一种TWS耳机模式切换方法及装置与流程
本发明涉及耳机,特别涉及一种tws耳机模式切换方法及装置。
背景技术:
1、近年来,在新一代消费电子设备快速普及的背景下,无线耳机出现明显的增长趋势。主动降噪耳机作为新的研究方向,受到越多技术人员的关注,带有主动降噪功能的无线耳机在公交车、地铁、飞机等嘈杂环境下具有舒适的体验,也受到越来越多市场和消费者的认可。
2、主动降噪耳机通过扬声器播放与噪声等幅反相的信号,抵消耳内的噪声,在耳道形成降噪区,有效降低了外部的嘈杂声音。在需要接受外界语音信号时,比如与人交流时,则需要耳机从主动降噪模式(anc模式)切换到透传模式(通透模式)。
3、传统的技术方案,要么是通过手动切换到透传模式来满足佩戴耳机的同时有效接受外部信息;要么是通过额外传感器(例如,骨传导传感器),识别佩戴者讲话后,切换到通透模式。
4、传统的技术方案存在以下弊端:
5、1、需要频繁切换模式,并且用户使用体验不够好;
6、2、使用额外传感器的方案,使用上相对手动切换,体验有了改善,但是额外付出的硬件传感器,增加了成本。
技术实现思路
1、基于上述现状,本发明的主要目的在于提供一种tws耳机模式切换方法及装置,以实现tws主动降噪耳机的智能免摘、自动切换模式的功能。
2、为实现上述目的,本发明采用的技术方案如下:
3、一种tws耳机模式切换方法,用于将耳机在由主动降噪模式切换至非主动降噪模式,所述耳机包括误差麦克风、参考麦克风、通话麦克风和扬声器,所述耳机处于主动降噪模式下,所述方法包括:
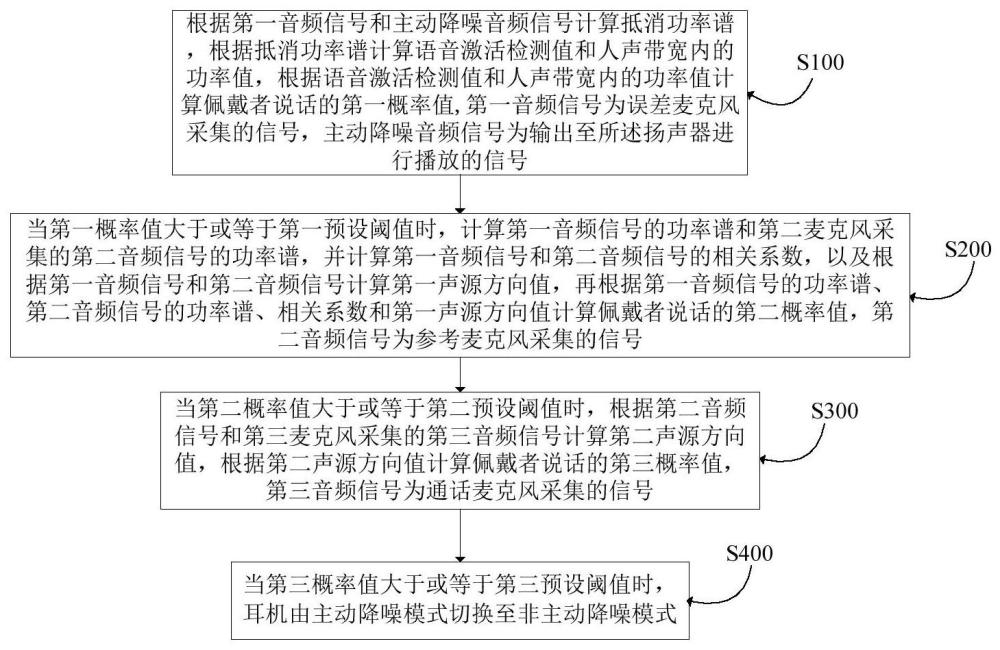
4、s100:根据第一音频信号和主动降噪音频信号计算抵消功率谱,根据所述抵消功率谱计算语音激活检测值和人声带宽内的功率值,根据所述语音激活检测值和所述人声带宽内的功率值计算佩戴者说话的第一概率值,所述第一音频信号为所述误差麦克风采集的信号,所述主动降噪音频信号为输出至所述扬声器进行播放的信号;
5、s200:当所述第一概率值大于或等于第一预设阈值时,计算所述第一音频信号的功率谱和第二音频信号的功率谱,并计算所述第一音频信号和所述第二音频信号的相关系数,以及根据所述第一音频信号和所述第二音频信号计算第一声源方向值,再根据所述第一音频信号的功率谱、第二音频信号的功率谱、相关系数和第一声源方向值计算佩戴者说话的第二概率值,所述第二音频信号为所述参考麦克风采集的信号;
6、s300:当所述第二概率值大于或等于第二预设阈值时,根据所述第二音频信号和第三音频信号计算第二声源方向值,根据所述第二声源方向值计算佩戴者说话的第三概率值,所述第三音频信号为所述通话麦克风采集的信号;
7、s400:当所述第三概率值大于或等于第三预设阈值时,所述耳机由主动降噪模式切换至非主动降噪模式。
8、优选地,所述s100中根据所述第一音频信号和所述主动降噪音频信号计算抵消功率谱包括:
9、计算所述第一音频信号每一帧的功率谱xf1(m,k),以及所述主动降噪音频信号每一帧的功率谱xf4(m,k);
10、通过标定或者自适应的方式,在各频点处,将第一音频信号功率值抵消掉主动降噪音频信号功率值,得到所述抵消功率谱xf(m,k):
11、xf(m,k)=xf1(m,k)-a(k)xf4(m,k);
12、其中,m为帧数,k为频点,a(k)为自适应或者标定后的权重。
13、优选地,所述s100中根据所述抵消功率谱计算人声带宽内的功率值包括:
14、对预设频率范围内的抵消功率谱进行积分运算,得到所述人声带宽内的功率值xf(m)。优选地,所述预设频率范围为100hz~1khz。
15、优选地,根据所述抵消功率谱计算语音激活检测值包括:
16、根据所述抵消功率谱基于能量特征、端点检测或深度学习的方法计算得到所述语音激活检测值。
