构建语音偶像方法与流程
本发明一种构建语音偶像方法,具体涉及语音识别、语义理解等语音技术以及深度学习方面的技术,尤其是具有语音功能的音箱技术。
背景技术:
现代社会已经进入高度发达的社会,物质资料已经十分充足,现今社会的物质资料已经极大地满足了人类对于物质生活的追求。现代人类对于精神生活的追求逐渐显现并已经达到很高的要求。
在追求精神生活的过程中很多人对于影视作品演员以及舞台表演人员产生偶像崇拜感。出于对于偶像的崇拜,他们渴望得到偶像的签名、合照,希望偶像看到自己的留言并期待偶像能够回复自己的留言。
随着直播技术和微博技术的发展,“粉丝”们的偶像可以在一个相对集中的时间里在直播平台上在线回答“粉丝”的一些问题,但是这种机会是比较少的;偶像也可以在微博上分散实时回答“粉丝”的问题。但是由于“粉丝”数量往往过于庞大,偶像不可能实时在线回答“粉丝”问题或者实时在微博上回答粉丝的问题。当偶像不在直播或者没有登录微博的时候,“粉丝”们无法与自己崇拜的偶像对话或者提问题。
技术实现要素:
本发明的目的在于为满足“粉丝”对于偶像的崇拜心理,提供一种构建语音偶像方法。“粉丝”可以用语音提出问题,语音偶像会实时回应“粉丝”提出的问题。本发明的有益效果是可以极大地满足“粉丝”与偶像交流的目的,语音偶像的性能也较为稳定,其对于提升现代人类对于精神生活的追求大有裨益。
为达到本发明的目的,本发明的构思是利用深度学习技术,通过大量数据的训练,训练出神经网络模型用以模拟偶像的思考风格的偶像风格学习模型以及用于合成语音的情感语音合成模型,最终实现和偶像声音以及说话风格相近或者一样的回答。
根据以上构思,本发明采用以下技术方案:
一种构建语音偶像方法,其特征在于操作步骤如下:
(1)语音偶像文本抽取:
a)大量收集关于偶像的文本材料;
b)对于步骤a收集的问题的文本材料应用LSTM神经网络将大段文本转化为文字向量;
c)将步骤b结果用作RNN训练模型的输入用以训练风格学习模型;
d)通过大量的数据的训练学习到偶像说话的风格。
(2)语音偶像语音合成:
e)大量收集关于偶像的语音文件;
f)将步骤a搜集的语音文件应用双向长短时记忆韵律层级模型得到情感语音合成模型;
g)将实施例一的结果用作语音合成的文本输入,将步骤b的情感语音合成模型用于语音合成。
所述本发明与现有技术相比较,具有如下显而易见的突出实质性特点和显著技术进步:
(1)所述步骤a大量收集关于偶像的文本材料,其中文本材料主要来源于以下几个途径:
i.偶像公开的访谈或者采访类视频资料经过语音识别技术得到的文本资料,将其用作风格训练模型的输入;
ii.偶像微博中的正文文本以及回复粉丝留言的文本,将其作为训练模型的输入。
(2)所述步骤b将文本用于LSMT神经网络得到文本向量,用以后续训练步骤使用。
(3)所述步骤c将步骤b结果用作RNN训练模型的输入用以训练风格学习模型
(4)所述步骤e大量收集关于偶像的语音文件;其中语音文件主要来源于偶像所有的公开的视频以及语音类文件资料。
(5)所述步骤f将步骤e搜集的语音文件应用双向长短时记忆韵律层级模型得到情感语音合成模型,应用此模型可结合深度学习的自动学习功能,语音合成的音频更自然更真实。
(6)所述步骤g将实施例一的结果用作语音合成的文本输入,将步骤f的情感语音合成模型用于语音合成,该步骤完成偶像音色以及情感的语音合成,由于使用了上述步骤,合成的语音基本以偶像原音呈现。
(7)本发明的方法合成的偶像回答以及声音都可以以很高的相似度来模拟偶像,使得粉丝有如临其境之感,对于丰富人类精神生活层面有着无可比拟的优势。
