基于联邦深度学习的多边缘协作缓存方法
本发明属于5g通信网络,移动边缘计算,具体涉及一种基于联邦深度学习的多边缘协作缓存方法。
背景技术:
1、随着5g通信技术的迅猛发展,其在工业制造、数字经济、车联网、智慧城市等领域的应用也在逐步扩大与深化。在传统云计算模式下,这些终端智能应用所产生的任务与数据会被上传至远程云数据中心进行处理,无疑造成了严重的网络拥塞和服务延迟。不同于云计算模式,移动边缘计算(mobile edge computing,mec)将计算与存储资源部署在更靠近智能终端设备的网络边缘,这大大缓解了网络拥塞问题并降低了服务延迟。因此,mec的出现可为终端智能应用的实时计算与数据存储提供强有力的技术支撑。
2、通常,mec节点部署在终端智能设备与云数据中心之间的网络边缘层,能够进行信号处理、分布式缓存以及无线资源协作等管理操作。其中,分布式缓存旨在将用户感兴趣的内容缓存至mec节点以降低访问延迟和数据重复存储,从而提升用户体验和减少系统开销。然而,mec节点的服务性能往往受限于其缓存空间大小以及高速缓存开销。因此,如何有效利用mec缓存空间进而提升缓存性能受到了学术界和工业界的广泛关注。通常,缓存性能受到多重因素制约,包括缓存大小、内容关联性、缓存分块和替换策略等。在上述多维空间中探索用户和内容特征之间的潜在联系,可有助于寻找最佳的缓存资源配置,进而提高用户访存资源的命中率。此外,对缓存空间进行多维划分也可协助系统对细分用户提供更为精准的流行内容推荐。但是,如何有效探索多维空间并对缓存空间进行多维划分目前仍是一个挑战性的难题。
3、为进一步优化全局缓存资源配置和降低服务延迟,多边缘协作缓存可视为一种可行的运行机制。通过这种机制,用户可从进行协作缓存的mec节点中找到其所连接mec节点中未命中的请求内容。但是,在大部分现有工作中,缓存命中率仍受限于低效率的多边缘协作以及不合理的缓存资源配置。作为一种以保护用户隐私为前提的分布式训练框架,联邦学习(federated learning,fl)被视为一种优化多边缘协作与缓存资源配置的可行的解决方案。随着用户对终端智能应用需求的日益增长与多样化,将fl应用于解决多边缘协作缓存问题时依然面临着以下重要挑战:
4、1)离散用户特征分布和请求内容的多样性:如何根据用户特征做出合适的内容推荐决策是提升缓存命中率的关键,但在离散的用户特征分布和多样化的内容库中寻找其潜在联系仍是一个难点。
5、2)可扩展性:随着终端智能设备数量的增加,其生成的数据量在不断上升且分布也更为离散,这造成了高昂的计算和通信开销,传统集中式的处理模式已无法高效地应对该问题。
技术实现思路
1、作为移动边缘计算(mobile edge computing,mec)的一项重要技术支撑,多边缘协作缓存的出现可更好满足终端智能应用的实时计算与数据存储需求进而提升用户体验。但是,多边缘协作缓存的性能通常受限于低效率的协作机制以及不合理的缓存资源配置策略。同时,如何在离散的用户特征分布与多样化的内容库之中寻找其潜在关联以提升缓存命中率仍是一个巨大的挑战。为了解决上述重要挑战,本发明提出了一种新颖的基于联邦深度学习的多边缘协作缓存(multi-edge collabo-rative caching with federateddeep learning,m2cf)方法。在m2cf中,首先设计了一种新型的多维缓存空间划分机制,对mec节点的缓存空间进行感知优化,使得用户在分类区间可获得精准的内容推荐。接着,设计了一种基于vq-vae的内容流行度预测算法,解决了后验坍塌问题并提高了区间用户内容流行度预测的准确性。最后,设计了一种基于联邦深度学习的模型训练与缓存替换策略,通过聚合各mec节点的本地模型以生成全局共享模型,进而更好适应优化后的不同缓存资源配置,提升多边缘协作缓存的命中率。基于movielens电影评分真实数据集,本发明在测试床上展开了大量对比实验以对m2cf方法进行全面评估。实验结果表明,m2cf方法展现出了更优秀的缓存性能与时效性能,且可以适应更为复杂的多边缘场景。
