一种优化无线前传时延的边缘缓存机制的制作方法
本发明涉及一种优化无线前传时延的边缘缓存机制,属于通信网络领域。
背景技术:
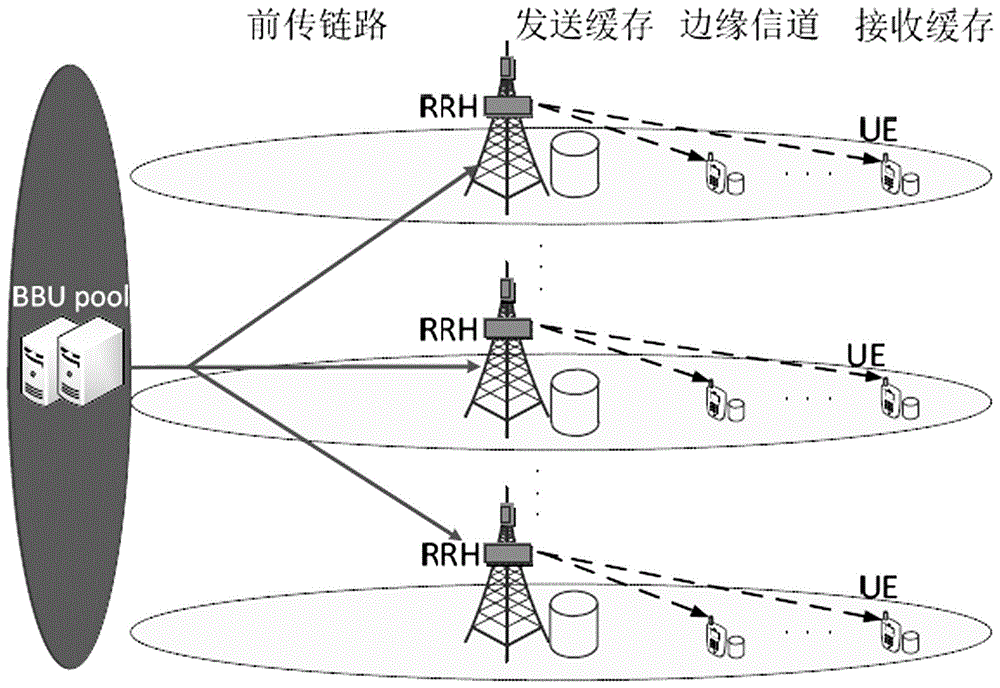
随着未来无线接入网中用户流量需求的迅猛增长,云无线接入网(c-rans)架构成为跨越4g网络后的关键推动因素,可以极大地降低成本,提供高级协同、协作处理能力及复用增益,是未来5g架构中最有前景的技术之一,移动前传链路是c-rans架构中的重要组成部分,需要具备高容量、低延时的要求,如图1所示,通过在上层(如bbu池)集中基带处理功能并通过更低一层的网络边缘基带功能层(如rrh)来发射,以实现更具成本优势的网络设计。
尽管云无线接入网(c-rans)架构具备巨大的应用潜力,crans如何在用户对流量需求的迅猛增长背景下提供更高的网络吞吐率来满足用户需求是亟待解决的障碍之一,根据目前的流量统计数据,因特网下行链路一半以上贡献于视频流业务,如youtube和netflix等,部分流媒体文件被大量的用户下载,组播的应用可以分发相同的内容到同一小区的多个用户或者通过协作多点(comp)分发相同的内容到不同小区的众多用户,从而有效提高频谱效率和整体网络吞吐率,多媒体广播/组播业务(embms)已经被纳入lte-advanced中,5g网络取得高数据速率的另一项技术是毫米波通信,可以为移动用户提供更高的数据传输速率,满足日益增长的高数据率需求,然而,相比于传统的低于6ghz频段,毫米波频段的通信其传输丢包率高得多,此外,毫米波链路对各种材料的阻挡敏感,比如砖和砂石,甚至人体,这些问题对链路容量有很大影响,从而影响到整体端到端用户的体验质量(qoe),比如,对于视距(los)和非视距(nlos)范围接收到的信干噪比(sinr)存在30db的差异,从而导致了在物理层提供的数据率和丢包率的差别,为了提供高质量的视频流,除了毫米波提供高数据率外,需要确保可靠、低丢包率和稳定的数据率。
采用云无线接入网(c-rans)架构的另一个关键障碍在于对无线前传链路延时的超高要求,以满足5g网络中未来延迟敏感应用的需要,对于在物理层带分裂的前传传输,混合自动重传请求(harq)协议设置了基带单元(bbu)与远程无线头(rrh)之间严格的最大延时限制,在lte中,不论在上行还是下行方向上,如果1帧持续1ms,发送的第n帧需要在第n+4帧时被确认(ack或者nack),所以,总的接收过程必须在3ms内完成,以遵守3gpplteharq时间要求,这个时间要求包括在无线接入点(raps)处物理资源块本地处理时间、数据中心的集中处理时间和后传往返时间,研究表明,bbu的处理时间是2754μs,只剩下最多246μs给前传rtt、单程即123μs,部分应用甚至要求单程100μs的延时限制,ieee802.1cm中建议的前传单程延时开销是100μs,也是基站(bs)与用户设备(ue)之间全部延时开销的一部分,100μs包含harq处理的进一步细分时间(比如基带处理,关于harq重传所需的调度时间等),这100μs前传延时确保5g延时敏感应用取得最佳性能,如果延时超过100μs,将会降低无线网络性能和用户体验,对于多媒体组播分发下行传输同样如此,通过边缘缓存的方法将下行链路harq与fec解耦合,可以在保持harq的往返时间严格有界的同时,放松对传输网络的要求,当增强型rrh收到用户的nack后,下行链路harq重传最终被接近ue的增强型rrh触发,通过这种方法,下行链路harq的rtt可以被极大降低,或者对于一个给定的harqrtt,留给传输网络延时的预算增加了。
