基于深度学习的机坪监控视频压缩方法及系统与流程
本发明属于视频处理技术和深度学习领域,具体涉及一种基于深度学习的机坪监控视频压缩方法及系统。
背景技术:
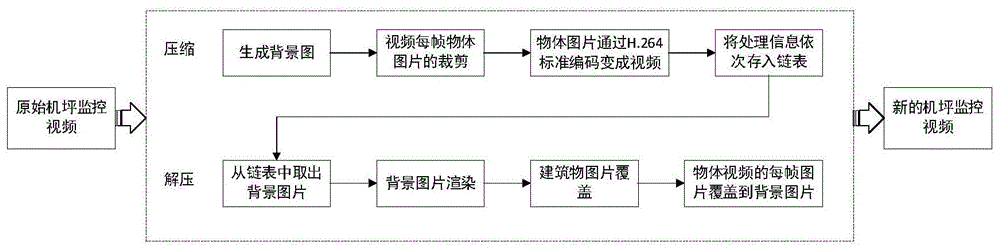
:随着视频使用范围的不断扩大和对高质量视频需求的不断增加,视频的供应方通过使用更高的空间分辨率、帧速率和动态范围来扩展视频参数空间,这大大增加了存储视频所需的比特率。特别是在学校、银行、民航等领域,国家对监控视频存储的时间要求更为严格。在民航领域,《民用运输机场安全保卫设施》(mh/t7003-2017)第15章明确了机场视频监控的规范,其中要求视频监控保存时限不少于90天,以符合《反恐法》要求。这就导致了机场对视频存储的需求更加迫切。在这种情况下,如果仅仅是增加存储的空间是不实际的,视频的压缩技术是一种切实可行的解决方法。在过去的几十年中,人们提出了几种传统的视频压缩的算法,比如说mpeg-4、h.264和h.265等。这些算法大多遵循预测编码架构。虽然他们经过精心设计和彻底调整,但它们是硬编码的,因此无法适应日益增长的需求和日益多样化的视频用例。基于深度学习的方法给视频压缩领域带来了变革性的发展。对于视频压缩任务,已经提出了许多基于dnn的方法用于帧内预测和残差编码、模式决策、熵编码、后处理。这些方法用于改善传统视频压缩算法的一个特定模块的性能。因此设计开发一种高效的基于深度学习的机坪监控视频压缩方法及系统显得是至关重要。技术实现要素:本发明为解决公知技术中存在的技术问题而提供一种基于深度学习的机坪监控视频压缩方法及系统;本发明只需要存储少量的图片、若干个尺寸非常小的视频以及一些数据,大大缩小了存储空间,提高了视频的压缩性能。本发明的第一目的是提供一种基于深度学习的机坪监控视频压缩方法,至少包括:步骤1,压缩视频时,选取原始机坪监控视频中的一帧图像,使用基于区域的卷积神经网络检测出图像中的车辆、飞机和人的位置,在这些位置覆盖上其他帧的图像中相应位置没有物体的图片,生成背景图片;步骤2,将原始机坪监控视频中的每一帧图像与背景图片的整体的色度进行对比,根据得到的色差确定每一帧图像整体的亮度、颜色和灯光整体参数;步骤3,使用基于区域的卷积神经网络检测航站楼、登机桥的亮灯和关灯的两种状态,记录这两种状态的图片、亮灯时间范围以及建筑位置;步骤4,使用基于区域的卷积神经网络将原始视频中的每一帧图像中的飞机、车辆和人检测出来,并将这些检测到的物体根据算法定位的位置裁剪下来,上述物体为飞机、车辆和人中的一个或多个,同一物体的每一张图像通过h.264标准编码以视频mp4的格式存储,并记录视频的起止帧数、位置信息;步骤5,将步骤1至步骤4处理的内容以结点的形式按照处理的顺序依次存入链表,链表的结构从前往后依次是背景图片、视频每一帧图像的整体参数、不亮灯时建筑物的图片、亮灯时建筑物的图片、建筑在视频图像中的位置、亮灯的起止时间、每个算法检测到的物体的视频、视频在图像中的位置以及小视频的起止帧数;步骤6,解压视频时,从链表的第一个结点处取出背景图片,然后取出背景图片后面的每帧图像的整体参数信息,根据每帧的亮度、颜色信息对背景图片进行渲染;步骤7,将前帧的时间与亮灯时间范围进行比较,确定选择何种状态的建筑物的图片,根据存储的这些图片在原始图片中的位置信息,将建筑物图片覆盖到已经渲染好的背景图片中;步骤8,将若干个物体视频从链表中取出,将视频中的每一帧图片根据位置信息覆盖到相应的背景图片中,将这些图片以每秒25帧的速度播放。