一种基于云边协同的数据分配方法及系统
本发明涉及数据分配,具体为一种基于云边协同的数据分配方法及系统。
背景技术:
1、随着物联网(iot)、大数据和云计算技术的快速发展,数据的产生、处理和存储需求呈指数级增长。在这种背景下,云计算提供了强大的数据处理能力,但由于数据传输延迟和带宽限制,直接依赖云端处理实时性要求高的任务存在显著挑战。此外,隐私和数据安全问题也促使数据处理需求向边缘计算转移,边缘计算旨在在数据产生的地点附近进行数据处理,从而减少延迟,提高效率,并解决带宽瓶颈问题。
2、然而,边缘计算资源相对有限,无法处理大规模数据分析和复杂的数据处理任务,这就需要一种有效的数据分配策略,以充分利用云计算和边缘计算的优势,实现数据处理的最优化。此外,如何根据数据的实时性需求和处理复杂度智能地在云端和边缘节点之间分配数据处理任务,成为了一个亟待解决的问题。
技术实现思路
1、鉴于上述存在的问题,提出了本发明。
2、因此,本发明解决的技术问题是:现有的数据分配方法存在资源利用率低、数据传输延迟高等问题。
3、为解决上述技术问题,本发明提供如下技术方案:一种基于云边协同的数据分配方法,包括:
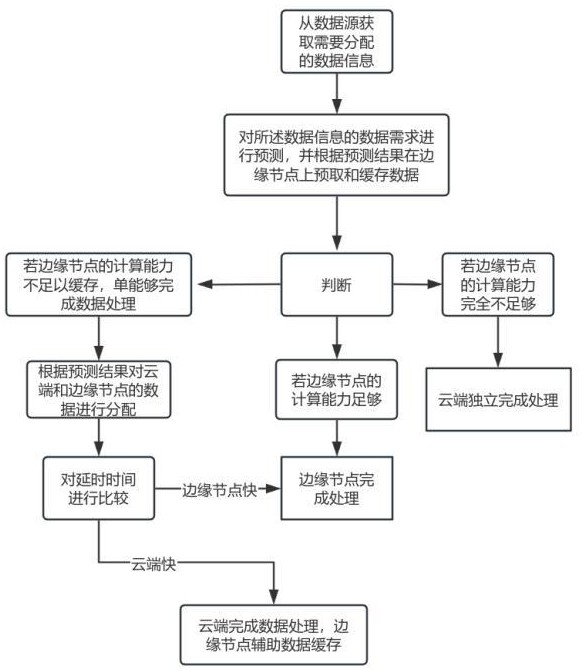
4、从数据源获取需要分配的数据信息;
5、对所述数据信息的数据需求进行预测,并根据预测结果在边缘节点上预取和缓存数据;
6、根据预测结果对云端和边缘节点的数据进行分配;
7、通过计算所述数据信息在云端计算的数据延时,对数据进行调度,完成云边协同的数据分配;
8、对所述数据信息的数据需求进行预测包括,基于历史数据的学习经验,利用社区检测算法对社区进行划分;其中每个节点表示数据,通过社区特征与实时数据特征的匹配,得到匹配程度超过阈值的社区,将每个社区内的所有节点作为数据需求的预测;
9、对所述社区的划分包括,从历史数据中提取复杂的时间序列特征和数据项间的关系特征:
10、;
11、其中,表示从历史数据中学习得到的多维特征向量;是时间t的原始数据向量在第k个时间窗口的表示;表示convlstm的参数;表示gat的参数;σ表示非线性激活函数;⊕ 表示特征向量的融合操作;k表示在时间序列分析中考虑的时间窗口的总数;表示时间 t 的图结构;
12、基于从历史数据中学习得到的多维特征向量,构建一个图g=(v,e),其中v 是节点集合,e 是边集合,边的权重基于节点间的相似度计算:
13、 ;
14、其中,表示第i节点在经过深度学习模型处理后得到的特征向量,表示第j节点在经过深度学习模型处理后得到的特征向量,σ 表示高斯核的带宽参数;
15、对社区进行划分:
16、 ;
17、其中,表示最优社区划分;c表示所有可能的社区划分方案;表示社区 c中的节点集合;表示社区大小的方差;λ表示平衡项。
18、作为本发明所述的基于云边协同的数据分配方法的一种优选方案,其中:所述数据信息包括,从数据源处获取的需要边缘节点或云端计算的数据信息;
19、利用高效的数据捕获技术,实时收集来自各种数据源的数据信息;并根据所述数据信息评估资源占用情况。
20、作为本发明所述的基于云边协同的数据分配方法的一种优选方案,其中:所述通过社区特征与实时数据特征的匹配包括,对于每个社区c,计算实时数据在社区内的适应程度:
21、 ;
22、其中,sim表示相似度,表示社区c的节点集合,表示实时数据点,表示实时数据点的特征向量,表示社区c中节点i的特征向量;
23、通过阈值判断得到最终的预测结果:
24、 ;
25、其中,表示适应程度达到阈值的社区集合,表示适应度的阈值,h表示所有社区的集合;
26、所述适应度的阈值通过对所有社区的适应度的比较得到,计算h中每个社区的适应度得到h个社区的适应度,从大到小依次排列;计算排列后每两个相邻社区的适应度差值,得到差值最大的两个适应度和,将对应的适应度作为适应度的阈值;
27、在边缘节点将预测结果中的所有社区包含的数据进行缓存。