此外,尽管目前移动前传协议有cpri、obsai和ori,但以太网已广泛应用于云、数据中心和核心网等,无线以太网传输(roe)将会成为无线前传通用的、具有成本效益的、现成的可替代方案,目前一些标准化活动正在重新定义基于分组架构的前传网络,旨在设计一个可变速率、多点到多点、基于分组的前传接口,比如下一代前传接口(ngfi),此外,ieee1904.3也指明了无线以太网传输(roe)的封装和映射,未来的无线前传网络将不断向更加复杂的、具备交换和聚合功能的多跳mesh网络演进,可以通过应用标准的以太网方法和基于sdn的交换能力来实现。
大多数之前的无线前传时延优化研究主要考虑上行链路harq优化机制与算法设计,对下行链路harq的时延优化机制鲜有研究,随着流媒体需求的迅猛增长,内容分发占据了移动流量中的很大比例,通过在网络边缘缓存热点请求内容以及组播结合网络编码技术的应用,可以取得更高的网络吞吐率、可靠性和更低的系统投递延时,因此,研究一种基于边缘缓存的无线前传时延优化方法显得尤为重要。
技术实现要素:
为了克服现有技术的不足,本发明提供一种优化无线前传时延的边缘缓存机制。
本发明解决其技术问题所采用的技术方案是:
一种优化无线前传时延的边缘缓存机制,包括以下步骤:
步骤1:根据内容分发组播应用中无线前传下行链路的具体特点,构建边缘缓存模型,提出基于分组最优缓存时间的分布式边缘缓存机制的具体实现方法;
步骤2:基于延迟受限条件下分组编码与调度模型,提出了基于组的调度策略实现方法。
所述步骤1包括:首先,均匀地设定nack到达延迟的分布函数f(t)的系列目标值fi∈[0,1],并找到满足f(ti)=fi的时间ti,在算法中,为k个目标值中的每个fi∈[0,1],1≤i≤k设置2个变量,分别是ti和hi,hi来保存搜索ti时f(tx)的值,其中,每一个目标值fi∈[0,1]被设置为i/k,首先,设置hi=0.5,ti为第一个nack到达延迟,每得到一个新的nack到达延迟lnack,将lnack与ti相比较,依照下式来更新hi的值:
如果更新得到的hi值比设定的目标值小且ti小于新得到的nack到达延迟,则将ti的值增加α×(lnack-ti),但依据分布函数的性质,需保证新得到的ti应该小于等于ti+1的值,同样,对于可能出现的另一种情况:如果hi值比设定的目标值大且ti大于新得到的编码包到达延迟,则将ti的值减少α×(ti-lcoded),同理,新得到的ti应该大于或等于ti-1。
