一种5’‑UTR元件及其在生产中的应用的制作方法
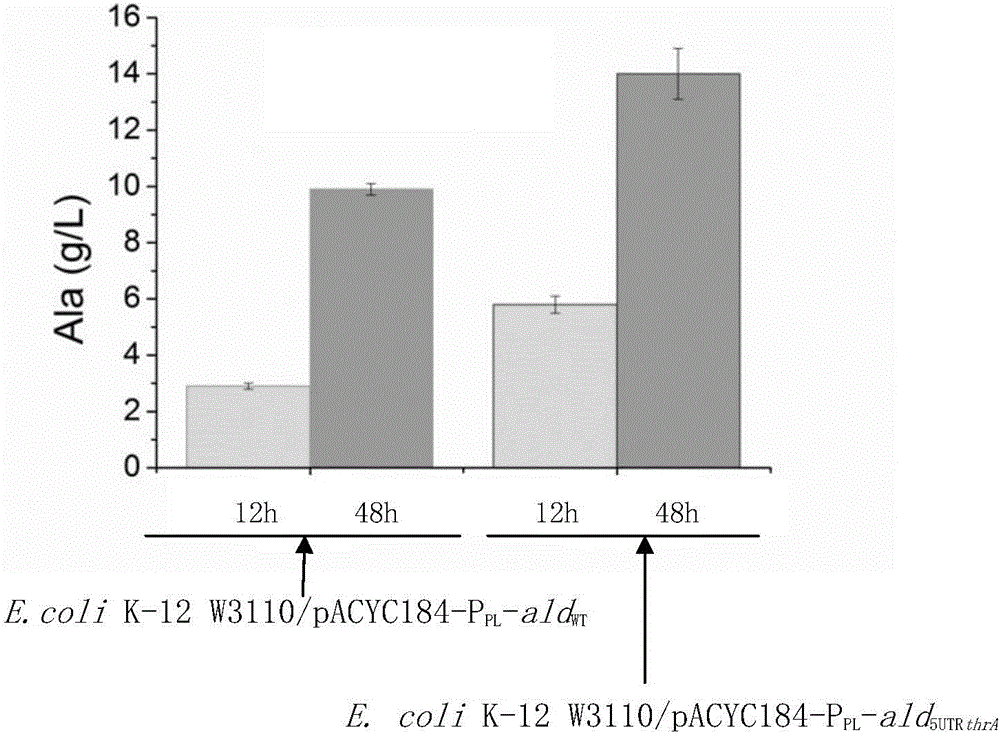
本发明属于生物
技术领域:
,涉及一种5’-UTR元件及其在生产中的应用,特别是在L-丙氨酸发酵生产中的应用。
背景技术:
:在生物反应器中表达目的蛋白,通常是将具有启动子和目的蛋白的编码基因的DNA分子导入生物反应器,由启动子启动编码基因的表达,得到目的蛋白。因此,增加目的蛋白的表达能力,具有非常大的应用前景。L-丙氨酸是人体非必需氨基酸,带有甜味,易溶于水,应用领域广泛。在食品工业中L-丙氨酸可提高食品的味感和蛋白质利用率。在医药领域,L-丙氨酸常被用作氨基酸类营养药,同时L-丙氨酸也是制造氨基丙醇和维生素B6等有机化合物的重要原料。近年来,L-丙氨酸还被用于合成聚酰胺、聚酯酰胺等工程塑料。特别是L-丙氨酸作为表面活性剂的合成前体,在洗化行业中的应用,大大提高了L-丙氨酸的市场需求量,拓展了L-丙氨酸的应用领域。目前,L-丙氨酸主要通过微生物发酵法生产。微生物发酵法以葡萄糖等可再生碳源为原料,通过细菌生产L-丙氨酸。在菌株中过表达丙氨酸脱氢酶是生产L-丙氨酸的关键。在发酵法生产L-丙氨酸的现有技术中,一般通过质粒增加丙氨酸脱氢酶基因的拷贝数,提高外源丙氨酸脱氢酶在大肠杆菌中的表达量(ApplMicrobiolBiotechnol(2004)65:56–60;BiotechnolLett(2006)28:1695–1700;ApplBiochemBiotechnol(2016)178:324–337)。然而,仅仅通过质粒拷贝数提高丙氨酸脱氢酶的表达量存在稳定性差和代谢负担重的缺点,因此,亟需开发高效的基因表达元件,提高相同基因拷贝数的丙氨酸脱氢酶表达量,提升工程菌发酵生产L-丙氨酸的性能。技术实现要素:本发明的目的是提供一种5’-UTR元件及其在生产中的应用。本发明首先提供了一种DNA分子甲,如序列表的序列14第294至n1位核苷酸所示,n1为310以上606以下的自然数。n1为310以上336以下的自然数。n1具体可为311或336或606。本发明还保护所述DNA分子甲作为调控元件,在促进目的基因表达中的应用。所述应用中,所述DNA分子甲位于所述目的基因的起始密码子与所述目的基因的启动子之间。所述目的基因具体可为编码丙氨酸脱氢酶的基因、lacZ基因或gfp基因。本发明还保护一种DNA分子乙,自上游至下游依次包括如下元件:启动子、所述DNA分子甲、目的基因。所述DNA分子乙自上游至下游依次包括如下元件:启动子、所述DNA分子甲、连接序列“GGTTCTGGTTCTGGTTCT”、目的基因。所述DNA分子乙自上游至下游依次由如下元件组成:启动子、限制性内切酶HindⅢ的酶切识别序列、所述DNA分子甲、连接序列“GGTTCTGGTTCTGGTTCT”、目的基因。所述目的基因具体可为lacZ基因或gfp基因。含有所述DNA分子乙的重组质粒乙也属于本发明的保护范围。