一种北斗短报文的压缩传输方法与流程
本发明属于数字通信中压缩编码
技术领域:
,尤其涉及一种北斗短报文的压缩传输方法。
背景技术:
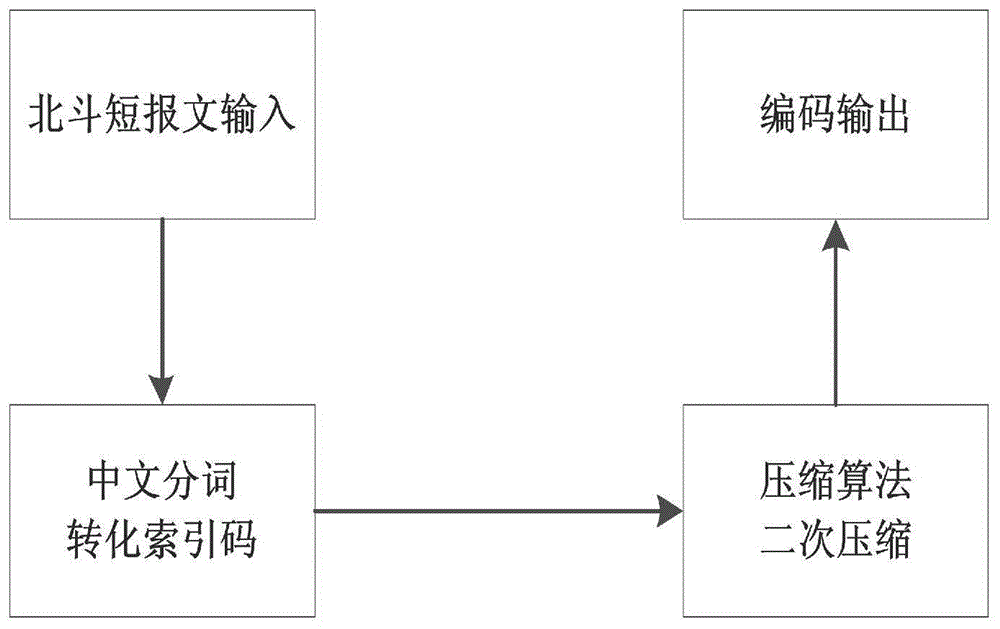
:中国北斗卫星导航系统是中国自行研制的全球卫星导航系统。是继美国全球定位系统(gps)、俄罗斯格洛纳斯卫星导航系统(glonass)之后第三个成熟的卫星导航系统。系统可在全球范围内全天候、全天时为各类用户提供高精度、高可靠定位、导航、授时服务,并具有短报文通信能力。北斗短报文通信是北斗系统的特色功能,可为用户机与用户机,用户机与地面中心站之间每次最多提供120个汉字的通信服务。但作为实际应用,容量的限制不足以满足现实的需求。因此,需要结合北斗系统的实际情况,设计一种数据压缩方式,即在有限的报文长度范围内,尽可能的将报警信息进行压缩,用相同的字符数量传达更多的信息,并且重构信息与原来信息完全相同,即无损的数据压缩。中文分词是对北斗短报文压缩处理的第一步,传统的压缩算法对以中文为主的北斗短报文压缩效果不明显,因此我们首先利用中文分词将北斗短报文转化为数字索引码,然后再进行压缩处理。目前,常用的中文分词方法包括:基于词典的分词方法、基于理解的分词方法和基于统计的分词方法。基于词典的分词方法是应用最广泛的中文分词方法,它又分为:正向最大匹配法、逆向最大匹配法和双向匹配法。正向最大匹配算法是指从左到右将待分词文本中的几个连续字符与词典匹配,如果匹配上,则切分出一个词。逆向最大匹配算法是正向最大匹配的逆向思维,首先将整个待切分的字符串去进行匹配,如果匹配不成功,则将匹配字段的最前一个字掉,一直循环至整个句子切分完毕。双向匹配算法是二者的结合,将二者的切分结果进行比较,从而选出最优解。据sunm.s.和benjamink.t.(1995)的研究表明,90.0%左右的句子,两种匹配法完全重合且正确,只有大概9.0%的句子两种切分方法得到的结果不一样,但其中必有一个是正确的。由此可见,双向匹配算法对中文的切分正确率较高。因此,计算复杂度低、算法正确率高、应用范围广的中文切分方法具有重要的研究意义和应用价值。lzw算法又叫“串表压缩算法”就是通过动态的建立一个字符串表,用较短的代码来表示较长的字符串来实现压缩,lzw算法是一种无损压缩算法。lzw算法能有效利用字符出现频率冗余度进行压缩,且字典是自适应生成的,它具有以下的几个特点:lzw压缩技术对于可预测性不大的数据具有良好的处理效果,常用与tjf格式的图像压缩;对于数据流中连续重复出现的字节和字串有很高的压缩比;lzw压缩技术还被用于文本程序等数据压缩领域;常见的arc、rkarc、pkzip高效压缩程序都是lzw压缩技术的变体;对于任意宽度和像素位长度的图像,都具有稳定的压缩过程;对机器硬件要求不高,在intel80386的机器上即可进行压缩和解压缩。技术实现要素:本发明的目的是为了克服北斗短报文在通信过程中存在长度受限的问题,提出一种北斗短报文的压缩传输方法。本发明采用的技术方案为:一种北斗短报文的压缩传输方法,包括如下步骤:步骤1,统计相关专用词汇,编写北斗常用词词典,并为每个词汇赋予索引码;步骤2,以编写好的北斗常用词词典为参考,利用中文分词算法将北斗短报文切分成k个词组;k≤m,m为北斗短报文的字符数;步骤3,将切分好的词组按照北斗常用词词典转化为各自的数字索引码;步骤4,利用lzw算法,将步骤3中得到的数字索引码组进行二次压缩,得到压缩短报文;完成对北斗短报文的压缩处理。其中,步骤2中的所述的中文分词算法具体为:采用双向匹配算法,将正向最大匹配算法与逆向最大匹配算法结果进行比较,得到最优解。其中,步骤4中lzw算法实时建立的词典中的词汇具有前缀性,相同前缀的词组被组合分配新的编号。本发明与现有技术相比所取得的有益效果为:本发明提出的一种北斗短报文的压缩传输方法,该方法计算复杂度低,对以中文为主的北斗短报文有着良好的压缩性能。