一种兼容非常态语音的智能家居控制系统及方法与流程
本发明涉及智能家居领域,具体涉及一种兼容非常态语音的智能家居控制系统及方法。
背景技术:
语言是人类最重要的交际工具,也是最自然的交互方式。作为一种人机交互方式,语音识别的目的就是让机器能“听懂”人类的语言。经过几十年的研究,语音识别技术已经应用到普通人的生活当中。随着生活水平的不断提高,智能家居的概念已经进入人们的日常生活,利用先进的计算机、嵌入式系统和网络通讯技术,提供安全舒适、宜人的高品位家庭生活。将语音识别技术引入到智能家居控制中,通过语音命令同样能够对家电控制,代替手动和遥控控制。
但是在实际应用场景中,语音识别系统的准确性受到许多因素的影响。现实生活中,用户受身体健康原因导致变声,常见的感冒导致的非常态语音,改变了说话人个性特征的分布,导致感冒语音与采用常态语音训练得到的语音识别模型不匹配,从而使语音识别系统的识别准确性显著下降。
技术实现要素:
本发明的主要目的在于克服现有技术的缺点与不足,提供了一种兼容非常态语音的智能家居控制系统及方法,
为了达到上述目的,本发明采用以下技术方案:
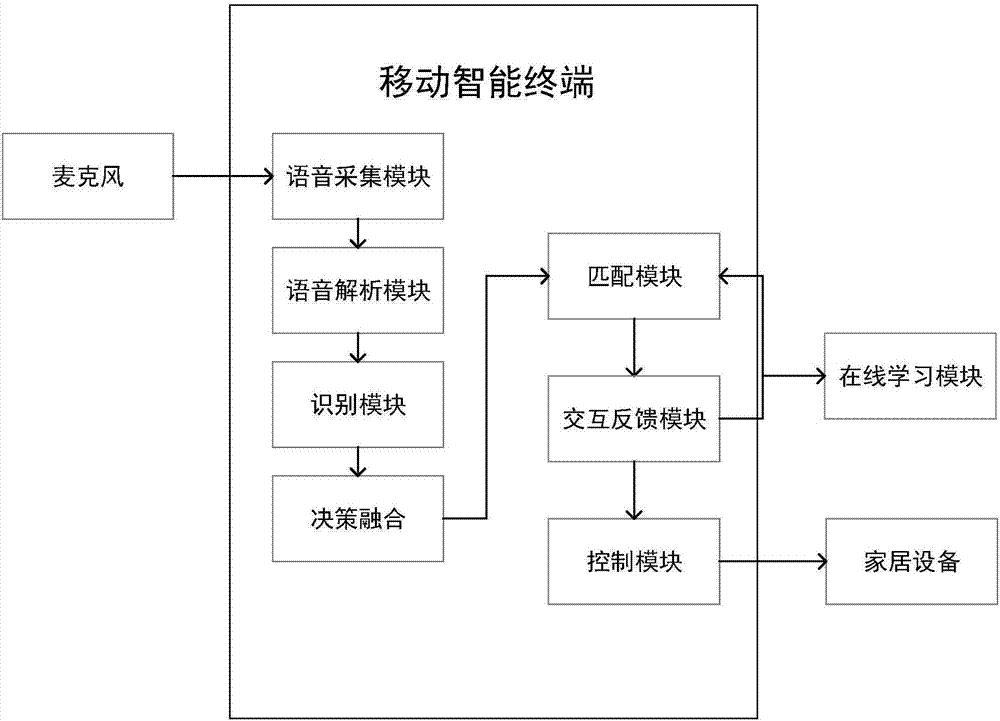
本发明提供的一种兼容非常态语音的智能家居控制系统,包括:语音解析模块、识别模块、决策融合模块、匹配模块、交互反馈模块、控制模块和在线学习模块;
所述语音解析模块,对输入的语音进行声学特征提取,通过svm分类器确定所述语音的状态类型,即根据最大后验概率确定该输入语音是常态语音状态类型还是非常态语音状态类型;
所述识别模块,对所述语音采用对应的识别模型进行语音识别;
所述决策融合模块,根据svm计算状态类型的后验概率和各识别模型的概率,以加权评分的投票策略进行决策融合;
所述匹配模块,将决策融合的输出结果与预设的执行动作、设备名称、情景模式匹配;
所述交互反馈模块,根据匹配模块的输出结果给出不同的语音交互反馈;
所述控制模块,当用户反馈识别内容正确,发送控制指令来控制智能家居设备的工作状态;
所述在线学习模块,当用户反馈识别内容错误,将语音以在线学习的方式存储到服务器中,更新系统语音模板。
作为优选的技术方案,所述语音解析模块中,包括提取所述语音的样本特征参数,样本特征参数包括:反映声带特征的基音频率、反映声道形状的共振峰频率以及人耳听觉模型的梅尔倒谱频率系数mfcc,然后对样本特征参数进行归一化,将基因频率、共振峰频率和mfcc统一到一个标准参考系中。
作为优选的技术方案,所述svm分类器是预先建立的,将提取的语音特征输入svm分类器后,进行下述处理:
在训练阶段,将不同声音状态的语音作为训练数据,进行语音特征提取和标注;
根据提取的语音特征,使用libsvm工具建立对应语音的状态类型的svm模型;
所述识别模块中,通过隐马尔可夫模型hmm建立对应声音状态的语音模板,并采集用户处于不同语音状态时的语音特征样本,其中,语音模块包括基音频率、共振峰频率、mfcc中的一种或多种;同时,排除不同说话人之间的性别、说话习惯和声道个性的干扰,建立语音模板。
作为优选的技术方案,所述决策融合模块中,采用下述方法:
svm分类器计算语音状态类型的后验概率;
得到各隐马尔可夫模型hmm语音模型识别的最大概率和次最大概率的文本;
根据文本以加权评分的投票策略进行决策融合,所述加权评分的投票策略具体方法如下:
常态语音类型和非常态语音类型是svm分类器的两类,分别用x1,x2代表,α1、α2是语音数据通过svm分类器计算x1,x2得出的后验概率,其中α2=1-α1;hmm识别模型包括常态语音hmm模型和非常态语音hmm模型;g11、g12是所述语音通过常态语音hmm识别模型得出的最大概率对应的文本、次大概率对应的文本,p11、p12是其对应文本的概率;g21、g22是所述语音通过非常态语音hmm模型识别得出的最大概率对应的文本、次最大概率对应的文本,p21、p22是其对应文本的概率;
inputsvm的输出α1,α2和hmm模型识别结果文本g11,g12,g21,g22及其概率p11,p12,p21,p22;
output最终识别结果gm;
step1:ifg11=g21,then{output=gm=g11;end};
setp2:ifg11≠g21and(g11=g22,g12=g21)then
end;
step3:ifg11≠g21≠g12and(g11=g22),then
end;
step4:ifg11≠g21≠g12≠g22,then
end。
作为优选的技术方案,所述匹配模块中,将识别内容与预设的执行动作、设备名称、情景模式匹配,包括:
匹配成功,则进入交互反馈模块;
匹配失败,则进入在线学习模块;
所述的交互反馈模块,用于对匹配模块得出的输出结果作出反馈,其步骤如下:
根据输出结果,系统发问:“你说的是不是……”;
用户反馈“是”,识别正确则触发控制模块发送控制指令来控制智能家居设备的工作状态;
当用户反馈“不是”,识别错误则进入在线学习模块。
作为优选的技术方案,所述的在线学习模块,是通过用户的反馈来处理缓存的语音文件,在线更新系统语音模板,其步骤如下:
当接收到用户反馈识别错误时,对于识别过程中始终缓存未识别语音缓存文件,系统返回语音提示“你的语音无法正确识别,是不是更新语音库”;
当用户确认“是”,则提示用户更正错误并将缓存语音文件赋以正确指令标号存储至服务器;
当用户确认“不是”或者没有回应,则删除缓存语音文件。
作为优选的技术方案,在线更新系统语音模板中,通过识别模块得到hmm模型参数,采用最大似然线性回归算法mllr对模型状态结构做自适应,考虑到用户储存至服务器的语音有限性,只对模型的均值做自适应,其他参数保持不变,进一步补偿状态调整后的模型与用户语音状态之间的不匹配。
本发明还提供了一种兼容非常态语音的智能家居控制方法,包括下述步骤:
(1)对输入语音的语音特征进行解析,并根据解析结果确定所述语音的状态类型,状态类型包括常态语音和非常态语音,所述非常态语音是指说话人发音器官功能失调的语音;
(2)对输入语音信息进行处理,提取语音特征,对样本特征参数进行归一化,将具有不同生理意义和单位的声音特征参数统一到一个标准参考系中,归一化公式如下:
其中max是样本数据的最大值,min是样本数据的最小值;
(3)在接收到语音信息后,智能终端可对语音信息进行处理,如果语音特征与感冒、鼻塞、咽喉炎、声带疲劳非常态语音模板匹配,则可确定用户声音状态异常;如果语音特征与身体状态良好时的正常语音模板匹配,则可确定用户声音正常;
(4)根据所述语音的状态类型采用与所述语音的状态类型对应的识别模型,得到识别内容,采用隐马尔可夫模型hmm建立对应的语音模板,需要排除不同说话人之间的性别、说话习惯和声道个性的干扰,来建立语音模板;
(5)根据svm计算状态类型的后验概率和各识别模型的概率,以加权评分的投票策略进行决策融合;