所述重组质粒乙具体可为在出发质粒的多克隆位点插入所述DNA分子乙得到的重组质粒。所述出发质粒为低拷贝、中拷贝或高拷贝数质粒,例如pSC101、pACYC184、pBR322或pTrc99a。所述出发质粒具体可为质粒pACYC184。所述重组质粒乙更具体可为在质粒pACYC184的XbaI和BamHⅠ酶切位点之间插入所述DNA分子乙得到的重组质粒。本发明还保护含有以上任一所述DNA分子乙的重组菌乙。所述重组菌乙具体可为将所述重组质粒乙导入出发菌得到的重组菌。本发明还保护一种DNA分子丙,自上游至下游依次包括如下元件:所述DNA分子甲、编码丙氨酸脱氢酶的基因。所述DNA分子丙自上游至下游依次由如下元件组成:所述DNA分子甲、编码丙氨酸脱氢酶的基因。所述DNA分子丙具体如序列表的序列18所示。含有所述DNA分子丙的重组质粒丙也属于本发明的保护范围。所述重组质粒丙具体可为在出发质粒的多克隆位点插入所述DNA分子丙得到的重组质粒。所述出发质粒为低拷贝、中拷贝或高拷贝数质粒,例如pSC101、pACYC184、pBR322或pTrc99a。所述出发质粒具体可为质粒pACYC184。所述重组质粒丙更具体可为在质粒pACYC184的XbaI和SphⅠ酶切位点之间插入所述DNA分子丙得到的重组质粒。本发明还保护含有以上任一所述DNA分子丙的重组菌丙。所述重组菌丙具体可为将所述重组质粒丙导入出发菌得到的重组菌。本发明还保护一种DNA分子丁,自上游至下游依次包括如下元件:启动子、DNA分子丙。所述DNA分子丁自上游至下游依次由如下元件组成:启动子、限制性内切酶BamHⅠ的酶切识别序列、DNA分子丙。含有所述DNA分子丁的重组质粒丁也属于本发明的保护范围。所述重组质粒丁具体可为在出发质粒的多克隆位点插入所述DNA分子丁得到的重组质粒。所述出发质粒为低拷贝、中拷贝或高拷贝数质粒,例如pSC101、pACYC184、pBR322或pTrc99a。所述出发质粒具体可为质粒pACYC184。所述重组质粒丁更具体可为在质粒pACYC184的XbaI和SphⅠ酶切位点之间插入所述DNA分子丁得到的重组质粒。本发明还保护含有以上任一所述DNA分子丁的重组菌丁。所述重组菌丁具体可为将所述重组质粒丁导入出发菌得到的重组菌。以上任一所述丙氨酸脱氢酶具体可为来源于枯草芽孢杆菌W168的丙氨酸脱氢酶。以上任一所述丙氨酸脱氢酶具体可为如下(a1)或(a2):(a1)由序列表中序列19所示的氨基酸序列组成的蛋白质;(a2)将序列19的氨基酸序列经过一个或几个氨基酸残基的取代和/或缺失和/或添加且具有丙氨酸脱氢酶功能的由序列19衍生的蛋白质。以上任一所述编码丙氨酸脱氢酶的基因为如下(a3)或(a4)或(a5)或(a6):(a3)编码区如序列表中序列18第44-1180位核苷酸所示的DNA分子;(a4)序列表中序列18第44-1262位核苷酸所示的DNA分子;(a5)在严格条件下与(a3)或(a4)限定的DNA序列杂交且编码丙氨酸脱氢酶的DNA分子;(a6)与(a3)或(a4)限定的DNA序列具有90%以上同源性且编码丙氨酸脱氢酶的DNA分子。