语音分割的方法及装置与流程
本发明涉及语音处理技术领域,尤其涉及一种语音分割的方法及装置。
背景技术:
目前,呼叫中心接收到的语音很多都混杂有多人的语音,这时需要先对语音进行语音分割(speaker diarization),才能进一步对目标语音进行语音分析。语音分割是指:在语音处理领域,当多个说话人的语音被合并录在一个声道中时,把信号中每个说话人的语音分别进行提取。传统的语音分割技术是基于全局背景模型和高斯混合模型进行分割,由于技术的限制,这种语音分割的方法分割的精度并不高,特别是对于对话交替频繁、以及有交叠的对话分割效果差。
技术实现要素:
本发明的目的在于提供一种语音分割的方法及装置,旨在有效提高语音分割的精度。
为实现上述目的,本发明提供一种语音分割的方法,其特征在于,所述语音分割的方法包括:
S1,自动应答系统在接收到终端发送的混合语音时,将所述混合语音分割成多个短语音段,并对各短语音段标注对应的说话人标识;
S2,利用时间递归神经网络对各说话人标识对应的短语音段建立声纹模型,基于所述声纹模型调整所述混合语音中对应的分割边界,以分割出各说话人标识对应的有效语音段。
优选地,所述步骤S1包括:
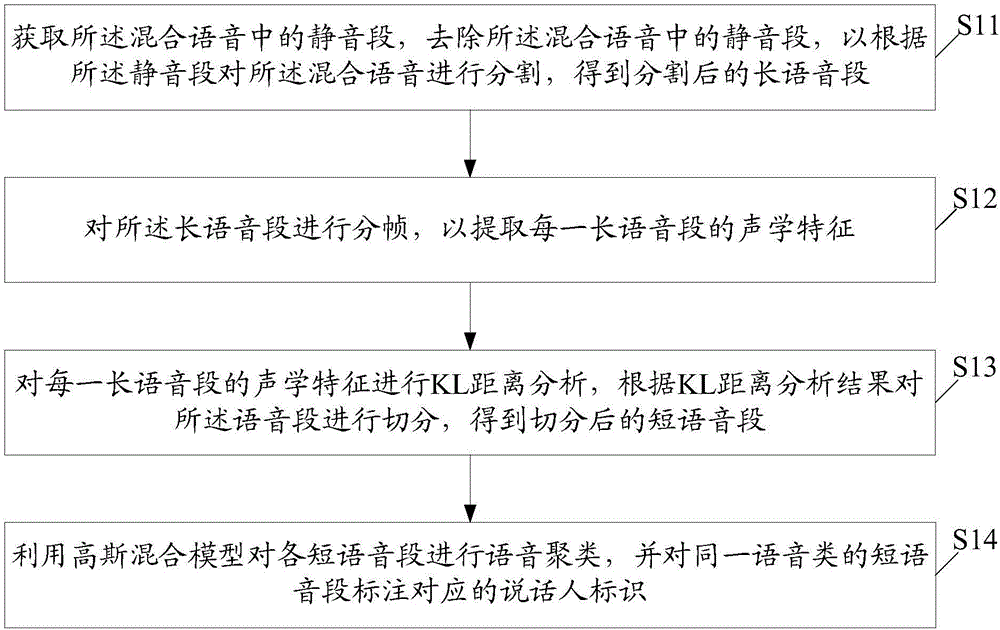
S11,获取所述混合语音中的静音段,去除所述混合语音中的静音段,以根据所述静音段对所述混合语音进行分割,得到分割后的长语音段;
S12,对所述长语音段进行分帧,以提取每一长语音段的声学特征;
S13,对每一长语音段的声学特征进行KL距离分析,根据KL距离分析结果对所述语音段进行切分,得到切分后的短语音段;
S14,利用高斯混合模型对各短语音段进行语音聚类,并对同一语音类的短语音段标注对应的说话人标识。
优选地,所述步骤S13包括:
对每一长语音段的声学特征进行KL距离分析,对时长大于预设时间阈值的长语音段在KL距离的最大值处进行切分,得到切分后的短语音段。
优选地,所述步骤S2包括:
S21,利用所述时间递归神经网络对各说话人标识对应的短语音段建立声纹模型,基于所述声纹模型提取表征说话人身份特征的预设类型向量;
S22,基于所述预设类型向量计算每一语音帧属于对应的说话人的最大后验概率;
S23,基于所述最大后验概率并利用预定算法调整该说话人的混合高斯模型;
S24,基于调整后的混合高斯模型获取每一语音帧对应的概率最大的说话人,并根据概率最大的说话人与语音帧的概率关系调整所述混合语音中对应的分割边界;
S25,迭代更新所述声纹模型n次,每次更新所述声纹模型时迭代m次所述混合高斯模型,以得到各说话人对应的有效语音段,n及m均为大于1的正整数。
优选地,所述步骤S2之后还包括:
基于所述有效语音段获取对应的应答内容,并将所述应答内容反馈给所述终端。
为实现上述目的,本发明还提供一种语音分割的装置,所述语音分割的装置包括:
分割模块,用于在接收到终端发送的混合语音时,将所述混合语音分割成多个短语音段,并对各短语音段标注对应的说话人标识;
调整模块,用于利用时间递归神经网络对各说话人标识对应的短语音段建立声纹模型,基于所述声纹模型调整所述混合语音中对应的分割边界,以分割出各说话人标识对应的有效语音段。
优选地,所述分割模块包括:
去除单元,用于获取所述混合语音中的静音段,去除所述混合语音中的静音段,以根据所述静音段对所述混合语音进行分割,得到分割后的长语音段;
