一种基于直播频道用户观看行为相似性的用户身份识别方法与流程
本发明涉及模式识别技术领域,尤其涉及一种基于直播频道用户观看行为相似性的用户身份识别方法。
背景技术:
随着技术的发展与人们对生活品质的追求,越来越多的用户选择拥有丰富频道内容和鲜明交互特性的iptv和网络电视作为放松娱乐的方式。用户在iptv和网络电视给定的频道列表中挑选频道,观看频道实时内容。由于在频道选择的过程中,用户是主动选择频道,可以判断其选择观看的频道是跟其喜好相一致的。依据此规律,能够推断出用户对特定频道的观看频率和用户对该频道的喜爱程度成正相关。
然而,随着科技的发展,现代人们对身份的隐藏手段越来越多,在现实中一个用户的住址、联系方式、甚至外表都可能在较短的时间之内发生较大的改变,这使得在某些需要找出刻意隐藏身份的人员的场景下,如识别藏匿的罪犯,身份识别的难度加大。这说明了在当今各种信息冗杂、真假难辨的现实情况下,传统的以固定id作为识别用户身份的方法在很多场景下会失去作用,因此需要有一种手段从另外的角度来识别特定的人。无论一个人的外在属性发生多大的改变,他/她的行为模式是不会在短时间内发生巨大变化的,用户爱好习惯的这种相对稳定倾向,在iptv和网络电视领域中体现在对频道的观看喜好也会保持相对的稳定,即用户对于各个频道的观看频率将保持稳定。
在用户身份识别领域中,存在着基于web用户行为模式的身份识别技术以及根据位置、网页等多种信息对用户身份进行识别的技术,但这些现有技术与本发明提出的方法和涉及的应用场景有较大的差别。在用户身份识别领域中尚未出现成熟的基于iptv和网络电视用户频道观看频率进行用户身份识别的技术。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于直播频道用户观看行为相似性的用户身份识别方法。
本发明的目的能够通过以下技术方案实现:
一种基于直播频道用户观看行为相似性的用户身份识别方法,包括步骤:
获取原始数据,并将数据划分为训练数据集和测试数据集;
根据用户观看频率对数据集进行处理,生成频率特征向量;
对训练数据集和测试数据集的频率特征向量进行相似性测度;
根据相似性测试的结果得到用户身份识别结果。
具体地,获取原始数据并将数据划分为训练数据集和测试数据集有两种方式,分别为离线方式和在线方式。
更进一步地,所述离线方式针对已有的数据集,设置固定的学习窗口天数window_train和固定的测试窗口天数window_test,根据window_train和window_test的大小来划分训练数据集和测试数据集。得到的测试数据集和训练数据集均包括数据结构<用户编号,观看频道>。
更进一步地,所述在线方式采用滑动窗口的形式,从iptv和网络电视等的数据中心获取实时数据,设置训练滑动窗口δτ1,测试滑动窗口δτ2,采集[t-δτ2,t]时间内的数据作为测试数据集,其中t表示训练数据的结束日期,时间t小于用户当前观看的日期。采集[t-δτ1-δτ2,t-δτ2]作为训练数据集。测试数据集和训练数据集均包含数据结构<用户编号,观看频道>。
具体地,所述根据用户观看频率对数据集进行处理,生成频率特征向量的步骤中,包括:
获取的训练数据集中包括用户编号userid1和观看频道chid,对训练数据集进行预处理,对每一位用户统计其对各个频道的观看频率;
在训练数据集中的每一位用户,生成一个对各个频道观看频率统计的频率特征向量ai=[ai1,ai2,…,ain],每个频率特征向量作为一组训练输入数据;其中,ain表示第i个用户对第n个频道的观看频率。
获取的测试数据集中包括用户编号userid2和观看频道chid,对测试数据集进行预处理,对每一位用户统计其对各个频道的观看频率;
