APP流行度预测模型构建方法、预测方法、设备及存储介质
app流行度预测模型构建方法、预测方法、设备及存储介质
技术领域
1.本发明属于大数据分析技术领域,尤其涉及一种app流行度预测模型构建方法、面向大规模城市用户的app流行度预测方法、智能设备及计算机可读存储介质。
背景技术:
2.随着蜂窝网络技术的飞速发展,网络的可获得性和网络的速率已经不再是限制用户通过手机沉浸式体验互联网的瓶颈,与此同时,各种不同类型的手机app相继出现,从全民皆宜的手机游戏、高清视频播放平台、到近几年飞速发展的短视频平台以及新兴的ar、vr应用,它们都让用户对于互联网的沉迷加深。而手机也早已超越了通信工具这一定义,成为用户生活中必不可少的重要工具。与之对应的是近些年手机流量的飞速式增长,根据中国互联网络信息中心2021年8月提供的报告显示,截止2021年6月,中国的手机网民规模达到了10.07亿,网民使用手机上网的比例为99.6%,仅2021年上半年,移动互联网接入流量就高达1033亿gb,同比增长38.7%,这与近些年电信领域的“提速降费”政策有关,用户可以以更加低廉的价格获得更多的流量。且中国国内市场上监测到的app数量为302万款,移动生态系统体量巨大,因此对于app使用模式的分析建模工作具有重要的意义。
3.以往对于大规模app测量分析建模工作,多使用的是app应用市场内的数据,以app的下载量、用户对app的评论和评分情况来进行分析建模。但是在以往的工作中发现,app市场内的下载量、评论、打分等数据都存在着造假行为,部分用户以恶意的方式下载app或者统一使用相似度很高的评论来让app的评分变高,让更多的用户看到这款app,从而达到在应用市场内推广app的效果。随着手机硬件的不断迭代发展,手机的内存、存储不断扩大,用户的手机内能下载存放的app越来越多,而用户实际经常使用的app其实只是一小部分,而剩余的app在手机内,随着实际经常使用的app一起更新,且研究表明,app的下载量总是在发布新版本的时候会有一次大量的增长,这就导致了用户对app的使用并没有增多,但是其应用市场内的下载量却一直在增长。而且以前的工作中,数据集并不包含用户的属性数据,数据不足以支撑从用户的角度来对app使用行为进行细粒度的分析和建模工作,所以对于app的测量分析工作,app在应用市场内的下载量、评论和评分这些指标已经不再适用。
技术实现要素:
4.本发明的目的在于提供一种app流行度预测模型构建方法、面向大规模城市用户的app流行度预测方法、智能设备及计算机可读存储介质,用以解决传统app应用市场内数据或指标(下载量、评论和评分)无法适用app使用行为分析,导致app使用行为分析结果不真实的问题。
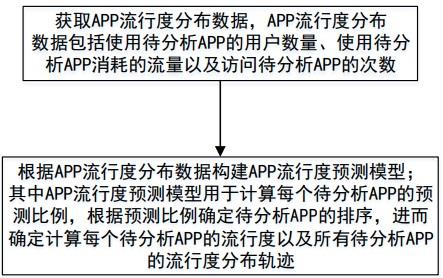
5.本发明是通过如下的技术方案来解决上述技术问题的:一种app流行度预测模型构建方法,包括以下步骤:获取app流行度分布数据,所述app流行度分布数据至少包括使用待分析app的用户数量、使用待分析app消耗的流量以及访问待分析app的次数中的一种;
根据所述app流行度分布数据构建app流行度预测模型,其中所述app流行度预测模型用于计算每个待分析app的预测比例,进而计算每个待分析app的流行度以及所有待分析app的流行度分布轨迹;其中所述预测比例为预测用户比例、预测流量比例和预测访问次数比例中的至少一种。
6.进一步地,所述app流行度预测模型的具体表达式为:f(n)=a
×e(b
×
n)
+c
×e(d
×
n)
其中,f(n)为待分析app的预测用户比例、预测流量比例或预测访问次数比例;n为按照真实用户比例、真实流量比例或真实访问次数比例降序排序后,待分析app的排名,所述真实用户比例是根据app流行度分布数据中的使用待分析app的用户数量计算得到,所述真实流量比例是根据app流行度分布数据中的使用待分析app消耗的流量计算得到,所述真实访问次数比例是根据app流行度分布数据中的访问待分析app的次数计算得到;a、b、c和d分别为app流行度预测模型的系数,系数a、b、c和d是将多组真实比例和对应的排名代入app流行度预测模型中来确定的。
