会话评价装置和方法与流程
本发明涉及会话评价装置和方法、以及存储用于执行会话评价方法的程序的存储介质。
背景技术:
迄今为止,已经提出了一种用于通过分析由说话者发出的语音本身来分析说话人的心理状态等的技术。例如,专利文献1提出了这样一种技术,该技术用于通过获取说话者的语音序列并检测存在于语音序列中的基音的间隔(音程)来诊断说话人的心理状态、健康状态等。
现有技术文献
专利文献
专利文献1:日本专利no.4495907
在至少两个人或说话人之间的会话中,当一个说话者已给出询问(说出的话)时,另一说话者对该询问(说出的话)发出一些回答(包括反馈语回复(backchannelfeedback))。在那时,给会话参与方的印象会根据以哪种氛围或细微差别(即,非语言特性)发出回答而不同,甚至在以相同措辞发出回答的情况下也是如此。因此,在上述专利文献1中所提出的技术构造为通过检测说话者的语音序列中的音程(音高间隔)来分析说话人的心理状态等。即,在专利文献1中所提出的技术既不将两个人之间的会话中的询问的语音特性与回答的语音特性进行比较,也不评价对特定询问所做出的回答的非语言特性。因此,在专利文献1中所提出的技术无法评价对会话中已经发出的特定询问的回答具有哪种非语言特性。
技术实现要素:
鉴于上述现有技术问题,本发明的目的是提供能够以客观方式评价对询问的回答的非语言特性(例如,该回答给已发出询问的会话参与方的印象是好还是坏)的会话评价装置和方法、以及存储用于执行会话评价方法的程序的存储介质。
在评价会话中的对询问的回答时,首先考虑在人与人之间进行了何种会话(对话),从而关注除了语言信息外的信息,特别是表征会话的声音音高(频率)。作为人与人之间的示例性对话,考虑了一个人(“人b”)对另一人(“人a”)给出的话语(例如,询问)作出回答的情况。在这样的情况下,当“人a”已发出询问时,不仅“人a”往往会对询问的特别部分的音高具有强烈印象,而且对该询问作出回答的“人b”往往也会对询问的特别部分的音高具有强烈印象。当“人b”以同意、许可、确认等为意图对询问作出回答时,这个人以表征回答的部分的音高与所述询问的上述让人印象深刻(已给人强烈印象)的音高具有特定关系(更具体地,协和音程关系)的这种方式来说出回答的语音(回答语音)。由于“人a”的询问的让人印象深刻的音高和表征“人b”对询问的回答的部分的音高具有上述关系,因此听到了回答的“人a”会对“人b”的回答具有良好、舒适且安心的印象。即,可以认为,在人与人之间的实际对话中,询问的音高和对该询问的回答的音高具有如上所述的特定关系,而不是彼此无关。因此,为了鉴于上述考虑而实现上述目的,本发明的发明人研发了一种被构建为以下文所述方式来适当地评价对询问的回答的改进的会话评价系统。
即,为了实现上述目的,本发明提供了一种改进的会话评价装置,其包括:接收部,其配置为接收与询问的语音有关的信息和与对该询问的回答的语音有关的信息;分析部,其配置为基于由接收部接收到的信息来获取询问的代表性音高和回答的代表性音高;以及评价部,其配置为基于由分析部获取的询问的代表性音高与回答的代表性音高之间的比较来评价对询问的回答。
由于回答的音高相对于询问的音高的音程(音高间隔)与会通过回答给发出了该询问的会话参与方的印象具有紧密关系,因此通过根据本发明的原理将询问的代表性音高与回答的代表性音高之间进行比较,能够以客观方式且高可靠性地评价对询问的回答的非语言特性(例如,该回答给发出了询问的会话参与方的印象是好还是坏)。
在本发明的一个实施例中,评价部可以配置为确定由分析部获取的询问的代表性音高与回答的代表性音高之间的差值是否在预定范围内;当差值不在预定范围内时,以一个八度音接一个八度音的方式确定音高偏移量,以使得差值落入预定范围内;以及使询问的代表性音高和回答的代表性音高中的至少一个偏移音高偏移量,并且基于在以音高偏移量进行音高偏移之后的询问的代表性音高与回答的代表性音高之间进行的比较来评价对询问的回答。即,根据本发明,当询问的音高和回答的音高彼此相差超出预定范围时,以一个八度音接一个八度音的方式来执行音高偏移控制,以使得询问与回答之间的音高差落入预定范围内,从而能够适当地进行询问的音高与回答的音高之间的比较。因此,即使在询问的语音音高与回答的语音音高如同在男人与女人之间或成年人与小孩之间的会话中的那样彼此相差了一个八度音程以上的情况下,也能够以适当方式评价对询问的回答。在本发明的一个实施例中,评价部可以配置为根据或基于询问的代表性音高与回答的代表性音高之间的差与预定参考值相差多少来评价对询问的回答。
在本发明的一个实施例中,会话评价装置还可以包括检测会话间隔的会话间隔检测部,该会话间隔是从询问的结束到回答的开始的时间间隔,并且评价部可以配置为还基于由会话间隔检测部检测到的会话间隔来评价对询问的回答。另外,作为对询问的回答的除了音高外的语音特性,从询问的结束到回答的开始的时间间隔(会话间隔)与通过回答给会话参与方的印象具有紧密关系。因此,本发明可以通过还评价询问与回答之间的会话间隔来更加高可靠性地评价回答。
本发明可以不仅被构造且实现为以上所述的装置或设备,而且还可以被构造且实现为方法发明。此外,本发明可以被布置并实现为可由诸如计算机或dsp(数字信号处理器)的处理器执行的软件程序、以及存储这样的软件程序的非暂时性计算机可读存储介质。在这样的情况下,该程序可以以存储介质的形式被提供给用户并且随后安装到用户的计算机中,或者替选地,经由通信网络从服务器设备传递到客户端的计算机并随后安装到客户端的计算机中。另外,在本发明中所采用的处理器可以是设置有专用硬件逻辑电路的专用处理器,而不是仅限于计算机或能够运行期望软件程序的其它通用处理器。
