用于测定自闭症谱系病症风险的方法和系统与流程
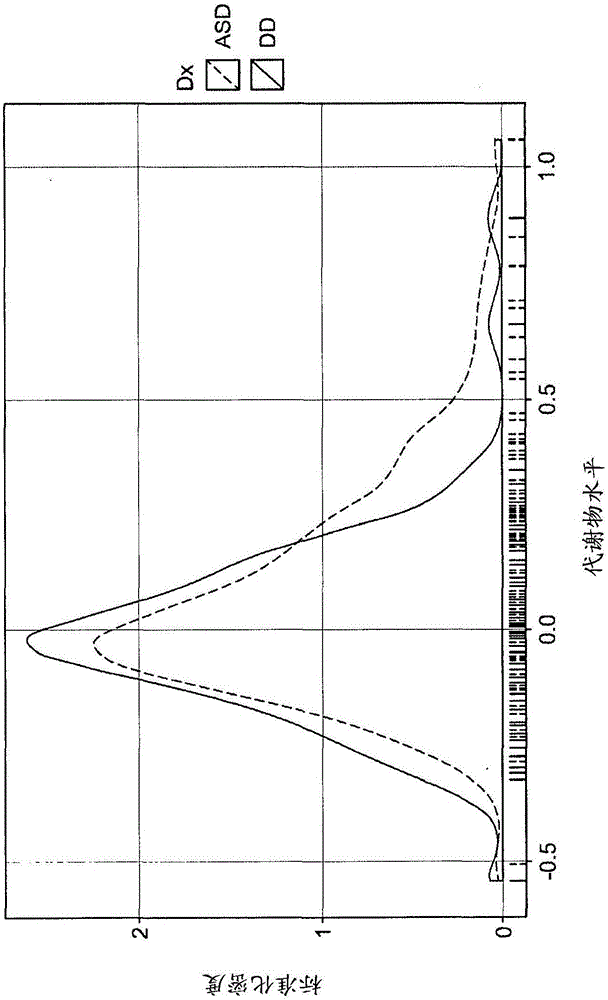
本申请要求2015年2月27日提交的美国专利申请号14/633,558的优先权;所述美国专利申请是于2014年9月22日提交的美国专利申请号14/493,141的部分继续申请,其要求2014年4月11日提交的美国临时专利申请No.61/978,773以及于2014年5月22日提交的美国临时专利申请号62/002,169的优先权;其中每一个的内容通过引用整体并入本文。发明领域本发明总的来说涉及对于自闭症谱系病症(ASD)和其他病症的风险的预测。背景自闭症谱系病症(ASD)是普遍的发育病症,其特征在于互动社交相互作用缺乏,语言困难,以及重复行为和限制性兴趣,通常在生命的前3年期间表现。ASD的病因学知之甚少,但被认为是多因素的,遗传和环境因素都会导致该疾病的发展。数据显示,尽管父母开始怀疑他们的孩子患有ASD的平均年龄是20个月,但是诊断的中位年龄达到54个月。从临床角度来看,一个重要的挑战是尽可能早地确定儿童是否患有ASD,是否需要专家转诊到自闭症治疗计划中。概述ASD的诊断通常由发育儿科医生和其他专家在使用在DiagnosticandStatisticalManualofMentalDisorders中阐述的标准仔细评估儿童之后作出。可靠的诊断通常需要由包括发育儿科医生、神经病学家、精神病学家、心理学家、言语和听力专家以及职业治疗师在内的多个专家对受试者进行认真评估。此外,ASD诊断的中位年龄为54个月,尽管父母怀疑ASD的平均年龄早至20个月这一事实。CDC(疾病控制中心)观察到最终确诊为ASD的儿童中只有18%是在36个月前确定的。遗憾的是,患有尚未诊断的ASD的幼儿错过了在儿童发育的重要窗口期间进行早期治疗干预的机会。需要有可靠地确定ASD风险的医学诊断测试,以特别地更早鉴定年幼儿童,此时治疗干预可能更加有效。本发明的实施方案源于以下发现:对群体内和群体之间分析物(诸如代谢物)测量值的分布曲线的分析提供了可用于建立或改进用于预测病症或病况诸如ASD的风险的分类器的信息。特别地,血液中代谢物水平的群体分布曲线的分析有助于预测受试者中自闭症谱系病症(ASD)的风险。例如,血液中代谢物水平的群体分布曲线的分析可用于区分受试者的自闭症谱系病症(ASD)与非ASD发育病症(诸如非因自闭症谱系病症引起的发育迟缓(DD))。区分两个组的生物标志物的统计分析通常假定两个群体的平均生物标志物水平不同,并且围绕该平均值的变化归因于由高斯分布最好表征的实验和/或群体变化。与此基线模型相反,本文观察到,对于一些分析物,ASD中或有时DD中的分布最好被表征为其本身由多个子分布组成,其中一个子分布与另一健康状态无法区分(例如,其中ASD和DD分布未分化),另一子分布在少数受试者中远远偏离平均值,例如,对于该群体,呈现组合分布的“尾部”。这种洞察导致与基线明显不同的分析框架;已发现,对于某些分析物,通过例如建立不需要内在高斯分布模型的排序,基于群体分布的顶部或底部来定义阈值,可实现更好的结果。因此,代谢物在本文中被描述为表现出“尾部富集”或“尾部”效应,其中在该代谢物的代谢物水平的分布曲线的远端部分存在特定群体(例如,ASD或DD)的样品的富集。由评估代谢物分布曲线中尾部效应的存在、不存在和/或方向(上或下)得到的信息可用于预测ASD的风险。已发现,对于特定代谢物,代谢物水平对应于分布曲线的顶部或底部(例如,十分位),即在分布曲线的“尾部”内(无论是在“右尾”还是“左尾”),高度地提示ASD的存在或不存在。此外,发现当合并具有低程度重叠、共同信息的多种代谢物时,风险预测得到改善。例如,对于ASD的评估,有一些特定的代谢物组提供互补诊断/风险评估信息。也就是说,通过分析第一代谢物的水平无法鉴定的ASD阳性个体(例如,第一代谢物的鉴定尾部内的个体)与通过分析第二代谢物可鉴定的ASD阳性个体并不相同(或者可能存在低的,非零度的重叠)。不希望受特定理论的束缚,该发现可能反映了ASD本身的多面性质。因此,在某些实施方案中,风险评估方法包括鉴定受试者是否落入涉及多种代谢物的多重已鉴定的代谢物尾部的任一种中,例如,其中不同代谢物尾部的预测物是至少部分不相连的,例如,它们具有低的共同信息,因此引入具有低共同信息的多个代谢物时风险预测改善。分类器具有预先确定水平的可预测性,例如,以AUC的形式-即对于分类器,将假阳性率(1-特异性)相对于真阳性率(灵敏度)作图的ROC曲线下面积-其中向分类器中添加表现尾效应、具有低共同信息的代谢物时AUC增加。在一些实施方案中,本发明源自以下发现:血液中代谢物水平的某些阈值可用于帮助预测受试者中自闭症谱系病症(ASD)的风险。在某些方面,从代谢物分布曲线中尾部效应的存在、不存在和/或方向(上或下)的评估推导的代谢物的这些阈值被用于预测ASD的风险。在某些方面,这些阈值可处在群体中代谢物水平分布的上端或下端。已发现,对于特定代谢物,代谢物水平高于上阈值和/或低于下阈值高度提示ASD的存在或不存在。在一些实施方案中,这些代谢物的水平可用于将ASD与其它形式的发育延迟(例如,非因自闭症谱系病症引起的发育迟缓(DD))区分开。在一个方面,本发明涉及区分受试者的自闭症谱系病症(ASD)与非ASD发育延迟(DD)的方法,所述方法包括:(i)测量获自所述受试者的样品中多种代谢物中的第一代谢物的水平,先前已在具有ASD的第一受试者群体中和具有非-ASD发育延迟(DD)的第二受试者群体中表征了所述第一代谢物的群体分布,其中所述第一代谢物被预先测定为表现出ASD尾部效应和/或DD尾部效应,每个尾部效应包括在相应(ASD或DD)群体的成员中富集的相关右尾或左尾,其中第一代谢物表现出具有右尾的ASD尾部效应,当该样品中第一代谢物的水平高于定义在第一(ASD)群体成员中富集的右尾的预先确定上(最小)阈值时,该样品中第一代谢物的水平在ASD尾部内,而当第一代谢物表现出具有左尾的ASD尾部效应时,当该样品中第一代谢物的水平低于定义在第一(ASD)群体成员中富集的左尾的预先确定下(最大)阈值时,样品中第一代谢物的水平在ASD尾部之内,并且,在第一代谢物表现出具有右尾的DD尾部效应时,当样品中第一代谢物的水平高于定义在第二(DD)群体成员中富集的右尾的预先确定上(最小)阈值时,样品中第一代谢物的水平在DD尾部内,并且在第一代谢物表现出具有左尾的DD尾部效应时,当样品中第一代谢物的水平低于定义在第二(DD)群体成员中富集的左尾的预先确定下(最大)阈值时,样品中第一代谢物的水平在DD尾部内;(ii)测量来自该样品的多种代谢物中的至少一种另外的代谢物的水平,其中在第一群体和第二群体中事先表征了所述至少一种另外的代谢物中的每一种的群体分布,被预先确定为表现出ASD尾部效应和DD尾部效应中的至少一种,并且,对于所述至少一种另外的代谢物中的每一种,根据步骤(i)鉴定样品中所述代谢物的水平是否在相应的ASD尾部和/或DD尾部内;和(iii)基于所述样品处于在步骤(i)和步骤(ii)中分析所述代谢物所鉴定的ASD尾部和/或所鉴定的DD尾部,以预先确定水平的可预测性确定(a)受试者具有ASD而不是DD或(b)受试者具有DD而不是ASD。在某些实施方案中,第一代谢物被预先测定为表现具有相关的上(最小)或下(最大)阈值的ASD尾部效应,所述阈值被预先测定为使得满足该标准的未知分类的样品(先前未表征的样品)是ASD而不是DD的几率不小于1.6:1,p<0.3。在某些实施方案中,所述几率不小于2:1,或不小于2.5:1,或不小于2.75:1,或不小于3:1,或不小于3.5:1,或不小于3.75:1,或不小于4:1。在任何前述内容中,p值(统计显著性值)满足p<0.3,或p<0.25,或p<0.2,或者p<0.15,或p<0.1,或p<0.05。在某些实施方案中,第一代谢物被预先确定来显示具有相关的上(最小)或下(最大)阈值的DD尾部效应,所述阈值被预先确定为使得满足该标准的未知分类的样品(先前未表征的样品)是DD而不是ASD的几率不小于1.6:1,p<0.3。在某些实施方案中,所述几率不小于2:1,或不小于2.5:1,或不小于2.75:1,或不小于3:1,或不小于3.25:1,或不小于3.5:1,或不小于3.75:1,或不小于4:1。在任何前述内容中,p值(统计显著性值)满足p<0.3,或p<0.25,或p<0.2,或者p<0.15,或p<0.1,或p<0.05。在某些实施方案中,预先确定水平的可预测性对应于将假阳性率(1-特异性)相对于真阳性率(灵敏度)绘制的接受者操作特征(ROC)曲线具有至少0.70的AUC(曲线下面积)。在某些实施方案中,一种或多种所述代谢物的预先确定上(最小)阈值是从第85位至第95位百分位的百分位数(例如,约第90百分位数,或约第85、第86、第87、第88、第89、第91、第92、第93、第94或第95百分位数,四舍五入至最接近的百分位数),并且其中一种或多种所述代谢物的预先确定的下(最大)阈值是从第10至第20百分位数的百分位数(例如,约第15位百分位数,或约第10、第11、第12、第13、第14、第16、第17、第18、第19或第20百分位数,四舍五入至最接近的百分位数)。在某些实施方案中,多种代谢物包括选自以下代谢物的至少两种代谢物:5-羟基吲哚乙酸(5-hydroxyindoleacetate,5-HIAA)、1,5-脱水葡糖醇(1,5-anhydroglucitol;1,5-AG)、3-(3-羟基苯基)丙酸(3-(3-hydroxyphenyl)propionate)、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(3-carboxy-4-methyl-5-propyl-2-furanpropanoate,CMPF)、3-吲哚氧基硫酸(3-indoxylsulfate)、4-乙基苯基硫酸(4-ethylphenylsulfate)、8-羟基辛酸(8-hydroxyoctanoate)、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸(indoleacetate)、异戊酰甘氨酸、乳酸(lactate)、N1-甲基-2-吡啶酮-5-甲酰胺、硫酸对甲酚(p-cresolsulfate)、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸(pipecolate)、黄嘌呤、羟基-百菌清、辛烯酰基肉碱和3-羟基马尿酸(3-hydroxyhippurate)。在某些实施方案中,多种代谢物包括选自以下代谢物的至少两种代谢物:苯乙酰谷氨酰胺、黄嘌呤、辛烯酰基肉碱、硫酸对甲酚、异戊酰甘氨酸、γ-CEHC、吲哚乙酸、哌可酸、1,5-脱水葡糖醇(1,5-AG)、乳酸、3-(3-羟基苯基)丙酸、3-吲哚氧基硫酸、泛酸(维生素B5)和羟基百菌清。在某些实施方案中,多种代谢物包括选自以代谢物的至少3种代谢物:苯乙酰谷氨酰胺、黄嘌呤、辛烯酰基肉碱、硫酸对甲酚、异戊酰甘氨酸、γ-CEHC、吲哚乙酸、哌可酸、1,5-脱水葡糖醇(1,5-AG)、乳酸、3-(3-羟基苯基)丙酸、3-吲哚氧基硫酸、泛酸(维生素B5)和羟基百菌清。在某些实施方案中,多种代谢物包含选自表6中所列的对中的至少一对代谢物。在某些实施方案中,多种代谢物包含选自表7中所列的三元组中的至少一个三元组代谢物。在某些实施方案中,多种代谢物包含至少一对代谢物,其被组合在一起作为一组两种代谢物,提供至少0.62(例如,至少约0.63、0.64或0.65)的AUC,其中AUC是针对仅基于所述两种代谢物的组的分类器,将假阳性率(1-特异性)相对于真阳性率(灵敏度)绘制的ROC曲线下面积。在某些实施方案中,所述多种代谢物包含至少一个三元组代谢物,其被组合在一起作为一组三种代谢物,提供至少0.66(例如,至少约0.67或0.68)的AUC,其中AUC是针对仅基于所述三种代谢物的组的分类器,将假阳性率(1-特异性)相对于真阳性率(灵敏度)绘制的ROC曲线下面积。在另一方面,本发明涉及确定受试者的自闭症谱系病症(ASD)风险的方法,所述方法包括:(i)分析来自从所述受试者获得的样品的多种代谢物的第一代谢物的水平,所述第一代谢物的群体分布事先在具有已知分类的参照受试者群体中进行了表征,其中所述第一代谢物被预先确定为表现出包含在ASD成员中富集的相关右尾或左尾的ASD尾部效应,以及其中第一代谢物表现出具有右尾的ASD尾部效应,当样品中第一代谢物的水平高于限定在ASD群体成员中富集的右尾的预先确定上(最小)阈值时,样品中第一代谢物的水平在ASD尾部内,并且其中第一代谢物表现出具有左尾的ASD尾部效应,当样品中第一代谢物的水平低于限定在ASD群体成员中富集的左尾的预衔测定下(最大)阈值时,样品中第一代谢物的水平在ASD尾部内;(ii)测量来自样品的多种代谢物中的至少一种另外的代谢物的水平,所述至少一种另外的代谢物中的每一种的群体分布事先在参照群体中进行了表征,并且被预先确定为表现出ASD尾部效应,以及对于所述至少一种另外的代谢物中的每一种,根据步骤(i)鉴定样品中所述代谢物的水平是否在相应的ASD尾部内;和(iii)基于样品位于针对步骤(i)和步骤(ii)中分析的代谢物所鉴定的ASD尾,以预先确定的可预测水平测定受试者具有ASD的风险。