基于联邦多智能体强化学习的车联网边缘资源分配方法
1.本发明涉及无线通信技术领域,尤其涉及一种基于联邦多智能体强化学习的车联网边缘资源分配方法。
背景技术:
2.近年来,车辆作为人类出行不可或缺的交通方式,已经成为驱动经济高速发展,提高人民生活质量的重要载体。车联网技术作为现代工业以及移动通信高速发展的产物,可以有效地处理道路安全、交通效率、自动驾驶和智能交通系统中的实时信息交互的延迟敏感服务。然而,随着车辆用户数量的爆炸性增长,传统的单一接入方式以及通信资源分配方案已经很难同时满足各类交通出行的需求。由于发生在车辆周围的车联网业务大多只需要在周边提供近距离通信,且大多数任务具有时效性,由此以车与车通信以及车与基础设施通信为主要通信方式的专用短程通信技术被广泛应用以支持高速传输(jameel f,wyne s,javed m a,et al.interference-aided vehicular networks:future research opportunities and challenges[j].ieee communications magazine,2018,56(10):36-42.)。然而车联网作为一种典型的具有高移动性的异构无线网络,其具有固定覆盖范围的节点难以持续稳定地提供服务,由此带来昂贵的切换开销,而可能引发传输中断,甚至导致交通安全业务处理无法有效完成。因此高效、快速的用户接入方案对于实现车联网高效性和高性能至关重要。
[0003]
随着人工智能的发展,深度强化学习(deep reinforcement learning,drl)被认为是解决复杂序列决策问题的有效方案,其可以通过直接与环境交互来学习最佳策略,而无需任何系统动态(例如,无线信道、车辆位置等)的先验知识,避免了使用传统解决方案解决马尔科夫决策问题时所需的状态转换矩阵的需求。近年来学者尝试引入drl算法来解决边缘资源分配问题,khan等人通过将云端集中处理的任务分解至各个路侧单元进行本地训练,利用一种分布式强化学习框架设计用户接入方案,最终可以在满足各个车辆传输速率要求的同时,最小化网络协调开销(khan h,elgabli a,samarakoon s,et al.reinforcement learning-based vehicle-cell association algorithm for highly mobile millimeter wave communication[j].ieee transactions on cognitive communications and networking,2019,5(4):1073-1085.)。然而,尽管现有研究针对车联网场景设计了多种用户接入方案,同时基于不同的业务需求提供了通信与能耗资源的协同管理策略,但是drl算法的训练依赖于车辆用户大量的信息交互,带来严重的隐私泄露问题。
技术实现要素:
[0004]
本发明的目的在于提供一种基于联邦多智能体强化学习的车联网边缘资源分配方法,从而在隐私保护的前提下,提升车联网连通性,降低切换开销以及能量损耗。
[0005]
实现本发明目的的技术解决方案为:一种基于联邦多智能体强化学习的车联网边
缘资源分配方法,具体步骤包括:
[0006]
步骤1、输入车联网环境,初始化智能体本地q网络和联邦网络参数,并对优化问题建模;
[0007]
步骤2、根据智能体能否获得奖励,分为α型车辆智能体和β型车辆智能体两类,在当前时隙内α型和β型车辆智能体分别获取自身与路侧单元之间的信道状态、可观测的路侧单元位置以及上个时隙相关联的路侧单元位置,级联作为q网络的输入;
[0008]
步骤3、采用高斯差分方法对q网络输出进行加密处理,并通过联邦网络输出α型和β型车辆智能体的联合边缘接入决策以及下行链路的功率分配决策;
[0009]
步骤4、α型车辆智能体得到系统反馈的连接增益、切换开销以及能量损耗的权衡奖励,同时系统将当前时隙的样本数据输入至缓存池中;
