一种基于颞骨模型的实验装置及方法与流程
本发明实施例属于医学研究
技术领域:
,具体地说,涉及一种基于颞骨模型的实验装置及方法。
背景技术:
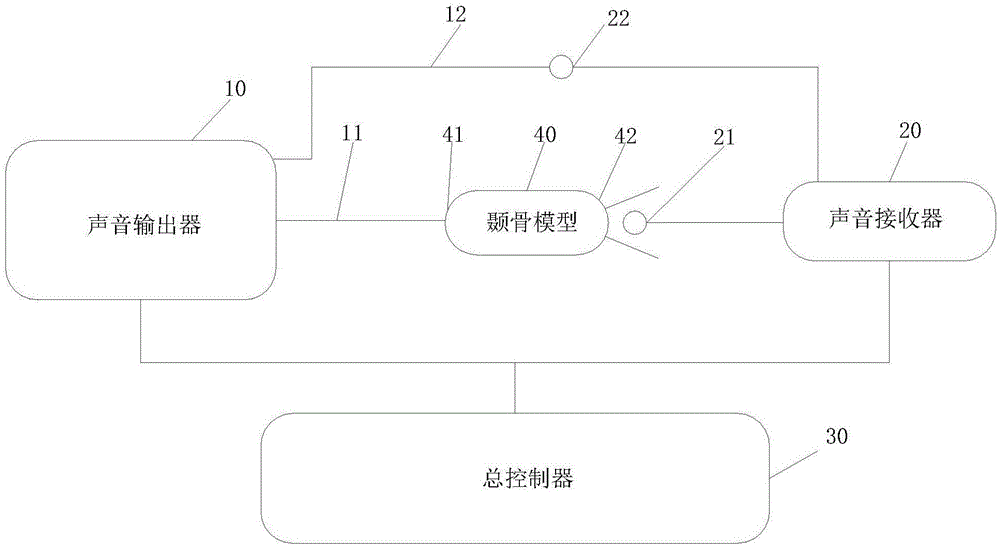
:血管性耳鸣是耳科和神经内科就诊的常见症状。我国约有900万患者,并且逐年增多。长时间耳鸣会严重影响患者生活质量、工作能力,甚至引起精神异常(抑郁症、烦躁等)、自杀等严重后果,给社会造成很大的经济和社会负担。但是,因为影响血管性耳鸣发生的相关因素并未完全清楚,导致缺乏针对性的治疗方法。目前,关于血管性耳鸣的研究仅局限于假设和临床观察,研究结果认为:颞骨蜂房气化是血管性耳鸣发生的条件之一。但是,不同气化程度、含气状态的颞骨蜂房对血管性耳鸣影响程度是怎样的还不得而知。而且,目前对于颞骨蜂房气化的研究存在局限性,例如,在人体和动物身上不可能针对多个因素,随意根据要求设计不同的实验条件进行研究,并且一部分实验还有可能会对研究对象的身体健康构成危害。由于实验研究方面存在的局限直接影响了颞骨蜂房气化对血管性耳鸣影响程度的深入研究,导致国内外对血管性耳鸣的实验研究均局限于颞骨的解剖学结构。因此,如何突破现有实验局限造成的瓶颈是目前亟待解决的技术问题。技术实现要素:有鉴于此,本发明实施例提供一种基于颞骨模型的实验装置及方法,通过不同类型的颞骨模型,进行声音变化的研究,有助于研究不同颞骨蜂房气化对血管性耳鸣影响程度,为深入研究血管性耳鸣提供有效手段。为解决现有技术中的技术问题,本发明实施例提供了一种基于颞骨模型的实验装置,包括:声音输出器、声音接收器、总控制器以及颞骨模型;所述声音输出器包括第一输出端,所述第一输出端密封设置在所述颞骨模型的声音传导路径的入口处;所述声音接收器包括第一接收端,所述第一接收端密封设置在所述颞骨模型的声音传导路径的出口处;所述总控制器分别与所述声音输出器、所述声音接收器相连接;其中,所述声音输出器根据预设强度并通过所述第一输出端输出的声音为第一输出声音,所述声音接收器通过所述第一接收端接收到的声音为第一接收声音,所述总控制器对比所述第一输出声音与所述第一接收声音的强度,得到第一强度差值。可选地,所述声音输出器还包括第二输出端,所述声音接收器还包括第二接收端;所述第二输出端与所述第二接收端相连接,其中,所述声音输出器通过所述第二输出端输出所述第一输出声音,所述声音接收器通过所述第二接收端接收到的声音为第二接收声音,所述总控制器根据所述第一接收声音与所述第二接收声音,对比得到第二强度差值,并通过所述第二强度差值对所述第一强度差值进行验证和/或修正。可选地,所述声音接收器包括声音收集部件;所述声音收集部件密封设置于所述颞骨模型的声音传导路径的出口处,所述声音收集部件设置有声音收集腔,所述声音接收器的接收端密封设置于所述声音收集腔内。可选地,所述声音收集腔具有贯穿结构,所述贯穿结构的一端大于与其相对的另一端的尺寸,尺寸小的一端密封设置于所述颞骨模型的声音传导路径的出口处。可选地,所述颞骨模型为尸头颞骨或采用材料制作的人工颞骨模型。相应地,本发明实施例还提供了一种基于颞骨模型的实验方法,包括:根据预设强度,从颞骨模型的声音传导路径的入口处输出第一输出声音;接收从所述颞骨模型的声音传导路径的出口处接收第一接收声音;对比所述第一输出声音与所述第一接收声音的强度,得到第一强度差值。可选地,还包括:输出所述第一输出声音并接收第二接收声音;根据所述第二接收声音与所述第一接收声音,对比得到第二强度差值,通过所述第二强度差值对所述第一强度差值进行验证和/或修正。可选地,所述颞骨模型为人工颞骨模型,相应的,所述方法还包括:通过材料制备人工颞骨模型的步骤;所述通过材料制备所述人工颞骨模型的步骤,包括:获取所述颞骨的多个断面扫描影像;分别对所述多个断面扫描影像进行重建,得到对应的多个重建断面图像;根据所述多个重建断面图像,建立所述颞骨的三维几何模型;根据所述三维几何模型,采用成型技术制造出所述颞骨的人工颞骨模型。