一种模块化机器人语音识别算法及其语音识别模块的制作方法
本发明涉及语音识别技术领域,具体地,涉及一种模块化机器人语音识别算法及其语音识别模块。
背景技术:
经过近五十多年的发展,语音识别技术在许多应用领域显示出巨大的应用前景。语音识别属于多维模式识别及智能计算机接口的范畴,是集声学、语音学、计算机、信息处理、人工智能等领域的综合技术,在工业、军事、交通、医学和民用等各领域得到了非常广泛的应用,例如自动语音信息获取系统、语言翻译系统、机器人系统、声控电话交换、语音拨号系统、信息网络查询、家庭服务、听写机、计算机控制系统等。目前大多数语音识别系统的关键技术都是基于HMM模型而开发的,HMM是一种统计模型,模型参数的估计需要大量的训练数据,而且训练过程计算量大,耗时长,运算起来极为复杂,在一般的硬件下根本不可能运行。而对于模块化机器人的声控部分来说,语音识别算法复杂,而且它对语音识别的准确率不高,只能模糊根据语音的高低进行语音识别。在申请公布号为CN 103971676A的中国发明专利中,公开了一种快速语音孤立词识别算法,采用过零率语音信号的特征参数进行提取,较好地解决了特征参数提取的问题,但还没有解决小型机器人语音识别模块化等问题。
技术实现要素:
本发明的目的在于提供一种模块化机器人语音识别算法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种模块化机器人语音识别算法,包括以下步骤:
S1、对语音特征函数f(x)间隔采样,得到m个函数值(X0(E),X1(E),L,Xm(E));
S2、以X0,X1,L,Xm作为希尔伯特空间的坐标,将时域中的特征函数f(X)={X0(E),X1(E),L,Xm(E)}转化为m维希尔伯特空间中的点,并将语音采样函数族F(x)转化为了希尔伯特空间中的一系列点;
S3、将希尔伯特空间作为语音信号新的特征空间,对F(x)系列点之间的相似关系进行分析,并采取高维超球覆盖方法得到模式识别模块;
S4、在希尔伯特空间中,对语音信号进行模式识别,完成语音识别。
在数学中,一般来说希尔伯特空间是对欧几里德空间的推广,因此并不像欧几里德空间,主要是在二维及三维空间里进行研究,其并不局限在有限的空间里。希尔伯特空间与欧几里德空间的主要不同之处在于欧几里德空间不是完备的,而希尔伯特空间却是完备的。在希尔伯特空间内引入了正交和投影的概念,这样可以在此空间内运用几何学的相关理论。在有限维空间里的向量的范数等于向量模的大小。假设在一个实或复向量空间H上定义了内积<x,y>,这里的内积是指定义了一种运算,不可逆地可以从任意两个向量得到一个标量,则上述空间的范数公式如下所示:
如果其对于这个范数来说是完备的,此空间称为是一个希尔伯特空间。这里的完备性是指,任何一个柯西序列都收敛到此空间中的某个元素,即它们与某个元素的范数差的极限为0。任何有限维内积空间例如欧几里德空间及其上的点积,都是希尔伯特空间。内积可以帮助人们从“几何的”观点来研究希尔伯特空间,并使用有限维空间中的几何语言来描述希尔伯特空间。在所有的无穷维拓扑向量空间中,希尔伯特空间性质最好,也最接近有限维空间的情形。
优选的,对于n维特征空间,做出不同的超球体,通过它们来覆盖空间内不同语音的样本点,求出n维超球方程为:
(X1-X1a)2+(X2-X2a)2+L+(Xn-Xna)2=R2。
优选的,所述S1步骤中采用的语音信号的特征函数为过零谱函数。这里,提取了的语音信号的特征参数——过零谱后,将过零谱函数在希尔伯特空间中展开也就得到了语音信号的特征空间。在这个语音特征空间中,不同语音样本点的相似度低,所以它们会相对分散,而同一语音的样本点相似度高,那么这些点就会大概聚在一起,最后能够形成一个类的类群。所以在特征空间中采用超球体来覆盖样本点的方法。
优选的,从特征提取到模式识别算法中不包含FFT运算。