[0010]
步骤5、判断样本数量是否足够,如果是则进入步骤6,否则直接进入步骤7;
[0011]
步骤6、当样本数量足够时,α型和β型车辆智能体分别更新本地q网络以及联邦网络的参数,更新完成后清空缓存池;
[0012]
步骤7、判断当前训练回合是否结束,如果否则返回步骤2开始下一个回合的训练,如果是则进入步骤8;
[0013]
步骤8、判断是否收敛,如果否则重置车联网环境,返回步骤1;如果是则训练结束,完成车联网边缘资源分配。
[0014]
本发明与现有技术相比,其显著优点为:(1)针对单智能体强化学习算法集中式处理带来的大量信息交互问题,考虑车联网中的多智能体场景,车辆用户协作决策,以提升车联网连通性,同时降低切换开销以及能量损耗;(2)通过采用高斯差分方法对智能体本地q网络的输出值进行隐私保护,使得智能体之间无法共享观测到的环境状态信息,极大地提升了本地数据的安全程度;(3)提出的基于联邦多智能体强化学习的方案,通过共享加密训练数据促进模型训练,提高系统的性能指标。
[0015]
下面结合附图对本发明做进一步的仔细描述。
附图说明
[0016]
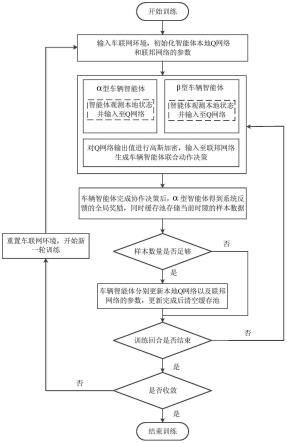
图1是本发明基于联邦多智能体强化学习的车联网边缘资源分配方法的流程图。
[0017]
图2为本发明实施例的车联网系统模型示意图。
[0018]
图3为本发明实施例中车联网系统的收敛性能随周期变化图。
[0019]
图4为本发明实施例中车联网系统的车辆用户平均性能随路侧单元数目变化图。
[0020]
图5为本发明实施例中车联网系统的车辆用户平均性能随下行链路传输功率最大阈值的变化图。
具体实施方式
[0021]
本发明提出一种基于联邦多智能体强化学习的车联网边缘资源分配方法。方案具体为在单位时隙t内,单个车辆用户作为一个智能体,通过观测车辆与路侧单元之间的信道状态以及路侧单元的位置信息,采用神经网络训练联合动作策略,从而提高传输速率、减低切换开销以及能量损耗,实现三者的权衡,结合图1~图2,包括以下步骤:
[0022]
步骤1、输入车联网环境,初始化智能体本地q网络和联邦网络参数,并对优化问题
建模;
[0023]
步骤2、根据智能体能否获得奖励进行分类,在当前时隙内α型和β型车辆智能体分别获取自身与路侧单元之间的信道状态、可观测的路侧单元位置以及上个时隙相关联的路侧单元位置,并级联作为q网络的输入;
[0024]
步骤3、采用高斯差分方法对q网络输出进行加密处理,并通过联邦网络输出α型和β型车辆智能体的联合边缘接入决策以及下行链路的功率分配决策;
[0025]
步骤4、α型车辆智能体得到系统反馈的连接增益、切换开销以及能量损耗的权衡奖励,同时系统将当前时隙的样本数据输入至缓存池中;
[0026]
步骤5、判断样本数量是否足够,如果是则进入步骤6,否则进入步骤7;
[0027]
步骤6、当样本数量足够时,α型和β型车辆智能体分别更新本地q网络以及联邦网络的参数,更新完成后清空缓存池;
[0028]
步骤7、判断当前训练回合是否结束,如果否则返回步骤2开始下一个回合的训练,如果是则进入步骤8;
[0029]
步骤8、判断是否收敛,如果否则重置车联网环境,返回步骤1;如果是则训练结束,完成车联网边缘资源分配。
[0030]
作为一种具体实施方式,步骤1所述的输入车联网环境,具体包括:
[0031]
(1)时隙模型:将连续的训练时间离散为多个时隙,表示为其中信道状态信息和系统参数在单个时隙的持续范围内保持不变,但可能在不同时隙之间随机变化。
[0032]
(2)网络模型:建立城市多车道高速公路模型,其中高速公路两侧均匀分布支持边缘通信的路侧单元,用集合表示;车辆从高速公路两端相向行驶,通过建立车与基础设施链路提升自身数据的传输速率,车辆用集合表示。
[0033]
(3)车辆移动模型:车辆的速度变化均遵循以下高斯-马尔科夫随机过程:
[0034][0035]
其中,v(t)表示车辆在时隙t的速度,v(t-1)表示车辆在时隙t-1的速度,表示速度近似均值,ζ表示速度近似方差,ξ表示记忆程度,z表示不相关的零均值单位方差的随机高斯过程。
[0036]
(4)切换模型:假设车辆可以观测到附近o
max
个路侧单元的信息,并自适应地选择关联的路侧单元。定义车辆k与所有路侧单元之间的关联变量为
[0037][0038]
其中表示路侧单元r在时隙t和车辆k相关联,反之,
[0039]
考虑路侧单元的覆盖范围有限,且单个时隙只能服务一个车辆。当相邻时隙车辆关联的路侧单元改变,则发生切换,即:
[0040][0041]
其中hk(t)表示相邻时隙之间车辆k产生的切换数目,1
{
·
}
表示在满足约束情况下置1,反之,置0。
[0042]
(5)功率分配模型:下行链路路侧单元的发射功率采用离散化的等级分布,表示为
[p
min
,p
max
]范围内的p个等级。令表示时隙t车辆k相关联的路侧单元r所配置的下行链路传输功率,则车辆k配置的下行链路路侧单元的功率分配变量为
[0043][0044]
其中表示车辆k在时隙t选择p作为下行链路路侧单元的功率,即反之,
[0045]
(6)无线通信模型:考虑系统中已通过干扰消除方法消除了车与基础设施链路之间的相互干扰。假设信道功率增益由小尺度衰落(瑞利衰落)以及路径损耗组成。令表示车辆k与路侧单元r之间的信道增益。根据香农公式,给定时隙t车辆用户k关联的路侧单元r以及其配置的下行链路功率,则车辆k可获得的传输速率表示为:
[0046][0047]
此外,假设所有车辆在每个时隙所需的最小数据速率相同且固定,用r
min
表示。
[0048]
作为一种具体实施方式,步骤1所述对优化问题建模,具体为:
[0049]
考虑优化联合边缘接入与功率分配,构建优化问题,优化目标为最大化连接增益、切换开销以及能量损耗的权衡:
[0050][0051][0052][0053]
其中ω1,ω2,ω3分别为连接增益、切换开销以及能量损耗的权值系数,且ω1+ω2+ω3=1;式c1保证车辆用户的无缝连接,式c2反映车辆用户的所需的最小数据速率约束。
[0054]
作为一种具体实施方式,步骤2所述根据智能体能否获得奖励,分为α型车辆智能体和β型车辆智能体两类,具体为;
[0055]
考虑到隐私保护,车辆智能体只能观测其自身的状态信息,且无法实时地或者准确地获得系统回馈的奖励。根据智能体能否获得奖励,将其划分为两类:
[0056]
α型车辆智能体:可以观察自己的局部状态,并及时准确地获得相应的系统奖励;
[0057]
β型车辆智能体:可以观察自己的局部状态,但由于隐私保护无法获得系统奖励。
[0058]
作为一种具体实施方式,步骤2所述在当前时隙内α型和β型车辆智能体分别获取自身与路侧单元之间的信道状态、可观测的路侧单元位置以及上个时隙相关联的路侧单元位置,具体为:
[0059]
在时隙t,每个车辆用户都作为智能体,通过和环境交互获得各自的观测状态,车辆k在时隙t的状态表示为:
[0060][0061]
其中,表示时隙t车辆k和其可观测的路侧单元之间的信道状态信息;表示时隙t车辆k可观测的路侧单元的位置;表示时隙t-1车辆k相关联的路侧单元的位置。
[0062]
作为一种具体实施方式,步骤3所述通过联邦网络输出α型和β型车辆智能体的联合边缘接入决策以及下行链路的功率分配决策,具体为:
[0063]
确定每个车辆智能体与环境交互做出的动作,包括选择相关联的路侧单元以及下行链路传输功率的选择。在时隙t,车辆k的动作表示为:
[0064][0065]
作为一种具体实施方式,步骤4所述α型车辆智能体得到系统反馈的连接增益、切换开销以及能量损耗的权衡奖励,具体为:
[0066]
当所有车辆智能体执行完动作后,环境将回馈一个全局奖励。定义每个用户的平均权衡作为全局奖励,表示为:
[0067][0068]
