一种音频处理方法及系统与流程
1.本发明涉及音频处理技术领域,特别涉及一种音频处理方法及系统。
背景技术:
2.目前,随着移动通讯技术的发展,观看网络直播已逐渐成为人们日常的娱乐消遣方式;例如:进入网络直播间与主播互动等。现有的直播时的音频处理都是直接由主播端的音频采集设备采集,上传至服务平台,观众通过手机登录服务平台进入直播间后,即可观看主播的直播内容;音频的处理也仅仅是语音增强、声源定位、回声消除、强降噪、降混响、语音边界检测及语音识别;并无对主播的音频的监管措施,使一些因主播个人或观众引导的不当言论被直播,而造成较为严重的后果。
技术实现要素:
3.本发明目的之一在于提供了一种音频处理方法,对主播的第一音频数据进行识别并进行监控和拦截,实现对主播音频的监管。
4.本发明实施例提供的一种音频处理方法,包括:
5.获取主播端的第一音频采集设备采集到主播的第一音频数据;
6.将第一音频数据输入预设的语音识别模型,获取第一信息;
7.对第一信息进行敏感度检测,确定敏感度;
8.当敏感度大于预设的敏感阈值时,将第一音频数据拦截。
9.优选的,音频处理方法,还包括:
10.基于第一音频数据的拦截情况,生成拦截数据;
11.当主播端的第一音频采集设备和图像采集设备停止工作后,通过提醒设备输出拦截数据;
12.当接收主播对于拦截数据的点选,输出拦截数据的明细和与拦截数据相关的事例列表;
13.其中,拦截数据相关的事例列表通过如下步骤确定:
14.对拦截数据对应的第一音频数据进行特征提取,获取多个特征值;
15.基于特征值,构建调取特征集;
16.获取预设的事例库;
17.将调取特征集与事例库中的事例特征集进行匹配,确定调取特征集与各个事例特征集之间的第一匹配度;
18.提取第一匹配度大于预设的第一阈值的事例特征集对应的事例,将提取的各个事例按照匹配度从大到小的顺序排列,构建事例列表。
19.优选的,对第一信息进行敏感度检测,确定敏感度,包括:
20.基于预设的敏感词提取模板,对第一信息进行敏感词提取,确定敏感词提取模板中各个敏感词出现的次数;
21.基于敏感词提取模板中各个敏感词出现的次数,构建评价向量;
22.获取预设的评价库;
23.将评价向量与评价库中各个标准向量进行匹配,确定评价向量与各个标准向量之间的第二匹配度;
24.当第二匹配度为评价库中最大且大于预设的第二阈值时,确定评价向量与标准向量匹配符合;
25.获取匹配符合的标准向量对应关联的敏感度。
26.优选的,音频处理方法,还包括:
27.接收主播的互动问答的互动指令;
28.确定互动指令对应的互动模式;
29.解析互动模式,确定观众问题的提取方式;
30.当提取方式为随机提取时,对观众输入在直播间内公屏的信息进行识别筛选,构建问题集;
31.从问题集中随机挑选问题并输出至主播端的显示屏;
32.接收主播的确认或拒绝操作;
33.当为确认操作时,将问题进行语音合成处理,并输出;
34.当为拒绝操作时,重新从问题集中随机挑选问题输出至显示屏;直至主播的操作为确认操作;
35.当提取方式为手动挑选时,对观众输入在直播间内公屏的信息进行识别筛选,构建问题列表;
36.依据问题的提出时间和提出的观众的权限,对问题列表中的问题进行排序;
37.接收主播对于问题列表中的问题的点选,确定点选的问题;
38.将点选的问题进行语音合成处理,并输出;
39.其中,依据问题的提出时间和提出的观众的权限,对问题列表中的问题进行排序,包括:
40.确定问题的提出时间距离当前时刻的时间差值,基于时间差值,查询第一优先值对照表,确定时间差值对应的第一优先值;
41.基于问题的提出的观众的权限,查询第二优先值对照标,确定权限对应的第二优先值;
42.基于第一优先值和第二优先值的和值从大到小的顺序对问题列表中的问题进行排序。
