一种基于元强化学习的无人机自组网跨层路由方法
本发明属于无线移动网络中的通信,具体涉及一种基于元强化学习的无人机自组网跨层路由方法。
背景技术:
1、近年来,无人机由于其灵活性强、成本低、部署简单等优点,已经不仅局限于军事任务上的应用,其在民用领域也得到了广泛的青睐。与传统的自组织网络相比,无人机建立的移动网络在特定环境下完成复杂任务的效率更高,更适用于执行紧急和危险的任务。(hao x,li w,wei h,et al.a survey on uav applications in smart citymanagement:challenges,advances,and opportunities[j].ieee journal of selectedtopics in applied earth observations and remote sensing,2023,16:8982-9010.)
2、与单无人机相比,多无人机自组网可以通过协调和合作完成更复杂的任务。此外,不同无人机之间可以共享信息、资源和任务负载,从而提高整体性能和效率;另一方面,由于多个无人机可以同时搜集数据,且多无人机自组网可以覆盖更大的区域,并收集到更全面和详细的信息,因此,多无人机自组网可以通过分布式数据处理,从而加快数据的处理速度。(m.g,p.r,m.et al.unmanned aerial vehicle communications for civilapplications:a review[j].ieee access,2022,10:102492-102531.)
3、在多无人机自组网中,当无人机规模较大时,无人机之间的信息交互可能会受到通信能力上限的限制,导致信息拥塞现象。为了确保多无人机之间的可靠通信,每架无人机都需要配备相应的通信设备。然而,在覆盖范围较广的情况下,这就要求通信设备具备高功率和高性能,从而增加了无人机的成本和能耗。因此,在对多无人机移动自组织网络的研究中,引入了跨层设计的思想来优化现有的路由方案,改善网络性能。多无人机组网中的跨层设计和优化,就是通过各无人机的应用层、网络层、数据链路层以及物理层之间的信息交互来改善无线网络总的系统性能,诸如网络吞吐量、时延、丢包率以及对大量业务的服务质量(quality of service,qos)的支持等。
4、传统路由通常分为主动式路由以及按需式路由。在主动式路由中,每个节点都会维护并更新一个或者多个表,这些表包含着此节点到其他节点的路由信息。当网络拓扑发生变化时,所有的节点都能知道并更新路由表。在主动式路由中,路由表记录了当前节点到其它所有节点的最新路由信息。优点是时延小,但是缺点是路由开销较大(m.e,r.m,a.e.performance evaluation of destination-sequenced distance-vector(dsdv)routing protocol[c].in:international conference on future networks.2009.186–190)。按需路由协议又名被动式路由。在动式路由中,它的主要设计目标是在需要进行通信时才建立路由路径,而不是提前建立全网的路由表。然而,按需路由协议也存在一些缺点,即由于按需路由协议需要在通信前先建立路由路径,因此可能会引入一定的延迟(perkinsc,belding-royer e,das s.ad hoc on-demand distance vector(aodv)routing[m].united states:rfc editor,2003.)。
5、在此基础上,基于元强化学习的路由方案也逐步登上历史舞台,智能体能够利用先前任务的经验,即通过设计和构建多个相关任务并在这些任务上进行训练,使智能体能够从中学习到可迁移的知识和策略,从而快速适应新任务。因此,部分学者受到强化学习和元学习的启发,提出了多智能体元近端策略优化,以在固定和时变的流量需求下优化网络性能(l.chen,b.hu,et al.multiagent meta-reinforcement learning for adaptivemultipath routing optimization[j].ieee transactions on neural networks andlearning systems,2022,33(10):5374-5386.)。
