一种机器人及其语音识别方法与流程
本发明涉及机器人技术领域,尤其涉及一种机器人及其语音识别方法。
背景技术:
语音识别技术是先将一段录音转换为文字,再对转换成的文字进行语义分析,通过语义分析生成语义答案,进而实现对于语音的识别。
随着科学技术的发展,人们的生活越来越智能化,机器人技术的应用也越来越广泛。当前的机器人普遍应用语音识别技术对接收的语音信息进行转换、分析,在得到语义答案后,即可执行相应的任务或者通过语言合成进行语言答复。
但是当前的机器人,在进行语音识别或者语言合成的期间,若用户再发出语音命令或者语音询问,机器人将会保持当前操作,而无法进行连续语音识别,进而错过用户当前的语音命令或者语音询问。
技术实现要素:
有鉴于此,本发明提供了一种机器人及其语音识别方法,以解决现有技术中的机器人无法进行连续语音识别的问题。
为实现上述目的,本申请提供的技术方案如下:
一种机器人的语音识别方法,所述方法包括:
在执行语音处理操作的同时,实时监测外界信息;所述语音处理操作为:语音识别或者语言合成;
在所述外界信息中存在唤醒信息的情况下,根据所述唤醒信息与控制指令之间的预设对应关系,查找到与所述唤醒信息相对应的控制指令;所述控制指令至少包括对用户当前输入的语音进行语音识别;
响应所述控制指令。
优选的,所述实时监测外界信息包括:实时监听外界环境中的语音信息;所述唤醒信息为:唤醒词;
或者,所述实时监测外界信息包括:实时采集外界环境中的图像信息;所述唤醒信息为:唤醒手势。
优选的,所述控制指令,包括:
中断所述语音处理操作,对所述用户当前输入的语音进行语音识别;
或者,维持所述语音处理操作,同时对所述用户当前输入的语音进行语音识别。
优选的,所述对所述用户当前输入的语音进行语音识别,包括:
采集用户当前输入的语音并生成录音;
将所述录音转换为文字;
对所述文字进行语义分析,得到语义答案。
优选的,所述采集用户当前输入的语音并生成录音,包括:
采集用户当前输入的语音并进行录制;
在采集完上一段语音之后的预设静音段时长内,若未再采集到语音,则完成录制,生成所述录音。
一种机器人,包括处理器,所述处理器包括:
监测模块,用于在执行语音处理操作的同时,实时监测外界信息;所述语音处理操作为:语音识别或者语言合成;
查找模块,用于在所述外界信息中存在唤醒信息的情况下,根据所述唤醒信息与控制指令之间的预设对应关系,查找到与所述唤醒信息相对应的控制指令;所述控制指令至少包括对用户当前输入的语音进行语音识别;
响应模块,用于响应所述控制指令。
优选的,所述监测模块用于实时监测外界信息时,具体用于:实时监听外界环境中的语音信息;所述唤醒信息为:唤醒词;
或者,所述监测模块用于实时监测外界信息时,具体用于:实时采集外界环境中的图像信息;所述唤醒信息为:唤醒手势。
优选的,所述处理器还包括:
中断模块,用于在所述响应模块对用户当前输入的语音进行语音识别之前,中断所述语音处理操作;
或者,维持模块,用于在所述响应模块对用户当前输入的语音进行语音识别同时,维持所述语音处理操作;
或者,所述机器人还包括:
另一处理器,用于在所述响应模块对用户当前输入的语音进行语音识别同时,维持所述语音处理操作。
优选的,所述响应模块用于响应所述控制指令时,具体用于:
采集用户当前输入的语音并生成录音;
将所述录音转换为文字;
对所述文字进行语义分析,得到语义答案。
优选的,所述响应模块用于采集用户当前输入的语音并生成录音时,具体用于:
采集用户当前输入的语音并进行录制;
在采集完上一段语音之后的预设静音段时长内,若未再采集到语音,则完成录制,生成所述录音。