43.优选的,音频处理方法,还包括:
44.在观众的问题的语音播放后,采集主播的第二音频数据;
45.将第二音频数据输入预设的语音识别模型,获取第二信息;
46.将第二信息输入唤醒识别词识别模型中,进行识别;
47.当识别到预设的唤醒词时,再次进行观众问题的提取;
48.在提取观众问题时,优先提取上一个问题的观众的问题。
49.本发明还提供一种音频处理系统,包括:
50.第一音频获取模块,用于获取主播端的第一音频采集设备采集到主播的第一音频
数据;
51.识别模块,用于将第一音频数据输入预设的语音识别模型,获取第一信息;
52.敏感度检测模块,用于对第一信息进行敏感度检测,确定敏感度;
53.拦截模块,用于当敏感度大于预设的敏感阈值时,将第一音频数据拦截。
54.优选的,音频处理系统,还包括:拦截记录模块;
55.拦截模块执行如下操作:
56.基于第一音频数据的拦截情况,生成拦截数据;
57.当主播端的第一音频采集设备和图像采集设备停止工作后,通过提醒设备输出拦截数据;
58.当接收主播对于拦截数据的点选,输出拦截数据的明细和与拦截数据相关的事例列表;
59.其中,拦截数据相关的事例列表通过如下步骤确定:
60.对拦截数据对应的第一音频数据进行特征提取,获取多个特征值;
61.基于特征值,构建调取特征集;
62.获取预设的事例库;
63.将调取特征集与事例库中的事例特征集进行匹配,确定调取特征集与各个事例特征集之间的第一匹配度;
64.提取第一匹配度大于预设的第一阈值的事例特征集对应的事例,将提取的各个事例按照匹配度从大到小的顺序排列,构建事例列表。
65.优选的,敏感度检测模块对第一信息进行敏感度检测,确定敏感度,执行如下操作:
66.基于预设的敏感词提取模板,对第一信息进行敏感词提取,确定敏感词提取模板中各个敏感词出现的次数;
67.基于敏感词提取模板中各个敏感词出现的次数,构建评价向量;
68.获取预设的评价库;
69.将评价向量与评价库中各个标准向量进行匹配,确定评价向量与各个标准向量之间的第二匹配度;
70.当第二匹配度为评价库中最大且大于预设的第二阈值时,确定评价向量与标准向量匹配符合;
71.获取匹配符合的标准向量对应关联的敏感度。
72.优选的,音频处理系统,还包括:语音合成模块;
73.语音合成模块执行如下操作:
74.接收主播的互动问答的互动指令;
75.确定互动指令对应的互动模式;
76.解析互动模式,确定观众问题的提取方式;
77.当提取方式为随机提取时,对观众输入在直播间内公屏的信息进行识别筛选,构建问题集;
78.从问题集中随机挑选问题并输出至主播端的显示屏;
79.接收主播的确认或拒绝操作;
80.当为确认操作时,将问题进行语音合成处理,并输出;
81.当为拒绝操作时,重新从问题集中随机挑选问题输出至显示屏;直至主播的操作为确认操作;
82.当提取方式为手动挑选时,对观众输入在直播间内公屏的信息进行识别筛选,构建问题列表;
83.依据问题的提出时间和提出的观众的权限,对问题列表中的问题进行排序;
84.接收主播对于问题列表中的问题的点选,确定点选的问题;
85.将点选的问题进行语音合成处理,并输出;
86.其中,依据问题的提出时间和提出的观众的权限,对问题列表中的问题进行排序,包括:
87.确定问题的提出时间距离当前时刻的时间差值,基于时间差值,查询第一优先值对照表,确定时间差值对应的第一优先值;
88.基于问题的提出的观众的权限,查询第二优先值对照标,确定权限对应的第二优先值;
89.基于第一优先值和第二优先值的和值从大到小的顺序对问题列表中的问题进行排序。
90.优选的,语音合成模块还执行如下操作:
91.在观众的问题的语音播放后,采集主播的第二音频数据;
