一种基于声纹模型训练的机器人语音识别控制方法与流程
本发明涉及语音识别技术,尤其涉及一种基于声纹模型训练的机器人语音识别控制方法。
背景技术:
目前,现有的很多机器人虽然具备语音识别的功能,但是在进行语音识别之前并没有对用户进行身份认证,这对用户的隐私安全造成极大的隐患。
技术实现要素:
针对现有的技术存在的上述问题,现提供一种基于声纹模型训练的机器人语音识别控制方法的技术方案,具体如下:
一种基于声纹模型训练的机器人语音识别控制方法,其中,所述方法包括:
接收用户的语音数据;
判断机器人当前语音识别模式为特定人语音识别模式或非特定人语音识别模式;
当判断机器人当前语音识别模式为特定人语音识别模式时,对所述语音数据进行声纹认证和语音识别;
当判断机器人当前语音识别模式为非特定人语音识别模式时,对所述语音数据进行语音识别。
优选的,接收用户的语音数据之前,需要建立背景模型库和用户声纹模型,还包括:
采用联合因子分析模型构建说话人空间、信道空间和残差空间三个子空间;所述联合因子分析模型的高斯均值向量表征为:
mki=mk+ukxi+vkys(i)+dkzks(i)
其中,k代表第k个高斯模型,i代表某一个语音段,s(i)表示说话人s的某一语音段,mk表示独立于说话人和会话内容的均值向量,uk表示特征信道矩阵,vk表示特征说话人矩阵,dk表示残差空间矩阵;xi表示信道因子向量,ys(i)表示依赖于说话人的声纹因子向量,zks(i)表示依赖于说话人和单个高斯模型的残差因子向量。
优选的,建立背景模型库包括:
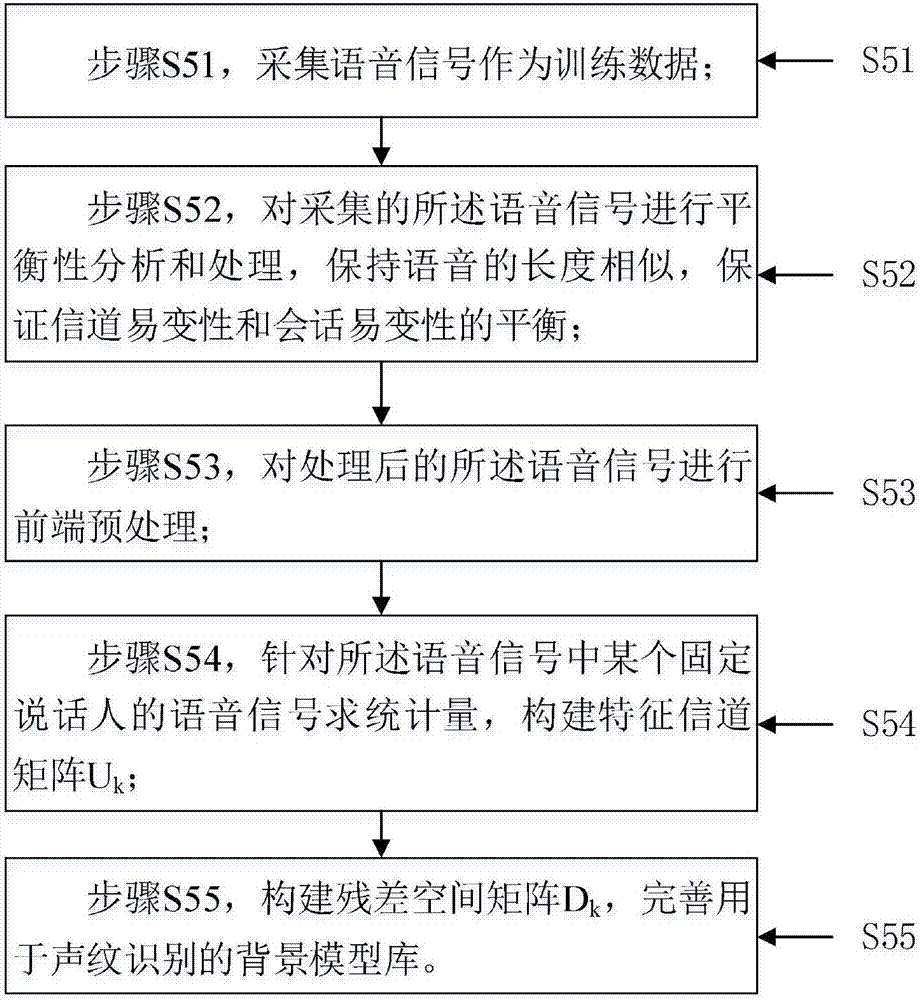
采集语音信号作为训练数据;
对采集的所述语音信号进行平衡性分析和处理,保持语音的长度相似,保证信道易变性和会话易变性的平衡;
对处理后的所述语音信号进行前端预处理;
针对所述语音信号中某个固定说话人的语音信号求统计量,构建特征信道矩阵uk;
构建残差空间矩阵dk,完善用于声纹识别的背景模型库。
优选的,对处理后的语音信号进行前端预处理包括:
将所述语音信号分段加窗并计算得到梅尔频率倒谱系数的特征参数流数据;
通过所述特征参数流数据训练通用背景模型;
将所有所述语音信号根据最大后验准则将其自适应到说话人模型上,并通过构建特征音空间的方法对表征特定所述说话人模型的参数进行降维处理;
通过稀疏数据的em算法最大化所有训练数据中的整体似然度,针对所有说话人的语音信号求统计量,构建特征说话人矩阵vk。
优选的,建立用户声纹模型包括:
接受用户的训练语音;
根据所述训练语音建立用户声纹模型;
接受用户的测试语音;
对所述测试语音进行测试归一化和零归一化分数规整,放大用户和其他人的分数区别,以此设定门限值。
优选的,根据所述训练语音建立用户声纹模型包括:
对所述训练语音对应的声纹模型进行训练和识别,通过最大似然法训练模型对信道因子向量xi、依赖于用户的声纹因子向量ys(i)、依赖于用户和单个高斯模型的残差因子向量zks(i)进行最大后验概率估计,其中,ys(i)用以表征用户的特征向量,xi和zks(i)用以补偿信道易变性和会话易变性的干扰;
建立用户声纹模型。
优选的,当判断机器人当前语音识别模式为特定人语音识别模式时,对所述语音数据进行声纹认证和语音识别,所述声纹认证包括:
对所述语音数据进行前端处理,前端处理包括端点检测和语音增强;
采用所述通用背景模型作为说话人的特征向量,根据所述语音数据对残差因子向量zks(i)和信道因子向量xi进行估计,将估计后的参数与机器人记录的用户的特征向量ys(i)进行结合,计算所述语音数据对应的分数;
比较所述语音数据对应的分数与所述门限值的大小:
当所述语音数据对应的分数大于或等于所述门限值,则声纹认证成功,通过机器人的语音识别器对所述语音数据进行识别;
当所述语音数据对应的分数小于所述门限值,则拒绝进行语音识别。
