用于XGPONOLT的OMCI组帧装置及组帧方法与流程
本发明涉及通信领域,特别是涉及一种在xgpon接入领域通过cpu发送omci(onu管理和控制接口)帧的组帧电路。
背景技术:
在pon(passiveopticalnetwork,无源光纤网络)中,olt(opticallineterminal,中文名为光线路终端)是用于连接光纤干线的终端设备。pon中使用光纤连接到olt,然后olt连接到onu(opticalnetworkunit,中文名为光网络单元。最后由onu提供数据、iptv(即交互式网络电视)、语音等业务给终端的用户。
为了保证高速、持续、稳定发送下行omci信令,在xgponolt的cpu向256个onu发送指令过程中,高速、健壮的控制电路将发挥非常重要的作用。
中国专利申请cn201310080961.3公开了一种xgpon系统中onu端的xgem组帧装置级组帧方法,其是一种onu上行按照2.5gbps最大带宽组建xgem帧的装置,但该方案是针对onu的,该方法和装置主要是接收到需转发到olt的业务报文后,快速地向olt转发,且不能实现用pciedma通道,连续组建超过1.6gbps大带宽速率的omci帧。
中国专利申请cn200910175197.1公开了一种下行成帧的方法、光线路终端及无源光网络系统,其提出了一种下行组帧,特别的,该方案在每个预设帧中周期性插入pcbd座位帧头形成定长的融合数据帧,不涉及用pciedma通道连续组建超过1.6gbps大带宽速率的omci帧的技术要求
技术实现要素:
本发明是为了解决上述问题而进行的,目的在于提供一种用于xgponolt的omci组帧装置及组帧方法,该装置能够连续以约1.6gbps速率,接收cpupciedma通道发送的omci帧,并基于xgem帧封装,完成omci帧到xgem帧的组帧,而且能在一定出错率的情况下,保证发送的健壮性。
本发明提供一种用于xgponolt的omci组帧装置,和cpu的pciedma通道连接,用于将cpu发出的dma数据块进行处理,其特征在于,包括:
dma写控制电路,和所述pciedma通道连接,用于控制mic计算omci帧数据缓存及mic计算omci帧描述fifo的写入过程;
mic计算读控制电路,和所述mic计算omci帧数据缓存及mic计算omci帧描述fifo的读口连接,用于对mic计算omci帧数据缓存及mic计算omci帧描述fifo的读口的读过程进行控制并计算得到mic值后,输出对应的带正确mic值的omci数据帧和帧描述;
omci帧重写电路,与所述mic计算读控制电路的输出端相连接,且与omci帧数据缓存和omci帧描述fifo的输入相连接,用于将对应的omci帧数据内容和描述,重写入omci帧数据缓存以及omci帧描述fifo中。
本发明提供的用于xgponolt的omci组帧装置,还可以具有这样的特征:
其中,所述mic计算读控制电路与mic计算omci帧数据缓存和mic计算omci帧描述fifo以及mic计算逻辑相连,
所述mic计算omci帧数据缓存和mic计算omci帧描述fifo输入端和所述dma写控制电路的输出端相连接,输出端和所述mic计算读控制电路的输入端相连接,所述mic计算逻辑和所述mic计算读控制电路连接。
本发明提供的用于xgponolt的omci组帧装置,还可以具有这样的特征:
其中,在所述omci帧重写电路中,所述omci帧重写电路的输入端和所述mic计算读控制电路输出端连接。
本发明提供的用于xgponolt的omci组帧装置,还可以具有这样的特征:
其中,xgem组帧器与omci帧数据缓存、omci帧描述fifo的输出端连接,
所述xgtc组帧器与所述xgem组帧器的输出端连接。
本发明还提供一种上述的用于xgponolt的omci组帧装置的组帧方法,用于将cpu的pciedma通道发出的dma数据块进行处理,得到对应的xgem帧和xgtc帧,其特征在于,包括以下步骤:
dma写控制电路将dma数据块内omci帧的帧数据内容写入mic计算omci帧数据缓存,将omci帧描述进行处理,写入mic计算omci帧描述fifo中,当dma数据块传输结束时,停止本次dma数据块写入过程;
根据mic计算omci帧描述fifo写入的帧描述信息,将omci帧从mic计算omci帧数据缓存读出,同时发送给mic计算逻辑,生成本帧对应的mic值;
根据描述内的mic_en指示,决定在每一个完整的omci帧尾部,是否替换mic值;
