一种基于基站分簇的文件副本缓存方法与流程
本发明涉及5g超密集异构网络中的边缘缓存技术领域,具体涉及一种基于基站分簇的文件副本缓存方法。
背景技术:
近年来,随着5g技术和物联网的快速发展,网络边缘设备和移动终端数量急剧增加,以云计算为核心的技术已经不能满足人们对于数据获取速度的要求,边缘计算技术应运而生。其中,边缘缓存技术起到了重要作用,边缘缓存是指在网络边缘设备上存储数据,其基本理念是将数据文件在接近数据源的设备上进行存储和传输。作为第五代移动通信系统的关键技术之一的超密集网络,为了满足日益增长的数据容量需求,可在热点区域内大规模部署小基站以满足数据容量的需求。小基站的密集部署一方面可以增加网络数据吞吐量,并缓解服务器端的访问压力;另一方面可以将服务器端的热点数据设置副本存储在基站中,这些副本就是所需要的文件数据的复制品,通过设置副本可以更加快速地向用户提供所需要的文件,但是随着基站的地理分布不同,副本的数量以及位置部署也不相同,为了尽可能的让用户直接从基站中获取文件信息,对副本具体设置需要做相关调研;同时随着小基站的密集部署,也会产生很明显的影响,例如小基站间的同层干扰以及小基站与宏基站间的跨层干扰在一定程度上会对用户产生信号的干扰,这就会影响用户的通信质量。
技术实现要素:
本发明的目的是提供一种能够使用户的访问速度和基站的空间利用率都得到提升,同时能减小基站间干扰对用户通信质量影响的超密集网中基站存储文件的副本缓存方法。
为实现上述目的,本发明采用了如下技术方案:一种基于基站分簇的文件副本缓存方法,包括以下步骤:
步骤一:根据基站对用户接收信号产生的干扰强度大小对超密集异构网络中的基站进行分簇,使得分簇后的基站对访问的用户产生的干扰强度最小;
步骤二:在分簇结果的基础上,通过基站缓存内容相似度的分析,对簇内各基站所要存取的文件副本进行部署缓存,具体包括以下步骤:
步骤(2.1):先计算簇内目标基站与簇内其他基站之间的缓存文件相似度;
步骤(2.2):设定相似度阈值,除目标基站外,将簇内所有与目标基站之间的缓存文件相似度大于相似度阈值的基站全部保存在新的集合ρα中,并将集合ρα中的基站文件全都放入集合cw中,然后去除集合cw中每个基站与目标基站的公共集合文件,并将集合cw中去除公共集合文件后的所有待缓存文件全部存入集合c′w中;
步骤(2.3):根据基站待缓存文件的流行度大小对集合c′w中的文件做排序处理,然后根据目标基站的可存储空间从集合c′w中删选出需要部署缓存的文件副本并放置于目标基站中;
步骤(2.4):将簇内每个基站作为目标基站进行步骤(2.1)~步骤(2.3)的迭代求解,从而对簇内每个基站所要存取的文件副本进行部署缓存。
进一步地,前述的一种基于基站分簇的文件副本缓存方法,其中:在步骤一中,基于基站干扰的分簇方法,具体包括以下步骤:
步骤(1.1):假设基站总个数为s个,每个基站范围内有t个用户,总的用户数量为s·t个;假设基站分簇的个数为na,分簇后的集合为
其中,pn和pm分别表示小基站的发送信号功率以及宏基站的发送信号功率;
其中,表达式约束条件如下:
s.t1≤cmin≤na≤cmax≤s(7)
1<m≤s-na(8)
rk≥γk(11)
式(7)和(8)表示确保至少每个簇中都分配一个小基站,式(9)中
步骤(1.2):使用遍历算法,将在数据范围内的na和m值每个数值都遍历计算一遍,根据最后所有求得的值中从小到大排序,选取出基站分簇个数最优解
进一步地,前述的一种基于基站分簇的文件副本缓存方法,其中:在步骤(2.1)中,两个基站间的缓存文件相似度的具体计算方法如下:
假定基站a确定缓存的文件集合为
其中,式中