7.进一步地,当所述app流行度分布数据为使用待分析app的用户数量时,所述app流行度预测模型的具体表达式为:f(n)=0.9792
×
e-0.02919n
+0.0637
×
e-0.005921n
其中,f(n)为待分析app的预测用户比例,n为按照真实用户比例降序排序后,待分析app的排名,真实用户比例等于使用该待分析app的用户数量与使用所有待分析app的用户总量之比。
8.进一步地,当所述app流行度分布数据为使用待分析app消耗的流量时,所述app流行度预测模型的具体表达式为:f(n)=0.4052
×
e-0.4716n
+0.02729
×
e-0.08452n
其中,f(n)为待分析app的预测流量比例,n为按照真实流量比例降序排序后,待分析app的排名,真实流量比例等于使用该待分析app消耗的流量与使用所有待分析app消耗的流量总量之比。
9.进一步地,当所述app流行度分布数据为访问待分析app的次数时,所述app流行度预测模型的具体表达式为:f(n)=0.7627
×
e-1.1n
+0.06057
×
e-0.1033n
其中,f(n)为待分析app的预测访问次数比例,n为按照真实访问次数比例降序排序后,待分析app的排名,真实访问次数比例等于访问该待分析app的次数与访问所有待分析app的次数总量之比。
10.基于同一发明构思,本发明还提供一种面向大规模城市用户的app流行度预测方法,包括以下步骤:获取城市的app流行度分布数据,利用如上所述app流行度预测模型构建方法构建该城市的app流行度预测模型;获取该城市所有待预测app的排名,根据待预测app的排名和所述app流行度预测模型计算出每个待预测app的预测比例;根据该城市每个待预测app的预测比例计算每个待预测app的流行度,进而计算所有待预测app的流行度分布轨迹。
11.进一步地,所述预测方法还包括:获取该城市的人口数量,根据所述人口数量和待预测app的预测比例计算出该待预测app的用户量流行度。
12.进一步地,所述待预测app的用户量流行度的计算公式为:m=f(n)
×
p其中,p为该城市的人口数量,f(n)为待预测app的预测比例,m为待预测app的用户量流行度。
13.基于同一发明构思,本发明还提供一种智能设备,所述设备包括:存储器,用于存储计算机程序;处理器,用于执行所述计算机程序时实现上述任一项所述的app流行度预测模型构建方法的步骤,或实现上述任一项所述的面向大规模城市用户的app流行度预测方法的步骤。
14.基于同一发明构思,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一项所述的app流行度预测模型构建方法的步骤,或实现上述任一项所述的面向大规模城市用户的app流行度预测方法的步骤。
15.有益效果与现有技术相比,本发明的优点在于:本发明所提供的一种app流行度预测模型构建方法、面向大规模城市用户的app流行度预测方法、智能设备及计算机可读存储介质,利用运营商数据(即app流行度分布数据)和指数函数来构建app流行度预测模型,构建的app流行度预测模型可以预测用户比例、流量比例以及访问次数比例,进而可以确定app的流行度以及流行度分布轨迹;相对于传统的使用app应用市场内数据或指标(例如下载量、评论和评分)来评价或分析app使用行为,本发明具有更高的真实性,提高了app流行度分析结果的准确性。
附图说明
16.为了更清楚地说明本发明的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一个实施例,对于本领域普通技术人员来说,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