在测试数据集中的每一位用户,生成一个对各个频道观看频率统计的频率特征向量bj=[bj1,bj2,…,bjn],每个频率特征向量作为一组测试输入数据。其中,bjn表示第j个用户对第n个频道的观看频率。
具体地,所述对训练数据集和测试数据集的频率特征向量进行相似性测度的步骤中,将测试输入数据中的每一组向量bj=[bj1,bj2,…,bjn]与训练输入数据中的每一组向量ai=[ai1,ai2,…,ain]进行相似性测度。
更进一步地,所述相似性测试方法包括但不限于欧式距离相似性测度法和余弦相似性测度法。
具体地,所述欧式距离相似性测度法的计算公式为:
将测得的距离作为频率特征向量bj和ai的相似度。
具体地,所述余弦相似性测度法的计算公式为:
将测得的余弦相似度作为频率特征向量bj和ai的相似度。
具体地,所述根据相似性测试的结果得到用户身份识别结果的步骤中,包括:
将相似性测度结果输入,针对测试数据集中的每一位用户,找到训练数据集中与之相似性最大的用户,即useri=argmax{similarityij};
每一组测试输入数据bj匹配到与之相似度最大的一组训练输入数据ai,判断该组训练输入数据ai=[ai1,ai2,…,ain]对应的userid1与该测试输入数据bj=[bj1,bj2,…,bjn]对应的userid2是同样的用户。
本发明相较于现有技术,具有以下的有益效果:
本发明所提出的用户识别方法仅需要获取用户的频道观看记录,不需要其他视频数据和描述就能够根据行为相似性进行用户匹配,成本较低且具有实际意义。
附图说明
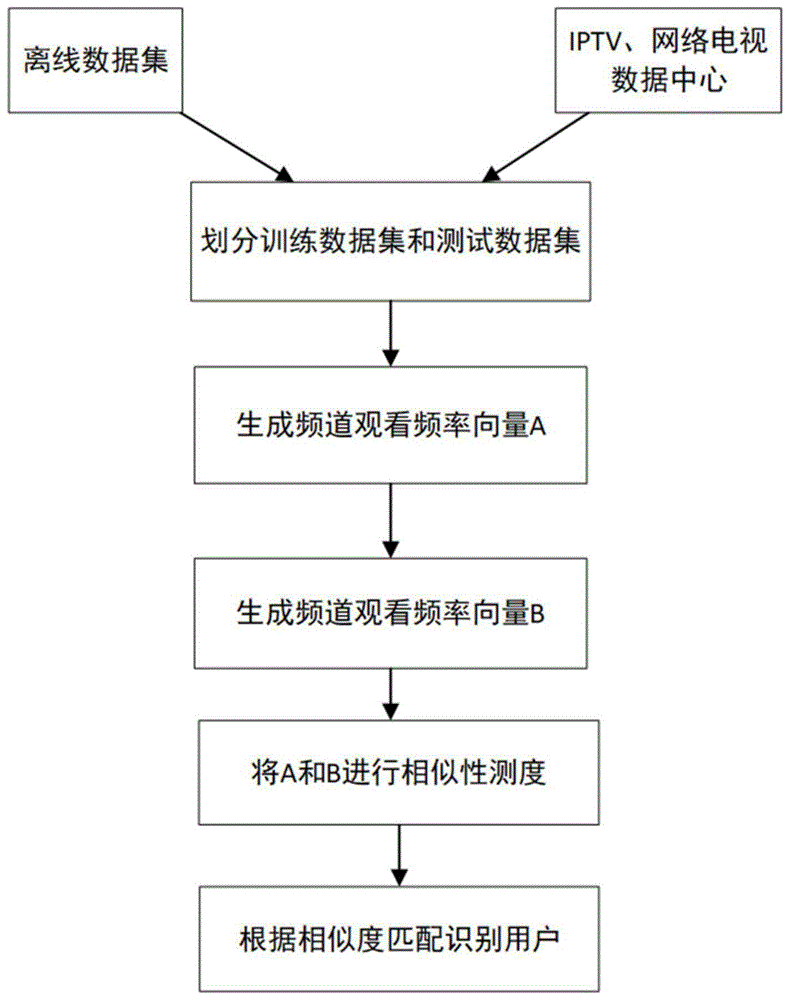
图1是一种基于直播频道用户观看行为相似性的用户身份识别方法的流程图。
图2是本发明实施例1中在离线方式下采用欧式距离相似性测度法进行iptv用户观看行为相似性的用户身份识别的流程图。
图3是本发明实施例2中在在线方式下采用余弦相似性测度法进行iptv用户观看行为相似性的用户身份识别的流程图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
如图1所示为一种基于直播频道用户观看行为相似性的用户身份识别方法的流程图,包括步骤:
获取原始数据,并将数据划分为训练数据集和测试数据集;
根据用户观看频率对数据集进行处理,生成频率特征向量;
对训练数据集和测试数据集的频率特征向量进行相似性测度;
根据相似性测试的结果得到用户身份识别结果。
实施例1
在本实施例中采用离线方式获取原始数据,采用欧氏距离相似性测度法进行相似性测度。
如图2所示为一种在离线方式下利用欧氏距离进行iptv用户观看行为相似性的用户识别方法的流程图,包括步骤:
s1、获取原始数据,并将数据划分为训练数据集和测试数据集;
从iptv数据中心获取数据集,用户数量为300,即用户编号userid范围为[1,300];频道数量为155,即频道编号chid范围为[1,155];总天数为31天。令固定的学习窗口天数window_train=20,固定的测试窗口天数window_test=11,即将前20天划分为训练数据集a,后11天划分为测试数据集b。令整个数据集的用户编号为userid1,即用户的真实身份编号。
s2、根据用户观看频率对数据集进行处理,生成频率特征向量;
在训练数据集a中的每一位用户,生成一个对各个频道观看频率统计的向量,每个频率特征向量ai=[ai1,ai2,…,ain]作为一组训练输入数据。