以上任一所述lacZ基因为如下(b1)或(b2)或(b3)或(b4):(b1)编码区如序列表中序列15第1-3075位核苷酸所示的DNA分子;(b2)序列表中序列15所示的DNA分子;(b3)在严格条件下与(b1)或(b2)限定的DNA序列杂交且编码β-半乳糖苷酶的DNA分子;(b4)与(b1)或(b2)限定的DNA序列具有90%以上同源性且编码β-半乳糖苷酶的DNA分子。以上任一所述gfp基因为如下(c1)或(c2)或(c3):(c1)编码区如序列表中序列16所示的DNA分子;(c2)在严格条件下与(c1)限定的DNA序列杂交且编码绿色荧光蛋白的DNA分子;(c3)与(c1)或(c2)限定的DNA序列具有90%以上同源性且编码绿色荧光蛋白的DNA分子。以上任一所述启动子具体可为强启动子,例如L启动子、trc启动子、T5启动子、lac启动子、tac启动子或T7启动子。以上任一所述启动子具体可为启动子PPL。启动子PPL为如下(d1)或(d2)或(d3):(d1)序列表中序列13所示的DNA分子;(d2)在严格条件下与(d1)限定的DNA序列杂交且具有启动子功能的DNA分子;(d3)与(d1)限定的DNA序列具有90%以上同源性且具有启动子功能的DNA分子。以上任一所述严格条件可为用0.1×SSPE(或0.1×SSC),0.1%SDS的溶液,在DNA或者RNA杂交实验中65℃下杂交并洗膜。以上任一所述出发菌可为细菌,进一步可为埃希氏菌属细菌,更具体可为大肠杆菌。以上任一所述出发菌更具体可为大肠杆菌K12W3110。以上任一所述出发菌更具体可为以大肠杆菌K12W3110为出发菌株,抑制metA基因、ilvA基因、lysA基因、tdh基因、tdcC基因和sstT基因表达得到的菌株。所述metA基因为编码高丝氨酸琥珀酰转移酶(MetA蛋白)的基因。所述MetA蛋白为如下(g1)或(g2):(g1)由序列表中序列2所示的氨基酸序列组成的蛋白质;(g2)将序列2的氨基酸序列经过一个或几个氨基酸残基的取代和/或缺失和/或添加且具有相同功能的由序列2衍生的蛋白质。所述metA基因为如下(g3)或(g4)或(g5)或(g6):(g3)编码区如序列表中序列1第752-1681位核苷酸所示的DNA分子;(g4)序列表中序列1所示的DNA分子;(g5)在严格条件下与(g3)或(g4)限定的DNA序列杂交且编码具有相同功能的蛋白质的DNA分子;(g6)与(g3)或(g4)限定的DNA序列具有90%以上同源性且编码具有相同功能的蛋白质的DNA分子。所述ilvA基因为编码苏氨酸脱氨酶(IlvA蛋白)的基因。所述IlvA蛋白为如下(h1)或(h2):(h1)由序列表中序列4所示的氨基酸序列组成的蛋白质;(h2)将序列4的氨基酸序列经过一个或几个氨基酸残基的取代和/或缺失和/或添加且具有相同功能的由序列4衍生的蛋白质。