可选地,所述多个断面扫描影像中的至少一个断面扫描影像采用如下方法进行重建:获取所述断面扫描影像对应的重建参数;根据所述重建参数,对所述断面扫描影像进行重建,得到对应的重建断面图像;其中,所述重建参数包括:重建基线、层厚/层间距、窗宽/窗位。另外,可选地,所述根据所述多个重建断面图像,建立所述三维几何模型,包括:根据所述多个重建断面图像,分别确定所述多个重建断面图像中各重建断面图像对应的轮廓参数;获取三维建模参数;根据所述多个重建断面图像中各重建断面图像对应的轮廓参数以及所述三维建模参数,建立所述三维几何模型;将所述三维几何模型转化为点阵模型;采用点密度均一化将所述点阵模型优化;根据优化后的所述点阵模型,生成面模型;对所述面模型进行至少一次的修补处理;根据预设生成厚度,对修补处理后的所述面模型进行抽壳处理,得到高精度三维几何模型;根据所述高精度三维几何模型,采用成型技术制造出所述颞骨的人工颞骨模型。根据本发明实施例提供的技术方案,通过不同类型的颞骨模型,进行声音变化的研究,有助于研究不同气化程度、含气状态的颞骨蜂房对血管性耳鸣影响程度,通过制作不同类型的颞骨模型,实现针对多个因素,根据要求设计不同的实验条件进行研究,为深入研究血管性耳鸣提供有效手段,同时,构建出的模型结构与真实耳部结构相一致,为研究结果的可靠性提供了重要前提,为针对耳鸣影响因素进行个性化研究提供依据。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明实施例的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。此处所说明的附图用来提供对本发明实施例的进一步理解,构成本发明实施例的一部分,本发明实施例的示意性实施例及其说明用于解释本发明实施例,并不构成对本发明实施例的不当限定。在附图中:图1为本发明实施例的装置基于颞骨模型的实验装置的结构示意图;图2为本发明实施例的优选地基于颞骨模型的实验装置的结构示意图;图3为本发明实施例的又一优选地基于颞骨模型的实验装置的结构示意图;图4为本发明实施例的基于颞骨模型的实验方法的流程示意图。附图标记10:声音输出器;11:第一输出端;12:第二输出端;20:声音接收器;21:第一接收端;22:第二接收端;23:声音收集部件;30:总控制器;40:颞骨模型;41:声音传导路径的入口处;42:声音传导路径的出口处。具体实施方式为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明实施例一部分实施例,而不是全部的实施例。基于本发明实施例中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明实施例保护的范围。在本发明的说明书、权利要求书及上述附图中描述的一些流程中,包含了按照特定顺序出现的多个操作,这些操作可以不按照其在本文中出现的顺序来执行或并行执行。操作的序号如101、102等,仅仅是用于区分各个不同的操作,序号本身不代表任何的执行顺序。另外,这些流程可以包括更多或更少的操作,并且这些操作可以按顺序执行或并行执行。需要说明的是,本文中的“第一”、“第二”等描述,是用于区分不同的消息、设备、模块等,不代表先后顺序,也不限定“第一”和“第二”是不同的类型。发明人在实现本发明的过程中发现,颞骨蜂房气化是血管性耳鸣发生的条件之一。但是,不同气化程度、含气状态的颞骨蜂房对血管性耳鸣影响程度是怎样的还不得而知。由于目前实验研究方面存在的局限直接影响了颞骨蜂房气化对血管性耳鸣影响程度的深入研究,导致国内外对血管性耳鸣的实验研究均局限于颞骨的解剖学结构。因此,为解决现有技术中的缺陷,本发明实施例提供了一种装置基于颞骨模型的实验装置及方法,以便通过不同类型的颞骨模型,进行声音变化的研究,有助于研究不同颞骨蜂房气化对血管性耳鸣影响程度,为深入研究血管性耳鸣提供有效手段。