在某些实施方案中,第一代谢物被预先确定为表现具有相关的上(最小)或下(最大)阈值的ASD尾部效应,所述阈值被预先确定为使得满足该标准的未知分类的样品(先前未表征的样品)是ASD而不是DD的几率不小于1.6:1,p<0.3。在某些实施方案中,所述几率不小于2:1,或不小于2.5:1,或不小于2.75:1,或不小于3:1,或不小于3.25:1,或不小于3.5:1,或不小于3.75:1,或不小于4:1。在任何前述内容中,p值(统计显著性值)满足p<0.3,或p<0.25,或p<0.2,或者p<0.15,或p<0.1,或p<0.05。在某些实施方案中,预先确定的可预测性水平对应于将假阳性率(1-特异性)相对于真阳性率(灵敏度)绘制的接受者操作特征(ROC)曲线具有至少0.70的AUC(曲线下面积)。在某些实施方案中,多种代谢物包括选自以下代谢物的至少两种代谢物:5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺、硫酸对甲酚、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、黄嘌呤、羟基-百菌清、辛烯酰基肉碱和3-羟基马尿酸。在另一方面,本发明涉及确定受试者的自闭症谱系病症(ASD)风险的方法,包括:(i)分析从受试者获得的样品中的多种代谢物的水平,所述多种代谢包括选自以下代谢物的至少两种代谢物:5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺、硫酸对甲酚、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、黄嘌呤、羟基-百菌清、辛烯酰基肉碱和3-羟基马尿酸;和(ii)基于所述多种代谢物的定量水平确定所述受试者具有ASD的风险。在某些实施方案中,受试者的年龄不超过约54个月。在某些实施方案中,受试者的年龄不超过约36个月。在某些实施方案中,所述多种代谢物包括选自以下代谢物的至少两种代谢物:苯乙酰谷氨酰胺、黄嘌呤、辛烯酰基肉碱、硫酸对甲酚、异戊酰甘氨酸、γ-CEHC、吲哚乙酸、哌可酸、1,5-脱水葡糖醇(1,5-AG)、乳酸、3-(3-羟基苯基)丙酸、3-吲哚氧基硫酸、泛酸(维生素B5)和羟基百菌清。在某些实施方案中,所述多种代谢物包括选自以下代谢物的至少3种代谢物:苯乙酰谷氨酰胺、黄嘌呤、辛烯酰基肉碱、硫酸对甲酚、异戊酰甘氨酸、γ-CEHC、吲哚乙酸、哌可酸、1,5-脱水葡糖醇(1,5-AG)、乳酸、3-(3-羟基苯基)丙酸、3-吲哚氧基硫酸、泛酸(维生素B5)和羟基百菌清。在某些实施方案中,所述多种代谢物包含选自表6中所列的对中的至少一对代谢物。在某些实施方案中,所述多种代谢物包含选自表7中所列的三元组的至少一个三元组的代谢物。在某些实施方案中,所述多种代谢物包含至少一对代谢物,其被组合在一起作为一组两种代谢物,提供至少0.62(例如,至少约0.63、0.64或0.65)的AUC,其中AUC是仅基于这一组两种代谢物的分类器将假阳性率(1-特异性)相对于真阳性率(灵敏度)绘制的ROC曲线下面积。在某些实施方案中,所述多种代谢物包含至少一种三元组的代谢物,其被组合在一起作为一组三种代谢物,提供至少0.66(例如,至少约0.67或0.68)的AUC,其中AUC是仅基于这一组三种代谢物的分类器将假阳性率(1-特异性)相对于真阳性率(灵敏度)绘制的ROC曲线下面积。在某些实施方案中,所述样品是血浆样品。在某些实施方案中,测量代谢物的水平包括进行质谱法。在某些实施方案中,进行质谱法包括进行选自热解质谱法、傅立叶变换红外光谱法、拉曼光谱法、气相色谱-质谱法、高压液相色谱法/质谱法(HPLC/MS)、液相色谱(LC)-电喷雾质谱法、帽-LC-串联电喷雾质谱法和超高效液相色谱/电喷雾电离串联质谱法。在另一方面,本发明涉及区分受试者中自闭症的样品谱系病症(ASD)与非ASD发育延迟(DD)的方法,包括:(i)分析获自受试者的样品中的多种代谢物的水平,所述多种代谢物包含选自以下代谢物中的至少两种代谢物:5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺、硫酸对甲酚、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、黄嘌呤、羟基-百菌清、辛烯酰基肉碱和3-羟基马尿酸,所述多种代谢物的水平和/或群体分布已事先在参照群体上进行了表征;和(ii)通过将来自受试者的样品的所述多种代谢物的水平与预先确定的阈值(例如,从具有已知分类的样品的参照群体确定的阈值)进行比较,以预先确定水平的可预测性确定(a)受试者具有ASD而不是DD或(b)受试者具有DD而不是ASD。在某些实施方案中,本发明提供了通过向不同代谢物分配权重以反映它们在风险预测中的相应功能来分析代谢物的方法。在一些实施方案中,可以从代谢物的生物学功能(例如,它们所属的途径)、其临床效用或其来自统计学或流行病学分析的显著性推导出权重分配。在某些实施方案中,本发明提供了使用不同技术测量代谢物的方法,包括但不限于色谱测定、质谱测定、荧光测定法测定、电泳测定、免疫亲和测定和免疫化学测定。在某些实施方案中,本发明提供了用于确定受试者的自闭症谱系病症(ASD)风险的方法,包括分析来自受试者的样品中多种代谢物的水平;以及基于所述多种代谢物的定量水平,以预先确定的可预测水平确定所述受试者是否具有ASD而不是非ASD发育病症。在某些实施方案中,所述多种代谢物包括选自以下代谢物中的至少一种代谢物:5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺、硫酸对甲酚、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、黄嘌呤、羟基-百菌清、辛烯酰基肉碱、3-羟基马尿酸及其组合。在某些实施方案中,所述多种代谢物包括选自以下代谢物中的至少两种代谢物:5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺、硫酸对甲酚、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、黄嘌呤、羟基-百菌清、辛烯酰基肉碱、3-羟基马尿酸及其组合。在某些实施方案中,所述多种代谢物包括选自以下的至少3种,至少4种,至少5种,至少6种,至少7种,至少8种,至少9种或至少10种代谢物:5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺,硫酸对甲酚、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、黄嘌呤、羟基-百菌清、辛烯酰基肉碱、3-羟基马尿酸及其组合。在某些实施方案中,所述多种代谢物包括另外的代谢物。在一些实施方案中,所述多种代谢物包括多于21种代谢物。在某些实施方案中,本发明提供了用于区分受试者的自闭症谱系病症(ASD)与非ASD发育病症的方法,包括以下步骤:分析来自受试者的样品中多种代谢物的水平,将代谢物的水平与其在一个参照群体中的相应群体分布相比较,以及通过将来自受试者的样品的多种代谢物的水平与先前表征的参照群体中所述多种代谢物的水平和/或群体分布相比较,以预先确定的可预测性水平确定受试者是否患有ASD而不是非ASD发育病症。例如,在某些实施方案中,本发明提供了诊断标准,其包括可利用具有如下AUC的ROC曲线预测受试者的ASD风险的至少一种代谢物:至少0.60、至少0.65、至少0.70、至少0.75、至少0.80、至少0.85或至少0.90的AUC。AUC是针对分类器将假阳性率(1-特异性)相对于真阳性率(灵敏度)绘制的ROC曲线下的面积。在某些实施方案中,用于分析的至少一种代谢物选自5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺,硫酸对甲酚、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、黄嘌呤、羟基-百菌清、辛烯酰基肉碱、3-羟基马尿酸及其组合。在某些实施方案中,用于分析的所述至少一种代谢物包含选自以下成员的至少两个或更多个(例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个、18个、19个、20个、21个)成员:5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺,硫酸对甲酚、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、黄嘌呤、羟基-百菌清、辛烯酰基肉碱和3-羟基马尿酸,其中建立每种代谢物(例如,显示尾部效应的每种所述代谢物)的非ASD人口分布曲线和ASD群体分布曲线。在某些实施方案中,用于分析的代谢物选自γ-CEHC、黄嘌呤、硫酸对甲酚、辛烯酰基肉碱、苯乙酰谷氨酰胺及其组合。在某些实施方案中,用于分析的代谢物是γ-CEHC。在某些实施方案中,用于分析的代谢物是黄嘌呤。在某些实施方案中,用于分析的代谢物是硫酸对甲酚。在某些实施方案中,用于分析的代谢物是辛烯酰基肉碱。在某些实施方案中,用于分析的代谢物是苯乙酰谷氨酰胺。在某些实施方案中,用于分析的代谢物是异戊酰基甘氨酸。在某些实施方案中,用于分析的代谢物是哌可酸。在某些实施方案中,用于分析的代谢物是吲哚乙酸。在某些实施方案中,用于分析的代谢物是辛烯酰基肉碱。在某些实施方案中,用于分析的代谢物是羟基百菌清。在某些实施方案中,所述多种代谢物包含互补的至少第一代谢物和第二代谢物(例如,第一和第二代谢物的ASD尾部样品基本上不重叠),从而由代谢物提供的预测子部分不相连,并且具有的共同信息少。在某些实施方案中,风险预测因引入共同信息少的多种代谢物而改善。在某些实施方案中,所述多种代谢物包括两种代谢物,其中被组合在一起作为一组两种代谢物的所述两种代谢物提供了至少0.62、0.63、0.64或0.65的AUC。在某些实施方案中,所述多种代谢物包括三种代谢物,其中被组合在一起作为一组三种代谢物的所述三种代谢物提供了至少0.66、0.67或0.68的AUC。在某些实施方案中,本发明提供了通过分析两组事先定义的代谢物的水平来区分受试者的自闭症谱系病症(ASD)与非ASD发育病症的方法。在某些实施方案中,第一组代谢物代表与ASD密切相关的代谢物,而第二组代谢物代表与对照病况(例如,DD)相关的代谢物。通过分析来自受试者的样品的两组代谢物,受试者具有ASD而不是对照病况的风险可通过本公开中描述的多种方法来确定。例如,这可以通过比较第一组代谢物的聚集的ASD尾部效应与第二组代谢物的聚集的非ASD尾部效应来实现。在某些实施方案中,本发明提供了用于区分受试者的自闭症谱系病症(ASD)与非ASD发育迟缓(DD)的方法,所述方法包括:(i)测量获自受试者的样品中的多种代谢物的水平,其中所述多种代谢物包括选自以下代谢物的至少两种代谢物:黄嘌呤、γ-CEHC、羟基-百菌清、5-羟基吲哚乙酸(5-HIAA)、吲哚乙酸、硫酸对甲酚、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、羟基异戊酰肉毒碱(C5)、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、3-羟基马尿酸及其组合;和(ii)计算样品中其水平等于或低于(a)如表9A中定义的指示ASD(ASD左尾效应)或(b)如表9B中定义的指示DD(DD左尾效应)的预先确定阈值浓度的代谢物数目;和/或(iii)计算样品中其水平等于或高于(a)如表9A中定义的指示ASD(ASD左尾效应)或(b)如表9B中定义的指示DD(DD左尾效应)的预先确定阈值浓度的代谢物数目;和(iv)基于步骤(ii)和/或(iii)中获得的数目,确定受试者具有ASD或DD。