17、优选地,所述s100中根据所述人声带宽内的功率值和所述语音激活检测值计算所述佩戴者说话的第一概率值为:
18、presult1(m)=β11*pxf(m)+β12*pvad(m)
19、其中,β11、β12加权值,β11+β12=1,pxf(m)为所述人声带宽内的功率概率值,pvad(m)为所述语音激活检测值的概率值,pvad(m)等于所述语音激活检测值,m为帧数。
20、优选地,所述pxf(m)为:
21、当所述xf(m)小于或等于预设功率参考值时,所述pxf(m)为所述xf(m)除以所述第一预设功率参考值,否则所述pxf(m)为1,所述预设功率参考值是根据误差麦克风的灵敏度,以及adc增益设置的功率参考值。
22、优选地,所述s200中计算所述第一音频信号和所述第二音频信号的相关系数为:
23、
24、其中,f1[n]为第一音频信号的采样值,f2[n+k]为第二音频信号的采样值,n为采样点,k为第二音频信号相对于第一音频信号延迟的采样点的个数。优选地,所述s200中根据所述第一音频信号和所述第二音频信号计算第一声源方向值包括:
25、s201:计算所述第一音频信号每一帧与所述第二音频信号每一帧之间的频率响应:
26、
27、其中,h1(m,k)中包括声源相位信息,m为帧数,k为频点,xf1(m,k)为第一音频信号功率谱,xf2(m,k)为第二音频信号的功率谱;
28、s202:根据所述频率响应通过反正切函数计算出每一帧的相位信息:
29、phase(m,k)=∠h1(m,k)
30、s203:对所述相位信息进行平滑处理:
31、phase(m,k)=(1-α)phase(m-1,k)+α*phase(m,k)
32、其中,α为平滑因子;
33、s204:根据所述平滑处理后的相位信息计算频点k的延时:
34、t1=phase(k)/(2*pi*k/l*fs)
35、t1为第一声源方向值,l为采样点个数,fs为采样率。
36、优选地,所述s200中根据所述第一音频信号的功率谱、第二音频信号的功率谱、相关系数和第一声源方向值计算佩戴者说话的第二概率值包括:
37、presult(m)=β21*ppwr(m)+β22*prec(m)+β23*ppha1(m)
38、其中,β21、β22、β23加权值,β21+β22+β23=1,ppwr(m)为第一音频信号的功率概率值和第二音频信号的功率概率值的加权值;
39、所述prec(m)是对所述第一音频信号和所述第二音频信号的相关系数进行归一化处理得到的;
40、所述ppha1(m)是根据所述第一声源方向值t1、预设第一延时阈值tref1和时间参数δt1计算得到的;
41、m为帧数。
42、优选地,所述ppwr(m)为:
43、计算所述第一音频信号每一帧的功率谱xf1(m,k),以及所述第二音频信号每一帧的功率谱xf2(m,k);
44、对预设频率范围内的xf1(m,k)和xf2(m,k)分别进行积分运算,得到第一音频信号功率xf1(m)和第二音频信号功率xf2(m);
45、当所述xf1(m)小于或等于第一预设功率参考值时,所述pxf1(m)为所述xf1(m)除以所述第一预设功率参考值,否则所述pxf1(m)为1,所述第一预设功率参考值是根据误差麦克风灵敏度和adc增益设置的功率参考值;
46、当所述xf2(m)小于或等于第二预设功率参考值时,所述pxf2(m)为所述xf2(m)除以所述第二预设功率参考值,否则所述pxf2(m)为1,所述第二预设功率参考值是根据参考麦克风灵敏度和adc增益设置的功率参考值;
47、所述ppwr为所述pxf1(m)和pxf2(m)的加权值。
48、优选地,所述s300中根据所述第二音频信号和所述第三音频信号计算第二声源方向值包括:
49、s301:计算所述第二音频信号每一帧与所述第三音频信号每一帧之间的频率响应:
50、
51、其中,h2(m,k)中包括声源相位信息,m为帧数,k为频点,xf2(m,k)为第二音频信号功率谱,xf3(m,k)为第三音频信号的功率谱;
52、s302:根据所述频率响应通过反正切函数计算出每一帧的相位信息:
53、phase(m,k)=∠h2(m,k)
54、s303:对所述相位信息进行平滑处理,
55、phase(m,k)=(1-α)phase(m-1,k)+α*phase(m,k)
56、α为平滑因子;
57、s304:根据所述平滑处理后的相位信息计算频点k的延时:
58、t2=phase(k)/(2*pi*k/l*fs)
59、l为采样点个数,fs为采样率,所述t2为第二声源方向值。
60、优选地,所述s300中根据所述第二声源方向值计算所述佩戴者说话的第三概率值包括:
61、presult3(m)=ppha2(m)
62、所述ppha2(m)是根据所述第二声源方向值t2、预设第一延时阈值tref2和时间参数δt2计算得到的。
63、优选地,所述方法还包括:
64、s500:在所述耳机处于非主动降噪模式下时,在预设时间内,依据所述s100计算所述第一概率值,若所述第一概率值小于所述第一预设阈值,则所述耳机切换到主动降噪模式,否则,依据所述s200计算所述第二概率值,若所述第二概率值小于所述第二预设阈值,则所述耳机切换到主动降噪模式,否则,依据所述s300计算所述第三概率值,若所述第三概率值小于所述第三预设阈值,则所述耳机切换到主动降噪模式,否则,所述耳机保持非主动降噪模式。
65、本发明还公开一种tws耳机模式切换装置,用于将耳机由主动降噪模式切换至非主动降噪模式,所述耳机包括误差麦克风、参考麦克风、通话麦克风和扬声器,所述耳机处于主动降噪模式下,所述装置包括第一概率值计算模块、第二概率值计算模块、第三概率值计算模块和模式切换模块:
66、所述第一概率值计算模块用于根据第一音频信号和主动降噪音频信号计算抵消功率谱,根据所述抵消功率谱计算语音激活检测值和人声带宽内的功率值,根据所述语音激活检测值和所述人声带宽内的功率值计算佩戴者说话的第一概率值,所述第一音频信号为所述误差麦克风采集的信号,所述主动降噪音频信号为输出至所述扬声器进行播放的信号;
67、所述第二概率值计算模块用于当所述第一概率值大于或等于第一预设阈值时,计算所述第一音频信号的功率谱和第二音频信号的功率谱,并计算所述第一音频信号和所述第二音频信号的相关系数,以及根据所述第一音频信号和所述第二音频信号计算第一声源方向值,再根据所述第一音频信号的功率谱、第二音频信号的功率谱、相关系数和第一声源方向值计算佩戴者说话的第二概率值,所述第二音频信号为所述参考麦克风采集的信号;
68、所述第三概率值计算模块用于当所述第二概率值大于或等于第二预设阈值时,根据所述第二音频信号和第三音频信号计算第二声源方向值,根据所述第二声源方向值计算佩戴者说话的第三概率值,所述第三音频信号为所述通话麦克风采集的信号;
69、所述模式切换模块用于当所述第三概率值大于或等于第三预设阈值时,输出模式切换信号,以将所述耳机由主动降噪模式切换切换至非主动降噪模式。
70、优选地,所述第一概率值计算模块包括抵消功率谱计算单元、人声带宽内的功率值计算单元、语音激活检测值计算单元和第一概率值计算单元,
71、所述抵消功率谱计算单元用于计算所述第一音频信号每一帧的功率谱,以及所述主动降噪音频信号每一帧的功率谱,并通过标定或者自适应的方式,在各频点处,将第一音频信号功率值抵消掉主动降噪音频信号功率值,得到所述抵消功率谱;
72、所述人声带宽内的功率值计算单元用于对预设频率范围内的抵消功率谱进行积分运算,得到所述人声带宽内的功率值;
73、所述语音激活检测值计算单元用于根据所述抵消功率谱计算得到所述语音激活检测值;