将替换了mic值的32bit位宽的omci帧,根据在64bit新数据总线内的奇偶位置,以及帧尾部长度大小,第二次写入64bit的omci帧数据缓存,并将omci帧描述写入omci帧描述fifo,并最后由omci帧数据缓存及omci帧描述fifo读侧的xgem组帧器,将其封装成带xgem帧头的omci帧,以10gbps的速率向下游发送。
本发明提供的组帧方法,还可以具有这样的特征:
其中,当pciedma通道产生结束标志信号tx_req_clr时,即表示相应完整单位的dma数据块传输结束,所述dma数据块包括多个omci帧,该omci帧包括omci帧描述和帧数据内容,omci帧描述包括帧属性描述和原始帧长描述。
对应的,所述dma写控制电路将dma数据块中的omci帧描述进行处理后,写入mic计算omci帧描述fifo中,将帧数据内容写入到mic计算omci帧数据缓存。
本发明提供的组帧方法,还可以具有这样的特征:
所述omci帧的数据结构包括空数据、帧属性描述、原始帧长描述、帧数据内容,
空数据全部为二进制的0,其长度为32bit,
dma写控制电路处理pciedma通道发出omci帧的过程包括:
在空闲状态,根据空数据全为零且包络有效的位置,搜索到帧描述的头部;
空数据状态后定义帧属性描述、原始帧长描述的发送过程,在发送过程中将帧属性描述写入寄存器,将原始帧长描述作为初始值,写入帧长描述递减计数器,同时帧长递增计数器被赋初值为零,接着再发送帧数据内容。
mic计算omci帧描述fifo的控制电路中存储有多个数据帧的帧描述条目,该帧描述条目的数据结构为:onu_num、portid、mic_en、frame_len、start_addr,
onu_num、portid、mic_en是帧的属性描述,
onu_num表示该数据帧所要下传的pononu的序列号,
portid表示omci帧的gemportid标记,
mic_en是是否进行mic值重算的标志,
frame_len是数据帧的实际字节长度,
start_addr是写入omci帧在mic计算omci帧数据缓存的起始地址,
发送帧数据的过程包括:
在发送数据帧的前一拍,将原始帧长描述作为初始值,写入帧长描述递减计数器,其后根据包络有效指示,每写入一拍数据进数据缓存,帧长描述递减计数器减去4字节,帧长递增计数器加上4字节;
当帧长描述递减计数器递减到小于或等于4字节时,便写入上述帧描述条目,写入mic计算omci帧描述fifo的描述条目的frame_len是写入数据帧的实际字节长度,即为帧长描述递减计数器加上帧长递增计数器的值。
本发明提供的组帧方法,还可以具有这样的特征:
当dma数据块中的某个omci数据帧的帧描述中的原始帧长描述与该数据帧的实际长度不匹配时,按照以下方法进行健壮性处理:
a.当某个omci数据帧的帧描述中的原始帧长描述大于该数据帧的实际长度时,把后续包络有效指示对应的数据当成空闲数据,补到数据帧的末尾;
当帧长描述递减计数器递减到小于或等于4时,写入mic计算omci帧描述fifo的描述条目的frame_len,为当前帧长描述递减计数器加上帧长递增计数器的值,写入帧描述条目的帧长值frame_len也是原始帧长描述;
然后回到空闲状态,继续根据空数据全为零且包络有效的位置,搜索到帧描述的头部;
若直到一个搬运块结束即tx_req_clr信号已给出时,帧长描述递减计数器仍不能递减到小于或等于4,则按照此时的帧长递增计数器加上4字节后,写入帧描述条目并停止数据帧内容的写入以保证此时写入帧长描述条目的帧长和实际写入缓存的帧长匹配;
b.当某个数据帧的帧描述中的原始帧长描述小于该数据帧的实际长度时,就不写入该帧多于原始帧长描述的帧尾数据;
当帧长描述递减计数器递减到小于或等于4时,写入mic计算omci帧描述fifo的描述条目的frame_len,为帧长描述递减计数器的值,加上帧长递增计数器的值,写入帧描述条目的帧长值frame_len其实就是原始帧长描述。
本发明提供的组帧方法,还可以具有这样的特征:
其中,依据mic计算omci帧描述fifo中写入的帧描述信息,将dma数据块内的omci帧从mic计算omci帧数据缓存中读出,并发送给mic计算逻辑,计算出对应的mic值。
本发明提供的组帧方法,还可以具有这样的特征:
其中,将添加了mic值的omci数据分片,每两个32bit合成一个64bit的总线数据;
