一种应用服务分类方法及装置与流程
本发明涉及计算机信息技术领域,具体涉及一种应用服务分类方法及装置。
背景技术:
传统的应用服务分类,如网站分类大多以网页分类为基础,利用数据挖掘中的web分类技术确定网页的类别,从而对这些网页所隶属的网站进行分类。利用文本内容信息进行网页分类的方法:对web文档分词;特征选择得到特征词汇项,得到网页的特征向量表示;对结构化表示的网页分类。
根据特征来源对网站分类的相关研究有:基于内容特征(例如html页面的标签信息等)、基于url信息、基于dns日志(例如whois信息、ip地址信息、as号码等)。解析url信息可以获得url词汇信息、协议类型、顶级域名信息、主机信息以及url长度等。
基于内容特征的识别方法:
golub使用网页中的title、headings、metadata和主要内容训练分类器。haveliwala和nie改进了传统的pagerank的网站关联方式,设计了基于网站主题的pagerank网站分类。此类方法需要占用更多的计算资源和网络带宽,并产生较大的时间开销;分析一个网页所需要的时间开销还取决于网络延迟和网页内容的复杂程度。
基于url信息的识别方法:
karagiannis提出blinc,从网络边缘被动采集流量,利用有效载荷分类应用的流量,由于https加密,无法访问有效载荷;大型运营商从共享的基础设施(如cdn/云和云计算平台)中提供服务,影响分类效果。baykan针对odp数据源中的15类网站,使用机器学习的算法(svm和nb),建立了各类网站的分类模型,并证明分类准确率、召回率和f值在80%左右。justinma从url信息、域名注册信息和主机信息中抽取特征,建立识别模型并进而识别恶意网站,但无法准确识别由算法随机生成的恶意url。anh从url结构信息出发,在前人工作基础上提出了四类轻量级的抗混淆词法特征,有效提升了恶意网站识别的准确率。li从网络拓扑关系出发,基于pagerank算法对恶意网页识别问题进行了深入研究,提出了相应的识别方法,使得误检率控制在2%以内。
基于dns日志的识别方法:
antonakakis提出notos,处理来自被动dns数据库的dns查询响应,并从观察到的fqdn和ip中提取一组41个特征。notos使用历史的ip地址和历史域名来提取有效的特征,以将恶意域名与合法域名区分开来。hsu提出一种基于来自给定客户端的http/https请求中的异常延迟来检测flux域名的实时系统,基于假设恶意网站提供内容往往有较大的延迟。bilge提出exposure,提取15个特征,需要1周的训练数据。perdisci提出fluxbuster,使用大规模被动dns流量来检测未知的fast-flux域名。manadhata提出一种恶意域名检测系统,通过将检测日志构建为主机的域名映射,系统将检测问题建模为图推断问题。foremski和tongaonkar提出利用sni和dns查询进行分类,主要针对协议分类,缺少细粒度的对于单一web服务的识别。trevisan基于主机名和ip进行web服务分类:通过发现并聚合给定服务的所有主机名,列举相应的ip地址;仅基于ip地址可以区分55%的web流量,用于分类的web服务的域名集合需要不断更新;多服务共享主机名,在云或cdn/云中托管的服务无法识别。chiba提出domain-profiler,主动收集dns日志,分析时间变化模式,预测给定的域名是否会被用于恶意目的,它能够在出现在公共黑名单之前的几天甚至几周内准确检测到先前未知的恶意域名。此类方法依赖dns流量,由于域前置和dns加密,识别在cdn/云中托管的网站服务类别准确率不高,误判较大。