(6)根据所述语音的状态类型采用与所述语音的状态类型对应的识别模型,得到识别内容,将识别内容与预设的执行动作、设备名称、情景模式匹配,如果匹配成功则进入交互反馈环节,匹配失败则进入在线学习环节;
(7)对匹配模块得出的输出结果作出反馈,其步骤:
根据输出结果,系统发问:“你说的是不是……”;用户反馈“是”,识别正确则触发控制模块发送控制指令来控制智能家居设备的工作状态;当用户反馈“不是”,识别错误则进入在线学习模块;
(8)通过用户的反馈来正确处理缓存的语音文件,在线更新系统语音模型,其步骤:当接收到用户反馈识别错误时,对于识别过程中始终缓存未识别语音缓存文件,统返回语音提示“你的语音无法正确识别,是不是更新语音库”;当用户确认“是”,则提示用户更正错误并将缓存语音文件赋以正确指令标号存储至服务器;当用户确认“不是”或者没有回应,则删除缓存语音文件。
作为优选的技术方案,步骤(3)中,对语音信息进行处理为提取语音的样本特征参数,样本特征参数包括:反映声带特征的基音频率、反映声道形状的共振峰频率、人耳听觉模型的梅尔倒谱系数mfcc;将所述语音特征输入到预先建立的svm分类器,根据最大后验概率对应的模型确定所述语音的状态类型;
在语音特征输入到预先建立的svm分类器之前,还包括以下:在训练阶段,将不同声音状态的语音作为训练数据,进行语音特征提取和标注,根据提取的语音特征,使用libsvm工具建立对应语音的状态类型的svm模型;另外,在输入到svm分类器之前,可先收集多用户处于不同语音状态下的语音文件,提取语音特征参数,并将特征参数输入svm训练,通过svm训练得出感冒和正常语音不同特征矢量的混合分类模型。
作为优选的技术方案,步骤(5)中,加权评分的投票策略进行决策融合的方法为:
常态语音类型和非常态语音类型是svm分类器的两类,分别用x1,x2代表,α1、α2是语音数据通过svm分类器计算x1,x2得出的后验概率,其中α2=1-α1;hmm识别模型包括常态语音hmm模型和非常态语音hmm模型;g11、g12是所述语音通过常态语音hmm识别模型得出的最大概率对应的文本、次大概率对应的文本,p11、p12是其对应文本的概率;g21、g22是所述语音通过非常态语音hmm模型识别得出的最大概率对应的文本、次最大概率对应的文本,p21、p22是其对应文本的概率;
inputsvm的输出α1,α2和hmm模型识别结果文本g11,g12,g21,g22及其概率p11,p12,p21,p22;
output最终识别结果gm;
step1:ifg11=g21,then{output=gm=g11;end};
setp2:ifg11≠g21and(g11=g22,g12=g21)then
end;
step3:ifg11≠g21≠g12and(g11=g22),then
end;
step4:ifg11≠g21≠g12≠g22,then
end。
本发明与现有技术相比,具有如下优点和有益效果:
本发明简单实用,对用户的语音信息处理进行特征提取,确定用户的语音状态,采用对应的语音模板进行识别和决策融合,解决了因用户语音状态发生改变导致系统识别率下降的问题,提高系统的语音识别率和适应性。本系统能在一段交互过程后,将用户反馈识别错误的语音段以在线学习的方式存储到服务器中,不断扩展和更新以适应用户的不同语音状态,更加智能化,提升用户体验,能广泛应用于智能家居相关领域。
附图说明
图1是本发明的兼容非常态语音的智能家居控制系统及方法的流程图;