作为一种具体实施方式,步骤1所述初始化智能体本地q网络和联邦网络,步骤3所述采用高斯差分方法对q网络输出进行加密处理,具体为:
[0069]
(1)本地q网络:分别为α型和β型车辆智能体和构建本地q网络,用来估计动作价值函数
[0070][0071]
其中表示带有折扣因子的未来累计奖励,γ表示折扣因子。因此,定义α型和β型车辆智能体的本地q网络输出值为q
α
(
·
;θ
α
)和q
β
(
·
;θ
β
),其中θ
α
和θ
β
分别是深度神经网络的权值参数。
[0072]
(2)高斯差分:基于隐私保护,采用高斯差分方法,分别对α型和β型车辆智能体本地q网络的输出加上服从高斯分布的随机变量,定义为:
[0073][0074][0075]
(3)联邦网络:采用多层感知机网络作为联邦网络,以加密的q网络输出作为输入,输出联合决策来预测联合动作,表示为:
[0076][0077]
其中mlp(
·
;θ
mlp
)表示多层感知机网络,[
·
|
·
]表示级联操作。
[0078]
当α型和β型车辆智能体更新网络模型时,分别将对方加密的q网络输出视作定值,即:
[0079][0080][0081]
作为一种具体实施方式,步骤4所述的将当前时隙的样本数据输入至缓存池中,具体为:
[0082]
为了提高强化学习算法的稳定性,采用经验回放方法;经验缓存池用来存储之前学习过程中每一步参数,并在之后的学习过程中随机从之前的样本中抽取一些样本进行学
习。其中经验池表示为α型车辆智能体抽取的n组样本表示为β型车辆智能体抽取的样本表示为当存储样本数量达到上限时,旧的样本将被移除为新样本存储预留空间。
[0083]
作为一种具体实施方式,步骤6所述的当样本数量足够时,α型和β型车辆智能体分别更新本地q网络以及联邦网络的参数,具体为:
[0084]
实际的模型训练过程中存在在线网络和目标网络,用来防止频繁更新,减少训练的发散和振荡。其中在线网络不断更新参数,用来训练神经网络,计算q估计值;目标网络则暂时固定参数,隔一段时间更新一次,计算q目标值。考虑到β型车辆智能体无法获得系统反馈的全局奖励,联邦网络的q估计值只能由α型车辆智能体计算得出并分享给β,表示为:
[0085][0086]
其中,rj为由α型车辆智能体获取的全局奖励,γ表示折扣因子。
[0087]
因此,网络的损失函数表示为:
[0088][0089][0090]
在实际计算中,一般采用随机梯度下降方法来优化损失函数。在训练过程中,首先,α型车辆智能体计算得到yj并传给β型车辆智能体;然后,β型车辆智能体更新其自身q网络和多层感知机网络并将参数θ
β
、θ
mlp
以及传给α型车辆智能体:
[0091][0092][0093]
最后,α型车辆智能体根据收到的参数去更新自身的q网络以及联邦网络参数:
[0094][0095][0096]
更新完所有的网络,如果车辆回合结束则训练过程结束,输出最优策略π
*
,否则开始下一次训练。
[0097]
下面结合附图以及具体实施例对本发明做进一步仔细说明。
[0098]
实施例
[0099]
本实施例提供一种基于联邦多智能体强化学习的车联网边缘资源分配方法,下面进行具体描述:
[0100]
1、建立车联网系统模型:
[0101]
本发明采用python软件模拟城市多车道高速公路场景,道路全长设置为1千米,两侧均匀分布12个路侧单元,其服务范围的半径为200米。考虑一对车辆从道路两端相向行驶,车辆最多可以观测到最近的4个路侧单元的信息,并从中选择1个进行接入。车辆移动模型服从高斯随机过程,其中车辆初始值为ξ=0.1,ζ=0.1。车辆和路侧单
元之间的信道模型如下,路径损耗模型:小尺度衰落服从瑞利分布。下行链路传输功率为[23,35]dbm,并且最小传输速率约束为8bit/s/hz。
[0102]
2.建立联邦多智能体强化学习算法框架:
[0103]