由以上可知,现有技术存在的缺陷是:基于内容特征的网站分类,解析成本大,需要占用大量计算资源和网络带宽,时间开销大。基于url信息的网站分类,依赖于url,由于https的广泛使用,无法获得url信息;依赖于url词特征,特征规模线性增长,特征集膨胀。基于dns日志的网站分类,由于域前置和dns加密,导致真实域名不可见;交叉使用的ip和域名,难以利用dns流量进行网络测量及网站识别。
技术实现要素:
本发明的目的在于提供一种应用服务分类方法及装置,基于访问流量,测绘应用服务如网站、app等对于cdn/云的使用模式,构建应用服务的cdn/云使用图谱,利用图结构特征分类网站,识别特定类型的应用服务。
为达到上述目的,本发明采用如下技术方案:
一种应用服务分类方法,步骤包括:
获取cdn/云厂商域名集合;
获取访问应用服务资源的流量,提取流量特征;
建立应用服务与cdn/云的使用关系,根据该使用关系构建cdn/云使用图谱;
提取cdn/云使用图谱中的各节点特征和图结构,构建特征模型;
基于该特征模型,识别特定类型应用服务,对应用服务进行分类。
进一步地,获取cdn/云厂商域名集合的方法包括:
通过搜索引擎查询cdn/云厂商公开过的域名,由该域名反查ip,由该ip反查解析记录,由该解析记录获取cdn/云厂商其他公开的域名;
通过在被访问流量中提取符合cdn/云节点特点的域名,以获取cdn/云厂商的域名,该特点包括包含某些cdn/云域名的关键词、或同一个域名存在多个ip等;
以上述两种方法获取的cdn/云厂商域名集合为基础,通过dns协议的cname字段和通信协议(如http协议、hls协议等)头部字段是否包含预设的特征串匹配,来获取更多的cdn/云厂商的域名。
进一步地,通过通信协议头部字段关联域名,找到欲获取资源所访问的网站,从中获取用户实际访问的应用服务入口页面地址。
进一步地,通信协议头部字段为url字段、referer字段、cookie字段、host字段、301跳转、302跳转等。
进一步地,获取访问网站资源的流量的方法包括:
多点主动测量:通过广泛分布的测量节点,在网页端和客户端大量访问目标应用服务的资源;
被动测量:在某区域网关获取用户访问应用服务的流量并进行预处理,获得用户访问预设类型的应用服务资源的流量。
进一步地,被动测量中判断是否为访问应用服务资源的流量的方法包括资源后缀名类型、资源大小、资源类型、网络协议、资源名称等。
进一步地,流量特征包括行为特征、语义特征,行为特征包括同一应用服务资源能够关联到多个服务端ip;语义特征包括cname或ns记录有cdn/云关键词,该cdn/云关键词为cdn/云通用特征串或cdn/云厂商的域名集合。
进一步地,cdn/云通用特征串包括cdn/云厂商在提供cdn/云服务时常使用的字符串,如gslb、cache、cachecdn、cloud、glb、gilb等。
进一步地,应用服务与cdn/云的使用关系包括:
应用服务对cdn/云的直接使用:应用服务的资源直接存放在特定cdn/云厂商的节点上;
应用服务对cdn/云的间接使用:应用服务的资源存放在特定cdn/云厂商租用的其他cdn/云厂商的节点上。
进一步地,应用服务对cdn/云的直接使用可以划分为多个属性维度,包括资源类型、地域、时间、网络环境、运营商等。
进一步地,构成cdn/云使用图谱的节点具有唯一id标号,id标号可以用包括ip、全称域名、特征子域名、厂商等属性来表示。
进一步地,构成cdn/云使用图谱的边具有唯一id标号之间的通联关系,包括跳转关系、共用域名关系、共用ip关系、相同组织隶属关系等,这种通联关系是可测量的,可变化的。
进一步地,节点特征主要包括资源描述(如url中)的词特征。
进一步地,分类采用的算法包括各种分类、聚类算法,如网络嵌入算法、svm算法、cnn算法等。
