控制方法以及控制装置与流程
本公开涉及通过语音来进行机器(设备)控制的控制方法、控制装置以及程序。
背景技术:
以往,已知通过语音进行机器控制的语音对话装置。然而,在以往的语音对话装置中,存在如下问题:误将在语音对话装置的周围进行的对话、从电视机和/或收音机等发出的语音等噪音识别为是用户对语音对话装置说的话,导致错误地使机器工作。
为了解决该问题,在专利文献1中公开了:进行用于确认语音的识别结果的确认说话,并在由用户说出表示肯定的单词时,进行识别出的内容的控制。另外,在专利文献2中公开了:对朝向控制对象机器的视线和/或手指动作等进行检测,仅在检测出这些动作的情况下,使基于语音对话的控制有效。
现有技术文献
专利文献
专利文献1:日本特开昭59-071927号公报
专利文献2:日本特开2007-121576号公报
技术实现要素:
发明所要解决的问题
然而,上述专利文献1、2需要进一步的改善。
用于解决问题的技术方案
本公开的一个技术方案中的方法是在控制装置中控制多个机器的方法,所述控制装置具备麦克风、传感器以及扬声器,所述麦克风收集所述控制装置周边的声音,所述传感器感测所述多个机器周边的人物,所述控制方法包括:从由所述麦克风收集到的声音中提取用于控制所述多个机器的说话;基于所述说话,确定所述多个机器中作为控制对象的对象机器;基于表示所述传感器感测到的结果的感测数据,判定是否要控制所述对象机器;在判定为要控制所述对象机器的情况下,针对所述说话生成用于对要控制所述对象机器这一情况进行确认的应答语音,使所述扬声器输出所述应答语音。
发明效果
根据本公开,能够在通过语音进行机器控制的情况下,结合用户的状态或者机器周围的状态,兼顾实现防止由语音的误识别所致的机器的误工作以及提高用户的便利性。
附图说明
图1是表示实施方式1中的语音对话装置的全貌的一例的图。
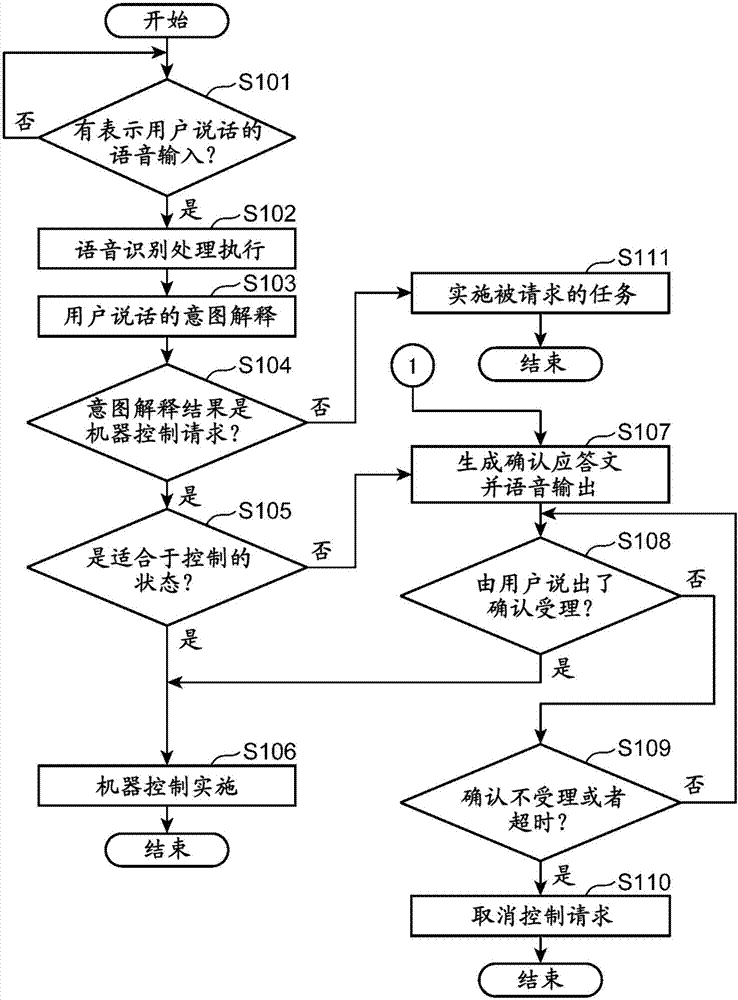
图2是表示实施方式1中的语音对话装置的处理流程的一例的图。
图3是表示实施方式1中的语音对话装置的处理流程的与图1至图2不同的一例的图。
图4是表示实施方式1中的语音对话装置的处理流程的与图1至图3不同的一例的图。
图5是表示实施方式2中的语音对话装置的全貌的一例的图。
图6是表示实施方式2中的语音对话装置的处理流程的一例的图。
图7是表示实施方式3中的语音对话装置的全貌的一例的图。
图8是表示实施方式3中的语音对话装置的处理流程的一例的图。
标号说明
100、200、300:语音对话装置
110:输入部
111:传感部
112:语音输入部
120、220、320:语音对话处理部
121:状态识别部
122、222:语音识别部
123、223:意图理解部
124、324:行动选择部
125:机器控制部
126:应答生成部
127:语音合成部
130:输出部
131:语音输出部
140:控制对象机器
228:触发字识别部
328:控制受理定时器
具体实施方式
(成为本公开的基础的见解)
有关语音对话装置的技术正在被进行研究,所述语音对话装置从用户说出的语音中解析说话的内容,并根据解析结果提供机器的控制和/或信息提供等服务。在语音对话装置中,并不通过画面操作、按钮操作等复杂的操作,而是通过基于语音的直观且容易的操作,进行机器的控制和/或信息取得。另一方面,作为课题,存在误识别周围的对话、从电视机和/或收音机等发出的语音这一问题。
针对这种问题,在上述专利文献1涉及的技术中,通过追加对语音的识别结果进行确认的步骤,避免因语音的误识别导致的使机器误工作。另外,在上述专利文献2涉及的技术中,通过控制基于用户的视线和/或手指动作确定出的控制对象机器,防止对控制对象以外的机器的控制和/或由噪音的输入所致的机器的误工作。
然而,用户通过语音控制的对象的机器和/或用户利用基于语音的控制的场景是多种多样的,根据控制对象的机器和/或利用的场景,每次说话时都确认语音的识别结果有可能很麻烦,或者说话时有可能无法使视线和/或手指动作朝向控制对象的机器。
例如,对于在机器前对冰箱、微波炉、烤箱、屋子和/或房间的门等的门的开闭工作进行语音控制这样的场景,每次说出“打开门”等时,都对“打开门吗”等确认说话进行应答是麻烦的。另外,对于将物品放入冰箱等在搬运物品的过程中通过语音进行冰箱门的开闭控制这样的场景,难以意识到冰箱的配置位置地进行说话、或者进行手指动作。另外,在利用能够通过语音控制来调节水量的水龙头、能够通过语音控制来点火的煤气炉和/或电磁炉的场景中,也难以在厨房的作业过程中使视线朝向控制对象的机器。
这样,在以往的语音对话装置中,并未对兼顾实现防止由语音的误识别所致的机器的误工作以及提高用户的便利性进行研究。
本公开的目的在于提供能够在通过语音进行机器控制的情况下,结合用户的状态或者机器周围的状态,兼顾实现防止由语音的误识别所致的机器的误工作以及提高用户的便利性的技术。
(1)本公开的一个技术方案的方法是在控制装置中控制多个机器的方法,所述控制装置具备麦克风、传感器以及扬声器,所述麦克风收集所述控制装置周边的声音,所述传感器感测所述多个机器周边的人物,所述控制方法包括:从由所述麦克风收集到的声音中提取用于控制所述多个机器的说话;基于所述说话,确定所述多个机器中作为控制对象的对象机器;基于表示所述传感器感测到的结果的感测数据,判定是否要控制所述对象机器;在判定为要控制所述对象机器的情况下,针对所述说话生成用于对要控制所述对象机器这一情况进行确认的应答语音,使所述扬声器输出所述应答语音。