以下将配合附图及实施例来详细说明本发明实施例的实施方式,藉此对本发明实施例如何应用技术手段来解决技术问题并达成技术功效的实现过程能充分理解并据以实施,以下结合附图对本发明的结构做进一步说明。实施例1:图1为本发明实施例的基于颞骨模型40的实验装置的结构示意图,如图1所示:本发明实施例提供了一种基于颞骨模型40的实验装置,包括:声音输出器10、声音接收器20、总控制器30以及颞骨模型40;声音输出器10包括第一输出端11,第一输出端11密封设置在颞骨模型40的声音传导路径的入口处41;声音输出器10包括但不限于有线传声器、无线传声器、电唱机、CD机、VCD/LD/DVD机以及电脑中的之一或及其组合,第一输出端11包括但不限于耳机、音响中的之一或及其组合。声音接收器20包括第一接收端21,第一接收端21密封设置在颞骨模型40的声音传导路径的出口处42;声音接收器20包括但不限于声音探测器,声音采集器、分贝仪、拾音器中的之一或及其组合,第一接收端21包括声音探测器的探头、声音采集器的探头、分贝仪的探头、拾音器的探头、麦克风中的之一或及其组合。总控制器30分别与声音输出器10、声音接收器20相连接;总控制器30包括但不限于电脑、声音控制器等。其中,声音输出器10根据预设强度并通过第一输出端11输出的声音为第一输出声音,声音接收器20通过第一接收端21接收到的声音为第一接收声音,总控制器30对比第一输出声音与第一接收声音的强度,对比得到第一强度差值,其中,第一强度差值为第一输出声音与第一接收声音之间的强度差值,根据不同实验的需要,可以为第一输出声音的强度减去第一接收声音的强度的差值,也可以是第一接收声音的强度减去第一输出声音的强度的差值,此处不做具体限定。具体举例说明,声音输出器10和总控制器30均为电脑,第一输出端11为耳机,声音接收器20为声音探测器,第一接收装置为声音探测器。颞骨模型40的声音传导路径包括但不限于:乙状窦沟骨壁缺损处为入口,经过乳突窦、乳突窦入口、鼓室、外耳道、至出口处。将耳机与电脑连接,将耳机的输出端与颞骨模型40的声音传导路径的入口处41连接,缝隙用石蜡进行密封,将声音探测器与电脑连接,将声音探测器的探头与颞骨模型40的声音传导路径的出口处42相连接,缝隙用石蜡进行密封。装置运行时,通过电脑根据预设强度发出第一输出声音,声音探测器收到的声音为第一接收声音,作为总控制器30的电脑通过接收到的第一接收声音与第一输出声音相对比,得到第一强度差值为第一输出声音与第一接收声音之间的强度差值,作为第一强度差值。将多个不同气化程度的颞骨模型40分别进行检查,得出各自的第一强度差值,通过装置分析就能够得到不同气化程度的颞骨对声音变化的影响,通过不同类型的颞骨模型40,进行声音变化的研究,有助于研究不同气化程度、含气状态的颞骨蜂房对血管性耳鸣影响程度。需要说明的是在进行多个颞骨模型40的同时检测的情况下,声音输出器10还可以包括多个第一输出端11,每一个第一输出端11连接一个颞骨模型40的声音传导路径的入口处41,声音接收器20相应的包括多个第一接收端21,每一个第一接收端21连接一个颞骨模型40的声音传导路径的出口处42,缝隙可以用石蜡进行密封。这样,在总控制器30的控制下就可以实现多个颞骨模型40的同时检测,快速对不同气化程度的颞骨对声音变化的影响进行分析研究。在图1所示的装置中,总控制器30与第一接收声音相对比的是第一输出声音,但是第一输出声音是总控制器30控制输出的声音,没用经过传导,是一个理想值。但是,声音在传导过程中自身会产生一定的衰减,不是初始发出的声音,因此,为了检测的真实性,本发明实施例在实施例1的基础上还提供了另一种实施方式。图2为本发明实施例的优选地基于颞骨模型40的实验装置的结构示意图,如图2所示:可选地,声音输出器10还包括第二输出端12,声音接收器20还包括第二接收端22;第二输出端12与第二接收端22相连接,其中,声音输出器10通过第二输出端12输出第一输出声音,声音接收器20通过第二接收端22接收到的声音为第二接收声音,总控制器30根据第一接收声音与第二接收声音,对比得到第二强度差值,并通过第二强度差值对第一强度差值进行验证和/或修正。