在某些实施方案中,本发明提供了用于确定受试者具有发生ASD的风险或处于发生ASD的风险中的方法,所述方法包括:(i)测量获自受试者的样品中的多种代谢物的水平,其中所述多种代谢物包括选自以下代谢物的至少两种代谢物:黄嘌呤、γ-CEHC、羟基-百菌清、5-羟基吲哚乙酸(5-HIAA)、吲哚乙酸、硫酸对甲酚、1,5-脱水葡糖醇(1,5-AG)、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、羟基异戊酰肉碱(C5)、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、3-羟基马尿酸及其组合;和(ii)检测以下中的两种或更多种:(a)黄嘌呤水平为182.7ng/ml或以上;(b)羟基-百菌清水平为20.3ng/ml或以上;(c)5-羟基吲哚乙酸水平为28.5ng/ml或以上;(d)乳酸水平为686600ng/ml或以上;(e)泛酸水平为63.3ng/ml或以上;(f)哌可酸水平为303.6ng/ml或以上;(g)γ-CEHC水平为32.0ng/ml或以下;(h)吲哚乙酸水平为141.4ng/ml或以下;(i)硫酸对甲酚水平为182.7ng/ml或以下;(j)1,5-脱水葡糖醇(1,5-AG)水平为11910.3ng/ml或以下;(k)3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)水平为7.98ng/ml或以下;(l)3-吲哚氧基硫酸水平为256.7ng/ml或以下;(m)4-乙基苯基硫酸水平为3.0ng/ml或以下;(n)羟基异戊酰肉碱(C5)水平为12.9ng/ml或以下;(o)N1-甲基-2-吡啶酮-5-甲酰胺水平为124.82ng/ml或以下;和(p)苯乙酰谷氨酰胺水平为166.4ng/ml或以下;和(iii)基于步骤(ii)中检测的代谢物水平,确定受试者具有ASD或处于发生ASD的风险中。在一些实施方案中,步骤(ii)中检测的代谢物水平是近似水平。在一些实施方案中,本发明提供了将受试者诊断为患有自闭症谱系病症(ASD)或处于发生该病症的风险中的方法,所述方法包括(i)测定获自所述受试者的样品中一种或多种代谢物的水平;(ii)将所测定的所述一种或多种代谢物的水平与所述一种或多种代谢物的预先确定水平进行比较,所述预先确定水平指示了受试者具有ASD或处于发生该病症的风险中;和(iii)基于所述一种或多种代谢物的测定水平与预先确定水平之间的差异,将所述受试者诊断为具有ASD或处于发生该病症的风险中;其中所述一种或多种代谢物选自5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺、硫酸对甲酚、泛酸(维生素B5)、对-苯乙酰谷氨酰胺、哌可酸、黄嘌呤,羟基-百菌清、辛烯酰基肉碱和3-羟基马尿酸。在一些实施方案中,本发明提供了诊断受试者为具有自闭症谱系病症(ASD)或处于发生该病症的风险中的方法,所述方法包括(i)测定获自所述受试者的样品中一种或多种代谢物的水平;(ii)将所测定的所述一种或多种代谢物的水平与所述一种或多种代谢物的预先确定水平进行比较,所述预先确定水平指示了受试者具有ASD或处于发生该病症的风险中;和(iii)基于所述一种或多种代谢物的测定水平与预先确定水平之间的差异,诊断所述受试者具有ASD或处于发生该病症的风险中;其中所述一种或多种代谢物选自5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺、硫酸对甲酚、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、黄嘌呤、羟基-百菌清、辛烯酰基肉碱和3-羟基马尿酸,条件是所述代谢物不是5-羟基吲哚乙酸(5-HIAA)、5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺、硫酸对甲酚、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、黄嘌呤、羟基-百菌清、辛烯酰基肉碱或3-羟基马尿酸。在某些实施方案中,本发明提供了通过测量来自受试者的某些代谢物的水平和遗传信息来确定受试者发生ASD风险的方法。在一些实施方案中,遗传信息包括拷贝数变异(CNV)和/或脆性X(FXS)测试。在另外的实施方式中,关于本发明的某些方面所描述的限制可以应用于本发明的其它方面。例如,在一些实施方式中,从属于一个独立权利要求的权利要求的限定可以应用于另一独立权利要求。附图说明图1举例说明两个群体(例如,ASD和DD)中的示例性代谢物的分布,以及该代谢物在这两个群体之间的平均偏移。图2举例说明示例性代谢物在两个群体(例如,ASD和DD)中的分布,以及这种代谢物在这两个群体之间的尾部效应(例如,ASD分布具有更密集的尾部)。图3举例说明代谢物5-羟基吲哚乙酸在两个群体(例如,ASD和DD)中的分布,其在这两个群体之间表现出统计上显著的平均偏移(t检验;p<0.01)和统计学上显著的右尾效应('极限值'表示尾部效应,Fisher's检验;p=0.001)。图4举例说明代谢物γ-CEHC在两个群体(例如,ASD和DD)中的分布,其在这两个群体之间表现出统计上显著的左尾效应(“极限值”表示尾部效应,Fisher's检验;p=0.008)图5举例说明代谢物苯基乙酰谷氨酰胺在两个群体(例如,ASD和DD)中的分布,其在这两个群体之间表现出统计上显著的平均偏移(t检验;p=0.001)和统计学上显著的左和右尾效应(“极限值”表示尾效应,Fisher's检验;p=0.0001)。所述分布在两个群体中表现为偏移的高斯曲线。图6举例说明两种示例性代谢物的相关性,证明了这两种代谢物具有不同的尾部效应分布并且是互补的。图7举例说明12种示例性代谢物在180名受试者中的尾部效应,以及它们对ASD和DD的预测能力。图8A举例说明使用示例性12种代谢物小组对180个样品的ASD和非ASD尾部效应的曲线图,证明了来自ASD患者的样品显示出ASD尾部效应的聚集。图8B举例说明使用示例性12种代谢物小组对180个样品的ASD和非ASD尾部效应的曲线图,以及对数据进行分元的示例性方法。图8C举例说明使用示例性21种代谢物小组对180个样品的ASD和非ASD尾部效应的曲线图,证明了来自ASD患者的样品显示出ASD尾部效应的聚集。图9举例说明示例性12种代谢物小组在所评估的代谢物数目增加时,对ASD的可预测性增加。图10A举例说明使用示例性12种代谢物小组的三分法对ASD的可预测性的影响。图10B举例说明在示例性21种代谢物小组的分析中三分法对ASD的可预测性的影响。图11A举例说明与用于分析示例性12种代谢物小组的非投票方法相比,使用投票方法对ASD的可预测性的改进。图11B举例说明与使用示例性21种代谢物小组的非投票方法相比,使用投票方法对ASD的可预测性的改进。图12举例说明使用示例性12种代谢物小组来实现ASD高可预测性的验证过程。图13A-13U举例说明21种示例性代谢物在ASD群体和非ASD群体中的群体分布。图14A-B举例说明通过从总共600种代谢物中包括和排除示例性的12种代谢物小组、示例性的21种代谢物小组和一组84种候选代谢物而产生的对ASD可预测性的影响,如通过尾部效应分析和平均偏移分析评估的。(黑名单=排除,白名单=包括,mx_12=示例性12种代谢物小组,mx_targeted21=示例性21种代谢物小组,mx-all-candidates=84种候选代谢物,所有特征=600种代谢物的总集)图14C-D举例说明通过从总共600种代谢物中包括(白名单)和排除(黑名单)示例性12种代谢物小组和示例性21种代谢物中小组产生的对ASD可预测性的影响,如通过尾部效应分析和平均偏移分析、以及通过比较逻辑回归与贝叶斯分析在两个样品组群(即,“圣诞节”("Christmas")和复活节("Easter"))中评估的。(黑名单=排除,白名单=包括,mx_12=示例性12种代谢物小组,mx_targeted21=示例性21种代谢物小组,mx-all-candidates=84种候选代谢物,所有特征=600种代谢物的总集)图15举例说明通过使用增加数目的选自示例性21种代谢物小组的亚组的代谢物而对ASD的可预测性产生的影响。图16A举例说明使用示例性12种代谢物小组将遗传信息添加至尾部效应分析的效果,证明了将ASD与非ASD分开的功效提高。图16B举例说明使用示例性21种代谢物小组将遗传信息添加至尾部效应分析的效果,证明了将ASD与非ASD区分开的功效提高。图17A-B举例说明通过比较尾部效应分析与平均偏移分析以及通过比较逻辑回归与贝叶斯分析来说明通过从总数目代谢物中包含和排除示例性21种代谢物小组对ASD可预测性产生的影响。(黑名单=排除,白名单=包括,mx_12=示例性12种代谢物组,mx_targeted21=示例性21种代谢物小组,mx_all_candidates=84种候选代谢物,所有特征=600种代谢物的总集)图18A-B通过比较尾部效应分析与平均偏移分析,以及通过在两个群组(即,"Christmas"和"Easter")中使用逻辑回归来说明,通过从总数目代谢物中包含和排除示例性21种代谢物小组对ASD可预测性产生的影响。(黑名单=排除,白名单=包括,mx_12=示例性12种代谢物组,mx_targeted21=示例性21种代谢物小组,mx_all_candidates=84种候选代谢物,所有特征=600种代谢物的总集)图19A-D举例说明通过使用"Christmas"组群,或"Easter"组群,或组合两者,比较尾部效应分析与平均偏移分析,以及比较逻辑回归与贝叶斯分析来说明,通过从总数目代谢物中包含和排除示例性的21种代谢物小组对ASD可预测性产生的影响。(黑名单=排除,白名单=包括,mx_12=示例性12种代谢物组,mx_targeted21=示例性21种代谢物小组,mx所有候选物=84种候选代谢物,所有特征=600种代谢物的总集)图20举例说明示例性21种代谢物小组的尾部效应分析用于预测ASD的特异性和灵敏度的代表性曲线图。图21举例说明评分系统,其中基于ASD和DD预测性代谢物的比值比的log2值的总和计算ASD或DD的风险得分。定义为了更容易地理解本发明,首先在下面定义某些术语。在整个说明书中阐述了以下术语和其他术语的附加定义。在本申请中,除非根据上下文另有说明,否则(i)术语“一个/种(a)”可被理解为是指“至少一个”;(ii)术语“或”可以理解为是指“和/或”;(iii)术语“包含”和“包括”可以被理解为包括详细例举的组件或步骤,无论是由它们本身还是与一个或多个附加的组件或步骤一起呈现;和(iv)术语“约”和“大约”可以被理解为允许如由本领域普通技术人员所理解的标准变化;和(v)当提供范围时,包括端点。药剂:本文所用的术语“药剂”可以指任何化学类别的化合物或实体,包括例如多肽、核酸、糖类、脂质,小分子、金属或其组合。大约:如本文所使用的,术语“近似”、“大约”或“约”旨在涵盖如本领域普通技术人员根据相关上下文所理解的正常统计变化。在某些实施方案中,除非另有说明或从上下文中明显看出(除其中这样的数字超过可能值的100%外),否则术语“近似”、“大约”或“约”是指以任一方向(大于或小于)落在所述参照值的25%、20%、19%、18%、17%、16%、15%、14%、13%、12%、11%、10%、9%、8%、7%、6%、5%、4%、3%、2%、1%或更小)内的一系列值。曲线下面积(AUC):分类器具有将假阳性率(1-特异性)相对于真实阳性率(灵敏度)绘制的相关ROC曲线(受试者工作特征曲线)。ROC曲线下面积(AUC)是分类器能够区分两个诊断组的程度的量度。与AUC为0.5的随机分类器相比,完美分类器具有1.0的AUC。与……相关联:如果一个事件或实体的存在、水平和/或形式与另一个事件或实体的存在、水平和/或形式相关,则所述两个事件或实体彼此“相关联”,如该术语在本文中所使用的。例如,如果特定实体的存在、水平和/或形式与疾病、病症或病况的发病率和/或易感性相关(例如,在整个相关群体中),则所述特定实体被认为与该特定疾病、病症或病况相关。自闭症谱系病症:如本文所用,术语“自闭谱系病症”被本领域技术人员认为是指以有关自闭症“谱”的发育病症,其特征在于交互社交缺陷、语言困难、重复行为和限制性兴趣中的一种或多种。自闭症谱系病症已在DSM-V(2013年5月)中被描述为包括连续的症状的病症,包括例如沟通障碍,诸如在交谈中不适当地响应,错读非语言交互作用,难以建立适合年龄的友谊,过度依赖于常规,对他们的环境变化高度敏感,和/或强烈关注不适当的项目。自闭症谱系病症另外地已例如通过DSM-IV-TR表征为包括自闭症、阿斯伯格病症、Rett氏病症、儿童崩解病症和未以其它方式说明的广泛性发育病症(包括非典型自闭症)。在一些实施方案中,使用标准化测试仪器诸如问卷和观察时间表来表征自闭症谱系病症(ASD)。例如,在一些实施方案中,ASD的特征在于(i)满足自闭症诊断观察时间表(ADOS)中的关于沟通加社交互动总计(CommunicationplusSocialInteractionTotal)的截止值的得分,以及满足自闭症诊断面试修订版(AutismDiagnosticInterview-Revised)(ADI-R)中的关于≤36个月时的社交互动、沟通、行为模式和发育异常性的截止值的得分;和/或(ii)满足ADOS中关于沟通和社交互动总计的ASD截止值的得分,以及满足在ADI-R中关于≤36个月时社会互动、沟通、行为模式和发育异常的截止值的得分,以及(ii)(a)满足ADI-R中关于社交互动和沟通的截止值的得分,或(ii)(b)满足ADI-R中关于社交互动或沟通的截止值和在关于社互动或沟通截止值的2个点内(其不满足截止值)的得分,或(ii)(c)在ADI-R中社交互动和沟通的截止值的1个点内的得分。