将总线数据和mic值进行再次拼接得到完整的omci数据帧后,通过omci帧重写电路写入对应的omci帧数据缓存中,将数据缓存的完整的omci数据帧经过xgem组帧器进行封装,得到xgem帧,xgem组帧器通过读出每一个帧描述的起始地址,确定xgem帧内容的读起始位置,其后的封装过程包括xgem帧头添加、crc重算、xgem帧分片组帧等xgpon协议规定的xgem组帧操作。
发明的作用和效果在于:根据本发明所涉及的xgponolt的omci组帧装置及组帧方法,因为具有dma写控制电路,和所述pciedma通道连接,用于控制mic计算omci帧数据缓存及mic计算omci帧描述fifo的写入过程,确保将dma数据块的omci帧数据和帧描述分别连续高速写入,对高速输出的dma数据块的缓存写过程进行控制,保证了数据块的持续高速处理,不会出现紊乱和堵塞;出现少量错误之后,仍然能够在后续发送中恢复正常,保持健壮性。
由于具有mic计算过程,保证数据帧读写及传输出现错误或被更改后,能被下游发现并丢弃。omci帧数据缓存、omci帧描述fifo的输出端与gem帧组帧器输入端连接,gtc帧组帧器与所述gem帧组帧器的输出端连接,能够对应生成gem帧和gtc帧。
附图说明
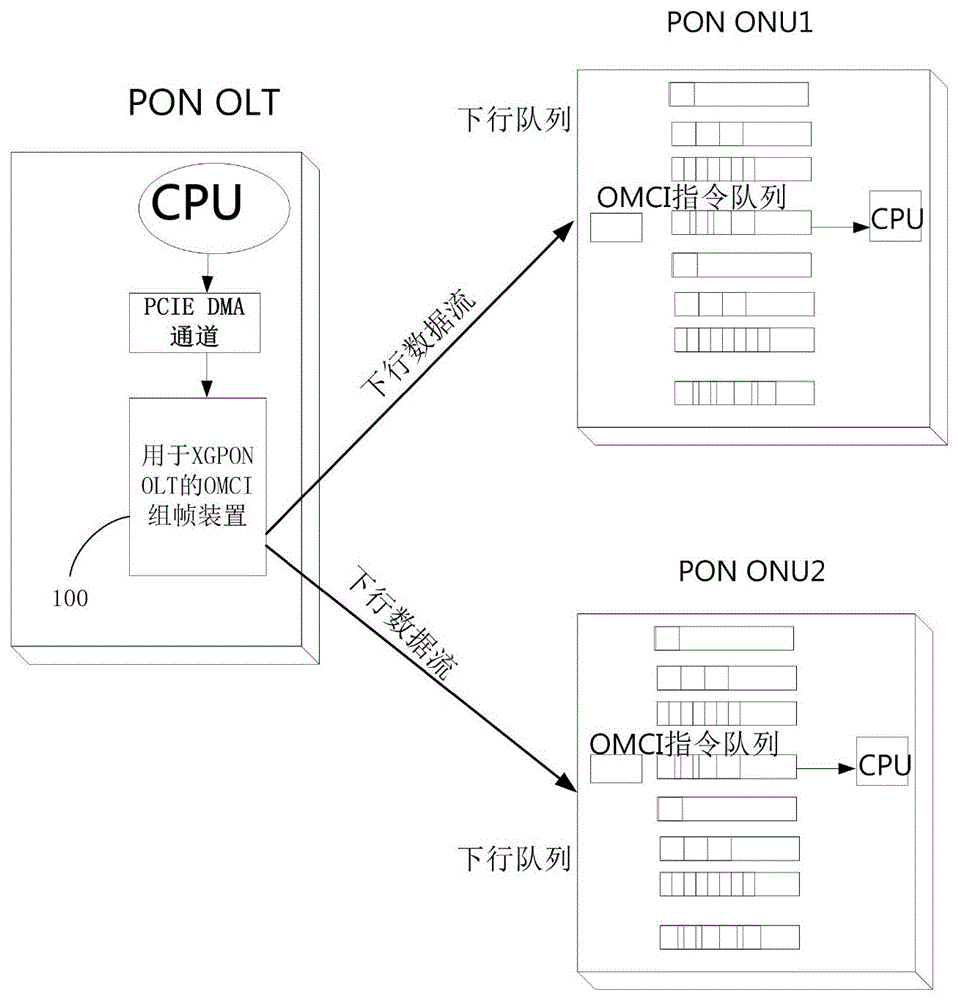
图1为本发明的实施例中的用于xgponolt的omci组帧装置与xgpononu连接的示意图。
图2为本发明的实施例中的用于xgponolt的omci组帧装置的结构框图。
图3为本发明的实施例中用于xgponolt的omci组帧装置的组帧方法的步骤示意图。
图4为本发明的实施例中dma数据块内单个omci数据帧的数据结构示意图。
图5为本发明的实施例中mic计算omci帧的帧描述结构示意图。
图6为本发明的实施例中的dma写控制电路的方法流程图。
图7为omci帧的mic值计算过程示意图。
图8为omci帧重写电路写入omci帧描述fifo的帧描述结构示意图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下实施例结合附图对本发明用于xgponolt的omci组帧装置及组帧方法作具体阐述。
在本实施例中出现的英文缩写的含义
xgpon,速率为10gbps的高速无源光网络。
olt,即pon中的光线路终端(olt:opticallineterminal)。
omci,omci(光网络单元管理控制接口,即onumanagementandcontrolinterface)是gpon标准中定义的一种olt与ont之间信息交互的协议,用于在gpon网络中olt对ont的管理,包括配置管理、故障管理、性能管理和安全管理等。按照该协议封装的数据帧即为omci帧。
onu,用户端的光网络单元/光网络终端(onu/ontopticalnetworkunit/opticalnetworkterminal)。
dma,directmemoryaccess直接存储器访问。
mic,messagesintegritycheck,消息完整性检查。
xgem,xgem(xg-ponencapsulationmode,xgpon封装方式)是一种在xgpon上封装数据的方式。
xgtc,xgtc(xgpontransmissionconvergence)的成帧子层。
pcie,pci-express(peripheralcomponentinterconnectexpress),是一种高速串行计算机扩展总线标准
fifo,firstinputfirstoutput的缩写,先入先出队列,这是一种传统的按序执行方法,先进入的指令先完成并引退,跟着才执行第二条指令。
bwmap,bandwidthmap,带宽映射。
ploam,physicallayeroperations,administrationandmaintenance物理层操作管理和维护。
serdes,serdes是英文serializer(串行器)/deserializer(解串器)的简称。它是一种主流的时分多路复用(tdm)、点对点(p2p)的串行通信技术。
ram,随机存取存储器(randomaccessmemory,ram),又称作“随机存储器”
upi,用户程序接口(userprograminterface)。
idle,即英文idle,空闲的意思,在本实施例中指进入空闲等待的状态。
图1为本发明的实施例中的用于xgponolt的omci组帧装置与xgpononu连接的示意图。