所述步骤2包括:其特征在于步骤2包括:基于组的调度结构主要包括:给定组播组内基于下一跳节点的虚队列结构,基于组的令牌队列和调度器,qij表示组gj中的第ith个虚队列,1≤i≤|gj|,1≤j≤m,对于一个含有m个组的编码结构,组gi对应着令牌队列gi(1≤i≤m),当组gi的最大残余时间紧迫性大于给定门限(这里设置为10)时,将向令牌队列gi插入相应令牌,当需要调度分组重传时,基于组的调度策略将检查每一个非空令牌队列gi(1≤i≤m)的队首,并从中选择具有最大权重(最大残余时间紧迫性)的一个,然后,该选中的令牌出队列,针对虚队列中对应的分组集合执行相应的编码操作、并将编码分组予以调度发送。
本发明的有益效果是:
1.根据无线前传下行链路组播内容分发的具体特点,提出分布式的边缘缓存机制的具体实现方法,弥补了无线前传已有研究中对下行链路harq的时延优化机制研究的不足。
2.基于分组最优缓存时间与延迟受限条件下分组编码与调度模型,可以充分利用边缘缓存资源来显著提高无线边缘信道丢包恢复效率,进而提高无线前传网络吞吐率和整体延时性能。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1是基于边缘缓存的无限前传的基本应用场景示意图;
图2是基于组的调度策略的流程示意图;
图3是典型的边缘缓存网络编码重传场景示意图。
具体实施方式
本发明要解决的技术问题是,针对无线前传的下行链路,提供一种基于分组的分布式边缘缓存机制,同时对热点请求内容的组播结合网络编码技术的应用,可以显著提高无线边缘信道分组投递可靠性,进而提高无线前传网络吞吐率和整体延时性能。
参照图3,所例示的是典型的边缘缓存网络编码重传场景,ue1(已收到分组p2,p3)请求分组p1;ue2(已收到分组p1,p3)请求分组p2;ue3(已收到分组p1,p2)请求分组p3。
为了解决上述问题,本发明所采用的技术方案联合考虑了发送方rrh:(1)分组最优缓存时间;(2)延迟受限条件下分组编码与调度算法,该方案包括:
对于发送方rrh分组最优缓存时间:
1)参照图1,一个rrh可以同时向多个用户设备ue进行组播,多个rrh也可以通过协作多点(comp)分发相同的内容到不同小区的众多用户,以实现延时敏感应用的内容分发;
2)各个rrh处的缓存管理目标是最大缓存系统总的组播恢复效用db:
其中s,b,t,ti,di(ti)分别是分组的大小,以分组为单位的缓存大小,缓存系统工作时间,分组i的缓存时间,分组i缓存ti时间的组播恢复效用;
3)将rrh分组缓存池中缓存相同时间的分组归为一类,并用nk表示第k类分组中分组个数,从而将最大缓存系统总的组播恢复效用目标转换成最大缓存系统缓存效率yb:
其中,ak,yk(tk)分别为rrh分组缓存池中第k类分组占缓存系统整体缓存效率的比例,分组缓存时间tk的缓存效率;
4)我们定义nack到达延迟的分布函数f(t)为nack到达延迟小于或者等于t秒的概率;该分布函数对应的概率密度函数为f(t),依据我们前面的定义,对于rrh分组缓存池中的一个分组,从该分组进入缓存池开始,如果其在t秒内被用于丢失恢复,则分组缓存池中缓存该分组的价值可以表示为:
d(t)=s·f(t)
对应的缓存效率我们可以表示为:
因此,可以认为,当分组缓存池中的每个分组缓存一个最优缓存时间to并取得最大缓存效率时,分组缓存池的系统缓存效率也就可以取得最大,以下给出了分组缓存池中分组最优缓存时间算法opt算法,在该算法中需要保证每组分组都至少缓存一个时间单位δ;
