包括原藻脂质通路基因的基因工程化的微生物株系的制作方法与工艺
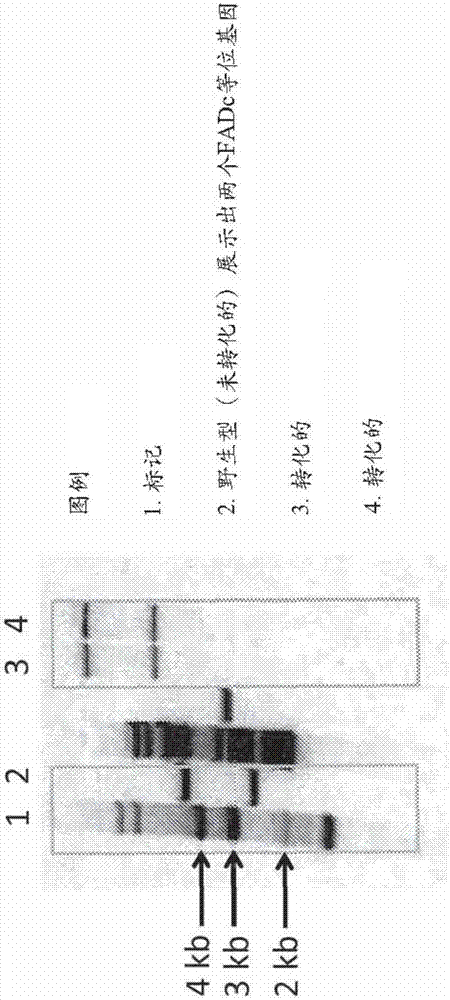
包括原藻脂质通路基因的基因工程化的微生物株系相关申请的交叉参考本申请根据35U.S.C.119(e)要求了2011年11月28日提交的美国临时专利申请号61/564,247、2011年12月29日提交的美国临时专利申请号61/581,538以及2012年7月20日提交的美国临时专利申请号61/674,251的权益。这些申请中的每一者为了所有目的以其全文通过引用结合在此。序列表的参考本申请包括了一份序列表。发明领域在某些实施例中,提供了基因工程化的微生物,例如原藻(Prototheca)株系,它们展示了改进的油生产并且因此用于化学、食品生产、燃料和工业化学品生产、微生物学以及分子生物学领域。相关披露的说明微藻,包括基因工程化的微藻,已被鉴别为用于食品和燃料的油的重要的新来源。参见PCT公开号WO2008/151149、WO2009/126843以及WO2010/045368,这些公开中的每一者为了所有目的以其全文通过引用结合在此。尽管小球藻(Chlorella)株系已成为发展微生物油制造方法中众多工作的焦点,但近年来原藻属的株系已被鉴别为也具有作为微生物油(包括用于特定应用的定制油)的新来源的希望。参见PCT公开号WO2010/063031、WO2010/063032、以及WO2011/150410以及WO2012/106560,这些公开中的每一者为了所有目的以其全文通过引用结合在此。概述在某些实施例中,本发明提供了一种重组(例如分离的)核酸,包含一种编码一种原藻脂质生物合成蛋白或其部分的编码序列。在一些实施例中,提供了一种重组核酸,包含一种编码一种原藻脂质生物合成蛋白的编码序列,其条件是该蛋白不是酮酰基酰基载体蛋白合成酶II、硬脂酰基酰基载体蛋白脱饱和酶或Δ12脂肪酸脱饱和酶。在一些实施例中,该蛋白不是SEQIDNO:270的一种酮酰基酰基载体蛋白合成酶II蛋白、SEQIDNO:271的一种硬脂酰基酰基载体蛋白脱饱和酶或SEQIDNO:272或273的一种Δ12脂肪酸脱饱和酶。在一些实施例中,该编码序列与一个启动子、一个非翻译控制元件和/或一个靶向序列(如一种质体靶向序列和线粒体靶向序列)处于可操作连接。该重组核酸可以是例如一种DNA分子。在某些实施例中,重组核酸是一种表达载体。该重组核酸可以例如包含一种编码一种mRNA的表达盒,该mRNA编码一种功能性原藻脂质生物合成酶。可替代地或另外,该重组核酸可以包含一种编码一种抑制性RNA的表达盒,该抑制性RNA抑制一种原藻脂质生物合成基因的表达。在一些实施例中,该脂质生物合成蛋白是表1中的一种蛋白。在一些实施例中,该蛋白与一种在此提供的蛋白或由一种在此提供的基因编码的一种蛋白具有至少50%、60%、70%、80%、85%、90%或95%序列一致性。在一些实施例中,该蛋白或编码该蛋白的该基因在表1中列出。在一些实施例中,由该核酸中的编码序列编码的蛋白包含一个或多个点突变、缺失、取代或其组合。在其他实施例中,该蛋白与表1中的一种蛋白相比具有至少一个点突变。在一些实施例中,由该编码序列编码的蛋白是一种功能蛋白。在一些实施例中,该蛋白为具有至少一个点突变的二酰基甘油二酰基转移酶(DGAT)。在其他实施例中,该重组核酸进一步编码蔗糖转化酶。在某些实施例中,还提供了一种基因工程化的微生物细胞,它经一种在此提供的重组核酸转化。在一些实施例中,该细胞是一种微生物、植物或酵母细胞。在特定实施例中,提供了一种细胞,该细胞包含一种或多种外源性基因,其中该外源性基因是一种选自表1中所列基因的原藻脂质生物合成基因。该基因工程化的微生物细胞可以例如是原藻属或小球藻属的一种细胞。在特定实施例中,该细胞包含一种内源性脂质生物合成基因和一种或多种选自表1中所列基因的外源性原藻脂质生物合成基因两者。在某些实施例中,该外源性基因可以编码一种脂质生物合成蛋白,其中该脂质生物合成蛋白的氨基酸序列与内源性脂质生物合成蛋白一致。举例来说,该外源性基因可以包含一种核苷酸序列,其中编码该脂质生物合成蛋白的氨基酸的核苷酸序列的密码子与天然核酸中的密码子相比已被改变。在不同实施例中,该外源性基因可以编码与天然原藻蛋白具有至少50%、60%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%氨基酸一致性的一种蛋白。在一些实施例中,该外源性基因可以与一个不是天然原藻启动子的启动子元件、一个不是天然原藻非翻译控制元件的非翻译控制元件和/或一个编码一种不是天然原藻转运肽的转运肽的核苷酸序列处于可操作连接。该转运肽可以例如是一种质体靶向序列或一种线粒体靶向序列。在某些实施例中,该细胞具有与SEQIDNO:5具有至少75%、80%、85%、90%、95%、96%、97%、98%或99%核苷酸一致性的一种23SrRNA序列。在特定实施例中,该细胞是一种原藻细胞,其中该细胞具有为至少10%C8-C14的一种脂肪酸谱。在某些实施例中,本发明的另一个方面是一种用于获得微生物油的方法,包括在使得油得以制造的条件下对上述一种基因工程化的细胞(例如一种原藻细胞)进行培养。在某些实施例中,由此制造的微生物油具有为至少10%C8-C14的一种脂肪酸谱。本发明还包括通过这种方法制造的一种微生物油。在特定实施例中,本发明提供了基因工程化的细胞,例如原藻属细胞,其中一种或多种选自表1中所列基因的内源性脂质生物合成基因的活性已被减弱。在不同实施例中,该内源性基因的活性已通过染色体基因缺失、染色体基因插入、移码突变、点突变和/或抑制性RNA减弱。在某些实施例中,该基因工程化的细胞可以进一步包含一种选自表1中所列基因的外源性原藻脂质生物合成通路基因。在特定实施例中,该基因工程化的细胞中的一种内源性脂质生物合成基因的一个或多个等位基因被减弱。在某些实施例中,该基因工程化的细胞中的内源性脂质生物合成基因的一个等位基因被编码例如一种选自表1的外源性原藻脂质生物合成通路基因的一种多核苷酸和一种可选择标记置换。在这一实施例的一个变体中,该内源性脂质生物合成基因的两个或更多个等位基因各自被编码一种选自表1的外源性原藻脂质生物合成通路基因的一种多核苷酸和一种可选择标记置换。在某些实施例中,该基因工程化的细胞具有与SEQIDNO:5具有至少75%、80%、85%、90%、95%、96%、97%、98%或99%核苷酸一致性的一种23SrRNA序列。在特定实施例中,该基因工程化的细胞是一种原藻细胞,其中该细胞具有为至少10%C8-C14的一种脂肪酸谱。在一些实施例中,该细胞具有为至少50%、60%或70%C12:0的一种脂肪酸谱。在一些实施例中,该细胞具有为至少70%、75%、80%、85%或90%C18:1的一种脂肪酸谱。在某些实施例中,本发明还提供了一种用于获得微生物油的方法,包括在使得油得以制造的条件下对可能是例如一种原藻细胞的这种基因工程化的细胞进行培养。在某些实施例中,由此制造的微生物油具有为至少10%C8-C14的一种脂肪酸谱。本发明还包括通过这种方法制造的一种微生物油。在另一个方面,本发明提供了一种基因工程化的微生物细胞,例如原藻细胞,其中一种或多种脂质生物合成基因已被修饰以增加或减少该一种或多种基因的表达,使得该基因工程化的株系的脂肪酸谱不同于它所来源的株系的脂肪酸谱。在一个实施例中,至少两种基因已被修饰。在不同实施例中,基因修饰包括以下修饰中的一者或多者:(i)一种基因或它的酶促产物的减弱;和(ii)一种基因或它的酶促产物的表达增加;(iii)一种基因或它的酶促产物的活性改变。在不同实施例中,该基因工程化的细胞具有一种或多种减弱的基因,其中该减弱的基因已通过一种选自下组的手段减弱,该组由以下各项组成:一个同源重组事件以及引入会编码一种干扰性RNA的一种外源性基因。在不同实施例中,一种基因的一个或多个等位基因被减弱。在不同实施例中,该基因工程化的细胞具有一种或多种过度表达的基因,其中这些过度表达的基因已通过一种选自下组的手段上调,该组由以下各项组成:将所述基因的额外拷贝引入所述细胞中;引入所述基因的新表达控制元件;以及改变该基因的蛋白质编码序列。在不同实施例中,一种基因的一个或多个等位基因是过度表达的。在不同实施例中,该基因工程化的细胞的经修饰基因选自下组,该组由以下各项组成:表1中呈现的原藻脂质生物合成基因。在不同实施例中,该基因工程化的细胞包含一种选自下组的外源性基因,该组由以下各项组成:表1中呈现的原藻脂质生物合成基因。在不同实施例中,该基因工程化的细胞包含一种基因的一个或多个过度表达的等位基因,该基因选自下组,该组由以下各项组成:表1中呈现的原藻脂质生物合成基因。在不同实施例中,该基因工程化的细胞具有一种选自下组的减弱的基因,该组由以下各项组成:表1中呈现的原藻脂质生物合成基因。在不同实施例中,该基因工程化的细胞具有一种基因的一个或多个减弱的等位基因,该基因选自下组,该组由以下各项组成:表1中呈现的原藻脂质生物合成基因。在不同实施例中,该基因工程化的细胞具有一种选自下组的脂肪酸谱,该组由以下各项组成:3%到60%C8:0、3%到60%C10:0、3%到70%C12:0、3%到95%C14:0、3%到95%C16:0、3%到95%C18:0、3%到95%C18:1、0%到60%C18:2、0%到60%C18:3或其组合。在不同实施例中,C10:0与C12:0的比率是至少3:1。在一些情况下,C10:0与C14:0的比率是至少10:1。在不同实施例中,C12:0与C14:0的比率是至少3:1。在不同实施例中,该基因工程化的细胞具有至少40%饱和脂肪酸、至少60%饱和脂肪酸、或至少85%饱和脂肪酸的一种脂肪酸谱。在另一个方面,本发明提供了用于获得微生物油的方法,包括在使得油得以制造的条件下对本发明的一种基因工程化的原藻细胞进行培养。在不同实施例中,该微生物油具有一种选自下组的脂肪酸谱,该组由以下各项组成:3%到40%C8:0、3%到60%C10:0、3%到70%C12:0、3%到95%C14:0、3%到95%C16:0、3%到95%C18:0、3%到95%C18:1、0%到60%C18:2、0%到60%C18:3或其组合。在不同实施例中,C10:0与C12:0的比率是至少3:1。在一些情况下,C10:0与C14:0的比率是至少10:1。在不同实施例中,C12:0与C14:0的比率是至少3:1。在不同实施例中,该基因工程化的细胞具有至少40%饱和脂肪酸、至少60%饱和脂肪酸、或至少85%饱和脂肪酸的一种脂肪酸谱。在一个另外的方面,本发明提供了微生物油和包含所述油或一种由其衍生的化学品的食品、燃料以及化学品。在另一个方面,本发明提供了适用于制造基因修饰的原藻和其他细胞的方法的重组核酸。本发明的核酸包含所有或某一部分的一种原藻脂质生物合成基因。在不同实施例中,这些核酸包含表达盒,这些表达盒由一种编码序列和调节该编码序列表达的控制序列组成,该编码序列可以编码一种会编码一种脂质生物合成蛋白、酶的mRNA或一种起抑制一种脂质生物合成基因表达作用的RNAi。在其他实施例中,这些核酸是表达载体,这些表达载体包含一个或多个表达盒并且在一种原藻或其他宿主细胞中稳定复制,或者通过整合到宿主细胞的染色体DNA中或者作为自由复制的载体。在其他实施例中,这些核酸仅包含一种原藻脂质生物合成基因的一部分,该部分可能是一种编码序列、一种外显子或一种控制元件的一部分。这些核酸适用于构建原藻和非原藻宿主细胞的表达盒,用于外源性DNA整合到原藻宿主细胞中,以及用于通过同源重组来构建适用于减弱的原藻脂质生物合成基因的核酸。在一些实施例中,提供了用于过度表达一种脂质生物合成基因的序列、组合物、宿主细胞以及方法。在一些方面,过度表达的脂质生物合成基因是LEC2、DGAT、ATP:柠檬酸裂解酶(ACL)、苹果酸酶、脂肪酶、脂肪酰基-CoA还原酶、酰基-CoA结合蛋白(ACBP)或硫辛酸合成酶(LS1)中的一者或多者。本发明的这些和其他方面和实施例描述于附图(这些附图的简要说明紧接其后)、以下发明的详细说明中,并且例示于以下实例中。以上和整个申请论述的任何或所有特征可以组合在本发明的不同实施例中。附图的简要说明图1展示了如实例37中所述的具有和不具有一种靶向的基因破坏的桑椹形原藻FADc等位基因的PstI限制性图谱。图2展示了实例37中所述的DNA印迹(Southernblot)的结果。详细说明为了方便读者,本发明的详细说明分为几个部分。第I部分提供了在此使用的术语的定义。第II部分提供了原藻脂质生物合成通路的概述。第III部分描述了用于本发明的原藻细胞的培养方法。第IV部分描述了用于本发明的原藻和基因工程化的细胞的遗传工程化方法。第V部分描述了由本发明提供的微生物油。第VI部分描述了本发明的核酸。第I部分.定义除非另有定义,否则在此使用的所有技术和科学术语都具有与本发明所属领域的普通技术人员通常理解的含义。下列参考文献为普通技术人员提供本发明中使用的许多术语的一般定义:辛格顿(Singleton)等人,《微生物学和分子生物学词典》(DictionaryofMicrobiologyandMolecularBiology)(第2版.1994);《剑桥科学与技术词典》(TheCambridgeDictionaryofScienceandTechnology)(沃克尔(Walker)编,1988);《遗传学词汇表》(TheGlossaryofGenetics),第5版,R.列赫尔(R.Rieger)等人(编),施普林格(SpringerVerlag)(1991);以及黑尔(Hale)和马汉姆(Marham),《哈珀柯林斯生物学词典》(TheHarperCollinsDictionaryofBiology)(1991)。除非另有说明,否则如在此所使用的下列术语具有赋予其的含义。一种“在微藻中具有活性”的核酸是指一种在微藻中具有功能的核酸。举例来说,一种已用于驱动抗生素抗性基因以赋予转基因微藻抗生素抗性的启动子在微藻中具有活性。“酰基载体蛋白”或“ACP”是在脂肪酸合成过程中作为硫酯在4'-磷酸泛酰巯基乙胺部分的远端硫醇处与生长的酰基链结合的一种蛋白,并且它包含脂肪酸合成酶复合体的一个组分。“酰基-CoA分子”或“酰基-CoA”是包含酰基部分的一种分子,该酰基部分在辅酶A的4'-磷酸泛酰巯基乙胺部分的远端硫醇处通过硫酯键与辅酶A共价连接。“等位基因”是指一个基因或基因位点的一种或两种或更多种形式。一种基因的等位基因可以共享100%或更少的核苷酸序列一致性。由一种基因的等位基因编码的基因产物可以共享100%或更少的氨基酸序列一致性。一种基因的不同等位基因和/或其中编码的基因产物的过度表达可以赋予一种基因工程化的生物体不同表型。一种基因的不同等位基因和/或其中编码的基因产物的减弱可以赋予一种基因工程化的生物体不同表型。“一种基因的减弱”是指(i)对一种基因进行基因工程化,以使它相对于一种野生型基因具有会引起一种基因产物(包括mRNA、抑制性RNA分子以及其他RNA的RNA、多肽)的量减少的不同控制序列;(ii)对一种细胞进行基因工程化,以使它相对于一种野生型细胞具有一种基因的更少或不可检测的拷贝和减少量的相应基因产物;和/或(iii)对一种基因的编码序列进行基因工程化,从而或者降低基因产物的稳定性和/或活性(即,如果增加一种RNA基因产物的稳定性,增加一种mRNA基因产物的翻译,和/或降低一种由该mRNA基因产物编码的蛋白的酶促活性水平,即通过使蛋白更不稳定或活性更小(这也可以称为“一种酶促产物的减弱”)。一种“减弱的基因产物”是一种基因通过任一种先前方法减弱的基因产物。一种“减弱的基因”是已通过在此描述的一种或多种会引起基因产物的量减少的方法基因工程化的一种基因。因此,一种基因的减弱会引起“一种基因的表达减少”、“该基因的下调”或“该基因的失活”。“无菌的”是实质上不受其他活生物体污染的一种生物体的培养物。“生物质”是通过细胞的生长和/或繁殖产生的物质。生物质可以包含细胞和/或细胞内的内含物以及细胞外物质,包括(但不限于)由一种细胞分泌的化合物。“催化剂”是一种试剂,如一种分子或大分子复合体,其能够帮助或促进反应物到产物的化学反应而不会成为产物的一部分。催化剂使反应速率增加,此后,催化剂可以作用于另一个反应物,以形成产物。催化剂总体上使反应所需的总活化能降低,以使反应更快地或者在更低温度下进行。因此,可以更快地到达反应平衡。催化剂的实例包括酶,其是生物催化剂;热,其是非生物催化剂;和在化石油精炼过程中使用的金属。“共培养”和其变体如“共培育”和“共发酵”是指在相同的生物反应器中存在两种或更多种类型的细胞。两种或更多种类型的细胞可以均是微生物,如微藻,或者可以是与一种不同的细胞类型一起培养的一种微藻细胞。培养条件可以是促进两种或更多种细胞类型的生长和/或繁殖的条件,或者是在维持余者的细胞生长的同时促进两种或更多种细胞中的一种或一个子集生长和/或增殖的条件。“编码序列”是指在一种细胞中编码由一种基因或表达盒转录的RNA的该基因或表达盒的一部分,特别是被翻译成由mRNA编码的蛋白的该mRNA的一部分。在翻译部分之间的一种基因的任何非翻译部分被称为“内含子”。“辅助因子”或“辅因子”是除底物之外为酶发挥其酶促活性所需的任何分子。“互补DNA”或“cDNA”是mRNA的一个DNA拷贝,通常通过信使RNA(mRNA)的反转录或扩增(例如通过聚合酶链反应(“PCR”))来获得。“控制序列”是指调节一种编码序列转录的一种基因或表达盒中的核酸序列,并且因此包括启动子、增强子、转录终止序列以及翻译起始序列。“培育”或其变体如“培养”和“发酵”是指通过使用所选择的和/或受控制的条件有意地促进一种或多种细胞的生长(细胞大小、细胞内含物和/或细胞活性增加)和/或繁殖(通过有丝分裂使细胞数目增加)。生长和繁殖两者的组合可以称作增殖。所选择的和/或受控制的条件的实例包括使用限定性培养基(具有已知特征,如pH值、离子强度以及碳源)、规定温度、氧张力、二氧化碳水平以及在生物反应器中生长。培育不是指自然界中微生物的生长或繁殖或以其他方式无人为干涉;例如,最终变成化石以产生地质原油的生物体的自然生长不是培育。“细胞溶解”是低渗环境中细胞的溶解。细胞溶解是由过度渗透或者水向细胞内侧运动(水分过多)引起。细胞不能承受内侧水的渗透压,并且因此它爆炸了。“脱脂粉”和“脱脂的微生物生物质”是或者通过使用机械(即,通过压榨机执行)或者溶剂提取或者两者从其中提取或分离油(包括脂质)后的微生物生物质。与从微生物生物质中提取或分离油/脂质之前相比,脱脂粉中油/脂质的量减少,但是其包含一些残留的油/脂质。“脱饱和酶”是脂质合成通路中负责将双键(不饱和)引入到脂肪酸或三酰基甘油酯分子的脂肪酸链中的酶。实例包括(但不限于)硬脂酰基-酰基载体蛋白脱饱和酶(SAD)和脂肪酸脱饱和酶(FAD),也称为脂肪酰基脱饱和酶。“表达盒”是指一种编码序列和一种启动子,任选地与一种或多种控制序列组合。酶的表达盒包含例如并且不限于一种翻译起始控制序列。“表达载体”或“表达构建体”或“质粒”或“重组DNA构建体”是指经由人为干涉产生的核酸,包括利用使得宿主细胞中特定核酸进行转录和/或翻译的一系列特定核酸元件通过重组方法或直接化学合成来产生。表达载体可以是质粒、病毒或核酸片段的一部分。典型地,表达载体包含待转录的核酸,它与启动子可操作地连接。一些表达盒是表达载体,但表达载体经常包含超过一个表达盒,例如用于可选择标记的表达盒有时被包括在表达载体中以用于将外源性基因引入到宿主细胞中。本领域的普通技术人员了解到,编码一种特定基因或其一部分的一种“重组核酸”是从它天然存在的特定环境中分离出来的。“外源性基因”是编码被引入(“转化”)到细胞中的RNA和/或蛋白表达的核酸,并且也被称为“转基因”。经转化的细胞可以被称为重组细胞,其中可以引入一个或多个额外的外源性基因。相对于被转化的细胞,外源性基因可以来自不同物种(并且因此是异源的),或者来自相同物种(并且因此是同源的)。因此,外源性基因可以包括相对于基因的内源性拷贝在细胞基因组中占据不同位置或者处于不同控制下的同源基因。外源性基因可以在细胞中存在超过一个拷贝。外源性基因可以作为(核或质体)基因组中的插入或者作为游离基因分子保持在细胞中。“外源提供”是指提供到细胞培养物的培养基中的分子。“压榨”是从原材料(如大豆和油菜籽)中提取油的一种机械方法。压榨机是一种螺旋型机器,其挤压材料通过封闭桶样的腔。原材料进入压榨机的一侧,并且废饼从另一侧离开,而油从箱体柱子之间渗出并被收集。该机器使用来自螺杆驱动的摩擦力和持续压力来移动并挤压原材料。油通过不能使固体通过的小开口渗出。由于原材料被挤压,摩擦力典型地使得其变热。“脂肪酸”应意指游离脂肪酸、脂肪酸盐或甘油脂中的脂肪酰基部分。“脂肪酸修饰酶”或“脂肪酸修饰性酶”是指改变脂肪酸的共价结构的酶。脂肪酸修饰酶的实例包括脂肪酶、脂肪酰基-CoA/醛还原酶、脂肪酰基-CoA还原酶、脂肪醛还原酶、脂肪醛脱羧酶。“脂肪酸谱”是指细胞中的脂肪酸或来源于细胞的油在链长和/或饱和模式方面的分布。在这一情形中,饱和模式可以包括饱和酸相对于不饱和酸的测量或者双键在细胞的不同脂肪酸中的位置的分布的更详细分析。脂肪酸谱例如通过使用气相色谱法容易地测定。在一种方法中,三酰基甘油的脂肪酸使用熟知的方法转化成脂肪酸甲酯(FAME)。FAME分子接着通过气相色谱法检测。举例来说,与任何其他脂肪酸(如C14:1)相比,针对不具有不饱和的14个碳原子的脂肪酸(C14:0)观察到一个单独峰。使用GC-FID测定的每一种类的FAME的峰面积与脂肪酸的重量百分比成比例。除非另外规定,否则脂肪酸谱被表示为总脂肪酸含量的重量百分比。当提及脂肪酸谱时,“至少4%C8-C14”意指细胞或提取的甘油脂组成中至少4重量%的总脂肪酸具有包括8、10、12或14个碳原子的链长。“脂肪酸合成酶”是指会改变脂肪酸的链长、饱和度或官能团修饰或者可以按其他方式引起细胞中脂肪酸谱改变的酶。脂肪酸合成酶的实例包括脂肪酰基-ACP硫酯酶、脱饱和酶(包括硬脂酰基酰基载体蛋白脱饱和酶(SAD)和脂肪酰基脱饱和酶(FAD))、脂肪酰基羟化酶以及β-酮基-酰基-ACP合成酶。“脂肪酰基-ACP硫酯酶”是在脂肪酸合成过程中催化从酰基载体蛋白(ACP)中裂解下脂肪酸的酶。“脂肪酰基-CoA/醛还原酶”是催化酰基-CoA分子还原成伯醇的酶。“脂肪酰基-CoA还原酶”是催化酰基-CoA分子还原成醛的酶。“脂肪醛脱羧酶”是催化脂肪醛转化成烷烃的酶。“脂肪醛还原酶”是催化醛还原成伯醇的酶。“固定碳源”是一种或多种包含碳的分子,典型地是有机分子,其在环境温度和压力下以固体或液体形式存在于培养基中,可以被培养于培养基中的微生物使用。“功能蛋白”是指活性已被保留的蛋白,即使它可能被减弱。“基因工程化的”、“基因工程学”以及“基因工程化”是指通过人为干涉改变活细胞的DNA和/或RNA。典型地,改变是通过引入一种或多种表达载体来介导的,但在一些情况下,功能等效改变可以仅通过诱变来实现。“甘油脂”是指在甘油的sn-1、sn-2或sn-3位置被一种或多种磷酸酯、脂肪酸、磷酸丝氨酸、磷酸胆碱、磷酸肌醇或磷酸乙醇胺酯化的甘油分子,或共价连接于甘油主链的其他部分。甘油脂的实例包括三酰基甘油酯(甘油三酯)、二酰基甘油酯(甘油二酯)、单酰基甘油酯(甘油单酯)、甘油-3-磷酸酯、溶血磷脂酸、磷脂酸、磷脂酰胆碱、磷脂酰丝氨酸、磷脂酰甘油以及磷脂酰乙醇胺。“甘油脂合成酶”是指参与甘油脂合成的酶。甘油脂合成酶起例如将酰基共价连接到经取代的甘油的作用。甘油脂合成酶的实例包括甘油-3-磷酸酯酰基转移酶、溶血磷脂酸酰基转移酶、二酰基甘油酰基转移酶、磷脂二酰基甘油酰基转移酶以及磷脂酸磷酸酶。“甘油磷脂”是在甘油主链的sn-1、sn-2或sn-3位置具有至少一个或多个共价结合的磷酸酯或一个共价结合的包含磷酸酯的部分(例如磷酸胆碱、磷酸丝氨酸、磷酸肌醇以及磷酸乙醇胺)的甘油脂。甘油磷脂包括磷酸甘油、溶血磷脂酸、磷脂酸、磷脂酰胆碱、磷脂酰丝氨酸、磷脂酰甘油以及磷脂酰乙醇胺。“异养的”在它关于培养条件时是在利用或代谢固定碳源的同时在实质上不存在光时培养。“匀浆物”是被物理破坏的生物质。“氢:碳比”是分子中氢原子和碳原子的比率(基于原子对原子)。该比率可以用于指碳氢化合物分子中碳和氢原子的数目。举例来说,具有最高比率的碳氢化合物是甲烷CH4(4:1)。“疏水部分”是物质的一部分或部分,其在疏水相中比在水相中可溶性更高。疏水部分实质上不溶于水并且通常是非极性的。“增加脂质产率”是指微生物培养物生产率增加,例如通过增加每升培养物的细胞干重、增加构成脂质的细胞的百分比或者增加每单位时间每升培养物体积的脂质总量实现。“诱导型启动子”是响应于特定刺激物而介导可操作连接的基因进行转录的启动子。这类启动子的实例可以是在改变pH值或氮水平的条件下被诱生的启动子序列。“处于可操作连接”是两个核酸序列(如控制序列(典型地是启动子)和相连序列(典型地是编码蛋白的序列,也被称为编码序列))之间的功能性连接。如果启动子可以介导外源性基因的转录,那么该启动子与该基因处于可操作连接。“原位”意指“在适当位置”或者“在其原始位置”。“营养物的限制性浓度”是限制培养的生物体的繁殖的培养物中化合物的浓度。“营养物的非限制性浓度”是在给定培养期的过程中支持最大繁殖的浓度。因此,在营养物的限制性浓度存在下,在给定培养期的过程中产生的细胞数目低于当营养物是非限制性时。当营养物以大于支持最大繁殖的浓度的浓度存在时,该营养物在培养物中被称为是“过量”的。“脂肪酶”是一种水溶性酶,它催化水不溶性脂质底物的酯键发生水解。脂肪酶催化脂质水解成甘油和脂肪酸。“脂质”是可溶于非极性溶剂(如醚和氯仿)并且相对或完全不溶于水的一类分子。脂质分子具有这些特性,因为它们主要由本质上疏水的长烃尾组成。脂质的实例包括脂肪酸(饱和的和不饱和的);甘油酯或甘油脂(如甘油单酯、甘油二酯、甘油三酯或中性脂肪,以及磷酸甘油酯或者甘油磷酸酯);非甘油酯(鞘脂类、甾醇脂质(包括胆固醇和类固醇激素)、异戊烯醇脂质(包括萜类)、脂肪醇、蜡以及聚酮类);以及复合脂质衍生物(连接糖的脂质、或糖脂、以及连接蛋白的脂质)。如在此所使用,术语“三酰基甘油酯”和“甘油三酯”是可互换的。“脂肪”和“油”是称为“三酰基甘油酯”的脂质的亚群。如不同于“脂肪”的“油”是指在普通室温和压力下总体上液态的三酰基甘油酯。脂肪酸常规地利用叙述由冒号分开的碳原子数目和双键数目的表示法命名。举例来说,油酸可以被称为C18:1,而癸酸可以被称为C10:0。“脂质生物合成通路”或“脂质生物合成的通路”或“脂质代谢通路”或“脂质通路”涉及脂质的合成或降解。因此,脂质生物合成通路的酶(例如脂质通路酶)包括脂肪酸合成酶、脂肪酸修饰酶以及甘油脂合成酶、以及影响脂质代谢(即或者脂质修饰或者降解)的蛋白(例如脂质通路蛋白)、以及化学修饰脂质的任何蛋白、以及载体蛋白。脂质生物合成蛋白还包括参与脂质代谢的转录因子和激酶。“脂质生物合成基因”是编码或者脂质合成、修饰或者降解中参与脂质代谢的蛋白以及化学修饰脂质的任何蛋白(包括载体蛋白)的任何基因。“脂质通路酶”是在脂质代谢(即,或者脂质合成、修饰或者降解)中起作用的任何酶、以及化学修饰脂质的任何蛋白以及载体蛋白。“裂解物”是包含已裂解细胞的内含物的溶液。“裂解”是生物体的质膜和任选细胞壁发生破裂,其足以释放至少部分细胞内的内容物,通常通过机械、病毒或者渗透机制损伤其完整性。“溶解”是生物体或细胞的细胞膜和任选细胞壁被破坏,其足以释放至少部分细胞内的内含物。“微藻”是包含叶绿体或质体并且任选地能够进行光合作用的真核微生物的生物体,或者是能够进行光合作用的原核微生物的生物体。微藻包括不能代谢固定碳源作为能量的专性光能自养生物以及可以完全依靠固定碳源生存的异养生物。微藻包括细胞分裂后即刻与姐妹细胞分离的单细胞生物体(如衣藻(Chlamydomonas))以及如团藻(Volvox,两种不同细胞类型的简单多细胞光合微生物)的微生物。微藻包括如小球藻、杜氏藻(Dunaliella)以及原藻的细胞。微藻还包括显示细胞-细胞粘附的其他微生物的光合生物体,如阿格门氏藻(Agmenellum)、鱼腥藻(Anabaena)以及桑椹藻(Pyrobotrys)。微藻还包括丧失进行光合作用的能力的专性异养微生物,如某些双鞭甲藻物种和原藻属的物种。“微生物(microorganism)”和“微生物(microbe)”是显微镜可见的单细胞生物体。对于两种蛋白或基因的“天然共表达”意指这些蛋白或其基因天然共表达于其来源的组织或生物体中,例如由于编码这两种蛋白的基因处于共同调节序列的控制下,或者由于其响应于相同刺激物而表达。“一种基因的过度表达”是指(i)对一种基因进行基因工程化,以使它相对于一种野生型基因具有会引起细胞中的一种基因产物(RNA以及当该RNA是一种mRNA时由该mRNA编码的蛋白)的量增加的不同控制序列;(ii)对一种细胞进行基因工程化,以使它相对于一种野生型细胞具有一种基因的更多的拷贝和增加量的相应基因产物;和/或(iii)对一种基因的编码序列进行基因工程化,从而或者增强基因产物的稳定性和/或活性(即,如果增加一种RNA基因产物的稳定性,增加一种mRNA基因产物的翻译,和/或提高一种由该mRNA基因产物编码的蛋白的酶促活性水平,即通过使蛋白更稳定或活性更大(这也可以称为“一种酶促产物的过度表达”)。一种“过度表达的基因”是一种基因通过任一种先前方法过度表达的产物。一种基因的过度表达由此引起“一种基因的表达增加”。“启动子”是引导核酸转录的核酸控制序列。如在此所使用,启动子包括转录起始位点附近的必需核酸序列,如在聚合酶II型启动子情况下是TATA元件。启动子任选地还包括远端的增强子或抑制子元件,其可以位于离转录起始位点远至数千个碱基对的位置。“原藻细胞”是指原藻属的微藻的任何细胞、株系以及物种。示意性原藻细胞和株系包括(但不限于)属于以下物种中的任一者的那些:威克海姆原藻(Protothecawickerhamii)、大型原藻(Protothecastagnora)、波多黎各原藻(Protothecaportoricensis)、桑椹形原藻(Protothecamoriformis)以及小型原藻(Protothecazopfii)。在一个重要实施例中,原藻细胞是桑椹形原藻的一个细胞或株系。更总体而言,微藻细胞、株系以及物种与桑椹形原藻的23srRNA或SEQIDNO:5中列出的那个共享大于75%序列一致性。“重组”是由于引入外源性核酸或改变天然核酸而被修饰的细胞、核酸、蛋白或载体。因此,例如重组细胞表达细胞天然(非重组)形式中未发现的基因或者表达与由非重组细胞表达的那些基因不同的天然基因。“重组核酸”是总体上通过对核酸进行处理(例如使用聚合酶和核酸内切酶)最初于体外形成的核酸,或以其他方式呈通常天然不存在的形式,包括分离的形式,即,其中核酸与核酸的天然形式和其一起天然出现的至少一个其他组分分离。可以产生重组核酸,例如以使两种或更多种核酸处于可操作连接。因此,针对本发明的目的来说,通过使通常天然不会连接的DNA分子相连接而于体外形成的分离的核酸或表达载体均被认为是重组的。重组核酸一经制备并引入到宿主细胞或生物体中,其即可以利用宿主细胞体内的细胞机器进行复制;然而,这种核酸一经重组产生,尽管其随后细胞内地复制,但就本发明的目的来说仍然认为其是重组的。类似地,“重组蛋白”是利用重组技术制备的蛋白,即通过重组核酸的表达。术语“置换(replacement)”或“置换(replace)”或“置换的”在用于提及一种基因序列利用另一者修饰时是指一种内源性基因通过与包含适合的侧接区域的一种外源性基因序列同源重组而被除去或基因敲除。“抑制性RNA”是指抑制基因表达的RNA。抑制性RNA包括双链干扰性RNA。抑制性RNA包括长RNA发夹,这些长RNA发夹在一些实施例中长度为约200到750个核苷酸,并且包含50到650个核苷酸的靶基因的编码序列和其利用足够长以允许编码序列和其互补序列形成双链序列的序列(典型地25到200个核苷酸)分离的互补序列。RNAi还包括微RNA,其比长RNA发夹更短,典型地仅包含靶基因的编码序列的19-22个核苷酸和其互补序列以及通过RNAi介导基因表达干扰的、接合细胞中酶的侧翼序列。“超声处理”是通过使用声波能量破坏生物材料(如细胞)的过程。“蔗糖利用基因”是当表达时帮助细胞能够利用蔗糖作为能量来源的基因。由蔗糖利用基因编码的蛋白在此被称为“蔗糖利用酶”并且包括蔗糖转运蛋白、蔗糖转化酶以及己糖激酶(如葡糖激酶和果糖激酶)。“一种外源性基因的上调”是指(i)对一种基因进行基因工程化,以使它相对于一种野生型基因具有会引起细胞中的一种基因产物(RNA以及当该RNA是一种mRNA时由该mRNA编码的蛋白)的量增加的不同控制序列;(ii)对一种细胞进行基因工程化,以使它相对于一种野生型细胞具有一种基因的更多的拷贝和增加量的相应基因产物;和/或(iii)对一种基因的编码序列进行基因工程化,从而或者增强基因产物的稳定性和/或活性(即,如果增加一种RNA基因产物的稳定性,增加一种mRNA基因产物的翻译,和/或提高一种由该mRNA基因产物编码的蛋白的酶促活性水平,即通过使蛋白更稳定或活性更大(这也可以称为“一种酶促产物的上调”)。一种“上调的基因”是一种基因通过任一种先前方法增加表达的产物。一种基因的上调由此引起“一种基因的表达增加”。第II部分原藻脂质生物合成通路在某些实施例中,本发明提供了已被修饰从而改变所产生的脂质或脂肪酸的性质和/或比例的重组原藻细胞。脂质生物合成通路可以进一步或者可替代地被修饰,从而改变通过脂质生物合成通路中脂质和中间物的酶促加工而产生的不同脂质分子的性质和/或比例。在不同实施例中,本发明的重组原藻细胞相对于其未转化的对应物具有优化的每单位体积和/或每单位时间脂质产率、碳链长度(例如针对可再生柴油制造或针对需要脂质原料的工业用化学品应用)、减少的双键或三键数目(任选地达到零)以及提高特定脂质物质或不同脂质群体的碳:氢比。在其他实施例中,这些脂质具有增加的双键数目。在特定实施例中,一种或多种控制脂肪酸和甘油脂代谢分支点的关键酶已被上调或下调,从而改进脂质制造。基因的上调或过度表达可以例如使用强启动子和/或增加转录的增强子元件例如通过用其中表达编码所关注的酶的基因的表达构建体转化细胞来实现。这类构建体可以包含一种可选择标记,使得转化子可以经受选择,这可以引起构建体的扩增和所编码酶的表达水平提高。基因的下调或减弱可以例如通过用经由同源重组除去所有或一部分染色体编码的相应基因的表达盒转化细胞来实现。脂质通路酶的表达水平还可以任选地通过使用抑制性RNA构建体来降低。任选地,内源性脂质通路基因可以被修饰,从而单独地或以组合形式改变其酶促特异性、表达水平或细胞定位。用于上调或下调的表达盒可以通过整合到宿主细胞的染色体DNA中或作为自由重复载体进行重复。桑椹形原藻(UTEX1435)脂质生物合成通路的基因和基因产物列于表1中并且详述于以下小部分A-K中。在指出时,提供了基因的不同等位基因。典型地,适度氨基酸变化见于两种蛋白之间,其中等位基因典型地在外显子中具0%-2%多态性并且在内含子中具4%-7%多态性。表1.原藻脂质生物合成基因A.乙酰基-COA-丙二酰基-COA到酰基-ACP脂肪酸合成早期涉及固定碳(例如葡萄糖、蔗糖等)或其他碳源转化成丙酮酸。接着,包括丙酮酸脱氢酶、二氢硫辛酰基转乙酰基酶以及二氢硫辛酰基脱氢酶的丙酮酸脱氢酶复合体(PDH)将三碳代谢物丙酮酸转化成二碳代谢物乙酰基-CoA。乙酰基-CoA羧化酶(ACC)复合体,利用碳酸氢盐作为底物,产生3碳化合物丙二酰基-CoA。丙二酰基-CoA:ACP酰基转移酶(MAT)接着催化来自丙二酰基-CoA的丙二酰基转移到酰基载体蛋白(ACP),由此产生丙二酰基-ACP。ACP被用作脂肪酸生物合成中不同中间反应的酰基载体。代谢物乙酰基-CoA和丙二酰基-CoA以及ACP蛋白因此是用于脂肪酸生物合成的重要起点。为了基因工程化一种微生物以使脂肪酸和脂质的产生增加,可以或者单独地或者以组合形式进行重组修饰,从而获得增加的乙酰基-CoA/丙二酰基-CoA/ACP产生。举例来说,为了增加丙二酰基-CoA产生,一种表达盒可以被生成并且用于转化微生物以在一种组成型或调节型启动子的控制下过度表达编码ACC酶复合体的一种或多种组分的聚核苷酸。根据本发明的实施例适用于上调的酶的额外实例包括丙酮酸脱氢酶复合体的酶(实例(一些来自微藻)包括基因库登录号NP_415392;AAA53047;Q1XDM1;以及CAF05587)。丙酮酸脱氢酶的上调可以增加乙酰基-CoA的产生,并且由此增加脂肪酸合成。乙酰基-CoA羧化酶复合体催化脂肪酸合成中的初始步骤。因此,构成这种复合体的一种或多种酶可以被上调以增加脂肪酸的产生(实例(一些来自微藻)包括基因库登录号BAA94752;AAA75528;AAA81471;YP_537052;YP_536879;NP_045833;以及BAA57908)。ACC酶复合体的酶可以包括异质型ACC酶BC亚基1、异质型ACC酶BCC亚基、异质型ACC酶a-CT亚基、以及异质型ACC酶b-CT亚基1。ACC以两种形式(一种胞质、同质型(单一亚基)形式和一种异质型(多个亚基)形式)存在于质体中。ACC的两种类型见于原藻(UTEX1435株系)中。在同质型ACC酶中鉴别出一种质体转运肽,指示该质体转运肽可以定位于质体和细胞质两者中。在一些实施例中,提供了用于表达一种或多种靶向质体的同质型ACC亚基的序列和相关组合物以及方法。使用所关注的基因自身上或从包含质体转运肽的原藻中的任何内源性靶向质体的基因获得的内源性质体转运肽,通过连接选自在此提供的那些中的任一者的前导子质体转运肽,或者通过使用异源性质体转运肽,可以实现质体靶向。在其他实施例中,提供了用于过度表达一种或多种靶向质体的异质型ACC亚基的序列和相关组合物以及方法。在一些实施例中,ACC过度表达使C18:2与C18:3脂肪酸的比率减小至少5%、10%、15%、20%、30%、40%或50%。在一些实施例中,ACC和一种或多种下游脂质生物合成基因是同时过度表达的。在一个实施例中,提供了用于同时过度表达ACC和DGAT的序列、组合物以及方法。淀粉水平(在原藻中总体上较低)可以通过过度表达ACC而被进一步降低以有利于脂质生物合成。在一些实施例中,淀粉产生与一种或多种下游脂质生物合成基因的过度表达一致地被减弱。在其他实施例中,提供了用于脂肪酸产生的序列、组合物以及方法,通过上调编码酰基载体蛋白(ACP)的聚核苷酸进行,该酰基载体蛋白在脂肪酸合成过程中携带生长中的酰基链。ACP的实例(一些来自微藻)包括基因库登录号A0T0F8;P51280;NP_849041;YP_874433以及SEQIDNO:207。酰基载体蛋白可以在亚细胞定位方面有所不同(SEQIDNO:63-65、SEQIDNO:195以及SEQIDNO:207)。SEQIDNO:194和SEQIDNO:206中列出的序列分别提供了在SEQIDNO:195和SEQIDNO:207中给出的桑椹形原藻氨基酸序列的编码序列。在本发明的一个实施例中,有利的是过度表达一个第一外源性ACP以及附随地下调一种不同的ACP。可以进行重组修饰以增加脂质生物合成通路中其他中间物的产生。举例来说,为了增加丙二酰基-ACP产生,一种表达盒可以被生成并且用于转化微生物,从而过度表达在SEQIDNO:174中给出的聚核苷酸,这些聚核苷酸编码具有将丙二酰基从丙二酰基-CoA转移到酰基载体蛋白(ACP)的活性的桑椹形原藻丙二酰基-CoA:ACP转酰基酶(MAT)(SEQIDNO:175)。这种表达盒可以包含一种具有驱动MAT表达的活性的组成型或诱导型启动子。在一些实施例中,提供了用于下调丙酮酸脱氢酶激酶(PDHK,丙酮酸脱氢酶复合体的一种负调节子)的序列和方法。会耗尽用于除脂肪酸以外的代谢物合成的丙酮酸或乙酰基-CoA池的酶可以针对前体代谢物与脂质生物合成通路酶竞争。这些竞争者酶的减弱可以使脂肪酸或脂质的产生增加。为了基因工程化一种微生物以使脂肪酸和脂质的产生增加,可以或者单独地或者以组合形式进行重组修饰,从而减弱针对代谢物前体竞争的酶。举例来说,为了减少用于乙酸酯产生的乙酰基-CoA的使用,可以产生一种表达盒以除去编码桑椹形原藻(UTEX1435)乙酸激酶(SEQIDNO:107-112)的一种基因或多种基因。乙酸激酶的减弱还可以通过包含在组成型或调节型启动子控制下的反义RNA的表达盒的构建和使用来实现。根据本发明的实施例适用于下调的酶的额外实例包括桑椹形原藻(UTEX1435)乳酸脱氢酶(SEQIDNO:117,核苷酸,SEQIDNO:118,蛋白质),该乳酸脱氢酶由丙酮酸或桑椹形原藻(UTEX1435)磷酸乙酰基转移酶(PTA,SEQIDNO:113-116)合成乳酸盐,该磷酸乙酰基转移酶催化乙酰基-CoA转化成乙酰磷酸(乙酸盐代谢中的一个步骤)。B.酰基-ACP到脂肪酸生长的酰基-ACP链通过一组四种酶促反应以2碳增量延伸,这些酶促反应涉及缩合、一个第一还原反应、脱水以及一个第二还原反应。这些反应由一种缩合酶(β-酮酰基-ACP合成酶,KAS)、一种第一还原酶(β-酮酰基-ACP还原酶,KAR)、一种脱水酶(β-羟基酰基-ACP脱水酶,HR)以及一种第二还原酶(烯酰基-ACP还原酶,ENR)催化。产生一种4碳化合物的丙二酰基-ACP与乙酰基-CoA之间的初始缩合反应由β-酮酰基-ACP合成酶(KAS)III催化。对延伸的酰基-ACP链的连续2碳加成(到C16:0)由KASI催化。酶KASII执行C16:0-ACP到C18:0-ACP的2碳延伸。取决于待产生的脂肪酸的所希望的性质,一种或多种KAS酶可以在微生物中减弱或过度表达。举例来说,为了对一种微生物进行工程化以使具有18个或更多个碳原子的脂肪酸的产生增加,一种表达盒可以被生成并且用于转化微生物以在一种组成型或诱导型启动子的控制下过度表达编码KASII酶的聚核苷酸。适用于本发明的实施例的KASII酶的实例是SEQIDNO:106(参见实例6)和SEQIDNO:211中提供的桑椹形原藻KASII酶。这些酶的蛋白质编码序列提供于SEQIDNO:105和SEQIDNO:210中。为了对一种微生物进行基因工程化以使短或中链脂肪酸的产生增加,一种表达盒可以被生成并且用于转化微生物以减少KASII的表达,如通过靶向基因敲低或使用抑制性RNA。任选地,KASII的基因敲除或基因敲低可以与使用聚核苷酸组合来转化微生物以过度表达编码或者KASI或者KASIII酶的聚核苷酸。适用于本发明的实施例的KASIII酶的一个实例是由SEQIDNO:214中给出的聚核苷酸序列编码的桑椹形原藻KASIII酶(提供于SEQIDNO:215中)。适用于本发明的实施例的KASI酶的实例是分别提供于SEQIDNO:70和68中的桑椹形原藻KASI酶等位基因1和2。这些酶的蛋白质编码序列分别提供于SEQIDNO:69和SEQIDNO:67中。在另一个实施例中,一种重组细胞被工程化以在KASII酶活性尚未减弱的遗传背景中过度表达KASI和/或KASIII酶。在再另一个实施例中,重组聚核苷酸被生成并且用于转化微生物以除去或下调KASI酶,从而使具有多于16个碳的脂肪酸的产生增加。任选地,KASI的基因敲除或基因敲低可以与使用聚核苷酸组合来转化微生物以过度表达编码KASII的聚核苷酸。为了基因工程化一种微生物以使特定脂肪酸和脂质的产生增加,可以或者单独地或者以组合形式进行重组修饰,从而使参与脂肪酸延伸的酶减弱或过度表达。这些酶包括β-酮酰基-ACP还原酶(KAR)、β-羟基酰基-ACP脱水酶(HD)以及烯酰基-ACP还原酶(ER)。举例来说,一种表达盒可以被生成并且用于转化微生物,从而在一种组成型或诱导型启动子的控制下过度表达编码一种KAR酶、一种β-羟基酰基-ACP脱水酶或一种烯酰基-ACP还原酶的聚核苷酸。可替代地,一种表达盒可以被生成并且用于转化微生物,从而过度表达可操作以基因敲除或减弱一种KAR酶、一种HD酶或一种ER酶的表达的聚核苷酸。适用于本发明的实施例的KAR酶的一个实例是由SEQIDNO:184中给出的聚核苷酸序列编码的桑椹形原藻KAR酶(提供于SEQIDNO:185中)。适用于本发明的实施例的HD酶的一个实例是由SEQIDNO:208中给出的聚核苷酸序列编码的桑椹形原藻HD酶(提供于SEQIDNO:209中)。适用于本发明的实施例的ER酶的实例是由在SEQIDNO:200中给出的聚核苷酸序列编码的桑椹形原藻ER(提供于SEQIDNO:201中)和桑椹形原藻(UTEX1435)反-2-烯酰基-CoA还原酶(SEQIDNO:197,由在SEQIDNO:196中给出的聚核苷酸序列编码)。根据本发明的实施例,可能有利的是在特定培养条件下,例如在脂质产生过程中和/或在已被工程化以改变额外的脂质生物合成基因或基因产物的微生物的遗传背景中上调或下调KAR、HD或ER酶。脂肪酰基-ACP硫酯酶(TE)酶通过将酰基-ACP水解成游离脂肪酸和ACP来终止延伸。TE可以展示针对特定碳长度和饱和度的酰基-ACP的特异性或者可以是能够裂解不同长度和饱和水平的酰基-ACP链的广谱TE。TE的底物特异性是确定脂肪酸的链长和饱和度的重要因素。取决于待产生的脂肪酸的所希望的长度或饱和度,一种或多种编码酰基-ACP硫酯酶的基因可以在微生物中减弱或过度表达。举例来说,展示偏好C18:1-ACP的内源性脂肪酰基-ACP硫酯酶基因可以被敲除或降低表达,同时附随地一种不同TE(展示针对饱和C12和C14-ACP的特异性)在微生物中过度表达,由此改变微生物中脂肪酸的群体。适用于本发明的实施例的酰基-ACP硫酯酶的一个实例包括由在SEQIDNO:71中给出的聚核苷酸序列编码的桑椹形原藻酰基-ACP硫酯酶FATA1(提供于SEQIDNO:72中)。实例5、实例34以及实例36描述了一种桑椹形原藻酰基-ACP硫酯酶的减弱。C.不饱和脂肪酸和脂肪酰基链碳-碳双键引入到脂肪酸、脂肪酰基-CoA或脂肪酰基-ACP链中依赖于脱饱和酶的活性。脱饱和酶可以展示针对其底物的碳链长度和饱和度的特异性。特异性脱饱和酶可以将饱和脂肪酸或饱和脂肪酰基-ACP转化成不饱和脂肪酸或不饱和脂肪酰基-ACP。其他脱饱和酶可以增加不饱和脂肪酸的碳-碳双键数目。硬脂酰基-ACP脱饱和酶(参见例如基因库登录号AAF15308;ABM45911;AAY86086以及SEQIDNO:59-62)例如催化硬脂酰基-ACP转化成油酰基-ACP。这种基因的上调可以增大由细胞产生的单不饱和脂肪酸的比例;而下调可以减小单不饱和物的比例。为了示意性目的,SAD负责从C18:0前体合成C18:1脂肪酸。额外的脱饱和酶是脂肪酰基脱饱和酶(FAD),包括磷脂酰甘油脱饱和酶(FAD4)、质体油酸酯脱饱和酶(FAD6)、质体亚油酸酯脱饱和酶(FAD7/FAD8)、内质网油酸酯脱饱和酶(FAD2)、内质网亚油酸酯脱饱和酶(FAD3)、Δ12脂肪酸脱饱和酶(Δ12FAD)以及Δ15脂肪酸脱饱和酶(Δ15FAD)。这些脱饱和酶还相对于脂质饱和度提供了修饰。为了示意性目的,Δ12脂肪酸脱饱和酶负责从C18:1前体合成C18:2脂肪酸,并且Δ15脂肪酸脱饱和酶负责从C18:2前体合成C18:3脂肪酸。再额外的脱饱和酶,包括棕榈酸盐特异性单半乳糖基二酰基甘油脱饱和酶(FAD5)、亚油酯酰脱饱和酶、ω-6脂肪酸脱饱和酶、ω-3脂肪酸脱饱和酶以及ω-6油酸酯脱饱和酶,提供了相对于脂质饱和度的修饰。一种或多种脱饱和酶(如ω-6脂肪酸脱饱和酶、ω-3脂肪酸脱饱和酶或ω-6油酸酯脱饱和酶)的表达可以被控制以改变不饱和与饱和脂肪酸的比率。我们已发现原藻具有极紧凑的基因组,具有极紧凑的启动子区和广泛使用的双向启动子。举例来说,原藻具有能够多重定位的FAD2和FAD3的单拷贝。FAD3编码两个替代性的起始位置,其中一者编码一种质体转运肽,而其中另一者不会。另外,FAD3在其3'UTR中包含ER保留信号,该ER保留信号以质体靶向形式从COOH羧基末端移走,并且以ER结合形式移回。这允许相同基因到达不同亚细胞位置,取决于生物体需求。质体中合成的酰基-ACP或者直接在细胞器内使用以形成脂质(包括甘油脂)或者输出到质体外部以用于合成包括磷脂、三酰基甘油或蜡的脂质。脂质生物合成基因可以展示针对在特定亚细胞位置的活性的特异性。D.脂肪酸到脂肪酰基-COA在从质体输出后,脂肪酸被再酯化成CoA以经由酰基-CoA合成酶的催化作用形成酰基-CoA。不同酰基-CoA合成酶可以在亚细胞定位方面有所不同并且展示针对不同链长的脂肪酸的特异性。酰基-CoA合成酶的一个实例是酶长链脂肪酰基-CoA合成酶。取决于待产生的三酰基甘油的所希望的性质,一种或多种编码酰基-CoA合成酶的基因可以在微生物中减弱或过度表达。E.脂肪酰基-COA到三酰基甘油三酰基甘油酯可以通过sn-甘油-3-磷酸酯分子的三个相继的酰基-CoA依赖性酰化来形成。第一酰化(甘油脂合成的限速步骤)由甘油-3-磷酸酯酰基转移酶(GPAT)催化,产生溶血磷脂酸。第二酰化步骤由酶酰基-CoA:溶血磷脂酸酰基转移酶(LPAAT)催化。在第三酰化步骤之前,酶磷脂酸磷酸酶(PAP)(或脂质)实现从磷脂酸去除磷酸酯基,产生sn-1,2-二酰基甘油(DAG)。最终酰基-CoA依赖性酰化由酰基-CoA:二酰基甘油酰基转移酶(DGAT)催化。微生物可以被基因工程化以使脂质的产生增加。举例来说,为了增加TAG的产生,一种表达盒可以被生成并且用于转化微生物以使聚核苷酸可操作以增加GPAT的表达。这种表达盒可以包含具有驱动GPAT表达的活性的组成型或诱导型启动子并且可以用于内源性GPAT活性已被减弱的株系的遗传背景。适用于本发明的一个实施例的GPAT的一个实例是由在SEQIDNO:186中给出的序列编码的桑椹形原藻GPAT(此处作为SEQIDNO:187给出)。微生物可以被基因工程化以使具有所希望的性质的三酰基甘油分子的产生增加。某些酰基转移酶(包括GPAT、LPAAT以及DGAT)可以展示针对亚细胞定位的特异性或针对被其转移到经取代的甘油主链的酰基-CoA链的长度和饱和度的底物特异性。另外,LPAAT和DGAT酶可以展示针对形成这些酶向其转移酰基-CoA的经取代的甘油的底物特异性。取决于待产生的三酰基甘油酯的所希望的性质,一种或多种编码GPAT、LPAAT、DGAT或其他酰基转移酶的基因可以在微生物中减弱或过度表达。举例来说,为了增加在sn-2位置酯化的具有中链脂肪酸的TAG的产生,一种表达盒可以被生成并且用于转化微生物以过度表达对于转移中链具有特异性的LPAAT。这种表达盒可以包含具有驱动LPAAT表达的活性的组成型或诱导型启动子并且可以用于内源性LPAAT活性已被减弱的株系的遗传背景。适用于本发明的实施例的LPAAT的实例包括分别由在SEQIDNO:81和SEQIDNO:84中给出的序列编码的在SEQIDNO:82和SEQIDNO:83中给出的桑椹形原藻LPAATE和LPAATA。以一种类似的方式,为了增加TAG的产生,一种表达盒可以被生成并且用于转化微生物以过度表达编码DGAT(具有将酰基-CoA转移到DAG分子的活性)的聚核苷酸。这种表达盒可以包含一种具有驱动DGAT2表达的活性的组成型或诱导型启动子。适用于本发明的DGAT的一个实例是桑椹形原藻二酰基甘油酰基转移酶2型(DGAT2)(SEQIDNO:183,由在SEQIDNO:182中给出的序列编码)。根据待由重组微生物产生的脂肪酸或脂质的所希望的特征,可能有利的是将上调以底物特异性为特征的TE与一种或多种展示相同底物特异性的GPAT、LPAAT或DGAT酶结合。适用于本发明的实施例的额外酰基转移酶包括桑椹形原藻膜结合O-酰基转移酶域包含蛋白(SEQIDNO:203,由SEQIDNO:202中提供的核苷酸序列编码)、桑椹形原藻假定性1-酰基-sn-甘油-3-磷酸酯酰基转移酶(SEQIDNO:179,由SEQIDNO:178中提供的核苷酸序列编码)以及桑椹形原藻酰基转移酶(SEQIDNO:217,由SEQIDNO:216中提供的核苷酸序列编码)。单酰基甘油酰基转移酶(MGAT)基因催化二酰基甘油的合成并且总体上也可以催化三酰基甘油生物合成中的最终步骤。因此,本发明中提供的MGAT基因的上调可能是所希望的。替代性脂质通路酶可以通过独立于以上途径的途径产生三酰基甘油酯分子。脂肪酰基-CoA非依赖性三酰基甘油通路的酶使用可以展现选择性底物特异性的酰基-溶血磷脂酰胆碱酰基转移酶转移磷脂酰胆碱(PC)部分之间的脂肪酰基,最终将其转移到二酰基甘油。F.额外脂质分子除了它们并入DAG和TAG中以外,脂肪酸或脂肪酰基分子还可以并入一系列脂质分子中,这些脂质分子包括(但不限于)磷脂、磷脂酰胆碱(PC)、磷脂酰丝氨酸(PS)、磷脂酰肌醇(PI)、神经鞘脂质(SL)、单半乳糖基二酰基甘油、二半乳糖基二酰基甘油、脂核苷酸以及蜡酯。合成PC、PS、PI、SL、蜡酯、脂核苷酸或半乳糖脂单半乳糖基二酰基甘油(MGDG)或二半乳糖基二酰基甘油(DGDG)的分子的酶可以针对包括脂肪酸或脂肪酰基分子的底物与引起最终合成DAG和TAG的酶竞争。编码参与PC、PS、PI、SL、单半乳糖基二酰基甘油、二半乳糖基二酰基甘油或蜡酯的合成、使用或降解的蛋白质的基因可以包括二酰基甘油胆碱磷酸转移酶(DAG-CPT)、胞苷二磷酸二酰基甘油合成酶(CTP-DAG合成酶)、磷脂酰肌醇合成酶(PI合成酶)、胆碱激酶(CK)、磷脂酰肌醇-3-激酶(PI3-激酶)、磷脂酰肌醇-4-激酶(PI4-激酶)、二酰基甘油激酶(DGK)、磷脂酰甘油-3-磷酸酯磷酸酶(PGPP)、磷酸胆碱胞苷酰转移酶(CPCT)、磷脂酸胞苷酰转移酶、磷脂酰丝氨酸脱羧酶(PSD)、磷脂酶C(PliC)、磷脂酶D(PliD)、神经鞘脂质脱饱和酶(SD)、单半乳糖基二酰基甘油合成酶(MGDG合成酶)、二半乳糖基二酰基甘油合成酶(DGDG合成酶)、酮酰基-CoA合成酶(KCS)、3-酮酰基还原酶(KR)以及蜡合成酶(WS)。取决于待产生的脂肪酸或脂质分子的所希望的性质,一种或多种编码利用脂肪酸或脂肪酰基分子作为底物来产生脂质分子的酶的基因可以在微生物中减弱或过度表达。在一个实施例中,提供了用于抑制DGK(它将DAG转化成PA)的序列、组合物以及方法。举例来说,DGK可以通过使用RNAi、发夹构建体或双或单基因敲除加以抑制。在其他实施例中,提供了用于过度表达ε亚型(DGKe)的序列、组合物以及方法。在一些方面,DGKe的过度表达引起具有某些酰基如C20:4的DAG的选择性去除。为了工程化一种微生物以使三甘油酯的产生增加,可能有利的是减弱会支持磷脂合成的酶。举例来说,为了使磷脂胞苷二磷酸(CDP)-二酰基甘油的产生减少,一种表达盒可以被生成并且用于转化微生物以减弱磷脂酸胞苷酰转移酶,该磷脂酸胞苷酰转移酶催化磷脂酸和胞苷三磷酸的缩合以产生CDP-二酰基甘油。适用于本发明的一个实施例的磷脂酸胞苷酰转移酶的一个实例是由利用SEQIDNO:176给出的聚核苷酸序列编码的桑椹形原藻磷脂酸胞苷酰转移酶(SEQIDNO:177)。这种表达盒可以包含具有驱动磷脂酸胞苷酰转移酶的表达下调的活性的组成型或诱导型启动子。另外,除三酰基甘油酯以外的额外脂质部分可以利用作为主链的磷酸化甘油的衍生。参与磷脂合成的酶(如磷脂酰甘油磷酸合成酶(PGP合成酶)可以针对包括甘油的磷酸化形式的底物与提供三酰基甘油的酶竞争。取决于待产生的脂质分子的所希望的性质,一种或多种编码磷脂酰甘油磷酸合成酶的基因可以在微生物中减弱或过度表达。硫辛酸酯合成酶(LS,也称为硫辛酰合成酶或硫辛酸合成酶)总体上定位于线粒体并且用于合成硫辛酸。硫辛酸是一种重要的辅因子和抗氧化剂。G.脂肪酸降解为了基因工程化一种微生物以使特定脂肪酸和脂质的产生增加,可以或者单独地或者以组合形式进行重组修饰,从而减少脂肪酸和脂质的降解。由于如酰基-CoA氧化酶、3-酮酰基-CoA硫解酶、酰基-CoA脱氢酶、乙醛酸循环体脂肪酸β-氧化多功能蛋白以及烯酰基-CoA水合酶的蛋白参与脂肪酸的降解,故这些和其他蛋白可以在微生物中减弱以减缓或防止脂肪酸降解。举例来说,为了工程化一种微生物以减少脂肪酸降解,一种表达盒可以被生成并且用于转化微生物,从而下调酰基-CoA氧化酶、烯酰基-CoA水合酶以及乙醛酸循环体脂肪酸β-氧化多功能蛋白中的一者或多者,或者通过基因敲除或者基因敲低途径。适用于本发明的实施例的酰基-CoA氧化酶的一个实例是由在SEQIDNO:190中给出的聚核苷酸序列编码的桑椹形原藻酰基-CoA氧化酶(提供于SEQIDNO:191中)。适用于本发明的实施例的烯酰基-CoA水合酶的一个实例是由在SEQIDNO:192中给出的聚核苷酸序列编码的桑椹形原藻烯酰基-CoA水合酶(提供于SEQIDNO:193中)。适用于本发明的实施例的乙醛酸循环体脂肪酸β-氧化多功能蛋白的一个实例是由在SEQIDNO:166中给出的聚核苷酸序列编码的桑椹形原藻(UTEX1435)乙醛酸循环体脂肪酸β-氧化多功能蛋白(呈现于SEQIDNO:167中)。根据待由重组微生物产生的脂肪酸的所希望的链长和饱和度,可能有利的是在已经工程化以改变额外脂质通路基因或基因产物的微生物的遗传背景中下调脂肪酸或脂质降解酶。长链酰基-CoA合成酶(在本领域中也称为长链酰基-CoA连接酶)将游离脂肪酸转化成酰基-CoA硫酯。这些酰基-CoA硫酯可以接着由参与脂肪β-氧化的酶降解。为了工程化一种微生物以减少脂肪酸降解,一种表达盒可以被生成并且用于转化微生物,从而下调长链酰基-CoA合成酶,或者通过基因敲除或者基因敲低途径。适用于本发明的一个实施例的长链酰基-CoA合成酶的一个实例是由在SEQIDNO:198中给出的聚核苷酸序列编码的呈现于SEQIDNO:199中的桑椹形原藻(UTEX1435)长链酰基-CoA合成酶。根据待由重组微生物产生的脂肪酸的所希望的链长和饱和度,可能有利的是在已经工程化以改变额外脂质通路基因或基因产物的微生物的遗传背景中下调长链酰基-CoA合成酶。H.单甘油酯、三甘油酯以及脂质降解一种使重组微生物产生的三甘油酯增加的策略是防止或减少这些分子的酶促降解。将三甘油酯水解成脂肪酸和甘油的酶(如单甘油酯脂肪酶和三酰基甘油脂肪酶)是可以在微生物中减弱以减缓或防止三甘油酯降解的蛋白的实例。举例来说,为了工程化一种微生物以减少三甘油酯降解,一种表达盒可以被生成并且用于转化微生物,从而下调单甘油酯脂肪酶或三酰基甘油脂肪酶,或者通过基因敲除或者基因敲低途径。适用于本发明的实施例的单甘油酯脂肪酶的一个实例是由在SEQIDNO:188中给出的聚核苷酸序列编码的呈现于SEQIDNO:189中的桑椹形原藻(UTEX1435)单甘油酯脂肪酶。适用于本发明的实施例的三酰基甘油脂肪酶的一个实例是由在SEQIDNO:168中给出的聚核苷酸序列编码的呈现于SEQIDNO:169中的桑椹形原藻(UTEX1435)三酰基甘油脂肪酶。根据本发明的实施例,可能有利的是在特定培养条件下,例如在脂质产生过程中,减弱一种或多种脂肪酶。I.全局调节子另外,可以对控制脂质生物合成通路的基因表达的全局调节子施用基因的上调和/或下调。因此,脂质合成的一种或多种全局调节子可以在适当时被上调或下调,从而分别抑制或增强多种脂肪酸合成基因的表达并且最终使脂质产生增加。实例包括甾醇调节元件结合蛋白(SREBP),如SREBP-1a和SREBP-1c(例如参见基因库登录号NP_035610和Q9WTN3)。在一个实施例中,全局调节子(如内源性LEC2同系物)可以被上调以使脂质产生增加。从脂质生物合成的过程中解除或改变氮感测也可以是有价值的(波义耳(Boyle)等人,《生物化学杂志》(J.Biol.Chem),2012年5月4日)。本发明中还呈现的是一种氮反应调节子NRR1,一种鳞状结合蛋白。在一些实例中,可能希望的是例如通过增加NRR1的表达来增加对氮饥饿的反应。J.脂滴蛋白真核细胞将三酰基甘油分子储存在不同细胞器中,经常称为脂滴。与脂滴蛋白相关的蛋白,如脂滴蛋白1(LDP1,SEQIDNO:119-120)对脂滴结构、形成、大小以及数目至关重要。在一些情况下,脂滴蛋白的减弱会引起脂滴大小的增加。在其他情况下,脂滴蛋白的突变序列的过度表达会引起脂滴大小和数目的增加。为了基因工程化一种微生物以达成脂肪酸和脂质的产生,可以或者单独地或者以组合形式进行重组修饰,从而改变脂滴蛋白的表达。举例来说,一种表达盒可以被生成以减弱或除去编码脂滴蛋白的基因或基因产物(SEQIDNO:119-120)。基因产物通过使用RNAi、RNA发夹或其他反义介导的策略的减弱可以与一种诱导型或组成型启动子结合。在另一个实施例中,一种表达盒可以被生成以过度表达一种或多种脂滴蛋白。脂滴蛋白的过度表达可以由组成型或诱导型启动子驱动。桑椹形原藻(UTEX1435)并不包含油质蛋白,藻类脂滴蛋白(LDP)的植物等效物。相反,藻类脂滴蛋白,如此处呈现的LDP1适用于过度表达以改变脂滴形态学。K.改变碳代谢许多酶促通路涉及将糖和代谢物代谢成适用于脂肪酸或脂质合成或其他细胞通路的中间物。在本发明的一个实施例中,有利的是改变酶的调节或活性,这些酶有助于产生参与脂质合成的代谢物或将脂质合成的中间物或代谢物用于除脂肪酸和脂质通路以外的通路。克雷布氏循环(Kreb'scycle)是消耗乙酰基-CoA以最终产生二氧化碳的这类代谢通路。克雷布氏循环的酶促参与者包括延胡索酸水合酶(在本领域中也称为延胡索酸酶)。为了工程化一种微生物以使特定脂肪酸或脂质的产生增加,一种表达盒可以被生成并且用于转化微生物,从而减弱延胡索酸水合酶,或者通过基因敲除或者基因敲低途径。适用于本发明的实施例的延胡索酸水合酶的一个实例是由在SEQIDNO:170中给出的聚核苷酸序列编码的呈现于SEQIDNO:171中的桑椹形原藻(UTEX1435)延胡索酸水合酶。根据本发明的实施例,可能有利的是在特定培养条件下,例如在脂质产生过程中,减弱延胡索酸水合酶。参与碳代谢的酶的一个额外实例是NAD依赖性甘油-3-磷酸脱氢酶,它将sn-甘油3-磷酸酯可逆地转化成磷酸二羟丙酮(在本领域中也称为磷酸甘油酮)。为了提高三酰基甘油主链前体分子(sn-甘油3-磷酸酯代谢物)的水平,一种表达盒可以被生成并且用于转化微生物以增加NAD依赖性甘油-3-磷酸脱氢酶的表达。适用于本发明的实施例的NAD依赖性甘油-3-磷酸脱氢酶的一个实例是由在SEQIDNO:204中给出的聚核苷酸序列编码的呈现于SEQIDNO:205中的桑椹形原藻(UTEX1435)NAD依赖性甘油-3-磷酸脱氢酶。根据本发明的实施例,可能有利的是在特定培养条件下,例如在脂质产生过程中,减弱NAD依赖性甘油-3-磷酸脱氢酶。在一些实施例中,可能有利的是组合用于三酰基甘油产生的数种通路酶的表达,例如PAP、G3PDH、GPAT、LPPAT以及DGAT组合。其他蛋白(如甘油磷酸二酯磷酸二酯酶)合成脂质通路的中间物。甘油磷酸二酯磷酸二酯酶将甘油磷酸二酯水解以形成sn-甘油3-磷酸酯(它可以用于脂质合成)。为了工程化一种微生物以使脂质的产生增加,一种表达盒可以被生成并且用于转化微生物以过度表达编码甘油磷酸二酯磷酸二酯酶的聚核苷酸。适用于本发明的实施例的甘油磷酸二酯磷酸二酯酶的一个实例是由在SEQIDNO:180中给出的聚核苷酸序列编码的桑椹形原藻(UTEX1435)甘油磷酸二酯磷酸二酯酶(SEQIDNO:181)。纤维素酶(如内切葡聚糖酶)适用于将纤维素化合物分解成可被细胞利用的糖。提供了一种内源性内切葡聚糖酶,它可能潜在地用于分泌以分解纤维素物质或作为用于疏松细胞壁以允许增强的脂滴形成的机制。第III部分.培育在某些实施例中,本发明总体上涉及培育用于产生微生物油(脂质)的微生物,例如产油微生物,如微藻(包括小球藻和原藻物种和株系)以及酵母、真菌、植物以及细菌物种和株系。在特定实施例中,这些微生物是重组微生物。以下论述集中于作为一种示意性物种的原藻。为了方便读者,这一部分再分成几个小部分。第1小部分描述了原藻物种和株系以及如何通过基因组DNA比较来鉴别新的原藻物种和株系以及相关微藻。第2小部分描述了适用于培育的生物反应器。第3小部分描述了用于培育的培养基。第4小部分描述了根据本发明的示意性培育方法生产油。1.原藻物种和株系原藻是用于产生脂质的引人注目的微生物,因为它可以产生高水平的脂质,特别是适用于燃料生产的脂质。与由其他微藻产生的脂质相比,由原藻产生的脂质具有链长更短并且饱和度更高的烃链。此外,原藻脂质总体上不含色素(叶绿素和某些类胡萝卜素的水平低到不可检测出),并且在任何情况下,所含的色素比来自其他微藻的脂质少得多。此外,相对于从其他微生物产生脂质,由本发明提供的重组原藻细胞可以用于以更高产率和效率并且以降低的成本产生脂质。用于本发明方法的示意性原藻株系包括威克海姆原藻、大型原藻(包括UTEX327)、波多黎各原藻、桑椹形原藻(包括UTEX株系1441、1435)以及小型原藻。另外,这种微藻异养地生长并且可以被基因工程化。原藻属的物种是专性异养生物。可以通过扩增基因组的某些目标区来鉴别用于本发明的原藻物种。举例来说,可以通过使用引物以及使用基因组任何区域的方法(例如使用吴(Wu)等人,《中国科学院植物学通报》(Bot.Bull.Acad.Sin.)(2001)42:115-121使用核糖体DNA序列来鉴别小球藻属的分离株(IdentificationofChlorellaspp.isolatesusingribosomalDNAsequences)中描述的方法)对核和/或叶绿体DNA进行扩增和测序来实现特定的原藻物种或株系的鉴别。本领域普通技术人员可以使用充分确定的系统发生学分析方法,如对核糖体内部转录间隔区(ITS1和ITS2rDNA)、23SrRNA、18SrRNA以及其他保守的基因组区域进行扩增和测序,从而不仅鉴别原藻的物种,还鉴别具有相似脂质谱和产生能力的其他烃和脂质产生性生物体。关于对藻类进行鉴别和分类的方法的实例还参见例如《遗传学》(Genetics),2005年8月;170(4):1601-10和《RNA》,2005年4月;11(4):361-4。因此,可以利用基因组DNA比较来鉴别用于本发明的适合的微藻物种。可以从微藻物种扩增保守的基因组DNA区域(如(但不限于)编码23SrRNA的DNA),并且与共有序列相比较,以便筛选与用于本发明的优选微藻分类学相关的微藻物种。对于原藻属内的物种进行的该DNA序列比较的实例展示于下文中。基因组DNA比较还可以适用于鉴别株系保藏中心错误鉴别的微藻物种。通常,株系保藏中心将基于表型和形态特征鉴别微藻物种。使用这些特征可能会导致对微藻物种或微藻属的错误分类。使用基因组DNA比较可能是基于其系统发生学关系对微藻物种进行分类的更好方法。用于本发明的微藻典型地具有与SEQIDNO:1-9中所列的至少一种序列具有至少99%、至少95%、至少90%或至少85%核苷酸一致性的编码23SrRNA的基因组DNA序列。对于进行序列比较来测定核苷酸或氨基酸一致性百分比,典型地一个序列充当参考序列,将测试序列与其进行比较。当使用序列比较算法时,将测试序列和参考序列输入计算机中,必要时指定子序列坐标,并且指定序列算法的程序参数。序列比较算法然后基于指定的程序参数计算一个或多个测试序列相对于参考序列的序列一致性百分比。可以例如通过史密斯(Smith)和沃特曼(Waterman),《应用数学进展》(Adv.Appl.Math.)2:482(1981)的局部同源性算法、通过尼德曼(Needleman)和温施(Wunsch),《分子生物学杂志》(J.Mol.Biol.)48:443(1970)的同源性比对算法、通过皮尔森(Pearson)和李普曼(Lipman),《美国科学院院报》(Proc.Nat'l.Acad.Sci.USA)85:2444(1988)的相似性搜索方法、通过这些算法的计算机实施(威斯康星州麦迪逊的科学车道575号遗传学计算机组的威斯康星遗传学软件包(WisconsinGeneticsSoftwarePackage,GeneticsComputerGroup,575ScienceDr.,Madison,WI)中的GAP、BESTFIT、FASTA以及TFASTA)或者通过目测检查(总体上参见奥苏贝尔(Ausubel)等人,见上文)来对序列进行最佳比对以进行比较。适用于测定序列一致性和序列相似性百分比的另一种实例算法是BLAST算法,该算法被描述于阿特休尔等人,《分子生物学杂志》215:403-410(1990)中。用于进行BLAST分析的软件是经由美国国家生物技术信息中心(NationalCenterforBiotechnologyInformation)(网址是www.ncbi.nlm.nih.gov)公开可获得的。这种算法参与首先通过鉴别查询序列中长度为W的短字来鉴别高得分序列对(HSP),这些短字在与数据库序列中具有相同长度的字比对时或者匹配或者满足某个正值阈值分数T。T被称为相邻字分数阈值(阿特休尔等人,见上文)。这些初始相邻字命中用作种子启动搜索,以寻找包含它们的更长HSP。这些字命中然后沿着各序列在两个方向上延伸,直到可以增加累积比对分数为止。对于核苷酸序列,使用参数M(一对匹配残基的奖励分数;始终>0)和N(错配残基的罚分;始终<0)计算累积分数。对于氨基酸序列,使用计分矩阵计算累积分数。各个方向上字命中的延伸在下列情况时停止:累积比对分数相对于其所达到的最大值减少了量X;由于一个或多个负得分的残基比对的累积而使累积分数降到零或以下;或到达任一序列的末端。对于鉴别核酸或多肽是否在本发明的范围内,BLAST程序的预设参数是适合的。BLASTN程序(对于核苷酸序列)使用的预设值是字长(W)为11,期望值(E)为10,M=5,N=-4以及对两条链进行比较。对于氨基酸序列,BLASTP程序使用的预设值是字长(W)为3,期望值(E)为10以及BLOSUM62计分矩阵。TBLATN程序(对于核苷酸序列,使用蛋白质序列)使用的预设值是字长(W)为3,期望值(E)为10以及BLOSUM62计分矩阵。(参见亨尼科夫(Henikoff)和亨尼科夫,《美国国家科学院院刊》89:10915(1989))。除了计算序列一致性百分比以外,BLAST算法还对两个序列之间的相似性进行统计分析(参见例如卡林(Karlin)和阿特休尔,《美国国家科学院院刊》90:5873-5787(1993))。由BLAST算法提供的一种相似性量度是最小概率总和(P(N)),这提供了两个核苷酸或氨基酸序列之间将偶然存在匹配的概率的指示。举例来说,如果将测试核酸与参考核酸比较时最小概率总和小于约0.1,更优选地小于约0.01,并且最优选地小于约0.001,那么该核酸被认为与参考序列相似。应了解,在此提供的肽和蛋白质序列可以具有对肽的功能不具有实质性作用的保守或非必需氨基酸取代。保守氨基酸取代包括一个脂肪族氨基酸(如丙氨酸、缬氨酸、亮氨酸以及异亮氨酸)经另一个脂肪族氨基酸置换;一个丝氨酸经一个苏氨酸置换;一个苏氨酸经一个丝氨酸置换;一个酸性残基(如天冬氨酸和谷氨酸)经另一个酸性残基置换;一个带有酰胺基的残基(如天冬酰胺和谷氨酰胺)经另一个带有酰胺基的残基置换;一个碱性残基(如赖氨酸和精氨酸)与另一个碱性残基交换;以及一个芳香族残基(如苯丙氨酸和酪氨酸)经另一个芳香族残基置换。在一些实施例中,该多肽具有约1、2、3、4、5、6、7、8、9、10、15、20、30、40、50、60、70、80、90、100个或更多个氨基酸取代、添加、插入或缺失。除了产生适合的脂质或烃以产生油、燃料以及油脂化学品之外,影响对用于本发明的微生物进行选择的其他考虑因素还包括:(1)脂质含量高(占细胞重量的百分比);(2)易于生长;(3)易于进行基因工程化;以及(4)易于对生物质进行加工。在特定实施例中,野生型或经基因工程化的微生物产生具有至少40%、至少45%、至少50%、至少55%、至少60%、至少65%或至少70%或更多的脂质的细胞。优选的生物体异养地生长(利用糖在光不存在下)。可以用于实施本发明的藻类的实例包括(但不限于)以下藻类:威克海姆原藻、大型原藻、波多黎各原藻、桑椹形原藻、小型原藻。2.生物反应器培养微生物以实现进行遗传操作和产生烃(例如脂质、脂肪酸、醛、醇以及烷烃)的目的。前一种类型的培养以小规模并且最初至少在起始微生物可以生长的条件下进行。以产生烃为目的的培养通常在生物反应器中大规模(例如10,000L、40,000L、100,000L或更大的生物反应器)进行。典型地在本发明的方法中在生物反应器内于液体培养基中对微藻(包括原藻物种)进行培养。典型地,生物反应器不允许光进入。使用生物反应器或发酵罐来培养微藻细胞,经历它们的生理周期的不同阶段。生物反应器提供很多优势以用于异养生长和繁殖方法中。为了产生用于食品的生物质,优选地在液体中(如在作为一个实例的悬浮液培养物中)使微藻大量发酵。生物反应器(如钢发酵罐)可以容纳非常大的培养物体积(本发明的不同实施例中使用40,000升和更大容量的生物反应器)。生物反应器典型地还允许控制培养条件,如温度、pH值、氧张力以及二氧化碳水平。举例来说,生物反应器典型地是可配置的,例如使用与管道连接的端口,以允许气体组分(如氧气或氮气)鼓泡通过液体培养物。使用生物反应器还可以更容易地对其他培养参数(如培养基的pH值、微量元素的身份和浓度以及其他培养基成分)进行操纵。生物反应器可以经过配置以使培养基在整个微藻复制和数目增加的时间段中流过生物反应器。在一些实施例中,例如可以在接种后但在细胞达到所希望的密度之前将培养基注入生物反应器中。在其他情况下,在培养开始时将生物反应器用培养基填充,并且在接种培养物后不再注入培养基。换句话说,在水性培养基中培养微藻生物质一段时间,期间微藻复制并且数目增加;然而,在整个这段时间内没有大量的水性培养介质流过生物反应器。因此在一些实施例中,在接种后没有水性培养介质流过生物反应器。可以使用配备有如旋转刀和叶轮、摇动机构、搅拌棒、用于加压气体注入的装置等装置的生物反应器对微藻培养物进行混合。混合可以是连续性的或间歇性的。举例来说,在一些实施例中,并不维持气体进入和培养基进入的紊流状态以使微藻复制,直至实现所述微藻的所希望的数目增加为止。可以使用生物反应器端口将气体、固体、半固体以及液体引入或提取到容纳微藻的生物反应器腔室中。虽然很多生物反应器具有超过一个端口(例如一个端口用于培养基进入,以及另一个端口用于取样),但没有必要让一个端口仅用于一种物质进入或排出。举例来说,一个端口可以用于使培养基流入生物反应器中并且随后用于取样、气体进入、气体排出或者其他目的。优选地,可以在不改变或危害培养物的无菌性质的情况下重复使用取样口。取样口可以经过配置而具有阀门或允许样品停止和开始流动或提供连续取样装置的其他装置。生物反应器典型地具有允许接种培养物的至少一个端口,并且这种端口还可以用于其他目的,如培养基或气体进入。生物反应器端口允许对微藻培养物的气体含量进行操纵。举例来说,生物反应器的一部分容积可以是气体而非液体,并且生物反应器的气体入口允许将气体泵入生物反应器中。可以被有利地泵入生物反应器中的气体包括空气、空气/CO2混合物、惰性气体(如氩气)以及其他气体。生物反应器典型地经过配备以使得使用者能够控制气体进入生物反应器的速率。如上所述,增加进入生物反应器中的气体流动可以用于增强培养物混合。增加的气体流动还会影响培养物的浊度。可以通过在水性培养基层面以下安置一个气体进入端口以使进入生物反应器的气体鼓泡到培养物表面,从而实现紊流。一个或多个气体排出端口使气体逸散,由此防止生物反应器中压力蓄积。优选地,气体排出端口通向防止污染性微生物进入生物反应器中的“单向”阀门。3.培养基微藻培养基典型地包含如固定氮源、固定碳源、微量元素、任选地用于维持pH值的缓冲液以及磷酸类物质(典型地以磷酸盐形式提供)的组分。其他组分可以包括盐(如氯化钠),尤其对于海水微藻来说。氮源包括有机和无机氮源,包括例如(但不限于)分子氮、硝酸类物质、硝酸盐、氨(纯氨或盐形式,如(NH4)2SO4和NH4OH)、蛋白质、大豆粉、玉米浸渍液以及酵母提取物。微量元素的实例包括锌、硼、钴、铜、锰以及钼,例如分别呈ZnCl2、H3BO3、CoCl2·6H2O、CuCl2·2H2O、MnCl2·4H2O以及(NH4)6Mo7O24·4H2O的形式。根据本发明的方法适用的微生物存在于全世界不同地方和环境中。由于它们与其他物种的分离以及它们发生的进化趋异,所以可以难以预测用于脂质和/或烃组分的最佳生长和产生的特定生长培养基。在一些情况下,某些微生物株系可能不能生长于特定的生长培养基中,这是因为存在某种抑制性组分或不存在该特定微生物株系所需要的某种必需的营养需求。固体和液体生长培养基总体上可以是从多种来源可获得的,并且适用于多种微生物株系的特定培养基的制备的说明可以例如在线见于http://www.utex.org/(由奥斯汀(Austin)的德克萨斯大学(UniversityofTexas),德克萨斯州奥斯汀的大学站A67001号(1UniversityStationA6700,Austin,Texas),78712-0183对于其藻类培养物保藏中心(UTEX)所维持的网站)上。举例来说,不同淡水和盐水培养基包括描述于PCT公开号2008/151149中的那些,该公开通过引用结合在此。在一个具体实例中,朊间质培养基适用于无菌培养,并且可以通过将1g朊间质蛋白胨加入到1升布氏培养基(BristolMedium)中来制备1L体积的培养基(pH值约6.8)。布氏培养基在水溶液中包含2.94mMNaNO3、0.17mMCaCl2·2H2O、0.3MgSO4·7H2O、0.43mM、1.29mMKH2PO4以及1.43mMNaCl。对于1.5%的琼脂培养基,可以将15g琼脂加入到1L溶液中。将溶液盖上并且进行高压灭菌,然后在使用前储存于冷藏温度下。另一个实例是原藻分离培养基(PIM),它包含10g/L邻苯二甲酸氢钾(KHP)、0.9g/L氢氧化钠、0.1g/L硫酸镁、0.2g/L磷酸氢钾、0.3g/L氯化铵、10g/L葡萄糖、0.001g/L盐酸硫胺素、20g/L琼脂、0.25g/L5-氟胞嘧啶,pH值范围是5.0到5.2(参见泊尔(Pore),1973,《应用微生物学》(App.Microbiology),26:648-649)。可以通过咨询上文所确认的URL或者通过咨询维持微生物培养物的其他组织(如SAG、CCAP或CCALA)容易地鉴别用于本发明方法的其他适合的培养基。SAG是指哥廷根大学(Universityof)(德国哥廷根(Germany))的藻类培养物保藏中心,CCAP是指由苏格兰海洋科学协会(ScottishAssociationforMarineScience)(英国苏格兰(Scotland,UnitedKingdom))管理的藻类和原生动物培养物保藏中心,并且CCALA是指植物学研究所(InstituteofBotany)(捷克共和国特热邦(CzechRepublic))的藻类培养物保藏实验室。另外,美国专利号5,900,370描述了适于原藻物种异养发酵的培养基配制品和条件。对于油类生产,选择固定碳源很重要,因为固定碳源的成本必须足够低以使油生产经济。因此,当适合的碳源包括例如乙酸酯、弗罗里多苷(floridoside)、果糖、半乳糖、葡糖醛酸、葡萄糖、甘油、乳糖、甘露糖、N-乙酰葡萄糖胺、鼠李糖、蔗糖和/或木糖时,选择包含那些化合物的原料是本发明方法的一个重要方面。根据本发明方法适用的适合的原料包括例如黑液、玉米淀粉、解聚的纤维素物质、乳清、糖蜜、马铃薯、高粱、蔗糖、甜菜、甘蔗、稻米以及小麦。碳源还可以按混合物形式提供,如蔗糖与解聚的甜菜废粕的混合物。该一种或多种碳源可以按至少约50μM、至少约100μM、至少约500μM、至少约5mM、至少约50mM以及至少约500mM浓度的一种或多种外源性提供的固定碳源形式提供。优选的是高度浓缩的碳源作为原料用于发酵。举例来说,在一些实施例中,在培育步骤之前将至少300g/L、至少400g/L、至少500g/L或至少600g/L的葡萄糖水平或更高葡萄糖水平的原料加入到馈料分批培育中,其中将高度浓缩的固定碳源在细胞生长并累积脂质时随时间推移馈入细胞中。在其他实施例中,在培育之前将至少500g/L、至少600g/L、至少700g/L、至少800g/L的蔗糖水平或更多蔗糖加入到馈料分批培育中,其中将高度浓缩的固定碳源在细胞生长并累积脂质时随时间推移馈入细胞中。高度浓缩的固定碳源(如蔗糖)的非限制性实例包括浓蔗汁、甘蔗汁、甜菜汁以及糖蜜。为了本发明的目的特别关注的碳源包括纤维素(呈解聚形式)、甘油、蔗糖以及高粱,它们中的每一者被更详细地论述于下文中。根据本发明,可以使用解聚的纤维素生物质作为原料来培养微生物。纤维素生物质(例如秸杆,如玉米秸)是廉价并且易于获得的;然而,试图使用这种物质作为用于酵母的原料以失败告终。具体来说,已经发现这些原料会抑制酵母生长,并且酵母不能利用由纤维素物质产生的5碳糖(例如来自半纤维素的木糖)。相反,微藻可以依靠经加工的纤维素物质生长。纤维素物质总体上包含约40%-60%纤维素;约20%-40%的半纤维素;以及10%-30%木质素。适合的纤维素物质包括来自于草本和木本能源作物的残余物,以及农作物(并非从主要食物或纤维产品的田间摘下),即植物部分,主要是茎和叶。实例包括农业废物,如甘蔗渣、稻壳、玉米纤维(包括茎、叶、壳以及棒)、小麦秸、稻草、甜菜废粕、柑桔渣、柑桔皮;林业废物,如硬木和软木间伐材,以及来自木材操作的硬木和软木残余物;木材废弃物,如锯木厂废弃物(木材碎片、锯末)以及纸浆厂废物;城市废物,如城市固体废物的纸质部分、城市木材废弃物以及城市绿色废物(如城市剪草);以及木材建筑废物。额外的纤维素物质包括专门的纤维素作物,如柳枝稷、杂交白杨木以及芒属、纤维甘蔗以及纤维高粱。由这些物质产生的五碳糖包括木糖。对纤维素物质进行处理以提高微生物可以利用这些物质中所包含的一种或多种糖的效率。本发明提供了用于在酸爆裂后对纤维素物质进行处理,以使这些物质适用于对微生物(例如微藻和产油酵母)进行异养培养的新颖方法。如上所论述,木质纤维生物质包含不同部分,包括纤维素,即β1,4连接的葡萄糖(一种六碳糖)的结晶聚合物;半纤维素,即更松散连接的聚合物,主要包含木糖(一种五碳糖)并且包含更小程度的甘露糖、半乳糖、阿拉伯糖;木质素,即一种复杂的芳香族聚合物,包含芥子醇和其衍生物以及果胶(它是α1,4连接的多聚半乳糖醛酸的线性链)。由于纤维素和半纤维素的聚合结构,故它们当中的糖(例如单体葡萄糖和木糖)呈不可能被很多微生物有效利用(代谢)的形式。对于这些微生物,对纤维素生物质进行进一步加工以产生构成聚合物的单体糖可以非常有助于确保纤维素物质被高效地用作原料(碳源)。在本发明方法的另一个实施例中,碳源是甘油,包括来自生物柴油酯基转移的酸化和非酸化甘油副产物。在一个实施例中,碳源包括甘油和至少一种其他碳源。在一些情况下,将所有该甘油和该至少一种其他固定碳源在发酵开始时提供给微生物。在一些情况下,将该甘油和该至少一种其他固定碳源以预定比率同时提供给微生物。在一些情况下,将该甘油和该至少一种其他固定碳源在发酵过程内以预定速率馈给微生物。一些微藻与在葡萄糖存在下相比在甘油存在下经历更快细胞分裂(参见PCT公开号2008/151149)。在这些情况下,细胞被首先馈入甘油以快速增大细胞密度并且被接着馈入葡萄糖以累积脂质的两阶段生长过程可以改进脂质产生的效率。使用酯基转移过程的甘油副产物在放回到产生过程中时提供了显著的经济优势。还提供了其他馈入方法,如甘油和葡萄糖的混合物。馈入这些混合物也赢得了相同的经济利益。另外,本发明提供了将替代性糖馈给微藻的方法,如与甘油呈不同组合形式的蔗糖。在本发明方法的另一个实施例中,碳源是转化糖。转化糖是通过将蔗糖拆分成其单糖组分(果糖和葡萄糖)而产生的。转化糖的产生可以通过本领域中已知的数种方法实现。一种这类方法是加热蔗糖水溶液。通常,使用催化剂以便加速蔗糖到转化糖的转化。这些催化剂可以是生物学催化剂,例如酶(如转化酶和蔗糖酶)可以被加入到蔗糖中以加速水解反应,从而产生转化糖。酸是非生物催化剂的一个实例,在与热成对时,可以加速水解反应。一旦制得转化糖,其与蔗糖比较更不倾向于结晶,并且因此,为储存和馈料分批发酵提供优势,馈料分批发酵是在微生物(包括微藻)的异养培育情况下,对于浓缩碳源存在需求。在一个实施例中,碳源是转化糖,优选地呈浓缩形式,优选地是至少800克/升,至少900克/升,至少1000克/升或至少1100克/升,随后进行培育步骤,该培育步骤任选地是馈料分批培育。将转化糖(优选地呈浓缩形式)在细胞生长并累积脂质时随时间推移馈入细胞中。在本发明方法的另一个实施例中,碳源是蔗糖,包括了包含蔗糖的复杂原料,如来自甘蔗加工的浓蔗汁。由于用于异养油生产的培养物的密度更高,故固定碳源(例如蔗糖、葡萄糖等)优选地呈浓缩形式,优选地是至少500克/升、至少600克/升、至少700克/升或至少800克/升固定碳源,随后进行培育步骤,该培育步骤任选地是馈料分批培育,其中将该物质在细胞生长并累积脂质时随时间推移馈入细胞中。在一些情况下,碳源是呈浓蔗汁形式的蔗糖,优选地呈浓缩形式,优选地是至少60%固体或约770克/升糖,至少70%固体或约925克/升糖,或至少80%固体或约1125克/升糖,随后进行培育步骤,该培育步骤任选地是馈料分批培育。将浓缩的浓蔗汁在细胞生长并累积脂质时随时间推移馈入细胞中。在一个实施例中,培养介质进一步包括至少一种蔗糖利用酶。在一些情况下,培养介质包括一种蔗糖转化酶。在一个实施例中,蔗糖转化酶是由通过微生物群体表达的一种外源性蔗糖转化酶基因编码的一种可分泌的蔗糖转化酶。因此,在一些情况下,如以下第IV部分中更详细地描述,微藻已经基因工程化以表达一种蔗糖利用酶,如一种蔗糖转运蛋白、一种蔗糖转化酶、一种己糖激酶、一种葡萄糖激酶或一种果糖激酶。包含蔗糖的复杂原料包括来自甘蔗加工的废糖蜜;使用这种甘蔗加工的低价废产物可以在烃和其他油的生产中提供显著的成本节约。适用于本发明方法的包含蔗糖的另一种复杂原料是高粱,包括高梁饴和纯高粱。高梁饴由甜高梁的汁液产生。其糖谱主要由葡萄糖(右旋糖)、果糖以及蔗糖组成。第IV-I部分.基因工程化方法和材料本发明提供了用于对适用于本发明方法的原藻细胞和重组宿主细胞进行基因修饰的方法和材料,包括(但不限于)重组桑椹形原藻、小型原藻、克鲁格尼原藻(Protothecakrugani)以及大型原藻宿主细胞。为了方便读者,对这些方法和材料的描述被分成几个小部分。在第1小部分中,描述了转化方法。在第2小部分中,描述了使用同源重组的基因工程化方法。在第3小部分中,描述了表达载体和组分。在第4小部分中,描述了可选择标记和组分。1.工程化方法-转化可以通过任何适合的技术转化细胞,该技术包括例如基因枪法、电穿孔(参见丸山(Maruyama)等人(2004)《生物技术》(BiotechnologyTechniques)8:821-826)、玻璃珠转化法以及碳化硅晶须转化法。可以使用的另一种方法涉及形成原生质体以及使用CaCl2和聚乙二醇(PEG)将重组DNA引入到微藻细胞中(参见金(Kim)等人(2002),《海洋生物技术》(Mar.Biotechnol.)4:63-73,它报导了使用这种方法转化椭圆形小球藻(Chorellaellipsoidea))。可以使用微藻的共转化以将两种不同的载体分子同时引入到细胞中(参见例如雅库比亚克(Jakobiak)等人(2004)《原生生物》(Protist);155(4):381-93)。还可以使用基因枪法(参见例如桑福德(Sanford),《生物技术趋势》(TrendsInBiotech.)(1988)6:299-302,美国专利号4,945,050);电穿孔(弗罗姆(Fromm)等人,《美国科学院院报》(1985)82:5824-5828);使用激光束、显微注射或能够将DNA引入微藻中的任何其他方法来转化原藻细胞。2.工程化方法-同源重组同源重组是互补DNA序列对齐并且交换同源区域的能力。将转基因DNA(“供体”)引入生物体中,该转基因DNA包含与所靶向的基因组序列同源的序列(“模板”),并且接着在相应的基因组同源序列位点处经历重组到基因组中。在大多数情况下,这一过程的机械步骤包括:(1)使同源DNA区段配对;(2)将双链断裂引入到供体DNA分子中;(3)利用游离的供体DNA末端侵入模板DNA分子,随后进行DNA合成;以及(4)解决双链断裂修复事件,这些事件产生最终的重组产物。在宿主生物体中进行同源重组的能力具有许多实际意义,这是因为其可以在分子遗传学层面上进行并且适用于产生能够生产特制油的产油微生物。同源重组本质上是精确的基因靶向事件,因此,用相同的靶向序列生成的大多数转基因株系将在表型上是基本一致的,需要筛选极少的转化事件。同源重组还以进入宿主染色体的基因插入事件为目标,产生极好的遗传稳定性,甚至在不存在遗传选择的情况下。由于不同的染色体基因座可能会影响基因表达,甚至是异源启动子/UTR介导的基因表达,所以同源重组可以是在未知基因组环境中查找基因座以及评估这些环境对基因表达的影响的方法。使用同源重组的特别有用的基因工程化应用是指派特异性宿主调节元件(如启动子/UTR)而以高度特异性方式驱动异源性基因表达。举例来说,用编码选择性标记的异源性基因除去或敲除脱饱和酶基因/基因家族可能预期会提高宿主细胞中产生的饱和脂肪酸的总百分比。实例3描述了同源重组靶向构建体以及在桑椹形原藻中发生的将这种脱饱和酶基因除去或敲除的工作实例。另一种减少内源性基因表达的途径是使用RNA诱导的下调或基因表达的沉默,包括(但不限于)RNAi或反义途径以及dsRNA途径。反义、RNAi、RNA发夹以及dsRNA途径为本领域所熟知并且包括引入在以mRNA形式表达时将引起发夹RNA形成的表达构建体或包含将以反义取向转录的一部分靶基因的表达构建体。所有四种途径将引起靶基因表达减少。实例3和4描述了利用RNA发夹途径减弱或下调内源性桑椹形原藻脂质生物合成基因的表达构建体和工作实例。由于同源重组是精确的基因靶向事件,所以它可以被用于对所关注的基因或区域内的任何一个或多个核苷酸进行精确修饰,只要已经鉴别出足够的侧接区域既可。因此,可以使用同源重组作为对影响RNA和/或蛋白质的基因表达的调节序列进行修饰的手段。它还可以被用于修饰蛋白质编码区以试图调节酶活性(如底物特异性、亲和力以及Km),并且因而影响宿主细胞代谢中所希望的变化。同源重组提供了操纵宿主基因组,从而引起基因靶向、基因转换、基因缺失、基因复制、基因倒置以及交换基因表达调节元件(如启动子、增强子以及3'UTR)的有效手段。可以通过使用包含内源性序列片段的靶向构建体来“靶向”内源性宿主细胞基因组内的所关注的基因或区域来实现同源重组。这些靶向序列可以位于或者所关注的基因或区域的5'端上、或者所关注的基因/区域的3'端上或者甚至侧接所关注的基因/区域。这些靶向构建体可以按具有额外载体骨架的超螺旋质粒DNA形式、无载体骨架的PCR产物形式或线性化分子形式转化到宿主细胞中。在一些情况下,可能有利的是首先利用限制酶使转基因DNA(供体DNA)内的同源序列暴露。这个步骤可以增加重组效率并且减少所不希望的事件发生。增加重组效率的其他方法包括使用PCR产生转化转基因DNA,该转基因DNA包含与所靶向的基因组序列同源的线性末端。为了非限制性说明的目的,供体DNA序列中适用于同源重组的区域包括桑椹形原藻的KE858DNA区域。KE858是一个1.3kb基因组片段,它涵盖与蛋白质的转移RNA(tRNA)家族共有同源性的蛋白质编码区的一部分。DNA印迹法已展示KE858序列在桑椹形原藻(UTEX1435)基因组中以单个拷贝形式存在。这个区域以及使用这个区域进行同源重组靶向的实例已描述于PCT公开号WO2010/063032中。供体DNA中适用的另一个区域是6S基因组序列的部分。在对桑椹形原藻进行同源重组中使用这个序列已描述于以下实例中。3.载体和载体组分鉴于在此的披露,可以通过为本领域普通技术人员所熟悉的已知技术来制备根据本发明实施例转化微生物的载体。载体典型地包含一个或多个基因,其中每个基因进行编码以使所希望的产物(基因产物)表达,并且与调节基因表达或使基因产物靶向重组细胞内的特定位置的一个或多个控制序列可操作地连接。为了帮助读者,这个小部分被分成几个小部分。A小部分描述了载体上典型地包含的控制序列以及由本发明提供的新颖控制序列。B小部分描述了载体中典型地包含的基因以及由本发明提供的新颖密码子优化方法和使用它们制备的基因。C小部分描述了载体上包含的以及由本发明提供的可选择标记。D小部分描述了用于鉴别基因的方法和程序。A.控制序列控制序列是调节编码序列的表达或将基因产物引导到细胞内或细胞外的特定位置的核酸。调节表达的控制序列包括例如调节编码序列转录的启动子和使编码序列转录终止的终止子。另一个控制序列是位于编码多聚腺苷酸化信号的编码序列末端上的3′端非翻译序列。将基因产物引导到特定位置的控制序列包括编码信号肽的那些,这些序列将它们所连接的蛋白质引导到细胞内或细胞外的特定位置。因此,设计用于在微藻中表达外源性基因的示例性载体包含所希望的基因产物(例如可选择标记、脂质通路酶或蔗糖利用酶)的编码序列,该编码序列与在微藻中具有活性的启动子可操作地连接。可替代地,如果载体不包含与所关注的编码序列可操作连接的启动子,那么可以将编码序列转化到细胞中,以使其在载体整合时与内源性启动子可操作地连接。已经证明可以在微藻中实施这种无启动子的转化方法(参见例如伦布雷拉斯(Lumbreras)等人植物杂志(PlantJournal)(1988),14(4),第441-447页)。许多启动子在微藻中具有活性,包括所转化的藻类的内源性启动子以及所转化的藻类的非内源性启动子(即来自其他藻类的启动子、来自高等植物的启动子以及来自植物病毒或藻类病毒的启动子)。在微藻中具有活性的示意性外源性和/或内源性启动子(以及在微藻中具有功能的抗生素抗性基因)描述于PCT公开号2008/151149和其中引用的参考文献中。用于表达外源性基因的启动子可以是与该基因天然连接的启动子或可以是异源性基因。一些启动子在超过一种微藻物种中具有活性。其他启动子是物种特异性的。示意性启动子包括已经显示在多个微藻物种中具有活性的启动子,如以下实例中使用的来自莱茵衣藻(Chlamydomonasreinhardtii)的β-微管蛋白,以及病毒启动子,如花椰菜花叶病毒(CMV)启动子和小球藻病毒启动子(参见例如《植物细胞报导》(PlantCellRep).2005年3月;23(10-11):727-35;《微生物学杂志》(JMicrobiol).2005年8月;43(4):361-5;《海洋生物技术》(NY).2002年1月;4(1):63-73)。适用于在原藻中表达外源性基因的另一个启动子是耐热性小球藻(Chlorellasorokiniana)谷氨酸脱氢酶启动子/5'UTR。任选地,使用这些序列中包含启动子的至少10、20、30、40、50或60个或更多个核苷酸。适用于在原藻中表达外源性基因的示意性启动子列于本申请的序列表中,如小球藻HUP1基因的启动子(SEQIDNO:10)和椭圆形小球藻硝酸还原酶启动子(SEQIDNO:11)。还可以利用小球藻病毒启动子在原藻中表达基因,如美国专利6,395,965中的序列编号1到7。在原藻中具有活性的额外的启动子可以见于例如《生物化学与生物物理研究通讯》(BiochemBiophysResCommun).1994年10月14日;204(1):187-94;《植物分子生物学》(PlantMolBiol).1994年10月;26(1):85-93;《病毒学》(Virology).2004年8月15日;326(1):150-9;以及《病毒学》.2004年1月5日;318(1):214-23中。其他适用的启动子详细描述于以下实例中。启动子总体上可以表征为或者组成型或者诱导型。组成型启动子总体上在所有时间(或在细胞生命周期中的某些时间)均具有相同水平的驱动表达的活性或功能。相反,诱导型启动子仅回应于刺激物而具有活性(或使其无活性),或被显著上调或下调。这两种类型的启动子均可应用于本发明的实施例。适用于本发明的实施例的诱导型启动子包括回应于刺激物而介导可操作连接的基因转录的那些,该刺激物如外源提供的小分子(例如葡萄糖,如SEQIDNO:10中)、温度(热或冷)、培养基中缺少氮、pH值等。适合的启动子可以激活基本上沉默的基因转录,或优选地实质性上调低水平转录的可操作连接基因的转录。以下实例描述了适用于原藻细胞的额外的诱导型启动子。终止区(也称为3'非翻译区)可以对于转录起始区(启动子)是原生的,可以对于所关注的DNA序列是原生的,或者可以从另一个来源获得。参见例如,陈(Chen)和奥罗斯科(Orozco),核酸研究(NucleicAcidsRes).(1988),16:8411。在本发明的一个实施例中,使用针对外源性酶或蛋白分室化表达提供的控制序列将外源性酶或蛋白引导到一种或多种细胞内细胞器中。所靶向的细胞器是叶绿体、质体、线粒体以及内质网。本发明的一个额外实施例提供了使蛋白质分泌到细胞外的重组聚核苷酸。可以使用质体靶向信号使原藻核基因组中编码的蛋白质靶向质体。小球藻内源性质体靶向序列是已知的,如小球藻核基因组中编码靶向质体的蛋白质的基因;参见例如基因库登录号AY646197和AF499684,并且在一个实施例中,本发明的载体中使用这些控制序列以使蛋白质的表达靶向原藻质体。以下实例描述了使用藻类质体靶向序列使外源性酶和蛋白靶向宿主细胞中的正确的区室。藻类质体靶向序列是从使用桑椹形原藻和原始小球藻(Chlorellaprotothecodies)细胞制得的cDNA文库获得的,并且这些cDNA文库描述于PCT申请号WO2010/063032中。在另一个实施例中,使外源性酶或蛋白在原藻中的表达靶向内质网。在表达载体中纳入适当的滞留或分选信号以确保蛋白质滞留于内质网(ER)中而不进入下游到高尔基体中。举例来说,来自瓦格宁根大学-国际植物研究所(WageningenUR-PlantResearchInternational)的IMPACTVECTOR1.3载体包括熟知的KDEL滞留或分选信号。在这种载体情况下,ER滞留具有实际优势,因为已报导使表达水平提高5倍或更多倍。这种情况的主要原因似乎是与细胞质中呈现的相比,ER包含更低浓度和/或不同的负责使已表达蛋白发生翻译后降解的蛋白酶。在绿微藻中具有功能的ER滞留信号是已知的。例如,参见《美国科学院院报》(Proc.Natl.Acad.Sci.USA).2005年4月26日;102(17):6225-30。在本发明的另一实施例中,目标在于使多肽分泌到细胞外进入培养基中。关于可以根据本发明的方法用于原藻的在小球藻中具有活性的分泌信号的实例,参见霍金斯(Hawkins)等人,《当代微生物学》(CurrentMicrobiology)第38卷(1999),第335-341页。B.基因和密码子优化典型地,基因包括启动子、编码序列以及终止控制序列。当通过重组DNA技术进行组装时,基因可以被称为表达盒,并且可以由限制性位点侧接以便于插入到用于将重组基因引入宿主细胞中的载体中。表达盒可以由来自基因组的DNA序列或其他核酸侧接,目的在于促成表达盒通过同源重组稳定整合到基因组中。可替代地,载体与其表达盒可以保持未整合,在这种情况下,载体典型地包括能够使异源性载体DNA进行复制的复制起点。载体上存在的常见基因是编码一种蛋白质的基因,该蛋白质的表达允许将包含该蛋白质的重组细胞与不表达该蛋白质的细胞区分开来。这种基因和其相应的基因产物被称作可选择标记。适用于转化原藻的转基因构建体中可以使用多种可选择标记中的任一种。适合的可选择标记的实例包括G418抗性基因、硝酸还原酶基因(参见道森(Dawson)等人(1997),《当代微生物学》35:356-362)、潮霉素磷酸转移酶基因(HPT;参见金(Kim)等人(2002),《海洋生物技术》4:63-73)、新霉素磷酸转移酶基因以及ble基因(它赋予脉霉素抗性)(黄(Huang)等人(2007),《微生物生物技术应用》(Appl.Microbiol.Biotechnol.)72:197-205)。测定微藻对抗生素的敏感性的方法是熟知的。举例来说,《分子和普通遗传学》(MolGenGenet).1996年10月16日;252(5):572-9。在总体上适用于转化微藻(包括原藻物种)的转基因构建体中还可以使用不基于抗生素的其他可选择标记。赋予利用先前不能由微藻利用的某些碳源的能力的基因也可以被用作可选择标记。举例来说,桑椹形原藻株系典型地不能很好地依赖蔗糖生长(如果有生长的话)。使用包含蔗糖转化酶基因的构建体可以赋予阳性转化体以蔗糖作为碳底物生长的能力。关于使用蔗糖利用作为可选择标记以及其他可选择标记的额外细节论述于下文中。为了本发明的目的,用于制备本发明的重组宿主细胞的表达载体将包括至少两种,并且通常三种基因,如果这些基因中的一者是可选择标记。举例来说,可以通过用本发明载体进行转化来制备本发明的经基因工程化的原藻,这些载体除了可选择标记外还包含一种或多种外源性基因,如蔗糖转化酶基因或酰基ACP-硫酯酶基因。可以使用诱导型启动子使一种或两种基因表达,该启动子允许控制这些基因表达的相对时机以增强脂质产率以及向脂肪酸酯的转化。两种或更多种外源性基因的表达可以处于相同诱导型启动子的控制下,或处于不同诱导型(或组成型)启动子的控制下。在后一种情况下,可以诱导一个第一外源性基因表达一个第一时间段(期间可以诱导或不诱导一个第二外源性基因表达)并且可以诱导一个第二外源性基因表达一个第二时间段(期间可以诱导或不诱导一个第一外源性基因表达)。在其他实施例中,两种或更多种外源性基因(除了任何可选择标记外)是:脂肪酰基-ACP硫酯酶和脂肪酰基-CoA/醛还原酶,两者组合作用产生醇产物。表达两种或更多种外源性基因的本发明实施例的其他示意性载体包括编码蔗糖转运蛋白与蔗糖转化酶的载体以及编码可选择标记与分泌型蔗糖转化酶的载体两者。经过任一种类型的载体转化的重组原藻由于经过工程化而能够利用甘蔗(和甘蔗衍生糖)作为碳源,所以能够以更低的生产成本生产脂质。插入上述两种外源性基因可以与经由定向和/或随机诱变破坏多糖生物合成相组合,这使得甚至更多碳流进入脂质生产。单独地和组合利用营养转换、改变脂质生产的工程化与用外源性酶进行处理来使得由微生物生产的脂质组成发生变化。该变化可以是所生产的脂质的量、所生产的一种或多种烃物质相对于其他脂质的量和/或微生物中产生的脂质物质类型方面的变化。举例来说,可以对微藻进行工程化以产生更高量和/或百分比的TAG。为了使重组蛋白最佳表达,有益的是使用具有由所转化宿主细胞优先使用的密码子的产生mRNA的编码序列。因此,转基因的适当表达可能需要转基因的密码子使用与表达转基因的生物体的特定密码子偏倚性相匹配。这种作用精确的根本机制有许多,但包括可供使用的氨基酰化tRNA池与细胞中正合成的蛋白质之间的适当平衡,以及当满足这个需要时使转基因信使RNA(mRNA)更加有效地翻译。当转基因中的密码子使用没有经过优化时,可供使用的tRNA池不足以使异源性mRNA有效翻译,导致核糖体中止和终止以及转基因mRNA可能不稳定。本发明提供了适用于使重组蛋白在原藻中成功表达的经密码子优化的核酸。通过研究从桑椹形原藻分离的cDNA序列来对原藻物种中的密码子使用进行分析。这个分析对超过24,000个密码子进行查询,并且结果示于下表2中。表2.原藻株系中的示意性优选密码子使用。在其他实施例中,对于除原藻株系以外的微藻株系,对重组载体中的基因进行密码子优化。举例来说,使基因重编码以在微藻中表达的方法描述于美国专利7,135,290中。在例如基因库的密码子使用数据库中可获得关于密码子优化的额外信息。尽管本发明的方法和材料允许将任何外源性基因引入原藻中,但与蔗糖利用和脂质通路修饰有关的基因受到特别关注,如以下部分中所论述。C.可选择标记蔗糖利用在一个实施例中,本发明的重组原藻细胞进一步包含一种或多种外源性蔗糖利用基因。在不同实施例中,该一种或多种基因编码一种或多种蛋白,该一种或多种蛋白选自下组,该组由以下各项组成:一种果糖激酶、一种葡萄糖激酶、一种己糖激酶、一种蔗糖转化酶、一种蔗糖转运蛋白。举例来说,蔗糖转运蛋白和蔗糖转化酶的表达使得原藻将蔗糖从培养基转运到细胞中并且将蔗糖水解,以产生葡萄糖和果糖。任选地,在内源性己糖激酶的活性不足以最大程度地使果糖磷酸化的情况下,还可以表达果糖激酶。适合的蔗糖转运蛋白的实例是基因库登录号CAD91334、CAB92307以及CAA53390。适合的果糖激酶的实例是基因库登录号P26984、P26420以及CAA43322。在一个实施例中,本发明提供了分泌一种蔗糖转化酶的一种原藻宿主细胞。蔗糖转化酶的分泌排除了表达可以将蔗糖转运到细胞中的转运蛋白的需求。这是因为分泌的转化酶催化蔗糖分子转化成葡萄糖分子和果糖分子,这两者均可以由本发明提供的微生物转运和利用。举例来说,具有分泌信号(如SEQIDNO:12(来自酵母)、SEQIDNO:13(来自高等植物)、SEQIDNO:14(真核细胞共有分泌信号)以及SEQIDNO:15(来自高等植物信号序列与真核细胞共有信号序列的组合)的分泌信号)的蔗糖转化酶的表达在细胞外部产生转化酶活性。这种蛋白质的表达(如能够通过在此披露的基因工程化方法使其表达)允许细胞已经能够利用胞外的葡萄糖作为能量来源以利用蔗糖作为胞外的能量来源。在包含蔗糖的培养基中表达转化酶的原藻物种是生产油的优选微藻物种。这种具有完全活性的蛋白质的表达和胞外靶向允许所得到的宿主细胞利用蔗糖生长,而它们的未经转化的对应物则不能。因此,本发明提供了具有经密码子优化的转化酶基因的原藻重组细胞(SEQIDNO:16),包括(但不限于)酵母转化酶基因,它被整合到其基因组中以使转化酶基因表达(如通过转化酶活性和蔗糖水解所评估)。适合的蔗糖转化酶的实例包括由基因库登录号CAB95010、NP_012104(SEQIDNO:17)以及CAA06839识别的那些。适合的转化酶的非限制性实例包括PCT公开号WO2010/063032中所述的那些,该公开通过引用结合在此。由原藻将转化酶分泌到培养介质中使得细胞同样能够利用来自甘蔗加工的废糖蜜生长,如同其利用纯试剂级葡萄糖生长一般;利用甘蔗加工的这种低价废产物可以在脂质和其他油生产方面提供显著的成本节约。因此,本发明提供了一种包含原藻微生物群体的微生物培养物和一种包含(i)蔗糖和(ii)蔗糖转化酶的培养介质。在不同实施例中,培养物中的蔗糖来源于高粱、甜菜、甘蔗、糖蜜或经解聚的纤维素物质(其可能任选地包含木质素)。在另一个方面,本发明的方法和试剂显著增加可以被重组原藻利用的原料的数目和类型。虽然此处举例说明的微生物经过改变以使它们可以利用蔗糖,但可以应用本发明的方法和试剂以使原料(如纤维素)是由能够分泌纤维素酶、果胶酶、异构酶等的本发明经工程化的宿主微生物可利用的,使得酶促反应的分解产物不再仅仅单纯地由宿主耐受,而是作为碳源由宿主利用。D.序列测定可以使用各种方法来鉴别脂质生物合成通路基因和酶的基因序列和氨基酸序列。聚核苷酸(例如基因组DNA、cDNA、RNA、PCR扩增的核苷酸)的序列可以通过测序技术测定,这些测序技术包括(但不限于)桑格尔测序(Sangersequencing)、焦磷酸测序、边合成边测序、利用寡核苷酸探针连接进行测序以及实时测序。