分类:如本文所用,“分类”是通过在已知类别内的收集的数据点之间找到共同特征,然后使用数学方法或其他方法将数据点分配至这些不同类别之一来学习将数据点分成不同类别的过程。在统计学中,分类是基于包含其子群体已知的观测的训练数据集来鉴定新观测所属的子群体(其中所述子群体的身份是未知的)的问题。因此,其要求是基于对一个或多个测量、性状或特征等的定量信息,并且基于其中已经建立先前确定的分组的训练组,将新的单独项目归到组中。分类有很多应用。在一些情况下,其被用作数据挖掘过程,而在其他情况下,进行更详细的统计建模。分类器:如本文所用,“分类器”是用于执行数据分类的方法、算法、计算机程序或系统。广泛使用的分类器的实例包括但不限于神经网络(多层感知器)、逻辑回归、支持向量机、k-最近邻、高斯混合模型、高斯朴素贝叶斯、决策树、偏最小二乘法行列式分析(partial-least-squaresdeterminantanalysis)(PSL-DA)、Fisher线性判别、逻辑回归、朴素贝叶斯分类器、感知器、支持向量机、二次分类器、Kernet估计、Boosting、神经网络、贝叶斯网络、隐马尔科夫模型和学习矢量量化。确定:本文描述的许多方法包括“确定”的步骤。通过阅读本说明书,本领域普通技术人员将理解,这种“确定”可以利用或通过使用本领域技术人员可用的各种技术中的任何技术来实现,所述技术包括例如明确提及的特定技术。在一些实施方案中,确定涉及物理样品的操作。在一些实施方案中,确定涉及对数据或信息的考虑和/或操作,例如利用适于执行相关分析的计算机或其他处理单元。在一些实施方案中,确定涉及从源接收相关信息和/或材料。在一些实施方案中,确定包括将样品或实体的一个或多个特性与可比较的参照进行比较。确定风险:如本文所用,确定风险包括计算或量化给定受试者具有或不具有特定病况或病症的概率。在一些实施方案中,可完全或部分基于确定的风险或风险得分(例如,比值比或范围)进行病症或疾病(例如,自闭症谱系病症(ASD)或发育迟缓(DD))的阳性或阴性诊断。发育迟缓:如本文所用,短语发育迟缓(DD)是指儿童发育的一个或多个过程,包括例如身体发育、认知发展、沟通发展、社交或情感发展或适应性发展的持续性或大或小延迟,所述延迟不是由自闭症谱系病症造成的。即使具有ASD的个体可能被认为是发育迟缓的,但本文使用的ASD的分类将被认为胜于DD的分类,因此ASD和DD的分类是相互排斥的。换句话说,除非另有说明,否则DD的分类被视为指非ASD的发育延迟。在一些实施方案中,DD的特征在于非自闭症(AU)和非ASD,但是(i)在Mullen量表上的得分为69或更低,在Vineland量表上得分为69或更低,以及在SCQ上的得分为14或更低,或(ii)在Mullen或Vineland上的得分为69或更低,并且在另一评估(得分77或更低)上的得分在截止值标准偏差的一半以内。诊断信息:如本文所用,诊断性信息或用于诊断的信息是在确定患者是否患有疾病或病症和/或将疾病或病症分类为表型类别或对疾病或病况的预后,或对疾病或病况的治疗(一般治疗或任何特定治疗)的可能反应具有重要性的任何类别中有用的任何信息。类似地,诊断是指提供任何类型的诊断信息,包括但不限于受试者是否可能患有疾病或病况(诸如,自闭症谱系病症)、在受试者中所表现的疾病或病况的状态、分期或特征,与病症的性质或分类相关的信息,与预后相关的信息和/或在选择适当治疗中有用的信息。治疗的选择可包括选择特定的治疗剂或其它治疗方式,诸如行为治疗、饮食改变等,关于是否放弃或进行治疗的选择,与给药方案相关的选择(例如,特定治疗剂或治疗剂的组合的一个或多个剂量的频率或水平)等标志物:如本文所用,标志物是指其存在或水平与特定疾病或病况相关或具有相关性的药剂。可选择地或另外,在一些实施方案中,特定标志物的存在或水平例如与特定信号传导途径的活性(或活性水平)相关,所述信号传导途径可能是特定病症的特征。标志物可能在或可能不在该疾病或病症中发挥病原学作用。标志物的存在或不存在的统计显著性可以根据具体标志物而变化。在一些实施方案中,标志物的检测是高度特异性的,因为其反映病症属于特定亚类的高概率。根据本发明,有用的标志物不需要以100%的准确度区分特定亚类的病症。代谢物:如本文所用,术语代谢物是指在身体化学或物理过程中产生的物质。术语“代谢物”包括代谢过程的任何化学或生物化学产物,诸如通过生物分子的加工、裂解或消耗产生的任何化合物。这样的分子的实例包括但不限于:酸和相关化合物;单、二和三羧酸类(饱和、不饱和以及脂族和环状、芳基、烷芳基);醛酸类、酮酸类;内酯形式;赤霉素;脱落酸;醇、多元醇、衍生物和相关化合物;乙醇、苄醇、甲醇;丙二醇、甘油、植醇;肌醇、糠醇、薄荷醇;醛、酮、醌、衍生物和相关化合物;乙醛、丁醛、苯甲醛、丙烯醛、糠醛、乙二醛;丙酮、丁酮;蒽醌;碳水化合物;单糖、二糖、三糖;生物碱、胺和其他碱;吡啶(包括烟酸、烟酰胺);嘧啶(包括胞嘧啶、胸腺嘧啶);嘌呤(包括鸟嘌呤、腺嘌呤、黄嘌呤/次黄嘌呤、激动素);吡咯;喹啉(包括异喹啉);吗啡喃、托烷、辛可宁类(cinchonans)、核苷酸、寡核苷酸、衍生物和相关化合物;鸟苷、胞嘧啶、腺苷、胸苷、肌苷;氨基酸、寡肽、衍生物和相关化合物;酯;酚类和相关化合物;杂环化合物和衍生物;吡咯、四吡咯(类咕啉和卟吩/卟啉、w/w/o金属离子);黄酮类;吲哚;脂质(包括脂肪酸和甘油三酯)、衍生物和相关化合物;类胡萝卜素、八氢番茄红素和固醇、类异戊二烯类,包括萜烯;和上述分子的修饰形式。在一些实施方案中,代谢物是内源性物质的代谢的产物。在一些实施方案中,代谢物是外源物质的代谢的产物。在一些实施方案中,代谢物是内源物质和外源物质的代谢的产物。如本文所使用的,术语“代谢组”是指体液、细胞、组织、器官或生物体中代谢物的化学分布或指纹。代谢物分布曲线:如本文所用,代谢物分布曲线是由将代谢物水平针对群体密度(例如,ASD或DD)作图的函数确定的概率分布曲线。在一些实施例中,分布曲线是数据的标准曲线拟合。在一些实施方案中,分布曲线是最小二乘多项式曲线拟合。在一些实施例中,分布曲线是不对称的或非高斯的。在一些实施方案中,分布曲线仅仅是具有相关诊断类别的病例对比代谢物值的曲线图(例如,“地块图”),其中没有曲线拟合。共同信息(mutualinformation):如本文所用,共同信息指的是两个变量的共同依赖性的度量(即,知道一个变量降低了关于另一个变量的不确定性的程度)。高的相互信息指示不确定性的大幅度减小;低共同信息表示小的减少;两个随机变量之间的零共同信息意味着变量是独立的。非自闭症谱系病症(非ASD):如本文所用,非自闭症谱系病症(非ASD)是指不是具有自闭症谱系病症的儿童或成人的分类。在一些实施方案中,“非ASD”通常是发展中的受试者。在一些实施方案中,非ASD群体由具有发育迟缓(DD)的受试者组成或包含具有发育迟缓(DD)的受试者。在一些实施方案中,“非ASD”由DD和正常发展的受试者组成或包含DD和正常发展的受试者。患者:如本文所用,术语“患者”或“受试者”是指例如为了实验、诊断、预防和/或治疗目的进行施用或可以施用测试或组合物的任何生物体。在一些实施方案中,患者罹患或易患一种或多种病症或病况。在一些实施方案中,患者显示障碍或病症的一种或多种症状。在一些实施方案中,怀疑患者患有一种或多种障碍或病况。可预测性:如本文所用,可预测性是指可以定性或定量地进行受试者疾病状态的正确预测或预报的程度。完全可预测性意味着严格的确定,但缺乏可预测性并不一定意味着缺乏确定。对可预测性的限制可能是由诸如缺乏信息或过度复杂等因素造成的。预后和预测信息:如本文所用,术语预后信息和预测信息可互换使用,是指可用于指示疾病或病况过程的任何方面的任何信息,无论存在还是不存在治疗。这样的信息可以包括但不限于患者的疾病被治愈的可能性,患者疾病将对特定治疗反应的可能性(其中反应可以以多种方式中的任一种定义)。预后和预测信息包括在诊断信息的广泛类别中。参照:术语“参照”在本文中通常用于描述针对其比较目标试剂、个体、群体、样品、序列或数值的标准或对照试剂、个体、群体、样品、序列或数值。在一些实施方案中,与目标试剂、个体、群体、样品、序列或数值的测试或测定基本上同时地测试和/或测定参照试剂、个体、群体、样品、序列或数值。在一些实施方案中,参照试剂、个体、群体、样品、序列或数值是历史参照,其任选地体现在有形介质中。通常,如本领域技术人员将理解的,在与用于测定或表征目标试剂、个体、群体、样品、序列或数值的那些条件相当的条件下测定或表征参照试剂、个体、群体、样品、序列或数值。回归分析:如本文所用,“回归分析”包括用于对数个变量建模和分析的任何技术,其中焦点在于因变量与一个或多个独立变量之间的关系。更具体地,回归分析有助于理解当任何一个独立变量变化、而其他独立变量保持固定时,因变量的典型值是如何变化的。最常见地,回归分析估计在独立变量时因变量的条件性期望值-即当独立变量保持固定时,因变量的平均值。较不常见的是,焦点在于给定独立变量时,因变量的条件性分布的分位数或其他位置参数。在所有情况下,估计目标是独立变量的函数,称为回归函数。在回归分析中,也有兴趣表征回归函数周围的因变量变化,其可通过概率分布来描述。回归分析广泛用于预测和预报,其中回归分析的使用与机器学习领域有实质重叠。回归分析也用于理解哪些独立变量与因变量相关,以及探索这些关系的形式。在有限的情况下,回归分析可用于推断独立变量与因变量之间的因果关系。已经开发了用于进行回归分析的大量技术。熟悉的方法诸如线性回归和普通最小二乘回归是参数化的,因为回归函数是根据从数据估计的有限数量的未知参数来定义的。非参数回归是指允许回归函数以指定的一组函数存在的技术,所述函数可以是无限维的。风险:如将从上下文理解的,疾病、病症或病况的“风险”是特定个体将被诊断为患有或将发展疾病、病症或病况的可能性的程度。在一些实施方案中,风险表示为百分比。在一些实施方案中,风险为0%、1%、2%、3%、4%、5%、6%、7%、8%、9%或10%直至100%。在一些实施方案中,风险表示为相对于与参照样品或参照样品组相关联的风险的风险。在一些实施方案中,参照样品或参照样品组具有疾病、病症或病况的已知风险。在一些实施方案中,参照样品或参照样品组来自与特定个体相当的个体。在一些实施方案中,相对风险度为0、1、2、3、4、5、6、7、8、9、10或更多。在一些实施方案中,相对风险度可表示为相对风险度(RR)或比值比(OddsRatio,OR)。样品:如本文所用,术语“样品”通常是指如本文所述的获自或源自目标来源的生物样品。在一些实施方案中,目标来源包括生物体,诸如动物或人。在一些实施方案中,生物样品是或包含生物组织或流体。在一些实施方案中,生物样品可以是或包含骨髓;血液;血浆;血清;血细胞;腹水;组织或细针活检样品;含细胞的体液;自由漂浮的核酸;痰液;唾液;尿;脑脊液液体、腹膜液、胸膜液、粪便、淋巴液、妇科液、皮肤拭子、阴道拭子、口腔拭子、鼻拭子;诸如导管灌洗液或支气管肺泡灌洗液等洗涤或灌洗液;吸出物;刮取物;骨髓样本;组织活检样本;外科样本;粪便、其他体液、分泌物和/或排泄物;和/或来自其的细胞等。在一些实施方案中,生物样品是或包含从个体获得的细胞。在一些实施方案中,获得的细胞是或包含来自从其获得样品的个体的细胞。在一些实施方案中,样品是通过任何适当的方式从目标来源直接获得的“初级样品”。例如,在一些实施方案中,通过选自以下的方法获得初级生物样品:活组织检查(例如,细针抽吸或组织活检)、手术、体液收集(例如,血液、淋巴、粪便等)等。在一些实施方案中,如从上下文将清楚的,术语“样品”是指通过加工初级样品(例如,通过除去其中的一种或多种组分和/或通过将一种或多种试剂添加至其中)获得的制剂。例如,使用半透膜进行过滤。这种“加工的样品”可以包含例如从样品提取的核酸或蛋白质,或通过使初级样品经受诸如mRNA的扩增或逆转录、某些组分的分离和/或纯化等技术而获得的核酸或蛋白质。受试者:“受试者”是指哺乳动物(例如人,在一些实施例中,包括出生前人形式)。在一些实施方案中,受试者患有相关疾病、病症或病况。在一些实施方案中,受试者对疾病,病症或病况敏感。在一些实施方案中,受试者显示疾病、病症或病况的一种或多种症状或特征。在一些实施方案中,受试者不显示疾病、病症或病况的任何症状或特征。在一些实施方案中,受试者是具有对疾病、病症或病况的易感性或风险特征的一个或多个特征的人。受试者可以是患者,其是指到医疗提供者处进行疾病的诊断或治疗的人。在一些实施方案中,受试者是被施予治疗的个体。