分帧单元,用于对所述长语音段进行分帧,以提取每一长语音段的声学特征;
切分单元,用于对每一长语音段的声学特征进行KL距离分析,根据KL距离分析结果对所述语音段进行切分,得到切分后的短语音段;
聚类单元,用于利用高斯混合模型对各短语音段进行语音聚类,并对同一语音类的短语音段标注对应的说话人标识。
优选地,所述切分单元具体用于对每一长语音段的声学特征进行KL距离分析,对时长大于预设时间阈值的长语音段在KL距离的最大值处进行切分,得到切分后的短语音段。
优选地,所述调整模块包括:
建模单元,用于利用所述时间递归神经网络对各说话人标识对应的短语音段建立声纹模型,基于所述声纹模型提取表征说话人身份特征的预设类型向量;
计算单元,用于基于所述预设类型向量计算每一语音帧属于对应的说话人的最大后验概率;
第一调整单元,用于基于所述最大后验概率并利用预定算法调整该说话人的混合高斯模型;
第二调整单元,用于基于调整后的混合高斯模型获取每一语音帧对应的概率最大的说话人,并根据概率最大的说话人与语音帧的概率关系调整所述混合语音中对应的分割边界;
迭代单元,用于迭代更新所述声纹模型n次,每次更新所述声纹模型时迭代m次所述混合高斯模型,以得到各说话人对应的有效语音段,n及m均为大于1的正整数。
优选地,所述语音分割的装置还包括:反馈模块,用于基于所述有效语音段获取对应的应答内容,并将所述应答内容反馈给所述终端。
本发明的有益效果是:本发明首先将混合语音进行分割,分割成多个短语音段,每一短语音段对应标识一个说话人,利用时间递归神经网络对各短语音段建立声纹模型,由于利用时间递归神经网络建立的声纹模型能够关联说话人跨时间点的声音信息,因此基于该声纹模型实现对短语音段的分割边界的调整,能够有效提高语音分割的精度,特别是对于对话交替频繁、以及有交叠的语音,语音分割的效果较好。
附图说明
图1为本发明语音分割的方法一实施例的流程示意图;
图2为图1所示步骤S1的细化流程示意图;
图3为图1所示步骤S2的细化流程示意图;
图4为本发明语音分割的装置一实施例的结构示意图;
图5为图4所示分割模块的结构示意图;
图6为图4所示调整模块的结构示意图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
如图1所示,图1为本发明语音分割的方法一实施例的流程示意图,该语音分割的方法包括以下步骤:
步骤S1,自动应答系统在接收到终端发送的混合语音时,将所述混合语音分割成多个短语音段,并对各短语音段标注对应的说话人标识;
本实施例中可应用于呼叫中心的自动应答系统中,例如保险呼叫中心的自动应答系统、各种客服呼叫中心的自动应答系统等等。自动应答系统接收到终端发送的原始的混合语音,该混合语音中混合有多种不同的声源产生的声音,例如有多人说话混合的声音,多人说话的声音与其他噪声混合的声音等等。
本实施例可以利用预定的方法将混合语音分割成多个短语音段,例如可以利用高斯混合模型(Gaussian Mixture Model,GMM)将混合语音分割成多个短语音段,当然,也可以利用其他传统的方法将混合语音分割成多个短语音段。
其中,经本实施例的语音分割后,每一短语音段应只对应一说话人,不同的短语音段中可能有多个短语音段属于同一个说话人,将同一个说话人的不同短语音段进行相同的标识。
步骤S2,利用时间递归神经网络对各说话人标识对应的短语音段建立声纹模型,基于所述声纹模型调整所述混合语音中对应的分割边界,以分割出各说话人标识对应的有效语音段。