74、所述第一概率值计算单元用于根据所述人声带宽内的功率值和所述语音激活检测值计算所述佩戴者说话的第一概率值。
75、优选地,所述第二概率值计算模块包括功率谱计算单元、相关系数计算单元、第一声源方向值计算单元和第二概率值计算单元,
76、所述功率谱计算单元用于计算第一音频信号的功率谱和第二音频信号的功率谱;
77、所述相关系数计算单元用于计算第一音频信号和第二音频信号的相关系数;
78、所述第一声源方向值计算单元用于根据所述第一音频信号的功率谱和所述第二音频信号的功率谱计算第一声源方向值;
79、所述第二概率值计算单元用于根据所述第一音频信号的功率谱、所述第二音频信号的功率谱、所述相关系数和所述第一声源方向值计算佩戴者说话的第二概率值。
80、优选地,所述第一声源方向值计算单元包括第一频率响应计算单元、第一相位计算单元和第一延时计算单元,
81、所述第一频率响应计算单元用于计算所述第一音频信号每一帧和所述第二音频信号每一帧的频率响应;
82、所述第一相位计算单元用于根据所述频率响应通过反正切函数计算出每一帧的相位信息,并对所述相位信息进行平滑处理:
83、所述第一延时计算单元用于根据所述平滑处理后的相位信息计算频点k的延时。
84、优选地,所述第三概率值计算模块包括第二声源方向值计算单元和第三概率值计算单元,
85、所述第二声源方向值计算单元用于根据所述第二音频信号的功率谱和所述第三音频信号的功率谱计算第二声源方向值;
86、所述第三概率值计算单元用于根据所述第二声源方向值计算佩戴者说话的第三概率值。
87、优选地,所述第二声源方向值计算单元包括第二频率响应计算单元、第二相位计算单元和第二延时计算单元,
88、所述第二频率响应计算单元用于计算所述第二音频信号每一帧和所述第三音频信号每一帧的频率响应;
89、所述第二相位计算单元用于根据所述频率响应通过反正切函数计算出每一帧的相位信息,并对所述相位信息进行平滑处理;
90、所述第二延时计算单元用于根据所述平滑处理后的相位信息计算频点k的延时。
91、优选地,所述模式切换模块还用于在所述耳机处于非主动降噪模式下时,在预设时间内,通过所述第一概率值计算模块计算所述第一概率值,若所述第一概率值小于所述第一预设阈值,则所述耳机切换到主动降噪模式,否则,通过所述第二概率值计算模块计算所述第二概率值,若所述第二概率值小于所述第二预设阈值,则所述耳机切换到主动降噪模式,否则,通过所述第三概率值计算模块计算所述第三概率值,若所述第三概率值小于所述第三预设阈值,则所述耳机切换到主动降噪模式,否则,所述耳机保持非主动降噪模式。
92、本发明还公开一种耳机模式切换芯片,能够执行本发明任一项所述的tws耳机模式切换方法。
93、本发明还公开一种tws耳机,包括本发明任一项所述的tws耳机模式切换装置,或者本发明的耳机模式切换芯片。
94、本发明还公开一种存储介质,所述存储介质存储有程序,其中,所述程序用于被执行实现本发明任一项所述的tws耳机模式切换方法。
95、本发明的tws耳机模式切换方法,基于功率、相关系数和声源方向分别计算三个概率值,组合判断当前是否从主动降噪模式切换至非主动降噪模式,三个概率是层层递归的关系,满足第一概率才能往下计算第二概率,通过软件分析实现tws主动降噪耳机的智能免摘切换模式的功能,改善用户体验。相对于传统方案,本方案无需使用额外的骨传导等传感器,用误差麦、参考麦、通话麦和扬声器对声源进行联合定位,确保识别佩戴者讲话的准确性,减少了成本。
96、本发明的其他有益效果,将在具体实施方式中通过具体技术特征和技术方案的介绍来阐述,本领域技术人员通过这些技术特征和技术方案的介绍,应能理解所述技术特征和技术方案带来的有益技术效果。
- 还没有人留言评论。精彩留言会获得点赞!