一种可扩展的通信协议数据包及其通信系统的制作方法
本发明涉及一种通信领域,具体涉及一种可扩展的通信协议数据包。
背景技术:
在网络应用系统中,模块与模块间的交互必不可少,它们通过不同的传输方式、不同的通信协议来进行数据交换,以实现不同的业务功能。在这个过程中,数据通信协议如同一种语言,定义了模块间通信的规则。从粒度来上划分,模块可以作为一个应用系统中的子系统,与同一个应用中的其它子系统进行内部交互,也可以作为一个应用系统的外部接口模块,与其它应用进行外部交互。那么,在这样不同的应用场景下,各个模块对数据交互的需求不同,对数据传输的安全性、稳定性要求也不同,用于定义数据交互的规则也自然不会相同,因此产生了多种数据通信协议。
目前最常见的通信协议,其数据内容位置都是固定的,也就是说在组包时各个字段的前后位置都是有顺序的,这也就使得数据包的灵活性差,而且一般的通信协议无法实现数据扩展,就算可以扩展其数据添加位置也是顺序增加,这对于一些需要优先处理的数据指令是十分不合理的。
技术实现要素:
本发明要解决的问题是提供一种可扩展的通信协议数据包,其对数据体中多个字段增设唯一的字段识别号,使得每个字段都被唯一识别,从而使得各个字段的前后位置可以自由调节,以适用于需要优先处理的数据指令组包,不仅扩展性强,而且灵活度好。
为实现上述目的,本发明采取的技术方案如下:一种可扩展的通信协议数据包,包括12个字节的数据头以及可变数据体,所述数据头包含起始位单元,版本号单元,命令单元,请求回复包区分单元,数据包长度单元,数据包错误单元及校验单元;所述可变数据体由多个字段自由组合,每个字段包括字段长度,唯一的字段识别号及字段内容。
作为优选,所述起始单元为三个字节,版本号单元为一个字节,命令单元为两个字节,请求回复区分单元为一个字节,数据包长度单元为两个字节,数据包错误单元为一个字节,校验单元为两个字节。
作为优选,所述字段中字段长度取值范围为0x0000~0xffff,字段识别号取值范围为0x00~0xff,字段内容的数据类型为bin、bcd、int或string。
一种可扩展的通信协议数据包的通信系统,包括发送端与接收端,发送端与接收端之间通过数据包进行通信,所述发送端实现数据包的组包或数据包的扩展,接收端对接收的数据包进行解包。
作为优选,所述发送端的组包过程为如下步骤:
a、发送端在每个内容字段前增加一个唯一的字段识别号,以及对应的字段长度形成一个完整的字段;
b、将多个字段组合形成数据体,其内部的字段前后位置不限;
c、在数据体前加上数据头组成一个完整的数据包,其数据头包括起始位单元,版本号单元,命令单元,请求回复包区分单元,数据包长度单元,数据包错误单元及校验单元,数据头组装完成后,首先对数据体内容进行校验获得校验字填入校验单元,再将每个字段的长度相加并加上数据头长度形成完整数据包长度填入数据包长度单元。
作为优选,发送端的数据包扩展过程为如下步骤:
a、发送端将需要扩展的内容字段前加上字段识别号,以及对应的字段长度形成一个完整的字段;
b、将扩展的字段加到数据包的数据体中,加入的位置前后不限;
c、数据头中的校验单元对扩展后的数据体进行内容校验,获得新的校验字填入校验单元,同时对整个数据包长度进行重新识别,并填入数据包长度单元,形成一个新的数据包;
d、发送端将扩展后的数据包发送给接收端。
有益效果:本发明所揭示的一种可扩展的通信协议数据包,具有如下有益效果:
可扩展性:数据体的字段都具有唯一的识别号,使得字段之间可自由扩展;
灵活性:数据体中的字段前后位置不限,可以根据字段识别号更改其所在位置,适用于不同优先级别数据的位置调节;
唯一性:上下行数据都可根据命令单元判断数据包作用,确保每个数据包内容的唯一性;
数据准确性:提供crc16校验,有效避免数据出错。
附图说明
图1为本发明数据包的结构图;
图2是本发明实例的通讯系统结构示意图。
具体实施方式
下面将结合本发明的内容,对本发明的技术方案进行清楚、完整的描述。
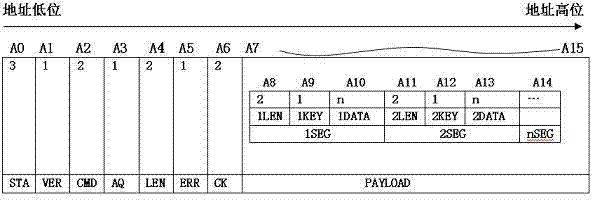
如图1所示,本发明所揭示的一种可扩展的通信协议数据包,包括12个字节的数据头以及可变数据体payload,其中:所述数据头包含起始位单元sta,版本号单元ver,命令单元cmd,请求回复包区分单元aq,数据包长度单元len,数据包错误单元err及校验单元crc,所述可变数据体由多个字段seg自由组合,每个字段包括字段长度nlen,唯一的字段识别号nkey及字段内容ndata。
