一种音频批量分割方法及装置与流程
本发明属于计算机技术领域,尤其涉及一种音频批量分割方法及装置。
背景技术:
目前根据录音文本的内容录制对应的音频后,需要进行后期音频处理,将录音文本的内容分割成多个对应的小音频段,现有的音频分割方法是:把音频导入Audition音频处理软件中,通过人工一边看录音文本,一边听录音后的音频,同时将每小段加上标识,之后导出标记有标识的小音频段,从而完成音频拆分,该方法依赖人工进行分割,需要花费大量的时间,从而增加人力成本,另外,通过人工去边看录音文本边标记,需要一直集中注意力,否则出错率很高,后期还需要人工进行校正,保证正确率,效率极低。
技术实现要素:
本发明的目的在于提供一种音频批量分割方法及装置,旨在解决现有技术中需要依赖人工对音频进行分割,导致人力成本过高、分割效率较低以及出错率较高的问题。
一方面,本发明提供了一种音频批量分割方法,所述方法包括下述步骤:
获取录音文本以及录音后的音频,将所述音频进行语音识别,得到对应的待匹配文本;
将所述待匹配文本与所述录音文本进行匹配;
根据预设匹配度,从所述音频中分割出对应的小音频段。
另一方面,本发明提供了一种音频批量分割装置,所述装置包括:
待匹配文本识别单元,用于获取录音文本以及录音后的音频,将所述音频进行语音识别,得到对应的待匹配文本;
文本匹配单元,用于将所述待匹配文本与所述录音文本进行匹配;以及
小音频分割单元,用于根据预设匹配度,从所述音频中分割出对应的小音频段。
在本发明实施例中,将录音后的音频通过语音识别得到待匹配文本,将待匹配文本与录音文本进行匹配后,从音频中分割出对应的小音频段,通过语音识别与文本匹配,实现将录音的音频,按录音文本的要求,直接批量分割成多个小音频段,无需逐个一一加标识再导出分割小音频段,从而提高拆分效率,节约人力成本以及降低出错率。
附图说明
图1是本发明实施例一提供的音频批量分割方法的实现流程图;以及
图2是本发明实施例二提供的音频批量分割装置的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
以下结合具体实施例对本发明的具体实现进行详细描述:
实施例一:
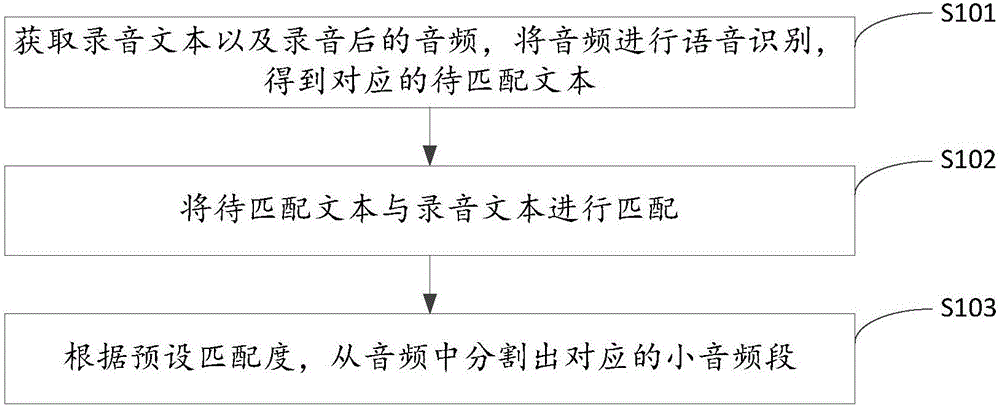
图1示出了本发明实施例一提供的音频批量分割方法的实现流程图,为了便于说明,仅示出了与本发明实施例相关的部分,详述如下:
在步骤S101中,获取录音文本以及录音后的音频,将音频进行语音识别,得到对应的待匹配文本。
在本发明实施例中,根据已有的录音文本进行录音,得到录音后的音频,录音之后需要对该音频进行处理,通过语音识别技术得到识别后的待匹配文本,该待匹配文本是对应该音频识别出的文本数据。
进一步地,根据说话的时间间隔,将音频分割为临时音频段;
将临时音频段进行语音识别,得到对应的待匹配文本。
具体地,为了降低数据处理量,可以通过预处理将音频根据说话的时间间隔进行临时分割,得到临时音频段,然后对该临时音频段进行语音识别,得到对应的待匹配文本。
在步骤S102中,将待匹配文本与录音文本进行匹配。
在本发明实施例中,通过对音频进行语音识别得到待匹配文本,将待匹配文本与录音文本进行匹配。
进一步地,获取待匹配文本的字符串;
将待匹配文本的字符串与录音文本的字符串进行逐字符匹配。
具体地,获取待匹配文本的字符串,通过将待匹配文本的字符串与录音文本的字符串进行逐字符匹配,有效地保证了匹配的精确度,同时提高匹配效率。
在步骤S103中,根据预设匹配度,从音频中分割出对应的小音频段。
在本发明实施例中,将待匹配文本与录音文本进行匹配,根据预设匹配度,从音频中分割出对应的小音频段,该小音频段包括对应字、词、短语和\或句子的音频。
进一步地,当待匹配文本与录音文本的匹配度大于预设匹配度时,从音频中分割出对应的小音频段。
具体地,当待匹配文本与录音文本的匹配度为全完匹配时,从音频中分割出对应的小音频段,还可以通过预设匹配度,将大于预设匹配度的待匹配文本所对应的音频中分割出对应的小音频段。根据实际经验,可以将预设匹配度设定为60%-80%。
又进一步地,当待匹配文本与录音文本的匹配度小于预设匹配度时,从录音文本中提取出未匹配到的文本。
