车载用语音识别装置以及车载设备的制作方法
本发明涉及对说话者的话语进行识别的车载用语音识别装置以及基于识别的结果进行动作的车载设备。
背景技术:
当车内有多个说话者的情况下,必须防止语音识别装置将某个说话者对其他说话者说出的话语误识别成是对本装置说出的话语的情况。因此,例如在专利文献1中揭示了一种语音识别装置,该语音识别装置等待接收用户说出的特定话语或用户进行的特定动作,若检测出该特定的话语等,则开始识别用于操作作为操作对象的设备的指令。
现有技术文献
专利文献
专利文献1
日本专利特开2013-80015号公报
技术实现要素:
发明所要解决的技术问题
根据现有的语音识别装置,能够防止语音识别装置违背说话者的意图而将话语识别成指令的情况,由此,能够防止作为操作对象的设备的误操作。另外,在人与人之间的一对多的对话中,说话者一般先呼叫名字等确定对话对象,然后再说话,因此,通过在对语音识别装置说出类似于呼叫的特定话语等之后再说出指令,能够在说话者与该装置之间实现自然的对话。
然而,在专利文献1所记载的语音识别装置中,在车内空间内说话者只有驾驶员的情况下,即使明显是对该装置说出的指令的情况下,说话者也必须在说出指令之前说出特定话语等,使人感到麻烦。在这种情况下,与语音识别装置的对话接近与人进行的一对一的对话,因此,存在说话者对于要对语音识别装置说出类似于呼叫的特定话语等这一点感到不自然的问题。
即,在现有的语音识别装置中,无论车内有多少人,说话者都必须对语音识别装置说出特定话语或进行特定动作,因此,存在说话者会感到对话不自然和繁琐的操作性问题。
本发明正是为了解决上述问题而完成的,其目的在于同时实现防止误识别和提高操作性这两点。
解决技术问题所采用的技术方案
本发明所涉及的车载用语音识别装置具有:语音识别部,该语音识别部识别语音,并输出识别结果;判断部,该判断部判断车内的说话者的人数为多人还是一人,并输出判断结果;识别控制部,该识别控制部根据来自语音识别部及判断部的输出结果,在判断为说话者的人数为多人的情况下,采用在接收到开始说话的指示之后所说出的语音的识别结果,在判断为说话者的人数为一人的情况下,可采用在接收到开始说话的指示之后所说出的语音的识别结果,也可采用在未接收到开始说话的指示时所说出的语音的识别结果。
发明效果
根据本发明,在车内有多个说话者的情况下,采用在接收到开始说话的指示之后所说出的语音的识别结果,因此,能够防止将某个说话者对其他说话者说出的话语误识别成指令的情况。另一方面,在车内有一个说话者的情况下,可采用在接收到开始说话的指示之后所说出的语音的识别结果,也可采用在未接收到开始说话的指示时所说出的语音的识别结果,因此,说话者在说出指令之前无需进行开始说话的指示。因此,能够消除对话的不自然和繁琐,能够提高操作性。
附图说明
图1是示出了本发明的实施方式1所涉及的车辆设备的结构例的框图。
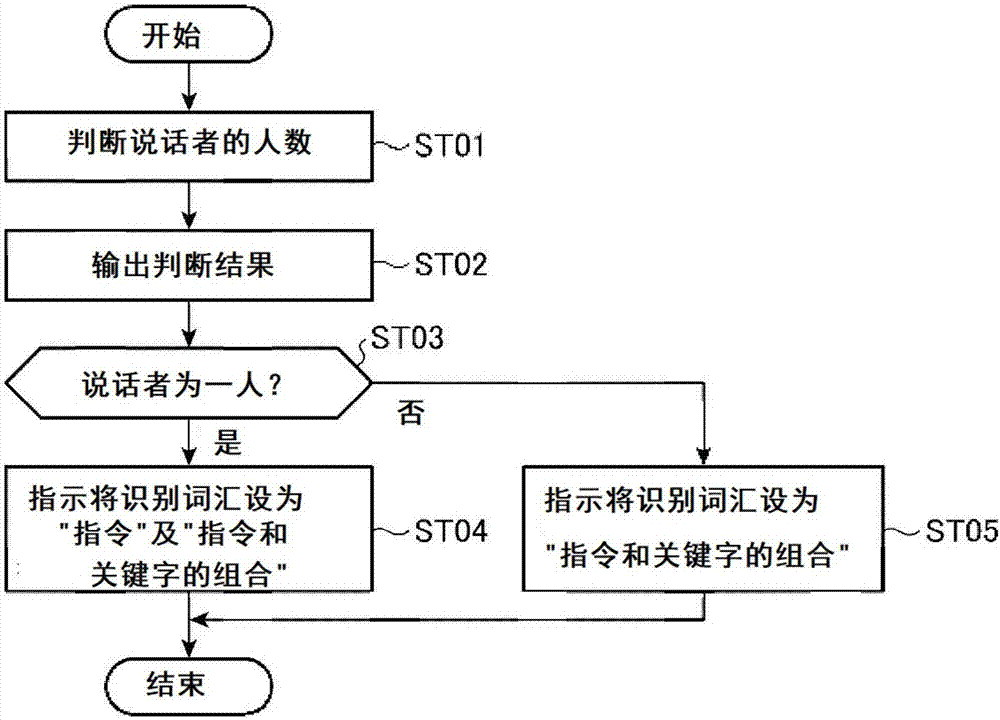
图2是示出了实施方式1所涉及的车载设备中根据车内说话者为一人还是多人来切换语音识别部中的识别词汇的处理的流程图。
图3是示出了实施方式1所涉及的车载设备中识别说话者的语音并根据识别结果来进行动作的处理的流程图。
图4是示出了本发明的实施方式2所涉及的车辆设备的结构例的框图。
图5是示出了实施方式2所涉及的车载设备所进行的处理的流程图,其中,图5(a)是判断为车内说话者为多人的情况下的处理,图5(b)是判断为车内说话者为一人的情况下的处理。
图6是本发明各个实施方式所涉及的车载设备及其周边设备的主要硬件结构图。
具体实施方式