2、本发明解决其技术问题具体采用的技术方案是:
3、一种基于联邦深度学习的多边缘协作缓存方法,其特征在于,采用多维缓存空间划分机制,对mec节点的缓存空间进行感知优化,使得用户在分类区间获得精准的内容推荐,并采用基于vq-vae的内容流行度预测算法,以解决后验坍塌问题并提高了区间用户内容流行度预测的准确性,以及采用基于联邦深度学习的模型训练与缓存替换策略,通过聚合各mec节点的本地模型以生成全局共享模型,进而适应优化后的不同缓存资源配置,提升多边缘协作缓存的命中率。
4、进一步地,首先,采用的基于联邦深度学习的多边缘协作缓存方法m2cf通过多维缓存空间划分对mec节点缓存空间进行感知优化,即在综合考虑多重因素的基础下为分类区间用户确定合适的缓存空间大小;接着,基于用户历史请求,m2cf方法利用vq-vae学习由一组离散向量构成的隐嵌入空间,进而解码器通过最近邻算法查找用于生成用户请求矩阵的离散隐向量,以补充和校准用户请求矩阵,从而提高内容流行度预测准确性;为了解决数据隐私和模型可拓展性问题,m2cf方法基于mec节点所保存的用户请求数据,利用联邦深度学习聚合各mec节点的本地模型进而生成全局共享模型以最小化全局损失;最后,采用主动缓存替换策略以更好适应优化后的缓存资源配置,进而提升缓存命中率。
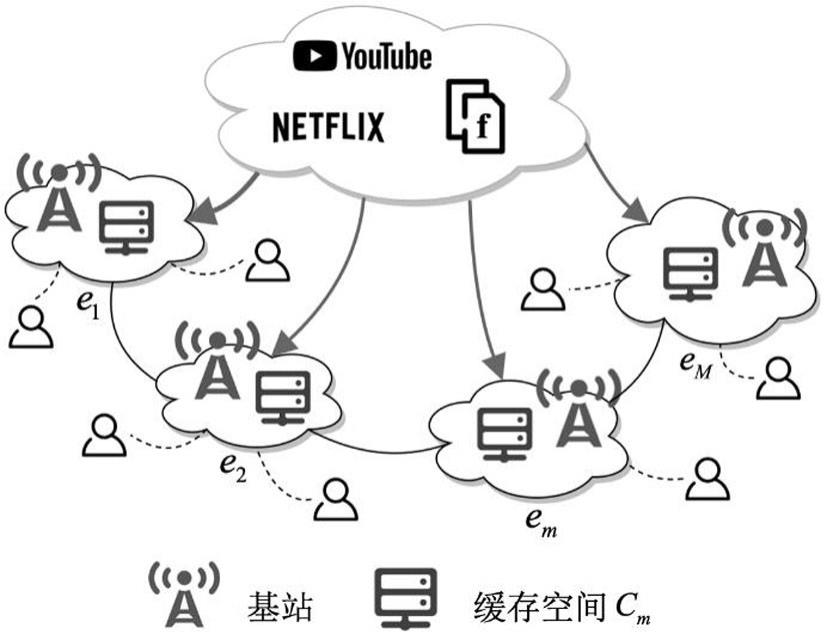
5、进一步地,采用的多边缘协作缓存系统包含m个mec节点和n个用户;其中,e={e1,e2,...,em,...,em}表示mec节点集合,u={u1,u2,...,un,...,un}表示用户集合,c={c1,c2,...,cm,...,cm}表示各mec节点的缓存空间;每个用户连接一个mec节点,用户和mec节点之间通过基站以无线链路进行通信,mec节点之间以及mec节点与云数据中心之间通过回程链路进行通信;云数据中心的内容库表示为集合f={f1,f2,...,fi,...,fi},其中,i为允许访问的内容数目;若用户un发起的内容请求fi已缓存至与其相连的mec节点,则用户un可直接从该mec节点获取所请求的内容;否则,用户un需要从相邻的mec节点或云数据中心获取所请求的内容;
6、对于某个mec节点,用户离散地分布在其覆盖范围内,其内容请求是动态的且具有时空依赖性;因此,通过预测内容流行度,进而将用户所感兴趣的内容主动缓存至与其相连的mec节点,以有效提升内容请求的命中率;在mec节点em的服务轮次r内,内容fi在该节点上的流行度表示为:
7、
8、其中,reqi,m表示mec节点em收到内容fi的请求次数,reqm表示mec节点em收到的所有用户请求次数;
9、基于多边缘协作缓存系统,通过结合多维缓存空间划分与联邦深度学习以实现对内容流行度的精确预测:
10、为了评估内容流行度预测的精度,预测模型的全局损失函数定义为:
11、
12、其中,w(r)表示全局预测模型参数,req表示所有mec节点收到的请求总次数,表示本地预测模型参数;在mec节点em的服务轮次r内,内容流行度预测值和实际值的均方误差,定义为:
13、
14、其中,为内容fi在节点em服务轮次r内的流行度预测值,pi,m(r)为内容流行度实际值;
