4.1提取的other数据集,同第三步中的训练集结合起来,构成第三层分类器的训练样本集,共包含n+2类样本,即n类目标应用样本,模糊流类及other类。
步骤4.3训练第三层分类器,具体方法为:选择随机森林及xgboost模型(chen等,xgboost:ascalabletreeboostingsystem(xgboost:一种可扩展的集合树系统),acminternationalconferenceonknowledgediscoveryanddatamining(acm知识发现与数据挖掘国际会议),2016,785-794)训练第三层分类器。对于每个模型,基于一对一法(周志华,机器学习,2016,63-66),即在任意两个类别间训练一个二元分类器,训练(n+2)*(n+1)/2个二元分类器。最终第三层分类器包含(n+2)*(n+1)个分类器。训练集的特征为前16个负载字节。
作为本发明技术方案的进一步改进,所述第五步移动应用流量识别具体方法如下:
步骤5.1第一层分类器分类,具体方法为:提取流量样本的端口及12种统计特征,使用第一层分类器识别。若识别为target,则进入步骤5.2。否则判定为背景类流量,结束。
步骤5.2第二层分类器分类,具体方法为:提取流量样本的端口及12种统计特征,使用第二层分类器识别。若识别为某一目标应用appi,则进入步骤5.3;若识别为模糊流,结束,不给出具体应用标签。
步骤5.3第三层分类器分类,具体方法为:提取流量样本的前16个字节,使用第三层的2*(n+1)个分类器进行识别。当2*(n+1)个分类器的识别结果与步骤5.2一致,则判定为appi,否则结束,不给出具体应用标签。
作为本发明技术方案的进一步改进,上述步骤5.3中的2*(n+1)个分类器分别为n+1个随机森林分类器及n+1个xgboost分类器。n+1个二元随机森林分类器包括appi类样本与appj类样本构成的训练集训练的二元分类器(j不等于i),appi类样本与other类样本构成的训练集训练的二元分类器以及appi类样本及模糊流类样本构成的训练集训练的二元分类器。n+1个二元xgboost分类器包括appi类样本与appj类样本构成的训练集训练的二元分类器(j不等于i),appi类样本与other类样本构成的训练集训练的二元分类器以及appi类样本及模糊流类样本构成的训练集训练的二元分类器。
与现有技术相比,本发明的有益效果是:
·由于未知应用成千上万,并且新应用层出不穷,这导致不可能收集完备的背景流量数据集。因此分类器不能学习所有的背景流量模式,从而不能有效的排除未学习过的背景流量。本发明设计的分类器在不具备完备的背景流量数据集的情况下,通过逐层更好的学习目标样本来具备排除非目标样本的能力,缓解未知流量对分类器的分类器性能带来的影响;
·本发明充分考虑了真实网络中的流量分布情况,提出的多层器能有效的检测网络中存在的大量背景流量,对将基于机器学习的移动应用流量识别方法部署于实际中具有一定的指导意义。
附图说明
图1是本发明总体流程图;
图2是本发明的分类器识别流程图;
图3是本发明实施例中第二层与第三层分类器的精度与召回率;
图4是本发明实施例中有无模糊流检测的分类器精度和召回率比较;
图5是本发明实施例中有无模糊流检测的分类器伪正数比较;
图6是本发明实施例中不同判定阈值的分类器性能比较;
图7是本发明实施例中分类器精度比较;
图8是本发明实施例中分类器召回率比较;
图9是本发明实施例中分类器伪正数比较。
具体实施方式
下面结合实例对本发明的实施方式进行进一步详细说明。
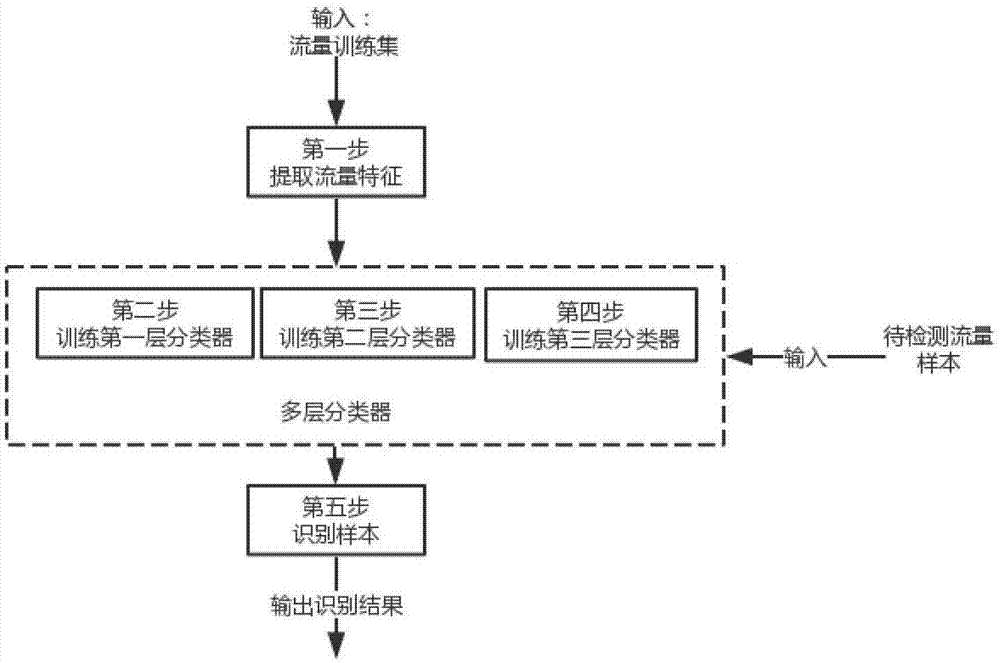