根据该构成,在用户的状态或者控制对象机器周围的状态是适合于控制的状态的情况下,能够抑制不必要地念诵确认应答文,迅速地进行用户所请求的机器控制。由此,能够提高用户的便利性。
另一方面,在用户的状态以及控制对象机器周围的状态并非适合于控制的状态的情况下,能够念诵确认应答文,抑制由于周围的噪音等语音的误识别而使机器误工作的可能。
即,根据该构成,能够结合用户的状态或者机器周围的状态,兼顾实现防止由语音的误识别所致的机器的误工作以及提高用户的便利性。
(2)在上述技术方案中,也可以为,在判定为要控制所述对象机器的情况下,进一步,通过解析所述说话来确定所述对象机器的控制项目;生成与所述控制项目对应的指令。
根据该构成,在用户的状态或者控制对象机器周围的状态是适合于控制的状态的情况下,能够抑制不必要地念诵确认应答文,迅速地进行用户所预想的控制对象机器的控制。
(3)在上述技术方案中,也可以为,所述感测数据表示从所述对象机器起的第1范围内是否存在人物,在所述感测数据表示从所述对象机器起的所述第1范围内不存在所述人物的情况下,判定为要控制所述对象机器。
根据该构成,在未在控制对象机器周围检测出人物,可认为即使进行控制对象机器的门的开闭等有动作的控制,发生事故的可能性也低的情况下,能够抑制不必要地念诵确认应答文,迅速地进行用户所请求的机器控制。由此,能够提高用户的便利性。
(4)在上述技术方案中,也可以为,所述传感器是摄像头,所述感测数据是所述摄像头拍摄所述第1范围而得到的图像。
根据该构成,能够恰当地检测出能够通过拍摄装置拍摄的包括控制对象机器在内的预定的范围内是否存在人物。
(5)在上述技术方案中,也可以为,所述控制装置还具备存储器,所述方法还包括:在所述图像表示所述第1范围内存在所述人物的情况下,基于所述人物的脸部或者躯体的特征和预先存储于所述存储器的表示多个人的脸部或者躯体的特征的信息,确定所述人物;基于预先存储于所述存储器的表示各所述多个人与各声纹之间的对应关系的信息、和从所述说话中提取出的声纹,判定与所确定出的所述人物对应的声纹是否与从所述说话中提取出的声纹一致;在判定为与所确定出的所述人物对应的声纹与从所述说话中提取出的声纹一致的情况下,基于所述图像,判定所确定出的所述人物的视线是否朝向所述对象机器;在判定为所确定出的所述人物的视线朝向所述对象机器的情况下,判定为要控制所述对象机器。
根据该构成,在处于控制对象机器周围的进行了说话的用户使视线朝向控制对象机器,可认为该用户关注着控制对象机器的情况下,能够抑制不必要地念诵确认应答文,迅速地进行用户所请求的机器控制。由此,能够提高用户的便利性。
(6)在上述技术方案中,也可以为,所述控制装置还具备存储器,所述方法还包括:在所述图像表示所述第1范围内存在所述人物的情况下,基于所述人物的脸部或者躯体的特征和预先存储于所述存储器的表示多个人的脸部或者躯体的特征的信息,确定所述人物;基于预先存储于所述存储器的表示各所述多个人与各声纹之间的对应关系的信息、和从所述说话中提取出的声纹,判定与所确定出的所述人物对应的声纹是否与从所述说话中提取出的声纹一致;在判定为与所确定出的所述人物对应的声纹与从所述说话中提取出的声纹一致的情况下,基于所述图像,判定所确定出的所述人物的脸部是否朝向所述对象机器;在判定为所确定出的所述人物的脸部朝向所述对象机器的情况下,判定为要控制所述对象机器。
根据该构成,在进行了说话的用户使脸部朝向控制对象机器,可认为该用户关注着控制对象机器的情况下,能够抑制不必要地念诵确认应答文,迅速地进行用户所请求的机器控制。由此,能够提高用户的便利性。
(7)在上述技术方案中,也可以为,所述控制装置还具备存储器,所述方法还包括:在所述图像表示所述第1范围内存在所述人物的情况下,基于从所述图像中提取出的所述人物的脸部或者躯体的特征和预先存储于所述存储器的表示多个人的脸部或者躯体的特征的信息,确定所述人物;基于预先存储于所述存储器的表示各所述多个人与各声纹之间的对应关系的信息、和从所述说话中提取出的声纹,判定与所确定出的所述人物对应的声纹是否与从所述说话中提取出的声纹一致;在判定为与所确定出的所述人物对应的声纹与从所述说话中提取出的声纹一致的情况下,基于所述图像,判定所确定出的所述人物的躯体是否朝向所述对象机器;在判定为所确定出的所述人物的躯体朝向所述对象机器的情况下,判定为要控制所述对象机器。
根据该构成,在进行了说话的用户使躯体朝向控制对象机器,可认为该用户关注着控制对象机器的情况下,能够抑制不必要地念诵确认应答文,迅速地进行用户所请求的机器控制。由此,能够提高用户的便利性。
(8)在上述技术方案中,也可以为,所述说话是第1说话,所述方法还包括:在输出所述应答语音后,从由所述麦克风收集到的声音中提取出针对所述应答语音的第2说话的情况下,判定所述第1说话的第1说话者和所述第2说话的第2说话者是否相同;在判定为所述第1说话者和所述第2说话者相同的情况下,生成用于控制所述对象机器的指令。
根据该构成,在误将周围的噪音等语音识别为是第二说话的情况下,能够防止进行与第一说话对应的机器控制。
(9)在上述技术方案中,也可以为,通过比较从所述第1说话中提取出的第1声纹、和从所述第2说话中提取出的第2声纹,判定所述第1说话者和所述第2说话者是否相同。
根据该构成,能够通过第一说话以及第二说话的声纹,高精度地判定第一说话以及第二说话的说话者是否相同。