17.图1是本发明优选实施例中app流行度预测模型构建方法流程图;图2是本发明优选实施例的排名前k的app合集之间杰卡德距离的示意图;图3是本发明优选实施例的流行度分布情况的cdf图;图4(a)是本发明优选实施例的流量比例和访问次数比例排名最前app资源占比图;图4(b)是本发明优选实施例的用户比例排名最前app资源占比图;图5(a)是本发明优选实施例的app流行度分布形状示意图;图5(b)是本发明优选实施例的app流行度分布形状与zipf分布形状对比示意图;图6(a)是本发明优选实施例的用户性别属性下app流行度分布cdf图;图6(b)是本发明优选实施例的用户年龄属性下app流行度分布cdf图;
图7是本发明优选实施例的不同年龄段用户app流行度分布的kl散度热力图;图8(a)是本发明优选实施例的城市a的app流行度分布kl散度热力图;图8(b)是本发明优选实施例的城市e的app流行度分布kl散度热力图;图8(c)是本发明优选实施例的城市j的app流行度分布kl散度热力图;图8(d)是本发明优选实施例的城市n的app流行度分布kl散度热力图;图9(a)是本发明优选实施例的2020年12月app流行度分布kl散度热力图;图9(b)是本发明优选实施例的2021年1月app流行度分布kl散度热力图;图9(c)是本发明优选实施例的2021年2月app流行度分布kl散度热力图;图10(a)是本发明优选实施例的不同数量用户app流量比例分布示意图;图10(b)是本发明优选实施例的不同数量用户app流行度分布与一千万用户app流行度分布的kl散度示意图;图10(c)是本发明优选实施例的不同数量用户平均流量示意图;图11(a)是本发明优选实施例的用户比例拟合效果示意图;图11(b)是本发明优选实施例的流量比例拟合效果示意图;图11(c)是本发明优选实施例的访问次数比例拟合效果示意图;图12(a)是本发明优选实施例的第一组实验用四种方法生成用户量的相对误差cdf图;图12(b)是本发明优选实施例的第一组实验用四种方法生成流量的相对误差cdf图;图12(c)是本发明优选实施例的第一组实验用四种方法生成访问次数的相对误差cdf图;图13(a)是本发明优选实施例的第一组实验用四种方法生成用户量的四种评价指标对比图;图13(b)是本发明优选实施例的第一组实验用四种方法生成流量的四种评价指标对比图;图13(c)是本发明优选实施例的第一组实验用四种方法生成访问次数的四种评价指标对比图;图14(a)是本发明优选实施例的第一组实验用四种方法生成用户量在不同城市的平均相对误差对比图;图14(b)是本发明优选实施例的用四种方法生成流量在不同城市的平均相对误差对比图;图14(c)是本发明优选实施例的用四种方法生成访问次数在不同城市的平均相对误差对比图;图15(a)是本发明优选实施例的第二组实验用四种方法生成用户量的相对误差cdf图;图15(b)是本发明优选实施例的第二组实验用四种方法生成用户量的四种评价指标对比图;图15(c)是本发明优选实施例的第二组实验用四种方法生成用户量在不同城市的平均相对误差对比图。
具体实施方式
18.下面结合本发明实施例中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
19.下面以具体地实施例对本技术的技术方案进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例不再赘述。
20.如图1所示,本发明实施例所提供的一种app流行度预测模型构建方法,包括以下步骤:步骤1:获取app流行度分布数据,所述app流行度分布数据包括使用待分析app的用户数量、使用待分析app消耗的流量以及访问待分析app的次数。
21.为了更好地评价或分析app的使用情况,本发明尝试使用一种更细粒度的数据,以求更真实地体现app被使用的情况,为此本实施例选用运营商数据,即使用app的用户数量、使用app消耗的流量以及访问app的次数,符合更细粒度的数据要求。