应该理解,本文中所使用的术语“询问”不仅指的是“问询(inquiry)”而且还纯粹地指对另一人(会话参与方)“说出的话语”,并且本文中所使用的术语“回答”指的是对这样的“询问”(说出的话语)的某种语言回应。简而言之,在两个以上的人之间的会话中,一个人对另一人的话语被称为“询问”,而其他人对询问的语音回应被称为“回答”。
附图说明
下文中,将参照附图仅以示例的方式详细地描述本发明的某些优选实施例。
图1是示出了根据本发明的第一实施例的会话评价装置的构造的框图;
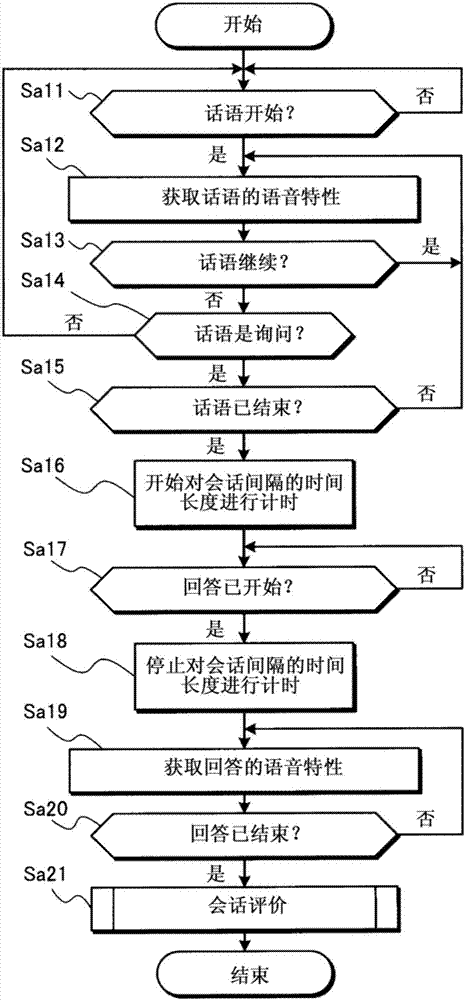
图2是在图1所示的会话评价装置中所执行的示例性主例程处理的流程图;
图3是图2所示的会话评价子例程的流程图;
图4是示出在第一实施例中的询问的示例性音高和回答的示例性音高的示图;
图5是这样一种示图,该示图示出了第一实施例中的询问的示例性音高和回答的示例性音高,并且更具体地示出了询问与回答之间存在一个八度音以上的音高差的情况;
图6是在第一实施例中的用于计算音高评价点的规则的说明图;
图7是在第一实施例中的用于计算会话音程评价分数的规则的具体示例的说明图;
图8是示出根据本发明的第二实施例的会话评价装置的构造的框图;
图9是在图8所示的会话评价装置中所执行的示例性主例程处理的流程图;
图10是示出根据本发明的第三实施例的会话评价装置的构造的框图;以及
图11是在图10所示的会话评价装置中所执行的示例性主例程处理的流程图。
具体实施方式
<第一实施例>
图1是示出根据本发明的第一实施例的会话评价装置10的构造的示图。在下文中将会话评价装置10描述为应用于如下的会话训练装置,所述会话训练装置经由单语音输入部102的麦克风输入两个人之间的会话的语音,评价会话中的对询问的回答,并且显示所评价的回答。这里假设的对询问的回答的示例包括答案和反馈语回复(感叹词),比如,“是”、“否”、“嗯啊”、“嗯...”、“好吧...”以及“我明白了”。
如图1所示,会话评价装置10包括cpu(中央处理单元)、存储部、单语音输入部102、显示部112和其它部件,其中,存储部包括存储器、硬盘装置等。在会话评价装置10中,通过cpu执行预先安装的应用程序来如下地构建多个功能块。更具体地,在会话评价装置10的第一实施例中,构建有语音获取部104、分析部106、判定部108、语言数据库122、会话间隔检测部109和评价部110。
虽然在附图中未具体示出,但是会话评价装置10还包括操作输入部等,以使得用户可以向该装置输入各种操作,进行各种设置等。另外,会话评价装置10的应用并非限于会话训练装置,本发明的会话评价装置10可以应用于终端装置(比如,智能电话或便携式电话、平板型个人计算机等)。另外,会话评价装置10可以应用于经由单语音输入部102的麦克风输入三个以上的人的会话语音的情况。在这样的情况下,当一个人发出了询问时,例如,其他人中的任一个可以对该询问作出回答。
虽然未详细地描述,但是语音输入部102包括将输入语音转换成电信号的麦克风以及实时地将转换后的语音信号转换成数字信号的a/d转换部。语音获取部104接收从语音输入部102输出的数字信号,并且将所接收到的数字信号暂时存储到存储器中。在第一实施例中,语音输入部102和语音获取部104共同起到接收部的作用,该接收部配置为接收与询问的语音有关的信息和与对该询问的回答的语音有关的信息。
分析部106对转换后的数字语音信号执行分析处理以提取话语(询问和回答)的语音特性(音高、音量等),并且分析部106构造或配置为获取询问的代表性音高和回答的代表性音高。作为示例,分析部106包括:第一音高获取部106a,其检测询问的特定部分的音高,并且基于该检测来获取询问的语音特性(通常为代表性音高);以及第二音高获取部106b,其检测回答的话音中所包括的音高,并且基于该检测来获取回答的语音特性(通常为代表性音高)。
第一音高获取部106a检测询问的语音信号中从说话开始持续到说话结束的说话部分的浊音段(voicedsegment)中的特定部分的音高(即,询问的代表性音高),然后向评价部110提供指示所检测到的询问的音高(代表性音高)的数据。说话部分的浊音段中的特定部分是适于提取询问所具有的音高相关特性的代表性部分。作为示例,特定部分(代表性部分)是紧接在说话结束之前的预定持续时间(例如,180毫秒)的末尾部分,并且第一音高获取部106a对末尾部分中的作为代表性音高的最高音高进行检测。这样的特定部分(代表性部分)不限于末尾部分,可以是整个说话部分或说话部分中的一部分。替选地,除最高音高之外,可以检测特定部分(代表性部分)中的最低音高或平均音高等作为代表性音高。
在如本实施例中的那样实时地输入语音的情况下,可以例如通过确定语音信号的音量已达到阈值以上来识别语音说话的开始,并且可以例如通过确定语音信号的音量已经持续在阈值以下达到预定时间段来识别语音说话的结束。应注意,为了防止喋喋不休,可以使用多个阈值来赋予滞后特性。另外,术语“浊音段”是指可检测到语音信号的音高的说话部分的区段。这样的音高可检测区段意味着语音信号具有周期部分并且该周期部分中的音高是可检测的。
如果询问的浊音段的末尾部分是清音(即,不涉及声带的振动的声音),则可以根据前一浊音部分来估计清音的音高。另外,询问的特定部分(代表性部分)不一定限于浊音段的末尾部分,也可以是例如浊音段的话语开始部分。另外,可以做出这样的布置:允许用户按照期望设定应该识别询问的哪个部分的音高。作为另一替选方案,仅可以将音量和音高中的一个而非将音量和音高两者用于浊音段检测,并且用户可以选择音量和音高中的哪一个应该用于浊音段检测。
第二音高获取部106b基于回答的语音信号来检测回答的音高,并且基于所检测到的音高来获取回答的语音的代表性音高(例如,说话部分的平均音高)。然后,第二音高获取部106b向评价部110提供指示所获取的回答的代表性音高的数据。应注意,第二音高获取部106b可以获取回答的语音的整个区间或预定的部分区间中的最高音高或最低音高而不是所述平均音高来作为代表性音高。替选地,第二音高获取部106b可以获取回答的语音的预定部分区间中的平均音高作为代表性音高。作为另一替选,第二音高获取部106b可以获取回答的语音的整个区间或预定的部分区间中的音高轨迹本身作为代表性音高。