进一步地,特定应用服务类型可为流媒体、直播、短视频等,也可为非法网站/app、恶意网站/app、钓鱼网站/app等。
一种应用服务分类装置,包括存储器和处理器,该存储器存储计算机程序,该程序被配置为由该处理器执行,该程序包括用于执行上述方法中各步骤的指令。
本发明方法通过测绘应用服务对于cdn/云的使用模式,利用与cdn/云的网状使用关系构建图谱,基于网络图结构解决应用服务分类问题,识别特定类型的应用服务。本发明方法将应用服务对cdn/云的使用模式作为识别的特征,提出了更适用于cdn/云环境下的特征模型。本发明方法将图结构分析方法应用于应用服务与cdn/云关系图,改进应用服务分类、识别已有方法的不足,应用了更适用于cdn/云环境下应用服务类型识别模型。
附图说明
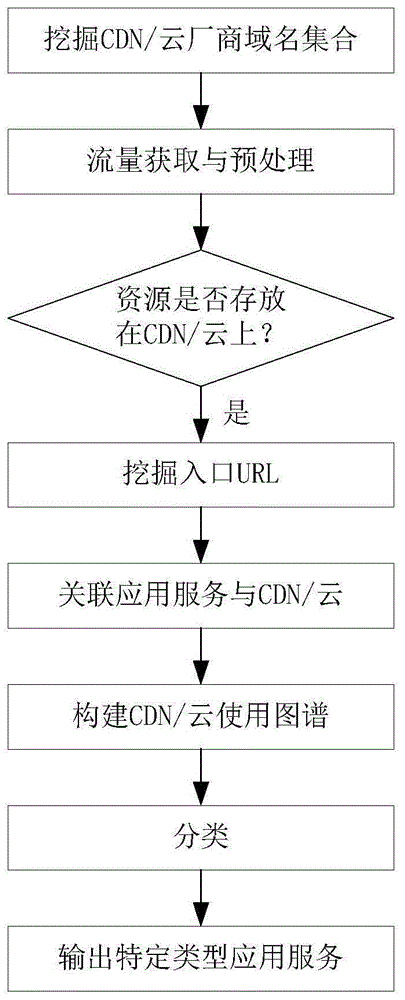
图1是本发明的一种应用服务分类方法流程图。
图2是cdn/云使用图谱示意图。
具体实施方式
为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。
cdn/云使得网络愈加错综复杂,网站为了更高效的利用网络资源,在不同地域,不同运营商实现用户体验最优化,应用服务在选择cdn\云服务提供商的时候具有一定策略,因此,可以根据不同应用服务在选择cdn\云服务提供商的时候策略的挖掘,来识别应用服务,并进行多类别分类。
图1所示为本发明提供的应用服务分类方法的流程图,该方法基于流量及cdn/云不同维度使用关系测绘,识别应用服务类型,主要步骤包括:
1.基于语义信息挖掘cdn/云厂商的域名集合,可以通过解析记录获取cdn/云厂商的域名:主流搜索引擎查询cdn/云厂商公开过的域名;由该公开过的域名反查ip;由ip反查解析记录。也可以通过cname特征和http中的特征串匹配获取cdn/云厂商的域名。
2.流量获取与预处理:获取访问应用服务资源的流量,通过以下主动或被动或主被动结合的测量方法。
1)多点主动测量:通过地理位置分布广泛的测量节点,主动发起资源请求,获取应用服务对cdn/云的使用情况,挖掘cdn/云服务使用关系。测量点需要对国家、运营商等形成比较全面的覆盖。
2)被动测量:获取流量并进行预处理(ip重组、链接还原等操作),通过预处理解析流量,并判断是否为待获取的流量,判断方法可以是url文件名、后缀名类型、文件大小等。
3.判断资源是否存放在cdn/云上:基于多特征识别是否从cdn/云节点获取资源,可以从行为特征(如同一文件能够关联到多个服务端ip),也可以从语义特征(如cname或ns记录有cdn/云关键词)去识别,特征均由流量中抽取得到。cdn/云关键词可以指cdn/云通用特征串(如cdn/云、gslb等),也可以是对应cdn/云厂商的域名集合(如akamai.net等)。
4.挖掘入口url:可以通过http头部字段关联域名,获取资源若干前跳访问的网站(资源对应的url是cacheurl,前一跳访问的url是入口url),挖掘实际用户访问的入口url对应的网站。用来关联域名的http头部可以是referer字段、cookie字段、host字段、302跳转等。
5.关联应用服务和cdn/云:访问资源流量的url是实际存放资源的地址,实际存放资源的域名的cname为cdn/云缓存服务器节点所对应的域名,建立各应用服务与cdn/云的使用关系。使用关系包括:
应用服务对cdn/云的直接使用:应用服务的资源直接存放在特定cdn/云厂商的节点上;直接使用可以划分为多个维度,如资源类型、地域、时间、网络环境、运营商等。
应用服务对cdn/云的间接使用:应用服务的资源存放在特定cdn/云厂商的节点上,该cdn/云厂商又租用另一cdn/云厂商的节点提供服务。