图2是本发明中的移动智能终端的结构示意图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
如图1所示,本实施例兼容非常态语音的智能家居控制方法包括:
打开app客户端,启动语音采集,接收用户输入的语音信息。
在本发明的一个实施例中,智能终端可接收用户输入的语音信息。其中,智能终端包括但不仅限于智能手机、平板电脑、智能机器人等具有语音识别功能的智能设备。举例来说,用户可以在智能终端说出“打开电视机”。
对输入语音的语音特征进行解析,并根据解析结果确定所述语音的状态类型。非常态语音是指说话人发音器官功能失调的语音,包括感冒、鼻塞、咽喉炎、声带疲劳等声音。
对输入语音信息进行处理,提取语音特征,需要对样本特征参数进行归一化,将具有不同生理意义和单位的声音特征参数统一到一个标准参考系中,归一化公式如下:
其中max是样本数据的最大值,min是样本数据的最小值。
在接收到语音信息后,智能终端可对语音信息进行处理,如果语音特征与感冒、鼻塞、咽喉炎、声带疲劳等非常态语音模板匹配,则可确定用户声音状态异常。如果语音特征与身体状态良好时的正常语音模板匹配,则可确定用户声音正常。举例来说,假设得到的最大后验概率对应的模型是感冒,则可确定用户声音状态异常,属于非常态语音。假设得到的最大后验概率对应的模型是咽喉炎,则可确定用户声音状态异常,属于非常态语音。
具体地,提取语音的样本特征参数,包括:反映声带特征的基音频率、反映声道形状的共振峰频率、人耳听觉模型的梅尔倒谱系数(mfcc)。将所述语音特征输入到预先建立的svm分类器,根据最大后验概率对应的模型确定所述语音的状态类型。
语音特征输入到预先建立的svm分类器之前,还包括以下:在训练阶段,将不同声音状态的语音作为训练数据,进行语音特征提取和标注,根据提取的语音特征,使用libsvm工具建立对应语音的状态类型的svm模型。另外,在输入到svm分类器之前,可先收集多用户处于不同语音状态下的语音文件,提取语音特征参数,并将特征参数输入svm训练,通过svm训练得出感冒和正常语音不同特征矢量的混合分类模型。
根据所述语音的状态类型采用与所述语音的状态类型对应的识别模型,得到识别内容,采用隐马尔可夫模型(hmm)建立对应的语音模板。需要排除不同说话人之间的性别、说话习惯和声道个性的干扰,来建立语音模板。
兼容非常态语音的智能家居控制系统及方法的加权评分的投票策略,具体算法说明如下:
常态语音类型和非常态语音类型是svm分类器的两类,分别用x1,x2代表,α1、α2是语音数据通过svm分类器计算x1,x2得出的后验概率,其中α2=1-α1;hmm识别模型包括常态语音hmm模型和非常态语音hmm模型;g11、g12是所述语音通过常态语音hmm识别模型得出的最大概率对应的文本、次大概率对应的文本,p11、p12是其对应文本的概率;g21、g22是所述语音通过非常态语音hmm模型识别得出的最大概率对应的文本、次最大概率对应的文本,p21、p22是其对应文本的概率;
inputsvm的输出α1,α2和hmm模型识别结果文本g11,g12,g21,g22及其概率p11,p12,p21,p22;
output最终识别结果gm。
step1:ifg11=g21,then{output=gm=g11;end};
setp2:ifg11≠g21and(g11=g22,g12=g21)then
end;
step3:ifg11≠g21≠g12and(g11=g22),then
end;