第二接收声音是第一输出声音经过了第二输出端12和第二接收端22的传导之后得到的声音,与第一接收声音相比更接近于真实的声音。因此,总控制器30通过第二强度差值为第一接收声音与第二接收声音之间的强度差值,作为第二强度差值,并通过第二强度差值对第一强度差值进行修正。验证和/或修正的方式包括但不限于:获取第一强度差值与第二强度差值的平均值作为最终强度差值,或者是计算得到第一强度差值与第二强度差值之间的差值,并判断得到的差值是否超过预设阈值,如果超过预设阈值就认为第一强度差值不准确,检查装置连接、设置是否有问题,如果没有超过预设阈值,则认为第一强度差值正确,将第一强度差值作为最终强度差值。本发明实施例中,如果仅仅通过声音接收器20的第一接收端21进行收集,虽然对缝隙处进行了密封的操作,但是也可能出现声音漫射的情况,对声音的变化研究具有影响,本发明实施例中,为了更好的对声音进行收集,在进行声音接收的时候增设了声音收集部件23。图3为本发明实施例的又一优选地基于颞骨模型40的实验装置的结构示意图;声音接收器20包括声音收集部件23;声音收集部件23密封设置于颞骨模型40的声音传导路径的出口处42,声音收集部件23设置有声音收集腔,声音接收器20的接收端密封设置于声音收集腔内。声音收集部件23的作用是将声音聚集,有利于声音收集装置对声音进行收集,可选地,声音收集部件23的声音收集腔具有贯穿结构,贯穿结构的一端大于与其相对的另一端的尺寸,尺寸小的一端密封设置于颞骨模型40的声音传导路径的出口处42。声音收集部件23的形状有利于声波能量的聚集。在具体实施时,声音收集部件23的形状类似于喇叭形状,将喇叭口小的一端设置于颞骨模型40的声音传导路径的出口处42,缝隙处可以用石蜡进行密封。声音接收器20的第一接收端21通过喇叭口大的一端进入声音收集部件23的声音收集腔中,缝隙通过石蜡进行密封。或者通过简易材料也可以制作声音收集装置,例如,纸杯,水瓶等等。本发明实施例中,颞骨模型40为尸头颞骨或采用材料制作的人工颞骨模型。下面以尸头颞骨制作颞骨模型40为例进行基于颞骨模型40的实验装置详细介绍。(1)颞骨模型40的制作含气颞骨模型40制作:从尸头骨中游离出完整的含气颞骨结构,并在乙状窦沟上曲段制作圆形骨壁缺失,缺失直径为5mm;将含气颞骨模型40根据不同程度的充填石蜡,完成不同不同程度含气的颞骨模型40;非含气颞骨模型40制作:将含气处填充完全,制作非含气颞骨模型40;(2)声音输出器10耳机耳塞直径5mm,将耳机的一个耳塞插入骨壁缺失部位,石蜡固定包埋密封,耳机连接电脑,电脑作为总控制器30和声音输出器10。(3)声音接收器20磨除外耳道鼓部骨质,完整除去鼓膜,将塑料套管制作的声音收集部件23置于外耳道内,将声音探测器放置在塑料套管内,声音探测器连接电脑,电脑作为总控制器30。通过以上步骤(1)-(3)最终形成包括声音发生装置、颞骨模型40及声音接收器20的完整的基于颞骨模型40的实验装置。如采用材料制作的人工颞骨模型时,基于颞骨模型40的实验装置还包括:颞骨模型40制造器,颞骨模型40制造装置用于根据颞骨扫描图像制作实体颞骨模型40。通过对颞骨进行扫描得到多张颞骨的扫描图像,并根据多张颞骨的扫描图像通过三维成型技术制作颞骨的人体颞骨模型40,制作模型时,还可以调节制作参数,制作出不同气化程度的颞骨模型40,通过制作不同类型的颞骨模型40,实现针对多个因素,根据要求设计不同的实验条件进行研究,为深入研究血管性耳鸣提供有效手段,同时,构建出的模型结构与真实耳部结构相一致,为研究结果的可靠性提供了重要前提,为针对耳鸣影响因素进行个性化研究提供依据。