联邦多智能体强化学习算法框架衍生于深度q网络算法(deep q network,dqn),通过值函数估计算法确定动作策略。算法框架主要由q网络以及联邦网络构成,其中采用三层全连接神经网络作为智能体的本地q网络,分别为输入层、输出层以及一个隐藏层,隐藏层的神经元数目为80;采用多层感知机网络作为联邦网络,以经过高斯差分处理的q网络输出值作为联邦网络输入,输出动作价值函数来预测联合动作。
[0104]
3.算法的训练阶段:
[0105]
首先分别输入当前状态s
α
(t)、s
β
(t),定义为即车辆智能体可观测的信道状态、路侧单元位置以及上个时隙相关联的路侧单元位置。其次定义联邦网络输出的动作为车辆智能体的联合动作,即车辆智能体的边缘接入决策以及下行链路功率的选择。
[0106]
算法输入状态之后,根据联邦网络预测的联合动作,当前动作与环境进行交互之后,α型车辆智能体获得全局奖励并且转移到下一个状态s
α
(t+1)、s
β
(t+1)。然后通过最小化在每次迭代i处改变的损失函数来更新网络。在训练过程中,选择衰减的学习率η(从0.01衰减到0.001),折扣因子γ=0.9。采用2000个训练集以及100个测试集,训练一次的样本数量设置为32,奖励函数的权值分别为ω1=0.5,ω2=0.25,ω3=0.25。首先,α型车辆智能体计算得到yj并传给β型车辆智能体;然后,β型车辆智能体更新其自身q网络和多层感知机网络并将参数θ
β
、θ
mlp
以及传给α型车辆智能体;最后,α型车辆智能体根据收到的参数去更新自身的q网络以及联邦网络参数。更新完所有的网络,如果车辆回合结束则训练过程结束,输出最优策略π
*
,否则开始下一次训练。
[0107]
考虑以下基准方案:鉴于α型车辆智能体可以独立训练模型,且β型车辆智能体共享相似的系统环境,因此可以只训练α型车辆智能体的模型,来获取α型和β型车辆智能体的联合动作策略,即dqn_α算法(其输入为s
α
(t),输出车辆智能体的联合动作q值)。
[0108]
如图3所示,首先本说明提出的联邦多智能体强化学习算法收敛性能优于对比算法。这表明即使训练数据受到噪声保护,β型车辆智能体仍然可以提供不可观察的训练策略来帮助α型车辆智能体学习联合策略。其次,由于两个智能体的状态信息都得到了有效利用,所提出的算法在保证令人满意的传输速率的前提下,大大减少了切换的次数。
[0109]
如图4所示,随着路侧单元数目的提升,两种方案的车辆用户平均权衡均提升,且传输速率也遵循同样的趋势。其原因是随着路侧单元数量的增加,车辆可以有更多机会连接到更近的路侧单元,从而提高数据速率。另外,得益于α型和β型车辆智能体之间的联邦策略学习,本说明所提出的联邦多智能体强化学习算法可以在隐私保护的基础上提高连接增益,且显著减少切换开销。
[0110]
如图5所示,本说明进一步研究了下行链路发射功率阈值对车辆用户平均性能的影响。首先,由于增加的发射功率有助于提高数据速率,因此随着功率阈值的增大,总权衡和连接效益都会增加。然而,由于功率分配与切换开销无直接关联,因此切换数量几乎保持
不变。其次,本说明提出的联邦多智能体强化学习框架共享了α型和β型车辆智能体的加密q值,在隐私保护的前提下可以促进模型的训练,进而促使车辆智能体在不同的下行链路发射功率阈值下做出更有效的联合决策。
[0111]
综上所述,本发明针对车联网未知高动态拓扑和信道状态特征,研究基于隐私保护的车联网联合边缘接入与功率分配问题,提出了一种基于联邦多智能体强化学习的车联网边缘资源分配方法。该方案采用高斯差分方法,在决策训练期间保留车辆智能体之间交互的隐私;同时引入多层感知机模型共享加密训练数据,促使智能体更好地进行模型训练。本发明提出的基于联邦多智能体强化学习的车联网边缘资源分配方法可在保护车辆用户本地状态隐私信息的前提下,提升车联网连通性,同时减低切换开销以及能量损耗,从而支持车联网中各类超高可靠、低延迟通信应用。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1