计算机可读存储介质和应用该介质的骨声纹检测耳机的制作方法
本发明涉及耳机技术领域,特别涉及计算机可读存储介质和应用该介质的骨声纹检测耳机,该介质内存有计算机程序,该计算机程序可被骨声纹检测耳机的处理器执行。
背景技术:
随着人工智能的飞速发展,人脸识别、指纹识别等各类新型的识别检测技术层出不穷,而声纹识别技术不是一个很新的识别技术,早在六七十年代,公安机关就开始使用声纹识别技术进行刑事案件的侦查工作,因其识别材料的采集更为自然而且造假难度更大,声纹识别依然是现代识别技术中不可或缺的方式。但是,仅靠声纹识别技术,在进行手机解锁及移动支付等仅需简单指令的场合,依然存在较大风险。与传统的通过空气进行声音的传导来实现的声纹识别技术不同,骨传导是通过颅骨及淋巴液系统进行声音的传递,是近几年来比较火热的一个研究方向,催生了市场的各种骨传导类穿戴产品,比如骨传导耳机、助听器等,但是受限于识别率,依然存在较大的误识别风险。
技术实现要素:
本发明的目的在于:提供一种识别率高的骨声纹检测耳机的声纹检测方法,以及应用该方法进行骨声纹识别的骨声纹检测耳机。
本发明的目的通过以下技术方案实现:
提供计算机可读存储介质,其存储有用于骨声纹检测的计算机程序,该程序被处理器执行时实现以下步骤:
骨声纹信号获取步骤,其获取骨传导感应器采集的骨声纹信号;
骨声纹信号处理步骤,其对获取的骨声纹信号进行有限时长的频域分析,提取该骨声纹信号的声纹特征;
骨声纹比对步骤,其把所述声纹特征与语音匹配库进行检索匹配,若匹配度超过预设的阈值,则判断当前获取的骨声纹信号为语音匹配库的目标信号。
其中,所述骨声纹信号处理步骤具体的,包括:
频谱转换步骤,其把骨声纹信号经有限时长的频域分析转换成能量频谱图;
特征向量获取步骤:其根据预设的采样区间,将原始骨声纹信号频谱图进行切割分段,获取采样区间内能量值超过预设值的频率点的能量值以及这些频率点之间的时间间隔,把这些频率点的能量值和时间间隔组成的空间向量作为这个采样区间的特征向量;
声纹特征提取步骤:其把多个采样空间的特征向量的集合作为该骨声纹信号的声纹特征。
其中,所述特征向量获取步骤中,时间间隔是指相邻两个频率点之间的时间间隔。
其中,所述能量频谱图上,越亮表示该时间点在该频率处的能量越大,反之,越暗表示该时间点在该频率处的能量越小。
其中,所述骨声纹信号获取步骤中,骨传导感应器采集的骨声纹信号是指:采集自垂直于所述骨传导感应器接收端表面的声纹信号。
其中,包括在骨声纹信号获取步骤之前执行的人体识别步骤,其获取至少两个设置在不同空间位置的人体感应模块采集的体表感应信号,若两个信号不是同时存在,则判断当前无法获取骨声纹信号。
其中,所述人体感应模块是红外感应模块或电容式感应模块。
还提供一种骨声纹检测耳机,包括处理器和上述计算机可读存储介质,该计算机可读存储介质上的计算机程序可被处理器执行。
其中,所述骨传导感应器设置在耳机近耳侧。
其中,在所述骨传导感应器两侧有相对设置的一组人体感应传感器。
本发明的有益效果:采用骨传导感应器采集骨声纹信号,其检测人说话时颅骨附带肌肉引起的振动,灵敏度很高,以垂直于人耳的方向,即与骨传导感应器接收端表面垂直的方向为z轴确定三维坐标,可以通过x/y/z三轴空间的数据正负及大小情况判断耳机是否佩戴好,以此确保采集的骨声纹信号有效。然后,对获取的骨声纹信号进行有限时长的频域分析,提取该骨声纹信号的声纹特征,把声纹特征与语音匹配库进行检索匹配,若匹配度超过预设的阈值,则判断当前获取的骨声纹信号为语音匹配库的目标信号,即通过数据库特征匹配,识别当前是否是本人说话。
附图说明
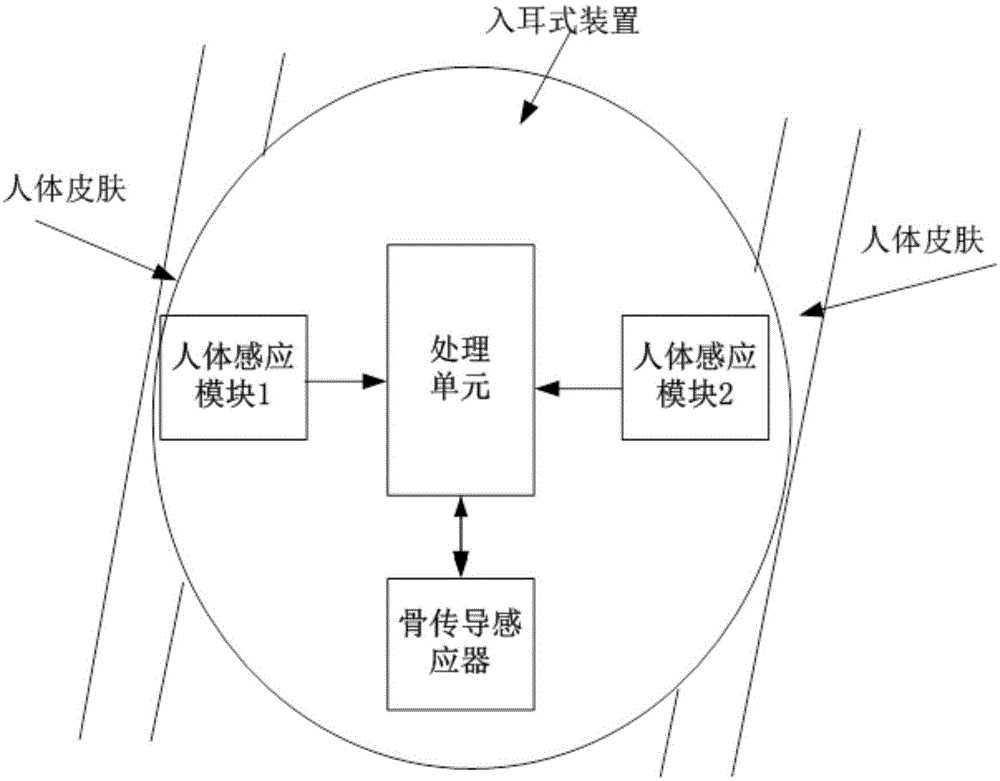
图1是骨声纹检测耳机的佩戴示意图。
图2是骨传导感应器的z轴声纹数据示意图。
图3是骨传导声纹特征的频谱图。
具体实施方式