本领域普通技术人员可以将核苷酸序列与公开的基因组序列数据库或所表达的序列进行比较。当对一种DNA序列进行测定或披露时,本领域普通技术人员可以比较来自公开的外显子序列的区段,或者可以将外显子序列组装到并不包含内含子序列的重新构建的序列中。聚核苷酸的序列还可以通过各种方法翻译成氨基酸、肽、多肽或蛋白,这些方法包括(但不限于)人工翻译或使用本领域中通常已知的生物信息学软件的计算机自动翻译。经测序的DNA、RNA、氨基酸、肽或蛋白的比较方法可以包括(但不限于)序列的人工评估或计算机自动化序列比较以及使用如BLAST(基础局部比对搜寻工具(BasicLocalAlignmentSearchTool);阿特休尔S.E等人,(1993)/.《分子生物学》(Mol.Biol.)215:403-410;也参见www.ncbi.nlm.nih.gov/BLAST/)的算法的鉴别。本说明书传授了编码一种或多种特定微生物基因和蛋白质的部分或全部氨基酸和核苷酸序列。享有如在此报导的序列的益处的熟练的业内人士现在可以使用所有或一部分所披露的序列以达成本领域普通技术人员已知的目的。桑椹形原藻(UTEX1435)的基因组测序是使用IlluminaHiSeq进行的,并且获得了双末端读长(100bp读长,约450bp片段大小)。基因组DNA是使用标准方案制备的并且利用水力剪切进行分段。还获得了使用Roche454技术的基因组数据(400bp片段大小),如同8kb末端配对文库般。转录组数据由IlluminaHiSeq双末端数据(100bp读长,约450bp片段大小)组成。对测序读长进行质量修整并且使用fastx工具过滤。基因组数据使用Velvet(泽尔比诺(Zerbino)等人,Velvet:使用deBruijn图进行从头短读长组装的算法(Velvet:algorithmsfordenovoshortreadassemblyusingdeBruijngraphs),《基因组研究》(GenomeResearch),2008年5月)使用优化的kmer和其他预设参数,并且使用太平洋生物科学ALLORA汇编程序(PacificBiosciencesALLORAassembler)组装。注解使用MAKERpipeline进行,并且基因利用BLAST针对nr数据库(NCBI)鉴别。另外,构建一个cDNA文库,并且使用桑格尔测序对来自这一文库的约1200个cDNA进行测序。这些cDNA接着被注解并且用作初始输入点,从而找出来自Illumina转录组的转录物并且帮助验证Illumina转录组和基因组序列数据的精确度。太平洋生物科学技术(PacificBiosciencestechnology)也被用于获得来自基因组样品的长读长。一个给定的碱基位置用如下表中所示的一个代码表示。在一些情况下,构建了两个代表性序列,其中分别有两个可能的碱基以及针对这两个替代物的相应蛋白质翻译。这些序列被称为“1型”和“2型”。碱基代码A腺嘌呤C胞嘧啶G鸟嘌呤T(或U)胸腺嘧啶(或尿嘧啶)RA或GYC或TSG或CWA或TKG或TMA或CBC或G或TDA或G或THA或C或TVA或C或GN任何碱基.或-空隙*终止子/无义密码子?未知氨基酸第IV-II部分.基因工程化的原藻细胞在一个第一方面,本发明提供了一种基因工程化的原藻细胞,其中一种或多种脂质生物合成基因已被修饰以增加或减少该一种或多种基因的表达,使得该基因工程化的株系的脂肪酸谱与其所来源的株系的脂肪酸谱不同。在一个实施例中,至少两种基因已被修饰。在不同实施例中,基因修饰包括以下修饰中的一者或多者:(i)一种基因或它的酶促产物的减弱;和(ii)一种基因或它的酶促产物的表达增加;(iii)一种基因或它的酶促产物的活性改变。在不同实施例中,该基因工程化的细胞具有一种或多种减弱的基因,其中该减弱的基因已通过一种选自下组的手段减弱,该组由以下各项组成:一个同源重组事件以及引入会编码一种干扰性RNA的一种外源性基因。在不同实施例中,一种基因的一个或多个等位基因被减弱。在不同实施例中,该基因工程化的细胞具有一种或多种过度表达的基因,其中这些过度表达的基因已通过一种选自下组的手段上调,该组由以下各项组成:将所述基因的额外拷贝引入所述细胞中;引入所述基因的新表达控制元件;以及改变该基因的蛋白质编码序列。在不同实施例中,一种基因的一个或多个等位基因是过度表达的。在不同实施例中,该基因工程化的细胞的经修饰基因选自下组,该组由以下各项组成:表1中呈现的原藻脂质生物合成基因。在不同实施例中,该基因工程化的细胞包含一种选自下组的外源性基因,该组由以下各项组成:表1中呈现的原藻脂质生物合成基因。在不同实施例中,该基因工程化的细胞包含一种基因的再一个过度表达的等位基因,该基因选自下组,该组由以下各项组成:表1中呈现的原藻脂质生物合成基因。在不同实施例中,该基因工程化的细胞具有一种选自下组的减弱的基因,该组由以下各项组成:表1中呈现的原藻脂质生物合成基因。在不同实施例中,该基因工程化的细胞具有一种基因的再一个减弱的等位基因,该基因选自下组,该组由以下各项组成:表1中呈现的原藻脂质生物合成基因。在不同实施例中,该基因工程化的细胞具有一种或多种过度表达的基因,其中该基因的表达已通过一种选自下组的手段增加,该组由以下各项组成:将所述基因的额外拷贝引入所述细胞中;以及引入所述基因的新表达控制元件。在不同实施例中,该过度表达的基因是一种外源性基因。在不同实施例中,该基因工程化的细胞的经修饰基因选自下组,该组由以下各项组成:表1中呈现的原藻脂质生物合成基因。在不同实施例中,该基因工程化的细胞具有一种选自下组的上调的基因,该组由以下各项组成:表1中呈现的原藻脂质生物合成基因。在不同实施例中,该基因工程化的细胞具有一种选自下组的减弱的基因,该组由以下各项组成:表1中呈现的原藻脂质生物合成基因。在不同实施例中,该基因工程化的细胞具有一种选自下组的脂肪酸谱,该组由以下各项组成:3%到60%C8:0、3%到60%C10:0、3%到70%C12:0、3%到95%C14:0、3%到95%C16:0、3%到95%C18:0、3%到95%C18:1、3%到60%C18:2、1%到60%C18:3或其组合。在不同实施例中,C10:0与C12:0的比率是至少3:1。在不同实施例中,C12:0与C14:0的比率是至少3:1。在一些情况下,C10:0与C14:0的比率是至少10:1。在不同实施例中,该基因工程化的细胞具有至少40%饱和脂肪酸、至少60%饱和脂肪酸、或至少85%饱和脂肪酸的一种脂肪酸谱。在不同实施例中,该基因工程化的细胞具有至少85%不饱和脂肪酸、至少90%不饱和脂肪酸、至少95%不饱和脂肪酸、或至少97%不饱和脂肪酸的一种脂肪酸谱。本发明的一个实施例还提供了重组原藻细胞,这些重组原藻细胞已经修饰以包含一种或多种编码脂质生物合成酶(如一种脂肪酰基-ACP硫酯酶(参见实例5)或一种酮酰基-ACP合成酶II(参见实例6))的外源性基因。在一些实施例中,将编码一种脂肪酰基-ACP硫酯酶和一种天然共表达的酰基载体蛋白的基因转化到一种原藻细胞中,该原藻细胞任选地具有一种或多种编码其他脂质生物合成蛋白的基因。在其他实施例中,ACP和脂肪酰基-ACP硫酯酶可能对彼此具有亲和力,这在这两者一起用于本发明的微生物和方法时赋予了一种优势,与它们是还是不是天然共表达于一种特定组织或生物体中无关。因此,本发明的实施例涵盖这些酶以及共享针对与彼此相互作用的亲和力的那些酶的天然共表达对两者,从而有助于一种长度特定的碳链从ACP裂解。在再其他实施例中,将一种编码一种脱饱和酶的外源性基因与一种或多种编码其他脂质生物合成基因的基因一起转化到原藻细胞中,从而提供关于脂质饱和度的修饰。在其他实施例中,一种内源性脱饱和酶基因在一种原藻细胞中是过度表达的(例如通过引入该基因的额外拷贝)。在一些实施例中,该脱饱和酶可以根据所希望的碳链长度加以选择,使得该脱饱和酶能够在指定碳长度底物或具有在特定范围内的碳长度的底物内进行位置特异性修饰。在另一个实施例中,如果所希望的脂肪酸谱在单不饱和物(如C16:1和/或C18:1)中增加,那么SAD的过度表达或异源性SAD的表达可以与一种脂肪酰基脱饱和酶(FAD)或另一种脱饱和酶基因的沉默或失活(例如通过一种内源性脱饱和酶基因的突变、RNAi、反义或敲除等)结合。在其他实施例中,该原藻细胞已经修饰以具有一种减弱的内源性脱饱和酶基因,其中该减弱使得该基因或脱饱和酶失活。在一些情况下,该突变的内源性脱饱和酶基因是一种脂肪酸脱饱和酶(FAD)。在其他情况下,该突变的内源性脱饱和酶基因是一种硬脂酰基酰基载体蛋白脱饱和酶(SAD)。实例4描述了硬脂酰基-ACP脱饱和酶和Δ12脂肪酸脱饱和酶的靶向除去。实例4还描述了RNA反义构建体减少一种内源性脱饱和酶基因的表达的用途。在一些情况下,可能有利的是使基因工程化技术中的一者或多者配对以便获得会产生所希望的脂肪酸谱的一种转基因细胞。在一个实施例中,一种原藻细胞包含一种减弱的内源性硫酯酶基因和一种或多种外源性基因。在非限制性实例中,具有一种减弱的内源性硫酯酶基因的一种原藻细胞还可以表达一种外源性脂肪酰基-ACP硫酯酶基因和/或一种蔗糖转化酶基因。以下实例5描述了一种转基因原藻细胞,该转基因原藻细胞包含一种内源性硫酯酶的靶向除去或基因敲除并且还表达一种倾向硫酯酶和一种蔗糖转化酶的赖特氏萼距花(Cupheawrightii)FatB2C10:0-C14:0。在其他实施例中,一种原藻脂质生物合成基因的一种等位基因已经减弱。在额外实施例中,一种原藻脂质生物合成基因的两个或更多个等位基因已经减弱。在额外实施例中,不同原藻脂质生物合成基因的一个或多个等位基因已经减弱。以下实例37描述了硬脂酰基-ACP脱饱和酶的多个等位基因的靶向基因敲除。以下实例34描述了酰基-ACP硫酯酶的多个等位基因的靶向敲除。以下实例8描述了酰基-ACP硫酯酶和脂肪酸脱饱和酶的靶向基因敲除。在一些情况下,一种基因的不同等位基因的靶向敲除可以对脂肪酸谱产生不同作用。第V部分.微生物油为了根据本发明的方法生产油,优选在暗处培养细胞,正如例如在使用不允许光照射培养物的极大(40,000升和更高)的发酵罐时。原藻物种在包含固定碳源的培养基中并且在不存在光下生长和繁殖以生产油;这种生长被称为异养生长。举例来说,将脂质产生性微藻细胞的接种物引入培养基中;细胞开始繁殖前存在停滞期(停滞阶段)。在停滞期后,繁殖速率平稳增加并且进入对数期或指数期。指数期后,由于营养素(如氮)减少、毒性物质增加以及群体感应机制而又使繁殖减慢。这减慢后,繁殖停止,并且取决于向细胞提供的特定环境,细胞进入静止期或平稳生长状态。为了获得富含脂质的生物质,典型地在指数期结束之后收集培养物,可以通过使氮或另一种关键的营养素(除了碳以外)被耗尽从而迫使细胞将过量存在的碳源转化成脂质而使指数期较早终止。可以操纵培养条件参数,以使总体油生产、所产生的脂质物质的组合和/或特定油的生产达到最佳。如上文所述,使用生物反应器或发酵罐以使细胞经历其生长周期的不同阶段。举例来说,可以将脂质产生性细胞的接种物引入培养基中,随后进入停滞期(停滞阶段),之后细胞开始生长。在停滞期后,生长速率平稳增加并且进入对数期或指数期。指数期后,由于营养素减少和/或毒性物质增加而又使生长减慢。这减慢后,生长停止,并且取决于向细胞提供的特定环境,细胞进入静止期或稳定状态。在此披露的细胞的脂质生产可以发生于对数期期间或之后,包括静止期,在静止期中提供或仍然可获得营养素以允许在不存在细胞分裂的情况下继续产生脂质。优选地,使用在此所述以及本领域已知的条件生长的微生物包含至少约20重量%的脂质,优选地至少约40重量%,更优选地至少约50重量%,并且最优选地至少约60重量%。工艺条件可以经过调整以增加适用于特定用途的脂质的产率和/或降低生产成本。举例来说,在某些实施例中,在限制性浓度的一种或多种营养素(如氮、磷或硫)存在下培养微藻,同时提供过量的固定碳能(如葡萄糖)。与在提供过量氮的培养物中微生物的脂质产率相比,限制氮倾向于使微生物的脂质产率增加。在特定实施例中,脂质产率增加至少约:10%、50%、100%、200%或500%。可以在总培养期的一部分或整个培养期内在限制量的营养素存在下培养微生物。在特定实施例中,在总培养期期间,使营养素的浓度在限制性浓度与非限制性浓度之间循环至少两次。可以通过在延长的时间段内继续培养同时提供过量的碳,但限制氮或不提供氮来使细胞的脂质含量增加。在另一个实施例中,通过在脂质通路酶(例如脂肪酸合成酶)的一种或多种辅因子存在下培养脂质产生性微生物(例如微藻)来使脂质产率增加。总体而言,一种或多种辅因子的浓度足以使微生物脂质(例如脂肪酸)产率与不存在该一种或多种辅因子的情况下的微生物脂质产率相比有所增加。在一个特定实施例中,通过将包含编码一种或多种辅因子的外源性基因的微生物(例如微藻)纳入培养物中来向培养物提供一种或多种辅因子。可替代地,可以通过纳入包含编码参与辅因子合成的蛋白质的外源性基因的微生物(例如微藻)来向培养物提供一种或多种辅因子。在某些实施例中,适合的辅因子包括脂质通路酶所需的任何维生素,如:生物素、泛酸盐。编码适用于本发明的辅因子的基因或参与这些辅因子合成的基因是熟知的,并且可以使用构建体和技术(如上述的那些)引入到微生物(例如微藻)中。在此所述的生物反应器、培养条件以及异养生长和繁殖方法的特定实例可以按任何适合的方式进行组合以改进微生物生长以及脂质和/或蛋白质生产的效率。已经使用不同的培养方法产生了具有高百分比的油/脂质累积(以干重计)的微藻生物质,这些培养方法是本领域已知的(参见PCT公布号2008/151149)。通过在此所述的培养方法产生并且根据本发明适用的微藻生物质包含以干重计至少2%的微藻油。在一些实施例中,微藻生物质包含以干重计至少10%、至少25%、至少50%、至少55%或至少60%的微藻油。在一些实施例中,微藻生物质包含从10%-90%的微藻油、从25%-75%。用于本发明的方法和组合物的在此所述的生物质的微藻油或从生物质中提取的微藻油可以包含具有一个或多个不同脂肪酸酯侧链的甘油脂。甘油脂包含与一个、两个或三个脂肪酸分子发生酯化的甘油分子,这些脂肪酸分子可以具有不同的长度并且具有不同的饱和度。如以下第IV部分中更详细地描述,可以经由培养条件或经由脂质通路工程化来操纵脂肪酸分子(和微藻油)的长度和饱和度特征以对本发明微藻油中的脂肪酸分子的性质或比例进行调节。因此,可以或者在单个藻类物种内通过将来源于两种或更多种微藻物种的生物质或藻类油混合在一起,或者通过将本发明的藻类油与来自其他来源的油共混来制备特定的藻类油的共混物,这些其他来源如大豆、油菜籽、芥花、棕榈、棕榈仁、椰子、玉米、废植物、乌桕油、橄榄、向日葵、棉籽、鸡脂肪、牛脂、猪油脂、微藻、大型藻类、微生物、萼距花、亚麻、花生、精选白色油脂、猪油、亚麻荠、芥菜籽、腰果、燕麦、羽扇豆、洋麻、金盏花、大麻(help)、咖啡豆、亚麻仁(亚麻籽)、榛子、大戟、南瓜籽、胡荽、山茶、芝麻、红花、稻米、油桐树、可可、干椰子肉、罂粟花、蓖麻籽、美洲山核桃、希蒙德木、夏威夷果、巴西坚果、鳄梨、石油或前述油中任一种的馏份。还可以通过将来自至少两种不同的微藻物种的生物质或油组合来操纵油组成,即甘油脂的脂肪酸成分的性质和比例。在一些实施例中,至少两种不同的微藻物种具有不同的甘油脂谱。可以如在此所描述的,优选地在异养条件下对不同的微藻物种进行共同培养或单独培养,以产生各自的油。不同微藻物种在细胞的甘油脂中可以包含不同百分比的不同脂肪酸组分。总体而言,原藻株系几乎没有或没有链长是C8-C14的脂肪酸。举例来说,桑椹形原藻(UTEX1435)、克鲁格尼原藻(UTEX329)、大型原藻(UTEX1442)以及小型原藻(UTEX1438)不包含(或不可检测量的)C8脂肪酸,介于0%-0.01%之间的C10脂肪酸、介于0.03%-2.1%之间的C12脂肪酸以及介于1.0%-1.7%之间的C14脂肪酸。微藻油还可以包括由微藻产生的或从培养介质掺入微藻油中的其他组分。这些其他组分可以按不同量存在,这取决于用于培养微藻的培养条件、微藻物种、用于从生物质中回收微藻油的提取方法以及可能影响微藻油组成的其他因素。这些组分的非限制性实例包括类胡萝卜素,存在量是从0.025-0.3mcg/g,优选地从0.05到0.244微克/克油;叶绿素A,存在量为从0.025-0.3mcg/g,优选地从0.045到0.268微克/克油;总叶绿素,量为少于0.03mcg/g,优选地少于0.025微克/克油;γ生育酚,存在量为从35-175mcg/g,优选地从38.3-164微克/克油;总生育酚,存在量为从50-300mcg/g,优选地从60.8到261.7微克/克油;少于0.5%,优选地少于0.25%的菜籽甾醇、菜油甾醇、豆甾醇或β谷甾醇;少于300微克/克油的总生育三烯酚;或总生育三烯酚,存在量为从225-350mcg/g,优选地从249.6到325.3微克/克油。其他组分可以包括(但不限于)磷脂、生育酚、生育三烯酚、类胡萝卜素(例如α-胡萝卜素、β-胡萝卜素、番茄红素等)、叶黄质(例如叶黄素、玉米黄质、α-隐黄质以及β-隐黄质)以及不同有机或无机化合物。在一些情况下,从原藻物种中提取的油包含介于0.001到0.05之间、优选地从0.003到0.039微克的叶黄素/克油;少于0.005,优选地少于0.003微克的番茄红素/克油;以及少于0.005,优选地少于0.003微克的β胡萝卜素/克油。稳定碳同位素值δ13C是13C/12C的比率相对于标准(例如PDB,来自南卡罗来纳州的皮狄组(Peedeeformation)的美洲箭石(Belemniteamericana)的化石骨架的天然焦)的表述。油的稳定碳同位素值δ13C(‰)可以与所用原料的δ13C值相关。在一些实施例中,油来源于依靠源自如玉米或甘蔗的C4植物异养生长的产油生物体。在一些实施例中,油的δ13C(‰)是从-10‰到-17‰或从-13‰到-16‰。在一个第二方面,本发明提供了用于获得微生物油的方法,包括在使得油得以产生的条件下对本发明的一种基因工程化的原藻细胞进行培养。在不同实施例中,该微生物油具有一种选自下组的脂肪酸谱,该组由以下各项组成:0.1%到60%C8:0、0.1%到60%C10:0、0.1%到60%C12:0、0.1%到95%C14:0、1%到95%C16:0、0.1%到95%C18:0、0.1%到95%C18:1、0.1%到60%C18:2、0.1%到60%C18:3或其组合。在不同实施例中,C10:0与C12:0的比率是至少3:1。在一些情况下,C10:0与C14:0的比率是至少10:1。在一些情况下,C10:0与C14:0的比率是至少2:1。在一些情况下,C12:0与C14:0的比率是至少2:1。在一些情况下,C12:0与C14:0的比率是至少3:1。在不同实施例中,该基因工程化的细胞具有至少40%饱和脂肪酸、至少60%饱和脂肪酸、或至少85%饱和脂肪酸的一种脂肪酸谱。在不同实施例中,该基因工程化的细胞具有至少85%不饱和脂肪酸、至少90%不饱和脂肪酸、至少95%不饱和脂肪酸、或至少97%不饱和脂肪酸的一种脂肪酸谱。在一个第三方面,本发明提供了微生物油和包含所述油或一种由其衍生的化学品的食品、燃料以及化学品。第VI部分.核酸在一个第五方面,本发明提供了适用于制造经基因修饰的原藻和其他细胞的方法的重组核酸。本发明的实施例提供了编码一种原藻脂质生物合成基因的编码序列的某一部分的聚核苷酸。在不同实施例中,这些核酸包含表达盒,这些表达盒由编码序列和调节该编码序列表达的控制序列组成,该编码序列可以针对编码一种脂质生物合成酶的mRNA或针对起抑制一种脂肪酸生物合成基因表达作用的RNAi编码。在其他实施例中,这些核酸是表达载体,这些表达载体包含一种或多种表达盒并且或者通过整合到宿主细胞的染色体DNA中或者作为自由复制的质粒而在一种原藻或其他宿主细胞中稳定复制。在其他实施例中,这些核酸包含一种原藻脂质生物合成基因的一部分,该部分可以是一种编码序列、一种外显子或一种控制元件的一部分。这些核酸适用于构建原藻和非原藻宿主细胞的表达盒、将外源性DNA整合到原藻宿主细胞中、调节在原藻和非原藻宿主细胞中表达的外源性基因的表达以及构建适用于如经由同源重组或反义RNA介导的基因敲低而将原藻脂质合成基因失活的核酸。实例实例1:用于培养原藻的方法对原藻株系进行培育以获得按干细胞重量计高百分比的油。将冷冻保存的细胞在室温下解冻,并且将500μl细胞加入到4.5ml培养基(4.2g/LK2HPO4、3.1g/LNaH2PO4、0.24g/LMgSO4·7H2O、0.25g/L单水合柠檬酸、0.025g/LCaCl22H2O、2g/L酵母提取物)加2%葡萄糖中,并且使这些细胞在6孔板中在28℃下在搅动(200rpm)下生长7天。干细胞重量通过将1ml培养物在预称重的艾本德管(Eppendorftube)中在14,000rpm下离心5分钟来测定。将培养物上清液丢弃,并且所得细胞团块用1ml去离子水洗涤。将培养物再离心,丢弃上清液,并且将细胞团块放置在-80℃下直到冷冻为止。接着,将样品冻干24小时,并且计算干细胞重量。为了测定培养物中的总脂质,将3ml培养物移出并且根据制造商的方案使用Ankom系统(纽约州马其顿的安康公司(AnkomInc.,Macedon,NY)进行分析。根据制造商的方案用一台AmkomXT10提取器对样品进行溶剂提取。总脂质被测定为经酸水解的干燥样品与经溶剂提取的干燥样品之间的质量差异。油占干细胞重量的百分比测量值展示于表3中。表3.以干细胞重量计的油百分比物种株系油%大型原藻UTEX32713.14桑椹形原藻UTEX144118.02桑椹形原藻UTEX143527.17对来自原藻属的多种株系的微藻样品进行基因型定型。如下从藻类生物质中分离基因组DNA。将来自液体培养物的细胞(约200mg)在14,000×g下离心5分钟。将细胞接着重悬于无菌蒸馏水中,在14,000×g下离心5分钟并且丢弃上清液。将直径为约2mm的单个玻璃珠加入到生物质中,并且将试管在-80℃下放置至少15分钟。将样品移出,并且加入150μl研磨缓冲液(1%肌氨酰、0.25M蔗糖、50mMNaCl、20mMEDTA、100mMTris-HCl(pH8.0),核糖核酸酶A0.5μg/μl)。团块通过短暂涡旋进行重悬,随后加入40μl5MNaCl。将样品短暂涡旋,随后加入66μl5%CTAB(十六烷基三甲基溴化铵)并且进行最终短暂涡旋。接着将样品在65℃下孵育10分钟,此后将它们在14,000×g下离心10分钟。将上清液转移到一个新鲜试管中,并且用300μl苯酚:氯仿:异戊醇12:12:1萃取一次,随后在14,000×g下离心5分钟。将所得水相转移到包含0.7体积异丙醇(约190μl)的一个新鲜试管中,通过颠倒进行混合并且在室温下孵育30分钟或在4℃下孵育过夜。DNA经由在14,000×g下离心10分钟来回收。所得团块接着用70%乙醇洗涤两次,随后用100%乙醇进行最终洗涤。将团块在室温下空气干燥20-30分钟,随后重悬于50μl10mMTrisCl、1mMEDTA(pH8.0)中。将如上所述制备的五微升总藻类DNA1:50稀释于10mMTris(pH8.0)中。如下设置最终体积为20μl的PCR反应。将十微升2×iProofHF超级混合物(伯乐公司(BIO-RAD))加入到10mM储备浓度的0.4μl引物SZ02613(5'-TGTTGAAGAATGAGCCGGCGAC-3')中。这种引物序列来自基因库登录号L43357中的位置567-588并且在高等植物和藻类质体基因组中高度保守。随后加入10mM储备浓度的0.4μl引物SZ02615(5'-CAGTGAGCTATTACGCACTC-3')。这种引物序列与基因库登录号L43357中的位置1112-1093互补并且在高等植物和藻类质体基因组中高度保守。接着,加入5μl稀释的总DNA和3.2μldH2O。PCR反应如下运行:98℃,45";98℃,8";53℃,12";72℃,20"持续35个循环,随后72℃持续1分钟并且保持在25℃下。为了纯化PCR产物,将20μl10mMTris(pH8.0)加入到每一反应物中,随后用40μl苯酚:氯仿:异戊醇12:12:1萃取,涡旋并且在14,000×g下离心5分钟。将PCR反应物施加到S-400柱(通用电气医疗集团(GEHealthcare))中并且在3,000×g下离心2分钟。将纯化的PCR产物随后TOPO克隆成PCR8/GW/TOPO,并且在LB/Spec板上选择阳性克隆株。使用M13正向和反向引物以两个方向对纯化的质粒DNA进行测序。总共,选择十二个原藻株系以对它们的23SrRNADNA进行测序,并且这些序列在序列表中列出。下文包括了株系和序列表编号的概述。对这些序列与UTEX1435(SEQIDNO:5)序列的总体差异进行分析。出现了差异最大的两对(UTEX329/UTEX1533和UTEX329/UTEX1440)。在这两种情况下,成对比对的结果是75.0%的成对序列一致性。下文还包括与UTEX1435的序列一致性百分比:使用HPLC针对脂肪酸谱对上文所列的株系的子集的脂质样品进行分析。结果展示于下表4中。表4.原藻物种中脂肪酸链的多样性针对类胡萝卜素、叶绿素、生育酚、其他甾醇以及生育三烯酚对从桑椹形原藻UTEX1435中提取(经由溶剂提取或使用压榨机)的油进行分析。结果总结于下表5中。表5.从桑椹形原藻(UTEX1435)中提取的油中的类胡萝卜素、叶绿素、生育酚/甾醇以及生育三烯酚分析。使用标准植物油加工方法对来自四个单独批次的从桑椹形原藻中提取的油进行提炼和漂白。简言之,在一台水平倾析器中净化从桑椹形原藻中提取的粗油,在水平倾析器中固体与油分离。然后将经净化的油转移到具有柠檬酸和水的贮槽中并且将其静置约24小时。24小时后,混合物在贮槽中形成2个单独的层。底层由水和胶组成,然后通过倾析将底层去除,之后将经脱胶的油转移到漂白槽中。然后将油与另外一定剂量的柠檬酸一起加热。然后将漂白粘土加入到漂白槽中,并且在真空下进一步加热混合物以蒸发掉存在的任何水。然后经由叶片式过滤器泵出混合物以便去除漂白粘土。然后使经过滤的油通过最终的5μm精细过滤器,并且接着进行收集以储存直到使用为止。然后针对类胡萝卜素、叶绿素、甾醇、生育三烯酚以及生育酚对经提炼和漂白(RB)的油进行分析。这些分析的结果总结于下表6中。“Nd”表示没有检测到并且检测灵敏度列于下文中:检测灵敏度类胡萝卜素(mcg/g)nd=<0.003mcg/g叶绿素(mcg/g)nd=<0.03mcg/g甾醇(%)nd=0.25%生育酚(mcg/g);nd=3mcg/g表6.来自经提炼和漂白的桑椹形原藻油的类胡萝卜素、叶绿素、甾醇、生育三烯酚以及生育酚分析。还对相同四批桑椹形原藻油进行微量元素分析并且结果总结于下表7中。表7.经提炼和漂白的桑椹形原藻油的元素分析。实例2:用于原藻的基因枪转化的通用方法根据来自制造商的方案制备Seashell金微载体(550纳米)。将质粒(20μg)与50μl结合缓冲液和60μl(30mg)S550d金载体混合,并且在冰中孵育1min。加入沉淀缓冲液(100μl),并将混合物在冰中再孵育1min。涡旋后,通过在一个艾本德5415C微量离心管中以10,000rpm旋转10秒以使涂有DNA的粒子成团块。用500μl的冷100%乙醇洗涤金团块一次,在微量离心管中短暂旋转使其成团块,并且用50μl冰冷乙醇重悬。短暂(1-2秒)超声处理后,立即将10μl涂有DNA的粒子转移到载体膜上。使原藻株系在一台回转振荡器上生长于朊间质培养基(2g/L酵母提取物、2.94mMNaNO3、0.17mMCaCl2·2H2O、0.3mMMgSO4·7H2O、0.4mMK2HPO4、1.28mMKH2PO4、0.43mMNaCl)以及2%葡萄糖中直到其细胞密度达到2×106个细胞/毫升为止。收集细胞,用无菌蒸馏水洗涤一次,并且重悬于50μl培养基中。将1×107个细胞展涂于非选择性朊间质培养板的中间三分之一区。用PDS-1000/He基因枪粒子递送系统(伯乐公司)轰击细胞。使用裂碟片(1350psi),并且将板置放在屏/巨载体组件下面6cm处。在25℃下使细胞复苏12-24h。复苏后,用橡胶刮刀从板上刮下细胞,与100μl培养基混合,并且展涂于包含适当抗生素选择的板上。在25℃下孵育7-10天后,在板上可看到代表经转化的细胞的群落。挑取群落,并且点样于选择性(或者抗生素或者碳源)琼脂板上进行第二轮选择。实例3:利用脂肪酸甲酯检测的脂肪酸分析脂质样品是由干燥生物质制备的。将20-40mg干燥生物质重悬于2mL5%H2SO4/MeOH中,并且加入200μl包含适当量的适合内标(C19:0)的甲苯。对混合物进行短暂地超声处理以分散生物质,接着在70℃-75℃下加热3.5小时。加入2mL庚烷以萃取脂肪酸甲酯,接着加入2mL6%K2CO3(水性)以对酸进行中和。对混合物进行剧烈搅拌,并且将上层的一部分转移到包含Na2SO4(无水)的小瓶中以进行使用标准FAME的气相色谱分析。实例4:改变微藻桑椹形原藻中的饱和脂肪酸水平A.利用基因敲除途径减少硬脂酰基ACP脱饱和酶和Δ12脂肪酸脱饱和酶表达作为使用基于生物信息学的途径(基于cDNA)、Illumia转录组以及Roche454测序对来自桑椹形原藻(UTEX1435)的基因组DNA进行基因组筛选的一部分,鉴别出参与脂肪酸脱饱和的两个特异性基因群组:硬脂酰基ACP脱饱和酶(SAD)和Δ12脂肪酸脱饱和酶(Δ12FAD)。硬脂酰基ACP脱饱和酶是脂质合成通路的一部分,并且它们的功能是将双键引入到脂肪酰基链中,例如从C18:0脂肪酸合成C18:1脂肪酸。Δ12脂肪酸脱饱和酶也是脂质合成通路的一部分,并且它们的功能是将双键引入到已不饱和的脂肪酸中,例如从C18:1脂肪酸合成C18:2脂肪酸。编码硬脂酰基ACP脱饱和酶的基因分成两个不同的家族。基于这些结果,三种基因破坏构建体经设计以通过靶向每一脱饱和酶家族内更高度保守的编码区来潜在地破坏多个基因家族成员。使用以下来设计三种同源重组靶向构建体:(1)Δ12脂肪酸脱饱和酶(d12FAD)或FAD2家族成员的编码序列的高度保守部分,和(2)靶向两个不同的SAD家族中的每一者的两种构建体(SAD1和SAD2),各自具有来自每一家族的编码序列的保守区。这个策略将可选择的标记基因嵌入这些高度保守的编码区中(靶向多个家族成员)而非典型的基因置换策略,在典型的基因置换策略中,同源重组将靶向靶基因的侧接区域。使用上述方法通过基因枪转化将所有构建体引入到细胞中,并且在被射入细胞中之前将构建体线性化。在包含蔗糖的板/培养基中选择转化体并且使用上述方法分析脂质谱的改变。来自三种靶向构建体中的每一者的相关序列被列于下文中。挑选通过用每一构建体进行转化而产生的代表性阳性克隆株并且测定这些克隆的脂肪酸谱。由来自每一转化体的干燥生物质制备脂质样品,并且使用如实例3中所述的标准脂肪酸甲酯气相色谱火焰离子化(FAMEGC/FID)检测方法分析这些样品的脂肪酸谱。由转化产生的转基因株系的脂肪酸谱(表示为总脂肪酸的面积%)展示于表8中。表8.脱饱和酶基因敲除的脂肪酸谱。每一构建体对所希望的脂肪酸种类具有可测量的影响,并且在所有三种情况下,C18:0水平显著增加,尤其在两种SAD基因敲除的情况下。对由SAD基因敲除产生的多个克隆株进行的进一步比较表明,SAD2B基因敲除株系中的C18:1脂肪酸与在SAD2A基因敲除株系的情况下所观测到的C18:1脂肪酸水平相比出现显著更大的减少。在桑椹形原藻背景下使用上述方法产生了额外的Δ12FAD基因敲除。为了鉴别Δ12FAD的潜在同源性,使用下列引物以便扩增编码假定性FAD的基因组区域:引物15’-TCACTTCATGCCGGCGGTCC-3’SEQIDNO:27引物25’-GCGCTCCTGCTTGGCTCGAA-3’SEQIDNO:28从使用上述引物的桑椹形原藻基因组DNA的基因组扩增产生的序列是高度相似的,但表明,在原藻中存在Δ12FAD的多基因或等位基因。基于这个结果,设计两种基因破坏构建体以设法使一个或多个Δ12FAD基因失活。该策略是将蔗糖转化酶(来自酿酒酵母(S.cerevisiae)的suc2)盒(SEQIDNO:29)(从而赋予水解蔗糖的能力而作为可选择标记)嵌入到高度保守的编码区中,而非使用典型的基因置换策略。称作pSZ1124的第一种构建体包含侧接驱动酿酒酵母suc2基因(SEQIDNO:31)表达的莱茵衣藻β-微管蛋白启动子(SEQIDNO:30)的5'和3'基因组靶向序列以及一种普通小球藻(Chlorellavulgaris)硝酸盐还原酶3'UTR(SEQIDNO:32)。称作pSZ1125的第二种构建体包含侧接驱动酿酒酵母suc2基因表达的莱茵衣藻β-微管蛋白启动子的5'和3'基因组靶向序列以及一种普通小球藻硝酸盐还原酶3'UTR。这些构建体的相关序列被列于序列表中:将pSZ1124和pSZ1125各自引入到桑椹形原藻背景中。基于水解蔗糖的能力选择阳性克隆株。表9总结了在利用pSZ1124和pSZ1125靶向载体的两个转基因株系中获得的脂肪酸谱(以面积%表示,使用上述方法产生)。表9.Δ12FAD基因敲除的脂肪酸谱C10:0C12:0C14:0C16:0C16:1C18:0C18:1C18:2C18:3α亲本0.010.031.1526.131.324.3957.208.130.61FAD2B0.020.030.8012.841.920.8674.747.080.33FAD2C0.020.041.4225.851.652.4466.111.390.22包含FAD2B(pSZ1124)构建体的转基因物在脂肪酸谱方面产生了极其令人感兴趣并且出乎意外的结果,因为预期将减少的C18:2水平仅减少了约一面积%。然而,C18:1脂肪酸水平显著增加,几乎仅以C16:0水平(显著降低)作为代价。包含FAD2C(pSZ1125)构建体的转基因物也产生了脂质谱的变化:C18:2水平显著降低以及C18:1水平相应增加。B.下调原藻细胞中的Δ12脱饱和酶(FADC)的RNA发夹途径将利用长发夹RNA构建成下调FADc(Δ12脱饱和酶基因)基因表达的载体引入桑椹形原藻UTEX1435遗传背景中。使用酿酒酵母suc2蔗糖转化酶基因作为一种可选择标记,赋予阳性克隆株依靠作为唯一碳源的蔗糖生长的能力,并且使用两种类型的构建体。第一种类型的构建体使用FADc编码区的第一外显子的一部分,该FADc编码区顺式连接于其第一内含子,后面是呈相反方向的第一外显子的重复单元。这类构建体被设计成在以mRNA形式表达时形成一个发夹。建立这第一类型的两种构建体,即,由桑椹形原藻Amt03启动子(SEQIDNO:37)驱动的一者,称为pSZ1468,和由莱茵衣藻β-微管蛋白启动子(SEQIDNO:30)驱动的一个第二者,称为pSZ1469。第二种类型的构建体使用呈反义取向的较大FADc外显子2,它或者由桑椹形原藻Amt03启动子(SEQIDNO:37)驱动,称为pSZ1470,或者由莱茵衣藻β-微管蛋白启动子(SEQIDNO:30)驱动,称为pSZ1471。所有四种构建体均具有一个酿酒酵母suc2蔗糖转化酶盒(SEQIDNO:29)和6S基因组区的一个5'(SEQIDNO:38)和3'(SEQIDNO:39)同源重组靶向序列以用于整合到核基因组中。每个长发夹RNA构建体的FADc部分以及每个构建体的相关部分的序列被列于如下序列表中:将四种构建体中的每一者转化到桑椹形原藻(UTEX1435)背景中,并且使用以蔗糖作为唯一碳源的板对阳性克隆株进行筛选。从每次转化挑选阳性克隆株,并且选择一个子集以测定pSZ1468、pSZ1469、pSZ1470以及pSZ1471中包含的发夹和反义盒对脂肪酸谱的影响。使从每次转化选择的克隆株生长在脂质产生条件下,并且使用如上所述的直接酯基转移方法测定脂肪酸谱。来自每次转化的代表性脂肪酸谱总结于下表10中。野生型1和2细胞是未转化的桑椹形原藻(UTEX1435)细胞,这些细胞用转化体中的每一者作为阴性对照进行。表10.包含使Δ12脱饱和酶基因(FADc)的表达下调的长发夹RNA构建体的桑椹形原藻细胞的脂肪酸谱。以上结果展示了,发夹构建体pSZ1468和pSZ1469展示出预期的表型:如分别与野生型1和野生型2相比,C18:2脂肪酸水平降低以及C18:1脂肪酸水平提高。反义构建体pSZ1470和pSZ1471并不引起C18:2脂肪酸水平降低,而是反而在分别与野生型1和野生型2比较时展示出略微提高以及C16:0脂肪酸水平略微降低。实例5:具有改变的脂肪酸谱的工程化的微藻如上所述,在原藻物种中整合异源性基因以减弱特定内源性脂质通路基因(经由基因敲除或基因敲低)可以改变脂肪酸谱。建立质粒构建体(列于表11中)以评估宿主细胞的脂肪酸谱是否可能因内源性脂肪酰基-ACP硫酯酶基因FATA1的敲除而受到影响。使用实例2的方法用以下表11中的质粒构建体中的一者对桑椹形原藻UTEX1435的一种经典诱变处理的衍生物(株系J)进行转化。每种构建体包含一种用于整合到核基因组中以打断内源性FATA1基因的区域和一种在莱茵衣藻β-微管蛋白启动子/5'UTR(SEQIDNO:30)和普通小球藻硝酸盐还原酶3'UTR(SEQIDNO:32)控制下的酿酒酵母suc2蔗糖转化酶编码区。这种酿酒酵母suc2表达盒被列为SEQIDNO:29并且充当一种选择标记。所有蛋白质编码区经过密码子优化以反映桑椹形原藻UTEX1435(参见表2)核基因所固有的密码子偏倚性。以下展示了针对用于核基因组整合的FATA1基因的靶向区域的相关序列。描述SEQIDNO:用于整合到FATA1基因座中的5'序列SEQIDNO:48用于整合到FATA1基因座中的3'序列SEQIDNO:49表11.用于转化桑椹形原藻(UTEX1435)株系J的质粒构建体。为了将赖特氏萼距花ACP-硫酯酶2(CwFatB2)基因(登录号:U56104)引入到株系J的FATA1-1基因座中,生成一种构建体以在桑椹形原藻Amt03启动子/5'UTR(SEQIDNO:37)和普通小球藻硝酸盐还原酶3'UTR(SEQIDNO:32)的控制下表达CwFatB2基因的蛋白质编码区。这种构建体的相关部分作为SEQIDNO:51提供于序列表中。赖特氏萼距花FatB2硫酯酶的经密码子优化的cDNA序列和氨基酸序列分别作为SEQIDNO:52和SEQIDNO:53列于序列表中。在FATA1-CrbTub_yInv_nr-FATA1转化到株系J中后,对原代转化体进行克隆纯化并且使其在与如实例1中披露的条件类似的标准脂质产生条件下在pH5.0下生长。由来自每一转化体的干燥生物质制备脂质样品,并且使用如实例3中所述的标准脂肪酸甲酯气相色谱火焰离子化(FAMEGC/FID)检测方法分析这些样品的脂肪酸谱。通过用pSZ1883转化到株系J中而产生的转基因株系的脂肪酸谱(表示为总脂肪酸的面积%)展示于表12中。表12.包含一种可选择标记以破坏一个内源性FATA1等位基因的桑椹形原藻细胞的脂肪酸谱。转化C14:0%C16:0%C18:0%C18:1%C18:2%野生型1.2325.682.8360.547.52转化体10.8616.951.7568.449.78转化体20.8517.331.7168.579.31转化体30.8217.401.7868.559.22转化体40.8417.431.7868.259.53转化体50.7517.642.0269.028.61这些结果展示了,除去宿主的内源性FATA1-1等位基因会改变工程化的微藻的脂肪酸谱。将一种可选择标记靶向内源性FATA1等位基因的影响是C16:0脂肪酸产生明确减少以及C18:1脂肪酸产生增加。在FATA1-CrbTub_yInv_nr::amt03_CwTE2_nr-FATA1转化到株系J中后,对原代转化体进行克隆纯化并且使其在标准脂质产生条件下在pH7.0下生长,其中所提供的不同碳源达到40g/L的总浓度。蔗糖浓度是40g/L。当仅将葡萄糖用作碳源时,提供了40g/L的葡萄糖。当将葡萄糖和果糖用作碳源时,提供了20g/L的葡萄糖并且提供了20g/L的果糖。由来自每一转化体的干燥生物质制备脂质样品,并且使用如实例3中所述的标准脂肪酸甲酯气相色谱火焰离子化(FAMEGC/FID)检测方法分析这些样品的脂肪酸谱。通过用pSZ1925转化到株系J中而产生的转基因株系的脂肪酸谱(表示为总脂肪酸的面积%)展示于表13中。所得脂肪酸谱列于表13中。表13.包含一种可选择标记和一种外源性硫酯酶以破坏一个内源性FATA1等位基因的桑椹形原藻细胞的脂肪酸谱。与将一种可选择标记单独靶向宿主的FATA1-1等位基因一致的是,伴随有一种外源性硫酯酶的一种可选择标记的整合会改变工程化的微藻的脂肪酸谱。如上,将一种外源性基因靶向FATA1-1等位基因引起C16:0脂肪酸产生明确减少。CwTE2硫酯酶在FATA1-1基因座处的额外表达还在取决于所分析的转化体中存在的外源性硫酯酶活性的水平的程度上影响了中链脂肪酸和C18:1脂肪酸产生。在如FATA1-CrbTub_yInv_nr::amt03_CwTE2_nr-FATA1的构建体中毗连如普通小球藻硝酸盐还原酶3'UTR的重复单元的基因可以在整合于宿主基因组中后得以扩增。在目标整合位点处扩增的转基因的拷贝数与如或者利用对脂肪酸谱的影响或者如由西方印迹法评估的重组蛋白累积所揭露的硫酯酶水平之间存在良好一致性。CwTE2基因已进行扩增的转基因株系展示了中链(C10:0-C14:0)脂肪酸显著增加以及C18:1脂肪酸同时发生的减少。相比之下,CwTE2几乎没有或没有进行扩增(大概1-2个拷贝)的那些转化体与外源性硫酯酶的更低表达一致,引起中链脂肪酸略微增加以及对C18:1脂肪酸增加的远为更大的影响。总体来说,这些数据展示了除去宿主的内源性FATA1-1等位基因会改变工程化的微藻的脂质谱。实例6:通过一种原藻脂质生物合成基因的过度表达来改变微藻的脂肪酸谱。如上所述,β-酮酰基-ACP合成酶II(KASII)在脂肪酸生物合成过程中催化C16:0-ACP到C18:0-ACP的2碳延伸。该酶在确定宿主生物体的脂肪酸谱方面是一种重要的脂质生物合成酶并且对于硬脂酸酯和油酸酯产生至关重要。建立质粒构建体以评估宿主细胞的脂肪酸谱是否可能因KASII基因的表达而受到影响。KASII基因序列的来源是选自桑椹形原藻UTEX1435或高等植物(大豆(Glycinemax)、向日葵(Helianthusannus)或蓖麻(Ricinuscommunis))。使用实例2的方法用以下表14中的质粒构建体中的一者对桑椹形原藻UTEX1435的一种经典诱变处理的衍生物(株系J)进行单独地转化。每种构建体包含一种用于整合到核基因组中的6S基因座处的区域和一种在莱茵衣藻β-微管蛋白启动子/5'UTR和普通小球藻硝酸盐还原酶3'UTR控制下的酿酒酵母suc2蔗糖转化酶编码区。这种酿酒酵母suc2表达盒被列为SEQIDNO:29并且充当一种选择标记。对于每一构建体来说,KASII编码区是在桑椹形原藻Amt03启动子/5'UTR(SEQIDNO:37)和普通小球藻硝酸盐还原酶3'UTR(SEQIDNO:32)的控制下。每一KASII酶的天然转运肽经原始小球藻硬脂酰基-ACP脱饱和酶转运肽(SEQIDNO:54)置换。所有蛋白质编码区经过密码子优化以反映桑椹形原藻UTEX1435核基因(参见表2)所固有的密码子偏倚性。以下展示了针对用于核基因组整合的6S基因座的靶向区域的相关序列。描述SEQIDNO:用于整合到6S基因座中的5'序列SEQIDNO:38用于整合到6S基因座中的3'序列SEQIDNO:39表14.用于转化桑椹形原藻(UTEX1435)株系J的质粒构建体。构建体6S::β-tub:suc2:nr::Amt03:S106SAD:PmKASII:nr::6S的相关核苷酸序列作为SEQID.NO:58提供于序列表中。包含原始小球藻S106硬脂酰基-ACP脱饱和酶转运肽的PmKASII的密码子优化的序列作为SEQID.NO:105提供于序列表中。SEQIDNO:106提供了SEQIDNO.105的蛋白质翻译。在每种质粒构建体单独转化到株系J中后,在以蔗糖作为唯一碳源的板上对阳性克隆株进行筛选。如前述实例中,对原代转化体进行克隆纯化并且使其在标准脂质产生条件下生长。此处,将转化体在pH7下培育,并且由来自如上所述的每一转化体的干燥生物质制备脂质样品。数种阳性转化体与一种野生型阴性对照相比的脂肪酸谱(表示为面积%)针对每一质粒构建体总结于下表15中。表15.经工程化以过度表达KASII基因的桑椹形原藻细胞的脂肪酸谱。表15中呈现的数据展示了,高等植物KASII基因中没有一者实现了转化的微藻细胞的脂肪酸谱变化。表达由除原藻Amt03启动子以外的启动子驱动的来自高等植物的KASII基因的额外质粒构建体也未能改变经转化的细胞的脂肪酸谱。与之形成鲜明对比,在使用表2中指示的密码子频率进行密码子优化的桑椹形原藻KASII基因的过度表达后,观察到C16:0链长明确减少以及C18:1长度的脂肪酸相伴增加。在表达由β-微管蛋白启动子驱动的PmKASII基因的构建体的转化后,观察到类似的脂肪酸谱变化。这些结果展示了,一种原藻脂质生物合成基因的外源性表达可以改变基因工程化的微藻的脂肪酸谱。实例7:由工程化的微生物产生的经加工油的特征用转化载体pSZ1500(SEQIDNO:137)转化桑椹形原藻(UTEX1435)的方法和作用先前已描述于PCT申请号PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中。根据如在此以及PCT/US2009/066141、PCT/US2009/066142、PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中所述的基因枪转化方法用pSZ1500对桑椹形原藻(UTEX1435)的一种经典诱变处理的(为了更高油生产)衍生物(株系A)进行转化。pSZ1500包含为了在桑椹形原藻UTEX1435中表达而经密码子优化的红花(Carthamustinctorius)油烯基-硫酯酶(CtOTE)基因的核苷酸序列。pSZ1500表达构建体包含了用于整合到核基因组中的FADc基因组区域的5'(SEQIDNO:138)和3'(SEQIDNO:139)同源重组靶向序列(侧接该构建体)和一种在莱茵衣藻β-微管蛋白启动子/5'UTR(SEQIDNO:5)和普通小球藻硝酸盐还原酶3'UTR(SEQIDNO:126)控制下的酿酒酵母suc2蔗糖转化酶编码区。这种酿酒酵母suc2表达盒被列为SEQIDNO:127并且充当一种选择标记。CtOTE编码区是在桑椹形原藻Amt03启动子/5'UTR(SEQIDNO:128)和普通小球藻硝酸盐还原酶3'UTR的控制下,并且天然转运肽经原始小球藻硬脂酰基-ACP脱饱和酶转运肽(SEQIDNO:129)置换。CtOTE和suc2的蛋白质编码区经过密码子优化以反映如PCT/US2009/066141、PCT/US2009/066142、PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中所述的桑椹形原藻UTEX1435核基因所固有的密码子偏倚性。在包含蔗糖作为唯一碳源的琼脂板上对株系A的原代pSZ1500转化体进行选择,克隆纯化,并且选择单个工程化的株系(株系D)以用于分析。株系D是如PCT/US2009/066141、PCT/US2009/066142、PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中所述般生长的。来自所产生的生物质的油的己烷提取接着使用标准方法进行,并且所得三甘油酯油被测定为不含残余己烷。使用压榨机从微藻提取油的其他方法描述于PCT申请号PCT/US2010/031108中并且特此通过引用结合。使用标准植物油加工方法对从株系D生物质中提取的不同批次的油进行提炼,漂白以及除臭。这些程序产生了油样品RBD437、RBD469、RBD501、RBD502、RBD503以及RBD529,这些油样品根据经由美国油类化学家学会(AmericanOilChemists'Society)、美国测试和材料学会(AmericanSocietyforTestingandMaterials)以及国际标准化组织(InternationalOrganizationforStandardization)定义的方法经历分析测试方案。这些分析的结果总结于下表16-21中。表16.针对油样品RBD469的分析结果。根据AOCS方法针对微量元素含量、固体脂肪含量以及罗维邦色度对RBD469油进行分析。这些分析的结果呈现于下表17、表18以及表19中。表17.RBD469油的ICP元素分析。表18.RBD469油的固体脂肪含量表19.RBD469油的罗维邦色度方法编号颜色结果单位AOCSCc13j-97红色2单位AOCSCc13j-97黄色27单位RBD469油经历酯基转移以产生脂肪酸甲酯(FAME)。RBD469的所得FAME谱展示于表20中。表20.RBD469油的FAME谱根据油稳定性指数AOCS方法Cd12b-92对未补充抗氧化剂的6种RBD油样品和补充有抗氧化剂的3种RBD油样品的油稳定性指数(OSI)进行分析。展示于表21中的是使用Metrohm873BiodieselRancimat执行,在110℃下进行的OSIAOCSCd12b-92测试的结果。除了用星号(*)表示处,结果是多次OSI运作的平均值。对未分析的那些样品加以指示(NA)。表21.有和无抗氧化剂的RBD油样品在110℃下的油稳定性指数未转化的桑椹形原藻(UTEX1435)酸谱包含低于60%的C18:1脂肪酸和高于7%的C18:2脂肪酸。相比之下,株系D(包括pSZ1500)展现出C18:1脂肪酸组成增加(达到高于85%)以及C18:2脂肪酸减少(达到低于0.06%)的脂肪酸谱。在提炼、漂白以及脱胶后,RBD油样品由从展现OSI值>26小时的株系E制成的油制备。在加入抗氧化剂的情况下,由株系D的油制备的RBD油的OSI从48.60小时增加到大于242小时。实例8:通过一种脂肪酸脱饱和酶和一种酰基-ACP硫酯酶的对偶基因破坏来提高工程化的微生物的油酸水平这一实例描述了使用一种转化载体来破坏先前针对高油酸和低亚油酸产生进行工程化的一种桑椹形原藻株系的一个FATA基因座。用于这一实例的转化盒包含一种可选择标记和编码一种桑椹形原藻KASII酶的核苷酸序列以对微生物进行工程化,其中经转化的微生物的脂肪酸谱已经改变以实现进一步增加的油酸以及更低的棕榈酸水平。实例7和PCT/US2012/023696中描述的株系D是随后根据实例2中和如PCT/US2009/066141、PCT/US2009/066142、PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中所述的基因枪转化方法用转化构建体pSZ1500(SEQIDNO:137)转化的桑椹形原藻(UTEX1435)的一种经典诱变处理的(为了更高油生产)衍生物。这一株系被用作宿主以用于用构建体pSZ2276转化以增加一种KASII酶的表达,同时附随地除去一种内源性酰基-ACP硫酯酶基因座,从而产生株系E。pSZ2276转化构建体包含用于整合到桑椹形原藻核基因组中的FATA1基因组区域的5'(SEQIDNO:140)和3'(SEQIDNO:141)同源重组靶向序列(侧接该构建体)、一种在原始小球藻肌动蛋白启动子/5'UTR(SEQIDNO:142)和普通小球藻硝酸盐还原酶3'UTR(SEQIDNO:126)控制下的拟南芥(A.thaliana)THIC蛋白质编码区。这种AtTHIC表达盒被列为SEQIDNO:143并且充当一种选择标记。桑椹形原藻KASII蛋白质编码区是在桑椹形原藻Amt03启动子/5'UTR(SEQIDNO:128)和普通小球藻硝酸盐还原酶3'UTR的控制下,并且KASII酶的天然转运肽经原始小球藻硬脂酰基-ACP脱饱和酶转运肽(SEQIDNO:129)置换。包含原始小球藻S106硬脂酰基-ACP脱饱和酶转运肽的PmKASII的密码子优化的序列作为SEQIDNO:144提供于序列表中。SEQIDNO:145提供了SEQIDNO:144的蛋白质翻译。PmKASII和suc2的蛋白质编码区经过密码子优化以反映如PCT/US2009/066141、PCT/US2009/066142、PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中所述的桑椹形原藻UTEX1435核基因所固有的密码子偏倚性。在缺乏硫胺素的琼脂板上对株系D的原代pSZ2276转化体进行选择,克隆纯化,并且选择单个工程化的株系(株系E)以用于分析。将株系E在异养脂质产生条件下在pH5.0和pH7.0下培育,如PCT/US2009/066141、PCT/US2009/066142、PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中所述。由来自每一转化体的干燥生物质制备脂质样品,并且使用如实例3中所述的标准脂肪酸甲酯气相色谱火焰离子化(FAMEGC/FID)检测方法分析这些样品的脂肪酸谱。通过用pSZ2276转化到株系D中而产生的转基因株系的脂肪酸谱(表示为总脂肪酸的面积%)展示于表22中。表22.针对增加的油酸和更低的亚油酸水平进行工程化的桑椹形原藻(UTEX1435)株系A、D以及E的脂肪酸谱。如表22中所示,使用一种CtOTE表达盒靶向打断FADc等位基因影响了转化的微生物的脂肪酸谱。株系D的脂肪酸谱(包含pSZ1500转化载体)展示出相对于株系A,C18:1脂肪酸组成增加以及C16:0和C18:2脂肪酸伴随减少。随后用pSZ2276对株系D进行转化以过度表达一种桑椹形原藻(UTEX1435)KASII蛋白质同时附随地除去一个FATA基因座(由此产生株系E),这对转化的微生物的脂肪酸谱产生了再进一步影响。株系E的脂肪酸谱展示出相对于株系A和D,C18:1脂肪酸组成增加,并且C16:0脂肪酸进一步减少。株系E在培养条件中在pH7下进行繁殖以诱导由Amt03启动子表达,这产生了相对于在pH5下培养的相同株系,C18:0和C18:1脂肪酸更高并且C16:0脂肪酸更低的一种脂肪酸谱。这些数据展示了使用多种基因修饰来影响宿主生物体的脂肪酸谱以实现油酸水平提高以及亚油酸和棕榈酸水平伴随降低。进一步,这一实例示出了使用重组聚核苷酸以用一种盒靶向一个内源性FATA等位基因的基因打断,该盒包含pH值可调节的启动子以控制一种外源性KASII蛋白质编码区的表达,以便改变宿主微生物的脂肪酸谱。实例9:一种脂肪酸脱饱和酶的条件表达这一实例描述了使用一种转化载体以在一种桑椹形原藻株系中表达一种Δ12脂肪酸脱饱和酶(FAD),该桑椹形原藻株系先前已针对在繁殖的种子和脂质生产两个阶段中的高油酸和极低亚油酸产生进行工程化。对天然油中的极低亚油酸水平进行探寻以用于某些应用。然而,在宿主微生物的细胞分裂阶段(“种子阶段”)过程中不存在亚油酸是不利的。亚油酸可以被补充到种子培养基中以加速细胞分裂,并且在脂质产生过程中并不加入,但这种加入强加了无用的成本。为了克服这种挑战,构建一种转化盒以用于调节FAD2酶的表达,使得在微生物的培养物的油生产阶段过程中,可以获得对于细胞分裂足够的亚油酸水平,并且可以产生亚油酸水平极低的油。这一实例中使用的转化盒包含一种可选择标记、一种pH值可调节的启动子、以及编码桑椹形原藻FAD2酶的核苷酸序列以对微生物进行工程化,其中经转化的微生物的脂肪酸谱已经改变以实现增加的油酸产生以及可调节的亚油酸产生。实例7和8以及PCT/US2012/023696中描述的株系D是随后根据如PCT/US2009/066141、PCT/US2009/066142、PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中所述的基因枪转化方法用转化构建体pSZ1500(SEQIDNO:137)转化的桑椹形原藻(UTEX1435)的一种经典诱变处理的(为了更高油生产)衍生物。这一株系被用作宿主以用于用构建体pSZ2413转化,从而引入一种pH值驱动的启动子以用于调节一种桑椹形原藻FAD2酶。pSZ2413转化构建体包含用于整合到桑椹形原藻核基因组中的6S基因组区域的5'(SEQIDNO:121)和3'(SEQIDNO:122)同源重组靶向序列(侧接该构建体)、一种在原始小球藻肌动蛋白启动子/5'UTR(SEQIDNO:142)和普通小球藻硝酸盐还原酶3'UTR(SEQIDNO:126)控制下的拟南芥THIC蛋白质编码区。这种AtTHIC表达盒被列为SEQIDNO:143并且充当一种选择标记。桑椹形原藻FAD2蛋白质编码区是在桑椹形原藻Amt03启动子/5'UTR(SEQIDNO:128)和普通小球藻硝酸盐还原酶3'UTR的控制下。PmFAD2的密码子优化的序列作为SEQIDNO:146提供于序列表中。SEQIDNO:147提供了SEQIDNO:146的蛋白质翻译。PmFAD2和suc2的蛋白质编码区经过密码子优化以反映如PCT/US2009/066141、PCT/US2009/066142、PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中所述的桑椹形原藻UTEX1435核基因所固有的密码子偏倚性。在缺乏硫胺素的琼脂板上对株系D的原代pSZ2413转化体进行选择,克隆纯化,并且选择工程化的株系(株系E)的分离株以用于分析。这些分离株在异养脂质产生条件下在pH7.0下(以激活FAD2由PmAmt03启动子表达)和在pH5.0下培育,如PCT/US2009/066141、PCT/US2009/066142、PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中所述。由来自每一转化体的干燥生物质制备脂质样品,并且使用如实例3中所述的标准脂肪酸甲酯气相色谱火焰离子化(FAMEGC/FID)检测方法分析这些样品的脂肪酸谱。通过用pSZ2413转化到株系D中而产生的转基因株系F(F-1到F-9)的九个代表性分离株的C18:2脂肪酸的所得谱(以面积%表示)展示于表23中。表23.桑椹形原藻(UTEX1435)株系A、D以及F的C18:2脂肪酸谱。如表23中所示,经由株系培养物处于不同pH值水平下实现的PmFAD2酶的经调节的表达的影响是转化的微生物中C18:2脂肪酸组成的明确增加。亚油酸占株系A脂肪酸的约6%到约7.3%。相比之下,株系D(包含pSZ1500转化载体以除去两个FAD2等位基因)的特征在于0.01%亚油酸的脂肪酸谱。用pSZ2413转化株系D以生成株系F,这产生了一种重组微生物,在该重组微生物中,亚油酸的产生由Amt03启动子调节。株系F分离株在培养条件中在pH7下进行繁殖以诱导由Amt03启动子表达FAD2,这产生了特征在于约4.5%到约7.5%亚油酸的一种脂肪酸谱。相比之下,株系F分离株在培养条件中在pH5下的繁殖产生了特征在于约0.33%到约0.77%亚油酸的一种脂肪酸谱。这些数据展示出重组聚核苷酸的效用和有效性,这些重组聚核苷酸允许FAD2酶的条件表达以改变工程化的微生物的脂肪酸谱,并且尤其在调节微生物细胞中C18:2脂肪酸的产生方面。实例10-33:介绍和表格以下实例10-33描述了不同微生物根据本发明的工程化。为了改变微生物的脂肪酸谱,可以对微生物进行基因修饰,其中内源性或外源性脂质生物合成通路酶被表达、过度表达或减弱。基因工程化一种微生物以改变其关于脂肪酸不饱和程度的脂肪酸谱并且减小或增大脂肪酸链长的步骤包括了设计并构建一种转化载体(例如一种质粒),用一种或多种载体转化该微生物,选择经转化的微生物(转化体),转化的微生物的生长,以及分析由工程化的微生物产生的脂质的脂肪酸谱。会改变宿主生物体的脂肪酸谱的转基因可以在许多真核微生物中表达。转基因在真核微生物中表达的实例可以在科学文献中找到,这些真核微生物包括莱茵衣藻、椭圆形小球藻、原始小球藻、嗜糖小球藻(Chlorellasaccarophila)、普通小球藻、凯氏小球藻(Chlorellakessleri)、耐热性小球藻、雨生红球藻(Haematococcuspluvialis)、胸状盘藻(Goniumpectorale)、强壮团藻(Volvoxcarteri)、特氏杜氏藻(Dunaliellatertiolecta)、绿色杜氏藻(Dunaliellaviridis)、盐生杜氏藻(Dunaliellasalina)、极锐新月藻-瘦新月藻-沿岸新月藻复合体(Closteriumperacerosum-strigosum-littoralecomplex)、微拟球藻属(Nannochloropsissp.)、假微型海链藻(Thalassiosirapseudonana)、三角褐指藻(Phaeodactylumtricornutum)、嗜腐舟形藻(Naviculasaprophila)、筒柱藻(Cylindrothecafusiformis)、隐蔽小环藻(Cyclotellacryptica)、小亚德里亚共生藻(Symbiodiniummicroadriacticum)、前沟藻属(Amphidiniumsp.)、角刺藻属(Chaetocerossp.)、高山被孢霉(Mortierellaalpina)以及解脂耶氏酵母(Yarrowialipolytica)。这些表达技术可以与本发明的传授组合以产生脂肪酸谱被改变的工程化的微生物。会改变宿主生物体的脂肪酸谱或改变由宿主生物体产生的甘油脂的区域专一分布的转基因也可以在许多原核微生物中表达。转基因在产油微生物(包括混浊红球菌(Rhodococcusopacus))中表达的实例可以在文献中找到。这些表达技术可以与本发明的传授组合以产生脂肪酸谱被改变的工程化的微生物。表24A-E.密码子偏好清单表24A表24B表24C表24D表24E原始小球藻中的优选密码子使用表25.脂质生物合成通路蛋白。实例10:对耐热性小球藻进行工程化根据本发明的重组基因在耐热性小球藻中的表达可以通过修改由如在此论述的道森等人传授的方法和载体来实现。简言之,道森等人,《当代微生物学》第35卷(1997)第356-362页报导了用质粒DNA对耐热性小球藻进行稳定核转化。使用微粒轰击的转化方法,道森将编码完整普通小球藻硝酸盐还原酶基因(NR,基因库登录号U39931)的质粒pSV72-NRg引入到突变的耐热性小球藻(NR-突变株)中。NR-突变株不能在不使用硝酸盐作为氮来源的情况下生长。硝酸盐还原酶催化硝酸盐转化成亚硝酸盐。在转化之前,耐热性小球藻NR-突变株不能在包含硝酸盐(NO3-)作为唯一氮源的培养介质上生长超过小集落阶段。普通小球藻NR基因产物在NR-突变株耐热性小球藻中的表达被用作一种会挽救硝酸盐代谢缺陷的可选择标记。在用pSV72-NRg质粒转化后,获得了能够在包含硝酸盐作为唯一碳源的琼脂板上生长超过小集落阶段的稳定表达普通小球藻NR基因产物的NR-突变株耐热性小球藻。对稳定转化体DNA的评估是通过DNA杂交分析(Southernanalysis)进行的,而对稳定转化体RNA的评估是通过核糖核酸酶保护进行的。转化的耐热性小球藻(NR突变株)的选择和维持是在琼脂板(pH7.4)上进行的,这些琼脂板包含0.2g/LMgSO4、0.67g/LKH2PO4、3.5g/LK2HPO4、1.0g/LNa3C6H5O7·H2O以及16.0g/L琼脂、一种适当氮源(例如NO3-)、微量营养素以及一种碳源。道森还报导了耐热性小球藻和耐热性小球藻NR突变株在液体培养介质中的繁殖。道森报导了质粒pSV72-NRg以及普通小球藻硝酸盐还原酶基因的启动子和3'UTR/终止子适合于实现耐热性小球藻NR-突变株中的异源性基因表达。道森还报导了普通小球藻硝酸盐还原酶基因产物的表达适用于在耐热性小球藻NR-突变株中用作可选择标记。在本发明的一个实施例中,对载体pSV72-NRg(包含编码用作可选择标记的普通小球藻硝酸盐还原酶(CvNR)基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在耐热性小球藻中表达根据表24A-D经过密码子优化以反映耐热性小球藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的CvNR启动子并且在蛋白质编码序列的3'区或下游可操作地连接于CvNR3'UTR/终止子。转化构建体可以另外包含耐热性小球藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化耐热性小球藻通过熟知转化技术包括微粒轰击或其他已知方法实现。可以将CvNR基因产物的活性用作可选择标记以挽救耐热性小球藻NR突变株系的氮同化缺陷并且选择稳定表达转化载体的耐热性小球藻NR-突变株。适用于耐热性小球藻脂质产生的生长培养基包括(但不限于)0.5g/LKH2PO4、0.5g/LK2HPO4、0.25g/LMgSO4-7H2O,具有补充微量营养素以及适当氮和碳源(帕特森(Patterson),《脂质》(Lipids)第5卷:7(1970),第597-600页)。耐热性小球藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例11:对普通小球藻进行工程化根据本发明的重组基因在普通小球藻中的表达可以通过修改由如在此论述的周(Chow)和童(Tung)等人传授的方法和载体来实现。简言之,周和童等人,《植物细胞报导》(PlantCellReports),第18卷(1999),第778-780页报导了用质粒DNA对普通小球藻进行稳定核转化。使用电穿孔的转化方法,周和童将质粒pIG121-Hm(基因库登录号AB489142)引入到普通小球藻中。pIG121-Hm的核苷酸序列包含编码β-葡萄糖醛酸酶(GUS)报导基因产物的序列,该序列可操作地连接于GUS蛋白质编码序列上游的CaMV35S启动子并且进一步可操作地连接于GUS蛋白质编码序列下游的胭脂氨酸合成酶(nos)基因的3'UTR/终止子。质粒pIG121-Hm的序列进一步包含潮霉素B抗生素抗性盒。这种潮霉素B抗生素抗性盒包含可操作地连接于编码潮霉素磷酸转移酶(hpt,基因库登录号BAH24259)基因产物的序列的CaMV35S启动子。在转化之前,普通小球藻不能在包含50μg/ml潮霉素B的培养介质中繁殖。在用pIG121-Hm质粒转化后,获得了在包含50μg/ml潮霉素B的培养介质中繁殖的普通小球藻的转化体。hpt基因产物在普通小球藻中表达能够实现转化的普通小球藻在50μg/ml潮霉素B存在下进行繁殖,由此确定潮霉素B抗性盒作为可选择标记用于普通小球藻的效用。GUS报导基因的可检测活性指示了CaMV35S启动子和nos3'UTR适用于实现普通小球藻中的异源性基因表达。稳定转化体的基因组DNA评估通过DNA杂交分析进行。转化的普通小球藻的选择和维持在包含YA培养基(琼脂和4g/L酵母提取物)的琼脂板上进行。普通小球藻在液体培养介质中的繁殖如由周和童论述般进行。已描述了普通小球藻在除YA培养基以外的培养基中的繁殖(例如,参见乍得(Chader)等人,《可再生能源杂志》(RevuedesEnergiesRenouvelabes),第14卷(2011),第21-26页和伊尔曼(Illman)等人,《酶和微生物技术》(EnzymeandMicrobialTechnology),第27卷(2000),第631-635页)。周和童报导了质粒pIG121-Hm、CaMV35S启动子以及根癌农杆菌(Agrobacteriumtumefaciens)胭脂氨酸合成酶基因3'UTR/终止子适合于实现普通小球藻中的异源性基因表达。另外,周和童报导了潮霉素B抗性盒适用于在普通小球藻中用作可选择标记。适用于实现普通小球藻中的异源性基因表达的另外的质粒、启动子、3'UTR/终止子以及可选择标记已论述于乍得等人,《可再生能源杂志》,第14卷(2011),第21-26页中。在本发明的一个实施例中,对pIG121-Hm(包含编码用作可选择标记的潮霉素B基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在普通小球藻中表达根据表24A-D经过密码子优化以反映普通小球藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的CaMV35S启动子并且在蛋白质编码序列的3'区或下游可操作地连接于根癌农杆菌胭脂氨酸合成酶基因3'UTR/终止子。转化构建体可以另外包含普通小球藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化普通小球藻通过熟知转化技术包括电穿孔或其他已知方法实现。潮霉素B抗性基因产物的活性可以被用作标记以在(但不限于)包含潮霉素的琼脂培养基上选择经转化载体转化的普通小球藻。适用于普通小球藻脂质产生的生长培养基包括(但不限于)补充有痕量金属和任选地1.5g/LNaNO3的BG11培养基(0.04g/LKH2PO4、0.075g/LCaCl2、0.036g/L柠檬酸、0.006g/L柠檬酸铁铵、1mg/LEDTA以及0.02g/LNa2CO3)。适用于培养普通小球藻以用于脂质产生的另外的培养基包括例如渡边培养基(Watanabemedium,包含1.5g/LKNO3、1.25g/LKH2PO4、1.25gl-1MgSO4·7H2O、20mgl-1FeSO4·7H2O与微量营养素)和低氮培养基(包含203mg/l(NH4)2HPO4、2.236g/lKCl、2.465g/lMgSO4、1.361g/lKH2PO4以及10mg/lFeSO4),如由伊尔曼等人,《酶和微生物技术》,第27卷(2000),第631-635页所报导。普通小球藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例12:对椭圆形小球藻进行工程化根据本发明的重组基因在椭圆形小球藻中的表达可以通过修改由如在此论述的陈等人传授的方法和载体来实现。简言之,陈等人,《当代遗传学》(CurrentGenetics),第39卷:5(2001),第365-370页报导了用质粒DNA对椭圆形小球藻进行稳定转化。使用电穿孔的转化方法,陈将质粒pBinUΩNP-1引入到椭圆形小球藻中。pBinUΩNP-1的核苷酸序列包含编码嗜中性粒细胞肽-1(NP-1)兔基因产物的序列,该序列可操作地连接于NP-1蛋白质编码区上游的玉米泛素(ubi1)基因启动子并且可操作地连接于NP-1蛋白质编码区下游的胭脂氨酸合成酶(nos)基因的3'UTR/终止子。质粒pBinUΩNP-1的序列进一步包含G418抗生素抗性盒。这种G418抗生素抗性盒包含编码氨基糖苷3'-磷酸转移酶(aph3')基因产物的序列。aph3'基因产物赋予抗生素G418抗性。在转化之前,椭圆形小球藻不能在包含30μg/mLG418的培养介质中繁殖。在用pBinUΩNP-1质粒转化后,获得了在包含30μg/mLG418的选择性培养介质中繁殖的椭圆形小球藻的转化体。aph3'基因产物在椭圆形小球藻中表达能够实现转化的椭圆形小球藻在30μg/mLG418存在下进行繁殖,由此确定G418抗生素抗性盒作为可选择标记用于椭圆形小球藻的效用。NP-1基因产物的可检测活性指示了ubi1启动子和nos3'UTR适用于实现椭圆形小球藻中的异源性基因表达。稳定转化体的基因组DNA评估通过DNA杂交分析进行。转化的椭圆形小球藻的选择和维持在具有15μg/mLG418(针对液体培养物)或具有30μg/mLG418(针对包含1.8%琼脂的固体培养物)的克诺普培养基(Knopmedium,包含0.2g/LK2HPO4、0.2g/LMgSO4·7H2O、0.12g/LKCl以及10mg/LFeCl3,pH6.0-8.0,补充有0.1%酵母提取物和0.2%葡萄糖)上进行。已报导了椭圆形小球藻在除克诺普培养基以外的培养基中的繁殖(参见曹(Cho)等人,《渔业科学》(FisheriesScience),第73卷:5(2007),第1050-1056页,贾维斯(Jarvis)和布朗(Brown),《当代遗传学》,第19卷(1991),第317-321页以及金等人,《海洋生物技术》,第4卷(2002),第63-73页)。已报导了适用于实现椭圆形小球藻中的异源性基因表达的另外的质粒、启动子、3'UTR/终止子以及可选择标记(参见贾维斯和布朗以及金等人,《海洋生物技术》,第4卷(2002),第63-73页)。陈报导了质粒pBinUΩNP-1、ubi1启动子以及根癌农杆菌胭脂氨酸合成酶基因3'UTR/终止子适合于实现椭圆形小球藻中的外源性基因表达。另外,陈报导了在pBinUΩNP-1上编码的G418抗性盒适用于在椭圆形小球藻中用作可选择标记。在本发明的一个实施例中,对载体pBinUΩNP-1(包含编码用作可选择标记的aph3'基因产物(赋予G418抗性)的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在椭圆形小球藻中表达根据表24A-D经过密码子优化以反映椭圆形小球藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的玉米ubi1启动子并且在蛋白质编码序列的3'区或下游可操作地连接于根癌农杆菌胭脂氨酸合成酶基因3'UTR/终止子。转化构建体可以另外包含椭圆形小球藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化椭圆形小球藻通过熟知转化技术包括电穿孔或其他已知方法实现。aph3'基因产物的活性可以被用作标记以在(但不限于)包含G418的克诺普琼脂培养基上选择经转化载体转化的椭圆形小球藻。适用于椭圆形小球藻脂质产生的生长培养基包括(但不限于)克诺普培养基以及由贾维斯和布朗以及金等人报导的那些培养介质。椭圆形小球藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例13:对凯氏小球藻进行工程化根据本发明的重组基因在凯氏小球藻中的表达可以通过修改由如在此论述的艾尔-谢赫(El-Sheekh)等人传授的方法和载体来实现。简言之,艾尔-谢赫等人,《生物杆菌》(BiologiaPlantarium),第42卷:2(1999),第209-216页报导了用质粒DNA对凯氏小球藻进行稳定转化。使用微粒轰击的转化方法,艾尔-谢赫将质粒pBI121(基因库登录号AF485783)引入到凯氏小球藻中。质粒pBI121包含卡那霉素/新霉素抗生素抗性盒。卡那霉素/新霉素抗生素抗性盒包含根癌农杆菌胭脂氨酸合成酶(nos)基因启动子、编码用于对卡那霉素和G418抗性的新霉素磷酸转移酶II(nptII)基因产物(基因库登录号AAL92039)的序列、以及根癌农杆菌胭脂氨酸合成酶(nos)基因的3'UTR/终止子。pBI121进一步包含编码β-葡萄糖醛酸酶(GUS)报导基因产物的序列,该序列可操作地连接于CaMV35S启动子并且可操作地连接于nos基因的3'UTR/终止子。在转化之前,凯氏小球藻不能在包含15mg/L卡那霉素的培养介质中繁殖。在用pBI121质粒转化后,获得了在包含15mg/L卡那霉素的选择性培养介质中繁殖的凯氏小球藻的转化体。nptII基因产物在凯氏小球藻中表达能够实现在15mg/L卡那霉素存在下进行繁殖,由此确定卡那霉素/新霉素抗生素抗性盒作为可选择标记用于凯氏小球藻的效用。GUS基因产物的可检测活性指示了CaMV35S启动子和nos3'UTR适用于实现凯氏小球藻中的异源性基因表达。稳定转化体的基因组DNA评估通过DNA杂交分析进行。如由艾尔-谢赫所报导,转化的凯氏小球藻的选择和维持在包含YEG培养基(1%酵母提取物、1%葡萄糖)和15mg/L卡那霉素的半固体琼脂板上进行。艾尔-谢赫还报导了凯氏小球藻在YEG液体培养介质中的繁殖。适用于培养凯氏小球藻以用于脂质产生的另外的培养基披露于萨托(Sato)等人,《BBA脂质的分子和细胞生物学》(BBAMolecularandCellBiologyofLipids),第1633卷(2003),第27-34页中。艾尔-谢赫报导了质粒pBI121、CaMV启动子以及胭脂氨酸合成酶基因3'UTR/终止子适合于实现凯氏小球藻中的异源性基因表达。另外,艾尔-谢赫报导了在pBI121上编码的卡那霉素/新霉素抗性盒适用于在凯氏小球藻中用作可选择标记。在本发明的一个实施例中,对载体pBI121(包含编码用作可选择标记的卡那霉素/新霉素抗性基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在凯氏小球藻中表达根据表24A-D经过密码子优化以反映凯氏小球藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的CaMV35S启动子并且在蛋白质编码序列的3'区或下游可操作地连接于根癌农杆菌胭脂氨酸合成酶基因3'UTR/终止子。转化构建体可以另外包含凯氏小球藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化凯氏小球藻通过熟知转化技术包括微粒轰击或其他已知方法实现。nptII基因产物的活性可以被用作标记以在(但不限于)包含卡那霉素或新霉素的YEG琼脂培养基上选择经转化载体转化的凯氏小球藻。适用于凯氏小球藻脂质产生的生长培养基包括(但不限于)YEG培养基以及由萨托等人报导的那些培养介质。凯氏小球藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例14:对特氏杜氏藻进行工程化根据本发明的重组基因在特氏杜氏藻中的表达可以通过修改由如在此论述的沃克(Walker)等人传授的方法和载体来实现。简言之,沃克等人,《应用藻类学杂志》(JournalofAppliedPhycology),第17卷(2005),第363-368页报导了用质粒DNA对特氏杜氏藻进行稳定核转化。使用电穿孔的转化方法,沃克将质粒pDbleFLAG1.2引入到特氏杜氏藻中。pDbleFLAG1.2包含编码博莱霉素抗生素抗性盒的序列,包含编码用于对抗生素脉霉素的抗性的印度斯坦链异壁菌(Streptoalloteichushindustanus)博莱霉素结合蛋白(ble)的序列,该序列可操作地连接于特氏杜氏藻核酮糖-1,5-二磷酸羧化酶/加氧酶小亚基基因(rbcS1,基因库登录号AY530155)的启动子和3'UTR。在转化之前,特氏杜氏藻不能在包含1mg/L脉霉素的培养介质中繁殖。在用pDbleFLAG1.2质粒转化后,获得了在包含1mg/L脉霉素的选择性培养介质中繁殖的特氏杜氏藻的转化体。ble基因产物在特氏杜氏藻中表达能够实现在1mg/L脉霉素存在下进行繁殖,由此确定博莱霉素抗生素抗性盒作为可选择标记用于特氏杜氏藻的效用。稳定转化体的基因组DNA评估通过DNA杂交分析进行。如由沃克报导,转化的特氏杜氏藻的选择和维持是在进一步包含4.5g/LNaCl和1mg/L脉霉素的杜氏藻培养基(DM,如由普瓦索利(Provasoli)等人,《微生物学档案》(ArchivfurMikrobiologie),第25卷(1957),第392-428页)中进行。适用于培养特氏杜氏藻以用于脂质产生的另外的培养基论述于乔木(Takagi)等人,《生物科学和生物工程杂志》(JournalofBioscienceandBioengineering),第101卷:3(2006),第223-226页和马萨尔(Massart)和安斯坦(Hanston),威尼斯2010年第三届国际生物质和废弃物能源研讨会论文集(ProceedingsVenice2010,ThirdInternationalSymposiumonEnergyfromBiomassandWaste)中。沃克报导了质粒pDbleFLAG1.2以及特氏杜氏藻核酮糖-1,5-二磷酸羧化酶/加氧酶小亚基基因的启动子和3'UTR适合于实现特氏杜氏藻中的异源性表达。另外,沃克报导了在pDbleFLAG1.2上编码的博莱霉素抗性盒适用于在特氏杜氏藻中用作可选择标记。在本发明的一个实施例中,对载体pDbleFLAG1.2(包含编码用作可选择标记的ble基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在特氏杜氏藻中表达根据表24A-D经过密码子优化以反映特氏杜氏藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的rbcS1启动子并且在蛋白质编码序列的3'区或下游可操作地连接于rbcS13'UTR/终止子。转化构建体可以另外包含特氏杜氏藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化特氏杜氏藻通过熟知转化技术包括电穿孔或其他已知方法实现。ble基因产物的活性可以被用作标记以在(但不限于)包含脉霉素的DM培养基上选择经转化载体转化的特氏杜氏藻。适用于特氏杜氏藻脂质产生的生长培养基包括(但不限于)DM培养基以及由乔木等人以及马萨尔和安斯坦描述的那些培养介质。特氏杜氏藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例15:对强壮团藻进行工程化根据本发明的重组基因在强壮团藻中的表达可以通过修改由如在此论述的霍曼(Hallman)和拉派尔(Rappel)等人传授的方法和载体来实现。简言之,霍曼和拉派尔等人,《植物杂志》(ThePlantJournal),第17卷(1999),第99-109页报导了用质粒DNA对强壮团藻进行稳定核转化。使用微粒轰击的转化方法,霍曼和拉派尔将pzeoE质粒引入到强壮团藻中。pzeoE质粒包含编码博莱霉素抗生素抗性盒的序列,包含编码用于对抗生素博莱霉素的抗性的印度斯坦链异壁菌博莱霉素结合蛋白(ble)的序列,该序列可操作地连接于强壮团藻β-微管蛋白基因(基因库登录号L24547)的启动子和3'UTR。在转化之前,强壮团藻不能在包含1.5μg/ml博莱霉素的培养介质中繁殖。在用pzeoE质粒转化后,获得了在包含大于20μg/ml博莱霉素的选择性培养介质中繁殖的强壮团藻的转化体。ble基因产物在强壮团藻中表达能够实现在20μg/ml博莱霉素存在下进行繁殖,由此确定博莱霉素抗生素抗性盒作为可选择标记用于强壮团藻的效用。稳定转化体的基因组DNA评估通过DNA杂交分析进行。如由霍曼和拉派尔报导,转化的强壮团藻的选择和维持在具有1mg/L脉霉素的团藻培养基(VM,如由普瓦索利和平特纳,《藻类生态学》(TheEcologyofAlgae),特种出版物号2(1959),泰纶C.A.(Tyron,C.A.)和哈特曼R.T.(Hartman,R.T.)编,匹兹堡:匹兹堡大学,第88-96页)中进行。适用于培养强壮团藻以用于脂质产生的培养基还由斯塔尔(Starr)在斯塔尔R,C,.《发育生物学》(DevBiol)增刊,第4卷(1970),第59-100页)中论述。霍曼和拉派尔报导了质粒pzeoE以及强壮团藻β-微管蛋白基因的启动子和3'UTR适合于实现强壮团藻中的异源性表达。另外,霍曼和拉派尔报导了在pzeoE上编码的博莱霉素抗性盒适用于在强壮团藻中用作可选择标记。已报导了适用于实现强壮团藻中的异源性基因表达并且适用作强壮团藻中的选择性标记的另外的质粒、启动子、3'UTR/终止子以及可选择标记(例如参见哈尔曼(Hallamann)和桑泊(Sumper),《国家科学院论文集》(ProceedingsoftheNationalAcademyofSciences),第91卷(1994),第11562-11566页和霍曼和沃德尼克(Wodniok),《植物细胞报导》(PlantCellReports),第25卷(2006),第582-581页)。在本发明的一个实施例中,对载体pzeoE(包含编码用作可选择标记的ble基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在强壮团藻中表达根据表24A-D经过密码子优化以反映强壮团藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的强壮团藻β-微管蛋白启动子并且在蛋白质编码序列的3'区或下游可操作地连接于强壮团藻β-微管蛋白3'UTR/终止子。转化构建体可以另外包含强壮团藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。本领域普通技术人员可以在强壮团藻基因组序列内鉴别出这些同源区(在普罗赫尼克(Prochnik)等人,《科学》(Science),第329卷:5988(2010),第223-226页的出版物中提及)。用转化载体稳定转化强壮团藻通过熟知转化技术包括微粒轰击或其他已知方法实现。ble基因产物的活性可以被用作标记以在(但不限于)包含博莱霉素的VM培养基上选择经转化载体转化的强壮团藻。适用于强壮团藻脂质产生的生长培养基包括(但不限于)VM培养基以及由斯塔尔论述的那些培养介质。强壮团藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例16:对雨生红球藻进行工程化根据本发明的重组基因在雨生红球藻中的表达可以通过修改由如在此论述的施泰因布伦纳(Steinbrenner)和桑德曼(Sandmann)等人传授的方法和载体来实现。简言之,施泰因布伦纳和桑德曼等人,《应用和环境微生物学》(AppliedandEnvironmentalMicrobiology),第72卷:12(2006),第7477-7484页报导了用质粒DNA对雨生红球藻进行稳定核转化。使用微粒轰击的转化方法,施泰因布伦纳将质粒pPlat-pds-L504R引入到雨生红球藻中。质粒pPlat-pds-L504R包含达草灭抗性盒,该达草灭抗性盒包含雨生红球藻八氢番茄红素脱饱和酶基因(Pds,基因库登录号AY781170)的启动子、蛋白质编码序列以及3'UTR,其中Pds的蛋白质编码序列在位置504处被修饰(由此将亮氨酸改变成精氨酸)以编码会赋予对除草剂达草灭的抗性的基因产物(Pds-L504R)。在用pPlat-pds-L504R转化之前,雨生红球藻不能在包含5μM达草灭的培养基上繁殖。在用pPlat-pds-L504R质粒转化后,获得了在包含5μM达草灭的选择性培养介质中繁殖的雨生红球藻的转化体。Pds-L504R基因产物在雨生红球藻中表达能够实现在5μM达草灭存在下进行繁殖,由此确定达草灭除草剂抗性盒作为可选择标记用于雨生红球藻的效用。稳定转化体的基因组DNA评估通过DNA杂交分析进行。如由施泰因布伦纳报导,转化的雨生红球藻的选择和维持在包含补充有2.42g/LTris-乙酸盐和5mM达草灭的OHA培养基(OHM(0.41g/LKNO3、0.03g/LNa2HPO4、0.246g/LMgSO4·7H2O、0.11g/LCaCl2·2H2O、2.62mg/L柠檬酸铁(III)×H2O、0.011mg/LCoCl2·6H2O、0.012mg/LCuSO4·5H2O、0.075mg/LCr2O3、0.98mg/LMnCl2·4H2O、0.12mg/LNa2MoO4×2H2O、0.005mg/LSeO2以及25mg/L生物素、17.5mg/L硫胺素、以及15mg/L维生素B12)上进行。雨生红球藻在液体培养物中的繁殖是由施泰因布伦纳和桑德曼使用基础培养基(如由小林(Kobayashi)等人,《应用和环境微生物学》,第59卷(1993),第867-873页)进行的。施泰因布伦纳和桑德曼报导了雨生红球藻八氢番茄红素脱饱和酶基因的pPlat-pds-L504R质粒和启动子和3'UTR适合于实现雨生红球藻中的异源性表达。另外,施泰因布伦纳和桑德曼报导了在pPlat-pds-L504R上编码的达草灭抗性盒适用于在雨生红球藻中用作可选择标记。已报导了适用于实现雨生红球藻中的异源性基因表达的另外的质粒、启动子、3'UTR/终止子以及可选择标记(参见凯瑟尔桑(Kathiresan)等人,《藻类学杂志》(JournalofPhycology),第45卷(2009),第642-649页)。在本发明的一个实施例中,对载体pPlat-pds-L504R(包含编码用作可选择标记的Pds-L504R基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在雨生红球藻中表达根据表24A-D经过密码子优化以反映雨生红球藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的雨生红球藻pds基因启动子并且在蛋白质编码序列的3'区或下游可操作地连接于雨生红球藻pds基因3'UTR/终止子。转化构建体可以另外包含雨生红球藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化雨生红球藻通过熟知转化技术包括微粒轰击或其他已知方法实现。Pds-L504R基因产物的活性可以被用作标记以在(但不限于)包含达草灭的OHA培养基上选择经转化载体转化的雨生红球藻。适用于雨生红球藻脂质产生的生长培养基包括(但不限于)基础培养基以及由小林等人、凯瑟尔桑等人以及龚(Gong)和陈,《应用藻类学杂志》,第9卷:5(1997),第437-444页)描述的那些培养介质。雨生红球藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例17:对极锐新月藻-瘦新月藻-沿岸新月藻复合体进行工程化根据本发明的重组基因在极锐新月藻-瘦新月藻-沿岸新月藻复合体中的表达可以通过修改由如在此论述的亚伯(Abe)等人传授的方法和载体来实现。简言之,亚伯等人,《植物细胞生理学》(PlantCellPhysiology),第52卷:9(2011),第1676-1685页报导了用质粒DNA对极锐新月藻-瘦新月藻-沿岸新月藻复合体进行稳定核转化。使用微粒轰击的转化方法,亚伯将质粒pSA106引入到极锐新月藻-瘦新月藻-沿岸新月藻复合体中。质粒pSA106包含博莱霉素抗性盒,包含编码印度斯坦链异壁菌博莱霉素结合蛋白基因(ble,基因库登录号CAA37050)的序列,该序列可操作地连接于极锐新月藻-瘦新月藻-沿岸新月藻复合体叶绿素a/b结合蛋白基因(CAB,基因库登录号AB363403)的启动子和3'UTR。在用pSA106转化之前,极锐新月藻-瘦新月藻-沿岸新月藻复合体不能在包含3μg/ml脉霉素的培养基上繁殖。在用pSA106转化后,获得了在包含3μg/ml脉霉素的选择性培养介质中繁殖的极锐新月藻-瘦新月藻-沿岸新月藻复合体的转化体。ble基因产物在极锐新月藻-瘦新月藻-沿岸新月藻复合体中表达能够实现在3μg/ml脉霉素存在下进行繁殖,由此确定博莱霉素抗生素抗性盒作为可选择标记用于极锐新月藻-瘦新月藻-沿岸新月藻复合体的效用。稳定转化体的基因组DNA评估通过DNA杂交分析进行。如由亚伯报导,转化的极锐新月藻-瘦新月藻-沿岸新月藻复合体的选择和维持首先在顶级琼脂与C培养基(0.1g/LKNO3、0.015g/LCa(NO3)2·4H2O、0.05g/L甘油磷酸酯-Na2、0.04g/LMgSO4·7H2O、0.5g/L三(羟甲基)氨基甲烷、痕量矿物质、生物素、维生素B1和B12)中进行,并且接着,随后分离到包含补充有脉霉素的C培养基的琼脂板上。如由亚伯报导,极锐新月藻-瘦新月藻-沿岸新月藻复合体在液体培养物中的繁殖是在C培养基中进行的。适用于极锐新月藻-瘦新月藻-沿岸新月藻复合体繁殖的另外的液体培养介质由关本(Sekimoto)等人,《DNA研究》(DNAResearch),10:4(2003),第147-153页论述。亚伯报导了pSA106质粒以及极锐新月藻-瘦新月藻-沿岸新月藻复合体CAB基因的启动子和3'UTR适合于实现极锐新月藻-瘦新月藻-沿岸新月藻复合体中的异源性基因表达。另外,亚伯报导了在pSA106上编码的博莱霉素抗性盒适用于在极锐新月藻-瘦新月藻-沿岸新月藻复合体中用作可选择标记。已报导了适用于极锐新月藻-瘦新月藻-沿岸新月藻复合体中的异源性基因表达的另外的质粒、启动子、3'UTR/终止子以及可选择标记(参见亚伯等人,《植物细胞生理学》,第49卷(2008),第625-632页)。在本发明的一个实施例中,对载体pSA106(包含编码用作可选择标记的ble基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在极锐新月藻-瘦新月藻-沿岸新月藻复合体中表达根据表24A-D经过密码子优化以反映极锐新月藻-瘦新月藻-沿岸新月藻复合体核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的极锐新月藻-瘦新月藻-沿岸新月藻复合体CAB基因启动子并且在蛋白质编码序列的3'区或下游可操作地连接于极锐新月藻-瘦新月藻-沿岸新月藻复合体CAB基因3'UTR/终止子。转化构建体可以另外包含极锐新月藻-瘦新月藻-沿岸新月藻复合体基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化极锐新月藻-瘦新月藻-沿岸新月藻复合体通过熟知转化技术包括微粒轰击或其他已知方法实现。ble基因产物的活性可以被用作标记以在(但不限于)包含脉霉素的C培养基上选择经转化载体转化的极锐新月藻-瘦新月藻-沿岸新月藻复合体。适用于极锐新月藻-瘦新月藻-沿岸新月藻复合体脂质产生的生长培养基包括(但不限于)C培养基以及由亚伯等人和关本等人报导的那些培养介质。极锐新月藻-瘦新月藻-沿岸新月藻复合体脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例18:对绿色杜氏藻进行工程化根据本发明的重组基因在绿色杜氏藻中的表达可以通过修改由如在此论述的孙(Sun)等人传授的方法和载体来实现。简言之,孙等人,《基因》(Gene),第377卷(2006),第140-149页报导了用质粒DNA对绿色杜氏藻进行稳定转化。使用电穿孔的转化方法,孙将编码完整绿色杜氏藻硝酸盐还原酶基因的质粒pDVNR引入到突变绿色杜氏藻(绿色杜氏藻NR-突变株)中。NR-突变株不能在不使用硝酸盐作为氮来源的情况下生长。硝酸盐还原酶催化硝酸盐转化成亚硝酸盐。在转化之前,绿色杜氏藻NR-突变株不能在包含硝酸盐(NO3-)作为唯一氮源的培养基中繁殖。绿色杜氏藻NR基因产物在NR-突变株绿色杜氏藻中的表达被用作一种挽救硝酸盐代谢缺陷的可选择标记。在用pDVNR质粒转化后,获得了能够在包含硝酸盐作为唯一碳源的琼脂板上生长的稳定表达绿色杜氏藻NR基因产物的NR-突变株绿色杜氏藻。稳定转化体的DNA评估通过DNA杂交分析进行。转化的绿色杜氏藻(NR突变株)的选择和维持是在包含5mMKNO3的琼脂板上进行的。孙还报导了绿色杜氏藻和绿色杜氏藻NR突变株在液体培养介质中的繁殖。适用于绿色杜氏藻繁殖的另外的培养基由戈迪略(Gordillo)等人,《应用藻类学杂志》,第10卷:2(1998),第135-144页和莫尔顿(Moulton)和伯福德(Burford),《水生生物学》(Hydrobiologia),第204-205卷:1(1990),第401-408页报导。孙报导了质粒pDVNR以及绿色杜氏藻硝酸盐还原酶基因的启动子和3'UTR/终止子适合于实现绿色杜氏藻NR-突变株中的异源性表达。孙还报导了绿色杜氏藻硝酸盐还原酶基因产物的表达适用于在绿色杜氏藻NR-突变株中用作可选择标记。在本发明的一个实施例中,对载体pDVNR(包含编码用作可选择标记的绿色杜氏藻硝酸盐还原酶(DvNR)基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在绿色杜氏藻中表达根据表24A-D经过密码子优化以反映绿色杜氏藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的DvNR启动子并且在蛋白质编码序列的3'区或下游可操作地连接于DvNR3'UTR/终止子。转化构建体可以另外包含绿色杜氏藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化绿色杜氏藻NR突变株通过熟知转化技术包括电穿孔或其他已知方法实现。可以将DvNR基因产物的活性用作可选择标记以挽救绿色杜氏藻NR突变株系的氮同化缺陷并且选择稳定表达转化载体的绿色杜氏藻NR-突变株。适用于绿色杜氏藻脂质产生的生长培养基包括(但不限于)由孙等人、莫尔顿和伯福德以及戈迪略等人论述的那些。绿色杜氏藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例19:对盐生杜氏藻进行工程化根据本发明的重组基因在盐生杜氏藻中的表达可以通过修改由如在此论述的根格(Geng)等人传授的方法和载体来实现。简言之,根格等人,《应用藻类学杂志》,第15卷(2003),第451-456页报导了用质粒DNA对盐生杜氏藻进行稳定转化。使用电穿孔的转化方法,根格将pUΩHBsAg-CAT质粒引入到盐生杜氏藻中。pUΩHBsAg-CAT包含乙型肝炎表面抗原(HBsAG)表达盒,该表达盒包含编码乙型肝炎表面抗原的序列,该序列可操作地连接于HBsAG蛋白质编码区上游的玉米ubi1启动子并且可操作地连接于HBsAG蛋白质编码区下游的根癌农杆菌胭脂氨酸合成酶基因(nos)的3'UTR/终止子。pUΩHBsAg-CAT进一步包含氯霉素抗性盒,包含编码会赋予对抗生素氯霉素的抗性的氯霉素乙酰转移酶(CAT)基因产物的序列,该序列可操作地连接于猿猴病毒40启动子和增强子。在用pUΩHBsAg-CAT转化之前,盐生杜氏藻不能在包含60mg/L氯霉素的培养基上繁殖。在用pUΩHBsAg-CAT质粒转化后,获得了在包含60mg/L氯霉素的选择性培养基中繁殖的盐生杜氏藻的转化体。CAT基因产物在盐生杜氏藻中表达能够实现在60mg/L氯霉素存在下进行繁殖,由此确定氯霉素抗性盒作为可选择标记用于盐生杜氏藻的效用。HBsAg基因产物的可检测活性指示了ubi1启动子和nos3'UTR/终止子适用于实现盐生杜氏藻中的基因表达。稳定转化体的基因组DNA评估通过DNA杂交分析进行。根格报导了转化的盐生杜氏藻的选择和维持是在包含具有60mg/L氯霉素的约翰逊氏培养基(Johnson'smedium,J1,由博罗维兹卡(Borowitzka)和博罗维兹卡(编),《微藻生物技术》(Micro-algalBiotechnology),剑桥大学出版社,剑桥,第460-461页描述)上进行的。盐生杜氏藻的液体繁殖由根格在具有60mg/L氯霉素的J1培养基中进行。已论述了盐生杜氏藻在除J1培养基以外的培养基中的繁殖(参见芬(Feng)等人,《分子生物学报导》(Mol.Bio.Reports),第36卷(2009),第1433-1439页和博罗维兹卡等人,《水生生物学》,第116-117卷:1(1984),第115-121页)。适用于实现盐生杜氏藻中的异源性基因表达的另外的质粒、启动子、3'UTR/终止子以及可选择标记已由芬等人报导。根格报导了质粒pUΩHBsAg-CAT、ubi1启动子以及根癌农杆菌胭脂氨酸合成酶基因3'UTR/终止子适合于实现盐生杜氏藻中的外源性基因表达。另外,根格报导了在pUΩHBsAg-CAT上编码的CAT抗性盒适用于在盐生杜氏藻中用作可选择标记。在本发明的一个实施例中,对载体pUΩHBsAg-CAT(包含编码用作可选择标记的CAT基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在盐生杜氏藻中表达根据表24A-D经过密码子优化以反映盐生杜氏藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的ubi1启动子并且在蛋白质编码序列的3'区或下游可操作地连接于根癌农杆菌胭脂氨酸合成酶基因3'UTR/终止子。转化构建体可以另外包含盐生杜氏藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化盐生杜氏藻通过熟知转化技术包括电穿孔或其他已知方法实现。CAT基因产物的活性可以被用作可选择标记以在(但不限于)包含氯霉素的J1培养基中选择经转化载体转化的盐生杜氏藻。适用于盐生杜氏藻脂质产生的生长培养基包括(但不限于)J1培养基以及由芬等人和博罗维兹卡等人描述的那些培养介质。盐生杜氏藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例20:对胸状盘藻进行工程化根据本发明的重组基因在胸状盘藻中的表达可以通过修改由如在此论述的莱尔凯(Lerche)和霍曼等人传授的方法和载体来实现。简言之,莱尔凯和霍曼等人,《BMC生物技术》(BMCBiotechnology),第9卷:64,2009报导了用质粒DNA对胸状盘藻进行稳定核转化。使用微粒轰击的转化方法,莱尔凯将质粒pPmr3引入到胸状盘藻中。质粒pPmr3包含巴龙霉素抗性盒,包含编码用于对抗生素巴龙霉素的抗性的龟裂链霉菌(Streptomycesrimosus)的氨基糖苷3'-磷酸转移酶(aphVIII)基因产物(基因库登录号AAB03856)的序列,该序列可操作地连接于aphVIII蛋白质编码区上游的强壮团藻hsp70A-rbcS3杂合启动子并且可操作地连接于aphVIII蛋白质编码区下游的强壮团藻rbcS3基因的3'UTR/终止子。在用pPmr3转化之前,胸状盘藻不能在包含0.06μg/ml巴龙霉素的培养基上繁殖。在用pPmr3转化后,获得了在包含0.75μg/ml和更多巴龙霉素的选择性培养介质中繁殖的胸状盘藻的转化体。aphVIII基因产物在胸状盘藻中表达能够实现在0.75μg/ml和更多巴龙霉素存在下进行繁殖,由此确定巴龙霉素抗生素抗性盒作为可选择标记用于胸状盘藻的效用。稳定转化体的基因组DNA评估通过DNA杂交分析进行。莱尔凯和霍曼报导了转化的胸状盘藻的选择和维持是在具有1.0μg/ml巴龙霉素的液体贾沃斯基氏培养基(Jaworski'smedium,20mg/LCa(NO3)2·4H2O、12.4mg/LKH2PO4、50mg/LMgSO4·7H2O、15.9mg/LNaHCO3、2.25mg/LEDTA-FeNa、2.25mg/LEDTANa2、2.48g/LH3BO3、1.39g/LMnCl2.4H2O、1mg/L(NH4)6MO7O24.4H2O、0.04mg/L维生素B12、0.04mg/L硫胺素-盐酸盐、0.04mg/L生物素、80mg/LNaNO3、36mg/LNa4HPO4.12H2O)中进行的。适用于实现胸状盘藻中的异源性基因表达的另外的质粒、启动子、3'UTR/终止子以及可选择标记由莱尔凯和霍曼进一步论述。莱尔凯和霍曼报导了质粒pPmr3、强壮团藻hsp70A-rbcS3杂合启动子以及强壮团藻rbcS3基因的3'UTR/终止子适合于实现胸状盘藻中的外源性基因表达。另外,莱尔凯和霍曼报导了编码pPmr3的巴龙霉素抗性盒适用于在胸状盘藻中用作可选择标记。在本发明的一个实施例中,对载体pPmr3(包含编码用作可选择标记的aphVIII基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在胸状盘藻中表达根据表24A-D经过密码子优化以反映胸状盘藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的强壮团藻hsp70A-rbcS3杂合启动子并且在蛋白质编码序列的3'区或下游可操作地连接于强壮团藻rbcS3基因3'UTR/终止子。转化构建体可以另外包含胸状盘藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化胸状盘藻可以通过熟知转化技术包括微粒轰击或其他已知方法实现。aphVIII基因产物的活性可以被用作可选择标记以在(但不限于)包含巴龙霉素的贾沃斯基氏培养基中选择经转化载体转化的胸状盘藻。适用于胸状盘藻脂质产生的生长培养基包括贾沃斯基氏培养基和由斯太因(Stein),《美国植物学杂志》(AmericanJournalofBotany),第45卷:9(1958),第664-672页报导的培养基。胸状盘藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例21:对三角褐指藻进行工程化根据本发明的重组基因在三角褐指藻中的表达可以通过修改由如在此论述的艾普特(Apt)等人传授的方法和载体来实现。简言之,艾普特等人,《分子遗传学与普通遗传学》(MolecularandGeneralGenetics),第252卷(1996),第572-579页报导了用载体DNA对三角褐指藻进行稳定核转化。使用微粒轰击的转化技术,艾普特将质粒pfcpA引入到三角褐指藻中。质粒pfcpA包含博莱霉素抗性盒,包含编码用于对抗生素脉霉素和博莱霉素的抗性的印度斯坦链异壁菌博莱霉素结合蛋白(ble)的序列,该序列可操作地连接于ble蛋白质编码区上游的三角褐指藻岩藻黄质叶绿素a结合蛋白基因(fcpA)的启动子并且可操作地连接于在ble蛋白质编码区3'区或下游的三角褐指藻fcpA基因的3'UTR/终止子。在用pfcpA转化之前,三角褐指藻不能在包含50μg/ml博莱霉素的培养基上繁殖。在用pfcpA转化后,获得了在包含50μg/ml博莱霉素的选择性培养介质中繁殖的三角褐指藻的转化体。ble基因产物在三角褐指藻中表达能够实现在50μg/ml博莱霉素存在下进行繁殖,由此确定博莱霉素抗生素抗性盒作为可选择标记用于三角褐指藻的效用。稳定转化体的基因组DNA评估通过DNA杂交分析进行。艾普特报导了转化的三角褐指藻的选择和维持是在包含具有50mg/L博莱霉素的LDM培养基(如由斯塔尔和泽克斯(Zeikus),《藻类学杂志》,第29卷,增刊,(1993))的琼脂板上进行的。艾普特报导了三角褐指藻转化体在具有50mg/L博莱霉素的LDM培养基中的液体繁殖。已论述了三角褐指藻在除LDM培养基以外的培养基中的繁殖(由扎斯拉夫斯卡亚(Zaslavskaia)等人,《科学》,第292卷(2001)第2073-2075页,和由拉多克维兹(Radokovits)等人,《代谢工程化》(MetabolicEngineering),第13卷(2011),第89-95页)。适用于实现三角褐指藻中的异源性基因表达的另外的质粒、启动子、3'UTR/终止子以及可选择标记已由艾普特等人、扎斯拉夫斯卡亚等人以及拉多克维兹等人在同一报导中加以报导。艾普特报导了质粒pfcpA和三角褐指藻fcpA启动子和3'UTR/终止子适合于实现三角褐指藻中的外源性基因表达。