实施例2图4为本发明实施例的基于颞骨模型的实验方法的流程示意图,如图4所示:相应地本发明实施例还提供了一种基于颞骨模型的实验方法,包括:步骤S101:根据预设强度,从颞骨模型40的声音传导路径的入口处41输出第一输出声音;基于颞骨模型的实验方法在具体实施时,可以依据实施例1中的基于颞骨模型40的实验装置进行实现,步骤S101中,总控制器30根据预设强度,控制声音输出器10发出第一输出声音,第一输出声音通过第一输出端11从颞骨模型40的声音传导路径的入口处41输出。步骤S102:接收从颞骨模型40的声音传导路径的出口处42接收第一接收声音;声音接收器20的第一接收端21从颞骨模型40的声音传导路径的出口处42接收第一接收声音,并发送至总控制器30。步骤S103:对比第一输出声音与第一接收声音的强度,得到第一强度差值。总控制器30根据接收到的第一接收声音与第一输出声音相对比,得到第一强度差值为第一输出声音与第一接收声音之间的强度差值,作为第一强度差值。将多个不同气化程度的颞骨模型40分别进行检查,得出各自的第一强度差值,通过分析就能够得到不同气化程度的颞骨对声音变化的影响,通过不同类型的颞骨模型40,进行声音变化的研究,有助于研究不同气化程度、含气状态的颞骨蜂房对血管性耳鸣影响程度。本发明实施例还包括:输出第一输出声音并接收第二接收声音;根据第二接收声音与第一接收声音,对比得到第二强度差值,通过第二强度差值对第一强度差值进行验证和/或修正。声音输出器10通过第二输出端12输出述第一输出声音,声音接收器20通过第二接收端22接收第二接收声音,总控制器30通过第二强度差值为第一接收声音与第二接收声音之间的强度差值,作为第二强度差值,并通过第二强度差值对第一强度差值进行修正。从颞骨模型40的声音传导路径的入口处41输出第一输出声音之前,还包括:通过尸头颞骨制作颞骨模型40或通过材料制作人工颞骨模型。通过尸头颞骨制作颞骨模型40如前,此处不进行赘述,下面对通过模型制造器根据颞骨扫描图像制作人工颞骨模型,进行进一步的详细介绍。颞骨模型40为人工颞骨模型,相应的,方法还包括:通过材料制备人工颞骨模型的步骤;通过材料制备人工颞骨模型的步骤,包括:步骤S201:获取颞骨的多个断面扫描影像;为保证构建的颞骨模型40的解剖结构与研究活体解剖结构一致,在构建颞骨模型40时需要以人体耳部颞骨的医学图像为基础,获取颞骨的多个断面扫描影像,人体耳部颞骨的医学图像的获取途径包括但不限于从患者图像数据库中调取、通过仪器扫描直接获取等,并对获取到的颞骨的多个断面扫描影像按照步骤S202进一步进行处理。获取人体耳部颞骨的医学图像的医学图像的方式可以通过以下方式进行获取:耳鸣患者CT图像采集,患者呈仰卧位,静脉注射对比剂,过程如下:使用PhilipsBrilliance64层螺旋CT(PhilipsHealthcare,Cleveland,Ohio)扫描数据,扫描范围自第6颈椎水平至颅顶,扫描参数:120kV,300mAs;准直:64×0.625mm;矩阵:512×512;旋转时间:0.75s;经手背静脉注射370mgI/ml碘海醇,剂量1ml/kg,注射速度5ml/s,对比剂注射完毕后以相同的流率注射20ml生理盐水,使用团注追踪技术(感兴趣区:200mm2;触发点:升主动脉;触发阈值:150HU)自动触发扫描,自颅底向头顶方向采集患者CT图像。采集到患者头部CT图像后进一步识别出耳部颞骨的图像部位。步骤S202:分别对多个断面扫描影像进行重建,得到对应的多个重建断面图像;对获取到的颞骨的多个断面扫描影像进行重建,先要获取重建参数,根据重建参数对断面扫描影像进行重建,得到重建断面图像,将重建断面图像按照步骤S203进一步进行处理。步骤S203:根据多个重建断面图像,建立颞骨的三维几何模型;根据多个重建断面图像,获取颞骨的三维几何模型的构建参数,并根据多个重建断面图像以及构建参数,构建颞骨的三维几何模型。步骤S204:根据三维几何模型,采用成型技术制造出颞骨的人工颞骨模型。