进一步地,前述的一种基于基站分簇的文件副本缓存方法,其中:在步骤(2.3)中,根据目标基站的可存储空间从集合c′w中删选出需要部署缓存的文件副本个数的具体计算公式如下:
其中,sbs为基站的缓存空间大小,
其中,表达式约束条件如下:
maxk(14)
0<i≤na(16)
1<u≤s-na(17)
l≤ρv,t<1(18)
式(16)、(17)表示确保至少每个簇中都分配一个小基站,式(18)中t表示目标小基站,m表示与目标基站的相似度值大于阈值l的基站;
通过上述技术方案的实施,本发明的有益效果是:基于基站分簇方法的提出与分析,根据基站对用户产生的干扰强度做划分,使得分完簇的基站对访问的用户产生的干扰强度最小,确保了用户的通信质量,提升了服务质量;基于内容相似度的副本部署分析,利用簇内基站间的相似值确定具体的缓存基站,同时对于文件缓存时考虑基站本身的存储空间大小,求得每个基站缓存的文件集合,降低了存储成本,增加了用户访问内容的命中率,减小了用户请求访问内容的时延。
附图说明
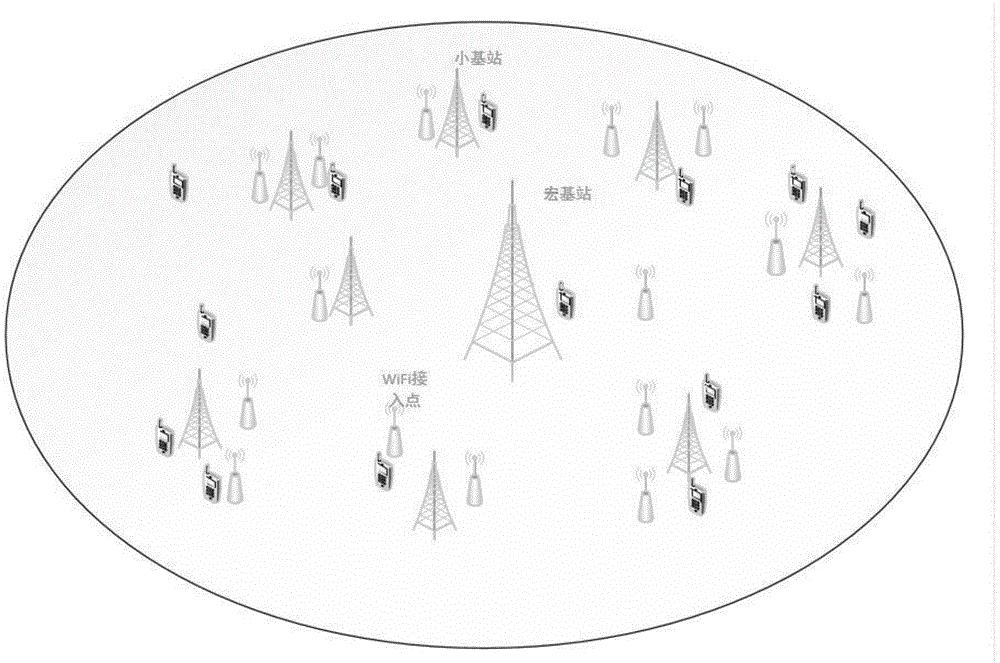
图1为本发明所述的一种基于基站分簇的文件副本缓存方法的基站系统模型图。
图2为本发明所述的一种基于基站分簇的文件副本缓存方法的基站分簇后的系统模型图。
图3为本发明所述的一种基于基站分簇的文件副本缓存方法的副本缓存部署流程示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,以下结合附图和具体实施例对本发明作进一步详细说明。
本发明考虑的是超密集异构网络中密集部署的小基站和wifi之间组成的系统模型,如图1所示,系统中包括1个mbs、s个sbs和l个wifi节点,mbs位于系统的中心,s个sbs随机部署在mbs的覆盖范围下,每个sbs覆盖范围内也存在一到多个wifi节点,并且假定每个sbs覆盖范围内有t个用户,用户可以接入wifi网也可以使用移动数据,网络结构采用的是宏基站集中式控制管理,假设每个小基站能够获取小基站与用户之间的信道状态信息;当用户访问数据时,请求的本地基站是主要的服务基站,则用户会受到周边小基站、wifi节点以及宏基站的干扰;考虑到wifi信号相比较基站信号对终端用户干扰效果的微弱,故本发明主要考量的是基站间的干扰影响。在超密集网络下使用联合簇传输模式时,通过设计多个基站联合传输的方式,可以将主要的干扰源化为有用信号,从而极大地提升用户速率。当用户ue向本地基站请求文件f时,系统中的文件数据会通过小基站i的子信道k来发送给用户ue,周边sbs、mbs以及wifi节点会对用户ue产生信号干扰也会存在,用户ue接收到的的信号强度为:
公式(1)中第一部分表示用户接收到本地基站的信号强度,其中pn和pm分别表示小基站的发送信号功率以及宏基站的发送信号功率;基站装有f根天线,用户端有g根接受天线,
基于上述信号的表达式可以得出用户ue接收信号的信干噪比(signalinterferencenoiseratio,sinr)为:
可以根据香农公式得出用户j的数据接收速率rij为:
rij=b·log(1+sinrij)(5)
若想要提升用户的数据接受速率,可以通过增加带宽b或者提高用户的信干噪比,由于带宽资源的紧缺,一般是不会通过增加带宽b来提升用户的接受速率rij,相应地可以通过提高用户的信干噪比来达到接受速率的要求;
本发明所述的一种基于基站分簇的文件副本缓存方法,包括以下步骤:
步骤一:根据基站对用户接收信号产生的干扰强度大小对超密集异构网络中的基站进行分簇,使得分簇后的基站对访问的用户产生的干扰强度最小;