具体说来,每个数据包都有固定的起始位单元sta,由三个字节组成,固定形式为0xff,0xff,0xfe,三个字节的设计使得数据体中出现该起始位数据的概率降低,确保接收端解析时准确识别数据头的起始单元。
版本号单元ver为一个字节,取值范围为0x00~0xff,用于表示本数据包的版本号,便于使用者做多版本兼容。
命令单元cmd为高低两个字节,取值范围为0x0000~0xffff,用于区分数据包功能,其高字节在前。
请求回复包区分单元aq为一个字节,表示请求包还是回复包,0x01表示请求包,0x00表示回复包。
数据长度单元len为高低两个字节,取值范围为0x0000~0xffff,用于表示整个数据包的总长度,分别为数据头长度(12字节)+数据体长度(各个字段的长度总和),高字节在前。
数据包错误单元err为一个字节,取值范围为0x00~0xff,在回复包中使用,表示回复包是否正确,0x00表示正确,其他值表示错误。
校验单元crc为高低两个字节,采用modbus-crc16的校验方式,以校验数据体判断其内容是否正确,两个字节的设计提升校验的可靠性,降低错包率。
所述可变数据体最多包含256个字段,每个字段都包括长度,识别号和字段内容三个部分,其中字段内容的数据格式为byte、short、int、byte*、string、bcd等,字段识别号为该字段的唯一识别号,取值范围为0x00~0xff,字段长度就是表示该字段的总长度,包括字段内容长度加上3个字节,取值范围为0x0000~0xffff。
一种可扩展的通信协议数据包的通信系统,实现对上述数据包的通信,包括发送端与接收端,发送端与接收端之间通过数据包进行通信,所述发送端实现数据包的组包或数据包的扩展,接收端对接收的数据包进行解包。
所述组包过程的具体步骤为:
a、发送端在每个内容字段前增加一个唯一的字段识别号,以及对应的字段长度形成一个完整的字段;
b、将多个字段组合形成数据体,其内部的字段前后位置不限;
c、在数据体前加上数据头组成一个完整的数据包,其数据头包括起始位单元,版本号单元,命令单元,请求回复包区分单元,数据包长度单元,数据包错误单元及校验单元,数据头组装完成后,首先对数据体内容进行校验获得校验字填入校验单元,再将每个字段的长度相加并加上数据头长度形成完整数据包长度填入数据包长度单元。
发送端的数据包扩展的具体步骤为:
a、发送端将需要扩展的内容字段前加上字段识别号,以及对应的字段长度形成一个完整的字段;
b、将扩展的字段加到数据包的数据体中,加入的位置前后不限;
c、数据头中的校验单元对扩展后的数据体进行内容校验,获得新的校验字填入校验单元,同时对整个数据包长度进行重新识别,并填入数据包长度单元,形成一个新的数据包;
d、发送端将扩展后的数据包发送给接收端。
下面结合具体的实施例对本发明的数据包以及其组包,解包过程进行描述。
按照地址顺序,数据包的内容排序依次为sta、ver、cmd、aq、len、err、crc、payload,再通信过程中无需指定各单元长度,机器可以直接读取;如果数据包总长度len超过65535,需新建一个命令字cmd;如果数据体payload长度超过65523,也需新建一个命令字cmd;如果数据段nseg个数超过255,也需新建一个命令字cmd。
如图1所示,如果起始位单元sta地址为a0,则ver地址a1=a0+3,cmd地址a2=a0+4,aq地址a3=a0+6,len地址a4=a0+7,err地址a5=a0+9,crc地址a6=a0+10,payload地址a7=a0+12;1len地址a8=a0+12;1key地址a9=a0+14;1data地址a10=a0+15;2len地址a11=a0+12+1seg长度;2key地址a12=a0+12+1seg长度+2;2data地址a0+12+1seg长度+3;nlen长度alenn=a0+12+1seg长度+……+(n-1)seg长度;nkey地址akeyn=a0+12+1seg长度+……+(n-1)seg长度+2;ndata地址adatan=a0+12+1seg长度+……+(n-1)seg长度+3;各字段seg位置可相互调换,即若payload中若含有3个seg,三个seg的位置可为1seg、2seg、3seg,或1seg、3seg、2seg,或2seg、1seg、3seg,或2seg、3seg、1seg,或3seg、1seg、2seg,或3seg、2seg、1seg等6种组合方式;