(10)在上述技术方案中,也可以为,所述说话是第1说话,所述指令是第1指令,所述方法还包括:在生成所述第1指令后的预定时间内,从由所述麦克风收集到的声音中提取出用于控制所述对象机器的第2说话的情况下,判定所述第1说话的第1说话者和所述第2说话的第2说话者是否相同;在判定为所述第1说话和所述第2说话相同的情况下,并不针对所述第2说话生成用于对要控制所述对象机器这一情况进行确认的应答语音,而生成与所述第2说话对应的第2指令。
根据该构成,在由一个用户连续地进行了用于控制同一机器的说话的情况下,能够避免连续地对该用户念诵确认应答文。由此,能够提高用户的便利性。
(11)在上述技术方案中,也可以为,通过比较从所述第1说话中提取出的第1声纹、和从所述第2说话中提取出的第2声纹,判定所述第1说话者和所述第2说话者是否相同。
根据该构成,能够通过第三说话以及第四说话的声纹,高精度地判定第三说话以及第四说话的说话者是否相同。
(12)在上述技术方案中,也可以为,还包括:定期地判定从由所述麦克风收集到的声音中提取出的说话中是否含有成为用于控制所述对象机器的触发的预定的单词;在判定为从由所述麦克风收集到的声音中提取出的说话中含有所述预定的单词的情况下,不管对于是否要控制所述对象机器的判定结果如何,均通过解析所述说话来确定所述对象机器的控制项目;生成与所述控制项目对应的指令。
根据该构成,能够在用户说出意味着机器控制的契机的预定的单词,该用户进行机器控制的意图明确的情况下,并不念诵确认应答文,而迅速地进行与说话对应的机器控制。由此,能够提高用户的便利性。
(13)在上述技术方案中,还包括:在判定为不控制所述对象机器的情况下,定期地基于表示所述传感器感测到的结果的感测数据,判定是否要控制所述对象机器;当在从由所述麦克风收集到的声音中提取出用于控制所述多个机器的说话后的预定时间内,判定为要控制所述对象机器的情况下,生成针对所述说话的用于控制所述对象机器的指令。
根据该构成,即使在用户的状态以及控制对象机器周围的状态并非适合于控制的状态的情况下进行了用于控制机器的说话,通过在该说话后的预定期间内,用户的状态或者控制对象机器周围的状态转变为适合于控制的状态,也能够进行与说话对应的机器控制。由此,在用户在移动过程中进行用于控制机器的说话这样的场景中,能够提高用户的便利性。
另外,本公开不仅公开如上的特征性的执行处理的方法,而且还公开具备用于执行方法中包含的特征性的步骤的处理部的控制装置。另外,还公开使计算机执行这种控制方法中包含的特征性的各步骤的计算机程序。当然,可以使这种计算机程序经由cd-rom等计算机可读取的非临时性的记录介质或者互联网等通信网络来流通。
此外,以下说明的实施方式均表示本公开的一个具体例。在以下的实施方式中表示的数值、形状、构成要素、步骤、步骤的顺序等是一例,并非旨在限定本公开。另外,对于以下的实施方式中的构成要素中的、没有记载在表示最上位概念的独立权利要求中的构成要素,作为任意的构成要素进行说明。另外,在所有的实施方式中,也可以组合各自的内容。
(实施方式1)
图1是表示实施方式1中的语音对话装置的全貌的一例的图。如图1所示,语音对话装置100通过光纤、无线、公共电话线路等未图示的网络与控制对象机器140连接。此外,对语音对话装置100可以连接至少一个以上的控制对象机器140。或者,也可以构成为物理性地将语音对话装置100分别组装于各控制对象机器140。
语音对话装置100具备输入部110、语音对话处理部120以及输出部130。
输入部110具备传感部111和语音输入部112。传感部111具备一个以上的能够取得与控制对象机器140的周围状态有关的信息的设备。例如,传感部111具备人感传感器、摄像头(拍摄装置)以及视线传感器。
人感传感器使用红外线和/或超声波等来检测从控制对象机器140到预定距离内是否存在人物,并将表示检测结果的数据(传感器数据)向后述的语音对话处理部120输出。摄像头对包括控制对象机器140的预定范围进行拍摄,并将表示拍摄到的图像的数据(传感器数据)向后述的语音对话处理部120输出。
视线传感器内置有对包括控制对象机器140的预定范围进行拍摄的摄像头(以下称为内置摄像头)。视线传感器基于内置摄像头拍摄到的图像中包含的黑眼珠以及白眼珠的区域,确定人物的视线方向,并将表示所确定的人物的视线方向的数据(传感器数据)向后述的语音对话处理部120输出。对于人物的视线方向,例如以内置摄像头拍摄到的图像中的垂直方向等预定方向为基准,通过人物的视线方向倾斜了多少度来表示。此外,视线传感器也可以输出用其他形式表示人物的视线方向的数据。
另外,传感部111也可以具备红外线摄像头和/或温度传感器等能够取得与控制对象机器140的周围状态有关的信息的其他设备,所述红外线摄像头输出表示用红外线对包括控制对象机器140的预定范围进行拍摄而得到的图像的数据,所述温度传感器检测控制对象机器140附近的温度并输出表示检测出的温度的数据。
语音输入部112将输入到集音设备(集音装置)的语音数据向后述的语音对话处理部120输出。集音设备例如包括安装于语音对话装置100主体的指向性麦克风和/或以有线或者无线方式与语音对话装置100连接的手持式麦克风、领夹式麦克风以及台式麦克风等。另外,语音输入部112也可以通过在与智能手机和/或平板电脑等具有集音功能以及通信功能的设备之间进行通信,取得输入到该设备的语音数据,将该取得的语音数据向后述的语音对话处理部120输出。
语音对话处理部120由根据程序而工作的cpu(centralprocessingunit,中央处理器)实现。语音对话处理部120作为状态识别部121(判定部)、语音识别部122(检测部)、意图理解部123(辨别部)、行动选择部124、机器控制部125、应答生成部126(生成部)以及语音合成部127进行工作。