根据步骤S203中构建的颞骨的三维几何模型,采用成型技术制造颞骨的人工颞骨模型。对于步骤S202来说,对多个断面扫描影像进行重建时,多个断面扫描影像中的至少一个断面扫描影像采用如下方法进行重建:获取断面扫描影像对应的重建参数;根据重建参数,对断面扫描影像进行重建,得到对应的重建断面图像;其中,重建参数包括:重建基线、层厚/层间距、窗宽/窗位。获取断面扫描影像对应的重建参数的方式包括但不限于以下方式:接收通过重建参数的设置界面输入的重建参数,在对断面扫描影像进行重建时,可以通过重建参数的设置界面人工进行输入重建参数,根据不同的重建方案,可以将重建参数进行相应的调整,从而完成不同的模型构建;和/或根据断面扫描影像,从存储器中获取到重建参数,其中,对断面扫描影像进行图像识别,识别出耳部结构,再通过识别出的耳部结构与存储器中预存储的耳部结构进行匹配,获取存储器中匹配的耳部结构相对应的重建参数;和/或根据断面扫描影像,获取人工在重建图像中勾画出的耳部结构的边界,根据边界,获取重建参数。获取到断面扫描影像对应的重建参数后,根据重建参数对断面扫描影像进行重建。具体实施时,本发明实施例中对断面扫描影像进行重建可以利用CTviewer软件对断面扫描图像进行重建,重建参数设置为:重建基线平行于水平半规管,重建层厚1mm,层间距1mm,窗宽/窗位为原始图像窗宽/窗位,得到对应的重建断面图像。对于步骤S203来说,根据多个重建断面图像,建立三维几何模型,包括:根据多个重建断面图像,分别确定多个重建断面图像中各重建断面图像对应的轮廓参数;获取三维建模参数;根据多个重建断面图像中各重建断面图像对应的轮廓参数以及三维建模参数,建立三维几何模型;建立耳部结构的三维几何模型需要先确定多个重建断面图像中各重建断面图像对应的耳部结构的轮廓参数,轮廓参数包括目标骨型结构边缘参数,确定耳部结构的轮廓参数的方式可包括但不限于以下方式:接收通过轮廓参数的设置界面输入的轮廓参数。和/或根据重建断面图像,从存储器中获取到轮廓参数。例如,对断面扫描影像进行图像识别,识别出耳部结构,再通过识别出的耳部结构与存储器中预存储的耳部结构进行匹配,获取存储器中匹配的耳部结构相对应的轮廓参数。和/或根据重建断面图像,获取人工在重建图像中勾画出的耳部结构的边界,根据边界,获取轮廓参数。同时,不同的构建方案对应的三维建模参数的设置可不同。具体实施时,可预先为多个构建方案分别设置对应的三维建模参数,后续可直接从中提取以获取所需的三维建模参数。具体的,三维建模参数可包括:层厚、层间距以及像素。例如,本实施例中三维建模参数中的层厚可以是0.625mm~1mm,层间距可以是0.625~1mm,像素可选择512*512~1024*1024。在一种可实现的方案中,上述步骤S203中,根据多个重建断面图像,建立颞骨的三维几何模型的步骤可采用现有技术中的Mimics软件(例如Mimics10.0)来实现。例如,将多个重建断面图像导入Mimics软件中;然后通过Mimics软件中的设置功能进行三维建模参数的设置;随后通过Mimics软件中的轮廓勾画功能勾画重建断面图像中的轮廓曲线,反复修改、校正;最后由Mimics软件基于该轮廓曲线及三维建模参数建立三维几何模型。对于步骤S204来说,在建立的颞骨的三维几何模型基础上,采用成型技术可以制造出颞骨的人工颞骨模型,利用颞骨的人工颞骨模型完成与真实颞骨一致的实验研究,为研究结果的可靠性提供了重要前提。制作人工颞骨模型的成型技术包括但不限于三维打印技术,为保证人工颞骨模型更加接近真实的颞骨,颞骨的三维几何模型的制作材质需要更加接近骨组织同时还要满足制作的需要,因此在制作颞骨的三维几何模型时可采用金属材料粉末作为三维打印材料。在制作材料上满足打印条件外,同时还要设置合适的打印参数,在打印材料和打印参数同时满足条件时,才能够制作出更加接近真实颞骨的人工颞骨模型,因此,本发明实施例中,根据颞骨的三维几何模型,采用金属材料粉末作为三维打印材料打印颞骨的人工颞骨模型,包括:对颞骨的三维几何模型进行切片,得到多个切片厚度在0.1~0.2mm的切片单元;以0.1~2mm的打印层厚及2~10mm/s的打印速度,使用金属材料粉末分别打印多个切片单元,以堆叠形成颞骨的人工颞骨模型。