如图2所示,通信系统包括发送端和接收端,发送端和接收端之间通过数据包进行通信,其中,发送端负责数据包的打包处理,接收端负责数据包的解包处理。本实施例的数据包可用于但不仅限于个人电脑间、个人电脑和设备间、设备间的通信领域。
发送端的详细打包过程如下:
s101:组合包头:
s1011:组合sta,即将数据包的第一个字节赋值为0xff,第二个字节赋值为0xff,第三个字节赋值为0x0f;
s1012:组合ver,根据头文件中的标识,将数据包的第四个字节赋值;
s1013:组合cmd,根据给定的cmd,将该参数拆分成高字节cmdh和低字节cmdl,将cmdh赋值到数据包的第5个字节,将cmdl赋值到数据包的第6个字节;
s1014:组合aq,根据给定的aq,将aq赋值到数据包的第7个字节;
s1015:组合len,将包头长度12拆分成高字节lenh=0x00、低字节lenl=0x0c,将高字节lenh赋值到数据包的第8字节,将低字节lenl赋值到数据包的第9字节;
s1016:组合err,根据给定的err,将该参数赋值到数据包的第10字节;
s10107:组合crc,将数据包的第11字节和第12字节都赋值为0x00;
s201:组合1seg,具体过程如下:
s2011:组合1len,根据1data,计算出1data的字节长度,然后将该字节长度+3,得到1seg的字节长度,将1seg的字节长度拆分成高字节1lenh和低字节1lenl,将高字节1lenh赋值到数据包的第13字节,将1lenl赋值到数据包的第14字节;
s2012:组合1key,根据给定的1key,将1key赋值到数据包的第15字节;
s2013:组合1data,根据1data,按字节将1data赋值到数据包第16字节以后的1data字节长度的位置;
s2014:重新组合len,根据1len,可以得到len=1len+len,并将len拆分成高字节lenh、低字节lenl,将高字节lenh赋值到数据包的第8字节,将低字节lenl赋值到数据包的第9字节;
s2015:组合crc,将数据包地址a7~a15的数据进行crc算法校验,得出crc值,并将crc值拆分成高字节crch和低字节crcl,并将crch赋值到数据包的第11字节,将crcl赋值到数据包的第12字节;
s301:组合2seg,具体过程如下:
s3011:组合2len,根据2data,计算出2data的字节长度,然后将该字节长度+3,得到2seg的字节长度。将2seg的字节长度拆分成高字节2lenh和低字节2lenl,将高字节2lenh赋值到数据包的第len+1字节,将2lenl赋值到数据包的第len+2字节;
s3012:组合2key,根据给定的2key,将2key赋值到数据包的第len+3字节;
s3013:组合2data,根据2data,按字节将2data赋值到数据包第len+4字节以后的2data字节长度的位置;
s3014:重新组合len,根据2len,可以得到len=2len+len,并将len拆分成高字节lenh、低字节lenl,将高字节lenh赋值到数据包的第8字节,将低字节lenl赋值到数据包的第9字节;
s3015:组合crc,将数据包地址a7~a15的数据进行crc算法校验,得出crc值,并将crc值拆分成高字节crch和低字节crcl,并将crch赋值到数据包的第11字节,将crcl赋值到数据包的第12字节;
s401:组合nseg,具体过程如下:
s4011:组合nlen,根据ndata,计算出ndata的字节长度,然后将该字节长度+3,得到nseg的字节长度。将2seg的字节长度拆分成高字节nlenh和低字节nlenl,将高字节nlenh赋值到数据包的第len+1字节,将2lenl赋值到数据包的第len+2字节;
s4012:组合nkey,根据给定的nkey,将nkey赋值到数据包的第len+3字节;
s4013:组合ndata,根据ndata,按字节将ndata赋值到数据包第len+4字节以后的2data字节长度的位置;
s4014:重新组合len,根据nlen,可以得到len=nlen+len,并将len拆分成高字节lenh、低字节lenl,将高字节lenh赋值到数据包的第8字节,将低字节lenl赋值到数据包的第9字节;