状态识别部121基于传感部111输出的一个以上的数据(以下称为输出数据),判定用户的状态或者控制对象机器140周围的状态是否为适合于控制的状态。
状态识别部121在通过执行公知的模式识别处理,识别为上述摄像头的输出数据所表示的控制对象机器140的周围的图像中不包括人物的情况下,判断为是未在控制对象机器140的周围检测出人物的状态。在该情况下,由于可认为即使进行控制对象机器140的门的开闭等有动作的控制,发生事故的可能性也低,因此,状态识别部121判定为控制对象机器140周围的状态是适合于控制的状态。
另外,设上述人感传感器的输出数据所表示的检测结果示出在从控制对象机器140到预定距离内不存在人物。在该情况下,状态识别部121也判断为是未在控制对象机器140的周围检测出人物的状态,判定为控制对象机器140周围的状态是适合于控制的状态。
另一方面,设在上述摄像头的输出数据所表示的控制对象机器140周围的图像中包括人物。或者,设上述人感传感器的输出数据所表示的检测结果示出在从控制对象机器140到预定距离内存在人物。在这些情况下,状态识别部121判断为是在控制对象机器140的周围检测出人物的状态。在该情况下,状态识别部121基于预先存储的表示上述视线传感器以及控制对象机器140的配置位置的信息,判定上述视线传感器的输出数据所表示的人物的视线方向是否为从上述视线传感器的配置位置朝向控制对象机器140的配置位置的方向。
状态识别部121在判定为人物的视线方向是从视线传感器的配置位置朝向控制对象机器140的配置位置的方向时,判断为该人物的视线朝向控制对象机器140。在该情况下,可认为该人物是为了使用控制对象机器140而使视线朝向控制对象机器140并关注着控制对象机器140的、控制对象机器140的用户。因此,状态识别部121在判断为该人物的视线朝向控制对象机器140的情况下,判定为控制对象机器140的用户的状态是适合于控制的状态。
此外,在状态识别部121判断为是在控制对象机器140的周围检测出人物的状态的情况下,也可以基于上述摄像头的输出数据所表示的控制对象机器140周围的图像,判断是否是该人物的视线、脸部或者躯体朝向控制对象机器140的状态。而且,在状态识别部121判断为是该人物的视线、脸部或者躯体朝向控制对象机器140的状态的情况下,也可以判定为控制对象机器140的用户的状态是适合于控制的状态。
在该情况下,在状态识别部121通过执行公知的模式识别处理,识别为上述摄像头的输出数据所表示的控制对象机器140周围的图像中包括人物的眼睛的情况下,基于黑眼珠以及白眼珠的区域和预先存储的表示上述摄像头以及控制对象机器140的配置位置的信息,判断人物的视线是否朝向控制对象机器140即可。
同样地,在状态识别部121使用公知的模式识别技术,识别为上述摄像头的输出数据所表示的控制对象机器140的周围的图像中包括人物的脸部或者躯体的情况下,基于人物的脸部或者躯体的区域、和预先存储的表示上述摄像头以及控制对象机器140的配置位置的信息,判断人物的脸部或者躯体是否朝向控制对象机器140即可。
语音识别部122通过执行公知的语音识别处理,检测语音输入部112输出的语音数据所表示的语音中包含的人物发出的语音,生成表示该说话的内容的文本数据。
意图理解部123通过执行公知的语言解析处理,解析语音识别部122生成的文本数据所表示的说话的内容,进行该说话的意图解释。例如,意图理解部123通过执行所谓基于规则的语言解析处理,解析说话的内容。具体而言,意图理解部123在预先确定的规则中,当在说话的内容中包含与可由语音对话装置100执行的任务(task)相关联的他动词(及物动词)的单词的情况下,解释为该说话是请求执行与该他动词的单词相关联的任务的说话。此外,可由语音对话装置100执行的任务包括用于控制机器的任务和/或用于取得互联网上提供的信息的任务等。
另外,意图理解部123将说话内容中包含的名词单词解释为任务的参数。例如,用于控制机器的任务的参数包括成为控制的对象的控制对象机器。用于取得信息的任务的参数包括要取得的对象的信息和/或用于访问该信息的取得地的地址信息等。也就是说,意图理解部123将请求执行用于控制机器的任务的说话内容中包含的名词单词,辨别为对有关机器进行控制的对象的控制对象机器140。
以下,说明由意图理解部123进行的说话的意图解释的具体例。在本具体例中,设冰箱以及微波炉作为控制对象机器140而与语音对话装置100连接。另外,设语音识别部122生成的文本数据所表示的说话的内容是“打开冰箱”。另外,设在上述规则中,对于用于进行打开控制对象机器140的门的控制的任务,关联有他动词“打开”。
在该情况下,与用于进行打开控制对象机器140的门的控制的任务相关联的他动词“打开”包含于作为说话的内容的“打开冰箱”中。因此,意图理解部123解释为该说话是请求执行用于进行打开控制对象机器140的门的控制的任务的说话。
另外,由于作为说话的内容的“打开冰箱”中包含名词的单词“冰箱”,因此,意图理解部123解释为该任务的参数是冰箱。也就是说,意图理解部123将冰箱辨别为控制对象机器140。这样,意图理解部123解释为该说话是请求进行打开冰箱门的控制的说话。
此外,意图理解部123也可以通过所谓机器学习等统计性解析方法等其他的解析方法来解析说话的内容,进行说话的意图解释。