进一步:步骤1中,背景图片的处理使用基于区域的卷积神经网络确定原始图片中飞机、车辆、人的位置,并将算法框定的区域从图像中裁剪出,比较原始图片的剩余部分与视频中其他图像的相似度,选择相似度高的、并且原始图中裁剪掉的区域没有运动物体的图片,将这张图片中与裁剪掉部分对应位置的图片覆盖到原始图片中,形成没有运动物体的背景图片。进一步:步骤2中的整体参数主要包括图像整体的亮度、颜色以及灯光,灯光主要包括灯光的位置、角度、颜色、强度。进一步:步骤3中,一段视频中只需要记录一次建筑物亮灯和关灯的状态。进一步:步骤4中,将目标检测到的同一物体图片通过h.264标准编码以视频的形式进行存储,基于区域的卷积神经网络检测到机坪监控视频中飞机、车辆和人的位置信息,根据位置信息,将物体的图片从图像中裁剪下来,并把同一个物体的图片通过h.264标准编码合成mp4格式的视频。进一步:步骤6中,在还原视频的每一帧背景图片时,首先根据亮度和颜色信息,对整体图片进行调整,具体是:将原始背景图片按一定比例与同大小的纯色图片进行融合,比例是由亮度来确定,图片颜色是由链表中存储的颜色信息来确定;然后,根据灯光的位置、角度、颜色和强度信息对背景图片进行局部调整;将已经经过整体亮度调整的背景图片与同大小的纯色图片在特定的区域按一定比例进行渐变融合,图片颜色由灯光颜色决定,区域由灯光的位置和角度来决定,比例由灯光的强度来决定。进一步:步骤7中,将建筑物两种状态的图片从链表中提取出来,将前帧的时间与亮灯时间进行对比,如果当前时间是在亮灯范围内,则选择亮灯的建筑物图片覆盖到记录的位置,否则,选择关灯的建筑物图片覆盖到相应位置。进一步:步骤8中,将若干个物体视频以及位置、起始帧信息从链表中取出,根据视频的起止帧数来确定物体开始和结束的视频图像,然后根据位置信息来确定物体视频中每一帧在背景图片中位置。本发明的第一目的是提供一种包含有上述基于深度学习的机坪监控视频压缩方法的系统。本发明具有的优点和积极效果是:本发明将机坪监控视频中的运动的物体与静止的物体分开以链表的方式进行存储。将视频进行压缩时,首先机坪监控视频中,任意选取一张图片,使用目标检测算法识别图像中运动的物体,并将其从图像中裁剪出来,形成一张没有运动物体的背景图。将背景图片存储在链表的第一个位置。然后将原始视频中每一帧的整体参数信息比如亮度、光照等依次存入链表。最后使用目标检测算法检测图片中运动的物体,将视频中每一帧图片的运动物体检测出来,并从图像中裁剪出,将同一个物体的图片合成一个小视频,将若干个物体小视频、小视频每一帧图像在原始视频中的位置以及小视频在原始视频中的起止帧数存储在链表中。通过这样的方式可以极大减少存储空间。视频解压时,首先将背景图片取出,然后根据每一帧图像存储的整体的参数信息比如亮度、光照等调节整体背景,最后将存储的物体小视频取出,将小视频中的每一帧根据存储的起止帧数和位置在调整过的背景图中进行定位,将形成的每一帧图像连成视频,最终形成与原始视频相似的视频。由于这种压缩方式只需要存储少量的图片、若干个尺寸非常小的视频以及一些数据,大大缩小了存储空间,提高了视频的压缩性能。附图说明图1为本发明优选实施例的流程图;图2为本发明优选实施例中压缩后各信息的存储结构图;图3为本发明提供的在原始视频中选取的将要作为背景图片的原始图片;图4为本发明提供的使用物体检测算法将运动物体全部裁剪掉之后形成的背景图片;图5为本发明提供的将要进行压缩的视频的其中的一帧图像;图6为本发明提供的使用fasterrcnn算法对图5进行检测得到的图像;图7为本发明提供的将检测到的物体裁剪下来得到的一系列图片;图8为本发明提供的结合存储的信息将背景图片进行渲染得到的夜间背景图片;图9为本发明提供的将物体图片还原到夜间背景图片后形成的图片;图10为本发明提供的原始图片与还原过后形成的图片每行像素平均值的对比图。具体实施方式为能进一步了解本发明的