另外,在执行与第一音高获取部106a和第二音高获取部106b有关的处理时,分析部106可以通过使用经由语音获取部104而被存储到存储器中的语音信号来检测特定部分和该特定部分的音高。替选地,分析部106可以通过使用经由语音获取部104而实时地接收到的语音信号来检测询问的音高。例如,在要实时地对询问的音高进行检测的情况下,将所输入的语音信号的音高与前一语音信号的音高进行比较,并且以更新方式存储所比较的音高中的较高音高。继续这样的操作直到询问的话语结束为止,使得最终更新的音高被识别为询问的音高。以该方式,可以将直到话语结束为止所检测到的最高音高识别为询问的音高。另外,在要对回答的音高进行检测的情况下,可以基于回答的音节来识别回答的音高。在回答是反馈语回复的情况下,例如,在回答的第二音节中或附近的音高往往接近整个回答的平均音高,因此,可以将在第二音节的开头处的音高识别为回答的音高。
判定部108对被转换为数字信号的话语的语音信号进行分析,对数字语音信号执行语音识别以将语音信号转换为字符串,由此识别说出的话语的一个或多个词的含义。因此,判定部108判定话语是询问还是回答,然后向分析部106提供指示判定结果的数据。在判定话语的含义时,判定部108参考在语言数据库122中预先创建的音素模型来判定话语的语音信号接近哪个音素,并且由此识别由语音信号定义的一个或多个词的含义。隐马尔科夫模型可以用作音素模型。
应注意,判定部108关于话语是询问还是回答的判定可以基于非语言特性而进行,而不是基于以上阐述的语言含义分析来进行。例如,如果话语在其末尾部分具有升调,则可以确定为询问。如果下一话语的语音具有两个音节,则可以将下一话语确定为是反馈语回复形式的回答。通常,如果话语是询问,则下一话语是对该询问的回答。因此,判定部108至少能够判定话语是否是询问就足矣。在这样的情况下,自动地将紧跟在已被判定为询问的话语之后的话语视为对该询问的回答。
顺便一提的是,在两个人之间的对话中对询问作出回答的情况下,从询问的结束到回答的开始的时间间隔(会话间隔)可以是除了音高外要考虑的一个因素。例如,当对一个人说出的似乎迫切要求二选一回答的询问做出回答“否”时,回答人为了足够谨慎通常会需要一段时间,好像停顿片刻一样,这是经验上常见的行为。另一方面,对于一个人说出的没有迫切要求二选一回答的诸如“谁”、“什么”、“何时”、“哪里”、“为什么”或“如何”这样的询问,其他人有时会需要一段时间来回答具体内容。在任何情况下,如果从询问的结束到回答的开始的时间间隔相对较长,则可能给说出了询问的人一种不舒服的感觉,而且随后的会话可能不会变得活跃。相反,如果从询问的结束到回答的开始的时间间隔太短,则说出了询问的人可能会有这样一种感觉:仿佛其他人的回答有意地叠盖该询问或者仿佛其他人没有认真地聆听说出了询问的人。因此,可能给说出了询问的人不舒服的感觉。
鉴于上述状况,本实施例以如下这样的方式构造:在评价对询问的回答时,除了测量并评价音高外,还可以测量并评价从询问的结束到回答的开始的时间间隔(也称为“会话间隔”)。更具体地,会话间隔检测部109通过使用内置于会话评价装置10中的定时器或实时时钟来检测从询问的结束到回答的开始的时间间隔(会话间隔)。在定时器用于计时目的的情况下,定时器响应于询问的结束而开始计时,并且响应于回答的开始而停止计时,使得询问的结束与回答的开始之间的时间间隔被检测为会话间隔。在实时时钟用于计时目的的情况下,获取询问的结束和回答的开始的各自的时间,然后将两个时间之间的时间间隔检测为会话间隔。指示所检测到的会话间隔的时间数据被提供至评价部110,以便通过评价部110以及前面所述的询问和回答的音高数据来评价时间数据。
评价部110基于从分析部106提供的询问和回答的音高数据以及从会话间隔检测部109提供的时间数据来评价对询问的回答,并且由此计算评价点或分数。更具体地,对于音高数据,评价部110计算询问的代表性音高与回答的代表性音高之间的差(音程),并且基于所算出的差(音程)与预定参考值相差多少来计算音高评价分数。同样地,对于指示会话间隔的时间数据,评价部110基于会话间隔的时间长度与预定参考值(参考时间间隔)相差多少来计算会话间隔评价分数。然后,评价部110计算音高评价分数与会话间隔评价分数之和,并将该和作为回答的最终评价分数,并且在显示部112上直观地显示该最终评价分数。因此,已做出回答的人可以检查回答的评价。稍后将讨论评价部110对回答进行评价的详情。
接下来,将给出关于会话评价装置10的第一实施例的操作的描述。图2是示出会话评价装置10的第一实施例中所执行的处理的流程图。会话评价装置10的cpu响应于用户执行预定操作(例如,在主菜单画面(未示出)上选择与处理相对应的图标等)而启动与该处理相对应的应用程序。通过执行该应用程序,cpu构建图1所示的功能块。
这里,将关于以下情况来描述会话评价装置10的操作:经由单话音输入部102的麦克风输入两个人之间的自然会话的语音,并且会话评价装置10在实时地获取语音的特性的同时对询问的回答进行评价。在像这样经由单话音输入部102输入自然会话的情况下,需要判定话语是否是询问,因为无法经由单话音输入部102清楚地识别话语是否是询问。这里,为了便于描述,做了这样的假设:如果话语已被确定为询问,则自动地将紧接在该询题之后的话语视为是回答,因而不执行关于紧接在后的话语是否是回答的特定判定处理。然而,会话评价装置10不限于此,并且可以被构造为执行用于确定紧接在已被确定为询问的话语之后的话语是否是回答的特定判定处理。