图2为本发明的实施例中的用于xgponolt的omci组帧装置的结构框图。
如图1、2所示,用于xgponolt的omci组帧装置具有dma写控制电路10、mic计算读控制电路40、omci帧重写电路50以及xgem组帧器70等单元构成。
dma写控制电路10,和xgponolt中的cpu的pciedma通道连接,且和mic计算omci帧数据缓存20及mic计算omci帧描述fifo30的写侧连接,用于控制dma数据块的写入过程。
mic计算读控制电路40,和mic计算omci帧数据缓存20及mic计算omci帧描述fifo30的读侧连接,用于对fifo的读过程进行控制。
mic计算逻辑41,与mic计算读控制电路40连接,用于在mic计算读控制电路40的控制下,对数据帧的mic值进行计算;计算mic值后,输出给对应的数据帧,在帧尾替换相应mic值。
mic计算omci帧数据缓存20,用于将dma写控制电路10中输出的dma数据块中的omci数据帧进行缓存。
mic计算omci帧描述fifo30,用于将从dma写控制电路10中输出的dma数据块中的omci帧描述按照fifo(firstinputfirstoutput,先进先出)的规则进行缓存并控制读出。
所述mic计算omci帧数据缓存20及mic计算omci帧描述fifo30的输入端和所述dma写控制电路10的输出端相连接,其输出端和所述mic计算读控制电路40的输入端相连接。所述mic计算omci帧描述fifo30用于将dma数据块中处理后的omci帧描述,按照fifo结构和所述mic计算omci帧数据缓存20中存储的omci数据帧进行关联;所述mic计算逻辑41和所述mic计算读控制电路40连接。
omci帧重写电路50,与所述mic计算读控制电路40连接;omci帧重写电路50,与omci帧数据缓存51和omci帧描述fifo52连接,用于将对应的omci协议帧内容和描述再次写入omci帧数据缓存51以及omci帧描述fifo52中。
xgem组帧器70,和所述omci帧数据缓存51和omci帧描述fifo52读出口连接。
xgem组帧器70不但和所述omci帧数据缓存51和omci帧描述fifo52的输出端相连,而且还同业务帧数据缓存及描述fifo60读输出端相连。xgem组帧器70根据内部优先级仲裁电路,一次响应一个omci帧或业务帧的读出请求。
xgtc组帧器80,与xgem组帧器70相连,完成xgem组帧之后的xgtc组帧。
在本实施例中,mic计算omci帧数据缓存20及mic计算omci帧描述fifo30读口属于155.52m的无源光网络时钟域;mic计算omci帧数据缓存20及mic计算omci帧描述fifo30的写口,属于pciedma通道cpu时钟域;
以下结合本实施例的用于xgponolt的omci组帧装置,来具体说明对应的组帧方法。
图3为本发明的实施例中用于xgponolt的omci组帧装置的组帧方法的步骤示意图。
如图3所示,用于xgponolt的omci组帧装置的组帧方法,将cpu的pciedma通道发出的dma数据块进行处理,得到可以连续背靠背发送的xgem帧和xgtc帧,包括以下步骤s1到s4:
步骤s1,将dma数据块内omci帧的帧数据内容写入mic计算omci帧数据缓存,将处理后的omci帧描述写入mic计算omci帧描述fifo中,当dma数据块传输结束时,停止本次dma数据块写入过程。
omci帧描述在帧尾写入mic计算omci帧数据缓存。帧尾写入描述,可以保证写入帧描述条目写入的实际帧长描述,和写入数据缓存的帧实际占用缓存大小相匹配,如果在写整个帧的过程中发现错误,可以通过回退数据缓存首地址的方式覆盖刷新已写入错误帧内容,且不写入描述条目,保证错误帧不会在读侧读出,不会再向下游转发且完全滤除。
具体的,pciedma通道通过以下过程控制每次dma发送过程的结束:
当pciedma通道产生一拍高有效的dma数据块结束标志信号tx_req_clr时,表示本次dma搬运结束;tx_req_clr信号和dma数据块的包络信号dma_data_we的最后一拍对齐。
dma写控制电路10响应dma通道产生的数据块结束标志信号tx_req_clr,并产生正确的写结束操作逻辑:在mic计算omci帧数据缓存20及mic计算omci帧描述fifo30处于非满状态时,dma通道发出的请求发送信号tx_req为高电平,保证上游pciedma数据能够写入到mic计算omci帧数据缓存20及mic计算omci帧描述fifo30中。搬运过程的dma数据块长度可以配置。比如,如果配置一个搬运过程的dma数据块长度为16k字节,则一次dma数据块可以装载8个1980字节的omci帧。
