基于哈希加密的声纹认证隐私保护方法与流程
本发明涉及声纹认证领域,具体的说是基于哈希加密的声纹认证隐私保护方法。
背景技术:
1、声纹认证技术是利用声纹识别进行身份认证的技术。声纹识别是根据语音中所蕴含的说话人的个性特征去识别该段语音所含说话人身份的过程。声纹认证的原理如下:
2、首先,在注册阶断,提取语音数据,对语音数据进行提取,提取出声纹特征,将声纹特征存入数据库,从而生成声纹特征模型库;
3、然后,在认证阶段,提取待识别语音数据,对待识别语音数据进行提取,提取出声纹特征,通过检索模型在与声纹特征模型库中的已存的声纹特征进行匹配,给出识别结果,若能匹配成功则认证通过,若不能匹配成功则不予认证通过。
4、声纹认证已在电话银行、电子购物、医疗服务等活动中得到广泛应用。与其他生物特征识别相比,尽管声纹识别具有不会遗失和忘记、不需要记忆、使用方便等特点。但是,在声纹特征采集过程、传输、存储过程中存在泄漏、截取、篡改的风险,在认证阶段,若出现恶意输入录制好的有关语音数据,将会导致认证成功,严重的会导致无法挽回的损失。如何有效地保护声纹特征不被他人利用、泄露或篡改,保护使用者的隐私,已成为困扰声纹认证技术难题。
技术实现思路
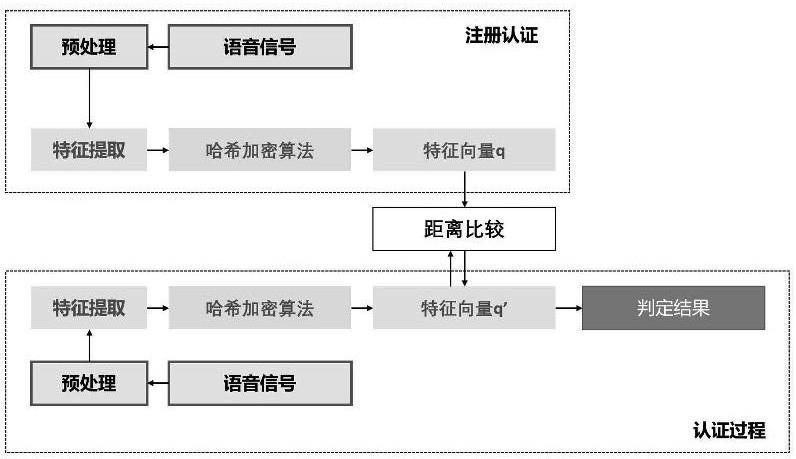
1、为了解决上述技术问题,本发明提出一种基于哈希加密的声纹认证隐私保护方法,包括注册阶断和认证阶段,其中,
2、(1)所述注册阶断包括如下步骤
3、a1,提取注册说话人的音频数据,得到音频原始文件,对音频原始文件通过声纹特征提取模型提取声纹特征向量x;
4、a2,随机生成正交矩阵a,且a中的元素rdk服从高斯分布的独立随机变量,即:rdk~n(0,1)(1<d,k<n);其中,
5、a∈rm×l是一个随机正交矩阵;r为实数集符号,m为信号长度(比特);l为信号维度数量;
6、元素rdk取自具有零均值和单位方差的正态分布;
7、n为正态分布符号;
8、n(0,1)为以0为均数,1为标准差的标准正态分布;
9、n为正交矩阵a的阶数;
10、d为维度,等于l;
11、k为信号长度,等于m;
12、a3,对声纹特征向量x进行处理,生成二进制哈希声纹特征向量q(x),通过随机投影然后带量化将得到的二进制哈希特征向量q(x)转换为位序列,生成哈希串特征向量q1;
13、a4,将步骤s1和步骤s2中的音频原始文件及声纹特征向量x保存至用户端;将步骤a3中得到的哈希串特征向量q1保存到服务端;
14、(2)所述认证阶断包括如下步骤:
15、b1,提取待验证语音音频数据,得到待验证音频原始文件,对待验证音频原始文件通过声纹特征提取模型提取声纹特征向量x’
16、b2,随机生成正交矩阵a,且a中的元素rdk服从高斯分布的独立随机变量,即:
17、rdk~n(0,1)(1<d,k<n);其中,
18、n为正态分布符号
19、n(0,1)为以0为均数,1为标准差的标准正态分布
20、n为正交矩阵a的阶数;
21、d为维度,等于l;
22、k为信号长度,等于m;
23、b3,对声纹特征向量x’进行处理,生成二进制哈希声纹特征向量q'(x'),通过随机投影然后带量化将二进制哈希特征向量q'(x')转换为位序列,生成哈希串特征向量q2;
24、b4,由哈希串特征向量q2与服务端哈希串特征向量q1进行匹配,计算q2于q1的汉明距离,得到决策结果,如完全匹配则认证,若不能完全匹配,则拒绝认证;
25、b5,若步骤b4决策结果通过,则将步骤b1和步骤b2中的待验证音频原始文件及声纹特征向量x'保存至用户端;将步骤b3中得到的哈希串特征向量q2保存到服务端。
26、进一步的,步骤a3对声纹特征向量x进行处理包括如下步骤:
27、计算特征向量q(x)=q(δ-1(ax+w)),生成二进制哈希q(x),
28、式中
29、q()为由q(y)=[y%2]给出的量化函数,y为随机变量,仅用了标识q的计算方式。
30、a为嵌入参数1.中的正交矩阵a