本实施例中,时间递归神经网络模型(Long-Short Term Memory,LSTM)拥有递归神经网络在传统前向反馈神经网络中引入的定向循环,用以处理层间输入前后、层内输出前后的关联。用时间递归神经网络在语音序列上建模,可以得到跨越时间点的语音信号特征,可以用于对关联信息处于任何长度、任何位置的语音序列进行处理。时间递归神经网络模型通过神经网络层内设计多个交互层,可以记忆到更远时间节点上的信息,在时间递归神经网络模型中用“忘记门层”丢弃与识别任务不相关的信息,接着用“输入门层”决定需要更新的状态,最后确定需要输出的状态并处理输出。
本实施例对于各说话人标识对应的短语音段,利用时间递归神经网络建立声纹模型,通过该声纹模型可以得到说话人跨越时间点的声音信息,基于这些声音信息可以调整混合语音中对应的分割边界,以对每一说话人对应的所有短语音段调整其分割边界,最终分割出各说话人标识对应的有效语音段,该有效语音段可以看作对应的说话人的完整语音。
与现有技术相比,本实施例首先将混合语音进行分割,分割成多个短语音段,每一短语音段对应标识一个说话人,利用时间递归神经网络对各短语音段建立声纹模型,由于利用时间递归神经网络建立的声纹模型能够关联说话人跨时间点的声音信息,因此基于该声纹模型实现对短语音段的分割边界的调整,能够有效提高语音分割的精度,特别是对于对话交替频繁、以及有交叠的语音,语音分割的效果较好。
在一优选的实施例中,如图2所示,在上述图1的实施例的基础上,上述步骤S1包括:
步骤S11,获取所述混合语音中的静音段,去除所述混合语音中的静音段,以根据所述静音段对所述混合语音进行分割,得到分割后的长语音段;
步骤S12,对所述长语音段进行分帧,以提取每一长语音段的声学特征;
步骤S13,对每一长语音段的声学特征进行KL距离分析,根据KL距离分析结果对所述语音段进行切分,得到切分后的短语音段,
步骤S14,利用高斯混合模型对各短语音段进行语音聚类,并对同一语音类的短语音段标注对应的说话人标识。
本实施例中,首先根据静音进行初步分割:确定混合语音中的静音段,将确定的静音段从混合语音中去除,以实现将混合语音根据静音段进行分割,静音段是通过对混合语音的短时语音能量和短时过零率的分析来确定的。
去除静音段后,首先假设在整个混合语音中,每人每次讲话时长为固定阈值Tu,若某段语音大于该时长,则可能多人说话,若小于该时长,则更可能只有一个人说话,基于这种假设,可以对静音分割后的每个长语音段的时长大于固定阈值Tu的语音段的声学特征进行帧间KL距离分析。当然,也可以对所有的长语音段的声学特征进行帧间KL距离分析。具体地,对得到的长语音段进行分帧,以得到每一长语音段的语音帧,提取语音帧的声学特征,对所有长语音段的声学特征进行KL距离(也即相对熵)分析,其中,声学特征包括但不限定于线性预测系数、倒频谱系数MFCC、平均过零率、短时频谱、共振峰频率及带宽。
其中,KL距离分析的含义是对于两个离散型的声学特征概率分布集合P={p1,p2,…,pn}和Q={q1,q2,…,qn},P和Q间的KL距离:当KL距离越大时,PQ两者差异越大,即PQ这两个集合来自两个不同人的语音。优选地,对时长大于预设时间阈值的长语音段在KL的最大值处进行切分,以提高语音分割的精度。