优选的,当判断机器人当前语音识别模式为非特定人语音识别模式时,对所述语音数据进行语音识别,所述语音识别包括:
对所述语音数据进行前端处理,前端处理包括端点检测和语音增强;
通过机器人的语音识别器对所述语音数据进行识别。
上述技术方案的有益效果:提供一种基于声纹模型训练的机器人语音识别控制方法,可通过声纹认证对用户进行身份认证,同时也提供了针对非特定人的语音识别方法,用户可自主选择不同的语音识别模式以满足不同的需求。
附图说明
图1为本发明的较佳的实施例中,一种基于声纹模型训练的机器人语音识别控制方法流程示意图;
图2-7为本发明的较佳的实施例中,于图1的基础上,一种基于声纹模型训练的机器人语音识别控制方法的分步骤流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
一种基于声纹模型训练的机器人语音识别控制方法,其流程如图1,所述方法包括:
步骤s1,接收用户的语音数据;
步骤s2,判断机器人当前语音识别模式为特定人语音识别模式或非特定人语音识别模式;
步骤s3,当判断机器人当前语音识别模式为特定人语音识别模式时,对所述语音数据进行声纹认证和语音识别;
步骤s4,当判断机器人当前语音识别模式为非特定人语音识别模式时,对所述语音数据进行语音识别。
本发明的较佳的实施例中,接收用户的语音数据之前,需要建立背景模型库和用户声纹模型,还包括:
采用联合因子分析模型构建说话人空间、信道空间和残差空间三个子空间;所述联合因子分析模型的高斯均值向量表征为:
mki=mk+ukxi+vkys(i)+dkzks(i)
其中,k代表第k个高斯模型,i代表某一个语音段,s(i)表示说话人s的某一语音段,mk表示独立于说话人和会话内容的均值向量,uk表示特征信道矩阵,vk表示特征说话人矩阵,dk表示残差空间矩阵;xi表示信道因子向量,ys(i)表示依赖于说话人的声纹因子向量,zks(i)表示依赖于说话人和单个高斯模型的残差因子向量。
本发明的较佳的实施例中,如图2所示,建立背景模型库包括:
步骤s51,采集语音信号作为训练数据;使用机器人,让前期测试人员在不同时间地点采集自己的声音作为训练语料,语料需要进行人工标注,包括录音地点、传输方式和说话人的身份(id)。
步骤s52,对采集的所述语音信号进行平衡性分析和处理,保持语音的长度相似,保证信道易变性和会话易变性的平衡;信道易变性是指在室内,语音不可避免地会携带背景环境的信息,对声纹模型会有不同程度的影响;会话易变性是指同一用户,说话时的语气、感情、说话的内容和语种的不同会对声纹模型带来影响。
步骤s53,对处理后的所述语音信号进行前端预处理;
步骤s54,针对所述语音信号中某个固定说话人的语音信号求统计量,构建特征信道矩阵uk;
步骤s55,构建残差空间矩阵dk,完善用于声纹识别的背景模型库。将背景模型库存储在机器人的存储设备中。
为了降低和消除步骤s52中所提到的干扰对声纹识别系统性能的影响,patrickkenny等研究者提出了一种在传统的gmm-ubm(高斯混合模型-通用背景噪声模型)声纹识别系统基础上的改进模型算法,称为联合因子分析(jointfactoranalysis,jfa),该方法在nist2008说话人识别评比中取得了最优的成绩,并且能够有效处理易变性对声纹模型带来的干扰。
jfa模型是一种两层模型,基于经典的gmm-ubm框架。传统的gmm-ubm模型已经验证,不同声纹模型的差异只在于每个高斯的均值向量,而每个高斯模型的权重和方差都可以直接来源于ubm的取值。传统的ubm-gmm模型抛弃了训练语音中大量的信道信息和会话信息。而jfa模型构建了三个子空间:说话人空间、信道空间和残差空间,最终的高斯均值向量表征为:
mki=mk+ukxi+vkys(i)+dkzks(i)(i)