下面,为了更详细地说明本发明,根据附图对本发明的实施方式进行说明。
实施方式1
图1是表示本发明的实施方式1所涉及的车载设备1的结构例的框图。该车载设备1具有语音识别部11、判断部12、识别控制部13以及控制部14。语音识别部11、判断部12及识别控制部13构成语音识别装置10。另外,车载设备1连接有语音输入部2、摄像机3、压力传感器4、显示部5及扬声器6。
在图1的示例中,示出了将语音识别装置10组装入车载设备1的结构,但也可以与车载设备1相独立地构成语音识别装置10。
车载设备1根据来自语音识别装置10的输出,在车内说话者有多人的情况下,根据接收到说话者说出的特定指示之后的话语内容进行动作。另一方面,在车内说话者为一人的情况下,无论是否有该指示,车载设备1都根据说话者的话语内容进行动作。
该车载设备1例如是导航装置或音频装置等安装于车辆中的设备。
显示部5例如是lcd(liquidcrystaldisplay:液晶显示器)或者有机el(electroluminescence:电致发光)显示器等。另外,显示部5可以是由lcd或有机el显示器与触摸传感器构成的显示一体型触摸面板,也可以是平视显示器。
语音输入部2读取说话者所说出的语音,利用例如pcm(pulsecodemodulation:脉冲编码调制)对该语音进行a/d(analog/digital:模拟/数字)转换,并输入至语音识别装置10。
语音识别部11具有“用于操作车载设备的指令(下面称为‘指令’)”和“关键字与指令的组合”,来作为识别词汇。而且,根据后述的识别控制部13的指示切换识别词汇。“指令”中例如包含“目的地设定”、“设施检索”以及“收音机”等识别词汇。
“关键字”是指用于对语音识别装置10明确指示说话者开始说出指令的词汇。而且,在本实施方式1中,说话者说出关键字相当于上述的“说话者说出的特定指示”。“关键字”可以是设计语音识别装置10时预先设定的词汇,也可以是说话者对语音识别装置10设定的词汇。例如“关键词”被设定为“三菱”的情况下,“关键字与指令的组合”成为“三菱、目的地设定”。
另外,语音识别部11也可以将各个指令以外的其它措辞作为识别对象。例如作为“目的地设定”的其它措辞,可以将“设定目的地”以及“想要设定目的地”等作为识别对象。
语音识别部11接收由语音输入部2数字化后的语音数据。而且,语音识别部11从该语音数据中检测出与说话者说出的内容相当的语音区间(下面记载为“话语区间”)。接着,提取出该话语区间的语音数据的特征量。然后,语音识别部11将由后述的识别控制部13所指示的识别词汇作为识别对象,对该特征量进行识别处理,将识别结果输出至识别控制部13。作为识别处理的方法,使用例如hmm(hiddenmarkovmodel:隐马尔可夫模型)法之类的一般方法即可,因此省略详细说明。
另外,语音识别部11在预先设定的期间内,对从语音输入部2接收到的语音数据检测出话语区间,进行识别处理。“预先设定的期间”中包含例如车载设备1启动的时段、从语音识别装置10启动或重启之后到语音识别装置10结束或停止为止的时段、或者语音识别部11启动的时段等期间。在本实施方式1中,说明了语音识别部11在从语音识别装置10启动之后到结束为止的时段内进行上述处理的情况。
另外,在本实施方式1中,以指令名称等具体的字符串为例对从语音识别部11输出的识别结果进行说明,但是例如也可以是由数字表示的id等,只要是能够在各指令间加以区分,输出的识别结果可以是任意形态。在下述的实施方式中也一样。
判断部12判断车内说话者为多人还是一人。然后,将该判断结果输出至后述的识别控制部13。