如图1所示,本发明基于多层分类器的移动应用流量识别方法包括以下步骤:
第一步,提取流量训练集特征,即对每个样本用特征进行表示,特征共计29种。
第二步,训练第一层分类器。将训练数据集样本分为target与other类,并训练一个二元随机森林分类器。训练结果如图2中的第一层分类器。
第三步,训练第二层分类器。首先提取模糊流,构造第二层分类器的训练集,共包含n+1类样本,并训练一个n+1元随机森林分类器,在细粒度上识别目标流量。训练结果如图2中的第二层分类器。
第四步,训练第三层分类器。首先重新提取背景流量样本,构造第三层分类器的训练集,共包含n+2类样本,然后训练第三层分类器,对每类模型,生成(n+2)*(n+1)/2个分类器。训练结果如图2中第三层基分类器池。
第五步,对待检测样本进行识别。如图2所示,对于待检测流样本,首先使用第一层分类器进行识别,识别为target类或other类。此时识别为target类的流量样本进入第二层分类器继续检测。这些样本中包含目标流量和背景流量。第二层分类器在细粒度上将target类识别为某一目标应用或者模糊流。若某一样本被识别为目标应用appi,则在第三层由相关的分类器继续进行识别。当第三层的分类器给出一致的识别结果时,则给出最终的识别结果,否则拒绝判断。
本发明采用真实网络流量进行了测试,并对本发明的有效性进行评估。
1)数据集
本地收集12个用户近三个月内产生的移动应用流量。其中,涉及的移动设备品牌包括华为、小米、三星等,涵盖的移动应用共160种,流量产生的网络环境包括2g、3g、4g以及无线网络。最终收集的流量被分为两个数据集,相关数据如表1。
表1.数据集详细
数据集1用于训练与测试提出的三层分类器。其中,有7个应用的流样本数超过5000,并被选为目标应用,剩余的131个应用作为非目标应用,其相关流量即为背景流量。数据集2仅用于测试三层分类器,并且其包含22种数据集1中不存在的应用,共占5569条流样本。因此,这22种应用可视为新出现的应用。两个数据集的详细构成如表2所示。
表2.数据集1与数据集2构成
2)实验设置
使用scikit-learn机器学习算法库实现分类器,并且将三层分类器与当前效果最好的方法一维卷积神经网络分类器(简记为1d-cnn)(wang等,end-to-endencryptedtrafficclassificationwithone-dimensionalconvolutionneuralnetworks(基于一维卷积神经网络的端到端加密流量识别方法),ieeeinternationalconferenceonintelligenceandsecurityinformatics(ieee情报与安全信息会议),2017,43-48)及单一随机森林基准分类器进行比较。基准分类器是一个n+1类的随机森林分类器,包含30棵树,最大深度为20。实现1d-cnn时,提取每条流的前784个负载构造一维向量作为模型的输入,并使用keras库训练n+1类1d-cnn分类器。其中,一维卷积神经网络模型的参数与原工作保持一致。模糊流未应用于基分类器及一维卷积神经网络分类器。对于三层分类器,其前两层的随机森林模型每个均包含30棵树,树最大深度为20。第三层的每个随机森林模型包括20棵树,最大深度为20。每个xgboost模型包括10棵树,最大树深为5。
真正数tp(truepositive)、伪正数fp(falsepositive)、伪负数fn(falsenegative)、精度(precision)及召回率(recall)五种评价指标用于评价提出的分类器的性能。
