基于级联人工神经网络的逐子载波无线转发站分配方法与流程
本发明涉及通信网络技术,具体涉及基于级联人工神经网络的逐子载波无线转发站分配方法。
背景技术:
近年来,传统点对点通信局限于近场传输,随着通信距离的增加,无法与时俱进。现代通信要求高带宽,高数据传输速度,高可靠性。因此协作通信网络和无线转发站辅助通信技术发展迅猛,弥补长距离的信道衰弱,多载波多无线转发站协作系统在第六代(6g)网络也将发挥重要作用。
对于多载波多无线转发站协作系统,逐子载波无线转发站分配技术于2007年首次提出,是多载波无线转发站分配的两大分配标准之一(另一基本标准是多载波单无线转发站分配)。后续研究对多载波无线转发站分配进一步分析,利用放大转发协议(af)和解码转发协议(df)来进行无线转发站转发信号的操作。af有时间延迟短的优点,但信噪比相对高;df有信噪比高,误码率低的优点,但处理时间延迟较长。
由于多载波多无线转发站协作系统中,无线转发站在空间中不均匀分布,因此如何在多载波环境中分配正确合适的无线转发站成为研究热点。传统上,多载波无线转发站可以用集中式方案或分布式方案来实现:
集中式方案要求中央处理器对所有信道和无线转发站进行分析,为每个子载波分配无线转发站,缺点是中央处理器复杂度极高,计算负载巨大;
分布式方案利用多个计时器采集不同信道的信道状态信息(csi),极大减轻了中央处理器的计算负载,但引入多个计时器可能带来难以接受的处理时延,因此也未能尽善尽美。
技术实现要素:
本发明针对传统逐子载波无线转发站分配采用的暴力算法的系统复杂度过高和处理时间延迟过长的弊端,在监督型机器学习的基础上,加入并行思想,利用级联人工神经网络来替代暴力检索方法,提供了一种基于级联人工神经网络的逐子载波无线转发站分配方法,具体技术方案如下:
基于级联人工神经网络的逐子载波无线转发站分配方法,包括以下步骤:
s1:根据逐子载波无线转发站分配标准设计级联人工神经网络的结构;
s2:采用监督型机器学习的方法对人工神经网络进行训练;
s3:采用训练好的级联人工神经网络逐子载波分配最优的无线转发站。
优选地,所述逐子载波无线转发站分配标准具体为:在不受所选无线转发站数量限制的情况下,逐子载波无线转发站分配标准可以分配多个无线转发站,最多可以分配与子载波数目相同的无线转发站,让每个子载波各自都能被最优的无线转发站处理转发,如下公式(1)所示:
其中,
优选地,所述步骤s1中设计级联人工神经网络的结构的步骤如下:
s11:构造k个主级人工神经网络,每个主级人工神经网络都具有m个输入,即每个子载波都把m个无线转发站遍历一遍,输入值为第k个子载波被m个无线转发站转发所对应的m个端到端信道功率增益;相应的主级人工神经网络的输出是这m个端到端信道功率增益中最大的那个端到端信道功率增益所对应的那个最优无线转发站,最优无线转发站对应的指示数设为1,其他无线转发站的指示数设为0;
s12:构造m个次级人工神经网络,把主级人工神经网络的输出作为次级人工神经网络的输入;对于第m个次级人工神经网络,有k个输入,即每个主级人工神经网络都有m个输出,把每个主级人工神经网络的第m个输出都输入到第m个次级人工神经网络内;第m个次级人工神经网络的输出是一个二进制数,指示是否对应分配第m个无线转发站;每个次级人工神经网络分别用作具有k个不完善输入的“或”门,并且所有m个次级人工神经网络都作为分类器在分布式的基础上运行。
优选地,所述步骤s2中采用监督型机器学习的方法对人工神经网络进行训练的步骤如下:
s21:构造带有标签的训练数据集:采用暴力搜索算法确定转发所有k个子载波的无线转发站的集合
s22:训练人工神经网络:初始化参数
s23:重复步骤s22,训练过程以迭代的方式进行,每次迭代更新链路权重和神经元激活阈值,从而使得级联人工神经网络所给出的输出与标签接近;当所有训练数据集全部被使用完之后,迭代过程停止,训练结束。