6.构建cdn/云使用图谱:节点可以对应cdn/云节点的ip、全称域名、二级域名、厂商等。以不同的维度对网站的cdn/云使用关系进行融合构建图谱,如图2所示,其中,图谱的边由上述步骤5构建。
7.分类:提取cdn/云使用图谱中各节点的特征,构建特征模型。各节点的特征主要包括url的词特征。基于特征模型,分类网站,识别特定类型网站。分类算法可以使用网络嵌入算法、svm算法以及cnn等机器学习算法。
8.输出特定应用服务类型:特定网站类型可以是流媒体、直播、短视频等,也可以是非法网站、恶意网站、钓鱼网站等。
本发明的关键点
随着互联网的发展,新兴技术的应用,cdn/云产业的发展导致应用服务,如网站、app等对于cdn/云的使用关系复杂;网络流量加密的发展趋势,同时,应用服务对cdn/云存在多类型使用关系,特定类型应用服务由于资源有限,对cdn/云的使用模式存在一定的特征。基于cdn/云使用状况测绘,发现应用服务使用cdn/云模式,解决应用服务类型识别问题。
为使本发明的上述特征和优点能更明显易懂,下文特举两个实施例以进一步说明:
实施例1
在地理位置分布广泛的测量点主动访问视频资源,模拟用户请求视频资源,同时,被动监测观看视频的流量,以构建cdn/云使用图谱,识别同类的视频网站。
将观看视频产生的网络流量进行预处理,从dns流量中识别出流量中域名的cname和ns记录,根据cdn/云特征字典库判断视频是否存放在cdn/云节点上。关联视频网站和cdn/云节点,在不同的地理位置,不同的时间,关联关系可能不同,另外,不同的资源可能会存放在不同的cdn上,多维度地建立cdn的特征子域名的cdn/云使用图谱。节点包括视频网站和cdn节点的特征子域名(如alicdn.com),边表示视频网站与cdn节点间存在租用关系。例如访问优酷上的视频资源,产生的dns流量中可以识别出优酷租用了阿里云的cdn节点,该节点cdn特征子域名为alicdn.com,则在构建图谱时,优酷存在指向alicdn.com节点的边。
将图结构和节点特征输入到网络嵌入算法(如图卷积神经网络算法,即gcn)中。gcn是作用于网络结构上的卷积神经网络,并使用一种基于边的标签传播规则实现半监督的网络表示学习,增加全连接层,利用交叉熵作为损失函数用于分类。利用gcn算法对视频网站进行分类,若结构相似特征相似,则为同类型网站。例如某几个cdn节点组成的特定子图结构专用于直播平台分发视频流量,若一个新的网站利用这几个节点的特定模式分发内容,则该网站有很大的概率可以判定为直播类型的视频网站。
实施例2
从某地镜像访问视频资源的流量,欲识别非法视频网站,以便对网站内容进行监管。
将镜像得到的网络流量进行预处理,通过url中的文件名后缀、特征码过滤得到视频流量,抽取视频流量对应的域名,从dns流量中识别出域名的cname,基于多特征判断视频是否存放在cdn/云节点上,包括行为特征和语义特征。行为特征包括同一文件对应多个服务端ip等,语义特征是指cname中出现cdn/云特征字典库中的字符串,如cdn、gslb等。基于跳转关系关联访问视频资源对应的视频网站,进一步关联视频网站和cdn/云节点,基于cdn的全称域名建立cdn/云使用图谱,节点包括视频网站和cdn节点的全称域名,边代表视频网站对cdn的依赖关系,若视频网站租用了特点cdn节点,即cname中出现cdn的特征字符串,则视频网站与该cdn节点存在连接关系。
cdn/云节点为具体的域名,基于http流量中url的词特征,构建图谱中各视频网站的特征模型。将图结构和节点特征输入到分类算法中(如svm算法),对视频网站进行分类,若该类中存在已知的非法视频网站,则该类中的其它视频网站也为非法视频网站。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!