在本实施方式1中,“说话者”是指可能会因语音而使语音识别装置10和车载设备1误动作的乘员,因此其中也包含婴儿和动物等。
例如判断部12获取由设置于车内的摄像机3拍摄的图像数据,分析该图像数据,判断车内的乘客人数为多人还是一人。另外,判断部12也可获取由设置于各个坐席的压力传感器4检测出的各个坐席的压力数据,根据该压力数据来判断是否有乘客坐在坐席上,从而判断车内的乘客人数为多人还是一人。判断部12将乘客人数判断为说话者人数。
上述判断方法可以使用公知技术,因此省略详细说明。另外,判断方法并不仅限于上述方法。图1中虽然示出了使用摄像机3和压力传感器4这两者的结构,但是例如也可以是仅使用摄像机3的结构。
而且,在虽然车内的乘客人数为多人、但可能说话的人数为一人的情况下,判断部12可以将说话者人数判断为一人。
例如判断部12分析从摄像机3获取的图像数据,判断乘客醒着或者睡着了,将醒着的乘客人数计入说话者人数。另一方面,由于睡着的乘客不可能说话,因此,判断部12不将睡着的乘客人数计入说话者人数。
识别控制部13在从判断部12接收到的判断结果是“多人”的情况下,指示语音识别部11将识别词汇设为“关键字和指令的组合”。另一方面,识别控制部13在该判断结果是“一人”的情况下,指示语音识别部11将识别词汇设为“指令”和“关键字和指令的组合”这两者。
语音识别部11在使用“关键字和指令的组合”来作为识别词汇的情况下,如果话语语音是关键字和指令的组合就能成功识别,除此以外的话语语音会导致识别失败。另外,语音识别部11在使用“指令”作为识别词汇的情况下,只有话语语音仅为指令才能成功识别,除此以外的话语语音会导致识别失败。
因此,在车内说话者为一人的状况下当该说话者仅说出了指令或者说出了关键字和指令的组合时,语音识别装置10识别成功,车载设备1执行与指令相对应的动作。另一方面,在车内有多个说话者的状况下当某一个说话者说出关键字和指令的组合时,语音识别装置10识别成功,车载设备1执行与指令相对应的动作,当某一个说话者仅说出指令时,语音识别装置10识别失败,车载设备1不执行与指令相对应的动作。
另外,在后面的说明中,识别控制部13虽然如上所述那样对语音识别部11指示识别词汇,但是识别控制部13在从判断部12接收到的判断结果是“一人”的情况下,也可指示语音识别部11,使得语音识别部11至少识别出“指令”。
在判断结果是“一人”的情况下,除了如上所述以使用“指令”和“关键字和指令的组合”作为识别词汇且至少能够识别“指令”的方式来构成语音识别部11以外,例如还可以将语音识别部11构成为利用字识别(wordspotting)等公知技术从包含“指令”的话语中仅将“指令”作为识别结果输出。
识别控制部13在从判断部12接收到的判断结果是“多人”的情况下,若从语音识别部11接收到识别结果,则采用在指示开始说出指令的“关键字”之后所说出的语音的识别结果。另一方面,识别控制部13在从判断部12接收到的判断结果是“一人”的情况下,若从语音识别部11接收到识别结果,则无论有无指示开始说出指令的“关键字”,都采用说出的语音的识别结果。此处所说的“采用”是决定将某一识别结果作为“指令”输出至控制部14的情况。
具体而言,识别控制部13在从语音识别部11接收到的识别结果中包含“关键字”的情况下,识别控制部13从识别结果中删除与“关键字”相对应的部分,将“关键字”之后说出的与“指令”相对应的部分输出至控制部14。另一方面,在识别结果中不包含“关键字”的情况下,识别控制部13直接将与“指令”相对应的识别结果输出至控制部14。