基本上:如本文所使用的,术语“基本上”是指表现出目标特征或性质的总体或接近总体程度或水平的定性条件。生物领域的普通技术人员将理解,生物和化学现象很少(如果有的话)达到完全和/或进行至完全或实现或者避免绝对结果。因此,本文使用术语“基本上”来涵盖许多生物和化学现象中固有的潜在缺乏完全性。患有:“患有”疾病、障碍或病况的个体已经被诊断为患有和/或表现出或已表现出所述疾病、障碍或病况的一种或多种症状或特征。易感于:对疾病、病症或病况“易感”的个体处于发展疾病、病症或病况的风险中。在一些实施方案中,已知这样的个体具有与相关疾病、病症和/或病况的发展的风险增加统计上相关的一种或多种易感性因素。在一些实施方案中,易患疾病、病症或病况的个体不显示该疾病、病症或病况的任何症状。在一些实施方案中,对疾病、病症或病况敏感的个体未被或尚未被诊断为患有所述疾病、病症和/或病况。在一些实施方案中,对疾病、病症或病况敏感的个体是已经暴露于与所述疾病、病症或病况发展相关的条件下的个体。在一些实施方案中,发展疾病、病症和/或病况的风险是基于群体的风险(例如,患有过敏的个体的家族成员等)尾部富集和尾部效应:如本文所用,术语“尾部富集”或“尾部效应”是指代谢物(或其他分析物)显示的分类增强性质,所述代谢物在代谢物水平的分布曲线的远端部分在来自特定群体的样品中具有相对高浓度。“上尾部”或“右尾部”是指分布曲线的远端部分大于平均值。“下尾部”或“左尾部”是指分布曲线的远端部分低于平均值。在一些实施方案中,尾部由基于排名的预先确定阈值确定。例如,如果样品对于某种代谢物的测量值高于对应于群体中该代谢物的从第85至第95(例如,第90)百分位数的值,或者低于对应于群体中该代谢物的从第10至第20(例如,第15)百分位数的值,则样品被指定为在尾部内。治疗剂:如本文所用,短语“治疗剂”是指当向受试者施用时具有治疗效果和/或引起所需的生物学和/或药理学效应的任何试剂。在一些实施方案中,如果药剂对于相关群体的施用与群体中期望的或有益的治疗结果在统计上相关,则无论施用该药剂的特定受试者是否经历所述期望的或有益的治疗结果,所述药剂被认为是治疗剂。训练集(trainingset):如本文所用,“训练集”是在信息科学的各个领域中用来发现潜在的预测关系的一组数据。训练集被用于人工智能、机器学习、遗传编程、智能系统和统计。在所有这些领域中,训练集具有相同的作用,并且通常与测试集结合使用。测试集(testset):如本文所用,“测试集”是在信息科学的各个领域中用来评估预测关系的强度和效用的一组数据。测试集可用于人工智能、机器学习、遗传编程、智能系统和统计。在所有这些领域中,测试集具有相同的作用。治疗:如本文所用,术语“治疗”(也称为“医疗”或“医治”)是指部分或完全缓解、改善、减轻、抑制、延迟特定疾病、病症和/或病况的一种或多种症状、特征和/或原因的发作,降低其严重度和/或降低其频率、发病率或严重度的物质或治疗(例如,行为治疗)的任何施用。这样的治疗可以是对未表现出相关疾病、病症和/或病况的体征的受试者和/或仅表现出所述疾病、病症和/或病况的早期体征的受试者进行的治疗。可选择地或另外,这样的治疗可以是对表现出相关疾病、病症和/或病况的一种或多种确定的体征的受试者进行的治疗。在一些实施方案中,治疗可以是对已被诊断为患有相关疾病、病症和/或病况的受试者进行的治疗。在一些实施方案中,治疗可以是对已知具有与相关疾病、病症和/或病况发展的风险增加在统计上相关的一种或多种易感性因子的受试者进行的治疗。发明详述本发明提供了用于基于样品(例如,血液样品或血浆样品)中代谢物水平的特异性分析来确定受试者中自闭症谱系病症(ASD)的风险的方法和系统。本发明的各个方面在以下部分中详细描述。部分和标题的使用并不意味着限制本发明。每个部分可应用于本发明的任何方面。在本申请中,除非另有说明,否则“或”的使用意味着“和/或”。自闭症谱系病症自闭症谱系病症(ASD)的临床诊断的标准已在DiagnosticsandStatisticalManualofMentalDisorders,第5版(DSM-V,2013年5月出版)中阐述。另外ASD已例如通过DSM-IV-TR表征为包括自闭症、阿斯伯格病症、Rett氏障碍、儿童崩解性障碍和未指定的广泛性发育障碍(包括非典型性自闭症)。在一些实施方案中,ASD的特征在于(i)满足ADOS中的关于沟通加社交互动总计(CommunicationplusSocialInteractionTotal)的截止值的得分,以及满足自闭症诊断面试修订版(AutismDiagnosticInterview-Revised)(ADI-R)中的关于≤36个月时的社交互动、沟通、行为模式和发育异常性的截止值的得分;和/或(ii)满足ADOS中关于沟通和社交互动总计的ASD截止值的得分,以及满足在ADI-R中关于≤36个月时社会互动、沟通、行为模式和发育异常的截止值的得分,以及(ii)(a)满足ADI-R中关于社交互动和沟通的截止值的得分,或(ii)(b)满足ADI-R中关于社交互动或沟通的截止值和在关于社互动或沟通截止值的2个点内(其不满足截止值)的得分,或(ii)(c)在ADI-R中社交互动和沟通的截止值的1个点内的得分。发育迟缓发育迟缓是儿童发育的一个或多个过程,包括例如身体发育、认知发展、沟通发展、社交或情感发展或适应性发展中或大或小的延迟,所述延迟不是由ASD造成的。在一些实施方案中,DD的特征在于非自闭症(AU)和非ASD,其(i)在Mullen量表上得分为69或更低,在Vineland量表上得分为69或更低,在SCQ上得分为14或更低,或(ii)在Mullen或Vineland上得分为69或更低,并且在另一评估上在截止值的半个标准偏差以内(得分77或更低)。即使具有ASD的个体可以被认为是发育迟缓的,但本文使用的ASD的分类将被认为优先于DD的分类,从而ASD和DD的分类是相互排斥的。ASD的风险评估呈现受损的语言、行为或社会发展的症状的儿童通常可以被临床医生看到(最常见地在初级保健环境中),但其不能确定该儿童是否患有ASD或一些其他病况、病症或分类(例如,DD)。对儿童进行诊断,特别是在大量语言发展之前的年龄进行诊断是很困难的,许多初级保健医生没有能力或资源来对其患者进行鉴别诊断。例如,ASD可能不容易与其他发育病症、病况或分类(例如DD)区分开。评估受试者中ASD的风险(包括非ASD和DD的概率)以及区分ASD与DD是有用的。ASD的风险评估为早期干预和治疗提供了机会。例如,非专科医生可使用ASD风险评估来启动向专科医生的转诊。专科医生可使用ASD风险评估来优先进行对患者的进一步评估。ASD风险的评估还可用于在最终诊断之前建立临时诊断,在该时间期间可向高风险儿童以及他或她的家人提供便利服务。本文描述了用于确定受试者中ASD的风险的方法。在一些实施方案中,确定ASD风险包括确定受试者具有ASD的机会是否大于约50%。在一些实施方案中,确定ASD风险包括确定受试者具有ASD的机会大于约60%、65%、70%、74%、80%、85%、90%、95%或98%。在一些实施方案中,确定ASD风险包括确定受试者具有ASD。在一些实施方案中,确定ASD风险包括确定受试者不具有ASD(即,非ASD)。在一些实施方案中,本发明提供了用于区分受试者的ASD与非ASD分类(例如,DD)的方法。在一些实施方案中,将ASD与非ASD分类/病况区分包括确定受试者具有ASD而不是非ASD分类的机会大于约60%、65%、70%、74%、80%、85%、90%、95%或98%(即,具有ASD而不具有非ASD分类的机会)。在一些实施方案中,非ASD分类是DD。在一些实施例中,非ASD分类是“正常的”。在一些实施方案中,本发明提供了用于确定受试者不具有ASD或DD的方法。分析方法本文描述了用于评估ASD风险或区分ASD与其它非ASD发育病症的方法。在一些实施方案中,风险评估是(至少部分地)基于来自受试者的样品例如血液样品中代谢物的测量和表征。在一些实施方案中,血浆样品来源于血液样品,并且分析血浆样品。代谢物可以以多种方式检测,包括基于色谱和/或质谱法的测定、荧光测定、电泳、免疫亲和、杂交、免疫化学、紫外光谱(UV)、荧光分析、放射化学分析、近红外光谱(近IR)、核磁共振光谱(NMR)、光散射分析(LS)和比浊法。在一些实施方案中,通过单独的或与质谱联用的液相或气相色谱或离子迁移率(电泳)或通过单独的质谱法分析代谢物。这样的方法已被用于鉴定和定量生物分子,诸如细胞代谢物。(参见,例如Li等,2000;Rowley等,2000;以及Kuster和Mann,1998)。质谱法可基于例如四极离子阱或飞行时间质谱法,具有单、双或三重质荷比扫描和/或过滤(MS、MS/MS或MS3),并在合适的电离方法诸如电喷雾电离、大气压化学电离、大气压光电离、基质辅助激光解吸电离(MALDI)或表面增强激光解吸电离(SELDI)之后进行。(参见,例如,国际专利申请公开号WO2004056456和WO2004088309)。在一些实施方案中,代谢物从生物样品中的第一分离可通过使用气相或液相色谱或离子迁移/电泳来实现。在一些实施方案中,质谱方法的电离可以通过电喷雾电离、大气压化学电离或大气压光电离来实现。在一些实施例中,质谱仪器包括四极,离子阱或飞行时间或傅里叶变换仪器。在一些实施方案中,通过非靶向的超高性能液体或气相色谱/电喷雾或大气压化学电离串联质谱平台(经优化用于生物系统的小分子补体的鉴定和相对定量)在质量标度上分析代谢物。(参见,例如,Evans等人,Anal.Chem。,2009,81,6656-6667)。在一些实施方案中,代谢物与生物样品的第一分离可通过使用气相或液相色谱或离子迁移/电泳来实现。在一些实施方案中,质谱方法的电离可通过电喷雾电离、大气压化学电离或大气压光电离来实现。在一些实施方案中,质谱仪器包括四极,离子阱或飞行时间或傅里叶变换仪器。在一些实施方案中,对含有目标代谢物的血液样品离心以将血浆与其他血液成份分离。在某些实施方案中,内部标准是不必要的。在一些实施方案中,将规定量的内标添加至血浆(其一部分)中,然后加入甲醇以沉淀血浆成分诸如蛋白质。通过离心将沉淀与上清液分离,并收获上清液。如果为了更精确的检测而增加目标代谢物的浓度,则蒸发上清液,并将残余物溶解在适量的溶剂中。如果目标代谢物的浓度不希望地高,则将上清液在合适的溶剂中稀释。将合适量的含有代谢物的样品加载到用流动相A与流动相B的适当混合物平衡的液相色谱柱上。在反相液相色谱的情况下,流动相A通常是具有或不具有少量添加剂诸如甲酸的水,流动相B通常为甲醇或乙腈。将适当梯度的流动相A和流动相B泵送通过柱,以通过保留时间或从柱洗脱的时间来实现目标代谢物的分离。当代谢物从柱中洗脱时,它们被离子化并被带入气相,并且通过质谱法检测和定量离子。通过对特定前体离子和由前体离子产生的特定产物离子进行双重过滤来实现检测的特异性。绝对定量可以通过将来自目标代谢物的离子计数针对给定代谢物的已知量内标产生的离子计数标准化,以及通过将标准化离子计数与使用已知量的纯代谢物和内标建立的校准曲线进行比较来获得。内标通常是纯代谢物的稳定同位素标记形式或代谢物的结构类似物的纯形式。或者,可通过针对选定的内部参照值(例如,给定组中运行的所有样品的代谢物水平的中位值)标准化来计算以任意单位表示的给定代谢物的相对定量。在一些实施方案中,通过免疫测定来测量一种或多种代谢物。许多特异性免疫测定形式及其变体可用于代谢物的测量。(参见,例如,E.Maggio,Enzyme-Immunoassay,(1980)(CRCPress,Inc.,BocaRaton,Fla.);还参见美国专利号4,727,022“MethodsforModulatingLigand-ReceptorInteractionsandtheirApplication”;美国专利号4,659,678“ImmunoassayofAntigens”;美国专利号4,376,110,“ImmunometricAssaysUsingMonoclonalAntibodies”;美国专利号4,275,149,“MacromolecularEnvironmentControlinSpecificReceptorAssays”;美国专利号4,233,402,“ReagentsandMethodEmployingChanneling”和美国专利号4,230,767,“HeterogenousSpecificBindingAssayEmployingaCoenzymeasLabel”)。可按照已知技术诸如被动结合将抗体缀合于适合于诊断测定的固体载体(例如,珠子,诸如蛋白质A或蛋白质G琼脂糖、微球体、平板、载玻片或由诸如胶乳或聚苯乙烯的材料形成的孔)。同样,可按照已知技术将本文所述的抗体缀合于可检测标记或基团,诸如放射性标记(例如,35S、125I、131I)、酶标记(例如,辣根过氧化物酶、碱性磷酸酶)和荧光标记(例如,荧光素、Alexa、绿色荧光蛋白)。