15、缓存命中率定义为:
16、
17、其中,θm(fi)用于判断节点em是否缓存了用户所请求的内容,其定义为:
18、
19、进一步地,多维缓存空间划分包含多维用户划分和缓存空间划分两部分;首先,多维用户划分对具有不同用户数量的特征群体进行划分,针对不同特征群体的用户偏好内容进行单独缓存和推荐;接着,基于分类区间,进一步根据包括用户的活跃度、访存集合占比的特性对缓存空间进行感知优化;
20、(1)多维用户划分
21、将用户的多维特征分别映射到了各坐标轴上,记为θ={l1,l2,...,lt,...,lt};
22、在初始阶段,即grade=0时,具有多个不同特征的用户同属于一个用户区间h0;当h0中的用户数量超过阈值ζ(grade)时,将沿着各维度将其均等分割为2t个的用户区间;同时,分割后的各维度长度将减半,即lt=lt/2;为了实现自适用户区间划分,进而更好地捕捉区间用户与其偏好内容之间的潜在关系,设置ζ(grade)=α2grade,其中,α为超参数;划分之后的用户区间记为集合h={h1,h2,...,hs,...,hs},其中,s表示用户区间数量;
23、(2)缓存空间划分
24、在所划分的用户区间hs中,用户数量记为num(hs),用户活跃度和访存集合占比分别表示为:
25、
26、
27、其中,reqs表示用户的请求数量,γ(hs)表示区间用户hs的访存集合大小;
28、因此,综合考虑用户数量、用户活跃度和访存集合占比,hs所分配的缓存空间大小为:
29、
30、其中,cachem表示hs所连接mec节点的缓存空间大小;
31、采用vq-vae利用一组可学习的离散向量来构成隐嵌入空间,以替代vae中的正态隐藏层分布;在进行内容流行度预测时,vq-vae寻找隐嵌入空间中与编码器网络输出编码距离最近的向量,进而将映射得到的向量通过解码器网络进行重构;
32、vq-vae通过学习用户请求矩阵x的隐性分布,以在解码器输出的重构矩阵中得到用户未来可能请求的内容并进行主动缓存;用户请求矩阵x包含mec节点中用户请求内容的历史信息,其定义为:
33、
34、其中,1≤n≤n,1≤i≤i,n和i分别表示当前mec节点所连接的用户序号和具有的内容库索引;x由若干样本组成,记为包含用户n的内容请求记录,元素值为1或0;当元素值为1时,标记用户所请求到的内容;当元素值为0时,标记用户感兴趣但请求失败的内容或不感兴趣的内容,通过vq-vae对矩阵x进行补充和校准;
35、在vq-vae中,隐嵌入空间定义为其中,k表示隐嵌入空间大小,d表示嵌入向量vc的维度;隐嵌入空间中共有k个嵌入向量vq-vae将xn作为输入,通过编码器网络输出zv(xn);接着,在隐嵌入空间v中通过最近邻查找计算离散隐变量z,而后验概率分布q(z|xn)为one-hot编码,其定义为:
36、
37、解码器的输入,即后验概率分布q(z|xn)中对应嵌入向量vk的集合定义为:
38、zq(xn)=vk, (11)
39、其中,k用于生成解码器输入的向量索引,其定义为:
40、k=argminj||tv(xn)-vj||2. (12)。
41、进一步地,为解决引入隐嵌入空间可能造成的梯度断裂问题,在vq-vae反向传播阶段将梯度▽zl从解码器网络复制到编码器网络;
42、在训练vq-vae过程中,损失函数由三部分构成,其定义为:
43、
44、其中,第一部分为重构损失,其目标是优化编码器和解码器网络,因反向传播梯度被直接复制到编码器网络,故不考虑损失logp(z|zq(xn));第二部分利用l2误差促使嵌入向量vc向编码器输出zv(xn)移动,目的是优化隐嵌入空间,根据zv(xn)的平均移动距离对隐嵌入空间进行更新;第三部分是为了防止编码器网络输出超出隐嵌入空间范围;λ取决于重构损失的大小,sg为stop-gradient算子,在前向传播时为恒等式且偏导数为0;