行动选择部124基于由意图理解部123得到的意图解释的结果以及由状态识别部121得到的判定结果,选择是使机器控制部125执行机器控制,还是使应答生成部126生成确认应答文,或是执行其他任务。关于确认应答文,将在后面进行说明。
机器控制部125在行动选择部124的指示下,生成用于对控制对象机器140进行控制的机器控制命令,将该机器控制命令向控制对象机器140输出。由此,控制对象机器140进行按照从机器控制部125输入的机器控制命令的工作。
应答生成部126在行动选择部124的指示下,生成确认应答文,将表示该确认应答文的文本数据向语音合成部127输出。确认应答文是指用于让用户确认说话的内容、回答确认结果的文章。例如,在说话的内容是“打开冰箱”的情况下,确认应答文为“打开电冰箱吗”,成为对说话的内容进行重问的内容。
具体而言,行动选择部124在使应答生成部126生成确认应答文的情况下,将输入到意图理解部123的表示说话的内容的文本数据向应答生成部126输出。应答生成部126通过执行公知的语言解析处理,解析该被输入的文本数据所表示的说话的内容,生成对该说话的内容进行重问的内容的确认应答文。
语音合成部127通过执行公知的语音合成处理,将表示由应答生成部126输入的确认应答文的文本数据转换为表示该确认应答文的语音数据,并向输出部130输出。
输出部130具备一个以上的语音输出部131。语音输出部131输出下述语音:即语音合成部127输出的语音数据所表示的语音。语音输出部131例如是组装于语音对话装置100的扬声器。此外,语音输出部131也可以由通过有线或者无线方式与语音对话装置100连接的扬声器构成。
在实施方式1的例子中,输出部130具备一个以上的语音输出部131,但也可以代替语音输出部131,而在组装于语音对话装置100的显示器等显示设备和/或与语音对话装置100连接的外部的显示设备中,显示应答生成部126生成的文本数据所表示的确认应答文等。
另外,也可以将输入部110、状态识别部121、语音识别部122、应答生成部126、语音合成部127以及输出部130设置于与语音对话装置100连接的各控制对象机器140。与此同时,也可以使能够在与语音对话装置100之间通信的外部服务器作为意图理解部123、行动选择部124以及机器控制部125进行工作。
以下,使用图2,说明在实施方式1中根据说话的用户的状态或者控制对象机器140周围的状态是否是适合于控制的状态,判断是否语音输出确认应答文,直至进行机器控制的处理流程。图2是表示实施方式1中的语音对话装置100的处理流程的一例的图。
当集音设备中被输入表示用户的说话的语音数据,语音输入部112将该语音数据向语音识别部122输出时(步骤s101:是),语音识别部122通过执行语音识别处理,检测被输入的语音数据所表示的语音中包含的用户发出的语音,生成表示该说话的内容的文本数据(步骤s102)。意图理解部123通过执行语言解析处理,解析语音识别部122生成的文本数据所表示的说话的内容,进行该说话的意图解释(步骤s103)。
在由意图理解部123解释为用户的说话是请求执行与用于控制机器的任务不同的其他任务的说话的情况下(步骤s104:否),行动选择部124基于由意图理解部123得到的意图解释的结果,执行用户所请求的上述其他任务(步骤s111)。
另一方面,在由意图理解部123解释为用户的说话是请求执行用于控制机器的任务的说话(以下称为请求机器控制的说话)的情况下(步骤s104:是),状态识别部121判定说话的用户的状态(以下称为用户的状态)或者控制对象机器140周围的状态(以下称为机器周围的状态)是否处于适合于控制的状态(步骤s105)。
在状态识别部121判定为用户的状态或者机器周围的状态是适合于控制的状态的情况下(步骤s105:是),行动选择部124基于由意图理解部123得到的意图解释的结果,指示机器控制部125,以使其进行用户所请求的控制对象机器140的控制。由此,机器控制部125生成用于进行该被指示的控制对象机器140的控制的机器控制命令,将该机器控制命令向控制对象机器140输出(步骤s106)。其结果,控制对象机器140进行按照被输入的机器控制命令的工作。
另一方面,在状态识别部121判定为用户的状态以及机器周围的状态并非适合于控制的状态的情况下(步骤s105:否),行动选择部124使应答生成部126生成确认应答文。当应答生成部126生成确认应答文,并输出表示确认应答文的文本数据时,行动选择部124使语音合成部127生成表示该确认应答文的语音数据,使语音输出部131输出表现该语音数据所表示的确认应答文的语音(步骤s107)。也就是说,语音输出部131通过语音念诵确认应答文。
相应地,设用户例如进行了“确定”、“是”等受理确认的说话(以下称为确认受理说话)。在该情况下,虽然在图2中省略了图示,但进行与步骤s101~s103同样的处理。其结果,当由意图理解部123解释为用户的说话是确认受理说话时(步骤s108:是),行动选择部124执行上述的步骤s106。
另一方面,当在没有由用户做出确认受理说话的状态下(步骤s108:否),经过了预先确定的一定的时间的情况下,行动选择部124取消由用户实施的控制对象机器140的控制的请求(步骤s110)。此外,上述的一定的时间也可以按每个控制对象机器140而个别地确定。
另外,在由用户进行说话,由此进行了与步骤s101~s102同样的处理的结果是,通过意图理解部123解释为用户的说话并非确认受理说话的情况下(步骤s109:是),行动选择部124也取消由用户实施的控制对象机器140的控制的请求(步骤s110)。