如图1所示,该骨声纹检测耳机包括作为入耳式装置的耳机外壳,耳机外壳内近耳侧设置有骨传导感应器,在骨传导感应器两侧有相对设置的一组作为人体感应模块的人体感应传感器,这两个人体感应传感器是红外或电容式感应模块,其贴附在人体表面来检测与人体表面的接触程度。骨传导感应器、两个人体感应传感器都电连接作为处理器的算法处理单元。
该骨声纹检测耳机通过如下方法实现骨声纹的检测。
首先,执行人体识别步骤,通过两个人体感应模块获取两个不同空间位置的体表感应信号,若两个信号不是同时存在,则判断当前无法获取骨声纹信号。采用两个人体感应模块可以保证装置是嵌入到人体的组织器官凹槽当中的,而不是单方向的人体表面误碰触。还可以在耳机表面添加更多数量的感应传感器,提高识别准确度。本实施例采用入耳式耳机,通过两个或更多不同空间位置的体表感应信号即可准确判断耳机是否在人耳朵内。对于tws耳机、头戴式有线运动耳机或者其他智能穿戴设备,也可以设置人体感应模块或其他传感器,比如气压、高度传感器等来辅助判断当前人说话的实时生理特征,以此提高安全性。
以骨传导感应器接收端表面为x/y轴所在平面,以垂直于人耳的方向,即与x/y轴所在平面垂直的方向为z轴确定三维坐标,可以通过x/y/z三轴空间的数据正负及大小情况判断耳机是否佩戴好,以此确保采集的骨声纹信号有效。比如,在耳机佩戴好后正常接收的声纹信号中,z轴方向声纹数据的方向为正(声纹数据的方向由耳内指向耳外,声纹数据的方向识别为骨传导感应器自身的功能,此处不再赘述),如果识别到向量偏移z轴正方向甚至反向,说明耳机未佩戴好。
在识别到耳机正确佩戴后,执行骨声纹信号获取步骤,采集自垂直于骨传导感应器接收端表面的z轴信号作为骨传导感应器采集的骨声纹信号。该骨声纹检测耳机采用骨传导感应器采集骨声纹信号,其检测人说话时颅骨附带肌肉引起的振动,灵敏度很高,然后,执行骨声纹信号处理步骤,对获取的骨声纹信号进行有限时长的频域分析,提取该骨声纹信号的声纹特征。比如,当耳机佩戴者说出“支付”时,骨传导感应器检测到如图2所示的z轴声纹数据,依次执行如下步骤来实现对骨声纹信号的处理:频谱转换步骤,其把骨声纹信号经有限时长的频域分析转换成如图3所示的能量频谱图,其中,越亮表示该时间点在该频率处的能量越大,反之,越暗表示该时间点在该频率处的能量越小;特征向量获取步骤:其获取采样区间内能量值超过预设值的频率点的能量值以及这些频率点之间的时间间隔(本实施例中时间间隔是指相邻两个频率点之间的时间间隔,实际检测中也可以根据测试需要进行调整),把这些频率点的能量值和时间间隔组成的空间向量作为这个采样区间的特征向量;声纹特征提取步骤:其把多个采样空间的特征向量的集合作为该骨声纹信号的声纹特征。
其中,在以0.25s为单位对能量频谱图中的信号进行切割得到的采样区间内,按照时间前进的顺序选取3个能量值大小最靠前的点a、b、c。这三个点对应的时域间隔为a→b:t1,b→c:t2,得到能量频谱图中这三个点的空间向量[a,b,c,t1,t2],将其作为这一时间区域内的骨声纹信号的特征向量,由多个这样的特征向量得到该骨声纹信号的声纹特征。以上a、b、c三点仅作为示例说明该方法,实际检测中也可以根据测试需要调整选取的频率点的位置和数量,比如,记录连续三个彼此相邻的采样区间的能量最大值点a1、b1、c1,获取这三个点对应的时域间隔a1→b1:t3,b1→c1:t4,即可得到能量频谱图中这三个点的空间向量[a1,b1,c1,t3,t4]。
最后,执行骨声纹比对步骤,其把声纹特征与语音匹配库进行检索匹配,若匹配度超过预设的阈值,则判断当前获取的骨声纹信号为语音匹配库的目标信号,从而实现对当前是否是本人说话的识别。
该骨声纹检测耳机通过上述方法实现的骨声纹检测,相对于传统的声纹检测提高了识别率,降低了误识别风险,避免出现传统声纹识别中容易出现的非本人实时发声的欺骗行为。
- 还没有人留言评论。精彩留言会获得点赞!