ASD风险的确定在一些实施方案中,本发明的方法允许本领域技术人员至少部分地基于测量获自受试者(其目前可能未表现出ASD和/或其他发育障碍的体征或症状,但尽管如此仍然可能处于患有或发展ASD和/或其他发育障碍的风险中)的样品中的代谢物水平来鉴定、诊断或以其他方式评估所述受试者。在某些实施方案中,可在测试样品中测量代谢物或其他分析物(例如,蛋白质组或基因组信息)的水平,并将该水平与正常对照水平或与具有不是ASD的发育障碍、病症或分类(例如,非ASD发育迟缓、DD)的受试者中的水平进行比较。在一些实施方案中,术语“正常对照水平”是指通常在未患ASD或不可能患有ASD或其他发育障碍的受试者中发现的一种或多种代谢物或其他分析物或指数的水平。在一些实施方案中,正常对照水平是范围或指数。在一些实施方案中,从先前测试的受试者的数据库确定正常对照水平。一种或多种代谢物或其他分析物的水平与正常对照水平相比的差异可以指示受试者具有ASD或处于发展ASD的风险中。相反,一种或多种代谢物的水平与一种或多种代谢物或其它分析物的正常对照水平相比缺少差异能够指示所述受试者不具有ASD或处于发展ASD的低风险。在一些实施方案中,参照值是从已知其诊断的对照受试者或群体(即,已被诊断为患有或被鉴定为患有ASD,或者经诊断不患有或被鉴定为不患有ASD)获得的值。在一些实施方案中,参照值是指数值或基线值,诸如本文所述的“正常对照水平”。在一些实施方案中,参照样品或指数值或基线值取自或来源于已暴露于ASD治疗的一个或多个受试者,或者可取自或来源于处于发展ASD的低风险的一个或多个受试者,或者可取自或来源于因暴露于治疗而已显示ASD风险因子改善的受试者。在一些实施方案中,参照样品或指数值或基线值取自或来源于尚未暴露于ASD治疗的一个或多个受试者。在一些实施方案中,从已经接受ASD的初始治疗和/或ASD的后续治疗以监测治疗进展的受试者收集样品。在一些实施方案中,参照值已从来自ASD的群体研究的风险预测算法或计算指数中导出。在一些实施方案中,参照值来自具有除ASD外的疾病或病症(诸如另一种发育障碍,例如非ASD发育迟缓(DD))的受试者或群体。在一些实施方案中,通过本发明的方法测量的代谢物水平的差异包括代谢物水平与正常对照水平、参照值、指数值或基线值相比有升高或降低。在一些实施方案中,代谢物水平相对于来自正常对照群体、一般群体或来自具有另一种疾病的群体的参照值有升高或降低指示ASD的存在,ASD的进展,ASD的加重或者ASD或ASD症状的改善。在一些实施方案中,代谢物水平相对于来自正常对照群体、一般群体或来自具有另一种疾病的群体的参照值有升高或降低指示发展ASD或与其相关的并发症的风险增加或降低。增加或减少可以指示ASD的一种或多种治疗方案的成功,或者可以指示ASD风险因子的改善或消退。增加或减少可以是例如参照值的至少5%,至少10%,至少15%,至少20%,至少25%,至少30%,至少35%,至少40%,至少45%,或至少50%。在一些实施方案中,如本文所述的代谢物水平的差异是统计上显著的差异。“统计学上显著的”是指大于预期仅仅随机发生的差异的差异。可通过本领域已知的任何方法测定统计学显著性。例如,统计学显著性可以通过p值来确定。p值是实验期间组之间偶然发生的差异的概率度量。例如,p值为0.01意味着该结果偶然发生的概率为1/100。p值越低,组之间的测量的差异就越不可能是偶然的。如果p值等于或低于0.05,则认为差异是统计上显著的。在一些实施方案中,统计上显著的p值等于或低于0.04、0.03、0.02、0.01、0.005或0.001。在一些实施方案中,统计上显著的p值等于或低于0.30、0.25、0.20、0.15或0.10(例如,在鉴定单一特定代谢物在包括其它代谢物的分类器中使用时是否具有加成性的预测值的情况下)。在一些实施方案中,通过t检验确定p值。在一些实施方案中,通过Fisher's检验获得p值。在一些实施方案中,统计显著性通过分析组中几种代谢物的组合并与数学算法组合以实现统计上显著的风险预测来实现。分类测试、测定或方法具有将假阳性率(1-特异性)相对于真阳性率(灵敏度)绘制的相关ROC曲线(接受者操作特征曲线)。ROC曲线下面积(AUC)是分类器能够区分两个诊断组的程度的量度。最大AUC是1.0(完美测试),最小面积是0.5(例如,其中正常与疾病没有区分的区域)。应当理解,当AUC接近1时,测试的准确度增加。在一些实施方案中,高程度的风险预测准确度是其中AUC至少为0.60的测试或测定。在一些实施方案中,高程度的风险预测准确度是其中AUC为至少0.65,至少0.70,至少0.75,至少0.80,至少0.85,至少0.90或至少0.95的测试或测定。通过评估尾部效应预测ASD风险在一些实施方案中,在群体间或群体之间(例如ASD群体与DD群体之间)或与正常对照群体相比较来评估代谢物水平的平均差异。在一些实施方案中,评估来自给定群体(即,ASD)的样品的代谢物在分布曲线的尾部的富集。也就是说,确定与第二群体(例如,DD)相比,来自指定群体(例如,ASD)的较大比例的样品是否存在于分布曲线的尾部(即,“尾部效应”)。在一些实施例中,鉴定和利用平均差和尾部效应。在一些实施例中,尾部由预先确定阈值确定。例如,如果样品对于某种代谢物的测量值高于群体中对应于该代谢物第90位百分位数(右尾或上尾)的数值,或者低于对应于第15位百分位数(左尾或下尾)的数值,则其被指定为位于尾部中。在一些实施方案中,给定代谢物的右(上)尾的阈值是对应于第80、第81、第82、第83、第84、第85、第86、第87、第88、第89、第90、第91、第92、第93、第94、第95、第96、第97、第98或第99百分位数的数值(例如,如果样品对于给定代谢物的测量高于与该百分位数相关的值,则其被指定在右尾中)。在一些实施方案中,给定代谢物的左(下)尾的阈值是对应于第25、第24、第23、第22、第21、第20、第19、第18、第17、第16、第15、第14、第13、第12、第11、第10、第9、第8、第7、第6、第5、第4、第3、第2或第1百分位数的数值(例如,如果样品对于给定代谢物的测量低于与该百分位数相关的数值,则其被指定在左尾中)。显示的百分位数值包括小数值。在一些实施方案中,从一个或多个群体的代谢物水平的曲线图中产生分布曲线。在一些实施方案中,从单个参照群体(例如,一般群体)产生分布曲线。在一些实施方案中,从两个群体,例如ASD群体和非ASD群体(诸如DD)产生分布曲线。在一些实施方案中,从三个或更多个群体(例如ASD群体、非ASD群体但具有另一种发育障碍/病症/分类诸如DD,和健康例如无发育障碍的对照群体)产生分布曲线。来自每个群体的代谢物分布曲线可用于进行不止一个风险评估(例如,诊断ASD,诊断DD,区分ASD与DD)。本文所述的利用尾部效应的评估方法可应用于两个以上的群体。在一些实施方案中,多种代谢物及其分布被用于风险评估。在一些实施方案中,使用两种或更多种代谢物的水平来预测ASD风险。在一些实施方案中,至少两种代谢物选自表1中列出的代谢物。在一些实施方案中,至少三种代谢物选自表1中列出的代谢物。在一些实施方案中,4种、5种、6种、7种、8种、9种、10种、11种、12种、13种、14种、15种、16种、17种、18种、19种、20种或21种选自表1中所列代谢物的代谢物被用于预测ASD风险。表1(表1A至1C)的进一步讨论参见下面的实施例部分。表1A.具有预示ASDvs.DD的尾部效应的示例性21种代谢物小组代谢物3-(3-羟基苯基)丙酸3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)3-吲哚氧基硫酸4-乙基苯基硫酸5-羟基吲哚乙酸8-羟基辛酸γ-CEHC羟基异戊酰肉碱(C5)吲哚乙酸异戊酰甘氨酸乳酸N1-甲基-2-吡啶酮-5-甲酰胺硫酸对甲酚泛酸(维生素B5)苯乙酰谷氨酰胺哌可酸黄嘌呤羟基-百菌清辛烯酰基肉碱3-羟基马尿酸1,5-脱水葡糖醇(1,5-AG)表1B.具有预示ASD的尾部富集的示例性代谢物表1C.具有预示DD的尾部富集的示例性代谢物在一些实施方案中,用于分析的至少两种代谢物选自苯乙酰谷氨酰胺、黄嘌呤、辛烯酰肉碱、硫酸对甲酚、异戊酰甘氨酸、γ-CEHC、吲哚乙酸、哌可酸、1,5-脱水葡糖醇(1,5-AG)、乳酸、3-(3-羟基苯基)丙酸、3-吲哚氧基硫酸、泛酸(维生素B5)、羟基-百菌清及其组合。在一些实施方案中,用于分析的至少三种代谢物选自苯乙酰谷氨酰胺、黄嘌呤、辛烯酰基肉碱、硫酸对甲酚、异戊酰甘氨酸、γ-CEHC、吲哚乙酸、哌可酸、1,5-脱水葡糖醇(1,5-AG)、乳酸、3-(3-羟基苯基)丙酸、3-吲哚氧基硫酸、泛酸(维生素B5)、羟基-百菌清及其组合。在一些实施方案中,关于特定组的代谢物缺乏尾部效应的信息被用于风险评估。在一些实施方案中,确定尾部效应的缺乏以提供无效结果(即,与负信息相反,是没有信息)。在一些实施方案中,尾部效应的缺乏被确定为指示一种分类优于另一种分类(例如,相对于ASD,更多地指示DD)。在一些实施例中,分布曲线是不对称的或非高斯的。在一些实施例中,分布曲线不遵循参数分布模式。在一些实施例中,将来自平均差异(例如,平均偏移)的信息与用于风险评估的尾部效应信息组合。在一些实施例中,来自平均差异的信息被用于风险评估而不使用尾部效应信息。在一些实施方案中,将代谢物的分析与其他类型的信息例如遗传信息、人口统计学信息和/或行为评估组合以确定受试者患ASD或其他疾病的风险。在一些实施方案中,至少部分地基于从受试者获得的生物样品(例如,血液、血浆、尿液、唾液、粪便)中某些代谢物的测量量进行ASD风险评估,其中某些代谢物在本文中被发现表现出“尾部效应”。本发明人已经发现,在与尾部效应相关的两个群体之间不一定具有统计上显著的平均偏移。因此,尾部效应是不同于平均偏移的一个特定现象。在某些实施方案中,当代谢物被表征为下述时,该特定代谢物表现出指示ASD群体而不是非ASD群体(例如DD群体)的右尾效应:●为非ASD群体(例如DD群体)中的该代谢物建立非ASD群体分布曲线,其中x轴表示第一代谢物的水平,y轴表示相应群体;●为ASD群体中的该代谢物建立ASD群体分布曲线,其中x轴表示第一代谢物的水平,y轴表示相应群体;以及●该非ASD群体分布曲线和该ASD群体分布曲线的特征在于(A)和(B)之一或两者:○(A)(i)对于x>该代谢物的水平n的ASD群体分布曲线下面积相比于(ii)对于x>该代谢物的水平n的非ASD群体分布曲线下面积的比率大于150%(例如,>200%、>300%、>500%、>1000%等),从而提供了用于区分具有>该代谢物水平n的样品的ASD分类与非ASD分类的预测效用,和○(B)如果其中n'是对应于用于产生分布曲线的组合非ASD和ASD群体的顶部十分位数(或从约5%至约20%的任何截止值)的最小阈值代谢物水平,那么对于代谢物水平至少为n'的未知样品(例如选自具有相等数目的ASD和非ASD成员的群体的随机样品),样品为ASD而不是非ASD的几率不小于1.6:1(例如,不小于2:1,不小于3:1,不小于4:1,不小于5:1,不小于6:1,不小于7:1,不小于8:1,不小于9:1或不小于10:1)(例如,其中p<0.3,p<0.2,p<0.1,p<0.05,p<0.03或p<0.01,例如,统计上显著的分类),从而提供了对该代谢物的水平>n'的样品区分ASD分类与非ASD分类的预测效用。在某些实施方案中,当代谢物被表征为下述时,该特定代谢物表现出指示ASD而非非ASD群体(例如,DD群体)的左尾效应:●为非ASD群体(例如,DD群体)中的该代谢物建立非ASD群体分布曲线,其中x轴表示第一代谢物的水平,y轴表示相应群体;●为ASD群体中的该代谢物建立ASD群体分布曲线,其中x轴表示第一代谢物的水平,y轴表示相应群体;以及●非ASD群体分布曲线和ASD群体分布曲线的特征在于(A)和(B)之一或两者:○(A)(i)对于x<该代谢物的水平m的ASD群体分布曲线下面积相比于(ii)对于x<该代谢物的水平m的非ASD群体分布曲线下面积的比率大于150%(例如,>200%、>300%、>500%、>1000%等),从而提供了用于区分具有<该代谢物水平m的样品的ASD分类与非ASD分类的预测效用,和○(B)如果其中m'是对应于用于产生分布曲线的组合非ASD和ASD群体的底部十分位数(或从约5%至约20%的任何截止值)的最大阈值代谢物水平,那么对于具有低于m'的代谢物水平的未知样品(例如选自具有相等数目的ASD和非ASD成员的群体的随机样品),样品为ASD而不是非ASD的几率不小于1.6:1(例如,不小于2:1,不小于3:1,不小于4:1,不小于5:1,不小于6:1,不小于7:1,不小于8:1,不小于9:1或不小于10:1)(例如,其中p<0.3,p<0.2,p<0.1,p<0.05,p<0.03或p<0.01,例如,统计上显著的分类),从而提供了对该代谢物的水平<m'的样品进行ASD分类与非ASD分类区分的预测效用。