首先,在步骤sa11处,将由语音输入部102转换的语音信号经由语音获取部104提供给分析部106,在分析部106中进行关于话语是否已开始的判定。通过判定语音信号的音量是否已达到阈值以上来进行关于话语是否已开始的判定。应注意,语音获取部104将语音信号存储到存储器中。
一旦在步骤sa11处确定了话语已开始,处理进行到步骤sa12,在步骤sa12处,分析部106的第一获取部106a对经由语音获取部104提供的语音信号执行音高分析处理,以获取话语的音高作为语音特性。除非在步骤sa11处确定了话语已开始,否则就重复步骤sa11,直到确定话语已开始为止。
在步骤sa13处,分析部106通过判定具有等于或大于阈值的音量的语音信号是否仍持续来判定话语是否仍继续。一旦在步骤sa13处确定了话语仍继续,处理就倒退至步骤sa12,在步骤sa12处,分析部106的获取部106a对语音信号执行音高分析处理以获取话语的音高。另一方面,一旦在步骤sa13处确定了话语未继续,处理就进行到步骤sa14,在步骤sa14中,通过判定部108做出关于最新的话语是否已经被确定为询问的判定。如果根据步骤sa14处的判定确定了最新话语不是询问,则处理倒退至步骤sa11以等待下一话语的开始。
另一方面,如果根据步骤sa14处的判定确定了最新的话语是询问,则在步骤sa15处例如通过判定语音信号的音量低于预定阈值的状态是否持续了预定时间来做出关于话语(询问)是否已结束的判定。
如果根据步骤sa15处的判定确定了话语(询问)尚未结束,则处理倒退至步骤sa12,以使得用于获取话语的音高的音高分析处理得以继续。一旦第一音高获取部106a通过对语音信号执行分析处理获取了话语(询问)的高音(例如,话语结尾部分中的最高音高),第一音高获取部106a就将询问的音高数据提供至评价部110。
另一方面,如果根据步骤sa15中的判定确定了话语(询问)已结束,则处理就进行到步骤sa16,在步骤sa16处,会话间隔检测部109开始对会话间隔的时间长度进行计时。
然后,在步骤sa17处,做出关于对询问的回答是否已开始的判定。由于询问已结束,因此下一话语是回答,因而,通过判定在询问的结束之后紧跟着的语音信号的音量是否已达到阈值以上来判定回答是否已开始。
如果根据步骤sa17处的判定确定了回答已开始,则在步骤sa18处,会话间隔检测部109停止对会话间隔的时间长度进行计时。以上述方式,可以测量从询问的结束到回答的开始的会话间隔的时间长度。然后,会话间隔检测部109向评价部110提供指示所测量的会话间隔的时间长度的数据。
在步骤sa19处,分析部106的第二音高获取部106b对来自语音获取部109的语音信号执行分析处理,以获取回答的音高作为语音特性。
在下一步骤sa20处,例如通过判定语音信号的音量低于预定阈值的状态是否持续了预定时间来做出如在步骤sa15处所执行的关于回答是否已结束的判定。
如果根据步骤sa20处的判定确定了回答尚未结束,则处理倒退至步骤sa19,在sa19处,继续用于获取回答的音高的音高分析处理。一旦第二音高获取部106b通过对语音信号执行分析处理获取了回答的音高(例如,平均音高),第二音高获取部106b就将回答的音高数据提供至评价部110。一旦在步骤sa20处确定了回答已结束,则处理倒退至步骤sa21,在步骤sa21处,评价部110对会话进行评价。
图3是示出在图2的步骤sa21处的会话评价处理的详情的流程图。首先,在步骤sb11处,评价部110基于从第一音高获取部106a获取的询问的音高数据与从第二音高获取部106b获取的回答的音高数据,计算询问的音高(代表性音高)与回答的音高(代表性音高)之间的差值;上述差值(音高差值)是通过从询问的音高中减去回答的音高而算出的音高差值的绝对值。
在下一步骤sb12处,评价部110判定所算出的音高差值是否在预定范围内。如果在步骤sb12处确定了所算出的音高差值在预定范围之外,则在步骤sb13处,评价部110调整回答的音高。更具体地,评价部110以一个八度音接一个八度音的方式确定回答的音高的音高偏移量,使得音高差值落入预定范围内(例如,一个八度音的范围内)。然后,评价部110通过音高偏移量来调整回答的音高,此后,处理倒退至步骤sb11,以使得评价部110重新计算询问的音高与调整或偏移后的回答的音高之间的音高差值。因此,即使在如同具有较高音高的自然语音的人(如女性或小孩)和具有较低音高的自然语音的人(如男性)之间的会话中那样在人与人之间的自然语音中存在一个八度音以上的音高差的情况下,评价部110可以调整人与人之间的自然语音的音高差,从而适当地评价对询问的回答。应注意,以该方式配置的评价部110可以适当地评价男性和女性之间的会话以及男性之间或女性之间的会话中的对询问的回答,所述会话有时可能会涉及自然话音中的一个八度音以上的音高差。
在步骤sb13处,评价部110可以以一个八度音接一个八度音的方式调整回答的音高,直到音高差值落入预定范围内(例如,在一个八度音的范围内)。而已关于调整回答的音高而仍不调整询问的音高的情况进行了以上描述,但本发明不限于此。可以调整询问的音高而仍不调整回答的音高,或者可以调整问询的音高和回答的音高这两者。
如果根据步骤sb12处的判定确定了音高差值在预定范围内,则在步骤sb14处,评价部110基于通过从询问的音高减去回答的音高而算出的音高差值来计算音高评价点(分数)。此时,如果如上所述那样在步骤sb13处已执行了音高调整,则评价部110使用基于调整后的音高而算出的音高差值来计算音高评价分数。由于音高差值是通过从询问的音高中减去回答的音高而计算的,因此当回答的音高低于询问的音高时,该音高差值变为正(加号)值,但当回答的音高高于询问的音高时,该音高差值变为负(减号)值。其目的在于:相比于回答的音高高于询问的音高的情况而言,对回答的音高低于询问的音高的情况给予更高评价。在步骤sb14处根据或基于音高差值与预定参考值相差多少来计算音高评估分数。例如,假设预定参考值是700音分(cent),并且当音高差值为700音分时,给予满分(100点)。在这样的情况下,通过随着音高差值与700音分参考值相差(偏离)更多而降低分数,来计算对询问的回答的音高评价分数。即,音高评价分数越接近100点,对询问的回答所进行的评价就越好。应注意,评价分数可随着音高差值越接近预定参考值而增大。