控制部14进行与从识别控制部13接收到的识别结果相对应的动作,从显示部5或扬声器6输出该动作的结果。例如,在从识别控制部13接收到的识别结果是“便利店检索”的情况下,控制部14使用地图数据来检索位于本车位置周边的便利店,使检索结果显示于显示部5,并且使表示找到便利店这一意思的引导输出至扬声器6。作为识别结果的“指令”与动作之间的对应关系被预先设定在控制部14中。
接着,利用图2和图3所示的流程图和具体示例,对实施方式1的车载设备1的动作进行说明。另外,以将“关键字”设定为“三菱”为例进行说明,但并不仅限于此。在语音识别装置10启动的时段,设为车载设备1反复进行图2及图3所示的流程图的处理。
图2中示出了根据车内说话者为一人还是多人来切换语音识别部11中的识别词汇的流程图。
首先,判断部12根据从摄像机3或压力传感器4获取的信息,判断车内说话者的人数(步骤st01)。然后,将判断结果输出至识别控制部13(步骤st02)。
接着,在从判断部12接收到的判断结果是“一人”的情况(步骤st03为“是”)下,为了设置成无论是否从说话者接收到特定指示都能够操作车载设备1,识别控制部13指示语音识别部11将识别词汇设定为“指令”和“关键字和指令的组合”(步骤st04)。另一方面,在从判断部12接收到的判断结果是“多人”的情况(步骤st03为“否”)下,为了设置成仅在从说话者接收到特定指示时能够操作车载设备1,识别控制部13指示语音识别部11将识别词汇设定为“关键字和指令的组合”(步骤st05)。
图3示出了识别说话者的语音且进行与识别结果相对应的动作的流程图。
首先,语音识别部11接收语音输入部2读取由说话者说出的语音并进行a/d转换后的语音数据(步骤st11)。接着,语音识别部11对从语音输入部2接收到的语音数据进行识别处理,并对识别控制部13输出识别结果(步骤st12)。语音识别部11在识别成功的情况下,将识别出的字符串等作为识别结果输出,在识别失败的情况下,将识别失败这一意思作为识别结果输出。
接着,识别控制部13从语音识别部11接收识别结果(步骤st13)。然后,识别控制部13根据该识别结果判断语音识别是否成功,在判断为语音识别部11的语音识别失败的情况(步骤st14为“否”)下,什么也不做。
例如,假设在车内有多个说话者的状况下,说出了“a君,检索便利店”。在此情况下,在图2的处理中判断为车内的说话者人数为多人,语音识别部11所使用的识别词汇例如为“三菱,检索便利店”等“关键字和指令的组合”,因此,语音识别部11语音识别失败。然后,识别控制部13根据从语音识别部11接收到的识别结果判断为“识别失败”(步骤st11~步骤st14“否”)。其结果是,车载设备1不进行任何动作。
另外,例如,由于处于根据目前为止的对话内容可知说话者对话的对象明显是a君这样的状况,因此,即使在说话者省略了“a君”而说出“检索便利店”的情况下,语音识别部11也同样地语音识别失败,因此,车载设备1不进行任何动作。
另一方面,在识别控制部13根据从语音识别部11接收到的识别结果判断为语音识别部11语音识别成功的情况(步骤st14“是”)下,判断该识别结果中是否包含关键字(步骤st15)。而且,识别控制部13在该识别结果中包含关键字的情况(步骤st15“是”)下,从该识别结果中删除关键字,并输出至控制部14(步骤st16)。
之后,控制部14从识别控制部13接收删除了关键字后的识别结果,进行与所接收到的识别结果相对应的动作(步骤st17)。