在某些实施方案中,当代谢物被表征为下述时,该特定代谢物表现出指示非ASD群体(例如DD群体)而不是ASD群体的右尾效应:●为非ASD群体(例如DD群体)中的该代谢物建立非ASD群体分布曲线,其中x轴表示第一代谢物的水平,y轴表示相应群体;●为ASD群体中的该代谢物建立ASD群体分布曲线,其中x轴表示第一代谢物的水平,y轴表示相应群体;以及●该非ASD群体分布曲线和该ASD群体分布曲线的特征在于(A)和(B)之一或两者:○(A)(i)对于x>该代谢物的水平n的非ASD群体分布曲线下面积相比于(ii)对于x>该代谢物的水平n的ASD群体分布曲线下面积的比率大于150%(例如,>200%、>300%、>500%、>1000%等),从而提供了用于区分具有>该代谢物水平n的样品的非ASD分类与ASD分类的预测效用,和○(B)如果其中n'是对应于用于产生分布曲线的组合非ASD和ASD群体的顶部十分位数(或从约5%至约20%的任何截止值)的最小阈值代谢物水平,那么对于代谢物水平至少为n'的未知样品(例如选自具有相等数目的ASD和非ASD成员的群体的随机样品),样品为非ASD而不是ASD的几率不小于1.6:1(例如,不小于2:1,不小于3:1,不小于4:1,不小于5:1,不小于6:1,不小于7:1,不小于8:1,不小于9:1或不小于10:1)(例如,其中p<0.3,p<0.2,p<0.1,p<0.05,p<0.03或p<0.01,例如,统计上显著的分类),从而提供了对该代谢物的水平>n'的样品区分非ASD分类与ASD分类的预测效用。在某些实施方案中,当代谢物被表征为下述时,该特定代谢物表现出指示非ASD群体(例如,DD群体)而非ASD的左尾效应:●为非ASD群体(例如,DD群体)中的该代谢物建立非ASD群体分布曲线,其中x轴表示第一代谢物的水平,y轴表示相应群体;●为ASD群体中的该代谢物建立ASD群体分布曲线,其中x轴表示第一代谢物的水平,y轴表示相应群体;以及●非ASD群体分布曲线和ASD群体分布曲线的特征在于(A)和(B)之一或两者:○(A)(i)对于x<该代谢物的水平m的非ASD群体分布曲线下面积相比于(ii)对于x<该代谢物的水平m的ASD群体分布曲线下面积的比率大于150%(例如,>200%、>300%、>500%、>1000%等),从而提供了用于区分具有该代谢物<水平m的样品的非ASD分类与ASD分类的预测效用,和○(B)如果其中m'是对应于用于产生分布曲线的组合非ASD和ASD群体的底部十分位数(或从约5%至约20%的任何截止值)的最大阈值代谢物水平,那么对于具有低于m'的代谢物水平的未知样品(例如选自具有相等数目的ASD和非ASD成员的群体的随机样品),样品为非ASD而不是ASD的几率不小于1.6:1(例如,不小于2:1,不小于3:1,不小于4:1,不小于5:1,不小于6:1,不小于7:1,不小于8:1,不小于9:1或不小于10:1)(例如,其中p<0.3,p<0.2,p<0.1,p<0.05,p<0.03或p<0.01,例如,统计上显著的分类),从而提供了对所述代谢物的水平<m'的样品进行非ASD分类与ASD分类区分的预测效用。在某些实施方案中,使用展示尾部效应的多种代谢物进行风险评估。已观察到,为了评估ASD,有一些特定的代谢物组(例如,两种或更多种代谢物)可以提供互补诊断/风险评估信息。例如,可通过分析第一代谢物(例如,在第一代谢物的已鉴定尾部内的个体)的水平而鉴定的ASD阳性个体与可通过分析第二代谢物而鉴定的ASD阳性个体不同(或者可能存在低的、非零度的重叠)。第一代谢物的尾部预测某些ASD个体,而第二代谢物的尾部预测另一些ASD个体。不希望受特定理论的束缚,该发现可能反映了ASD本身的多面性质。因此,在某些实施方案中,风险评估方法包括鉴定受试者是否落入涉及多种代谢物的多种已鉴定代谢物尾部中的任一种中,例如,当不同代谢物尾部的预测物至少部分不相连时,例如,它们具有低的相互信息,因此,当引入相互信息少的多个代谢物时,风险预测得到改善。在一些实施方案中,本发明提供了用于确定/诊断患有ASD或处于ASD风险中的受试者的方法中的一种或多种结合成员,每种结合成员能够特异性结合选自以下代谢物中的代谢物:5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸酯、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺、硫酸对甲酚、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、黄嘌呤、羟基-百菌清、辛烯酰肉碱和3-羟基马尿酸。在一些实施方案中,本发明提供了一种或多种结合成员用于诊断/测定患有ASD或处于患有ASD的风险中的受试者的用途,所述结合成员能够特异性结合选自以下代谢物中的代谢物:5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺、硫酸对甲酚、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、黄嘌呤、羟基-百菌清、辛烯酰基肉碱和3-羟基马尿酸。结合成员可选自核酸分子、蛋白质、肽、抗体或其片段,其全部能够结合特定代谢物。在某些实施方案中,结合成员可被标记以帮助检测和测定结合的代谢物的水平。本发明还提供被固定于固体载体的多个结合成员,其中所述多个结合成员选自5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰肉碱(C5)、吲哚乙酸、异戊酰甘氨酸、乳酸、N1-甲基-2-吡啶酮-5-甲酰胺、硫酸对甲酚、泛酸(维生素B5)、苯乙酰谷氨酰胺、哌可酸、黄嘌呤、羟基-百菌清、辛烯酰肉碱和3-羟基马尿酸,其中所述多个结合成员占所述固体载体上结合成员群体的至少20%、30%、40%、50%、60%、70%、80%或90%。在一些实施方案中,本发明提供用于实施本文所述方法的试剂盒,特别是用于确定/诊断受试者患有ASD或处于患有ASD的风险中的试剂盒。试剂盒允许使用者确定选自以下代谢物的一种或多种代谢物在处于测试的样品中的存在情况、水平(升高或下降):5-羟基吲哚乙酸(5-HIAA)、1,5-脱水葡糖醇(1,5-AG)、3-(3-羟基苯基)丙酸、3-羧基-4-甲基-5-丙基-2-呋喃丙酸(CMPF)、3-吲哚氧基硫酸、4-乙基苯基硫酸、8-羟基辛酸、γ-CEHC、羟基异戊酰基肉碱(5)、吲哚乙酸,异戊酰甘氨酸,乳酸,N1-甲基-2-吡啶酮-5-甲酰胺,硫酸对甲酚,泛酸(维生素B5),苯乙酰谷氨酰胺,哌可酸,黄嘌呤,羟基-百菌清,辛烯酰肉碱和3-羟基马尿酸;所述试剂盒包含(a)具有多个结合成员的固体载体,其中每个所述结合成员独立地特异于固定在其上的所述一种或多种代谢物中的一种;(b)包含标记的显影剂;和任选地(c)一种或多种选自洗涤溶液、稀释剂和缓冲剂中的组分。实施例受试者从18个月至60个月的受试者收集血液样品,所述受试者被转到19个发育评价中心用于评价除了孤立活动问题外的可能的发育障碍。对所有受试者获得知情同意。从研究中排除了事先在专门进行儿科发育评估的诊所诊断为ASD或者不能或不愿意完成研究程序的受试者。受试者是登记在SynapDx自闭症谱系病症基因表达分析(STORY)研究中的那些受试者。按照当前关于良好临床实践(GCP)的ICH指南和适用的监管要求来进行STORY研究。GCP是用于设计、进行、记录和报告涉及人受试者参与的研究的国际伦理和科学质量标准。遵守本标准提供了公共保证:根据源于赫尔辛基宣言的原则,保护研究对象的权利、安全和健康,并且临床研究数据是可信的。图1至12中所示的结果基于来自STORY研究中的男性的180份血液样品。样本集包括122个ASD样品和58个DD(非ASD)样品。ASD诊断遵循DSM-V诊断标准。其他结果基于来自STORY研究中男性受试者的299个血液样品的更广泛集合。较宽的样品组包括198个ASD样品和101个DD样品。对于所有测试,在EDTA管中收集约3mL血液样品,并通过离心管来制备血浆。然后将血浆冷冻并运送至实验室进行分析。在实验室进行样品的甲醇提取,并通过优化的超高效液相或气相色谱/串联质谱(UHPLC/MS/MS或GC/MS/MS)法分析提取物(参见,例如,Anal.Chem.,2009,81,6656-6667)。数据分析对男性和女性受试者定量其血液样品中的代谢物。分析样品的代谢物水平,并定量为针对在给定日对所有样品测量的中值浓度标准化的任意单位的浓度。例如,大于1的单位是指大于该日样品中值的代谢物的量,小于1的单位是指小于该中值的量。然后进行交叉验证,其中样品被随机分成非重叠的训练/测试集,针对其评估机器学习分类器的无偏性能。已经鉴定了21种代谢物,所述代谢物单独地和共同地高度信息化预测ASD,特别是在男性受试者中。实施例1:辨别代谢物水平信息该实施例显示,可从样品分布中的尾部效应的鉴定和分析中辨别用于ASD风险评估的有价值的信息,否则所述信息将被常规分析(例如,基于平均偏移的分析)所遗漏。一旦确定了代谢物水平,就有多种方式来实现用于风险评估的信息,包括平均偏移和尾部效应。令人惊奇的是,发现平均偏移提供一些但不是最优的预测信息。在图1中显示了示例性平均偏移。在该图中,ASD分布偏移至非ASD分布(DD)的右侧。除了常规均值偏移分析(meanshiftanalysis)以外,本发明人还从样品中辨别出附加信息。对ASD和非ASD(此处为DD)样品绘制代谢物分布曲线,并且发现对于测量的代谢物的亚组,来自ASD或DD群体的样品富集在右(上)或左(低)尾部(即,尾部效应)。代表性尾部效应示于图2中。值得注意的是,两个分布共享几乎相同的平均值(即,平均偏移或均值偏移最小或没有)。因此,不能从平均偏移的常规分析中辨别出代谢物的预测值。代谢物可能表现出右(上)尾部效应或左(下)尾部效应,或两者。代表性代谢物5-HIAA的ASD和非ASD(这里是DD)分布曲线显示在图3中。观察到清楚的右尾效应,例如ASD分布在右尾部具有更大的AUC。因此,证明了具有高水平的该代谢物的样品高度富集在ASD群体成员中。使用该代谢物,平均偏移(由t检验值指示)和右尾(由“极限值”Fisher检验值指示)都是统计上显著的。另一种说明性代谢物γ-CEHC的ASD和非ASD(此处为DD)分布曲线示于图4中。观察到清楚的左尾效应,例如ASD分布在左尾中具有更大的AUC。因此,证明了具有低水平的该代谢物的样品高度富集在ASD群体成员中。对于该代谢物来说,平均偏移(由t检验值指示)不是统计上显著的,而左尾是统计上显著的。这些数据说明了尾部效应的鉴定和分析提供了通过常规平均偏移分析不能获得的用于风险评估的附加信息。实施例2:显示尾部效应的选定代谢物强烈预测ASD本实施例说明了尾部效应用于预测ASD的评估。本发明人在从男性受试者获得的样品中鉴定了许多代谢物的统计上显著的尾部效应。尾部效应单独和总体地提供关于受试者属于哪个群体(即,ASD群体或DD群体)的信息。表1显示了表现出具有高预测能力的ASD对比DD尾部效应的21种代谢物的示例性小组。表1B显示具有预测ASD的尾部效应的21种代谢物小组的代谢物。指示了每个尾部效应的统计显著性(p值)以及其在分布曲线上的位置(即,左尾效应或右尾效应)。大于1的比值比指示对于ASD的预测能力。例如,5HIAA具有右尾,比值比为4.91,表明在STORY研究数据集(其中ASD与DD样品的比率为2:1)中,对于每个DD样品有约10个ASD样品在右尾中。通过bootstrap法估计置信区间。通过替换进行重采样,从STORY数据生成了1000个单独的bootstrap。对于每个bootstrap,确定尾部的位置和相应的比值比。从观察到的比值比的分布计算90%置信区间。基于这些标准,发现21种代谢物小组中的19种代谢物对于ASD有预测性。表1C显示具有预测DD的尾部效应的代谢物。指示了每个尾部效应的统计显著性(p值)以及其在分布曲线上的位置(即,左尾效应或右尾效应)。小于1的比值比指示DD的预测能力。基于这些标准,发现21种代谢物小组中的8种代谢物预测DD。对于ASD,考虑到STORY研究中DD与ASD样品的比率为1:2,类似地测定比值比和90%的置信区间。值得注意的是,某些代谢物表现出对ASD或DD有预测能力的单尾效应(或左或右),而其它代谢物表现出左和右尾效应二者,它们一起提供了针对ASD和DD的预测能力。例如,苯乙酰谷氨酰胺和对甲酚硫酸显示左尾和右尾两种效应。表1中所列的21种代谢物的尾部效应在图13A至13U的图中单个地显示。对于每个图,显示了一种代谢物在ASD和DD两个群体中的分布。每个图顶部的图例显示该代谢物的左尾和右尾的统计学显著性(通过Fisher's检验产生的p值)。一些代谢物,例如苯乙酰谷氨酰胺,显示平均变化和尾部效应。如图5所示,苯乙酰谷氨酰胺显示统计上显著的平均偏移(t检验;p=0.001),并且在两个群体之间具有统计上显著的左和右尾效应(“极限值”表示尾部效应,Fisher检验;p=0.0001)。