技术实现思路
1、本发明旨在提供一种基于元强化学习的无人机自组网跨层路由方法,将无人机建模为智能体并从环境中获取先验知识,从而达到启发智能体的学习过程,加速学习速度,帮助智能体在相似任务上更快地找到有效的策略。
2、实现本发明目的的技术解决方案为:一种基于元强化学习的无人机自组网跨层路由方法,具体步骤为:
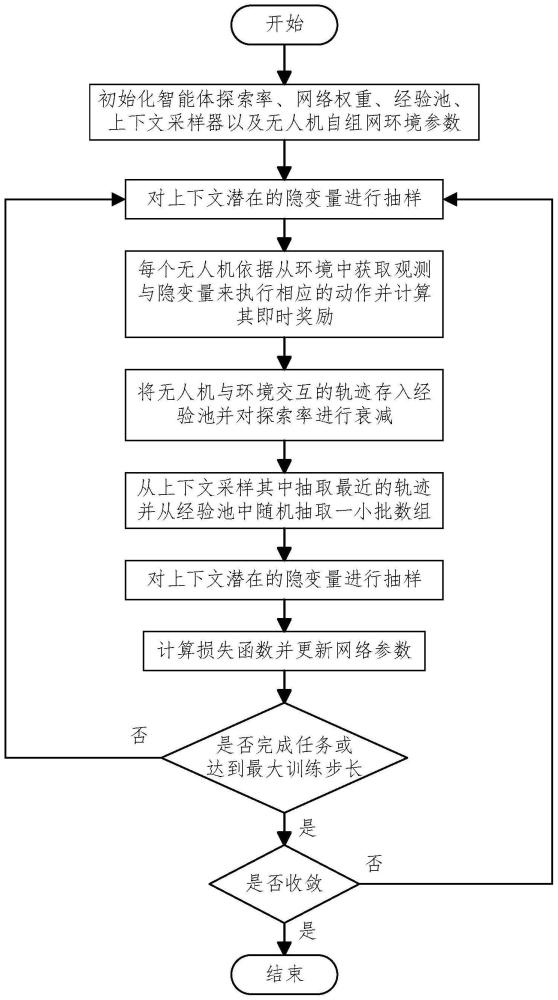
3、步骤1:初始化智能体探索率、各网络的权重、经验池、上下文采样器以及无人机自组网的环境参数;
4、步骤2:对上下文潜在的隐变量进行抽样;
5、步骤3:每个无人机依据从环境中获取的观测以及隐变量来执行相应的动作并计算奖励;
6、步骤4:将无人机与环境交互的轨迹存入经验池之中,并对智能体的探索率进行退火;
7、步骤5:更新上下文并将其存入上下文采样器;
8、步骤6:从上下文采样其中抽取最近的轨迹并从经验池中随机抽取一小批数据;
9、步骤7:对上下文潜在的隐变量进行抽样;
10、步骤8:计算损失函数,并更新各网络参数;
11、步骤9:检查是否完成路由任务或者系统的达到最大训练步长,结束当前回合,重置无人自组网环境,开始下一轮的训练。
12、进一步地,将连续时间离散化,即将时间分为t个相等的时隙,则其时隙集合表示为假设网络中有n个无人机,可以用来表示。假设推理网络,策略网络,目标网络,中心策略网络,中心目标网络以及互信息网络的参数分别为φ,ψ,ψ',θ,θ'以及ω。
13、进一步的,步骤1中所述的无人机自组网网络环境,其无人机自组网网络环境包含:
14、(1)网络模型:无人机按照高斯马尔可夫移动模型移动,假设无人机n在时隙t的位置为wn=[xn(t),yn(t)]。因此,无人机n与无人机n'在时隙t的欧氏距离可以表示为ln,n'(t)=||wn(t)-wn'(t)||2。假设每个无人机可以以固定的功率p将数据包传输至另一个无人机,因此,无人机n和无人机n'可以建立一条有效的通信链路en,n'(t)或en',n(t),当两者接收到来自对方的信号功率和均超过预先设定好的功率阈值pth,即将网络在时隙t的拓扑图建模为无向图,将网络中的无人机视为节点,将无人机之间的有效通信链路视为图的边,即将所构建的图表示为其中是有效通信链路的集合,即图中边的集合。假设是无人机n在时隙t的邻居节点的集合。
15、(2)跨层路由模型:在应用层中,数据包考虑三种优先级:1)实时语音数据包,2)视频数据包,3)具有一定延迟容忍的数据包。在网络层中,考虑了各邻居节点的队列容量以及地理位置信息,待转发数据包的目标节点的报文、大小、累计时延以及其对应的优先级。在物理层中,考虑传输链路的信干噪比以及数据包的丢失率。
16、(3)时延模型:将无人机之间的通信信道建模为空对空(a2a)的通信方式,在时隙t,无人机n'从无人机n所接收到的信号功率可以计算为
17、
18、式中,g1和g2分别表示无人机发送方和接收方的天线的增益,l(wn(t),wn'(t))代表大尺度衰落,而ls((wn(t),wn'(t)))则代表小尺度衰落。则无人机n至无人机n'的信干噪比可以表示为
19、
20、式中,b表示正在与无人机n'通信的无人机,表示无人机b在无人机n'处施加的干扰,δ2是高斯噪声方差,因此,无人机n到无人机n'的通信链路容量可以表示为
21、cn,n'(t)=w·log2(1+χn,n'(t))
22、式中,w是信道的带宽。假设为待转发数据包的大小,因此,将数据包从无人机n传输至无人机n'所需的时延可以用下式表示
23、
24、其中,表示无人机n到无人机n'的握手时延,表示数据包在无人机n中所需的排队时延,表示传输时延,表示传播时延,其中vc表示光的传播速度。