其中,所述一个dma数据块可以包括多个omci帧,该omci帧包括帧描述和帧数据(frame_data)。
图4为本发明的实施例中omci数据帧的数据结构示意图。
dma数据块内的omci数据是帧描述和帧数据的混合体:每个omci数据帧的开头128bit为该帧的帧描述,包括空数据、帧属性描述,原始帧长描述,其后为帧数据;以上数据对应的包络信号dma_data_we为高电平,其余为低电平。定义pcie与dma通道的接口dma帧写入的数据结构如图4所示。
每个dma数据块内的omci帧的第一个32bit(dummydata,空数据)要和128bit(4个doubleword)边界对齐,即只能从第1、5、9…个doubleword处开始,dummydata即全0数据最先写入。也就是说,如果上一个帧的最后一个字节没有达到128bit边界,后面会填充无效字节,直到128bit边界,帧描述中的length字段所描述的长度为数据包的长度,即原始帧长描述。
一个dma数据块根据其配置长度不同,可以装载一个或者多个omci帧。如果cpu发现剩余的数据块空间不能够装一个完整的omci帧,则放在下一个搬运过程的数据块中发送。
dma通道数据宽度为32bit,即4字节,固定采用持续4拍突发burst,每个突发burst传4x4=16字节数据。前一个突发和后一个突发之间可能存在间隙,也可能不存在间隙。帧尾不足16字节的,填充dummy字段补成16字节。dma写控制电路10将omci帧描述后面的数据frame_data写入mic计算omci帧数据缓存20;在已经发送完frame_data的帧尾时刻,将dma数据块的omci帧结构头部的帧属性描述、重新计算后的帧长描述frame_len及帧起始地址start_addr,以omci帧描述fifo结构写入到mic计算omci帧描述fifo30内。mic计算omci帧描述fifo的每一个地址的内容的数据结构对应图5。
mic计算omci帧数据缓存20设定的缓存空间大小为4k(4096)字节,满足同时装载两个最长的omci帧的需求。mic计算omci帧数据缓存20采用4k字节的缓存结构,这是考虑到omci的最大帧长是1980字节,能够同时存储两个最长帧而不发生满溢出问题。fifo的深度为1024,宽度为32bit,宽度设计主要考虑到upi数据总线的宽度32bit。当一个数据的帧尾只有1~3个字节有效时,需要将不足4字节的位置补0,补成4字节写入。
图5为本发明的实施例中omci帧的帧描述结构示意图。
mic计算omci帧描述fifo30中存储有多个数据帧的帧描述条目,每一个帧描述条目mic_dscp_info的数据结构定义如图5所示:
onu_num:8bitomci帧的onunum标记,可以用来表示最大256个onu序列号。
portid:14bitomci帧的gemportid标记,可以表示最大16k个portid。
mic_en:决定是否进行mic重算的标志。
frame_len:11bit表示数据帧长,表示最大长度为2048字节的帧。
mic计算的数据帧描述的缓存深度为27=128;描述缓存大于4k/48=83,采用2的7次方128个地址。
start_addr:写入mic计算omci帧数据缓存20的omci帧的起始地址。
图6是dma写控制电路的方法流程图。
mic计算omci帧数据缓存的普通正常读写,即当omci帧描述的原始帧长信息framelen和后续burst(脉冲)长度严格匹配时,控制电路可以通过每帧的原始帧长描述信息,确定该帧数据在缓存内的起始和结束位置。每一个帧的写入起始位置,即是上一个帧的写入结束位置的下一个地址。根据ram连续读写的性质,当前帧的写入起始位置,加上帧长描述信息对应的时钟数,就是下一个帧的起始地址。
dma写控制电路10在写满出现或者写帧描述和实际帧长不匹配的时候,通过mic计算omci帧数据缓存20及mic计算omci帧描述fifo30非正常读写处理机制,和通过dma数据块的tx_req_clr指示,保证写满时以及写帧描述和实际帧长不匹配时的健壮性。在一次出错以后,能够在下一个dma数据块恢复正常。dma写控制电路的方法流程图可以用图6表示.
