语音抓包解析方法、系统、移动终端及存储介质与流程
本发明属于声纹识别技术领域,尤其涉及一种语音抓包解析方法、系统、移动终端及存储介质。
背景技术:
随着ai智能,声纹识别技术的不断发展,声纹越来越多的应用到各个领域,如电信,金融,保险等等人工工作人员当中,声纹识别是ai领域的一个重要发展方向。
当前人工工作人员,采用的多数是软终端电话的方式,通过部署在电脑上等设备上的软终端电话进行对客户的通话,或者接听客户的来电。
目前声纹识别采用的主要是离线识别,也即在工作人员和客户通话结束后,再把呼叫中心云端保存的离线语音文件拷贝传给声纹引擎系统。这就导致了一个不足之处,做不到在通话过程中,实时的获取语音文件并进行声纹识别。
技术实现要素:
本发明实施例要解决的技术问题是,由于采用离线识别所导致的不能实时的获取语音文件并进行声纹识别的问题。
本发明实施例是这样实现的,一种语音抓包解析方法,所述方法包括:
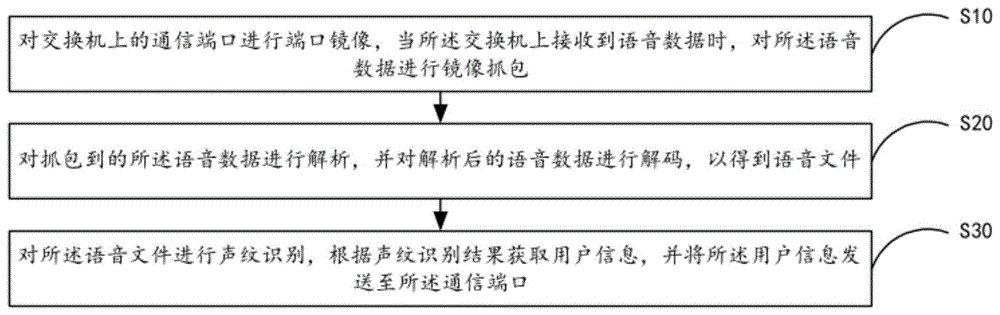
对交换机上的通信端口进行端口镜像,当所述交换机上接收到语音数据时,对所述语音数据进行镜像抓包;
对抓包到的所述语音数据进行解析,并对解析后的语音数据进行解码,以得到语音文件;
对所述语音文件进行声纹识别,根据声纹识别结果获取用户信息,并将所述用户信息发送至所述通信端口。
更进一步的,所述对解析后的语音数据进行解码的步骤包括:
获取所述语音数据的数据类型,当所述数据类型为sip类型时,获取所述语音数据中存储的任务识别码和任务字段;
根据所述任务识别码和所述任务字段进行任务注册,以得到语音任务;
对所述语音任务进行初始化,在完成初始化后开启任务,以得到pcm文件,并将所述pcm文件转换为wav文件。
更进一步的,所述获取所述语音数据的数据类型的步骤之后,所述方法还包括:
当所述数据类型为rtp类型时,获取所述语音数据中存储的所述任务识别码、编解码类型和rtp数据流;
根据所述任务识别码、所述编解码类型和所述rtp数据流进行文件编写,以得到所述pcm文件,并将所述pcm文件转换为所述wav文件。
更进一步的,所述对所述语音数据进行镜像抓包的步骤包括:
采用linux下库函数接口libpcap的方式对所述语音数据进行抓包,以获取所述语音数据。
更进一步的,所述将所述用户信息发送至所述通信端口的步骤之前,所述方法还包括:
获取所述通信端口上携带的筛选标识,并根据所述筛选标识获取筛选条件;
根据所述筛选条件对所述用户信息进行筛选,并根据筛选结果对所述用户信息进行过滤删除。
本发明实施例的另一目的在于提供一种语音抓包解析系统,所述系统包括:
数据抓包模块,用于对交换机上的通信端口进行端口镜像,当所述交换机上接收到语音数据时,对所述语音数据进行镜像抓包;
数据解码模块,用于对抓包到的所述语音数据进行解析,并对解析后的语音数据进行解码,以得到语音文件;
声纹识别模块,用于对所述语音文件进行声纹识别,根据声纹识别结果获取用户信息,并将所述用户信息发送至所述通信端口。
更进一步的,所述数据解码模块还用于:
获取所述语音数据的数据类型,当所述数据类型为sip类型时,获取所述语音数据中存储的任务识别码和任务字段;
根据所述任务识别码和所述任务字段进行任务注册,以得到语音任务;
对所述语音任务进行初始化,在完成初始化后开启任务,以得到pcm文件,并将所述pcm文件转换为wav文件。
更进一步的,所述数据解码模块还用于:
当所述数据类型为rtp类型时,获取所述语音数据中存储的所述任务识别码、编解码类型和rtp数据流;
根据所述任务识别码、所述编解码类型和所述rtp数据流进行文件编写,以得到所述pcm文件,并将所述pcm文件转换为所述wav文件。
本发明实施例的另一目的在于提供一种移动终端,包括存储设备以及处理器,所述存储设备用于存储计算机程序,所述处理器运行所述计算机程序以使所述移动终端执行上述的语音抓包解析方法。
本发明实施例的另一目的在于提供一种存储介质,其存储有上述的移动终端中所使用的计算机程序,该计算机程序被处理器执行时实现上述的语音抓包解析方法的步骤。
本发明实施例,通过对通信端口进行端口镜像的设计,使得该通信端口在进行通话过程中,能实时的抓取到通话语音,并通过对该通话语音进行解析、解码和声纹识别的设计,以使能及时获取到该通话语音中用户的信息,方便了工作人员进行对后续对话的选择性。
附图说明
图1是本发明第一实施例提供的语音抓包解析方法的流程图;
图2是本发明第二实施例提供的语音抓包解析方法的流程图;
图3是本发明第三实施例提供的语音抓包解析系统的结构示意图;