另外,艾普特报导了在pfcpA上编码的博莱霉素抗性盒适用于在三角褐指藻中用作可选择标记。在本发明的一个实施例中,对载体pfcpA(包含编码用作可选择标记的ble基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在三角褐指藻中表达根据表24A-D经过密码子优化以反映三角褐指藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的三角褐指藻fcpA基因启动子并且在蛋白质编码序列的3'区或下游可操作地连接于三角褐指藻fcpA基因3'UTR/终止子。转化构建体可以另外包含三角褐指藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。本领域普通技术人员可以在三角褐指藻基因组序列内鉴别出这些同源区(在鲍勒(Bowler)等人,《自然》(Nature),第456卷(2008),第239-244页的出版物中提及)。用转化载体稳定转化三角褐指藻通过熟知转化技术包括微粒轰击或其他已知方法实现。ble基因产物的活性可以被用作标记以在(但不限于)包含巴龙霉素的LDM培养基中选择经转化载体转化的三角褐指藻。适用于三角褐指藻脂质产生的生长培养基包括(但不限于)如由拉多克维兹等人报导的f/2培养基。三角褐指藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例22:对角刺藻属进行工程化根据本发明的重组基因在角刺藻属中的表达可以通过修改由如在此论述的山口(Yamaguchi)等人传授的方法和载体来实现。简言之,山口等人,《海藻研究》(PhycologicalResearch),第59卷:2(2011),第113-119页报导了用质粒DNA对角刺藻属进行稳定核转化。使用微粒轰击的转化方法,山口将质粒pTpfcp/nat引入到角刺藻属中。pTpfcp/nat包含诺尔丝菌素抗性盒,包含编码诺尔丝菌素乙酰基转移酶(nat)基因产物(基因库登录号AAC60439)的序列,该序列可操作地连接于nat蛋白质编码区上游的假微型海链藻岩藻黄质叶绿素a/c结合蛋白基因(fcp)启动子并且可操作地连接于在3'区(nat蛋白质编码序列下游)的假微型海链藻fcp基因3'UTR/终止子。nat基因产物赋予对抗生素诺尔丝菌素的抗性。在用pTpfcp/nat转化之前,角刺藻属不能在包含500μg/ml诺尔丝菌素的培养基上繁殖。在用pTpfcp/nat转化后,获得了在包含500μg/ml诺尔丝菌素的选择性培养介质中繁殖的角刺藻属的转化体。nat基因产物在角刺藻属中表达能够实现在500μg/ml诺尔丝菌素存在下进行繁殖,由此确定诺尔丝菌素抗生素抗性盒作为可选择标记用于角刺藻属的效用。稳定转化体的基因组DNA评估通过DNA杂交分析进行。山口报导了转化的角刺藻属的选择和维持是在包含具有500μg/ml诺尔丝菌素的f/2培养基(如由吉拉尔R.R.(Guilard,R.R.),用于饲喂海洋无脊椎动物的浮游植物的培养(CultureofPhytoplanktonforfeedingmarineinvertebrates),《海洋无脊椎动物的培养》(CultureofMarineInvertebrateAnimals),史密斯和畅利(Chanley)(编)1975,普莱纽姆出版社(PlenumPress),纽约,第26-60页)的琼脂板上进行的。如由山口进行的角刺藻属转化体的液体繁殖是在具有500mg/L诺尔丝菌素的f/2培养基中进行的。已报导了角刺藻属在另外的培养介质中的繁殖(例如纳波利塔诺(Napolitano)等人,《世界水产业协会杂志》(JournaloftheWorldAquacultureSociety),第21卷:2(1990),第122-130页和沃克曼(Volkman)等人,《实验海洋生物学和生态学杂志》(JournalofExperimentalMarineBiologyandEcology),第128卷:3(1989),第219-240页)。适用于实现角刺藻属中的异源性基因表达的另外的质粒、启动子、3'UTR/终止子以及可选择标记已由山口等人在同一报导中加以报导。山口报导了质粒pTpfcp/nat和假微型海链藻fcp启动子和3'UTR/终止子适合于实现角刺藻属中的外源性基因表达。另外,山口报导了在pTpfcp/nat上编码的诺尔丝菌素抗性盒适用于在角刺藻属中用作可选择标记。在本发明的一个实施例中,对载体pTpfcp/nat(包含编码用作可选择标记的nat基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在密切相关的扁面角刺藻中表达根据表24A-D经过密码子优化以反映扁面角刺藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的假微型海链藻fcp基因启动子并且在蛋白质编码序列的3'区或下游可操作地连接于假微型海链藻fcp基因3'UTR/终止子。转化构建体可以另外包含角刺藻属基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化角刺藻属通过熟知转化技术包括微粒轰击或其他已知方法实现。nat基因产物的活性可以被用作可选择标记以在(但不限于)包含诺尔丝菌素的f/2琼脂培养基中选择经转化载体转化的角刺藻属。适用于角刺藻属脂质产生的生长培养基包括(但不限于)f/2培养基以及由纳波利塔诺等人和沃克曼等人论述的那些培养介质。角刺藻属脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例23:对筒柱藻进行工程化根据本发明的重组基因在筒柱藻中的表达可以通过修改由如在此论述的波尔森(Poulsen)和克罗格(Kroger)等人传授的方法和载体来实现。简言之,波尔森和克罗格等人,《FEBS杂志》(FEBSJournal),第272卷(2005),第3413-3423页报导了用质粒DNA对筒柱藻进行转化。使用微粒轰击的转化方法,波尔森和克罗格将pCF-ble质粒引入到筒柱藻中。质粒pCF-ble包含博莱霉素抗性盒,包含编码用于对抗生素博莱霉素和脉霉素的抗性的印度斯坦链异壁菌博莱霉素结合蛋白(ble)的序列,该序列可操作地连接于ble蛋白质编码区上游的筒柱藻岩藻黄素叶绿素a/c结合蛋白基因(fcpA,基因库登录号AY125580)启动子并且可操作地连接于在3'区(ble蛋白质编码区的下游)的筒柱藻fcpA基因3'UTR/终止子。在用pCF-ble转化之前,筒柱藻不能在包含1mg/ml博莱霉素的培养基上繁殖。在用pCF-ble转化后,获得了在包含1mg/ml博莱霉素的选择性培养介质中繁殖的筒柱藻的转化体。ble基因产物在筒柱藻中表达能够实现在1mg/ml博莱霉素存在下进行繁殖,由此确定博莱霉素抗生素抗性盒作为可选择标记用于筒柱藻的效用。波尔森和克罗格报导了转化的筒柱藻的选择和维持是在包含具有1mg/ml博莱霉素的人造海水培养基的琼脂板上进行的。波尔森和克罗格报导了筒柱藻转化体在具有1mg/ml博莱霉素的人造海水培养基中的液体繁殖。已论述了筒柱藻在另外的培养介质中的繁殖(例如梁(Liang)等人,《应用藻类学杂志》,第17卷:1(2005),第61-65页和奥克特(Orcutt)和帕特森,《脂质》,第9卷:12(1974),第1000-1003页)。适用于实现角刺藻属中的异源性基因表达的另外的质粒、启动子以及3'UTR/终止子已由波尔森和克罗格在同一报导中加以报导。波尔森和克罗格报导了质粒pCF-ble和筒柱藻fcp启动子和3'UTR/终止子适合于实现筒柱藻中的外源性基因表达。另外,波尔森和克罗格报导了在pCF-ble上编码的博莱霉素抗性盒适用于在筒柱藻中用作可选择标记。在本发明的一个实施例中,对载体pCF-ble(包含编码用作可选择标记的ble基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在筒柱藻中表达根据表24A-D经过密码子优化以反映筒柱藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的筒柱藻fcp基因启动子并且在蛋白质编码序列的3'区或下游可操作地连接于筒柱藻fcp基因3'UTR/终止子。转化构建体可以另外包含筒柱藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化筒柱藻通过熟知转化技术包括微粒轰击或其他已知方法实现。ble基因产物的活性可以被用作可选择标记以在(但不限于)包含博莱霉素的人造海水琼脂培养基中选择经转化载体转化的筒柱藻。适用于筒柱藻脂质产生的生长培养基包括(但不限于)人造海水以及由梁等人以及奥克特和帕特森报导的那些培养基。筒柱藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例24:对前沟藻属进行工程化根据本发明的重组基因在前沟藻属中的表达可以通过修改由如在此论述的滕路易斯(tenLohuis)和米勒(Miller)等人传授的方法和载体来实现。简言之,滕路易斯和米勒等人,《植物杂志》,第13卷:3(1998),第427-435页报导了用质粒DNA对前沟藻属进行稳定转化。使用在碳化硅晶须存在下搅动的转化技术,滕路易斯将质粒pMTNPT/GUS引入到前沟藻属中。pMTNPT/GUS包含新霉素抗性盒,包含编码新霉素磷酸转移酶II(nptII)基因产物(基因库登录号AAL92039)的序列,该序列可操作地连接于nptII蛋白质编码区的上游或5'的根癌农杆菌胭脂氨酸合成酶(nos)基因启动子并且可操作地连接于在3'区(nptII蛋白质编码区的下游)的nos基因的3'UTR/终止子。nptII基因产物赋予对抗生素G418的抗性。pMTNPT/GUS质粒进一步包含编码β-葡萄糖醛酸酶(GUS)报导基因产物的序列,该序列可操作地连接于CaMV35S启动子并且进一步可操作地连接于CaMV35S3'UTR/终止子。在用pMTNPT/GUS转化之前,前沟藻属不能在包含3mg/mlG418的培养基上繁殖。在用pMTNPT/GUS转化后,获得了在包含3mg/mlG418的选择性培养介质中繁殖的前沟藻属的转化体。nptII基因产物在前沟藻属中表达能够实现在3mg/mlG418存在下进行繁殖,由此确定新霉素抗生素抗性盒作为可选择标记用于前沟藻属的效用。GUS报导基因的可检测活性指示了CaMV35S启动子和3'UTR适用于实现前沟藻属中的基因表达。稳定转化体的基因组DNA评估通过DNA杂交分析进行。滕路易斯和米勒报导了前沟藻属转化体在补充有F/2富集溶液(由供应商西格玛公司(Sigma)提供)和3mg/mlG418的包含海水的培养基中的液体繁殖以及前沟藻属转化体在补充有F/2富集溶液和3mg/mlG418的包含海水的琼脂培养基上的选择和维持。已报导了前沟藻属在另外的培养介质中的繁殖(例如曼苏尔(Mansour)等人,《应用藻类学杂志》,第17卷:4(2005)第287-v300页。用于实现前沟藻属中的异源性基因表达的另外的质粒(包含另外的启动子、3'UTR/终止子以及可选择标记)已由滕路易斯和米勒在同一报导中加以报导。滕路易斯和米勒报导了质粒pMTNPT/GUS以及nos和CaMV35S基因的启动子和3'UTR/终止子适合于实现前沟藻属中的外源性基因表达。另外,滕路易斯和米勒报导了在pMTNPT/GUS上编码的新霉素抗性盒适用于在前沟藻属中用作可选择标记。在本发明的一个实施例中,对载体pMTNPT/GUS(包含编码用作可选择标记的nptII基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在前沟藻属中表达根据表24A-D经过密码子优化以反映密切相关的物种强壮前沟藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的根癌农杆菌胭脂氨酸合成酶(nos)基因启动子并且在蛋白质编码序列的3'区或下游可操作地连接于nos3'UTR/终止子。转化构建体可以另外包含前沟藻属基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化前沟藻属通过熟知转化技术包括硅纤维介导的显微注射或其他已知方法实现。nptII基因产物的活性可以被用作可选择标记以在(但不限于)包含G418的海水琼脂培养基中选择经转化载体转化的前沟藻属。适用于前沟藻属脂质产生的生长培养基包括(但不限于)人造海水以及由曼苏尔等人以及滕路易斯和米勒报导的那些培养基。前沟藻属脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例25:对小亚德里亚共生藻进行工程化根据本发明的重组基因在小亚德里亚共生藻中的表达可以通过修改由如在此论述的滕路易斯和米勒等人传授的方法和载体来实现。简言之,滕路易斯和米勒等人,《植物杂志》,第13卷:3(1998),第427-435页报导了用质粒DNA对小亚德里亚共生藻进行稳定转化。使用硅纤维介导的显微注射的转化技术,滕路易斯将质粒pMTNPT/GUS引入到小亚德里亚共生藻中。pMTNPT/GUS包含新霉素抗性盒,包含编码新霉素磷酸转移酶II(nptII)基因产物(基因库登录号AAL92039)的序列,该序列可操作地连接于nptII蛋白质编码区的上游或5'的根癌农杆菌胭脂氨酸合成酶(nos)基因启动子并且可操作地连接于在3'区(nptII蛋白质编码区的下游)的nos基因的3'UTR/终止子。nptII基因产物赋予对抗生素G418的抗性。pMTNPT/GUS质粒进一步包含编码β-葡萄糖醛酸酶(GUS)报导基因产物的序列,该序列可操作地连接于CaMV35S启动子并且进一步可操作地连接于CaMV35S3'UTR/终止子。在用pMTNPT/GUS转化之前,小亚德里亚共生藻不能在包含3mg/mlG418的培养基上繁殖。在用pMTNPT/GUS转化后,获得了在包含3mg/mlG418的选择性培养介质中繁殖的小亚德里亚共生藻的转化体。nptII基因产物在小亚德里亚共生藻中表达能够实现在3mg/mlG418存在下进行繁殖,由此确定新霉素抗生素抗性盒作为可选择标记用于小亚德里亚共生藻的效用。GUS报导基因的可检测活性指示了CaMV35S启动子和3'UTR适用于实现小亚德里亚共生藻中的基因表达。稳定转化体的基因组DNA评估通过DNA杂交分析进行。滕路易斯和米勒报导了小亚德里亚共生藻转化体在补充有F/2富集溶液(由供应商西格玛公司(Sigma)提供)和3mg/mlG418的包含海水的培养基中的液体繁殖以及小亚德里亚共生藻转化体在补充有F/2富集溶液和3mg/mlG418的包含海水的琼脂培养基上的选择和维持。已论述了小亚德里亚共生藻在另外的培养介质中的繁殖(例如伊格莱希亚斯-普列托(Iglesias-Prieto)等人,《国家科学院的论文集》,第89卷:21(1992)第10302-10305页)。用于实现小亚德里亚共生藻中的异源性基因表达的另外的质粒(包含另外的启动子、3'UTR/终止子以及可选择标记)已由滕路易斯和米勒在同一报导中加以论述。滕路易斯和米勒报导了质粒pMTNPT/GUS以及nos和CaMV35S基因的启动子和3'UTR/终止子适合于实现小亚德里亚共生藻中的外源性基因表达。另外,滕路易斯和米勒报导了在pMTNPT/GUS上编码的新霉素抗性盒适用于在小亚德里亚共生藻中用作可选择标记。在本发明的一个实施例中,对载体pMTNPT/GUS(包含编码用作可选择标记的nptII基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在小亚德里亚共生藻中表达根据表24A-D经过密码子优化以反映小亚德里亚共生藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的根癌农杆菌胭脂氨酸合成酶(nos)基因启动子并且在蛋白质编码序列的3'区或下游可操作地连接于nos3'UTR/终止子。转化构建体可以另外包含小亚德里亚共生藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化小亚德里亚共生藻通过熟知转化技术包括硅纤维介导的显微注射或其他已知方法实现。nptII基因产物的活性可以被用作可选择标记以在(但不限于)包含G418的海水琼脂培养基中选择经转化载体转化的小亚德里亚共生藻。适用于小亚德里亚共生藻脂质产生的生长培养基包括(但不限于)人造海水以及由伊格莱希亚斯-普列托等人以及滕路易斯和米勒报导的那些培养基。小亚德里亚共生藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例26:对微拟球藻属进行工程化根据本发明的重组基因在微拟球藻属W2J3B中的表达可以通过修改由如在此论述的基利恩(Kilian)等人传授的方法和载体来实现。简言之,基利恩等人,《国家科学院的论文集》,第108卷:52(2011)第21265-21269页报导了用转化构建体对微拟球藻进行稳定核转化。使用电穿孔的转化方法,基利恩将转化构建体C2引入到微拟球藻属W2J3B中。C2转化构建体包含博莱霉素抗性盒,包含用于对抗生素脉霉素和博莱霉素的抗性的印度斯坦链异壁菌博莱霉素结合蛋白(ble)的编码序列,该序列可操作地连接于ble蛋白质编码区上游的微拟球藻属W2J3B堇菜黄质/叶绿素a结合蛋白基因VCP2的启动子并且可操作地连接于ble蛋白质编码区下游的微拟球藻属W2J3B堇菜黄质/叶绿素a结合基因VCP1的3'UTR/终止子。在用C2转化之前,微拟球藻属W2J3B不能在包含2μg/ml博莱霉素的培养基上繁殖。在用C2转化后,获得了在包含2μg/ml博莱霉素的选择性培养介质中繁殖的微拟球藻属W2J3B的转化体。ble基因产物在微拟球藻属W2J3B中表达能够实现在2μg/ml博莱霉素存在下进行繁殖,由此确定博莱霉素抗生素抗性盒作为可选择标记用于微拟球藻的效用。稳定转化体的基因组DNA评估通过PCR进行。基利恩报导了微拟球藻属W2J3B转化体在包含五倍水平的痕量金属、维生素以及磷酸盐溶液并且进一步包含2μg/ml博莱霉素的F/2培养基(由吉拉尔和赖瑟(Ryther),《加拿大微生物学杂志》(CanadianJournalofMicrobiology),第8卷(1962),第229-239页)中的液体繁殖。基利恩还报导了微拟球藻属W2J3B转化体在包含人造海水2mg/ml博莱霉素的F/2培养基上的选择和维持。已论述了微拟球藻在另外的培养介质中的繁殖(例如赵(Chiu)等人,《生物资源技术》(BioresourTechnol.),第100卷:2(2009),第833-838页和帕耳(Pal)等人,《应用微生物学和生物技术》(AppliedMicrobiologyandBiotechnology),第90卷:4(2011),第1429-1441页)。用于实现微拟球藻属W2J3B中的异源性基因表达的另外的转化构建体(包含另外的启动子和3'UTR/终止子)以及用于选择转化体的可选择标记已由基利恩在同一报告中加以描述。基利恩报导了转化构建体C2和微拟球藻属W2J3B堇菜黄质/叶绿素a结合蛋白基因VCP2的启动子以及微拟球藻属W2J3B堇菜黄质/叶绿素a结合蛋白基因VCP1的3'UTR/终止子适合于实现微拟球藻属W2J3B中的外源性基因表达。另外,基利恩报导了在C2上编码的博莱霉素抗性盒适用于在微拟球藻属W2J3B中用作可选择标记。在本发明的一个实施例中,对转化构建体C2(包含编码用作可选择标记的ble基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在微拟球藻属W2J3B中表达根据表24A-D经过密码子优化以反映微拟球藻属核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的微拟球藻属W2J3BVCP2基因启动子并且在蛋白质编码序列的3'区或下游可操作地连接于微拟球藻属W2J3BVCP1基因3'UTR/终止子。转化构建体可以另外包含微拟球藻属W2J3B基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化微拟球藻属W2J3B通过熟知转化技术包括电穿孔或其他已知方法实现。ble基因产物的活性可以被用作可选择标记以在(但不限于)包含博莱霉素的F/2培养基中选择经转化载体转化的微拟球藻属W2J3B。适用于微拟球藻属W2J3B脂质产生的生长培养基包括(但不限于)F/2培养基以及由赵等人和帕耳等人报导的那些培养基。微拟球藻属W2J3B脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例27:对隐蔽小环藻进行工程化根据本发明的重组基因在隐蔽小环藻中的表达可以通过修改由如在此论述的都纳希(Dunahay)等人传授的方法和载体来实现。简言之,都纳希等人,《藻类学杂志》,第31卷(1995),第1004-1012页报导了用质粒DNA对隐蔽小环藻进行稳定转化。使用微粒轰击的转化方法,都纳希将质粒pACCNPT5.1引入到隐蔽小环藻中。质粒pACCNPT5.1包含新霉素抗性盒,包含新霉素磷酸转移酶II(nptII)基因产物的编码序列,该序列可操作地连接于nptII编码区上游的隐蔽小环藻乙酰基-CoA羧化酶(ACC酶)基因(基因库登录号L20784)的启动子并且在3'区(nptII编码区的下游)可操作地连接于隐蔽小环藻ACC酶基因的3'UTR/终止子。nptII基因产物赋予对抗生素G418的抗性。在用pACCNPT5.1转化之前,隐蔽小环藻不能在包含100μg/mlG418的50%人造海水培养基上繁殖。在用pACCNPT5.1转化后,获得了在包含100μg/mlG418的选择性50%人造海水培养基中繁殖的隐蔽小环藻的转化体。nptII基因产物在隐蔽小环藻中表达能够实现在100μg/mlG418存在下进行繁殖,由此确定新霉素抗生素抗性盒作为可选择标记用于隐蔽小环藻的效用。稳定转化体的基因组DNA评估通过DNA杂交分析进行。都纳希报导了隐蔽小环藻在补充有1.07mM硅酸钠和100μg/mlG418的人造海水培养基(ASW,如由布朗L(Brown,L.),《藻类学》(Phycologia),第21卷(1982),第408-410页论述)中的液体繁殖。都纳希还报导了隐蔽小环藻转化体在包含具有100μg/mlG418的ASW培养基的琼脂板上的选择和维持。已论述了隐蔽小环藻在另外的培养介质中的繁殖(例如斯瑞哈兰(Sriharan)等人,《应用生物化学与生物技术》(AppliedBiochemistryandBiotechnology),第28-29卷:1(1991),第317-326页和帕尔(Pahl)等人,《生物科学和生物工程杂志》,第109卷:3(2010),第235-239页)。都纳希报导了质粒pACCNPT5.1和隐蔽小环藻乙酰基-CoA羧化酶(ACC酶)基因的启动子适合于实现隐蔽小环藻中的外源性基因表达。另外,都纳希报导了在pACCNPT5.1上编码的新霉素抗性盒适用于在隐蔽小环藻中用作可选择标记。在本发明的一个实施例中,对载体pACCNPT5.1(包含编码用作可选择标记的nptII基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在隐蔽小环藻中表达根据表24A-D经过密码子优化以反映隐蔽小环藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的隐蔽小环藻ACC酶启动子并且在蛋白质编码序列的3'区或下游可操作地连接于隐蔽小环藻ACC酶3'UTR/终止子。转化构建体可以另外包含隐蔽小环藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化隐蔽小环藻通过熟知转化技术包括微粒轰击或其他已知方法实现。nptII基因产物的活性可以被用作标记以在(但不限于)包含G418的琼脂ASW培养基中选择经转化载体转化的隐蔽小环藻。适用于隐蔽小环藻脂质产生的生长培养基包括(但不限于)ASW培养基以及由斯瑞哈兰等人,1991和帕耳等人报导的那些培养基。隐蔽小环藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例28:对嗜腐舟形藻进行工程化根据本发明的重组基因在嗜腐舟形藻中的表达可以通过修改由如在此论述的都纳希(Dunahay)等人传授的方法和载体来实现。简言之,都纳希等人,《藻类学杂志》,第31卷(1995),第1004-1012页报导了用质粒DNA对嗜腐舟形藻进行稳定转化。使用微粒轰击的转化方法,都纳希将质粒pACCNPT5.1引入到嗜腐舟形藻中。质粒pACCNPT5.1包含新霉素抗性盒,包含新霉素磷酸转移酶II(nptII)基因产物的编码序列,该序列可操作地连接于nptII编码区上游的隐蔽小环藻乙酰基-CoA羧化酶(ACC酶)基因(基因库登录号L20784)的启动子并且在3'区(nptII编码区的下游)可操作地连接于隐蔽小环藻ACC酶基因的3'UTR/终止子。nptII基因产物赋予对抗生素G418的抗性。在用pACCNPT5.1转化之前,嗜腐舟形藻不能在包含100μg/mlG418的人造海水培养基上繁殖。在用pACCNPT5.1转化后,获得了在包含100μg/mlG418的选择性人造海水培养基中繁殖的嗜腐舟形藻的转化体。nptII基因产物在嗜腐舟形藻中表达能够实现在G418存在下进行繁殖,由此确定新霉素抗生素抗性盒作为可选择标记用于嗜腐舟形藻的效用。稳定转化体的基因组DNA评估通过DNA杂交分析进行。都纳希报导了嗜腐舟形藻在补充有1.07mM硅酸钠和100μg/mlG418的人造海水培养基(ASW,如由布朗L(Brown,L.),《藻类学》,第21卷(1982),第408-410页论述)中的液体繁殖。都纳希还报导了嗜腐舟形藻转化体在包含具有100μg/mlG418的ASW培养基的琼脂板上的选择和维持。已论述了嗜腐舟形藻在另外的培养介质中的繁殖(例如塔德罗斯(Tadros)和约翰森(Johansen),《藻类学杂志》,第24卷:4(1988),第445-452页和斯瑞哈兰等人,《应用生物化学与生物技术》,第20-21卷:1(1989),第281-291页)。都纳希报导了质粒pACCNPT5.1和隐蔽小环藻乙酰基-CoA羧化酶(ACC酶)基因的启动子适合于实现嗜腐舟形藻中的外源性基因表达。另外,都纳希报导了在pACCNPT5.1上编码的新霉素抗性盒适用于在嗜腐舟形藻中用作可选择标记。在本发明的一个实施例中,对载体pACCNPT5.1(包含编码用作可选择标记的nptII基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在嗜腐舟形藻中表达根据表24A-D经过密码子优化以反映密切相关的薄膜舟形藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的隐蔽小环藻ACC酶基因启动子并且在蛋白质编码序列的3'区或下游可操作地连接于隐蔽小环藻ACC酶基因3'UTR/终止子。转化构建体可以另外包含嗜腐舟形藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。用转化载体稳定转化嗜腐舟形藻通过熟知转化技术包括微粒轰击或其他已知方法实现。nptII基因产物的活性可以被用作可选择标记以在(但不限于)包含G418的琼脂ASW培养基中选择经转化载体转化的嗜腐舟形藻。适用于嗜腐舟形藻脂质产生的生长培养基包括(但不限于)ASW培养基以及由斯瑞哈兰等人1989以及塔德罗斯和约翰森报导的那些培养基。嗜腐舟形藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例29:对假微型海链藻进行工程化根据本发明的重组基因在假微型海链藻中的表达可以通过修改由如在此论述的波尔森(Poulsen)等人传授的方法和载体来实现。简言之,波尔森等人,《藻类学杂志》,第42卷(2006),第1059-1065页报导了用质粒DNA对假微型海链藻进行稳定转化。使用微粒轰击的转化方法,波尔森将质粒pTpfcp/nat引入到假微型海链藻中。pTpfcp/nat包含诺尔丝菌素抗性盒,包含编码诺尔丝菌素乙酰基转移酶(nat)基因产物(基因库登录号AAC60439)的序列,该序列可操作地连接于nat蛋白质编码区上游的假微型海链藻岩藻黄质叶绿素a/c结合蛋白基因(fcp)启动子并且可操作地连接于在3'区(nat蛋白质编码序列下游)的假微型海链藻fcp基因3'UTR/终止子。nat基因产物赋予对抗生素诺尔丝菌素的抗性。在用pTpfcp/nat转化之前,假微型海链藻不能在包含10μg/ml诺尔丝菌素的培养基上繁殖。在用pTpfcp/nat转化后,获得了在包含100μg/ml诺尔丝菌素的选择性培养介质中繁殖的假微型海链藻的转化体。nat基因产物在假微型海链藻中表达能够实现在100μg/ml诺尔丝菌素存在下进行繁殖,由此确定诺尔丝菌素抗生素抗性盒作为可选择标记用于假微型海链藻的效用。稳定转化体的基因组DNA评估通过DNA杂交分析进行。波尔森报导了转化的假微型海链藻的选择和维持是在包含具有100μg/ml诺尔丝菌素的改良的ESAW培养基(如由哈里森(Harrison)等人,《藻类学杂志》,第16卷(1980),第28-35页论述)的液体培养物中进行的。已论述了假微型海链藻在另外的培养介质中的繁殖(例如沃克曼等人,《实验海洋生物学和生态学杂志》,第128卷:3(1989),第219-240页)。适用于假微型海链藻的另外的质粒(包含另外的可选择标记)已由波尔森在同一报导中加以论述。波尔森报导了质粒pTpfcp/nat和假微型海链藻fcp启动子和3'UTR/终止子适合于实现假微型海链藻中的外源性基因表达。另外,波尔森报导了在pTpfcp/nat上编码的诺尔丝菌素抗性盒适用于在假微型海链藻中用作可选择标记。在本发明的一个实施例中,对载体pTpfcp/nat(包含编码用作可选择标记的nat基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在假微型海链藻中表达根据表24A-D经过密码子优化以反映假微型海链藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的假微型海链藻fcp基因启动子并且在蛋白质编码序列的3'区或下游可操作地连接于假微型海链藻fcp基因3'UTR/终止子。转化构建体可以另外包含假微型海链藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。本领域普通技术人员可以在假微型海链藻基因组序列内鉴别出这些同源区(在阿姆勃路斯特(Armbrust)等人,《科学》,第306卷:5693(2004):第79-86页的出版物中提及)。用转化载体稳定转化假微型海链藻通过熟知转化技术包括微粒轰击或其他已知方法实现。nat基因产物的活性可以被用作标记以在(但不限于)包含诺尔丝菌素的ESAW琼脂培养基中选择经转化载体转化的假微型海链藻。适用于假微型海链藻脂质产生的生长培养基包括(但不限于)ESAW培养基以及由沃克曼等人和哈里森等人论述的那些培养介质。假微型海链藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例30:对莱茵衣藻进行工程化根据本发明的重组基因在莱茵衣藻中的表达可以通过修改由如在此论述的切鲁蒂(Cerutti)等人传授的方法和载体来实现。简言之,切鲁蒂等人,《遗传学》,第145卷:1(1997),第97-110页报导了用转化载体对莱茵衣藻进行稳定核转化。使用微粒轰击的转化方法,切鲁蒂将转化构建体P[1030]引入到莱茵衣藻中。构建体P[1030]包含壮观霉素抗性盒,包含编码氨基葡糖苷3″-腺嘌呤转移酶(aadA)基因产物的序列,该序列可操作地连接于aadA蛋白质编码区上游的莱茵衣藻核酮糖-1,5-二磷酸羧化酶/加氧酶小亚基基因(RbcS2,基因库登录号X04472)启动子并且在3'区(aadA蛋白质编码序列的下游)可操作地连接于莱茵衣藻RbcS2基因3'UTR/终止子。aadA基因产物赋予对抗生素壮观霉素的抗性。在用P[1030]转化之前,莱茵衣藻不能在包含90μg/ml壮观霉素的培养基上繁殖。在用P[1030]转化后,获得了在包含90μg/ml壮观霉素的选择性培养介质中繁殖的莱茵衣藻的转化体,由此确定壮观霉素抗生素抗性盒作为可选择标记用于莱茵衣藻的效用。稳定转化体的基因组DNA评估通过DNA杂交分析进行。切鲁蒂报导了转化的莱茵衣藻的选择和维持是在包含具有90μg/ml壮观霉素的Tris-乙酸盐-磷酸盐培养基(TAP,如由哈里斯(Harris),《衣藻原始资料》(TheChlamydomonasSourcebook),学术出版社,圣地牙哥,1989描述)的琼脂板上进行的。切鲁蒂另外报导了莱茵衣藻在具有90μg/ml壮观霉素的TAP液体培养物中的繁殖。已论述了莱茵衣藻在替代性培养介质中的繁殖(例如邓特(Dent)等人,《非洲微生物学研究杂志》(AfricanJournalofMicrobiologyResearch),第5卷:3(2011),第260-270页和扬涛(Yantao)等人,《生物技术与生物工程》(BiotechnologyandBioengineering),第107卷:2(2010),第258-268页)。适用于莱茵衣藻的另外的构建体(包含另外的可选择标记)以及适用于促进莱茵衣藻中的异源性基因表达的许多调节序列(包括原聚体和3'UTR)为本领域中已知并且已经论述(关于综述,参见拉达科维兹(Radakovits)等人,《真核细胞》(EurkaryoticCell),第9卷:4(2010),第486-501页)。切鲁蒂报导了转化载体P[1030]和莱茵衣藻启动子和3'UTR/终止子适合于实现莱茵衣藻中的外源性基因表达。另外,切鲁蒂报导了在P[1030]上编码的壮观霉素抗性盒适用于在莱茵衣藻中用作可选择标记。在本发明的一个实施例中,对载体P[1030](包含编码用作可选择标记的aadA基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在莱茵衣藻中表达根据表24A-D经过密码子优化以反映莱茵衣藻核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的莱茵衣藻RbcS2启动子并且在蛋白质编码序列的3'区或下游可操作地连接于莱茵衣藻RbcS23'UTR/终止子。转化构建体可以另外包含莱茵衣藻基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。本领域普通技术人员可以在莱茵衣藻基因组序列内鉴别出这些同源区(在莫臣特(Merchant)等人,《科学》,第318卷:5848(2007),第245-250页的出版物中提及)。用转化载体稳定转化莱茵衣藻通过熟知转化技术包括微粒轰击或其他已知方法实现。aadA基因产物的活性可以被用作标记以在(但不限于)包含壮观霉素的TAP琼脂培养基上选择经转化载体转化的莱茵衣藻。适用于莱茵衣藻脂质产生的生长培养基包括(但不限于)ESAW培养基以及由扬涛等人和邓特等人论述的那些培养介质。莱茵衣藻脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例31:对解脂耶氏酵母进行工程化根据本发明的重组基因在解脂耶氏酵母中的表达可以通过修改由如在此论述的菲克斯(Fickers)等人传授的方法和载体来实现。简言之,菲克斯等人,《微生物方法杂志》(JournalofMicrobiologicalMethods),第55卷(2003),第727-737页报导了用质粒DNA对解脂耶氏酵母进行稳定核转化。使用乙酸锂转化方法,菲克斯将质粒JMP123引入到解脂耶氏酵母中。质粒JMP123包含潮霉素B抗性盒,包含编码潮霉素B磷酸转移酶基因产物(hph)的序列,该序列可操作地连接于hph蛋白质编码区上游的解脂耶氏酵母LIP2基因启动子(基因库登录号AJ012632)并且可操作地连接于hph蛋白质编码区下游的解脂耶氏酵母LIP2基因3'UTR/终止子。在用JMP123转化之前,解脂耶氏酵母不能在包含100μg/ml潮霉素的培养基上繁殖。在用JMP123转化后,获得了能够在包含100μg/ml潮霉素的培养基上繁殖的转化的解脂耶氏酵母,由此确定潮霉素B抗生素抗性盒作为可选择标记用于解脂耶氏酵母。解脂耶氏酵母LIP2基因的启动子和3'UTR/终止子的JMP123上提供的核苷酸序列充当供体序列以用于hph编码序列同源重组到LIP2基因座中。稳定转化体的基因组DNA评估通过DNA杂交法(Southern)进行。菲克斯报导了转化的解脂耶氏酵母的选择和维持是在包含具有100μg/ml潮霉素的标准YPD培养基(酵母提取物蛋白胨右旋糖)的琼脂板上进行的。转化的解脂耶氏酵母的液体培养是在具有潮霉素的YPD培养基中进行的。已报导了用于培养解脂耶氏酵母的其他培养基和技术,并且已报导了用于解脂耶氏酵母的许多其他质粒、启动子、3'UTR以及可选择标记(例如参见皮涅蒂(Pignede)等人,《应用和环境生物学》(AppliedandEnvironmentalBiology),第66卷:8(2000),第3283-3289页,庄(Chuang)等人,《新生物技术》(NewBiotechnology),第27卷:4(2010),第277-282页以及巴特(Barth)和盖拉丁(Gaillardin),(1996),K,W.(编),《生物技术中的非常规酵母》(NonconventionalYeastsinBiotecnology),施普林格出版社(Sprinter-Verlag),柏林-海德堡,第313-388页)。菲克斯报导了转化载体JMP123和解脂耶氏酵母LIP2基因启动子和3'UTR/终止子适合于实现解脂耶氏酵母中的异源性基因表达。另外,菲克斯报导了在JMP123上编码的潮霉素抗性盒适用于在解脂耶氏酵母中用作可选择标记。在本发明的一个实施例中,对载体JMP123(包含编码用作可选择标记的hph基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在解脂耶氏酵母中表达根据表24A-D经过密码子优化以反映解脂耶氏酵母核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的解脂耶氏酵母LIP2基因启动子并且在蛋白质编码序列的3'区或下游可操作地连接于解脂耶氏酵母LIP2基因3'UTR/终止子。转化构建体可以另外包含解脂耶氏酵母基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。本领域普通技术人员可以在解脂耶氏酵母基因组序列内鉴别出这些同源区(在杜军(Dujun)等人,《自然》,第430卷(2004),第35-44页中的出版物提及)。用转化载体稳定转化解脂耶氏酵母通过熟知转化技术包括乙酸锂转化或其他已知方法实现。hph基因产物的活性可以被用作标记以在(但不限于)包含潮霉素的YPD培养基上选择经转化载体转化的解脂耶氏酵母。适用于解脂耶氏酵母脂质产生的生长培养基包括(但不限于)YPD培养基以及由庄等人描述的那些培养介质。解脂耶氏酵母脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例32:对高山被孢霉进行工程化根据本发明的重组基因在高山被孢霉中的表达可以通过修改由如在此论述的麦肯齐(Mackenzie)等人传授的方法和载体来实现。简言之,麦肯齐等人,《应用和环境微生物学》,第66卷(2000),第4655-4661页报导了用质粒DNA对高山被孢霉进行稳定核转化。使用原生质体转化方法,麦肯齐将质粒pD4引入到高山被孢霉中。质粒pD4包含潮霉素B抗性盒,包含编码潮霉素B磷酸转移酶基因产物(hpt)的序列,该序列可操作地连接于hpt蛋白质编码区上游的高山被孢霉组蛋白H4.1基因启动子(基因库登录号AJ249812)并且可操作地连接于hpt蛋白质编码区下游的构巢曲霉(Aspergillusnidulans)N-(5'-磷酸核糖基)邻氨基苯甲酸酯异构酶(trpC)基因3'UTR/终止子。在用pD4转化之前,高山被孢霉不能在包含300μg/ml潮霉素的培养基上繁殖。在用pD4转化后,获得了在包含300μg/ml潮霉素的培养基上繁殖的转化的高山被孢霉,由此确定潮霉素B抗生素抗性盒作为可选择标记用于高山被孢霉。稳定转化体的基因组DNA评估通过DNA杂交法进行。麦肯齐报导了转化的高山被孢霉的选择和维持是在包含潮霉素的PDA(马铃薯右旋糖琼脂)培养基上进行的。麦肯齐对转化的高山被孢霉的液体培养是在具有潮霉素的PDA培养基或S2GYE培养基(包含5%葡萄糖、0.5%酵母提取物、0.18%NH4SO4、0.02%MgSO4-7H2O、0.0001%FeCl3-6H2O、0.1%微量元素、10mMK2HPO4-NaH2PO4)中进行的。已报导了用于培养高山被孢霉的其他培养基和技术,并且已报导了用于高山被孢霉的其他质粒、启动子、3'UTR以及可选择标记(例如参见安度(Ando)等人,《应用和环境生物学》,第75卷:17(2009)第5529-35页和陆(Lu)等人,《应用生物化学与生物技术》,第164卷:7(2001),第979-90页)。麦肯齐报导了转化载体pD4和高山被孢霉组蛋白H4.1启动子以及构巢曲霉trpC基因3'UTR/终止子适合于实现高山被孢霉中的异源性基因表达。另外,麦肯齐报导了在pD4上编码的潮霉素抗性盒适用于在高山被孢霉中用作可选择标记。在本发明的一个实施例中,对载体pD4(包含编码用作可选择标记的hpt基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在高山被孢霉中表达根据表24A-D经过密码子优化以反映高山被孢霉核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的高山被孢霉组蛋白H4.1基因启动子并且在蛋白质编码序列的3'区或下游可操作地连接于构巢曲霉trpC3'UTR/终止子。转化构建体可以另外包含高山被孢霉基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。本领域普通技术人员可以在高山被孢霉基因组序列内鉴别出这些同源区(在王(Wang)等人,《公共科学图书馆期刊》(PLOSOne),第6卷:12(2011)的出版物中提及)。用转化载体稳定转化高山被孢霉通过熟知转化技术包括原生质体转化或其他已知方法实现。hpt基因产物的活性可以被用作标记以在(但不限于)包含潮霉素的PDA培养基上选择经转化载体转化的高山被孢霉。适用于高山被孢霉脂质产生的生长培养基包括(但不限于)S2GYE培养基以及由陆等人和安度等人描述的那些培养介质。高山被孢霉脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例33:对混浊红球菌PD630进行工程化根据本发明的重组基因在混浊红球菌PD630中的表达可以通过修改由如在此论述的卡尔朔伊尔(Kalscheuer)等人传授的方法和载体来实现。简言之,卡尔朔伊尔等人,《应用和环境微生物学》,第52卷(1999),第508-515页报导了用质粒DNA对混浊红球菌进行稳定转化。使用电穿孔的转化方法,卡尔朔伊尔将质粒pNC9501引入到混浊红球菌PD630中。质粒pNC9501包含硫链丝菌肽抗性(thior)盒,包含远青链霉菌(Streptomycesazureus)23SrRNAA1067甲基转移酶基因的完整核苷酸序列,该序列包含基因的启动子和3'终止子序列。在用pNC9501转化之前,混浊红球菌不能在包含1mg/ml硫链丝菌肽的培养基上繁殖。在用pNC9501转化混浊红球菌PD630后,获得了在包含1mg/ml硫链丝菌肽的培养介质上繁殖的转化体,由此确定硫链丝菌肽抗性盒在混浊红球菌PD630中作为可选择标记的用途。由卡尔朔伊尔描述的第二质粒pAK68包含抗性thior盒以及以下各者的基因序列:富养罗尔斯通氏菌(Ralstoniaeutropha)β-酮硫解酶(phaB)、乙酰乙酰基-CoA还原酶(phaA)以及聚3-羟基烷酸合成酶(phaC)基因以用于聚羟基烷酸酯生物合成,由lacZ启动子驱动。在缺乏聚羟基烷酸酯生物合成的混浊红球菌PD630株系的pAK68转化后,获得了与未转化的株系相比产生更高量的聚羟基烷酸酯的转化的混浊红球菌PD630。引入的富养罗尔斯通氏菌phaB、phaA以及phaC酶的可检测活性指示了在pAK68质粒上编码的调节元件适用于混浊红球菌PD630中的异源性基因表达。卡尔朔伊尔报导了转化的混浊红球菌PD630的选择和维持是在包含硫链丝菌肽的标准卢里亚培养液(LuriaBroth,LB)培养基、营养素培养液(NB)或无机盐培养基(MSM)上进行的。已描述了用于培养混浊红球菌PD630的其他培养基和技术(例如参见黑泽(Kurosawa)等人,《生物技术杂志》(JournalofBiotechnology),第147卷:3-4(2010),第212-218页和阿尔瓦雷斯(Alverez)等人,《应用微生物和生物技术》(AppliedMicrobialandBiotechnology),第54卷:2(2000),第218-223页)。卡尔朔伊尔报导了转化载体pNC9501和pAK68、远青链霉菌23SrRNAA1067甲基转移酶基因的启动子以及lacZ基因适合于实现混浊红球菌PD630中的异源性基因表达。另外,卡尔朔伊尔报导了在pNC9501和pAK68上编码的thior盒适用于在混浊红球菌PD630中用作可选择标记。在本发明的一个实施例中,对载体pNC9501(包含编码用作可选择标记的thior基因产物的核苷酸序列)进行构建以及修饰,从而进一步包含脂质生物合成通路表达盒序列,由此产生一种转化载体。脂质生物合成通路表达盒编码一种或多种选自表25的脂质生物合成通路蛋白,每一蛋白质编码序列为了在混浊红球菌PD630中表达根据表24A-D经过密码子优化以反映混浊红球菌核基因所固有的密码子偏倚性。针对表25的每一脂质生物合成通路蛋白,密码子优化的基因序列可以单独地可操作地连接于蛋白质编码序列上游的lacZ基因启动子。转化构建体可以另外包含混浊红球菌PD630基因组的同源区以用于转化载体的靶向基因组整合。可以对同源区加以选择以破坏内源性脂质生物合成通路基因的一个或多个基因组位点。本领域普通技术人员可以在混浊红球菌PD630基因组序列内鉴别出这些同源区(在侯德(Holder)等人,《公共科学图书馆遗传学》(PLOSGenetics),第7卷:9(2011)的出版物中提及)。混浊红球菌PD630用转化载体的转化通过熟知转化技术包括电穿孔或其他已知方法实现。远青链霉菌23SrRNAA1067甲基转移酶基因产物的活性可以被用作标记以在(但不限于)包含硫链丝菌肽的LB培养基上选择经转化载体转化的混浊红球菌PD630。适用于混浊红球菌PD630脂质产生的生长培养基包括(但不限于)由黑泽等人和阿尔瓦雷斯等人论述的那些培养介质。混浊红球菌PD630脂质的脂肪酸谱评估可以通过在此描述的标准脂质提取和分析方法评估。实例34:对微藻进行工程化以用于脂肪酸营养缺陷体将经工程化以表达赖特氏萼距花硫酯酶(CwTE2)的桑椹形原藻(UTEX1435)用作宿主生物体以用于进一步基因修饰,从而敲除内源性硫酯酶等位基因FATA1-1和FATA1-2两者。此处,生成一个第一转化构建体以在FATA1-1基因座处整合新霉素表达盒。这种构建体pSZ2226包含核基因组的FATA1-1基因座的5'(SEQIDNO:150)和3'(SEQIDNO:151)同源重组靶向序列(侧接该构建体)以及一种在莱茵衣藻β-微管蛋白启动子/5'UTR(SEQIDNO:5)和普通小球藻硝酸盐还原酶3'UTR(SEQIDNO:126)控制下的新霉素抗性蛋白质编码序列。这种NeoR表达盒被列为SEQIDNO:135并且充当一种可选择标记。在pSZ2226的转化后,在包含蔗糖和G418的琼脂板上选择单独的转化体。选择出一个单一分离株(株系H)以用于进一步基因修饰。生成一个第二转化构建体pSZ2236以将能够实现硫胺素可选择标记表达的聚核苷酸在FATA1-2基因座处整合到株系H中。pSZ2236包含用于整合到桑椹形原藻核基因组中的FATA1-2基因组区域的5'(SEQIDNO:152)和3'(SEQIDNO:153)同源重组靶向序列(侧接该构建体)以及一种在原始小球藻肌动蛋白启动子/5'UTR(SEQIDNO:142)和普通小球藻硝酸盐还原酶3'UTR(SEQIDNO:126)控制下的拟南芥THIC蛋白质编码区。这种AtTHIC表达盒被列为SEQIDNO:143并且充当一种可选择标记。在用pSZ2236转化株系H以生成株系I后,在包含游离脂肪酸的琼脂板上选择单独的转化体。株系I能够在缺乏硫胺素并且补充有游离脂肪酸的琼脂板和培养基中繁殖。实例35:对微生物进行工程化以用于增加硬脂酸产生根据如在此和PCT/US2009/066141、PCT/US2009/066142、PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中所描述的基因枪转化方法用质粒构建体pSZ2281对桑椹形原藻(UTEX1435)的经典诱变处理的株系(株系J)进行转化。pSZ2281包含编码RNA发夹(SAD2hpC,SEQIDNO:154)的聚核苷酸以下调硬脂酰基-ACP脱饱和酶的表达,6S基因组区域的5'(SEQIDNO:121)和3'(SEQIDNO:122)同源重组靶向序列(侧接该构建体)以用于整合到核基因组中,以及在莱茵衣藻β-微管蛋白启动子/5'UTR(SEQIDNO:125)和普通小球藻硝酸盐还原酶3'UTR(SEQIDNO:126)控制下的酿酒酵母suc2蔗糖转化酶编码区(SEQIDNO:124)以表达在SEQIDNO:123中给出的蛋白质序列。这种酿酒酵母suc2表达盒被列为SEQIDNO:127并且充当一种可选择标记。编码SAD2hpCRNA发夹的聚核苷酸序列是在原始小球藻肌动蛋白启动子/5'UTR(SEQIDNO:142)和普通小球藻硝酸盐还原酶3'UTR(SEQIDNO:126)的控制下。在用构建体pSZ2281转化株系J由此生成株系K后,在包含蔗糖作为唯一碳源的琼脂板上选择阳性克隆株。单独的转化体在适用于脂质产生的异养条件(如在此和PCT/US2009/066141、PCT/US2009/066142、PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中详述的那些)下进行克隆纯化并且繁殖。脂质样品由干燥生物质制备,并且使用如实例3中所述的标准脂肪酸甲酯气相色谱火焰离子化检测方法分析(也参见PCT/US2012/023696)。依靠葡萄糖作为唯一碳源繁殖的桑椹形原藻UTEX株系J和依靠蔗糖作为唯一碳源繁殖的株系K的三种代表性分离株的脂肪酸谱(表示为总脂肪酸的面积%)呈现于表26中。表26.经工程化以表达靶向硬脂酰基ACP脱饱和酶基因/基因产物的发夹RNA构建体的桑椹形原藻细胞的脂肪酸谱。表26中呈现的数据展示了SAD2发夹RNA构建体的表达对转化的生物体的C18:0和C18:1脂肪酸谱的明确影响。包含SAD2发夹RNA构建体的株系K转化体的脂肪酸谱展示了饱和C18:0脂肪酸的百分比增加以及不饱和C18:1脂肪酸的伴随减少。未转化的株系的脂肪酸谱包含约3%C18:0。转化的株系的脂肪酸谱包含约37%C18:0。这些数据示出了能够实现SADRNA发夹构建体在桑椹形原藻中表达的聚核苷酸的成功表达以及这些聚核苷酸改变工程化的宿主微生物中的饱和脂肪酸百分比并且尤其在增大C18:0脂肪酸浓度以及减少微生物细胞中的C18:1脂肪酸方面的用途。实例36:对微生物进行工程化以通过内源性酰基-ACP硫酯酶的基因敲低来增加油酸产生根据如在此和PCT/US2009/066141、PCT/US2009/066142、PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中所描述的基因枪转化方法用构建体pSZ2402-pSZ2407中的每一者对桑椹形原藻(UTEX1435)的经典诱变处理的株系(株系J)进行独立地转化。构建体pSZ2402-pSZ2407中的每一者包含编码针对桑椹形原藻FATA1mRNA转录物靶向的发夹RNA的不同聚核苷酸以下调脂肪酰基-ACP硫酯酶的表达,6S基因组区的5'(SEQIDNO:121)和3'(SEQIDNO:122)同源重组靶向序列以用于整合到核基因组中,以及在莱茵衣藻β-微管蛋白启动子/5'UTR(SEQIDNO:125)和普通小球藻硝酸盐还原酶3'UTR(SEQIDNO:126)控制下的酿酒酵母suc2蔗糖转化酶编码区(SEQIDNO:124)以表达在SEQIDNO:123中给出的蛋白质序列。这种酿酒酵母suc2表达盒被列为SEQIDNO:127并且充当一种可选择标记。对应于每一发夹的聚核苷酸的序列表身份列于表27中。编码每一RNA发夹的聚核苷酸序列是在莱茵衣藻β-微管蛋白启动子/5'UTR(SEQIDNO:125)和普通小球藻硝酸盐还原酶3'UTR(SEQIDNO:126)的控制下。表27.用于转化桑椹形原藻(UTEX1435)株系J的质粒构建体。1.质粒构建体2.发夹名称3.SEQIDNO:4.pSZ24025.PmFATA-hpB6.SEQIDNO:1607.pSZ24038.PmFATA-hpC9.SEQIDNO:16110.pSZ240411.PmFATA-hpD12.SEQIDNO:16213.pSZ240514.PmFATA-hpE15.SEQIDNO:16316.pSZ240617.PmFATA-hpF18.SEQIDNO:16419.pSZ240720.PmFATA-hpG21.SEQIDNO:165在用表27中列出的每种构建体对株系J进行独立转化后,在包含蔗糖作为唯一碳源的琼脂板上选择阳性克隆株。单独的转化体在适用于脂质产生的异养条件(如PCT/US2009/066141、PCT/US2009/066142、PCT/US2011/038463、PCT/US2011/038464以及PCT/US2012/023696中详述的那些)下进行克隆纯化并且繁殖。脂质样品由干燥生物质制备,并且使用如实例3中所述的标准脂肪酸甲酯气相色谱火焰离子化检测方法分析。依靠葡萄糖作为唯一碳源繁殖的桑椹形原藻UTEX株系J和依靠蔗糖作为唯一碳源繁殖的株系J的每种转化的代表性分离株的脂肪酸谱(表示为总脂肪酸的面积%)呈现于表28中。表28.经工程化以表达靶向脂肪酰基-ACP硫酯酶基因/基因产物的发夹RNA构建体的桑椹形原藻细胞的脂肪酸谱。表28中呈现的数据展示了FATA发夹RNA构建体的表达对转化的生物体的C18:0和C18:1脂肪酸谱的明确影响。包含FATA发夹RNA构建体的株系J转化体的脂肪酸谱展示了C18:1脂肪酸的百分比增加以及C16:0和C18:0脂肪酸的伴随减少。未转化的株系J的脂肪酸谱为约26.66%C16:0、3%C18:0以及约59%C18:1脂肪酸。相比之下,转化的株系的脂肪酸谱包括低到8.6%的C16:0和1.54%C18:0以及大于78%的C18:1脂肪酸。这些数据指示了,桑椹形原藻(UTEX1435)的FATA1酶展示出对长度C18的脂肪酸的水解的优先特异性。这些数据示出了聚核苷酸FATARNA发夹构建体在桑椹形原藻中改变工程化的微生物的脂肪酸谱并且尤其在增大C18:1脂肪酸浓度以及减少微生物细胞中的C18:0和C16:0脂肪酸方面的效用和成功使用。实例37:通过脂肪酸脱饱和酶的多个对偶基因破坏来改变工程化的微生物的脂肪酸水平这一实例描述了使用一种转化载体以用一个转化盒破坏桑椹形原藻的FADc基因座,该转化盒包含一种可选择标记和编码外源性SAD酶的序列以工程化微生物,其中转化的微生物的脂肪酸谱已经改变。根据实例2中详述的基因枪转化方法用转化构建体pSZ1499(SEQIDNO:246)对桑椹形原藻(UTEX1435)的一种经典诱变处理的(为了更高油生产)衍生物(株系A)进行转化。pSZ1499包含为了在桑椹形原藻UTEX1435中表达而经密码子优化的齐墩果树硬脂酰基-ACP脱饱和酶基因的核苷酸序列。pSZ1499表达构建体包含用于整合到核基因组中的FADc基因组区的5'(SEQIDNO:247)和3'(SEQIDNO:248)同源重组靶向序列(侧接该构建体)以及在莱茵衣藻β-微管蛋白启动子/5'UTR和普通小球藻硝酸盐还原酶3'UTR控制下的酿酒酵母suc2蔗糖转化酶编码区。这种酿酒酵母suc2表达盒被列为SEQIDNO:159并且充当一种选择标记。齐墩果树硬脂酰基-ACP脱饱和酶编码区是在桑椹形原藻Amt03启动子/5'UTR(SEQIDNO:89)和普通小球藻硝酸盐还原酶3'UTR的控制下,并且天然转运肽经原始小球藻硬脂酰基-ACP脱饱和酶转运肽(SEQIDNO:49)置换。整个齐墩果树SAD表达盒被称为pSZ1499并且可以写为FADc5'_btub-Suc2-nr_amt03-S106SAD-OeSAD-nr-FADc3'。在包含蔗糖作为唯一碳源的板上选择原代转化体。单独的转化体在pH7.0下在标准脂质产生条件下(类似于如实例1中披露的条件)进行克隆纯化并且生长。脂肪酸谱使用如实例3中所述的标准脂肪酸甲酯气相色谱火焰离子化(FAMEGC/FID)检测方法分析。来自由转化载体的转化产生的一组代表性克隆株的所得脂肪酸谱展示于表29中。表29中另外呈现了由未转化的株系C株系获得的脂质的脂肪酸谱,该株系在包含葡萄糖作为唯一碳源的脂质产生条件(pH5.0)下生长。表29.经多重工程化以敲除内源性FADc等位基因并且表达齐墩果树硬脂酰基-ACP脱饱和酶的桑椹形原藻(UTEX1435)的脂肪酸谱。如表29中所示,株系C使用pSZ1499的转化影响了转化的微生物的脂肪酸谱。未转化的桑椹形原藻(UTEX1435)株系C株系展现出包含低于60%C18:1脂肪酸以及大于7%C18:2脂肪酸的一种脂肪酸谱。相比之下,用pSZ1499转化的株系C株系展现出C18:1脂肪酸组成增加以及C18:0和C18:2脂肪酸伴随减小的脂肪酸谱。在用pSZ1499转化的株系C的脂肪酸谱中未检测出C18:2脂肪酸。在pSZ1499转化体中不存在可检测的C18:2脂肪酸指示了,用携有用于整合到多个FADc基因组基因座中的同源重组靶向序列的pSZ1499转化已消除了FAD活性。进行DNA印迹分析以验证多个FADc等位基因被pSZ1499转化载体打断。使用标准分子生物学方法从株系C和pSZ1499转化体中提取基因组DNA。在用限制酶PstI消化之后,使来自每一样品的DNA在0.8%琼脂糖凝胶上跑胶。将来自这一凝胶的DNA转移到Nylon+膜(安玛西亚公司(Amersham))上,该DNA接着与对应于FADc3'区的P32标记的聚核苷酸探针杂交。图1展示了pSZ1499转化盒的图谱,桑椹形原藻(UTEX1435)的两个经测序的FADc等位基因以及被pSZ1499转化载体破坏的等位基因的预测大小。FADc等位基因1包含一个PstI限制性位点,而FADc等位基因2没有。SAD盒的整合会将PstI限制性位点引入到破坏的FADc等位基因中,产生在DNA杂交法上拆分的约6kb片段,与哪个等位基因被破坏无关。图2展示了DNA印迹分析的结果。在两种转化体中检测出在约6kb处一个杂交条带。未检测出更小的杂交条带(这些条带将指示未被打断的等位基因)。这些结果指示了两个FADc等位基因都被pSZ1499破坏。用SAD表达盒除去FADc脂肪酸脱饱和酶的两个等位基因产生了包含约74%C18:1的脂肪酸谱。总体来说,这些数据展示了聚核苷酸允许FAD等位基因的敲除以及硬脂酰基-ACP脱饱和酶的伴随性外源性表达以改变工程化的微生物的脂肪酸谱的效用和有效性。在此引用的所有参考文献(包括专利、专利申请以及出版物,包括基因库登录号)特此以其全文通过引用结合,无论先前被特别地结合或未结合。在此提及的出版物为了描述和披露可以与本发明结合使用的试剂、方法以及概念的目的引用。在此没有什么被解释为承认这些参考文献是相对于在此描述的本发明的现有技术。具体地说,以下专利申请为了所有目的特此以其全文通过引用结合:题为“微生物中的油生产(ProductionofOilinMicroorganisms)”的2008年6月2日提交的PCT申请号PCT/US2008/065563;题为“微生物油提取和分离的方法(MethodsofMicrobialOilExtractionandSeparation)”的2010年4月14日提交的PCT申请号PCT/US2010/31108;题为“异养微生物中定制油的生产(ProductionofTailoredOilsinHeterotrophicMicroorganisms)”的2009年11月30日的PCT公开号WO2010/063032;题为“由重组异养微生物生产的定制油(TailoredOilsProducedFromRecombinantHeterotrophicMicroorganisms)”的2011年5月27日提交的PCT申请号PCT/US2011/038463;以及题为“由重组异养微生物生产的定制油(TailoredOilsProducedfromRecombinantHeterotrophicMicroorganisms)”的2012年2月2日提交的PCT申请号PCT/US/2012/023696。SEQIDNO:1UTEX329克鲁格尼原藻TGTTGAAGAATGAGCCGGCGAGTTAAAAAGAGTGGCATGGTTAAAGAAAATACTCTGGAGCCATAGCGAAAGCAAGTTTAGTAAGCTTAGGTCATTCTTTTTAGACCCGAAACCGAGTGATCTACCCATGATCAGGGTGAAGTGTTAGTAAAATAACATGGAGGCCCGAACCGACTAATGTTGAAAAATTAGCGGATGAATTGTGGGTAGGGGCGAAAAACCAATCGAACTCGGAGTTAGCTGGTTCTCCCCGAAATGCGTTTAGGCGCAGCAGTAGCAGTACAAATAGAGGGGTAAAGCACTGTTTCTTTTGTGGGCTTCGAAAGTTGTACCTCAAAGTGGCAAACTCTGAATACTCTATTTAGATATCTACTAGTGAGACCTTGGGGGATAAGCTCCTTGGTCAAAAGGGAAACAGCCCAGATCACCAGTTAAGGCCCCAAAATGAAAATGATAGTGACTAAGGATGTGGGTATGTCAAAACCTCCAGCAGGTTAGCTTAGAAGCAGCAATCCTTTCAAGAGTGCGTAATAGCTCACTGSEQIDNO:2UTEX1440威克海姆原藻TGTTGAAGAATGAGCCGGCGACTTAAAATAAATGGCAGGCTAAGAGATTTAATAACTCGAAACCTAAGCGAAAGCAAGTCTTAATAGGGCGTCAATTTAACAAAACTTTAAATAAATTATAAAGTCATTTATTTTAGACCCGAACCTGAGTGATCTAACCATGGTCAGGATGAAACTTGGGTGACACCAAGTGGAAGTCCGAACCGACCGATGTTGAAAAATCGGCGGATGAACTGTGGTTAGTGGTGAAATACCAGTCGAACTCAGAGCTAGCTGGTTCTCCCCGAAATGCGTTGAGGCGCAGCAATATATCTCGTCTATCTAGGGGTAAAGCACTGTTTCGGTGCGGGCTATGAAAATGGTACCAAATCGTGGCAAACTCTGAATACTAGAAATGACGATATATTAGTGAGACTATGGGGGATAAGCTCCATAGTCGAGAGGGAAACAGCCCAGACCACCAGTTAAGGCCCCAAAATGATAATGAAGTGGTAAAGGAGGTGAAAATGCAAATACAACCAGGAGGTTGGCTTAGAAGCAGCCATCCTTTAAAGAGTGCGTAATAGCTCACTGSEQIDNO:3UTEX1442大型原藻TGTTGAAGAATGAGCCGGCGAGTTAAAAAAAATGGCATGGTTAAAGATATTTCTCTGAAGCCATAGCGAAAGCAAGTTTTACAAGCTATAGTCATTTTTTTTAGACCCGAAACCGAGTGATCTACCCATGATCAGGGTGAAGTGTTGGTCAAATAACATGGAGGCCCGAACCGACTAATGGTGAAAAATTAGCGGATGAATTGTGGGTAGGGGCGAAAAACCAATCGAACTCGGAGTTAGCTGGTTCTCCCCGAAATGCGTTTAGGCGCAGCAGTAGCAACACAAATAGAGGGGTAAAGCACTGTTTCTTTTGTGGGCTTCGAAAGTTGTACCTCAAAGTGGCAAACTCTGAATACTCTATTTAGATATCTACTAGTGAGACCTTGGGGGATAAGCTCCTTGGTCAAAAGGGAAACAGCCCAGATCACCAGTTAAGGCCCCAAAATGAAAATGATAGTGACTAAGGACGTGAGTATGTCAAAACCTCCAGCAGGTTAGCTTAGAAGCAGCAATCCTTTCAAGAGTGCGTAATAGCTCACTGSEQIDNO:4UTEX288桑椹形原藻TGTTGAAGAATGAGCCGGCGAGTTAAAAAGAGTGGCATGGTTAAAGATAATTCTCTGGAGCCATAGCGAAAGCAAGTTTAACAAGCTAAAGTCACCCTTTTTAGACCCGAAACCGAGTGATCTACCCATGATCAGGGTGAAGTGTTGGTAAAATAACATGGAGGCCCGAACCGACTAATGGTGAAAAATTAGCGGATGAATTGTGGGTAGGGGCGAAAAACCAATCGAACTCGGAGTTAGCTGGTTCTCCCCGAAATGCGTTTAGGCGCAGCAGTAGCAACACAAATAGAGGGGTAAAGCACTGTTTCTTTTGTGGGCTTCGAAAGTTGTACCTCAAAGTGGCAAACTCTGAATACTCTATTTAGATATCTACTAGTGAGACCTTGGGGGATAAGCTCCTTGGTCAAAAGGGAAACAGCCCAGATCACCAGTTAAGGCCCCAAAATGAAAATGATAGTGACTAAGGATGTGGGTATGTTAAAACCTCCAGCAGGTTAGCTTAGAAGCAGCAATCCTTTCAAGAGTGCGTAATAGCTCACTGSEQIDNO:5UTEX1439、UTEX1441、UTEX1435、UTEX1437桑椹形原藻TGTTGAAGAATGAGCCGGCGACTTAAAATAAATGGCAGGCTAAGAGAATTAATAACTCGAAACCTAAGCGAAAGCAAGTCTTAATAGGGCGCTAATTTAACAAAACATTAAATAAAATCTAAAGTCATTTATTTTAGACCCGAACCTGAGTGATCTAACCATGGTCAGGATGAAACTTGGGTGACACCAAGTGGAAGTCCGAACCGACCGATGTTGAAAAATCGGCGGATGAACTGTGGTTAGTGGTGAAATACCAGTCGAACTCAGAGCTAGCTGGTTCTCCCCGAAATGCGTTGAGGCGCAGCAATATATCTCGTCTATCTAGGGGTAAAGCACTGTTTCGGTGCGGGCTATGAAAATGGTACCAAATCGTGGCAAACTCTGAATACTAGAAATGACGATATATTAGTGAGACTATGGGGGATAAGCTCCATAGTCGAGAGGGAAACAGCCCAGACCACCAGTTAAGGCCCCAAAATGATAATGAAGTGGTAAAGGAGGTGAAAATGCAAATACAACCAGGAGGTTGGCTTAGAAGCAGCCATCCTTTAAAGAGTGCGTAATAGCTCACTGSEQIDNO:6UTEX1533威克海姆原藻TGTTGAAGAATGAGCCGTCGACTTAAAATAAATGGCAGGCTAAGAGAATTAATAACTCGAAACCTAAGCGAAAGCAAGTCTTAATAGGGCGCTAATTTAACAAAACATTAAATAAAATCTAAAGTCATTTATTTTAGACCCGAACCTGAGTGATCTAACCATGGTCAGGATGAAACTTGGGTGACACCAAGTGGAAGTCCGAACCGACCGATGTTGAAAAATCGGCGGATGAACTGTGGTTAGTGGTGAAATACCAGTCGAACTCAGAGCTAGCTGGTTCTCCCCGAAATGCGTTGAGGCGCAGCAATATATCTCGTCTATCTAGGGGTAAAGCACTGTTTCGGTGCGGGCTATGAAAATGGTACCAAATCGTGGCAAACTCTGAATACTAGAAATGACGATATATTAGTGAGACTATGGGGGATAAGCTCCATAGTCGAGAGGGAAACAGCCCAGACCACCAGTTAAGGCCCCAAAATGATAATGAAGTGGTAAAGGAGGTGAAAATGCAAATACAACCAGGAGGTTGGCTTAGAAGCAGCCATCCTTTAAAGAGTGCGTAATAGCTCACTGSEQIDNO:7UTEX1434桑椹形原藻TGTTGAAGAATGAGCCGGCGAGTTAAAAAGAGTGGCGTGGTTAAAGAAAATTCTCTGGAACCATAGCGAAAGCAAGTTTAACAAGCTTAAGTCACTTTTTTTAGACCCGAAACCGAGTGATCTACCCATGATCAGGGTGAAGTGTTGGTAAAATAACATGGAGGCCCGAACCGACTAATGGTGAAAAATTAGCGGATGAATTGTGGGTAGGGGCGAAAAACCAATCGAACTCGGAGTTAGCTGGTTCTCCCCGAAATGCGTTTAGGCGCAGCAGTAGCAACACAAATAGAGGGGTAAAGCACTGTTTCTTTTGTGGGCTCCGAAAGTTGTACCTCAAAGTGGCAAACTCTGAATACTCTATTTAGATATCTACTAGTGAGACCTTGGGGGATAAGCTCCTTGGTCGAAAGGGAAACAGCCCAGATCACCAGTTAAGGCCCCAAAATGAAAATGATAGTGACTAAGGATGTGAGTATGTCAAAACCTCCAGCAGGTTAGCTTAGAAGCAGCAATCCTTTCAAGAGTGCGTAATAGCTCACTGSEQIDNO:8UTEX1438小型原藻TGTTGAAGAATGAGCCGGCGAGTTAAAAAGAGTGGCATGGTTAAAGAAAATTCTCTGGAGCCATAGCGAAAGCAAGTTTAACAAGCTTAAGTCACTTTTTTTAGACCCGAAACCGAGTGATCTACCCATGATCAGGGTGAAGTGTTGGTAAAATAACATGGAGGCCCGAACCGACTAATGGTGAAAAATTAGCGGATGAATTGTGGGTAGGGGCGAAAAACCAATCGAACTCGGAGTTAGCTGGTTCTCCCCGAAATGCGTTTAGGCGCAGCAGTAGCAACACAAATAGAGGGGTAAAGCACTGTTTCTTTCGTGGGCTTCGAAAGTTGTACCTCAAAGTGGCAAACTCTGAATACTCTATTTAGATATCTACTAGTGAGACCTTGGGGGATAAGCTCCTTGGTCAAAAGGGAAACAGCCCAGATCACCAGTTAAGGCCCCAAAATGAAAATGATAGTGACTAAGGATGTGAGTATGTCAAAACCTCCAGCAGGTTAGCTTAGAAGCAGCAATCCTTTCAAGAGTGCGTAATAGCTCACTGSEQIDNO:9UTEX1436桑椹形原藻TGTTGAAGAATGAGCCGGCGACTTAGAAAAGGTGGCATGGTTAAGGAAATATTCCGAAGCCGTAGCAAAAGCGAGTCTGAATAGGGCGATAAAATATATTAATATTTAGAATCTAGTCATTTTTTCTAGACCCGAACCCGGGTGATCTAACCATGACCAGGATGAAGCTTGGGTGATACCAAGTGAAGGTCCGAACCGACCGATGTTGAAAAATCGGCGGATGAGTTGTGGTTAGCGGTGAAATACCAGTCGAACCCGGAGCTAGCTGGTTCTCCCCGAAATGCGTTGAGGCGCAGCAGTACATCTAGTCTATCTAGGGGTAAAGCACTGTTTCGGTGCGGGCTGTGAGAACGGTACCAAATCGTGGCAAACTCTGAATACTAGAAATGACGATGTAGTAGTGAGACTGTGGGGGATAAGCTCCATTGTCAAGAGGGAAACAGCCCAGACCACCAGCTAAGGCCCCAAAATGGTAATGTAGTGACAAAGGAGGTGAAAATGCAAATACAACCAGGAGGTTGGCTTAGAAGCAGCCATCCTTTAAAGAGTGCGTAATAGCTCACTGSEQIDNO:10来自小球藻的HUP启动子(基因库登录号X55349的子序列)GATCAGACGGGCCTGACCTGCGAGATAATCAAGTGCTCGTAGGCAACCAACTCAGCAGCTGCTTGGTGTTGGGTCTGCAGGATAGTGTTGCAGGGCCCCAAGGACAGCAGGGGAACTTACACCTTGTCCCCGACCCAGTTTTATGGAGTGCATTGCCTCAAGAGCCTAGCCGGAGCGCTAGGCTACATACTTGCCGCACCGGTATGAGGGGATATAGTACTCGCACTGCGCTGTCTAGTGAGATGGGCAGTGCTGCCCATAAACAACTGGCTGCTCAGCCATTTGTTGGCGGACCATTCTGGGGGGGCCAGCAATGCCTGACTTTCGGGTAGGGTGAAAACTGAACAAAGACTACCAAAACAGAATTTCTTCCTCCTTGGAGGTAAGCGCAGGCCGGCCCGCCTGCGCCCACATGGCGCTCCGAACACCTCCATAGCTGTAAGGGCGCAAACATGGCCGGACTGTTGTCAGCACTCTTTCATGGCCATACAAGGTCATGTCGAGATTAGTGCTGAGTAAGACACTATCACCCCATGTTCGATTGAAGCCGTGACTTCATGCCAACCTGCCCCTGGGCGTAGCAGACGTATGCCATCATGACCACTAGCCGACATGCGCTGTCTTTTGCCACCAAAACAACTGGTACACCGCTCGAAGTCGTGCCGCACACCTCCGGGAGTGAGTCCGGCGACTCCTCCCCGGCGGGCCGCGGCCCTACCTGGGTAGGGTCGCCATACGCCCACGACCAAACGACGCAGGAGGGGATTGGGGTAGGGAATCCCAACCAGCCTAACCAAGACGGCACCTATAATAATAGGTGGGGGGACTAACAGCCCTATATCGCAAGCTTTGGGTGCCTATCTTGAGAAGCACGAGTTGGAGTGGCTGTGTACGGTCGACCCTAAGGTGGGTGTGCCGCAGCCTGAAACAAAGCGTCTAGCAGCTGCTTCTATAATGTGTCAGCCGTTGTGTTTCAGTTATATTGTATGCTATTGTTTGTTCGTGCTAGGGTGGCGCAGGCCCACCTACTGTGGCGGGCCATTGGTTGGTGCTTGAATTGCCTCACCATCTAAGGTCTGAACGCTCACTCAAACGCCTTTGTACAACTGCAGAACTTTCCTTGGCGCTGCAACTACAGTGTGCAAACCAGCACATAGCACTCCCTTACATCACCCAGCAGTACAACASEQIDNO:11来自AY307383的椭圆形小球藻硝酸盐还原酶启动子CGCTGCGCACCAGGGCCGCCAGCTCGCTGATGTCGCTCCAAATGCGGTCCCCCGATTTTTTGTTCTTCATCTTCTCCACCTTGGTGGCCTTCTTGGCCAGGGCCTTCAGCTGCATGCGCACAGACCGTTGAGCTCCTGATCAGCATCCTCAGGAGGCCCTTTGACAAGCAAGCCCCTGTGCAAGCCCATTCACGGGGTACCAGTGGTGCTGAGGTAGATGGGTTTGAAAAGGATTGCTCGGTCGATTGCTGCTCATGGAATTGGCATGTGCATGCATGTTCACAATATGCCACCAGGCTTTGGAGCAAGAGAGCATGAATGCCTTCAGGCAGGTTGAAAGTTCCTGGGGGTGAAGAGGCAGGGCCGAGGATTGGAGGAGGAAAGCATCAAGTCGTCGCTCATGCTCATGTTTTCAGTCAGAGTTTGCCAAGCTCACAGGAGCAGAGACAAGACTGGCTGCTCAGGTGTTGCATCGTGTGTGTGGTGGGGGGGGGGGGGTTAATACGGTACGAAATGCACTTGGAATTCCCACCTCATGCCAGCGGACCCACATGCTTGAATTCGAGGCCTGTGGGGTGAGAAATGCTCACTCTGCCCTCGTTGCTGAGGTACTTCAGGCCGCTGAGCTCAAAGTCGATGCCCTGCTCGTCTATCAGGGCCTGCACCTCTGGGCTGACCGGCTCAGCCTCCTTCGCGGGCATGGAGTAGGCGCCGGCAGCGTTCATGTCCGGGCCCAGGGCAGCGGTGGTGCCATAAATGTCGGTGATGGTGGGGAGGGGGGCCGTCGCCACACCATTGCCGTTGCTGGCTGACGCATGCACATGTGGCCTGGCTGGCACCGGCAGCACTGGTCTCCAGCCAGCCAGCAAGTGGCTGTTCAGGAAAGCGGCCATGTTGTTGGTCCCTGCGCATGTAATTCCCCAGATCAAAGGAGGGAACAGCTTGGATTTGATGTAGTGCCCAACCGGACTGAATGTGCGATGGCAGGTCCCTTTGAGTCTCCCGAATTACTAGCAGGGCACTGTGACCTAACGCAGCATGCCAACCGCAAAAAAATGATTGACAGAAAATGAAGCGGTGTGTCAATATTTGCTGTATTTATTCGTTTTAATCAGCAACCAAGTTCGAAACGCAACTATCGTGGTGATCAAGTGAACCTCATCAGACTTACCTCGTTCGGCAAGGAAACGGAGGCACCAAATTCCAATTTGATATTATCGCTTGCCAAGCTAGAGCTGATCTTTGGGAAACCAACTGCCAGACAGTGGACTGTGATGGAGTGCCCCGAGTGGTGGAGCCTCTTCGATTCGGTTAGTCATTACTAACGTGAACCCTCAGTGAAGGGACCATCAGACCAGAAAGACCAGATCTCCTCCTCGACACCGAGAGAGTGTTGCGGCAGTAGGACGACAAGSEQIDNO:12酵母分泌信号MLLQAFLFLLAGFAAKISASSEQIDNO:13高等植物分泌信号MANKSLLLLLLLGSLASGSEQIDNO:14共有真核生物分泌信号MARLPLAALGSEQIDNO:15组合高等植物/真核生物分泌信号MANKLLLLLLLLLLPLAASGSEQIDNO:16密码子优化的酵母蔗糖转化酶ATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGASEQIDNO:17酵母蔗糖转化酶,基因库登录号NP_012104.1MTNETSDRPLVHFTPNKGWMNDPNGLWYDEKDAKWHLYFQYNPNDTVWGTPLFWGHATSDDLTNWEDQPIAIAPKRNDSGAFSGSMVVDYNNTSGFFNDTIDPRQRCVAIWTYNTPESEEQYISYSLDGGYTFTEYQKNPVLAANSTQFRDPKVFWYEPSQKWIMTAAKSQDYKIEIYSSDDLKSWKLESAFANEGFLGYQYECPGLIEVPTEQDPSKSYWVMFISINPGAPAGGSFNQYFVGSFNGTHFEAFDNQSRVVDFGKDYYALQTFFNTDPTYGSALGIAWASNWEYSAFVPTNPWRSSMSLVRKFSLNTEYQANPETELINLKAEPILNISNAGPWSRFATNTTLTKANSYNVDLSNSTGTLEFELVYAVNTTQTISKSVFADLSLWFKGLEDPEEYLRMGFEVSASSFFLDRGNSKVKFVKENPYFTNRMSVNNQPFKSENDLSYYKVYGLLDQNILELYFNDGDVVSTNTYFMTTGNALGSVNMTTGVDNLFYIDKFQVREVKSEQIDNO:18桑椹形原藻Δ12FAD基因敲除同源重组靶向构建体的5′供体DNA序列GCTCTTCGGGTTTGCTCACCCGCGAGGTCGACGCCCAGCATGGCTATCAAGACGAACAGGCAGCCTGTGGAGAAGCCTCCGTTCACGATCGGGACGCTGCGCAAGGCCATCCCCGCGCACTGTTTCGAGCGCTCGGCGCTTCGTAGCAGCATGTACCTGGCCTTTGACATCGCGGTCATGTCCCTGCTCTACGTCGCGTCGACGTACATCGACCCTGCGCCGGTGCCTACGTGGGTCAAGTATGGCGTCATGTGGCCGCTCTACTGGTTCTTCCAGGTGTGTGTGAGGGTTGTGGTTGCCCGTATCGAGGTCCTGGTGGCGCGCATGGGGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCCTTCGGCACGGGTGTCTGGGTGTGCGCGCACGAGTGCGGCCACCAGGCCTTTTCCTCCAGCCAGGCCATCAACGACGGCGTGGGCCTGGTGTTCCACAGCCTGCTGCTGGTGCCCTACTACTCCTGGAAGCACTCGCACCGCCGCCACCACTCCAACACGGGGTGCCTGGACAAGGACGAGGTGTTTGTGCCGCCGCACCGCGCAGTGGCGCACGAGGGCCTGGAGTGGGAGGAGTGGCTGCCCATCCGCATGGGCAAGGTGCTGGTCACCCTGACCCTGGGCTGGCCGCTGTACCTCATGTTCAACGTCGCCTCGCGGCCGTACCCGCGCTTCGCCAACCACTTTGACCCGTGGTCGCCCATCTTCAGCAAGCGCGAGGTACCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACGGCGCGCCSEQIDNO:19桑椹形原藻Δ12FAD基因敲除同源重组靶向构建体的3′供体DNA序列CAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAGCATCGAGGTGGTCATCTCCGACCTCGCGTTGGTGGCGGTGCTCAGCGGGCTCAGCGTGCTGGGCCGCACCATGGGCTGGGCCTGGCTGGTCAAGACCTACGTGGTGCCCTACATGATCGTGAACATGTGGCTGGTGCTCATCACGCTGCTCCAGCACACGCACCCGGCCCTGCCGCACTACTTCGAGAAGGACTGGGACTGGCTACGCGGCGCCATGGCCACCGTCGACCGCTCCATGGGCCCGCCCTTCATGGACAGCATCCTGCACCACATCTCCGACACCCACGTGCTGCACCACCTCTTCAGCACCATCCCGCACTACCACGCCGAGGAGGCCTCCGCCGCCATCCGGCCCATCCTGGGCAAGTACTACCAATCCGACAGCCGCTGGGTCGGCCGCGCCCTGTGGGAGGACTGGCGCGACTGCCGCTACGTCGTCCCCGACGCGCCCGAGGACGACTCCGCGCTCTGGTTCCACAAGTGAGCGCGCCTGCGCGAGGACGCAGAACAACGCTGCCGCCGTGTCTTTTGCACGCGCGACTCCGGCGCTTCGCTGGTGGCACCCCCATAAAGAAACCCTCAATTCTGTTTGTGGAAGACACGGTGTACCCCCACCCACCCACCTGCACCTCTATTATTGGTATTATTGACGCGGGAGTGGGCGTTGTACCCTACAACGTAGCTTCTCTAGTTTTCAGCTGGCTCCCACCATTGTAAAGAGCCTCTAGAGTCGACCTGCAGGCATGCAAGCTTGGCGTAATCATGGTCATAGCTGTTTCCTGTGTGAAATTGTTATCCGCTCACAATTCCACACAACATACGAGCCGGAAGCATAAAGTGTAAAGCCTGGGGTGCCTAATGAGTGAGCTAACTCACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCTCTTCCSEQIDNO:20桑椹形原藻Δ12FAD基因敲除同源重组靶向构建体GCTCTTCGGGTTTGCTCACCCGCGAGGTCGACGCCCAGCATGGCTATCAAGACGAACAGGCAGCCTGTGGAGAAGCCTCCGTTCACGATCGGGACGCTGCGCAAGGCCATCCCCGCGCACTGTTTCGAGCGCTCGGCGCTTCGTAGCAGCATGTACCTGGCCTTTGACATCGCGGTCATGTCCCTGCTCTACGTCGCGTCGACGTACATCGACCCTGCGCCGGTGCCTACGTGGGTCAAGTATGGCGTCATGTGGCCGCTCTACTGGTTCTTCCAGGTGTGTGTGAGGGTTGTGGTTGCCCGTATCGAGGTCCTGGTGGCGCGCATGGGGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCCTTCGGCACGGGTGTCTGGGTGTGCGCGCACGAGTGCGGCCACCAGGCCTTTTCCTCCAGCCAGGCCATCAACGACGGCGTGGGCCTGGTGTTCCACAGCCTGCTGCTGGTGCCCTACTACTCCTGGAAGCACTCGCACCGCCGCCACCACTCCAACACGGGGTGCCTGGACAAGGACGAGGTGTTTGTGCCGCCGCACCGCGCAGTGGCGCACGAGGGCCTGGAGTGGGAGGAGTGGCTGCCCATCCGCATGGGCAAGGTGCTGGTCACCCTGACCCTGGGCTGGCCGCTGTACCTCATGTTCAACGTCGCCTCGCGGCCGTACCCGCGCTTCGCCAACCACTTTGACCCGTGGTCGCCCATCTTCAGCAAGCGCGAGGTACCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACGGCGCGCCATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGACAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAGCATCGAGGTGGTCATCTCCGACCTCGCGTTGGTGGCGGTGCTCAGCGGGCTCAGCGTGCTGGGCCGCACCATGGGCTGGGCCTGGCTGGTCAAGACCTACGTGGTGCCCTACATGATCGTGAACATGTGGCTGGTGCTCATCACGCTGCTCCAGCACACGCACCCGGCCCTGCCGCACTACTTCGAGAAGGACTGGGACTGGCTACGCGGCGCCATGGCCACCGTCGACCGCTCCATGGGCCCGCCCTTCATGGACAGCATCCTGCACCACATCTCCGACACCCACGTGCTGCACCACCTCTTCAGCACCATCCCGCACTACCACGCCGAGGAGGCCTCCGCCGCCATCCGGCCCATCCTGGGCAAGTACTACCAATCCGACAGCCGCTGGGTCGGCCGCGCCCTGTGGGAGGACTGGCGCGACTGCCGCTACGTCGTCCCCGACGCGCCCGAGGACGACTCCGCGCTCTGGTTCCACAAGTGAGCGCGCCTGCGCGAGGACGCAGAACAACGCTGCCGCCGTGTCTTTTGCACGCGCGACTCCGGCGCTTCGCTGGTGGCACCCCCATAAAGAAACCCTCAATTCTGTTTGTGGAAGACACGGTGTACCCCCACCCACCCACCTGCACCTCTATTATTGGTATTATTGACGCGGGAGTGGGCGTTGTACCCTACAACGTAGCTTCTCTAGTTTTCAGCTGGCTCCCACCATTGTAAAGAGCCTCTAGAGTCGACCTGCAGGCATGCAAGCTTGGCGTAATCATGGTCATAGCTGTTTCCTGTGTGAAATTGTTATCCGCTCACAATTCCACACAACATACGAGCCGGAAGCATAAAGTGTAAAGCCTGGGGTGCCTAATGAGTGAGCTAACTCACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCTCTTCCSEQIDNO:21桑椹形原藻SAD2A基因敲除同源重组靶向构建体的5′供体DNA序列GCTCTTCCGCCTGGAGCTGGTGCAGAGCATGGGTCAGTTTGCGGAGGAGAGGGTGCTCCCCGTGCTGCACCCCGTGGACAAGCTGTGGCAGCCGCAGGACTTCCTGCCCGACCCCGAGTCGCCCGACTTCGAGGACCAGGTGGCGGAGCTGCGCGCGCGCGCCAAGGACCTGCCCGACGAGTACTTTGTGGTGCTGGTGGGCGACATGATCACGGAGGAGGCGCTGCCGACCTACATGGCCATGCTCAACACCTTGGACGGTGTGCGCGACGACACGGGCGCGGCTGACCACCCGTGGGCGCGCTGGACGCGGCAGTGGGTGGCCGAGGAGAACCGGCACGGCGACCTGCTGAACAAGTACTGTTGGCTGACGGGGCGCGTCAACATGCGGGCCGTGGAGGTGACCATCAACAACCTGATCAAGAGCGGCATGAACCCGCAGACGGACAACAACCCTTACTTGGGCTTCGTCTACACCTCCTTCCAGGAGCGCGCCACCAAGTAGGTACCSEQIDNO:22桑椹形原藻SAD2A基因敲除同源重组靶向构建体的3′供体DNA序列CAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAAGGATCGTAGAGCTCCAGCCACGGCAACACCGCGCGCCTGGCGGCCGAGCACGGCGACAAGGGCCTGAGCAAGATCTGCGGGCTGATCGCCAGCGACGAGGGCCGGCACGAGATCGCCTACACGCGCATCGTGGACGAGTTCTTCCGCCTCGACCCCGAGGGCGCCGTCGCCGCCTACGCCAACATGATGCGCAAGCAGATCACCATGCCCGCGCACCTCATGGACGACATGGGCCACGGCGAGGCCAACCCGGGCCGCAACCTCTTCGCCGACTTCTCCGCCGTCGCCGAGAAGATCGACGTCTACGACGCCGAGGACTACTGCCGCATCCTGGAGCACCTCAACGCGCGCTGGAAGGTGGACGAGCGCCAGGTCAGCGGCCAGGCCGCCGCGGACCAGGAGTACGTTCTGGGCCTGCCCCAGCGCTTCCGGAAACTCGCCGAGAAGACCGCCGCCAAGCGCAAGCGCGTCGCGCGCAGGCCCGTCGCCTTCTCCTGGAGAGAAGAGCCTCTAGAGTCGACCTGCAGGCATGCAAGCTTGGCGTAATCATGGTCATAGCTGTTTCCTGTGTGAAATTGTTATCCGCTCACAATTCCACACAACATACGAGCCGGAAGCATAAAGTGTAAAGCCTGGGGTGCCTAATGAGTGAGCTAACTCACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCTCTTCCSEQIDNO:23桑椹形原藻SAD2A基因敲除同源重组靶向构建体GCTCTTCCGCCTGGAGCTGGTGCAGAGCATGGGTCAGTTTGCGGAGGAGAGGGTGCTCCCCGTGCTGCACCCCGTGGACAAGCTGTGGCAGCCGCAGGACTTCCTGCCCGACCCCGAGTCGCCCGACTTCGAGGACCAGGTGGCGGAGCTGCGCGCGCGCGCCAAGGACCTGCCCGACGAGTACTTTGTGGTGCTGGTGGGCGACATGATCACGGAGGAGGCGCTGCCGACCTACATGGCCATGCTCAACACCTTGGACGGTGTGCGCGACGACACGGGCGCGGCTGACCACCCGTGGGCGCGCTGGACGCGGCAGTGGGTGGCCGAGGAGAACCGGCACGGCGACCTGCTGAACAAGTACTGTTGGCTGACGGGGCGCGTCAACATGCGGGCCGTGGAGGTGACCATCAACAACCTGATCAAGAGCGGCATGAACCCGCAGACGGACAACAACCCTTACTTGGGCTTCGTCTACACCTCCTTCCAGGAGCGCGCCACCAAGTAGGTACCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACGGCGCGCCATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGACAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAAGGATCGTAGAGCTCCAGCCACGGCAACACCGCGCGCCTGGCGGCCGAGCACGGCGACAAGGGCCTGAGCAAGATCTGCGGGCTGATCGCCAGCGACGAGGGCCGGCACGAGATCGCCTACACGCGCATCGTGGACGAGTTCTTCCGCCTCGACCCCGAGGGCGCCGTCGCCGCCTACGCCAACATGATGCGCAAGCAGATCACCATGCCCGCGCACCTCATGGACGACATGGGCCACGGCGAGGCCAACCCGGGCCGCAACCTCTTCGCCGACTTCTCCGCCGTCGCCGAGAAGATCGACGTCTACGACGCCGAGGACTACTGCCGCATCCTGGAGCACCTCAACGCGCGCTGGAAGGTGGACGAGCGCCAGGTCAGCGGCCAGGCCGCCGCGGACCAGGAGTACGTTCTGGGCCTGCCCCAGCGCTTCCGGAAACTCGCCGAGAAGACCGCCGCCAAGCGCAAGCGCGTCGCGCGCAGGCCCGTCGCCTTCTCCTGGAGAGAAGAGCCTCTAGAGTCGACCTGCAGGCATGCAAGCTTGGCGTAATCATGGTCATAGCTGTTTCCTGTGTGAAATTGTTATCCGCTCACAATTCCACACAACATACGAGCCGGAAGCATAAAGTGTAAAGCCTGGGGTGCCTAATGAGTGAGCTAACTCACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCTCTTCCSEQIDNO:24桑椹形原藻SAD2B基因敲除同源重组靶向构建体的5′供体DNA序列GCTCTTCCCGCCTGGAGCTGGTGCAGAGCATGGGGCAGTTTGCGGAGGAGAGGGTGCTCCCCGTGCTGCACCCCGTGGACAAGCTGTGGCAGCCGCAGGACTTCCTGCCCGACCCCGAGTCGCCCGACTTCGAGGACCAGGTGGCGGAGCTGCGCGCGCGCGCCAAGGACCTGCCCGACGAGTACTTTGTGGTGCTGGTGGGCGACATGATCACGGAGGAGGCGCTGCCGACCTACATGGCCATGCTCAACACCTTGGACGGTGTGCGCGACGACACGGGCGCGGCTGACCACCCGTGGGCGCGCTGGACGCGGCAGTGGGTGGCCGAGGAGAACCGGCACGGCGACCTGCTGAACAAGTACTGTTGGCTGACGGGGCGCGTCAACATGCGGGCCGTGGAGGTGACCATCAACAACCTGATCAAGAGCGGCATGAACCCGCAGACGGACAACAACCCTTACTTGGGCTTCGTCTACACCTCCTTCCAGGAGCGCGCCACCAAGTAGGTACCSEQIDNO:25桑椹形原藻SAD2B基因敲除同源重组靶向构建体的3′供体DNA序列CAGCCACGGCAACACCGCGCGCCTTGCGGCCGAGCACGGCGACAAGAACCTGAGCAAGATCTGCGGGCTGATCGCCAGCGACGAGGGCCGGCACGAGATCGCCTACACGCGCATCGTGGACGAGTTCTTCCGCCTCGACCCCGAGGGCGCCGTCGCCGCCTACGCCAACATGATGCGCAAGCAGATCACCATGCCCGCGCACCTCATGGACGACATGGGCCACGGCGAGGCCAACCCGGGCCGCAACCTCTTCGCCGACTTCTCCGCGGTCGCCGAGAAGATCGACGTCTACGACGCCGAGGACTACTGCCGCATCCTGGAGCACCTCAACGCGCGCTGGAAGGTGGACGAGCGCCAGGTCAGCGGCCAGGCCGCCGCGGACCAGGAGTACGTCCTGGGCCTGCCCCAGCGCTTCCGGAAACTCGCCGAGAAGACCGCCGCCAAGCGCAAGCGCGTCGCGCGCAGGCCCGTCGCCTTCTCCTGGAGAAGAGCCTCTAGAGTCGACCTGCAGGCATGCAAGCTTGGCGTAATCATGGTCATAGCTGTTTCCTGTGTGAAATTGTTATCCGCTCACAATTCCACACAACATACGAGCCGGAAGCATAAAGTGTAAAGCCTGGGGTGCCTAATGAGTGAGCTAACTCACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCTCTTCCSEQIDNO:26桑椹形原藻SAD2B基因敲除同源重组靶向构建体GCTCTTCCCGCCTGGAGCTGGTGCAGAGCATGGGGCAGTTTGCGGAGGAGAGGGTGCTCCCCGTGCTGCACCCCGTGGACAAGCTGTGGCAGCCGCAGGACTTCCTGCCCGACCCCGAGTCGCCCGACTTCGAGGACCAGGTGGCGGAGCTGCGCGCGCGCGCCAAGGACCTGCCCGACGAGTACTTTGTGGTGCTGGTGGGCGACATGATCACGGAGGAGGCGCTGCCGACCTACATGGCCATGCTCAACACCTTGGACGGTGTGCGCGACGACACGGGCGCGGCTGACCACCCGTGGGCGCGCTGGACGCGGCAGTGGGTGGCCGAGGAGAACCGGCACGGCGACCTGCTGAACAAGTACTGTTGGCTGACGGGGCGCGTCAACATGCGGGCCGTGGAGGTGACCATCAACAACCTGATCAAGAGCGGCATGAACCCGCAGACGGACAACAACCCTTACTTGGGCTTCGTCTACACCTCCTTCCAGGAGCGCGCCACCAAGTAGGTACCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACGGCGCGCCATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGACAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGACAGCCACGGCAACACCGCGCGCCTTGCGGCCGAGCACGGCGACAAGAACCTGAGCAAGATCTGCGGGCTGATCGCCAGCGACGAGGGCCGGCACGAGATCGCCTACACGCGCATCGTGGACGAGTTCTTCCGCCTCGACCCCGAGGGCGCCGTCGCCGCCTACGCCAACATGATGCGCAAGCAGATCACCATGCCCGCGCACCTCATGGACGACATGGGCCACGGCGAGGCCAACCCGGGCCGCAACCTCTTCGCCGACTTCTCCGCGGTCGCCGAGAAGATCGACGTCTACGACGCCGAGGACTACTGCCGCATCCTGGAGCACCTCAACGCGCGCTGGAAGGTGGACGAGCGCCAGGTCAGCGGCCAGGCCGCCGCGGACCAGGAGTACGTCCTGGGCCTGCCCCAGCGCTTCCGGAAACTCGCCGAGAAGACCGCCGCCAAGCGCAAGCGCGTCGCGCGCAGGCCCGTCGCCTTCTCCTGGAGAAGAGCCTCTAGAGTCGACCTGCAGGCATGCAAGCTTGGCGTAATCATGGTCATAGCTGTTTCCTGTGTGAAATTGTTATCCGCTCACAATTCCACACAACATACGAGCCGGAAGCATAAAGTGTAAAGCCTGGGGTGCCTAATGAGTGAGCTAACTCACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCTCTTCCSEQIDNO:27引物15′-TCACTTCATGCCGGCGGTCC-3′SEQIDNO:28引物25′-GCGCTCCTGCTTGGCTCGAA-3′SEQIDNO:29酿酒酵母suc2盒CTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACGGCGCGCCATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGACAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGASEQIDNO:30莱茵衣藻TUB2启动子/5′UTRCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACSEQIDNO:31密码子优化的suc2基因ATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGASEQIDNO:32普通小球藻硝酸盐还原酶3′UTRGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAGGATCCSEQIDNO:33pSZ1124(FAD2B)5′基因组靶向序列GCTCTTCGAGACGTGGTCTGAATCCTCCAGGCGGGTTTCCCCGAGAAAGAAAGGGTGCCGATTTCAAAGCAGAGCCATGTGCCGGGCCCTGTGGCCTGTGTTGGCGCCTATGTAGTCACCCCCCCTCACCCAATTGTCGCCAGTTTGCGCAATCCATAAACTCAAAACTGCAGCTTCTGAGCTGCGCTGTTCAAGAACACCTCTGGGGTTTGCTCACCCGCGAGGTCGACGCCCAGCATGGCTATCAAGACGAACAGGCAGCCTGTGGAGAAGCCTCCGTTCACGATCGGGACGCTGCGCAAGGCCATCCCCGCGCACTGTTTCGAGCGCTCGGCGCTTCGTAGCAGCATGTACCTGGCCTTTGACATCGCGGTCATGTCCCTGCTCTACGTCGCGTCGACGTACATCGACCCTGCGCCGGTGCCTACGTGGGTCAAGTATGGCGTCATGTGGCCGCTCTACTGGTTCTTCCAGGTGTGTGTGAGGGTTGTGGTTGCCCGTATCGAGGTCCTGGTGGCGCGCATGGGGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCCTTCGGCACGGGTGTCTGGGTGTGCGCGCACGAGTGCGGCCACCAGGCCTTTTCCTCCAGCCAGGCCATCAACGACGGCGTGGGCCTGGTGTTCCACAGCCTGCTGCTGGTGCCCTACTACTCCTGGAAGCACTCGCACCGGGTACCSEQIDNO:34pSZ1124(FAD2B)3′基因组靶向序列CCGCCACCACTCCAACACGGGGTGCCTGGACAAGGACGAGGTGTTTGTGCCGCCGCACCGCGCAGTGGCGCACGAGGGCCTGGAGTGGGAGGAGTGGCTGCCCATCCGCATGGGCAAGGTGCTGGTCACCCTGACCCTGGGCTGGCCGCTGTACCTCATGTTCAACGTCGCCTCGCGGCCGTACCCGCGCTTCGCCAACCACTTTGACCCGTGGTCGCCCATCTTCAGCAAGCGCGAGCGCATCGAGGTGGTCATCTCCGACCTGGCGCTGGTGGCGGTGCTCAGCGGGCTCAGCGTGCTGGGCCGCACCATGGGCTGGGCCTGGCTGGTCAAGACCTACGTGGTGCCCTACCTGATCGTGAACATGTGGCTCGTGCTCATCACGCTGCTCCAGCACACGCACCCGGCGCTGCCGCACTACTTCGAGAAGGACTGGGACTGGCTGCGCGGCGCCATGGCCACCGTGGACCGCTCCATGGGCCCGCCCTTCATGGACAACATCCTGCACCACATCTCCGACACCCACGTGCTGCACCACCTCTTCAGCACCATCCCGCACTACCACGCCGAGGAGGCCTCCGCCGCCATCAGGCCCATCCTGGGCAAGTACTACCAGTCCGACAGCCGCTGGGTCGGCCGCGCCCTGTGGGAGGACTGGCGCGACTGCCGCTACGTCGTCCCGGACGCGCCCGAGGACGACTCCGCGCTCTGGTTCCACAAGTGAGTGAGTGAGAAGAGCSEQIDNO:35pSZ1125(FAD2C)5′基因组靶向序列GCTCTTCGAGGGGCTGGTCTGAATCCTTCAGGCGGGTGTTACCCGAGAAAGAAAGGGTGCCGATTTCAAAGCAGACCCATGTGCCGGGCCCTGTGGCCTGTGTTGGCGCCTATGTAGTCACCCCCCCTCACCCAATTGTCGCCAGTTTGCGCACTCCATAAACTCAAAACAGCAGCTTCTGAGCTGCGCTGTTCAAGAACACCTCTGGGGTTTGCTCACCCGCGAGGTCGACGCCCAGCATGGCTATCAAGACGAACAGGCAGCCTGTGGAGAAGCCTCCGTTCACGATCGGGACGCTGCGCAAGGCCATCCCCGCGCACTGTTTCGAGCGCTCGGCGCTTCGTAGCAGCATGTACCTGGCCTTTGACATCGCGGTCATGTCCCTGCTCTACGTCGCGTCGACGTACATCGACCCTGCACCGGTGCCTACGTGGGTCAAGTACGGCATCATGTGGCCGCTCTACTGGTTCTTCCAGGTGTGTTTGAGGGTTTTGGTTGCCCGTATTGAGGTCCTGGTGGCGCGCATGGAGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCCTTCGGCACGGGTGTCTGGGTGTGCGCGCACGAGTGCGGCCACCAGGCCTTTTCCTCCAGCCAGGCCATCAACGACGGCGTGGGCCTGGTGTTCCACAGCCTGCTGCTGGTGCCCTACTACTCCTGGAAGCACTCGCACCGGGTACCSEQIDNO:36pSZ1125(FAD2C)3′基因组靶向序列CCGCCACCACTCCAACACGGGGTGCCTGGACAAGGACGAGGTGTTTGTGCCGCCGCACCGCGCAGTGGCGCACGAGGGCCTGGAGTGGGAGGAGTGGCTGCCCATCCGCATGGGCAAGGTGCTGGTCACCCTGACCCTGGGCTGGCCGCTGTACCTCATGTTCAACGTCGCCTCGCGGCCGTACCCGCGCTTCGCCAACCACTTTGACCCGTGGTCGCCCATCTTCAGCAAGCGCGAGCGCATCGAGGTGGTCATCTCCGACCTGGCGCTGGTGGCGGTGCTCAGCGGGCTCAGCGTGCTGGGCCGCACCATGGGCTGGGCCTGGCTGGTCAAGACCTACGTGGTGCCCTACCTGATCGTGAACATGTGGCTCGTGCTCATCACGCTGCTCCAGCACACGCACCCGGCGCTGCCGCACTACTTCGAGAAGGACTGGGACTGGCTGCGCGGCGCCATGGCCACCGTGGACCGCTCCATGGGCCCGCCCTTCATGGACAACATCCTGCACCACATCTCCGACACCCACGTGCTGCACCACCTCTTCAGCACCATCCCGCACTACCACGCCGAGGAGGCCTCCGCCGCCATCAGGCCCATCCTGGGCAAGTACTACCAGTCCGACAGCCGCTGGGTCGGCCGCGCCCTGTGGGAGGACTGGCGCGACTGCCGCTACGTCGTCCCGGACGCGCCCGAGGACGACTCCGCGCTCTGGTTCCACAAGTGAGTGAGTGAGAAGAGCSEQIDNO:37amt03启动子/UTR序列GGCCGACAGGACGCGCGTCAAAGGTGCTGGTCGTGTATGCCCTGGCCGGCAGGTCGTTGCTGCTGCTGGTTAGTGATTCCGCAACCCTGATTTTGGCGTCTTATTTTGGCGTGGCAAACGCTGGCGCCCGCGAGCCGGGCCGGCGGCGATGCGGTGCCCCACGGCTGCCGGAATCCAAGGGAGGCAAGAGCGCCCGGGTCAGTTGAAGGGCTTTACGCGCAAGGTACAGCCGCTCCTGCAAGGCTGCGTGGTGGAATTGGACGTGCAGGTCCTGCTGAAGTTCCTCCACCGCCTCACCAGCGGACAAAGCACCGGTGTATCAGGTCCGTGTCATCCACTCTAAAGAGCTCGACTACGACCTACTGATGGCCCTAGATTCTTCATCAAAAACGCCTGAGACACTTGCCCAGGATTGAAACTCCCTGAAGGGACCACCAGGGGCCCTGAGTTGTTCCTTCCCCCCGTGGCGAGCTGCCAGCCAGGCTGTACCTGTGATCGAGGCTGGCGGGAAAATAGGCTTCGTGTGCTCAGGTCATGGGAGGTGCAGGACAGCTCATGAAACGCCAACAATCGCACAATTCATGTCAAGCTAATCAGCTATTTCCTCTTCACGAGCTGTAATTGTCCCAAAATTCTGGTCTACCGGGGGTGATCCTTCGTGTACGGGCCCTTCCCTCAACCCTAGGTATGCGCGCATGCGGTCGCCGCGCAACTCGCGCGAGGGCCGAGGGTTTGGGACGGGCCGTCCCGAAATGCAGTTGCACCCGGATGCGTGGCACCTTTTTTGCGATAATTTATGCAATGGACTGCTCTGCAAAATTCTGGCTCTGTCGCCAACCCTAGGATCAGCGGCGTAGGATTTCGTAATCATTCGTCCTGATGGGGAGCTACCGACTACCCTAATATCAGCCCGACTGCCTGACGCCAGCGTCCACTTTTGTGCACACATTCCATTCGTGCCCAAGACATTTCATTGTGGTGCGAAGCGTCCCCAGTTACGCTCACCTGTTTCCCGACCTCCTTACTGTTCTGTCGACAGAGCGGGCCCACAGGCCGGTCGCAGCCSEQIDNO:38桑椹形原藻的5′6S基因组供体序列GCTCTTCGCCGCCGCCACTCCTGCTCGAGCGCGCCCGCGCGTGCGCCGCCAGCGCCTTGGCCTTTTCGCCGCGCTCGTGCGCGTCGCTGATGTCCATCACCAGGTCCATGAGGTCTGCCTTGCGCCGGCTGAGCCACTGCTTCGTCCGGGCGGCCAAGAGGAGCATGAGGGAGGACTCCTGGTCCAGGGTCCTGACGTGGTCGCGGCTCTGGGAGCGGGCCAGCATCATCTGGCTCTGCCGCACCGAGGCCGCCTCCAACTGGTCCTCCAGCAGCCGCAGTCGCCGCCGACCCTGGCAGAGGAAGACAGGTGAGGGGGGTATGAATTGTACAGAACAACCACGAGCCTTGTCTAGGCAGAATCCCTACCAGTCATGGCTTTACCTGGATGACGGCCTGCGAACAGCTGTCCAGCGACCCTCGCTGCCGCCGCTTCTCCCGCACGCTTCTTTCCAGCACCGTGATGGCGCGAGCCAGCGCCGCACGCTGGCGCTGCGCTTCGCCGATCTGAGGACAGTCGGGGAACTCTGATCAGTCTAAACCCCCTTGCGCGTTAGTGTTGCCATCCTTTGCAGACCGGTGAGAGCCGACTTGTTGTGCGCCACCCCCCACACCACCTCCTCCCAGACCAATTCTGTCACCTTTTTGGCGAAGGCATCGGCCTCGGCCTGCAGAGAGGACAGCAGTGCCCAGCCGCTGGGGGTTGGCGGATGCACGCTCAGGTACCSEQIDNO:39桑椹形原藻的3′6S基因组供体序列GAGCTCCTTGTTTTCCAGAAGGAGTTGCTCCTTGAGCCTTTCATTCTCAGCCTCGATAACCTCCAAAGCCGCTCTAATTGTGGAGGGGGTTCGAATTTAAAAGCTTGGAATGTTGGTTCGTGCGTCTGGAACAAGCCCAGACTTGTTGCTCACTGGGAAAAGGACCATCAGCTCCAAAAAACTTGCCGCTCAAACCGCGTACCTCTGCTTTCGCGCAATCTGCCCTGTTGAAATCGCCACCACATTCATATTGTGACGCTTGAGCAGTCTGTAATTGCCTCAGAATGTGGAATCATCTGCCCCCTGTGCGAGCCCATGCCAGGCATGTCGCGGGCGAGGACACCCGCCACTCGTACAGCAGACCATTATGCTACCTCACAATAGTTCATAACAGTGACCATATTTCTCGAAGCTCCCCAACGAGCACCTCCATGCTCTGAGTGGCCACCCCCCGGCCCTGGTGCTTGCGGAGGGCAGGTCAACCGGCATGGGGCTACCGAAATCCCCGACCGGATCCCACCACCCCCGCGATGGGAAGAATCTCTCCCCGGGATGTGGGCCCACCACCAGCACAACCTGCTGGCCCAGGCGAGCGTCAAACCATACCACACAAATATCCTTGGCATCGGCCCTGAATTCCTTCTGCCGCTCTGCTACCCGGTGCTTCTGTCCGAAGCAGGGGTTGCTAGGGATCGCTCCGAGTCCGCAAACCCTTGTCGCGTGGCGGGGCTTGTTCGAGCTTGAAGAGCSEQIDNO:40来自pSZ1468的长发夹RNA表达盒的FADc部分ACTAGTATGGCTATCAAGACGAACAGGCAGCCTGTGGAGAAGCCTCCGTTCACGATCGGGACGCTGCGCAAGGCCATCCCCGCGCACTGTTTCGAGCGCTCGGCGCTTCGTAGCAGCATGTACCTGGCCTTTGACATCGCGGTCATGTCCCTGCTCTACGTCGCGTCGACGTACATCGACCCTGCACCGGTGCCTACGTGGGTCAAGTACGGCATCATGTGGCCGCTCTACTGGTTCTTCCAGGTGTGTTTGAGGGTTTTGGTTGCCCGTATTGAGGTCCTGGTGGCGCGCATGGAGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCGTACGGGAAGAACCAGTAGAGCGGCCACATGATGCCGTACTTGACCCACGTAGGCACCGGTGCAGGGTCGATGTACGTCGACGCGACGTAGAGCAGGGACATGACCGCGATGTCAAAGGCCAGGTACATGCTGCTACGAAGCGCCGAGCGCTCGAAACAGTGCGCGGGGATGGCCTTGCGCAGCGTCCCGATCGTGAACGGAGGCTTCTCCACAGGCTGCCTGTTCGTCTTGATAGCCATSEQIDNO:41来自pSZ1468的FADc长发夹RNA表达盒的相关部分GCTCTTCGCCGCCGCCACTCCTGCTCGAGCGCGCCCGCGCGTGCGCCGCCAGCGCCTTGGCCTTTTCGCCGCGCTCGTGCGCGTCGCTGATGTCCATCACCAGGTCCATGAGGTCTGCCTTGCGCCGGCTGAGCCACTGCTTCGTCCGGGCGGCCAAGAGGAGCATGAGGGAGGACTCCTGGTCCAGGGTCCTGACGTGGTCGCGGCTCTGGGAGCGGGCCAGCATCATCTGGCTCTGCCGCACCGAGGCCGCCTCCAACTGGTCCTCCAGCAGCCGCAGTCGCCGCCGACCCTGGCAGAGGAAGACAGGTGAGGGGGGTATGAATTGTACAGAACAACCACGAGCCTTGTCTAGGCAGAATCCCTACCAGTCATGGCTTTACCTGGATGACGGCCTGCGAACAGCTGTCCAGCGACCCTCGCTGCCGCCGCTTCTCCCGCACGCTTCTTTCCAGCACCGTGATGGCGCGAGCCAGCGCCGCACGCTGGCGCTGCGCTTCGCCGATCTGAGGACAGTCGGGGAACTCTGATCAGTCTAAACCCCCTTGCGCGTTAGTGTTGCCATCCTTTGCAGACCGGTGAGAGCCGACTTGTTGTGCGCCACCCCCCACACCACCTCCTCCCAGACCAATTCTGTCACCTTTTTGGCGAAGGCATCGGCCTCGGCCTGCAGAGAGGACAGCAGTGCCCAGCCGCTGGGGGTTGGCGGATGCACGCTCAGGTACCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACGGCGCGCCATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGACAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAGGATCCCGCGTCTCGAACAGAGCGCGCAGAGGAACGCTGAAGGTCTCGCCTCTGTCGCACCTCAGCGCGGCATACACCACAATAACCACCTGACGAATGCGCTTGGTTCTTCGTCCATTAGCGAAGCGTCCGGTTCACACACGTGCCACGTTGGCGAGGTGGCAGGTGACAATGATCGGTGGAGCTGATGGTCGAAACGTTCACAGCCTAGGGATATCGAATTCGGCCGACAGGACGCGCGTCAAAGGTGCTGGTCGTGTATGCCCTGGCCGGCAGGTCGTTGCTGCTGCTGGTTAGTGATTCCGCAACCCTGATTTTGGCGTCTTATTTTGGCGTGGCAAACGCTGGCGCCCGCGAGCCGGGCCGGCGGCGATGCGGTGCCCCACGGCTGCCGGAATCCAAGGGAGGCAAGAGCGCCCGGGTCAGTTGAAGGGCTTTACGCGCAAGGTACAGCCGCTCCTGCAAGGCTGCGTGGTGGAATTGGACGTGCAGGTCCTGCTGAAGTTCCTCCACCGCCTCACCAGCGGACAAAGCACCGGTGTATCAGGTCCGTGTCATCCACTCTAAAGAGCTCGACTACGACCTACTGATGGCCCTAGATTCTTCATCAAAAACGCCTGAGACACTTGCCCAGGATTGAAACTCCCTGAAGGGACCACCAGGGGCCCTGAGTTGTTCCTTCCCCCCGTGGCGAGCTGCCAGCCAGGCTGTACCTGTGATCGAGGCTGGCGGGAAAATAGGCTTCGTGTGCTCAGGTCATGGGAGGTGCAGGACAGCTCATGAAACGCCAACAATCGCACAATTCATGTCAAGCTAATCAGCTATTTCCTCTTCACGAGCTGTAATTGTCCCAAAATTCTGGTCTACCGGGGGTGATCCTTCGTGTACGGGCCCTTCCCTCAACCCTAGGTATGCGCGCATGCGGTCGCCGCGCAACTCGCGCGAGGGCCGAGGGTTTGGGACGGGCCGTCCCGAAATGCAGTTGCACCCGGATGCGTGGCACCTTTTTTGCGATAATTTATGCAATGGACTGCTCTGCAAAATTCTGGCTCTGTCGCCAACCCTAGGATCAGCGGCGTAGGATTTCGTAATCATTCGTCCTGATGGGGAGCTACCGACTACCCTAATATCAGCCCGACTGCCTGACGCCAGCGTCCACTTTTGTGCACACATTCCATTCGTGCCCAAGACATTTCATTGTGGTGCGAAGCGTCCCCAGTTACGCTCACCTGTTTCCCGACCTCCTTACTGTTCTGTCGACAGAGCGGGCCCACAGGCCGGTCGCAGCCACTAGTATGGCTATCAAGACGAACAGGCAGCCTGTGGAGAAGCCTCCGTTCACGATCGGGACGCTGCGCAAGGCCATCCCCGCGCACTGTTTCGAGCGCTCGGCGCTTCGTAGCAGCATGTACCTGGCCTTTGACATCGCGGTCATGTCCCTGCTCTACGTCGCGTCGACGTACATCGACCCTGCACCGGTGCCTACGTGGGTCAAGTACGGCATCATGTGGCCGCTCTACTGGTTCTTCCAGGTGTGTTTGAGGGTTTTGGTTGCCCGTATTGAGGTCCTGGTGGCGCGCATGGAGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCGTACGGGAAGAACCAGTAGAGCGGCCACATGATGCCGTACTTGACCCACGTAGGCACCGGTGCAGGGTCGATGTACGTCGACGCGACGTAGAGCAGGGACATGACCGCGATGTCAAAGGCCAGGTACATGCTGCTACGAAGCGCCGAGCGCTCGAAACAGTGCGCGGGGATGGCCTTGCGCAGCGTCCCGATCGTGAACGGAGGCTTCTCCACAGGCTGCCTGTTCGTCTTGATAGCCATCTCGAGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAAAGCTGTAGAGCTCTTGTTTTCCAGAAGGAGTTGCTCCTTGAGCCTTTCATTCTCAGCCTCGATAACCTCCAAAGCCGCTCTAATTGTGGAGGGGGTTCGAATTTAAAAGCTTGGAATGTTGGTTCGTGCGTCTGGAACAAGCCCAGACTTGTTGCTCACTGGGAAAAGGACCATCAGCTCCAAAAAACTTGCCGCTCAAACCGCGTACCTCTGCTTTCGCGCAATCTGCCCTGTTGAAATCGCCACCACATTCATATTGTGACGCTTGAGCAGTCTGTAATTGCCTCAGAATGTGGAATCATCTGCCCCCTGTGCGAGCCCATGCCAGGCATGTCGCGGGCGAGGACACCCGCCACTCGTACAGCAGACCATTATGCTACCTCACAATAGTTCATAACAGTGACCATATTTCTCGAAGCTCCCCAACGAGCACCTCCATGCTCTGAGTGGCCACCCCCCGGCCCTGGTGCTTGCGGAGGGCAGGTCAACCGGCATGGGGCTACCGAAATCCCCGACCGGATCCCACCACCCCCGCGATGGGAAGAATCTCTCCCCGGGATGTGGGCCCACCACCAGCACAACCTGCTGGCCCAGGCGAGCGTCAAACCATACCACACAAATATCCTTGGCATCGGCCCTGAATTCCTTCTGCCGCTCTGCTACCCGGTGCTTCTGTCCGAAGCAGGGGTTGCTAGGGATCGCTCCGAGTCCGCAAACCCTTGTCGCGTGGCGGGGCTTGTTCGAGCTTGAAGAGCSEQIDNO:42来自pSZ1469的长发夹RNA表达盒的FADc部分ACTAGTATGGCTATCAAGACGAACAGGCAGCCTGTGGAGAAGCCTCCGTTCACGATCGGGACGCTGCGCAAGGCCATCCCCGCGCACTGTTTCGAGCGCTCGGCGCTTCGTAGCAGCATGTACCTGGCCTTTGACATCGCGGTCATGTCCCTGCTCTACGTCGCGTCGACGTACATCGACCCTGCACCGGTGCCTACGTGGGTCAAGTACGGCATCATGTGGCCGCTCTACTGGTTCTTCCAGGTGTGTTTGAGGGTTTTGGTTGCCCGTATTGAGGTCCTGGTGGCGCGCATGGAGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCGTACGGGAAGAACCAGTAGAGCGGCCACATGATGCCGTACTTGACCCACGTAGGCACCGGTGCAGGGTCGATGTACGTCGACGCGACGTAGAGCAGGGACATGACCGCGATGTCAAAGGCCAGGTACATGCTGCTACGAAGCGCCGAGCGCTCGAAACAGTGCGCGGGGATGGCCTTGCGCAGCGTCCCGATCGTGAACGGAGGCTTCTCCACAGGCTGCCTGTTCGTCTTGATAGCCATSEQIDNO:43来自pSZ1469的FADc长发夹RNA表达盒的相关部分GCTCTTCGCCGCCGCCACTCCTGCTCGAGCGCGCCCGCGCGTGCGCCGCCAGCGCCTTGGCCTTTTCGCCGCGCTCGTGCGCGTCGCTGATGTCCATCACCAGGTCCATGAGGTCTGCCTTGCGCCGGCTGAGCCACTGCTTCGTCCGGGCGGCCAAGAGGAGCATGAGGGAGGACTCCTGGTCCAGGGTCCTGACGTGGTCGCGGCTCTGGGAGCGGGCCAGCATCATCTGGCTCTGCCGCACCGAGGCCGCCTCCAACTGGTCCTCCAGCAGCCGCAGTCGCCGCCGACCCTGGCAGAGGAAGACAGGTGAGGGGGGTATGAATTGTACAGAACAACCACGAGCCTTGTCTAGGCAGAATCCCTACCAGTCATGGCTTTACCTGGATGACGGCCTGCGAACAGCTGTCCAGCGACCCTCGCTGCCGCCGCTTCTCCCGCACGCTTCTTTCCAGCACCGTGATGGCGCGAGCCAGCGCCGCACGCTGGCGCTGCGCTTCGCCGATCTGAGGACAGTCGGGGAACTCTGATCAGTCTAAACCCCCTTGCGCGTTAGTGTTGCCATCCTTTGCAGACCGGTGAGAGCCGACTTGTTGTGCGCCACCCCCCACACCACCTCCTCCCAGACCAATTCTGTCACCTTTTTGGCGAAGGCATCGGCCTCGGCCTGCAGAGAGGACAGCAGTGCCCAGCCGCTGGGGGTTGGCGGATGCACGCTCAGGTACCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACGGCGCGCCATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGACAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAGGATCCCGCGTCTCGAACAGAGCGCGCAGAGGAACGCTGAAGGTCTCGCCTCTGTCGCACCTCAGCGCGGCATACACCACAATAACCACCTGACGAATGCGCTTGGTTCTTCGTCCATTAGCGAAGCGTCCGGTTCACACACGTGCCACGTTGGCGAGGTGGCAGGTGACAATGATCGGTGGAGCTGATGGTCGAAACGTTCACAGCCTAGGGATATCGAATTCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACACTAGTATGGCTATCAAGACGAACAGGCAGCCTGTGGAGAAGCCTCCGTTCACGATCGGGACGCTGCGCAAGGCCATCCCCGCGCACTGTTTCGAGCGCTCGGCGCTTCGTAGCAGCATGTACCTGGCCTTTGACATCGCGGTCATGTCCCTGCTCTACGTCGCGTCGACGTACATCGACCCTGCACCGGTGCCTACGTGGGTCAAGTACGGCATCATGTGGCCGCTCTACTGGTTCTTCCAGGTGTGTTTGAGGGTTTTGGTTGCCCGTATTGAGGTCCTGGTGGCGCGCATGGAGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCGTACGGGAAGAACCAGTAGAGCGGCCACATGATGCCGTACTTGACCCACGTAGGCACCGGTGCAGGGTCGATGTACGTCGACGCGACGTAGAGCAGGGACATGACCGCGATGTCAAAGGCCAGGTACATGCTGCTACGAAGCGCCGAGCGCTCGAAACAGTGCGCGGGGATGGCCTTGCGCAGCGTCCCGATCGTGAACGGAGGCTTCTCCACAGGCTGCCTGTTCGTCTTGATAGCCATCTCGAGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAAAGCTGTAGAGCTCTTGTTTTCCAGAAGGAGTTGCTCCTTGAGCCTTTCATTCTCAGCCTCGATAACCTCCAAAGCCGCTCTAATTGTGGAGGGGGTTCGAATTTAAAAGCTTGGAATGTTGGTTCGTGCGTCTGGAACAAGCCCAGACTTGTTGCTCACTGGGAAAAGGACCATCAGCTCCAAAAAACTTGCCGCTCAAACCGCGTACCTCTGCTTTCGCGCAATCTGCCCTGTTGAAATCGCCACCACATTCATATTGTGACGCTTGAGCAGTCTGTAATTGCCTCAGAATGTGGAATCATCTGCCCCCTGTGCGAGCCCATGCCAGGCATGTCGCGGGCGAGGACACCCGCCACTCGTACAGCAGACCATTATGCTACCTCACAATAGTTCATAACAGTGACCATATTTCTCGAAGCTCCCCAACGAGCACCTCCATGCTCTGAGTGGCCACCCCCCGGCCCTGGTGCTTGCGGAGGGCAGGTCAACCGGCATGGGGCTACCGAAATCCCCGACCGGATCCCACCACCCCCGCGATGGGAAGAATCTCTCCCCGGGATGTGGGCCCACCACCAGCACAACCTGCTGGCCCAGGCGAGCGTCAAACCATACCACACAAATATCCTTGGCATCGGCCCTGAATTCCTTCTGCCGCTCTGCTACCCGGTGCTTCTGTCCGAAGCAGGGGTTGCTAGGGATCGCTCCGAGTCCGCAAACCCTTGTCGCGTGGCGGGGCTTGTTCGAGCTTGAAGAGCSEQIDNO:44来自pSZ1470的长发夹RNA表达盒的FADc部分ACTAGTTCACTTGTGGAACCAGAGCGCGGAGTCGTCCTCGGGCGCGTCCGGGACGACGTAGCGGCAGTCGCGCCAGTCCTCCCACAGGGCGCGGCCGACCCAGCGGCTGTCGGACTGGTAGTACTTGCCCAGGATGGGCCTGATGGCGGCGGAGGCCTCCTCGGCGTGGTAGTGCGGGATGGTGCTGAAGAGGTGGTGCAGCACGTGGGTGTCGGAGATGTGGTGCAGGATGTTGTCCATGAAGGGCGGGCCCATGGAGCGGTCCACGGTGGCCATGGCGCCGCGCAGCCAGTCCCAGTCCTTCTCGAAGTAGTGCGGCAGCGCCGGGTGCGTGTGCTGGAGCAGCGTGATGAGCACGAGCCACATGTTCACGATCAGGTAGGGCACCACGTAGGTCTTGACCAGCCAGGCCCAGCCCATGGTGCGGCCCAGCACGCTGAGCCCGCTGAGCACCGCCACCAGCGCCAGGTCGGAGATGACCACCTCGATGCGCTCGCGCTTGCTGAAGATGGGCGACCACGGGTCAAAGTGGTTGGCGAAGCGCGGGTACGGCCGCGAGGCGACGTTGAACATGAGGTACAGCGGCCAGCCCAGGGTCAGGGTGACCAGCACCTTGCCCATGCGGATGGGCAGCCACTCCTCCCACTCCAGGCCCTCGTGCGCCACTGCGCGGTGCGGCGGCACAAACACCTCGTCCTTGTCCAGGCACCCCGTGTTGGAGTGGTGGCGGCGGTGCGAGTGCTTCCAGGAGTAGTAGGGCACCAGCAGCAGGCTGTGGAACACCAGGCCCACGCCGTCGTTGATGGCCTGGCTGGAGGAAAAGGCCTGGTGGCCGCACTCGTGCGCGCACACCCAGACACCCGTGCCGAAGGCGCCCTGGAAGGTGCCGGGAGGGTAGCCGGGGGGGTCAGCGGGACAGGCGCCTTCTCCTCCATGCGCGCCACCAGGACCTCAATACGGGCAACCAAAACCCTCAAACACACCTGGAAGAACCAGTAGAGCGGCCACATGATGCCGTACTTGACCCACGTAGGCACCGGTGCAGGGTCGATGTACGTCGACGCGACGTAGAGCAGGGACATGACCGCGATGTCAAAGGCCAGGTACATGCTGCTACGAAGCGCCGAGCGCTCGAAACAGTGCGCGGGGATGGCCTTGCGCAGCGTCCCGATCGTGAACGGAGGCTTCTCCACAGGCTGCCTGTTCGTCTTGATAGCCATSEQIDNO:45来自pSZ1470的FADc长发夹RNA表达盒的相关部分GCTCTTCGCCGCCGCCACTCCTGCTCGAGCGCGCCCGCGCGTGCGCCGCCAGCGCCTTGGCCTTTTCGCCGCGCTCGTGCGCGTCGCTGATGTCCATCACCAGGTCCATGAGGTCTGCCTTGCGCCGGCTGAGCCACTGCTTCGTCCGGGCGGCCAAGAGGAGCATGAGGGAGGACTCCTGGTCCAGGGTCCTGACGTGGTCGCGGCTCTGGGAGCGGGCCAGCATCATCTGGCTCTGCCGCACCGAGGCCGCCTCCAACTGGTCCTCCAGCAGCCGCAGTCGCCGCCGACCCTGGCAGAGGAAGACAGGTGAGGGGGGTATGAATTGTACAGAACAACCACGAGCCTTGTCTAGGCAGAATCCCTACCAGTCATGGCTTTACCTGGATGACGGCCTGCGAACAGCTGTCCAGCGACCCTCGCTGCCGCCGCTTCTCCCGCACGCTTCTTTCCAGCACCGTGATGGCGCGAGCCAGCGCCGCACGCTGGCGCTGCGCTTCGCCGATCTGAGGACAGTCGGGGAACTCTGATCAGTCTAAACCCCCTTGCGCGTTAGTGTTGCCATCCTTTGCAGACCGGTGAGAGCCGACTTGTTGTGCGCCACCCCCCACACCACCTCCTCCCAGACCAATTCTGTCACCTTTTTGGCGAAGGCATCGGCCTCGGCCTGCAGAGAGGACAGCAGTGCCCAGCCGCTGGGGGTTGGCGGATGCACGCTCAGGTACCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACGGCGCGCCATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGACAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAGGATCCCGCGTCTCGAACAGAGCGCGCAGAGGAACGCTGAAGGTCTCGCCTCTGTCGCACCTCAGCGCGGCATACACCACAATAACCACCTGACGAATGCGCTTGGTTCTTCGTCCATTAGCGAAGCGTCCGGTTCACACACGTGCCACGTTGGCGAGGTGGCAGGTGACAATGATCGGTGGAGCTGATGGTCGAAACGTTCACAGCCTAGGGATATCGAATTCGGCCGACAGGACGCGCGTCAAAGGTGCTGGTCGTGTATGCCCTGGCCGGCAGGTCGTTGCTGCTGCTGGTTAGTGATTCCGCAACCCTGATTTTGGCGTCTTATTTTGGCGTGGCAAACGCTGGCGCCCGCGAGCCGGGCCGGCGGCGATGCGGTGCCCCACGGCTGCCGGAATCCAAGGGAGGCAAGAGCGCCCGGGTCAGTTGAAGGGCTTTACGCGCAAGGTACAGCCGCTCCTGCAAGGCTGCGTGGTGGAATTGGACGTGCAGGTCCTGCTGAAGTTCCTCCACCGCCTCACCAGCGGACAAAGCACCGGTGTATCAGGTCCGTGTCATCCACTCTAAAGAGCTCGACTACGACCTACTGATGGCCCTAGATTCTTCATCAAAAACGCCTGAGACACTTGCCCAGGATTGAAACTCCCTGAAGGGACCACCAGGGGCCCTGAGTTGTTCCTTCCCCCCGTGGCGAGCTGCCAGCCAGGCTGTACCTGTGATCGAGGCTGGCGGGAAAATAGGCTTCGTGTGCTCAGGTCATGGGAGGTGCAGGACAGCTCATGAAACGCCAACAATCGCACAATTCATGTCAAGCTAATCAGCTATTTCCTCTTCACGAGCTGTAATTGTCCCAAAATTCTGGTCTACCGGGGGTGATCCTTCGTGTACGGGCCCTTCCCTCAACCCTAGGTATGCGCGCATGCGGTCGCCGCGCAACTCGCGCGAGGGCCGAGGGTTTGGGACGGGCCGTCCCGAAATGCAGTTGCACCCGGATGCGTGGCACCTTTTTTGCGATAATTTATGCAATGGACTGCTCTGCAAAATTCTGGCTCTGTCGCCAACCCTAGGATCAGCGGCGTAGGATTTCGTAATCATTCGTCCTGATGGGGAGCTACCGACTACCCTAATATCAGCCCGACTGCCTGACGCCAGCGTCCACTTTTGTGCACACATTCCATTCGTGCCCAAGACATTTCATTGTGGTGCGAAGCGTCCCCAGTTACGCTCACCTGTTTCCCGACCTCCTTACTGTTCTGTCGACAGAGCGGGCCCACAGGCCGGTCGCAGCCACTAGTTCACTTGTGGAACCAGAGCGCGGAGTCGTCCTCGGGCGCGTCCGGGACGACGTAGCGGCAGTCGCGCCAGTCCTCCCACAGGGCGCGGCCGACCCAGCGGCTGTCGGACTGGTAGTACTTGCCCAGGATGGGCCTGATGGCGGCGGAGGCCTCCTCGGCGTGGTAGTGCGGGATGGTGCTGAAGAGGTGGTGCAGCACGTGGGTGTCGGAGATGTGGTGCAGGATGTTGTCCATGAAGGGCGGGCCCATGGAGCGGTCCACGGTGGCCATGGCGCCGCGCAGCCAGTCCCAGTCCTTCTCGAAGTAGTGCGGCAGCGCCGGGTGCGTGTGCTGGAGCAGCGTGATGAGCACGAGCCACATGTTCACGATCAGGTAGGGCACCACGTAGGTCTTGACCAGCCAGGCCCAGCCCATGGTGCGGCCCAGCACGCTGAGCCCGCTGAGCACCGCCACCAGCGCCAGGTCGGAGATGACCACCTCGATGCGCTCGCGCTTGCTGAAGATGGGCGACCACGGGTCAAAGTGGTTGGCGAAGCGCGGGTACGGCCGCGAGGCGACGTTGAACATGAGGTACAGCGGCCAGCCCAGGGTCAGGGTGACCAGCACCTTGCCCATGCGGATGGGCAGCCACTCCTCCCACTCCAGGCCCTCGTGCGCCACTGCGCGGTGCGGCGGCACAAACACCTCGTCCTTGTCCAGGCACCCCGTGTTGGAGTGGTGGCGGCGGTGCGAGTGCTTCCAGGAGTAGTAGGGCACCAGCAGCAGGCTGTGGAACACCAGGCCCACGCCGTCGTTGATGGCCTGGCTGGAGGAAAAGGCCTGGTGGCCGCACTCGTGCGCGCACACCCAGACACCCGTGCCGAAGGCGCCCTGGAAGGTGCCGGGAGGGTAGCCGGGGGGGTCAGCGGGACAGGCGCCTTCTCCTCCATGCGCGCCACCAGGACCTCAATACGGGCAACCAAAACCCTCAAACACACCTGGAAGAACCAGTAGAGCGGCCACATGATGCCGTACTTGACCCACGTAGGCACCGGTGCAGGGTCGATGTACGTCGACGCGACGTAGAGCAGGGACATGACCGCGATGTCAAAGGCCAGGTACATGCTGCTACGAAGCGCCGAGCGCTCGAAACAGTGCGCGGGGATGGCCTTGCGCAGCGTCCCGATCGTGAACGGAGGCTTCTCCACAGGCTGCCTGTTCGTCTTGATAGCCATCTCGAGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAAAGCTGTAGAGCTCTTGTTTTCCAGAAGGAGTTGCTCCTTGAGCCTTTCATTCTCAGCCTCGATAACCTCCAAAGCCGCTCTAATTGTGGAGGGGGTTCGAATTTAAAAGCTTGGAATGTTGGTTCGTGCGTCTGGAACAAGCCCAGACTTGTTGCTCACTGGGAAAAGGACCATCAGCTCCAAAAAACTTGCCGCTCAAACCGCGTACCTCTGCTTTCGCGCAATCTGCCCTGTTGAAATCGCCACCACATTCATATTGTGACGCTTGAGCAGTCTGTAATTGCCTCAGAATGTGGAATCATCTGCCCCCTGTGCGAGCCCATGCCAGGCATGTCGCGGGCGAGGACACCCGCCACTCGTACAGCAGACCATTATGCTACCTCACAATAGTTCATAACAGTGACCATATTTCTCGAAGCTCCCCAACGAGCACCTCCATGCTCTGAGTGGCCACCCCCCGGCCCTGGTGCTTGCGGAGGGCAGGTCAACCGGCATGGGGCTACCGAAATCCCCGACCGGATCCCACCACCCCCGCGATGGGAAGAATCTCTCCCCGGGATGTGGGCCCACCACCAGCACAACCTGCTGGCCCAGGCGAGCGTCAAACCATACCACACAAATATCCTTGGCATCGGCCCTGAATTCCTTCTGCCGCTCTGCTACCCGGTGCTTCTGTCCGAAGCAGGGGTTGCTAGGGATCGCTCCGAGTCCGCAAACCCTTGTCGCGTGGCGGGGCTTGTTCGAGCTTGAAGAGCSEQIDNO:46来自pSZ1471的长发夹RNA表达盒的FADc部分ACTAGTTCACTTGTGGAACCAGAGCGCGGAGTCGTCCTCGGGCGCGTCCGGGACGACGTAGCGGCAGTCGCGCCAGTCCTCCCACAGGGCGCGGCCGACCCAGCGGCTGTCGGACTGGTAGTACTTGCCCAGGATGGGCCTGATGGCGGCGGAGGCCTCCTCGGCGTGGTAGTGCGGGATGGTGCTGAAGAGGTGGTGCAGCACGTGGGTGTCGGAGATGTGGTGCAGGATGTTGTCCATGAAGGGCGGGCCCATGGAGCGGTCCACGGTGGCCATGGCGCCGCGCAGCCAGTCCCAGTCCTTCTCGAAGTAGTGCGGCAGCGCCGGGTGCGTGTGCTGGAGCAGCGTGATGAGCACGAGCCACATGTTCACGATCAGGTAGGGCACCACGTAGGTCTTGACCAGCCAGGCCCAGCCCATGGTGCGGCCCAGCACGCTGAGCCCGCTGAGCACCGCCACCAGCGCCAGGTCGGAGATGACCACCTCGATGCGCTCGCGCTTGCTGAAGATGGGCGACCACGGGTCAAAGTGGTTGGCGAAGCGCGGGTACGGCCGCGAGGCGACGTTGAACATGAGGTACAGCGGCCAGCCCAGGGTCAGGGTGACCAGCACCTTGCCCATGCGGATGGGCAGCCACTCCTCCCACTCCAGGCCCTCGTGCGCCACTGCGCGGTGCGGCGGCACAAACACCTCGTCCTTGTCCAGGCACCCCGTGTTGGAGTGGTGGCGGCGGTGCGAGTGCTTCCAGGAGTAGTAGGGCACCAGCAGCAGGCTGTGGAACACCAGGCCCACGCCGTCGTTGATGGCCTGGCTGGAGGAAAAGGCCTGGTGGCCGCACTCGTGCGCGCACACCCAGACACCCGTGCCGAAGGCGCCCTGGAAGGTGCCGGGAGGGTAGCCGGGGGGGTCAGCGGGACAGGCGCCTTCTCCTCCATGCGCGCCACCAGGACCTCAATACGGGCAACCAAAACCCTCAAACACACCTGGAAGAACCAGTAGAGCGGCCACATGATGCCGTACTTGACCCACGTAGGCACCGGTGCAGGGTCGATGTACGTCGACGCGACGTAGAGCAGGGACATGACCGCGATGTCAAAGGCCAGGTACATGCTGCTACGAAGCGCCGAGCGCTCGAAACAGTGCGCGGGGATGGCCTTGCGCAGCGTCCCGATCGTGAACGGAGGCTTCTCCACAGGCTGCCTGTTCGTCTTGATAGCCATSEQIDNO:47来自pSZ1471的FADc长发夹RNA表达盒的相关部分GCTCTTCGCCGCCGCCACTCCTGCTCGAGCGCGCCCGCGCGTGCGCCGCCAGCGCCTTGGCCTTTTCGCCGCGCTCGTGCGCGTCGCTGATGTCCATCACCAGGTCCATGAGGTCTGCCTTGCGCCGGCTGAGCCACTGCTTCGTCCGGGCGGCCAAGAGGAGCATGAGGGAGGACTCCTGGTCCAGGGTCCTGACGTGGTCGCGGCTCTGGGAGCGGGCCAGCATCATCTGGCTCTGCCGCACCGAGGCCGCCTCCAACTGGTCCTCCAGCAGCCGCAGTCGCCGCCGACCCTGGCAGAGGAAGACAGGTGAGGGGGGTATGAATTGTACAGAACAACCACGAGCCTTGTCTAGGCAGAATCCCTACCAGTCATGGCTTTACCTGGATGACGGCCTGCGAACAGCTGTCCAGCGACCCTCGCTGCCGCCGCTTCTCCCGCACGCTTCTTTCCAGCACCGTGATGGCGCGAGCCAGCGCCGCACGCTGGCGCTGCGCTTCGCCGATCTGAGGACAGTCGGGGAACTCTGATCAGTCTAAACCCCCTTGCGCGTTAGTGTTGCCATCCTTTGCAGACCGGTGAGAGCCGACTTGTTGTGCGCCACCCCCCACACCACCTCCTCCCAGACCAATTCTGTCACCTTTTTGGCGAAGGCATCGGCCTCGGCCTGCAGAGAGGACAGCAGTGCCCAGCCGCTGGGGGTTGGCGGATGCACGCTCAGGTACCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACGGCGCGCCATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGACAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAGGATCCCGCGTCTCGAACAGAGCGCGCAGAGGAACGCTGAAGGTCTCGCCTCTGTCGCACCTCAGCGCGGCATACACCACAATAACCACCTGACGAATGCGCTTGGTTCTTCGTCCATTAGCGAAGCGTCCGGTTCACACACGTGCCACGTTGGCGAGGTGGCAGGTGACAATGATCGGTGGAGCTGATGGTCGAAACGTTCACAGCCTAGGGATATCGAATTCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACACTAGTTCACTTGTGGAACCAGAGCGCGGAGTCGTCCTCGGGCGCGTCCGGGACGACGTAGCGGCAGTCGCGCCAGTCCTCCCACAGGGCGCGGCCGACCCAGCGGCTGTCGGACTGGTAGTACTTGCCCAGGATGGGCCTGATGGCGGCGGAGGCCTCCTCGGCGTGGTAGTGCGGGATGGTGCTGAAGAGGTGGTGCAGCACGTGGGTGTCGGAGATGTGGTGCAGGATGTTGTCCATGAAGGGCGGGCCCATGGAGCGGTCCACGGTGGCCATGGCGCCGCGCAGCCAGTCCCAGTCCTTCTCGAAGTAGTGCGGCAGCGCCGGGTGCGTGTGCTGGAGCAGCGTGATGAGCACGAGCCACATGTTCACGATCAGGTAGGGCACCACGTAGGTCTTGACCAGCCAGGCCCAGCCCATGGTGCGGCCCAGCACGCTGAGCCCGCTGAGCACCGCCACCAGCGCCAGGTCGGAGATGACCACCTCGATGCGCTCGCGCTTGCTGAAGATGGGCGACCACGGGTCAAAGTGGTTGGCGAAGCGCGGGTACGGCCGCGAGGCGACGTTGAACATGAGGTACAGCGGCCAGCCCAGGGTCAGGGTGACCAGCACCTTGCCCATGCGGATGGGCAGCCACTCCTCCCACTCCAGGCCCTCGTGCGCCACTGCGCGGTGCGGCGGCACAAACACCTCGTCCTTGTCCAGGCACCCCGTGTTGGAGTGGTGGCGGCGGTGCGAGTGCTTCCAGGAGTAGTAGGGCACCAGCAGCAGGCTGTGGAACACCAGGCCCACGCCGTCGTTGATGGCCTGGCTGGAGGAAAAGGCCTGGTGGCCGCACTCGTGCGCGCACACCCAGACACCCGTGCCGAAGGCGCCCTGGAAGGTGCCGGGAGGGTAGCCGGGGGGGTCAGCGGGACAGGCGCCTTCTCCTCCATGCGCGCCACCAGGACCTCAATACGGGCAACCAAAACCCTCAAACACACCTGGAAGAACCAGTAGAGCGGCCACATGATGCCGTACTTGACCCACGTAGGCACCGGTGCAGGGTCGATGTACGTCGACGCGACGTAGAGCAGGGACATGACCGCGATGTCAAAGGCCAGGTACATGCTGCTACGAAGCGCCGAGCGCTCGAAACAGTGCGCGGGGATGGCCTTGCGCAGCGTCCCGATCGTGAACGGAGGCTTCTCCACAGGCTGCCTGTTCGTCTTGATAGCCATCTCGAGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAAAGCTGTAGAGCTCTTGTTTTCCAGAAGGAGTTGCTCCTTGAGCCTTTCATTCTCAGCCTCGATAACCTCCAAAGCCGCTCTAATTGTGGAGGGGGTTCGAATTTAAAAGCTTGGAATGTTGGTTCGTGCGTCTGGAACAAGCCCAGACTTGTTGCTCACTGGGAAAAGGACCATCAGCTCCAAAAAACTTGCCGCTCAAACCGCGTACCTCTGCTTTCGCGCAATCTGCCCTGTTGAAATCGCCACCACATTCATATTGTGACGCTTGAGCAGTCTGTAATTGCCTCAGAATGTGGAATCATCTGCCCCCTGTGCGAGCCCATGCCAGGCATGTCGCGGGCGAGGACACCCGCCACTCGTACAGCAGACCATTATGCTACCTCACAATAGTTCATAACAGTGACCATATTTCTCGAAGCTCCCCAACGAGCACCTCCATGCTCTGAGTGGCCACCCCCCGGCCCTGGTGCTTGCGGAGGGCAGGTCAACCGGCATGGGGCTACCGAAATCCCCGACCGGATCCCACCACCCCCGCGATGGGAAGAATCTCTCCCCGGGATGTGGGCCCACCACCAGCACAACCTGCTGGCCCAGGCGAGCGTCAAACCATACCACACAAATATCCTTGGCATCGGCCCTGAATTCCTTCTGCCGCTCTGCTACCCGGTGCTTCTGTCCGAAGCAGGGGTTGCTAGGGATCGCTCCGAGTCCGCAAACCCTTGTCGCGTGGCGGGGCTTGTTCGAGCTTGAAGAGCSEQIDNO:48桑椹形原藻FATA1基因敲除同源重组靶向构建体的5′供体DNA序列GCTCTTCGGAGTCACTGTGCCACTGAGTTCGACTGGTAGCTGAATGGAGTCGCTGCTCCACTAAACGAATTGTCAGCACCGCCAGCCGGCCGAGGACCCGAGTCATAGCGAGGGTAGTAGCGCGCCATGGCACCGACCAGCCTGCTTGCCAGTACTGGCGTCTCTTCCGCTTCTCTGTGGTCCTCTGCGCGCTCCAGCGCGTGCGCTTTTCCGGTGGATCATGCGGTCCGTGGCGCACCGCAGCGGCCGCTGCCCATGCAGCGCCGCTGCTTCCGAACAGTGGCGGTCAGGGCCGCACCCGCGGTAGCCGTCCGTCCGGAACCCGCCCAAGAGTTTTGGGAGCAGCTTGAGCCCTGCAAGATGGCGGAGGACAAGCGCATCTTCCTGGAGGAGCACCGGTGCGTGGAGGTCCGGGGCTGACCGGCCGTCGCATTCAACGTAATCAATCGCATGATGATCAGAGGACACGAAGTCTTGGTGGCGGTGGCCAGAAACACTGTCCATTGCAAGGGCATAGGGATGCGTTCCTTCACCTCTCATTTCTCATTTCTGAATCCCTCCCTGCTCACTCTTTCTCCTCCTCCTTCCCGTTCACGCAGCATTCGGGGTACCSEQIDNO:49桑椹形原藻FATA1基因敲除同源重组靶向构建体的3′供体DNA序列GACAGGGTGGTTGGCTGGATGGGGAAACGCTGGTCGCGGGATTCGATCCTGCTGCTTATATCCTCCCTGGAAGCACACCCACGACTCTGAAGAAGAAAACGTGCACACACACAACCCAACCGGCCGAATATTTGCTTCCTTATCCCGGGTCCAAGAGAGACTGCGATGCCCCCCTCAATCAGCATCCTCCTCCCTGCCGCTTCAATCTTCCCTGCTTGCCTGCGCCCGCGGTGCGCCGTCTGCCCGCCCAGTCAGTCACTCCTGCACAGGCCCCTTGTGCGCAGTGCTCCTGTACCCTTTACCGCTCCTTCCATTCTGCGAGGCCCCCTATTGAATGTATTCGTTGCCTGTGTGGCCAAGCGGGCTGCTGGGCGCGCCGCCGTCGGGCAGTGCTCGGCGACTTTGGCGGAAGCCGATTGTTCTTCTGTAAGCCACGCGCTTGCTGCTTTGGGAAGAGAAGGGGGGGGGTACTGAATGGATGAGGAGGAGAAGGAGGGGTATTGGTATTATCTGAGTTGGGTGAAGAGCSEQIDNO:50GCTCTTCGGAGTCACTGTGCCACTGAGTTCGACTGGTAGCTGAATGGAGTCGCTGCTCCACTAAACGAATTGTCAGCACCGCCAGCCGGCCGAGGACCCGAGTCATAGCGAGGGTAGTAGCGCGCCATGGCACCGACCAGCCTGCTTGCCAGTACTGGCGTCTCTTCCGCTTCTCTGTGGTCCTCTGCGCGCTCCAGCGCGTGCGCTTTTCCGGTGGATCATGCGGTCCGTGGCGCACCGCAGCGGCCGCTGCCCATGCAGCGCCGCTGCTTCCGAACAGTGGCGGTCAGGGCCGCACCCGCGGTAGCCGTCCGTCCGGAACCCGCCCAAGAGTTTTGGGAGCAGCTTGAGCCCTGCAAGATGGCGGAGGACAAGCGCATCTTCCTGGAGGAGCACCGGTGCGTGGAGGTCCGGGGCTGACCGGCCGTCGCATTCAACGTAATCAATCGCATGATGATCAGAGGACACGAAGTCTTGGTGGCGGTGGCCAGAAACACTGTCCATTGCAAGGGCATAGGGATGCGTTCCTTCACCTCTCATTTCTCATTTCTGAATCCCTCCCTGCTCACTCTTTCTCCTCCTCCTTCCCGTTCACGCAGCATTCGGGGTACCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACGGCGCGCCATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGACAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAGGATCGTAGAGCTCACTAGTATCGATTTCGAAGACAGGGTGGTTGGCTGGATGGGGAAACGCTGGTCGCGGGATTCGATCCTGCTGCTTATATCCTCCCTGGAAGCACACCCACGACTCTGAAGAAGAAAACGTGCACACACACAACCCAACCGGCCGAATATTTGCTTCCTTATCCCGGGTCCAAGAGAGACTGCGATGCCCCCCTCAATCAGCATCCTCCTCCCTGCCGCTTCAATCTTCCCTGCTTGCCTGCGCCCGCGGTGCGCCGTCTGCCCGCCCAGTCAGTCACTCCTGCACAGGCCCCTTGTGCGCAGTGCTCCTGTACCCTTTACCGCTCCTTCCATTCTGCGAGGCCCCCTATTGAATGTATTCGTTGCCTGTGTGGCCAAGCGGGCTGCTGGGCGCGCCGCCGTCGGGCAGTGCTCGGCGACTTTGGCGGAAGCCGATTGTTCTTCTGTAAGCCACGCGCTTGCTGCTTTGGGAAGAGAAGGGGGGGGGTACTGAATGGATGAGGAGGAGAAGGAGGGGTATTGGTATTATCTGAGTTGGGTGAAGAGCSEQIDNO:51GCTCTTCGGAGTCACTGTGCCACTGAGTTCGACTGGTAGCTGAATGGAGTCGCTGCTCCACTAAACGAATTGTCAGCACCGCCAGCCGGCCGAGGACCCGAGTCATAGCGAGGGTAGTAGCGCGCCATGGCACCGACCAGCCTGCTTGCCAGTACTGGCGTCTCTTCCGCTTCTCTGTGGTCCTCTGCGCGCTCCAGCGCGTGCGCTTTTCCGGTGGATCATGCGGTCCGTGGCGCACCGCAGCGGCCGCTGCCCATGCAGCGCCGCTGCTTCCGAACAGTGGCGGTCAGGGCCGCACCCGCGGTAGCCGTCCGTCCGGAACCCGCCCAAGAGTTTTGGGAGCAGCTTGAGCCCTGCAAGATGGCGGAGGACAAGCGCATCTTCCTGGAGGAGCACCGGTGCGTGGAGGTCCGGGGCTGACCGGCCGTCGCATTCAACGTAATCAATCGCATGATGATCAGAGGACACGAAGTCTTGGTGGCGGTGGCCAGAAACACTGTCCATTGCAAGGGCATAGGGATGCGTTCCTTCACCTCTCATTTCTCATTTCTGAATCCCTCCCTGCTCACTCTTTCTCCTCCTCCTTCCCGTTCACGCAGCATTCGGGGTACCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACGGCGCGCCATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGACAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAGGATCCCGCGTCTCGAACAGAGCGCGCAGAGGAACGCTGAAGGTCTCGCCTCTGTCGCACCTCAGCGCGGCATACACCACAATAACCACCTGACGAATGCGCTTGGTTCTTCGTCCATTAGCGAAGCGTCCGGTTCACACACGTGCCACGTTGGCGAGGTGGCAGGTGACAATGATCGGTGGAGCTGATGGTCGAAACGTTCACAGCCTAGGGATATCGAATTCGGCCGACAGGACGCGCGTCAAAGGTGCTGGTCGTGTATGCCCTGGCCGGCAGGTCGTTGCTGCTGCTGGTTAGTGATTCCGCAACCCTGATTTTGGCGTCTTATTTTGGCGTGGCAAACGCTGGCGCCCGCGAGCCGGGCCGGCGGCGATGCGGTGCCCCACGGCTGCCGGAATCCAAGGGAGGCAAGAGCGCCCGGGTCAGTTGAAGGGCTTTACGCGCAAGGTACAGCCGCTCCTGCAAGGCTGCGTGGTGGAATTGGACGTGCAGGTCCTGCTGAAGTTCCTCCACCGCCTCACCAGCGGACAAAGCACCGGTGTATCAGGTCCGTGTCATCCACTCTAAAGAGCTCGACTACGACCTACTGATGGCCCTAGATTCTTCATCAAAAACGCCTGAGACACTTGCCCAGGATTGAAACTCCCTGAAGGGACCACCAGGGGCCCTGAGTTGTTCCTTCCCCCCGTGGCGAGCTGCCAGCCAGGCTGTACCTGTGATCGAGGCTGGCGGGAAAATAGGCTTCGTGTGCTCAGGTCATGGGAGGTGCAGGACAGCTCATGAAACGCCAACAATCGCACAATTCATGTCAAGCTAATCAGCTATTTCCTCTTCACGAGCTGTAATTGTCCCAAAATTCTGGTCTACCGGGGGTGATCCTTCGTGTACGGGCCCTTCCCTCAACCCTAGGTATGCGCGCATGCGGTCGCCGCGCAACTCGCGCGAGGGCCGAGGGTTTGGGACGGGCCGTCCCGAAATGCAGTTGCACCCGGATGCGTGGCACCTTTTTTGCGATAATTTATGCAATGGACTGCTCTGCAAAATTCTGGCTCTGTCGCCAACCCTAGGATCAGCGGCGTAGGATTTCGTAATCATTCGTCCTGATGGGGAGCTACCGACTACCCTAATATCAGCCCGACTGCCTGACGCCAGCGTCCACTTTTGTGCACACATTCCATTCGTGCCCAAGACATTTCATTGTGGTGCGAAGCGTCCCCAGTTACGCTCACCTGTTTCCCGACCTCCTTACTGTTCTGTCGACAGAGCGGGCCCACAGGCCGGTCGCAGCCACTAGTATGGTGGTGGCCGCCGCCGCCAGCAGCGCCTTCTTCCCCGTGCCCGCCCCCCGCCCCACCCCCAAGCCCGGCAAGTTCGGCAACTGGCCCAGCAGCCTGAGCCAGCCCTTCAAGCCCAAGAGCAACCCCAACGGCCGCTTCCAGGTGAAGGCCAACGTGAGCCCCCACGGGCGCGCCCCCAAGGCCAACGGCAGCGCCGTGAGCCTGAAGTCCGGCAGCCTGAACACCCTGGAGGACCCCCCCAGCAGCCCCCCCCCCCGCACCTTCCTGAACCAGCTGCCCGACTGGAGCCGCCTGCGCACCGCCATCACCACCGTGTTCGTGGCCGCCGAGAAGCAGTTCACCCGCCTGGACCGCAAGAGCAAGCGCCCCGACATGCTGGTGGACTGGTTCGGCAGCGAGACCATCGTGCAGGACGGCCTGGTGTTCCGCGAGCGCTTCAGCATCCGCAGCTACGAGATCGGCGCCGACCGCACCGCCAGCATCGAGACCCTGATGAACCACCTGCAGGACACCAGCCTGAACCACTGCAAGAGCGTGGGCCTGCTGAACGACGGCTTCGGCCGCACCCCCGAGATGTGCACCCGCGACCTGATCTGGGTGCTGACCAAGATGCAGATCGTGGTGAACCGCTACCCCACCTGGGGCGACACCGTGGAGATCAACAGCTGGTTCAGCCAGAGCGGCAAGATCGGCATGGGCCGCGAGTGGCTGATCAGCGACTGCAACACCGGCGAGATCCTGGTGCGCGCCACCAGCGCCTGGGCCATGATGAACCAGAAGACCCGCCGCTTCAGCAAGCTGCCCTGCGAGGTGCGCCAGGAGATCGCCCCCCACTTCGTGGACGCCCCCCCCGTGATCGAGGACAACGACCGCAAGCTGCACAAGTTCGACGTGAAGACCGGCGACAGCATCTGCAAGGGCCTGACCCCCGGCTGGAACGACTTCGACGTGAACCAGCACGTGAGCAACGTGAAGTACATCGGCTGGATTCTGGAGAGCATGCCCACCGAGGTGCTGGAGACCCAGGAGCTGTGCAGCCTGACCCTGGAGTACCGCCGCGAGTGCGGCCGCGAGAGCGTGGTGGAGAGCGTGACCAGCATGAACCCCAGCAAGGTGGGCGACCGCAGCCAGTACCAGCACCTGCTGCGCCTGGAGGACGGCGCCGACATCATGAAGGGCCGCACCGAGTGGCGCCCCAAGAACGCCGGCACCAACCGCGCCATCAGCACCTGATTAATTAACTCGAGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAAAGCTTGAGCTCTTGTTTTCCAGAAGGAGTTGCTCCTTGAGCCTTTCATTCTCAGCCTCGATAACCTCCAAAGCCGCTCTAATTGTGGAGGGGGTTCGAAGACAGGGTGGTTGGCTGGATGGGGAAACGCTGGTCGCGGGATTCGATCCTGCTGCTTATATCCTCCCTGGAAGCACACCCACGACTCTGAAGAAGAAAACGTGCACACACACAACCCAACCGGCCGAATATTTGCTTCCTTATCCCGGGTCCAAGAGAGACTGCGATGCCCCCCTCAATCAGCATCCTCCTCCCTGCCGCTTCAATCTTCCCTGCTTGCCTGCGCCCGCGGTGCGCCGTCTGCCCGCCCAGTCAGTCACTCCTGCACAGGCCCCTTGTGCGCAGTGCTCCTGTACCCTTTACCGCTCCTTCCATTCTGCGAGGCCCCCTATTGAATGTATTCGTTGCCTGTGTGGCCAAGCGGGCTGCTGGGCGCGCCGCCGTCGGGCAGTGCTCGGCGACTTTGGCGGAAGCCGATTGTTCTTCTGTAAGCCACGCGCTTGCTGCTTTGGGAAGAGAAGGGGGGGGGTACTGAATGGATGAGGAGGAGAAGGAGGGGTATTGGTATTATCTGAGTTGGGTGAAGAGCSEQIDNO:52赖特氏萼距花FatB2(CwTE2)硫酯酶的密码子优化的序列ATGGTGGTGGCCGCCGCCGCCAGCAGCGCCTTCTTCCCCGTGCCCGCCCCCCGCCCCACCCCCAAGCCCGGCAAGTTCGGCAACTGGCCCAGCAGCCTGAGCCAGCCCTTCAAGCCCAAGAGCAACCCCAACGGCCGCTTCCAGGTGAAGGCCAACGTGAGCCCCCACGGGCGCGCCCCCAAGGCCAACGGCAGCGCCGTGAGCCTGAAGTCCGGCAGCCTGAACACCCTGGAGGACCCCCCCAGCAGCCCCCCCCCCCGCACCTTCCTGAACCAGCTGCCCGACTGGAGCCGCCTGCGCACCGCCATCACCACCGTGTTCGTGGCCGCCGAGAAGCAGTTCACCCGCCTGGACCGCAAGAGCAAGCGCCCCGACATGCTGGTGGACTGGTTCGGCAGCGAGACCATCGTGCAGGACGGCCTGGTGTTCCGCGAGCGCTTCAGCATCCGCAGCTACGAGATCGGCGCCGACCGCACCGCCAGCATCGAGACCCTGATGAACCACCTGCAGGACACCAGCCTGAACCACTGCAAGAGCGTGGGCCTGCTGAACGACGGCTTCGGCCGCACCCCCGAGATGTGCACCCGCGACCTGATCTGGGTGCTGACCAAGATGCAGATCGTGGTGAACCGCTACCCCACCTGGGGCGACACCGTGGAGATCAACAGCTGGTTCAGCCAGAGCGGCAAGATCGGCATGGGCCGCGAGTGGCTGATCAGCGACTGCAACACCGGCGAGATCCTGGTGCGCGCCACCAGCGCCTGGGCCATGATGAACCAGAAGACCCGCCGCTTCAGCAAGCTGCCCTGCGAGGTGCGCCAGGAGATCGCCCCCCACTTCGTGGACGCCCCCCCCGTGATCGAGGACAACGACCGCAAGCTGCACAAGTTCGACGTGAAGACCGGCGACAGCATCTGCAAGGGCCTGACCCCCGGCTGGAACGACTTCGACGTGAACCAGCACGTGAGCAACGTGAAGTACATCGGCTGGATTCTGGAGAGCATGCCCACCGAGGTGCTGGAGACCCAGGAGCTGTGCAGCCTGACCCTGGAGTACCGCCGCGAGTGCGGCCGCGAGAGCGTGGTGGAGAGCGTGACCAGCATGAACCCCAGCAAGGTGGGCGACCGCAGCCAGTACCAGCACCTGCTGCGCCTGGAGGACGGCGCCGACATCATGAAGGGCCGCACCGAGTGGCGCCCCAAGAACGCCGGCACCAACCGCGCCATCAGCACCTGASEQIDNO:53赖特氏萼距花FatB2(CwTE2)硫酯酶的蛋白质序列;基因库登录号U56104MVVAAAASSAFFPVPAPRPTPKPGKFGNWPSSLSQPFKPKSNPNGRFQVKANVSPHPKANGSAVSLKSGSLNTLEDPPSSPPPRTFLNQLPDWSRLRTAITTVFVAAEKQFTRLDRKSKRPDMLVDWFGSETIVQDGLVFRERFSIRSYEIGADRTASIETLMNHLQDTSLNHCKSVGLLNDGFGRTPEMCTRDLIWVLTKMQIVVNRYPTWGDTVEINSWFSQSGKIGMGREWLISDCNTGEILVRATSAWAMMNQKTRRFSKLPCEVRQEIAPHFVDAPPVIEDNDRKLHKFDVKTGDSICKGLTPGWNDFDVNQHVSNVKYIGWILESMPTEVLETQELCSLTLEYRRECGRESVVESVTSMNPSKVGDRSQYQHLLRLEDGADIMKGRTEWRPKNAGTNRAISTSEQIDNO:54密码子优化的原始小球藻(UTEX250)硬脂酰基ACP脱饱和酶转运肽cDNA序列。ACTAGTATGGCCACCGCATCCACTTTCTCGGCGTTCAATGCCCGCTGCGGCGACCTGCGTCGCTCGGCGGGCTCCGGGCCCCGGCGCCCAGCGAGGCCCCTCCCCGTGCGCGGGCGCGCCSEQID.NO:55密码子优化的大豆KASIIATGGCCACCGCATCCACTTTCTCGGCGTTCAATGCCCGCTGCGGCGACCTGCGTCGCTCGGCGGGCTCCGGGCCCCGGCGCCCAGCGAGGCCCCTCCCCGTGCGCGGGCGCGCCTCCACCCACTCCGGCAAGACCATGGCCGTGGCCCTGCAGCCCACCCAGGAGATCACCACCATCAAGAAGCCCCCCACCAAGCAGCGCCGCGTGGTGGTGACCGGCCTGGGCGTGGTGACCCCCCTGGGCCACGAGCCCGACATCTTCTACAACAACCTGCTGGACGGCGCCTCCGGCATCTCCGAGATCGAGACCTTCGACTGCGCCGAGTACCCCACCCGCATCGCCGGCGAGATCAAGTCCTTCTCCACCGACGGCTGGGTGGCCCCCAAGCTGTCCAAGCGCATGGACAAGTTCATGCTGTACATGCTGACCGCCGGCAAGAAGGCCCTGGTGGACGGCGGCATCACCGACGACGTGATGGACGAGCTGAACAAGGAGAAGTGCGGCGTGCTGATCGGCTCCGCCATGGGCGGCATGAAGGTGTTCAACGACGCCATCGAGGCCCTGCGCATCTCCTACAAGAAGATGAACCCCTTCTGCGTGCCCTTCGCCACCACCAACATGGGCTCCGCCATGCTGGCCATGGACCTGGGCTGGATGGGCCCCAACTACTCCATCTCCACCGCCTGCGCCACCTCCAACTTCTGCATCCTGAACGCCGCCAACCACATCATCCGCGGCGAGGCCGACGTGATGCTGTGCGGCGGCTCCGACGCCGCCATCATCCCCATCGGCCTGGGCGGCTTCGTGGCCTGCCGCGCCCTGTCCCAGCGCAACACCGACCCCACCAAGGCCTCCCGCCCCTGGGACATCAACCGCGACGGCTTCGTGATGGGCGAGGGCGCCGGCGTGCTGCTGCTGGAGGAGCTGGAGCACGCCAAGGAGCGCGGCGCCACCATCTACGCCGAGTTCCTGGGCGGCTCCTTCACCTGCGACGCCTACCACGTGACCGAGCCCCGCCCCGACGGCGCCGGCGTGATCCTGTGCATCGAGAAGGCCCTGGCCCAGTCCGGCGTGTCCAAGGAGGACGTGAACTACATCAACGCCCACGCCACCTCCACCCCCGCCGGCGACCTGAAGGAGTACCAGGCCCTGATGCACTGCTTCGGCCAGAACCCCGAGCTGCGCGTGAACTCCACCAAGTCCATGATCGGCCACCTGCTGGGCGCCGCCGGCGGCGTGGAGGCCGTGGCCACCATCCAGGCCATCCGCACCGGCTGGGTGCACCCCAACATCAACCTGGAGAACCCCGACAACGGCGTGGACGCCAAGGTGCTGGTGGGCTCCAAGAAGGAGCGCCTGGACGTGAAGGCCGCCCTGTCCAACTCCTTCGGCTTCGGCGGCCACAACTCCTCCATCATCTTCGCCCCCTACATGGACTACAAGGACCACGACGGCGACTACAAGGACCACGACATCGACTACAAGGACGACGACGACAAGTGASEQID.NO:56密码子优化的向日葵KASIIATGGCCACCGCATCCACTTTCTCGGCGTTCAATGCCCGCTGCGGCGACCTGCGTCGCTCGGCGGGCTCCGGGCCCCGGCGCCCAGCGAGGCCCCTCCCCGTGCGCGGGCGCGCCTGCCGCCGCGGCGGCCGCGTGGCCATGGCCATCGCCATCCAGCCCTCCTCCATCGAGATGGAGGAGGAGACCACCCTGACCAAGCGCAAGCAGCCCCCCACCAAGCAGCGCCGCGTGGTGGTGACCGGCATGGGCGTGGAGACCCCCATCGGCAACAACCCCGACCAGTTCTACAACAACCTGCTGCAGGGCGTGTCCGGCATCACCCAGATCGAGGCCTTCGACTGCTCCTCCTACCCCACCCGCATCGCCGGCGAGATCAAGAACTTCTCCACCGACGGCTGGGTGGCCCCCAAGCTGTCCAAGCGCATGGACCGCTTCATGCTGTACATGCTGACCGCCGGCAAGAAGGCCCTGGCCGACGCCGGCATCTCCCCCTCCGACTCCGACGAGATCGACAAGTCCCGCTGCGGCGTGCTGATCGGCTCCGCCATGGGCGGCATGAAGGTGTTCAACGACGCCATCGAGGCCCTGCGCGTGTCCTACCGCAAGATGAACCCCTTCTGCGTGCCCTTCGCCACCACCAACATGGGCTCCGCCATGCTGGCCATGGACCTGGGCTGGATGGGCCCCAACTACTCCATCTCCACCGCCTGCGCCACCTCCAACTTCTGCATCCTGAACGCCGCCAACCACATCATCCGCGGCGAGGCCGACATGATGCTGTGCGGCGGCTCCGACGCCGTGATCATCCCCATCGGCCTGGGCGGCTTCGTGGCCTGCCGCGCCCTGTCCGAGCGCAACACCGACCCCGCCAAGGCCTCCCGCCCCTGGGACTCCGGCCGCGACGGCTTCGTGATGGGCGAGGGCGCCGGCGTGCTGCTGCTGGAGGAGCTGGAGCACGCCAAGAAGCGCGGCGCCAAGATCTACGCCGAGTTCCTGGGCGGCTCCTTCACCTGCGACGCCTACCACATGACCGAGCCCCACCCCGAGGGCGCCGGCGTGATCCTGTGCATCGAGAAGGCCCTGTCCCAGGCCGGCGTGCGCCGCGAGGACGTGAACTACATCAACGCCCACGCCACCTCCACCCCCGCCGGCGACCTGAAGGAGTACCACGCCCTGCTGCACTGCTTCGGCAACAACCAGGAGCTGCGCGTGAACTCCACCAAGTCCATGATCGGCCACCTGCTGGGCGCCGCCGGCGCCGTGGAGGCCGTGGCCACCGTGCAGGCCATCCGCACCGGCTGGATCCACCCCAACATCAACCTGGAGAACCCCGACCAGGGCGTGGACACCAAGGTGCTGGTGGGCTCCAAGAAGGAGCGCCTGAACGTGAAGGTGGGCCTGTCCAACTCCTTCGGCTTCGGCGGCCACAACTCCTCCATCCTGTTCGCCCCCTTCCAGATGGACTACAAGGACCACGACGGCGACTACAAGGACCACGACATCGACTACAAGGACGACGACGACAAGTGASEQID.NO:57密码子优化的蓖麻KASIIATGGCCACCGCATCCACTTTCTCGGCGTTCAATGCCCGCTGCGGCGACCTGCGTCGCTCGGCGGGCTCCGGGCCCCGGCGCCCAGCGAGGCCCCTCCCCGTGCGCGGGCGCGCCTCCCACTACTACTCCTCCAACGGCCTGTTCCCCAACACCCCCCTGCTGCCCAAGCGCCACCCCCGCCTGCACCACCGCCTGCCCCGCTCCGGCGAGGCCATGGCCGTGGCCGTGCAGCCCGAGAAGGAGGTGGCCACCAACAAGAAGCCCCTGATGAAGCAGCGCCGCGTGGTGGTGACCGGCATGGGCGTGGTGTCCCCCCTGGGCCACGACATCGACGTGTACTACAACAACCTGCTGGACGGCTCCTCCGGCATCTCCCAGATCGACTCCTTCGACTGCGCCCAGTTCCCCACCCGCATCGCCGGCGAGATCAAGTCCTTCTCCACCGACGGCTGGGTGGCCCCCAAGCTGTCCAAGCGCATGGACAAGTTCATGCTGTACATGCTGACCGCCGGCAAGAAGGCCCTGGCCGACGGCGGCATCACCGAGGACATGATGGACGAGCTGGACAAGGCCCGCTGCGGCGTGCTGATCGGCTCCGCCATGGGCGGCATGAAGGTGTTCAACGACGCCATCGAGGCCCTGCGCATCTCCTACCGCAAGATGAACCCCTTCTGCGTGCCCTTCGCCACCACCAACATGGGCTCCGCCATGCTGGCCATGGACCTGGGCTGGATGGGCCCCAACTACTCCATCTCCACCGCCTGCGCCACCTCCAACTTCTGCATCCTGAACGCCGCCAACCACATCATCCGCGGCGAGGCCGACATCATGCTGTGCGGCGGCTCCGACGCCGCCATCATCCCCATCGGCCTGGGCGGCTTCGTGGCCTGCCGCGCCCTGTCCCAGCGCAACGACGACCCCACCAAGGCCTCCCGCCCCTGGGACATGAACCGCGACGGCTTCGTGATGGGCGAGGGCGCCGGCGTGCTGCTGCTGGAGGAGCTGGAGCACGCCAAGAAGCGCGGCGCCAACATCTACGCCGAGTTCCTGGGCGGCTCCTTCACCTGCGACGCCTACCACATGACCGAGCCCCGCCCCGACGGCGTGGGCGTGATCCTGTGCATCGAGAAGGCCCTGGCCCGCTCCGGCGTGTCCAAGGAGGAGGTGAACTACATCAACGCCCACGCCACCTCCACCCCCGCCGGCGACCTGAAGGAGTACGAGGCCCTGATGCGCTGCTTCTCCCAGAACCCCGACCTGCGCGTGAACTCCACCAAGTCCATGATCGGCCACCTGCTGGGCGCCGCCGGCGCCGTGGAGGCCATCGCCACCATCCAGGCCATCCGCACCGGCTGGGTGCACCCCAACATCAACCTGGAGAACCCCGAGGAGGGCGTGGACACCAAGGTGCTGGTGGGCCCCAAGAAGGAGCGCCTGGACATCAAGGTGGCCCTGTCCAACTCCTTCGGCTTCGGCGGCCACAACTCCTCCATCATCTTCGCCCCCTACAAGATGGACTACAAGGACCACGACGGCGACTACAAGGACCACGACATCGACTACAAGGACGACGACGACAAGTGASEQIDNO:58包含密码子优化的桑椹形原藻KASII的pSz2041的相关部分GCTCTTCGCCGCCGCCACTCCTGCTCGAGCGCGCCCGCGCGTGCGCCGCCAGCGCCTTGGCCTTTTCGCCGCGCTCGTGCGCGTCGCTGATGTCCATCACCAGGTCCATGAGGTCTGCCTTGCGCCGGCTGAGCCACTGCTTCGTCCGGGCGGCCAAGAGGAGCATGAGGGAGGACTCCTGGTCCAGGGTCCTGACGTGGTCGCGGCTCTGGGAGCGGGCCAGCATCATCTGGCTCTGCCGCACCGAGGCCGCCTCCAACTGGTCCTCCAGCAGCCGCAGTCGCCGCCGACCCTGGCAGAGGAAGACAGGTGAGGGGGGTATGAATTGTACAGAACAACCACGAGCCTTGTCTAGGCAGAATCCCTACCAGTCATGGCTTTACCTGGATGACGGCCTGCGAACAGCTGTCCAGCGACCCTCGCTGCCGCCGCTTCTCCCGCACGCTTCTTTCCAGCACCGTGATGGCGCGAGCCAGCGCCGCACGCTGGCGCTGCGCTTCGCCGATCTGAGGACAGTCGGGGAACTCTGATCAGTCTAAACCCCCTTGCGCGTTAGTGTTGCCATCCTTTGCAGACCGGTGAGAGCCGACTTGTTGTGCGCCACCCCCCACACCACCTCCTCCCAGACCAATTCTGTCACCTTTTTGGCGAAGGCATCGGCCTCGGCCTGCAGAGAGGACAGCAGTGCCCAGCCGCTGGGGGTTGGCGGATGCACGCTCAGGTACCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACTCTAGAATATCAATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGACAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAGGATCCCGCGTCTCGAACAGAGCGCGCAGAGGAACGCTGAAGGTCTCGCCTCTGTCGCACCTCAGCGCGGCATACACCACAATAACCACCTGACGAATGCGCTTGGTTCTTCGTCCATTAGCGAAGCGTCCGGTTCACACACGTGCCACGTTGGCGAGGTGGCAGGTGACAATGATCGGTGGAGCTGATGGTCGAAACGTTCACAGCCTAGGGATATCGAATTCGGCCGACAGGACGCGCGTCAAAGGTGCTGGTCGTGTATGCCCTGGCCGGCAGGTCGTTGCTGCTGCTGGTTAGTGATTCCGCAACCCTGATTTTGGCGTCTTATTTTGGCGTGGCAAACGCTGGCGCCCGCGAGCCGGGCCGGCGGCGATGCGGTGCCCCACGGCTGCCGGAATCCAAGGGAGGCAAGAGCGCCCGGGTCAGTTGAAGGGCTTTACGCGCAAGGTACAGCCGCTCCTGCAAGGCTGCGTGGTGGAATTGGACGTGCAGGTCCTGCTGAAGTTCCTCCACCGCCTCACCAGCGGACAAAGCACCGGTGTATCAGGTCCGTGTCATCCACTCTAAAGAACTCGACTACGACCTACTGATGGCCCTAGATTCTTCATCAAAAACGCCTGAGACACTTGCCCAGGATTGAAACTCCCTGAAGGGACCACCAGGGGCCCTGAGTTGTTCCTTCCCCCCGTGGCGAGCTGCCAGCCAGGCTGTACCTGTGATCGAGGCTGGCGGGAAAATAGGCTTCGTGTGCTCAGGTCATGGGAGGTGCAGGACAGCTCATGAAACGCCAACAATCGCACAATTCATGTCAAGCTAATCAGCTATTTCCTCTTCACGAGCTGTAATTGTCCCAAAATTCTGGTCTACCGGGGGTGATCCTTCGTGTACGGGCCCTTCCCTCAACCCTAGGTATGCGCGCATGCGGTCGCCGCGCAACTCGCGCGAGGGCCGAGGGTTTGGGACGGGCCGTCCCGAAATGCAGTTGCACCCGGATGCGTGGCACCTTTTTTGCGATAATTTATGCAATGGACTGCTCTGCAAAATTCTGGCTCTGTCGCCAACCCTAGGATCAGCGGCGTAGGATTTCGTAATCATTCGTCCTGATGGGGAGCTACCGACTACCCTAATATCAGCCCGACTGCCTGACGCCAGCGTCCACTTTTGTGCACACATTCCATTCGTGCCCAAGACATTTCATTGTGGTGCGAAGCGTCCCCAGTTACGCTCACCTGTTTCCCGACCTCCTTACTGTTCTGTCGACAGAGCGGGCCCACAGGCCGGTCGCAGCCACTAGTATGGCCACCGCATCCACTTTCTCGGCGTTCAATGCCCGCTGCGGCGACCTGCGTCGCTCGGCGGGCTCCGGGCCCCGGCGCCCAGCGAGGCCCCTCCCCGTGCGCGGGCGCGCCGCCGCCGCCGCCGACGCCAACCCCGCCCGCCCCGAGCGCCGCGTGGTGATCACCGGCCAGGGCGTGGTGACCTCCCTGGGCCAGACCATCGAGCAGTTCTACTCCTCCCTGCTGGAGGGCGTGTCCGGCATCTCCCAGATCCAGAAGTTCGACACCACCGGCTACACCACCACCATCGCCGGCGAGATCAAGTCCCTGCAGCTGGACCCCTACGTGCCCAAGCGCTGGGCCAAGCGCGTGGACGACGTGATCAAGTACGTGTACATCGCCGGCAAGCAGGCCCTGGAGTCCGCCGGCCTGCCCATCGAGGCCGCCGGCCTGGCCGGCGCCGGCCTGGACCCCGCCCTGTGCGGCGTGCTGATCGGCACCGCCATGGCCGGCATGACCTCCTTCGCCGCCGGCGTGGAGGCCCTGACCCGCGGCGGCGTGCGCAAGATGAACCCCTTCTGCATCCCCTTCTCCATCTCCAACATGGGCGGCGCCATGCTGGCCATGGACATCGGCTTCATGGGCCCCAACTACTCCATCTCCACCGCCTGCGCCACCGGCAACTACTGCATCCTGGGCGCCGCCGACCACATCCGCCGCGGCGACGCCAACGTGATGCTGGCCGGCGGCGCCGACGCCGCCATCATCCCCTCCGGCATCGGCGGCTTCATCGCCTGCAAGGCCCTGTCCAAGCGCAACGACGAGCCCGAGCGCGCCTCCCGCCCCTGGGACGCCGACCGCGACGGCTTCGTGATGGGCGAGGGCGCCGGCGTGCTGGTGCTGGAGGAGCTGGAGCACGCCAAGCGCCGCGGCGCCACCATCCTGGCCGAGCTGGTGGGCGGCGCCGCCACCTCCGACGCCCACCACATGACCGAGCCCGACCCCCAGGGCCGCGGCGTGCGCCTGTGCCTGGAGCGCGCCCTGGAGCGCGCCCGCCTGGCCCCCGAGCGCGTGGGCTACGTGAACGCCCACGGCACCTCCACCCCCGCCGGCGACGTGGCCGAGTACCGCGCCATCCGCGCCGTGATCCCCCAGGACTCCCTGCGCATCAACTCCACCAAGTCCATGATCGGCCACCTGCTGGGCGGCGCCGGCGCCGTGGAGGCCGTGGCCGCCATCCAGGCCCTGCGCACCGGCTGGCTGCACCCCAACCTGAACCTGGAGAACCCCGCCCCCGGCGTGGACCCCGTGGTGCTGGTGGGCCCCCGCAAGGAGCGCGCCGAGGACCTGGACGTGGTGCTGTCCAACTCCTTCGGCTTCGGCGGCCACAACTCCTGCGTGATCTTCCGCAAGTACGACGAGATGGACTACAAGGACCACGACGGCGACTACAAGGACCACGACATCGACTACAAGGACGACGACGACAAGTGAATCGATAGATCTCTTAAGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAAAGCTTAATTAAGAGCTCTTGTTTTCCAGAAGGAGTTGCTCCTTGAGCCTTTCATTCTCAGCCTCGATAACCTCCAAAGCCGCTCTAATTGTGGAGGGGGTTCGAATTTAAAAGCTTGGAATGTTGGTTCGTGCGTCTGGAACAAGCCCAGACTTGTTGCTCACTGGGAAAAGGACCATCAGCTCCAAAAAACTTGCCGCTCAAACCGCGTACCTCTGCTTTCGCGCAATCTGCCCTGTTGAAATCGCCACCACATTCATATTGTGACGCTTGAGCAGTCTGTAATTGCCTCAGAATGTGGAATCATCTGCCCCCTGTGCGAGCCCATGCCAGGCATGTCGCGGGCGAGGACACCCGCCACTCGTACAGCAGACCATTATGCTACCTCACAATAGTTCATAACAGTGACCATATTTCTCGAAGCTCCCCAACGAGCACCTCCATGCTCTGAGTGGCCACCCCCCGGCCCTGGTGCTTGCGGAGGGCAGGTCAACCGGCATGGGGCTACCGAAATCCCCGACCGGATCCCACCACCCCCGCGATGGGAAGAATCTCTCCCCGGGATGTGGGCCCACCACCAGCACAACCTGCTGGCCCAGGCGAGCGTCAAACCATACCACACAAATATCCTTGGCATCGGCCCTGAATTCCTTCTGCCGCTCTGCTACCCGGTGCTTCTGTCCGAAGCAGGGGTTGCTAGGGATCGCTCCGAGTCCGCAAACCCTTGTCGCGTGGCGGGGCTTGTTCGAGCTTGAAGAGCSEQIDNO:59桑椹形原藻(UTEX1435)SAD2等位基因2ATGGCGTCTGCCGTCACCTTTGCGTGCGCCCCTCCCCGCGGCGCGGTCGCCGCGCCGGGTCGCCGCGCTGCCTCGCGTCCCCTGGTGGTGCACGCCGTCGCCAGCGAGGCCCCGCTGGGCGTGCCGCCCTCGGTGCAGCGCCCCTCCCCCGTGGTCTACTCCAAGCTGGACAAGCAACACCGCCTGACGCCCGAGCGCCTGGAGCTGGTGCAGAGCATGGGTCAGTTGCGGAGGAGAGGGTGCTCCCCGTGCTGCACCCCGTGGACAAGCTGTGGCAGCCGCAGGACTTCCTGGCCCGACCCCGAGTCGCCCGACTTCGAGGACCAGGTGGCGGAGCTGCGCGCGCGCGCCAAGGACCTGCCCGACGAGTACTTTGTGGTGCTGGTGGGCGACATGATCACGGAGGAGGCGCTGCCGACCTACATGGCCATGCTCAACACCTTGGACGGTGTGCGCGACGACACGGGCGCGGCTGACCACCCGTGGGCGCGCTGGACGCGGCAGTGGGTGGCCGAGGAGAACCGGCACGGCGACCTGCTGAACAAGTACTGTTGGCTGACGGGGCGCGTCAACATGCGGGCCGTGGAGGTGACCATCAACAACCTGATCAAGAGCGGCATGAACCCGCAGACGGACAACAACCCTTACTTGGGCTTCGTCTACACCTCCTTCCAGGAGCGCGCGACCAAGTACAGCCACGGCAACACCGCGCGCCTGGCGGCCGAGCACGGCGACAAGGGCCTGAGCAAGATCTGCGGGCTGATCGCCAGCGACGAGGGCCGGCACGAGATCGCCTACACGCGCATCGTGGACGAGTTCTTCCGCCTCGACCCCGAGGGCGCCGTCGCCGCCTACGCCAACATGATGCGCAAGCAGATCACCATGCCCGCGCACCTCATGGACGACATGGGCCACGGCGAGGCCAACCCGGGCCGCAACCTCTTCGCCGACTTCTCCGCCGTCGCCGAGAAGATCGACGTCTACGACGCCGAGGACTACTGCCGCATCCTGGAGCACCTCAACGCGCGCTGGAAGGTGGACGAGCGCCAGGTCAGCGGCCAGGCCGCCGCGGACCAGGAGTACGTTCTGGGCCTGCCCCAGCGCTTCCGGAAACTCGCCGAGAAGACCGCCGCCAAGCGCAAGCGCGTCGCGCGCAGGCCCGTCGCCTTCTCCTGGATCTCCGGACGCGAGATTATGGTCTAGSEQIDNO:60桑椹形原藻(UTEX1435)SAD2等位基因2MASAVTFACAPPRGAVAAPGRRAASRPLVVHAVASEAPLGVPPSVQRPSPVVYSKLDKQHRLTPERLELVQSMGQLRRRGCSPCCTPWTSCGSRRTSWPDPESPDFEDQVAELRARAKDLPDEYFVVLVGDMITEEALPTYMAMLNTLDGVRDDTGAADHPWARWTRQWVAEENRHGDLLNKYCWLTGRVNMRAVEVTINNLIKSGMNPQTDNNPYLGFVYTSFQERATKYSHGNTARLAAEHGDKGLSKICGLIASDEGRHEIAYTRIVDEFFRLDPEGAVAAYANMMRKQITMPAHLMDDMGHGEANPGRNLFADFSAVAEKIDVYDAEDYCRILEHLNARWKVDERQVSGQAAADQEYVLGLPQRFRKLAEKTAAKRKRVARRPVAFSWISGREIMVSEQIDNO:61桑椹形原藻(UTEX1435)SAD2等位基因1ATGGCGTCTGCCGTCACCTTTGCGTGCGCCCCTCCCCGCGGCGCGGTCGCCGCGCCGGGTCGCCGCGCTGCCTCGCGTCCCCTGGTGGTGCGCGCGGTCGCCAGCGAGGCCCCGCTGGGCGTTCCGCCCTCGGTGCAGCGCCCCTCCCCCGTGGTCTACTCCAAGCTGGACAAGCAGCACCGCCTGACGCCCGAGCGCCTGGAGCTGGTGCAGAGCATGGGGCAGTTTGCGGAGGAGAGGGTGCTGCCCGTGCTGCACCCCGTGGACAAGCTGTGGCAGCCGCAGGACTTTTTGCCCGACCCCGAGTCGCCCGACTTCGAGGATCAGGTGGCGGAGCTGCGCGCGCGCGCCAAGGACCTGCCCGACGAGTACTTTGTGGTGCTGGTGGGGGACATGATCACGGAGGAGGCGCTGCCGACCTACATGGCCATGCTCAACACGCTGGACGGCGTGCGCGACGACACGGGCGCGGCCGACCACCCGTGGGCGCGCTGGACGCGGCAGTGGGTGGCCGAGGAGAACCGGCACGGCGACCTGCTGAACAAGTACTGCTGGCTGACGGGGCGCGTCAACATGCGGGCCGTGGAGGTGACCATCAACAACCTGATCAAGAGCGGCATGAACCCGCAGACGGACAACAACCCTTATTTGGGGTTCGTCTACACCTCCTTCCAGGAGCGCGCCACCAAGTACAGCCACGGCAACACCGCGCGCCTTGCGGCCGAGCACGGCGACAAGAACCTGAGCAAGATCTGCGGGCTGATCGCCAGCGACGAGGGCCGGCACGAGATCGCCTACACGCGCATCGTGGACGAGTTCTTCCGCCTCGACCCCGAGGGCGCCGTCGCCGCCTACGCCAACATGATGCGCAAGCAGATCACCATGCCCGCGCACCTCATGGACGACATGGGCCACGGCGAGGCCAACCCGGGCCGCAACCTCTTCGCCGACTTCTCCGCGGTCGCCGAGAAGATCGACGTCTACGACGCCGAGGACTACTGCCGCATCCTGGAGCACCTCAACGCGCGCTGGAAGGTGGACGAGCGCCAGGTCAGCGGCCAGGCCGCCGCGGACCAGGAGTACGTCCTGGGCCTGCCCCAGCGCTTCCGGAAACTCGCCGAGAAGACCGCCGCCAAGCGCAAGCGCGTCGCGCGCAGGCCCGTCGCCTTCTCCTGGATCTCCGGGCGCGAGATCATGGTCTAGSEQIDNO:62桑椹形原藻(UTEX1435)SAD2等位基因1MASAVTFACAPPRGAVAAPGRRAASRPLVVRAVASEAPLGVPPSVQRPSPVVYSKLDKQHRLTPERLELVQSMGQFAEERVLPVLHPVDKLWQPQDFLPDPESPDFEDQVAELRARAKDLPDEYFVVLVGDMITEEALPTYMAMLNTLDGVRDDTGAADHPWARWTRQWVAEENRHGDLLNKYCWLTGRVNMRAVEVTINNLIKSGMNPQTDNNPYLGFVYTSFQERATKYSHGNTARLAAEHGDKNLSKICGLIASDEGRHEIAYTRIVDEFFRLDPEGAVAAYANMMRKQITMPAHLMDDMGHGEANPGRNLFADFSAVAEKIDVYDAEDYCRILEHLNARWKVDERQVSGQAAADQEYVLGLPQRFRKLAEKTAAKRKRVARRPVAFSWISGREIMVSEQIDNO:63桑椹形原藻(UTEX1435)线粒体ACP等位基因1ATGGCGTTCTTGCAGCGGACGAGCGCGCTGGTGCGCCAGGGTGTCCTGTCTCGCCTCGCCGTGCAGGCCAGCCCCGCCCTGAACAGCGTCCGGGCCTTCGCCTCGGCGTCCTACCTGGACAAGAATGAGGTGACGCACCGCGTGCTGTCGATTGTCAAGAACTTTGACCGCGTCGACGCCGGCAAGGTCACGGACTCTGCCAACTTCCAGTCCGACCTGGGTCTGGACTCACTAGACACCGTGGAGCTGGTCATGGCCCTGGAGGAGGAGTTTGCGATCGAGATCCCGGATGCGGAGGCNGACAAGATCCTCTCCGTCCCGGAGGCGATTTCCTACATTGCCGCGAACCCCATGGCCAAGTAGSEQIDNO:64桑椹形原藻(UTEX1435)线粒体ACP等位基因1ATGGCGTTCTTGCAGCGGACGAGCGCGCTGGTGCGCCAGGGTGTCCTGTCTCGCCTCGCCGTGCAGGCCAGCCCCGCCCTGAACAGCGTCCGGGCCTTCGCCTCGGCGTCCTACCTGGACAAGAATGAGGTGACGCACCGCGTGCTGTCGATTGTCAAGAACTTTGACCGCGTCGACGCCGGCAAGGTCACGGACTCTGCCAACTTCCAGTCCGACCTGGGTCTGGACTCACTAGACACCGTGGAGCTGGTCATGGCCCTGGAGGAGGAGTTTGCGATCGAGATCCCGGATGCGGAGGCNGACAAGATCCTCTCCGTCCCGGAGGCGATTTCCTACATTGCCGCGAACCCCATGGCCAAGTAGSEQIDNO:65桑椹形原藻(UTEX1435)线粒体ACP等位基因1MAFLQRTSALVRQGVLSRLAVQASPALNSVRAFASASYLDKKEVTDRVLSIVKNFDRVDAGKVTDSANFQSDLGLDSLDTVELVMALEEEFAIEIPDAEADKILSVPEAISYIAANPMAKSEQIDNO:66桑椹形原藻(UTEX1435)LPAAT-EATGGTTGCGGCTCAGGAAGACGGCTCCATGGAGAGGAGGACCTCGGCCAACCCCTCCGTGGGTCTTAGCAGCTTAAAGCACGTTCCGCTGAGTGCGGTGGACCTCCCGAATTTCGAGTCCGCTCCCAAGGGTGCGGCCAGCCCCGATGTCCATCGTCAGATAGAGGAACTGGTGGATAAGGCACGCGCAGATCGGTCACCGGCCTCGTTGTCGCTCCTAGCCGATGTGCTGGACATCAGCGGGCCGCTGCAGGACGCGGCCTCGGCGATGGTGGACGACTCCTTCCTGCGCTGCTTCACCTCCACCATGGACGAGCCCTGGAACTGGAACTTTTACCTGTTCCCGCTCTGGGCGCTCGGCGTCGTCGTCCGCAACCTGATCCTGTTCCCCCTGCGCCTCCTCACCATCGTGCTGGGGACGCTGCTCTTCGTGCTGGCCTTTGCCGTGACGGGCTTTCTCCCCAAGGAGAAGCGGCTCGCGGCCGAGCAGCGGTGCGTCCAGTTCATGGCGCAGGCGTTCGTGGCCTCCTGGACAGGCGTGATCCGGTACCACGGCCCCCGCCCCGTGGCGGCGCCCAACCGCGTGTGGGTCGCCAACCACACGTCCATGATCGACTACGCGGTGCTGTGCGCCTACTGCCCGTTTGCGGCCATCATGCAGCTGCACCCCGGCTGGGTGGGCGTCTTCCAGACGCGCTACCTGGCCTCGCTGGGCTGCCTCTGGTTCAACCGCACGCAGGCCAAGGACCGCACGCTCGTGGCCAAGCGCATGCGCGAGCACGTGGCCAGCGCGACCAGCACGCCGCTGCTCATCTTCCCCGAGGGCACCTGCGTCAACAACGAGTACTGCGTCATGTTCCGCAAGGGCGCCTTTGACCTGGGCGCCACCGTCTGCCCCGTGGCCATCAAGTACAACAAGATCTTCGTCGACGCCTTTTGGAACAGCAAGCGCCAGTCCTTCTCCGCGCACCTCATGAAGATCATGCGCTCGTGGGCCCTCGTCTGCGACGTCTACTTCCTGGAGCCCCAGACGCGGAGGGAGGGCGAGTCGGTCGAGGCGTTTGCGAACCGCSEQIDNO:67桑椹形原藻KASI等位基因2,核苷酸序列ATGGTCGCGACCCTGTCCCTCGCCGGCCCCGCCTGCAACACGCAGTGCGTATCCAGCAAGCGGGTTGTCGCCTTCAACCGCCCCCATGTTGGCGTCCGGGCTCGATCAGCCGTGGTCGCCCGAGCTGCGAAGCGGGACCCCACCCAGCGCATTGTGATCACCGGAATGGGCGTGGCCTCCGTGTTTGGCAACGATGTCGAGACCTTTTACGACAAGCTTCTGGAAGGAACGAGCGGCGTGGACCTGATTTCCAGGTTTGACATCTCCGAGTTCCCGACCAAGTTTGCGGCGCAGATCACCGGCTTCTCCGTGGAGGACTGCGTGGACAAGAAGAACGCGCGGCGGTACGACGACGCGCTGTCGTACGCGATGGTGGCCTCCAAGAAGGCCCTGCGCCAGGCAGGCCTGGAGAAGGACAAGTGCCCCGAGGGCTACGGGGCGCTGGACAAGACGCGCACGGGCGTGCTGGTCGGCTCGGGCATGGGCGGGCTGACGGTCTTCCAGGACGGCGTCAAGGCGCTGGTGGAGAAGGGCTACAAGAAGATGAGCCCCTTCTTCATCCCCTACGCCATCACCAACATGGGCTCCGCGCTGGTGGGCATCGACCAGGGCTTCATGGGCCCCAACTACTCCGTCTCCACAGCCTGCGCGACGTCCAACTACGCATTTGTGAACGCGGCCAACCACATCCGCAAGGGCGACGCGGACGTCATGGTCGTCGGCGGCACCGAGGCCTCCATCGTGCCCGTGGGCCTGGGCGGCTTTGTGGCCTGCCGCGCGCTGTCCACGCGCAACGACGAGCCCAAGCGCGCGAGCCGGCCGTGGGACGAGGGCCGCGACGGCTTTGTGATGGGCGAGGGCGCGGCCGTGCTGGTCATGGAGTCGCTGGAGCACGCGCAGAAGCGTGGCGCGACCATCCTGGGCGAGTACCTGGGCGGCGCCATGACCTGCGACGCGCACCACATGACGGACCCGCACCCCGAGGGCCTGGGCGTGAGCACCTGCATCCGCCTGGCGCTCGAGGACGCCGGCGTCTCGCCCGACGAGGTCAACTACGTCAACGCGCACGCCACCTCCACCCTGGTGGGCGACAAGGCCGAGGTGCGCGCGGTCAAGTCGGTCTTTGGCGACATGAAGGGTATCAAGATGAACGCCACCAAGAGTATGATCGGGCACTGCCTGGGCGCCGCCGGCGGCATGGAGGCCGTCGCGACGCTCATGGCCATCCGCACCGGCTGGGTGCACCCCACCATCAACCACGACAACCCCATCGCCGAGGTCGATGGCCTGGACGTCGTCGCCAACGCCAAGGCCCAGCACGACATCAACGTCGCCATCTCCAACTCCTTCGGCTTTGGCGGGCACAACTCCGTCGTCGCCTTTGCGCCCTTCCGCGAGTAGSEQIDNO:68桑椹形原藻KASI等位基因2,蛋白质序列MVATLSLAGPACNTQCVSSKRVVAFNRPHVGVRARSAVVARAAKRDPTQRIVITGMGVASVFGNDVETFYDKLLEGTSGVDLISRFDISEFPTKFAAQITGFSVEDCVDKKNARRYDDALSYAMVASKKALRQAGLEKDKCPEGYGALDKTRTGVLVGSGMGGLTVFQDGVKALVEKGYKKMSPFFIPYAITNMGSALVGIDQGFMGPNYSVSTACATSNYAFVNAANHIRKGDADVMVVGGTEASIVPVGLGGFVACRALSTRNDEPKRASRPWDEGRDGFVMGEGAAVLVMESLEHAQKRGATILGEYLGGAMTCDAHHMTDPHPEGLGVSTCIRLALEDAGVSPDEVNYVNAHATSTLVGDKAEVRAVKSVFGDMKGIKMNATKSMIGHCLGAAGGMEAVATLMAIRTGWVHPTINHDNPIAEVDGLDVVANAKAQHDINVAISNSFGFGGHNSVVAFAPFRE*SEQIDNO:69桑椹形原藻(UTEX1435)KASI等位基因1,核苷酸序列ATGGTCGCGACCCTCTCCCTCGCCGGCCCCGCCTGCAACACGCAGTGCGTATCCGGCAAGCGGGCTGTCGCCTTCAACCGCCCCCATGTTGGCGTCCGGGCTCGATCAGCCGTGGTCGCCCGGGCTGCGAAGCGGGACCCCACCCAGCGCATTGTGATCACCGGAATGGGCGTGGCCTCCGTGTTTGGCAACGATGTCGAGACCTTTTACAACAAGCTTCTGGAAGGAACGAGCGGCGTGGACCTGATTTCCAGGTTTGACATCTCCGAGTTCCCGACCAAGTTTGCGGCGCAGATCACCGGCTTCTCCGTGGAGGACTGCGTGGACAAGAAGAACGCGCGGCGGTACGACGACGCGCTGTCGTACGCGATGGTGGCCTCCAAGAAGGCCCTGCGCCAGGCGGGACTGGAGAAGGACAAGTGCCCCGAGGGCTACGGAGCGCTGGATAAGACGCGCGCGGGCGTGCTGGTCGGCTCGGGCATGGGCGGGCTGACGGTCTTCCAGGACGGCGTCAAGGCGCTGGTGGAGAAGGGCTACAAGAAGATGAGCCCCTTCTTCATCCCCTACGCCATCACCAACATGGGCTCCGCGCTGGTGGGCATCGACCAGGGCTTCATGGGGCCCAACTACTCCGTCTCCACGGCCTGCGCGACCTCCAACTACGCCTTTGTGAACGCGGCCAACCACATCCGCAAGGGCGACGCGGACGTCATGGTCGTGGGCGGCACCGAGGCCTCCATCGTGCCCGTGGGCCTGGGCGGCTTTGTGGCCTGCCGCGCGCTGTCCACGCGCAACGACGAGCCCAAGCGCGCGAGCCGGCCGTGGGACGAGGGCCGCGACGGCTTCGTGATGGGCGAGGGCGCGGCCGTGCTGGTCATGGAGTCGCTGGAGCACGCGCAGAAGCGCGGCGCGACCATCCTGGGCGAGTACCTGGGGGGCGCCATGACCTGCGACGCGCACCACATGACGGACCCGCACCCCGAGGGCCTGGGCGTGAGCACCTGCATCCGCCTGGCGCTCGAGGACGCCGGCGTCTCGCCCGACGAGGTCAACTACGTCAACGCGCACGCCACCTCCACCCTGGTGGGCGACAAGGCCGAGGTGCGCGCGGTCAAGTCGGTCTTTGGCGACATGAAGGGCATCAAGATGAACGCCACCAAGTCCATGATCGGGCACTGCCTGGGCGCCGCCGGCGGCATGGAGGCCGTCGCCACGCTCATGGCCATCCGCACCGGCTGGGTGCACCCCACCATCAACCACGACAACCCCATCGCCGAGGTCGACGGCCTGGACGTCGTCGCCAACGCCAAGGCCCAGCACAAAATCAACGTCGCCATCTCCAACTCCTTCGGCTTCGGCGGGCACAACTCCGTCGTCGCCTTTGCGCCCTTCCGCGAGTAGSEQIDNO:70桑椹形原藻(UTEX1435)KASI等位基因1,蛋白质序列MVATLSLAGPACNTQCVSGKRAVAFNRPHVGVRARSAVVARAAKRDPTQRIVITGMGVASVFGNDVETFYNKLLEGTSGVDLISRFDISEFPTKFAAQITGFSVEDCVDKKNARRYDDALSYAMVASKKALRQAGLEKDKCPEGYGALDKTRAGVLVGSGMGGLTVFQDGVKALVEKGYKKMSPFFIPYAITNMGSALVGIDQGFMGPNYSVSTACATSNYAFVNAANHIRKGDADVMVVGGTEASIVPVGLGGFVACRALSTRNDEPKRASRPWDEGRDGFVMGEGAAVLVMESLEHAQKRGATILGEYLGGAMTCDAHHMTDPHPEGLGVSTCIRLALEDAGVSPDEVNYVNAHATSTLVGDKAEVRAVKSVFGDMKGIKMNATKSMIGHCLGAAGGMEAVATLMAIRTGWVHPTINHDNPIAEVDGLDVVANAKAQHKINVAISNSFGFGGHNSVVAFAPFRESEQIDNO:71桑椹形原藻(UTEX1435)FATA等位基因1ATGGCACCGACCAGCCTGCTTGCCAGTACTGGCGTCTCTTCCGCTTCTCTGTGGTCCTCTGCGCGCTCCAGCGCGTGCGCTTTTCCGGTGGATCATGCGGTCCGTGGCGCACCGCAGCGGCCGCTGCCCATGCAGCGCCGCTGCTTCCGAACAGTGGCGGTCAGGGCCGCACCCGCGGTAGCCGTCCGTCCGGAACCCGCCCAAGAGTTTTGGGAGCAGCTTGAGCCCTGCAAGATGGCGGAGGACAAGCGCATCTTCCTGGAGGAGCACCGCATTCGGGGCAACGAGGTGGGCCCCTCGCAGCGGCTGACGATCACGGCGGTGGCCAACATCCTGCAGGAGGCGGCGGGCAACCACGCGGTGGCCATGTGGGGCCGGAGCTCGGAGGGTTTCGCGACGGACCCGGAGCTGCAGGAGGCGGGTCTCATCTTTGTGATGACGCGCATGCAGATCCAGATGTACCGCTACCCGCGCTGGGGCGACCTGATGCAGGTGGAGACCTGGTTCCAGACGGCGGGCAAGCTGGGCGCGCAGCGCGAGTGGGTGCTGCGCGACAAGCTGACCGGCGAGGCGCTGGGCGCGGCCACCTCGAGCTGGGTCATGATCAACATCCGCACGCGCCGGCCGTGCCGCATGCCGGAGCTCGTCCGCGTCAAGTCGGCCTTCTTCGCGCGCGAGCCGCCGCGCCTGGCGCTGCCGCCCGCGGTCACGCGTGCCAAGCTGCCCAACATCGCGACGCCGGCGCCGCTGCGCGGGCACCGCCAGGTCGCGCGCCGCACCGACATGGACATGAACGGGCACGTGAACAACGTGGCCTACCTGGCCTGGTGCCTGGAGGCCGTGCCCGAGCACGTCTTCAGCGACTACCACCTCTACCAGATGGAGATCGACTTCAAGGCCGAGTGCCACGCGGGCGACGTCATCTCCTCCCAGGCCGAGCAGATCCCGCCCCAGGAGGCGCTCACGCACAACGGCGCCGGCCGCAACCCCTCCTGCTTCGTCCATAGCATTCTGCGCGCCGAGACCGAGCTCGTCCGCGCGCGAACCACATGGTCGGCCCCCATCGACGCGCCCGCCGCCAAGCCGCCCAAGGCGAGCCACTGASEQIDNO:72桑椹形原藻(UTEX1435)FATA等位基因1MAPTSLLASTGVSSASLWSSARSSACAFPVDHAVRGAPQRPLPMQRRCFRTVAVRAAPAVAVRPEPAQEFWEQLEPCKMAEDKRIFLEEHRIRGNEVGPSQRLTITAVANILQEAAGNHAVAMWGRSSEGFATDPELQEAGLIFVMTRMQIQMYRYPRWGDLMQVETWFQTAGKLGAQREWVLRDKLTGEALGAATSSWVMINIRTRRPCRMPELVRVKSAFFAREPPRLALPPAVTRAKLPNIATPAPLRGHRQVARRTDMDMNGHVNNVAYLAWCLEAVPEHVFSDYHLYQMEIDFKAECHAGDVISSQAEQIPPQEALTHNGAGRNPSCFVHSILRAETELVRARTTWSAPIDAPAAKPPKASHSEQIDNO:73桑椹形原藻(UTEX1435)FAD亚油酸酯等位基因2ATGGTCGCTGCGGGCGACGTCGCTGGAGCCACCGCCTCTGAGGGAGATGGCCGGGCCCTGGCCAACCCGCCGCCCTTCACGCTGGCCGACATCCGCAACGCCATTCCCAAGGACTGCTTCCGCAAGAGCGCGGCCAAGTCGTTGGCGTACCTGGGTCTGGACCTTTCCATCGTCACGGGCATGGCTGTGCTGGCCTACAAAATCAACTCGCCGTGGCTCTGGCCCCTGTACTGGTTTGCCCAGGGAACGATGTTTTGGGCCCTGTTTGTCGTCGGCCACGACTGTGGCCACCAGAGCTTTAGCACGAGCAAGCGGCTGAACGACGCGGTCGGTCTTTTCGTACACTCCATCATCGGCGTGCCGTACCACGGCTGGCGCATCTCCCACCGCACCCACCACAACAACCACGGCCACGTGGAGAACGACGAGTCCTGGTACCCGCCCACCGAGAGCGGGCTCAAGGCGATGACCGACATGGGCCGGCAGGGGCGCTTCCACTTTCCCACCATGCTCTTTGTCTACCCCTTTTACCTCTTCTGGCGGTCCCCGGGCAAGACCGGGTCCCACTTTAGCCCCTCCACCGACCTCTTCGCCTCGTGGGAGGCCCCCCTGATCCGGACGTCAAACGCGTGCCAGCTGGCGTGGCTGGGCGCGCTGGCGGCGGGGACCTGGGCGCTGGGCGTGCTGCCCATGCTCAACCTGTACCTCGCGCCCTACGTGATATCGGTGGCGTGGCTGGATCTGGTGACGTACCTGCACCACCACGGCCCCTCGGACCCGCGCGAGGAGATGCCCTGGTACCGCGGCCGCGAGTGGAGCTACATGCGCGGCGGGCTGACCACCATCGACCGCGACTACGGCCTCTTCAACAAGGTCCACCACGACATTGGGACGCACGTCGTGCACCACCTGTTCCCGCAGATCCCGCACTACAACCTCTGCCGCGCCACGGAGGCCGCCAAGAAGGTGCTGGGGCCCTACTACCGCGAGCCCGAGCGCTGCCCGCTGGGCCTGCTGCCCGTGCACCTGCTCGCGCCCCTGCTCCGCTCCCTCGGCCAGGACCACTTTGTCGACGACGCGGGCTCCGTCCTCTTCTACCGCCGCGCCGAGGGCATCAACCCCTGGATCCAGAAGCTCCTGCCCTSEQIDNO:74桑椹形原藻(UTEX1435)FAD亚油酸酯等位基因2MVAAGDVAGATASEGDGRALANPPPFTLADIRNAIPKDCFRKSAAKSLAYLGLDLSIVTGMAVLAYKINSPWLWPLYWFAQGTMFWALFVVGHDCGHQSFSTSKRLNDAVGLFVHSIIGVPYHGWRISHRTHHNNHGHVENDESWYPPTESGLKAMTDMGRQGRFHFPTMLFVYPFYLFWRSPGKTGSHFSPSTDLFASWEAPLIRTSNACQLAWLGALAAGTWALGVLPMLNLYLAPYVISVAWLDLVTYLHHHGPSDPREEMPWYRGREWSYMRGGLTTIDRDYGLFNKVHHDIGTHVVHHLFPQIPHYNLCRATEAAKKVLGPYYREPERCPLGLLPVHLLAPLLRSLGQDHFVDDAGSVLFYRRAEGINPWIQKLLPSEQIDNO:75桑椹形原藻(UTEX1435)FAD亚油酸酯等位基因1ATGGTCGCTGCGGGCGACGTCGCTAGAGCCACCGCCTCTGAGGGAGATGGCCGGGCCCTGGCCAACCCGCCGCCCTTCACGCTGGCCGACATCCGCAACGCCATTCCCAAGGACTGCTTCCGCAAGAGCGCGGCTAAGTCGTTGGCGTACCTGGGTTTGGACCTCTCCATCATCACGGGCATGGCTGTGCTGGCCTACAAAATCAACTCGCCGTGGCTCTGGCCCCTGTACTGGTTTGCCCAGGGAACGATGTTTTGGGCCCTGTTTGTCGTCGGACACGACTGTGGCCACCAGAGCTTTAGCACGAGCAAGCGGCTGAACGACGCGGTCGGTCTTTTTGTGCACTCCATCATCGGCGTGCCGTACCACGGCTGGCGCATCTCCCACCGCACCCACCACAACAACCACGGCCACGTGGAGAACGACGAGTCCTGCGAAAGCGGGCTCAAGGCGATGACCGATATGGGCCGGCAGGGCCGATTCCACTTTCCCTCCATGCTCTTTGTCTACCCCTTTTACCTCTTCTGGCGGTCCCCGGGCAAGACCGGGTCCCACTTTAGCCCCGCCACAGACCTCTTCGCCTTGTGGGAGGCCCCCCTGATCCGGACGTCCAACGCGTGCCAGCTGGCGTGGCTGGGCGCGCTGGCGGCGGGGACCTGGGCGCTGGGCGTGCTGCCGATGCTGAACCTGTACCTCGCGCCCTACGTGATCTCGGTGGCCTGGCTGGACCTGGTGACGTACCTGCACCACCACGGCCCCTCGGACCCGCGCGAGGAGATGCCCTGGTACCGCGGCCGGGAGTGGAGCTACATGCGCGGCGGGCTGACCACAATCGACCGCGACTACGGTCTTTTCAACAAGGTCCACCACGACATCGGGACGCACGTCGTGCACCACCTGTTCCCGCAGATCCCGCACTACAACCTCTGCCGCGCCACGAAGGCCGCCAAGAAGGTGCTGGGGCCCTACTACCGCGAGCCCGAGCGCTGCCCGCTGGGCCTGCTGCCCGTGCACCTGCTCGCGCCCCTGCTCCGCTCCCTCGGCCAGGACCACTTTGTCGACGACGCGGGCTCCGTCCTCTTCTACCGGCGCGCCGAGGGCATCAACCCCTGGATCCAGAAGCTCCTGCCCTSEQIDNO:76桑椹形原藻(UTEX1435)FAD亚油酸酯等位基因1MVAAGDVARATASEGDGRALANPPPFTLADIRNAIPKDCFRKSAAKSLAYLGLDLSIITGMAVLAYKINSPWLWPLYWFAQGTMFWALFVVGHDCGHQSFSTSKRLNDAVGLFVHSIIGVPYHGWRISHRTHHNNHGHVENDESCESGLKAMTDMGRQGRFHFPSMLFVYPFYLFWRSPGKTGSHFSPATDLFALWEAPLIRTSNACQLAWLGALAAGTWALGVLPMLNLYLAPYVISVAWLDLVTYLHHHGPSDPREEMPWYRGREWSYMRGGLTTIDRDYGLFNKVHHDIGTHVVHHLFPQIPHYNLCRATKAAKKVLGPYYREPERCPLGLLPVHLLAPLLRSLGQDHFVDDAGSVLFYRRAEGINPWIQKLLPSEQIDNO:77桑椹形原藻(UTEX1435)FAD-CΔ-12脱饱和酶(FADc)等位基因2MAIKTNRQPVEKPPFTIGTLRKAIPAHCFERSALRSSMYLAFDIAVMSLLYVASTYIDPAPVPTWVKYGIMWPLYWFFQGAFGTGVWVCAHECGHQAFSSSQAINDGVGLVFHSLLLVPYYSWKHSHRRHHSNTGCLDKDEVFVPPHRAVAHEGLEWEEWLPIRMGKVLVTLTLGWPLYLMFNVASRPYPRFANHFDPWSPIFSKRERIEVVISDLALVAVLSGLSVLGRTMGWAWLVKTYVVPYMIVNMWLVLITLLQHTHPALPHYFEKDWDWLRGAMATVDRSMGPPFMDSILHHISDTHVLHHLFSTIPHYHAEEASAAIRPILGKYYQSDSRWVGRALWEDWRDCRYVVPDAPEDDSALWFHKSEQIDNO:78桑椹形原藻(UTEX1435)FADc等位基因2ATGGCTATCAAGACGAACAGGCAGCCTGTGGAGAAGCCTCCGTTCACGATCGGGACGCTGCGCAAGGCCATCCCCGCGCACTGTTTCGAGCGCTCGGCGCTTCGTAGCAGCATGTACCTGGCCTTTGACATCGCGGTCATGTCCCTGCTCTACGTCGCGTCGACGTACATCGACCCTGCACCGGTGCCTACGTGGGTCAAGTACGGCATCATGTGGCCGCTCTACTGGTTCTTCCAGGGCGCCTTCGGCACGGGTGTCTGGGTGTGCGCGCACGAGTGCGGTCACCAGGCCTTTTCCTCCAGCCAGGCCATCAACGACGGCGTGGGCCTGGTGTTCCACAGCCTGCTGCTGGTGCCCTACTACTCCTGGAAGCACTCGCACCGCCGCCACCACTCCAACACGGGGTGCCTGGACAAGGACGAGGTGTTTGTGCCGCCGCACCGTGCGGTGGCGCACGAGGGCCTGGAGTGGGAGGAGTGGCTGCCCATCCGCATGGGCAAGGTGCTGGTCACCTTGACCCTGGGCTGGCCGCTGTACCTCATGTTCAACGTCGCCTCCCGCCCTTACCCGCGCTTCGCCAACCACTTTGACCCGTGGTCGCCCATCTTCAGCAAGCGCGAGCGCATCGAGGTGGTCATCTCCGACCTCGCGTTGGTGGCGGTGCTCAGCGGGCTCAGCGTGCTGGGCCGCACCATGGGCTGGGCCTGGCTGGTCAAGACCTACGTGGTGCCCTACATGATCGTGAACATGTGGCTGGTGCTCATCACGCTGCTCCAGCACACGCACCCGGCCCTGCCGCACTACTTCGAGAAGGACTGGGACTGGCTACGCGGCGCCATGGCCACCGTCGACCGCTCCATGGGCCCGCCCTTCATGGACAGCATCCTGCACCACATCTCCGACACCCACGTGCTGCACCACCTCTTCAGCACCATCCCGCACTACCACGCCGAGGAGGCCTCCGCCGCCATCCGGCCCATCCTGGGCAAGTACTACCAATCCGACAGCCGCTGGGTCGGCCGCGCCCTGTGGGAGGACTGGCGCGACTGCCGCTACGTCGTCCCCGACGCGCCCGAGGACGACTCCGCGCTCTGGTTCCACAAGTGASEQIDNO:79桑椹形原藻(UTEX1435)油酸酯脱饱和酶ATGGCTATCAAGACGAACAGGCAGCCTGTGGAGAAGCCTCCGTTCACGATCGGGACGCTGCGCAAGGCCATCCCCGCGCACTGTTTCGAGCGCTCGGCGCTTCGTAGCAGCATGTACCTGGCCTTTGACATCGCGGTCATGTCCCTGCTCTACGTCGCGTCGACGTACATCGACCCTGCGCCGGTGCCTACGTGGGTCAAGTATGGCGTCATGTGGCCGCTCTACTGGTTCTTCCAGGTGTGTGTGAGGGTTGTGGTTGCCCGTATCGAGGTCCTGGTGGCGCGCATGGGGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCCTTCGGCACGGGTGTCTGGGTGTGCGCGCACGAGTGCGGCCACCAGGCCTTTTCCTCCAGCCAGGCCATCAACGACGGCGTGGGCCTGGTGTTCCACAGCCTGCTGCTGGTGCCCTACTACTCCTGGAAGCACTCGCACCGCCGCCACCACTCCAACACGGGGTGCCTGGACAAGGACGAGGTGTTTGTGCCGCCGCACCGCGCAGTGGCGCACGAGGGCCTGGAGTGGGAGGAGTGGCTGCCCATCCGCATGGGCAAGGTGCTGGTCACCCTGACCCTGGGCTGGCCGCTGTACCTCATGTTCAACGTCGCCTCGCGGCCGTACCCGCGCTTCGCCAACCACTTTGACCCGTGGTCGCCCATCTTCAGCAAGCGCGAGCGCATCGAGGTGGTCATCTCCGACCTGGCGCTGGTGGCGGTGCTCAGCGGGCTCAGCGTGCTGGGCCGCACCATGGGCTGGGCCTGGCTGGTCAAGACCTACGTGGTGCCCTACCTGATCGTGAACATGTGGCTCGTGCTCATCACGCTGCTCCAGCACACGCACCCGGCGCTGCCGCACTACTTCGAGAAGGACTGGGACTGGCTGCGCGGCGCCATGGCCACCGTGGACCGCTCCATGGGCCCGCCCTTCATGGACAACATCCTGCACCACATCTCCGACACCCACGTGCTGCACCACCTCTTCAGCACCATCCCGCACTACCACGCCGAGGAGGCCTCCGCCGCCATCAGGCCCATCCTGGGCAAGTACTACCAGTCCGACAGCCGCTGGGTCGGCCGCGCCCTGTGGGAGGACTGGCGCGACTGCCGCTACGTCGTCCCGGACGCGCCCGAGGACGACTCCGCGCTCTGGTTCCACAAGTGASEQTD.NO:80桑椹形原藻(UTEX1435)FAD-BΔ-12脱饱和酶(FADc等位基因1),蛋白质MAIKTNRQPVEKPPFTIGTLRKAIPAHCFERSALRSSMYLAFDIAVMSLLYVASTYIDPAPVPTWVKYGVMWPLYWFFQGAFGTGVWVCAHECGHQAFSSSQAINDGVGLVFHSLLLVPYYSWKHSHRRHHSNTGCLDKDEVFVPPHRAVAHEGLEWEEWLPIRMGKVLVTLTLGWPLYLMFNVASRPYPRFANHFDPWSPIFSKRERIEVVISDLAXVAVLSGLSVLGRTMGWAWLVKTYVVPYLIVNMWLVLITLLQHTHPALPHYFEKDWDWLRGAMATVDRSMGPPFMDNILHHISDTHVLHHLFSTIPHYHAEEASAAIRPILGKYYQSDSRWVGRALWEDWRDCRYVVPDAPEDDSALWFHKSEQID.NO:81桑椹形原藻(UTEX1435)LPAAT-EATGGTTGCGGCTCAGGAAGACGGCTCCATGGAGAGGAGGACCTCGGCCAACCCCTCCGTGGGTCTTAGCAGCTTAAAGCACGTTCCGCTGAGTGCGGTGGACCTCCCGAATTTCGAGTCCGCTCCCAAGGGTGCGGCCAGCCCCGATGTCCATCGTCAGATAGAGGAACTGGTGGATAAGGCACGCGCAGATCGGTCACCGGCCTCGTTGTCGCTCCTAGCCGATGTGCTGGACATCAGCGGGCCGCTGCAGGACGCGGCCTCGGCGATGGTGGACGACTCCTTCCTGCGCTGCTTCACCTCCACCATGGACGAGCCCTGGAACTGGAACTTTTACCTGTTCCCGCTCTGGGCGCTCGGCGTCGTCGTCCGCAACCTGATCCTGTTCCCCCTGCGCCTCCTCACCATCGTGCTGGGGACGCTGCTCTTCGTGCTGGCCTTTGCCGTGACGGGCTTTCTCCCCAAGGAGAAGCGGCTCGCGGCCGAGCAGCGGTGCGTCCAGTTCATGGCGCAGGCGTTCGTGGCCTCCTGGACAGGCGTGATCCGGTACCACGGCCCCCGCCCCGTGGCGGCGCCCAACCGCGTGTGGGTCGCCAACCACACGTCCATGATCGACTACGCGGTGCTGTGCGCCTACTGCCCGTTTGCGGCCATCATGCAGCTGCACCCCGGCTGGGTGGGCGTCTTCCAGACGCGCTACCTGGCCTCGCTGGGCTGCCTCTGGTTCAACCGCACGCAGGCCAAGGACCGCACGCTCGTGGCCAAGCGCATGCGCGAGCACGTGGCCAGCGCGACCAGCACGCCGCTGCTCATCTTCCCCGAGGGCACCTGCGTCAACAACGAGTACTGCGTCATGTTCCGCAAGGGCGCCTTTGACCTGGGCGCCACCGTCTGCCCCGTGGCCATCAAGTACAACAAGATCTTCGTCGACGCCTTTTGGAACAGCAAGCGCCAGTCCTTCTCCGCGCACCTCATGAAGATCATGCGCTCGTGGGCCCTCGTCTGCGACGTCTACTTCCTGGAGCCCCAGACGCGGAGGGAGGGCGAGTCGGTCGAGGCGTTTGCGAACCGCSEQID.NO:82桑椹形原藻(UTEX1435)LPAAT-E,蛋白质MVAAQEDGSMERRTSANPSVGLSSLKHVPLSAVDLPNFESAPKGAASPDVHRQIEELVDKARADRSPASLSLLADVLDISGPLQDAASAMVDDSFLRCFTSTMDEPWNWNFYLFPLWALGVVVRNLILFPLRLLTIVLGTLLFVLAFAVTGFLPKEKRLAAEQRCVQFMAQAFVASWTGVIRYHGPRPVAAPNRVWVANHTSMIDYAVLCAYCPFAAIMQLHPGWVGVFQTRYLASLGCLWFNRTQAKDRTLVAKRMREHVASATSTPLLIFPEGTCVNNEYCVMFRKGAFDLGATVCPVAIKYNKIFVDAFWNSKRQSFSAHLMKIMRSWALVCDVYFLEPQTRREGESVEAFANRSEQID.NO:83桑椹形原藻(UTEX1435)LPAAT-A,蛋白质MPPPEAPTNGDLAAPFVRKDRFGEYGMAPQPPMVKVVLALEALVLLPLRAVSVFILVVLYWLICNASVALPPKYCAAVTVTAGRLVCRWALFCFGFHYIKWVNLAGAEEGPRPGGIVSNHCSYLDILLHMSDSFPAFVARQSTAKLPFIGIISQIMSCLYVNRDRSGPNHVGVADLVKQRMQDEAEGKTPPEYRPLLLFPEGTTSNGDYLLPFKTGAFLAGVPVQPVVLHYHRLPVYVPNEEEKADPKLYAQNVRKAMMEVAGTKDTTAVFEDKMRYLNSLKRKYGKPVPKKIESEQID.NO:84桑椹形原藻(UTEX1435)LPAAT-AAAATTATTGGCCTCATCCGCGAGGGTCGGAGCCTTTCAAACGTCACAAGCTGTATATTTGAGTCCCTCTCAATTCGTTTGAAATGAAGGAGCAAGTGGTTAATGCCCCCCCCTGAGGCCCCCACGAATGGGGACCTTGCGGCCCCCTTTGTGCGGAAGGACCGGTTCGGGGAGTATGGCATGGCCCCGCAGCCCCCGATGGTGAAGGTGGTGTTGGCACTCGAGGCCTTGGTGCTCTTGCCGCTGCGCGCGGTGAGCGTGTTCATCCTCGTCGTGCTATACTGGCTCATTTGCAATGCTTCGGTCGCACTCCCGCCCAAGTACTGCGCGGCCGTCACGGTCACCGCTGGGCGCTTGGTCTGCCGGTGGGCGCTCTTCTGCTTCGGATTCCACTACATCAAGTGGGTGAACCTGGCGGGCGCGGAGGAGGGCCCCCGCCCGGGCGGCATTGTTAGCAACCACTGCAGCTACCTGGACATCCTGCTGCACATGTCCGATTCCTTCCCCGCCTTTGTGGCGCGCCAGTCGACGGCCAAGCTGCCCTTTATCGGCATCATCAGCCAAATTATGAGCTGCCTCTACGTGAACCGCGACCGCTCGGGGCCCAACCACGTGGGTGTGGCCGACCTGGTGAAGCAGCGCATGCAGGACGAGGCCGAGGGGAAGACCCCGCCCGAGTACCGGCCGCTGCTCCTCTTCCCCGAGGGCACCACCTCCAACGGCGACTACCTGCTTCCCTTCAAGACCGGCGCCTTCCTGGCCGGGGTGCCCGTCCAGCCCGTCGTCCTCCACTACCACAGGTTGCCCGTGTACGTCCCCAATGAGGAGGAAAAGGCCGACCCCAAGCTGTACGCCCAAAACGTCCGCAAAGCCATGATGGAGGTCGCCGGGACCAAGGACACGACGGCGGTGTTTGAGGACAAGATGCGCTACCTGAACTCCCTGAAGAGAAAGTACGGCAAGCCTGTGCCTAAGAAAATTGAGTGAACCCCCGTCGTCGACCAAAGAGSEQID.NO:85桑椹形原藻(UTEX1435)SAD1等位基因2,蛋白质MASAAFTMSACPAMTGRAPEARRSGRPVATRLRAVAAPPRSQGLTPTIVRQDVLHSATDLQIEVIKDLTPVFESKILPLLPGVDDLWQPTDYLPASNSERFFDEIGELRERSASLSDELLVCLVGDMITEEALPTYMAMINTLDGMRDETGRDAHPYARWTRSWVAEENRHGDLLNKYLWLTGRVDMLAVERTIQRLISTGMDPGTENHPYHGFVFTSFQERATKLSHGATARIAHAAGDEALAKICGTIARDESRHEMAYTRTMEAIFERDPSGAVVAFAHMMLRKITMPAHLMDDGRHERATGRSLFDDYAAVAERIGVYTAKDYISILKHLIKRWKVEGLTGLTPEARQAQDLLCSLPTRFERLARHKSKKVTDTPPAQVQFSWVFQRPVAMSEQID.NO:86桑椹形原藻(UTEX1435)SAD1等位基因2ATGGCTTCCGCGGCATTCACCATGTCGGCGTGCCCCGCGATGACTGGCAGGGCCCCTGAGGCACGTCGCTCCGGACGGCCAGTCGCCACCCGCCTGAGGGCTGTGGCGGCCCCGCCGCGTTCCCAGGGCCTCACCCCCACCATCGTCCGCCAAGATGTGTGCTGCACTCTGCCACGGACCTGCAGATCGAGGTGATCAAGGACCTGACCCCCGTGTTTGAGTCCAAGATCCTGCCCCTGCTGCCCGGCGTGGACGACCTGTGGCAGCCGACGGACTACCTTCCCGCCTCCAACTCGGAGCGTTTCTTCGACGAGATCGGGGAGCTGCGCGAGCGCTCGGCGTCGCTGTCGGACGAGCTTCTGGTGTGCCTGGTGGGCGACATGATCACGGAGGAGGCGCTGCCGACCTACATGGCCATGATCAACACGCTGGACGGGATGCGGGACGAGACGGGGCGCGACGCGCACCCGTACGCGCGCTGGACGCGCAGCTGGGTGGCGGAGGAGAACCGCCACGGCGACCTGCTGAACAAGTACCTCTGGCTGACGGGGCGCGTGGACATGCTGGCCGTGGAGCGCACGATCCAGCGCCTCATCTCCACGGGCATGGACCCGGGCACGGAGAACCACCCCTACCACGGCTTCGTCTTCACCTCCTTCCAGGAGCGCGCGACCAAGCTGAGCCACGGCGCCACCGCGCGCATCGCGCACGCCGCCGGCGACGAGGCGCTGGCCAAGATCTGCGGCACCATCGCGCGCGACGAGTCGCGCCACGAGATGGCCTACACGCGCACGATGGAGGCCATCTTCGAGCGCGACCCCTCGGGCGCGGTCGTCGCCTTTGCGCACATGATGCTGCGCAAGATCACCATGCCCGCGCACCTCATGGACGACGGCCGCCACGAGCGCGCCACGGGACGCTCGCTCTTCGACGACTACGCGGCCGTCGCCGAGCGCATCGGCGTCTACACCGCCAAGGACTACATCTCCATCCTCAAGCACCTCATCAAGCGCTGGAAGGTGGAGGGCCTGACCGGGCTGACCCCGGAGGCGCGCCAGGCGCAGGACCTGCTCTGCTCCCTCCCCACCCGCTTCGAGCGCCTGGCCAGGCACAAGTCCAAGAAGGTGACCGACACGCCCCCGGCCCAGGTCCAGTTCTCCTGGGTCTTCCAGAGGCCCGTCGCCATGTAAAGAGATTGGCGCCTGATTCGGTTTGGATCCGAGGATTTCCAATCGGTGAGAGGGACTGGGTGCCCAACTACCGCCCTTGCACCATCGCCCTTGCACTATTTATTCCCACTTTCTGCTCGCCCTGCCGGGCGATTGCGGGCGTTTCTGCCCTTGACGTATTAATTTCGCCCCTGCTGGCGCGAGGGTTCTTCAAGTTGATAAGAACGCACTCCCGCCAGCTCTGTACTTTTTCTGCGGGGCCCCTGCATGGCTTGTTCCCTATGCTTGCTCGATCGACGGCGCCCATTGCCCACGGCGTCGCCGCATCCATGTGAAGAAACACGGSEQID.NO:87桑椹形原藻(UTEX1435)SAD1等位基因1ATGGCTTCCGCGGCATTCACCATGTCGGCGTGCCCCGCGATGACTGGCAGGGCCCCTGGGGCACGTCGCTCCGGACGGCCAGTCGCCACCCGCCTGAGGGCTGTGGCGGCCCCGCCGCGTTCCCAGGGCCTCACCCCCACCATCGTCCGCCAAGATGTGTGCTGCACTCTGCCACGGACCTGCAGATCGAGGTGATCAAGGACCTGACCCCCGTGTTTGAGTCCAAGATCCTGCCCCTGCTGCCCGGCGTGGACGACCTGTGGCAGCCGACGGACTACCTGCCCGCCTCCAACTCGGAGCGCTTCTTCGACGAGATCGGGGAGCTGCGCGAGCGCTCGGCGGCGCTGTCGGACGAGCTGCTGGTGTGCCTGGTCGGCGACATGATCACGGAGGAGGCGCTGCCGACCTACATGGCCATGATCAACACGCTGGACGGGATGCGGGACGAGACGGGGCGCGACGCGCACCCGTACGCGCGCTGGACACGCAGCTGGGTGGCGGAGGAGAACCGCCACGGCGACCTGCTGAACAAGTACCTCTGGCTGACGGGGCGCGTGGACATGCTGGCCGTGGAGCGCACCATCCAGCGCCTCATCTCCACGGGCATGGACCCGGGCACGGAGAACCACCCCTACCACGGCTTCGTCTTCACCTCCTTCCAGGAGCGCGCGACCAAGCTGAGCCACGGCGCCACCGCGCGCATCGCGCACGCCGCCGGCGACGAGGCCCTGGCCAAGATCTGCGGCACCATCGCGCGCGACGAGTCACGCCACGAGATGGCCTACACGCGCACGATGGAGGCCATCTTCGAGCGCGACCCCTCGGGCGCGGTCGTCGCCTTTGCGCACATGATGCTGCGCAAGATCACCATGCCCGCGCACCTCATGGACGACGGGCGGCACGAGCGCGCCACGGGGCGCTCGCTCTTCGACGACTACGCGGCCGTGGCCGAGCGCATCGGCGTCTACACCGCCAAGGACTACATCTCCATCCTCAAGCACCTCATCAAGCGCTGGAAGGTGGAGGGCCTGACCGGGCTGACCCCGGAGGCGCGCCAGGCCCAGGACCTGCTCTGCTCCCTCCCCGCCCGCTTTGAGCGCCTGGCCAAGCACAAGTCCAAGAAGGTGACCGACACGCCCCCGGCCCAGGTCCAGTTCTCCTGGGTCTTCCAGAGGCCCGTCGCCATGTAAAGTGGCAGAGATTGGCGCCTGATTCGATTTGGATCCAAGGATCTCCAATCGGTGATGGGGACTGAGTGCCCAACTACCACCCTTGCACTATCGTCCTCGCACTATTTATTCCCACCTTCTGCTCGCCCTGCCGGGCGATTGCGGGCGTTTCTGCCCTTGACGTATCAATTTCGCCCCTGCTGGCGCGAGGATTCTTCATTCTAATAAGAACTCACTCCCGCCAGCTCTGTACTTTTCCTGCGGGGCCCCTGCATGGCTTGTTCCCAATGCTTGCTCGATCGACGGCGCCCATTGCCCACGGCGCTGCCGCATCCATGTGAAGAAACACGGSEQID.NO:88桑椹形原藻(UTEX1435)SAD1等位基因1MASAAFTMSACPAMTGRAPGARRSGRPVATRLRAVAAPPRSQGLTPTIVRQDVLHSATDLQIEVIKDLTPVFESKILPLLPGVDDLWQPTDYLPASNSERFFDEIGELRERSAALSDELLVCLVGDMITEEALPTYMAMINTLDGMRDETGRDAHPYARWTRSWVAEENRHGDLLNKYLWLTGRVDMLAVERTIQRLISTGMDPGTENHPYHGFVFTSFQERATKLSHGATARIAHAAGDEALAKICGTIARDESRHEMAYTRTMEAIFERDPSGAVVAFAHMMLRKITMPAHLMDDGRHERATGRSLFDDYAAVAERIGVYTAKDYISILKHLIKRWKVEGLTGLTPEARQAQDLLCSLPARFERLAKHKSKKVTDTPPAQVQFSWVFQRPVAMSEQID.NO:89桑椹形原藻(UTEX1435)质体ACP等位基因1MAMSMTSCRAVCAPRATLRVQAPRVAVRPFRAQRMICRAVDKASVLSDVRVIIAEQLGTDVEKVNADAKFADLGADSLDTVEIMMALEEKFDLQLDEEGAEKITTVQEAADLISAQIGASEQID.NO:90桑椹形原藻(UTEX1435)质体ACP等位基因2MAMSMTSCRAVCAPRATLRVQAPRVAVRPFRAQRMICRAVDKASVLSDVRVIIAEQLGTDVEKVNADAKFADLGADSLDTVEXMMALEEKFDLQLDEEGAEKITTVQEAADLISAQXGASEQID.NO:91桑椹形原藻(UTEX1435)乙酰基-CoA羧化酶α-CT亚基等位基因2ATGCTGCTCTCGCGCTTCAACCCCATCAGCGAGAAGGCCACCAACGCCACGGTGCTCGACTTTGAGAAACCTTTGGTGGAACTTGATCATAAAATTCGCGAGGTCCGCAAAGTCGCGGAGGAGAACGGCGTGGACGTCACGGAGCAGATCCGCGAGCTGGAGGACCGCGCGCAGCAGGTAGTCGAGTCTGTGTGGAGAGGGTTGCGAAAGGAGACGTACTCCAAGCTGACGCCGATCCAGCGGCTGCAGGTGGCGCGCCACCCCAACCGCCCCACTTTCTTGGACATTGCGCTCAACATCACGGACAAGTTTGTGGAGCTGCACGGCGATCGCGCGGGGTACGACGACCCGGCGCTCGTCTGCGGCATCGCGTCGATCGACAACGTGAGCTTCATGTTCATGGGCCACCAGAAGGGCCGCAACACCAAGGAGAACATCTACCGCAATTTCGGCATGCCGCAGCCCAACGGCTACCGCAAGGCGCTGCGCTTCATGCGCCTGGCGGACAAGTTTGGCTTCCCCATCGTCACGTTTGTGGACACGCCCGGCGCGTACGCGGGGCTCAAGGCCGAGGAGCTGGGCCAGGGCGAGGCCATCGCGGTCAACCTGCGCGAGATGTTTGGCTTCCGCGTGCCCATCATCTCCATCGTCATCGGCGAGGGCGGCTCCGGCGGCGCGCTGGCCATCGGCTGCGCCAACCGCATGCTCATCATGGAGAACGCGGTGTACTACGTGGCCTCTCCCGAGGCCTGCGCGGCCATCCTGTGGAAGAGCCGCGACAAGGCGGGCCTGGCCACCGAGGCGCTCAAGATCACGCCCGCCGACCTGGTCAAGCTCAAGGTCATGGACGAGATCGTGCCGGAGCCGCTGGGCGCCGCGCACACCGACCCCATGGGCGCCTTCCCGGCCGTGCGCGAGGCCATCCTGCGCCACSEQID.NO:92桑椹形原藻乙酰基-CoA羧化酶α-CT亚基等位基因1ATGTTCAATAGATACTATCTTGCAACAAGATTGCACTTGGGTTTGGTCGTCTGCTGTTGTGCACTACCATGTGACGTTGTGCTCGTCCATTCTGTTCCCGTCCAGGTCCGCAAAGTCGCGGAGGAGAACGGCGTGGACGTCACGGAGCAGATCCGCGAGCTGGAGGACCGCGCGCAGCAGGTAGTCGAGTCTGTGTGGAGAGGGGTGGGATACTTTGGAAGAATGGGTGCTGTGGAGTCCAGTCATTTGAAGGAAAGGGTAGTCGACTTCCCTCTGTGGTCGTATCTATCTTCTCCAAGCATATCTCACTTTGCCCCTCTTCTCCGCCCCCCTCCATTACCAACCCGTCCACAGTTGCGAAAGGAGACGTACTCCAAGCTGACGCCGATCCAGCGGCTGCAGGTGGCGCGCCACCCCAACCGCCCCACTTTCTTGGACATTGCGCTCAACATCACGGACAAGTTTGTGGAGCTGCACGGCGATCGCGCGGGGTACGACGACCCGNNNNNNNNNNAGAACGGCGTGGACGTCACGGAGCAGATCCGCGAGCTGGAGGACCGCGCGCAGCAGTGTAGTCAACTTTTCTGTGGTTCTATCCATCTTCCCCAAGTATATCTCACCCCCTCTTCCCCCCCTCTCCCCTTTAACAACACCCCGTCCACAGTTGCGAAAGGAGACATACTCCAAGCTGACGCCGATCCAGCGGCTGCAGGTGGCGCGCCACCCCAACCGCCCTACTTTCTTGGACATTGCGCTCAACATCACGGACAAGTTTGTGGAGCTGCACGGCGACCGCGCGGGGTACGACGACCCCGCGCTCGTCTGCGGCATCGCGTCGATCGACAACGTGAGCTTCATGTTCATGGGCCACCAGAAGGGCCGCAACACCAAGGAGAACATCTACCGCAATTTCGGCATGCCGCAGCCCAACGGCTACCGCAAGGCGCTGCGCTTCATGCGCCTGGCGNNNNNNNNNNCGACAACGTGAGCTTCATGTTCATGGGCCACCAGAAGGGCCGCAACACCAAGGAGAACATCTACCGAAACTTTGGCATGCCGCAGCCCAACGGCTACCGCAAGGCGCTGCGCTTCATGCGCCTGGCCGACAAGTTTGGCTTCCCCATCGTCACGTTTGTGGACACGCCCGGCGCGTACGCGGGGCTCAAGGCCGAGGAGCTGGGCCAGGGCGAGGCCATCGCGGTCAACCTGCGCGAGATGTTTGGCTTCCGCGTGCCCATCATCTCCATCGTCATCGGCGAGGGCGGCTCCGGCGGCGCGCTGGCCATCGGCTGCGCCAACCGCATGCTCATCATGGAGAACGCGGTGTACTACGTGGCCTCTCCCGAGGCCTGCGCGGCCATCCTGTGGAAGAGCCGCGACAAGGCGGGCCTGGCCACCGAGGCGCTCAAGATCACGCCCGCCGACCTGGTCAAGCTCAAGGTCATGGACGAGATCGTGCCGGAGCCGCTGGGCGCCGCGCACACCGACCCCATGGGCGCCTTCCCGGCCGAGGAGGCCGACTACATCGAGCAGATGGCCGAGCGCTGGCGGTGGTGGGACAGCCTGCTGGAGGACAAGAAGGACATCGTCAACCCGCCAAAGACCGAGCACCCGGGCTGGCTCATCCCGGGCTTTGCCGAGTTCGCCATCGGCGTCGCCAAGGCCGCCGACGCGCGCCAGGCGCGCATGGGGCTCGAGGGCGAGAGCGCCGCGCACGCCAACGACGCCGGCATCGGCACCGAGAGGGACGGCGGCGCCGAGGGCAACGGCGCGAACGCCGAGAACGGGGCGCACGACGAGTCGTCTATCGCGGAGACCGAGTGASEQID.NO:93桑椹形原藻(UTEX1435)1b-ACC酶-BC-AMAPASVNLTQVCGGANVEFPSVPQGDMGDHGLIQHVDSIAFRATPCPAAVAGRRQFPRGAGPSRRSQRSTGSARLTPSASTPSRLVARAETGTNGSAALTPIHKVLIANRGEIAVRVIRACKELGIKTVAVYSTADRECLHAQLADEAVCIGEAPSSESYLNIPTILSAAMSRGADAIHPGYGFLSENAEFVDICKDHGINFIGPGSEHIRVMGDKATARETMKQAGVPTVPGSDGLVETPEEALEVADQVGFPVMIKATAGGGGRGMRLAMTRDEFLPLLRAAQGEAQAAFGNGAVYLERYVKDPRHIEFQVLADKHGNVIHLGERDCSIQRRNQKLLEEAPSPALTPEVRAAMGEAATNAARSIGYVGVGTIEFLWEPAGFYFMEMNTRIXXXXCARSGHSGVCPGGAGETQAWRAIAHSPGTKEVIGWVCKDSKERPFKRPPRLAGRALESSSNSSTGAASRSAANSVGDGINIQRGGARANRLSKENNTQETRAPFGQTKRERRLEGQVGTQAVEGAPRHMSEQID.NO:94桑椹形原藻异质型乙酰基-CoA羧化酶BC亚基等位基因2MAPASVNLTQVCCSAGHGLRPARATPCPAAVAGRRQFPRGAGPSRRSQRSTGSARLTPSASTPSRLVARAETGTNGSAALTPIHKVLIANRGEIAVRVIRACKELGIKTVAVYSTADRECLHAQLADEAVCIGEAPSSESYLNIPTILSAAMSRGADAIHPGYGFLSENAEFVDICKDHGINFIGPGSEHIRVMGDKATARETMKQAGVPTVPGSDGLVETPEEALEVADQVGFPVMIKATAGGGGRGMRLAMTRDEFLPLLRAAQGEAQAAFGNGAVYLERYVKDPRHIEFQVLADKHGNVIHLGERDCSIQRRNQKLLEEAPSPALTPEVRAAMGEAATNAARSIGYVGVGTIEFLWEPAGFYFMEMNTRIQVEHPVTEMITGVDLIQEQIRAAMGEPLRLTQEDIVIKGHSIECRINAEDPFKGFRPGPGRVTAYLPPGGPNVRMDSHVYPDYLVPSNYDSLLGKLIVWGEDRQAAIERMKRALDEMVVAGVPTTAPYHLLILDHEAFRAGDVDTGFIPKHGDDLILPPEAARKKPNVVVEAAKRAHSRSKASV*SEQID.NO:95桑椹形原藻(UTEX1435)异质型乙酰基-CoA羧化酶BCCP-A亚基等位基因1MSGTFYSSPAPGEPPFVKVGDSVKKGQTVCIIEAMKLMNEIEAESSGTIVKVVAEHGKPVTPGAPLFIIKPSEQID.NO:96桑椹形原藻(UTEX1435)异质型乙酰基-CoA羧化酶BCCP-A亚基等位基因2MPSFTKALPRLGGGLVPKPAVSVTDSGKSDLLMRFFESDWFDAWIALTYVALGSEGRSCVEMAGLRAVRRFGTDWGHPGEWVWLERRVGLLREVVWPGRSRQSDALGPCIGVGGRARAGFKIARVQLTPLGDDYVTHYKPTRPPSRPPPLTAGCGDLPVAAHPAVHAAAQQLARARPDRPLLALAAHCGQDVLAAPRHQPGQPHRHARHRAPRSMRAGRPGRHLGTRGEETEGGRTXXXXPAGGPCRPPAAPPPPAPAVEGVEISSPMSGTFYSSPAPGEPPFVKVGDSVKKGQTVCIIEAMKLMNEIEAEVGDSGVVAVKEGSEQID.NO:97桑椹形原藻(UTEX1435)乙酰基-CoA羧化酶α-CT亚基等位基因1MSDPVASGCDSMTSSQCRVGAWASPMAVARTRAVARPIPRSRNPRLRVRAGIDPPDLPKPREEEKKHGDWFQMLLSRFNPISEKATNATVLDFEKPLVELDHKIREVRKVAEENGVDVTEQIRELEDRAQQLRKETYSKLTPIQRLQVARHPNRPTFLDIALNITDKFVELHGDRAGYDDPALVCGIASIDNVSFMFMGHQKGRNTKENIYRNFGMPQPNGYRKALRFMRLADKFGFPIVTFVDTPGAYAGLKAEELGQGEAIAVNLREMFGFRVPIISIVIGEGGSGGALAIGCANRMLIMENAVYYVASPEACAAILWKSRDKAGLATEALKITPADLVKLKVMDEIVPEPLGAAHTDPMGAFPAVREAILRHWRELQPLSPVQMRADRYMKFRHIGVYAEHMVPGGQIEAVEAFRESLPGAKTKAGTYAPTQEEADYIEQMAERWRWWDSLLEDKKDIVNPPKTEHPGWLIPGFAEFAIGVAKAADARQARQGLEGESAAHANDAGIGTERDGSAEVNGANAKNGAHDESLAEAE*SEQID.NO:98桑椹形原藻(UTEX1435)乙酰基-CoA羧化酶α-CT亚基等位基因2蛋白质MLLSRFNPISEKATNATVLDFEKPLVELDHKIREVRKVAEENGVDVTEQIRELEDRAQQVVESVWRGLRKETYSKLTPIQRLQVARHPNRPTFLDIALNITDKFVELHGDRAGYDDPALVCGIASIDNVSFMFMGHQKGRNTKENIYRNFGMPQPNGYRKALRFMRLADKFGFPIVTFVDTPGAYAGLKAEELGQGEAIAVNLREMFGFRVPIISIVIGEGGSGGALAIGCANRMLIMENAVYYVASPEACAAILWKSRDKAGLATEALKITPADLVKLKVMDEIVPEPLGAAHTDPMGAFPAVREAILRHSEQID.NO:99桑椹形原藻(UTEX1435)乙酰基-CoA羧化酶α-CT亚基等位基因2ATGCTGCTCTCGCGCTTCAACCCCATCAGCGAGAAGGCCACCAACGCCACGGTGCTCGACTTTGAGAAACCTTTGGTGGAACTTGATCATAAAATTCGCGAGGTCCGCAAAGTCGCGGAGGAGAACGGCGTGGACGTCACGGAGCAGATCCGCGAGCTGGAGGACCGCGCGCAGCAGGTAGTCGAGTCTGTGTGGAGAGGGTTGCGAAAGGAGACGTACTCCAAGCTGACGCCGATCCAGCGGCTGCAGGTGGCGCGCCACCCCAACCGCCCCACTTTCTTGGACATTGCGCTCAACATCACGGACAAGTTTGTGGAGCTGCACGGCGATCGCGCGGGGTACGACGACCCGGCGCTCGTCTGCGGCATCGCGTCGATCGACAACGTGAGCTTCATGTTCATGGGCCACCAGAAGGGCCGCAACACCAAGGAGAACATCTACCGCAATTTCGGCATGCCGCAGCCCAACGGCTACCGCAAGGCGCTGCGCTTCATGCGCCTGGCGGACAAGTTTGGCTTCCCCATCGTCACGTTTGTGGACACGCCCGGCGCGTACGCGGGGCTCAAGGCCGAGGAGCTGGGCCAGGGCGAGGCCATCGCGGTCAACCTGCGCGAGATGTTTGGCTTCCGCGTGCCCATCATCTCCATCGTCATCGGCGAGGGCGGCTCCGGCGGCGCGCTGGCCATCGGCTGCGCCAACCGCATGCTCATCATGGAGAACGCGGTGTACTACGTGGCCTCTCCCGAGGCCTGCGCGGCCATCCTGTGGAAGAGCCGCGACAAGGCGGGCCTGGCCACCGAGGCGCTCAAGATCACGCCCGCCGACCTGGTCAAGCTCAAGGTCATGGACGAGATCGTGCCGGAGCCGCTGGGCGCCGCGCACACCGACCCCATGGGCGCCTTCCCGGCCGTGCGCGAGGCCATCCTGCGCCACSEQID.NO:100桑椹形原藻(UTEX1435)1d-ACC酶-CT-α-AATGGATCTCTTCCGCAGCGAGGAGGTGCACCTGATGCAGCTCATGATCCCCGCCGAGGTCGCCCACGACACGATGGTGGCCCTGGGCGAGGTGGGGATGCTGCAGTTCAAGGACCTCAACCCCGACAAGCCGGCCTTCCAGCGCACGTTCGCCAACCAGATCAAGCGGTGCGACGAGATGGCGCGGCAGCTGCGCTTCTTCCAGGCGGAGCTGGACAAGCACGAGGTGCCCGCTTCGCGGCGCGCGGGCGACCCGCCCAGCCCCGACCTGGACCAGCTGGAGTCGCAGCTTGCGGCGCTGGAGTCGGAGCTGGTGCAGCTCAACGGCAACGCGGAGCGCCTGGGACTAGGCGGTCGGCCCGCGCCTGTCGTCCCTTTGGAGGAGGAGAAGAAGCACGGCGACTGGTTCCAAATGCTGCTCTCGCGCTTCAACCCCATCAGCGAGAAGGCCACCAACGCCACGGTGCTCGACTTTGAGAAACCTTTGGTGGAACTTGATCATAAAATTCGCGAGTTGCGAAAGGAGACATACTCCAAGCTGACGCCGATCCAGCGGCTGCAGGTGGCGCGCCACCCCAACCGCCCTACTTTCTTGGACATTGCGCTCAACATCACGGACAAGTTTGTGGAGCTGCACGGCGACCGCGCGGGGTACGACGACCCCGCGCTCGTCTGCGGCATCGCGTCGATCGACAACGTGAGCTTCATGTTCATGGGCCACCAGAAGGGCCGCAACACCAAGGAGAACATCTACCGAAACTTTGGCATGCCGCAGCCCAACGGCTACCGCAAGGCGCTGCGCTTCATGCGCCTGGCCGACAAGTTTGGCTTCCCCATCGTCACGTTTGTGGACACGCCCGGCGCGTACGCGGGGCTCAAGGCCGAGGAGCTGGGCCAGGGCGAGGCCATCGCGGTCAACCTGCGCGAGATGTTTGGCTTCCGCGTGCCCATCATCTCCATCGTCATCGGCGAGGGCGGCTCCGGCGGCGCGCTGGCCATCGGCTGCGCCAACCGCATGCTCATCATGGAGAACGCGGTGTACTACGTGGCGTCCCCGGAAGCCTGTGCGGCCATCCTGTGGAAGAGCCGCGACAAGGCGGGCCTGGCCACCGAGGCGCTCAAGATCACGCCCGCCGACCTGGTCAAGCTCAAGGTCATGGACGAGATCGTACCCGAGCCGCTGGGCGCCGCGCACACCGACCCCATGGGCGCCTTCCCGGCCGTGCGCGAGGCCATTCGCCAGAAAAACGTCGTGGAAAACTTTGAGGCGGCGCTGGAGTACAACCCCGAGGCGTTTGGCACCGTCACCATGCTGTACGTGCCCATGACGGTCAACGGCACGCCCCTCAAGGCCTTTATCGATTCGGGCGCACAGATGACCATCATGTCCCGCAGCTGCGCGGAGCGGTGCGGGCTGCTCCGTCTCATGGACACGCGGTGGCAGGGGACAGCCGTCGGCGTCGGCTCGGCCAAGATCCTGGGGAGGATCCACATGGCTCCGCTGGTCGCGGCCGGCCACCACCTGCCCATCTCCATCACCGTGCTGGATCAGGAGGGCATGGACTTTCTCTTTGGGCTGGACAACCTCAAGCGGCACCAATGCTGCATCGACCTGAAGGCAAACGCGCTTCGGTTTGGGTCGACAGAGGCCGAGATCCCGTTTCTGCCGGAGCACGAGGTCCCCAGGCATCAGCACCAGCTCGCCGGGGAGGACGCCGCGAGCGGTAGAACCGCAGCCACGGCCCCTCCCAGCACCGCTCCCGCACCGACCAACCAGCCCACAGTGCAAGCAGCTCCGCCAGCACCAAATGCTCAGCTGGAGGAAAAGGTGTCGAAACTCATGGGCCTGGGCGGCGTGATCCAGCTATGGGATTACCGCATGGGCACGCTCATCGATCGATTCGAGGAGCATGAGGGACCCGTGCGTGGCGTGCACTTTCATCCCACCCAGCCGCTCTTCGTGTCTGGCGGGGACGACTACAAGATCAAAGTGTGGAACTACAAGACGCGCSEQID.NO:101桑椹形原藻(UTEX1435)异质型乙酰基-CoA羧化酶BCCP-A亚基等位基因1ATGTCCGGCACTTTCTACTCCTCCCCCGCCCCCGGCGAGCCACCGTTTGTCAAGGTCGGCGACAGCGTCAAGAAGGGCCAGACGGTCTGCATCATCGAGGCCATGAAGCTGATGAACGAGATCGAGGCCGAGTCTTCTGGAACAATCGTCAAGGTTGTGGCCGAGCACGGCAAGCCTGTCACCCCCGGCGCCCCCCTGTTCATCATCAAGCCCTGASEQID.NO:102桑椹形原藻(UTEX1435)异质型乙酰基-CoA羧化酶BCCP-A亚基等位基因2ATGCCGAGCTTTACCAAGGCGCTCCCCAGGCTGGGAGGGGGACTGGTCCCCAAGCCCGCAGTGAGCGTGACGGACAGCGGCAAGTCCGACTTGCTCATGCGTTTCTTTGAGAGCGATTGGTTCGACGCCTGGATTGCTCTTACGTACGTTGCGCTCGGTTCGGAGGGGCGTTCCTGTGTCGAGATGGCGGGGTTGCGAGCTGTGAGACGTTTTGGAACGGATTGGGGGCACCCTGGGGAGTGGGTTTGGCTGGAGCGGCGGGTGGGCTTGTTGAGGGAGGTGGTCTGGCCTGGTCGTTCAAGGCAGTCTGACGCATTGGGGCCGTGCATTGGCGTCGGGGGGCGTGCCCGCGCTGGTTTCAAAATCGCTCGCGTCCAATTGACGCCATTAGGTGATGATTATGTGACGCATTACAAACCCACCCGGCCCCCGTCGCGCCCGCCCCCGTTGACAGCGGGATGTGGAGACCTACCTGTCGCAGCTCACCCAGCTGTGCATGCTGCAGCCCAACAGCTCGCTCGAGCGCGTCCTGATCGACCTCTGCTCGCGCTCGCTGCGCATTGCGGTCAAGACGTACTGGCTGCTCCTCGCCATCAGCCAGGACAACCCCACAGACACGCACGTCATCGCGCTCCGCGATCGATGCGAGCAGGCCGCCCTGGAAGGCACCTGGGTACGAGGGGAGAGGAGACAGAGGGGGGGAGGACCNNNNNNNNNNCACCGGCCGGCGGGCCTTGTCGGCCTCCCGCCGCGCCGCCGCCGCCCGCCCCCGCCGTCGAGGGCGTGGAGATCAGCTCGCCCATGTCCGGCACCTTCTACTCCTCCCCCGCCCCCGGCGAGCCGCCGTTTGTCAAGGTCGGCGACAGCGTCAAGAAGGGCCAGACGGTCTGCATCATCGAGGCCATGAAGCTCATGAACGAGATCGAGGCCGAGGTGGGCGACAGCGGAGTGGTGGCGGTGAAAGAGGGGTAASEQID.NO:103桑椹形原藻(UTEX1435)异质型乙酰基-CoA羧化酶BC亚基等位基因2ATGATCACNGGCGTGGACCTGATCCAGGAGCAGATCCGCGCCGCCATGGGCGAGCCGCTGCGCCTGAGACAGGAGGACATCGTGATCAAGGGCCACAGCATCGAGTGCCGCATCAACGCGGAGGACCCNTTCAAGGGCTTCCGCCCGGGGCCGGGGCGCGTGACCGCCTACCTGCCGCCCGGCGGGCCCAACGTGCGCATGGACAGCCACGTCTACCCCGACTACCTGGTGCCCTCCAACTACGACTCCCTGCTGGGCAAGCTCATCGTCTGGGGCGAGGACCGCCAGGCGGCCATCGAGCGCATGAAGCGCGCGCTGGACGAGATGSEQID.NO:104桑椹形原藻ACC-BC-1核苷酸序列ATGGCGCCAGCCTCTGTCAACCTGACCCAGGTTTGCTGCTCCGCCGGGCATGGTCTGCGTCCCGCGAGGGCGACGCCCTGCCCTGCGGCGGTGGCCGGCCGGAGGCAGTTCCCCCGCGGCGCCGGCCCCTCCCGTCGCTCCCAGCGCTCGACGGGCTCCGCGAGGTTGACGCCCTCTGCCTCCACGCCCTCCCGCCTGGTCGCCCGCGCCGAGACGGGCACCAATGGCTCCGCCGCCCTGACCCCCATCCACAAGGTGCTGATCGCCAACCGTGGCGAGATCGCGGTTCGCGTGATCCGGGCCTGCAAGGAGCTGGGCATCAAGACGGTGGCCGTCTACTCCACGGCCGACCGCGAGTGCCTGCACGCGCAGCTGGCGGACGAGGCGGTGTGCATCGGCGAGGCGCCCAGCTCCGAGTCCTACCTCAACATCCCGACCATCCTCTCGGCGGCCATGTCGCGCGGCGCGGACGCGATCCACCCCGGCTACGGCTTTCTGTCCGAGAACGCCGAGTTTGTGGACATCTGCAAGGACCACGGCATCAACTTCATCGGCCCCGGGTCGGAGCACATCCGCGTGATGGGCGACAAGGCCACCGCGCGCGAGACGATGAAGCAGGCGGGCGTGCCGACGGTGCCCGGCTCGGACGGGCTGGTGGAGACGCCCGAGGAGGCGCTGGAGGTGGCGGACCAGGTGGGCTTCCCCGTGATGATCAAGGCCACGGCCGGCGGCGGCGGGCGCGGCATGCGCCTGGCCATGACGCGCGACGAGTTTTTGCCGCTGCTGCGCGCGGCGCAGGGCGAGGCGCAGGCGGCCTTTGGCAACGGCGCCGTCTACCTGGAGCGCTACGTGAAGGACCCGCGGCACATCGAGTTCCAGGTGCTGGCGGACAAGCACGGCAACGTGATCCACCTGGGCGAGCGCGACTGCTCCATCCAGCGCCGCAACCAGAAGCTGCTGGAGGAGGCGCCCAGCCCCGCGCTCACGCCCGAGGTGCGCGCGGCCATGGGCGAGGCGGCCACCAACGCCGCGCGCAGCATCGGCTACGTGGGCGTGGGCACCATCGAGTTCCTGTGGGAGCCGGCCGGCTTCTACTTCATGGAGATGAACACGCGCATCCAGGTGGAGCACCCGGTGACGGAGATGATCACGGGCGTGGACCTGATCCAGGAGCAGATCCGCGCCGCCATGGGCGAGCCGCTGCGCCTGACGCAGGAGGACATCGTGATCAAGGGCCACAGCATCGAGTGCCGCATCAACGCGGAGGACCCGTTCAAGGGCTTCCGCCCGGGGCCGGGGCGCGTGACCGCCTACCTGCCGCCCGGCGGGCCCAACGTGCGCATGGACAGCCACGTCTACCCCGACTACCTGGTGCCCTCCAACTACGACTCCCTGCTGGGCAAGCTCATCGTCTGGGGCGAGGACCGCCAGGCGGCCATCGAGCGCATGAAGCGCGCGCTGGACGAGATGGTCGTCGCCGGCGTGCCCACCACCGCGCCCTACCACCTGCTCATCCTCGACCACGAGGCCTTCCGCGCGGGCGACGTCGACACGGGCTTCATCCCCAAGCACGGCGACGACCTCATCCTGCCCCCGGAGGCCGCGCGCAAGAAGCCAAACGTCGTCGTCGAGGCCGCCAAGCGCGCCCACAGCCGCAGCAAGGCCTCCGTCTGASEQIDNO:105密码子优化的桑椹形原藻(UTEX1435)KASIIATGGCCACCGCATCCACTTTCTCGGCGTTCAATGCCCGCTGCGGCGACCTGCGTCGCTCGGCGGGCTCCGGGCCCCGGCGCCCAGCGAGGCCCCTCCCCGTGCGCGGGCGCGCCGCCGCCGCCGCCGACGCCAACCCCGCCCGCCCCGAGCGCCGCGTGGTGATCACCGGCCAGGGCGTGGTGACCTCCCTGGGCCAGACCATCGAGCAGTTCTACTCCTCCCTGCTGGAGGGCGTGTCCGGCATCTCCCAGATCCAGAAGTTCGACACCACCGGCTACACCACCACCATCGCCGGCGAGATCAAGTCCCTGCAGCTGGACCCCTACGTGCCCAAGCGCTGGGCCAAGCGCGTGGACGACGTGATCAAGTACGTGTACATCGCCGGCAAGCAGGCCCTGGAGTCCGCCGGCCTGCCCATCGAGGCCGCCGGCCTGGCCGGCGCCGGCCTGGACCCCGCCCTGTGCGGCGTGCTGATCGGCACCGCCATGGCCGGCATGACCTCCTTCGCCGCCGGCGTGGAGGCCCTGACCCGCGGCGGCGTGCGCAAGATGAACCCCTTCTGCATCCCCTTCTCCATCTCCAACATGGGCGGCGCCATGCTGGCCATGGACATCGGCTTCATGGGCCCCAACTACTCCATCTCCACCGCCTGCGCCACCGGCAACTACTGCATCCTGGGCGCCGCCGACCACATCCGCCGCGGCGACGCCAACGTGATGCTGGCCGGCGGCGCCGACGCCGCCATCATCCCCTCCGGCATCGGCGGCTTCATCGCCTGCAAGGCCCTGTCCAAGCGCAACGACGAGCCCGAGCGCGCCTCCCGCCCCTGGGACGCCGACCGCGACGGCTTCGTGATGGGCGAGGGCGCCGGCGTGCTGGTGCTGGAGGAGCTGGAGCACGCCAAGCGCCGCGGCGCCACCATCCTGGCCGAGCTGGTGGGCGGCGCCGCCACCTCCGACGCCCACCACATGACCGAGCCCGACCCCCAGGGCCGCGGCGTGCGCCTGTGCCTGGAGCGCGCCCTGGAGCGCGCCCGCCTGGCCCCCGAGCGCGTGGGCTACGTGAACGCCCACGGCACCTCCACCCCCGCCGGCGACGTGGCCGAGTACCGCGCCATCCGCGCCGTGATCCCCCAGGACTCCCTGCGCATCAACTCCACCAAGTCCATGATCGGCCACCTGCTGGGCGGCGCCGGCGCCGTGGAGGCCGTGGCCGCCATCCAGGCCCTGCGCACCGGCTGGCTGCACCCCAACCTGAACCTGGAGAACCCCGCCCCCGGCGTGGACCCCGTGGTGCTGGTGGGCCCCCGCAAGGAGCGCGCCGAGGACCTGGACGTGGTGCTGTCCAACTCCTTCGGCTTCGGCGGCCACAACTCCTGCGTGATCTTCCGCAAGTACGACGAGATGGACTACAAGGACCACGACGGCGACTACAAGGACCACGACATCGACTACAAGGACGACGACGACAAGTGASEQIDNO:106桑椹形原藻(UTEX1435)KASIIMATASTFSAFNARCGDLRRSAGSGPRRPARPLPVRGRAAAAADANPARPERRVVITGQGVVTSLGQTIEQFYSSLLEGVSGISQIQKFDTTGYTTTIAGEIKSLQLDPYVPKRWAKRVDDVIKYVYIAGKQALESAGLPIEAAGLAGAGLDPALCGVLIGTAMAGMTSFAAGVEALTRGGVRKMNPFCIPFSISNMGGAMLAMDIGFMGPNYSISTACATGNYCILGAADHIRRGDANVMLAGGADAAIIPSGIGGFIACKALSKRNDEPERASRPWDADRDGFVMGEGAGVLVLEELEHAKRRGATILAELVGGAATSDAHHMTEPDPQGRGVRLCLERALERARLAPERVGYVNAHGTSTPAGDVAEYRAIRAVIPQDSLRINSTKSMIGHLLGGAGAVEAVAAIQALRTGWLHPNLNLENPAPGVDPVVLVGPRKERAEDLDVVLSNSFGFGGHNSCVIFRKYDEMDYKDHDGSEQIDNO:107桑椹形原藻(UTEX1435)乙酸激酶1(ACK1)等位基因1ATGGTTTTGAACGCGGGGAGTTCGTCCCTCAAGTTCAAGGTGTTTGACAAGATCGGGGGCAAGCTGCAGCCCCTGGCGTCCGGTCTGTGCGAGCGCATCGGCGACACCGCCAACTCCCGCATGAAGGCCTTTACGGAAAAGGACGGCAACGTGCTGGTGGAGGAGGGTTTCCAGGACCACCAGGACGCGCTCGGGGTCGTGTCGCGCTTTCTTGGTGATGCCTTTTCGTCCGGCTTCACGGAGCGCATGCACAGCGTGGGACACCGCGTGGTGCACGGCCTGACGATCAGCGAGCCCGTGCTGATCGACGAGGGCGTGCTCGCGACCATCCGCGAGGCGATCGACCTCGCGCCGCTGCACAACCCGGCCGGGCTGCAGGGCATCGAGGCGGCCATGCGCACCTTTGCCTCGGCGCCGCACGTGGCCGTGTTTGACACGGCCTTCCACCCGCTCTGCGCGCGCAACCTGGGGCTCTACCTGGCGGTGCGCGCGGACGGCCACGGGCGGCCGCAGTACCGCGTGTACTGCGCGGTCCACTCGGCGCGCGAGCAGGAGCGCGACCGCAAGGCCTGGCAGGCGCGGCAGGAGGCGGCGCGCGCCTCGGCCGACCTGGAGGCGCGGCGCGGCCAGGCGCTCGCGCGCCTGGCCGAGCTGGGCTGGGTCCTGCTCCTCCAGGTGCACGACGAGGTCATCCTGGAAGGGCCGCGCGAGTCCGCCGACGAGGCGCGCGAGCGCGTCGTTGCCTGCATGCGCAGCCCTTTCACGGGCGCCACCGCGCAGCCCCTGCTCGTCGACCTGGTCGTCGACGCCAAGCACGCCGACACCTGGTACGACGCCAAGTAGSEQIDNO:108桑椹形原藻(UTEX1435)乙酸激酶1(ACK1)等位基因1,蛋白质MVLNAGSSSLKFKVFDKIGGKLQPLASGLCERIGDTANSRMKAFTEKDGNVLVEEGFQDHQDALGVVSRFLGDAFSSGFTERMHSVGHRVVHGLTISEPVLIDEGVLATIREAIDLAPLHNPAGLQGIEAAMRTFASAPHVAVFDTAFHPLCARNLGLYLAVRADGHGRPQYRVYCAVHSAREQERDRKAWQARQEAARASADLEARRGQALARLAELGWVLLLQVHDEVILEGPRESADEARERVVACMRSPFTGATAQPLLVDLVVDAKHADTWYDAKSEQIDNO:109桑椹形原藻(UTEX1435)乙酸激酶1(ACK1)等位基因2ATGAAGGTATTCGCAGATTTTGGGGGCGGACTTGGGGCTGGCGTGGGTTCGCCTTGCTCCGCCCATGGGGTTTGGGTGCAGATCACGATGAATGAGAGAGAGAGGGAGGAGAGTGGGGCACTGCGTGGTGGGTGGGGTTTGTTGGTCGCTCCTCTCCAGGTCTCCAGAAGACAAGGAGAAATGGAGGGCCTTTACGGAAAAGGACGGCAACGTGCTGGTGGAGGAGGGTTTCCAGGACCACCAGGACGCGCTCGGGGTCGTGTCGCGCTTTCTTGGCGATGCCTTTTCGTCCGGCTTCACGGAGCGCATGCACAGCGTGGGGCACCGCGTGGTGCACGGGCTGACGATCAGCGAGCCCGTGCTGATCGACGAGGGCGTGATCGCGACCATCCGCGAGGCGATCGACCTGGCGCCGCTGCACAACCCGGCCGGGCTGCAGGGCATCGAGGCGGCCATGCGCACCTTTGCCTCGGCGCCGCACGTSGCCCGTGGCGTGCGCCGCTACGGCTTCCACGGCTCCAGCTACGCGTACCTCGTCCCGCGCGCCGCGGCCGTGCTGGGCAAGCCCGCCGCCGAGCTGMMSCGCCAGGCGCTCAGGTCCGCCATCCAGCCCTTCCACACGGGGCCGTCGAAGGCTGGACGGTGGCGGGGCCGCTGCTTGTCGGCGCTGGTGCCGTCCTCTTCGTCGCTGCTGGTGCTGACCTCATCGGGCTGTCGCAGCAGGCTGGCGTTGCAGGCCGTGGGTTGCAGCTCCACGAGGACCCTGCCGTGGTGTGCGGGTGGGGGTGGGTGAGCGGGACAGCCGTGGTGAGCGGGCTGCGAATGCAGTTGCGCCAATCAGGCGCCTGASEQIDNO:110桑椹形原藻(UTEX1435)乙酸激酶1(ACK1)等位基因2,蛋白质MKVFADFGGGLGAGVGSPCSAHGVWVQITMNEREREESGALRGGWGLLVAPLQVSRRQGEMEGLYGKGRQRAGGGGFPGPPGRARGRVALSWRCLFVRLHGAHAQRGAPRGARADDQRARADRRGRDRDHPRGDRPGAAAQPGRAAGHRGGHAHLCLGAAR?PWRAPLRLPRLQLRVPRPARRGRAGQARRRA??PGAQVRHPALPHGAVEGWTVAGPLLVGAGAVLFVAAGADLIGLSQQAGVAGRGLQLHEDPAVVCGWGWVSGTAVVSGLRMQLRQSGASEQIDNO:111桑椹形原藻(UTEX1435)乙酸激酶1(ACK2)ATGGTTTTGAACGCGGGGAGTTCGTCCCTGAAGTTCAAGGTGTTTGACAAGATCGGAGGGAAGCTGCAGCCCCTGGCGTCCGGTCTGTGCGAGCGCATCGGCGACACCGCCAACTCCCGCATGAAGGCCTTTACGGAAAAGGACGGCAACGTGCTGGTGGAGGAGGGTTTCCAGGACCACCAGGACGCGCTCGGGGTCGTGTCGCGCTTTCTTGGTGATGCCTTTTCGTCCGGCTTCACGGAGCGCATGCACAGCGTGGGGCACCGCGTGGTGCACGGGCTGACGATCAGCGAGCCCGTGCTGATCGACGAGGGCGTGATCGCGACCATCCGCGAGGCGATCGACCTGGCGCCGCTGCACAACCCGGCCGGGCTGCAGGGCATCGAGGCGGCCATGCGCACCTTTGCCTCGGCGCCGCACGTCGCCGTGTTCGACACGGCTTTCCACCAGACCATGCCGCCCAGCGCCTTCATGTACGCGCTGCCCTACGAGCTGTACGAGGCGCAGGGCGTGCGCCGCTACGGCTTCCACGGCTCCAGCTACGCCTACCTCGTCCCGCGCGCGGCGGCCGCGCTGGGCAAGCCCGCCGCCGAGCTGAACGCGGTCGTCTGCCACCTGGGCGCCGGCGCCAGCATGGCCGCCATCCGCGGCGGGCGCTCGGTGGACACCACCATGGGCCTCACCCCGCTGGAGGGCCTKGTCATGGGCACGCGCTGCGGCGACATCGACCCCGCCATCGTGACCTACCTGCTGGGCAAGGGCCACTCGGCCAAGGACGTGGACGCGCTCATGAACAAGAAGAGCGGCTTYGCCGGSCTGGCMGGGCACGCCGACCTGCGCCTGGTCATCGAGGGCGCCGACAAGGGCGACGAGCGCTGCCGCGTCGCGCTGGAGGTCTGGCGCCACCGCATCCGCAAGTACATCGGSGCCTACGCGATGCAGCTGGGCGCGCCSCTGGACGCCATCGTCTTCTCCGCCGGCATCGGCGAGAACAGCTCCATCCTGCGCAAGTACCTGCTGGAGGACCTGGAGTGGTGGGGCATCGAGCTGGACGAGGGCAAGAACAGTCTCTGCGTGGACGGCGTCGCGGGCGACATCTCCCGCGAYGGCTCYAAGACCCGCCTGCTCGTCATCCCCACCGACGAGGAGCTSAGCATCGCCGAACAGAGCATCGACGTCGTCAACGGCCTGGCCGCCTGASEQIDNO:112桑椹形原藻(UTEX1435)乙酸激酶1(ACK2),蛋白质MVLNAGSSSLKFKVFDKIGGKLQPLASGLCERIGDTANSRMKAFTEKDGNVLVEEGFQDHQDALGVVSRFLGDAFSSGFTERMHSVGHRVVHGLTISEPVLIDEGVIATIREAIDLAPLHNPAGLQGIEAAMRTFASAPHVAVFDTAFHQTMPPSAFMYALPYELYEAQGVRRYGFHGSSYAYLVPRAAAALGKPAAELNAVVCHLGAGASMAAIRGGRSVDTTMGLTPLEGLVMGTRCGDIDPAIVTYLLGKGHSAKDVDALMNKKSGFAGLAGHADLRLVIEGADKGDERCRVALEVWRHRIRKYIGAYAMQLGAPLDAIVFSAGIGENSSILRKYLLEDLEWWGIELDEGKNSLCVDGVAGDISRDGSKTRLLVIPTDEELSIAEQSIDVVNGLAASEQIDNO:113桑椹形原藻磷酸乙酰基转移酶等位基因1ATGAGTCTGTCGTCTTCTCGGAGTTTGCGGCGGACGCTGAGCCTGCTGAGGCCGGTGGCGGCGTCCACGCCCCTGTTTGCGCGCCACCTGTCGAGCCGCGGCATCCCGGACGCGGACACGGTCTACTGCACGGACGTCTCCGCGCAGCGCGGCAACTCGCCCATCCTGCTGGGCCTGTTTGAGTACTTCCAGCGCCAGTCGCCCGACGTGGGCTTCTTCCAGCCCATCGGCGCGGACCCGCTGAAGAGCTACAAGCCGGCCCCCGGCGCGCCCAAGCACATCGCGCTCATCCACCAGGCCATGGGCCTGAAGGACTCGCCCGAGTCGATGTACGGCGTGACCGAGGACGAGGCCAAGCGCCTGCTGACGGCGGGGCGCTACGACGAGCTGGTGGACCGCGTGTTCACCAAGTTCCAGGCGGTCAAGCGCAGCAAGGAGATCGTGGTGATCGAGGGCGCCACCGTGCAGGGCATCGGCAACCACAACGAGCTCAACGCGCGCCTGGCCTCCGAGCTGGACAGCGGCGTGCTGATGATCATGGACCTCAACAGCGACGCGCCGGGGAGCGGCGAGGACATCGCCGGGCGCGCGCTGCGGTACAAGCGCGAGTTCGAGGCGGAGCGCGCGCGCGTGAGCGGGCTCATCCTGAACAAGGTGCCCTTTGGCGCGGAGGAGGCGCTGATCGAGGCGGTCCGGCGCGAGCTGGAGGGCCGGGACCTGCCCTTTGCGGGCGGCCTGCCCTACAGCCGCGTCATCGGCACCGCACGCGTGAACGAGATCGTCGAGTCGCTGGGCGCCAAGCTGCTGTTCGGGCGGCAGGAGCTGATCGACAGCGACGTCACGGGGTACATGATCGCCGCGCAGGCCATCGACGCCTTTCTGACGAAACTAGAGACGCTGCGCTCGCAGCGCACGAGCGAGGGCCAGGACTTTTTCCGGCCGCTGGTGGTGACCAACAAGGACCGGCAGGACCTGATCCTGGGCCTGGCGGCCGCGTCCCTGGCGGGCACGGGCCCGCAGCTGGGCGGGCTCATCCTCGCGGACGCGGACCTGACCGACCTGACCCCCGAGACGCGCGCGATCGTTAGCAAGCTCAACCCGGACCTGCCCATGCTGGAGGTGCCCTACGGCACCTTTGAGACGGCGCGCCGCCTGACGCGCGTGACGCCGGGCATCCTGCCCAGCTCGGTGCGCAAGGTTCGCGAGGCCAAGGCGCTCTTCCACCGGTACGTGGACGCAGACGTCATCGCGGCCGGGCTGGTGCGGCCGCAGCGCCCCAGCCTGACCCCCAAGCGCTTCCTGTACCAGATCGAGGAGATCTGCAAGGGCGAGCTGCAGAACGTGGTGCTCCCCGAGTCGCACGACCACCGTGTGCTCACGGCCGCGGCCGAGGTCGCGGCCAAGGGCCTGGCGCGCGTGACGCTGCTGGGCAGCCCCGAGGAGGTGGAGTCGGCCGCGCGCCGCTTCAACGTCGACATCAGCAAGTGCGACGTGATCGACTACAAGCACTCGCCCGAGCTGGACCGGTACGCGGACTGGCTGGTGGAGAAGCGCAAGGCCAAGGGCCTGACCAAGGAGGGCGCGCTGGACCAGCTGCAGGACCTCAACATGTACGCCACCGTCATGGTGGCCGTCGGCGACGCGGACGGCATGGTGTCGGGCGCGACCTGCACCACGGCCAACACCATCCGGCCTGCGCTGCAGGTGCTCAAGACGCCCGACCGCAAGCTCGTCTCCTCCATCTTCTTCATGTGCCTGCCGGACAAGGTCCTCGTCTACGGCGACTGCGCGGTCAACGTGACGCCCGCGCCGGGCGAGCTGGCGCAGATCGCGACCGTGTCGGCCGACACGGCCGCCGCCTTTGGCATCGACCCGCGCGTGGCCATGCTCTCCTACTCGACCCTGGGCTCTGGCTCGGGGCCGCAGGTGGACATGGTCACCGAGGCCACGCGCCTCGCGCGCGAGGCGCGCCCCGACCTCAACATTGAGGGGCCCATCCAGTACGACGCCGCTGTCGACCCCGCCGTGGCCGCCACCAAGATCAAGGCGCACTCCGAGGTCGCGGGGCGCGCCTCCGTCTGCATCTTCCCGGATCTCAACACGGGGAACAACACCTACAAGGCCGTGCAGCAGTCCACGGGCGCCATCGCCATCGGACCGCTCATGCAGGGCCTCGCGCGCCCCGTCAACGATCTCTCCCGCGGCTGCACCGTCGCCGACATCGTCAACACCGTCGCCTGCACGGCCGTCCAGGCCATCGGGCTCAAAGCGCGCGACGCCGAGGCGGCGCGCGCGGGGGCCGCGGCTGCTGCTGCTTGASEQIDNO:114桑椹形原藻磷酸乙酰基转移酶,蛋白质MSLSSSRSLRRTLSLLRPVAASTPLFARHLSSRGIPDADTVYCTDVSAQRGNSPILLGLFEYFQRQSPDVGFFQPIGADPLKSYKPAPGAPKHIALIHQAMGLKDSPESMYGVTEDEAKRLLTAGRYDELVDRVFTKFQAVKRSKEIVVIEGATVQGIGNHNELNARLASELDSGVLMIMDLNSDAPGSGEDIAGRALRYKREFEAERARVSGLILNKVPFGAEEALIEAVRRELEGRDLPFAGGLPYSRVIGTARVNEIVESLGAKLLFGRQELIDSDVTGYMIAAQAIDAFLTKLETLRSQRTSEGQDFFRPLVVTNKDRQDLILGLAAASLAGTGPQLGGLILADADLTDLTPETRAIVSKLNPDLPMLEVPYGTFETARRLTRVTPGILPSSVRKVREAKALFHRYVDADVIAAGLVRPQRPSLTPKRFLYQIEEICKGELQNVVLPESHDHRVLTAAAEVAAKGLARVTLLGSPEEVESAARRFNVDISKCDVIDYKHSPELDRYADWLVEKRKAKGLTKEGALDQLQDLNMYATVMVAVGDADGMVSGATCTTANTIRPALQVLKTPDRKLVSSIFFMCLPDKVLVYGDCAVNVTPAPGELAQIATVSADTAAAFGIDPRVAMLSYSTLGSGSGPQVDMVTEATRLAREARPDLNIEGPIQYDAAVDPAVAATKIKAHSEVAGRASVCIFPDLNTGNNTYKAVQQSTGAIAIGPLMQGLARPVNDLSRGCTVADIVNTVACTAVQAIGLKARDAEAARAGAAAAAA*SEQIDNO:115桑椹形原藻(UTEX1435)磷酸乙酰基转移酶等位基因2ATGGTCAACGACTTGGTGGGAGCCATGGCGATGGTCGGCGACGGCAAGCACGGGCGCAGGGCAGCACGGGGCGGTCAGCGAGGGGCTTGGGTGCAACTGTGTGGGTCGTCAGCAGGCCCTAATCAATCCAGGGACCCTTCTTCAGCGCAATTGGCCTCGTTCTATCGCGATCGCGATGACATATACTCTCGTCACCTCAAGGGGTTGAGCGAGTTCGCATTCATAAGTCAGTGGCATCGGTCTTGCCGGGTTTGGGCATTGTGCCTGGGTCTGATCTGGAAACCCGACTCGCCGAAGGTGCCCATCGGCCGGTCATCGCGGGACCCCCCCACCCCCGCCGGCCTCGTTGATTGGCAGCATGAGTCTGTCGTCTTCTCGGAGTTTGCGGCGGACGCTGAGCCTGCTGAGGTGCGATGCAAGGGCGTCCCTGGGCGATTTGACGGGCGGTTACCTAAGGCGGAGCGACGTGCGGCTCCGGCGGGCAGCCGACACGTGGGCTTGTTGCCATGGACAGGCCCAGATCCCGATCCGATGGGCCCTGTAACGTTTGCTTATTTGCCGACGCCCTTTGCCACGGCCTGCCCGCCAGAAATGCCGGGCAGCGCCCCGTTGCGCCGCTTCCCCATGCTTCTCGCCTCGAATCACATTTCGACACTCCTCCGACGTCTCTCCACCCCTCCCCGAATCACGCAGGCCAGTGGCGGCGTCCACGCACCTGTTTGCGCGCCACCTGTCGAGCCGCGGCATCCCGGACGCGGACACGGTCTACTGCACGGACGTCTCCGCGCAGCGCGGCAACTCGCCCATCCTGCTGGGCCTGTTCGAGTACTTCCAGCGCCAGTCGCCCGACGTGGGCTTCTTCCAGCCCATCGGCGCGGACCCGCTGAGGAGCTACAAGCCTGCCCCCGGCGCGCCCAAGCACATCGCGCTCATCCACCAGGCCATGGGCCTGAAGGACTCGCCCGAGTCGATGTACGGCGTGACCGAGGACGAGGCCAAGCGCCTGCTGACGGCGGGGCGCTACGACGAGCTGGTGGACCGCGTGTTCACCAAGTTCCAGGCGGTCAAACGCAGCAAGGAGATTGTGGTGATCGAGGGCGCCACCGTGCAGGGCATCGGCAACCACAACGAGCTCAACGCGCGCCTGGCCTCCGAGCTGGACAGCGGCGTGCTGATGATCATGGACCTSAACMGSGACGCSCCSGGSAGCGGCGAGGACATCGCCGGGCGCGCGCTGCGGTACAAGCGCGAGTTCGAGGCGGAGCGCGCGCGCGTGAGCGGGCTCATCCTGAACAAGGTGCCCTTTGGCGCGGAGGAGGCGCTGATCGAGGCGGTCCGGCGCGAGCTGGAGGGCCGGGACCTGCCCTTTGCGGGCGGCCTGCCCTACAGCCGCGTCATCGGCACCGCGCGCGTGAACGAGATCGTCGAGTCGCTGGGCGCCAAGCTGCTGTTCGGGCGGCASGAGCTGATCGACAGCGACGTCACGGGGTACATGATCGCCGCGCAGGCCATCGACGCSTTYCTGACSAARCTRGAGACGCTGCGCTCGCAGCGCACGAGCGAGGGCCAGGACTTTTTCCGGCCGCTGGTGGTGACCAACAAGGACCGGCAGGACCTGATCCTGGGCCTGGCGGCCGCGTCSCTGGCGGGCACGGGCCCGCAGCTGGGCGGGCTCATCCTSGCSGACGCGGACCTGACCGACCTGACCCCCGAGACGCGCGCGATCGTTAGSEQIDNO:116桑椹形原藻(UTEX1435)磷酸乙酰基转移酶等位基因2,蛋白质MVNDLVGAMAMVGDGKHGRRAARGGQRGAWVQLCGSSAGPNQSRDPSSAQLASFYRDRDDIYSRHLKGLSEFAFISQWHRSCRVWALCLGLIWKPDSPKVPIGRSSRDPPTPAGLVDWQHESVVFSEFAADAEPAEVRCKGVPGRFDGRLPKAERRAAPAGSRHVGLLPWTGPDPDPMGPVTFAYLPTPFATACPPEMPGSAPLRRFPMLLASNHISTLLRRLSTPPRITQASGGVHAPVCAPPVEPRHPGRGHGLLHGRLRAARQLAHPAGPVRVLPAPVARRGLLPAHRRGPAEELQACPRRAQAHRAHPPGHGPEGLARVDVRRDRGRGQAPADGGALRRAGGPRVHQVPGGQTQQGDCGDRGRHRAGHRQPQRAQRAPGLRAGQRRADDHGPSEQIDNO:117桑椹形原藻乳酸脱氢酶ATGGCTGAGGGGAGCATCGACTACAAGGTGGCTGTCTTCAGCTCCAGCGAGTGGGTGACCGACTCGTTCGCCGAGCCCCTCAAGATCTTCAAGGAGGTCTCCTACCTGCCGGCCCGCCTGGAGCCGACCAGCGCTGCCCTGGCGCACGGCTTTGACGCGGTGTGCATCTTTGTGAACGACGACGCTGGCGCGGAGACGCTCAAGGTTCTGGCGGAGGGCGGCGTGAAGCTGATCGCCATGCGCTGCGCAGGGTACGACCGCGTGGACCTGGCCGCGGCCAAGGAGCTGGGCATCCGCGTGGTGCGCGTGCCGGCCTACAGTCCGCGCTCGGTGGCGGAGCACGCGCTGGCGCTGATGATGGCGCTGGCGCGCAACATCAAGGCCTCGCAGATCAAGATGGCGGCCGGGTCCTACACGCTCAACGGCCTGGTGGGCGTGGAGCTGACGGGCAAGACCTTTGGCGTGGTGGGCACGGGCGCCATCGGGCGCGAGTTCGTCAAGCTGCTCAAGGGCTTTGAGGGCAAGGTGCTGGGCTACGACCCCTACCCGACCGACGCGGCGCGCGAGCTGGGCGTGGAGTACGTCGACCTGGACACGCTGCTGGCGCAGTCGGACGTCATCTCGCTGCACGTGCCGCTGCTGCCCAGCACGCAGAAGCTGCTGGGCACCGAGTCGCTGAGCAAGCTCAAGCCCACCGCGCTGGTCATCAACGTCAGCCGCGGCGGGCTCATCGACACCGAGGCCTGCATCCAGGCGCTGCAGGAGGACAAGTTTGCGGGCCTGGCCGTCGACGTCTACGAGGGCGAGGGCGCGCTCTTCTTCCAGGACTGGGCCAACATGAACGCCGCGCGCCGCATGAAGCAGTGGGACCAGAAGTTCATCGCGCTCAAGTCCATGCCCCAGGTCATCGTCACGCCGCACATCGCCTTCCTCACGCACAGCGCGCTCGACGCCATCGCCGCCACCACGCGCGACAACCTGCTCGCCGCCGCGCAGGGCAAGGACCTCGTCAACGAGGTCAASEQIDNO:118桑椹形原藻乳酸脱氢酶蛋白质MAEGSIDYKVAVFSSSEWVTDSFAEPLKIFKEVSYLPARLEPTSAALAHGFDAVCIFVNDDAGAETLKVLAEGGVKLIAMRCAGYDRVDLAAAKELGIRVVRVPAYSPRSVAEHALALMMALARNIKASQIKMAAGSYTLNGLVGVELTGKTFGVVGTGAIGREFVKLLKGFEGKVLGYDPYPTDAARELGVEYVDLDTLLAQSDVISLHVPLLPSTQKLLGTESLSKLKPTALVINVSRGGLIDTEACIQALQEDKFAGLAVDVYEGEGALFFQDWANMNAARRMKQWDQKFIALKSMPQVIVTPHIAFLTHSALDAIAATTRDNLLAAAQGKDLVNEVSEQIDNO:119桑椹形原藻(UTEX1435)LDP1ATGGCNGCTGTCGCTGAGAACCCCGCTCCCCCCCGCCCGAACAGCCTTAAGAAGCTGGGCTTCGTTCCCGAGGCCGGCGCGAAGAGCTACGAGATTGCCACCAATGTCTACACTACGGCAAAGAGCTACGTTCCCGCTAGCCTGCAGCCCAAGCTGGAGAAGGTGGAGGAGTCTGTGACCAGCGTGAGCGCCCCGTACGTGGCCAAGGCCCAGGACAAGACCGCGACCCTGCTCAAGGTGGCCGACGAGAAGGTTGATGAGGCCTTCGCCAAGGCCACCCAGGTCTACCTTAACAACAGCAAGTACGTCGCCGACACCCTGGACAAGCAGCGCGCCTACCACGCGCAGAACCTCGAGTCCTACAAGGCCGCGCGCGAGCACTACCTCAAGGTCGTCGAAAGCGGCGTCGAGTACGTGAAGAAGAACGGCATCTCCGGCACCGCCAAGGCCGCCGCCGACGAGGTGGCCGCGCGCGTGAGCGAGGCGCGCGCCGTCCCCGGCGCCCTGCTGCACCGCGTGCAGGAGGCCGTGGACAAGCTGCTGGCCAGCACGCCCGTGCACGGCACGGTCGAGCGCCTGAAGCCGGCCCTGGACAGCGCCTACCAGCGCTACAGCTCCCTGCACGACAACGTCGTCTCCAGCGACCAGTACCGCAAGGTCGTGAAGACCGGCTCGGACGTGCTCGCCCGCGTCGAGGCCTCGCCCATCTTCGCCAAGTCCAAGGCGACCCTGTACCCCTACGTCGCGCCCTACGCGGAGCCCGCGGCAGCGCGCCTGCAGCCCTACTACCTCCGGGTGGTCGAGCACCTCGCGCCCAAGGACGCCTGAATTTGTGGACGCGGCGGTCGCACTGCTGCCGCGTTGCGCGGTCTCGCTTGATCGCGGGGCTGCCCCCTTGGAGCGCTTGTTCGCGCCGGCGCGACGCGCCGTCCCAGTTGATTGTCGGGGCGGGGCGCCGTCACCGCGCGTGGGCCATCGGAATTGGATCTGCTGAGAATGCAAAGGGCGACCGGTGASEQIDNO:120桑椹形原藻(UTEX1435)LDP1蛋白质MAAVAENPAPPRPNSLKKLGFVPEAGAKSYEIATNVYTTAKSYVPASLQPKLEKVEESVTSVSAPYVAKAQDKTATLLKVADEKVDEAFAKATQVYLNNSKYVADTLDKQRAYHAQNLESYKAAREHYLKVVESGVEYVKKNGISGTAKAAADEVAARVSEARAVPGALLHRVQEAVDKLLASTPVHGTVERLKPALDSAYQRYSSLHDNVVSSDQYRKVVKTGSDVLARVEASPIFAKSKATLYPYVAPYAEPAAARLQPYYLRVVEHLAPKDASEQIDNO:1216S5′基因组供体序列GCTCTTCGCCGCCGCCACTCCTGCTCGAGCGCGCCCGCGCGTGCGCCGCCAGCGCCTTGGCCTTTTCGCCGCGCTCGTGCGCGTCGCTGATGTCCATCACCAGGTCCATGAGGTCTGCCTTGCGCCGGCTGAGCCACTGCTTCGTCCGGGCGGCCAAGAGGAGCATGAGGGAGGACTCCTGGTCCAGGGTCCTGACGTGGTCGCGGCTCTGGGAGCGGGCCAGCATCATCTGGCTCTGCCGCACCGAGGCCGCCTCCAACTGGTCCTCCAGCAGCCGCAGTCGCCGCCGACCCTGGCAGAGGAAGACAGGTGAGGGGGGTATGAATTGTACAGAACAACCACGAGCCTTGTCTAGGCAGAATCCCTACCAGTCATGGCTTTACCTGGATGACGGCCTGCGAACAGCTGTCCAGCGACCCTCGCTGCCGCCGCTTCTCCCGCACGCTTCTTTCCAGCACCGTGATGGCGCGAGCCAGCGCCGCACGCTGGCGCTGCGCTTCGCCGATCTGAGGACAGTCGGGGAACTCTGATCAGTCTAAACCCCCTTGCGCGTTAGTGTTGCCATCCTTTGCAGACCGGTGAGAGCCGACTTGTTGTGCGCCACCCCCCACACCACCTCCTCCCAGACCAATTCTGTCACCTTTTTGGCGAAGGCATCGGCCTCGGCCTGCAGAGAGGACAGCAGTGCCCAGCCGCTGGGGGTTGGCGGATGCACGCTCAGGTACCSEQIDNO:1226S3′基因组供体序列GAGCTCCTTGTTTTCCAGAAGGAGTTGCTCCTTGAGCCTTTCATTCTCAGCCTCGATAACCTCCAAAGCCGCTCTAATTGTGGAGGGGGTTCGAATTTAAAAGCTTGGAATGTTGGTTCGTGCGTCTGGAACAAGCCCAGACTTGTTGCTCACTGGGAAAAGGACCATCAGCTCCAAAAAACTTGCCGCTCAAACCGCGTACCTCTGCTTTCGCGCAATCTGCCCTGTTGAAATCGCCACCACATTCATATTGTGACGCTTGAGCAGTCTGTAATTGCCTCAGAATGTGGAATCATCTGCCCCCTGTGCGAGCCCATGCCAGGCATGTCGCGGGCGAGGACACCCGCCACTCGTACAGCAGACCATTATGCTACCTCACAATAGTTCATAACAGTGACCATATTTCTCGAAGCTCCCCAACGAGCACCTCCATGCTCTGAGTGGCCACCCCCCGGCCCTGGTGCTTGCGGAGGGCAGGTCAACCGGCATGGGGCTACCGAAATCCCCGACCGGATCCCACCACCCCCGCGATGGGAAGAATCTCTCCCCGGGATGTGGGCCCACCACCAGCACAACCTGCTGGCCCAGGCGAGCGTCAAACCATACCACACAAATATCCTTGGCATCGGCCCTGAATTCCTTCTGCCGCTCTGCTACCCGGTGCTTCTGTCCGAAGCAGGGGTTGCTAGGGATCGCTCCGAGTCCGCAAACCCTTGTCGCGTGGCGGGGCTTGTTCGAGCTTGAAGAGCSEQIDNO:123酿酒酵母转化酶蛋白质序列MLLQAFLFLLAGFAAKISASMTNETSDRPLVHFTPNKGWMNDPNGLWYDEKDAKWHLYFQYNPNDTVWGTPLFWGHATSDDLTNWEDQPIAIAPKRNDSGAFSGSMVVDYNNTSGFFNDTIDPRQRCVAIWTYNTPESEEQYISYSLDGGYTFTEYQKNPVLAANSTQFRDPKVFWYEPSQKWIMTAAKSQDYKIEIYSSDDLKSWKLESAFANEGFLGYQYECPGLIEVPTEQDPSKSYWVMFISINPGAPAGGSFNQYFVGSFNGTHFEAFDNQSRVVDFGKDYYALQTFFNTDPTYGSALGIAWASNWEYSAFVPTNPWRSSMSLVRKFSLNTEYQANPETELINLKAEPILNISNAGPWSRFATNTTLTKANSYNVDLSNSTGTLEFELVYAVNTTQTISKSVFADLSLWFKGLEDPEEYLRMGFEVSASSFFLDRGNSKVKFVKENPYFTNRMSVNNQPFKSENDLSYYKVYGLLDQNILELYFNDGDVVSTNTYFMTTGNALGSVNMTTGVDNLFYIDKFQVREVKSEQIDNO:124用于在桑椹形原藻(UTEX1435)中表达的密码子优化的酿酒酵母转化酶蛋白质编码序列ATGctgctgcaggccttcctgttcctgctggccggcttcgccgccaagatcagcgcctccatgacgaacgagacgtccgaccgccccctggtgcacttcacccccaacaagggctggatgaacgaccccaacggcctgtggtacgacgagaaggacgccaagtggcacctgtacttccagtacaacccgaacgacaccgtctgggggacgcccttgttctggggccacgccacgtccgacgacctgaccaactgggaggaccagcccatcgccatcgccccgaagcgcaacgactccggcgccttctccggctccatggtggtggactacaacaacacctccggcttcttcaacgacaccatcgacccgcgccagcgctgcgtggccatctggacctacaacaccccggagtccgaggagcagtacatctcctacagcctggacggcggctacaccttcaccgagtaccagaagaaccccgtgctggccgccaactccacccagttccgcgacccgaaggtcttctggtacgagccctcccagaagtggatcatgaccgcggccaagtcccaggactacaagatcgagatctactcctccgacgacctgaagtcctggaagctggagtccgcgttcgccaacgagggcttcctcggctaccagtacgagtgccccggcctgatcgaggtccccaccgagcaggaccccagcaagtcctactgggtgatgttcatctccatcaaccccggcgccccggccggcggctccttcaaccagtacttcgtcggcagcttcaacggcacccacttcgaggccttcgacaaccagtcccgcgtggtggacttcggcaaggactactacgccctgcagaccttcttcaacaccgacccgacctacgggagcgccctgggcatcgcgtgggcctccaactgggagtactccgccttcgtgcccaccaacccctggcgctcctccatgtccctcgtgcgcaagttctccctcaacaccgagtaccaggccaacccggagacggagctgatcaacctgaaggccgagccgatcctgaacatcagcaacgccggcccctggagccggttcgccaccaacaccacgttgacgaaggccaacagctacaacgtcgacctgtccaacagcaccggcaccctggagttcgagctggtgtacgccgtcaacaccacccagacgatctccaagtccgtgttcgcggacctctccctctggttcaagggcctggaggaccccgaggagtacctccgcatgggcttcgaggtgtccgcgtcctccttcttcctggaccgcgggaacagcaaggtgaagttcgtgaaggagaacccctacttcaccaaccgcatgagcgtgaacaaccagcccttcaagagcgagaacgacctgtcctactacaaggtgtacggcttgctggaccagaacatcctggagctgtacttcaacgacggcgacgtcgtgtccaccaacacctacttcatgaccaccgggaacgccctgggctccgtgaacatgacgacgggggtggacaacctgttctacatcgacaagttccaggtgcgcgaggtcaagTGASEQIDNO:125莱茵衣藻TUB2(B-tub)启动子/5′UTRCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACSEQIDNO:126普通小球藻硝酸盐还原酶3′UTRGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAAAGCTTSEQIDNO:127具有莱茵衣藻β-微管蛋白启动子/5′UTR和普通小球藻硝酸盐还原酶3′UTR的酿酒酵母suc2基因的密码子优化的表达盒的核苷酸序列CTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACGGCGCGCCATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGACAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAGGATCCSEQIDNO:128桑椹形原藻(UTEX1435)Amt03启动子GGCCGACAGGACGCGCGTCAAAGGTGCTGGTCGTGTATGCCCTGGCCGGCAGGTCGTTGCTGCTGCTGGTTAGTGATTCCGCAACCCTGATTTTGGCGTCTTATTTTGGCGTGGCAAACGCTGGCGCCCGCGAGCCGGGCCGGCGGCGATGCGGTGCCCCACGGCTGCCGGAATCCAAGGGAGGCAAGAGCGCCCGGGTCAGTTGAAGGGCTTTACGCGCAAGGTACAGCCGCTCCTGCAAGGCTGCGTGGTGGAATTGGACGTGCAGGTCCTGCTGAAGTTCCTCCACCGCCTCACCAGCGGACAAAGCACCGGTGTATCAGGTCCGTGTCATCCACTCTAAAGAGCTCGACTACGACCTACTGATGGCCCTAGATTCTTCATCAAAACGCCTGAGACACTTGCCCAGGATTGAAACTCCCTGAAGGGACCACCAGGGGCCCTGAGTTGTTCCTTCCCCCCGTGGCGAGCTGCCAGCCAGGCTGTACCTGTGATCGAGGCTGGCGGGAAAATAGGCTTCGTGTGCTCAGGTCATGGGAGGTGCAGGACAGCTCATGAAACGCCAACAATCGCACAATTCATGTCAAGCTAATCAGCTATTTCCTCTTCACGAGCTGTAATTGTCCCAAAATTCTGGTCTACCGGGGGTGATCCTTCGTGTACGGGCCCTTCCCTCAACCCTAGGTATGCGCGCATGCGGTCGCCGCGCAACTCGCGCGAGGGCCGAGGGTTTGGGACGGGCCGTCCCGAAATGCAGTTGCACCCGGATGCGTGGCACCTTTTTTGCGATAATTTATGCAATGGACTGCTCTGCAAAATTCTGGCTCTGTCGCCAACCCTAGGATCAGCGGCGTAGGATTTCGTAATCATTCGTCCTGATGGGGAGCTACCGACTACCCTAATATCAGCCCGACTGCCTGACGCCAGCGTCCACTTTTGTGCACACATTCCATTCGTGCCCAAGACATTTCATTGTGGTGCGAAGCGTCCCCAGTTACGCTCACCTGTTTCCCGACCTCCTTACTGTTCTGTCGACAGAGCGGGCCCACAGGCCGGTCGCAGCCSEQIDNO:129用于在桑椹形原藻中表达的密码子优化的原始小球藻(UTEX250)硬脂酰基ACP脱饱和酶转运肽cDNA序列。