例如假设在车内有多个说话者的状况下,说出了“三菱,检索便利店”。在此情况下,在图2的处理中判断为车内的说话者为多人,语音识别部11中的识别词汇为“关键字和指令的组合”。因此,语音识别部11成功识别包含关键字在内的上述话语,识别控制部13根据从语音识别部11接收到的识别结果来判断为“识别成功”(步骤st11~步骤st14“是”)。
然后,识别控制部13向控制部14输出从接收到的该识别结果“三菱,检索便利店”中删除了作为“关键字”的“三菱”后的“检索便利店”,来作为指令(步骤st15“是”、步骤st16)。之后,控制部14利用地图数据来检索位于本车位置周边的便利店,使检索结果显示于显示部5,并且使表示找到便利店这一意思的引导输出至扬声器6(步骤st17)。
另一方面,在该识别结果中不包含关键字的情况(步骤st15“否”)下,识别控制部13向控制部14直接输出该识别结果来作为指令。控制部14进行与从识别控制部13接收到的识别结果相对应的动作(步骤st18)。
例如假设在车内的说话者为一人的状况下,说出了“检索便利店”。在此情况下,在图2的处理中判断为车内的说话者为一人,语音识别部11中的识别词汇为“指令”及“关键字和指令的组合”这两者。因此,语音识别部11中的识别处理成功,识别控制部13根据从语音识别部11接收到的识别结果来判断为“识别成功”(步骤st11~步骤st14“是”)。然后,识别控制部13向控制部14输出接收到的该识别结果“检索便利店”。之后,控制部14利用地图数据来检索位于本车位置周边的便利店,使检索结果显示于显示部5,并且使表示找到便利店这一意思的引导输出至扬声器6(步骤st17)。
例如假设在车内的说话者为一人的状况下,说出了“三菱,检索便利店”。在此情况下,在图2的处理中判断为车内的说话者为一人,语音识别部11中的识别词汇为“指令”及“关键字和指令的组合”这两者,因此,语音识别部11中的识别处理成功,识别控制部13根据从语音识别部11接收到的识别结果来判断为“识别成功”(步骤st11~步骤st14“是”)。在此情况下,由于识别结果中不仅包含指令还包含关键字,因此,识别控制部13从所接收到的识别结果“三菱,检索便利店”中删除不需要的“三菱”,向控制部14输出“检索便利店”。
如上所述,根据该实施方式1,语音识别装置10构成为具有:语音识别部11,该语音识别部11识别语音并输出识别结果;判断部12,该判断部12判断车内的说话者的人数为多人还是一人并输出判断结果;以及识别控制部13,该识别控制部13根据来自语音识别部11及判断部12的输出结果,在判断为说话者的人数为多人的情况下采用在接收到开始说话的指示后所说出的语音的识别结果,在判断为说话者的人数为一人的情况下既可以采用在接收到开始说话的指示后所说出的语音的识别结果,也可以采用未接收到开始说话的指示时所说出的语音的识别结果,因此,在车内有多个说话者的情况下,能够防止将某个说话者对其他说话者说出的话语误识别成指令的情况。另外,在车内的说话者仅有一人的情况下,由于说话者在说出指令之前无需说出特定的话语,因此,能够消除对话的不自然和繁琐,能够提高操作性。因此,能够实现如同人与人之间交流那样的自然对话。
另外,根据实施方式1,车载设备1构成为具有语音识别装置10和控制部14,该控制部14根据语音识别装置10所采用的识别结果来进行动作,因此,在车内有多个说话者的情况下,能够防止根据某个说话者对其他说话者说出的话语进行误动作的情况。另外,在车内的说话者仅有一人的情况下,由于说话者在说出指令之前无需说出特定的话语,因此,能够消除对话的不自然和繁琐,能够提高操作性。