3)各层性能测试
使用数据1对提出的多层分类器的每层分类性能进行测试。首先,数据集1按照7:3的比例被随机分为训练集与测试集。然后训练并测试10次,最后给出平均结果。对于第一层分类器,其精度与召回率分别为12.21%和99.40%。这一结果与预期一致,即只能排除少量的背景流量,目标应用流量的识别精度会较低,但召回率很高。第二层和第三层分类器对各应用的精度及召回率如图3所示。图3表明分类器具有非常高的精度,对背景流量表现出优秀的排除能力。但同时第二层分类器对后三类应用的识别召回率非常低。这是因为在第二层分类器,最后三类应用的测试样本分别有57.29%、47.43%及33.97%的样本被判定为模糊流。通过仔细检查第二层分类器的训练数据集,发现最后三种应用与数据集1中的其他非目标应用有很大的联系。例如,qq是一种流行的即时通信软件并且集成了非常多的功能,如新闻推送、邮件管理及音乐播放等。然而,这些功能分别有对应的独立应用,即腾讯新闻、qq邮箱及qq音乐。这导致qq产生的流量很有可能与其他背景应用流量有相似或相同的特征。为了减少误判,分类器会优先将其识别为模糊流而不给出详细类别,从而使得qq流量的识别召回率较低。淘宝及百度存在类似的情形。
4)模糊流检测测试
根据上述实验,可以看出独立识别模糊流对第二层分类器的召回率有巨大的影响。因此,本实验对多层分类器采用或不采用模糊流检测的性能进行比较。采用的数据集为数据集1,实验方法与上述实验相同。最终的多层分类器性能比较如图4、图5所示,其中图4统计的是有无模糊流检测的分类器精度和召回率比较,图5统计的是有无模糊流检测的分类器伪正数比较。
从图4、图5可知,当没有模糊流检测时,各个应用的召回率均会上升,尤其是后三种应用的召回率得到大幅度提升。但相应的伪正数增高,识别精度略微降低。当对分类器的伪正判断容忍度较低时,可选择具有模糊流检测的分类器。当追求高召回率时,则可去除模糊流检测。
5)第三层分类器阈值测试
第三层分类器使用多个二元分类器来学习目标应用流量的特征。如果当所有相关的二元分类器都给出一致的判定结果时才确定流的标签,这种方法会使得分类器的识别精度大,伪正排除能力强,但很可能也易于排除第二层的真正判断,使分类器的召回率变低。因此在此对第三层分类器的不同判断阈值进行试验与比较。实验设置与前两个实验保持一致,比较结果如图6所示。图中的rf的取值表示至少几个随机森林模型给出与第二层一致的分类结果,xg的取值表示至少几个xgboost分类器给出与第二层分类器一致的分类结果,才可确定一条流的标签。
从图6可知,随着判定条件越来越严格,分类器的精度逐渐从80%上升至99%,召回率逐渐从66%下降至53%。不论是xg的取值变大还是rf的取值变大,都会引起精度的上升及召回率的下降。当对召回率要求较高时,可适当降低xg或rf的取值,当对精度要求较高时,则可增大xg或rf的取值。
6)分类器比较
本实验对提出的三层分类器与基准分类器及一维卷积神经网络分类器(1d-cnn)进行比较。对于提出的三层分类器,使用模糊流检测,并将第三层分类器的验证条件设定为最严格的情况,即所有相关的分类器的识别结果都必须与第二层分类器的识别结果保持一致。
(1)数据集1测试
