一种电力销售大数据处理方法与流程
本发明涉及一种电力销售大数据处理方法。
背景技术:
近十年来,在业界和学术界的积极推动和研究下,大数据处理技术在技术栈的各个层次都己经得到了长足的发展和进步。但是,面临日益快速发展的大数据应用需求,大数据处理技术还存在以下几个方面有待进一步研究解决的技术问题:
1)分布式存储系统性能优化和功能增强:大数据存储系统处于大数据处理软件系统的底层,对于上层大数据应用有很大的性能影响,是进行后续大数据计算分析和提供大数据应用服务的重要基础。第一,存储硬件发展迅速,大数据存储应用场景也复杂多变。因此,现有的大数据存储系统,尤其是使用日益广泛的层次化存储系统,需要不断地进行性能提升和功能增强,以满足大数据应用对大规模数据快速读写访问的性能需求。第二,众多分布式文件系统的性能特性和配置参数对上层应用的性能影响较大,分布式文件系统的用户也需要能够定量和定性地分析选择最为合适的分布式文件系统和配置参数。第三,日益产生的大规模众多垂直领域的数据(如rdf语义数据)也急需有效的存储管理和查询手段。
2)主流大数据计算平台的性能提升和功能增强:目前以apachehadoop和apachespark为主的大数据技术框架己经成为了主流的大数据处理平台,并得到了广泛的应用。然而,主流大数据并行计算系统在设计与实现的过程中通常只重点考虑某类大数据应用的共性问题,这些系统在处理种类繁多的上层大数据应用时,还需要进一步的性能优化提升和功能增强,以提升上层应用的计算性能。
3)典型大数据分析应用算法的并行化设计:大数据的核心价值体现在应用,然而当数据规模增长到数百tb规模或者pb级规模时,现有串行化算法将会带来难以接受的时间开销,使得应用算法失效。因此,除了寻找计算复杂度较低的新算法以及降低数据尺度等方法外,一个重要的方法是研究应用相关核心算法的并行化。大数据应用分析算法的并行化设计并无标准统一的方法,而是要根据具体的算法进行特定的并行化优化设计。一般性较为简单的机器学习和数据分析算法的并行化设计相对较为容易,但复杂的机器学习和数据挖掘算法的并行化设计则相对较为困难。随着大数据应用的不断推广,需要深入研究典型的大数据应用的复杂分析算法的并行化。
技术实现要素:
本发明所要解决的技术问题是提供一种大数据处理方法,采用本方法可以大大高对于大数据的存储及访问速度。
本发明所采用的技术方案是:一种电力销售大数据处理方法,其包括如下步骤:
步骤一、基于alluxio建立分层式缓存调度框架,将数据访问模式和缓存策略以及上层大数据应用融合;
步骤二、基于步骤一形成的分层式缓存调度框架,建立不同数据访问模式的缓存调度策略;
步骤三、基于alluxio建立分层式大数据存储缓存调度框架和验证系统。
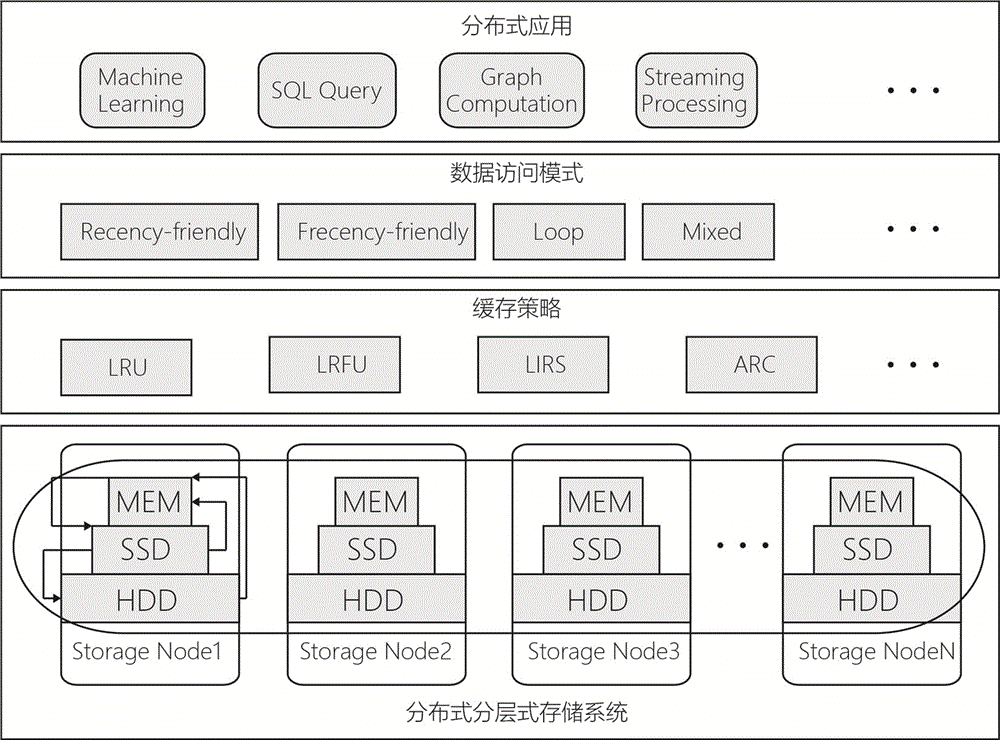
所述分层式缓存调度框架包括大数据应用层、数据访问模式层、缓存策略层以及分布式分层式存储系统。
分布式分层式存储系统的每个worker数据存储服务器工作节点均包含mem-ssd-hdd的三层存储系统。
alluxio系统分层式存储缓存调度工作过程是:当客户端发起一个请求向worker申请空间的时候,如果worker的mem层有足够的空余空间,那么会直接分配空间给客户端:如果worker的mem层没有足够的空余存储空间,那么将递归地替换evict部分数据块到下一层存储层。
在分层式缓存调度框架内设置有用于获取所有数据块行为动作的监听器。
缓存策略层采用的缓存策略包括lru、lrfu、lirs以及arc。
数据访问模式层采用的数据访问模式包括recency-friendly、frequency-friendly、loop以及mixed。
大数据应用层的分布式应用包括machinelearning、sqlquery、graphcomputation、streamingprocessing。