长语音段经过切分后得到短语音段,短语音段的数量大于长语音段的数量。然后进行短语音段聚类:对切分后的短语音段进行聚类,以将所有短语音段聚为多个语音类,并为各个短语音段标注对应的说话人标识,其中,属于同一语音类的短语音段标注相同的说话人标识,不属于同一语音类的短语音段标注不同的说话人标识。聚类方法是:采用K个成分的高斯混合模型拟合每段短语音段,以均值作为特征向量,使用k-means聚类方法把所有短语音段聚为多类。
在一优选的实施例中,如图3所示,在上述的实施例的基础上,上述步骤S2包括:
步骤S21,利用所述时间递归神经网络对各说话人标识对应的短语音段建立声纹模型,基于所述声纹模型提取表征说话人身份特征的预设类型向量;
步骤S22,基于所述预设类型向量计算每一语音帧属于对应的说话人的最大后验概率;
步骤S23,基于所述最大后验概率并利用预定算法调整该说话人的混合高斯模型;
步骤S24,基于调整后的混合高斯模型获取每一语音帧对应的概率最大的说话人,并根据概率最大的说话人与语音帧的概率关系调整所述混合语音中对应的分割边界;
步骤S25,迭代更新所述声纹模型n次,每次更新所述声纹模型时迭代m次所述混合高斯模型,以得到各说话人对应的有效语音段,n及m均为大于1的正整数。
本实施例中,利用时间递归神经网络对各说话人标识对应的短语音段建立声纹模型,基于所述声纹模型提取表征说话人身份特征的预设类型向量,优选地,该预设类型向量为i-vector向量,i-vector向量是反映说话人声学差异的一个重要特征。
在整个混合语音中,根据预设类型向量计算每一语音帧属于某一说话人的最大后验概率,利用计算最大后验概率,在混合语音中通过预设算法重新调整说话人的混合高斯模型,例如,通过Baum-Welch算法重新调整说话人的混合高斯模型,该混合高斯模型为k(一般为3-5个)个高斯模型的集合。利用重新调整后的混合高斯模型寻找每一语音帧概率最大的说话人。根据语音帧与寻找到的该说话人的概率关系调整混合语音的分割边界,例如将分割边界向前微调或者向后微调。最后,迭代更新上述声纹模型n次,每次更新声纹模型时迭代m次混合高斯模型,以得到各个说话人对应的有效语音段,n及m均为大于1的正整数。
本实施例借助深度学习的时间递归神经网络建立声纹模型,用各说话人声纹对应的身份特征对应各语音帧以计算语音帧属于某一说话人的概率,基于该概率修正模型,最终调整语音分割的边界,可以有效提高说话人语音分割的精度,降低错误率,且可扩展性好。
在一优选的实施例中,在上述的实施例的基础上,该方法在上述步骤S2之后还包括:基于所述有效语音段获取对应的应答内容,并将所述应答内容反馈给所述终端。
本实施例中,自动应答系统关联对应的应答库,该应答库中存储有不同的问题对应的应答内容,自动应答系统在接收到终端发送的混合语音后,将其分割为说话人标识对应的有效语音段,从这些有效语音段中获取与该自动应答系统有关问题的一个有效语音段,针对该有效语音段在应答库中进行匹配,并将匹配得到的应答内容反馈给终端。
如图4所示,图4为本发明语音分割的装置一实施例的结构示意图,该语音分割的装置包括:
分割模块101,用于在接收到终端发送的混合语音时,将所述混合语音分割成多个短语音段,并对各短语音段标注对应的说话人标识;
本实施例的语音分割的装置中包括自动应答系统,例如保险呼叫中心的自动应答系统、各种客服呼叫中心的自动应答系统等等。自动应答系统接收到终端发送的原始的混合语音,该混合语音中混合有多种不同的声源产生的声音,例如有多人说话混合的声音,多人说话的声音与其他噪声混合的声音等等。