附图说明
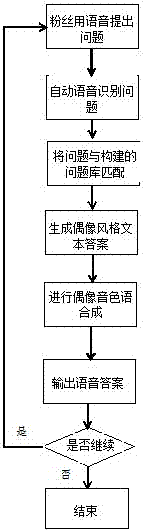
附图1是本发明的操作流程框图。
附图2是本发明的偶像风格学习模型训练示意图。
附图3是本发明的情感语音合成模型训练示意图。
具体实施方式
本发明的优选实施例结合附图详述如下:
实施例一:
参见图1,本构建语音偶像方法,其特征在于操作步骤如下:
(1)语音偶像文本抽取
a)大量收集关于偶像的文本材料;
b)对于步骤a收集的问题的文本材料应用LSTM神经网络将大段文本转化为文字向量;
c)将步骤b结果用作RNN训练模型的输入用以训练风格学习模型;
d)通过大量的数据的训练学习到偶像说话的风格。
(2)语音偶像语音合成:
e)大量收集关于偶像的语音文件;
f)将步骤a搜集的语音文件应用双向长短时记忆韵律层级模型得到情感语音合成模型;
g)将实施例一的结果用作语音合成的文本输入,将步骤b的情感语音合成模型用于语音合成。
实施例二:
本实施例与实施例一基本相同,特征之处如下:
(1)所述步骤a大量收集关于偶像的文本材料,其中文本材料主要来源于以下几个途径:
i.偶像公开的访谈或者采访类视频资料经过语音识别技术得到的文本资料,将其用作风格训练模型的输入;
ii.偶像微博中的正文文本以及回复粉丝留言的文本,将其作为训练模型的输入。
(2)所述步骤b将文本用于LSMT神经网络得到文本向量,用以后续训练步骤使用。
(3)所述步骤c将步骤b结果用作RNN训练模型的输入用以训练风格学习模型
(4)所述步骤e大量收集关于偶像的语音文件;其中语音文件主要来源于偶像所有的的公开的视频以及语音类文件资料。
(5)所述步骤f将步骤e搜集的语音文件应用双向长短时记忆韵律层级模型得到情感语音合成模型,应用此模型可结合深度学习的自动学习功能,语音合成的音频更自然更真实。
(6)所述步骤g将实施例一的结果用作语音合成的文本输入,将步骤f的情感语音合成模型用于语音合成,该步骤完成偶像音色以及情感的语音合成,由于使用了上述步骤,合成的语音基本以偶像原音呈现。
实施例三:
(1)参见图2,由偶像文本问题得出偶像文本答案,其操作步骤如下:
a.大量收集关于偶像的文本材料;
b.对于步骤a收集的文本材料应用LSTM神经网络将大段文本转化为文字向量;
c.将步骤b结果用作RNN训练模型的输入用以训练风格学习模型;
d.通过大量的数据的训练学习到偶像说话的风格。
(2)参见图3,由偶像文本答案得出偶像语音答案:
e.大量收集关于偶像的语音文件;
f.将步骤a搜集的语音文件应用双向长短时记忆韵律层级模型得到情感语音合成模型;
g.将实施例一的结果用作语音合成的文本输入,将步骤b的情感语音合成模型用于语音合成。
步骤(1)中的长短时间记忆神经网络(LSTM)计算过程如下所示:
前向推算:
输入门:
遗忘门:
如上述两行公示所示:遗忘门的输入来自于t时刻外面的输入,t-1时刻隐含单元的输出。以及来自t-1时刻单元的输出;
单元:
单元的输入是:t时刻遗忘门的输出*t-1时刻单元的输出+t时刻单元的输出+t时刻输入门的输出*激活函数计算(t时刻外面的输入+t-1时刻隐含单元的输出);
输出门:
输出门的输入是:t时刻外面的输入,t-1时刻隐含单元的输出以及t时刻单元单元的输出;
单元输出:
模块的输出是t时刻输出门的输出*t时刻单元单元的输出。
向后推算:
单元输出:
输出门:
单元:
遗忘门:
输入门:
运用该方法将循环神经网络的隐含层换为长短时记忆模块,可有效解决循环神经网络存取上下文信息范围有限的问题。
- 还没有人留言评论。精彩留言会获得点赞!