与现有技术相比,本发明的有益效果是:本模块化机器人语音识别算法,在模式识别阶段,提出了基于希尔伯特空间的超球覆盖语音识别算法,在特征提取阶段,提取出了新的特征参数——过零谱,大大减小了语音特征提取阶段的算法复杂度;该算法较现有算法而言,使用了新的特征参数并提出新的模式识别算法,两个阶段都没有做FFT,复杂度低且识别率提高,比较简单,适合于较小的模块化机器人的声控系统。
这里,还提供一种模块化机器人语音识别模块,包括壳体、固定于壳体上的电路板、语音输入单元、信号输出单元,所述语音输入单元、信号输出单元分别与电路板连接,所述电路板上加载了包含实现模块化机器人语音识别算法的软件程序。这种模块化机器人语音识别模块,便于应用于机器人小型化的语音识别中,具有体积小、反应快、识别率高的特点。
附图说明
图1为本发明实施例的语音特征函数曲线f(x);
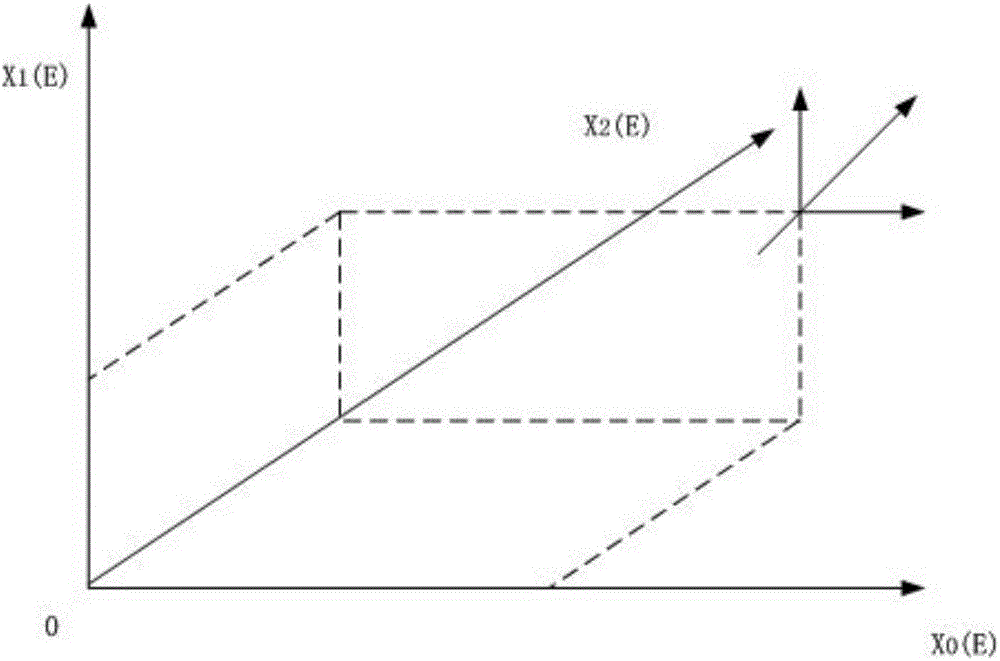
图2为图1所示曲线f(x)的m个函数值构成的向量(X0(E),X1(E),L,Xm(E))转化为m维空间里的点f(X)={X0(E),X1(E),L,Xm(E)}的映射图;
图3为本发明实施例的语音识别模块结构示意图;
其中:1.电路板,2.壳体,3.语音输入单元,4.信号输出单元。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参照图1、图2所示,一种模块化机器人语音识别算法,包括以下步骤:
S1、对语音特征函数f(x)间隔采样,得到m个函数值(X0(E),X1(E),L,Xm(E));
S2、以X0,X1,L,Xm作为希尔伯特空间的坐标,将时域中的特征函数f(X)={X0(E),X1(E),L,Xm(E)}转化为m维希尔伯特空间中的点,并将语音采样函数族F(x)转化为了希尔伯特空间中的一系列点;
S3、将希尔伯特空间作为语音信号新的特征空间,对F(x)系列点之间的相似关系进行分析,并采取高维超球覆盖方法得到模式识别模块;
S4、在希尔伯特空间中,对语音信号进行模式识别,完成语音识别。
图1的曲线图表示的是f(x)这个语音函数,其中横坐标表示时间,分别用X0,X1,L,Xt-n,Xt,Xt+n,L,Xm表示,纵坐标表示每个时间点所对应的语音值,分别用X0(E),X1(E),L,Xm(E)表示;如图2所示,主要列举了f(x)的三个函数值构成的向量(X0(E),X1(E),X2(E)转化为三维空间里的点f(X)={X0(E),X1(E),X2(E)}的映射图。对超过三维的空间,可以依此类推。
进一步的,对于n维特征空间,做出不同的超球体,通过它们来覆盖空间内不同语音的样本点,求出n维超球方程为:
(X1-X1a)2+(X2-X2a)2+L+(Xn-Xna)2=R2。
进一步的,所述S1步骤中采用的语音信号的特征函数为过零谱函数。
进一步的,从特征提取到模式识别算法中不包含FFT运算。
下面以语音“开”“关”两个字为例,对本发明进行进一步说明。
采用过零率对语音特征参数进行提取:
选取“开”“关”两个字,对录下的八组“开”“关”语音信号进行分帧、去噪、端点检测等处理,其中每组“开”“关”语音都被分成了16帧,然后求出各自的每一帧的过零谱。
过零谱其实就是一种时频函数。提取过零谱的过程分为如下几步:
第一步:首先是预处理过程,对语音信号进行分帧处理,本文中将语音信号都是分成16帧,然后进行端点检测;
第二步:寻找出每一帧语音信号的过零点,并记录其过零点的位置;
第三步:过零点个数作为x轴坐标,上步记录的过零点的位置作为y轴坐标,在二维坐标画出曲线,得到的即为过零谱函数曲线图。
在整个算法过程中,由于只计算了语音信号的过零点,因此其算法复杂度是O(n)。把过零谱参数与需要做FFT复杂算法的频域参数比较的话,计算过零谱的算法相对简单;与时域参数比较的话,系统识别率要高于时域参数。