然后,在步骤sb15处,评价部110基于指示从会话间隔检测部109提供的会话间隔的时间数据来计算会话间隔评价分数。在步骤sb15处,基于从询问的结束到回答的开始的会话间隔的时间长度与预定参考值相差多少来计算会话间隔评价分数。例如,假设预定参考值为180毫秒,并且当会话间隔的时间长度为180毫秒时给出满分(100点)。在这种情况下,通过随着会话间隔的时间长度与180毫秒参考值相差(或偏差)越多而增加分数,来计算会话间隔评价分数。即,会话间隔评价分数越接近100点,就可以越好地评价对询问的回答。应注意,会话间隔评价分数可以随着会话间隔的时间长度越接近预定参考值而增加。
然后,在步骤sb16处,评价部110基于对询问的回答的音高评价分数与会话间隔评价分数来计算总评价分数。通过简单地将音高评价分数与会话间隔评价分数加在一起来计算总评价分数。替选地,可以通过首先为音高评价分数和会话间隔评价分数添加预定的权重、然后将这样加权后的音高评价分数和会话间隔评价分数相加在一起来计算总评价分数。
然后,在步骤sb17处,评价部110在显示部112上显示对询问的回答的评价的结果(评价结果),此后,该处理回到图2的步骤sa21。更具体地,在显示部112上仅显示作为评价结果的总评价分数。因而,能够以客观方式依据评价分数来检查对询问的回答的评价。应注意,音高评价分数和会话间隔评价分数可以独立地显示在显示部112上,而不是仅显示总评价分数。
另外,作为对询问的回答的评价分数的显示,不仅可以在显示部112上显示评价分数的数值,还可以显示与评价分数相对应的图形、符号或标记(比如,照明或动画)。另外,可以以除了如上所述那样视觉地显示在显示部112的屏幕上外的任意其它适当方式来指示或通知对询问的回答的评价结果。例如,在会话评价装置10应用于便携式终端的情况下,可以使用振动功能或发声功能来以与评价分数相对应的振动模式来使会话评价装置10振动或者生成与评价分数相对应的可听声音来通知评价结果。
另外,在会话评价装置10应用于诸如毛绒玩具或机器人的玩具的情况下,对询问的回答的评价结果可以通过毛绒玩具或机器人的动作(姿势)来指示或通知。例如,如果评价分数较高,则可以使得毛绒玩具或机器人做出开心的动作,而如果评价分数较低,则可以使得毛绒玩具或机器人做出失望的动作。以该方式,可以以更令人愉快的方式执行基于对询问的回答的会话训练。
以下将参考附图更详细地描述由本实施例中的评价部110执行的音高调整(在步骤sb12和sb13处)。更具体地,以下将在将询问与回答之间的音高差值在一个八度音的范围内(因而,将不执行音高调整)的情况和询问与回答之间的音高差值不在一个八度音的范围内(因而,将执行音高调整)的情况进行比较的同时描述音高调整。
图4和图5均是示出所输入的询问的语音与所输入的对询问的回答的语音之间的关系的示图,其中,纵轴表示音高,而横轴表示时间。更具体地,图4示出了在询问与回答之间的音高差值在一个八度音范围内的情况下的关系,而图5示出了在询问与回答之间的音高差值没有在一个八度音范围内的情况下的关系。
另外,在图4和图5中,由附图标记q指示的实线示意性地以直线示出了询问的音高变化。附图标记dq指示询问q中的特定部分的音高(例如,询问q中的话语结尾部分的最高音高)。另外,在图4中,由附图标记a指示的实线示意性地以直线示出了对询问q的回答的音高变化,附图标记da指示回答a的平均音高。附图标记d指示询问q的音高dq与回答a的音高da之间的差值。另外,在图4中,附图标记tq指示询问的结束时间,附图标记ta指示回答的开始时间。此外,附图标记t指示tq与ta之间的时间间隔,即,从询问q的结束到回答a的开始之间的时间间隔。
在图5中,由附图标记a’指示的虚线以直线示出了在经历了偏移一个八度音的音高调整之后的回答a的音高变化。附图标记da’指示这样的调整过音高后的回答a’的平均音高。附图标记d’指示询问的音高dq与调整过音高后的回答a’的平均音高da’之间的差值。
在图4的所示示例中,音高差值d在一个八度音(即,1200音分)范围内,从而不需要音高调整。因此,在步骤sb11处计算音高差值d之后,在步骤sb14处基于通过从询问q的音高dq中减去回答a的音高da而获得的音高差值来计算音高评价分数,而没有执行步骤sb13。由于回答a的音高da低于询问q的音高dq,因此在这种情况下的音高差值是正(加号)值,因而与差值d相同。
另一方面,在图5的所示示例中,由于音高差值d超过一个八度音(1200音分),因此需要音高调整。在图5的所示示例中,如在具有较高自然语音的一个人说出询问q而具有比说出询问q的人的自然语音低一个八度音以上的自然语音的另一人说出回答的情况下一样,回答a的音高远远低于询问q的音高。因此,即使当两个人以相同音高说出相同语音时,如果两个人各自的自然语音之间存在一个八度音以上的音高差,则只要是利用未经调整的音高差对回答进行评价,回答的评价分数就会由于各自的自然语音的这种音高差而极大地不同,从而使得对回答的评价可能不合理。因此,在本实施例中,在图3的步骤sb13处通过将回答a的音高da向上偏移一个八度音r来将回答a的音高da调整为回答a’的音高da’。因此,询问q的音高dq与这样调整后的回答的音高da’之间的音高差值d’减小到一个八度音(1200音分)范围内。以该方式,能够使人的语音机制的影响最小化,从而计算适当的音高评价分数。应注意,音高调整可以通过如下方式执行:以一个八度音接一个八度音的方式将回答的音高向下偏移,而不是如上那样以一个八度音接一个八度音的方式将回答的音高向上偏移。