s4015:组合crc,将数据包地址a7~a15的数据进行crc算法校验,得出crc值,并将crc值拆分成高字节crch和低字节crcl,并将crch赋值到数据包的第11字节,将crcl赋值到数据包的第12字节;
在上述步骤过程中,数据包头的组合过程为第一个步骤,不可以调整,数据体中各个字段的组合过程顺序可以前后调节,每个seg组合完成后可以进行crc校验,也可以在所有seg组合完成后进行crc校验。
接收端对数据包中数据头的解析过程如下:
s501:判断sta,若sta不为0xff、0xff、0xfe,则返回对应的错误;若正确,则执行s502;
s502:判断ver,若ver不为指定的ver,则返回对应的错误;若正确,则执行s503;
s503:判断cmd,若cmd不在所设定的cmd返回内,则返回对应的错误;若正确,则执行s504;
s504:判断aq,若aq和接收端、发送端所商议的方向不一致时,返回对应的错误;若正确,则执行s505
s505:判断len,若len和接收到的数据包长度不一致或len和包头字节长度与payload字节长度之和不一致,或者len和数据包包头字节长度与payload中所有seg的总长不一致,则返回对应的错误;若正确则执行s506
s506:判断err,当aq为请求包时,err必须为0,否则返回对应的错误;当aq为回复包时,请求端可根据err,判断其发送的请求包是否有错误;
s507:判断crc,接收端根据payload,将数据包地址a7~a15进行crc算法校验,得出新的crc,若新的crc和数据包中的crc不一致,则返回对应的错误;若一致则执行s508;
s508:当s501~s507都没有错误时,返回cmd。
接收端对数据包中数据体的解析过程如下:
s601:读取地址a7的值,根据1seg的1len,获取到1seg的长度;
s602:根据地址a8的值,得到1seg的1key,与所需的key进行比较,若不相等则执行s603;
s603:根据1len,计算出2len的地址,计算方法为12+1len;
s604:得到2seg的2key,与所需的key进行比较,若不相等,则执行s605;
s605:根据1len~(n-1)len,计算出nlen的地址,计算方法为12+1len+2len…+(n-1)len;
s606:得到nseg的nkey与所需的key进行比较,若不相等,则重复s605和s606两步骤;
s607:根据nlen,计算出ndata的直接长度,算法为nlen-3;
s608:根据发送接收双方所商议的ndata类型,获取ndata值,不同的数据类型获取方式不同,具体如下:
byte型:直接读取ndata内容;
int型:从ndata的第一个字节,然后左移8位,和第二个字节进行或运算,得到int16型的数据;然后将int16型的数据左移8位,和第三个字节进行或运算,得到int24姓的数据;然后将int24型的数据左移8位,和最后一个字节进行或运算,得到int型数据;最后,将数据返回;
byte*型:定义一个byte数组,从ndata的第一个字节至最后一个字节,分别赋值到byte数组对应的字节中;
string型:定义一个string型数据,从ndata的第一个字节至最后一个字节,分别赋值到string型数据的对应字节中。
在上述解包步骤中,数据包中各seg的字节长度可以不固定,根据nlen的值可以计算出ndata的字节长度,计算方法为nlen-3。payload的字节长度由1len、2len…nlen进行计算,计算方法为1len+2len+…nlen,接收端可以根据数据包起始地址a0,相机确认得出其余个单元的地址并进行读取。
本发明提供的数据包,传输的信息在转化为payload后具有较短的字节长度,可以使得单个数据包长度减小;各seg含有自己的key,用于区分seg功能,起到seg顺序可以互换,无需指定seg的地址,实现高灵活性;数据包读取前进行sta/crc比对校正,确保数据准确性。通过nlen、nkey、ndata确定nseg结构,进而确定payload结构,有效保证payload信息还原的准确性并且对数据包具有较好的识别度,有利于加快数据的传输、解析速度。
以上对本发明创造的一个实施例进行了详细说明,但所述内容仅为本发明创造的较佳实施例,不能被认为用于限定本发明创造的实施范围。凡依本发明创造申请范围所作的均等变化与改进等,均归属于本发明创造的专利涵盖范围之内。
- 还没有人留言评论。精彩留言会获得点赞!