所述recency-friendly数据访问模式的基本形式是:
(a1,a2,...,ak-1,ak,ak,ak-1,...,a2,a1)n
其中,k表示数据块的个数,n表示循环访问的次数。
所述frequency-friendly数据访问模式基本形式是:
((a1,a2,...,ak-1,ak)apε(b1,b2,...,bm))n
其中,k表示被访问超过一次的数据块个数,a表示循环访问这k个数据块的次数;m表示在一轮访问中只被访问一次的数据块个数,凡表示访问这m个数据块的概率;n表示整个访问过程循环的次数;当k<cachesize的时候,访问次数超过一次的数据块完全存放到cache,而k+m>cachesize的时候,cache存放不下所有的数据块,部分数据块被替换出当前的cache。
本发明的积极效果为:本发明针对分层式大数据存储系统,设计并提供一个通用化可扩展的分层式缓存调度框架,通过该框架,将不同的数据访问模式和缓存策略以及上层的大数据应用融合起来,并为用户提供一组覆盖多种不同数据访问模式的高效缓存调度策略,从而加速上层大数据应用的数据读写访问性能。缓存调度框架本身具有很好的通用性,是平台独立的,其架构、访问模式和缓存策略可以适用于任何分层式存储系统。
附图说明
图1为本发明分层式缓存调度框架;
图2为本发明alluxio的总体架构;
图3为本发明alluxio系统分层式存储缓存调度工作过程;
图4为本发明alluxio系统分层式存储缓存调度软件结构。
具体实施方式
alluxio是一个统一的大数据存储系统,它可以支持基于mem-ssd-hdd(内存一固态盘一硬盘)的分层式大数据分布式存储管理。alluxio早期名称为tachyon[91],出自加州大学伯克利分校的amp实验室。其初期的主要设计思想是,使用分布式内存来存储管理数据,从而加速大数据存储系统的读写速度。然而,虽然目前的大数据处理服务器节点上内存配置容量己经较高(64gb,甚至128gb或256gb),但相对于实际应用中的tb甚至pb级数据规模而言,完全基于内存来存储管理大规模数据仍然是远远不够的,因而,需要基于mem-ssd-hdd的分层式大数据分布式存储体系结构,对存储数据进行基于内存的缓存调度处理。
在这种分层式存储场景下,需要研究基于大规模分层式存储结构的内存缓存调度策略与技术方法,以尽可能提高数据在分布式内存缓存层中访问的命中率,以此发挥内存数据存储在读写访问性能上的优势。这就是本节研究问题和研究动机的由来。
在分层式大数据存储系统中,存储设备被按层次组织在一起,并且性能越高的存储设备离cpu越近。类似的系统架构己经在cpu缓存中使用了数十年。访问比较频繁的数据会被优先存储到访问性能更高的存储介质中,如内存或者ssd,而较少被访问的数据会被移到访问速度较低的hdd层。
由于性能越高的存储介质,其价格越高、配置容量相对越小,因此,在这种分层式存储系统中,随着数据访问的变化,通常需要对存储在高性能介质中的数据,依据一定的缓存替换策略进行替换,这就需要有高效的缓存替换策略。因此,在分层式分布式数据存储环境中,高效缓存调度策略的设计和使用是一个非常重要的问题。
基于此,本专利研究并提出了一种适用于分层式大数据存储系统的通用可扩展的缓存调度框架,允许方便地添加定制化的缓存策略,从而在不同的应用场景里取得较好的性能。
进一步,根据数据访问局部性原理,存储在一个服务器节点的数据通常会以一定的访问模式(如顺序、循环等)被读写访问。为了基于缓存调度机制进一步提高数据读写访问性能,可以充分利用应用层存在的特定数据访问模式,设计和构建特定于数据访问模式、更为合理有效的缓存调度策略。
由于没有一个缓存调度策略能够有效适用于所有的数据访问模式,基于前述的分层式大数据存储系统通用化缓存调度框架,本文研究提供了一组覆盖不同数据访问模式的缓存调度策略,以便于用户能够针对实际应用选择最有效的缓存策略。