发明内容、特点及功效,兹例举以下实施例,并配合附图详细说明如下:视频是由很多帧图片组成的,图片分为矢量图和位图。矢量图像,也称为面向对象的图像,在数学定义为一系列由线连接的点。矢量文件中的图形元素称为对象。每个对象都是一个自成一体的实体,它具有颜色、形状、轮廓、大小和屏幕位置等属性。既然每个对象都是一个自成一体的实体,就可以在维持它原有清晰度和弯曲度的同时,多次移动和改变它的属性,而不会影响图例中的其他对象。基于矢量的绘图与分辨率无关,这意味着它们可以按最高分辨率显示到输出设备上。根据矢量图的特性,我们考虑将视频中运动的物体与背景图片分开。这里提出的深度压缩的方法是针对于机坪的监控视频的,机坪是飞行区供飞机上下旅客、装卸货物、加油、停放或维修使用的特定场所。机坪运行有以下几个特点:(1)机坪内的活动车辆类型比较固定;(2)机坪保障作业系统性强;(3)机坪中静止物体相对固定,运动物体比较容易检测到。根据机坪运作的特征,本发明提出了一种基于深度学习的视频压缩的方法,这种方法可以极大提高机坪监控视频的压缩性能,节省更多的存储空间。为了提高控制系统的安全行,本发明采用下述技术手段予以实现:一种基于深度学习的机坪监控视频压缩方法,由于机坪上的车辆种类相对固定,运动的物体不像机场候机楼那么密集,所以可以将机坪监控视频中的运动的物体与静止的物体分开以链表的方式进行存储。将视频进行压缩时,首先机坪监控视频中,任意选取一张图片,使用目标检测算法识别图像中运动的物体,并将其从图像中裁剪出来,形成一张没有运动物体的背景图。将背景图片存储在链表的第一个位置。然后将原始视频中每一帧的整体参数信息比如亮度、光照等依次存入链表。最后使用目标检测算法检测图片中运动的物体,将视频中每一帧图片的运动物体检测出来,并从图像中裁剪出,将同一个物体的图片合成一个小视频,将若干个物体小视频、小视频每一帧图像在原始视频中的位置以及小视频在原始视频中的起止帧数存储在链表中。通过这样的方式可以极大减少存储空间。视频解压时,首先将背景图片取出,然后根据每一帧图像存储的整体的参数信息比如亮度、光照等调节整体背景,最后将存储的物体小视频取出,将小视频中的每一帧根据存储的起止帧数和位置在调整过的背景图中进行定位,将形成的每一帧图像连成视频,最终形成与原始视频相似的视频。深度压缩的具体步骤如下所示:首先,将视频的某一帧中运动物体使用目标检测的方法比如基于区域的卷积神经网络检测出来,然后将运动物体从图片中裁出,图像中剩下的部分与视频中的其他图像进行比较,计算两张图片之间的相似度。计算图像相似度的主要思想是计算原始图像与其他图像之间的平方差,并计算其余图像与原始图像的方差的商(方差小的是被除数)。商越大,相似度越高。选择其他图像中与这张原始图像相似度高的,并且在原始图片裁剪的位置没有运动物体的图片,将图片上与原始图片被裁剪掉的位置对应的图片覆盖到原始图片中,这样就形成了一张没有运动物体的背景图。将背景图插入到链表的最前面。然后依次处理视频中每一帧的图像。视频中的图像与原始图像之间可能会出现色差,色差是由光的强度、角度和位置的变化引起的。将这些图片与原始图片相比较,将二者的色差存入到链表,然后将能在图像中检测到的灯光的颜色、位置、强度以及角度存入到链表中。背景建筑和登机桥存在亮灯和不亮灯两种情况,由于机场的候机楼和登机桥大多使用整面玻璃作为建筑的墙壁,把不亮灯的图片渲染成亮灯时候的图片的过程比较复杂,由此增加了视频压缩和解压的时间,而且建筑物中灯光的位置、强度和颜色等相对固定,所以直接将亮灯时和不亮灯时建筑的图片存储进链表,并附加上建筑的位置以及亮灯和光灯时间。