92.将第二音频数据输入预设的语音识别模型,获取第二信息;
93.将第二信息输入唤醒识别词识别模型中,进行识别;
94.当识别到预设的唤醒词时,再次进行观众问题的提取;
95.在提取观众问题时,优先提取上一个问题的观众的问题。
96.本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
97.下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
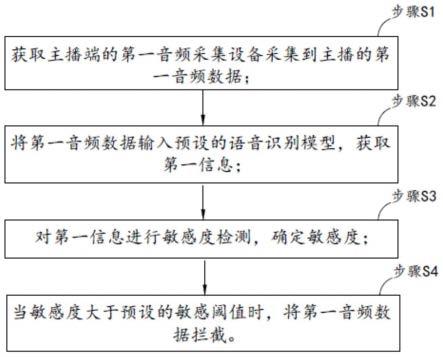
98.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
99.图1为本发明实施例中一种音频处理方法的示意图。
具体实施方式
100.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
101.本发明实施例提供了一种音频处理方法,如图1所示,包括:
102.步骤s1:获取主播端的第一音频采集设备采集到主播的第一音频数据;
103.步骤s2:将第一音频数据输入预设的语音识别模型,获取第一信息;
104.步骤s3:对第一信息进行敏感度检测,确定敏感度;
105.步骤s4:当敏感度大于预设的敏感阈值时,将第一音频数据拦截。
106.上述技术方案的工作原理及有益效果为:
107.在直播时,主播端通过第一音频采集设备和第一图像采集设备分别采集音频和图像数据,然后发送至服务平台,观众通过观众端(例如:手机上的客户端)登录到服务平台上,可以实时收看到主播端的主播的直播;为了实现对主播直播的敏感内容的拦截,首先通过第一音频采集设备采集主播的第一音频数据,将第一音频数据识别为第一信息,对第一信息进行敏感度检测,当敏感度超出敏感阈值时,将第一音频数据拦截;通过引入敏感度监测实现对主播在直播时的敏感的言论的拦截,实现有效的监管。其中,语音识别模型是对语音进行识别,将其转换为文字类型的数据的第一信息。上述拦截步骤可以由主播端或服务平台执行,当然由主播端执行时,拦截速度更快。
108.在一个实施例中,音频处理方法,还包括:
109.基于第一音频数据的拦截情况,生成拦截数据;
110.当主播端的第一音频采集设备和图像采集设备停止工作后,通过提醒设备输出拦截数据;第一音频采集设备和图像采集设备停止工作可以判断为主播暂停了直播或者关闭了直播的界面;此时主播有时间通过提醒设备确认拦截情况,提醒设备包括:显示屏,显示屏显示拦截数据;
111.当接收主播对于拦截数据的点选,输出拦截数据的明细和与拦截数据相关的事例列表;
112.其中,拦截数据相关的事例列表通过如下步骤确定:
113.对拦截数据对应的第一音频数据进行特征提取,获取多个特征值;特征值包括表示预设的关键词对应的音频数据是否出现的特征值,当出现时特征值的数值为1,当未出现时数值为0;此外还有表示关键词出现的次数的特征值;
114.基于特征值,构建调取特征集;将特征值按照预设的顺序进行排序;
115.获取预设的事例库;事例库是根据过往的涉及敏感言论的直播构建的;在事例库中事例特征集与事例关联存储;事例特征集为根据事例涉及的敏感内容,通过进行特征提取后构建的;
116.将调取特征集与事例库中的事例特征集进行匹配,确定调取特征集与各个事例特征集之间的第一匹配度;第一匹配度的计算公式如下:其中,z1表示第一匹配度;a
ij
表示调取特征集中第i行第j列的数据;b
ij
表示事例特征集中第i行第j列的数据;n表示总行数;m表示总列数;
117.提取第一匹配度大于预设的第一阈值的事例特征集对应的事例,将提取的各个事例按照匹配度从大到小的顺序排列,构建事例列表。