dma写控制电路10区分两种情况达成健壮性目标:
dma写控制电路10如遇到帧尾长度描述和实际长度不匹配,dma写控制电路10中的写帧状态机需要区分情况分别处理,保证fifo读写的健壮性,在写状态机侧使ram写入实际数据帧长和描述帧长一致,不发生连续读取的ram读写地址紊乱的故障。本装置能保证来自pcie上游接口个别帧长有错误的情况下,仍能保证ram连续读写的稳定性。dma数据块中的某个omci帧的帧描述中的原始帧长描述与该数据帧的实际长度不匹配时,按照以下方法进行健壮性处理:
某个数据帧的帧描述中的原始帧长描述大于该数据帧的实际长度时,把后续包络有效指示对应的数据当成空闲数据,补到数据帧的末尾;
当帧长描述递减计数器递减到小于等于4的时刻,按照上文中的附图5omci帧的帧描述结构写入帧描述条目;写入帧描述条目的帧长值就是原始帧长描述;然后回到空闲状态,继续根据空数据全为零且包络有效的位置,搜索到帧描述的头部;
若直到一个搬运块结束tx_req_clr信号已给出,帧长描述递减计数器仍不能递减到小于等于4,则按照此时的帧长递增计数器加上4字节后,写入帧描述条目,停止数据帧内容的写入,保证此时写入帧长描述条目的帧长和实际写入omci帧数据缓存的帧长匹配;这时写入的帧长递增计数器之所以要加上4字节,是因为tx_req_clr信号给出时,dma写入数据的包络信号dma_data_we同时还为高电平,下一拍包络信号dma_data_we才翻转为第电平,所以omci帧数据内容还要再写一拍,即4字节,才能停止写入mic计算omci帧数据缓存。
当某个数据帧的帧描述中的原始帧长描述小于该数据帧的实际长度时,就不写入该帧多于原始帧长描述的帧尾数据;
当帧长描述递减计数器递减到小于或等于4时,写入帧描述条目。写入帧描述条目的帧长值就是原始帧长描述。
遇到实际帧长和帧长描述不匹配的情形,mic_en一律不重算,保证这种错误帧能在接收端因mic效验不能通过而丢弃。
以上情形均能保证错误帧写入时的帧长描述属性和数据缓存写入帧内容的长度匹配,保证写入mic计算omci帧数据缓存20和mic计算omci帧描述的帧长描述一致性,而不发生地址紊乱错误。
如图6所示的dma写控制电路的方法,其有效性结合附图6可以通过以下的论述证明:
写入mic计算omci帧数据缓存的实际帧长的占用拍数,就是搜索到原始帧长描述,对帧长描述递减计数器进行初始化后,假设后续包络信号dma_data_we的持续拍数为n,则帧长递增计数器等于4n字节。
帧长描述递减计数器为原始帧长描述减去4n字节,当帧长描述递减计数器递减到小于等于4字节时,此时的帧长描述递减计数器加上帧长递增计数器,等于原始帧长描述-4(n-1)+4(n-1),消去4(n-1),实际就是等于原始帧长描述;帧长描述递减计数器最后一拍若不足4字节,也要占用一拍4字节的mic计算omci帧数据缓存地址.读侧根据帧长描述只取最后一拍的有效字节。
如遇tx_req_clr为高但帧长描述递减计数器还未递减至小于等于4字节的非正常情况,写入mic计算omci帧描述fifo的帧长描述为4(n-1)+4字节,除以一拍四字节,正好等于dma_data_we的持续拍数n。
以上的帧长描述递减计数器、帧长递增计数器均是由“dma写控制电路10”维护的,实际上帧长描述递减计数器、帧长递增计数器也是运行在dma写控制电路10中的。
步骤s2,根据mic计算omci帧描述fifo写入的帧描述信息,将omci帧从mic计算omci帧数据缓存读出,同时发送给mic计算逻辑,生成本帧对应的mic值。
对应的,mic计算逻辑41根据帧长描述,一旦计算到omci帧尾,就根据mic_en指示,完成对omci数据帧mic值的替换。mic计算omci帧数据缓存20采用4k字节的缓存结构,这是考虑到omci的最大帧长是1980字节,能够同时装载两个最长omci帧,而不发生满溢出问题。如果发生写入突发速率过大,omci帧的mic值计算数据缓存还是出现了满的情况,omci帧写电路在帧尾不写入帧描述,并将已经写入mic计算omci帧数据缓存20的帧内容,通过回退到之前本帧的写起始地址的方式清除,后续omci帧从该起始地址之后写入,覆盖并刷新先前已写入内容。
mic计算读控制电路40从mic计算omci帧描述fifo30读出并锁存onu_num、portid、frame_len等描述信息。
mic计算omci帧描述fifo30深度为27=128,原因在于fifo的缓存大于4k字节/48字节=83,采用2的7次方128个地址。base类型的omci帧长度是48字节。不考虑连续omci报文都是小于48字节的情形,128个地址可满足基本连续读写需求。