根据实施方式1,判断部12在车内的乘客人数为多人但可能说话人数为一人的情况下,判断为说话者的人数为一人,因此,例如在驾驶者以外的乘客睡着的状态下,驾驶者无需说出特定的话语,就能够使车载设备1动作。
实施方式2
图4是表示本发明的实施方式2所涉及的车载设备1的结构例的框图。对于与实施方式1中说明的相同的结构,标注同一标号并省略重复说明。
实施方式2中,将用于明示说话者开始说出指令的“特定指示”设为“指示开始说出指令的手动操作”。车载设备1在车内的说话者为多人的情况下,根据在指示说话者开始说出指令的手动操作之后所说出的内容进行动作。另一方面,在车内的说话者为一人的情况下,无论是否有该操作,车载设备1都根据说话者的话语内容进行动作。
指示输入部7是接收说话者通过手动输入的指示的部件。例如,可以例举经由硬件的开关、组装入显示器的触摸传感器、或者遥控器来识别说话者的指示的识别装置。
指示输入部7若接收到用于指示开始说出指令的输入,则对识别控制部13a输出该开始说话的指示。
识别控制部13a在从判断部12接收到的判断结果是“多人”的情况下,若从指示输入部7接收到开始说出指令的指示,则对语音识别部11a通知开始说出指令。
然后,识别控制部13a采用在从指示输入部7接收到开始说出指令的指示之后从语音识别部11a接收到的识别结果,并对控制部14输出。另一方面,在未从指示输入部7接收到开始说出指令的指示的情况下,识别控制部13a不采用由语音识别部11a输出的识别结果,并将其废弃。即,识别控制部13a不对控制部14输出该识别结果。
识别控制部13a在从判断部12接收到的判断结果为“一人”的情况下,无论是否从指示输入部7接收到开始说话的指示,都采用从语音识别部11a接收到的识别结果,并对控制部14输出。
语音识别部11a无论车内的说话者的人数为一人或多人,都采用“指令”来作为识别词汇,从语音输入部2接收语音数据并进行识别处理,并将识别结果输出至识别控制部13a。在判断部12的判断结果为“多人”的情况下,因为通过识别控制部13a的通知来明示开始说出指令,因此,语音识别部11a能够提高识别率。
接下来,利用图5所示的流程图,对实施方式2的车载设备1的动作进行说明。另外,在本实施方式2中说明了如下情况:即,在语音识别装置10启动的时段,判断部12判断车内的说话者是否为多人,并将该判断结果输出至识别控制部13a。另外,说明了语音识别部11a在语音识别装置10启动的时段,无论是否有上述那样的开始说出指令的指示,都对从语音输入部2接收到的语音数据进行识别处理,并将识别结果输出至识别控制部13a。
图5(a)是表示判断部12判断为车内的说话者为多人的情况下的处理的流程图。假设在语音识别装置10启动的时段,车载设备1反复进行图5(a)所示的流程图的处理。
首先,识别控制部13a若从指示输入部7接收到开始说出指令的指示(步骤st21为“是”),则对语音识别部11a通知开始说出指令(步骤st22)。接着,识别控制部13a从语音识别部11a接收识别结果(步骤st23),根据该识别结果判断语音识别是否成功(步骤st24)。
然后,识别控制部13a在判断为“识别成功”的情况(步骤st24“是”)下,对控制部14输出识别结果。之后,控制部14进行与从识别控制部13a接收到的识别结果相对应的动作(步骤st25)。另一方面,识别控制部13a在判断为“识别失败”的情况(步骤st24“否”)下,不进行任何动作。
识别控制部13a在未从指示输入部7接收到开始说出指令的指示的情况(步骤st21“否”)下,即使从语音识别部11a接收到识别结果,也废弃该识别结果。即,即使语音识别装置10识别出由说话者说出的语音,车载设备1也不进行任何动作。