本实施例可以利用预定的方法将混合语音分割成多个短语音段,例如可以利用高斯混合模型(Gaussian Mixture Model,GMM)将混合语音分割成多个短语音段,当然,也可以利用其他传统的方法将混合语音分割成多个短语音段。
其中,经本实施例的语音分割后,每一短语音段应只对应一说话人,不同的短语音段中可能有多个短语音段属于同一个说话人,将同一个说话人的不同短语音段进行相同的标识。
调整模块102,用于利用时间递归神经网络对各说话人标识对应的短语音段建立声纹模型,基于所述声纹模型调整所述混合语音中对应的分割边界,以分割出各说话人标识对应的有效语音段。
本实施例中,时间递归神经网络模型(Long-Short Term Memory,LSTM)拥有递归神经网络在传统前向反馈神经网络中引入的定向循环,用以处理层间输入前后、层内输出前后的关联。用时间递归神经网络在语音序列上建模,可以得到跨越时间点的语音信号特征,可以用于对关联信息处于任何长度、任何位置的语音序列进行处理。时间递归神经网络模型通过神经网络层内设计多个交互层,可以记忆到更远时间节点上的信息,在时间递归神经网络模型中用“忘记门层”丢弃与识别任务不相关的信息,接着用“输入门层”决定需要更新的状态,最后确定需要输出的状态并处理输出。
本实施例对于各说话人标识对应的短语音段,利用时间递归神经网络建立声纹模型,通过该声纹模型可以得到说话人跨越时间点的声音信息,基于这些声音信息可以调整混合语音中对应的分割边界,以对每一说话人对应的所有短语音段调整其分割边界,最终分割出各说话人标识对应的有效语音段,该有效语音段可以看作对应的说话人的完整语音。
在一优选的实施例中,如图5所示,在上述图4的实施例的基础上,上述分割模块101包括:
去除单元1011,用于获取所述混合语音中的静音段,去除所述混合语音中的静音段,以根据所述静音段对所述混合语音进行分割,得到分割后的长语音段;
分帧单元1012,用于对所述长语音段进行分帧,以提取每一长语音段的声学特征;
切分单元1013,用于对每一长语音段的声学特征进行KL距离分析,根据KL距离分析结果对所述语音段进行切分,得到切分后的短语音段;
聚类单元1014,用于利用高斯混合模型对各短语音段进行语音聚类,并对同一语音类的短语音段标注对应的说话人标识。
本实施例中,首先根据静音进行初步分割:确定混合语音中的静音段,将确定的静音段从混合语音中去除,以实现将混合语音根据静音段进行分割,静音段是通过对混合语音的短时语音能量和短时过零率的分析来确定的。
去除静音段后,首先假设在整个混合语音中,每人每次讲话时长为固定阈值Tu,若某段语音大于该时长,则可能多人说话,若小于该时长,则更可能只有一个人说话,基于这种假设,可以对静音分割后的每个长语音段的时长大于固定阈值Tu的语音段的声学特征进行帧间KL距离分析。当然,也可以对所有的长语音段的声学特征进行帧间KL距离分析。具体地,对得到的长语音段进行分帧,以得到每一长语音段的语音帧,提取语音帧的声学特征,对所有长语音段的声学特征进行KL距离(也即相对熵)分析,其中,声学特征包括但不限定于线性预测系数、倒频谱系数MFCC、平均过零率、短时频谱、共振峰频率及带宽。