打印参数的设置与打印材料均满足制作条件,制作出的人工颞骨模型除了在结构上与真实的颞骨接近,同时,在形态上也保持一致,为实验研究的真实性和研究结果的可靠性提供了重要的前提。建立三维几何模型,还包括:对三维几何模型进行优化处理,得到高精度三维几何模型。其中,优化的方式包括但不限于:将三维几何模型转化为点阵模型;采用点密度均一化将点阵模型优化;根据优化后的点阵模型,生成面模型;对面模型进行至少一次的修补处理;根据预设生成厚度,对修补处理后的面模型进行抽壳处理,得到高精度三维几何模型;根据三维几何模型,采用成型技术制造出颞骨的人工颞骨模型,包括:根据高精度三维几何模型,采用成型技术制造出颞骨的人工颞骨模型。具体举例来说,可利用Geomagic9.0软件对颞骨的三维几何模型进行优化。即将颞骨的三维几何模型图像导入Geomagic9.0软件,设置合适的坐标系,将三维几何模型转化为点阵模型,采用点密度均一化将点阵优化,再将点阵模型生成面模型;然后将面模型通过多种手段修补模型破损部位,并反复以上修补步骤,直到面模型光滑无坏面。根据预设生成厚度(该预设生成厚度包括但不限于目标骨型厚度等),利用抽壳功能,创建有厚度的面封闭实体,完成对三维几何模型的优化,得到高精度三维几何模型。高精度三维几何模型具有更加细致、更加逼真的效果。根据高精度三维几何模型制作的人工颞骨模型更加接近于真实的颞骨。同时,根据高精度三维几何模型制造颞骨的人工颞骨模型的制作步骤以及三维打印的材料选取、打印速度以及打印厚度的设置可参考上述根据三维几何模型制造出颞骨的人工颞骨模型的描述,此处不再一一赘述。实施例1所示的装置可以执行实施例2所示实施例的方法,实现原理、技术效果参考以及特征相对应,可以相互参照,此处不再一一赘述。应用场景以下通过尸头颞骨为使用场景,对基于颞骨模型的实验装置如何进行检测声音变化实验进行详细介绍:1、扫描8个颞骨区结构完好无损的干燥人颅骨,包括16个颞骨;2、通过CT扫面得到颞骨的断面扫描影像,具体为:利用PhillipsBrilliance64层螺旋CT扫描仪(PhilipsHealthcare,Cleveland,Ohio),对双侧颞骨CT轴位容积进行扫描,扫描参数如下:扫描参数:采集层厚0.67mm,螺距0.33mm窗宽4000Hu,窗位700Hu矩阵512×512,准直器16×0.625mm电压140kV,电流250mA3、将得到的颞骨的断面扫描影像利用CTviewer软件进行重建,重建参数为:重建基线平行于水平半规管,重建层厚1mm,层间距1mm,窗宽/窗位为原始图像窗宽/窗位,边缘强化等级为0.7;4、对颞骨蜂房气体容积重建,规定重建阈值下限为1024HU,上限为224HU,仅使用切割功能,颞骨气化容积由计算机三维重建系统自动得出。步骤1-4完成颞骨的气化程度判定,下面通过步骤5和6完成制作装置基于颞骨模型的实验装置。5、确定颞骨模型的声音传导路径,声音输出器至乙状窦沟骨壁缺损处为入口,经过乳突窦、乳突窦入口、鼓室、外耳道、至出口处,声音接收器;6、颞骨骨壁缺损模型的制作,游离出完整的颞骨结构,乙状窦沟上曲段制作圆形骨壁缺失,缺失直径为5mm;声音输出器,耳机耳塞直径5mm,将耳机的一个耳塞插入骨壁缺失部位,石蜡固定包埋密封,另外一个耳机耳塞游离于模型之外,耳机连接电脑,电脑作为总控制器和声音输出器;声音接收器,磨除外耳道鼓部骨质,完整除去鼓膜,将塑料套管制作的声音收集部件置于外耳道内石蜡固定包埋密封,将声音探测器放置在塑料套管内石蜡固定包埋密封,声音探测器连接电脑,电脑作为总控制器。7、对声音进行检测前还需对装置进行检测是否准确,包括:通过声音信号探测器,检测耳机的两个耳塞对于同一声音的强度表达一致,检测通过颞骨模型声音传导路径接受统一声音的声音强度有差异。