优选地,所述步骤s21中包括先将{g(m,k)}归一化,具体如下:
优选地,所述步骤s22中采用量化函数将次级人工神经网络的输出逐项量化,具体是将最大项转换为1,其他项转换为0;1与所选无线转发站相关联,0与落选无线转发站相关联。
本发明的有益效果为:本发明的级联人工神经网络框架可以降低传统逐子载波无线转发站分配方案的系统复杂度,可以降低传统逐子载波无线转发站分配方案的处理时延,本发明所提出的级联结构将一个复杂的,单一训练网络不易理解的决策问题,拆分为多个简单的最大最小化问题,提升了人工神经网络的训练效率。
附图说明
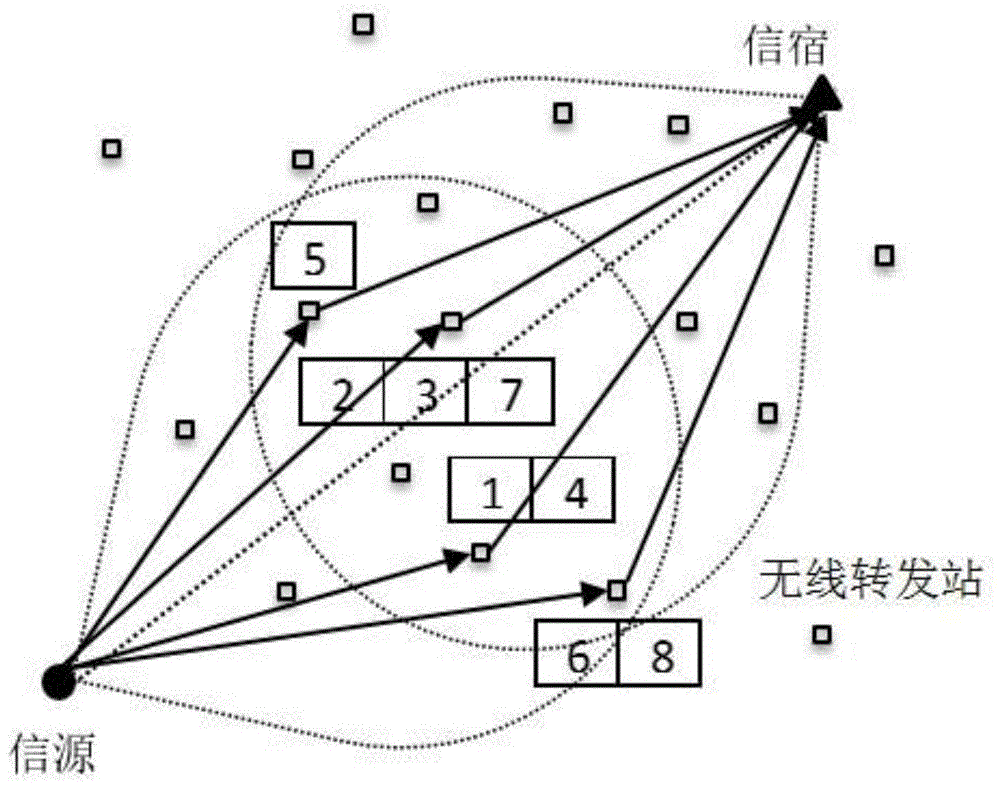
图1为逐子载波无线转发站分配的多载波协作系统实现示例图;
图2为本发明的级联人工神经网络的结构示意图;
图3(a)-(d)为实施例中逐子载波无线转发站分配的级联人工神经网络各个训练指标的曲线图。
具体实施方式
为了更好的理解本发明,下面结合附图和具体实施例对本发明作进一步说明:
设多载波协作通信网络中包括一个信源,一个信宿,以及由半双工协议操作的m个无线转发站。所有m个无线转发站都在分布在一个群集区域内,并准备把来自信源的信号转发给信宿。本发明将所有m个无线转发站的集合表示为
对于经典的多载波协作通信网络,本发明具有以下共同的假设:
(1)瞬时csi在信源和信宿处都是已知的,即信源和信宿实时监控掌握着瞬时csi;
(2)在所有通信节点之间,时域和频域分别都是完美同步的;
(3)网络拓扑在整个传输帧上没有变化,所有m个无线转发站都位于一个群集内,与信源和信宿之间的距离相比,该无线转发站群集的尺寸相对较小;
(4)信源与信宿之间由于超长距离、深度衰落等原因而被阻塞,因此,从信源到信宿的端到端传输必须由一个或多个无线转发站转发;
(5)将信息流功率平均分给所有具有发射功率pt的信号发射器和子载波,即所有信号发射器和子载波的传输速率和发射功率是一样的;
(6)k个子载波、m个无线转发站上的每条信道的衰落相互都是独立同分布的(即i.i.d.),且没有任何干扰和相关性,信道衰弱模型和相关分布都不变;
(7)所有通信节点的接收机处的噪声也是互相独立同分布的(即i.i.d.),其平均噪声功率为n0,都是加性高斯白噪声(awgn)。
基于以上假设,本发明用等效端到端信道功率增益g(m,k)来体现第k个子载波被第m个无线转发站转发的端到端传输可靠性:
g(m,k)=min{g1(m,k),g2(m,k)};(1)
和
(1)式和(2)式分别用于df和af无线转发站辅助网络,其中gi(m,k)表示第i跳的信道功率增益。在实际应用中,等效的端到端信道功率增益{g(m,k)}是逐子载波无线转发站分配的主要参考之一,在逐子载波无线转发站分配方案中被用作性能度量。为了便于信息处理,本发明按矩阵形式组织等效的端到端信道功率增益{g(m,k)},如下所示:
其中g(k)=[g(1,k),g(2,k),…,g(m,k)]t,h(m)=[g(m,1),g(m,2),…,g(m,k)]。
监督型机器学习(ml)是最近的ml技术之一,对于模型驱动的学习非常有效。为了执行监督型机器学习(ml),需要带有标签的训练数据集。相关研究表明,预计在下一代网络中,大多数通信节点都能够配备信道估计功能,所以本发明假设系统的各个节点都能完全知晓由{g(m,k)}所表示的csi。同样,根据逐子载波无线转发站分配标准,本发明可以采用暴力搜索算法来确定无线转发站的最佳集合
在原则上,人工神经网络的输入是给定某种形式的训练数据,然后人工神经网络把输入的训练数据通过多层神经元计算处理,得到某种形式的输出。本发明中的人工神经网络输出可以用于检索一组选定的无线转发站,命名为