28、作为本发明所述的基于云边协同的数据分配方法的一种优选方案,其中:所述评估资源占用情况包括,获取边缘节点能够正常运行计算时,计算能力的最大值jmax,以及边缘节点持续运行所占用的计算能力jp;得到本次计算可用的计算能力jb=jmax-jp;
29、分别评估缓存和不缓存数据的情况下,数据在边缘节点的处理器资源占用情况,在缓存数据时:
30、 ;
31、在不缓存数据时:
32、 ;
33、其中,表示进行缓存时占用的计算能力;表示不进行缓存时占用的计算能力;表示实时数据的实际数据量;表示预测结果中所有社区的数据量;表示每个单位的数据所占用的计算能力,,q表示历史记录数量,q表示历史记录索引,表示第q次记录中的数据量,表示第q次记录中所占用的计算能力;
34、所述根据预测结果对云端和边缘节点的数据进行分配包括,当时,则不在边缘节点上进行数据处理,同时评估对预测结果的缓存所占用的资源,若,则通过边缘节点进行数据需求的预测,并将数据预测的结果和实时数据传入云端,在云端完成数据处理;若,则不通过边缘节点进行数据需求的预测,仅通过云端完成数据缓存和处理;
35、当时,仅使用边缘节点完成数据处理;
36、当时,则在云端和边缘节点之间,对数据进行调度。
37、作为本发明所述的基于云边协同的数据分配方法的一种优选方案,其中:计算所述数据信息在云端计算的数据延时包括,计算所述数据信息在云端计算时,信息传输的数据延时,同时计算所述数据信息在边缘节点不进行缓存导致的数据延时,通过对比数据延时的长短,从而对数据进行调度;
38、所述在云端计算时,信息传输的数据延时,表示为:
39、 ;
40、其中表示需要处理的原始数据大小;表示数据压缩率;表示数据大小;表示数据类型;表示 动态网络带宽;表示网络效率;表示数据类型的压缩敏感系数,在0到1之间;表示数据大小的压缩调整系数,代表数据大小对压缩效果的影响程度;表示网络的基础带宽;γ表示网络负载对带宽的影响系数;表示时间t的网络负载率,范围从0到1,1表示网络完全拥塞;
41、;
42、其中,表示网络效率评估中的权重系数,且满足;λ表示延迟对效率影响的衰减系数;latency(t)表示时间t的网络延迟;lossrate(t)表示时间t的网络丢包率;表示当前可用网络带宽;表示网络的最大理论带宽;
43、所述在边缘节点不进行缓存导致的数据延时,表示为:
44、 ;
45、其中,表示数据加载速率。
46、作为本发明所述的基于云边协同的数据分配方法的一种优选方案,其中:所述对数据进行调度包括,当时,则仅使用边缘节点完成数据处理;
47、当时,则使用云端对数据进行处理,同时在边缘节点对数据需求的预测结果进行加载,将加载后的数据传输到云端,作为数据缓存的备选项;若在边缘节点对数据需求的预测结果进行加载时,云端完成数据处理,则终止加载。
48、一种采用本发明所述方法的基于云边协同的数据分配系统,其特征在于:
49、采集单元,从数据源获取需要分配的数据信息;
50、计算单元,对所述数据信息的数据需求进行预测,并根据预测结果在边缘节点上预取和缓存数据;
51、分配单元,根据预测结果对云端和边缘节点的数据进行分配;通过计算所述数据信息在云端计算的数据延时,对数据进行调度,完成云边协同的数据分配
52、一种计算机设备,包括:存储器和处理器;所述存储器存储有计算机程序,其特征在于:所述处理器执行所述计算机程序时实现本发明中任一项所述的方法的步骤。
53、一种计算机可读存储介质,其上存储有计算机程序,其特征在于:所述计算机程序被处理器执行时实现本发明中任一项所述的方法的步骤。
54、本发明的有益效果:本发明提供的基于云边协同的数据分配方法,能够显著减少数据从产生到处理所需的时间。通过智能地在云端和边缘节点之间分配数据处理任务,能够根据任务的实时性需求和处理复杂度,动态优化资源分配。这不仅提高了数据处理的效率,还确保了资源的最大化利用,避免了资源浪费。通过利用社区检测算法对数据进行智能分类和预处理,使本发明能够支持大规模分布式数据的高效处理。这对于处理来自智能城市、工业物联网等场景的海量数据尤为重要,能够为这些应用提供强大的数据处理能力。
- 还没有人留言评论。精彩留言会获得点赞!