22.运营商数据的来源为基站,当用户使用流量访问网络时,基站会记录下该条网络访问的具体信息,也就是用户的上网日志信息。具体来说,可以通过运营商数据得知:在某个月(month_id),用户(user_id)在某个app(app_third_label)上使用了多少流量(app_consume_gps);该app有多少次的网络访问次数(app_use_time);该app有多个用户使用。还可以结合用户的属性表,得知用户的性别、年龄和套餐情况等,因此,本发明还可以获取app应用市场数据以外的细粒度数据,以支撑对app的使用模式从用户角度进行细粒度的分析和建模。
23.示例性的,从某个城市的电信运营商处可以得到:该城市使用的app的数量为3137个,每个app的用户数量(即使用某个app的用户数量)、消耗流量(即使用某个app消耗的流量)以及访问次数(即访问某个app的次数),根据这3137个app的流行度分布数据来构建app流行度预测模型。
24.步骤2:根据所述app流行度分布数据构建app流行度预测模型,其中所述app流行度预测模型用于计算每个待分析app的预测比例,进而计算每个待分析app的流行度以及所有待分析app的流行度分布轨迹。
25.本实施例中,利用指数函数来构建app流行度预测模型,具体表达式为:f(n)=a
×e(b
×
n)
+c
×e(d
×
n)
(1)其中,f(n)为待分析app的预测用户比例、预测流量比例或预测访问次数比例;n为按照真实用户比例、真实流量比例或真实访问次数比例降序排序后,待分析app的排名,所述真实用户比例是根据app流行度分布数据中的使用待分析app的用户数量计算得到,所述真实流量比例是根据app流行度分布数据中的使用待分析app消耗的流量计算得到,所述真实访问次数比例是根据app流行度分布数据中的访问待分析app的次数计算得到;a、b、c和d分别为app流行度预测模型的系数,系数a、b、c和d是将多组真实比例和对应的排名代入app流行度预测模型中来确定的。
26.具体地,当所述app流行度分布数据为使用待分析app的用户数量时,所述app流行度预测模型的具体表达式为:
f(n)=0.9792
×
e-0.02919n
+0.0637
×
e-0.005921n
(2)其中,f(n)为待分析app的预测用户比例,n为按照真实用户比例降序排序后,待分析app的排名,真实用户比例等于使用该待分析app的用户数量与使用所有待分析app的用户总量之比。
27.示例性的,从运营商处获得3137个app中每个app的用户数量,则可以根据每个app的用户数量计算出每个app的真实用户比例,即真实用户比例等于某个app的用户数量除以3137个app的用户总量;对每个app的真实用户比例进行降序排序,可以得到每个app的排名;在matlab中,将每个app的排名以及该app的真实用户比例代入至式(1)中,通过拟合即可得到式(1)的系数a、b、c和d的具体值。本实施例中,当app流行度分布数据为使用待分析app的用户数量时,系数a、b、c和d的具体值如式(2)所示。
28.具体地,当所述app流行度分布数据为使用待分析app消耗的流量时,所述app流行度预测模型的具体表达式为:f(n)=0.4052
×
e-0.4716n
+0.02729
×
e-0.08452n
(3)其中,f(n)为待分析app的预测流量比例,n为按照真实流量比例降序排序后,待分析app的排名,真实流量比例等于使用该待分析app消耗的流量与使用所有待分析app消耗的流量总量之比。
29.当所述app流行度分布数据为使用待分析app消耗的流量时,式(1)的系数a、b、c和d的确定方式与app流行度分布数据为使用待分析app的用户数量时一致,具体值如式(3)所示,在此不再赘述。
30.具体地,当所述app流行度分布数据为访问待分析app的次数时,所述app流行度预测模型的具体表达式为:f(n)=0.7627
×
e-1.1n
+0.06057
×
e-0.1033n
(4)其中,f(n)为待分析app的预测访问次数比例,n为按照真实访问次数比例降序排序后,待分析app的排名,真实访问次数比例等于访问该待分析app的次数与访问所有待分析app的次数总量之比。