图5(b)是表示判断部12判断为车内的说话者为一人的情况下的处理的流程图。假设在语音识别装置10启动的时段,车载设备1反复进行图5(b)所示的流程图的处理。
首先,识别控制部13a从语音识别部11a接收识别结果(步骤st31)。接着,识别控制部13a根据该识别结果来判断语音识别是否成功(步骤st32),在判断为“识别成功”的情况下,对控制部14输出该识别结果(步骤st32“是”)。之后,控制部14进行与从识别控制部13a接收到的识别结果相对应的动作(步骤st33)。
另一方面,识别控制部13a在判断为“识别失败”的情况(步骤st32“否”)下,不进行任何动作。
如上所述,根据该实施方式2,语音识别装置10构成为具有:语音识别部11a,该语音识别部11a识别语音并输出识别结果;判断部12,该判断部12判断车内的说话者的人数为多人还是一人并输出判断结果;以及识别控制部13a,该识别控制部13a根据语音识别部11a及判断部12的输出结果,在判断为说话者的人数为多人的情况下采用在接收到开始说话的指示后所说出的语音的识别结果,在判断为说话者的人数为一人的情况下既可以采用在接收到开始说话的指示后所说出的语音的识别结果,也可以采用未接收到开始说话的指示时所说出的语音的识别结果,因此,在车内有多个说话者的情况下,能够防止将某个说话者对其他说话者说出的话语误识别成指令的情况。另外,在车内的说话者仅有一人的情况下,由于说话者在说出指令之前无需进行特定的动作,因此,能够消除对话的不自然和繁琐,能够提高操作性。因此,能够实现如同人与人之间交流那样的自然对话。
另外,根据实施方式2,车载设备1构成为具有语音识别装置10和控制部14,该控制部14根据语音识别装置10所采用的识别结果来进行动作,因此,在车内有多个说话者的情况下,能够防止根据某个说话者对其他说话者说出的话语进行误动作的情况。另外,在车内的说话者仅有一人的情况下,由于说话者在说出指令之前无需进行特定的动作,因此,能够消除对话的不自然和繁琐,能够提高操作性。
实施方式2中也与上述实施方式1相同,判断部12在车内的乘客人数为多人但可能说话的人数为一人的情况下,能够判断为说话者的人数为一人,因此,例如在驾驶者以外的乘客睡着的状况下,驾驶者无需进行特定的动作,就能够使车载设备1动作。
接着,说明语音识别装置10的变形例。
在图1所示的语音识别装置10中,语音识别部11无论车内的说话者为多人或一人,都使用“指令”及“关键字和指令的组合”来作为识别词汇,对话语语音进行识别。语音识别部11仅将“指令”作为识别结果输出,或者将“关键字”和“指令”作为识别结果输出,或者将识别失败这一意思作为识别结果输出。
识别控制部13在从判断部12接收到的判断结果是“多人”的情况下,若从语音识别部11接收到识别结果,则采用在“关键字”之后所说出的语音的识别结果。
即,在从语音识别部11接收到的识别结果中包含“关键字”和“指令”的情况下,识别控制部13从识别结果中删除与“关键字”相对应的部分,将“关键字”之后说出的与“指令”相对应的部分输出至控制部14。另一方面,在从语音识别部11接收到的识别结果中未包含“关键字”的情况下,识别控制部13不采用该识别结果并将其废弃,且不对控制部14输出。
另外,在语音识别部11识别失败的情况下,识别控制部13不进行任何动作。
识别控制部13在从判断部12接收到的判断结果是“一人”的情况下,若从语音识别部11接收到识别结果,则无论是否有“关键字”,都采用所说出的语音的识别结果。