本发明提出一个通用化可扩展的分层式大数据存储系统缓存调度框架,该框架允许以可插拔(plugin)方式,在需要时快速添加新的缓存策略。基于上述框架,研究实现并提供一组覆盖不同数据访问模式的缓存调度策略,以此加速上层大数据应用中的数据读写访问性能。所提供的缓存策略包括lrfu(cleastrecently/frequentlyused),lirs(lowinter-referencerecencyset)以及arc<adaptivereplacementcache)策略。基于alluxio实现了分层式大数据存储缓存调度框架和验证系统。验证系统集成了所实现的多种调度策略,大大增强了alluxio系统的缓存调度能力,提升了alluxio系统原有缓存策略的性能。
为了更好地理解和设计不同的缓存策略,表1.1列出了从应用中总结出的常用数据访问模式,不同的数据访问模式有着不同的访问特性。
表1.1常见的数据访问模式
(1)recency-friendly数据访问模式,基本形式是:
(a1,a2,...,ak-1,ak,ak,ak-1,...,a2,a1)n式(1.1)
其中,k表示数据块的个数,n表示循环访问的次数。
该数据访问模式有良好的数据局部性,即当前被访问的数据在不久的将来有很大的概率被再一次访问。这种访问模式在大数据应用中很常见。
frequency-friendly数据访问模式,基本形式是:
((a1,a2,...,ak-1,ak)apε(b1,b2,...,bm))n式(1.2)
其中,k表示被访问超过一次的数据块个数,a表示循环访问这k个数据块的次数;m表示在一轮访问中只被访问一次的数据块个数,凡表示访问这m个数据块的概率;n表示整个访问过程循环的次数。当
k<cachesize的时候,访问次数超过一次的数据块可以完全存放到cache,而k+m>cachesize的时候,cache存放不下所有的数据块,部分数据块被替换出当前的cache。这种场景下好的替换策略应该优先替换出只被访问一次的数据块b1,b2,...,bm。
在这种访问模式下,系统中的数据块以一种不均匀的频率被访问。缓存更加频繁被访问的
数据块将会带来更大的访问性能提升。
loop数据访问模式,基本形式是:
(a1,a2,...,ak-1,ak)n式(1.3)
其中,k表示循环被访问的数据块个数,n表示循环的次数。
该数据访问模式表示数据块以一种循环的方式被不断访问。这种访问模式在大数据迭代计
算应用中比较常见,如k-means和pagerank。在该数据访问模式下,替换最近访问的数据块会
取得较好的效果,而替换最久没被访问的数据块会导致每次访问的数据块都不在内存。
mixed数据访问模式,基本形式是:
其中,k表示循环被访问的数据块个数,a表示循环访问这k个数据块的次数;m表示在一轮访问中只被访问一次的数据块个数,pε表示访问这m个数据块的概率;n1表示以recency-friendly模式访问数据块的循环次数,n2表示以frequency-friendly模式访问数据块的循环次数,n表示整个访问过程循环的次数。
该数据访问模式通常是多种访问模式的混合。表1.1列举的是recency-friendly访问模式和frequency-friendly访问模式的混合。这种访问模式也是比较常见的,因为实际的大数据应用一般都会包含多种不同的访问模式。
对应于上述不同的数据访问模式,实际应用中可以采用相应的缓存调度策略以尽可能达到最高效的读写访问性能。研究发现,最基本的lru缓存策略仅仅对recency-friendly数据访问模式效果良好;lrfu策略能够对recency-friendly,frequency-friendly以及循环访问模式都取得稳定的性能;lirs策略对frequency-fiiendly和loop访问模式可取得比较高的性能;arc策略对mixed,recency-friendly,frequency-friendly访问模式都能取得比较好的效果。这些高效的缓存策略具有加速上层spark,hadoop等大数据应用的潜能。