118.上述技术方案的工作原理及有益效果为:
119.将主播在直播时的拦截情况,生成拦截数据;拦截数据包括:被拦截的语音的时间、内容等明细数据;在主播点选拦截数据时还将与该拦截对应的事例数据一并输出;方便主播对敏感的话语进行了解总结,以便下一次直播时规避敏感言论。在输出事例列表时根据匹配度大小进行排序,方便主播的查看。
120.为了实现敏感度的确定,在一个实施例中,对第一信息进行敏感度检测,确定敏感度,包括:
121.基于预设的敏感词提取模板,对第一信息进行敏感词提取,确定敏感词提取模板中各个敏感词出现的次数;
122.基于敏感词提取模板中各个敏感词出现的次数,构建评价向量;
123.获取预设的评价库;评价库为事先基于大量数据分析构建;
124.将评价向量与评价库中各个标准向量进行匹配,确定评价向量与各个标准向量之间的第二匹配度;第二匹配度为评价向量与标准向量之间的相似度;相似度计算可以采用余弦相似度计算法;
125.当第二匹配度为评价库中最大且大于预设的第二阈值时,确定评价向量与标准向量匹配符合;
126.获取匹配符合的标准向量对应关联的敏感度。
127.在一个实施例中,音频处理方法,还包括:
128.接收主播的互动问答的互动指令;主播通过点选显示屏上的互动虚拟按钮发出互动指令;
129.确定互动指令对应的互动模式;通过主播点选的互动按钮对应的互动模式实现互动指令对应的互动模式的确定;
130.解析互动模式,确定观众问题的提取方式;互动模式可以分为两种,其中一种为随机提取用户问题进行回答;另一种为主播挑选问题进行回答;
131.当提取方式为随机提取时,对观众输入在直播间内公屏的信息进行识别筛选,构建问题集;
132.从问题集中随机挑选问题并输出至主播端的显示屏;
133.接收主播的确认或拒绝操作;
134.当为确认操作时,将问题进行语音合成处理,并输出;通过将问题转变为语音输出,无需主播进行问题的复述,并且通过语音进行问题输出可以提高互动体验;
135.当为拒绝操作时,重新从问题集中随机挑选问题输出至显示屏;直至主播的操作为确认操作;
136.当提取方式为手动挑选时,对观众输入在直播间内公屏的信息进行识别筛选,构建问题列表;
137.依据问题的提出时间和提出的观众的权限,对问题列表中的问题进行排序;
138.接收主播对于问题列表中的问题的点选,确定点选的问题;
139.将点选的问题进行语音合成处理,并输出;
140.其中,依据问题的提出时间和提出的观众的权限,对问题列表中的问题进行排序,包括:
141.确定问题的提出时间距离当前时刻的时间差值,基于时间差值,查询第一优先值对照表,确定时间差值对应的第一优先值;
142.基于问题的提出的观众的权限,查询第二优先值对照标,确定权限对应的第二优先值;
143.基于第一优先值和第二优先值的和值从大到小的顺序对问题列表中的问题进行
排序。通过将问题排序方便主播的选取。
144.在一个实施例中,音频处理方法,还包括:
145.在观众的问题的语音播放后,采集主播的第二音频数据;
146.将第二音频数据输入预设的语音识别模型,获取第二信息;
147.将第二信息输入唤醒识别词识别模型中,进行识别;
148.当识别到预设的唤醒词时,再次进行观众问题的提取;预设的唤醒词包括:“进行下一个问题”、“让我看看下一个问题”等
149.在提取观众问题时,优先提取上一个问题的观众的问题。
150.上述技术方案的工作原理及有益效果为:
151.通过对同一个观众的问题进行追踪,提高了观众的互动体验;实现了互动观众与主播的隔空对话。
152.本发明还提供一种音频处理系统,包括:
153.第一音频获取模块,用于获取主播端的第一音频采集设备采集到主播的第一音频数据;