根据以上所述的本实施方式1的语音对话装置100,在用户进行了请求控制机器的说话的情况下,在用户的状态或者控制对象机器140周围的状态是适合于控制的状态的情况下,能够抑制不必要地念诵确认应答文,迅速地进行用户所请求的机器控制。由此,能够提高用户的便利性。另一方面,在用户的状态以及控制对象机器140周围的状态并非适合于控制的状态的情况下,能够念诵确认应答文,抑制由于周围的噪音等语音的误识别而使机器误工作的可能。
另外,状态识别部121在判断为说话的用户的视线、脸部或者躯体是未朝向控制对象机器140的状态的情况下,判定为用户的状态并非适合于控制的状态。在该情况下,念诵确认应答文。由此,能够排除在用户未关注控制对象机器140的状态时,因不念诵确认应答文而进行控制对象机器140的门的开闭等有动作的控制,从而发生事故的危险性。
此外,在步骤s103中,意图理解部123在用户的说话的内容仅包含与机器控制关联的他动词的情况下,即使解释为该说话是请求机器控制的说话,由于说话的内容没有包含名词,因此也无法辨别控制对象机器140。
在该情况下,意图理解部123也可以生成询问控制对象机器140的询问文,使用语音合成部127以及语音输出部131,用语音输出该生成的询问文。相应地,在由用户进行表示控制对象机器140的说话,进行了与步骤s101、s102同样的处理之后,意图理解部123也可以将该说话的内容所含的表示控制对象机器140的名词辨别为上述任务的参数、也就是控制对象机器140。
另外,在步骤s108中,解释为用户的说话是确认受理说话(第二说话)的情况下,也可以对于在步骤s101中输出的请求机器控制的说话(第一说话)的语音数据、和该步骤s108中的通过与步骤s101同样的处理输出的确认受理说话的语音数据,判定声纹是否一致,仅在一致的情况下进行被用户请求的机器控制。
以下,使用图3对该情况的处理流程进行说明。此外,到状态识别部121判定用户的状态或者机器周围的状态是否为适合于控制的状态为止的处理流程与图2所示的步骤s101~s105相同,因此省略说明。
在状态识别部121判定为用户的状态以及机器周围的状态并非适合于控制的状态的情况下(步骤s105:否),行动选择部124存储在步骤s101中输出的、请求执行与机器控制有关的任务的说话(以下称为控制请求说话)的语音数据(步骤s201)。
然后,与步骤s107同样地,行动选择部124使应答生成部126生成确认应答文,使用语音合成部127以及语音输出部131,输出表示该确认应答文的语音(步骤s202)。
相应地,设用户进行确认受理说话的结果是,通过与步骤s108同样的处理,由意图理解部123解释为用户的说话是确认受理说话(步骤s203:是)。在该情况下,行动选择部124通过执行公知的声纹比较处理,判定在步骤s201中存储的控制请求说话的语音数据所表示的语音的声纹、和步骤s203中的通过与步骤s101同样的处理输出的确认受理说话的语音数据所表示的语音的声纹是否一致(步骤s204)。
行动选择部124在判定为声纹一致的情况下,判断为进行控制请求说话的用户和进行确认受理说话的用户是同一人物(步骤s204:是),与步骤s106同样地,使机器控制部125执行用户所请求的机器控制(步骤s205)。
另一方面,行动选择部124在判定为声纹不一致的情况下(步骤s204:否),判断为进行控制请求说话的用户和进行确认受理说话的用户并非同一人物,取消由用户提出的控制的请求(步骤s207)。由此,能够防止在将周围的噪音等语音误识别为是确认受理说话的情况下,进行由控制请求说话所请求的机器控制。
当在没有由用户做出确认受理说话的状态下(步骤s203:否),经过了预先确定的一定的时间的情况下,或者,在步骤s203中解释为用户的说话并非确认受理说话的情况下(步骤s206:是),行动选择部124也取消由用户提出的控制的请求(步骤s207)。
另外,当在从根据检测到用于控制机器的第一说话(第三说话),而生成与第一说话对应的机器控制命令后,到经过预定的期间之前,检测到用于控制该机器的第二说话(第四说话)的情况下,对于第一说话的语音数据和第二说话的语音数据,判定声纹是否一致,在一致的情况下,也可以不生成确认应答文,而生成与第二说话对应的机器控制命令。以下,使用图4对该情况的处理流程进行说明。
在按照图2所示的处理流程,由机器控制部125生成与第一说话对应的机器控制命令,实施了与第一说话对应的机器控制的情况下(步骤s301:是),行动选择部124存储在图2所示的步骤s101中输出的第一说话的语音数据(步骤s302)。
设在该状态下,进行了第二说话,且进行了与步骤s101~s103同样的处理的结果是,由意图理解部123解释为第二说话是请求与作为对应于第一说话的机器控制的对象的控制对象机器140相同的控制对象机器140的机器控制的说话(步骤s304:是)。在该情况下,与步骤s105同样地,状态识别部121判定用户的状态或者机器周围的状态是否处于适合于控制的状态(步骤s305)。
在状态识别部121判定为用户的状态以及机器周围的状态并非适合于控制的状态的情况下(步骤s305:否),行动选择部124通过执行公知的声纹比较处理,判定在步骤s302中存储的第一说话的语音数据所表示的语音的声纹、和步骤s304中的通过与步骤s101同样的处理输出的第二说话的语音数据所表示的语音的声纹是否一致(s307)。