下标的含义如下,k代表第k个高斯模型,i代表某一个语音段(会话),s(i)表示说话人s的某一语音段i。上述公式中:mk表示独立于说话人和会话内容的均值向量,一般是取ubm中的相应高斯的均值向量;uk表示信道因子负载方阵;vk表示说话人因子负载方阵;dk表示说话人残差计量方阵,为对角矩阵;
以上矩阵都需要大量的背景数据进行训练,取得相应的最大似然的模型。这些训练过程都不需要用户参与。而隐藏的用户参数和会话参数需要机器人采集用户的声音进行训练和最大似然。这些隐藏的用户参数和会话参数为:xi代表依赖于会话的信道因子向量;ys(i)代表依赖于说话人的声纹因子向量;zks(i)表示依赖于说话人和单个高斯模型的残差因子向量;通常认为xi,ys(i)和zks(i)都是符合(0,1)分布的标准高斯分布。jfa通过引入的两个新的子空间(信道空间和残差空间)的参数估计,将信道易变性和会话易变性的影响考量进最终的声纹模型中,从而是最终的高斯均值向量(这个向量表征了每个特定的说话人的声纹特征)。
jfa模型使得声纹识别系统能够很好地抑制和消除语音接收设备带来的种种易变性干扰。
本发明的较佳的实施例中,如图3所示,对处理后的语音信号进行前端预处理包括:
步骤s531,将所述语音信号分段加窗并计算得到梅尔频率倒谱系数的特征参数流数据;
步骤s532,通过所述特征参数流数据训练通用背景模型;
步骤s533,将所有所述语音信号根据最大后验准则将其自适应到说话人模型上,并通过构建特征音空间的方法对表征特定所述说话人模型的参数进行降维处理;
步骤s534,通过稀疏数据的em算法最大化所有训练数据中的整体似然度,针对所有说话人的语音信号求统计量,构建特征说话人矩阵vk。em算法包括e步骤和m步骤,重复两个步骤进行迭代,直至收敛到一个很小的范围为止。
本发明的较佳的实施例中,如图4所示,建立用户声纹模型包括:
步骤s61,接受用户的训练语音;机器人通过专门的语音接收设备接收用户录入的各种语音。
步骤s62,根据所述训练语音建立用户声纹模型;
步骤s63,接受用户的测试语音;
步骤s64,对所述测试语音进行测试归一化和零归一化分数规整,放大用户和其他人的分数区别,以此设定门限值。
本发明的较佳的实施例中,如图5所示,根据所述训练语音建立用户声纹模型包括:
步骤s621,对所述训练语音对应的声纹模型进行训练和识别,通过最大似然法训练模型对信道因子向量xi、依赖于用户的声纹因子向量ys(i)、依赖于用户和单个高斯模型的残差因子向量zks(i)进行最大后验概率估计,其中,ys(i)用以表征用户的特征向量,xi和zks(i)用以补偿信道易变性和会话易变性的干扰;
步骤s622,建立用户声纹模型。
本发明的较佳的实施例中,如图6所示,当判断机器人当前语音识别模式为特定人语音识别模式时,对所述语音数据进行声纹认证和语音识别,所述声纹认证包括:
步骤s31,对所述语音数据进行前端处理,前端处理包括端点检测和语音增强;
步骤s32,采用所述通用背景模型作为说话人的特征向量,根据所述语音数据对残差因子向量zks(i)和信道因子向量xi进行估计,将估计后的参数与机器人记录的用户的特征向量ys(i)进行结合,计算所述语音数据对应的分数;
步骤s33,比较所述语音数据对应的分数与所述门限值的大小:
当所述语音数据对应的分数大于或等于所述门限值,则声纹认证成功,通过机器人的语音识别器对所述语音数据进行识别;
当所述语音数据对应的分数小于所述门限值,则拒绝进行语音识别。
本发明的较佳的实施例中,如图7所示,当判断机器人当前语音识别模式为非特定人语音识别模式时,对所述语音数据进行语音识别,所述语音识别包括:
步骤s41,对所述语音数据进行前端处理,前端处理包括端点检测和语音增强;
步骤s42,通过机器人的语音识别器对所述语音数据进行识别。
以上所述仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书及图示内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!