以下将参照附图更详细地描述在由本实施例中的评价部110(在步骤sb14处)执行的音高评价分数计算。图6是说明用于计算音高评价分数的方案或规则的示图,其中,横轴表示询问与回答之间的音高差值d,而纵轴表示音高评价分数。在图6中,附图标记d0表示音高差值的参考值(例如,700音分)。图6中的实线指示用于音高评价分数计算的基准线。用于音高评价分数计算的基准线被表示为直线,以使得随着音高差值d在音高差值d相对于音高参考值增大的方向上或者在音高差值d相对于音高参考值d0减小的方向上偏离音高参考值d0更多,音高评价分数减小。更具体地,以在距基准值d0预定范围之外(即,在从下限值dl到上限值dh的范围之外)音高评价分数变为零的方式,来设置用于音高评价得分计算的基准线。因此,如果假设例如当音高差值等于参考值d0时将音高评价分数计算为满分(100点),则音高评价得分随着音高差值在预定范围(即,从下限值dl到上限值dh的范围)内与参考值d0偏差更多而减小,并且当音高差值在预定范围之外(即,在从下限值dl到上限值dh的范围之外)时,将音高评价分数计算为零。应注意,尽管在图6中将用于音高评价分数计算的参考线示出为相对于与纵轴平行的虚拟直线具有线对称形状并且经过参考值d0,但是用于音高评价分数计算的基准线不一定具有线对称形状。例如,用于音高评价分数计算的基准线的直线可以在参考值d0之前的直线的区域与在参考值d0之后的直线的区域之间不同地(以不同角度)倾斜。另外,用于音高评价分数计算的基准线不一定是直线,也可以是曲线。此外,用于音高评价得分计算的基准线可以具有非线性形状而不是线性形状。
假设这样一种情况:在通过使用图6所示的用于音高评价分数计算的基准线来计算音高评价分数时,通过从询问q的音高中减去回答a的音高而算出的音高差值为“dx”。在该情况下,与根据用于音高评价分数计算的基准线而计算得到的值dx相对应的sdx变为加入点或减去点。因此,假设初始音高评价分数为零点,则可以通过将加入点与初始零点分数相加或者从初始零点分数减掉减去点来计算音高评价分数。
优选的是,将音高差值的参考值d0设置为使得对询问的回答具有最佳音高。在本实施例中,如上所述那样将参考值d0设置为700音分,这是使得回答的音高比询问的音高低了约五度(即,使得回答的音高与询问的音高为协和音程关系)的音高差值。即,优选的是,参考值d0被设置为使得回答的音高与询问的音高具有协和音程关系的音高差值。由于一般在人与人之间的会话中,当一个人对另一人提出的询问给出完全肯定的回答并且通过从询问的音高中减去回答的音高而算出的音高差值更接近协和音程关系时,可以使得回答是给予良好、舒服且安心的印象的更适当的回答。因此,通过从询问的音高减去回答的音高而算出的音高差值越接近参考值,就可以越好地评价对询问的回答。此外,应注意,回答的音高与询问的音高的关系不一定限于回答的音高比询问的音高低了约五度,可以是除了所述的回答音高比询问音高低了约五度之外的任何其它协和音程关系,比如纯八度、纯五度、纯四度、大三度或小三度、大六度或小六度。另外,回答的音高与询问的音高的关系不一定限于这样的协和音程关系,并且可以是非协和音程关系,这是因为凭经验知道某些非协和音程关系能够赋予良好印象。
以下将参照附图更详细地描述由本实施例中的评价部110执行的会话间隔分数计算(在步骤sb15处)。图7是说明用于计算会话间隔评价分数的方案或规则的具体示例的示图,其中,横轴表示会话间隔的时间长度t,纵轴表示会话间隔评价分数。在图7中,附图标记t0指示会话间隔评价(也称为“参考时间间隔”)的参考值(例如,180毫秒)。图7中的实线以直线表示用于会话间隔评价分数计算的基准线,以使得随着会话间隔的时间长度t在时间长度t增大的方向上或在时间长度t减小的方向上与参考值to偏离越多,会话间隔评价分数减小。更具体地,以在距参考值t0预定范围之外(即,在从下限值tl到上限值th的范围之外)会话间隔评价分数变为零,来设置用于会话间隔评价分数的基准线。因此,假设:当会话间隔的时间长度l等于参考值t0时将会话间隔评价分数计算为满分(100点),会话间隔评价分数随着时间长度tl在预定范围(即,从下限值tl到上限值th的范围)内与参考值t0偏差更多而减小,以及当时间长度tl在预定范围之外(即,在从下限值tl到上限值th的以外的范围)时,将会话间隔评价分数计算为零。应注意,在图7中将用于会话间隔评价分数计算的基准线示出为相对于与纵轴平行的虚拟直线具有线对称形状并且经过参考值t0,而用于会话间隔评价分数计算的基准线不一定具有线对称形状。例如,用于会话间隔评价分数的基准线的直线可以在参考值t0之前的直线的区域与在参考值t0之后的直线的区域之间不同地(以不同角度)倾斜。另外,用于会话间隔评价分数计算的基准线不一定是直线,也可以是曲线。另外,用于会话间隔评价分数计算的基准线除了线性形状外还可以具有非线性形状。
假设这样一种情况:在通过使用图7所示的用于会话间隔评价分数计算的基准线来计算会话间隔评价分数时,从询问q到回答a的会话间隔的时间长度为“tx”。在这种情况下,与根据用于会话间隔评价分数计算的基准线而计算出的值tx相对应的stx变为加入点或减去点。因此,假设初始会话间隔评价分数为零点,则可以通过将加入点与初始零点分数相加或者从初始零点分数减去减去点来计算会话间隔评价分数。
优选的是,将在从询问的结束到回答的开始的区域中的最佳时间长度设置为会话间隔的时间长度的参考值t0。在本实施例中,参考值t0被设置为例如如上所述的180毫秒,这是因为180毫秒是使得对询问的回答给会话参与方良好、舒服且安心的印象的会话间隔时间长度。因此,从询问的结束到回答的开始的会话间隔的时间长度越接近参考值t0,就可以越好地评价对询问的回答。