31.当所述app流行度分布数据为访问待分析app的次数时,式(1)的系数a、b、c和d的确定方式与app流行度分布数据为使用待分析app的用户数量时一致,具体值如式(4)所示,在此不再赘述。
32.由于隐私原因,一些公开的报告中并不会公开app的用户数量、消耗流量和访问次数等,通常仅公开所有app的用户总量、消耗流量总量和访问次数总量,因此无法获知某个排名的app的具体使用数据(用户数量、消耗流量和访问次数)。本发明根据各app的流行度分布数据构建app流行度预测模型,将某个排名app的排名输入至该app流行度预测模型中,即可得到该app的具体使用数据。
33.流行度是指app的流行程度,是衡量app使用行为的一种指标,本发明采用用户数量、消耗流量以及访问次数来评价流行度。app流行度分布也可以称为app使用轨迹,可以是具体值,也可以是比例值,app流行度分布在分析分布时采用,突出app的流行程度;app使用轨迹在分析不同因素对app使用的影响时采用,突出app被使用的程度。根据某个app的排名和本发明的app流行度预测模型可以计算出该app的预测用户比例、预测流量比例和预测访问次数比例,将这些预测比例乘以对应的总量(即所有app的用户总量、消耗流量总量以及
访问次数总量)即可得到该app的流行度,所有app的流行度的集合即为流行度分布轨迹。
34.示例性的,利用app流行度预测模型计算出所有app的预测流量比例,再计算所有app的预测消耗流量,则得到某个城市以消耗流量为评价或分析指标的所有app流行度分布轨迹如{32gb, 21gb,
ꢀ……
, 0.4gb}。
35.用户的属性表中有较多维度,如用户的年龄、性别、套餐价格、套餐流量等,挑选其中较为代表性的年龄和性别属性进行研究分析。具体来说,首先将用户按照性别分成两组,然后分别单独计算每组内使用的app的用户比例、流量比例和访问次数比例用于分析;对用户的年龄属性使用类似的处理方式,即将用户按照年龄分成四组,分别计算每组内使用的app的用户比例、流量比例和访问次数比例,用于后续的研究分析。
36.与以往研究采用应用市场内的下载量、用户评分、评价数据不同,本发明采用三种更加具有代表性的指标来刻画app流行度:使用该app的用户数量、app消耗的流量以及访问app的次数,这三个指标可以更好地表征app给开发者、运营商、广告商将带来多少收入。由于在不同的城市和时间上,三个指标在绝对值上会有很明显的差距,因此为了更加直观地测量不同app的流行度,采用三种指标的比例来进行测量分析,具体来说分别是:用户比例user_ratioi,流量比例traffic_ratioi,访问次数比例frequency_ratioi,具体的计算方法如下:其中,i是app的下标,n是app的总数。另外,ui代表使用第i个appi的用户数量,u代表所有app用户总数,ti代表appi消耗的流量,t代表所有app消耗的流量总量,fi代表appi的访问次数,f代表所有app的访问次数总量。这里需要注意,不同于traffic_ratioi和frequency_ratioi,所有user_ratioi之和大于1,因为一个用户可以使用很多个app。
37.不同指标对app流行度的影响:采用杰卡德距离来计算按照不同指标排序的app集合的距离,ak(user)、ak(tra)、ak(fre)分别代表按照用户比例、流量比例和访问次数比例排序后的top-k app集合(按照某种指标降序排序后的前k个app集合),两个集合之间的杰卡德距离j计算公式如下:图2显示了不同的k值下,不同的app集合的杰卡德距离变化情况,可以看到,ak(user)和ak(tra)两个集合的杰卡德距离随着k的变化在0.4到0.5之间变化;ak(tra)和ak(user)两个集合的距离不论k的大小,都一直大于0.5;三组关系(即ak(user)和ak(tra)、ak(tra)和ak(fre)、ak(user)和ak(fre))中,两组关系会随着k的增大而距离变小,但是流量和访问次数的app集合之间的杰卡德距离(ak(tra)和ak(fre))没有这个趋势,这条曲线一直在0.4到0.5之间波动。
