一种超大规模天线阵列的低导频开销混合预编码方法
本发明涉及一种超大规模天线阵列的低导频开销混合预编码方法,属于无线通信物理层,涉及到波束训练技术,波束分配技术以及预编码器设计技术。
背景技术:
1、在第五代无线通信网络中,大规模多输入多输出技术通过在基站部署大规模的天线阵列,从而有效地改善了通信系统的频谱效率,并因此受到了广泛的关注。然而,通过应用大规模多输入多输出技术所带来的频谱效率的改善却难以满足第六代无线通信网络中急剧增长的频谱效率的需求。为了满足第六代网络在频谱效率上的需求,超大规模天线阵列技术被提出。通过在基站部署远超大规模多输入多输出技术中的天线,超大规模天线阵列技术可以获得可观的波束增益从而能够进一步改善通信系统的频谱效率,以满足第六代无线网络的需求。在超大规模阵列技术中,可观的波束增益的获得依赖于基站端可靠的模拟预编码器和数字预编码器的设计。然而,超大规模天线阵列的预编码器的设计却面临挑战。一方面,基站需要进行基于码本的波束训练来获得各个用户的最优波束,从而构建模拟预编码器。超大规模天线阵列的庞大的天线孔径使得近场通信以及近场码本需要被考虑,而包含大量码字的近场码本使得波束训练所需的导频开销急剧上升,从而带来了模拟预编码器设计上的挑战。另一方面,数字预编码器的获取依赖于可靠的信道估计。然而在超大规模天线阵列中,信道矩阵维度增大,信道估计所需的复杂度和导频开销急剧上升,从而带来了数字预编码器设计上的挑战。综上,对于超大规模阵列技术的低导频开销混合预编码器设计具有重大的研究意义,同时也具有技术挑战。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种超大规模天线阵列的低导频开销混合预编码方法,旨在通过利用图神经网络来充分探索并利用同一系统中的用户间的相关性,从而减少近场环境下的混合预编码方案中波束训练和信道估计步骤所需的导频开销,并提高波束训练的估计精度。本发明还通过设计合理的波束分配方案以及数字预编码器,减少了波束冲突以及用户间的干扰,有效提高了下行信息发送速率。具体地说,本发明基于训练好的gnn波束估计模型,基站端可以在仅测试远场宽波束码字的情况下估计出每个用户的最优近场码字,从而大幅降低了导频开销。
2、为了达到上述目的,本发明采用如下技术方案:
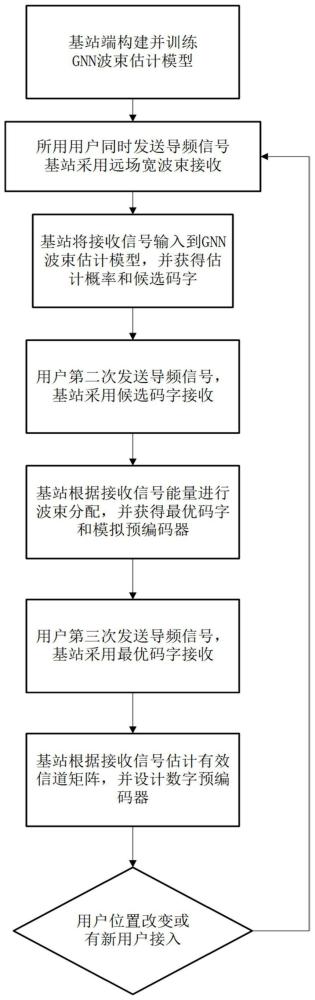
3、一种超大规模天线阵列的低导频开销混合预编码方法,包括如下步骤:
4、步骤s1、基站端构建并训练基于图神经网络的gnn波束估计模型,获得并且固定图神经网络的模型参数;
5、步骤s2、基站端配置有nbs根天线以及nrf个射频链路,k个用户均配置单天线;所有用户同时向基站发送相互正交的导频信号,基站依次采用预定义的远场宽波束码本中的每个码字来接收所有用的户导频信号;基站获得相应的接收信号并将其构建成向量形式;
6、步骤s3、基站将向量形式的接收信号输入到gnn波束估计模型,gnn波束估计模型输出k个概率向量,其中第k个概率向量的第i个元素代表用户k的最优近场码字为近场码本中第i个近场码字的估计概率;
7、步骤s4、基于每个用户的概率向量,基站获得每个用户的候选码字;
8、步骤s5、每个用户依次向基站发送时间上正交的导频信号,基站则依次采用相应用户的候选码字来接收该用户的导频信号;
9、步骤s6、基站根据导频信号的能量对每个用户的候选码字进行排序;基站根据排序结果为每个用户分配最终的最优波束;基于所分配的最优近场码字,基站设计出模拟预编码器;
10、步骤s7、所有用户同时向基站发送正交的导频信号,基站采用每个用户的最优近场码字来接收所有用户的导频信号,并且基于所接收到的导频信号估计每个用户的有效信道矩阵以及设计数字预编码器。
11、所述步骤s1中构建并训练以图神经网络为基础的gnn波束估计模型,具体步骤为:
12、步骤s101:基站端构建gnn波束估计模型;gnn波束估计模型包含特征更新模块以及输出模块;特征更新模块由三层图神经网络层组成,输出模块由两层全连接网络层以及一层softmax层组成;
13、步骤s102:基站端收集多组超大规模多输入多输出的多用户通信系统中的用户信道数据以及用户坐标;基站根据用户坐标确定该用户的最优近场码字,并作为该用户的信道数据的标签;
14、步骤s103:基站将收集的多用户的信道数据及其相应的标签作为图神经网络的训练样本,并且采用adama优化器以及学习率衰减策略对gnn波束估计模型进行训练,训练过程中模型参数不断被更新,使得损失函数最小,损失函数的表达式如下:
15、
16、其中s代表近场码本中的码字数量;代表gnn波束估计模型估计的用户k的最优码字为第k个近场码字的实际的概率;pk,s代表用户k的最优码字为第k个近场码字的实际的估计概率:当用户k的最优码字为第k个近场码字时,pk,s=1,否则pk,s=0;
17、当损失函数趋近收敛时,保存并固定模型参数。
18、所述步骤s2中基站采用远场宽波束码本来接收所有用户的导频信号,具体包括:
19、步骤s201、所有用户同时向基站发送由k个符号组成的正交导频信号;基于预定义的远场宽波束码本,基站按顺序挑选nrf个远场宽波束码字组成模拟预编码器并将数字预编码器设置为单位矩阵来接收导频信号;
20、步骤s202、基站根据导频信号的正交性解调得到每个用户的导频信号向量,每个导频信号向量包含nrf个元素,分别对应在采用这nrf个码字接收时基站获得的该用户的导频信号;
21、步骤s203、重复步骤s201和步骤s202,直到远场宽波束码本中的所有码字都被测试完毕,基站分别获得每个用户在所有不同的远场宽波束码字接收下的导频信号,并分别将其构建成向量形式。
22、所述步骤s4中基站获得每个用户的候选码字,具体包括:
23、步骤s401、基于步骤s3获得的每个用户的概率向量,对于第k个概率向量,基站选取值最大的nrf个估计概率,并获得这nrf个估计概率所对应的nrf个近场码字;所获得的nrf个近场码字即为用户k的候选码字;
24、步骤s402、重复步骤s401,直至基站获得所有用户的候选码字。
25、所述步骤s5中基站依次测试每个用户的候选码字,具体包括:
26、步骤s501、用户k向基站发送一个导频符号;基站选取用户k的nrf个候选码字组成模拟预编码器并将数字预编码器设置为单位矩阵来接收导频信号;基站获得一个nrf维的接收信号向量,其第i个元素代表在以第i个候选码字接收时基站接收到的用户k的导频信号;
27、步骤s502、重复步骤s501:用户依次向基站发送导频符号,基站依次采用相对应的候选码字进行接收,直至所有用户发送完毕,基站获得k个nrf维的接收信号向量。
28、所述步骤s6中基站对每个用户的候选码字进行排序以及对每个用户进行波束分配,具体包括:
29、步骤s601、基于步骤s5获得的k个nrf维的接收信号向量,对于第k个接收信号向量,基站对其中的元素进行取模运算并进行降序排序;重新排序后的接收信号向量中的第i个接收信号记为ck,i,其对应的候选码字代表用户k的优先级位列第i位的候选码字;
30、步骤s602、重复步骤s601,直至基站获得所有用户的候选码字的优先级;
31、步骤s603、基于所获得的所有用户的候选码字的优先级信息,基站初始化每个用户的最优码字为该用户的优先级最高的候选码字;
32、步骤s604、基站对每个用户的最优近场码字进行优化调整:当用户m和用户n的最优近场码字相同时,基站比较cm,1和cn,1的模值大小,若cm,1的模值大于cn,1的模值,则用户m的最优近场码字保持不变,基站将cn,1从第n个接收信号向量中删除并选择当前接收信号向量中的第i个接收信号cn,1所对应的候选码字作为用户n的最优近场码字,反之亦然;
33、步骤s605、重复步骤s604,直至任意两个用户的最优近场码字的均不相同;
34、步骤s606、基站获得k个用户的k个最优近场码字。k个近场码字组成基站端的模拟预编码器。
35、所述步骤s7中基站估计用户的有效信道矩阵以及设计数字预编码器,具体包括:
36、步骤s701、所有用户同时向基站发送由k个符号组成的正交导频信号;基站采用在步骤s6获得的模拟预编码器并且将数字预编码器设置为单位矩阵来接收所有用户的导频信号;基站获得k个信号接收向量,记为r1,r2,...,rk;
37、步骤s702、基站基于步骤s701获得的k个信号接收向量估计有效信道矩阵,有效信道矩阵的表达式为:
38、步骤s703、基站基于步骤s702获得的有效信道矩阵设计基站端的数字预编码器,数字预编码器的表达式为:其中pdl和分别为基站下行信息传输的发送功率和噪声功率。
39、本发明的有益效果是:
40、相比于现有的混合预编码设计方案,本发明考虑了超大规模天线阵列所带来的近场通信,采用基于图神经网络的gnn波束估计模型取代传统的穷举搜索,大幅降低了波束训练所需的导频开销并提高了波束训练的精度。此外,本发明还通过合理的波束分配方减少了用户间的波束冲突以及干扰,并且通过估计有效信道的方式减少设计数字预编码器所需的导频开销和复杂度。
- 还没有人留言评论。精彩留言会获得点赞!