step4:ifg11≠g21≠g12≠g22,then
end。
根据所述语音的状态类型采用与所述语音的状态类型对应的识别模型,得到识别内容,将识别内容与预设的执行动作、设备名称、情景模式匹配,如果匹配成功则进入交互反馈环节,匹配失败则进入在线学习环节。
交互反馈模块主要用于对匹配模块得出的输出结果作出反馈,其步骤:根据输出结果,系统发问:“你说的是不是……”;用户反馈“是”,识别正确则触发控制模块发送控制指令来控制智能家居设备的工作状态;当用户反馈“不是”,识别错误则进入在线学习模块。
在线学习模块,是通过用户的反馈来正确处理缓存的语音文件,在线更新系统语音模型,其步骤:当接收到用户反馈识别错误时,对于识别过程中始终缓存未识别语音缓存文件,统返回语音提示“你的语音无法正确识别,是不是更新语音库”;当用户确认“是”,则提示用户更正错误并将缓存语音文件赋以正确指令标号存储至服务器;当用户确认“不是”或者没有回应,则删除缓存语音文件。
一个具体的实施例中,预设的执行动作包括打开、关闭等,预设的设备名称包括空调、电视机、风扇、窗帘等,预设的情景模式有音量调大、风量减小、上一首、下一首等。当然,预设的执行动作、设备名称、情景模式是需要根据家居设置的,并不限于以上几种。
在本发明的一个实施例中,预设的设备有电视机、空调。用户说出“打开电视机”,第一步进行语音特征提取。第二步进行语音解析,选择常态语音模板识别和非常态语音模板进行识别,根据后验概率和识别概率进行决策融合。第三步,得到语音识别内容“打开电视机”。第四步,与“打开”“电视机”逐一进行匹配。第五步,匹配成功,进入交互反馈模块则系统发问“你说的是不是打开电视机”,用户反馈“是”,则发送控制指令打开电视机。第六步,若匹配不成功,则系统发问“你的语音无法正确识别,是不是更新语音库”,用户回答“是”,则提示用户更正错误并将缓存语音文件赋以正确指令标号存储至服务器,用户回答“不是”或者没有回应,则删除缓存语音文件。在电视机打开的时候,用户说出“湖南卫视”,和以上步骤相同,发送控制指令,电视机频道切换到“湖南卫视”。用户可直接用语音切换电视频道。
若用户的语音无法正确识别,通过用户的反馈来正确处理缓存的语音文件,在线更新系统语音模型,其步骤如下:当接收到用户反馈识别错误时,对于识别过程中始终缓存未识别语音缓存文件;系统返回语音提示“你的语音无法正确识别,是不是更新语音库”;当用户确认“是”,则提示用户更正错误并将缓存语音文件赋以正确指令标号存储至服务器;当用户确认“不是”或者没有回应,则删除缓存语音文件。
在本发明的一个实施例中,用户说出“打开空调”,得到错误的识别结果,用户反馈识别错误,系统返回语音提示“你的语音无法正确识别,是否加入语音库”,当用户反馈“是”,则等待用户更正错误,标记为“打开空调”的正确指令标号,也就是将缓存语音段赋以正确指令标号存储,当用户反馈“不是”或者没有回应,则删除缓存语音段。
实施本发明的兼容非常态语音的智能家居控制系统及方法,具有以下有益效果:本发明简单实用,对用户的语音信息处理进行特征提取,确定用户的语音状态,采用对应的语音模板进行识别和决策融合提高系统的语音识别率和适应性。本系统能在一段交互过程后,将用户反馈识别错误的语音段以在线学习的方式存储到服务器中,不断扩展和更新以适应用户的不同语音状态,更加智能化,提升用户体验,能广泛应用于智能家居相关领域。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!