图1描述了通用化分层存储系统缓存调度的整体框架。该框架的设计目标是,针对分层式大数据存储系统,设计并提供一个通用化可扩展的分层式缓存调度框架,通过该框架,将不同的数据访问模式和缓存策略以及上层的大数据应用融合起来,并为用户提供一组覆盖多种不同数据访问模式的高效缓存调度策略,从而加速上层大数据应用的数据读写访问性能。
上述缓存调度框架本身具有很好的通用性,是平台独立的,其架构、访问模式和缓存策略可以适用于任何分层式存储系统。
图2描述了alluxio系统的分层式分布式存储架构(启动一个主进程管理元数据、多个从进程存储实际数据),其中每个worker数据存储服务器工作节点都包含了mem-ssd-hdd的三层存储系统。
图3描述了alluxio的多层存储结构及其缓存调度是如何工作的。当客户端发起一个请求向worker申请空间的时候,如果worker的mem层有足够的空余空间,那么会直接分配空间给客户端:如果worker的mem层没有足够的空余存储空间,那么将递归地替换(evict部分数据块到下一层存储层。因为每次替换都有一定的时间开销,因此alluxio越少次数的数据块替换操作将会给上层应用带来越高的性能。
图4描述了基于alluxio验证系统设计实现的可扩展的缓存调度框架的详细软件结构。该框架允许以可插拔(plugin)方式,在需要时快速添加新的缓存策略。
软件框架中设置了一个监听器(b1ockeventlistener)获取所有数据块的行为动作。在分层式存储系统中,数据块的行为包括:commit(提交)、access(读写访问)、move(移动)、remove(删除)等。一旦其中一个行为被触发,监听器将会通知所有的缓存策略更新它们所维护的元数据信息。一个新的缓存策略被添加到缓存调度框架,只需要实现监听器中这些行为的接口。通过集成该通用框架和多个缓存调度策略后,大幅提升了alluxio系统缓存框架的通用性和稳定性。
本发明专利在大数据分布式存储技术与系统方面,改进了以下三方面的工作:
(1)alluxio层次化分布式存储系统缓存替换策略与性能优化:基于参与研究开发的著名的统一分布式内存存储开源系统alluxio,为该系统的多层存储系统研究实现并提供了一个通用化可扩展的缓存替换策略框架,并在该框架上研究提供了一组覆盖不同数据访问模式的缓存策略来加速上层的大数据应用,所研究实现的缓存策略包括lru策略、lrfu策略、lirs策略以及arc策略等。
(2)通用分布式文件系统性能测试方法与测试工具dfs-perf:为了便于用户选择合适的分布式文件系统和配置参数,并能够定量地分析不同分布式文件系统的性能差异,本文研究并实现了一个通用化可扩展的分布式文件系统性能测试框架。
(3)大规模rdf语义数据存储管理技术与系统rainbow:为了高效地管理大规模语义网rdf数据,本文研究实现了基于分布式层次化索引与存储架构的rdf语义数据存储管理技术与系统rainbow。通过分析百万量级的真实用户查询日志以及标准评测集的查询语句,研究提出并设计实现了一种混合式的rdf语义数据索引策略,以高效地存储和查询大规模rdf数据。
为了很好地支持该混合索引策略,研究采用了一种分布式的rdf语义数据层次化索引存储架构。最终,基于hbase和openrdf框架,研究实现了一个完整的大规模rdf语义数据存储管理和查询原型系统rainbow。
通过改进存储系统性能优化的算法,可以大大提高对于大数据的存储及访问速度。
- 还没有人留言评论。精彩留言会获得点赞!