与pciedma通道接口的dma写控制电路10的写控制逻辑分成以下几个状态:空闲等待idle状态、描述解析、数据写入状态。实现写入mic计算omci帧描述fifo30的帧长描述,和实际写入的mic计算omci帧数据缓存20的长度相匹配,是一个重要步骤。该操作通过omci帧的原始帧长描述信息根据到达burst递减,以及实际写入mic计算omci帧数据缓存20的实际burst长度累加,在omci帧的帧尾写入时刻,最后才写入到mic计算omci帧描述fifo30中。
mic计算逻辑41与mic计算读控制电路40相连,mic计算读控制电路40按照aescmac的时序,连续4拍读出32bit数据总线位宽后,将其拼成128bit数据和包络,送入aescmac的ip核。mic计算逻辑41和mic计算读控制电路40相连组成的组合,是以omci的mic校验值计算为核心来进行工作的,具体过程为:
对于omci通道,发送方采用4字节的信息完整性检查(mic)域用于检验和防止欺骗。mic域采用aes_cmac生成。aes_cmac算法以aes_ecb算法为基础,通常用于消息的认证和完整性校验,类似与以太网协议中经常使用的crc校验。
图7为omci帧的mic值计算过程示意图。
transationid,业务编号。
messagetype,信息类型。
deviceid,设备编号。
meid,本设备编号。
messagecontents,信息内容。
diectioncode,传输方向代码。
message,信息,待传输的信息。
aes-cmac-32,aes即高级加密标准(英语:advancedencryptionstandard,缩写:aes),在密码学中又称rijndael加密法,是美国联邦政府采用的一种区块加密标准。cmac的全称是cypher-basedmessageauthenticationcode,基于aes等对称加密方式实现消息认证。aes-cmac-32是一种已有的的加密-解密标准算法。aes-cmac-32engine即运行aes-cmac-32加密-解密标准算法的加解密器。本发明应用aes-cmac-32engine在32比特位宽的mic计算omci帧数据缓存的读总线上,生成4字节/32比特的mic值。
omciik,就是omci帧的密钥值,在本发明中就是16字节/128比特aes-cmac-32engine的密钥值。
mic域的计算方法,如图7所示:
omci-mic=aes-cmac(omci_ik,(cdir|omci_content),32)
其中cdir(就是diectioncode)用于指示上行还是下行方向,cdir=0x01为下行方向,cdir=0x02为上行方向。omci_content指示omci消息的内容除去最后4个字节,omci_ik是用来计算omci帧mic域的密钥值。
在从mic计算omci帧数据缓存20中读出omci帧时,根据帧头中的mic_en指示或者全局的upi配置omci_mic_force,决定是否重新进行omci帧的mic校验计算并进行替换。当需要进行mic计算和替换时,需要将计算生成4字节的mic值替换以前的4字节。
当已经有omci数据帧被mic计算读控制电路40根据mic计算omci帧描述fifo30的当前描述信息读出后,若mic计算omci帧描述fifo30为非空状态,且上一个帧的帧长指针递减小于等于16,且下游dma重写电路50反馈的描述信号读允许信号dscp_rd_allow信号为高,则产生mic计算omci帧描述fifo30读信号mic_dscp_rd_en,开启从mic计算读控制电路40读取下一个omci帧的帧描述过程。描述信号读允许信号dscp_rd_allow信号由dma重写电路50的写状态机向omci帧数据缓存51及omci帧描述fifo52内写omci帧的状态产生。
如果已经开始了读取omci帧的帧描述过程,并开始了mic计算omci帧数据缓存20的读取,则禁止在omci帧数据的读过程中读取帧描述,直到最后aescmac电路计算出mic值的这一拍,根据aescmac的mic_data_en信号,释放读mic计算omci帧描述fifo30描述信号读允许信号dscp_rd_allow,重新回到mic计算omci帧数据缓存20和mic计算omci帧描述fifo30的读等待状态。
当开始读一个omci帧的帧内容之后,同时产生与aescmacip核接口控制信号。帧头描述读信号mic_dscp_rd_en的下一拍,读出描述,并提取omci帧的帧长信息到帧长指针。从帧长指针刚才锁存描述的帧长信息这一拍开始,连续对32bit位宽数据fifo读4拍,然后将4拍连续的32bit数据拼接成128bit数据及包络送至aescmacip核。这第一个128bit送至aescmacip核数据,且最高8bit添加一个directioncode,后续128bitmic值计算输入信号mic_data_chk依次向后挪8bit。如图7所示。每次连读4拍32bit数据之后,帧长指针frame_ptr减16字节。连读4拍32bit数据产生一拍128bitaescmac输入数据及包络之后,再等待若干拍,等待的这段时间,可以看成是16字节数据读间隙,再启动下一次连续4拍32bit的读过程。