为了使用监督型机器学习来进行逐子载波无线转发站分配,本发明使用级联人工神经网络。具体而言,与仅一次尝试实现逐子载波无线转发站分配标准的方法相反,本发明将逐子载波无线转发站分配的计算分为两个步骤。随后,本发明通过分别执行第一步计算和第二步计算来构造人工神经网络的主级和次级。训练数据集作为主级人工神经网络的输入,主级人工神经网络的输出作为次级人工神经网络的输入。次级人工神经网络的输出则作为级联人工神经网络所产生的最终优化方案。通过这种级联结构,可以提高监督型机器学习(ml)的训练效率,尤其是当优化维度大于1或者优化问题为非线性时。
以逐子载波的方式分配多个无线转发站,从而对所有子载波传输的信号都可以实现最佳性能,图1为逐子载波无线转发站分配方案的示意图。基于级联人工神经网络的逐子载波无线转发站分配方法,包括以下步骤:
s1:根据逐子载波无线转发站分配标准设计级联人工神经网络的结构;逐子载波无线转发站分配标准具体为:在不受所选无线转发站数量限制的情况下,逐子载波无线转发站分配标准可以分配多个无线转发站,最多可以分配与子载波数目相同的无线转发站,让每个子载波各自都能被最优的无线转发站处理转发。与多载波单无线转发站分配标准相比,逐子载波无线转发站分配标准会导致更高的吞吐量和更好的可靠性。执行逐子载波无线转发站分配会增加更高的系统复杂度和信令开销,因为需要多个无线转发站才能成功实现转发任务。逐子载波无线转发站分配标准如下公式(4)所示:
其中,
通过观察(4)式可得,在无线转发站分配过程中,独立地对待每个子载波,为每个子载波分配各自的最优无线转发站,互不干扰,所分配的无线转发站相互可能相同,也可能不同,一个无线转发站可能转发多个子载波,最多分配与子载波数目相同数目的无线转发站,即每个子载波的最优无线转发站互相不同。设计级联人工神经网络的结构的步骤如下:
s11:构造k个主级人工神经网络,每个主级人工神经网络都具有m个输入,即每个子载波都把m个无线转发站遍历一遍,输入值为第k个子载波被m个无线转发站转发所对应的m个端到端信道功率增益;相应的主级人工神经网络的输出是这m个端到端信道功率增益中最大的那个端到端信道功率增益所对应的那个最优无线转发站,最优无线转发站对应的指示数设为1,其他无线转发站的指示数设为0;从本质上说,这些主级人工神经网络充当分类器,并且是同质的,共享相同的体系结构。
s12:构造m个次级人工神经网络,把主级人工神经网络的输出作为次级人工神经网络的输入;对于第m个次级人工神经网络,有k个输入,即每个主级人工神经网络都有m个输出,把每个主级人工神经网络的第m个输出都输入到第m个次级人工神经网络内;第m个次级人工神经网络的输出是一个二进制数,指示是否对应分配第m个无线转发站;每个次级人工神经网络分别用作具有k个不完善输入的“或”门,并且所有m个次级人工神经网络都作为分类器在分布式的基础上运行。同样,每个次级人工神经网络都被设置为同质的,共享相同的体系结构。用于执行逐子载波无线转发站分配的级联人工神经网络模型如图2所示。
s2:采用监督型机器学习的方法对人工神经网络进行训练;步骤如下:
s21:构造带有标签的训练数据集:采用暴力搜索算法确定转发所有k个子载波的无线转发站的集合
s22:训练人工神经网络:初始化参数
由于次级人工神经网络的输出通常是十进制,需要对其量化以明确输出值对应分配哪个无线转发站。逐子载波无线转发站分配方案的逐项量化函数是ξps{·},量化后的输出
s23:重复步骤s22,训练过程以迭代的方式进行,每次迭代更新链路权重和神经元激活阈值,从而使得级联人工神经网络所给出的输出与标签接近;当所有训练数据集全部被使用完之后,迭代过程停止,训练结束。
主级和次级人工神经网络的技术规范如下表1和表2所示。