在opt算法中,迭代计算结束后根据对to与δ的比较,获得最优的分组缓存时间,当to与δ相等时,分组的缓存时间和缓存效率分别为t0和y(t0);当to与δ不相等时,分组的缓存时间则以概率α0设为t0、以概率α1设为t1,系统缓存效率则为两种概率情况下的加权结果,即式所示:
yb=α0(λt0/b)y(t0)+α1(λt1/b)y(t1)
对于延迟受限条件下分组编码与调度:
1)对延迟受限条件下可靠组播中有编码意识的重传机制主要由两部分组成:首先,rrh在组播发送了n个分组并缓存后,由用户设备ue通过nack向发送方反馈接收状态;然后,rrh根据收到的nack请求更新各组播接收方的接收状态,同时根据已缓存分组信息开始重传,当存在编码机会时,由rrh组播编码融合后的分组;否则,若存在于rrh缓存中,则直接组播重传该分组;若被请求分组不存在于缓存中,则直接向bbu池请求重传丢失的分组,此外,通过在延迟受限条件下调度技术的应用,可以有效降低网络开销和前传时延,提高用户体验(qoe);
2)发送方rrh已发送的组播原始分组表示为p={p1,p2,l,pj,l,pm},1≤j≤m,其n个接收者集合表示为r={r1,r2,l,ri,l,rn},1≤i≤n,给定组播各分组长度为s(bits),从发送方rrh至各组播接收者r={r1,r2,l,ri,l,rn},1≤i≤n的分组投递率表示为k={k1,k2,l,ki,l,kn},1≤i≤n,时间按照时隙划分,并且每个分组的发送需要一个时隙,时隙t将占用时间间隔[t,t+1),t(p)表示分组p的延迟限制;rc(p)表示分组p当前在其延迟时间限制前还剩下的时隙数,h(ri)表示接收者ri已经成功收到的分组集合;w(ri)=p-h(ri)表示接收者ri需要恢复的分组集合,为了降低编解码计算复杂度,采用异或编、解码操作,编码在一起的分组的数量称为该分组的编码度,一个编码度为n的编码分组可以表示为
3)为求解最优编码组合问题,构造对应该问题的加权图g(v,e,ω),从而将搜索一个好的分组组合问题转化为搜索该图中的最大加权团,通过将图中的顶点逐个分离,将最终找到一个合适的编码解,搜索最优编码解的详细过程如下:
a)构造加权图模型
对节点ri请求集合w(ri)中的任意分组pj,都对应图g(v,e,ω)中一个顶点vij∈v(g),图g中的边集合e中的一条边可以定义为:对于组播组中任意接收节点,节点
b)基于权重的码选择算法
基于权重的码选择算法可以分为2个阶段:procedure①和procedure②,在procedure①,将从图g(v,e,ω)中搜索最大团,即含有最多顶点数的团,根据团的定义,如果最优编码解对应为图g(v,e,ω)中团c且团c包含顶点v,则集合c-v中的每一个顶点是顶点v的邻接顶点,在每一次,如果存在一个顶点v,该顶点的度d(v)小于图g(v,e,ω)中顶点的最大度,我们将从图g(v,e,ω)中导出一个子图gv,该子图gv由顶点v和他的邻接顶点组成,并将顶点v从图g(v,e,ω)中去除,集合c用于保存搜索到的最大团结果,如果子图gv的顶点数大于集合c中的顶点数,我们就搜索子图gv中的最大团,并将搜索到的结果保存在集合cv中,如果集合cv中的顶点数大于集合c中的顶点数,就用cv中的搜索结果替换c中保存的最大团结果,否则的话,保持集合c不变并将继续搜索,直到顶点集合v(g)为空为止,若我们无法找到一个顶点v,使得他的度小于图g(v,e,ω)中顶点的最大度,我们就直接搜索图g(v,e,ω)中顶点的最大度,且由于有限的顶点数目,该搜索过程可以在有限步内完成,当得到procedure①中的最大团c后,在procedure②,将搜索在集合c中能取得最大权重的顶点子集,该算法如下所示:
4)基于组的调度机制,边缘缓存可以服务于多个组播和非组播内容分发时的丢包重传,为了最大化编码机会的同时又满足不同实时应用的延迟限制要求,依据不同组播组来划分“组”(组的大小为1时即视为单播),重传调度时采用基于组的调度策略来选择编码分组或非编码分组发送,依据给定分组不同的下一跳构建虚队列,|gj|表示组|gj|中含有的虚队列数目,当存在m个组时,总共有|g1|+|g2|+k+|gm|个虚队列,
首先,定义属于组gi的编码解ci的剩余时间紧迫性d(i)为:
在上式中,t(p)表示分组p的延迟限制;rc(p)表示分组p在延迟受限条件下的剩余时间,显然,剩余时间越少,调度其发送也就越紧迫,具有最大残余时间紧迫性的组将被选中,从而该组对应的可编码分组集合将被优先调度发送,调度策略可归结为如下表达式:
i=argmax1≤i≤md(i),
在上式中,i表示可编码分组集合ci被选中并且其相应的编码分组被调度发送。此外,当一个组播组为非实时数据流时,其剩余时间紧迫性可以被定义为1,从而这样的归结方式仍然是适用的。
下面具体解释一下如何实现边缘缓存中基于分组的最优缓存时间与延迟受限条件下分组编码与调度的实现。
1、nack到达延迟分布函数f(t)的测定
首先,均匀地设定nack到达延迟的分布函数f(t)的系列目标值fi∈[0,1],并找到满足f(ti)=fi的时间ti。在算法中,为k个目标值中的每个fi∈[0,1],1≤i≤k设置2个变量,分别是ti和hi。hi来保存搜索ti时f(tx)的值。其中,每一个目标值fi∈[0,1]被设置为i/k。首先,设置hi=0.5,ti为第一个nack到达延迟。每得到一个新的nack到达延迟lnack,将lnack与ti相比较,依照下式来更新hi的值:
如果更新得到的hi值比设定的目标值小且ti小于新得到的nack到达延迟,则将ti的值增加α×(lnack-ti)。但依据分布函数的性质,需保证新得到的ti应该小于等于ti+1的值。同样,对于可能出现的另一种情况:如果hi值比设定的目标值大且ti大于新得到的编码包到达延迟,则将ti的值减少α×(ti-lcoded)。同理,新得到的ti应该大于或等于ti-1,如下算法所示,在这里,设定k=50,α=0.01可以较好地逼近编码包到达延迟的分布函数f(t):
2、基于组的调度策略的实现方法
参照图2,基于组的调度结构主要包括:给定组播组内基于下一跳节点的虚队列结构,基于组的令牌队列和调度器。
以上的实施方式不能限定本发明创造的保护范围,专业技术领域的人员在不脱离本发明创造整体构思的情况下,所做的均等修饰与变化,均仍属于本发明创造涵盖的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!