其中,KL距离分析的含义是对于两个离散型的声学特征概率分布集合P={p1,p2,…,pn}和Q={q1,q2,…,qn},P和Q间的KL距离:当KL距离越大时,PQ两者差异越大,即PQ这两个集合来自两个不同人的语音。优选地,对时长大于预设时间阈值的长语音段在KL的最大值处进行切分,以提高语音分割的精度。
长语音段经过切分后得到短语音段,短语音段的数量大于长语音段的数量。然后进行短语音段聚类:对切分后的短语音段进行聚类,以将所有短语音段聚为多个语音类,并为各个短语音段标注对应的说话人标识,其中,属于同一语音类的短语音段标注相同的说话人标识,不属于同一语音类的短语音段标注不同的说话人标识。聚类方法是:采用K个成分的高斯混合模型拟合每段短语音段,以均值作为特征向量,使用k-means聚类方法把所有短语音段聚为多类。
在一优选的实施例中,如图6所示,在上述实施例的基础上,上述调整模块102包括:
建模单元1021,用于利用所述时间递归神经网络对各说话人标识对应的短语音段建立声纹模型,基于所述声纹模型提取表征说话人身份特征的预设类型向量;
计算单元1022,用于基于所述预设类型向量计算每一语音帧属于对应的说话人的最大后验概率;
第一调整单元1023,用于基于所述最大后验概率并利用预定算法调整该说话人的混合高斯模型;
第二调整单元1024,用于基于调整后的混合高斯模型获取每一语音帧对应的概率最大的说话人,并根据概率最大的说话人与语音帧的概率关系调整所述混合语音中对应的分割边界;
迭代单元1025,用于迭代更新所述声纹模型n次,每次更新所述声纹模型时迭代m次所述混合高斯模型,以得到各说话人对应的有效语音段,n及m均为大于1的正整数。
本实施例中,利用时间递归神经网络对各说话人标识对应的短语音段建立声纹模型,基于所述声纹模型提取表征说话人身份特征的预设类型向量,优选地,该预设类型向量为i-vector向量,i-vector向量是反映说话人声学差异的一个重要特征。
在整个混合语音中,根据预设类型向量计算每一语音帧属于某一说话人的最大后验概率,利用计算最大后验概率,在混合语音中通过预设算法重新调整说话人的混合高斯模型,例如,通过Baum-Welch算法重新调整说话人的混合高斯模型,该混合高斯模型为k(一般为3-5个)个高斯模型的集合。利用重新调整后的混合高斯模型寻找每一语音帧概率最大的说话人。根据语音帧与寻找到的该说话人的概率关系调整混合语音的分割边界,例如将分割边界向前微调或者向后微调。最后,迭代更新上述声纹模型n次,每次更新声纹模型时迭代m次混合高斯模型,以得到各个说话人对应的有效语音段,n及m均为大于1的正整数。
本实施例借助深度学习的时间递归神经网络建立声纹模型,用各说话人声纹对应的身份特征对应各语音帧以计算语音帧属于某一说话人的概率,基于该概率修正模型,最终调整语音分割的边界,可以有效提高说话人语音分割的精度,降低错误率,且可扩展性好。
在一优选的实施例中,在上述的实施例的基础上,所述语音分割的装置还包括:反馈模块,用于基于所述有效语音段获取对应的应答内容,并将所述应答内容反馈给所述终端。
本实施例中,自动应答系统关联对应的应答库,该应答库中存储有不同的问题对应的应答内容,自动应答系统在接收到终端发送的混合语音后,将其分割为说话人标识对应的有效语音段,从这些有效语音段中获取与该自动应答系统有关问题的一个有效语音段,针对该有效语音段在应答库中进行匹配,并将匹配得到的应答内容反馈给终端。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!