38.killer app现象:探究在不同的指标下,app流行度的整体分布情况。图3是三种不同指标下app流行
度的cdf图(即累积分布图)。首先,不同app的流行度有很大的差异,比如在流量和网络访问次数上,不同app的流行度值范围从10-12
到10-1
,差距非常大;其次是存在killer app现象,即排名前几的app占用了大量的资源,具体来说,图4(a)、图4(b)是流量比例和访问次数比例、用户比例下top-app流行度的柱状图,可以看到top-3、top-5、top-10app分别消耗了56.8%,70%和82.7%的流量资源以及45.1%、53.7%、65.7%的访问次数资源。
39.不是zipf分布:在以往的工作中,app在应用市场内的流行度是以app的下载量来衡量的,而以此为衡量指标的下载量呈现出zipf分布,而在各指标下,即在活跃用户量、消耗流量、访问次数下,app的流行度并不服从zipf分布。图5(a)是三种不同指标下app整体流行度分布情况的ccdf图(即互补累积分布图),可以从图5(b)看到和zipf分布在ccdf图中所表现出来的直线有明显差别,因此在三种指标下,app的流行度不再服从zipf分布。
40.上下文对app使用的影响:细粒度的app使用建模对于精确的服务供应非常重要,因此将研究上下文对应用程序使用的影响。实验显示,不论是用户属性(性别、年龄),还是时间和地点,对于app流行度的整体分布情况的影响都是微小的。
41.人口统计学的影响:首先探讨人口特征的影响,例如性别和年龄,其中年龄分布在四个范围内,分别为16-25、26-40、41-60和61-80。图6(a)显示了app流量比例按性别划分的cdf,可以观察到,男性和女性用户在微观层面上的app使用行为几乎相同,曲线非常接近。图6(b)显示了app流量比例在不同年龄的cdf,可以得出类似的观察结果,不同年龄的用户app流行度几乎相同,其中所有cdf曲线紧密交织。更具体地说,26-40和41-60用户更积极地使用app,并且流量分布较小。为了准确测量流行度分布差异,采用了kullback
–
leibler(kl)散度,即相对熵,表示为,其计算公式为:其中,p和q是两组具有相同概率空间x的离散概率分布,对男性和女性的分布m和f,kl散度d
kl
(f
tra
||m
tra
)、d
kl
(f
fre
||m
fre
)、d
kl
(f
user
||m
user
)分别为0.0065、0.0043、0.0054,进一步证明了性别对于app流行分布情况的影响是轻微的。图7显示了流量指标下用户不同年龄段之前流行度分布情况的kl散度,可以看到这些值都非常小,不超过0.08。因此可以得出结论,人口统计学的影响是微不足道的,因为不同性别和年龄的用户在微观层面上几乎有相同的app使用行为,即app的流行度分布几乎相同。
42.时间的影响:为了探究app流行度分布情况是否会随着时间变化,选择一些典型的城市来检查宏观上时间对于app使用模式的影响,图8(a)~图8(d)展示了在流量比例下,四个城市在不同月份的app使用模式之间的kl散度情况,其中a城市是该省人口最多的省会城市,e和j是两个中等城市,n是我国著名的旅游城市之一。可以得到以下两个结论:首先,对于所有城市来说,时间kl距离都很小,都普遍小于0.04,所有结果都不超过0.09,这表明app流行度在时间上似乎没有明显的变化;其次,与其他月份相比,2021年02月份的流行度与其他月份的kl距离在所有城市中都较为明显。例如,2020年11月和2020年12月份的kl散度值很小,不超过
0.01,而2021年02月份的值在0.05到0.09之间。这种现象的发生是因为2021年02月份包含春节,在这期间,全国有大量人口进行迁移,这可能会影响app的使用行为。尽管如此,在时间维度,kl散度的值都比较小,时间对app流行度的影响轻微。