行动选择部124在判定为声纹一致的情况下,判断为进行第一说话的用户和进行第二说话的用户是同一人物(步骤s307:是),与步骤s106同样地,使机器控制部125执行由第二说话所请求的机器控制(步骤s306)。
另一方面,行动选择部124在判定为声纹不一致的情况下(步骤s307:否),判断为是与进行第一说话的用户不同的另一用户进行了第二说话,进行图2所示的步骤s107。由此,能够抑制下述情况:在与进行第一说话的用户不同的另一用户继第一说话之后进行了请求机器控制的第二说话的情况下,尽管该另一用户的状态以及控制对象机器140的状态并非适合于控制的状态,也并不念诵针对第二说话的确认应答文,而实施与第二说话对应的机器控制。
另外,当在没有做出请求与作为对应于第一说话的机器控制的对象的控制对象机器140相同的控制对象机器140的机器控制的第二说话的状态下(步骤s304:否),经过了预先确定的一定的期间的情况下(步骤s309:是),行动选择部124废弃在步骤s302中存储的第一说话的语音数据(步骤s310)。
如果按照图4所示的处理流程进行处理,在由同一用户连续地进行了请求同一机器的机器控制的说话的情况下,能够避免该用户连续地进行确认受理说话。
此外,设按照图2~图4所示的各处理流程进行处理,进行了控制对象机器140的机器控制之后,即使经过一定的时间,也未进行使控制对象机器140返回到进行该机器控制之前的状态的控制。在该情况下,行动选择部124也可以自动地进行返回到进行该机器控制之前的状态的控制。
例如,设实施了由用户的说话所请求的打开冰箱门的控制。在该状态下,即使经过一定的时间,也未进行请求关闭冰箱门的控制的说话的情况下,行动选择部124也可以自动地进行关闭冰箱门的控制。由此,能够防止忘记关门,防止即使在万一由于周围的噪音等语音的误识别而错误地使机器工作了的情况下,门变为打开不变的状态。也就是说,在如门的开闭控制那样,进行了一方的控制后,要进行回到原状态的控制的情况下,本构成是有用的。
另外,也可以为,状态识别部121使用公知的模式识别技术,在由传感部111具备的摄像头拍摄到的图像中包含人物的情况下,识别该图像中包含的人物的脸部和/或躯体等的特征,基于该特征来确定该人物。与此同时,也可以预先存储被认为会利用语音对话装置100的人物的声纹。
而且,在图3所示的处理流程中,行动选择部124也可以省略步骤s201,在步骤s204中,使用预先存储的声纹中的、该状态识别部121所确定的、进行了控制请求说话的用户的声纹。同样地,在图4所示的处理流程中,行动选择部124也可以省略步骤s302,在步骤s307中,使用预先存储的声纹中的、该状态识别部121所确定的、进行了第一说话的用户的声纹。
(实施方式2)
在实施方式2中,其特征在于,持续地尝试从被输入到集音设备的语音数据中检测意味着基于语音的机器控制的契机的、预定的触发字,在检测到触发字的情况下,不依据用户的状态或者机器周围的状态是否为适合于控制的状态的判定结果,进行说话的意图解释,基于该意图解释的结果,生成与说话对应的机器控制命令。此外,在以下的说明中,为了简化说明,对与上述实施方式1同样的构成部分附加同一标号,并简化说明。
图5是表示实施方式2中的语音对话装置200的全貌的图。语音对话装置200与图1所示的语音对话装置100的不同点在于,语音对话处理部220还作为触发字识别部228进行工作。另外,不同点还在于,语音识别部222将生成的文本数据还输出到触发字识别部228。另外,不同点还在于,意图理解部223基于状态识别部121的判定结果或者触发字识别部228的后述的判定结果,使与意图理解部123同样的说话的意图解释处理有效。
触发字识别部228通过执行公知的语言解析处理,解析语音识别部222生成的文本数据所表示的说话的内容,检测该说话的内容中是否包含意味着基于语音的机器控制的契机的、预定的触发字(例如“麦克风开启”等)。
以下,使用图6来说明实施方式2中的处理流程。在由状态识别部121判定为用户的状态或者机器周围的状态是适合于控制的状态的情况下(步骤s401:是),意图理解部223使意图解释处理有效(步骤s403)。另外,在由状态识别部121判定为用户的状态以及机器周围的状态并非适合于控制的状态的情况下(步骤s401:否),当由触发字识别部228检测到触发字时(步骤s402:是),意图理解部223也使意图解释处理有效(步骤s403)。
当由状态识别部121判定为用户的状态以及机器周围的状态并非适合于控制的状态(步骤s401:否),且并未由触发字识别部228检测到触发字时(步骤s402:否),进行步骤s401。由此,触发字识别部228持续地尝试检测触发字。
在意图解释处理被设为有效的状态下,当集音设备中被输入表示用户的说话的语音数据,语音输入部112将该语音数据向语音识别部222输出时(步骤s404:是),意图理解部223解析语音识别部222生成的文本数据所表示的说话的内容,进行该说话的意图解释(步骤s405)。在该情况下,行动选择部124基于由意图理解部223得到的意图解释的结果,执行由用户的说话所请求的任务(步骤s406)。
当在步骤s403中意图解释处理被设为有效后,在用户未说话的状态下(步骤s404:否),经过了预先确定的一定的时间、或者由状态识别部121判定为用户的状态或者机器周围的状态并非适合于控制的状态的情况下(步骤s407:是),意图理解部223使意图解释处理无效(步骤s408)。
另一方面,在未经过预先确定的一定的时间(未超时)、并且由状态识别部121判定为用户的状态或者机器周围的状态是适合于控制的状态的情况下(步骤s407:否),成为等待由用户进行的说话的状态。