25、进一步地,步骤2中对上下文潜在的隐变量进行抽样,即从潜在上下文中学习一个隐变量z,该策略可以通过转换智能体与环境交互的轨迹为条件来适应新的任务,该轨迹在本小节中表示为上下文c,将上下文输出至参数为φ的推理网络中来推断出潜在隐变量z。具体而言,将无人机与环境交互得到的mdp元组输入至推理网络中iφ(z|c)中,以此来寻求潜在隐变量z基于上下文c的后验分布g(z|c)。
26、进一步地,步骤3中每个无人机依据从环境中获取的观测以及隐变量z来执行相应的动作并计算奖励,具体为:
27、(1)无人机的观测
28、每个无人机从网络层、物理层获取相应的观测信息,第n个无人机在时隙t的观测可以表示为:
29、
30、其中,即包含无人机n及周围邻居节点的队列长度信息,则表示无人机n与周围邻居节点之间的欧氏距离。其中,表示无人机n待转发数据包的大小,则表示待转发数据包的终点报文,m表示待转发数据包的优先级,则表示待转发数据包的累计时延。因此,系统的状态可以表示为
31、s(t)=[o1(t),o2(t),...,on(t)]
32、(2)无人机的动作
33、假设无人机n在时隙t的动作是从相邻节点中选择下一跳无人机,即则所有无人机在时隙t的联合动作可以表示为
34、a(t)=[a1(t),a2(t),...,an(t)]
35、(3)系统奖励
36、为了最小化数据包的平均传输时间,将系统奖励设置为所有无人机即时奖励的和,即其中rn(t)由三部分组成,当待转发的数据包到达目标节点时,无人机n的即时奖励为一个正整数,即代表着路由任务完成,给予一个正向的奖励;若下一跳链路失效,即下一跳无人机队列已满,则无人机n的即时奖励为一个负整数,给予其相应的惩罚。此外,rn(t)=exp(-dn,n'(t)),旨在选择时延最短的链路。
37、进一步地,步骤4中将无人机与环境交互的轨迹存入经验池之中,并对智能体的探索率进行退火。具体为,将元组(s(t),a(t),r(t),s'(t))存入经验池中。假设无人机的初始探索率为εt,则其退火过程为εt=εt·εdecay。
38、进一步地,步骤4中更新上下文,即将无人机与环境交互的得到的mdp元组存入上下文采样器中。
39、进一步的,步骤5中从上下文采样器中抽取最近的轨迹并从经验池中随机抽取一小批数据用来训练。
40、进一步的,步骤8中,计算损失函数,并更新各网络参数的方法,具体为
41、(1)潜在的上下文隐藏变量z整合至每个智能体的策略之中,即整合至基于动作-价值函数中:
42、
43、(2)为每个无人机搭配一个参数为ψ的效用网络,因此每个智能体的动作价值函数可以表示为qn(on(t),an(t);z,ψ),此外,为了探索各无人机之间最优的协作式的路由策略,考虑一个系统q值,其可以从参数化为β的中央策略网络中获得,即
44、
45、为了使元训练阶段更加稳定,为每个无人机搭建一个参数化为ψ'的目标网络,其可以表示为因此,系统的最大目标q值可以表示为,
46、
47、即其通过参数化为β'的中心目标网络获得,其中,o'n(t),a'n(t)以及s'(t)表示下一时刻的观测,动作以及状态。
48、(3)为了寻求最优的q函数,在元训练阶段,第一个损失函数可以表示为
49、
50、式中,另外,是从经验池中采样的回合数,为了适应新的任务并减轻对训练任务的过拟合,在这里引入一个参数化为ω的互信息网络,则第二个损失函数可以表示为
51、
52、其中λω(z)可以通过参数化为ω的互信息网络获得,即将无人机的动作价值函数输入至互信息网络,则该网络输出的是关于隐藏变量z单位高斯先验分布。
53、(4)依据随机梯度下降法更新各网络的参数,其可以表示为
54、
55、
56、
57、
58、其中,α和β是学习率。此外,每隔一段时间,将参数ψ复制给ψ',将β复制给β'。
59、本发明与现有技术相比,其显著优点为:(1)多个智能体相互协作,通过使用中心策略网络来学习全局的动作-价值函数,即学习一个协作式的路由策略;(2)智能体在奖励以及隐变量的指引下联合优化他们的动作-价值函数;(3)使用互信息网络来生成潜在上下文变量的先验分布,通过约束潜在变量和上下文之间的互信息,从而使得潜在变量可以包含对任务适应至关重要的基本上下文信息。
- 还没有人留言评论。精彩留言会获得点赞!