基于希尔伯特空间的超球覆盖语音识别算法:
在二维空间中假设语音的第一帧样本点为(X11(E),X12(E)),第二帧样本点为(X21(E),X22(E)),以此类推可得全部十六帧的样本点。将第一帧样本点转化为二维特征空间的(X11(E),X12(E)),将第二帧样本点转化为二维特征空间的点(X21(E),X22(E)),同理可将余下各帧样本点转化为二维特征空间的点。本文“开”“关”各有16组数据,所以在二维特征空间中每一帧都可得到16个样本点。以其中一帧为例,利用圆覆盖样本点的算法步骤如下所示:
步骤1:曲线拟合。将样本点用一次线性拟合得到y与x的近似关系
y=kx+d
εi=yi-(kix+d) i=1,2,L,n
其中εi为(xi,yi)到拟合点(xi,kix+d)的误差,k、d为待定系数。
根据最小均方误差准则可得:
再根据极值原理
确定未知量k和d的值,这样可以得到一次直线拟合函数。
步骤2:求圆的圆心。
求出所有样本点在直线y=kx+d上的投影(xi',yi'),其中i=1,2,L,n。找出投影点中相距最远的点min(xi',yi'),max(x'j,y'j),过这两点分别作直线y1垂直于y0,y2垂直于y0。则圆的圆心坐标为
步骤3:求圆的半径。
找出所有样本点中离直线y=kx+d最远的点P(xd,yd),则圆的半径为则最后求出的圆为(x-xa)2+(y-ya)2=R2。
假设语音的第一帧样本点为(X11(E),X12(E),X13(E)),第二帧样本点(X21(E),X22(E),X23(E)),第三帧样本点(X31(E),X32(E),X33(E)),以此类推下去可得全部十六帧的样本点。将第一帧样本点转化为三维特征空间的点(X11(E),X12(E),X13(E)),将第二帧样本点转化为三维特征空间的点(X21(E),X22(E),X23(E)),将第二帧样本点转化为三维特征空间的点(X31(E),X32(E),X33(E)),同理可将余下各帧样本点转化为三维特征空间的点。
对于三维特征空间,最后的目的是做出不同的球体,通过它们来覆盖空间内不同语音的样本点。以其中一帧为例,具体的算法步骤如下所示:
第一步,首先按照在二维空间中的直线拟合方法,假设存在着一个平面z1=k1x+k2y+d,由最小均方误差准则会得到令解得k1、k2、d,则该平面的法向量为
第二步,在上一步的基础上,滑动该法平面,记使z1可以过样本点的两个临界位置为(xi',yi',zi'),(x'j,y'j,z'j),令zi'>z'j,则球的圆心坐标为
第三步,求出球的半径。
找出所有样本点中离直线最远的点Q(xd,yd,zd),则球的半径为
则最后得到球的方程为
Φ(x,y,z)=(x-xa)2+(y-ya)2+(z-za)2=R2。
如果是n维希尔伯特空间,假设语音的第i帧样本点为(Xi1(E),Xi2(E),L,Xin(E))则转化到n维希尔伯特空间会得到点{Xi1(E),Xi2(E),L,Xin(E)}。首先根据最小均方误差准则,求出一个n-1维超平面,再将空间内所有样本点投影到此超平面上,则投影点可视为n-1维空间内的样本点,如此反复,最后即可将n维空间降为三维空间,再根据上述算法,类比上式就可求出n维超球方程为
(x1-x1a)2+(x2-x2a)2+L+(xn-xna)2=R2。
参照图3所示,一种模块化机器人语音识别模块,包括壳体2、固定于壳体上的电路板1、语音输入单元3、信号输出单元4,所述语音输入单元3、信号输出单元4分别与电路板1连接,所述电路板1上加载了包含实现模块化机器人语音识别算法的软件程序。这里,语音识别模块可对语音“开”“关”信号进行准确识别。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!