43.空间的影响:用来自某省14个城市的app使用数据探讨空间的影响,即app在不同城市的流行度的差异。图9(a)~图9(c)显示了不同城市流量比例分布之间的kl散度,并给出了2020年12月、2021年01月和2021年02月三个月的结果。由图9(a)~图9(c)可以获得类似的结论:首先,对于所有月份,任何两个城市之间的kl差异都很小,所有值都小于0.05,表明空间的影响可以忽略不计;此外,通过观察每一列,可以看到城市a与其他城市的kl差异最小,而k、l、n市与其他城市的kl差异较大,这可能是由于人口数量问题。因此,可以得出结论,app在拥有大量用户的不同城市中的流行度分布几乎相同。
44.宏观app使用模式的建模:由于隐私方面的原因,相关部门无法直接公布app流行度分布数据,但是前面已经论述过app流行度分布的价值所在,所以在实施例对宏观应用程序使用进行数学建模,然后基于此设计轻量级跟踪合成方案,从而将合成的轨迹数据加以公开,达到保护隐私且为各方提供数据的目的。
45.由上述分析可知上下文对app流行度分布的影响很小,这促使进一步探究app流行度分布形状。具体来说,随机选择0.1k(千)、1k、5k、100k、5m(百万)、7m、8m、9m、10m 用户,并使用12月份的数据计算用户数量在流量比例下的流行度分布的kl距离。图10(a)描绘了在不同用户数量下app使用流量比例ccdf图,可以得出以下结论:无论用户数量多少,所有流行度分布曲线都具有相似的形状,其中只有少数app占据大量的资源,而其余大部分app的比例很小。图10(b)展示了随着用户数量的改变,app流行度的分布情况与10m用户量情况下流行度分布情况的kl散度的变化趋势,可以明显看到,随着用户量的增加,其分布的kl散度明显减小,即流行度分布情况趋于相同。图10(c)是用户平均使用流量情况随着用户数量的变化而变化的折线图,可以得到:用户量较少的情况下,人均使用流量不稳定,会有很大的波动,而随着用户量达到一定数量(图10(c)中为5m),人均使用流量趋于稳定,为6g左右。可以解释为,当用户数量相对较大时,大多数用户的一般使用行为会占主导地位,而少量用户所造成的随机效应可能是边际效应。
46.轻量级轨迹合成:对于市场使用或理论研究而言,获取app流行度分布是基础,即每个应用程序可以拥有多少用户、多少流量以及多少访问次数,但由于隐私和商业问题,通常无法直接得到。基于的分析结果,本发明设计一种称为lts的轻量轨迹合成方案,用于合成宏观app流行度分布。本实施例,使用指数函数来拟合相关轨迹,如式(1);用户量比例、流量比例以及访问次数比例三个指标下,得到不同的拟合参数如式(2)~(4)。
47.给定top-n应用列表,a={app1, app
2 , app3,
…
},a为app集合,在用户总量/消耗流量总量/访问次数总量为p时:按照用户数量排名,app用户数量的轨迹u={u1, u
2 ,u3,
…
},每个app用户数量ui= f
user
(ni)
×
p;按照消耗流量排名,app消耗流量的轨迹,t={tra1, tra
2 , tra3,
…
},每个app消
耗流量trai=f
tra
(ni)
×
p;按照访问次数排名,app的访问次数的轨迹,f={fre1,fre2,fre3,
…
},每个app访问次数frei=f
fre
(ni)
×
p。
48.使用以上预测模型进行轨迹的合成,在评价指标sse、rmse、r-square、adjustedr-square上都优于幂律分布的拟合效果,拟合效果如图11(a)~图11(c)所示。
49.为了评估预测模型拟合的性能效果,使用2020年11月至2021年2月收集的数据,覆盖了1900多万用户,涉及3137个应用程序。具体来说,设计了两组实验来评估模型的性能:首先,通过每个城市当月的app流行度分布来生成各自城市当月的app流行度分布并评估合成城市规模app流行度分布的整体效果,其中每个城市都有人口信息和app流行度分布数据;其次,通过从随机挑选某个城市来生成其他目标城市当月的app流行度分布,来检验所提出的预测模型在拟合城市规模app流行度分布任务上的鲁棒性。使用python进行开发,并基于pytorch实现核心功能。实验在一台拥有4个cpu的服务器上进行,每个cpu包含192个intel(r)xeon(r)platinum8260cpu@2.40ghz,24核,使用一个图形处理单元卡(nvidiatianx)加速培训过程。