分布在ASD与DD群体之间表现为偏移的高斯曲线。表2显示了用于基于ASD和非ASD群体中每种代谢物的潜在群体分布而确定21种代谢物小组的尾部效应的阈值。示例性地,上阈值对应于第90百分位数分布,而下阈值对应于第15百分位数分布。可通过使用表2中的值与群体中代谢物的平均浓度来计算阈值的绝对测量值(例如,ng/ml,nM等)。表2.代谢物分布曲线的左尾(等于或低于第15位百分位数)和右尾(等于或高于第90位百分位数)的阈值水平实施例3:用多种代谢物预测ASD可将由多种代谢物(例如,表1中列出的那些)提供的信息单独地或作为一组用于辅助疾病风险预测。特别信息性的代谢物组包括彼此不相关且具有低共线性(即低相互性)的成员。例如,图6显示了与γ-CEHC水平相比较的5HIAA水平,表明两种代谢物的信息性水平之间缺乏相关性。例如,在5HIAA的尾部中鉴定的ASD个体(图3)通常与在γ-CEHC的尾部中鉴定的ASD个体不相同。因此,代谢物5HIAA和γ-CEHC被认为提供互补信息。富集了具有低共同性的代谢物的尾部提供了互补性分类信息。图7是一个图表,指示对于180个样品中的每一个,样品是否在12种代谢物小组的每种代谢物的尾部内。在该示例性小组中,两种代谢物(黄嘌呤和硫酸对甲酚)的尾部对于非ASD(例如DD)是预测性的,而其他10种代谢物的尾部预测ASD。当评估多种代谢物时,尾部效应加总计数的组合数量增加,并且潜在的尾部效应加总计数增加。当测量未知样品时,可以绘制来自ASD和来自非ASD群体的尾部效应加总计数的分布图,将所得分布用于确定ASD与非ASD之间的合适分离。如图8A所示,可通过使用投票(例如,分箱)方案进一步分析ASD和非ASD(此处为DD)样品,以进一步利用由针对其观察到尾部效应的代谢物提供的互补信息。显示了总共12种代谢物的数据。在一个具体方案中,对于给定样品,对样品落入ASD预测性尾部内的代谢物数目进行求和,对样品落入非ASD(此处为DD)的预测性尾部内的代谢物数目也求和。这两个值被作为x和y坐标绘图(图8A)。值得注意的是,随着ASD富集代谢物的数量增加(在y轴上较高)和随着非ASD富集代谢物的数量减少(在x轴上较低),在ASD点中非ASD点的混合似乎更少,例如,这暗示ASD的假阳性诊断的可能性较低。另一方面,随着ASD富集代谢物的数量减少(在y轴上较低)和随着非ASD富集的代谢物的数量增加(在x轴上较高),在非ASD点中ASD点的混合较少,例如这表明对DD的假阳性诊断的可能性较低。将样品分成四个不同的箱,如图8B所示。顶部和右下方的箱子特别显示清楚的分离,有利于ASD或DD风险评估。在图8所示的四个箱中,对ASD最强烈预测的箱包括具有2个或更多个ASD富集的特征以及0或1个非ASD富集的特征的样品。具有1个ASD富集的特征和0或1个非ASD富集的特征的箱也预测ASD,尽管不如上述箱强烈。具有1个或多个非ASD富集的特征和0个ASD富集的特征的箱强烈预测非ASD。在一些情况下,没有ASD富集的特征也没有非ASD富集的特征的样品箱也可以提供预测信息。在一个示例性投票方案中,对于给定的样品进行投票,例如,ASD富集的代谢物获得点评分,非ASD富集的代谢物减去点评分。具有阳性结果(例如,等于或大于1)的样品可以被认为是ASD(或具有显著的ASD风险),具有阴性结果(等于或小于-1)的样品可以被认为是非ASD(或具有显著的非ASD可能性)。具有零结果的样品可以被认为可能是非ASD或ASD,这取决于样品中ASD相比于非ASD的分布,或者可作为不确定或“无分类结果”样品返回。类似地,图8C显示了表1中描述的21种代谢物小组的投票结果。在另一个示例性评分系统(图21所示)中,针对每种代谢物,将ASD和DD特征的比值比(theoddsratio)的log2值(log2OR)求和以计算ASD或DD的风险评分。尾部效应信息可用于区分具有ASD或非ASD状况的受试者。同样,尾部效应信息可用于预测受试者患另一疾病或病症(例如,DD)的风险。例如,如图8A和8C所示的非ASD群体(例如,DD)的尾部效应分布可用于建立该群体中给定数量的代谢物的平均尾部效应总和的参照值。该平均值可用作参照而与来自未知受试者的样品的平均尾部效应的总和进行比较,并且可用于评估受试者患ASD的风险,而不必获得ASD和非ASD人群中代谢物的群体分布曲线。还可将尾部效应信息,例如,如在上面的示例性投票方案或类似方案中所描述的,与常规平均偏移信息和/或其他分类信息组合用于改进的分类结果。本文证明,ASD风险的可预测性可通过分析某些代谢物的组合来提高。例如,图9-11和图13-14A-D说明了如何使用投票方案可增加分类器的AUC并且改善预测能力。使用12种代谢物小组的亚组时,随着亚组中代谢物的数目增加(从1到12),ASD预测能力增加(y轴)(图9)。使用不同的分类器(即,逻辑回归、朴素贝叶斯或支持向量机(supportvectormachine,SVM))和不同特征的选择也影响AUC(图9)。图10A显示使用12种代谢物小组对相同群体使用不同特征和分类器的ASD风险三分法预测,而图10B显示使用21种代谢物小组的结果。图11A和11B显示使用12种代谢物小组(图11A)和21种代谢物小组(图11B)的投票方案中ASD风险预测的改善。这些分析表明,通过选择目标代谢物并使用适当的统计工具,可以实现ASD风险评估的高度可信度。例如,如图12所示,使用12种代谢物,按照上述方法获得至少0.74的AUC。实施例4:从代谢组学数据选择高影响代谢物筛选来自ASD和DD受试者的样品用于检测约600种已知代谢物(示于表3中)。从初始600种代谢物的组,鉴定出84种候选代谢物表现出尾部效应。阐明样品中检测到的84种代谢物的亚组,在表4中列出了其名称。基于高的个别代谢物AUC,从84种候选代谢物的组中选择代谢物组(例如12和21种代谢物小组)。基于诸如与药物或年龄相关性的因素,将某些候选代谢物从小组中排除。表3:测定的600种代谢物的初始组中四百六十五(465)种阐明的代谢物表4:鉴定的显示尾部效应的候选代谢物测试两组代谢物(由图7的代谢物组成的12种代谢物小组和由表1的代谢物组成的21种代谢物小组)进行ASD风险预测。结果显示所述12种和21种代谢物小组强烈有助于ASD的预测。包括和排除该12种或21种代谢物小组的代谢物对ASD预测的影响的概述示于图14A-D中。白名单表示使用仅来自12种或21种代谢物小组的数据的分类器的AUC值,而黑名单表示不包括12种或21种代谢物组但是使用来自84种候选代谢物的组或完全组的600种代谢物(所有候选物=84种候选代谢物;所有特征=600种代谢物)的分类器的AUC值。进行平均偏移(上图)和尾部分析(下图)。这些数据显示,ASD的预测性信息归因于所述12种或21种代谢物小组中的代谢物,无论是通过平均偏移还是通过尾分析评估的。因此,观察到显示强尾部效应的代谢物(12种和21种代谢物小组中的代谢物)预测ASD优先于DD的能力远远大于来自600种代谢物小组的其它代谢物(其不显示强尾部效应)。图14C-D扩展了来自图14A-B的结果,并且除了逻辑回归之外还包括使用朴素贝叶斯分析的附加分析。另外,图14B还显示了分解成不同样品组群(即,"Christmas"和"Easter")的结果。最左边的小组显示AUC结果,其中分类器在192个样品上训练并且仅在Christmas组群中交叉验证;中间左小组显示AUC结果,其中分类器在299个样品上训练并在Christmas和Easter组群上交叉验证;中间右小组显示了AUC结果,其中分类器仅在来自Easter组群的样品上进行训练并且仅在Easter组群中交叉验证;最右边的小组显示AUC结果,其中分类器在来自Christmas和Easter组群的样品上训练并且在Easter组群上交叉验证。使用12种或21种代谢物小组中的代谢物(例如,表现出尾部效应的代谢物)获得最高AUC。根据添加到统计分析中的特征的数目,通过包括12种或21种代谢物小组(白名单)以及过排除它们(黑名单)而显示AUC预测,图17A-B、18A-B和19A-D进一步扩展了图14A-D的结果。顶部小组显示了平均偏移分析的结果,而底部的那些小组显示尾部效应分析。在每个单独的小组中,条块代表不同的代谢物小板,如下面的符号和图例中所示。描述了当评估总共21种代谢物的亚组时用于ASD风险预测的累积AUC的示例性曲线图示于图15中。在该图中,x轴显示来自选自21种代谢物的组的亚组中的代谢物的数量。y轴显示ASD的预测能力。对于x轴上的每个数字,分析许多随机代谢物组合并绘制它们的AUC值(点)。该曲线显示了由所使用的代谢物(选自21种代谢物的组)的数量增加引起的AUC的增加。另一方面,该图证明甚至具有少量代谢物(例如,3或5种)的亚组也显示高AUC。因此,某些代谢物似乎具有特别重要的预测性尾部。描述来自表1的21种代谢物中包含产生高AUC值的3、4、5、6和7种代谢物的代表性亚组的示例性表格示于表5中。对于每个亚组大小(3、4、5、6或7种),分析代谢物组的50个随机选择。例如,对于来自21种代谢物小组的3种代谢物亚组,评估了3种代谢物亚组的50个随机组合(总共1330个可能的排列中的组合)。显示了来自具有最高AUC的50个随机组的组合。因此,含有少于21种代谢物的某些代谢物组合产生高AUC值。代谢物诸如γ-CEHC、硫酸对甲酚、黄嘌呤、苯乙酰谷氨酰胺、异戊酰甘氨酸、辛烯酰肉碱和羟基-百菌清出现在产生高AUC值的多个亚组中,表明这些代谢物可能与患者的ASD状态密切相关。因此,这些代谢物(单独地或彼此组合地)或其它代谢物一起似乎特别可用于预测患者的ASD风险。表5:代谢物的示例性亚组和ASD的预测以成对组合方式评估来自表1的21种代谢物的双代谢物亚组对于ASD的可预测性。具有robustAUC的代表性成对组合示于表6中。类似地,以三元组合方式评估来自表1的21种代谢物的三种代谢物亚组的对于ASD的可预测性。具有robustAUC的代表性三元组合示于表7中。表6.提供robustAUC的示例性代谢物对表7.提供robustAUC的示例性代谢物三元组实施例5:12种代谢物小组分类器的验证基于图7所示的12种高信息性代谢物,将来自所测试的180个样品(其中约三分之二是ASD)的数据用于产生分类器。在130个样品的第二群组中测试该分类器区分ASD与非ASD区(此处,DD)的能力。该方法提供了真实预测性能的无偏估计,对应于0.74的AUC。该过程的示意图如图12所示。实施例6:将遗传信息加入代谢物可以改善ASD风险预测发现将遗传信息添加至代谢物信息中改善了某些组的ASD风险预测。例如,将拷贝数变异(CNV)数据与代谢物信息组合显著降低了ASD风险预测的置信区间,如图16A和16B所示。如图16A所示,添加遗传信息进一步增强了ASD与非ASD组之间的分离。除了CNV以外,包括但不限于脆性X(FXS)状态的其他遗传信息也可进一步有助于诊断测试,其可以以提高的准确度和减少I型和/或II型错误来预测ASD风险。如图16B所示,包括这样的附加信息(例如,“PathoCV”)增加了ASD与DD组之间的分离,因此有助于区分这两种病症。实施例7:从代谢物分析中出现的显著的生物学途径代谢物信息的进一步分析揭示了表1中呈现的代谢物簇,其在不同的生物学途径中起着显著的作用。例如,21种代谢物中的7种与肠道微生物活性相关(33%),示于表8中。所有7种都是氨基酸代谢物。7种中的6种是芳香族氨基酸的代谢物,并且具有苯环。表8:涉及肠微生物活性的七种代谢物如表1所示的与ASD强烈相关的代谢物的分析揭示了与某些生物学途径的联系。例如,提供ASD的预测信息的特定代谢物提示II期生物转化的削弱,削弱的代谢苯环的能力,肾脏的再吸收失调,肉碱代谢的失调和大的中性氨基酸向脑中的转运的不平衡。生物途径信息可被进一步用于改善ASD风险评估和/或探索ASD的病因和病理生理学。此类信息也可用于开发治疗ASD的药物治疗剂。实施例8:血液中代谢物浓度的阐明对实施例2中描述的21种代谢物中的19种,通过质谱法测定血浆样品中的绝对代谢物浓度。使用从含有已知量的代谢物的标准样品产生的校准曲线计算血浆中的绝对代谢物浓度(ng/ml)。表9A显示了预测ASD的17种代谢物。提供了尾部效应的方向(左或右),用于确定尾部效应的存在的阈值(即,左尾效应为第15百分位数,右尾效应为第90百分位数)和比值比(log2)。正的比值比表明代谢物的尾部效应预测ASD。表9B显示预测DD的7种代谢物。提供了尾部效应的方向(左或右),用于确定尾部效应的存在的阈值(即,左尾效应为第15百分位数,右尾效应为第90百分位数)和比值比(log2)。负的比值比表明代谢物的尾部效应预测DD。表9A.具有预测ASD的尾部富集的示例性代谢物表9B.具有预示DD的尾部富集的示例性代谢物当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1