根据以上所述的实施方式2的语音对话装置200,在由触发字识别部228解释为用户的说话是触发字的说话的情况下,不依照状态识别部121的判定结果,使意图理解部223的意图解释处理有效,进行与用户的说话对应的机器控制。由此,能够在用户说出触发字,该用户进行机器控制的意图明确的情况下,并不念诵确认应答文,而迅速地进行与说话对应的机器控制。由此,用户的便利性提高。另外,在用户的状态或者机器周围的状态处于适合于控制的状态的情况下,用户能够不进行触发字的说话,而迅速地进行所请求的机器控制。由此,能够提高用户的便利性。
此外,也可以省略步骤s401,触发字识别部228通过重复步骤s402直到检测到触发字,从而持续地尝试检测触发字。而且,意图理解部223也可以仅在由触发字识别部228检测到触发字的情况下(步骤s402:是),使意图解释处理有效。
(实施方式3)
在实施方式3中,其特征在于,即使在判定为用户的状态以及机器周围的状态并非适合于控制的状态的情况下,也继续判定用户的状态或者机器周围的状态是否为适合于控制的状态,并在从检测到用户的说话起到预定的期间内,判定为用户的状态或者机器周围的状态是适合于控制的状态的情况下,生成与说话对应的机器控制命令。此外,在以下的说明中,为了简化说明,对与上述实施方式1同样的构成部分附加同一标号,并简化说明。
图7是表示实施方式3中的语音对话装置300的全貌的图。语音对话装置300与图1所示的语音对话装置100不同点在于,在语音对话处理部320中还设置有控制受理定时器328。另外,不同点还在于,行动选择部324进而基于由控制受理定时器328实施的时间经过的通知来进行工作。
在控制受理定时器328中,当在用户的状态以及机器周围的状态并非适合于控制的状态的状态下,进行了请求机器控制的说话的情况下,通过行动选择部324,设定从进行了该说话到用户的状态或者机器周围的状态转变至适合于控制的状态为止的容许时间。控制受理定时器328在被设定了该容许时间后,当经过了该容许时间时,将经过了容许时间这一情况通知给行动选择部324。
行动选择部324当在用户的状态以及机器周围的状态并非适合于控制的状态的状态下进行了请求机器控制的说话的情况下,对控制受理定时器328设定上述容许时间。行动选择部324在该设定后、由控制受理定时器328通知经过了容许时间之前,在用户的状态或者机器周围的状态转变至适合于控制的状态的情况下,进行与实施方式1的行动选择部124同样的工作。
以下,使用图8来说明实施方式3中的处理流程。此外,关于步骤s101~s104、s111,与图2的处理流程同样地执行,因此省略说明。在步骤s102中由语音识别部122检测到用户的说话后,由意图理解部123解释为该用户的说话是请求机器控制的说话的情况下(步骤s104:是),行动选择部324对控制受理定时器328设定预先确定的容许时间(步骤s505)。对控制受理定时器328设定了容许时间后,状态识别部121判定用户的状态或者机器周围的状态是否为适合于控制的状态(步骤s506)。
在状态识别部121判定为用户的状态或者机器周围的状态是适合于控制的状态的情况下(步骤506:是),与步骤s106同样地,行动选择部324使机器控制部125执行用户所请求的机器控制(步骤s507)。
另一方面,在状态识别部121判定为用户的状态以及机器周围的状态并非适合于控制的状态的情况下(步骤s506:否),行动选择部324等待用户的状态或者机器周围的状态转移为适合于控制的状态,直到被控制受理定时器328通知经过了容许时间为止(步骤s508:否)。由此,行动选择部324即使在由状态识别部121判定为用户的状态以及机器周围的状态并非适合于控制的状态的情况下(步骤s506:否),仍使状态识别部121继续判定用户的状态或者机器周围的状态是否为适合于控制的状态。
当在状态识别部121没有判定为用户的状态或者机器周围的状态是适合于控制的状态的状态下,被控制受理定时器328通知经过了容许时间的情况下(步骤s508:是),行动选择部324取消由用户实施的机器控制的请求(步骤s509)。
根据以上所述的实施方式3的语音对话装置300,即使在用户的状态以及机器周围的状态并非适合于控制的状态的情况下进行了请求机器控制的说话,通过在该说话后到经过容许时间为止的期间中,用户的状态或者机器周围的状态转变为适合于控制的状态,也能够进行该机器控制。
例如,设以向冰箱的收纳为目的,用户在门口等远离冰箱的位置,并且在冰箱周围存在人物的状态下,一边拿着要收纳的食品,一边进行请求打开冰箱门的控制的说话。此时,根据实施方式3的语音对话装置300,在步骤s506中,状态识别部121判定为用户的状态以及机器周围的状态并非适合于控制的状态。然而,用户在上述说话后到经过容许时间的期间内,移动到冰箱前并使视线、脸部或者躯体朝向冰箱时,或者冰箱的周围变得不存在人物时,在步骤s506中,由状态识别部121判定为用户的状态成为适合于控制的状态。然后,在步骤s507中,执行打开冰箱门的控制。
这样,根据实施方式3的语音对话装置300,尤其在从远离控制对象机器140的位置接近控制对象机器140的移动过程中进行请求机器控制的说话这样的场景中,能够提高用户的便利性。此外,关于容许时间,设想该场景从而例如确定为十余秒即可。但是,并非旨在将容许时间限定于此。另外,在步骤s505中,行动选择部324也可以根据在步骤s104中所辨别出的控制对象机器140,个别地设定不同的容许时间。
- 还没有人留言评论。精彩留言会获得点赞!