表1.用于执行第k个子载波无线转发站分配的第k个主级人工神经网络的技术规格
s3:采用训练好的级联人工神经网络逐子载波分配最优的无线转发站。
为了衡量逐子载波无线转发站分配的级联人工神经网络的训练性能,本发明采用以下性能指标。
对于主级人工神经网络,本发明将主级的均方误差(pmse)定义为:
pmse用来衡量主级人工神经网络的训练性能,之中的
同理,对于次级人工神经网络,本发明将次级mse(smse)定义为:
用来测量次级人工神经网络的训练性能m,其中m是由(4)式的暴力搜索算法产生的m×1向量,其中与所选无线转发站对应的条目为1,其余不选则的无线转发站所对应的条目为0。
通过逐子载波人工神经网络分配的后处理方法,本发明采用均方量化误差(msqe)和相对误差(re)来衡量级联人工神经网络的整体性能,mese和re定义为:
和
本发明在图3(a)-(b)中显示了针对不同无线转发站数目、不同子载波数目和不同协作无线转发站网络协议(af、df)的逐子载波无线转发站分配方案的级联人工神经网络仿真结果。得到的最重要结论是,级联人工神经网络技术适用于逐子载波无线转发站分配技术,因为从图3可得,经过前100个初始震荡周期之后,psme、smse、msqe、re四个性能指标值都随着训练迭代次数的增加而不断下降,即性能得到了提升。
协作网络配置于静态空间中,设4无线转发站可供转发分配m=4,2个子载波可用于传输信息k=2。
针对逐子载波无线转发站分配技术,本发明通过以下架构参数初始化它的级联人工神经网络:
构造训练数据集:利用matlab随机指数分布函数和{g1(m,k)}{g2(m,k)}~exprnd(1)生成105个{g(m,k)}训练数据集,根据(4)式的暴力搜索来标注它们的标签。为了减轻信道实现的随机性,并能体现基于级联神经网络逐子载波无线转发站分配技术的统计性质,本发明在相同模拟配置下对所有先前实验的模拟结果取平均值。
针对第1个子载波的主级人工神经网络的训练过程:
(1)输入:对于第1个子载波,根据{g(m,1)}。
(2)初始化:设范围扩展系数
(3)处理过程:第l层中神经元的数目表示为
(4)输出:根据
针对第2个子载波的主级人工神经网络的训练过程:
(1)输入:对于第2个子载波,根据{g(m,1)}。
(2)初始化:设范围扩展系数
(3)处理过程:第l层中神经元的数目表示为
(4)输出:根据
针对第1个无线转发站的次级人工神经网络的训练过程:
(1)输入:一个次级人工神经网络有2个输入:分别是每个主级人工神经网络输出向量
(2)初始化:设范围扩展系数
(3)处理过程:第l层中神经元的数目表示为
(4)输出:只有一个输出
针对第2个无线转发站的次级人工神经网络的训练过程:
(1)输入:一个次级人工神经网络有2个输入:分别是每个主级人工神经网络输出向量
(2)初始化:设范围扩展系数
(3)处理过程:第l层中神经元的数目表示为
(4)输出:只有一个输出
针对第3个无线转发站的次级人工神经网络的训练过程:
(1)输入:一个次级人工神经网络有2个输入:分别是每个主级人工神经网络输出向量
(2)初始化:设范围扩展系数
(3)处理过程:第l层中神经元的数目表示为
(4)输出:只有一个输出
针对第4个无线转发站的次级人工神经网络的训练过程:
(1)输入:一个次级人工神经网络有2个输入:分别是每个主级人工神经网络输出向量
(2)初始化:设范围扩展系数
(3)处理过程:第l层中神经元的数目表示为
(4)输出:只有一个输出
级联神经网络的最终输出:四个无线转发站中被分配的那个无线转发站作为逐子载波无线转发站分配方案的所分配的无线转发站。
本发明不局限于以上所述的具体实施方式,以上所述仅为本发明的较佳实施案例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!