分簇时,首先定义簇数量的划分范围[cmin,,cmax],对每个簇内的基站数设置数值约束,避免簇与簇之间的差距过大,并且默认所有的小基站的自身相关参数都是一样的,随着距离的增大,信号的强度也逐渐减小产生衰落;接下来可根据小基站对用户产生的干扰强度做分簇,将拟定分完簇的用户所受到的簇内干扰和最小;基站分簇后的系统模型如图2所示;基于基站干扰的分簇方法,具体包括以下步骤:
步骤(1.1):假设基站总个数为s个,每个基站范围内有t个用户,总的用户数量为s·t个;假设基站分簇的个数为na,分簇后的集合为
其中,pn和pm分别表示小基站的发送信号功率以及宏基站的发送信号功率;
其中,表达式约束条件如下:
s.t1≤cmin≤na≤cmax≤s(7)
1<m≤s-na(8)
rk≥γk(11)
其中,式(6)表示分完簇的整个系统所产生的干扰之和最小并且n0为已知常量,式(7)和(8)表示确保至少每个簇中都分配一个小基站,式(9)中
步骤(1.2):由于最优化表达式(6)中的参数na和m都是未知变量需要求解的,s·t为已知的常量(s和t均为已知常量),故想要求解出最优的na和m时,使用遍历算法,将在数据范围内的na和m值每个数值都遍历计算一遍,根据最后所有求得的值中从小到大排序,选取出基站分簇个数最优解
步骤二:在分簇结果的基础上,通过基站缓存内容相似度的分析,对簇内各基站所要存取的文件副本进行部署缓存,具体包括以下步骤:
步骤(2.1):先计算簇内目标基站与簇内其他基站之间的缓存文件相似度;
其中,两个基站间的缓存文件相似度的具体计算方法如下:
假定基站a确定缓存的文件集合为
其中,式中
步骤(2.2):设定相似度阈值,除目标基站外,将簇内所有与目标基站之间的缓存文件相似度大于相似度阈值的基站全部保存在新的集合ρα={ρα1,ρα2……ραv}中,其中α为所要对比的目标基站,v为满足与目标基站缓存文件相似度大于相似度阈值l的基站个数;并将集合ρα中的基站文件全都放入集合
步骤(2.3):根据基站待缓存文件的流行度大小对集合c′w中的文件做排序处理,然后根据目标基站的可存储空间从集合c′w中删选出需要部署缓存的文件副本并放置于目标基站中;
其中,根据目标基站的可存储空间从集合c′w中删选出需要部署缓存的文件副本个数的具体计算公式如下:
其中,sbs为基站的缓存空间大小,
其中,表达式约束条件如下:
maxk(14)
0<i≤na(16)
1<u≤s-na(17)
l≤ρv,t<1(18)
式(16)、(17)表示确保至少每个簇中都分配一个小基站,式(18)中t表示目标小基站,v表示与目标基站的相似度值大于阈值l的基站,
步骤(2.4):将簇内每个基站作为目标基站进行步骤(2.1)~步骤(2.3)的迭代求解,从而对簇内每个基站所要存取的文件副本进行部署缓存。
本发明的优点是:基于基站分簇方法的提出与分析,根据基站对用户产生的干扰强度做划分,使得分完簇的基站对访问的用户产生的干扰强度最小,确保了用户的通信质量,提升了服务质量;基于内容相似度的副本部署分析,利用簇内基站间的相似值确定具体的缓存基站,同时对于文件缓存时考虑基站本身的存储空间大小,求得每个基站缓存的文件集合,降低了存储成本,增加了用户访问内容的命中率,减小了用户请求访问内容的时延。
以上仅为本发明的较佳实施例,但并不限制本发明的专利范围,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来而言,其依然可以对前述各具体实施方式所记载的技术方案进行修改,或者对其中部分技术特征进行等效替换。凡是利用本发明说明书及附图内容所做的等效结构,直接或间接运用在其他相关的技术领域,均同理在本发明专利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!