音高差值的参考值d0和会话间隔时间长度的参考值t0(即,参考时间间隔t0)中的每一个均不一定限于用于评价对询问的完全肯定的回答的参考值。即,可以根据对询问的特定类型的回答(比如,具有如愤怒反应或冷淡反应的特殊感受的回答)来改变会话间隔时间长度的参考值t0,使得可以根据回答类型更加适当地评价回答。在评价愤怒的回答时,例如,可以使得会话间隔时间长度的参考值t0比用于完全肯定的回答的参考值(180毫秒)更短。以该方式,可以评价对询问的回答的愤怒程度。另外,在评价冷淡的回答时,可以使得会话间隔时间长度的参考值t0比用于完全肯定的回答的参考值(180毫秒)更长。以该方式,可以评价对询问的回答的冷淡程度。
另外,可以与上述的各种类型的回答相关联地提供音高差值的多个前述参考值d0和会话间隔时间长度的多个参考值t0。例如,可以分别提供用于完全肯定的回答的参考值(参考时间间隔)、用于愤怒回答的参考值(参考时间间隔)和用于冷淡回答的参考值(参考时间间隔)。
另外,可以将音量和音高评价为询问和回答的语音特性。更具体地,将询问和回答的各自的音量获取为询问和回答的语音特性,计算询问的音量与回答的音量之间的差值,并且基于所算出的差值与预定参考值相差多少来计算音量评价分数。将这样算出的音量评价分数与上述的音高评价分数和会话间隔评价分数相加,从而计算总评价分数。也可以根据回答的类型来改变音量差值的上述参考值(参考音量值),或者可以与不同类型的回答相关联地提供多个这样的参考音量值。例如,对于冷淡的回答,使得参考音量值比针对完全肯定的回答的参考音量值更低,从而可以评价对询问的回答的冷淡程度。
另外,在重复地输入询问的语音与回答的语音并且针对各个回答而计算出评价分数的情况下,可以在图3的上述步骤sb14、sb15和sb16处将针对各个回答而算出的评价分数相加。
如上详述的那样,根据本发明的第一实施例的会话评价装置10可以通过将对询问的回答的语音特性与询问的语音特性进行比较来评价对询问的回答的语音特性。因此,利用会话评价装置10,能够以客观方式检验将被给予至会话参与方的回答的印象。由于作为询问和回答各自的语音特性的询问的音高和回答的音高与给会话参与方的印象具有密切关系,因此会话评价装置10可以通过经由与询问的音高进行比较而对回答的音高进行评价,来执行对询问的回答的可靠性高的评价。除了音高之外,作为询问和回答各自的另一语音特性的从询问的结束到回答的开始的时间间隔(会话间隔)也与会给予会话参与方的印象具有密切关系。因此,会话评价装置10可以通过不仅评价询问和回答的音高而且评价询问与回答之间的会话间隔来对针对询问的回答执行甚至更加可靠的评价。
应注意,在会话评价装置10的第一实施例应用于诸如智能电话或便携式电话的终端装置的情况下,终端装置可以执行语音的输入和语音特性的获取,并且可以通过经由网络与终端装置连接的外部服务器来执行会话的评价。替选地,终端装置可以执行语音的输入,并且外部服务器可以执行语音特性的获取以及会话的评价。
<第二实施例>
接下来,将描述本发明的第二实施例。图8是示出了根据本发明的第二实施例的会话评价装置10的构造的框图。以上已关于如下这样一种情况描述了第一实施例:经由单语音输入部102的麦克风输入一个人响应于另一人说出的询问而说出的回答,然后评价所输入的回答。然而,在第二实施例中,输入并评价一个人响应于扬声器134通过话音合成而再现的询问而说出的回答。应注意,在第二实施例中的具有与会话评价装置10的第一实施例中元件的功能相似的元件由与第一实施例中的附图标记相同的附图标记指示,并且这里将不进行详细描述以避免不必要的重复。
会话评价装置10的第二实施例包括询问选择部130、询问再现部132和询问数据库124。应注意,在会话评价装置10的第二实施例中未设置图1所示的判定部108和语言数据库122。这是因为在会话评价装置10的第二实施例中,选择并且经由扬声器134可听地再现具有预定音高的询问的语音数据(询问语音数据),因此不需要确定话语是否是询问。
询问数据库125预先存储了多个询问语音数据(即,多个询问的语音数据)。这种询问语音数据是由模特儿说出的各种语音的记录。对于例如为wav或mp3格式的每条询问语音数据,预先确定当以标准方式再现时的每个波形样本(每个波形周期)的音高以及特定部分(代表性部分)的代表性音高(例如,话语结尾部分的最高音高),并且将指示特定部分的代表性音高的数据与语音数据相关联地预先存储在询问数据库124中。应注意,“以标准方式再现”是指在与记录语音数据时的条件相同的条件下(即,在相同音高、相同音量、相同说活速率等下)再现语音数据。
应注意,由多个人a、b、c…中的各个人说出的相同内容的询问语音可以预先存储在询问数据库124中作为询问语音数据。例如,这些人a、b、c...可以是名人(知名人士)、天才、歌手等,并且询问语音数据与这样的不同的人相关联地预先存储在询问数据库124中。为了如上所述那样将询问语音数据与这样的不同的人相关联地预先存储在询问数据库124中,询问语音数据可以经由存储介质(比如,存储卡)预先存储在询问数据库124中,或者替选地,会话评价装置10可以配备有网络连接功能,以使得可以将询问语音数据从特定服务器下载到询问数据库124中。另外,可以免费地或付费地从存储卡或服务器获取询问语音数据。
另外,可以做出这样的配置:用户可以经由操作输入部等选择哪个人应该是询问语音数据的模特。替选地,可以针对各种不同的条件(日期、周、月等)中的每一个而随机地确定哪个人应该是询问语音数据的模特。作为另一替选,经由语音输入部102的麦克风记录(或者经由另一装置转换成数据)的用户自身的语音以及用户的家庭成员和熟人的语音可以预先存储在数据库中作为询问话音数据。因此,当以与用户关系密切的人的语音说出询问时,用户会感觉如同与关系亲密的人进行对话一样。