图4是本发明第四实施例提供的移动终端的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
为了说明本发明所述的技术方案,下面通过具体实施例来进行说明。
实施例一
请参阅图1,是本发明第一实施例提供的语音抓包解析方法的流程图,包括步骤:
步骤s10,对交换机上的通信端口进行端口镜像,当所述交换机上接收到语音数据时,对所述语音数据进行镜像抓包;
其中,该交换机上设有多个不同的通信端口,该通信端口与一终端设备电性连接,该终端设备上部署了软终端电话,该软终端电话用于当前工作人员与用户之间的通讯,且该步骤中,通过配置交换机的web界面,以达到对该通信端口进行镜像的效果;
因此,该步骤中,当交换机上的任意通信端口接收到语音数据时,均可通过镜像的方式及时抓取该语音数据;
步骤s20,对抓包到的所述语音数据进行解析,并对解析后的语音数据进行解码,以得到语音文件;
其中,该语音数据的类型包括udp、sip、sdp和rtp等,该步骤中,通过对语音数据进行解析和解码的设计,以使对该语音数据中存储的信息进行归类和格式转换,以保障后续该语音文件的传输;
步骤s30,对所述语音文件进行声纹识别,根据声纹识别结果获取用户信息,并将所述用户信息发送至所述通信端口;
其中,本地存储有用户数据库,该用户数据库中存储多个不同用户声纹与用户信息之间的对应关系,该用户信息中可以存储有用户的姓名、职业、家庭住址、健康状态、学习成绩、个人简历资料和信用信息等;
通过将该语音文件中的当前声纹与该用户数据库中的用户声纹进行匹配,以获取目标声纹和该目标声纹对应的用户信息,并将该用户信息发送至对应通信端口,以使该通信端口对应的工作人员能及时的查看到用户信息;
例如,银行工作人员对客户的贷款申请进行电话验证,在通话过程中,工作人员就可以实时的获取贷款人的信用情况,借贷情况,联系人等等,进而判断是否可以对该贷款人进行贷款,若信用很差,即可随时结束通话,若信用等信息很好,则可以进行下一步的审核,从而提高的效率和安全性;
本实施例,通过对通信端口进行端口镜像的设计,使得该通信端口在进行通话过程中,能实时的抓取到通话语音,并通过对该通话语音进行解析、解码和声纹识别的设计,以使能及时获取到该通话语音中用户的信息,方便了工作人员进行对后续对话的选择性。
实施例二
请参阅图2,是本发明第二实施例提供的语音抓包解析方法的流程图,包括步骤:
步骤s11,对交换机上的通信端口进行端口镜像,当所述交换机上接收到语音数据时,采用linux下库函数接口libpcap的方式对所述语音数据进行抓包,以获取所述语音数据;
其中,该交换机上设有多个不同的通信端口,该通信端口与一终端设备电性连接,该终端设备上部署了软终端电话,该软终端电话用于当前工作人员与用户之间的通讯,且该步骤中,通过配置交换机的web界面,以达到对该通信端口进行镜像的效果;
步骤s21,获取所述语音数据的数据类型,当所述数据类型为sip类型时,获取所述语音数据中存储的任务识别码和任务字段,并根据所述任务识别码和所述任务字段进行任务注册,以得到语音任务;
步骤s31,对所述语音任务进行初始化,在完成初始化后开启任务,以得到pcm文件,并将所述pcm文件转换为wav文件,以得到语音文件;
步骤s41,当所述数据类型为rtp类型时,获取所述语音数据中存储的所述任务识别码、编解码类型和rtp数据流;
步骤s51,根据所述任务识别码、所述编解码类型和所述rtp数据流进行文件编写,以得到所述pcm文件,并将所述pcm文件转换为所述wav文件,以得到语音文件;
步骤s61,对所述语音文件进行声纹识别,根据声纹识别结果获取用户信息,获取所述通信端口上携带的筛选标识,并根据所述筛选标识获取筛选条件;
其中,该筛选条件用于对获取到的用户信息进行筛选和过滤,该筛选条件中的参数条件可以根据需求自主进行设置,例如该参数条件可以为:“获取用户信用信息”、“剔除用户个人简历信息”、“剔除用户工作经验信息”、“获取用户教育信息”等;
具体的,该步骤中,可以将wav语音文件通过http的方式传输至预设声纹引擎进行声纹识别,以获取对应的用户信息;优选的,该步骤中,该筛选标识可以采用文字标识、数字标识或图像标识的方式进行标记,该筛选标识用于指向对应的筛选条件;
步骤s71,根据所述筛选条件对所述用户信息进行筛选,根据筛选结果对所述用户信息进行过滤删除,并将过滤后的所述用户信息发送至所述通信端口;