具体地,将待匹配文本与录音文本进行匹配,当待匹配文本与录音文本的匹配度小于预设匹配度时,从录音文本中提取出未匹配到的文本,以便于后期再次对该未匹配到的文本,进一步进行处理。
在本发明实施例中,将录音后的音频通过语音识别得到待匹配文本,将待匹配文本与录音文本进行匹配后,从音频中分割出对应的小音频段,通过语音识别与文本匹配,实现将录音的音频,按录音文本的要求,直接批量分割成多个小音频段,无需逐个一一加标识再导出分割小音频段,从而提高拆分效率,节约人力成本以及降低出错率。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于一计算机可读取存储介质中,所述的存储介质,如ROM/RAM、磁盘、光盘等。
实施例二:
图2示出了本发明实施例二提供的音频批量分割装置的结构示意图,为了便于说明,仅示出了与本发明实施例相关的部分。在本发明实施例中,音频批量分割装置包括:待匹配文本识别单元21、文本匹配单元22以及小音频分割单元23,其中:
待匹配文本识别单元21,用于获取录音文本以及录音后的音频,将音频进行语音识别,得到对应的待匹配文本。
在本发明实施例中,根据已有的录音文本进行录音,得到录音后的音频,录音之后需要对该音频进行处理,通过语音识别技术得到识别后的待匹配文本,该待匹配文本是对应该音频识别出的文本数据。
进一步地,该待匹配文本识别单元21包括:临时分割单元211以及待匹配文本识别子单元212,其中:
临时分割单元211,用于根据说话的时间间隔,将音频分割为临时音频段;以及
待匹配文本识别子单元212,用于将临时音频段进行语音识别,得到对应的待匹配文本。
具体地,为了降低数据处理量,可以通过预处理将音频根据说话的时间间隔进行临时分割,得到临时音频段,然后对该临时音频段进行语音识别,得到对应的待匹配文本。
文本匹配单元22,用于将待匹配文本与录音文本进行匹配。
在本发明实施例中,通过对音频进行语音识别得到待匹配文本,将待匹配文本与录音文本进行匹配。
进一步地,该文本匹配单元22包括:字符串单元221以及文本匹配子单元222,其中:
字符串单元221,用于获取待匹配文本的字符串;以及
文本匹配子单元222,用于将待匹配文本的字符串与录音文本的字符串进行逐字符匹配。
具体地,获取待匹配文本的字符串,通过将待匹配文本的字符串与录音文本的字符串进行逐字符匹配,有效地保证了匹配的精确度,同时提高匹配效率。
小音频分割单元23,用于根据预设匹配度,从音频中分割出对应的小音频段。
在本发明实施例中,将待匹配文本与录音文本进行匹配,根据预设匹配度,从音频中分割出对应的小音频段,该小音频段包括对应字、词、短语和\或句子的音频。
进一步地,该小音频分割单元23,包括:
分割子单元231,用于当待匹配文本与录音文本的匹配度大于预设匹配度时,从音频中分割出对应的小音频段,该小音频段包括对应字、词、短语和\或句子的音频。
具体地,当待匹配文本与录音文本的匹配度为全完匹配时,从音频中分割出对应的小音频段,还可以通过预设匹配度,将大于预设匹配度的待匹配文本所对应的音频中分割出对应的小音频段。根据实际经验,可以将预设匹配度设定为60%-80%。
又进一步地,该小音频分割单元23,还包括:
提取单元232,用于当待匹配文本与录音文本的匹配度小于预设匹配度时,从录音文本中提取出未匹配到的文本。
具体地,将待匹配文本与录音文本进行匹配,当待匹配文本与录音文本的匹配度小于预设匹配度时,从录音文本中提取出未匹配到的文本,以便于后期再次对该未匹配到的文本,进一步进行处理。
在本发明实施例中,将录音后的音频通过语音识别得到待匹配文本,将待匹配文本与录音文本进行匹配后,从音频中分割出对应的小音频段,通过语音识别与文本匹配,实现将录音的音频,按录音文本的要求,直接批量分割成多个小音频段,无需逐个一一加标识再导出分割小音频段,从而提高拆分效率,节约人力成本以及降低出错率。
在本发明实施例中,音频批量分割装置的各单元可由相应的硬件或软件单元实现,各单元可以为独立的软、硬件单元,也可以集成为一个软、硬件单元,在此不用以限制本发明。该装置各单元的实施方式具体可参考前述实施例一的描述,在此不再赘述。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!