基于深度强化学习的车队网络内计算卸载与功率分配方法
本发明属于人工智能领域,尤其涉及一种基于深度强化学习的车队网络内计算卸载与功率分配方法。
背景技术:
1、随着车联网技术的发展和基于人工智能算法的应用,网联自动驾驶汽车成为提高交通安全和减少环境污染的重要解决方案,同时也是智能交通系统的重要组成单元。由于网联自动驾驶汽车拥有高度的自主性和网联性,将他们组成一个车队行驶是一种高效且生态的驾驶方案。车队由一辆头车(用pl表示)和一组具有相同行驶方向的成员车辆组成(用pm表示)。在队列网络中,成员车辆定期与头车共享信息,从而使车辆能以较小的空间间距紧密地行驶在一起。这种驾驶方式可以降低车辆能耗,提高驾驶安全性和舒适性。
2、然而,车队协同控制的成功实施和上层控制应用的集成在很大程度上取决于车载设备的高性能通信能力和计算能力。特别是自动驾驶系统必须依靠强大的计算能力来感知周围的交通状况、融合多源的异构数据以及实现基于人工智能的驾驶决策。此外,一些车载应用任务的实现也需要大量的车载资源。因此,先进的通信技术和辅助计算在实现编队车辆的连接性、自主性和驾驶员的舒适性方面发挥着至关重要的作用。为了克服这些挑战,车辆边缘计算是一种有效的解决方案。然而,该方案也存在一些挑战:1)在一些偏远地区,路侧基础设施覆盖面稀疏,沿路铺设基础设施来实现全覆盖是不切实际的。因此,实时的基于v2i卸载服务难以实现。2)车辆的高移动性导致v2v网络拓扑结构频繁变化,从而使得v2v卸载服务不稳定,难以满足用户的体验质量。3)高度动态的交通环境要求车辆用户根据当前的环境状态做出实时的决策。
技术实现思路
1、为车队网络中的计算卸载与资源分配方案提供建模思路,为解决动态车队网络中的联合优化问题提供解决方案。本发明提供一种基于深度强化学习的车队网络内计算卸载与功率分配方法。
2、本发明的一种基于深度强化学习的车队网络内计算卸载与功率分配方法,具体为:
3、车队系统为:
4、车队由一辆头车(pl)和一组具有相同行驶方向的成员车辆(pm)组成;pl配备边缘计算(ec)服务器,为资源受限的pm提供计算卸载服务;将时间线离散化为t个时隙,每个时隙的持续时间为τ0,时隙的索引集表示为:t={1,2,3,...,t,...,t},在每个时隙t,pm可生成任务数据;队列车辆表示为集合m={0,1,2,...m,...,m},其中m=0表示pl,m表示pm总数;每个pm可以在本地执行任务数据或通过v2v通信卸载到pl;采用noma技术来实现pm和pl之间的链路。
5、创建车队的动态运动模型:
6、使用智能驾驶模型idm来表征编队车辆的跟车行为,将最后一个pm的初始位置定义为坐标原点,只考虑队列车辆的纵向速度和位置;时隙t处pm m的速度和加速度分别为vm(t)和am(t);时隙t处pm m的头部坐标是xm(t),其中m∈{1,2,...,m};则相对速度为△vm(t)=vm(t)-vm-1(t);pm m与其前车之间的车间距离,即该车辆头部与前一辆车尾之间的距离为△dm(t)=xm-1(t)-xm(t)-dm-1,len,其中dm-1,len表示pm m-1的车辆长度;pm m的运动状态取决于pm m-1的运动学特征,根据idm,pm m的加速度可写为:
7、
8、其中,amax是最大加速度,vmax是稳定交通流下的理想速度,δ∈[1,5]表示驾驶员灵敏度特性,f(·)是与速度和相对速度相关的函数,定义为:
9、
10、其中,d0表示理想的车头间距,t0表示理想的车头时距,bmax表示最大减速;因此,pmm在时隙t处的速度和位置为:
11、vm(t)=vm(t-1)+am(t-1)·τ0 (3)
12、
13、因此,pm m和pl之间的通信距离为:
14、dm,0(t)=x0(t)-xm(t) (5)
15、车队的通信模型