其中,当该用户信息发送至对应通信端口时,可以采用文字显示、音频显示或图像显示的方式在对应终端设备上进行显示,进而有效的方便了工作人员对筛选后的用户信息的查看;
本实施例,通过对通信端口进行端口镜像的设计,使得该通信端口在进行通话过程中,能实时的抓取到通话语音,并通过对该通话语音进行解析、解码和声纹识别的设计,以使能及时获取到该通话语音中用户的信息,方便了工作人员进行对后续对话的选择性。
实施例三
请参阅图3,是本发明第三实施例提供的语音抓包解析系统100的结构示意图,包括:数据抓包模块10、数据解码模块11和声纹识别模块12,其中:
数据抓包模块10,用于对交换机上的通信端口进行端口镜像,当所述交换机上接收到语音数据时,对所述语音数据进行镜像抓包。
其中,所述数据抓包模块10还用于:采用linux下库函数接口libpcap的方式对所述语音数据进行抓包,以获取所述语音数据。
数据解码模块11,用于对抓包到的所述语音数据进行解析,并对解析后的语音数据进行解码,以得到语音文件。
声纹识别模块12,用于对所述语音文件进行声纹识别,根据声纹识别结果获取用户信息,并将所述用户信息发送至所述通信端口。
本实施例中,所述数据解码模块11还用于:获取所述语音数据的数据类型,当所述数据类型为sip类型时,获取所述语音数据中存储的任务识别码和任务字段;根据所述任务识别码和所述任务字段进行任务注册,以得到语音任务;对所述语音任务进行初始化,在完成初始化后开启任务,以得到pcm文件,并将所述pcm文件转换为wav文件。
进一步的,所述数据解码模块11还用于:当所述数据类型为rtp类型时,获取所述语音数据中存储的所述任务识别码、编解码类型和rtp数据流;根据所述任务识别码、所述编解码类型和所述rtp数据流进行文件编写,以得到所述pcm文件,并将所述pcm文件转换为所述wav文件。
优选的,本实施例中,所述语音抓包解析系统100还包括:
信息筛选模块13,用于获取所述通信端口上携带的筛选标识,并根据所述筛选标识获取筛选条件;根据所述筛选条件对所述用户信息进行筛选,并根据筛选结果对所述用户信息进行过滤删除。
本实施例,通过对通信端口进行端口镜像的设计,使得该通信端口在进行通话过程中,能实时的抓取到通话语音,并通过对该通话语音进行解析、解码和声纹识别的设计,以使能及时获取到该通话语音中用户的信息,方便了工作人员进行对后续对话的选择性。
实施例四
请参阅图4,是本发明第四实施例提供的移动终端101,包括存储设备以及处理器,所述存储设备用于存储计算机程序,所述处理器运行所述计算机程序以使所述移动终端101执行上述的语音抓包解析方法。
本实施例还提供了一种存储介质,其上存储有上述移动终端101中所使用的计算机程序,该程序在执行时,包括如下步骤:
对交换机上的通信端口进行端口镜像,当所述交换机上接收到语音数据时,对所述语音数据进行镜像抓包;
对抓包到的所述语音数据进行解析,并对解析后的语音数据进行解码,以得到语音文件;
对所述语音文件进行声纹识别,根据声纹识别结果获取用户信息,并将所述用户信息发送至所述通信端口。所述的存储介质,如:rom/ram、磁碟、光盘等。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,仅以上述各功能单元、模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能单元或模块完成,即将存储装置的内部结构划分成不同的功能单元或模块,以完成以上描述的全部或者部分功能。实施方式中的各功能单元、模块可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中,上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。另外,各功能单元、模块的具体名称也只是为了便于相互区分,并不用于限制本申请的保护范围。
本领域技术人员可以理解,图3中示出的组成结构并不构成对本发明的语音抓包解析系统的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置,而图1-2中的语音抓包解析方法亦采用图3中所示的更多或更少的部件,或者组合某些部件,或者不同的部件布置来实现。本发明所称的单元、模块等是指一种能够被所述目标语音抓包解析系统中的处理器(图未示)所执行并功能够完成特定功能的一系列计算机程序,其均可存储于所述目标语音抓包解析系统的存储设备(图未示)内。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!