8、对8个颞骨结构声音变化进行检测在纯音测听室中,施加不同频率(125Hz、250Hz、500Hz、1000Hz、2000Hz、4000Hz、8000Hz)的声音信号,调节电脑声音软件使位于外耳道内的声音探测器测量值为34.0dB(临床测量的24例SS-PT患者的声音强度的平均值),读出游离于模型之外的耳塞的声音响度,即为施加声音的响度,每个模型反复测量3次,取平均值。结论:颞骨模型的颞骨气化程度及含气容积含气8个模型非含气3个模型(充填石蜡)Ⅰ级(a2.4cm3、b2.2cm3)Ⅰ级(2.6cm3)Ⅱ级(a3.4cm3、b4.0cm3)Ⅱ级(3.3cm3)Ⅲ级(a6.9cm3、b6.7cm3)Ⅲ级(6.5cm3)Ⅳ级(a12.4cm3、b13.2cm3)声音传导模型声音发生端到接收端距离(单位:mm),随着气化程度的增加,距离也增加气化分级ⅠⅡⅢⅣ含气组41.745.247.648.4非含气组44.947.651.1含气组Ⅰ级模型声音强度的变化结果含气组Ⅱ级模型声音强度的变化结果含气组Ⅲ级模型声音强度的变化结果输出声音(dB)输入声音频率(Hz)平均输入声音(dB)34.0125>91.634.025082.634.050083.134.0100085.834.0200090.634.04000>91.634.08000>91.6含气组Ⅳ级模型声音强度的变化结果非含气组Ⅰ级模型声音强度的变化结果非含气组Ⅱ级模型声音强度的变化结果输出声音(dB)输入声音频率(Hz)平均输入声音(dB)34.0125>91.634.0250>91.634.050084.034.0100088.634.0200082.134.04000>91.634.0800075.1非含气组Ⅲ级模型声音的变化结果非含气组模型对于声音的衰减均非常明显根据实验得出,不同颞骨气化程度及含气状态在SS-PT耳鸣声音传导中的作用规律,声音在颞骨蜂房内传导均是衰减,与颞骨气化程度有一定关系,声音频率越高,衰减越重,解释了SS-PT均为低频噪声。综上所述,根据发明实施例提供的技术方案,根据本发明实施例提供的技术方案,通过不同类型的颞骨模型,进行声音变化的研究,有助于研究不同气化程度、含气状态的颞骨蜂房对血管性耳鸣影响程度,通过制作不同类型的颞骨模型,实现针对多个因素,根据要求设计不同的实验条件进行研究,为深入研究血管性耳鸣提供有效手段,同时,构建出的模型结构与真实耳部结构相一致,为研究结果的可靠性提供了重要前提,为针对耳鸣影响因素进行个性化研究提供依据。需要说明的是,虽然结合附图对本发明的具体实施方式进行了详细地描述,但不应理解为对本发明的保护范围的限定。在权利要求书所描述的范围内,本领域技术人员不经创造性劳动即可做出的各种修改和变形仍属于本发明的保护范围。本发明实施例的示例旨在简明地说明本发明实施例的技术特点,使得本领域技术人员能够直观了解本发明实施例的技术特点,并不作为本发明实施例的不当限定。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上,可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的,本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。上述说明示出并描述了本发明实施例的若干优选实施例,但如前所述,应当理解本发明实施例并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述申请构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明实施例的精神和范围,则都应在本发明实施例所附权利要求的保护范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1