由上述方案可知,本发明提供的机器人及其语音识别方法,在执行语音识别或者语言合成的语音处理操作的同时,实时监测外界信息,以确定外界信息中是否存在唤醒信息;并在外界信息中存在唤醒信息的情况下,根据唤醒信息与控制指令之间的预设对应关系,查找到与唤醒信息相对应的控制指令;然后响应控制指令,对用户当前输入的语音进行语音识别;也即,当机器人正在进行语音识别或者语言合成时,一旦监测到外界信息中存在唤醒信息,即对用户当前输入的语音进行语音识别,进而对于用户输入的语音实现连续识别,确保能够接收到用户最新发出的语音命令或者语音询问。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的机器人的语音识别方法的流程图;
图2为本发明另一实施例提供的机器人的语音识别方法的部分流程图;
图3为本发明另一实施例提供的处理器的结构示意图;
图4为本发明另一实施例提供的处理器的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供了一种机器人的语音识别方法,以解决现有技术中的机器人无法进行连续语音识别的问题。
参见图1,该机器人的语音识别方法,包括:
S101、在执行语音处理操作的同时,实时监测外界信息;
语音处理操作为:语音识别或者语言合成;
当机器人正在对用户输入的上一段语音进行语音识别时,或者,机器人正在根据上一次语音识别的结果进行语言合成时,用户也有可能再发出一段新的语音命令或者语音询问,因此,这些情况下,机器人需要时刻保持对于外界信息的监测。在具体的实际应用中,从机器人开机后,即可以时刻保持对于外界信息的监测,以确定用户是否发出语音命令或者语音询问,进而执行后续操作。
优选的,可以通过实时监听外界环境中的语音信息,或者,通过实时采集外界环境中的图像信息,来实现对于外界信息的实时监测;此处不做具体限定,均在本申请的保护范围内。
S102、在外界信息中存在唤醒信息的情况下,根据唤醒信息与控制指令之间的预设对应关系,查找到与唤醒信息相对应的控制指令;
控制指令至少包括对用户当前输入的语音进行语音识别;
具体的,用户再输入一段语音后,可能会对上一段语音所表达的内容想要进行补充或者修改,此时用户可以通过该唤醒信息告知机器人,将要再输入一段语音,需要机器人重新进行语音识别。
当通过实时监听外界环境中的语音信息,来实现对于外界信息的实时监测时,该唤醒信息为:唤醒词,比如“你好”、“稍等一下”等等,此处不做具体限定,可以根据用户的语言习惯进行设定。
当通过实时采集外界环境中的图像信息,来实现对于外界信息的实时监测时,该唤醒信息为:唤醒手势,比如摆手等动作,此处不做具体限定,可以根据用户的操作习惯进行设定。
当然,在具体的实际应用中,该唤醒信息还可以设定为其他内容,此处不做具体限定,可以视其具体应用环境而定,均在本申请的保护范围内。
在机器人应用之前,首先为机器人提前设置好唤醒信息与控制指令之间的预设对应关系,当机器人监测到唤醒信息时,能够查找到相应的控制指令,至少触发新的语音识别操作,进而能够及时识别用户当前输入的语音命令或者语音询问。
S103、响应控制指令。
对相应的控制指令进行响应后,即对用户当前输入的语音进行语音识别,即可确保能够接收到用户最新输入的语音命令或者语音询问。
本实施例提供的该机器人的语音识别方法,当机器人正在进行语音识别或者语言合成时,一旦监测到外界信息中存在唤醒信息,即对用户当前输入的语音进行语音识别,进而对于用户输入的语音实现连续识别,确保能够接收到用户最新发出的语音命令或者语音询问。
本发明另一实施例还提供了另外一种机器人的语音识别方法,在上述实施例及图1的基础之上,其控制指令包括:
中断语音处理操作,对用户当前输入的语音进行语音识别;