接着使用目标检测算法,将每一帧中运动物体的图片裁剪出来,将同一个物体的图片通过h.264标准编码后以视频格式存入链表,并在每个小视频后面依次存入小视频的起止帧数、小视频中每一帧的图片在原始图像中的位置。将这些以链表的形式存储,链表的结构是背景图片、每一帧图像的亮度等信息、亮灯和不亮灯时建筑的图片、建筑的位置、亮灯时间、关灯时间、运动物体的小视频、小视频的起止帧数、小视频中每帧图像在原始视频图像中的位置。视频解压时,遍历链表中结点,将存储的信息依次恢复。将链表中的第一个结点背景图片取出,结合每一帧中的参数信息,对原始背景图片进行渲染,形成新视频每一帧图像中背景。当对背景进行渲染时,首先要调整图像的整体亮度,原始背景图像与相同尺寸的其他颜色的图片成比例融合,颜色是由存储的色差信息来决定。然后根据存储的光照位置、强度、角度等信息在背景图中添加光照。接着,根据固定物体的不同性质在背景图中划分区域。比如说建筑物以及廊桥的固定部分,判断图像的时间存在于开灯时间范围还是光灯时间范围,根据判断结果复制相应的建筑图像。地面的情况比较特殊,地面上由很多移动的物体,所以不可以直接复制原始图像。根据灯光的角度、颜色、强度来渲染地面部分。由于不同的材料对灯光的反射不同,需要对不同材料的路面进行单独处理。机坪监控视频中一般会出现两种类型的地面,分别是水泥路面和柏油路面。将二者使用目标检测算法分隔开进行单独处理。两者的原理是相同的,在灯光能照射到的区域使用存储的灯光颜色与图像按一定的比例进行渐变融合,渐变的方向由存储的光照的方向来决定,比例是由光照的强度和路面的材料共同决定。然后将记录运动物体变化的小视频从链表中取出,根据视频的起止时间和每一帧的位置在已经调整好的背景图像中定位,将各种运动物体还原到视频中。通过这样的一种方式,生成与原始视频相似的视频,从而达到视频压缩的目的。由于这种压缩方式只需要存储少量的图片、若干个尺寸非常小的视频以及一些数据,大大缩小了存储空间,提高了视频的压缩性能。请参阅图1至图10,由附图1可知,本发明共需两个实现阶段,分别是视频图像的压缩阶段和解压阶段。本发明公开了一种基于深度学习的机坪视频压缩方法,该方法包括以下几个步骤:步骤1,在原始机坪视频中选取一帧,如附图2所示。使用基于区域的卷积神经网络将附图2中运动的物体检测出来,基于区域的卷积神经网络不仅可以检测出物体的种类,还可以定位物体的位置,将有运动物体的部分从图像中裁剪出来,将剩余部分与视频中其余视频图像进行相似度的对比,选择相似度最高的那张图片,复制这张图片中与附图2相对应的部分,并将其覆盖到附图2中,形成原始的背景图片,如附图3所示。将原始图片存储在链表的开始位置。附图3中已经将飞机、车辆、人等运动物体去除,留下了登机桥、候机楼等固定不变的物体。步骤2,把视频中每一帧图像的整体信息以字符串的形式存入链表中。这些信息包括图像的亮度、图像中能看到的灯光的位置、灯光的强度、灯光的角度、灯光的颜色等。步骤3,机坪监控视频中,有可能会拍到航站楼、廊桥等建筑物,这些建筑物的其中一个特点时墙壁是由大块玻璃组成,开灯时会将建筑物里面的状态显示出来,如果只存储一种状态的话,另外一种状态很难去进行复原,所以我们将建筑的开灯和不开灯的这两种状态都存储下来。使用物体检测算法将建筑物亮灯和不亮灯时的两种状态检测出来,将复制的两种状态的建筑物的图片、建筑物在图片中的位置以及亮灯的起止时间依次存入链表。步骤4,将视频中每一帧中的物体用基于区域的卷积神经网络检测出来。将同一个物体的图片整合成若干个小视频,并记录小视频中每帧的位置以及小视频的起止帧数,将这些信息依次存储进链表中。以视频中的一帧为例来说明具体的处理过程。