在测试数据集b中,重构数据集,随机将用户真实编号userid1替换成用户虚拟编号userid2,即userid1与userid2具有映射关系,供检验该方法正确率使用。然后依据userid2,对每一位用户,生成一个对各个频道观看频率统计的向量bj=[bj1,bj2,…,bjn],作为一组测试输入数据。
s3、对训练数据集和测试数据集的频率特征向量进行相似性测度;
对于测试数据集b中的每一位用户对应的频道观看频率向量bj=[bj1,bj2,…,bjn],与a中每一位用户对应的频道观看频率向量ai=[ai1,ai2,…,ain]计算欧式距离:
s4、根据相似性测试的结果得到用户身份识别结果。
针对测试数据集中的每一位用户,找到在训练数据集中与之相似性最大的用户,即useri=argmax{similarityij}。每一组测试输入数据匹配到与之相似度最大的一组训练输入数据,则判断该组训练输入数据ai=[ai1,ai2,…,ain]对应的userid1与该测试输入数据bj=[bj1,bj2,…,bjn]对应的userid2是同样的用户。
根据测试数据集b中user1和user2的映射关系,对比测试集用户真实的身份和通过该方法识别的用户身份,计算该方法的识别用户身份的正确率:
实施例2
在本实施例中采用在线方式获取原始数据,采用余弦相似性测度法进行相似性测度。
如图3所示为一种在在线方式下利用余弦相似性进行iptv用户观看行为相似性的用户识别方法的流程图,包括步骤:
s1、获取原始数据,并将数据划分为训练数据集和测试数据集;
在iptv的数据中心中,通过日志采集系统,获取用户观看频道行为的生成时序,实时获取用户观看频道数据集。设置训练滑动窗口δt1,测试滑动窗口δt2,采集[t-δt2,t]时间内的数据作为原始测试数据b,其中t表示训练数据的结束日期,时间t不得大于等于用户当前观看的日期;采集[t-δt1-δt2,t-δt2]作业训练原始数据a,测试原始数据和训练原始数据均包含以下数据结构<用户编号,观看频道>。令整个数据集的用户编号为userid1,即用户的真实身份编号。
s2、根据用户观看频率对数据集进行处理,生成频率特征向量;
在训练数据集a中的每一位用户,生成一个对各个频道观看频率统计的向量,每个频率特征向量ai=[ai1,ai2,…,ain]作为一组训练输入数据。
在测试数据集b中,重构数据集,随机将用户真实编号userid1替换成用户虚拟编号userid2,即userid1与userid2具有映射关系,供检验该方法正确率使用。然后依据userid2,对每一位用户,生成一个对各个频道观看频率统计的向量bj=[bj1,bj2,…,bjn],作为一组测试输入数据。
s3、对训练数据集和测试数据集的频率特征向量进行相似性测度;
对于测试数据集b中的每一位用户对应的频道观看频率向量bj=[bj1,bj2,…,bjn],与a中每一位用户对应的频道观看频率向量ai=[ai1,ai2,…,ain]计算余弦相似性:
s4、根据相似性测试的结果得到用户身份识别结果。
针对测试数据集中的每一位用户,找到在训练数据集中与之相似性最大的用户,即useri=argmax{similarityij}。每一组测试输入数据匹配到与之相似度最大的一组训练输入数据,则判断该组训练输入数据ai=[ai1,ai2,…,ain]对应的userid1与该测试输入数据bj=[bj1,bj2,…,bjn]对应的userid2是同样的用户,即完成了用户识别任务。
根据测试数据集b中user1和user2的映射关系,对比测试集用户真实的身份和通过该方法识别的用户身份,计算该方法的识别用户身份的正确率:
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!