或者,维持语音处理操作,同时对用户当前输入的语音进行语音识别。
当监测的外界信息中存在唤醒信息时,机器人可以直接中断当前正在进行的语音处理操作,比如语音识别或者语言合成;或者,也可以在输出一段预设语音提示之后,比如“请稍等”之类的语音提示,再中断当前的操作;然后再进行新的语音识别。该预设语音提示可以根据具体应用环境进行设定,此处不做具体限定,均在本申请的保护范围内。
或者,也可以维持当前正在进行的语音处理操作,同时对用户当前输入的语音进行语音识别。具体可以视其应用环境而定,此处不做具体限定,均在本申请的保护范围内。
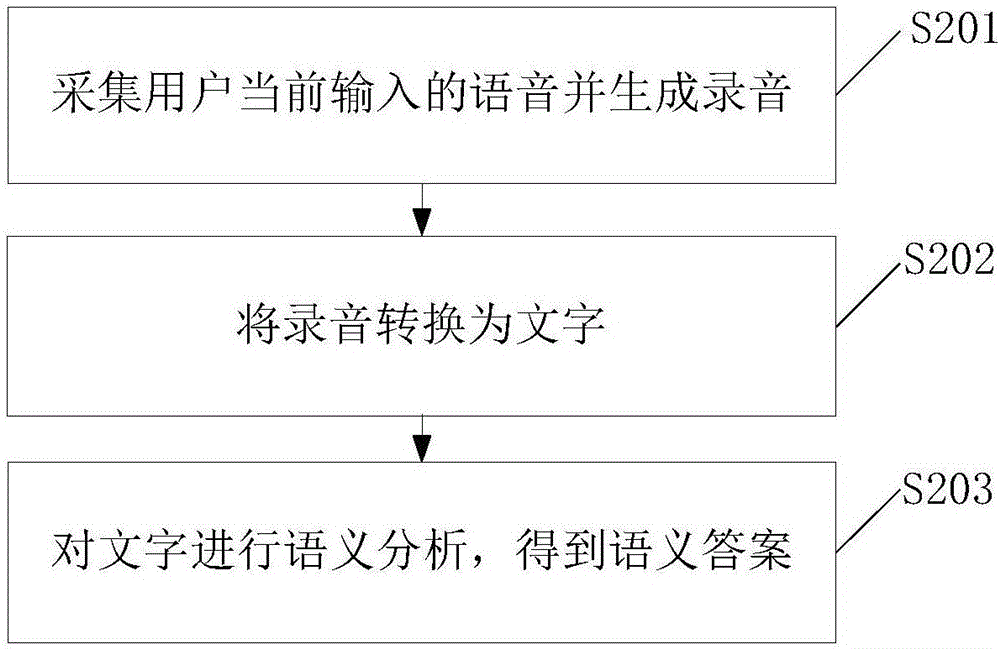
优选的,对用户当前输入的语音进行语音识别的过程,具体可以参见图2,包括:
S201、采集用户当前输入的语音并生成录音;
S202、将录音转换为文字;
S203、对文字进行语义分析,得到语义答案。
当机器人监测到用户发出唤醒信息,则无论机器人正在进行语音识别还是语言合成,都将按顺序开始执行图3中的各个步骤,即进入语音识别过程。
优选的,图2中的步骤S201,包括:
采集用户当前输入的语音并进行录制;
在采集完上一段语音之后的预设静音段时长内,若未再采集到语音,则完成录制,生成录音。
在具体的实际应用中,可以为语音识别进行静音段的时间设置,具体可以包括预设的前静音段和后静音段,设置前静音段目的是等待用户语音输入的时间,设置后静音段的作用是确认用户语音输入结束等待时间;这两个静音段不能太长也不能特别短,太长了感觉有迟延,太短了会截断用户后面的语音输入。其具体时长可以根据实际应用环境而定,此处不做具体限定,均在本申请的保护范围内。
综上,可以得到,该机器人的语音识别方法,时刻保持对外界信息的监测,当监测到用户发出唤醒信息时,便可随时中断当前正在进行的语音处理操作,进入语音识别过程,以实现机器人的连续语音识别功能;当识别到语义答案后,即通过语言合成进行相应的语言答复。
本发明另一实施例还提供了一种机器人,包括处理器,该处理器参见图3,包括:
监测模块101,用于在执行语音处理操作的同时,实时监测外界信息;语音处理操作为:语音识别或者语言合成;
查找模块102,用于在外界信息中存在唤醒信息的情况下,根据唤醒信息与控制指令之间的预设对应关系,查找到与唤醒信息相对应的控制指令;控制指令至少包括对用户当前输入的语音进行语音识别;
响应模块103,用于响应控制指令。
优选的,监测模块101用于实时监测外界信息时,具体用于:实时监听外界环境中的语音信息;唤醒信息为:唤醒词;
或者,监测模块101用于实时监测外界信息时,具体用于:实时采集外界环境中的图像信息;唤醒信息为:唤醒手势。
优选的,处理器参见图4,还包括:
中断模块104,用于在响应模块对用户当前输入的语音进行语音识别之前,中断语音处理操作;
或者,维持模块105,用于在响应模块对用户当前输入的语音进行语音识别同时,维持语音处理操作;
或者,机器人还包括:
另一处理器,用于在响应模块对用户当前输入的语音进行语音识别同时,维持语音处理操作。
优选的,响应模块103用于响应控制指令时,具体用于:
采集用户当前输入的语音并生成录音;
将录音转换为文字;
对文字进行语义分析,得到语义答案。
优选的,响应模块103用于采集用户当前输入的语音并生成录音时,具体用于:
采集用户当前输入的语音并进行录制;
在采集完上一段语音之后的预设静音段时长内,若未再采集到语音,则完成录制,生成录音。
其他具体的工作原理与上述实施例相同,此处不再一一赘述。
本发明中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!