即,在从语音识别部11接收到的识别结果中包含“关键字”和“指令”的情况下,识别控制部13从识别结果中删除与“关键字”相对应的部分,将“关键字”之后说出的与“指令”相对应的部分输出至控制部14。另一方面,在从语音识别部11接收到的识别结果中不包含“关键字”的情况下,识别控制部13直接将与“指令”相对应的识别结果输出至控制部14。
另外,在语音识别部11识别失败的情况下,识别控制部13不进行任何动作。
接着,说明本发明的实施方式1、2所示的车载设备1及其周边设备的主要硬件结构示例。图6是本发明各个实施方式所涉及的车载设备1及其周边设备的主要硬件结构图。
车载设备1中的语音识别部11、11a、判断部12、识别控制部13、13a以及控制部14各自的功能利用处理电路来实现。即,车载设备1具有处理电路,该处理电路用于判断车内的说话者人数为多人还是一人,在判断为说话者人数为多人的情况下,采用在接收到开始说话的指示后所说出的语音的识别结果,在判断为说话者人数为一人的情况下,无论是否接收到开始说话的指示,都采用所说出的语音的识别结果,并进行与所采用的识别结果相对应的动作。处理电路是执行存储器102中所存储的程序的处理器101。处理器101可以是cpu(centralprocessingunit:中央处理器)中央处理装置、处理装置、运算装置、微处理器、微机、或者dsp(digitalsignalprocessor:数字信号处理器)等。另外,可以利用多个处理器101来实现车载设备1的各个功能。
语音识别部11、11a、判断部12、识别控制部13、13a、以及控制部14的各个功能通过软件、固件、或软件和固件的组合来实现。软件或固件以程序的形式来表述,并储存于存储器102。处理器101读取存储于存储器102的程序并执行,从而实现各部分的功能。即,车载设备1具有存储器102,该存储器102存储有在利用处理器101执行时,最终执行图2和图3所示的各个步骤或者图5所示的各个步骤的程序。这些程序也可以是在计算机中执行语音识别部11、11a、判断部12、识别控制部13、13a以及控制部14的步骤或方法的程序。存储器102例如可以是ram(randomaccessmemory:随机存取存储器)、rom(readonlymemory:只读存储器)、闪存、eprom(erasableprogrammablerom:可擦可编程只读存储器)、eeprom(electricallyeprom:电可擦可编程只读存储器)等非易失性或易失性的半导体存储器,也可以是硬盘、软盘等磁盘,也可以是迷你盘、cd(compactdisc:压缩光盘)、dvd(digitalversatiledisc:数字通用光盘)等光盘。
输入装置103是语音输入部2、摄像机3、压力传感器4及指示输入部7。输出装置104是显示部5和扬声器6。
此外,本发明在其发明范围内,能够自由组合各实施方式,或者将各实施方式的任意构成要素进行变形,或者也可以在各实施方式中省略任意的构成要素。
工业上的实用性
本发明所涉及的语音识别装置,在说话者的人数为多人的情况下,采用在接收到开始说话的指示之后所说出的语音的识别结果,在说话者的人数为一人的情况下,无论是否接收到指示都采用所说出的语音的识别结果,因此,适用于一直识别说话者的话语的车载用语音识别装置等。
标号说明
1车载设备,2语音输入部,3摄像机,4压力传感器,5显示部,6扬声器,7指示输入部,10语音识别装置,11、11a语音识别部,12判断部,13、13a识别控制部,14控制部,101处理器,102存储器,103输入装置,104输出装置。
- 还没有人留言评论。精彩留言会获得点赞!