31、w为嵌入参数,w∈rm是从[0,δ]中均匀抽取的随机数组成的向量
32、δ为精度参数;
33、δ-1为精度参数的倒数,-1表示倒数。
34、w∈rm是由从[0,δ]均匀抽取的随机数组成的向量;r为实数集符号,m为信号长度(比特);
35、进一步的,步骤b3对声纹特征向量x'进行处理包括如下步骤:
36、计算特征向量q'(x')=q(δ-1(ax’+w)),生成的二进制哈希q'(x');
37、式中
38、q()为由q(y)=[y%2]给出的量化函数,y为随机变量,仅用了标识q的计算方式。
39、a为嵌入参数1.中的正交矩阵a
40、w为嵌入参数,w∈rm是从[0,δ]中均匀抽取的随机数组成的向量
41、δ为精度参数;
42、δ-1为精度参数的倒数,-1表示倒数。
43、w∈rm是由从[0,δ]均匀抽取的随机数组成的向量;r为实数集符号,m为信号长度(比特);
44、进一步的,步骤b4由哈希串特征向量q2与服务端哈希串特征向量q1进行匹配检索过程中通过将声纹检索过程建模为矩阵乘法并利用矩阵运算并行化技术加速检索。
45、进一步的,通过将声纹检索过程建模为矩阵乘法并利用矩阵运算并行化技术加速检索包括如下步骤:
46、考虑到底库说话人相互之间的无关性和每条查询之间的无关性,对于一个批次的查询,
47、c1,将其每条录音通过声纹编码器编码并归一化为查询声纹;
48、c2,将该批次的查询划分为多个小批次查询{1,2,……j……j},每个小批次查询构成一个m×e的小批次查询矩阵qj,其中
49、j是批次序号;
50、j是批次总数;
51、m是该小批次的录音数目;
52、e是声纹编码维度,保证m≦e且m尽量接近e;
53、c3,对于底库数据,将底库中的声纹编码划分为多个小批次底库{1,2,…k…k};
54、k是底库序号;
55、k是底库总量;
56、n是该小批次的底库说话人数目;
57、e是底库数据维度数量;
58、保证n≦e且n尽量接近e;
59、c4,基于cannon算法利用多处理器并行技术快速求解矩阵乘法rjk=qjbkt;得到小批次打分矩阵rjk;式中
60、j是批次序号;
61、qj查询矩阵;
62、k是底库序号;
63、bk是底库矩阵;
64、t是转置符号;
65、c5,对所有底库批次合并rjk得到rj,再对所有查询批次合并rj得到r即为该批次的打分矩阵r;
66、对于每个查询u,打分矩阵r中对应行的最大响应所对应的底库说话人v*即为检索结果:
67、v*=argmaxv(ruv),式中
68、argmax是计算符号,v标识说话人;
69、ruv是打分结果。
70、进一步的,将步骤a4中得到的哈希串特征向量q1保存到服务端步骤中,采用加权异构信息加密存储的方法,将哈希串特征向量q1保存到服务端。
71、进一步的,将步骤b5中得到的哈希串特征向量q2保存到服务端步骤中,采用加权异构信息加密存储的方法,将哈希串特征向量q2保存到服务端。
72、进一步的,加权异构信息加密存储的方法包括如下步骤:
73、d1,先利用混沌序列获取加权异构信息的初始密钥,将加密后的信息输出,设置每一名用户的属性,得到用户的权限控制结构;
74、d2,令为a'sg互联网系统的属性集,满足a'sg={a'sg1,a'sg2,……a'sgn}的条件,式中
75、n为属性集a'sg中加权异构信息的数量;
76、d3,将g上的双线映射定义为:
77、
78、p是用户个数;
79、n是映射常数;
80、g和gt均为乘法循环群;
81、将g定义为乘法循环群的生成元;
82、d4,将m个乘法循环群元素{s1,s2,……sm}∈g与a'sg属性集进行并联,在并联集合中随机选取两个指数{a,b},计算加权异构信息的初始密钥,表示为:
83、
84、pg'as为加权异构信息的初始密钥;
85、m是乘法循环群元素数量;
86、d5,假设c”xv为待加密的异构信息id,k'sgh为随机选取的对称密钥,η'为加权异构信息在加密存储过程中的时间戳,kop为用户的权限类型,则加密后的异构信息z'sf为:
87、
88、其中,dfkk表示用户访问互联网系统的结构;
89、为tensor product.张量乘法;
90、d6,基于加密处理后的加权异构信息,定义用户权限列表中的每一项用户属性,
91、即:
92、式中
93、为可以实现文件共享的用户权限列表;
94、k'sg为互联网文件的有效状态;
95、y'poi为互联网系统中用户的公钥;
96、β'ouhg为已经删除权限的用户列表;
97、j'klll为用户访问互联网系统的结构us属性集。
98、有益效果:
99、(1)本发明方法将身份验证问题映射到类似于密码匹配的过程。在注册时可以保证声纹特征数据的安全性。同时也能保证用户的身份验证效率和语音信息的安全性。
100、(2)本发明通过将身份验证问题转化为密码匹配问题,有效消除了隐私问题。
101、(3)超向量和哈希的计算是在用户的客户端设备上执行的。服务器仅从注册数据和身份验证过程中获取已通过sha-256等单向函数加密的哈希值。这种方式的说话人身份验证与基于文本的密码匹配一样安全。
102、(4)本方法采用基于安全二进制嵌入(sbe)原理的哈希算法,将音频转换为哈希值,以允许哈希值之间存在小程度不匹配的方式相互比较。同时,算法提供信息论保证,即如果声纹向量之间的距离据够远,则向量哈希之间的距离不会提供有关向量之间真实关系的信息。此外,如果散列函数的密钥保持私有,则它们不能被反转以从它们的散列中恢复超向量。
103、(5)本方法通过随机投影然后将向量转换为位序列,生成的哈希向量具有以下属性:
104、如果两个向量之间的欧氏距离低于阈值,则它们哈希之间的汉明距离与欧氏距离成正比;在阈值以上,汉明距离不提供有关两个向量之间真实距离的信息。从而有效保障了判定的准确性,避免了误判。
105、(6)本发明通过给定一个l维向量x∈rl,x的m位sbe定义为q(x)=q(δ-1(ax+w));其中δ是精度参数,a∈rm×l是一个随机矩阵,其元素取自具有零均值和单位方差的正态分布,w∈rm是由从[0,δ]均匀抽取的随机数组成的向量;q()是由q(y)=[y%2]给出的量化函数。
106、通过上式生成的二进制哈希q(x)具有以下属性:
107、给定两个具有欧几里得距离d(x,x')=||x-x'||的向量x和x',第i个位的概率,qi(x)和qi(x')分别是哈希值;q(x)和q(x')是否相同只取决于向量之间的距离d(x,x')而不是x和x'本身。
108、q(x)和q(x')之间的归一化(每比特)汉明距离dh(q(x),q(x'))的概率最大为
109、
110、其中t是控制因子。如果d(x,x')小于阈值,汉明距离e[dh(q(x),q(x'))]的期望为其于d(x,x')保持线性;如果x和x'之间的距离大于该阈值,则dh(q(x),q(x’))的边界为0.5-4π-2exp(-0.5π2σ2δ-2d(x,x′)2),即迅速收敛到0.5并且没有任何关于x和x’之间真实距离的信息。
111、由此,如果嵌入参数a和w对于可能试图从其哈希向量中推断数据的潜在对手来说仍然未知,则嵌入提供了信息论安全性。任何试图从其嵌入q(x)中恢复信号x或仅使用它们的嵌入来推断两个信号之间的关系的任何算法都将失败。本发明方法能够比较特征接近的声纹数据,而无需实际保存数据。构造了一种相对安全的分类判别器的保护方案。即保证了不可逆性、可更新性;同时对恶意输入的数据也有一定的针对性,使其的判别结果不会随意通过阈值。
112、(7)本发明方法通过将声纹检索过程建模为矩阵乘法并利用矩阵运算并行化技术加速检索过程。极大地减少了平均计算时间,提高了检索和匹配效率。
113、(8)本发明采用加权异构信息加密存储的方法,将哈希串特征向量q2保存到服务端,使用混沌序列方法,将加权异构信息的公钥和主密钥作为初始密钥,设置用户访问权限的限制条件,并通过用户权限控制结构设置用户的访问权限。极大地提升了加权异构信息的加密存储性能。
- 还没有人留言评论。精彩留言会获得点赞!