154.识别模块,用于将第一音频数据输入预设的语音识别模型,获取第一信息;
155.敏感度检测模块,用于对第一信息进行敏感度检测,确定敏感度;
156.拦截模块,用于当敏感度大于预设的敏感阈值时,将第一音频数据拦截。
157.在一个实施例中,音频处理系统,还包括:拦截记录模块;
158.拦截模块执行如下操作:
159.基于第一音频数据的拦截情况,生成拦截数据;
160.当主播端的第一音频采集设备和图像采集设备停止工作后,通过提醒设备输出拦截数据;
161.当接收主播对于拦截数据的点选,输出拦截数据的明细和与拦截数据相关的事例列表;
162.其中,拦截数据相关的事例列表通过如下步骤确定:
163.对拦截数据对应的第一音频数据进行特征提取,获取多个特征值;
164.基于特征值,构建调取特征集;
165.获取预设的事例库;
166.将调取特征集与事例库中的事例特征集进行匹配,确定调取特征集与各个事例特征集之间的第一匹配度;
167.提取第一匹配度大于预设的第一阈值的事例特征集对应的事例,将提取的各个事例按照匹配度从大到小的顺序排列,构建事例列表。
168.在一个实施例中,敏感度检测模块对第一信息进行敏感度检测,确定敏感度,执行如下操作:
169.基于预设的敏感词提取模板,对第一信息进行敏感词提取,确定敏感词提取模板中各个敏感词出现的次数;
170.基于敏感词提取模板中各个敏感词出现的次数,构建评价向量;
171.获取预设的评价库;
172.将评价向量与评价库中各个标准向量进行匹配,确定评价向量与各个标准向量之
间的第二匹配度;
173.当第二匹配度为评价库中最大且大于预设的第二阈值时,确定评价向量与标准向量匹配符合;
174.获取匹配符合的标准向量对应关联的敏感度。
175.在一个实施例中,音频处理系统,还包括:语音合成模块;
176.语音合成模块执行如下操作:
177.接收主播的互动问答的互动指令;
178.确定互动指令对应的互动模式;
179.解析互动模式,确定观众问题的提取方式;
180.当提取方式为随机提取时,对观众输入在直播间内公屏的信息进行识别筛选,构建问题集;
181.从问题集中随机挑选问题并输出至主播端的显示屏;
182.接收主播的确认或拒绝操作;
183.当为确认操作时,将问题进行语音合成处理,并输出;
184.当为拒绝操作时,重新从问题集中随机挑选问题输出至显示屏;直至主播的操作为确认操作;
185.当提取方式为手动挑选时,对观众输入在直播间内公屏的信息进行识别筛选,构建问题列表;
186.依据问题的提出时间和提出的观众的权限,对问题列表中的问题进行排序;
187.接收主播对于问题列表中的问题的点选,确定点选的问题;
188.将点选的问题进行语音合成处理,并输出;
189.其中,依据问题的提出时间和提出的观众的权限,对问题列表中的问题进行排序,包括:
190.确定问题的提出时间距离当前时刻的时间差值,基于时间差值,查询第一优先值对照表,确定时间差值对应的第一优先值;
191.基于问题的提出的观众的权限,查询第二优先值对照标,确定权限对应的第二优先值;
192.基于第一优先值和第二优先值的和值从大到小的顺序对问题列表中的问题进行排序。
193.在一个实施例中,语音合成模块还执行如下操作:
194.在观众的问题的语音播放后,采集主播的第二音频数据;
195.将第二音频数据输入预设的语音识别模型,获取第二信息;
196.将第二信息输入唤醒识别词识别模型中,进行识别;
197.当识别到预设的唤醒词时,再次进行观众问题的提取;
198.在提取观众问题时,优先提取上一个问题的观众的问题。
199.显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1