并且根据lzw压缩算法的特性,该方法具有重复词汇越多,压缩效果越明显的特点。附图说明图1为本发明一种北斗短报文的压缩传输流程图;图2为本发明中基于词典的中文分词算法的词典模型图;图3为本发明具体实施方式中lzw压缩算法工作流程图。具体实施方式为了更好的说明本发明的目的和优点,下面结合附图1-3和实施例对本发明的技术方案作进一步说明。在本具体实施方式中,将使用如下短报文信息作为实例描述:shortmessage[]={s1s2s3s4s5s6s7s4s5s6s7}北斗短报文在通信过程中,一次最多只能传输120个字符,为了清楚的描述算法工作原理,选取11个字符作为压缩目标。并根据压缩算法特性,待压缩目标中存在重复字符s4s5s6s7。为了描述算法的需要,进一步缩小问题的规模,假设正向最大匹配算法与逆向最大匹配算法结果相同,并以正向最大匹配算法作为实例进行算法描述,问题规模缩小的并不影响本实例的示范过程,北斗短报文压缩传输流程如图1所示。一种北斗短报文的压缩传输方法,所述的待压缩的北斗短报文为:shortmessage[]={s1s2s3s4s5s6s7s4s5s6s7},包括如下步骤:步骤1,统计相关专用词汇,编写北斗常用词词典,并为每个词汇赋予索引码;步骤2,按照图1的流程顺序,首先将待压缩短报文进行中文分词处理,假设分词所参照的词典为:dic[]={“s1s2”“s1s2s3”“s4s5”“s6s7”}以正向最大匹配算法为例,从左至右对待切分短报文进行扫描,扫描至s1s2发现是词典中的词,但不能确定是否为最大词汇,继续扫描,发现s1s2s3是词典中的词,仍不能确定是否为最大词汇,直至扫描到最后,确定切分出第一个词s1s2s3。继续扫描,直至整个短报文被切分为如下词组:word[]={s1s2s3s4s5s6s7s4s5s6s7}步骤3,将切分好的词组转换为各自的索引码;将已经切分好的词组,按照如图2所示的转换规则,转换为各自的数字索引码形式,词组将被转换为如下形式(in为该词汇在词典中的索引码):word[]={iciaibiaib}步骤4,利用lzw算法对索引码组进行二次压缩;将步骤3生成的索引码组按照如图3所示的进行二次压缩处理,lzw算法对待压缩词组进行扫描,动态的建立词组表,扫描过程中,将前缀(iaib)录入词典,待扫描至下一个(iaib)发现该前缀已经存在于词典中,采用新的编号(n+1)(n为词典中词的个数)代替,直至压缩完毕,索引码组被压缩至如下形式:code[]={iciaib(n+1)}至此,对北斗短报文压缩编码的过程结束。lzw算法将动态的建立词典,词典中的词汇具有如下的性质:(ω表示中词典已存在的前缀)经lzw算法二次压缩,得到如下的压缩短报文:msg(a)=a1/a2/.../an,(n≤k)为具体分析所述压缩方法对北斗短报文的压缩效果,选取不同长度的报警短信,并分为:10字组、20字组、50字组、100字组、120字组、150字组和200字组。每组选取5个报警片段,进行编码压缩,求每组压缩后的平均字数及压缩比(压缩前报文字数/压缩后短报文平均字数),并记录数据。结果如表1所示,可以看出新方法对北斗短报文有着良好的压缩效果。实验所用计算机配置为:intelcore3.30ghz处理器,8gb内存,matlabr2016a软件平台。表1北斗短报文压缩传输实验结果压缩前短报文字数压缩后短报文平均字数压缩比10字组9.41.06420字组18.61.07550字组46.41.078100字组92.41.082120字组110.81.083150字组138.21.085虽然结合附图描述了本发明的实施方式,但是对于本领域技术人员来说,在不脱离本发明原理的前提下,还可以做出若干变形和改进,这些也应视为属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1