ACTAGTATGGCCACCGCATCCACTTTCTCGGCGTTCAATGCCCGCTGCGGCGACCTGCGTCGCTCGGCGGGCTCCGGGCCCCGGCGCCCAGCGAGGCCCCTCCCCGTGCGCGGGCGCGCCSEQIDNO:130ATGGTGGTGGCCGCCGCCGCCAGCAGCGCCTTCTTCCCCGTGCCCGCCCCCCGCCCCACCCCCAAGCCCGGCAAGTTCGGCAACTGGCCCAGCAGCCTGAGCCAGCCCTTCAAGCCCAAGAGCAACCCCAACGGCCGCTTCCAGGTGAAGGCCAACGTGAGCCCCCACGGGCGCGCCCCCAAGGCCAACGGCAGCGCCGTGAGCCTGAAGTCCGGCAGCCTGAACACCCTGGAGGACCCCCCCAGCAGCCCCCCCCCCCGCACCTTCCTGAACCAGCTGCCCGACTGGAGCCGCCTGCGCACCGCCATCACCACCGTGTTCGTGGCCGCCGAGAAGCAGTTCACCCGCCTGGACCGCAAGAGCAAGCGCCCCGACATGCTGGTGGACTGGTTCGGCAGCGAGACCATCGTGCAGGACGGCCTGGTGTTCCGCGAGCGCTTCAGCATCCGCAGCTACGAGATCGGCGCCGACCGCACCGCCAGCATCGAGACCCTGATGAACCACCTGCAGGACACCAGCCTGAACCACTGCAAGAGCGTGGGCCTGCTGAACGACGGCTTCGGCCGCACCCCCGAGATGTGCACCCGCGACCTGATCTGGGTGCTGACCAAGATGCAGATCGTGGTGAACCGCTACCCCACCTGGGGCGACACCGTGGAGATCAACAGCTGGTTCAGCCAGAGCGGCAAGATCGGCATGGGCCGCGAGTGGCTGATCAGCGACTGCAACACCGGCGAGATCCTGGTGCGCGCCACCAGCGCCTGGGCCATGATGAACCAGAAGACCCGCCGCTTCAGCAAGCTGCCCTGCGAGGTGCGCCAGGAGATCGCCCCCCACTTCGTGGACGCCCCCCCCGTGATCGAGGACAACGACCGCAAGCTGCACAAGTTCGACGTGAAGACCGGCGACAGCATCTGCAAGGGCCTGACCCCCGGCTGGAACGACTTCGACGTGAACCAGCACGTGAGCAACGTGAAGTACATCGGCTGGATTCTGGAGAGCATGCCCACCGAGGTGCTGGAGACCCAGGAGCTGTGCAGCCTGACCCTGGAGTACCGCCGCGAGTGCGGCCGCGAGAGCGTGGTGGAGAGCGTGACCAGCATGAACCCCAGCAAGGTGGGCGACCGCAGCCAGTACCAGCACCTGCTGCGCCTGGAGGACGGCGCCGACATCATGAAGGGCCGCACCGAGTGGCGCCCCAAGAACGCCGGCACCAACCGCGCCATCAGCACCTGASEQIDNO:131赖特氏萼距花FatB2硫酯酶;基因库登录号U56104MVVAAAASSAFFPVPAPRPTPKPGKFGNWPSSLSQPFKPKSNPNGRFQVKANVSPHPKANGSAVSLKSGSLNTLEDPPSSPPPRTFLNQLPDWSRLRTAITTVFVAAEKQFTRLDRKSKRPDMLVDWFGSETIVQDGLVFRERFSIRSYEIGADRTASIETLMNHLQDTSLNHCKSVGLLNDGFGRTPEMCTRDLIWVLTKMQIVVNRYPTWGDTVEINSWFSQSGKIGMGREWLISDCNTGEILVRATSAWAMMNQKTRRFSKLPCEVRQEIAPHFVDAPPVIEDNDRKLHKFDVKTGDSICKGLTPGWNDFDVNQHVSNVKYIGWILESMPTEVLETQELCSLTLEYRRECGRESVVESVTSMNPSKVGDRSQYQHLLRLEDGADIMKGRTEWRPKNAGTNRAISTSEQIDNO:137pSZ1500GGGCTGGTCTGAATCCTTCAGGCGGGTGTTACCCGAGAAAGAAAGGGTGCCGATTTCAAAGCAGACCCATGTGCCGGGCCCTGTGGCCTGTGTTGGCGCCTATGTAGTCACCCCCCCTCACCCAATTGTCGCCAGTTTGCGCACTCCATAAACTCAAAACAGCAGCTTCTGAGCTGCGCTGTTCAAGAACACCTCTGGGGTTTGCTCACCCGCGAGGTCGACGCCCAGCATGGCTATCAAGACGAACAGGCAGCCTGTGGAGAAGCCTCCGTTCACGATCGGGACGCTGCGCAAGGCCATCCCCGCGCACTGTTTCGAGCGCTCGGCGCTTCGTAGCAGCATGTACCTGGCCTTTGACATCGCGGTCATGTCCCTGCTCTACGTCGCGTCGACGTACATCGACCCTGCACCGGTGCCTACGTGGGTCAAGTACGGCATCATGTGGCCGCTCTACTGGTTCTTCCAGGTGTGTTTGAGGGTTTTGGTTGCCCGTATTGAGGTCCTGGTGGCGCGCATGGAGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCCTTCGGCACGGGTGTCTGGGTGTGCGCGCACGAGTGCGGCCACCAGGCCTTTTCCTCCAGCCAGGCCATCAACGACGGCGTGGGCCTGGTGTTCCACAGCCTGCTGCTGGTGCCCTACTACTCCTGGAAGCACTCGCACCGGGTACCCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACTCTAGAATATCAATGCTGCTGCAGGCCTTCCTGTTCCTGCTGGCCGGCTTCGCCGCCAAGATCAGCGCCTCCATGACGAACGAGACGTCCGACCGCCCCCTGGTGCACTTCACCCCCAACAAGGGCTGGATGAACGACCCCAACGGCCTGTGGTACGACGAGAAGGACGCCAAGTGGCACCTGTACTTCCAGTACAACCCGAACGACACCGTCTGGGGGACGCCCTTGTTCTGGGGCCACGCCACGTCCGACGACCTGACCAACTGGGAGGACCAGCCCATCGCCATCGCCCCGAAGCGCAACGACTCCGGCGCCTTCTCCGGCTCCATGGTGGTGGACTACAACAACACCTCCGGCTTCTTCAACGACACCATCGACCCGCGCCAGCGCTGCGTGGCCATCTGGACCTACAACACCCCGGAGTCCGAGGAGCAGTACATCTCCTACAGCCTGGACGGCGGCTACACCTTCACCGAGTACCAGAAGAACCCCGTGCTGGCCGCCAACTCCACCCAGTTCCGCGACCCGAAGGTCTTCTGGTACGAGCCCTCCCAGAAGTGGATCATGACCGCGGCCAAGTCCCAGGACTACAAGATCGAGATCTACTCCTCCGACGACCTGAAGTCCTGGAAGCTGGAGTCCGCGTTCGCCAACGAGGGCTTCCTCGGCTACCAGTACGAGTGCCCCGGCCTGATCGAGGTCCCCACCGAGCAGGACCCCAGCAAGTCCTACTGGGTGATGTTCATCTCCATCAACCCCGGCGCCCCGGCCGGCGGCTCCTTCAACCAGTACTTCGTCGGCAGCTTCAACGGCACCCACTTCGAGGCCTTCGACAACCAGTCCCGCGTGGTGGACTTCGGCAAGGACTACTACGCCCTGCAGACCTTCTTCAACACCGACCCGACCTACGGGAGCGCCCTGGGCATCGCGTGGGCCTCCAACTGGGAGTACTCCGCCTTCGTGCCCACCAACCCCTGGCGCTCCTCCATGTCCCTCGTGCGCAAGTTCTCCCTCAACACCGAGTACCAGGCCAACCCGGAGACGGAGCTGATCAACCTGAAGGCCGAGCCGATCCTGAACATCAGCAACGCCGGCCCCTGGAGCCGGTTCGCCACCAACACCACGTTGACGAAGGCCAACAGCTACAACGTCGACCTGTCCAACAGCACCGGCACCCTGGAGTTCGAGCTGGTGTACGCCGTCAACACCACCCAGACGATCTCCAAGTCCGTGTTCGCGGACCTCTCCCTCTGGTTCAAGGGCCTGGAGGACCCCGAGGAGTACCTCCGCATGGGCTTCGAGGTGTCCGCGTCCTCCTTCTTCCTGGACCGCGGGAACAGCAAGGTGAAGTTCGTGAAGGAGAACCCCTACTTCACCAACCGCATGAGCGTGAACAACCAGCCCTTCAAGAGCGAGAACGACCTGTCCTACTACAAGGTGTACGGCTTGCTGGACCAGAACATCCTGGAGCTGTACTTCAACGACGGCGACGTCGTGTCCACCAACACCTACTTCATGACCACCGGGAACGCCCTGGGCTCCGTGAACATGACGACGGGGGTGGACAACCTGTTCTACATCGACAAGTTCCAGGTGCGCGAGGTCAAGTGACAATTGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAGGATCCCGCGTCTCGAACAGAGCGCGCAGAGGAACGCTGAAGGTCTCGCCTCTGTCGCACCTCAGCGCGGCATACACCACAATAACCACCTGACGAATGCGCTTGGTTCTTCGTCCATTAGCGAAGCGTCCGGTTCACACACGTGCCACGTTGGCGAGGTGGCAGGTGACAATGATCGGTGGAGCTGATGGTCGAAACGTTCACAGCCTAGGGATATCGAATTCGGCCGACAGGACGCGCGTCAAAGGTGCTGGTCGTGTATGCCCTGGCCGGCAGGTCGTTGCTGCTGCTGGTTAGTGATTCCGCAACCCTGATTTTGGCGTCTTATTTTGGCGTGGCAAACGCTGGCGCCCGCGAGCCGGGCCGGCGGCGATGCGGTGCCCCACGGCTGCCGGAATCCAAGGGAGGCAAGAGCGCCCGGGTCAGTTGAAGGGCTTTACGCGCAAGGTACAGCCGCTCCTGCAAGGCTGCGTGGTGGAATTGGACGTGCAGGTCCTGCTGAAGTTCCTCCACCGCCTCACCAGCGGACAAAGCACCGGTGTATCAGGTCCGTGTCATCCACTCTAAAGAACTCGACTACGACCTACTGATGGCCCTAGATTCTTCATCAAAAACGCCTGAGACACTTGCCCAGGATTGAAACTCCCTGAAGGGACCACCAGGGGCCCTGAGTTGTTCCTTCCCCCCGTGGCGAGCTGCCAGCCAGGCTGTACCTGTGATCGAGGCTGGCGGGAAAATAGGCTTCGTGTGCTCAGGTCATGGGAGGTGCAGGACAGCTCATGAAACGCCAACAATCGCACAATTCATGTCAAGCTAATCAGCTATTTCCTCTTCACGAGCTGTAATTGTCCCAAAATTCTGGTCTACCGGGGGTGATCCTTCGTGTACGGGCCCTTCCCTCAACCCTAGGTATGCGCGCATGCGGTCGCCGCGCAACTCGCGCGAGGGCCGAGGGTTTGGGACGGGCCGTCCCGAAATGCAGTTGCACCCGGATGCGTGGCACCTTTTTTGCGATAATTTATGCAATGGACTGCTCTGCAAAATTCTGGCTCTGTCGCCAACCCTAGGATCAGCGGCGTAGGATTTCGTAATCATTCGTCCTGATGGGGAGCTACCGACTACCCTAATATCAGCCCGACTGCCTGACGCCAGCGTCCACTTTTGTGCACACATTCCATTCGTGCCCAAGACATTTCATTGTGGTGCGAAGCGTCCCCAGTTACGCTCACCTGTTTCCCGACCTCCTTACTGTTCTGTCGACAGAGCGGGCCCACAGGCCGGTCGCAGCCACTAGTATGGCCACCGCATCCACTTTCTCGGCGTTCAATGCCCGCTGCGGCGACCTGCGTCGCTCGGCGGGCTCCGGGCCCCGGCGCCCAGCGAGGCCCCTCCCCGTGCGCGGGCGCGCCGCCACCGGCGAGCAGCCCTCCGGCGTGGCCTCCCTGCGCGAGGCCGACAAGGAGAAGTCCCTGGGCAACCGCCTGCGCCTGGGCTCCCTGACCGAGGACGGCCTGTCCTACAAGGAGAAGTTCGTGATCCGCTGCTACGAGGTGGGCATCAACAAGACCGCCACCATCGAGACCATCGCCAACCTGCTGCAGGAGGTGGGCGGCAACCACGCCCAGGGCGTGGGCTTCTCCACCGACGGCTTCGCCACCACCACCACCATGCGCAAGCTGCACCTGATCTGGGTGACCGCCCGCATGCACATCGAGATCTACCGCTACCCCGCCTGGTCCGACGTGATCGAGATCGAGACCTGGGTGCAGGGCGAGGGCAAGGTGGGCACCCGCCGCGACTGGATCCTGAAGGACTACGCCAACGGCGAGGTGATCGGCCGCGCCACCTCCAAGTGGGTGATGATGAACGAGGACACCCGCCGCCTGCAGAAGGTGTCCGACGACGTGCGCGAGGAGTACCTGGTGTTCTGCCCCCGCACCCTGCGCCTGGCCTTCCCCGAGGAGAACAACAACTCCATGAAGAAGATCCCCAAGCTGGAGGACCCCGCCGAGTACTCCCGCCTGGGCCTGGTGCCCCGCCGCTCCGACCTGGACATGAACAAGCACGTGAACAACGTGACCTACATCGGCTGGGCCCTGGAGTCCATCCCCCCCGAGATCATCGACACCCACGAGCTGCAGGCCATCACCCTGGACTACCGCCGCGAGTGCCAGCGCGACGACATCGTGGACTCCCTGACCTCCCGCGAGCCCCTGGGCAACGCCGCCGGCGTGAAGTTCAAGGAGATCAACGGCTCCGTGTCCCCCAAGAAGGACGAGCAGGACCTGTCCCGCTTCATGCACCTGCTGCGCTCCGCCGGCTCCGGCCTGGAGATCAACCGCTGCCGCACCGAGTGGCGCAAGAAGCCCGCCAAGCGCATGGACTACAAGGACCACGACGGCGACTACAAGGACCACGACATCGACTACAAGGACGACGACGACAAGTGAATCGATAGATCTCTTAAGGCAGCAGCAGCTCGGATAGTATCGACACACTCTGGACGCTGGTCGTGTGATGGACTGTTGCCGCCACACTTGCTGCCTTGACCTGTGAATATCCCTGCCGCTTTTATCAAACAGCCTCAGTGTGTTTGATCTTGTGTGTACGCGCTTTTGCGAGTTGCTAGCTGCTTGTGCTATTTGCGAATACCACCCCCAGCATCCCCTTCCCTCGTTTCATATCGCTTGCATCCCAACCGCAACTTATCTACGCTGTCCTGCTATCCCTCAGCGCTGCTCCTGCTCCTGCTCACTGCCCCTCGCACAGCCTTGGTTTGGGCTCCGCCTGTATTCTCCTGGTACTGCAACCTGTAAACCAGCACTGCAATGCTGATGCACGGGAAGTAGTGGGATGGGAACACAAATGGAAAGCTTAATTAAGAGCTCCCGCCACCACTCCAACACGGGGTGCCTGGACAAGGACGAGGTGTTTGTGCCGCCGCACCGCGCAGTGGCGCACGAGGGCCTGGAGTGGGAGGAGTGGCTGCCCATCCGCATGGGCAAGGTGCTGGTCACCCTGACCCTGGGCTGGCCGCTGTACCTCATGTTCAACGTCGCCTCGCGGCCGTACCCGCGCTTCGCCAACCACTTTGACCCGTGGTCGCCCATCTTCAGCAAGCGCGAGCGCATCGAGGTGGTCATCTCCGACCTGGCGCTGGTGGCGGTGCTCAGCGGGCTCAGCGTGCTGGGCCGCACCATGGGCTGGGCCTGGCTGGTCAAGACCTACGTGGTGCCCTACCTGATCGTGAACATGTGGCTCGTGCTCATCACGCTGCTCCAGCACACGCACCCGGCGCTGCCGCACTACTTCGAGAAGGACTGGGACTGGCTGCGCGGCGCCATGGCCACCGTGGACCGCTCCATGGGCCCGCCCTTCATGGACAACATCCTGCACCACATCTCCGACACCCACGTGCTGCACCACCTCTTCAGCACCATCCCGCACTACCACGCCGAGGAGGCCTCCGCCGCCATCAGGCCCATCCTGGGCAAGTACTACCAGTCCGACAGCCGCTGGGTCGGCCGCGCCCTGTGGGAGGACTGGCGCGACTGCCGCTACGTCGTCCCGGACGCGCCCGAGGACGACTCCGCGCTCTGGTTCCACAAGTGAGTGAGTGASEQIDNO:1385′FADc基因组区供体DNAGGGCTGGTCTGAATCCTTCAGGCGGGTGTTACCCGAGAAAGAAAGGGTGCCGATTTCAAAGCAGACCCATGTGCCGGGCCCTGTGGCCTGTGTTGGCGCCTATGTAGTCACCCCCCCTCACCCAATTGTCGCCAGTTTGCGCACTCCATAAACTCAAAACAGCAGCTTCTGAGCTGCGCTGTTCAAGAACACCTCTGGGGTTTGCTCACCCGCGAGGTCGACGCCCAGCATGGCTATCAAGACGAACAGGCAGCCTGTGGAGAAGCCTCCGTTCACGATCGGGACGCTGCGCAAGGCCATCCCCGCGCACTGTTTCGAGCGCTCGGCGCTTCGTAGCAGCATGTACCTGGCCTTTGACATCGCGGTCATGTCCCTGCTCTACGTCGCGTCGACGTACATCGACCCTGCACCGGTGCCTACGTGGGTCAAGTACGGCATCATGTGGCCGCTCTACTGGTTCTTCCAGGTGTGTTTGAGGGTTTTGGTTGCCCGTATTGAGGTCCTGGTGGCGCGCATGGAGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCCTTCGGCACGGGTGTCTGGGTGTGCGCGCACGAGTGCGGCCACCAGGCCTTTTCCTCCAGCCAGGCCATCAACGACGGCGTGGGCCTGGTGTTCCACAGCCTGCTGCTGGTGCCCTACTACTCCTGGAAGCACTCGCACCGSEQIDNO:1393′FADc基因组区供体DNACCGCCACCACTCCAACACGGGGTGCCTGGACAAGGACGAGGTGTTTGTGCCGCCGCACCGCGCAGTGGCGCACGAGGGCCTGGAGTGGGAGGAGTGGCTGCCCATCCGCATGGGCAAGGTGCTGGTCACCCTGACCCTGGGCTGGCCGCTGTACCTCATGTTCAACGTCGCCTCGCGGCCGTACCCGCGCTTCGCCAACCACTTTGACCCGTGGTCGCCCATCTTCAGCAAGCGCGAGCGCATCGAGGTGGTCATCTCCGACCTGGCGCTGGTGGCGGTGCTCAGCGGGCTCAGCGTGCTGGGCCGCACCATGGGCTGGGCCTGGCTGGTCAAGACCTACGTGGTGCCCTACCTGATCGTGAACATGTGGCTCGTGCTCATCACGCTGCTCCAGCACACGCACCCGGCGCTGCCGCACTACTTCGAGAAGGACTGGGACTGGCTGCGCGGCGCCATGGCCACCGTGGACCGCTCCATGGGCCCGCCCTTCATGGACAACATCCTGCACCACATCTCCGACACCCACGTGCTGCACCACCTCTTCAGCACCATCCCGCACTACCACGCCGAGGAGGCCTCCGCCGCCATCAGGCCCATCCTGGGCAAGTACTACCAGTCCGACAGCCGCTGGGTCGGCCGCGCCCTGTGGGAGGACTGGCGCGACTGCCGCTACGTCGTCCCGGACGCGCCCGAGGACGACTCCGCGCTCTGGTTCCACAAGTGAGTGAGTGASEQIDNO:140桑椹形原藻FATA1基因敲除同源重组靶向构建体的5′供体DNA序列GCTCTTCGGAGTCACTGTGCCACTGAGTTCGACTGGTAGCTGAATGGAGTCGCTGCTCCACTAAACGAATTGTCAGCACCGCCAGCCGGCCGAGGACCCGAGTCATAGCGAGGGTAGTAGCGCGCCATGGCACCGACCAGCCTGCTTGCCAGTACTGGCGTCTCTTCCGCTTCTCTGTGGTCCTCTGCGCGCTCCAGCGCGTGCGCTTTTCCGGTGGATCATGCGGTCCGTGGCGCACCGCAGCGGCCGCTGCCCATGCAGCGCCGCTGCTTCCGAACAGTGGCGGTCAGGGCCGCACCCGCGGTAGCCGTCCGTCCGGAACCCGCCCAAGAGTTTTGGGAGCAGCTTGAGCCCTGCAAGATGGCGGAGGACAAGCGCATCTTCCTGGAGGAGCACCGGTGCGTGGAGGTCCGGGGCTGACCGGCCGTCGCATTCAACGTAATCAATCGCATGATGATCAGAGGACACGAAGTCTTGGTGGCGGTGGCCAGAAACACTGTCCATTGCAAGGGCATAGGGATGCGTTCCTTCACCTCTCATTTCTCATTTCTGAATCCCTCCCTGCTCACTCTTTCTCCTCCTCCTTCCCGTTCACGCAGCATTCGGGGTACCSEQIDNO:141桑椹形原藻FATA1基因敲除同源重组靶向构建体的3′供体DNA序列GACAGGGTGGTTGGCTGGATGGGGAAACGCTGGTCGCGGGATTCGATCCTGCTGCTTATATCCTCCCTGGAAGCACACCCACGACTCTGAAGAAGAAAACGTGCACACACACAACCCAACCGGCCGAATATTTGCTTCCTTATCCCGGGTCCAAGAGAGACTGCGATGCCCCCCTCAATCAGCATCCTCCTCCCTGCCGCTTCAATCTTCCCTGCTTGCCTGCGCCCGCGGTGCGCCGTCTGCCCGCCCAGTCAGTCACTCCTGCACAGGCCCCTTGTGCGCAGTGCTCCTGTACCCTTTACCGCTCCTTCCATTCTGCGAGGCCCCCTATTGAATGTATTCGTTGCCTGTGTGGCCAAGCGGGCTGCTGGGCGCGCCGCCGTCGGGCAGTGCTCGGCGACTTTGGCGGAAGCCGATTGTTCTTCTGTAAGCCACGCGCTTGCTGCTTTGGGAAGAGAAGGGGGGGGGTACTGAATGGATGAGGAGGAGAAGGAGGGGTATTGGTATTATCTGAGTTGGGTGAAGAGCSEQIDNO:142原始小球藻肌动蛋白启动子/5′UTRACTAGAGAGTTTAGGTCCAGCGTCCGTGGGGGGGGACGGGCTGGGAGCTTGGGCCGGGAAGGGCAAGACGATGCAGTCCCTCTGGGGAGTCACAGCCGACTGTGTGTGTTGCACTGTGCGGCCCGCAGCACTCACACGCAAAATGCCTGGCCGACAGGCAGGCCCTGTCCAGTGCAACATCCACGGTCCCTCTCATCAGGCTCACCTTGCTCATTGACATAACGGAATGCGTACCGCTCTTTCAGATCTGTCCATCCAGAGAGGGGAGCAGGCTCCCCACCGACGCTGTCAAACTTGCTTCCTGCCCAACCGAAAACATTATTGTTTGAGGGGGGGGGGGGGGGGGCAGATTGCATGGCGGGATATCTCGTGAGGAACATCACTGGGACACTGTGGAACACAGTGAGTGCAGTATGCAGAGCATGTATGCTAGGGGTCAGCGCAGGAAGGGGGCCTTTCCCAGTCTCCCATGCCACTGCACCGTATCCACGACTCACCAGGACCAGCTTCTTGATCGGCTTCCGCTCCCGTGGACACCAGTGTGTAGCCTCTGGACTCCAGGTATGCGTGCACCGCAAAGGCCAGCCGATCGTGCCGATTCCTGGGGTGGAGGATATGAGTCAGCCAACTTGGGGCTCAGAGTGCACACTGGGGCACGATACGAAACAACATCTACACCGTGTCCTCCATGCTGACACACCACAGCTTCGCTCCACCTGAATGTGGGCGCATGGGCCCGAATCACAGCCAATGTCGCTGCTGCCATAATGTGATCCAGACCCTCTCCGCCCAGATGCCGAGCGGATCGTGGGCGCTGAATAGATTCCTGTTTCGATCACTGTTTGGGTCCTTTCCTTTTCGTCTCGGATGCGCGTCTCGAAACAGGCTGCGTCGGGCTTTCGGATCCCTTTTGCTCCCTCCGTCACCATCCTGCGCGCGGGCAAGTTGCTTGACCCTGGGCTGGTACCAGGGTTGGAGGGTATTACCGCGTCAGGCCATTCCCAGCCCGGATTCAATTCAAAGTCTGGGCCACCACCCTCCGCCGCTCTGTCTGATCACTCCACATTCGTGCATACACTACGTTCAAGTCCTGATCCAGGCGTGTCTCGGGACAAGGTGTGCTTGAGTTTGAATCTCAAGGACCCACTCCAGCACAGCTGCTGGTTGACCCCGCCCTCGCAAAACGCCTTTGTACAACTGCASEQIDNO:143AtTHIC表达盒,包含原始小球藻肌动蛋白启动子/5′UTR、用于在桑椹形原藻中表达的密码子优化的拟南芥THIC蛋白质编码序列、以及普通小球藻硝酸盐还原酶3′UTRagtttaggtccagcgtccgtggggggggacgggctgggagcttgggccgggaagggcaagacgatgcagtccctctggggagtcacagccgactgtgtgtgttgcactgtgcggcccgcagcactcacacgcaaaatgcctggccgacaggcaggccctgtccagtgcaacatccacggtccctctcatcaggctcaccttgctcattgacataacggaatgcgtaccgctctttcagatctgtccatccagagaggggagcaggctccccaccgacgctgtcaaacttgcttcctgcccaaccgaaaacattattgtttgagggggggggggggggggcagattgcatggcgggatatctcgtgaggaacatcactgggacactgtggaacacagtgagtgcagtatgcagagcatgtatgctaggggtcagcgcaggaagggggcctttcccagtctcccatgccactgcaccgtatccacgactcaccaggaccagcttcttgatcggcttccgctcccgtggacaccagtgtgtagcctctggactccaggtatgcgtgcaccgcaaaggccagccgatcgtgccgattcctggggtggaggatatgagtcagccaacttggggctcagagtgcacactggggcacgatacgaaacaacatctacaccgtgtcctccatgctgacacaccacagcttcgctccacctgaatgtgggcgcatgggcccgaatcacagccaatgtcgctgctgccataatgtgatccagaccctctccgcccagatgccgagcggatcgtgggcgctgaatagattcctgtttcgatcactgtttgggtcctttccttttcgtctcggatgcgcgtctcgaaacaggctgcgtcgggctttcggatcccttttgctccctccgtcaccatcctgcgcgcgggcaagttgcttgaccctgggctgtaccagggttggagggtattaccgcgtcaggccattcccagcccggattcaattcaaagtctgggccaccaccctccgccgctctgtctgatcactccacattcgtgcatacactacgttcaagtcctgatccaggcgtgtctcgggacaaggtgtgcttgagtttgaatctcaaggacccactccagcacagctgctggttgaccccgccctcgcaatctagaATGgccgcgtccgtccactgcaccctgatgtccgtggtctgcaacaacaagaaccactccgcccgccccaagctgcccaactcctccctgctgcccggcttcgacgtggtggtccaggccgcggccacccgcttcaagaaggagacgacgaccacccgcgccacgctgacgttcgacccccccacgaccaactccgagcgcgccaagcagcgcaagcacaccatcgacccctcctcccccgacttccagcccatcccctccttcgaggagtgcttccccaagtccacgaaggagcacaaggaggtggtgcacgaggagtccggccacgtcctgaaggtgcccttccgccgcgtgcacctgtccggcggcgagcccgccttcgacaactacgacacgtccggcccccagaacgtcaacgcccacatcggcctggcgaagctgcgcaaggagtggatcgaccgccgcgagaagctgggcacgccccgctacacgcagatgtactacgcgaagcagggcatcatcacggaggagatgctgtactgcgcgacgcgcgagaagctggaccccgagttcgtccgctccgaggtcgcgcggggccgcgccatcatcccctccaacaagaagcacctggagctggagcccatgatcgtgggccgcaagttcctggtgaaggtgaacgcgaacatcggcaactccgccgtggcctcctccatcgaggaggaggtctacaaggtgcagtgggccaccatgtggggcgccgacaccatcatggacctgtccacgggccgccacatccacgagacgcgcgagtggatcctgcgcaactccgcggtccccgtgggcaccgtccccatctaccaggcgctggagaaggtggacggcatcgcggagaacctgaactgggaggtgttccgcgagacgctgatcgagcaggccgagcagggcgtggactacttcacgatccacgcgggcgtgctgctgcgctacatccccctgaccgccaagcgcctgacgggcatcgtgtcccgcggcggctccatccacgcgaagtggtgcctggcctaccacaaggagaacttcgcctacgagcactgggacgacatcctggacatctgcaaccagtacgacgtcgccctgtccatcggcgacggcctgcgccccggctccatctacgacgccaacgacacggcccagttcgccgagctgctgacccagggcgagctgacgcgccgcgcgtgggagaaggacgtgcaggtgatgaacgagggccccggccacgtgcccatgcacaagatccccgagaacatgcagaagcagctggagtggtgcaacgaggcgcccttctacaccctgggccccctgacgaccgacatcgcgcccggctacgaccacatcacctccgccatcggcgcggccaacatcggcgccctgggcaccgccctgctgtgctacgtgacgcccaaggagcacctgggcctgcccaaccgcgacgacgtgaaggcgggcgtcatcgcctacaagatcgccgcccacgcggccgacctggccaagcagcacccccacgcccaggcgtgggacgacgcgctgtccaaggcgcgcttcgagttccgctggatggaccagttcgcgctgtccctggaccccatgacggcgatgtccttccacgacgagacgctgcccgcggacggcgcgaaggtcgcccacttctgctccatgtgcggccccaagttctgctccatgaagatcacggaggacatccgcaagtacgccgaggagaacggctacggctccgccgaggaggccatccgccagggcatggacgccatgtccgaggagttcaacatcgccaagaagacgatctccggcgagcagcacggcgaggtcggcggcgagatctacctgcccgagtcctacgtcaaggccgcgcagaagTGAcaattggcagcagcagctcggatagtatcgacacactctggacgctggtcgtgtgatggactgttgccgccacacttgctgccttgacctgtgaatatccctgccgcttttatcaaacagcctcagtgtgtttgatcttgtgtgtacgcgcttttgcgagttgctagctgcttgtgctatttgcgaataccacccccagcatccccttccctcgtttcatatcgcttgcatcccaaccgcaacttatctacgctgtcctgctatccctcagcgctgctcctgctcctgctcactgcccctcgcacagccttggtttgggctccgcctgtattctcctggtactgcaacctgtaaaccagcactgcaatgctgatgcacgggaagtagtgggatgggaacacaaatggaggatccSEQIDNO:144包含原始小球藻S106硬脂酰基-ACP脱饱和酶转运肽的PmKASII的密码子优化的序列ATGgccaccgcatccactttctcggcgttcaatgcccgctgcggcgacctgcgtcgctcggcgggctccgggccccggcgcccagcgaggcccctccccgtgcgcgggcgcgccgccgccgccgccgacgccaaccccgcccgccccgagcgccgcgtggtgatcaccggccagggcgtggtgacctccctgggccagaccatcgagcagttctactcctccctgctggagggcgtgtccggcatctcccagatccagaagttcgacaccaccggctacaccaccaccatcgccggcgagatcaagtccctgcagctggacccctacgtgcccaagcgctgggccaagcgcgtggacgacgtgatcaagtacgtgtacatcgccggcaagcaggccctggagtccgccggcctgcccatcgaggccgccggcctggccggcgccggcctggaccccgccctgtgcggcgtgctgatcggcaccgccatggccggcatgacctccttcgccgccggcgtggaggccctgacccgcggcggcgtgcgcaagatgaaccccttctgcatccccttctccatctccaacatgggcggcgccatgctggccatggacatcggcttcatgggccccaactactccatctccaccgcctgcgccaccggcaactactgcatcctgggcgccgccgaccacatccgccgcggcgacgccaacgtgatgctggccggcggcgccgacgccgccatcatcccctccggcatcggcggcttcatcgcctgcaaggccctgtccaagcgcaacgacgaGcccgagcgcgcctcccgcccctgggacgccgaccgcgacggcttcgtgatgggcgagggcgccggcgtgctggtgctggaggagctggagcacgccaagcgccgcggcgccaccatcctggccgagctggtgggcggcgccgccacctccgacgcccaccacatgaccgagcccgacccccagggccgcggcgtgcgcctgtgcctggagcgcgccctggagcgcgcccgcctggcccccgagcgcgtgggctacgtgaacgcccacggcacctccacccccgccggcgacgtggccgagtaccgcgccatccgcgccgtgatcccccaggactccctgcgcatcaactccaccaagtccatgatcggccacctgctgggcggcgccggcgccgtggaggccgtggccgccatccaggccctgcgcaccggctggctgcaccccaacctgaacctggagaaccccgcccccggcgtggaccccgtggtgctggtgggcccccgcaaggagcgcgccgaggacctggacgtggtgctgtccaactccttcggcttcggcggccacaactcctgcgtgatcttccgcaagtacgacgagatggactacaaggaccacgacggcgactacaaggaccacgacatcgactacaaggacgacgacgacaagTGASEQIDNO:145包含原始小球藻S106硬脂酰基-ACP脱饱和酶转运肽的PmKASII的密码子优化的氨基酸序列MATASTFSAFNARCGDLRRSAGSGPRRPARPLPVRGRAAAAADANPARPERRVVITGQGVVTSLGQTIEQFYSSLLEGVSGISQIQKFDTTGYTTTIAGEIKSLQLDPYVPKRWAKRVDDVIKYVYIAGKQALESAGLPIEAAGLAGAGLDPALCGVLIGTAMAGMTSFAAGVEALTRGGVRKMNPFCIPFSISNMGGAMLAMDIGFMGPNYSISTACATGNYCILGAADHIRRGDANVMLAGGADAAIIPSGIGGFIACKALSKRNDEPERASRPWDADRDGFVMGEGAGVLVLEELEHAKRRGATILAELVGGAATSDAHHMTEPDPQGRGVRLCLERALERARLAPERVGYVNAHGTSTPAGDVAEYRAIRAVIPQDSLRINSTKSMIGHLLGGAGAVEAVAAIQALRTGWLHPNLNLENPAPGVDPVVLVGPRKERAEDLDVVLSNSFGFGGHNSCVIFRKYDEMDYKDHDGDYKDHDIDYKDDDDKSEQIDNO:146密码子优化的桑椹形原藻(UTEX1435)FAD2蛋白质编码序列ATGgccatcaagaccaaccgccagcccgtggagaagccccccttcaccatcggcaccctgcgcaaggccatccccgcccactgcttcgagcgctccgccctgcgctcctccatgtacctggccttcgacatcgccgtgatgtccctgctgtacgtggcctccacctacatcgaccccgcccccgtgcccacctgggtgaagtacggcgtgatgtggcccctgtactggttcttccagggcgccttcggcaccggcgtgtgggtgtgcgcccacgagtgcggccaccaggccttctcctcctcccaggccatcaacgacggcgtgggcctggtgttccactccctgctgctggtgccctactactcctggaagcactcccaccgccgccaccactccaacaccggctgcctggacaaggacgaggtgttcgtgcccccccaccgcgccgtggcccacgagggcctggagtgggaggagtggctgcccatccgcatgggcaaggtgctggtgaccctgaccctgggctggcccctgtacctgatgttcaacgtggcctcccgcccctacccccgcttcgccaaccacttcgacccctggtcccccatcttctccaagcgcgagcgcatcgaggtggtgatctccgacctggccctggtggccgtgctgtccggcctgtccgtgctgggccgcaccatgggctgggcctggctggtgaagacctacgtggtgccctacctgatcgtgaacatgtggctggtgctgatcaccctgctgcagcacacccaccccgccctgccccactacttcgagaaggactgggactggctgcgcggcgccatggccaccgtggaccgctccatgggcccccccttcatggacaacatcctgcaccacatctccgacacccacgtgctgcaccacctgttctccaccatcccccactaccacgccgaggaggcctccgccgccatccgccccatcctgggcaagtactaccagtccgactcccgctgggtgggccgcgccctgtgggaggactggcgcgactgccgctacgtggtgcccgacgcccccgaggacgactccgccctgtggttccacaagTAGSEQIDNO:147桑椹形原藻FAD2的密码子优化的桑椹形原藻(UTEX1435)氨基酸序列MAIKTNRQPVEKPPFTIGTLRKAIPAHCFERSALRSSMYLAFDIAVMSLLYVASTYIDPAPVPTWVKYGVMWPLYWFFQGAFGTGVWVCAHECGHQAFSSSQAINDGVGLVFHSLLLVPYYSWKHSHRRHHSNTGCLDKDEVFVPPHRAVAHEGLEWEEWLPIRMGKVLVTLTLGWPLYLMFNVASRPYPRFANHFDPWSPIFSKRERIEVVISDLALVAVLSGLSVLGRTMGWAWLVKTYVVPYLIVNMWLVLITLLQHTHPALPHYFEKDWDWLRGAMATVDRSMGPPFMDNILHHISDTHVLHHLFSTIPHYHAEEASAAIRPILGKYYQSDSRWVGRALWEDWRDCRYVVPDAPEDDSALWFHKSEQIDNO:148来自pSZ1358的欧洲油菜C18:0优选硫酯酶的密码子优化的编码区ACTAGTATGCTGAAGCTGTCCTGCAACGTGACCAACAACCTGCACACCTTCTCCTTCTTCTCCGACTCCTCCCTGTTCATCCCCGTGAACCGCCGCACCATCGCCGTGTCCTCCGGGCGCGCCTCCCAGCTGCGCAAGCCCGCCCTGGACCCCCTGCGCGCCGTGATCTCCGCCGACCAGGGCTCCATCTCCCCCGTGAACTCCTGCACCCCCGCCGACCGCCTGCGCGCCGGCCGCCTGATGGAGGACGGCTACTCCTACAAGGAGAAGTTCATCGTGCGCTCCTACGAGGTGGGCATCAACAAGACCGCCACCGTGGAGACCATCGCCAACCTGCTGCAGGAGGTGGCCTGCAACCACGTGCAGAAGTGCGGCTTCTCCACCGACGGCTTCGCCACCACCCTGACCATGCGCAAGCTGCACCTGATCTGGGTGACCGCCCGCATGCACATCGAGATCTACAAGTACCCCGCCTGGTCCGACGTGGTGGAGATCGAGACCTGGTGCCAGTCCGAGGGCCGCATCGGCACCCGCCGCGACTGGATCCTGCGCGACTCCGCCACCAACGAGGTGATCGGCCGCGCCACCTCCAAGTGGGTGATGATGAACCAGGACACCCGCCGCCTGCAGCGCGTGACCGACGAGGTGCGCGACGAGTACCTGGTGTTCTGCCCCCGCGAGCCCCGCCTGGCCTTCCCCGAGGAGAACAACTCCTCCCTGAAGAAGATCCCCAAGCTGGAGGACCCCGCCCAGTACTCCATGCTGGAGCTGAAGCCCCGCCGCGCCGACCTGGACATGAACCAGCACGTGAACAACGTGACCTACATCGGCTGGGTGCTGGAGTCCATCCCCCAGGAGATCATCGACACCCACGAGCTGCAGGTGATCACCCTGGACTACCGCCGCGAGTGCCAGCAGGACGACATCGTGGACTCCCTGACCACCTCCGAGATCCCCGACGACCCCATCTCCAAGTTCACCGGCACCAACGGCTCCGCCATGTCCTCCATCCAGGGCCACAACGAGTCCCAGTTCCTGCACATGCTGCGCCTGTCCGAGAACGGCCAGGAGATCAACCGCGGCCGCACCCAGTGGCGCAAGAAGTCCTCCCGCATGGACTACAAGGACCACGACGGCGACTACAAGGACCACGACATCGACTACAAGGACGACGACGACAAGTGAATCGATSEQIDNO:149欧洲油菜C18:0优选硫酯酶的氨基酸序列(登录号CAA52070.1)MLKLSCNVTNNLHTFSFFSDSSLFIPVNRRTIAVSSSQLRKPALDPLRAVISADQGSISPVNSCTPADRLRAGRLMEDGYSYKEKFIVRSYEVGINKTATVETIANLLQEVACNHVQKCGFSTDGFATTLTMRKLHLIWVTARMHIEIYKYPAWSDVVEIETWCQSEGRIGTRRDWILRDSATNEVIGRATSKWVMMNQDTRRLQRVTDEVRDEYLVFCPREPRLAFPEENNSSLKKIPKLEDPAQYSMLELKPRRADLDMNQHVNNVTYIGWVLESIPQEIIDTHELQVITLDYRRECQQDDIVDSLTTSEIPDDPISKFTGTNGSAMSSIQGHNESQFLHMLRLSENGQEINRGRTQWRKKSSRSEQIDNO:150桑椹形原藻FATA1等位基因15′同源供体区GGAGTCACTGTGCCACTGAGTTCGACTGGTAGCTGAATGGAGTCGCTGCTCCACTAAACGAATTGTCAGCACCGCCAGCCGGCCGAGGACCCGAGTCATAGCGAGGGTAGTAGCGCGCCATGGCACCGACCAGCCTGCTTGCCAGTACTGGCGTCTCTTCCGCTTCTCTGTGGTCCTCTGCGCGCTCCAGCGCGTGCGCTTTTCCGGTGGATCATGCGGTCCGTGGCGCACCGCAGCGGCCGCTGCCCATGCAGCGCCGCTGCTTCCGAACAGTGGCGGTCAGGGCCGCACCCGCGGTAGCCGTCCGTCCGGAACCCGCCCAAGAGTTTTGGGAGCAGCTTGAGCCCTGCAAGATGGCGGAGGACAAGCGCATCTTCCTGGAGGAGCACCGGTGCGTGGAGGTCCGGGGCTGACCGGCCGTCGCATTCAACGTAATCAATCGCATGATGATCAGAGGACACGAAGTCTTGGTGGCGGTGGCCAGAAACACTGTCCATTGCAAGGGCATAGGGATGCGTTCCTTCACCTCTCATTTCTCATTTCTGAATCCCTCCCTGCTCACTCTTTCTCCTCCTCCTTCCCGTTCACGCAGCATTCGGSEQIDNO:151桑椹形原藻FATA1等位基因13′同源供体区GACAGGGTGGTTGGCTGGATGGGGAAACGCTGGTCGCGGGATTCGATCCTGCTGCTTATATCCTCCCTGGAAGCACACCCACGACTCTGAAGAAGAAAACGTGCACACACACAACCCAACCGGCCGAATATTTGCTTCCTTATCCCGGGTCCAAGAGAGACTGCGATGCCCCCCTCAATCAGCATCCTCCTCCCTGCCGCTTCAATCTTCCCTGCTTGCCTGCGCCCGCGGTGCGCCGTCTGCCCGCCCAGTCAGTCACTCCTGCACAGGCCCCTTGTGCGCAGTGCTCCTGTACCCTTTACCGCTCCTTCCATTCTGCGAGGCCCCCTATTGAATGTATTCGTTGCCTGTGTGGCCAAGCGGGCTGCTGGGCGCGCCGCCGTCGGGCAGTGCTCGGCGACTTTGGCGGAAGCCGATTGTTCTTCTGTAAGCCACGCGCTTGCTGCTTTGGGAAGAGAAGGGGGGGGGTACTGAATGGATGAGGAGGAGAAGGAGGGGTATTGGTATTATCTGAGTTGGGTSEQIDNO:152桑椹形原藻FATA1等位基因25′同源供体区AATGGAGTCGCTGCTCCACTAATCGAATTGTCAGCACCGCCAGCCGGCCGAGGACCCGAGTCATAGCGAGGGTAGTAGCGCGCCATGGCACCGACCAGCCTGCTTGCCCGTACTGGCGTCTCTTCCGCTTCTCTGTGCTCCTCTACGCGCTCCGGCGCGTGCGCTTTTCCGGTGGATCATGCGGTCCGTGGCGCACCGCAGCGGCCGCTGCCCATGCAGCGCCGCTGCTTCCGAACAGTGGCTGTCAGGGCCGCACCCGCAGTAGCCGTCCGTCCGGAACCCGCCCAAGAGTTTTGGGAGCAGCTTGAGCCCTGCAAGATGGCGGAGGACAAGCGCATCTTCCTGGAGGAGCACCGGTGCGCGGAGGTCCGGGGCTGACCGGCCGTCGCATTCAACGTAATCAATCGCATGATGATCACAGGACGCGACGTCTTGGTGGCGGTGGCCAGGGACACTGCCCATTGCACAGGCATAGGAATGCGTTCCTTCTCATTTCTCAGTTTTCTGAGCCCCTCCCTCTTCACTCTTTCTCCTCCTCCTCCCCTCTCACGCAGCATTCGTGGSEQIDNO:153桑椹形原藻FATA1等位基因23′同源供体区CACTAGTATCGATTTCGAACAGAGGAGAGGGTGGCTGGTAGTTGCGGGATGGCTGGTCGCCCGTCGATCCTGCTGCTGCTATTGTCTCCTCCTGCACAAGCCCACCCACGACTCCGAAGAAGAAGAAGAAAACGCGCACACACACAACCCAACCGGCCGAATATTTGCTTCCTTATCCCGGGTCCAAGAGAGACGGCGATGCCCCCCTCAATCAGCCTCCTCCTCCCTGCCGCTCCAATCTTCCCTGCTTGCATGCGCCCGCGAGAGGCTGTCTGCGCGCCCCGTCAGTCACTCCCCGTGCAGACGCCTCGTGCTCGGTGCTCCTGTATCCTTTACCGCTCCTTTCATTCTGCGAGGCCCCCTGTTGAATGTATTCGTTGCCTGTGTGGCCAAGCGCGCTGCTGGGCGCGCCGCCGTCGGGCGGTGCTCGGCGACTCTGGCGGAAGCCGGTTGTTCTTCTGTAAGCCACGCGCTTGCTGCTTTTGGAAAAGAGGGGGGTTTACTGAATGGAGGAGGAGCAGGATAATTGGTAGTATCTGAGTTGTTGSEQIDNO:154SAD2发夹CactagtGCGCTGGACGCGGCAGTGGGTGGCCGAGGAGAACCGGCACGGCGACCTGCTGAACAAGTACTGTTGGCTGACGGGGCGCGTCAACATGCGGGCCGTGGAGGTGACCATCAACAACCTGATCAAGAGCGGCATGAACCCGCAGACGGACAACAACCCTTACTTGGGCTTCGTCTACACCTCCTTCCAGGAGCGCGCGACCAAGTACAGCCACGGCAACACCGCGCGCCTTGCGGCCGAGCAGTGTGTTTGAGGGTTTTGGTTGCCCGTATCGAGGTCCTGGTGGCGCGCATGGGGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCGTACGggatccTGCTCGGCCGCAAGGCGCGCGGTGTTGCCGTGGCTGTACTTGGTCGCGCGCTCCTGGAAGGAGGTGTAGACGAAGCCCAAGTAAGGGTTGTTGTCCGTCTGCGGGTTCATGCCGCTCTTGATCAGGTTGTTGATGGTCACCTCCACGGCCCGCATGTTGACGCGCCCCGTCAGCCAACAGTACTTGTTCAGCAGGTCGCCGTGCCGGTTCTCCTCGGCCACCCACTGCCGCGTCCAGCGCaagcttSEQIDNO:155MSIQFALRAAYIKGTCQRLSGRGAALGLSRDWTPGWTLPRCWPASAAATAPPRARHQERAIHLTSGRRRHSALASDADERALPSNAPGLVMASQANYFRVRLLPEQEEGELESWSPNVRHTTLLCKPRAMLSKLQMRVMVGDRVIVTAIDPVNMTVHAPPFDPLPATRFLVAGEAADMDITVVLNKADLVPEEESAALAQEVASWGPVVLTSTLTGRGLQELERQLGSTTAVLAGPSGAGKSSIINALARAARERPSDASVSNVPEEQVVGEDGRALANPPPFTLADIRNAIPKDCFRKSAAKSLAYLGDLSITGMAVLAYKINSPWLWPLYWFAQGTMFWALFVVGHDCGHQSFSTSKRLNDALAWLGALAAGTWTWALGVLPMLNLYLAPYVWLLVTYLHHHGPSDPREEMPWYRGREWSYMRGGLTTIDRDYGLFNKVHHDIGTHVVHHSEQIDNO:156MFWALFVVGHDCGHQSFSTSKRLNDAVGLFVHSIIGVPYHGWRISHRTHHNNHGHVENDESWYPPTESGLKAMTDMGRQGRFHFPSMLFVYPFYLFWRSPGKTGSHFSPATDLFALWEAPLIRTSNACQLAWLGALAAGTWALGVLPMLNLYLAPYVISVAWLDLVTYLHHHGPSDPREEMPWYRGREWSYMRGGLTTIDRDYGLFNKVHHDIGTHVVHHLFPQIPHYNLCRATKAAKKVLGPYYREPERCPLGLLPVHLLAPLLRSLGQDHFVDDAGSVLFYRRAEGINPWIQKLLPWLGGARRGADAQRDAAQSEQIDNO:157亚麻荠ω-3FAD7-2MANLVLSECGIRPLPRIYTTPRSNFVSNNNKPIFKFRPFTSYKTSSSPLACSRDGFGKNWSLNVSVPLTTTTPIVDESPLKEEEEEKQRFDPGAPPPFNLADIRAAIPKHCWVKNPWKSMSYVLRDVAIVFALAAGASYLNNWIVWPLYWLAQGTMFWALFVLGHDCGHGSFSNNPRLNNVVGHLLHSSILVPYHGWRISHRTHHQNHGHVENDESWHPMSEKIYQSLDKPTRFFRFTLPLVMLAYPFYLWARSPGKKGSHYHPESDLFLPKEKTDVLTSTACWTAMAALLICLNFVVGPVQMLKLYGIPYWINVMWLDFVTYLHHHGHEDKLPWYRGKEWSYLRGGLTTLDRDYGVINNIHHDIGTHVIHHLFPQIPHYHLVEATEAVKPVLGKYYREPDKSGPLPLHLLGILAKSIKEDHYVSDEGDVVYYKADPNMYGEIKVGADSEQIDNO:158桑椹形原藻Δ12脱饱和酶等位基因2MAIKTNRQPVEKPPFTIGTLRKAIPAHCFERSALRSSMYLAFDIAVMSLLYVASTYIDPAPVPTWVKYGIMWPLYWFFQGAFGTGVWVCAHECGHQAFSSSQAINDGVGLVFHSLLLVPYYSWKHSHRRHHSNTGCLDKDEVFVPPHRAVAHEGLEWEEWLPIRMGKVLVTLTLGWPLYLMFNVASRPYPRFANHFDPWSPIFSKRERIEVVISDLALVAVLSGLSVLGRTMGWAWLVKTYVVPYMIVNMWLVLITLLQHTHPALPHYFEKDWDWLRGAMATVDRSMGPPFMDSILHHISDTHVLHHLFSTIPHYHAEEASAAIRPILGKYYQSDSRWVGRALWEDWRDCRYVVPDAPEDDSALWFHKSEQIDNO:159亚麻荠ω-3FAD7-1MANLVLSECGIRPLPRIYTTPRSNFVSNNNKPIFKFRPLTSYKTSSPLFCSRDGFGRNWSLNVSVPLATTTPIVDESPLEEEEEEEKQRFDPGAPPPFNLADIRAAIPKHCWVKNPWKSMSYVLRDVAIVFALAAGAAYLNNWIVWPLYWLAQGTMFWALFVLGHDCGHGSFSNNPRLNNVVGHLLHSSILVPYHGWRISHRTHHQNHGHVENDESWHPMSEKIYQSLDKPTRFFRFTLPLVMLAYPFYLWARSPGKKGSHYHPESDLFLPKEKTDVLTSTACWTAMAALLICLNFVVGPVQMLKLYGIPYWINVMWLDFVTYLHHHGHEDKLPWYRGKEWSYLRGGLTTLDRDYGVINNIHHDIGTHVIHHLFPQIPHYHLVEATEAVKPVLGKYYREPDKSGPLPLHLLGILAKSIKEDHYVSDEGDVVYYKADPNMYGEIKVGADSEQIDNO:160PmFATA-hpBactagtCATTCGGGGCAACGAGGTGGGCCCCTCGCAGCGGCTGACGATCACGGCGGTGGCCAACATCCTGCAGGAGGCGGCGGGCAACCACGCGGTGGCCATGTGGGGCCGGAGCGTGTGTTTGAGGGTTTTGGTTGCCCGTATTGAGGTCCTGGTGGCGCGCATGGGGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCGTACGggatccGCTCCGGCCCCACATGGCCACCGCGTGGTTGCCCGCCGCCTCCTGCAGGATGTTGGCCACCGCCGTGATCGTCAGCCGCTGCGAGGGGCCCACCTCGTTGCCCCGAATGaagcttSEQIDNO:161PmFATA-hpCactagtGGAGGGTTTCGCGACGGACCCGGAGCTGCAGGAGGCGGGTCTCATCTTTGTGATGACGCGCATGCAGATCCAGATGTACCGCTACCCGCGCTGGGGCGACCTGATGCAGGTGGAGACCTGGTTCCAGAGTGTGTTTGAGGGTTTTGGTTGCCCGTATTGAGGTCCTGGTGGCGCGCATGGGGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCGTACGggatccTCTGGAACCAGGTCTCCACCTGCATCAGGTCGCCCCAGCGCGGGTAGCGGTACATCTGGATCTGCATGCGCGTCATCACAAAGATGAGACCCGCCTCCTGCAGCTCCGGGTCCGTCGCGAAACCCTCCaagcttSEQIDNO:162PmFATA-hpDactagtCGGCGGGCAAGCTGGGCGCGCAGCGCGAGTGGGTGCTGCGCGACAAGCTGACCGGCGAGGCGCTGGGCGCGGCCACCTCGAGCTGGGTCATGATCAACATCCGCACGCGCCGGCCGTGCCGCATGCCGGGTGTGTTTGAGGGTTTTGGTTGCCCGTATCGAGGTCCTGGTGGCGCGCATGGGGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCGTACGggatccCCGGCATGCGGCACGGCCGGCGCGTGCGGATGTTGATCATGACCCAGCTCGAGGTGGCCGCGCCCAGCGCCTCGCCGGTCAGCTTGTCGCGCAGCACCCACTCGCGCTGCGCGCCCAGCTTGCCCGCCGaagcttSEQIDNO:163PmFATA-hpEactagtGTCCGCGTCAAGTCGGCCTTCTTCGCGCGCGAGCCGCCGCGCCTGGCGCTGCCGCCCGCGGTCACGCGTGCCAAGCTGCCCAACATCGCGACGCCGGCGCCGCTGCGCGGGCACCGCCAGGTCGCGCGCCGCACCGACATGGACATGAACGGGCACGTGAACAACGTGGCCTACCTGGCCTGGTGCCTGGAGTGTGTTTGAGGGTTTTGGTTGCCCGTATTGAGGTCCTGGTGGCGCGCATGGGGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCGTACGggatccTCCAGGCACCAGGCCAGGTAGGCCACGTTGTTCACGTGCCCGTTCATGTCCATGTCGGTGCGGCGCGCGACCTGGCGGTGCCCGCGCAGCGGCGCCGGCGTCGCGATGTTGGGCAGCTTGGCACGCGTGACCGCGGGCGGCAGCGCCAGGCGCGGCGGCTCGCGCGCGAAGAAGGCCGACTTGACGCGGACaagcttSEQIDNO:164PmFATA-hpFactagtCCGTGCCCGAGCACGTCTTCAGCGACTACCACCTCTACCAGATGGAGATCGACTTCAAGGCCGAGTGCCACGCGGGCGACGTCATCTCCTCCCAGGCCGAGCAGATCCCGCCCCAGGAGGCGCTCACGCACAACGGCGCCGGCCGCAACCCCTCCTGCTTCGTCCATAGCATTCTGCGCGCCGAGACCGAGCGTGTGTTTGAGGGTTTTGGTTGCCCGTATCGAGGTCCTGGTGGCGCGCATGGGGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCGTACGggatccGCTCGGTCTCGGCGCGCAGAATGCTATGGACGAAGCAGGAGGGGTTGCGGCCGGCGCCGTTGTGCGTGAGCGCCTCCTGGGGCGGGATCTGCTCGGCCTGGGAGGAGATGACGTCGCCCGCGTGGCACTCGGCCTTGAAGTCGATCTCCATCTGGTAGAGGTGGTAGTCGCTGAAGACGTGCTCGGGCACGGaagcttSEQIDNO:165PmFATA-hpGactagtTCGTCCGCGCGCGAACCACATGGTCGGCCCCCATCGACGCGCCCGCCGCCAAGCCGCCCAAGGCGAGCCACTGAGGACAGGGTGGTTGGCTGGATGGGGAAACGCTGGTCGCGGGATTCGATCCTGCTGCTTATATCCTCGTGTGTTTGAGGGTTTTGGTTGCCCGTATTGAGGTCCTGGTGGCGCGCATGGGGGAGAAGGCGCCTGTCCCGCTGACCCCCCCGGCTACCCTCCCGGCACCTTCCAGGGCGCGTACGggatccGAGGATATAAGCAGCAGGATCGAATCCCGCGACCAGCGTTTCCCCATCCAGCCAACCACCCTGTCCTCAGTGGCTCGCCTTGGGCGGCTTGGCGGCGGGCGCGTCGATGGGGGCCGACCATGTGGTTCGCGCGCGGACGAaagcttSEQIDNO:166桑椹形原藻(UTEX1435)乙醛酸循环体脂肪酸β-氧化多功能蛋白ATGTCGAAGGAGCCGCAGTCTTTCTACAAGGTGGAGGATGGAGTGGCCATCATCACCATCTCCTACCCTCCCATGAACGCCCTTCACCCCACGCTGATCAAGGACATGTTCAACAACGTCCGTCGCGCCCAGGAGGATGCCAGCGCCAAGGCCATCGTCATCACCGGTGCCAACGGTCGCTTCTGCGCCGGCTTTGACATCAACCAGTTCCAGAACAAGAGCGCCGGCGCSGGCGGCGGCATCGACATGAGCATCAACAACGCGTTTGTSGAGCTCATCGAGAACGGSCGCAAGCCGACGGTGGCCGCGATCGAGCGGCTGGCCCTGGGCGGCGGGTGCGAGCTGGCGCTGGCCTGCAACGCGCGCGTAGCGGCGCCCGGCACCATCATGGGCCTGCCCGAGCTGACGCTGGGCATTTTGCCCGGCTTTGGCGGCACGCAGCGCCTGCCGCGCGTGGTGGGCCTTGAGAAGGGCCTGTCCATGATCCTGACCAGCAAGCCCATCAAGGARCCCGAGGCGCTCAAGCTGGGCCTGCTGGACGAGGTGGTGCCCGCGCCGCAGCTGCTGGCGCGCGCCAAGGCCTTTGCGCTGGAGATCGTGMCSGGGCAGCGCCCGCGCGTCAACGCGCTCCAGCGCACGGACAAGCTGCCCGCGTACGCGGACGCGCTGCAGATCATCCAGTTTGCGCGCGAGCAGACGGCCAAGCGCGCGCCCAACCTGCAGCACCCGCTCTTCACGCTGGACGCGATCCAGGCCGGCATCGAGCACGGCGGGCTCAAGGGCCTGCGCGCCGAGGCCGACGCCTTTGCGCGCTCGGCGGCGCTGCCCACGCACGACTCGCTGGTGCACGTCTTCTTCGCGCAGCGCTCGACCAAGCGCGTGCGCGGAGTGACCGACGTCGGGCTCAAGCCACGTGCGGTCAAGAGGATCGCCGTGCTGGGCGGCGGGCTCATGGGCTCGGGCATCGCCACCGCCTCGGCGCTGGCGGGCGTSGAGGTGCTGCTCAAGGAYATCAARSAYAAYTTCCTSGAGGGCGGCCTGGGCCGCATCCGCGCCAACCTGGCGTCCAAGGTCAAGCGGAAGCAGCTCTCGCAGCAGGCGGCGGACGCCGCGATGGCCCGCGTCAAGGGCGTGCTCACCTACGACGACTTCAAGACSGTCGACATGGTGATCGAGGCGGCCATCGAGAAGGTGGACCTGAAGCAGGACATCTTCGTGGACCTGGTCAGGGCCACGCGCCCCGACTGCATCCTGGCCACCAACACGTCGACCATCAACATCGAGACGGTGGGCGCCAAGATCCCGGGCGACCTGGGCCGCGTGATCGGCGCGCACTTTTTCTCGCCRGCGCACATCATGCCCCTGCTGGAGATCGTGCGCTCGGACAAGACCAGCGCGCAGGTCATCCTGGACACGCTCGAGTACGGCAGCAAGATCAAGAAGACGCCCGTCGTGGTGGGCAACTGCACGGGCTTTGCGGTCAACCGCGTCTTCTTCCCCTACTCCATGGCCGCGACCATTCTCTTGGACTCGGGGCTCGACCCCTACGCCATCGACGCCGCCATCACGGCCTTTGGCATGCCCATGGGGCCCTTCCGCCTGGGCGACCTGGTCGGCCTGGACGTCTCGCTCTTCGTGGGCGCCTCCTACCTGCAGGACTACGGCGACCGCGTCTACCGCGGCGCCATGGTCCCGCTGCTCAACGAGGCCGGCCGRCTGGGCGAGAAGACCGGCGCCGGCTGGTACAAGTTTGACGACCGCCGCCGCGCGAGCCCGGACCCGGCGCTGGCGCCGCTCCTCTCGCCCAAGGACATCGCCGAGTTCATCTTCTTCCCGGTCGTCAACGAGGCCTGCCGCGTCGTGGCCGAGGGCATCGTGGACAAGCCCTCCGACCTGGACATCGCCACCGTCATGTCCATGGGCTTCCCGGCCTACCGCGGCGGCATCCTCTTCTACGGCGACATCGTCGGCGCCAAGTACGTCGTCGACCGTCTCAACGCCTGGGCCAAGCAGTACCCCGCGCAGGCCGGCTTCTTCAAGCCCTGCGACTACCTCCTSCGCGCCGCGCAGACCGGCACCAAGCTCGAGGCCGGCAACAAGCCCGCCTCCAAGATCTGASEQIDNO:167桑椹形原藻(UTEX1435)乙醛酸循环体脂肪酸β-氧化多功能蛋白MSKEPQSFYKVEDGVAIITISYPPMNALHPTLIKDMFNNVRRAQEDASAKAIVITGANGRFCAGFDINQFQNKSAGXGGGIDMSINNAFXELIENXRKPTVAAIERLALGGGCELALACNARVAAPGTIMGLPELTLGILPGFGGTQRLPRVVGLEKGLSMILTSKPIKXPEALKLGLLDEVVPAPQLLARAKAFALEIVXGQRPRVNALQRTDKLPAYADALQIIQFAREQTAKRAPNLQHPLFTLDAIQAGIEHGGLKGLRAEADAFARSAALPTHDSLVHVFFAQRSTKRVRGVTDVGLKPRAVKRIAVLGGGLMGSGIATASALAGXEVLLKXIXXXFXEGGLGRIRANLASKVKRKQLSQQAADAAMARVKGVLTYDDFKXVDMVIEAAIEKVDLKQDIFVDLVRATRPDCILATNTSTINIETVGAKIPGDLGRVIGAHFFSXAHIMPLLEIVRSDKTSAQVILDTLEYGSKIKKTPVVVGNCTGFAVNRVFFPYSMAATILLDSGLDPYAIDAAITAFGMPMGPFRLGDLVGLDVSLFVGASYLQDYGDRVYRGAMVPLLNEAGXLGEKTGAGWYKFDDRRRASPDPALAPLLSPKDIAEFIFFPVVNEACRVVAEGIVDKPSDLDIATVMSMGFPAYRGGILFYGDIVGAKYVVDRLNAWAKQYPAQAGFFKPCDYLXRAAQTGTKLEAGNKPASKISEQIDNO:168桑椹形原藻(UTEX1435)三酰基甘油脂肪酶(TAGL)ATGGACAGGGCGTGGATGCTGGACCGCGAGCTGGCGGCCAACCGCAGCCGGGGCCTTGACTGGGGCGTGGCGCGGGCGCTGTCGGCCTACGTCTCGGCCTCGTACTGCAACAGCACGAGCCTGGCCGCGTGGAACTGCACGCGCTGCTCGCCGCGCGGCATCGACGGCAACGCCACGTGGATRGACCCCAACTTTGCGCTGGAGGCGCTGGCCTGGGACGAGGCCTGGGACCTGCTGGGCTACGTGGGCTGGAGCGAGGAGATGGGCGCGACCGTGATCGCCTTCCGCGGCACCGACTCGCACAGCTACCACAACTGGGTGGCCAACATGCGCACCTGGCGCACCGACCTCAACCTGACCATGCACGGCGCGCCGGCCAACGCGCTCGTGCACGGCGGCTTCTGGTTCTCCTGGAACGCCAGCTCCCTGGCCACCTCCGTGACCGCGGCCGTGCTGCGCCTGCAGCGGCGCCACGGCGCGCACCCGGTCTACGTGTCGGGGCACTCGCTGGGCGGCGCGCTGGCCACCATCTGCGCGCTGGAGCTGCGCACCATGCYCCYCKTGCGCGACGTGCACCTGGTCACCTTTGGCAGCCCGCGCGTGGGCAACGCCGTCTTCGCCGGCTGGTTCGAGCGGCGCATCACCTCGCACTGGCGCTTCACGCACAACCGCGARATCGTGCCCAGCGTGCCGCCGCCCTACATGGGCTTCTGGCACCTGGCGCGCGAGGTCTGGGTGCTGGACAACGCGCGCCTCAACCCGCTCGTCGGCGTCTGCGACGGGACGGGGGAGGACATGCAGTGCCACAACTCCATGTGCCACCTGGGCCTCTGCTCCTCCATCGCAGACCACCTCCTCTACATCTCKGAGATGTACACCCCGAGGCCCATGGGCTGCTGASEQIDNO:169桑椹形原藻(UTEX1435)三酰基甘油脂肪酶(TAGL)MDRAWMLDRELAANRSRGLDWGVARALSAYVSASYCNSTSLAAWNCTRCSPRGIDGNATWXDPNFALEALAWDEAWDLLGYVGWSEEMGATVIAFRGTDSHSYHNWVANMRTWRTDLNLTMHGAPANALVHGGFWFSWNASSLATSVTAAVLRLQRRHGAHPVYVSGHSLGGALATICALELRTMXXXRDVHLVTFGSPRVGNAVFAGWFERRITSHWRFTHNRXIVPSVPPPYMGFWHLAREVWVLDNARLNPLVGVCDGTGEDMQCHNSMCHLGLCSSIADHLLYIXEMYTPRPMGCSEQIDNO:170桑椹形原藻(UTEX1435)延胡索酸水合酶ATGAGTACCCGCACGGAGCGCGACACGTTTGGGCCCCTGGAGGTTCCCTCCGACAGGTACTGGGGTGCCCAGACGCAGCGTTCCCTGCAAAACTTCAAGATCGGCGGCGCCCCCGAGCGCATGCCGGAGCCGGTGGTGCGTGCCTTTGGCGTGCTCAAGGGCGCGGCGGCCAAGGTGAACATGGACCTGGGCGTGCTGGACAAGACCAAGGGCGAGGCGATCGTGGCGGCGGCCAAGGAGGTGGCGGAGGGCAAGCTGACGGACCACTTCCCCCTGGTGGTGTGGCAGACGGGGTCTGGCACGCAGAGCAACATGAACGCCAACGAGGTGATTGCCAACCGCGCGATCGAGATGCTGGGCGGCGAGCTGGGCGACAAGAGCGTGGTGCACCCCAACGACCACTGCAACAAGGGCCAGAGCTCCAACGACACCTTCCCCACGGTGATGCACATCGCGGGCGTGACGGAGATCAGCCGCCGCCTGGTGCCCGGGTTGCGCCACCTGGCGGAGGCGCTGCGCGCCAAGGAGAAGGAGTTTGCCGGCATCATCAAGATCGGGCGCACGCACACGCAGGACGCGACGCCGCTGACGCTGGGCCAGGAGTTCAGCGGCTACGCGACGCAGGTCGAGTACGGCATCGAGCGCGTGCAGGCCGCGCTGCCGCGGCTGAGCATGCTGGCGCAGGGCGGCACCGCGGTGGGCACGGGGCTGAACGCCAAGGTCGGCTTTGCGGAGAAGGTGGCCGAGGCGGTGGCCGCCGACACGGGCCTGCCCTTCACCACCGCGCCCAACAAGTTTGAGGCGCTGGCCGCGCACGACGCGGTGGTGGAGGCCAGCGGCGCGCTCAACACCGTGGCTGTGAGCCTGATGAAGGTCGCCAACGACGTGCGCTTCCTGGGCAGCGGCCCGCGCTGCGGCCTGGGCGAGCTGAGCCTGCCCGAGAACGAGCCGGGCTCCTCCATCATGCCGGGCAAGGTCAACCCCACGCAGTGTGAGGCGCTGACCATGGTCTGCGCGCAGGTGATGGGCAACCACGTGGCCGTCAGCGTGGGCGGCTCCAACGGCCACTTTGAGCTCAACGTGTTCAAGCCCATGATGATCCGCAACCTGCTGCACTCGGCGCGCCTGCTCGCCGACGCCGCCACCTCCTTCACCGACAACTGCGTCGTGGGCATCAGGGCCAACGAGGGCCGCATCGCGCAGCTCCTGCACGAGTCCCTCATGCTCGTCACCGCGCTCAACAACCACATCGGCTACGACAAGGCCGCCGCCATCGCCAAGAAGGCGCACAAGGACGGCAGCACGCTCAAGCAGGCCGCGCTCGAGCTCGGCTACTGCACCGAGCAGGAGTTTGCCGACTGGGTCAAGCCCGAGGACATGCTCGCGCCCACGCCCTAGSEQIDNO:171桑椹形原藻(UTEX1435)延胡索酸水合酶MSTRTERDTFGPLEVPSDRYWGAQTQRSLQNFKIGGAPERMPEPVVRAFGVLKGAAAKVNMDLGVLDKTKGEAIVAAAKEVAEGKLTDHFPLVVWQTGSGTQSNMNANEVIANRAIEMLGGELGDKSVVHPNDHCNKGQSSNDTFPTVMHIAGVTEISRRLVPGLRHLAEALRAKEKEFAGIIKIGRTHTQDATPLTLGQEFSGYATQVEYGIERVQAALPRLSMLAQGGTAVGTGLNAKVGFAEKVAEAVAADTGLPFTTAPNKFEALAAHDAVVEASGALNTVAVSLMKVANDVRFLGSGPRCGLGELSLPENEPGSSIMPGKVNPTQCEALTMVCAQVMGNHVAVSVGGSNGHFELNVFKPMMIRNLLHSARLLADAATSFTDNCVVGIRANEGRIAQLLHESLMLVTALNNHIGYDKAAAIAKKAHKDGSTLKQAALELGYCTEQEFADWVKPEDMLAPTPSEQIDNO:172桑椹形原藻(UTEX1435)琥珀酸半醛脱氢酶ATGTCGACCRTGTCCGAATCCAAGGAGATCCARGTCCGGGACGATGTCCTGAAGCGGCTCAARGACCCATCCCTCRTGCACACCGAGTCGTACATCGGGGGCAGCTGGGTGAACGCTGCCGATGACGACAGGGTGGAGGTGCACGACCCGGCCAGTGGCGAGGTGCTCGCCCGCGTGACTCATGCCAAGGCTGTGGAGACCAAGGCGGCCATCGCSGAGGCGTCCTCTGTGTTTGGCATGTGGTCGGCRAAGTCMGGCCWGGAGCGGTCCAACATCCTRCGCCGCTGGTTTGAGCTGCTGCGTGAGAATCAGGACGACATRGCGACGCTCATGACCCTGGAGAGCGGCAAGCCCCTGGSCCAGGCCAAGGCCGAGATCGCGAGCGGCCTGGGCTCTGTGGAGTGGTTTGCGGAGGAGGCCAAGCGCGTGGACGGCGACATTCTGTGCAGCCCCTTCCCCAACAAGCGCTACCTGGTCATGCGGCAGCCCATCGGCGTGGTGGGCGCCATCACGCCCTGGAACTTTCCCTTTTCCATGATCACGCGCAAGATCTCGCCCGCCCTGGCGGCCGGCTGCACGGTGGTGCTGAAGCCGAGCGAGCTGACGCCGCTGACGGCGCTGGCGATGGCCGAGCTGGGGGAGCGGGCCGGCATCCCGCTGGGCGTGCTCAACGTCGTCGTGGGCGACGCCAAGTCCATCGGCGACGAGCTCATCAAGAGCGACGAGGTGCGCAAGGTCGCCTTCACCGGCTCCACCCGCATCGGCAAGATCCTCATGGCCGGCGCGGCCAACACGGTCAAGAAGGTCTCCATGGAGCTGGGCGGGAACGCGCCCTACATCGTCTTCCCAGACGCCGACCTCAAGGCGGCGGCCTCCCAGGCGGCGGCGTCCTCCCACCGCAACGCCGGGCAGACGTGCATCTGCACCAACCGGGTGCTTGTCCACGAAAGCGTGCACGACGAGTTTGTCAAGGAGCTGGTGGCAGCGGTGCAGGAATTCAGGCTGGGTCACGGCACCGACCCCAGCACCACGCACGGCCCGCTCATCCAGCCGGGGGCCGTCGACAAGGTGGAGGAGAAGGTGCAGGACGCGGTGGCCAAGGGCGCGACGGTGCAGACCGGGGGCAAGCGCCCCACGTTCAGCGAGAACAGCCCCCTCAACAACGGCTTCTTCTTCGAGCCCACCGTCATCTCCAATGCGACCATCGACATGAAGGTGTTCAGGGAGGAGATCTTCGGGCCCGTGACCCCCGTGTTCAAGTTTTCCTCGGACGAGGAGGCCGTCAAGCTGGCGAACAACACCGAGTACGGGCTGGCTGCCTACCTCTTCACCAAGGACCTCGCGCGCGCCTGGAAGGTGTCCGAGGCGCTCGAGTTCGGCATGGTCGGCGTGAACGACGTGCTCATCACCAGCTACGTCTCGCCCTTTGGCGGCGTCAAGCAGTCGGGCCTSGGCCGCGAGGAGTCCAAGTACGGCATCGARGAGTACCTGCAGATGAAGTCGGTGTGCATGAACCTGGGGTACTGASEQIDNO:173桑椹形原藻(UTEX1435)琥珀酸半醛脱氢酶MSTXSESKEIXVRDDVLKRLXDPSLXHTESYIGGSWVNAADDDRVEVHDPASGEVLARVTHAKAVETKAAIXEASSVFGMWSXKXGXERSNIXRRWFELLRENQDDXATLMTLESGKPLXQAKAEIASGLGSVEWFAEEAKRVDGDILCSPFPNKRYLVMRQPIGVVGAITPWNFPFSMITRKISPALAAGCTVVLKPSELTPLTALAMAELGERAGIPLGVLNVVVGDAKSIGDELIKSDEVRKVAFTGSTRIGKILMAGAANTVKKVSMELGGNAPYIVFPDADLKAAASQAAASSHRNAGQTCICTNRVLVHESVHDEFVKELVAAVQEFRLGHGTDPSTTHGPLIQPGAVDKVEEKVQDAVAKGATVQTGGKRPTFSENSPLNNGFFFEPTVISNATIDMKVFREEIFGPVTPVFKFSSDEEAVKLANNTEYGLAAYLFTKDLARAWKVSEALEFGMVGVNDVLITSYVSPFGGVKQSGXGREESKYGIXEYLQMKSVCMNLGYSEQIDNO:174桑椹形原藻(UTEX1435)丙二酰基辅酶A:酰基载体蛋白转酰基酶ATGGCCGCTACGCTCAGCATGAAGTCCGTGGCGCTGCAGCGTCCCACCAGGTGTGGGCCTGCACCCCGCACAGTGGTCCGGGCGCCGGCCATGCGCGTCCGGGCTGCAGCCACCGCCGCCCCGGAGGCCCCCGCCGCGGACCACGCGTTTGACGACTACCAGCCCCGCACGGCCATCCTCTTCCCTGGGCAGGGCGCGCAGAGCGTGGGCATGGCGGGCGAGCTRGTCAAGTCGGTGCCCAAGGCGGCSCACATGTTTGACGAGGCCTCYGCCATCCTKGGCTACGACCTGCTCAAGACSTGCGTGGAGGGCCCCAAGGAGCGCCTGGACAGCACGGTGGTGAGCCAGCCGGCCATCTACGTGACGAGCCTGGCGGCCGTCGAGAAGCTGCGCGCCGACGAGGGCGACGAGGCGGTGGCGGCCGTCGACGTGGCGGCGGGCCTGTCCCTGGGCGAGTACACGGCCCTGGCCTTTGCCGGCGCCTTCAGCTTCGAGGACGGGCTGCGACTGGTCGCGCTGCGCGGCGCCAGCATGCAGCGCGCGGCCGACGCGGCCGCCAGCGGCATGGTCTCCGTCATCGGCCTCTCGGCCGCCGCGACCGAGGCGCTGTGCGAGGCGGCCAACGCCGAGGTCCCGCCCGAGCAGGCCGTGCGCGTGGCCAACTACCTCTGCAACGGCAACTACGCCGTGAGCGGCGGCCTYGAGGGCTGCGCGGCCGTCGAGCGCCTRGCCAAGGCGCACAARGCGCGCATGACCGTGCGCCTGGCCGTGGCCGGCGCCTTCCACACGGCCTACATGCAGCCGGCCGTGGAGGCGCTGACCGCGGCCCTGGCCAGCACGGACATCGCCGCRCCGCGCATCCCCGTCGTCTCCAACGTCGACGCYGCGCCGCACGCCGACCCGGACACCATCCGCGCCCTGCTGGCCCGCCAGGTCACCGCGCCCGTGCAGTGGGAGACCACGCTCAACACCCTGCTCTCCCGCGGCCTCCAGCGCTCCTACGAGGTCGGCCCGGGCAAGGTCATCGCCGGCATCATCAAGCGCGTCAACAAGAAGCACCCGGTGACCAACATCACTGCCTGASEQIDNO:175桑椹形原藻(UTEX1435)丙二酰基辅酶A:酰基载体蛋白转酰基酶MAATLSMKSVALQRPTRCGPAPRTVVRAPAMRVRAAATAAPEAPAADHAFDDYQPRTAILFPGQGAQSVGMAGEXVKSVPKAXHMFDEAXAIXGYDLLKXCVEGPKERLDSTVVSQPAIYVTSLAAVEKLRADEGDEAVAAVDVAAGLSLGEYTALAFAGAFSFEDGLRLVALRGASMQRAADAAASGMVSVIGLSAAATEALCEAANAEVPPEQAVRVANYLCNGNYAVSGGXEGCAAVERXAKAHXARMTVRLAVAGAFHTAYMQPAVEALTAALASTDIAXPRIPVVSNVDXAPHADPDTIRALLARQVTAPVQWETTLNTLLSRGLQRSYEVGPGKVIAGIIKRVNKKHPVTNITASEQIDNO:176桑椹形原藻(UTEX1435)磷脂酸胞苷酰转移酶ATGCAGTTGCAGCGAGCGCTCACGGTGCGCCTGCGGAGGAGGGGCTGGCGTCGCAACTCGTTCAACAATGTGGACGCCGTCTCGCCCAAGCTTGTGCGCAAGWCATCCAATGCCGGGCAGCAGACACAGTCGGAGGACAGGTTTAGGTCCTTCAAGGTCAGGACCCTGTCCACAATCGTCCTCATCGCCACCTTCATCGGCATCATCGCCACGGGGCACGTGCCCCTCATGCTCATGATCCTGGGCATCCAGTTTCTGATGGTCMGGGAGCTSTTTGCGCTGGCGAGGGTSGCGCCCCAGGAGCGCAAGGTCCCCGGCTTCCGGGCGCAGCAGTGGTACTTTTTCTTCGTGGCCGCCTTTTACCTGTACATCCGCTTCATCAAGACCAACCTCACGGTGGAGCTCTCCTCCTCGGCGCAAACGGCGGCCATGTTTGGCTGGATCATCCGCCACCACACGCTCCTCTCCTTCGCCCTCTACACGGCCGGGTTCGTGTCGTTCGTGCTGCGCCTGAARAAGGGACTCTACAGYTACCAGTTCCAGCAGTACGCCTGGACGCACATGATCCTCATGGTCATCTTCCTGCCTTCGTCCTTCTTTGTGTACAACCTCTTCGAGGGGCTGATCTGGTTCCTGCTCCCCGCGGCCTTGGTCGTGGTCAACGACATYGCGGCCTACCTGGCAGGCTTTTTCTTTGGGAGGACCCCKCTGATCAAGCTGTCTCCCAAGAAGACGTGGGAGGGCTTYATCGGCGGCCTGGCGGGCACGGTGGTGGTGGGCTGGTATCTGGCCAAGTTGCTGTCTCAATTCAACTGGTTCATCTGTCCTCGGCGGGACCTGTCCATCATCCAGCCTCTGCACTGTGACAGCAAGCTGGACATCTACCAGCCAGAGACATTCTACCTGACAGATGTCTTGACGCTCTTGCCGGCCGACCTGGCCACCGCGGTGGTCACGGGGCTCACCCGCCTCTCGCCCGGCTGGCAGGAAGCTGCGCGGCAGGTGTCCCTGACCTGCCTGCCCATGCAGCTGCACGCGGTCGTGCTGGCGACGTTTGCGAGCCTGATCGCACCCTTTGGCGGCTTCTTCGCCTCGGGCTTCAAGCGCGGCTTCAAGATCAAGGACTTTGGCGACAGCATCCCCGGCCACGGCGGCATGACCGACCGCATGGACTGCCAGGTGGTCATGTCGGTCTTCTCCTWCATCTACCTCACGTCCTACGTGGCGCCCGCGGGCCCCACCGTCGGCAGCGTCCTGGCGGCCGCCGTGAAGCTGGCGCCGCTGGARCAGCTGGACCTGTTTGAGCGCATGGCCAACGTGCTGGTGGGCTCCAAGGTCCTGTCCCCGGCCATCGGCGAGACCATCGCCGCCACCGCGCGCCGCAAGCTCCAGACGGGCGCCCTTTAGSEQIDNO:177桑椹形原藻(UTEX1435)磷脂酸胞苷酰转移酶MQLQRALTVRLRRRGWRRNSFNNVDAVSPKLVRKXSNAGQQTQSEDRFRSFKVRTLSTIVLIATFIGIIATGHVPLMLMILGIQFLMVXEXFALARXAPQERKVPGFRAQQWYFFFVAAFYLYIRFIKTNLTVELSSSAQTAAMFGWIIRHHTLLSFALYTAGFVSFVLRLXKGLYXYQFQQYAWTHMILMVIFLPSSFFVYNLFEGLIWFLLPAALVVVNDXAAYLAGFFFGRTXLIKLSPKKTWEGXIGGLAGTVVVGWYLAKLLSQFNWFICPRRDLSIIQPLHCDSKLDIYQPETFYLTDVLTLLPADLATAVVTGLTRLSPGWQEAARQVSLTCLPMQLHAVVLATFASLIAPFGGFFASGFKRGFKIKDFGDSIPGHGGMTDRMDCQVVMSVFSXIYLTSYVAPAGPTVGSVLAAAVKLAPLXQLDLFERMANVLVGSKVLSPAIGETIAATARRKLQTGALSEQIDNO:178桑椹形原藻(UTEX1435)1-酰基-sn-甘油-3-磷酸酯酰基转移酶,假定性ATGTTGCTGCCCTTTGAGCTCATGTTCGACCGCTACAGGCGGCATATTCTGAACAAGATCAACCAGTTTTGGGCGCGGGTGGCCGCGTGGCCGTTTTACGGCGTCATCGTGGAYGGCCGCGAGAACCTGCCRCCTCCCGGCGAAGCCGTGATCTATGTCGCCAACCACCAGAGCTACCTGGACATCACGGCGCTGCTGCACATGGGCGCMGACTTCAAGTACGTCTCCAAGGCCGCCCTTTTCATGGTGCCTTTCCTGGGCTGGGCCATGTTCCTCACAGGGCACGTCCGGCTCGTRCGAGACGACCGCGAGTCGCAGCAAAAATGCTTGAAACAGTGCGACACCCTCCTCCGCAACGGCACCTCCGTCGCCTTTTTCCCCGAGGGCACGCGGAGCCAGGATGGSAAGATGCATGCCTTCAAAAAGGGCGCCTTTATGGTGGCGGCCAGGGCGCGGGTGAACGTCGTGCCCGTCACGATCGAGGGCTCCGGCGACCTGATGCCCAGCCGGAACGAGTACCTGATGACCTACGGCGACATTCGGGTGCGCATCCACCCGCCCATCGCCTCGCGCGGCCGGTCGCTGGAGTCGCTGCGCCTGGCGGCGCAGGAGGCGGTGGCGTCCGSGCTGCCCGAGCGCCTGATCGGGGACGACATCCGGCCGCGCKAGCTGGAGGCGCCCACGCCGGCGCCGACAGAGGCGACAGAGGCGAGAGAGGCGCCGCTGCACGAACAGCGCTGASEQIDNO:179桑椹形原藻1-酰基-sn-甘油-3-磷酸酯酰基转移酶,假定性MLLPFELMFDRYRRHILNKINQFWARVAAWPFYGVIVXGRENLXPPGEAVIYVANHQSYLDITALLHMGXDFKYVSKAALFMVPFLGWAMFLTGHVRLXRDDRESQQKCLKQCDTLLRNGTSVAFFPEGTRSQDXKMHAFKKGAFMVAARARVNVVPVTIEGSGDLMPSRNEYLMTYGDIRVRIHPPIASRGRSLESLRLAAQEAVASXLPERLIGDDIRPRXLEAPTPAPTEATEAREAPLHEQRSEQIDNO:180桑椹形原藻(UTEX1435)甘油磷酸二酯磷酸二酯酶ATGTCCAAGGCTTCTTCCACCATCGTCTCCGCTCCTGCGGGCCCGCAGGAGTCGCCCGCTCGCTACAGTACCGAGTCGACCGAGATCCGGAGCTCYCCCCTGTTTGGACGCCTTTTGGACGTCAAGAGCAACGTTGTCGCCCTTGGAGGGCACAGAGGYCTGGGCGCCAACTACTGGGACAAGCCGGCGCAGGGCTCGCTCCGCCGCTTCAGCGTGCGAGAGAACACCATCCCCTCCTTCCTCAAGTCGGTTGCGGCCGGCGCCAGCTTCATCGAGTTTGACGTGCAGGTCACGCGGGACGGCGTGCCTGTGATCTGGCACGACAACTATGTGGTAACGGGCACGCCCGATTGCTTTGTGAACCGGCTGATCAGCGACCTGAGCTACGACGAGTTTGTGAGCCTGGTGCCGGCCAGCGCCGAYCTGGCGCGCCAGAAGGCGGGCCAGGTGGCGGGCCTGCGCGCGGAGGACGTGGAGGGCAGCACGCGCTTGCTGCGCGCGCTGGTGGGCGACGAGCCRGTGGACCCSGGCAACCCGACCGTGGCGGGGTGGGAGGCCGACTCGGAGTCGCGCCTGCCCAGCTTGGCCGAGCTGTTCGCAGCCATCCCCTCGCACGTCGCCTTTGACATCGAGATCAAGGTCGCGACCAGCAGCCGCACGGTGCACACGCCGCTGCGCGAGGTGGAGCGCCTGCTGTCCGCCATCCTGACGGCCGTGGACGCGGCGCAGGAGGCGGCCGAGGCCGCGGGCCGCCCGCGGCGCGAGATCCTGTACAGCTCCTTCGACCCGGACGTCTGCGCGGAGCTGGCGCAGCGCCGCCCCGACGCGGCCGTCATGTTCCTGTCGGGCGGCGGGCAGTATGCGCACTCGGACCCCCGCCGCACCTCCTTTGCGGCCGCCATCGACTGGGCGCGCGGCGCCAACCTGGCCGGCGTGATCTTCCACGCGGGCCGCCTGCGCACCGCGCTCGAGGCGGTCGTGCGCGACGCGCTGGCCGCGGGCCTCCAGGTCATGACCTACGGCCAGGACAACACCGACGCCGGCTACGTGGAGGAGCAGTACGCTCGCGGCGTCCGCGGCGTCATCGTGGACGACGTCAGCTCGGTCGTGGACGCGCTCGTCCAGCGCGGCGTCGCGCGGCGCTCGGTCGCGCTGGCCGCCGGCGAGGGCAAGCAGAACGGCGTGCCGGACTCGGAGAAGGTGAAGGCCTCGCCCGCGCGCCTGCCGGCCCTGGCCGCCGCCTGCTAASEQIDNO:181桑椹形原藻(UTEX1435)甘油磷酸二酯磷酸二酯酶MSKASSTIVSAPAGPQESPARYSTESTEIRSXPLFGRLLDVKSNVVALGGHRXLGANYWDKPAQGSLRRFSVRENTIPSFLKSVAAGASFIEFDVQVTRDGVPVIWHDNYVVTGTPDCFVNRLISDLSYDEFVSLVPASAXLARQKAGQVAGLRAEDVEGSTRLLRALVGDEXVDXGNPTVAGWEADSESRLPSLAELFAAIPSHVAFDIEIKVATSSRTVHTPLREVERLLSAILTAVDAAQEAAEAAGRPRREILYSSFDPDVCAELAQRRPDAAVMFLSGGGQYAHSDPRRTSFAAAIDWARGANLAGVIFHAGRLRTALEAVVRDALAAGLQVMTYGQDNTDAGYVEEQYARGVRGVIVDDVSSVVDALVQRGVARRSVALAAGEGKQNGVPDSEKVKASPARLPALAAACSEQIDNO:182桑椹形原藻(UTEX1435)二酰基甘油酰基转移酶2型ATGACGGAGGCCGTCTCGGACAGGGATGCTCTSCAACCGGAGCTGGGCTTCGTSCAGAAGCTGGGCATGTACTTTGCGCTGCCAGTTTGGATGATAGGCCTCGTGGTGGGCGCCCTCTGGCTMCCCGTGACCGTGGTGTGCCTCTTCATCTTCCCAAAGCTGGCGACATTGAGTCTGGGGCTGCTGCTGGTGGCGATGCTCACCCCCCTGTCGCTGCCCTGCCCCAAGCCGCTGGCCCGCTTCCTGGCCTACTGCACCACCGCCGCGGCCGAGTACTACCCCGTGCGSTTCATCTACGAGGACAAGGAGGAGATGGAGGCCACCAAGGGCCCCGTCATCATCGGGTACGAGCCCCACAGCGTCATGCCRCAGGCCATCTCCATGTTRGCCGAGTACCCGCACCCCGCCGTGGTCGGCCCGCTGCGCAAGGCGCGCGTGCTGGCKTCCAGCACCGGCTTCTGGACGCCGGGCATGCGGCACCTGTGGTGGTGGCTGGGCACGCGCCCCGTGAGCAAGCCCTCCTTCCTCGCCCAGCTGCGCAAGCAGCGCTCCGTCGCCCTCTGCCCGGGCGGCGTGCAGGAGTGCCTCTACATGGCCCACGGCAAGGAGGTCGTCTACCTCCGCAAACGCTTTGGATTTGTCAAACTGGCCATCCAGACCGGCACCCCGCTGGTCCCGGTCTTCGCCTTTGGCCAGACGGAGACCTACACCTTTGTGCGGCCCTTCATCGACTGGGAGACGCGCCTGCTGCCGCGGTCCAAGTACTTTTCGCTGGTGCGCCGCATGGGCTACGTGCCCATGATCTTCTTCGGCCACCTGGGCACGGCCATGCCCAAGCGCGTGCCCATCCACATCGTCATCGGCCGGCCCATCGAGGTGCCGCAGCAGGACGAGCCCGACCCGGCCACGGTGCAGCAGTACCTCGACAAGTTCATCGACGCCATGCAGGCAATGTTTGAGAAGCACAAGGCCGACGCCGGCTACCCCAACCTGACGCTCGAGATCCACTGASEQIDNO:183桑椹形原藻(UTEX1435)二酰基甘油酰基转移酶2型MTEAVSDRDAXQPELGFXQKLGMYFALPVWMIGLVVGALWXPVTVVCLFIFPKLATLSLGLLLVAMLTPLSLPCPKPLARFLAYCTTAAAEYYPVXFIYEDKEEMEATKGPVIIGYEPHSVMXQAISMXAEYPHPAVVGPLRKARVLXSSTGFWTPGMRHLWWWLGTRPVSKPSFLAQLRKQRSVALCPGGVQECLYMAHGKEVVYLRKRFGFVKLAIQTGTPLVPVFAFGQTETYTFVRPFIDWETRLLPRSKYFSLVRRMGYVPMIFFGHLGTAMPKRVPIHIVIGRPIEVPQQDEPDPATVQQYLDKFIDAMQAMFEKHKADAGYPNLTLEIHSEQIDNO:184桑椹形原藻(UTEX1435)酮酰基-CoA还原酶(KCR)ATGGACGCTCAAGGATACCTCGTSAAGGCGTCCGAGTCKCCAGCATGGACGTACCTGGTSCTGCTGGCCTCGGCGCTGTTCGCCATCAAGGTCGTGGGATTYGTCCTGACGGTTCTGGGCGGGCTGTACGCCCACTTTCTCCGCAAGGGAAAGAAACTGCGGCGATATGGGGACTGGGCAGTGGTGACTGGCGCGACAGACGGCATCGGCAAGGCCTACGCTGAGGCCCTCGCGAAGCAAAAGCTGCGCCTGGTGCTGATCTCGCGGACAGAGTCGCGTCTTGAGGAGGAGGCCCGGCTGCTGCAGGACAAGTTTGGCGTGGAGGTGAAGATCATCCCCGCCGACCTCAGCTCCTCGGACGAGGCCGTGTTTGCCCGGATCGGCAAGGGCCTGGAGGGCCTGGACATTGGCATCCTGGTGAACAATGCCGGCATGTCCTACCCCCACCCGGAGTACCTGCACCTGGTCGACGACGAGACCCTGGCCAACCTCATCAATCTCAACGTCGCCACCCCGACCAAGCTGTGCAAGATGGTGCTGGGCGGCATGAAGGAGCGCGGCCGCGGCYTGGTGGTCAACGTYGGSAGCGGCGTCGCGAGCGCCATTCCCTCGGGGCCCCTCCTCTCGGCCTACACCGCCAGCAAGGCGTACGTGGACCAGCTGAGCGAGTCGCTGAACGACGAGTACAAGGAGTTTGGCGTGCAGGTGCAGAACCAGGCGCCGCTGTTTGTGGCCACCAAGATGTCCAAGATCCGCAAGCCGCGCATCGACGCGCCCACGCCCGGCACCTGGGCCGCCRCCGCSGTYCGCGCCATGGGRTTCGAGACGCTGTCCTTCCCCTACTGGTTCCACGCGCTGCAGGCGGCCGTCGTGGAGCGCCTGCCGGAGGCCATGATCCGCTACCAGGTCATGCAGATCCACCGCAGCCTGCGCCGCGCGGCCTACAAGAAGAAGGCGCGCGCGTCCGCCGCCGCCCTGGCGGACGAGGGCGTCTCCGCGGAGCCCAAGAAGGACCTGTGASEQIDNO:185桑椹形原藻(UTEX1435)酮酰基-CoA还原酶(KCR)MDAQGYLXKASEXPAWTYLXLLASALFAIKVVGXVLTVLGGLYAHFLRKGKKLRRYGDWAVVTGATDGIGKAYAEALAKQKLRLVLISRTESRLEEEARLLQDKFGVEVKIIPADLSSSDEAVFARIGKGLEGLDIGILVNNAGMSYPHPEYLHLVDDETLANLINLNVATPTKLCKMVLGGMKERGRGXVVNXXSGVASAIPSGPLLSAYTASKAYVDQLSESLNDEYKEFGVQVQNQAPLFVATKMSKIRKPRIDAPTPGTWAAXXXRAMXFETLSFPYWFHALQAAVVERLPEAMIRYQVMQIHRSLRRAAYKKKARASAAALADEGVSAEPKKDLSEQIDNO:186桑椹形原藻(UTEX1435)甘油-3-磷酸酯酰基转移酶ATGGAGAGGAGGACCTCGGCCAACCCCTCCGTGGGTCTTAGCAGCTTAAAGCACGTTCCGTTGAGCGCGGTGGACCTCCCCAATTTCGAGTCCGTTCCCAAGGGTGCGGCCAGCCCCGATGTCCATCGTCAGATAGAGGAGCTGGTGGACAAGGCACGCGCAGATCGGTCACCGGCATCGTTGTCGCTCCTAGCCGATGTGCTGGACATCAGCGGGCCGCTGCAGGACGCGGCCTCGGCGATGGTGGACGACTCCTTCCTGCGCTGCTTCACCTCCACCATGGACGAGCCCTGGAACTGGAACTTTTACCTGTTCCCGCTCTGGGCGCTCGGCGTCGTCGTRCGCAACRTGATCCTGTTCCCCCTGCGCCTCCTCACCATCGTGCTGGGGACGCTGCTCTTCGTGCTGGCCTTTGCCGTGACGGGCTTCCTCCCCAAGGAGAGGCGGCTCGCGGCCGAGCAGCGGTGCGTCCAGTTCATGGCGCAGGCATTCGTGGCCTCCTGGACAGGCGTGATCCGGTACCACGGCCCCCGCCCCGTGGCGGCGCCCAACCGCGTGTGGGTCGCCAACCACACGTCCATGATCGACTACGCGGTGCTGTGCGCCTACTGCCCGTTTGCGGCCATCATGCAGCTGCACCCSGGCTGGGTGGGCGTCTTRCAGACGCGCTACCTGGCCTCGCTGGGCTGCCTCTGGTTCAACCGCACGCAGGCCAAGGACCGCACGCTCGTGGCCAAGCGCATGCGCGAGCACGTGGCCAGCGCGACCAGCACGCCGCTGCTCATCTTCCCCGAGGGCACCTGCGTCAACAACGAGTACTGCGTCATGTTCCGCAAGGGCGCCTTRGACCTGGGCGCCACCGTCTGCCCCGTSGCCATCAAGTACAACAAGATCTTCGTCGACGCCTTTTGGAACAGCAAGCGCCAGTCCTTCTCCGCGCACCTCATGAAGATCATGCGCTCGTGGGCCCTCGTCTGCGACGTCTACTTCCTGGAGCCCCAGACGCGGAGGGAGGGCGAGTCGGTCGAGGCGTTTGCGAACCGCGTGCAGGCGCTGATCGCGCAAAAGGCCCGGCTGAAGGTCGCGCCCTGGGACGGCTACCTCAAGTACTACAACCTGGCCGAGAAGCACCCGGACCTGATCGAGAACCAGCGGCGCCAGTACAGCGCCGTCATCAAAAAGTARGCCGAGGASTGASEQIDNO:187桑椹形原藻(UTEX1435)甘油-3-磷酸酯酰基转移酶MERRTSANPSVGLSSLKHVPLSAVDLPNFESVPKGAASPDVHRQIEELVDKARADRSPASLSLLADVLDISGPLQDAASAMVDDSFLRCFTSTMDEPWNWNFYLFPLWALGVVXRNXILFPLRLLTIVLGTLLFVLAFAVTGFLPKERRLAAEQRCVQFMAQAFVASWTGVIRYHGPRPVAAPNRVWVANHTSMIDYAVLCAYCPFAAIMQLHXGWVGVXQTRYLASLGCLWFNRTQAKDRTLVAKRMREHVASATSTPLLIFPEGTCVNNEYCVMFRKGAXDLGATVCPXAIKYNKIFVDAFWNSKRQSFSAHLMKIMRSWALVCDVYFLEPQTRREGESVEAFANRVQALIAQKARLKVAPWDGYLKYYNLAEKHPDLIENQRRQYSAVIKKXAEXSEQIDNO:188桑椹形原藻(UTEX1435)单甘油酯脂肪酶ATGCCCCTCCCGAACGCCATAGAGCTCCCGGGCGCCGATCCCAAATCGAGCTCGGTGTACAGCTTTCAGGGGCACAGCACGAATCTGCAAGTCAACGCCAGGGGCGTCGCKCAGTCCGTGTACGACGARGTCGACCCCGCAACGTACCTGGGGCCCAGAGGGCGGCAGGAGACGGTCGTGAACGCGCAGGGCCTCACGCTGCGGGTTTACTACTGGCCGGCAGAGCAGCCCAAGGCAATCTTGCAGTTTGTGCACGGACATGGCGCGCACGCACTGTTTGAACTCTTGGAMATCGATGAGGCTGGAAAGCCGCCAACGTACGCTGGCTGGGTGGCCAAGCTCAATGCCGCGGGCATCAGCGTGGTCGCCCACGACAATCAGGGCTGCGGGCGCTCAGAGGCGGCGCGGGGCCTGCGCTTCTACATCGAGTCCTTTGACGATTTTGTCAAGGACGTGTTGCTTCTCCGCAGGGAGCTGGTGAAGCAAGAGGGCTTTGACAGCYTGCCGGTYTTCCTGGGGGGCATCTCACTWGGYGGCTGCATAGCGCTCACCTCCCTGCTCGAAGAGCCCGACCARTACCRCGGGCTGTGCCTGCTGGCGCCCATGATCTCGCTSCAAAAGGTGTCCCGCAAGGGCCTYAAYCCCTACCTGCGGCCGCTGGCGGCGCTGCTGAGCCGCGTCGTCCCGTGGGCGCCCATCATCGCGACCGACCGCACCTCCAACTCTGTYCTCCAGCTGCAGTGGGATGCAGACCCACTGACCGCGCACATGAACACGCGCGTCCGCAACGCCAACGAGTACCTCTGCGCGACGGAGCGCGTGACGGCCCGGCTGRGCRCGYTGCAGAAGCCCTTCATCGTCTTCCACTCGGAGAACGACACAATGTGCGACGCGGACGGCTCCAAGCAGCTCTACGCCGAGGCACAGTCCAGCGACAAGACCATCCGCTTTGTCAACAGCATGTGGCACGTGCTGGTCAAGGARCCGGGCAACGAGGAGGTCYTGCAGASTCTGGTGCAGTGGATCCTCGAMCGGGCGTGASEQIDNO:189桑椹形原藻(UTEX1435)单甘油酯脂肪酶MPLPNAIELPGADPKSSSVYSFQGHSTNLQVNARGVXQSVYDXVDPATYLGPRGRQETVVNAQGLTLRVYYWPAEQPKAILQFVHGHGAHALFELLXIDEAGKPPTYAGWVAKLNAAGISVVAHDNQGCGRSEAARGLRFYIESFDDFVKDVLLLRRELVKQEGFDSXPXFLGGISXXGCIALTSLLEEPDXYXGLCLLAPMISXQKVSRKGXXPYLRPLAALLSRVVPWAPIIATDRTSNSXLQLQWDADPLTAHMNTRVRNANEYLCATERVTARLXXXQKPFIVFHSENDTMCDADGSKQLYAEAQSSDKTIRFVNSMWHVLVKXPGNEEVXQXLVQWILXRASEQIDNO:190桑椹形原藻(UTEX1435)酰基-CoA氧化酶ATGGATGCTCAGAAGCGAGTCCAAGTCTTGTCCGGTCACTTGTCCGAAACTGCGGGCGATGCCGTGGCGGTCTGCCGGGCGGACACCCTGGCCGCGGGGGTGAGCCCCAAGTTCGACCAGGCCCAGGACATGACCGTGTTTCCCCCGGCCAACCACGATGCGCTCTTCCTCAGCGACCTGCTGACTCCCGAGGAAAAGGATGTGCAAATGCGCGTCCGCAAGTTTGCGGAGGAGACCGTTGCGCCCAACGTGATTCCCTACTGGGAAAAGGCCGAGTTCCCGCACGCGCTGCGKCCCGAGTTTGGRAAGCTGGGCATCGGCGGCGGGCACAACAAGGGGCACGGCTGCCCCGGCCTGAGCACCATGGCGGCGGCSTCGGCGGTGGTGGAGCTGGCGCGCGTGGACGGCTCCATGAGCACYTTTTTCCTGGTSCACACCTACCTGGGCGCGATGACGGTGGGCCTGCTGGGCTCSGAGGCGCAGAAGCGGGAGCTGCTGCCCGGCTTCCACRCCTTTGACAAGGTGTGCAGCTGGGCGCTGACGGAGCCGAGCAACGGGTCGGACGCCTCGGCGCTGACCACGACCGCGCGSCGCGTGGAGGGCGGCTGGCTGCTCMGCGGGCGCAAGCGCTGGATCGGCAACGCGACCTTTGCGGACATCATCATCGTCTGGGCGCGCAGCAGCGTGACGGGGCAGGTCAACGCCTTCATCGTGCGCAGGGGCGCGCCGGGGCTGACCACGAGCAAGATCGAGAACAARATCGCGCTGCGCTGCGTGCAGAACGCCGACATCCTGATGGAGGACGTGTTTGTCCCCGACGCGGACCGCCTGCCCGGSGTCAACTCGTTCGCGGACGCGGCGGGCATGCTGGCCATGTCGCGCTGCCTGGTGGCCTGGCAGCCGGTGGGCCTGGTGGTGGGYGTGTACGACATGGTGCTGCGCTACACGCAGCAGCGCCGCCAGTTTGGCGCGCCGCTGGCCGCCTTCCAGCTGGTGCAGGAGCGGCTGGCGCGCATGCTGGGCACCATCCAGGCCATGTACCTCATGTGCGCGCGCCTGAGCAAGCTCTACGACGAGGGCCGCATGACGCACGAGCAGGCCAGCCTGGTCAAGGCCTGGACCACCGCGCGCTCGCGCGAGGTCGTCGCGCTCGGCCGCGAGTGCCTGGGCGGCAACGGCATCGTCGGCGAGTTCCTCGTGGCCAAGGCCTTTGTCGACGCCGAGGCGTATTACACGTATGAAGGGACCTACGACGTCAACGTGCTCGTCGCCGCGCGCGGCCTCACCGGCTACGCCGCCTTCAAGACGCCCGGCCGCGGCGGCAAGAAGGACGMCGCCGCGAAGAAGGAGCACTGASEQIDNO:191桑椹形原藻(UTEX1435)酰基-CoA氧化酶MDAQKRVQVLSGHLSETAGDAVAVCRADTLAAGVSPKFDQAQDMTVFPPANHDALFLSDLLTPEEKDVQMRVRKFAEETVAPNVIPYWEKAEFPHALXPEFXKLGIGGGHNKGHGCPGLSTMAAXSAVVELARVDGSMSXFFLXHTYLGAMTVGLLGXEAQKRELLPGFHXFDKVCSWALTEPSNGSDASALTTTAXRVEGGWLLXGRKRWIGNATFADIIIVWARSSVTGQVNAFIVRRGAPGLTTSKIENXIALRCVQNADILMEDVFVPDADRLPXVNSFADAAGMLAMSRCLVAWQPVGLVVXVYDMVLRYTQQRRQFGAPLAAFQLVQERLARMLGTIQAMYLMCARLSKLYDEGRMTHEQASLVKAWTTARSREVVALGRECLGGNGIVGEFLVAKAFVDAEAYYTYEGTYDVNVLVAARGLTGYAAFKTPGRGGKKDXAAKKEHSEQIDNO:192桑椹形原藻(UTEX1435)烯酰基-CoA水合酶ATGGCGCCGAGCCCGACCTTCAAGGCACTCAAGGTCTGGATGGACGACGATCTGGTGGGACACATCCAGCTCAATCGTCCTCAAGCCGCCAATTCGATGAATGAGGAGATGTGGACGGAGCTGCCGCAGGCCACAGCGTGGTTGGAGAGCCAGTCTGCGCGCGTCATWCTGGTCACGGGCGCSGGCAAGAACTTTTGCGCGGGCATCGACGTGGCGAGCCTCGGCTCGACCGTGCTCTCCCACGKCGCCGGCTGCGCGGCGCGCTCGGCCTACCGCTTCCGCMCGGGCCTGACCAMSCTGCAGGAGGCCATGACYGCCCTGGAGCGCGTGCGCTGCCCCACCGTGGCGCTGGTGCACGGYCACTGTGTSGGGGCCGGCGTCGACCTCATCACGGCCTGCGACATCCGKTTTGCCACGGCGGACGCCAAGCTSTGCGTCAAGGAGGTCGARCTGGCCGTGATCGCCGACATGGGCACGCTCCAGCGCCTCCCAGGCATCGTGGGSCAKGGCCACGCCCGCGAGCTGTCGCTGACGGCCCGGGTCTTCTCCGGGGAGGAAGCAAAGCAGATGGGTCTCGCCACCGCGGCGCTGCCGAGCCGGGACGAGCTGGAGAGGCACGGCCGCGCGGTCGCGCAGGGCATCGCGGCTAAATCCCCCGTGGCCGTGGCTGGGACCAAGCAGGTGCTGCTCTACCAAAGGGACCACACCGTCGCCGATGGCCTGGACTACGTCAACACCTGGAACGCTGGCATGCTGCACTCGGCTGATTTCGCCGAGGTGTTTGCGGCCATGAAGGAGAGGCGTAAGCCGGTGTTCAGCAAGCTCTGASEQIDNO:193桑椹形原藻(UTEX1435)烯酰基-CoA水合酶MAPSPTFKALKVWMDDDLVGHIQLNRPQAANSMNEEMWTELPQATAWLESQSARVXLVTGXGKNFCAGIDVASLGSTVLSHXAGCAARSAYRFRXGLTXLQEAMXALERVRCPTVALVHXHCXGAGVDLITACDIXFATADAKXCVKEVXLAVIADMGTLQRLPGIVXXGHARELSLTARVFSGEEAKQMGLATAALPSRDELERHGRAVAQGIAAKSPVAVAGTKQVLLYQRDHTVADGLDYVNTWNAGMLHSADFAEVFAAMKERRKPVFSKLSEQIDNO:194桑椹形原藻(UTEX1435)线粒体酰基载体蛋白等位基因2ATGGCGTTCTTGCAGCGGACGAGCGCGCTGGTGCGCCAGGGTGTCCTGTCTCGCCTCGCCGTGCAGGCCAGCCCCGCCCTGAACAGCGTCCGGGCCTTCGCCTCGGCGTCCTACCTGGACAAGAATGAGGTGACGCACCGCGTGCTGTCGATTGTCAAGAACTTTGACCGCGTCGACGCCGGCAAGGTCACGGACTCTGCCAACTTCCAGTCCGACCTGGGTCTGGACTCACTAGACACCGTGGAGCTGGTCATGGCCCTGGAGGAGGAGTTTGCGATCGAGATCCCGGATGCGGAGGCCGACAAGATCCTCTCCGTCCCGGAGGCGATTTCCTACATTGCCGCGAACCCCATGGCCAAGTAGSEQIDNO:195桑椹形原藻(UTEX1435)线粒体酰基载体蛋白等位基因2MAFLQRTSALVRQGVLSRLAVQASPALNSVRAFASASYLDKNEVTHRVLSIVKNFDRVDAGKVTDSANFQSDLGLDSLDTVELVMALEEEFAIEIPDAEADKILSVPEAISYIAANPMAKSEQIDNO:196桑椹形原藻(UTEX1435)反-2-烯酰基-CoA还原酶ATGCCACTGGAAATTCTTGTCAAGACCAGGAATGGTCGACCTGCCTTTTCCAGAGACGGCGGCGCCATTACTGTCGATAGCACGAGTGCGACGGTGCAGGAGGTCAAGGGCCTCATCGCTCGCGCCAAGAAGTTGAGCCCCGCCCGCCTGCGCCTGACGTTGCCCGCGCCGGCCGGCACGCGGCCCACGGTGCTGGAGGACAAGAAGCCCTTGGCCGACTATGGTCTGCACGACGGCGCCAGCCTCGTGCTCAAGGACCTGGGACCTCAGATCGGGTACCAGATGGTCTTTTTCTGGGAGTARTTRGGGCCGCTGGCCATCTACCCCCTCTTCTACTTCCTGCCYTCCTTGATTTACGGAAGGRCGACCGAGCACGTCTTTGCMCAAAAGGCAGCGCTCGCCTTCTGGACCTTRCACTACGSGAAGCGCATCRTGGAGWCCTTTTTCGTGCACAYGTTTGGGCACGCCACGATGCCCGTGCGCAATCTGGTGAAGAACTGCAGCTATTACTGGAGCTTTGGCGCCTTCATCTCCTACTTRGTGAACCACCCGCTCTACMCGGCGCCTCCCGCGGCCCAGACCGCCGTCGCCTTTGTGGCCGCCACCCTCTGCACGCTCTCGAACTTCAAGTGTCATCTGATCCTGAGCAACCTGCGTGCGCCCGGAGGCAGCGGCTATGTCATTCCGCGTGGCTTCCTGTTTGACTACGTCACCTGTGCCAACTACACCGCTGAAATCTGGAGCTGGATTTTCTTCTCCATCGGCACCCAGTGCTTGCCGGCYCTCYTYTTCACCGTRGCTGGYGCCGCGCAAATGGCCATCTGGGCCGGGGGCAAGCATTGCCGTCTGAAAAAGCTCTTCGACGGCAAGGAGGGCCGCGAGCGCTACCCCAAGCGCTACATCATGRTTCCCCCGCTGTACTGASEQIDNO:197桑椹形原藻(UTEX1435)反-2-烯酰基-CoA还原酶MPLEILVKTRNGRPAFSRDGGAITVDSTSATVQEVKGLIARAKKLSPARLRLTLPAPAGTRPTVLEDKKPLADYGLHDGASLVLKDLGPQIGYQMVFFWEXXGPLAIYPLFYFLXSLIYGRXTEHVFXQKAALAFWTXHYXKRIXEXFFVHXFGHATMPVRNLVKNCSYYWSFGAFISYXVNHPLYXAPPAAQTAVAFVAATLCTLSNFKCHLILSNLRAPGGSGYVIPRGFLFDYVTCANYTAEIWSWIFFSIGTQCLPXLXFTXAXAAQMAIWAGGKHCRLKKLFDGKEGRERYPKRYIMXPPLYSEQIDNO:198桑椹形原藻(UTEX1435)长链脂肪酸-CoA连接酶ATGGCTTCCAAGTATCCCCGGCTGACCAAGGTCTCCGATGGCGTGYCTGCCAACGAGGAGGGCGTCGAGTTTGGACCCGAATACAGTTGCACATTCATGAAGGAAAAGACGCTGTCCGTGCCCGGGATCAAGTCTCTGGGCGAGCTCTTTGCGGACTCGGTGTCGCAGCACAAGCGCCGGCCGTGCCTGGGCAAGCGCACCAAGGACGGCTACAGCTGGCGCACGTACGAGCAGACGGGCCGCGAGATCGCGGCCATGGGCGCGGCCTTTGCCGCGCGCGGCCTGGCCCAGCAGTCGCGTGTGGGCGTGTACGGGCCCAACGCGCCCGAGTGGATGATCACGATGCAGGCGTGCAACCGCCAGGGCTACTACTGCGTGCCGCTGTACGACTCKCTGGGCGAGACCGCGGTGGAGTTCATCATCAAGCACGCGGAGGTGAGCGCGGTGGCGGTGGCCGGGCCCAAGCTGGCRGAGCTGGCCAARGCSCTGCCCAACGTGGCGAGCCAGGTCAAGACGGTGGTCTTYTGGGACGASGCCGACCGYGCGGCGGTGGAGGCGGTGCAGGCGCTGGGCGTGGGCGTGTTTGGCTTCGACGAGTTTGTGAAGCAGGGCGAGGCCGCGGAGGCCGTGCCGCCCGCCAGCGTGGAGGGCGAGGACCTGTGCACCATCATGTACACGAGCGGCACGACGGGCGACCCCAAGGGCGTCATGCTCACGCACCGCGCCGTGATCGCGACYGTGCTGAGCCTGSACGCGTTYCTGAAGAGYGTGGACGTGGCGCTGGGCGAGGGCGAYGCCATYYTKTCYTTCCTGCCGCTGGCGCACATCTTYGACCGCGCGGCGGAGGAGCTGATGCTCTACGTGGGCGGCAGCATCGGCTACTGGAGCGGCAACGTCAAGGGCCTGCTGGGCGACATCGCGGCGCTGCGCCCGACGCTCTTCTGCTCCGTGCCGCGCGTGTTTGACCGCATCTACTCCTCGGTCACGGGCAAGGTRGAGAGYGGCGGCTGGCTCAAGCGCACCATGTTCCACCACGCCTTCAAGACCAAGTTYGGGCGGCTGAAGCGCGGCGTGCCGCAGGCCAAGGCCGGCGGCATCTGGGACAAGATCGTGTTCAAGAAGATCAAGGAGGCGCTGGGCGGGCGGTGCAAGATCATCGTCTCGGGCGGCGCGCCGCTGTCGACGCACGTGGAGGAGTTCCTGCGCGTCTGCATGTGCTCGCATGTGGTGCAGGGGTACGGGCTGACCGAGACCTGCGCGGCCAGCTTCATCGCGGAGCCGGCCGACATCCGCCAGATGGGCACGGTCGGCCCGCCGCAGCCGGCGGTCAGCTTCCGCCTGGAGGGCGTGCCGGAGATGAAGTACAGCCCCAGCGCGGACCCCGCGCGTGGCGAGCTGCTCATCCGCGGGCCCGCGCTCTTCTCCGGCTACTACAAGGACCAGGAGAAGACGGACGAGGTGGTCACGCCGGACGGCTGGTTCCACACGGGCGACATCGCGGAGATCACGCCCGCCGGCGCCATCCGCATCATCGACCGCAAGAAGAACATCTTCAAGCTCGCGCAGGGCGAGTACGTGGCCGTSGAGAAGCTGGAGAACACGTACAAGATGTCGCCGGCCGTGGAGCAGATCTGGGTCTACGGCAACAGCTTCGAGAGCGTGCTCGTGGCCGTGGTCGTGCCCAGCGAGGACAAGGTCAAGGCCCACGGCGGCTCCAGCGCCGCGCAGCTCGCCTCGGACGCYGCCTTCAAGAAGGCCGTGCTGGACGACCTCACCGCCGCCGCCAAGGCCGACAAGCTCAAGGGCTTCGAGATGGTCAAGGGCGTCATCATCGAGCCCGAGCCCTTCAGCGTCGAGAACAACCTGCTCACGCCCACCTTCAAGCTCAAGCGGCCGCAGCTGCTCGACCATTACCGCACCGAGATCGACGCGCTCTACGCGAGTCTGAAGAAGTAGSEQIDNO:199桑椹形原藻(UTEX1435)长链脂肪酸-CoA连接酶MASKYPRLTKVSDGVXANEEGVEFGPEYSCTFMKEKTLSVPGIKSLGELFADSVSQHKRRPCLGKRTKDGYSWRTYEQTGREIAAMGAAFAARGLAQQSRVGVYGPNAPEWMITMQACNRQGYYCVPLYDXLGETAVEFIIKHAEVSAVAVAGPKLXELAXXLPNVASQVKTVVXWDXADXAAVEAVQALGVGVFGFDEFVKQGEAAEAVPPASVEGEDLCTIMYTSGTTGDPKGVMLTHRAVIAXVLSLXAXLKXVDVALGEGXAXXXFLPLAHIXDRAAEELMLYVGGSIGYWSGNVKGLLGDIAALRPTLFCSVPRVFDRIYSSVTGKXEXGGWLKRTMFHHAFKTKXGRLKRGVPQAKAGGIWDKIVFKKIKEALGGRCKIIVSGGAPLSTHVEEFLRVCMCSHVVQGYGLTETCAASFIAEPADIRQMGTVGPPQPAVSFRLEGVPEMKYSPSADPARGELLIRGPALFSGYYKDQEKTDEVVTPDGWFHTGDIAEITPAGAIRIIDRKKNIFKLAQGEYVAXEKLENTYKMSPAVEQIWVYGNSFESVLVAVVVPSEDKVKAHGGSSAAQLASDXAFKKAVLDDLTAAAKADKLKGFEMVKGVIIEPEPFSVENNLLTPTFKLKRPQLLDHYRTEIDALYASLKKSEQIDNO:200桑椹形原藻(UTEX1435)烯酰基-CoA还原酶ATGGCGTCCYCYCAGCTCCTGTCCAAGTCCCAGGGTCTGGTCGGTGCCCTGAAGGACGTCAGGGCCGTCCGGGTGYCCCTGCCCCGCGCCGGACCCCYTGCCGCCCCTCGCGCCGATGCCTACTCGAGCTCCAGGGCGCCTGCCTCCATGGTGCTGGCCCCCCAGCGCCGCGGGCTGAGCGTGAAGGCTGCCGCCAGCACCAGCCCTGCCGGCACCGGCTTGCCCATTGATCTGCGGGGCAAGAAGGCCTTTATCGCGGGCGTCGCCGACGACCAGGGTTTTGGCTGGGCCATRGCCAAGCAGCTGGCTGAGGCGGGCGCGGAGATCTCCCTGGGCGTGTGGGTGCCTGCCCTGAACATTTTCGAGAGCAACTACCGCCGCGGCAAGTTTGACGAGAACCGCAAGCTGGCCAACGGCGGCCTGATGGAGTTTGCGCACATCTACCCCATGGATGCGGTCTTCGACTCGCCCGCGGACGTGCCCGAGGACATTGCCAGCAACAAGCGCTACGCCGGGAACAAGGGCTGGACGGTGAGCGAGACGGCCGACAAGGTCGCGGCCGACGTGGGCAAGATCGACATCCTGGTGCACTCGCTGGCCAACGGGCCCGAGGTGCAGAAGCCGCTGCTGGAGACCAGCCGCCGCGGCTACCTCGCCGCSCTGAGCGCCTCCTCCTACTCCCTCATCTCCATGGTCCAGCGCTTTGGCCCGCTCATGAACCCCGGCGGCGCCGTCATCTCGCTGACCTACAACGCCTCCAACCTGGTCATCCCCGGCTACGGCGGCGGCATGAGCACGGCCAAGGCCGCGCTCGAGTCCGACACGCGCGTGCTGGCCTACGAGGCCGGCCGCAAGTACCACGTGCGCGTGAACACCATCAGCGCCGGGCCGCTCGGCTCGCGCGCCGCCAAGGCCATCGGCTTCATCGACGACATGATCCGCTACTCGTACGAGAACGCGCCCATCCAGAAGGAGCTCAGCGCCTACGAGGTCGGCGCSGCCGCCGCCTTCCTCTGCTCCCCGCTCGCCTCGGCCGTCACTGGCCACGTCATGTTTGTCGACAACGGCCTCAACACCATGGGCCTCGCCCTCGACTCCAAGACCCTCGACCYCAGCGAGTGASEQIDNO:201桑椹形原藻(UTEX1435)烯酰基-CoA还原酶MASXQLLSKSQGLVGALKDVRAVRVXLPRAGPXAAPRADAYSSSRAPASMVLAPQRRGLSVKAAASTSPAGTGLPIDLRGKKAFIAGVADDQGFGWAXAKQLAEAGAEISLGVWVPALNIFESNYRRGKFDENRKLANGGLMEFAHIYPMDAVFDSPADVPEDIASNKRYAGNKGWTVSETADKVAADVGKIDILVHSLANGPEVQKPLLETSRRGYLAXLSASSYSLISMVQRFGPLMNPGGAVISLTYNASNLVIPGYGGGMSTAKAALESDTRVLAYEAGRKYHVRVNTISAGPLGSRAAKAIGFIDDMIRYSYENAPIQKELSAYEVGXAAAFLCSPLASAVTGHVMFVDNGLNTMGLALDSKTLDXSESEQIDNO:202桑椹形原藻(UTEX1435)膜结合O-酰基转移酶域包含蛋白ATGGCGCAGAACCTCATCCTCTCCATGCCGTGGGAGGAGTCGGCGTGCTCGTCCCTGGGCCTGTCCCTTTCTGAGCTGCGATTTGTTGTATCATTTTTTGCCTACGTGCTCGTGTCCGCCGTGCTCCGCCACATCCGTGGCACCCGGACCCGGCACTGGTTTGCCCTCGTCACCGGGTTCCTGCTCATCTACTACCCCTTTGGCTCGGGCGTGATGCACGCCTTTGTGTCCTCCACCRTGGTGTACCTGGCKATGGCGGCAGTGCCCTCCCACTGCGGGACSCTGGCCTGGCTCATRGCCTTTCCGTACCTCATCCTCAACCACGTGCTCCAGGCCAGCGGCCTMAGCTGGAAGGAGGGCCAYCTGGATTTCACGGGCGCGCAAATGGTGCTGACGTTGAAGCTGATCGCCGTCGGCGTCTGCTACCAGGACGGCCGGTCCGGCCAGTCGTACGCRAGCCACTACCGCCAGTCCATGCGCCTGCCCYCGCTGCCGGGCCTCCTGGAGTACTACAGCTACTGCTTTGCCTACGGCAACCTCCTGGCCGGCCCCTTTTTCGAGGCGAAAGAGTACTTTGATTTCATGGCSCGGCAGGGRGAGTGGGACGAGGGCGAGCACGGCCGCCTGCCCYGCGGCCTGGGCGCCGGCCTGGTCCGCTTCCTCAAGGGCATCCTGTGCGCCGCGCTGTGGATGCAGCTGGGCAAGCGCTTCAGCGCGAGTCTGCTCGAGTCGGTCTTCTGGACCACGCTGTCCGTCCCGCGACGAATGGCGCTGATCTGGGTCATCGGCTTTGCCGCGCGGCTCAAGTACTACTTTGTCTGGTCGGTGGCCGAGTCTGGGCTCATCCTGTCSGGCCAGTGCTTCGCCGGCAAGACCCAAAAGGGCAAGGCGCAGTGGACGCGGTACATCAACACCAAGATCAGGGAGCTGACGTCGGGCATCTGGCACGGGCTCTTCCCCGGCTACTGGGCCTTTTTCGGGACGAGCGCGCTCATGTTCGAGGCGGCCAAGACCATCTACCGCTACGAGCTGGGCTGGCCGGCCTGGCTGCGCGCGGCGCTGCCCTGGCGCGCCCTCAAGATGGCGCTCACGGCCTTTGTGCTCAACTATGCCGCCATGTCCTTCCTGGTGCTCACCTGGGCCGACACCTGGGCCGTCTGGAAGTCGGTGGGCTTCCTGGGGCACACGCTGCTGCTCCTGATCCTCATAGTCGGCGTCGTGCTGCCGCCCCGCCGCCGACACAAGGGCCAGGCCACCACCGCGCCCGTGGTCACGCCCGCCGCCATCCCGGCCGAGGGAGAGCTGCCMCAYAAGAAGGCAGAGTGASEQIDNO:203桑椹形原藻(UTEX1435)膜结合O-酰基转移酶域包含蛋白MAQNLILSMPWEESACSSLGLSLSELRFVVSFFAYVLVSAVLRHIRGTRTRHWFALVTGFLLIYYPFGSGVMHAFVSSTXVYLXMAAVPSHCGXLAWLXAFPYLILNHVLQASGXSWKEGXLDFTGAQMVLTLKLIAVGVCYQDGRSGQSYXSHYRQSMRLPXLPGLLEYYSYCFAYGNLLAGPFFEAKEYFDFMXRQXEWDEGEHGRLPXGLGAGLVRFLKGILCAALWMQLGKRFSASLLESVFWTTLSVPRRMALIWVIGFAARLKYYFVWSVAESGLILXGQCFAGKTQKGKAQWTRYINTKIRELTSGIWHGLFPGYWAFFGTSALMFEAAKTIYRYELGWPAWLRAALPWRALKMALTAFVLNYAAMSFLVLTWADTWAVWKSVGFLGHTLLLLILIVGVVLPPRRRHKGQATTAPVVTPAAIPAEGELXXKKAESEQIDNO:204桑椹形原藻(UTEX1435)NAD依赖性甘油-3-磷酸脱氢酶ATGTCCGTCCAACCCATTTCCGAGGAGCTGACCAAGGTGACCGTCATCGGCGCCGGCGCCTGGGGTACCGCCCTCGCCATCCACTGCGCCCGCAAGGGCCATGACACCATGTTGTGGGCCATGGAGCCGCACGCGGTGGAGGAGATCAACACCAAGCACACCAACGAGACTTTCCTGAAGAACGTGCCCCTGCCTGAGTCGCTCAAGGCGACGGGCGACATCAAGGAGGCCGTGGAGCGCGCGGAGATGATCCTGACCGTCATCCCGACTCCCTTCTTGTTCAAGTCGATGAGCGGGATCAAGGAGTACCTGAGGGAGGACCAGTACATCGTGTCCTGCACCAAGGGCATTCTGAACGACACCCTGGAGACCCCCGACGGCATCATCCGCCGCGCCCTGCCCGATAACCTCTGCAAGAGGCTGGCGTTCCTGTCGGGCCCCTCCTTTGCGGCCGAGGTGGGCCGCGACTTCCCCACGGCGGTCACCATCGCGGCCGAGGACCCGGCCGTGGCGCAGCGCGTGCAGCAGCTCATGTCCACCAACCGCTTCCGCTGCTACCGCACCACCGACGTCGTGGGCGTCGAGCTCGCTGGCGCGCTGAAGAACGTGCTGGCCATCGCCTGCGGCATCTCCGACGGCTGCGGCTTTGGCAACAACGGCCGCGCGGCGCTCATCACGCGCGGGCTGGACGAGATCACGCGCATCGCGGTGGCCAGCGGCGCCAACCCGCTGACCCTGGCGGGCCTGGCGGGCGTGGGCGACATCGTGCTCACCTGCTGCGGCGACCTGAGCCGCAACCGCACGGTCGGCCTGCGCCTGGGCAAGGGTGAGAAGCTGGACCACATCGTCAAGACGCTGGGCGCCACGGCCGAGGGCGTGCTCACCTCGCGCGCGGCCTACGACCTCACCAAGAAGCTGGGCATCGACTGCGCCGTCATCCACGGCATCTACCGCGTCGTGAACGAGGAGGCCGAGCCCATGAAGGTCGTGGCCGAGACCATGGCGCGCCCGCTGCGCGCCGAGGTGGCCGAGAGCGTCGCCGAGGCCGCCGTCACCAACGCCCGCAACCTCGCCGAGTAGSEQIDNO:205桑椹形原藻(UTEX1435)NAD依赖性甘油-3-磷酸脱氢酶MSVQPISEELTKVTVIGAGAWGTALAIHCARKGHDTMLWAMEPHAVEEINTKHTNETFLKNVPLPESLKATGDIKEAVERAEMILTVIPTPFLFKSMSGIKEYLREDQYIVSCTKGILNDTLETPDGIIRRALPDNLCKRLAFLSGPSFAAEVGRDFPTAVTIAAEDPAVAQRVQQLMSTNRFRCYRTTDVVGVELAGALKNVLAIACGISDGCGFGNNGRAALITRGLDEITRIAVASGANPLTLAGLAGVGDIVLTCCGDLSRNRTVGLRLGKGEKLDHIVKTLGATAEGVLTSRAAYDLTKKLGIDCAVIHGIYRVVNEEAEPMKVVAETMARPLRAEVAESVAEAAVTNARNLAESEQIDNO:206桑椹形原藻质体酰基-载体蛋白(ACP)等位基因1ATGGCGATGTCTATGACCTCCTGCCGCGCCGTCTGCGCCCCTCGCGCCACCCTCCGGGTGCAGGCTCCCCGCGTGGCTGTCCGCCCCTTCCGCGCCCAGCGCATGATCTGCCGCGCTGTGGACAAGGCTAGCGTCCTGAGCGACGTGCGCGTGATCATTGCCGAGCAGCTGGGCACCGATGTCGAGAAGGTCAACGCCGACGCCAAGTTTGCCGACCTGGGTGCCGACTCCCTGGACACCGTTGAGATCATGATGGCTCTGGAGGAGAAGTTTGACCTGCAGCTCGATGAGGAGGGTGCGGAGAAGATCACCACCGTGCAGGAGGCCGCTGACCTCATCTCCGCCCAGATCGGCGCTTGASEQIDNO:207桑椹形原藻(UTEX1435)质体酰基-载体蛋白(ACP)等位基因1MAMSMTSCRAVCAPRATLRVQAPRVAVRPFRAQRMICRAVDKASVLSDVRVIIAEQLGTDVEKVNADAKFADLGADSLDTVEIMMALEEKFDLQLDEEGAEKITTVQEAADLISAQIGASEQIDNO:208桑椹形原藻(UTEX1435)3-羟基酰基-CoA脱水酶ATGTCGCTGAGGAGCGCCTACCTCACTGTTTATAATGCGTCGCTCGCGCTGGGCTGGGCGTACCTGCTGTGGCTGAGCGTGTCTGTCCTRGCCGCTGGCGGCAGCCTGTGGGACCTGTGGAAGACTGTGGAGGTGCCTCTCAAGGTCGTTCAGACGGCGGCGATCGCGGAAGTTGTGCATGCCAGTGTTGGCATTGTCCGCTCGCCCCCACTCGTCACTGCCCTGCAAGTGGCTTCGCGAGTGTTCCTGGTCTGGGGCGTGGTGAATCTGGCTCCAGAGGTGGCGACCGGCTCGCAGGTGGCCGCCATTCCCATCCCCGGGGTCGGCCGCGTGGGCCTCTCCTTTGCGACCCTGGTCATCGCCTGGGCCCTCAGCGAGATCATCCGCTACGGCCACTTTGCCGCCAAGGAGGCGGGCATTGCCAGCAAGCTGCTGCTCTGGCTTCGCTACACCGGCTTCCTGGTGCTCTACCCGCTGGGCGTCTCCAGCGAGCTGACCATGATCTACCTAGTGGCTCCCTACGTCAAGGAGCGCGGCATCCTGAGCCTGGAGATGCCCAACGCCGCCAACTTTGCCTTTAGCTACTACGCCGCGCTCTGGATCGTCAGCCTCACCTACATTCCCGKMYWWCMKMKGWWRKMCGGGTACATGCTCAAGCAGCGGAAAAAGATGCTTGGTGGTGGCGCCAAGGCCAAGAAACTGGCTTGASEQIDNO:209桑椹形原藻(UTEX1435)3-羟基酰基-CoA脱水酶MSLRSAYLTVYNASLALGWAYLLWLSVSVXAAGGSLWDLWKTVEVPLKVVQTAAIAEVVHASVGIVRSPPLVTALQVASRVFLVWGVVNLAPEVATGSQVAAIPIPGVGRVGLSFATLVIAWALSEIIRYGHFAAKEAGIASKLLLWLRYTGFLVLYPLGVSSETMIYLVAPYVKERGILSLEMPNAANFAFSYYAALWIVSLTYIPXXXXXXGYMLKQRKKMLGGGAKAKKLASEQIDNO:210桑椹形原藻(UTEX1435)酮酰基-ACP合成酶IIATGCAGACCGCGCACCAGCGGCCCCCGACCGAGGGGCACTGCTTCGGTGCGAGGCTGCCCACGGCGTCGAGGCGGGCGGTGCGCCGGGCATGGTCCCGCATCGCGCGCGCGGCGGCCGCGGCCGACGCAAACCCCGCCCGCCCTGAGCGCCGCGTGGTCATCACGGGCCAGGGCGTGGTGACCAGCCTGGGCCAGACGATCGAGCAGTTTTACAGCAGCCTGCTGGAGGGCGTGAGCGGCATCTCGCAGATCCAAAAGTTTGACACCACGGGCTACACGACGACGATCGCGGGCGAGATCAAGTCGCTGCAGCTGGACCCGTACGTGCCCAAGCGCTGGGCCAAGCGCGTGGACGACGTCATCAAGTACGTCTACATCGCGGGCAAGCAGGCGCTGGAGAACGCGGGGCTGCCGATCGAGGCGGCGGGGCTGGCGGGCGCGGGGCTGGACCCGGCGCTGTGCGGCGTGCTCATCGGCACCGCCATGGCGGGCATGACGTCCTTCGCGGCGGGCGTGGAGGCGCTGACGCGCGGCGGCGTGCGCAAGATGAACCCCTTTTGCATCCCCTTCTCCATCTCCAACATGGGCGGCGCGATGCTGGCGATGGACATCGGCTTCATGGGCCCCAACTACTCCGTCTCCACAGCCTGCGCGACGTCCAACTACGCATTTGTGAACGCGGCCAACCACATCCGCAAGGGCGACGCGGACGTCATGGTCGTGGGCGGCACCGAGGCCTCCATCGTGCCCGTGGGCCTGGGCGGCTTTGTGGCCTGCCGCGCGCTGTCCACGCGCAACGACGAGCCCAAGCGCGCGAGCCGGCCGTGGGACGAGGGCCGCGACGGCTTTGTGATGGGCGAGGGCGCGGCCGTGCTGGTCATGGAGTCGCTGGAGCACGCGCAGAAGCGTGGCGCGACCATCCTGGGCGAGTACCTGGGGGGCGCCATGACCTGCGACGCGCACCACATGACGGACCCGCACCCCGAGGGCCTGGGCGTGAGCACCTGCATCCGCCTGGCGCTCGAGGACGCCGGCGTCTCGCCCGACGAGGTCAACTACGTCAACGCGCACGCCACCTCCACCCTGGTGGGCGACAAGGCCGAGGTGCGCGCGGTCAAGTCGGTCTTTGGCGACATGAAGGGTATCAAGATGAACGCCACCAAGAGTATGATCGGGCACTGCCTGGGCGCCGCCGGCGGCATGGAGGCCGTCGCCACGCTCATGGCCATCCGCACCGGCTGGGTGCACCCCACCATCAACCACGACAACCCCATCGCCGAGGTCGATGGCCTGGACGTCGTCGCCAACGCCAAGGCCCAGCACGACATCAACGTCGCCATCTCCAACTCCTTCGGCTTTGGCGGGCACAACTCCGTCGTCGCCTTTGCGCCCTTCCGCGAGTAGSEQIDNO:211桑椹形原藻(UTEX1435)酮酰基-ACP合成酶IIMQTAHQRPPTEGHCFGARLPTASRRAVRRAWSRIARAAAAADANPARPERRVVITGQGVVTSLGQTIEQFYSSLLEGVSGISQIQKFDTTGYTTTIAGEIKSLQLDPYVPKRWAKRVDDVIKYVYIAGKQALENAGLPIEAAGLAGAGLDPALCGVLIGTAMAGMTSFAAGVEALTRGGVRKMNPFCIPFSISNMGGAMLAMDIGFMGPNYSVSTACATSNYAFVNAANHIRKGDADVMVVGGTEASIVPVGLGGFVACRALSTRNDEPKRASRPWDEGRDGFVMGEGAAVLVMESLEHAQKRGATILGEYLGGAMTCDAHHMTDPHPEGLGVSTCIRLALEDAGVSPDEVNYVNAHATSTLVGDKAEVRAVKSVFGDMKGIKMNATKSMIGHCLGAAGGMEAVATLMAIRTGWVHPTINHDNPIAEVDGLDVVANAKAQHDINVAISNSFGFGGHNSVVAFAPFRESEQIDNO:212桑椹形原藻(UTEX1435)甾醇14脱饱和酶ATGGACGCCTTTGGCGAGCTCATCATCCTGACCGCCTCGCGCACGCTGCTGGGCCGCGAGGTGCGCGAGTCCATGTTCCGCGAGGTGGCCGACCTCTTCCACGACCTGGACGACGGCATGCGCCCGCTGAGCGTGCTCTTCCCCTACCTGCCGACCGCCTACCACAGGCGCCGCGACGTCGCGCGCCGGCGCCTGCAGGACATCTTCAAGCGCGTCATCGCCGCGCGCCGCGCCTCGGGCGTCAAGGAGGACGACGTGCTGCAGGCGCTGATCGACGCGCGCTACCGCAAGGTCTACGACGGCCGCGCCACGACGGACGAGGAGATCACGGGCCTCCTCATCGCGCTGCTCTTCGCCGGCCAGCACACCAGCTCCGTGACCTCCACCTGGACGGGYCTCTACATGATGMCSGGCGACCAGCGCTACTTCAYGGTGGTCGAGGAGGAGCAGCGCCGCGTCGTCGCCGAGCACGGCGACGCGCTCGACTTTGACGTGCTCAACGGCATGGACCGCCTGCACCTGGCCATCATGGAGGCCCTGCGCCTGCAGCCGCCCCTCGTCCTCCTCATGCGCTACGCCAAGGAGCCCTTCGAGGTCGTCACCTCCGACGGCAAGGCCTTCACCGTGCCCAAGGGCGACATTGTGGCGACCTCGCCCTCCTTCTCCCACCGCCTCAAAAACGTGTTCCGGGATCCCAACGACTTCCAYCCCGAYCGCTTTGAAGCGCCCCGCGACGAGGACAAGGCCGTGCCCTTCTCCTACATCGGRTTTGGCGGCGGGCGGCACGGGTGCATGGGCTCGCAGTTCGCCTACCTCCAGATCAAGACCATCTGGAGCGTGCTCCTCCGCAACTTCACCTTTGAGCTGGTGGACCCCTTCCCGGAGCCGGACTGGGCCTCCATGGTCATCGGGCCCAAGCCCTGCCGCGTGCGCTACACGCGCCGAAAGACGCCCCTGGCCTGASEQIDNO:213桑椹形原藻(UTEX1435)甾醇14脱饱和酶MDAFGELIILTASRTLLGREVRESMFREVADLFHDLDDGMRPLSVLFPYLPTAYHRRRDVARRRLQDIFKRVIAARRASGVKEDDVLQALIDARYRKVYDGRATTDEEITGLLIALLFAGQHTSSVTSTWTXLYMMXGDQRYFXVVEEEQRRVVAEHGDALDFDVLNGMDRLHLAIMEALRLQPPLVLLMRYAKEPFEVVTSDGKAFTVPKGDIVATSPSFSHRLKNVFRDPNDFXPXRFEAPRDEDKAVPFSYIXFGGGRHGCMGSQFAYLQIKTIWSVLLRNFTFELVDPFPEPDWASMVIGPKPCRVRYTRRKTPLASEQIDNO:214桑椹形原藻(UTEX1435)酮酰基-ACP合成酶IIIATGCGCATACTGGGCAGCGGTTCCTCCACCCCTTCCACGGTGCTGAGCAACGCCGATCTGGAGCAGCTGGTGGAGACGAACGACGAGTGGATCGTTGCCCGGACTGGCATCCGGCGCCGGCACATCCTGGGCCCGGGGGAGACGCTCACCCACCACTGCACCCTGGCCTGCCAGCGCGCGCTAGAGATGGCGGGCGTGGACGCCAAGGACGTGGACCTCATCCTGCTGGCCACGTCCAGCCCGGACGACTCCTTTGGCAGCGCCTGTGCTGTGCAGGCCGAGCTCGGGGCCAAGAGCGCGGCCGCCTACGACCTCACCGCCGCCTGCTCCGGCTTTGTCATGAGCACGGTCACCGCCACCCAATTCTTGAGAACGGGGGTGTACAAGAACATCCTGGTCATCGGCGCGGACGCCCTGTCCCGCTACATCGACTGGCGGGACCGGAGCACGTGCATCCTGTTTGGCGACGGCGCCGGCGCTGTCCTCCTCCAGCGCGACGATCGCGAGGGTGAGGACTCCCTTCTCGGGTTCGACATGCACTCTGATGGGCACGGCCAGAAGCACCTCCACGCCGGCTTCATGGGCTGCGGCAACAAGGCCTTCTCGGAGCAGCCCTCCAGCGCCGCCGCTTTCGGCAACATGTACATGAACGGCAGCGAGGTCTTCAAGTTTGCCGTGCGAGCCGTGCCGCGGGTGGTGGAGGCCTCGCTGAAAATGGCGGGGCTGAGCGTGTCCGACATCGACTGGCTGGTCCTGCACCAGGCCAACCAACGAATTTTGACGGCTGCCGCCGATCGGCTGGGTGTCCCCGCTGAGAAAGTGGTGTCCAATGTGGCCGAGTACGGCAACACGTCGGCCGCCTCCATCCCCCTCGTGCTGGACGAATCGGTCCGGCAGGGCCTGATCAAGCCGGGCGACATCCTGGGCATGGCAGGGTTTGGGGCTGGCCTGTCCTGGGCGGGAGCCATCCTCCGATGGGGCTAGSEQIDNO:215桑椹形原藻(UTEX1435)酮酰基-ACP合成酶IIIMRILGSGSSTPSTVLSNADLEQLVETNDEWIVARTGIRRRHILGPGETLTHHCTLACQRALEMAGVDAKDVDLILLATSSPDDSFGSACAVQAELGAKSAAAYDLTAACSGFVMSTVTATQFLRTGVYKNILVIGADALSRYIDWRDRSTCILFGDGAGAVLLQRDDREGEDSLLGFDMHSDGHGQKHLHAGFMGCGNKAFSEQPSSAAAFGNMYMNGSEVFKFAVRAVPRVVEASLKMAGLSVSDIDWLVLHQANQRILTAAADRLGVPAEKVVSNVAEYGNTSAASIPLVLDESVRQGLIKPGDILGMAGFGAGLSWAGAILRWGSEQIDNO:216桑椹形原藻(UTEX1435)酰基转移酶ATGAAGGAGCAAGTGGTTATGCCCCCCCCTGAGGCCCCCACGAATGGGGACCTTGCGGCCCCCTTTGTGCGGAAGGACCGGTTCGGGGAGTATGGCATGGCCCCGCAGCCCCCGATGGTGAAGGTGGTGCTGGCACTCGAGGCCTTGGTGCTCTTGCCGCTGCGCGCGGTGAGCGTGCTCATCCTCGTCGTGCTGTACTGGCTCATTTGCAATGCTTCGGTCGCACTCCCGCCCAAGTACTGCGCGGCCGTCACGGTCACCGCTGGGCGCTTGGTCTGCCGGTGGGCGCTCTTCTGCTTCGGATTCCACTACATCAAGTGGGTGAACCTGGCGGGCGCGGAGGAGGGCCCCCGCCCGGGCGGCATTGTTAGCAACCACTGCAGCTACCTGGACATCCTGCTGCACATGTCCGATTCCTTCCCCGCCTTTGTGGCGCGCCAGTCGACGGCCAAGCTGCCCTTTATCGGCATCATCAGCCAAAATTATGAGCTGCCTCTACGTGAACCGCGACCGCTCGGGGCCCAACCACGTGGGTGTGGCCGACCTGGTGAAGCAGCGCATGCAGGACGAGGCCGAGGGGAAGACCCCGCCCGAGTACCGGCCGCTGCTCCTCTTCCCCGAGGGCACCACCTCCAACGGCGACTACCTGCTTCCCTTCAAGACCGGCGCCTTCCTGGCCGGGGTGCCCGTCCAGCCCGTCGTCCTCCACTACCACAGGGGAACCCTGTGGCCCACGTGGGAGACGATTCCGGCCAAGTGGCACATCTTCCTGATGCTCTGCCACCCCCGCCACAAAGTGACCGTGATGAAGTTGCCCGTGTACGTCCCCAATGAGGAGGAAAAGGCCGACCCCAAGCTGTACGCCCAAAACGTCCGCAAAGCCATGATGGAGGTCGCCGGGACCAAGGACACGACGGCGGTGTTTGAGGACAAGATGCGCTACCTGAACTCCCTGAAGAGAAAGTACGGCAAGCCTGTGCCTAAGAAAATTGAGTGASEQIDNO:217桑椹形原藻(UTEX1435)酰基转移酶MKEQVVMPPPEAPTNGDLAAPFVRKDRFGEYGMAPQPPMVKVVLALEALVLLPLRAVSVLILVVLYWLICNASVALPPKYCAAVTVTAGRLVCRWALFCFGFHYIKWVNLAGAEEGPRPGGIVSNHCSYLDILLHMSDSFPAFVARQSTAKLPFIGIISQIMSCLYVNRDRSGPNHVGVADLVKQRMQDEAEGKTPPEYRPLLLFPEGTTSNGDYLLPFKTGAFLAGVPVQPVVLHYHRGTLWPTWETIPAKWHIFLMLCHPRHKVTVMKLPVYVPNEEEKADPKLYAQNVRKAMMEVAGTKDTTAVFEDKMRYLNSLKRKYGKPVPKKIESEQIDNO:218桑椹形原藻ENR1-1(烯酰基-ACP还原酶)1cDNA序列;1型ATGGCGTCCGCACAGCTCCTGTCCAAGTCCCAGGGTCTGGTCGGTGCCCTGAAGGACGTCAGGGCCGTCCGGGTGACCCTGCCCCGCGCCGGACCCCGTGCCGCCCCTCGCGCCGATGCCTACTCGAGCTCCAGGGCGCCTGCCTCCATGGTGCTGGCCCCCCAGCGCCGCGGGCTGAGCGTGAAGGCTGCCGCCAGCACCAGCCCTGCCGGCACCGGCTTGCCCATTGATCTGCGGGGCAAGAAGGCCTTTATCGCGGGCGTCGCCGACGACCAGGGTTTTGGCTGGGCCATCGCCAAGCAGCTGGCTGAGGCGGGCGCGGAGATCTCCCTGGGCGTGTGGGTGCCTGCCCTGAACATTTTCGAGAGCAACTACCGCCGCGGCAAGTTTGACGAGAACCGCAAGCTGGCCAACGGCGGCCTGATGGAGTTTGCGCACATCTACCCCATGGATGCGGTCTTCGACTCGCCCGCGGACGTGCCCGAGGACATTGCCAGCAACAAGCGCTACGCCGGGAACAAGGGCTGGACGGTGAGCGAGACGGCCGACAAGGTCGCGGCCGACGTGGGCAAGATCGACATCCTGGTGCACTCGCTGGCCAACGGGCCCGAGGTGCAGAAGCCGCTGCTGGAGACCAGCCGCCGCGGCTACCTCGCCGCGCTGAGCGCCTCCTCCTACTCCCTCATCTCCATGGTCCAGCGCTTTGGCCCGCTCATGAACCCCGGCGGCGCCGTCATCTCGCTGACCTACAACGCCTCCAACCTGGTCATCCCCGGCTACGGCGGCGGCATGAGCACGGCCAAGGCCGCGCTCGAGTCCGACACGCGCGTGCTGGCCTACGAGGCCGGCCGCAAGTACCACGTGCGCGTGAACACCATCAGCGCCGGGCCGCTCGGCTCGCGCGCCGCCAAGGCCATCGGCTTCATCGACGACATGATCCGCTACTCGTACGAGAACGCGCCCATCCAGAAGGAGCTCAGCGCCTACGAGGTCGGCGCGGCCGCCGCCTTCCTCTGCTCCCCGCTCGCCTCGGCCGTCACTGGCCACGTCATGTTTGTCGACAACGGCCTCAACACCATGGGCCTCGCCCTCGACTCCAAGACCCTCGACCACAGCGAGTGASEQIDNO:219桑椹形原藻ENR1-1(烯酰基-ACP还原酶)1cDNA序列;2型ATGGCGTCCGCACAGCTCCTGTCCAAGTCCCAGGGTCTGGTCGGTGCCCTGAAGGACGTCAGGGCCGTCCGGGTGACCCTGCCCCGCGCCGGACCCCGTGCCGCCCCTCGCGCCGATGCCTACTCGAGCTCCAGGGCGCCTGCCTCCATGGTGCTGGCCCCCCAGCGCCGCGGGCTGAGCGTGAAGGCTGCCGCCAGCACCAGCCCTGCCGGCACCGGCTTGCCCATTGATCTGCGGGGCAAGAAGGCCTTTATCGCGGGCGTCGCCGACGACCAGGGTTTTGGCTGGGCCATCGCCAAGCAGCTGGCTGAGGCGGGCGCGGAGATCTCCCTGGGCGTGTGGGTGCCTGCCCTGAACATTTTCGAGAGCAACTACCGCCGCGGCAAGTTTGACGAGAACCGCAAGCTGGCCAACGGCGGCCTGATGGAGTTTGCGCACATCTACCCCATGGATGCGGTCTTCGACTCGCCCGCGGACGTGCCCGAGGACATTGCCAGCAACAAGCGCTACGCCGGGAACAAGGGCTGGACGGTGAGCGAGACGGCCGACAAGGTCGCGGCCGACGTGGGCAAGATCGACATCCTGGTGCACTCGCTGGCCAACGGGCCCGAGGTGCAGAAGCCGCTGCTGGAGACCAGCCGCCGCGGCTACCTCGCCGCGCTGAGCGCCTCCTCCTACTCCCTCATCTCCATGGTCCAGCGCTTTGGCCCGCTCATGAACCCCGGCGGCGCCGTCATCTCGCTGACCTACAACGCCTCCAACCTGGTCATCCCCGGCTACGGCGGCGGCATGAGCACGGCCAAGGCCGCGCTCGAGTCCGACACGCGCGTGCTGGCCTACGAGGCCGGCCGCAAGTACCACGTGCGCGTGAACACCATCAGCGCCGGGCCGCTCGGCTCGCGCGCCGCCAAGGCCATCGGCTTCATCGACGACATGATCCGCTACTCGTACGAGAACGCGCCCATCCAGAAGGAGCTCAGCGCCTACGAGGTCGGCGCGGCCGCCGCCTTCCTCTGCTCCCCGCTCGCCTCGGCCGTCACTGGCCACGTCATGTTTGTCGACAACGGCCTCAACACCATGGGCCTCGCCCTCGACTCCAAGACCCTCGACCGCAGCGAGTGASEQIDNO:220桑椹形原藻ENR1-1(烯酰基-ACP还原酶)1蛋白质序列;1型MASAQLLSKSQGLVGALKDVRAVRVTLPRAGPRAAPRADAYSSSRAPASMVLAPQRRGLSVKAAASTSPAGTGLPIDLRGKKAFIAGVADDQGFGWAIAKQLAEAGAEISLGVWVPALNIFESNYRRGKFDENRKLANGGLMEFAHIYPMDAVFDSPADVPEDIASNKRYAGNKGWTVSETADKVAADVGKIDILVHSLANGPEVQKPLLETSRRGYLAALSASSYSLISMVQRFGPLMNPGGAVISLTYNASNLVIPGYGGGMSTAKAALESDTRVLAYEAGRKYHVRVNTISAGPLGSRAAKAIGFIDDMIRYSYENAPIQKELSAYEVGAAAAFLCSPLASAVTGHVMFVDNGLNTMGLALDSKTLDHSE*SEQIDNO:221桑椹形原藻ENR1-1(烯酰基-ACP还原酶)1蛋白质序列;2型MASAQLLSKSQGLVGALKDVRAVRVTLPRAGPRAAPRADAYSSSRAPASMVLAPQRRGLSVKAAASTSPAGTGLPIDLRGKKAFIAGVADDQGFGWAIAKQLAEAGAEISLGVWVPALNIFESNYRRGKFDENRKLANGGLMEFAHIYPMDAVFDSPADVPEDIASNKRYAGNKGWTVSETADKVAADVGKIDILVHSLANGPEVQKPLLETSRRGYLAALSASSYSLISMVQRFGPLMNPGGAVISLTYNASNLVIPGYGGGMSTAKAALESDTRVLAYEAGRKYHVRVNTISAGPLGSRAAKAIGFIDDMIRYSYENAPIQKELSAYEVGAAAAFLCSPLASAVTGHVMFVDNGLNTMGLALDSKTLDRSE*SEQIDNO:222桑椹形原藻异质型乙酰基-CoA羧化酶b-CT亚基ATGGCACTTCCACTTCCGCCACTCCCATCACTTCCAAAACTTCCAAAAATTCAATTTCCTTTTTTTTCTTGGTTAGATTGGGGAAAAGATAAACGACTTGAGAAAAAAAAAGAAATTGAAAATAAAATAGAGCAACAAATACCGAATCTAATAAAGTTAAGTGCACTTAAATATAAGAGAGATGTTAAAGCTGAAAAAGATTTAGGTTTATGGACTCGTTGTGAAAATTGTGGTGTTATTATATACATAAAACATTTACAAGTAAACAAAAAAGTTTGTATAGGATGTAATTATCATATATTAATGAGCAGTTTTGAACGAATTGCTCGCTTTCTTGACATAGAAAGTTGGACTCCATTAAATGAAACAATGTCTTCAGGTAATCCTTTAGGATTTAGTGATCAAAAATCATATACAGAAAGATTAATAGAGTCTCAAGAATTAACAGGATTACAGGATGCAGTTCAAACAGGAACTGGCGTTATAGAAGGTATTCCTTTAGCACTCGGAATGATGGATTTCCATTTTATGGGTGGTAGTATGGGTTCTGTTGTTGGAGAAAAATTAACTCGTTTAATTGAATATGCAACAATTAAAGGCCTTTCTTTAGTAATTTTTTGTGCTTCTGGTGGTGCTCGTATGCAAGAAGGTATTTTAAGTTTAATGCAAATGGCTAAAATTTCTGCTGCATTAAATCGTCATCAAAATATAGCAAAACTTTTATATATCCCAGTTTTAACATCACCTACTACAGGAGGAGTTACTGCAAGTTTTGCGATGCTAGGAGATTTAATTTATGCAGAACCTCGTGCACTTATTGGTTTTGCTGGACGACGAGTTATTTCTCAAACACTTCAAGAACAATTACCAAAAGATTTTCAAACAGCTGAATATTTATTACATCATGGATTAATTGATTTAATTATTTCAAGATTTTTCTTAAAACAAGCATTAGCTGAAACAGTTATTTTATTTCAACAAGCTCCTTCAAAAGAAATAGGATCTATTGAATTCCGTGAACGTGTTACTTTAACAAAAGTTGAAGAAGAATTATTAAGACGTTCAATAATCGAGAATGAAAACTCTTTTAAAAAAATGTTAGAATCGTTTTTATCTTTTATTCCAGGAAGAAAAAAAGCAATTTCAACAGATTTAGCATTTAATGAAGTTCTTGATGAAGCTTTTGATAATTCATTAAATGCTTCTATAACAAAAGACTTCAGTTATATGCTTTCTTCAACTAAATTAATTGAAGCTTAASEQIDNO:223桑椹形原藻异质型乙酰基-CoA羧化酶b-CT亚基MALPLPPLPSLPKLPKIQFPFFSWLDWGKDKRLEKKKEIENKIEQQIPNLIKLSALKYKRDVKAEKDLGLWTRCENCGVIIYIKHLQVNKKVCIGCNYHILMSSFERIARFLDIESWTPLNETMSSGNPLGFSDQKSYTERLIESQELTGLQDAVQTGTGVIEGIPLALGMMDFHFMGGSMGSVVGEKLTRLIEYATIKGLSLVIFCASGGARMQEGILSLMQMAKISAALNRHQNIAKLLYIPVLTSPTTGGVTASFAMLGDLIYAEPRALIGFAGRRVISQTLQEQLPKDFQTAEYLLHHGLIDLIISRFFLKQALAETVILFQQAPSKEIGSIEFRERVTLTKVEEELLRRSIIENENSFKKMLESFLSFIPGRKKAISTDLAFNEVLDEAFDNSLNASITKDFSYMLSSTKLIEA*SEQIDNO:224桑椹形原藻甘油-3-磷酸酯酰基转移酶(GPAT)核苷酸TCGGCACCTGGATGAGGGCCTGGACGACATGCCAGCCCATGTCAAGGTTGCTGCCCGTGGGCATGACAGTGCAAGGGAAATAGGTCATCTTTCACACGCTCACTATAATCAATGAAACATCTACTTTCATCATATTGCAGTCTTCTTTGATGGGAGTCGGTCTAACAATCCCCATCAGTCACGGCCGGCTGGCACTAGGTACCTGGCAAGGAGTCTACTTGAATGAGCACAGGGATTGCGGGGGCGCACGCCATCTGATTGTGACGCTGCAGGGGTGCTCTTCCTGATGAGGGTTGGGCCCCATGGCAGCTCGGCGCAATCTGGATCTGATCCCATGCTGGGGCTTTAAAACTGCGTTCCGACATGCGACAGGGACAATGCGCGCCCCCACTGACGGCCTTTCATAGCCGTCAGCATAAACAAGATACCACTTGACAGAGTTGCGGGTTGCAAGGGGCTCAAGGCCTCTGGGGGCGCGCCGCTCTTCGCCATGCAAACCTTGGCTAGCACCCGCACCGTGCCCGCGGCGTCGGGCACCGATCGGGCCGCTCATGGGGCGATCAGATATCATGCCCAGCGCATTCAATCAAGGTTTGCGGCTTCAAGGAGGGGCGCCCGGGCTCTGGGCCCCCCCCGGGCTGTGGCGTCTGCCAAGACGTCCCCTGGGGAGCTGCGCCTGCCCTTTAGCCACGTCCGCTCGGAGGAAGAGCTGTTCGCCATTTTGCGGTCCGGCGTGGCGCATGGCCAGCTGCCCGCGTCGATTCTGAACCGCGCCTCGGAGCTCATGGAGTCGTACACGGCATCCATGAAGGCCGGCGGCGTTAGCGACCCGAGCGCTTACACGGTCAAGATAATGGCGGAGCACTTTGGTCTGTCCATGCTGCAAATGGCCCATCGGCACAAGTTTGATTCGGCGCACAAGCGGGTGCTGGAGCCGTACGACTACTACTCCTTTGGCCAGCGCTACATCCAGGGCCTCATCGACATGCAGCGCTCCTGCCTGGGCCACGTGGACCGCTTCGCCGAGATCCAAGCGCAGCTGGACAGAGGCGAGAACGTGGTGCTGCTCGCAAACCACCAGACGGAGGCCGACCCCGCGGTGTGGGCGCTGCTGCTGGAGTCGCGCTTCCCGAAGCTGGCGACGGAGGTGGCGTACGTGGCGGGCGACCGCGTGATCACCGACCCGCTCTGCATCCCCTTTTCGCTGGGCCGCAACCTCTACTGCGTGCACTCCAAGAAGCACCTGGACGACGTCCCGGAGCTCAAGGCGGAGAAGGCCGCGACAAACCGCCAGACCCTGCGCGTCATGGCCCGCGACCTGGCCGCGGGCGGGGTGCTCCTCTGGGTTGCGCCCTCGGGCGGCCGGGACCGCGCCGTCTGCCCGAGCACGGGCGAGACCCTGCCCGACCCCTTTGACCCCGCGGTCGTGGAGCTCATGCGGGCCCTGCTCGCCAAGGCCGGCCGGCCGGGGCACCTCTGGCCCCTGGCCATGTACTCTGCCAGGGTGATGCCCCCGCCGACGACCATTGAGAAGGACATTGGCGAACGGCGGGTCGTCGGCTTTGCCGGCTGCGGTCTCTCCCCCGGACCCGAACTCGATGTGGCAGCCCTGGTGCCTCCCAACGTGACGGACCGTGCGCAGCGGCAGCAGCTGCTCTCGGATGCGGCGTTTGAGTCCATCTCTCACGAGTACGACCGGCTGTTGAAAGCGGTGCATGGGCAGCTGAGTGGTGCGGAAGCCGAGGCGTACACCCAGCCCAAGCTCGAGTCCTAGTTGCTGCAAGTTTCCCTCGCGCTGGGCGGCGGTGTGCCACCCAAGCGTTGGGGACCTGGGTTTTCCAGGCTTGGCCTCCCACCGCCGGTCAAGACTGGCTCTCGACCTCGGCGACCCCGGCTTTCCCTGTCGTCCAATGTGTGCGGCACTCTGAGCGACGACCACCACCCAGTGATGCCTCAGTTTTTCACTAGCTCTTGCGCATAGATAGCCCCCTCTGAAACCTGTTCATGCCTTCACCCTCTTCCAAGAGTCACCTGCAACCTTTTTGGCACCAAAAAAAASEQIDNO:225桑椹形原藻甘油-3-磷酸酯酰基转移酶(GPAT),蛋白质MQTLASTRTVPAASGTDRAAHGAIRYHAQRIQSRFAASRRGARALGPPRAVASAKTSPGELRLPFSHVRSEEELFAILRSGVAHGQLPASILNRASELMESYTASMKAGGVSDPSAYTVKIMAEHFGLSMLQMAHRHKFDSAHKRVLEPYDYYSFGQRYIQGLIDMQRSCLGHVDRFAEIQAQLDRGENVVLLANHQTEADPAVWALLLESRFPKLATEVAYVAGDRVITDPLCIPFSLGRNLYCVHSKKHLDDVPELKAEKAATNRQTLRVMARDLAAGGVLLWVAPSGGRDRAVCPSTGETLPDPFDPAVVELMRALLAKAGRPGHLWPLAMYSARVMPPPTTIEKDIGERRVVGFAGCGLSPGPELDVAALVPPNVTDRAQRQQLLSDAAFESISHEYDRLLKAVHGQLSGAEAEAYTQPKLES*SEQIDNO:226桑椹形原藻PAP,核苷酸GGCCGGCGTGAAGCCCTCCAAGGGCAGGCTGGTCCCCGTGGCCAACCCGGCCTGGAGCGCGCTCATCAACTCCCACTGGCACCAGTACCTTGCCATGGTTCTGGGCTACCTCGTGTGCCTCTACAGCGACCGGGCCACGCCCTTTCGCCGCGCCATCTACCACGAGACCGACGCCGAGCTCTGGAGGTATAGCTACCCGCTGCTCCCGAACCAGGTCCCCGCCCAGGCGGTGGTGCTCCTCTGCTTCACCGCCCCCTTTGCCGTCATCCTGCCCTTTTACTTTGCGGGCCGCATCTCGCGCATCGTGGCGCACCACGGCCTGCTCCAGGCCTTTGCGGCCGTCGTGATCACTGGCCTTATCACCAACCTCATCAAGCTGAATGTGGCGCGTCCCCGGCCCGACTTTGTGGCGCGGTGCTGGCCCCACGGCGCCGCGCGCGCCTTCACCGACGTGGGCGTGCCCATCTGCGCGCCCGACGCGATCGACTGGGTGGAGGGCCTCAAGTCCTTCCCCTCCGGGCACACCTCCTGGGCCGCCTCGGGCATGGCCTACCTCACGCTCTGGCTGGTGGGCGCGCTGCGCGTTTTCTCCGGCGCGGCGCGGCCGACCAGCATCGCGGCCGCGCTGTGCCCGCTGTGCCTGGCCGCCTGGATCGGCATGACGCGCATCCAGGACCGGTGGCACCACACGGAGGACGTCATGGTCGGCTTCAGCCTGGGCAGCACGATTGCCTACCTCTGCTACCGCGCGGTGCACTGCCCCGTCAACGGACCGCACGCGGGCGCGCTCACCGCGCTGGCCCTGCCGGACGAGGGGCCCGGCGCCGGGCCCAGCATCAGCCGCGAGCCGAGCTTTGCGCAGATGGCGGCCGCGGCCGGCGTGGGCGTGCCCCTGCAGCCCGTGCGCTACAACCCCCTCGTGGAAACCACGCCCGAAGAGACCGTCTAGGACGGGGGGTGGGGCGAGAGGATGTCAAGGCTGCTGTCGGTGTGCTGTTTCTTTATGCCCTGGCCAGTCTGCCAGTGCATGCACCACAATTTTGACGACTGTACCGCTAAACACGAGCTCCCCCTGCCAGGTGACCTCGATGCGTGTGGCAAAAGAAACGTGTATTTTGTGCTTCCCGCCCGTGCCGTTGCGCGGGCAGGTTTTTCTACCGCCTCCTTCTGGAATGTGTCGGGCCGCTCGATCGAGGGCAGTGGCCCCTGCCATTCTTCTTATTTTTAGAATTTGATCCTCAGSEQIDNO:227桑椹形原藻PAP,蛋白质MVLGYLVCLYSDRATPFRRAIYHETDAELWRYSYPLLPNQVPAQAVVLLCFTAPFAVILPFYFAGRISRIVAHHGLLQAFAAVVITGLITNLIKLNVARPRPDFVARCWPHGAARAFTDVGVPICAPDAIDWVEGLKSFPSGHTSWAASGMAYLTLWLVGALRVFSGAARPTSIAAALCPLCLAAWIGMTRIQDRWHHTEDVMVGFSLGSTIAYLCYRAVHCPVNGPHAGALTALALPDEGPGAGPSISREPSFAQMAAAAGVGVPLQPVRYNPLVETTPEETV*SEQIDNO:228桑椹形原藻DGAT1-1,核苷酸CTGGAGCTGTGCTGGCCGCTGCTGGCGCTGCTGGCGCTGGCCGACGCCGCGGCCAGCGAGTGGGTCGTCTTCGCGCTCAACCTGCTCAACACGAGCGCGATCCTGGGCGTCCCCGCGGCCGTCATCCACTACACACACTCTGAGCTCTTGCCCGGCTTTGCGCTCTGCACCGTCTCGGTCATCCTCTGGCTCAAGACCGTCTCCTATGCGCACTGCAACTGGGACCTGCGCATGGCGCACCGCGCGGGCGAGCTGCGCGACGGCGAGCGCGGCAGCGCCTGGGTCCCGCGCGACTGCGCCGCGCAGCTCAAGTACCCGGAGAACCTCACGCTCCGGAACTTGGGATATTTCCTCGCGGCCCCCACGCTGTGCTACCAGCTGAGCTACCCGCGGTCGGAGCGGTTCCGGCTCAAGTGGCTGCTGCGCCGCGTGCTCATGTTTGCCCTCACCATCACGCTGATGATGTTCATGATCGAGCAGTACGTGAACCCGCTCATCCACAACAGCCTGCAGCCGATGATGAGCATGGACTGGCTGCGCCTGTTCGAGCGCGTGCTCAAGCTGTCGCTGCCCAACCTCTACCTCTGGCTGCTCATGTTCTACGCGGGCTTCCACCTCTGGCTCAACATCGCCGCCGAGCTGACCATGTTTGGCGACCGCGAGTTCTACAAGGAGTGGTGGAACGCGACCACCATCGGCGAGTACTGGCGCCTCTGGAACCAGCCCGTGCACCAGTGGATGCTGCGCCACTGCTACTTCCCCTGCGTGCGCCACGGCGTGCCCAAGGTCTGGGCAGGCATCGTCGTCTTCTTCGTCAGTGCCGTCTTCCACGAGTGGATCGTCGCGCTGCCCCTGCACATGGTCAAGGGCTGGGCCSEQIDNO:229桑椹形原藻DGAT1-1,蛋白质MELCWPLLALLALADAAASEWVVFALNLLNTSAILGVPAAVIHYTHSELLPGFALCTVSVILWLKTVSYAHCNWDLRMAHRAGELRDGERGSAWVPRDCAAQLKYPENLTLRNLGYFLAAPTLCYQLSYPRSERFRLKWLLRRVLMFALTITLMMFMIEQYVNPLIHNSLQPMMSMDWLRLFERVLKLSLPNLYLWLLMFYAGFHLWLNIAAELTMFGDREFYKEWWNATTIGEYWRLWNQPVHQWMLRHCYFPCVRHGVPKVWAGIVVFFVSAVFHEWIVALPLHMVKGWASEQIDNO:230桑椹形原藻DGAT1-2,核苷酸CTGGAGCTGTGCTGGCCGCTGCTGGCGCTGCTGGCGCTGGCCGACGCCGCGGCCAGCGAGTGGGTCGTCTTCGCTTTGAACCTGGTCAACACGAGCGCGATCCTGGGCGTCCCCGCCGCGGTCATCCACTACACGCACTCTGAGCTGCTGCCCGGCTTTGCGCTCTGCACCGTGTCGGTCATCCTCTGGCTCAAGACCGTGTCCTACGCGCACTGCAACTGGGACCTGCGCATGGCGCACCGCGCGGGCGAGCTGCGCGACGGCGAGCGCGACAGCGCCTGGGTCCCGCGCGACTGCACCGCGCAGCTCAAGTACCCGGAGAACCTCACGCTGCGCAACCTGGGCTACTTTTTGGCGGCGCCCACGCTGTGCTACCAGCTGAGCTACCCGCGGTCGGAGCGGTTCCGGCTCAAGTGGCTGCTGCGCCGCGTGCTCATGTTTGCGCTCACCATCACGCTGATGATGTTCATGATCGAGCAGTACGTGAACCCGCTGATCCACAACAGCCTGCAGCCGATGATGAGCATGGACTGGCTGCGCCTCTTCGAGCGCGTGCTCAAGCTGTCGCTGCCCAACCTCTACCTCTGGCTGCTCATGTTCTACGCGGGCTTCCACCTCTGGCTCAACATCGCCGCCGAGCTGACCATGTTTGGCGACCGCGAGTTCTACAAGGAGTGGTGGAACGCGACCACCGTCGGCGAGTACTGGCGCCTCTGGAACCAGCCCGTGCACCAGTGGATGCTGCGACACTGCTACTTCCCCTGCGTGCGCCACGGCGTGCCCAAGGTCTGGGCCGGCATCGTCGTCTTCTTCGTCAGCGCCGTCTTCCACGAGTGGATCGTCGCGCTGCCCCTGCACATGGTCAAGGGCTGGGCCSEQIDNO:231桑椹形原藻DGAT1-2,蛋白质MELCWPLLALLALADAAASEWVVFALNLVNTSAILGVPAAVIHYTHSELLPGFALCTVSVILWLKTVSYAHCNWDLRMAHRAGELRDGERDSAWVPRDCTAQLKYPENLTLRNLGYFLAAPTLCYQLSYPRSERFRLKWLLRRVLMFALTITLMMFMIEQYVNPLIHNSLQPMMSMDWLRLFERVLKLSLPNLYLWLLMFYAGFHLWLNIAAELTMFGDREFYKEWWNATTVGEYWRLWNQPVHQWMLRHCYFPCVRHGVPKVWAGIVVFFVSAVFHEWIVALPLHMVKGWASEQIDNO:232桑椹形原藻DGAT2,核苷酸ATGCCCCGATTACGAAATATTGCTACTGCGTTGCTGATCGGGCCCGCTGCCCGTGCCTGCACCATGGGGCACGCCATTGACGTTCGACCCGTTGAACCGGACACACATTTTTTAAATTTAATTCATCTCAGTAGTCGTCGCAATGACGGAGGCCGTCTCGGACAGGGATGCTCTGCAACCGGAGCTGGGCTTCGTGCAGAAGCTGGGCATGTACTTTGCGCTGCCAGTTTGGATGATAGGCCTCGTGGTGGGCGCCCTCTGGCTTCCCGTGACCGTGGTGTGCCTCTTCATCTTCCCAAAGCTGGCGACATTGAGTCTGGGGCTGCTGCTGGTGGCGATGCTCACCCCCCTGTCGCTGCCCTGCCCCAAGCCGCTGGCCCGCTTCCTGGCCTACTGCACCACCGCCGCGGCCGAGTACTACCCCGTGCGCTTCATCTACGAGGACAAGGAGGAGATGGAGGCCACCAAGGGCCCCGTCATCATCGGGTACGAGCCCCACAGCGTCATGCCTCAGGCCATCTCCATGTTTGCCGAGTACCCGCACCCCGCCGTGGTCGGCCCGCTGCGCAAGGCGCGCGTGCTGGCATCCAGCACCGGCTTCTGGACGCCGGGCATGCGGCACCTGTGGTGGTGGCTGGGCACGCGCCCCGTGAGCAAGCCCTCCTTCCTCGCCCAGCTGCGCAAGCAGCGCTCCGTCGCCCTCTGCCCGGGCGGCGTGCAGGAGTGCCTCTACATGGCCCACGGCAAGGAGGTCGTCTACCTCCGCAAACGCTTTGGATTTGTCAAGTACGAGTTTGTGTGCAGCAAAGGGGGGTGGAGAGATGTCCTCCAATCTCACCAATCCAATCTACTCTTCCTCATGACTCCCGTTCATGTCACCGTACGCGCAGACTGGCCATCCAGACCGGCACCCCGCTGGTCCCGGTCTTCGCCTTTGGCCAGACGGAGACCTACACCTTTGTGCGGCCCTTCATCGACTGGGAGACGCGCCTGCTGCCGCGGTCCAAGTACTTTTCGCTGGTGCGCCGCATGGGCTACGTGCCCATGATCTTCTTCGGCCACCTGGGCACGGCCATGCCCAAGCGCGTGCCCATCCACATCGTCATCGGCCGGCCCATCGAGGTGCCGCAGCAGGACGAGCCCGACCCGGCCACGGTGCAGCAGTACCTCGACAAGTTCATCGACGCCATGCAGGCAATGTTTGAGAAGCACAAGGCCGACGCCGGCTACCCCAACCTGACGCTCGAGATCCACTGASEQIDNO:233桑椹形原藻DGAT2,蛋白质MPRLRNIATALLIGPAARACTMGHAIDVRPVEPDTHFLNLIHLSSRRNDGGRLGQGCSATGAGLRAEAGHVLCAASLDDRPRGGRPLASRDRGVPLHLPKAGDIESGAAAGGDAHPPVAALPQAAGPLPGLLHHRRGRVLPRALHLRGQGGDGGHQGPRHHRVRAPQRHASGHLHVCRVPAPRRGRPAAQGARAGIQHRLLDAGHAAPVVVAGHAPREQALLPRPAAQAALRRPLPGRRAGVPLHGPRQGGRLPPQTLWICQVRVCVQQRGVERCPPISPIQSTLPHDSRSCHRTRRLAIQTGTPLVPVFAFGQTETYTFVRPFIDWETRLLPRSKYFSLVRRMGYVPMIFFGHLGTAMPKRVPIHIVIGRPIEVPQQDEPDPATVQQYLDKFIDAMQAMFEKHKADAGYPNLTLEIH*SEQIDNO:234桑椹形原藻KASIII,核苷酸ATGTCGACAGCTCGGGCAATGGCCGCGGGGCCGCCCTCTCGGTGTTTTGCTCCCAGCTCAACCCAGGCAGCCTGCGTCCGCCCGGTTAACCCCTCGCGAAGGGTCTGTGCCCGGGCGGGCATGCGCATGCTGGGCAGCGGTTCCTCCACCCCTTCCACGGTGCTGAGCAACGCCGATCTGGAGCAGCTGGTGGAGACGAACGACGAGTGGATCGTTGCCCGGACTGGCATCCGGCGCCGGCACATCCTGGGCCCTGGGGAGACGCTCACCCACCACTGCACCCTGGCCTGCCAGCGCGCGCTAGAGATGGCGGGCGTGGACGCCAAGGACGTGGACCTCATCCTGCTGGCCACGTCCAGCCCGGACGACTCCTTTGGCAGCGCCTGTGCTGTGCAGGCCGAGCTCGGGGCCAAGAGCGCGGCCGCCTACGACCTCACCGCCGCCTGCTCCGGCTTTGTCATGAGCACGGTCACCGCCACCCAGTTCTTGAGAACGGGGGTGTACAAGAACATCCTGGTCATCGGCGCGGACGCCCTGTCCCGCTACATCGACTGGCGGGACCGGAGCACCTGCATCCTGTTTGGCGACGGCGCCGGCGCCGTCCTCCTCCAGCGCGACGATCGCGAGGGCGAGGACTCCCTTCTCGGGTTCGACATGCACTCTGGTACGCTGCAATGGTCGAAGCGGGGCATCCATCCAACCCTTCCACACACCGNNNNNNNNNNCGCGGCCGCCTACGACCTCACCGCCGCCTGCTCCGGCTTTGTCATGAGCACGGTCACCGCCACCCAATTCTTGAGAACGGGGGTGTACAAGAACATCTTGGTCATCGGCGCGGACGCCCTGTCCCGCTACATCGACTGGCGGGACCGGAGCACGTGCATCCTGTTTGGCGACGGCGCCGGCGCTGTCCTCCTCCAGCGCGACGATCGCGAGGGTGAGGACTCCCTTCTCGGGTTCGACATGCACTCTGGTACGCTGCAATGGTGGGGGGTGGACGAAGAGGGGACGAATTGGAGCCATCAAGCTGCCCATGCGTGCTGTACTGTGCTCTTCCACGGGCCACACCTAGCATCCATCCAACCTTTCCACCCACGCTCTTCAGATGGGCACGGCCAGAAGCACCTCCACGCCGGCTTCATGGGCTGCGGCAACAAGGCCTTCTCGGAGCAGCCCTCCAGCGCCGCCGCTTTCGGCAACATGTACATGAACGGCAGCGAGGTCTTCAAGTTTGCCGTGCGAGCCGTGCCGCGGGTGGTGGAGGCCTCGCTGAAAAAGGCGGGGCTGAGCGTGTCCGACATCGACTGGCTGGTCCTGCACCAGGCCAACCAACGAATTTTGACGGCTGCCGCCGATCGGCTGGGTGTCCCCGCTGGTGCGCACGCATGCGGTGCTGCGGCTGGGGATGCGCTGTTCGACTGTGTGTCACAGCGCCATTTTGCCGACCCGGGCGCTCTGTGTGGTGGGATGCTCAACGCTCAGTCCCGATTTCTTAAGAAAGTGGTGTCTAATGTGGCCGAGTACGGCAACACCTCGGCCGCGTCCATCCCCCTCGTGCTGGACGAATCGGTCCGGCAGGGCCTGATCAAGCCGGGCGACATCCTGGGCATGGCAGGGTTTGGGGCTGGCCTGTCCTGGGCGGGAGCCATCCTCCGATGGGGCSEQIDNO:235桑椹形原藻KASIII,蛋白质MLGSGSSTPSTVLSNADLEQLVETNDEWIVARTGIRRRHILGPGETLTHHCTLACQRALEMAGVDAKDVDLILLATSSPDDSFGSACAVQAELGAKSAAAYDLTAACSGFVMSTVTATQFLRTGVYKNILVIGADALSRYIDWRDRSTCILFGDGAGAVLLQRDDREGEDSLLGFDMHSDELEPSSCPCVLCCALPWATPSIHPTLPHT????AAAYDLTAACSGFVMSTVTATQFLRTGVYKNILVIGADALSRYIDWRDRSTCILFGDGAGAVLLQRDDREGEDSLLGFDMHSDGHGQKHLHAGFMGCGNKAFSEQPSSAAAFGNMYMNGSEVFKFAVRAVPRVVEASLKKAGLSVSDIDWLVLHQANQRILTAAADRLGVPAEKVVSNVAEYGNTSAASIPLVLDESVRQGLIKPGDILGMAGFGAGLSWAGAILRWGSEQIDNO:236桑椹形原藻胆碱激酶,核苷酸ATGGCGGGCGTCCCACACAGCTCTCTGGAGCTCGATCCGCTGTCGAGCAGAGCCGAGCTCGAGGTGGGGATCAGGGCGGTCTGCCGCGATCTGCTGCCGGGCTGGAAGGGCCTTGCCGACGATGCGATAGAGATCACCACCATTACGGGCGGGATCAGCAATGCGCTGTACAAGGCGACCCCGACCGTGGACGGGGACCTGGGACCGGTCCTCTGCCGGGTGTACGGCCTCAACACCGATCACTTTATCGAGCGGAAGAAGGAGGTGGCCATCATGCAGATTGTGAACGAGCACGGATTTGGCACCGAGGTGCTGGGGACGTTTGCGACGGGCCGGCTGGAGGCCTTTTTGCCTCAAAAGTGCCTGGAGCCGGAGCARCTCAAGGACCCCCAGATCTCRGCGGCCATTGCCCGGGCCATGGCCCGTTTCCACGCCGTCCCRGGGCCGGGCCCCAAGACGGCGTCCACGCCGTTTGGCCGCATCCACAAGTGGCTGGACATGGCGAGCGGGTTTACCTGGGACGACCCGCAGAAGCGGGAGGGGTTTGAGGCGTTTGACCTCTCGGAGCTGCGGCRGCAGGTGGAGGAGGTGGAGGCGCTCTGCRGCGCRGTCGGSGGCCCCATCGTCTTYGGGCACAACGATCTCCTGGCCGGCAACGTCATGGCCTCGGAGGCCTTTCTGCAGCGCGCGCAGCGCGGCGAGCGGCCGGACCCGGACKCGGACGTCCGCGCGAGCGCCGAGAGCGACCTGACCTTTATCGACTTTGAGTATGCCGACTGGACGCCGCGAGGATTCGACTGGGGCAACCACTTTAACGAGTGATTTGCGGGCTTCGACGGCAACTACGACAACTACCCAACCCCCGCCGAGGCGGCCGTGTTTGTGCGGGCCTACATGGCGGCGGAGCGCGGCTGCGAGGRRAGCGCGGTCCCGGACGCGGACGTGGACCGSGCGGTGRTCGAGGCGGAYCTGTTTGCGCTGGCYAGCCACCAKTACTGGGGCGCCTGGTGCTTCYTGCAGGCGCARTGGTCMAARCTKSEQIDNO:237桑椹形原藻胆碱激酶,蛋白质MAGVPHSSLELDPLSSRAELEVGIRAVCRDLLPGWKGLADDAIEITTITGGISNALYKATPTVDGDLGPVLCRVYGLNTDHFIERKKEVAIMQIVNEHGFGTEVLGTFATGRLEAFLPQKCLEPEQLKDPQISAAIARAMARFHAVPGPGPKTASTPFGRIHKWLDMASGFTWDDPQKREGFEAFDLSELR?QVEEVEALC?AVGGPIVFGHNDLLAGNVMASEAFLQRAQRGERPDPD?DVRASAESDLTFIDFEYADWTPRGFDWGNHFNE*FAGFDGNYDNYPTPAEAAVFVRAYMAAERGCE?SAVPDADVDRAV?EADLFALASH?YWGAWCFLQAQWSKLSEQIDNO:238桑椹形原藻丙酮酸脱氢酶,α亚基,核苷酸ATGTCGTCAGTCGTGATCAGCTCCAGGACGGGCTGCCTCCCCCGCGCCGCGGCGGGGCCGGGCCGCCCCCAGCTCGCCTGCTCGTTCCGGCCGGGGTCCCACCCGCCCCGGGCGGGCGCCCCCGGCCCCCGCCCGCGCCGCGGCGTGGCCCCGCTGTCTGCCGTGGCTACCCCGCTCAAGGATGCGCCCGCGCAGCCCTCCAGCAAGCCCTCGATCAGCGCCGAGGTGGCCAAGGAGCTCTACCGGGACATGGTGCTTGGTCGGGAGTTTGAGGAGATGTGCGCGCAGATGTACTACCGCGGCAAGATGTTTGGATTCGTGCACCTCTACTCGGGCCAGGAGGCCGTGTCGACAGGCGTGATCAAGGGCTGCCTTCGCAAGGACGACTACATCTGCTCCACGTACCGGGACCACGTGCACGCGCTGAGCAAGGGCGTGGCGGCGCGCAAGGTGATGGCGGAGCTGTTTGGCAAGCGTACGGGCGTGTGCCGCGGCCAGGGTGGGTCCATGCACATGTTTGACGCGGAGCACGGGCTGCTGGGCGGGTACGCCTTCATCGGCGAGGGTATCCCCGTGGGCCTGGGCGCGGCCTTCTCGGTGGCCTACCGCCGCAACGTGCTCGGCGAGGACGGCGCGGACCAGGTGTCTGTCAACTTCTTCGGGGACGGCACCTGCAACGTGGGCCAGTTCTACGAGTCGCTCAACATGGCCAGCCTGTACAAGCTGCCCTGCATCTTTGTGGTGGAGAACAACCTGTGGGCCATCGGCATGAACCACCCGCGGTCCACGGGGCCCACGCTGGGCGACCAGGAGCCCTGGATCTACAAGAAGGGACCCGCCTTTGGCATGCCGGGCGTGCGCGTGGACGGCATGGACGTGCTCAAGGTGCGGGAGGTCGCGCTGGAGGCCGTGGAGCGCGCGCGCCGCGGCGAGGGGCCCACGCTGATCGAGGCCGAGACCTACCGCTTCCGCGGGCACTCCCTGGCCGACCCGGACGAGCTGCGCAGCAAGGAGGAGAAGGCCAAGTACGCGGCGCGCGACCCCATCCCGCAGCTCAAGCGCTTCATGCTCGACAAGGGACTGGCCACCGAGGAGGAGCTGCGCGACCTCGAGGCCGGCGTCGCCGCCGAGGTGGAGGAGTCGGTCACCTTTGCCGAGGCCAGCCCCAAGCCCGACATGTCCCAGCTCCTGGAAAACGTGTTTGCCGACCCCAAGGGCSEQIDNO:239桑椹形原藻丙酮酸脱氢酶,α亚基,蛋白质MSSVVISSRTGCLPRAAAGPGRPQLACSFRPGSHPPRAGAPGPRPRRGVAPLSAVATPLKDAPAQPSSKPSISAEVAKELYRDMVLGREFEEMCAQMYYRGKMFGFVHLYSGQEAVSTGVIKGCLRKDDYICSTYRDHVHALSKGVAARKVMAELFGKRTGVCRGQGGSMHMFDAEHGLLGGYAFIGEGIPVGLGAAFSVAYRRNVLGEDGADQVSVNFFGDGTCNVGQFYESLNMASLYKLPCIFVVENNLWAIGMNHPRSTGPTLGDQEPWIYKKGPAFGMPGVRVDGMDVLKVREVALEAVERARRGEGPTLIEAETYRFRGHSLADPDELRSKEEKAKYAARDPIPQLKRFMLDKGLATEEELRDLEAGVAAEVEESVTFAEASPKPDMSQLLENVFADPKG*SEQIDNO:240桑椹形原藻丙酮酸脱氢酶,β亚基,核苷酸ATGCAGAGCGCGCTCAAAACCGTGACCAACCCCGTGTCGGGGGTCTCGCCCCGCCCCGCCCCGGTCGGGTCCCGGGTGCCCGGCGTCCATGTGGCCCGGCGCCAGGTCTTCCGAGGTGGGCCCCTGCGTGCCAAGTCGGCCAAGAAGGAGATGATGATGTGGGAGGCCCTGCGCGAGGGCCTGGACGAGGAGATGGAGCGCGACCCCAAAGTCTGCCTCATCGGCGAGGACGTGGGTCACTACGGCGGTTCGTACAAGGTGTCGTACGGCCTGCACAAAAAGTACGGCGACATGCGCCTGCTGGACACGCCCATCTGCGAGAACGGCTTCCTGGGCATGGGCGTGGGCGCGGCGATGACGGGCCTGCGGCCCGTGGTGGAGGGCATGAACATGGGCTTCCTGCTGCTGGCCTTCAACCAGATCAGCAACAACTGCGGCATGCTGCACTACACGAGCGGCGGGCAGTTCAAGGTGCCCATGGTCGTGCGCGGGCCCGGCGGCGTGGGGCGCCAGCTGGGCGCCGAGCACTCGCAGCGGCTGGAGTCCTACTTCCAGTCCATCCCCGGCGTGCAGCTGGTGGCGGTGTCCACGCCCAAGAACGCCAAGGCCCTCTTCAAGGCCGCCATCCGCTCGGACAACCCCATCATCTTCTTCGAACACGTGCTCCTGTACAACATCAAGGGCGAGGTGGAGGGCCCCGACCACGTGCAGAGCCTGGAGCGCGCCGAGGTCGTGCGCCCGGGCGCGGACGTGACGGTGCTCTGCTACTCGCGCATGCGCTACGTGGCCATGCAGGCCGTGCAGCAGCTGGAGCGCGAGGGCTACGACCCCGAGGTCATCGACCTCATCTCCCTCAAGCCCTTCGACATGGAGACCATCGCGCGCTCCGTGCGCAAGACGCGGCGCGTCATCATCGTGGAGGAGTGCATGAAGACCGGCGGCATCGGCGCCTCGCTCTCCGCCGTCATCCACGAGTCCCTCTTCGACGACCTCGACCACGAGGTCATCCGCCTCTCCTCCCAGGACGTGCCCACCGCCTACGCCTACGAACTGGAGGCAGCAACCATCGTCCAGCCCGAAAAGGTCATCGCCGCCGTGAAAAAGGTCGTCGGCAGCCCCTCCAAGGCCCTCAGCTACGCGTGASEQIDNO:241桑椹形原藻丙酮酸脱氢酶,β亚基,蛋白质MQSALKTVTNPVSGVSPRPAPVGSRVPGVHVARRQVFRGGPLRAKSAKKEMMMWEALREGLDEEMERDPKVCLIGEDVGHYGGSYKVSYGLHKKYGDMRLLDTPICENGFLGMGVGAAMTGLRPVVEGMNMGFLLLAFNQISNNCGMLHYTSGGQFKVPMVVRGPGGVGRQLGAEHSQRLESYFQSIPGVQLVAVSTPKNAKALFKAAIRSDNPIIFFEHVLLYNIKGEVEGPDHVQSLERAEVVRPGADVTVLCYSRMRYVAMQAVQQLEREGYDPEVIDLISLKPFDMETIARSVRKTRRVIIVEECMKTGGIGASLSAVIHESLFDDLDHEVIRLSSQDVPTAYAYELEAATIVQPEKVIAAVKKVVGSPSKALSYA*SEQIDNO:242桑椹形原藻丙酮酸脱氢酶,DLATE2亚基,核苷酸ATGCCGGCGCTCTCGCCCACGATGTCCCAGGGCAACCTGGTGGAGTGGACGGTGAAGGAGGGGCAGGAGGTCGCGCCCGGCGACTCCCTGGCCGAGGTCGAGACGGACAAGGCCACCATGACGTGGGAGAATCAGGATGACGGCTTTGTGGCCAAGATCCTGGTGCCCGCCGGCGCCCAGGGCATCGAGGTCGGCACGCCCGTCCTGGTACTGGTCGAGGACGAGGCGGACGTGGCCGCCTTCAAGGACTACAAGCCCCAGGGCCAGGCAGCGGCGGCCGGGGACAATAAGGAGGAGGGGTCCGAGAGCAAGGCCCCGGCCGCGAAGGCCGAGAAGGCGAGTGCGGCGTCTGGCGTGGCGAGGAACGACCACCTGCTTGGCCCCGCGGCCCGGCTGCTGCTGCAGGGCGTGGGGCTGTCGGTCGAGGACGTGACGCCCACGGGGCCGCACGGCGTCGTGACCAAGGGCGACGTCCTGGCGGCGATCGAGAGCGGCGCCAAGCCCGCGCCGAAGAAGGAGGAGGCGAAGAAGAGCGAGAAGGTGGTCGCGAAGAAGGAGGCGGCAACCCCCGCGCAGGAGGCCGCGGCGGCGCCGTCGGGCGGCCGCGCGCGGCGCCAGCGCGGCCAGTACACGGACGTGCCCAACTCGCAGATTCGGAAGATCATCGCCAGCCGCCTGTCCGAGTCCAAGTCGACCATCCCGCACCTCTACCTCTCCGCGGACGTGGACCTGACCGCGCTGGCGGCGCTGCGCGCCGCGCTCAAGGCGCAGGGCCTGAAGATCTCGGTCAACGACTGCGTGGTCAAGGCGGCCGCGGGCGCGCTGGCGGCCGTCCCCGCGGCCAACTTCCACTGGGACGACGCCGAGGAGCGGGCGCGGGCGGTGCGGAGCGAGGGCGTGGACATCTCCATCGCCGTGGCCACGGACAAGGGCCTCATCACGCCCGTCGTGCGCGGCGCCGACGGCAAGGCCTTAACCGCCGTGGCGTCCGAGATCCGGGAGCTGGCGGGCCGCGCGCGCAAGAACAAGCTGCGGCCGGAGGAGTTCCAGGGCGGCTCCTTCTCCATCAGCAATCTGGGCATGTTTGGCATCGACAGCTTCTGCGCCATCATCAACCCGCCCCAGGCCTGCATCATGGCCGTCGGCGCGGGGCGCGAGGAGACCGTGCTCGTGGACGGCCGGCCCCAGACCAAGACCATCATGACGGTCACCCTCTCCGCGGATCACAGGGTCTACGACGGTGAAATTGCGTCGGCGCTCCTGGAGTCCTTCAAGGCCAAGATCGAGGCGCCCTACACGCTCCTCCTGGCTTGASEQIDNO:243桑椹形原藻丙酮酸脱氢酶,DLATE2亚基,蛋白质MPALSPTMSQGNLVEWTVKEGQEVAPGDSLAEVETDKATMTWENQDDGFVAKILVPAGAQGIEVGTPVLVLVEDEADVAAFKDYKPQGQAAAAGDNKEEGSESKAPAAKAEKASAASGVARNDHLLGPAARLLLQGVGLSVEDVTPTGPHGVVTKGDVLAAIESGAKPAPKKEEAKKSEKVVAKKEAATPAQEAAAAPSGGRARRQRGQYTDVPNSQIRKIIASRLSESKSTIPHLYLSADVDLTALAALRAALKAQGLKISVNDCVVKAAAGALAAVPAANFHWDDAEERARAVRSEGVDISIAVATDKGLITPVVRGADGKALTAVASEIRELAGRARKNKLRPEEFQGGSFSISNLGMFGIDSFCAIINPPQACIMAVGAGREETVLVDGRPQTKTIMTVTLSADHRVYDGEIASALLESFKAKIEAPYTLLLA*SEQIDNO:244桑椹形原藻酰基-CoA结合蛋白1,核苷酸ATGTCGAGCGACTTGGAGCCCAAGTTCAAAAAGGCCGTGTGGCTGATCCGCAACGGACCCCCGGCCGAGGGCGCCACCACCGAGACCAAGCTGCTCTACTACGCGCACTACAAGCAGGCCACGGAGGGCGATGTCACGGGGTCGCAGCCCTGGCGGGCGCAGTTCGAGGCCCGGGCCAAGTGGGACGCCTGGGCCAAGCTCAAGGGCATGAGYCGGGAGGAAGCTATGCAGAAATACATCGACCTCATCAGCAAGTCCAGACCCGACTGGGAGAACAACCCTGCTCTCAAGGACTACCAGGAGGAGTAGSEQIDNO:245桑椹形原藻酰基-CoA结合蛋白1,蛋白质MSSDLEPKFKKAVWLIRNGPPAEGATTETKLLYYAHYKQATEGDVTGSQPWRAQFEARAKWDAWAKLKGMSREEAMQKYIDLISKSRPDWENNPALKDYQEE*SEQIDNO:246桑椹形原藻酰基-CoA结合蛋白2,核苷酸(转录物)GCTCGGCCTCCTCCACCTCGCCCTCCTTCTCCTCCTTGGCCTCCTCATCACAAGTTCAATTTTTGATCACTTGCATGTATACGTTGTTTCGATACACGACATCGGCTCTGGGTCCCTCGAGAGTTCACTGATCCGTCCCACTTGCGGGCCGCACGGTGCGATGAGCGCCGCGCGCGAGGTGCAGGAGGAGGAGGAGGACCATTTCGAGGCGGCGGCCGAGCAACTGACCGTGACCATCGCGACGGGCACGAGACTGCCGGACGCCTCCCTGCTGGAGCTGTACGCCCTGTACAAGCAGGGCTCGGAGGGGCCCTGCTCCAGGCCCAAGCCGTCCTTCCTGGATCCCAAGGGCCGAACCAAATGGAAGGCCTGGCACGACCTGGGCGCCATGCCCCGCGATGAGGCCAGGGACAAGTACGTCGTCGCGGTGCGGCGACTGCTGGGCGGCGCGCCTGAGGGCCAGCCGCAGCCGGCGGCCTACGGCAGCACGGGCCCGGCGGTGAGCACCCCGGCCCGCGCCCTCGGCGAGGAGGCGGGGGACGCGGTGGGCGAGGGGGCCGACGACGTGGGGCCCCTCCACGCGGCGCTGGCCGATGGAGACGCGGCGCGGTTCGCGGCCGCCGTCGCCGAGGCCACGACCGGCCAGGCCGAGCGGCGGGACGCGGAGGGGGGCACCCCCCTCCACATCGCCGCGGATGCCGGCAACGTCGAGGCCATTGACCTCCTGAGAGCCAAGGGAGTCGACCTGGATCTGAAAGATCAGGACGGCATGACGGCGCTGCACTATGCGGCGCTGGCGAGCCAGCGAGAGGCGTACGAGGCCTTGCTTGAAGCGGGCGCGGATAGCAGTGTCCGAGACGCCGAGGGCCAGTCGCCCGCCGACCTGGCGCCCCCGGACTGGAACCGCGCGTGACGGGTGGGTTGTATGCCAAAACATTTGGAGACTGGAGTTTCCCAATCGGTGACTGGCCCCGCGCTTCGTGCCAAATTCTAGACAATTTCATGAGTCAGAGAGAGACGGCTCGGGTGCGGCTGCAACAGACTGCGCTTTCTGTAAGCAAGGCACTCTCGACAGATGGCGCTCCCGATGCCGGGCGCGAGCGCGCGCATCGCTACCCTGCGCGCTGCGCTTCTCCCTCCTCCTCGTGCAGGAGGCGGAGCCGCGCGGCGCGGATGACGTTGTGCATGGTGGCGGCGATGGTCATGGGCCCGATGCCGCCSEQIDNO:247桑椹形原藻酰基-CoA结合蛋白2,蛋白质LGLLHLALLLLLGLLITSSIFDHLHVYVVSIHDIGSGSLESSLIRPTCGPHGAMSAAREVQEEEEDHFEAAAEQLTVTIATGTRLPDASLLELYALYKQGSEGPCSRPKPSFLDPKGRTKWKAWHDLGAMPRDEARDKYVVAVRRLLGGAPEGQPQPAAYGSTGPAVSTPARALGEEAGDAVGEGADDVGPLHAALADGDAARFAAAVAEATTGQAERRDAEGGTPLHIAADAGNVEAIDLLRAKGVDLDLKDQDGMTALHYAALASQREAYEALLEAGADSSVRDAEGQSPADLAPPDWNRA*SEQIDNO:248桑椹形原藻苹果酸酶,核苷酸CGAGCCCTGGGGCCGTGCACCCTTTGGAGCAGCCAGGTGCAGCGACACCCTTTGGTACGCAGCCTGGCCACAGGCCCCTGCACTTTTACCTAGACTACATCTGATTGAATTTTATGTATGCTTGTCGTAATCGCGCATCTCCCGGTGTGCCCCATTGCCTGCAGTAGGCCTTCTCGATCGCTTACCCGGCTAGCAGCGTCTGGGTGCGGTGGATCGCCTCGGACGACCCCAACTTCCCCTACAAGCCCCTGGAGGTGAACGCCACGAGCGTGGTGCACCACCGCGGCATGGAGCTGCTGCAGAACCCGGTGTTCAACAAGGGCACCGCCTACTCTGTGGCCGAGCGGGAGCGCCTGGGCGTGCGCGGTCTGCTCCCGCCGCAGGTGCTGCCCGTGTCGCGCCAGATGGCGCGCGTCATGGACCGGTACTGGCACGGCTCCGACTTCATCAGCCCCGAGGAGATCGAGTCGGGCGGCATCACGCACGAGCACACCCGCAAGTGGCTCGTCCTGACCGAGCTCCAGGACCGGAATGAGACGCTGTTTTACCGCTGCCTGATAGAAAACTTTGTGGAGATGGCGCCGATTCTGTACACGCCAACGGTGGGCTGGGCGTGCCTGAACTACCACAAGCTCTTCCGCCGCCCGCGCGGCATGTACTTCTCGGCCTTTGACCACGGCAAGATGTCGACCATGGTGCACAACTGGCCGCACGAGGAGGTGGACGCGATCGTGGTCACGGACGGCTCGCGCATCCTGGGGCTGGGCGACCTCGGCTGCAACGGGCTGGGCATCCCCGTGGGCAAGCTGGACTTGTACGTGGCCGCGGGCGGCTTCCACCCCTCGCGCGTGCTGCCCTGCGTGGTCGACGTGGGCACCAACAACGAGGCCCTGCGCGCCGACCCGCAGTACCTGGGCGTCAAGCAGGCGCGCCTCGTGGGCGACGCCTACTACTCCCTGCTCGACGAGTTTGTGCAGGCCGTCATGCTGCGCTGGCCGCACGCCGTGCTCCAGTTCGAGGACTTTGCCATGGAGCACGCGGCGCCACTGCTGGCGCGCTACCGCAACCACCACACCGTCTTCAACGACGACATCCAGGGCACCGCCTGCGTCGCGCTGGCGGGGCTCTACGGCGCGCTGCGCGTGCTGGGCCGCGGGCCCGCCGACCTCACCGGCCTGCGCATCGCCGTTGTGGGCGCCGGCAGTGCCGGCATGGGCGTCGTGTCCATGATCGCGAAAGGCATGGAGCAGCACGGGCTGACGCCGGAGGAGGCGGCGGACAACTTTTGGGTGCTGGACGCCGACGGGCTGATTACGGAGGAGCGCGCCAACCTGCCGGCCCACGTCCGGCGCTTTGCGCGCTCCGACGAGCGCGGCACCGACGGCGAGCGCCTGCTGGAGACCATCCGCCGCGTCAAGCCGACCTGCCTCATCGGCCTCTCGGGCGCGGGGCGCCTCTTCATTAAGGACGTGCTCCAGGCCATGGCGGAGGTGACGCCGCGCCCCATCATCTTCCCCATGAGCAACCCCATCGCCAAGATGGAGTGCACGCACCAGGAGGCCATCAAGCACACCAAGGGCAAGGCGGTGTTTGCCTCTGGGAGCCCGCAGGGCCCGGTGGAGTGGGAGGGCCACTCGCACGCCCCCTCGCAGGCCAACAACATGTACATCTTCCCCGGCATCGCGCTGGGGGCCTGGCTGGCGCGGTCGGGCACGATCACGGACCGCATGCTCATGGCCTCGGCGGAGGCCCTGGCCCAGTGCACCACGCCCGCGGAGCTCGCCCTCGGCATGGTCTACCCCAGCATGACCCGCATCAGGGAAATTTCGCTGAGGGTGGCCGAAGCGGTGATCGAGGCCGCCGGCGCCTTGGCCCAGAACGAGCGCCTGCTCAAGGCAAAGGCCGAGGGGCCCGAGGCCCTGCGGGACTACATCCAGGCGCACATGTACCACCCAGAGTACACAACCTTGGTCTACAAAGAAAGCCGGTAAATTGCCGAGCTTGCTTGAACGTCTGATGTTTTGGCCCATAATGAGGCAGCCTCTGGCCAGCGCGTGCCCTTGCTTTCCCTTGCTGGTCCTTTTAAAGTTGGTTTCGCTCCCTATGGTGTGTTTGTGCGATGTGTAGAAAGTSEQIDNO:249桑椹形原藻苹果酸酶,蛋白质LEVNATSVVHHRGMELLQNPVFNKGTAYSVAERERLGVRGLLPPQVLPVSRQMARVMDRYWHGSDFISPEEIESGGITHEHTRKWLVLTELQDRNETLFYRCLIENFVEMAPILYTPTVGWACLNYHKLFRRPRGMYFSAFDHGKMSTMVHNWPHEEVDAIVVTDGSRILGLGDLGCNGLGIPVGKLDLYVAAGGFHPSRVLPCVVDVGTNNEALRADPQYLGVKQARLVGDAYYSLLDEFVQAVMLRWPHAVLQFEDFAMEHAAPLLARYRNHHTVFNDDIQGTACVALAGLYGALRVLGRGPADLTGLRIAVVGAGSAGMGVVSMIAKGMEQHGLTPEEAADNFWVLDADGLITEERANLPAHVRRFARSDERGTDGERLLETIRRVKPTCLIGLSGAGRLFIKDVLQAMAEVTPRPIIFPMSNPIAKMECTHQEAIKHTKGKAVFASGSPQGPVEWEGHSHAPSQANNMYIFPGIALGAWLARSGTITDRMLMASAEALAQCTTPAELALGMVYPSMTRIREISLRVAEAVIEAAGALAQNERLLKAKAEGPEALRDYIQAHMYHPEYTTLVYKESR*SEQIDNO:250桑椹形原藻ATP:柠檬酸裂解酶亚基A,核苷酸(转录物)TTTTTTTTAGGGTATCCAGACTTCAACTGCTAGGTTGATCAGTGCATAATACAGTGGTGACCACAGCTGTCGAGGATGCTCTAGGGGGCACCGTATCCAGGCGTTCTAGCGAATCGACAATTGCACGAATAGAATCTATCATGCGCGATTGCGGGCAGGTGGGGGCGCATGAACAGCTTCGCCAGCCCTTGACGGGAGAAAAAGCTACATGCGCTTCTTGAGACGCGCATCTACAGACGCGCATCCAGTCCTGTACATCTTCAGATGCGCCTCGTGAGACGCGTGGATCCAGACACGCACCCCTGCCTTCAGGCGGCGCTGGAGGCCTTGGCGTCGGCGGCGTCGGCCTCGGCCAGGTGGTCGATGGCGCGCTTGCAGATGCTGGTCATGGTGGTCTCGGGGCCGTAGACCTCGATGTCGATGCCCGTCTCCTGGCCCAGCTTGCGCATGGCCTCCAGGCCGGCCCTGTAGTTGGGCCCGCCGCGGCGCACGAAGAGCTTGAGGCGCGCGCCGCGGATGGCGCCCTCGCGCTCGCGGATGGCGGCGATGATGCCGCGGAAGGTGGCGGCGACGTCGGTGAAGTTGGCGATGCCGCCGCCGATGAGCAGCGCGCGCGCGCGGCCGTCGGCGCCGGCGGTGGCGCAGTCGAGCAGGCGCAGCGCGTAGGCGTGCGTCTCGGCCGCGGAGGGCCCGCCCGAGTACTCGGCGTAGTTGCCCAGCTCCGCGGCCGCGCCGAGGTCGCCGACCGTGTCCGCGTAGATGACGCTGGCGCCGCCGCCGGCGACCATGGTCCACACGCGTCCGGACGGGTTGAGGATGCTCAGCTTCAGGCTCGCGCCCGTGCCCTCGTCCATGCCCGCCACGGCCGCCTCGGCCGCGCTCAGGCGGCGGCCAAAGGGCAGCGGGAACTCCAGGCCCTCGCCGCCCCACTTCTTGGCCGAGCGGAAGCCCGCGGTGTCGTCCAGCTCGCCGCGCATGTCCAGCGGGAAGGGGCGCCCGTCCGGCCCCAGCGTGAAGGGGTTCATCTCCATCAGCGTGAAGTCCAGGTCCACGTACACCGCGTAGGCCCCCGCGATGAAGGCCTCCAGCCCGGGCCGCACCTCCAGCGGCAGCGTGGCCACCAGCGGCGCCAGCTTCTCGCCGGACAGCTCCTCCTCCACGCCCACGCTGATCGTGCGCACAAGGTCCCAGTTGTCCTCGATCTCCATGCCGCCCGCCTCCGAGAAGGAGATGTCCGCGCCCGTGCGCGTGCCCTGGATGCAAAGGTAGTACTCCTCCTCGTGCGGCACAAACGGCTCGATGATGAAGCAGTCGATCACACCCTTGACCGTGCCCATGTCGATGACCTTGCCCATGCGCTGGCCGATAAACTCCTCAGCGCCGGCCAAGTCCAGCTTGAGGCCCACGAGGTCGTGCTTGCCGCGCTTTCCAAACAGACAATCGGGCTTGACCACCAGCGGGACCTGCGTCAACCAGGGGTGCTCGCCCACCAACTCGCCAAAGTTGGTGTCCTTTTTGACCTGGGCCACCCTGATGGGCAGGTCCAGGCCCGCCAGACGCGCCATGTGCGTCTTCAGCAGCGTCTTGGAGTTGTACTCCCTGATCTTTTTGCGTGCCATGGCGATCTAATGCGTCCCTGGTCTTGGTGGAGCCGGAGAGGCCTGGACAGAAAGCGATCGCGGGGTCGCTGGCGGGACGTCCGCGGACAACGAAGCGCGGCCCAAGCCGACCAGCACGCACCCGTCAAGCCTCACGGATGCCGAGCACGACGCGATTCGTGACTGTTGGAGCGGTAGGTAGCCTTGAATCCAGCAATACGGCCGTCTGGAACACTGAGCGGCTTGTGAGCGACCTCGCGCCTATGCAATAAGGGGTTGGTTTCGAGTGCTGACGAGGCTCTCCTAGCCTCGGGCACAGTGGGAATTCCTGGCCGCCAAAAAGGTCGCGAGCAGCCCCAGTGGGCGCTTTCAGTGATGTACAGAGCAGCCCGAGCGTTTATCTTACATTTTACTTGGTGACAGTGGATGGGTGTTTGAAATGAAGTTACCTGTGTCTGATCACTTATGATGACACCAGTGTTGGTTGGCACGGCGAATGCATATGGATGGCATGCAGAAGAATACACCCTCCGTTTTTGCTGCTGGCACAAATTCTCACTGCAAAGTCTCATGTTTATTCTGTGCAGTCCCTTCTTAGTTATAGACTCGGTCCAATTACGAACAATTTGCATGGGATGGGTGCTCAACTCATTCCCTGCCAGATACCACAAACAGACCCCAACATAGCCAGACTCATCTATTGTTGCAAGTCAAATCAAGCTGCTCACAAAAGTATGATTATGGTGGGAGCCTGTGCTTGCTCAAAGAATGTGATCACGAATGGCGCAGCCCTGCAGCATTTCCCGTGAATATATATGTATATAAACGAACACATCCAGGTATTGCCTGCAGCGTTATTCATTTTAGATTGATCAAGAAAGAGTAAGCTTTTGTGTGTTGTTGSEQIDNO:251桑椹形原藻ATP:柠檬酸裂解酶亚基A,蛋白质MARKKIREYNSKTLLKTHMARLAGLDLPIRVAQVKKDTNFGELVGEHPWLTQVPLVVKPDCLFGKRGKHDLVGLKLDLAGAEEFIGQRMGKVIDMGTVKGVIDCFIIEPFVPHEEEYYLCIQGTRTGADISFSEAGGMEIEDNWDLVRTISVGVEEELSGEKLAPLVATLPLEVRPGLEAFIAGAYAVYVDLDFTLMEMNPFTLGPDGRPFPLDMRGELDDTAGFRSAKKWGGEGLEFPLPFGRRLSAAEAAVAGMDEGTGASLKLSILNPSGRVWTMVAGGGASVIYADTVGDLGAAAELGNYAEYSGGPSAAETHAYALRLLDCATAGADGRARALLIGGGIANFTDVAATFRGIIAAIREREGAIRGARLKLFVRRGGPNYRAGLEAMRKLGQETGIDIEVYGPETTMTSICKRAIDHLAEADAADAKASSAA*SEQIDNO:252桑椹形原藻ATP:柠檬酸裂解酶亚基B,核苷酸(转录物)GCCGGGGGCTGCGCCCTCATGCTTCCCGTGGCCCTCATTGTGAACAACCTCAGTCCTCACCGTCGCTACCCGACCTTCTGGTGGTGAGGGGCTGCAGCGCCTGTGTTATCTTACCGTGGTGGGTCCACATGTCTTGCGAGCAACAGTGGCCAGCGCAGACACGCGAGTGCCCACGTTTAGATATTTATGCCATCTTTCTTTGTTGAGTGAGCATCCACGCCAATAGCTCTCTTCAGGTGCAGGCTTTTCATTATATCATTTTGCGATTCGCATGCTGGTTCCTGTGTGCATTTACAATCCAGGTCGACAATTTCTTCCCACTGGCAAACCTGCACTCATCGCTACCCCACCAACCGTGGTTGCCTTTTTGCCTCCCATTGAGCCATTGCCAATATATAAAATATAATACCAACCCTACGTCATCATATCATTTATTCCATGTGCAAACCCTCGCTCGTACCAATGACAATGAGAAAACAAGGTGGCGTCCGCAGTGCTCAAGGCAAAGGGGGCGGCGGTTTGCCACGACCACCGGGGACGCCTTTCGAATGCCGCGTCAGCATGGTGAGCGGGAGGCATTAGCGAGGGATTGGCCAAAAGCGGTCGCTTCCGGCCTCCCAGCCCGTACCGGGCCCAAAGCCAATCGCCAAGGCCTCTACAGCCCACACGAAAGAGGTGCTACAGGCGCTCAGAGCGACCGCTCGATCACGATGCCCACGTCCCCACGCACGCCGGGCCGCTACGGCCAGGCGGGCCAGCTCTTCAGCAAGCAGACGCAGGCCATCTTCTACAACTGGAAGCAACTGCCAGTGCAGCGCATGCTGGACTTCGACTTTCTGTGCGGTCGCACCCTTCCCTCTGTGGCATGCATTGTCCAGCCCGGCAGCCAGCAAGGGTTCCAAAAGGTCTTCTTCGGCCCGGAGGAGGTGGCCATCCCGCAGTACGGCTCGATCGCCGAGGCGGTGGAGCAGCACCCGCGCGCGGACGTGCTGATCAACATGTCGAGTTTCCGGAGCGCGTTTGAGTCGTCGCTGGAGGCGCTGCAGCAGCCGACGATCCGCACGGTGGCCATCATCGCCGAGGGCGTGCCCGAGCGCGACACCAAGAAGCTGATCGCCGTGGCCCAGCGCGCGAACAAGGTCATCCTGGGCCCGGCCACCGTGGGCGGCGTGCAGGCGGGCGCCTTCAAGGTCGCGGACGCGGCCGGCACGCTGGACAACATCGTCGCCTGCAAGCTGTACCGCCCCGGCAGCGTGGGCTTTGTGAGCAAGTCGGGCGGCATGAGCAACGAGCTGTACAACGTGATCGCGCGCGCGGCGGACGGCATCTACGAGGGCATCGCCATCGGCGGCGACGCCTACCCGGGTTCGACGCTGTCGGACCACTGCCTGCGCTACCAGCACATCCCCGGCGTCAAGATGATCGTCGTGCTGGGCGAGATCGGCGGGCGCGACGAGTACTCGCTGGTCAAGGCGCTGGAGGCGGGCGCCATCACCAAGCCCGTCGTGGCCTGGGTGTCGGGCACGTGCGCGACGCTGTTCCAGACCGAGGTCCAGTTTGGGCACGCGGGCGCCAAGAGCGGCGGCGCCGACGAGTCCGCGCAGGCCAAGAACGCGGCGCTGCGCGCGGCGGGCGCGGTCGTGCCCGACTCGTTCGAGGACCTGGAGCCGACCATCAAGCGCGTCTACGACGAGCTGGTGGGCGCGGGCGCGATCGTGCCCGCGCCGCTGCCGCCGCCGCCCTCGGTGCCGGAGGACCTCGCGGCCGCCAAGCGCGCGGGGCGCGTGCGCGTGCCCACGCACATCGTCTCCTCCATCTGCGACGACCGCGGCGAGGAGCCGACCTTCAACGGAGAGTCCATGAGCGCGCTCATGGAGCGCGGCGCCACCGTCGCCGACGCCATCGGCCTGCTCTGGTTCAAGCGCCGCCTGCCGCCCTACGCCACGCGCTTCATCGAGATGTGCGTCGTGCTCTGCGCCGACCATGGTCCCTGCGTCTCCGGCGCACACAACACCATCGTCACCGCGCGCGCGGGGAAGGACCTCATCTCCTCCCTCGTCTCGGGCCTGCTCACCATCGGGCCGCGCTTTGGCGGCGCCATCGACGGCGCCGCGCAGCACTTCAAGGAGGCGGTTGAGAAAGGCTGGGAGCCCGACGAGTTCGTGGAGATCATGAAGCGCCGCGGCGTGCGCGTGCCGGGCATCGGCCACCGCATCAAGTCCAAGGACAACCGCGACAAGCGCGTGGAGCTGCTGCAGCGCTACGCCCGCGAACGCTTCCCGTCCACCCGCTTCCTGGACTACGCCATCGAGGTCGAGGGCTACACCCTGCAAAAGGCCGCCAACCTGGTGCTCAACGTCGACGGCTGCATCGGCGCGCTCTTCCTCGACCTCCTGCACTCGGTCGGCATGTTTGCCAAGCCTGAGATCGACGACATCGTCCAGATCGGCTACCTAAACGGCCTCTTCGTCCTCGCGCGCGCCATCGGGCTCATCGGGCACTGCCTCGACCAGAAGCGCCTGGGGCAGCCCCTCTACCGCCACCCCTGGGACGACGTCCTCTACACCSEQIDNO:253桑椹形原藻ATP:柠檬酸裂解酶亚基B,蛋白质MPTSPRTPGRYGQAGQLFSKQTQAIFYNWKQLPVQRMLDFDFLCGRTLPSVACIVQPGSQQGFQKVFFGPEEVAIPQYGSIAEAVEQHPRADVLINMSSFRSAFESSLEALQQPTIRTVAIIAEGVPERDTKKLIAVAQRANKVILGPATVGGVQAGAFKVADAAGTLDNIVACKLYRPGSVGFVSKSGGMSNELYNVIARAADGIYEGIAIGGDAYPGSTLSDHCLRYQHIPGVKMIVVLGEIGGRDEYSLVKALEAGAITKPVVAWVSGTCATLFQTEVQFGHAGAKSGGADESAQAKNAALRAAGAVVPDSFEDLEPTIKRVYDELVGAGAIVPAPLPPPPSVPEDLAAAKRAGRVRVPTHIVSSICDDRGEEPTFNGESMSALMERGATVADAIGLLWFKRRLPPYATRFIEMCVVLCADHGPCVSGAHNTIVTARAGKDLISSLVSGLLTIGPRFGGAIDGAAQHFKEAVEKGWEPDEFVEIMKRRGVRVPGIGHRIKSKDNRDKRVELLQRYARERFPSTRFLDYAIEVEGYTLQKAANLVLNVIGCIGALFLDLLHSVGMFAKPEIDDIVQIGYLNGLFVLARAIGLIGHCLDQKRLGQPLYRHPWDDVLYTSEQIDNO:254桑椹形原藻LEC2,核苷酸(转录物)GAGTTTCAAGTTGTGCTCTCCACTTCCGCGCGCATTGCGACGAATTCTCACGCCCTTTGTGCAGGTGTCCAGTTCCACATCGGGAGGCATGGGGGGCCCGCCACCTCGGCGCGTCAAACGGCGTCAGGTAGGGCGGGCACGCTGGCACTCTTGCCCGATGACCCGTACCGAGCAGTACTGCCATGCCTCGGGTCGGAGACGGTCGGCACCGCCCCTGATCGCGACCACTTCCAAATGATCAAACCCTTGCAGACACGATGGACGTCGCGGCGGTGATACTGTCGCCCCAGACAACGCCGCGCCTGGCCGCAGGCCGGGTCGGTGTCGGACGCTCCGCGCAGGCGCCCAGACGACTGGGTGCCGGTGGCAGCGAGGACGAAGAAAGGGATGTACTGGACCTCAAGCTTCCAGGAGTGGGCGGGACGCCTCTGTCGCCCTGGAATGCGGTGATCCTGGAGGACCAGCCATCGACGAAGGACGACGCACGTGCCACGCAACACGATGAGAGTCCACGCCGACGGGCTTCCCGCCGCAAGATCTGAAGAGGCTCCGATTTAGAGTTCCATGGCCAATGGTTTTCTTGTACAAATGATTTACATGCAGTACTGTTCGAACACACCTCTCGACACCGGGCATATCGCCTCGCAGGGCAATCGAAGGCCGTCAAATCTGGCGGTAGTCGTGGGAAGTGACCCTGCCCGGGGGGGCAATCCGTACCATCAGCGAGGTGCGCAGGACCAGGCACGTCTGCCGTATATTTGAGGGCTTCCCTAGGGGTCGAGTCACCTTGCTCGGCTTCATTTTGCAGGTTTTACCAAAAAACCTGCTTGGCATTTTTCTTAACAGGGCATCTTGAGGTGCGACATACCTGATACCGACGAGCTCGAGCCAACCCTTCGCTCGCTGCGGCATTTTTGTAACGGTCGACCACGGAGCATTGCGGCAGCGATAATGTCCAATACTACGATCAAAGTACTGTGCTACAAGTCTCTGACGCACAGCGATGTGACGACGGAGATTGCCAAGTCTGGGCGACTGGTTCTGCCGAGGGCCCAGGTCACGGCCTGCCTGCAGCGCCTCCTGGCCCTCGGCAGCGCCGGCGGAGCCCCAGGCAAGGGTCGAGCGGGATCTCTGTGCGGTGCCGTCCCCTTGTTCATGCACGACATGGAGGGCAAGGTCTGGAACTTTCAGCTGAAGACATGGCACAACGTTGTGGCCTCTGGAGGCCGGGCAACCTACGTGTTGGAGAATACTGCTGGTTTTGTGCACGAAAACAAGCTTCAACCGGGAAGCTGGCTGGCTATTTGCGAGCAGGACGACCGCCTGGTCCTCCGCACCGACATCGTCAAGGGCCGCGATTTCCTGCTCCCCGTGGTGGCGCCCGCGACCACGGTCAAGAAGCCCTCCTCCCCCAGTTTTGCGCCCTGGTCCTCCAAGAGTTCGGACCTCTCGGCCGCCAGCATGACCCTGGTGAGCCTGGGCCACGACACGCCCTCCAGCAGCGAGGACAAGGCCTCCGCGCCGTCCCCCACCATCCTGTCGGTGCCGCTGGTGCGCCCGCGCCCCATGTACGGCGCCATCAGCGTCCAGCAGGTGCCGCGGTTGGGCTGGGCGCTGAGCATGGTGCCGCACCAGCCGCGCGGCCAGCCGTGCTGGTAACCCCGGGTCGCCCTTCCGGCGTGCTTCCAAGCACACCCCTGCCCCTTCCCAAGCCCGCGCGGCCCGCTCCGCGCGGCTTCCTCCCCCCGAACCCACCAACAACGTGACCTCGACGGCCACGCCCGTCGGGGCTCGGGACCTTGGCACCCCTTCAGTCGCACTACCCCGTCCCCACCCAATAACCAGTGTGCTTGGAAATAAACCGGCAGCGTCCTCAGCCGCCACCAGCTCACCCTCACCCCCGTTCCCTTACGCGCCCGCGGGACGCCCCTCGTCCCGGCAAGCCCGGGCGCACGTTGCCCACCCTCGATGTCTCACACGTGTACTCGCCCTTTTCTCGATCGGGCTCCCAAGCTTGTCAATTTTGCCGCGCGCGGCCCCTCTCTTGCACTGTGGCACCGGACCCAAACTCTCATTATTTTTGTTGCACTTGAACCCTGCACACCCGACCTTGGCCCCACCGGCACCTTGCGCAAGCCCAGAGTGTCCCGCAAATTCATTCTTGGTGCGGCTCGGCCGACTTCTGCCCAAAGCGCGCGGCCGCCCTCGTATAGATACTGCTCTTTTCTCTTACTGTGAGATCTCCCTCGGTACCCGGGGTCGCGGCTGCCAGGCGCCGCAGCAGGCCGCCAGGTGGCGTAGGCCGACCAGCGCCCAGAGCAGGTTGAGCAGGTAGAAAAAGTTGGCGTTCAGGCCGCCAAGATCCAGCCACACATGGGCCACAGCGGCGTGCGTCGCCAGCAGCGTCATCCACAGGCACTGCCAGGCGCTGGGGTCGCGCCCTCTCCGCCGCAGCACGGCCGCGCTCGTCGCCATGCACAGCGCCAGGCCASEQIDNO:255桑椹形原藻叶状子叶2LEC2,蛋白质MSNTTIKVLCYKSLTHSDVTTEIAKSGRLVLPRAQVTACLQRLLALGSAGGAPGKGRAGSLCGAVPLFMHDMEGKVWNFQLKTWHNVVASGGRATYVLENTAGFVHENKLQPGSWLAICEQDDRLVLRTDIVKGRDFLLPVVAPATTVKKPSSPSFAPWSSKSSDLSAASMTLVSLGHDTPSSSEDKASAPSPTILSVPLVRPRPMYGAISVQQVPRLGWALSMVPHQPRGQPCW*SEQIDNO:256桑椹形原藻DGK/SpiK,核苷酸(转录物)GGTTTGAGAGGAACAATTTGGGGATGGGCGGTGGCACTGGGATGAGGCACTGGGATGAGGCGCTCATTGTCAAAGAATAAAACGGAATGGACGAATCGGTCAGGGCCGCCAGCACCGGCCAGGGCCCAGGAGGCAGGCGTTTCAAGGGCGGGAATGGGGCCCCCAGCTAGTTTCGCGCTCGTCAGCCCTCCACGCCTCTGGCAAACACGTCGATCACTCCGCGGTGGAGCTGCGCGTTGATCGTGCGGCTTTGAATGAGCTCCCCATCGACGTTCCAGTGGCTCTCCTGGCCAACCGCTTCGATGTGCACCGCGTGGGCGGGCAGGACCTGGATGTAGGACCCGTGCTGCCCGCCCGCCTCGAGGCCGATGTGCGACATCCTGAGCAGAAACTTGAGGTACTGGAGGCGGCTGCACCGCCTGATGAGCACCAGGTGCAGCAGGCCGTCGCTCAGGTGACCATACTTGGCGACGCCCTTTTTCGACTTGTCAGAGCGGCAGGGCATGATGACGAGCATGATGCCTGCAAACTCCTGCTCCGGGAGGTGCACAAACTCTGCTCGCCGCCGCTCCCAGAGCTCCTCGGCCGAGGCGGTGAACCCCGCCGCGCCGTCGCGGCCCTCGCGCCCGCCGCGCGCGCAGAACTCGCAGTTGGCGAGGCAGGCGTGGCTGAAGCTGGCCCGACCCGGTCCGGCGGCCGGGGCCAGGTACGAGACGCGCGCGGCGTAGGCCCTGTTCGCGGCGAGCATCTTGGCGCCCACCAGCTCGTACCGCGCGGGCCCCAGCCAGCGCAGGCGCTCCGACTCGGCCATGAGGTCGCCCATGAAGCCGTAGCTGACCATGCAGGTCGCAAACTCGGGCAGGCCCGGCTCCCGCTCCAGACGCAGCACATCCAGCGCCACGGCGTCGCCCAGCACGACGTGCACCGCGGCCGTGAAGGCCGAACGCGTGCCGTTGAGCGTGCAGGCCACGGCGTCGGTGCTGCCGGCCGGGATGTGGCCGATGCGGAACTGCGCCCCCGGCGCGACGGCCGCGCACCCGGCCGCGCGCAGGCCCAGCACACCGTTGACGATCTCGTGGAAGAGCCCGTCCCCGCCCACGGCCACCACGCCGTCAAACGCGCGGCGCGAGGGTGAGCGCGAGCGCCGCGGCTTGTCGCGGTCGGCGCCAGCGGGGGACAGGGAACGGCGCTCCGCGCCCGCGTCAGCGTCGCTCTCGGCGCCGCCGCCGATCACCTGGCGCACGATGGTGACGGCGTGCTGCGGCTCCTGCGTCTCCACCACCGCGACCTTGATCCCGGCCTTTCGGAAGACGGGCGCCACGGTGGAGCTCCAGGTCGAGGGCGCCTGGCGCGAGCCGCCCACCGGGTTCACGATCACCAGCAGCCGCCGCGGGCGCCAGGTCTGCGCCCGCATGCCGGCTTGCAGCTGGGCGTGCCACGCACGTAGCAGCTCCTCGTCTGTGGAGACCAGGGTCACTTGGCGCGGATGCCAGTACGAGGGGTTGGAGGGCGCGCGCCGAAAGGTGAAGAGCGTGAGGGCCCAGGCCTTCTCGAGCCAGGAACACCACTGGCGACGGAGCGACGAGGGCTTGACCTCCGCCGCGATGATCTCTTGCAGCGGCAGCGACTCTGCACGCTGCCCGAAGCCTGGCAAGAGGTTGACGCAGCCGTCCATCTCAAACGCCCAGCTCAAGCCGCCCTCGCTGCCCGCCAGATCCAGACTGACTTGCGCCGGCACGCCGTCCACCTGCATCGGCACGCCCTGCAGCTCCGCCTCGCTGAGGCGCTTGGGAAAGGAGGAGGACCGCGATATCGAGGGGTGCATGAGTGGGGGCTGCCTGGGGTGCGCCATCAGGCTGGGCGACGCATTGGTACCTCGTGTCCGATGCGGAGAAGACAGCGATCCCGCCCGGGAAGAGGGCAGGCTCACGGAATCGTCGTCCATGTGCGATGACGGGCGCTGAAGCACCAGCTCGGTGCAGAGAACGTCACGGGGAGCTCCGCGCATGTCCCACTACCGACCCAACCGCACGCAGGGAGACGGTCCGTCAGGCATGAACGCGATGCGCATAAGGAAGCAACAACCATGCGTGTGTGGCAATCGAACGGCGAAATGGGCCGATTCTTGGCAAAGGGGGGAGGCTGGCGAGGGACGCACACCGCGTCTTCCGTCGGCATCACGTGGATCTGTCGTTCATGCATCGGGATGCCTTACATGCAACCATTGGCGCCGAGGCAGGCGCGAATGAGCCGAGCAACAGTGTACGCACGCCAGGAATCAATTATACTGACTAGACATTTCTGCCATGAACCTTTCGTACTCGCTCTCCACGGCAGCAGGCGCTGGCGGGGCGGGAGCGGGGGCGGGAGGGGGAGGGGGCGGCGGTGGCGCCTCGTCGTCGGCCATACCCCCGACTGGCGGGGGGGGGGGCGGCGGCGGAACGTCGTCCGTGGGCGGCGGTCCCGGGACCGCCGCCCCGCTAGCGTCGTACATGCCGTGGTACGCGCCCGCCTGATCGGGCGCGGGCGGCGGCACCGCCCCGTACTGCGCGCCGTAGGCGTACGGGTCGGCGGCGCCAGGGTAGGCCGCGTACGGGTCGGCTGGGGCCTCGGCGCCGGGGTACGCACCCGGCGGCGGGGGCACGGCGCCGTACGCCCCGCCGGGCGGCGGCGGCGGCGGGTAGGCGCCGCCGTAGGGCGGTGGTGGGGCGCCGTACCCCGGGCCGTASEQIDNO:257桑椹形原藻DGK/SpiK,蛋白质MQVDGVPAQVSLDLAGSEGGLSWAFEMDGCVNLLPGFGQRAESLPLQEIIAAEVKPSSLRRQWCSWLEKAWALTLFTFRRAPSNPSYWHPRQVTLVSTDEELLRAWHAQLQAGMRAQTWRPRRLLVIVNPVGGSRQAPSTWSSTVAPVFRKAGIKVAVVETQEPQHAVTIVRQVIGGGAESDADAGAERRSLSPAGADRDKPRRSRSPSRRAFDGVVAVGGDGLFHEIVNGVLGLRAAGCAAVAPGAQFRIGHIPAGSTDAVACTLNGTRSAFTAAVHVVLGDAVALDVLRLEREPGLPEFATCMVSYGFMGDLMAESERLRWLGPARYELVGAKMLAANRAYAARVSYLAPAAGPGRASFSHACLANCEFCARGGREGRDGAAGFTASAEELWERRRAEFVHLPEQEFAGIMLVIMPCRSDKSKKGVAKYGHLSDGLLHLVLIRRCSRLQYLKFLLRMSHIGLEAGGQHGSYIQVLPAHAVHIEAVGQESHWNVDGELIQSRTINAQLHRGVIDVFARGVEG*SEQIDNO:258桑椹形原藻酮酰基-ACP还原酶(KAR)核苷酸TGGAGTTCAGACGTGTGCTCTTCCGATCTCGCGTGGTGAGCAAGCCTGCGCCGACGTGTTTGGTTTCTTCTTCATGTTGTTGCTCGGAGGCGCCGTCGATTAGTTTGCCACCTGACCACCGTGCCCACAGTCCCCGACCAGCTCACTGGCACTTTACTGCATGCTCATGCCGCCGTCGATGCTGAGGACCTGGCCGGTGATGTAGGCGGCGGCCGGGTCGGTGAGGAGGAACTTGACCAGCCCGGCGACCTGGTCGGGCGTGCCGTAGCTGTTGAGCGGGATCTTGGCGAGGATGGCCTTCTCGACCTCGGGGTTGAGCACGCCCGTCATCTCCGACTCGATGAAGCCCGGCGCGATGGCGTTGACGAGCACCTTGCGGCCGGCCAGCTCGCGCGCGAGGGAGCGCGTCATGCCGATGACGCCGGCCTTGGAGGAGGCGTAGTTGACCTGGCCCGCGTTGCCCATGAGCCCGACCACGGAGGTGATGTTGACGATGCGCCCGCGCCGCGCCTTGGCCATGACCTTGGCCGCGGCCTGGCTCGCGTAGAACACGCCGGACAGGTTGACGTCGATGACCTGCTGCCACTGCTCGGGCTTCATGCGCAGCAGCAGCGTGTCGCGCGTGATGCCCGCGTTGTTGACCAGCGCGTCCACGCGGCCCCACCGGTCCACCGCCGCCTTGATCAGCGCCTGCGCGTCCTCGATCTTGGACAGGTCCCCCTTGACCACGATCGCCTCGCCGCCAGAGGCCTCGATCTGGTGCGCCACCTCCTCCGCGGCCCCGCTGGACGCCGCATAGTTGACCAGCACCTTGCCGCCCGCGGCGCCCAGCTTGAGCGCGATCGCGCGGCCAATGCCGCGCGAGGAGCCCGTCACCACCGTCACGCCCTGCTCCAGCTCCTTCTGGAGGGAGACGCCGTTGGGCGACGAGGCCACGGAGGCAGCGATCCATGCCGATCAACAGCCGGCTTTTCAGAACCTTAATCATGCAGAGCTCCGTGATGAACGTGCCGGCGACCCTTTCGGCGGGATGTGCCCTTAGGGCCTCCCCCCGCCTGCCGGCCGCTCGCCCGGCGCAGCACGCTGCCGGTCGCCGGTCGCCGGGCCAGCTGCAGGTCACGCGCGCCGCTGCCTCCGTGGCCTCGTCGCCCAACGGCGTCTCCCTCCAGAAGGAGCTGGAGCAGGGCGTGACGGTGGTGACGGGCTCCTCGCGCGGCATTGGCCGCGCGATCGCGCTCAAGCTGGGCGCCGCGGGCGGCAAGGTGCTGGTCAACTATGCGGCGTCCAGCGGGGCCGCGGAGGAGGTGGCGCACCAGATCGAGGCCTCTGGCGGCGAGGCGATCGTGGTCAAGGGGGACCTGTCCAAGATCGAGGACGCGCAGGCGCTGATCAAGGCGGCGGTGGACCGGTGGGGCCGCGTGGACGCGCTGGTCAACAACGCGGGCATCACGCGCGACACGCTGCTGCTGCGCATGAAGCCCGAGCAGTGGCAGCAGGTCATCGACGTCAACCTGTCCGGCGTGTTCTACGCGAGCCAGGCCGCGGCCAAGGTCATGGCCAAGGCGCGGCGCGGGCGCATCGTCAACATCACCTCCGTGGTCGGGCTCATGGGCAACGCGGGCCAGGTCAACTACGCCTCCTCCAAGGCCGGCGTCATCGGCATGACGCGCTCCCTCGCGCGCGAGCTGGCCGGCCGCAAGGTGCTCGTCAACGCCATCGCGCCGGGCTTCATCGAGTCGGAGATGACGGGCGTGCTCAACCCCGAGGTCGAGAAGGCCATCCTCGCCAAGATCCCGCTCAACAGCTACGGCACGCCCGACCAGGTCGCCGGGCTGGTCAAGTTCCTCCTCACCGACCCGGCCGCCGCCTACATCACCGGCCAGGTCCTCAGCATCGACGGCGGCATGAGCATGCAGTAAAGTGCCAGTGAGCTGGTCGGGGACTGTGGGCACGGTGGTCAGGTGGCAAACTAATCGACGGCGCCTCCGAGCAACAACATGAAGAAGAAACCAAACACGTCGGCGCAGGCTTGCTCACCACGCGAGATCGGAAGAGCACACGTCTGAACTCCASEQIDNO:259桑椹形原藻酮酰基-ACP还原酶(KAR)蛋白质MQSSVMNVPATLSAGCALRASPRLPAARPAQHAAGRRSPGQLQVTRAAASVASSPNGVSLQKELEQGVTVVTGSSRGIGRAIALKLGAAGGKVLVNYAASSGAAEEVAHQIEASGGEAIVVKGDLSKIEDAQALIKAAVDRWGRVDALVNNAGITRDTLLLRMKPEQWQQVIDVNLSGVFYASQAAAKVMAKARRGRIVNITSVVGLMGNAGQVNYASSKAGVIGMTRSLARELAGRKVLVNAIAPGFIESEMTGVLNPEVEKAILAKIPLNSYGTPDQVAGLVKFLLTDPAAAYITGQVLSIDGGMSMQ*SEQIDNO:260桑椹形原藻硫辛酸酯合成酶(LS)转录物ACTCAATCGACCCGCACGCGAGTACGAAAAGATTCCATGGTGCGAAACGTTGAATGCCATAGTTTGTAACGGGCCAGGCGTACGCGTGCGGGTCGATTGAGTTGACGTCCCGTAGCCCCGCTGGGCGGTCACCTGAGTGAATTTGGAGCGAGCCGCATCCGACGACGGGTACCTGTCATTCGAAACACCCGTATCATTACGGGAGTTTTGTATTGCCAAACTTTTATAATTGAACTGCCCGACAGTACATTCCGCTTGGAAAGCATGTCGTCTCGGATCGACATGGGCGTGTCGACGTCCGGGAGGGTGGGCAACCCAATGACTGAGCGATCAGCCGCCCACCAATTGCGGGCGACCGCTGCACGCGTGCCAAGACGGCATGCACCCTTCAAATCCGCCGCAAGGCATCGCGGGCCAGCGGCGATGCGCTCGGCGGCGTTTGACGAGCTGGTGGCGCTGGCCCGGGCCAAGGACCCCACCCTGCCCCTGCCCAAGCGCAAGCCGGCCAGCCCGCGCCCCAAGCCCCCCAAGGCGCCCTGGCTGCGGCAGCGCGCCCCCCAGGGCGAGCGCTACGAGTACCTCAAGCAGCAGCTGACGGGCCTGAAGCTGGCGACCGTGTGCCAGGAGGCGCAGTGCCCCAACATCGGCGAGTGCTGGTCGGGCGGCGCCGAGGGGATCGGCACGGCCACCATCATGGTGCTGGGTGACACCTGCACGCGCGGCTGCCGCTTCTGCGCTGTCAAGACGTCGCGTGCGCCGCCGCCGCCGGACGCGGACGAGCCCGAGAACACGGCCGCGGCGGTGGCCGACTGGGGCGTCGGGTACGTGGTGCTGACCTCGGTCGACCGCGACGACCTGCCCGACGGCGGCGCGGGTCACTTTGCGGCCACGGTGCGCGCGATCAAGCGCCGGCGCCCCGAGGTCCTGGTCGAGTGCCTGACCCCCGACTTTTCGGGGGACGAGGCGCTCGTCGCCGAGCTGGCGCGGTGCGGGCTAGACGTCTTTGCGCACAACGTGGAGACGGTGGCGCGCCTGCAGCGGCGCGTGCGTGACCACCGCGCCGGCTACGAGCAGACGCTGGCCGTGCTGCGCGCGGCCAAGCGCGCCTGCCCCTCGCTGCTCACCAAGTCCTCCATCATGCTCGGGCTCGGCGAGCGCGACGAGGAGGTCGAGCAGACCATGCGCGACCTGCGGGGGGCGGGCGTGGACATCCTGACCCTGGGGCAGTACCTGCAGCCCACGCACCGCCACCTGGAGGTCCAGGACATGGTCCACCCAGACGCCTTTGACCACTGGCGAGAGGTCGGAGAAGCAATGGGGTTCCGGTACGTGGCCTCGGGTCCGCTGGTGCGGTCCTCGTACAGAGCCGGCGAGTTTTACGTGGCAGCCATGCTCAGGGAAGGAAAGCGCGGCGGCGCGGGGGCGCAGTTGTCGCCCTGAGGCGGCGGTGGCAGTCTCTTGAGGCTTTTGGGTGCGCAATCTCAAACACGTGTGTCTGTCCTGCGCGGGACCGAGAGGCATCATATTCCGCACGAGCGTGCATCATCCGGATGCAAACACCTATTCTCGTATTCTAATCTTGTGAATTATAGGCTGGCGTCACCAGCTGCTGAATCATGCGTTTTGGAGGCACCGCCCCTGAATATTTGGCGGCCCACTGCAACGCTGTAAGAATCTTCTTGCCCTTTCACCCGGAAGTTCAAATATCTCTGCGTAAACAGCAGGCGTAGAAACAGAAACGAGCGACGCATGGTAGCGGGAGGAACGAAACAAGGCGCGCTGCTCAGGGGCAAGGGGCATTCGTCATCACAGATTCCGCCCAGCTCCCAATTTCCCCAACCACTGCTAGATCTGGCGCGCGCCGCGGCTGTCGAGGCGGACCACCTGACTGGAGTTGGTCTCCAGCCCGCCGTGGCGGAGAAAGGCCTCGGACATGGCGCGCGCGACGCGCTCGCCGGTGGCCGGGTCCGGCACGACCGCCACGGCCSEQIDNO:261桑椹形原藻硫辛酸酯合成酶(LS)蛋白质MSSRIDMGVSTSGRVGNPMTERSAAHQLRATAARVPRRHAPFKSAARHRGPAAMRSAAFDELVALARAKDPTLPLPKRKPASPRPKPPKAPWLRQRAPQGERYEYLKQQLTGLKLATVCQEAQCPNIGECWSGGAEGIGTATIMVLGDTCTRGCRFCAVKTSRAPPPPDADEPENTAAAVADWGVGYVVLTSVDRDDLPDGGAGHFAATVRAIKRRRPEVLVECLTPDFSGDEALVAELARCGLDVFAHNVETVARLQRRVRDHRAGYEQTLAVLRAAKRACPSLLTKSSIMLGLGERDEEVEQTMRDLRGAGVDILTLGQYLQPTHRHLEVQDMVHPDAFDHWREVGEAMGFRYVASGPLVRSSYRAGEFYVAAMLREGKRGGAGAQLSP*SEQIDNO:262桑椹形原藻同质型乙酰基-CoA羧化酶,核苷酸ATGACGGTGGCCAATCCCCCGGAAGCCCCGTTCGACAGCGAGGGTTCCTCGCTGGCGCCCGACAATGGGTCCAGCAAGCCCACCAAGCTGAGCTCCACCCGGTCCTTGCTGTCCATCTCCTACCGGGAGCTCTCGCGTTCCAACCAGCAGTCGCGGTCGTTCACTTCGCGGGGGGTGCCAGGGAGGACGGACGTTTCGGATGAGCTGGAGCGCCGCATCCTCGAGTGGCAGGGCGATCGCGCCATCCACAGCGTGCTGGTGGCCAACAACGGTCTGGCGGCGGTCAAGTTCATCCGGTCGATCCGGTCGTGGTCGTACAAGACGTTTGGGAACGAGCGTGCGGTGAAGCTGATCGCGATGGCGACGCCCGAGGACATGCGCGCGGACGCGGAGCACATCCGCATGGCGGACCAGTTTGTGGAGGTCCCCGGCGGCAAGAACGTGCAGAACTACGCCAACGTGGGCCTGATCACCTCGGTGGCGGTGCGCACCGGGGTGGACGCGGTCGACTGCGGGGGGCAGATCCGGTTCGTGCGCACCGGGGTGGACGCGGTGTGGCCCGGCTGGGGCCACGCGTCCGAGTTCCCGGAGCTGCCCGAGTCGCTGGGCGCCACGCCCTCGCAGATCCGGTTCGTGGGCCCGCCCGCGGGGCCCATGGCGGCCCTGGGCGACAAGGTGGGCTCCACCATCCTGGCGCAGGCGGCGGGCGTGCCCACGCTGGCCTGGTCCGGCTCGGGCGTGAGCATCGCCTACGCGGACTGCCCGCGCGGCGAGATCCCGCCCGAGGTCTACCGCCGCGCCTGCATCGACTCGCTGGAGGCGGCGCTGGCCTGCTGCGAGCGCATCGGCTACCCGGTCATGCTCAAGGCCAGCTGGGGCGGCGGCGGCAAGGGCATCCGCAAGGTGCTCAGCGCCGACGAGGTCAAGCTGGCCTACACCCAGGTCTGCGGCGAGGTCCCCGGCTCGCCCGTGTTCGCCATGAAGCTCGCGCCGCAGTCGCGCCACCTGGAGGTCCAGCTGCTCTGTGACGCGCACGGCCAGGTCTGCTCGCTCTACTCGCGCGACTGCTCCGTGCAGCGCCGCCACCAGAAGGTGGTGGAGGAGGGGCCCGTCACCGCCGCGCCGCCCGAGGTGCTGGAGGGCATGGAGCGCTGCGCGCGCTCCCTGGCGCGCGCCGTCGGCTACGTCGGCGCCGCCACGGTCGAGTACCTCTACATGGTCGAGACGCGGGAGTACTGCTTCCTGGAGCTCAACCCGCGCCTGCAGGTGGAGCACCCGGTGACGGAGATGATCACGGGCGTGAACATCCCCGCCGCGCAGCTGCTCGTCGCGGCCGGCGTGCCCCTGCACCGCATCCCCGACATCCGCAGGCTGTACCGCGCGCCGCTGGCCGAGGACGGCCCCATCGACTTTGAGGACGACGCCGCGCGCCTGCCGCCCAACGGGCACGTGCTGGCGGTGCGCGTGACGGCCGAGAACGCGCACGACGGCTTCAAGCCCACCTCGGGCGCGATCGAGGAGATCAGCTTCCGCTCCACGCCCGACGTCTGGGGCTACTTCTCGGTCAAGGGCGGCAGCGCCGTGCACGAGTTCGCCGACAGCCAGTTCGGCCACCTGTTCGCGCGCGGCGACTCGCGCGAGGCGGCCGTGCGGGCCATGGTGGTGGCGCTCAAGGAGATCAAGATCAGGGGCGAGATCCAGACGCCCGTCGACTACGTCGCGCGCATGATCCAGACCGACGACTTCCTGGGCAACCGCCACCACACGGGCTGGCTGGACGCGCGCATCGCGGCGCAGGTCGGCGCCGAGCGCCCGCCCTGGTTCCTGGTCGTCATCGCGGGCGCCGTGCTGCGCGCGACGCGCGCCGTGAACGAGCGCGCGGCCGCCTTTTTGGACCACCTACGCAAGGGCCAGCTCCCGCCCAGCGAGGTCCCGCTCACGCGCGTGGCCGAGGAGTTTGTGGTCGACGGCACCAAGTACGCGGTCGACGTCACGCGCACGGGGCCGCAGGCCTACCGCGTCGCGCTGCGCGACCCCGAGGGCGACGGCGCCCCCGGGCACGCGCGCCGCGAGAGCCTCGCCTCCGCGGCCGGCGCGGCCAGCTCCGTCGACGTCATCGCGCGCACGCTGCAGGACGGCGGCCTGCTGCTGCAGGTGCGACGGGCGCGTGCACGTGCTGCACAGCGAGGAGGAGGCGCTGGGCACGCGCCTGGTCATCGACTCGGCCACGTGCCTGCTCAGCAACGAGCACGACCCCTCGCAGCTCGTGGCCGTCAGCACGGGCAAGCTCGTGCGCCACCTCGTCGCCGAGGGCGAGCACGTGCGCGCGGACGAGCCCTACGCCGAGGTCGAGGTCATGAAGATGATGATGACGCTGCTCGCGCCCCGCGGCCGGCGCGGTGCGCTGGGAGGTGGCCGAGGGCGCCGCGCTGGCGCCGGGCCTGCTGCTCGCGCGCCTGGAGGAAGCTGGGACGACCCTCCCGCCGTGCGCCCGCGAGCCCTTCCGCGGCGCCTTCCCCGACCTGGGCCCGCCCTCGCCCGACTTTGACGGCCTGGCCGCGCGCTACCGCTCCGCGCTCGAGGCCGCGCAGGACGTGCTCGACGGCTTCGAGGGCGACGTGCCCGCGGTCGTCGCCGCGCTGCTGGCCGCGCTGGACGACCCCGCGCTCTCCCTCGTCCTGCTGGACGAGGCGCTGGCCGTGGTCGCGCCGCGGCTGCCGGCCGCGCTGGCCGCGCGCCTGGAGGCCGCGGCTGGCCGAGGGCGCCGCCGAGATGGCGGGCGAGCTCTCGGACGACGAGCAGGACGCCGCGCTGGCGGCGCCGGGTCGCCGCGCGAAGGGAGGGGCCTCCACGCGCGCTTCGTGGTCAAGCGCCGCGACCCGGCGGCGCGCCTGCAGCCGCGCGTCTTCGAGGAGGGCCGCCGGCGCGCGGCGCTGGCCTCGCCGCCTCCTGCTCGAGCGCTACCTGGACGTGGAGGAGCGCTTCGAGTCCGGCGGCGCCAAGACGGACCAGGAGGTCATCGACGGCCTGCGCGGCACGCACAGCGCCGACCCGGGCAAGGTGCTGGAGATCGTGGTCGCGCACCAGTCGGCCGGCCCGCGCGCCGACCTGGTGCACCGCCTGCTCAACGCGCTGGTGCTGCCCTCGCCCGAGGCCTACCGCCCCATCCTGCGCCGCCTGGCCGCGCTGACGGGCGCCGGCAGCGCCGCGCCCGCGCAGCGCGCGCGCCGCCTGCTGGAGCACAGCCTGCTGGGCGAGCTGCGCGTGCTGGTCGCTGCGCGCGCNGTCCGGCCNTGGACATGGTTCAGCGACGCCGCGCTGCGCGGGCTGTGCCTGGGCGAGTCGCCGGGCGAGCCCGTCTCGCCGCGCGCGGAGCTGGCCAGCGCGCTCGCGGCCGAGTCCTCGGTCGCGTCGCCCACCTCGCGGCGGTCCACGCTCGCGGAGGGGCTCTACGTCGGCCTGGGCAACCTGGCGGCTGCCGCCGCGAGCAGCGTGGAGGCGCGCATGGCCATGCTGGTCGAGGCCCCCGCCGCGGTCGACGACGCGCTGGCCACGCTGCTGGACCACCCGGACCCGGTGCTCCAGCGCCGCGCGCTGTCCACCTACGTCCGCCGCATCTACTTCCCGGGCGTGCTGCACGAGCCGCAGGTCGTCGGGCGTCGGGCCGGCGCGCGGTCCGTCCGCGTCTGGGCGACGCGGGGCGCGCCCGGCGCGATGGCGCCGCGGCCCAGCAGGACCAGCATGGCCGGGCTCGCGCCGGGGACGCTGCACGTGGTCCTGACCGCCGAGGGCGCCGCCGCGCTGCAGCTGGACGCCGCCGCGCAGGCCGCGCTGGGCACGCTTGACGTCTCCGGCTACGTCGCGCCCGAGCACCAGCAGCAGCCGGGGCTGCCGGACGCCTCGGTCGTCGCGGCCAGTGCCGCCGCCGCGGTGTCGGCGCTCGCGCCCGCGCTGCGCGAGGCCGGCTACAGCGCCGTCTCCTTCCTCACCAAGCGCGGCGGCGTCGAGCCCCTGCGCGTCGTGTTTTACGACGGCACGTCGAGCGGCAGCGCTGCCGCGCCCGACTCCTCGTCCACCCAAACTGGCCATCGACCGGCTGGTCCCTGGACCCCGTGCTCGGCACGGTCGAGCCGCCGACGGCCGAGGCGCTGGAGCTGGCCTGTCTGGCCGGCCGCGCGGGCGCCTCGCACGACGCCTCGCGCAACCGTGGCACATGTGGACCGTGGCCGAGCGCGCCGGCAAGCGCAGCGCGGTGCTGCGCCGCACCTTTTTGCGCGGCGCGGTGCGCTCGCTGGGCCGGCCGGCGCTGCTGAGCGCGGCCTACGCGGGAACGGCCCCGCTGTCGCGGCGGCGGCGCTGGCCGAGCTGGAGCAGACGGTGGAGGCGGCGGCCGCCGAGCTGGAGCGGCTGGGCAAGGGCCGCGTGGGCGGCGCCTCGTCCCGACTGGACGCACCGTGCTTGTCGGTGCTGATGCTCGCTGCCGCTGGGCGCGTCCGAGCCGCGCGAAGGGAAAGGCGCCGTCGCGCGCGCGCTGGCCGCGCCGCGGCCATCGCCTCGCGCCACGTGGCGGCCCTGCGCCGCGCGGCGCTGGCGCAGTGGGAGGTCTGCCTGCGCACCGGCTCGGGCGGCGCCTCGCACCGCGAGGGCGGCTGGCGCGTGGTCGTGTCCTCGCCCACGGGGCACGAGGCCGGCGAGGCCTTTGTGGACGTCTACCGCGAGGCCGCCGACGGCACGCTGCGCGCGGTCAACCCCAGCCTGCGCGCGCCGGGCCCGCTGGACGGCCAGTCCGTGCTCGCGCCCTACCCGACGCTCGCGCCGCTGCAGCAGCGCCGGCTGACGGCTCGGCGGCACAAGACCACGTACGCGTACGACTTCCCGGCCGTATTCGAGGACGCGCTGCGCTCGATCTGGCTGCAGCGCGCCGTGGAGCTGGGCGCCACCGGGCTGGAGGCCGCGCGCGAGGACCTGCTGCCGCCCGGGACCGCCTGGTCACGGCCGGAGCTGGTGCTGGACACGGAGGAGGCGATCTACGAAAACGGCGCCGCGCACATTCGCCTGACCGACCGCGCGCCCTCGATGAACGACCTCGGCGTCGTGGCCTGGCGCCTGACGCTGGCCACGCCCGAGTGCCCGCGCGGCCGCGCCGTCGTGGCCATCGCCAACGACATCACCTACAACTCCGGCTCCTTCGGCCCGCGCGAGGACGCCTTCTTCAAGGCCGCCACCGAGTACGCGCTGGCCGAGCGCCTGCCGGTGGTCTACCTGGCGGCCAACTCCGGCGCGCGCGTCGGGCTGGCCGAGGAGGTCAAGCGCTGCCTGCGCGTGGAGTGGAGCGTGCCGGGCGACCCGACCAAGGGCCACAAGTACCTCTACCTGGACGACGAGGACTACCGCTCCATCACGGGCCGCGCCGCGGGCCGCACGCTGCCCGTCAGCTGCTCGGCCAAGGTCGGCGCCGACGGGCGCACGCGGCACGTGCTGCACGACGTCATCGGGCTCGAGGACGGGCTGGGCGTCGAGTGCCTGAGCGGGTCCGGGGCCATCGCCGGCGCCTTTGCGCGCGCCTTCCGCGAGGGCTTCACCGTCACGCTCGTGTCGGGGCGCACCGTGGGCATCGGCGCCTACCTCGCGCGCCTGGGCCGGCGCTGCGTGCAGCGCCGCGAGCAGCCCATCATCCTCACCGGCTTCGCCGCGCTCAACAAGCTGCTGGGGCGCGAGGTGTACACCTCRCAGCAGCAGCTGGGCGGCCCGCGCGTCATGGGCGCCAACGGCGTCAGCCACCACGTCGTGGACGACGACCTGCAGGGCGTGCACGCCGTGCTGCGCTGGCTGGCCTACACGCCCGCGCGCGTGGGCGAGCTGCCGCCCACGCTGCGCGCGGCCGACCCCGTSGACCGCCGCGTGACCTACGCGCCGGCCGAGAACGAGAAGCTGGACCCGCGCCTGGCCGTGGCGGGCGGCGACGCGCCCGAGCCCGTGACGGGCCTCTTCGACCGCGGCAGCTGGACCGAGGCGCAGGCGGGCTGGGCACAGACCGTGGTCACGGGGCGCGCGCGCCTGGGCGGCATCCCCGTGGGCGTGGTGGCCGTGGAGGTGAACGCGGTGTCGCTGCACATCCCCGCCGACCCGGGCATGCCCGACTCGGCCGAGCGCACCATCCCGCAGGCGGGCCAGGTCTGGTTCCCGGACTCAGCGCTCAAGACCGCGCAGGCGATCGAGGAGTTTGGCCTGGAGGGCCTGCCCCTCTTCATCCTGGCCAACTGGCGCGGCTTCTCGGGCGGGCAGCGCGACCTGTTCGAGGGCGTGCTGCAGGCGGGCAGCCAGATCGTGGAGATGCTCCGCACCTACCGCCGCCCGGTSACCGTCTACCTGGGCCCGGCTGCGAGCTGCGCGGCGGCGCCTGGGTCGTGCTCGACTCCCATCAACCCGGCCAGCATCGAGATGTACGCCGACCCCACCGCGCAGGGCGCCGTGCTCGAGCCGCAGGGTGTCGTGGAGATCAAGTTCAGGACCCCAGACCTCCTCGCCGCCATGCACCGGCTGGACGAAAAGATCATCGCGCTCAAGTCGGACGACTCGCCCAGCGCGCTGGCGGCCATCAAGGCGCGAGAAAGCGAGCTGCTGCCCGTCTACAGCCAGGTCGCGCACCAGTTCGCGCAGATGCACGACGGCCCCGTGCGCATGCTCGCCAAGGGCGTGCTGCGCGGCATCGTGCCCTGGTCGGCCGCGCGCGCCTTCCTGGCCACGCGCCTGCGCCGGCGCCTGGCCGAGGAGGCGCTGCTTCGCCAGATCGCGGCGGCCGACGCGTCCGTCGAGCACGCCGACGCGCTGGCCATGCTGCGCTCCTGGTTCCTCAGCTCGCCGCCCACGGGCGGCGCGCCCGGCGCGCCCGGCGCGCTCGGCGCGCTGCTCAAGGAGACGGTCGTCGCGCCGCCCGACGCGGGCGAGGCGCCGCTGGCGCTCTGGCAGGACGACCTCGCCTTCCTGGACTGGAGCGAGGCCGAGGCCGGCGCCTCGCGCGTCGCGCTCGAGCTCAAGAGCCTGCGCGTCAACGTCGCCATGCGCAGCGTCGACAGACTGTGCCAGACCCCGGAGGGCACCGCCGGGCTCGTCAAGGGACTGGACGAGGCCATCAAGTCCAACCCGTCCCTCCTCCTCTGCCTCCGCTCGCTGGTCAAGCCGTAGSEQIDNO:263桑椹形原藻同质型乙酰基-CoA羧化酶,蛋白质MTVANPPEAPFDSEGSSLAPDNGSSKPTKLSSTRSLLSISYRELSRSNQQSRSFTSRGVPGRTDVSDELERRILEWQGDRAIHSVLVANNGLAAVKFIRSIRSWSYKTFGNERAVKLIAMATPEDMRADAEHIRMADQFVEVPGGKNVQNYANVGLITSVAVRTGVDAVDCGGQIRFVRTGVDAVWPGWGHASEFPELPESLGATPSQIRFVGPPAGPMAALGDKVGSTILAQAAGVPTLAWSGSGVSIAYADCPRGEIPPEVYRRACIDSLEAALACCERIGYPVMLKASWGGGGKGIRKVLSADEVKLAYTQVCGEVPGSPVFAMKLAPQSRHLEVQLLCDAHGQVCSLYSRDCSVQRRHQKVVEEGPVTAAPPEVLEGMERCARSLARAVGYVGAATVEYLYMVETREYCFLELNPRLQVEHPVTEMITGVNIPAAQLLVAAGVPLHRIPDIRRLYRAPLAEDGPIDFEDDAARLPPNGHVLAVRVTAENAHDGFKPTSGAIEEISFRSTPDVWGYFSVKGGSAVHEFADSQFGHLFARGDSREAAVRAMVVALKEIKIRGEIQTPVDYVARMIQTDDFLGNRHHTGWLDARIAAQVGAERPPWFLVVIAGAVLRATRAVNERAAAFLDHLRKGQLPPSEVPLTRVAEEFVVDGTKYAVDVTRTGPQAYRVALRDPEGDGAPGHARRESLASAAGAASSVDVIARTLQDGGLLLQVRRARARAAQRGGGAGHAPGHRLGHVPAQQRARPLAARGRQHGQARAPPRRRGRARARGRALRRGRGHEDDDDAARAPRPARCAGRWPRAPRWRRACCSRAWRKLGRPSRRAPASPSAAPSPTWARPRPTLTAWPRATAPRSRPRRTCSTASRATCPRSSPRCWPRWTTPRSPSSCWTRRWPWSRRGCRPRWPRAWRPRLAEGAAEMAGELSDDEQDAALAAPGRRAKGGASTRASWSSAATRRRACSRASSRRAAGARRWPRRLLLERYLDVEERFESGGAKTDQEVIDGLRGTHSADPGKVLEIVVAHQSAGPRADLVHRLLNALVLPSPEAYRPILRRLAALTGAGSAAPAQRARRLLEHSLLGELRVLVAARAVRPWTWFSDAALRGLCLGESPGEPVSPRAELASALAAESSVASPTSRRSTLAEGLYVGLGNLAAAAASSVEARMAMLVEAPAAVDDALATLLDHPDPVLQRRALSTYVRRIYFPGVLHEPQVVGRRAGARSVRVWATRGAPGAMAPRPSRTSMAGLAPGTLHVVLTAEGAAALQLDAAAQAALGTLDVSGYVAPEHQQQPGLPDASVVAASAAAAVSALAPALREAGYSAVSFLTKRGGVEPLRVVFYDGTSSGSAAAPDSSSTQTGHRPAGPWTPCSARSSRRRPRRWSWPVWPAARAPRTTPRATVAHVDRGRARRQAQRGAAPHLFARRGALAGPAGAAERGLRGNGPAVAAAALAELEQTVEAAAAELERLGKGRVGGASSRLDAPCLSVLMLAAAGRVRAARRERRRRARAGRAAAIASRHVAALRRAALAQWEVCLRTGSGGASHREGGWRVVVSSPTGHEAGEAFVDVYREAADGTLRAVNPSLRAPGPLDGQSVLAPYPTLAPLQQRRLTARRHKTTYAYDFPAVFEDALRSIWLQRAVELGATGLEAAREDLLPPGTAWSRPELVLDTEEAIYENGAAHIRLTDRAPSMNDLGVVAWRLTLATPECPRGRAVVAIANDITYNSGSFGPREDAFFKAATEYALAERLPVVYLAANSGARVGLAEEVKRCLRVEWSVPGDPTKGHKYLYLDDEDYRSITGRAAGRTLPVSCSAKVGADGRTRHVLHDVIGLEDGLGVECLSGSGAIAGAFARAFREGFTVTLVSGRTVGIGAYLARLGRRCVQRREQPIILTGFAALNKLLGREVYTSQQQLGGPRVMGANGVSHHVVDDDLQGVHAVLRWLAYTPARVGELPPTLRAADPVDRRVTYAPAENEKLDPRLAVAGGDAPEPVTGLFDRGSWTEAQAGWAQTVVTGRARLGGIPVGVVAVEVNAVSLHIPADPGMPDSAERTIPQAGQVWFPDSALKTAQAIEEFGLEGLPLFILANWRGFSGGQRDLFEGVLQAGSQIVEMLRTYRRPVTVYLGPAASCAAAPGSCSTPINPASIEMYADPTAQGAVLEPQGVVEIKFRTPDLLAAMHRLDEKIIALKSDDSPSALAAIKARESELLPVYSQVAHQFAQMHDGPVRMLAKGVLRGIVPWSAARAFLATRLRRRLAEEALLRQIAAADASVEHADALAMLRSWFLSSPPTGGAPGAPGALGALLKETVVAPPDAGEAPLALWQDDLAFLDWSEAEAGASRVALELKSLRVNVAMRSVDRLCQTPEGTAGLVKGLDEAIKSNPSLLLCLRSLVKP*SEQIDNO:264桑椹形原藻氮反应调节子(NRR1)ATGGAGGAGCCGGACCAACAGGACCCTGCGGGCTCCGGGACCACCCAGGCCGAGGCTGAAAAGAGGAGTGCATCCCCAAAGCCCGTCAGCGAGGCCACCAGCGACGGCAAGGCCTCCTCCGTGGCCACGGCGGCCGAAGCCAAGCCCGAAAGCTCTCCAGGCGAGGATGTGGCCGCCCTCTACCCCGGCATCCCCGTCCTGCCGGACCTGGGCCGGTTGCGGGACAACCGGCGCGACGTGCCCCTGACCTGCCAGGTGGTGGGCTGCGGCGAGAGCCTCAGCGGGCACGCCGAGTACTACCGGCGGTACCGCGTCTGCAAGCGCCACCTCAAGGGCTCGGCGCTGATCGTGGACGGGGTGCCGCAGCGATTCTGCCAGCAGTGCGGTCGCTTCCACCTGCTGGAGGCCTTTGACGGCGAGAAGAGAAACTGCCGCGCCCGGCTGGAGGAGCACAACTCGCGGCGGCGAAAGGTCATGGCGCCGGGGGGCGGCGGCCAGGTGACGGGCGCGCGCGCGACGCGCCGGGAGTCGGAGCGGCACGGCCGCGGCATGGACCTGCGCGGCGCCGGGCTCGAGGTCGCTCGGTCGCCCGSEQIDNO:265桑椹形原藻氮反应调节子(NRR1),蛋白质MEEPDQQDPAGSGTTQAEAEKRSASPKPVSEATSDGKASSVATAAEAKPESSPGEDVAALYPGIPVLPDLGRLRDNRRDVPLTCQVVGCGESLSGHAEYYRRYRVCKRHLKGSALIVDGVPQRFCQQCGRFHLLEAFDGEKRNCRARLEEHNSRRRKVMAPGGGGQVTGARATRRESERHGRGMDLRGAGLEVARSPSEQIDNO:266桑椹形原藻单酰基甘油酰基转移酶(MGAT1)CGCAAAGGGTGTTCAGTGGTCGATGGGGACGAACTTGACGTCCTCGTAGCCTGGGAAGCTGGGCGCGTAGCGTGCGAAGAGGTCCTCCAGCGAGGCGTAGAACCGCGCGTGGACGTCGTCGATCTGGGCCTGCGAGGGGCCCTCTGGCGCCACCTTTGTCGCCGGGAGGATGGGCTTGCCGATCACAAACCTGAGTCCTGTGGGGCGGGGGAAGGGCGACACCTGGTAGCGCCCGCCGATGAGGTAGGGCACGGGGAAGCCCAGGCGCTTGTAGGTCCAGCGCAGCATGCCCGGCAGGTTGACCAGGTTTTGGAGCGAGTCGACCTCGCCCAGCGCCAGCACCGGCACGAGCGCGGCCTCGCTCTGCAGCGCCAGCCGCACAAAGCCCTTGTGGCTGCGGAACACGCAAAACTCCCGCGTCGGCCGCGCGATGCGGTGCGTGTGCACCAGCTCGGCCTGGCCACCGGGGACGAGCAGCACGGCGCCCTTCTCGCGCAGCGCGCGGAGGAAGGATCGCCGCGAGACGACGCGCAGGCCGAGCCAGGCCAGCAGGTCGCGCAGCAAGGGCACCGCAAACACGATCGAGGCGCAGAGCGTCACGGGGCGGATGCCGGGGAGCAGGCGCCGGAAGCCGGGCAGCAGCGGCAGGTAGCCGGCCGCCAGCGGGTACAGACCGTGCACGGCAAAGCCAAAGACGTGGCGGCGCTCGGGGTCGTACTGGTCCGCCTCGCCGTCGCGCAGGATCTCCAGCGACCCTACCCAGGCCGGGAGCACCTCCTCCGACCGCCGCCCAAACCAGTCCCGGAACAGCGGCCACTCCCGCCGGCCTGTCTCGCCAAAGGGCCCGCCAATCAGGGTGATGCTGTAGTACACAAAGGCCGAAGCGAGCAGGAGCGTCAGGGCAATCTCCAGCGGAAAGAGAAGAAAGTAGAGCGCAATGATTGTGCACAGCAACTGGACCGGGGCGTAGAGGAGGGTGATGACAAGGGCGTCGGAGAGCCGGGTCCGTAGGTCGGTCGGCCGCAGCGCGCGCTCCGAGAGCGACGCGCTGAGTCCGCGCACGAGCTCCATGGTCCGCACGGGGCCCTTGTACAGCAACAGCGAGCCGGCCAGCACCAGGTGGGAGAAGACCATGAAGATGCCTGCGGTCTGGGCAAAGCGCTGCGCGCTGTGCACGATGCCGATGGTGCTGTGGGCCATGAGGTAGATGATGAGGCTCAGCCCCGCGGAGTAGAGCGCCCACCCCAGGGCCTGCGTGGCCACGAACCAGCCGCCGCCCTTGAAGGGCTGGAAAAAGTGCCATGCGGCCGGCGCGGCCTCATCGCCGCCCTCGGAGTCGCTCTCGCTGCCGGGCTCGGACTTGCGATGCACGTGCCGCAGGTGGCCCGCCAGCCCGTAGGTCACAAAGGCGGCCATGGTCAAGCATGCGCCCGAGAGCGCCAGGTACGCCAGCCGCACGGGCGCGTCCTCCAGCAGGTTGGCGCCCAGGTGCAGCAGCGCGGCGCCCAGCGCGACCCAGAGCGACCCCATCCCGATCACGACGTACGAGGCCGCGGCGGACGACGGCAGCGACTTGACGTCCCACAAGACATCGGTGTGGCCCTGCTGGAGACCCGCGAGGATGCGCATGGGCTTGGCCGCGGGGTCAAAGACCAGCACGGCAGACACCTGGAAGAGCTGGGAGGACACGGCTCCCACGGCCGCGGCGGCCACCAGCAGCTCCACCGTCAGGCTAGACATCCAATCGTGCCGCGCGGCCGACAGAATGGGCACCACTACGGCGCAGCTCAGGAGCCAAGCTGAGAAGGACATGGCCTGGAAGACGAGGGTGCGTACCCCGCCCATCGTGCCCCAGCTCCACCCGGGCCGGACCTGGGTCTTGCCCCTGCCCAGCTGCACGGCGCGGTGCAGCCATCGCGCCCCGCCAACGTAGGTGAGGGGCGTGGACACCGCGAACACCACCCAGCAGGCCGCCAGGCAAATGACCACGTGGTCGCCGGAGAGGACCGACTCCGAGAGGGAGTGGCTCACCGACGTCATAGCAAGGGCCCTCGTCCGTCAGACAGACTCATTCGATGCACATCCCTGCTCCCGCGGTGGGAATGAGGTTGGGAAAAAGATGGGATCGACCTGGGAATGGAAGCGAACTGCCAGGAAGGCATCGTCACCGGGGGTTCCGACAACCATATCGTCATTGATGCATCGGGGCCTCCGGGGAGGCGTCTGCCGCCGGACATGGGAGCGATCAGGCGACCGGAGTGTTTAAGCGAGCACACGACCAGCACCGTCGTTGAGCCTCGAAAGTGATGCAAASEQIDNO:267桑椹形原藻单酰基甘油酰基转移酶(MGAT1),蛋白质MTSVSHSLSESVLSGDHVVICLAACWVVFAVSTPLTYVGGARWLHRAVQLGRGKTQVRPGWSWGTMGGVRTLVFQAMSFSAWLLSCAVVVPILSAARHDWMSSLTVELLVAAAAVGAVSSQLFQVSAVLVFDPAAKPMRILAGLQQGHTDVLWDVKSLPSSAAASYVVIGMGSLWVALGAALLHLGANLLEDAPVRLAYLALSGACLTMAAFVTYGLAGHLRHVHRKSEPGSESDSEGGDEAAPAAWHFFQPFKGGGWFVATQALGWALYSAGLSLIIYLMAHSTIGIVHSAQRFAQTAGIFMVFSHLVLAGSLLLYKGPVRTMELVRGLSASLSERALRPTDLRTRLSDALVITLLYAPVQLLCTIIALYFLLFPLEIALTLLLASAFVYYSITLIGGPFGETGRREWPLFRDWFGRRSEEVLPAWVGSLEILRDGEADQYDPERRHVFGFAVHGLYPLAAGYLPLLPGFRRLLPGIRPVTLCASIVFAVPLLRDLLAWLGLRVVSRRSFLRALREKGAVLLVPGGQAELVHTHRIARPTREFCVFRSHKGFVRLALQSEAALVPVLALGEVDSLQNLVNLPGMLRWTYKRLGFPVPYLIGGRYQVSPFPRPTGLRFVIGKPILPATKVAPEGPSQAQIDDVHARFYASLEDLFARYAPSFPGYEDVKFVPIDH*SEQIDNO:268桑椹形原藻纤维素酶,内切葡聚糖酶(EG1)CTCCTCCCAGCCACCGTCCACCAAATCCCACCTCTCGCCCGCTCAGACGTTGATGTAGGTGCCGCAGATGTCGGAGCGGCGGAAGATGCCGTACTGCTGCAGGCACTGCTCCCAGAGCCCAGAGGGCAGCTTGCTGGCGCCGGCCAGGGCGCCGATCAGGCCCGCGTTGTTCTCCACGCCCACGTAGGCCGCGGTCGTGTCGCGCGTGTCCACAAAGTTGTCCGAGCTGGCCGTGCCGTACACGAGCGCGCCCGTGAGCGTGTGCGTGTCGGGGTCGGGCGACAGCAGACCGGTCACGCGGTTGCACACCTCTGGCTCGGCCGGGCAGGCCGCGTCGCGGTCCTGCGTGCGCTTGGGCGGGTTCTTGCCAAAGCCGACGACGAGCGAGCGCCCCGAGTCGCCCAGCACGTAGCGGATCTGGCTCAGGCCCCAGCACTGGTACTCAAACACGCGCGTCGACCCGGGGTCGTTCAGCGAGTCCGCGTAGGCCAGCGCCGCAAAGGCCGTGTTCATGGTGGAGCCCAGCGGCGCGCTCATGGGGTTGTAGGCGCGGCCCTTGAGCGTGTAGTTGGCCGCCAGGTCGGAGCAGATCCAGGACTTGAGGAACAGCTCCGACTGGCTCTGGAAGGTCACGCCGCCCGTCTCCTGCGCCAGCAGCACGTTGGTCGGCCAGAACACGTTGTCCCAGTCAAACGCGTACTTGAAGTCGCTCACCGACGACTCGTACTCCAGGTGGTTCACGTACTGGCTGTACATGTTGGTCAGGTACTGCTGCTCCCCCGTCGCCTTGTACATCCAGCTGCTCGACCACGCCAGGTCGTCGTAAAACGTGCTCGAGTTGTACACCTTGGAAATGTTCCAGTCCTGCACCGAGTAGTGGCCCAGGTCGGTGGAGGCGATGTCGTACACGGCCTTGGCCTTGGTCAGCAGCTCCGTCGCGTAGGCCGCGTCGCCGCTGGCGTTGAACACGATGGAGGCCGAGGCCAGCGCCGCCGCGACCTGGCCGCCCAGGTCGCTCGCGCCCTTGGCCATGTCCACCACGTACGCGGGCCGGTCCGTGGTGTAGTCCTCCAGACGGTACCAGTTGAGCTCCTCCTGCTGGATGTTGCCAATCCTGGACAGAATGTAGGTGGTGTTGCTCGTCGTCTGCACCGTCTTGAGCAGGTAGTCCGTGGACCAGCGCAGGTTGTCCAGCAGCGACGCGGAGCTGCCCGCGTCCCCGATGGCCTCGCCGTAGGTCTGGTAGGCCCAGGACATGAGCGTCGCCGTAAAGGCGATGGGCAGCGTGGCCTTGAAGTTGCCGGCCGCCATGCCCGTCACGTAGCCGCCCTCCAGGTCCCAGGTCGCGCCCAGCTTGACCGCCTGCGGCACCGACTTGGTCGACGAGGAGGGGCTGATCGTGGAAGGCGGCGGCAGGGTGGGGATGAGCGACGAAGGCGAGGAGCCCGGGGTGCTGGGCGACGAGCCCGCCACGGGCGACCACACCAGGTTGGCAAACGGSEQIDNO:269桑椹形原藻纤维素酶,内切葡聚糖酶(EG1),蛋白质PFANLVWSPVAGSSPSTPGSSPSSLIPTLPPPSTISPSSSTKSVPQAVKLGATWDLEGGYVTGMAAGNFKATLPIAFTATLMSWAYQTYGEAIGDAGSSASLLDNLRWSTDYLLKTVQTTSNTTYILSRIGNIQQEELNWYRLEDYTTDRPAYVVDMAKGASDLGGQVAAALASASIVFNASGDAAYATELLTKAKAVYDIASTDLGHYSVQDWNISKVYNSSTFYDDLAWSSSWMYKATGEQQYLTNMYSQYVNHLEYESSVSDFKYAFDWDNVFWPTNVLLAQETGGVTFQSQSELFLKSWICSDLAANYTLKGRAYNPMSAPLGSTMNTAFAALAYADSLNDPGSTRVFEYQCWGLSQIRYVLGDSGRSLVVGFGKNPPKRTQDRDAACPAEPEVCNRVTGLLSPDPDTHTLTGALVYGTASSDNFVDTRDTTAAYVGVENNAGLIGALAGASKLPSGLWEQCLQQYGIFRRSDICGTYINV*SEQIDNO:270桑椹形原藻KASIIMQTAHQRPPTEGHCFGARLPTASRRAVRRAWSRIARAAAAADANPARPERRVVITGQGVVTSLGQTIEQFYSSLLEGVSGISQIQKFDTTGYTTTIAGEIKSLQLDPYVPKRWAKRVDDVIKYVYIAGKQALESAGLPIEAAGLAGAGLDPALCGVLIGTAMAGMTSFAAGVEALTRGGVRKMNPFCIPFSISNMGGAMLAMDIGFMGPNYSISTACATGNYCILGAADHIRRGDANVMLAGGADAAIIPSGIGGFIACKALSKRNDEPERASRPWDADRDGFVMGEGAGVLVLEELEHAKRRGATILAELVGGAATSDAHHMTEPDPQGRGVRLCLERALERARLAPERVGYVNAHGTSTPAGDVAEYRAIRAVIPQDSLRINSTKSMIGHLLGGAGAVEAVAAIQALRTGWLHPNLNLENPAPGVDPVVLVGPRKERAEDLDVVLSNSFGFGGHNSCVIFRKYDESEQIDNO:271桑椹形原藻硬脂酰基ACP脱饱和酶MASAVTFACAPPRGAVAAPGRRAASRPLVVRAVASEAPLGVPPSVQRPSPVVYSKLDKQHRLTPERLELVQSMGQFAEERVLPVLHPVDKLWQPQDFLPDPESPDFEDQVAELRARAKDLPDEYFVVLVGDMITEEALPTYMAMLNTLDGVRDDTGAADHPWARWTRQWVAEENRHGDLLNKYCWLTGRVNMRAVEVTINNLIKSGMNPQTDNNPYLGFVYTSFQERATKYSHGNTARLAAEHGDKNLSKICGLIASDEGRHEIAYTRIVDEFFRLDPEGAVAAYANMMRKQITMPAHLMDDMGHGEANPGRNLFADFSAVAEKIDVYDAEDYCRILEHLNARWKVDERQVSGQAAADQEYVLGLPQRFRKLAEKTAAKRKRVARRPVAFSWISGREIMVSEQIDNO:272桑椹形原藻d12脱饱和酶等位基因1MAIKTNRQPVEKPPFTIGTLRKAIPAHCFERSALRSSMYLAFDIAVMSLLYVASTYIDPAPVPTWVKYGVMWPLYWFFQGAFGTGVWVCAHECGHQAFSSSQAINDGVGLVFHSLLLVPYYSWKHSHRRHHSNTGCLDKDEVFVPPHRAVAHEGLEWEEWLPIRMGKVLVTLTLGWPLYLMFNVASRPYPRFANHFDPWSPIFSKRERIEVVISDLALVAVLSGLSVLGRTMGWAWLVKTYVVPYLIVNMWLVLITLLQHTHPALPHYFEKDWDWLRGAMATVDRSMGPPFMDNILHHISDTHVLHHLFSTIPHYHAEEASAAIRPILGKYYQSDSRWVGRALWEDWRDCRYVVPDAPEDDSALWFHKSEQIDNO:273桑椹形原藻Δ12脱饱和酶等位基因2MAIKTNRQPVEKPPFTIGTLRKAIPAHCFERSALRSSMYLAFDIAVMSLLYVASTYIDPAPVPTWVKYGIMWPLYWFFQGAFGTGVWVCAHECGHQAFSSSQAINDGVGLVFHSLLLVPYYSWKHSHRRHHSNTGCLDKDEVFVPPHRAVAHEGLEWEEWLPIRMGKVLVTLTLGWPLYLMFNVASRPYPRFANHFDPWSPIFSKRERIEVVISDLALVAVLSGLSVLGRTMGWAWLVKTYVVPYMIVNMWLVLITLLQHTHPALPHYFEKDWDWLRGAMATVDRSMGPPFMDSILHHISDTHVLHHLFSTIPHYHAEEASAAIRPILGKYYQSDSRWVGRALWEDWRDCRYVVPDAPEDDSALWFHK
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1