附图4是机坪监控视频中其中一帧的图像,首先使用基于区域的卷积神经网络将运动的物体检测出来,如附图5所示,图中的飞机、车辆等物体被检测出来,并用框标记了它们在图中的位置,将这些物体从附图5中裁剪出来,如附图6所示,并且记录这些物体在图中的位置,也就是标记框的坐标信息。附图6中的物体图片的大小依次是3.44kb、3.31kb、1.39kb、2.41kb、1.16kb、5.84kb、4.91kb以及41.3kb。链表的结构如附图7所示,从前往后依次是背景图片(bg)、视频每一帧图像的整体参数(p1-pn)、不亮灯时建筑物的图片(cbp)、亮灯时建筑物的图片(lbp)、建筑在视频图像中的位置(bl)、亮灯的起止时间(lt)、每个运动物体的小视频(v1-vn)、小视频在图像中的位置(fl1-fln)以及小视频的起止帧数(f1-fn)。实验中我们选取了某机场机坪14个小时的监控视频进行实验,下面的表格是利用深度压缩方法(基于深度学习的机坪视频压缩方法)对这个监控视频进行压缩之后以链表的形式存储的各项信息的大小。表1链表中各项信息的存储容量表物体大小背景图片624kb图像的整体信息96.13mb亮灯和关灯时建筑图片以及位置345.6kb物体视频11.31gb视频位置及起止帧信息102.5mb步骤5,下面就是视频的解压过程。首先将背景图片从链表的前端取出,根据存储的每一帧的亮度、灯光等关照信息对背景图片进行渲染。图像的参数信息是以字符串的形式进行存储。附图4中的参数信息是以“0.2,2,1,5,3,15…”这样的形式存储在链表中,在还原这张图片时,将参数信息从链表中取出。字符串中的第一个数据是控制图像整体的亮度信息,后面依次是灯光的位置、强度、角度以及颜色信息。结合这些信息对刚才取出的背景图片进行处理,然后将亮灯和关灯的建筑物图片、建筑的位置信息以及亮灯的时间从链表中取出,将当前帧的时间与亮灯时间做比较,当前帧的时间为“2018.04.07星期三21:28:24”,处于建筑亮灯的时间范围,所以选择建筑亮灯的图片,根据建筑的位置信息,将其覆盖到这一帧图像中。从而形成与原始视频图像背景相似的图像,如附图8所示。步骤6,将物体视频以及视频的视频位置等信息从链表中取出,根据物体视频在原始视频中的起止帧的位置定位到物体图片需要覆盖的起始图片,然后根据位置坐标将物体视频中的每一帧覆盖到已经渲染好的图片上。附图9是将物体图片覆盖到已经渲染好的图片中,将附图9与原始视频中对应的图片进行对比,它们之间的相似度是0.9552731260665681,每行像素的平均值的对比图如附图10所示。我们实验的视频是每秒25帧,如果不使用任何的视频压缩算法,存储14个小时的视频大约需要781gb,如果使用本发明提出的基于深度学习的机坪视频压缩方法对机坪监控视频进行压缩,大概需要11.51gb,与原始视频的相似度大约为95%。由此可见,这种基于深度学习的机坪监控视频压缩方法可以极大提高视频压缩的效率,大大节省了机场巨大视频资源的存储空间。本发明采用以上的技术方案,相比于传统的视频压缩方法,引入了深度学习的相关方法,使用物体检测方法将运动物体检测出来,并将运动物体与背景图片分开进行存储。这样只需要存储一张背景图片、若干个物体变化视频以及相应的参数信息,在保证原始视频质量良好的前提下,极大缩小了视频存储空间。以上所述仅是对本发明的较佳实施例而已,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所做的任何简单修改,等同变化与修饰,均属于本发明技术方案的范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1