当帧长指针每次读一个16字节burst递减,直到小于等于16字节之后,则可以判定已经到了omci帧的尾部,此时送给aescmacip核帧尾指示和尾长指示。
步骤s3,根据描述内的mic_en指示,决定在每一个完整的omci帧尾部,是否替换mic值。
步骤s4,将替换了mic值的32bit位宽的omci帧,根据在64bit新数据总线内的奇偶位置,以及帧尾部长度大小,第二次写入64bit的omci帧数据缓存,并将omci帧描述写入omci帧描述fifo,并最后由omci帧数据缓存及omci帧描述fifo读侧的xgem组帧器,将其封装成带xgem帧头的omci帧,以10gbps的速率向下游发送。
将添加了mic值的omci帧对应第二次写入omci帧数据缓存51和omci帧描述fifo52中,并经过xgem组帧器及xgtc组帧器,将数据帧和帧描述封装为与总线位宽匹配的xgem帧xgtc帧。
完成omci帧的mic计算后,还要通过omci帧重写电路50,完成xgem组帧所用的omci帧数据缓存51及omci帧描述fifo52的写过程。xgem组帧用的omci帧数据缓存51采用一个4k字节的同步双口ram,因为omci帧最长可达1980字节,一样可以连续同时装两个最大的omci帧。omci重写电路50把32bit位宽变成64bit位宽,和10ggem组帧器的位宽、接口ram数据宽度一致。omci重写数据缓存规格64bitx512;omci帧重写电路主要完成下面两个步骤的处理:
1.普通数据处理。将前级mic计算读控制电路40读取出来的32bit的dma数据块内的omci帧,每两拍合成64bit总线数据,完成32bit到64bit的总线位宽变换功能。
2.把aescmacip核计算得到的mic值,根据帧尾一拍剩余长度的不同,和mic数据拼接成完整的omci帧,写入omci帧数据缓存51。
图8为omci帧描述fifo的每个描述条目数据结构示意图。
xgem组帧用omci帧描述fifo52采用深度128个地址的fifo。xgem组帧用omci帧描述fifo数据结构定义如图8所示,每个条目解释如下:
start_addr2:写入omci帧数据缓存51的起始地址。
mic计算读控制电路40从mic计算omci帧描述fifo30读出并锁存onu_num、portid、frame_len等描述信息。本级omci帧重写电路将这些描述信息与本帧在omci帧数据缓存51的写起始地址start_addr2合并到一起,放在一起再次写入omci帧描述fifo52。
完整的omci帧通过以上装置写入omci帧数据缓存51和omci帧描述fifo52后,通过xgem组帧70读控制电路中的xgem帧组帧状态机和xgtc组帧器中的xgtc帧组帧状态机的读控制动作,完成g.987.3协议的xgpon下行xgem\xgtc帧的封装,封装过程包括xgem帧头添加、crc重算、xgem分片帧组帧、gtc帧头添加,进一步根据情况还可以加入bwmap结构调整和ploam消息发送等功能。如图1所示,xgem/xgtc帧组帧完成后,通过下行serdes及光通道传送至各onu。
实施例的作用和效果在于:根据实施例提供的xgponolt的omci组帧装置及组帧方法,因为具有dma写控制电路,和所述pciedma通道连接,用于控制mic计算omci帧数据缓存及mic计算omci帧描述fifo的写入过程,确保将dma数据块的omci帧数据和帧描述分别连续高速写入;由于具有dma写控制电路,对高速输出的dma数据块的缓存写过程进行控制,保证了数据块的连续高速处理,不会出现紊乱和堵塞;出现少量错误之后,仍然能够在后续发送中恢复正常,保证健壮性。
由于具有mic计算过程,保证数据帧读写及传输出现错误或被更改后,能被下游发现并丢弃。
由于具有dma写控制电路,对高速输出的dma数据块的缓存写过程进行控制,保证了数据块的持续高速处理,不会出现紊乱和堵塞。
进一步,由于具有缓存健壮性处理,即使cpu发送出现了少量描述和帧长不匹配的错误帧,也能够在后续发送中恢复正常,保持健壮性。
本发明不局限于上述实施方式,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围之内。本说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!