基于语音驱动数字人模型的视频生成方法及系统与流程
本发明涉及图像处理,尤其涉及的是一种基于语音驱动数字人模型的视频生成方法及系统。
背景技术:
1、随着科学技术的发展,尤其是图像处理和视频处理技术的发展,用户对于图像处理和视频处理的要求也越来越高。例如,一种需求为由第一用户进行讲话,以驱动第二用户的脸进行同样的讲话,即生成第二用户进行同样讲话的视频。
2、现有技术中,通常拍摄第一用户和第二用户的讲话视频,然后对视频进行逐帧处理,对于视频中的每一帧图像,将第一用户和第二用户的图像中嘴部区域进行截取和替换。现有技术的问题在于,必须采集第一用户对应的视频,无法直接通过采集的语音实现视频生成,不利于提高视频生成的便利性。同时,直接对两个用户的图像(或视频)进行嘴部区域的替换,替换后的第二用户所对应的图像中的嘴部区域的图像实际仍是第一用户的嘴部区域的图像,实际上没有达到用第一用户的语音驱动第二用户进行同样讲话的目的,不利于提高语音驱动的视频的生成效果。并且,直接替换后生成的第二用户对应的视频中嘴部区域与脸部其它区域并不能很好的匹配,即不利于提高生成的视频的展示效果。
3、因此,现有技术还有待改进和发展。
技术实现思路
1、本发明的主要目的在于提供一种基于语音驱动数字人模型的视频生成方法及系统,旨在解决现有技术中只通过对两个用户的视频中每一帧图像中嘴部区域进行截取和替换的视频处理方案不利于提高视频生成的便利性,且不利于提高语音驱动的视频的生成效果和展示效果的问题。
2、为了实现上述目的,本发明第一方面提供一种基于语音驱动数字人模型的视频生成方法,其中,上述基于语音驱动数字人模型的视频生成方法包括:
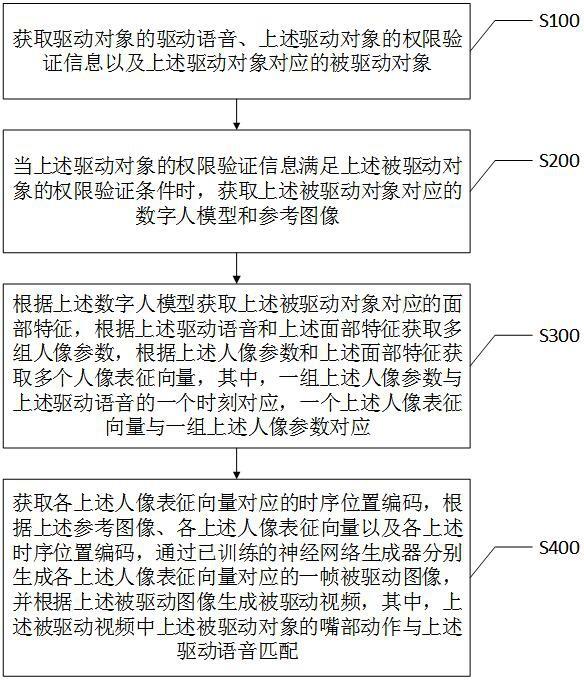
3、获取驱动对象的驱动语音、上述驱动对象的权限验证信息以及上述驱动对象对应的被驱动对象;
4、当上述驱动对象的权限验证信息满足上述被驱动对象的权限验证条件时,获取上述被驱动对象对应的数字人模型和参考图像;
5、根据上述数字人模型获取上述被驱动对象对应的面部特征,根据上述驱动语音和上述面部特征获取多组人像参数,根据上述人像参数和上述面部特征生成多个人像表征向量,其中,一组上述人像参数与上述驱动语音的一个时刻对应,一个上述人像表征向量与一组上述人像参数对应;
6、获取各上述人像表征向量对应的时序位置编码,根据上述参考图像、各上述人像表征向量以及各上述时序位置编码,通过已训练的神经网络生成器分别生成各上述人像表征向量对应的一帧被驱动图像,并根据上述被驱动图像生成被驱动视频,其中,上述被驱动视频中上述被驱动对象的嘴部动作与上述驱动语音匹配。
7、可选的,上述根据上述驱动语音和上述面部特征获取多组人像参数,根据上述人像参数和上述面部特征生成多个人像表征向量,包括:
8、根据上述驱动语音提取获得多个时刻对应的语音信息;
9、根据上述语音信息和上述面部特征获取多个参数估计数据,其中,一个参数估计数据包括上述面部特征和一个时刻对应的语音信息;
10、分别将各上述参数估计数据输入已训练的语音驱动数字化身参数估计神经网络以分别获取各上述参数估计数据对应的一组人像参数;
11、根据上述人像参数和上述面部特征,分别生成各组上述人像参数对应的人像表征向量。
12、可选的,上述人像参数包括人脸关键点参数、肩部关键点参数和头部姿态。
13、可选的,上述语音驱动数字化身参数估计神经网络根据如下步骤进行训练:
14、将参数估计训练数据中的训练参数估计数据输入上述语音驱动数字化身参数估计神经网络,通过上述语音驱动数字化身参数估计神经网络生成上述训练参数估计数据对应的训练人像参数,其中,上述参数估计训练数据包括多组参数估计训练信息组,每一组参数估计训练信息组包括训练参数估计数据和标注人像参数;
15、根据上述训练人像参数和上述标注人像参数,对上述语音驱动数字化身参数估计神经网络的网络参数进行调整,并继续执行上述将参数估计训练数据中的训练参数估计数据输入上述语音驱动数字化身参数估计神经网络的步骤,直至满足第一预设训练条件,以得到已训练的语音驱动数字化身参数估计神经网络。
16、可选的,上述根据上述人像参数和上述面部特征,分别生成各组上述人像参数对应的人像表征向量,包括:
17、根据所有上述人脸关键点参数和上述面部特征获取多个待优化数据,其中,一个上述待优化数据包括上述面部特征和一个上述人脸关键点参数;
18、分别将各上述待优化数据输入已训练的三维关键点调优神经网络以分别获取各上述待优化数据对应的人脸网格点优化数据;
19、根据各组对应的人脸网格点优化数据、肩部关键点参数和头部姿态分别获取各上述人像表征向量。
20、可选的,任意一个人像表征向量根据如下步骤获得:
21、获取一组对应的人脸网格点优化数据、肩部关键点参数和头部姿态;
22、根据预设的投影函数对第一乘积进行投影获得面部二维图像表征向量,其中,上述第一乘积由上述人脸网格点优化数据和上述头部姿态点乘获得;
23、根据上述投影函数对上述肩部关键点进行投影获得肩部二维图像表征向量;
24、将上述面部二维图像表征向量和上述肩部二维图像表征向量相加获得上述人像表征向量。
25、可选的,上述三维关键点调优神经网络根据如下步骤进行训练:
26、将调优训练数据中的训练待优化数据输入上述三维关键点调优神经网络,通过上述三维关键点调优神经网络生成上述训练待优化数据对应的训练人脸网格点优化数据,其中,上述调优训练数据包括多组调优训练信息组,每一组调优训练信息组包括训练待优化数据和标注人脸网格点优化数据;
27、根据上述训练人脸网格点优化数据和上述标注人脸网格点优化数据,对上述三维关键点调优神经网络的网络参数进行调整,并继续执行上述将调优训练数据中的训练待优化数据输入上述三维关键点调优神经网络的步骤,直至满足第二预设训练条件,以得到已训练的三维关键点调优神经网络。
28、可选的,上述神经网络生成器根据如下步骤进行训练:
29、将第三训练数据中的训练参考图像、训练人像表征向量和训练时序位置编码输入上述神经网络生成器,通过上述神经网络生成器生成对应的一帧训练被驱动图像,其中,上述第三训练数据包括多组第三训练信息组,每一组第三训练信息组包括训练参考图像、训练人像表征向量、训练时序位置编码和训练真实图像,上述训练人像表征向量根据上述训练真实图像获得;
30、根据上述训练被驱动图像和上述训练真实图像,对上述神经网络生成器的网络参数进行调整,并继续执行上述将第三训练数据中的训练参考图像、训练人像表征向量和训练时序位置编码输入上述神经网络生成器的步骤,直至满足第三预设训练条件,以获得已训练的神经网络生成器。
31、可选的,上述参考图像用于为上述已训练的神经网络生成器提供上述被驱动对象对应的图像纹理细节,上述被驱动图像与上述参考图像的图像纹理细节相同,上述时序位置编码用于为上述已训练的神经网络生成器提供时间信息。
32、本发明第二方面提供一种基于语音驱动数字人模型的视频生成系统,其中,上述基于语音驱动数字人模型的视频生成系统包括:
33、数据获取模块,用于获取驱动对象的驱动语音、上述驱动对象的权限验证信息以及上述驱动对象对应的被驱动对象;
34、权限验证模块,用于当上述驱动对象的权限验证信息满足上述被驱动对象的权限验证条件时,获取上述被驱动对象对应的数字人模型和参考图像;
35、数据处理模块,用于根据上述数字人模型获取上述被驱动对象对应的面部特征,根据上述驱动语音和上述面部特征获取多组人像参数,根据上述人像参数和上述面部特征生成多个人像表征向量,其中,一组上述人像参数与上述驱动语音的一个时刻对应,一个上述人像表征向量与一组上述人像参数对应;
36、视频生成模块,用于获取各上述人像表征向量对应的时序位置编码,根据上述参考图像、各上述人像表征向量以及各上述时序位置编码,通过已训练的神经网络生成器分别生成各上述人像表征向量对应的一帧被驱动图像,并根据上述被驱动图像生成被驱动视频,其中,上述被驱动视频中上述被驱动对象的嘴部动作与上述驱动语音匹配。
37、本发明第三方面提供一种智能终端,上述智能终端包括存储器、处理器以及存储在上述存储器上并可在上述处理器上运行的基于语音驱动数字人模型的视频生成程序,上述基于语音驱动数字人模型的视频生成程序被上述处理器执行时实现上述任意一种基于语音驱动数字人模型的视频生成方法的步骤。
38、本发明第四方面提供一种计算机可读存储介质,上述计算机可读存储介质上存储有基于语音驱动数字人模型的视频生成程序,上述基于语音驱动数字人模型的视频生成程序被处理器执行时实现上述任意一种基于语音驱动数字人模型的视频生成方法的步骤。
39、由上可见,本发明方案中,获取驱动对象的驱动语音、上述驱动对象的权限验证信息以及上述驱动对象对应的被驱动对象;当上述驱动对象的权限验证信息满足上述被驱动对象的权限验证条件时,获取上述被驱动对象对应的数字人模型和参考图像;根据上述数字人模型获取上述被驱动对象对应的面部特征,根据上述驱动语音和上述面部特征获取多组人像参数,根据上述人像参数和上述面部特征生成多个人像表征向量,其中,一组上述人像参数与上述驱动语音的一个时刻对应,一个上述人像表征向量与一组上述人像参数对应;获取各上述人像表征向量对应的时序位置编码,根据上述参考图像、各上述人像表征向量以及各上述时序位置编码,通过已训练的神经网络生成器分别生成各上述人像表征向量对应的一帧被驱动图像,并根据上述被驱动图像生成被驱动视频,其中,上述被驱动视频中上述被驱动对象的嘴部动作与上述驱动语音匹配。
40、与现有技术中相比,本发明方案并不需要采集驱动对象对应的视频,而只需要采集驱动对象的驱动语音,有利于提高视频生成的便利性。同时,本发明方案并不是简单的进行嘴部区域图像的替换,而是根据驱动语音和被驱动对象对应的面部特征,获得各个时刻的人像参数及其对应的人像表征向量,然后根据时序位置编码、参考图像和人像表征向量,通过已训练的神经网络生成器生成各帧的被驱动图像并最终获得被驱动视频。
41、可见,被驱动视频并不是通过简单的嘴部区域图像替换获得的,而是将被驱动对象的面部特征、被驱动对象的参考图像和驱动对象对应的语音信息等数据进行融合后生成的。可以实现由被驱动对象进行与驱动对象相同的讲话,且被驱动图像中的五官特征、纹理细节等都由被驱动对象提供,不会错误地保留驱动对象原有的实际纹理或实际嘴部图像,有利于获得更好的被驱动视频,提高语音驱动的视频的生成效果和展示效果。
- 还没有人留言评论。精彩留言会获得点赞!