询问选择部130从询问数据库124选择一条询问语音数据,并且读出并获取所选择的询问语音数据和与该所选择的询问语音数据相关联的代表性音高数据。询问选择部130将所获取的询问语音数据提供至询问再现部132,并且将所获取的代表性音高数据提供至分析部106。询问选择部130可以根据任意期望规则来从多个询问语音数据当中选择一个询问语音数据;例如,询问选择部130可以以随机方式或经由未示出的操作部选择一条询问语音数据。询问再现部132经由扬声器134可听地再现从询问选择部130提供的询问语音数据。
接下来,将给出关于会话评价装置10的第二实施例的操作的描述。图9是示出在会话评价装置10的第二实施例中所执行的处理的流程图。首先,在步骤sc11处,询问选择部130从数据库124中选择询问。然后,在步骤sc12处,询问选择部130获取所选询问的语音数据和特性数据(音高数据)。询问选择部130将所获取的询问语音数据提供至询问再现部132,并且将所获取的音高数据提供至分析部106。然后,分析部106的第一音高获取部106a获取从询问选择部130提供的代表性音高数据,并且将所获取的代表性音高数据提供至评价部110。
在紧接着的步骤sc13处,询问再现部132经由扬声器134可听地再现所选择的询问语音数据。然后,在步骤sc14处,进行关于询问的再现是否已结束的判定。如果根据在步骤sc14处的判定确定了询问的再现已结束,则开始对会话间隔的时间长度进行计时。此后,以与图2所示的回答说出处理(步骤sa17至sa21)类似的方式,在步骤sc16至sc20中执行回答说出处理。
在会话评价装置10的该第二实施例中,经由扬声器134可听地再现询问的语音,并且一旦经由语音输入部102的麦克风输入对询问的回答的语音,回答的评价值(分数)就显示在显示部112上。由于在该实施例中经由扬声器134可听地再现询问,因此即使在没有说出询问的会话参与方的情况下,用户也可以自己对自己的询问进行回答。另外,由于经由扬声器134可听地再现了询问,因此,经由语音输入部102的麦克风仅输入回答就足矣,这可以消除判定从语音输入部102输入的话语是否是询问的需求。
应注意,分析部106的第一音高获取部106a可以被构造为:分析在无需话音输入部102的介入的情况下由询问选择部130选择的询问语音数据,计算以标准方式再现的询问语音数据的平均音高,然后向评价部110提供指示作为代表性音高数据的所算出的平均音高的数据。这样的构造可以消除将代表性音高数据与询问语音数据相关联地预先存储在数据库124中的需要。
在上述的第二实施例中,语音输入部102和语音获取部104一起起到接收回答的语音的声音信号的接收部的作用,并且询问选择部130和第一音高获取部106a一起起到接收与用于对询问的语音进行合成的数据相关的语音合成相关数据(上述的存储的代表性音高数据或所选择的询问语音数据)的接收部的作用。
作为第二实施例的变型,与上述实施例相反,可以经由语音输入部102的麦克风输入询问的语音,并且可以经由扬声器134通过语音合成可听地再现对询问的回答的语音。在这样的情况下,语音输入部102和语音获取部104一起起到接收询问的语音的声音信号的接收部的作用,并且询问选择部130和第二音高获取部106b一起起到接收与用于对回答的语音进行合成的数据相关的语音合成相关数据(存储的代表性音高数据或所选择的回答语音数据)的接收部的作用。
<第三实施例>
接下来,将描述本发明的第三实施例。图10是示出根据本发明的第三实施例的会话评价装置10的构造的框图。以上已经关于经由单语音输入部102的麦克风输入两个人之间的会话的语音的情况来描述了第一实施例。然而,在第三实施例中,经由两个话音输入部102a和102b各自的麦克风分别地输入两个人之间的会话的语音。应注意,具有与会话评价装置10的第一实施例中元件的功能类似的功能的第三实施例中的元件由与第一实施例中的附图标记相同的附图标记指示,并且这里将不进行详细描述以避免不必要的重复。
在会话评价装置10的第三实施例中未设置图1所示的判定部108和语言数据库122。由于会话评价装置10的第三实施例以经由单独的(仅询问和仅回答的)语音输入部102a和102b输入各个人的语音的这种方式来构造,因而,不需要执行关于话语是否是询问的特定判定操作,只要说出询问的人使用仅询问的语音输入部102a并且输说出回答的人使用仅回答的语音输入部102b即可。在第三实施例中,语音输入部102a和102b以及语音获取部104一起起到被配置为单独地接收询问的语音的声音信号和回答的声音信号的接收部的作用。
接下来,将给出关于会话评价装置10的第三实施例的操作的描述。图11是示出在会话评价装置10的第三实施例中所执行的处理的流程图,除了图2的流程图中的用于判定话语是否是询问的操作未包括在图11的流程图中外,其它部分均类似于图2的流程图。另外,图11所示的步骤sd11、sd12和sd13类似于图2所示的步骤sa11、sa12和sa15,只不过图2的步骤sa11、sa12和sa15处出现的词“话语”被图11中的词“询问”所替代。图11中所示的步骤sd14至sd19类似于图2所示的步骤sa16至sa21。
在会话评价装置10的该第三实施例中,一旦经由语音输入部102a的麦克风输入询问的语音,就经由其它语音输入部102b的麦克风输入对询问的回答的语音。因此,通过分析部106和评价部110对针对所输入的询问的语音的所输入的回答的语音进行评价,并且在显示部112上显示所得到的回答的评价值(分数)。由于经由语音输入部102a和102b各自的麦克风分别地输入询问和回答,因此会话评价装置10的第三实施例可以消除对从语音输入部102a和102b中的每一个输入的话语是否是询问进行判定的需要。
- 还没有人留言评论。精彩留言会获得点赞!