50.对照实验:lstm是递归神经网络的一种变体,广泛用于捕获长短期时间相关性,并从过去的数据预测未来数据。
51.gan是一种用于数据生成的常见深度学习模型,它由两个相互竞争的神经网络实现。
52.zipf是以往工作中常用与建模app流行度的分布。
53.评价指标和分别代表原始数据x和推断数据位于第i位值,其中1≤i≤n,n代表app的总数。为了进行性能比较,采用了以下五个指标,这是用于评估预测性能的最流行的指标。
54.相对误差(re):指每个原始值和推断值之间的相对误差,计算公式为。
55.误差平方和(sse):指原始值和推断值之间的误差平方和,计算公式为。
56.均方根误差(rmse):是指原始数据值与预测值之间的差值的标准偏差,计算公式为。
57.•
r2:是回归模型中的统计度量,表征了自变量可以解释的因变量中的方差比例,计算公式为,其中,,。
58.•
adjustedr2:是r-square的改进版本,通过考虑其他独立变量的影响,增加了精度和可靠性,这些独立变量往往会歪曲r-squared测量的结果,其计算公式为
,其中r2是回归模型中的统计度量,n是总样本量,以及p是自变量的数量。
59.基于同一发明构思,本发明实施例还提供一种面向大规模城市用户的app流行度预测方法,包括以下步骤:步骤1:获取城市的app流行度分布数据,利用如上所述app流行度预测模型构建方法构建该城市的app流行度预测模型,如式(1)~(4);步骤2:获取该城市所有待预测app的排名,根据待预测app的排名和所述app流行度预测模型计算出每个待预测app的预测比例;步骤3:根据该城市每个待预测app的预测比例计算每个待预测app的流行度,进而计算所有待预测app的流行度分布轨迹;步骤4:获取该城市的人口数量,根据所述人口数量和待预测app的预测比例计算出该待预测app的用户量流行度,由所有app的用户量流行度生成城市级别的app流行度分布轨迹。
60.给定top-n应用列表,a={app1,app2,app3,
…
},a为app集合,在用户总量/消耗流量总量/访问次数总量为p时:按照用户数量排名,app用户数量的轨迹u={u1,u2,u3,
…
},每个app用户数量ui=f
user
(ni)
×
p;按照消耗流量排名,app消耗流量的轨迹,t={tra1,tra2,tra3,
…
},每个app消耗流量trai=f
tra
(ni)
×
p;按照访问次数排名,app的访问次数的轨迹,f={fre1,fre2,fre3,
…
},每个app访问次数frei=f
fre
(ni)
×
p。
61.使用数学公式(fit)、lstm、gan、zipf分别对用户量、流量、访问次数进行轨迹的生成或预测实验。进行了两组实验,首先,通过每个城市的流行度分布生成各自的app流行度分布,实验的效果如图12(a)~图12(c)、图13(a)~图13(c)、图14(a)~图14(c)所示,图12(a)~图12(c)展示了不同方法在生成app流行度分布时相对误差的cdf图(图12(b)中lstm和gan重合),图13(a)~图13(c)展示了不同方法生成数据的评价指标sse、rmse、r2、adjustedr2的效果对比,图14(a)~图14(c)展示了在不同城市,不同方法的相对误差均值的分布情况,可以看到,不论在哪种维度下,本发明的预测模型都要优于另外两种方法。
62.图15(a)~图15(c)为使用随机挑选城市当月app流行度分布(和用户量)生成其他目标城市当月轨迹的性能对比图,可以得到同样的结论,因此本发明的预测模型在时间上仍然具有鲁棒性。
63.以上所揭露的仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或变型,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1