16、在时间t,pl从上行链路中的pm m接收到的信号可以通过以下方式计算:
17、
18、其中:是pm m的发射功率,是pm m的最大发射功率,hm(t)是pm m和pl之间的信道增益,cm(t)是复杂数据信号;y0,m(t)的第一部分是来自目标pm的期望信号,第二部分是来自其他pm的干扰,第三部分n(t)是加性高斯白噪声。
19、当pl接收到信号时,采用sic解码方案,按照信号的降序减少来自其他pm的干扰:
20、
21、其中,pi,o(t)(hi(t))2≤pm,o(t)(hm(t))2,i∈{1,2,...,m},i≠m,时隙t处pm m和pl之间的信道增益为:
22、
23、其中:g0为一米参考距离的信道功率增益,α为路径损耗指数,n0(t)为复杂高斯变量,则pm m对应的信号干扰加噪声(sinr)为:
24、
25、其中σ2是白噪声功率。
26、根据香农公式,在给定带宽b下,时隙t上行链路中pm m的数据传输速率为:
27、rm,o(t)=b log2(1+ζm(t)) (10)
28、建立计算模型:
29、假设pm m的任务数据临时存储在缓冲队列中;对于pm m,假设生成的任务数据服从平均值为λm的泊松分布。
30、(1)本地计算模型
31、pm m在时隙t期间可以处理的任务数据量为:
32、
33、其中是pm m分配的每秒cpu周期,是分配的本地执行功率,是最大计算能力,κm是pm m处理器的有效开关电容,l0是每比特任务数据计算所需的cpu周期数。
34、(2)计算卸载模型
35、pm m的计算卸载过程包括三个步骤:1)pm m将任务数据传输给pl,2)pl的ec服务器计算卸载的任务数据,3)pl将执行结果返回给pm m;由于在pl处执行后的数据大小远远小于输入数据的大小,因此在第三步忽略传输时间;假设第一步和第二步可以在一个时隙τ0内完成,任务数据的传输时间为tm,off(t),则ec服务器中的数据处理时间为τ0-tm,off(t),根据(10)可得到方程组:
36、
37、其中qm,o(t)是pm m卸载的任务数据,是ec服务器分配给pm m的cpu周期数,是pl分配给pm m的计算功率,是最大计算功率,κ0是ec服务器处理器的有效开关电容;通过求解(12),可得到传输时间tm,off(t);pm m在时隙t可以卸载的任务数据大小为:
38、
39、问题建模:
40、对于时隙t的pm m,在本地计算和卸载到pl的任务数据的大小分别为qm,l(t)和qm,o(t),因此,所有已执行任务数据的大小为qm,l(t)+qm,o(t),使用qm(t)来表示缓冲队列的当前长度,om(t)表示时隙t中生成的任务数据数量,下一个时隙t+1中的缓冲队列长度为:
41、
42、根据排队理论和little公式,使用平均缓冲区队列长度来表示平均任务数据计算延迟;假设安装在pl中的ec服务器具有高频多核cpu,ec服务器可以并行计算卸载的任务数据;为了保证pm的卸载任务数据可以立即处理,设置q0(t)=0,车队系统的平均缓冲队列长度可通过以下方式计算:
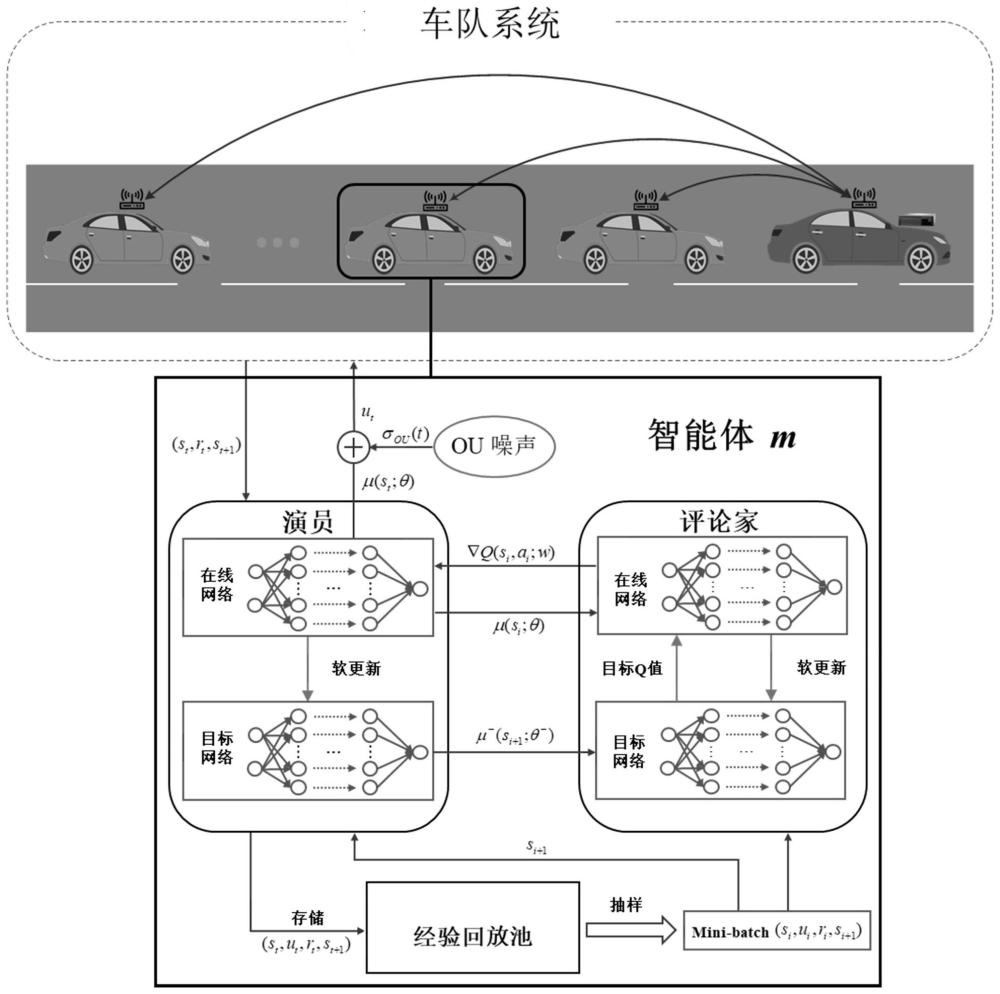
43、
44、车队系统的平均能耗可以写成:
45、
46、模型的目标是最小化车队系统平均能耗和任务数据处理延迟的加权和,并联合优化动态条件下的计算卸载和功率分配;设p={pm,l,pm,o,p0,m}是决策变量,则功率决策问题表述为:
47、
48、基于ddpg的计算卸载和功率分配:
49、根据基于多智能体drl的方法,将车队网络视为一个环境,将每个pm视为可以与动态环境交互的智能体;由于pl具有高性能多核cpu,因此立即处理卸载的任务数据,忽略pl的计算延迟,即tm,off(t)=τ0;每个智能体追求的目标是最大化长期折扣奖励;在学习过程中,智能体基于状态做出的决策是奖励驱动的,因此如何定义奖励函数将直接影响智能体学习策略的质量;智能体的环境状态空间、动作空间和奖励函数如下:
50、1)状态空间
51、pm m的状态sm(t)∈sm由本地状态和全局状态组成;本地状态包括生成的任务数据om(t)缓冲队列长度qm(t)和信道增益hm(t),全局状态包括sinrζm(t);因此,第m个agent的状态空间为:
52、sm(t)={om(t),qm(t),hm(t),ζm(t)} (18)
53、2)动作空间
54、基于状态sm(t),智能体执行包括本地计算功率pm,l(t)和传输功率pm,o(t)的联合动作;因此,第m个智能体的动作空间空间为:
55、μm(t)={pm,l(t),pm,o(t)} (19)
56、在每个学习步骤中,为了确保对环境状态空间进行更有效的随机探索以获得最优策略,在操作空间中添加了ou随机噪声:
57、um(t)=μm(t)+σou(t) (20)
58、3)奖励函数
59、基于(17)中定义的目标的奖励函数,使智能体能够在迭代中逐步学习最优策略,奖励函数的设计如下所述:
60、能耗奖励:在学习过程中,为了使智能体学习最优功率分配策略,将每时每刻的能耗添加到奖励函数中;任务数据计算的能耗为:
61、em(t)=pm,l(t)·τ0+pm,o(t)·τ0 (21)
62、计算延迟奖励:缓冲队列长度可以测量任务数据的计算延迟;为了减少任务数据的执行延迟,在奖励函数中引入了qm(t)。
63、惩罚奖励:智能体的行为会影响缓冲队列长度;在(14)中,如果qm(t)小于0,则表示智能体过度分配计算功率;如果qm(t)超过阈值,则表示智能体分配的功率不足以完全计算到达的任务数据,从而导致任务数据堆积;为了防止上述问题,在奖励函数中添加了两个惩罚项,以确保智能体执行更准确的操作:
64、
65、其中pm,over(t)是过度分配的本地计算能力,p1和p2分别是过度分配功率和超过阈值的惩罚因素;是一个二进制函数,当缓冲区队列的长度超过其最大值时等于1,否则等于0;
66、因此,基于上述定义,使用加权系数ω1和ω2对奖励值求和,智能体m的奖励函数为:
67、rm(t)=-ω1θ1em(t)-ω2θ2qm(t)-pm(t) (23)
68、学习算法由学习过程和测试过程组成;对于每个学习步骤,第m个智能体从当前环境获取其局部状态sm(t)并输出确定性动作μm(t);为了使智能体能够充分探索环境以获得最优策略,将ou噪声σou(t)添加到μm(t)中;智能体完成动作输出后会获得rm(t)奖励,评价该动作有多好;当所有智能体完成该过程后,环境进入下一个状态,每个智能体将获得转换元组(sm(t),um(t),rm(t),sm+1(t)),该元组将被存储在经验回放池bm中用于模型训练;因此,对于每个智能体,从经验回放池中随机选择包含n个转换元组的小批量样本,并将其馈送到ddpg中以更新网络参数;目标网络的目标q值可以通过以下方式计算:
69、
70、其中γ是折扣系数;评论家在线网络采用随机梯度下降方法更新网络参数,如下所示:
71、
72、
73、其中αw是评论家在线网络的学习率;基于评论家在线提供的梯度actor在线网络采用确定性策略梯度法更新网络参数:
74、
75、
76、其中αθ是演员在线网络学习率;软更新方法用于通过两个在线网络部分更新两个目标网络:
77、θ-←τ·θ+(1-τ)·θ- (29)
78、w-←τ·w+(1-τ)·w- (30)
79、其中τ是更新系数,τ<<1。
80、本发明的有益技术效果为:
81、本发明所提出的车队网络中计算卸载和功率分配优化模型综合考虑了车辆的移动性、通信干扰以及车辆协作。能够适应快速移动的车队网络环境。能够捕获环境状态的时序特征,能做出更加准确的功率分配动作。
- 还没有人留言评论。精彩留言会获得点赞!