数据集1按7:3的比例被随机分为训练集与测试集,训练及测试10次后给出测试结果的平均值。比较的三种分类器包括单一随机森林模型构成的基分类器,wang等人提出的一维卷积神经网络模型(1d-cnn)(wang等,end-to-endencryptedtrafficclassificationwithone-dimensionalconvolutionneuralnetworks(基于一维卷积神经网络的端到端加密流量识别方法),ieeeinternationalconferenceonintelligenceandsecurityinformatics(ieee情报与安全信息会议),2017,43-48),以及本发明的三层分类器。比较结果如表3前四行所示,对各个应用的识别精度,召回率及伪正数分别如图7、图8、图9。
表3.四种分类器的分类性能比较
结果表明提出的分类器具有最高的精度,实现近99%的识别精度,产生的伪正数远远低于另外两类分类器。相比于基分类器,本发明提出的三层分类器产生的伪负数减少了94%,表明第三层分类器具有优秀的背景流量检测能力。但提出的多层分类器的由于对后三种应用的识别召回率极低导致其平均召回率远低于基分类器。当识别目标为应用覆盖率时,低召回率并不影响识别结果,但要求伪正判断尽可能的少,因此本方法非常适合此类场景的应用。当识别目标为流覆盖率时,本方法在召回率上还有待提升,但若对识别精度有一定要求的场景,本方法仍在识别精度上有很大的优势。
此外,注意到后三类具有低召回率的应用在训练样本上低于前四类样本,因此重新训练分类器,并采用smoteenn方法(batista等人,astudyofthebehaviorofseveralmethodsforbalancingmachinelearningtrainingdata(几种机器学习训练数据平衡方法的研究),acmsigkddexplorationsnewsletter(acmsigkdd探索通讯),2004,20-29)在训练过程中对各类样本进行采样,使各类训练样本数量均衡。从而检查样本数量对模型分类性能的影响。重新训练后的分类器命名为“三层分类器+smoteenn”,其识别结果可见于表3最后一行及图6-8。可以看出样本数量并不是影响分类器召回率的主要原因。虽然通过均衡样本提高了一定的召回率,但对识别精度的负面影响反而较大。
(2)数据集2测试
使用数据集1训练分类器,并将数据集2作为测试集测试分类器,进一步验证分类器的识别性能。测试结果如表4所示。
表4所示结果与数据集1的测试结果类似,相比于另两种分类器,本发明提出的三层分类器具有最好的背景流量检测能力。在数据集2上,三层分类器共产生了152个伪正判断,其中,有45条流来自新出现应用,即排除了约99.2%的完全未知流量。相比之下,随机森林产生了1478个伪正判断,有403条流来自新出现应用;1d-cnn产生3963个伪正判断,有1348条流来自新出现应用。然后对剩余的107个伪正判断进行详细的分析。对于31条被错误分类为腾讯视频的流,其中有3条来自qq音乐,28条流来自腾讯新闻。而qq音乐、腾讯新闻、腾讯视频皆为腾讯公司的应用软件,并且由于功能需求极易可能访问相同的资源。此外,对于qq,有46个伪正判断来自腾讯地图、腾讯微博等,与腾讯视频伪正情况类似。对于搜狗拼音的1个伪正判断,通过检查该流的ip地址,并与训练集中的其他具有相同ip地址的流进行比较,发现,训练集中的相关流的标签全部为搜狗拼音。因此,这一伪正判断的样本很有可能是具有错误的样本标签。
表4.数据集2测试结果
因此通过逐层精细化的学习目标应用流量的特征,本发明加强了分类器对背景流量的检测能力,使得其能检测从未学习过的流量。实验结果表明,本方法具有极高的识别精度,并能有效的检测未知应用及新兴应用产生的背景流量,在需要实现应用覆盖的识别场景中有极大的应用优势。
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!