45、vq-vae的对数似然函数定义为:
46、logp(xn)≈logp(xn|zq(xn))p(zq(xn)). (14)
47、根据jensen’s不等式,将公式(13)进一步改写为:
48、logp(xn)≥logp(xn|zq(xn))p(zq(xn)). (15)。
49、进一步地,m2cf方法具体分为三个部分:
50、(1)云数据中心更新;云数据中心初始化服务轮次数rmax,全局内容流行度预测模型w(r);在每一个服务轮次中,云数据中心首先共享最新的全局内容流行度预测模型至每个mec节点,而每个mec节点会同步更新本地模型;在此过程中,对上传至mec节点的数据进行脱敏处理以使其不涉及用户隐私;接着,云数据中心通过fedavg对进行联邦聚合,以生成最新的全局内容流行度预测模型;
51、(2)mec节点更新;mec节点初始化训练轮数cmax,训练批b和学习率η;在输入全局内容流行度预测模型之后,mec节点开始进行本地训练;采用vq-vae将用户历史请求记录作为训练数据,通过adam进行本地模型的训练训练结束后,mec节点将最新的本地模型上传至云数据中心;
52、(3)mec节点缓存替换:首先,初始化mec节点缓存空间大小cachetemp,同时通过多维缓存空间划分得到用户区间集合h;接着,调用vq-vae对mec节点的内容流行度进行预测和排序,并放入临时缓存库ctemp;并从预测的缓存列表中选取当前区间用户最感兴趣的cacheh条内容进而替换hs的缓存列表cs;当所有区间用户完成缓存更新之后,对缓存列表hs进行聚合和去重处理;最后,更新mec节点可用的缓存空间大小;重复以上步骤,直至无可用的缓存空间。
53、该形成的方案的主要特性包括:
54、(1)m2cf方法通过多维缓存空间划分对mec节点缓存空间进行感知优化,即在综合考虑多重因素的基础下为分类区间用户确定合适的缓存空间大小。
55、(2)基于用户历史请求,m2cf方法利用vq-vae学习由一组离散向量构成的隐嵌入空间,进而解码器通过最近邻算法查找用于生成用户请求矩阵的离散隐向量。通过这种方式,补充和校准用户请求矩阵,从而提高内容流行度预测的准确性。
56、(3)m2cf方法基于mec节点所保存的用户请求数据,利用联邦深度学习聚合各mec节点的本地模型进而生成全局共享模型,以最小化全局损失。
57、(4)m2cf方法基于重新设计的主动缓存替换策略,以更好适应优化后的缓存资源配置,进而提升缓存命中率。
58、相比于现有技术,本发明及其优选方案首先,设计了一种多维缓存空间划分机制,对mec节点缓存空间进行感知优化,使得用户可在分类区间可获得精准的内容推荐。接着,设计了一种基于vq-vae的内容流行度预测算法,解决了后验坍塌问题并提高了区间用户内容流行度预测的准确性。最后,设计了一种基于联邦深度学习的主动缓存替换策略以更好适应优化后的不同缓存资源配置,提升多边缘协作缓存的命中率。基于movielens电影评分真实数据集,本发明在测试床上展开了大量对比实验对所提出的m2cf方法进行了全面的评估。实验结果表明,与4种基准方法相比,m2cf取得了更高的缓存命中率且接近最优结果。特别地,通过消融实验验证了多维缓存空间划分和协作缓存对提升多边缘协作缓存性能的促进作用。同时,m2cf在不同mec节点数、缓存空间大小场景中均展现出了优秀的缓存性能与时效性能,且可以适应更为复杂的多边缘场景。
- 还没有人留言评论。精彩留言会获得点赞!