所述ilvA基因为如下(h3)或(h4)或(h5)或(h6):(h3)编码区如序列表中序列3第638-2182位核苷酸所示的DNA分子;(h4)序列表中序列3所示的DNA分子;(h5)在严格条件下与(h3)或(h4)限定的DNA序列杂交且编码具有相同功能的蛋白质的DNA分子;(h6)与(h3)或(h4)限定的DNA序列具有90%以上同源性且编码具有相同功能的蛋白质的DNA分子。所述lysA基因为编码二氨基庚二酸脱羧酶(LysA蛋白)的基因。所述LysA蛋白为如下(i1)或(i2):(i1)由序列表中序列6所示的氨基酸序列组成的蛋白质;(i2)将序列6的氨基酸序列经过一个或几个氨基酸残基的取代和/或缺失和/或添加且具有相同功能的由序列6衍生的蛋白质。所述lysA基因为如下(i3)或(i4)或(i5)或(i6):(i3)编码区如序列表中序列5第639-1901位核苷酸所示的DNA分子;(i4)序列表中序列5所示的DNA分子;(i5)在严格条件下与(i3)或(i4)限定的DNA序列杂交且编码具有相同功能的蛋白质的DNA分子;(i6)与(i3)或(i4)限定的DNA序列具有90%以上同源性且编码具有相同功能的蛋白质的DNA分子。所述tdh基因为编码苏氨酸脱水酶(Tdh蛋白)的基因。所述Tdh蛋白为如下(j1)或(j2):(j1)由序列表中序列8所示的氨基酸序列组成的蛋白质;(j2)将序列8的氨基酸序列经过一个或几个氨基酸残基的取代和/或缺失和/或添加且具有相同功能的由序列8衍生的蛋白质。所述tdh基因为如下(j3)或(j4)或(j5)或(j6):(j3)编码区如序列表中序列7第753-1778位核苷酸所示的DNA分子;(j4)序列表中序列7所示的DNA分子;(j5)在严格条件下与(j3)或(j4)限定的DNA序列杂交且编码具有相同功能的蛋白质的DNA分子;(j6)与(j3)或(j4)限定的DNA序列具有90%以上同源性且编码具有相同功能的蛋白质的DNA分子。所述tdcC基因为编码苏氨酸吸收转运蛋白(TdcC蛋白)的基因。所述TdcC蛋白为如下(k1)或(k2):(k1)由序列表中序列10所示的氨基酸序列组成的蛋白质;(k2)将序列10的氨基酸序列经过一个或几个氨基酸残基的取代和/或缺失和/或添加且具有相同功能的由序列10衍生的蛋白质。所述tdcC基因为如下(k3)或(k4)或(k5)或(k6):(k3)编码区如序列表中序列9第701-2032位核苷酸所示的DNA分子;(k4)序列表中序列9所示的DNA分子;(k5)在严格条件下与(k3)或(k4)限定的DNA序列杂交且编码具有相同功能的蛋白质的DNA分子;(k6)与(k3)或(k4)限定的DNA序列具有90%以上同源性且编码具有相同功能的蛋白质的DNA分子。所述sstT基因为编码苏氨酸吸收转运蛋白(SstT蛋白)的基因。所述SstT蛋白为如下(m1)或(m2):(m1)由序列表中序列12所示的氨基酸序列组成的蛋白质;(m2)将序列12的氨基酸序列经过一个或几个氨基酸残基的取代和/或缺失和/或添加且具有相同功能的由序列12衍生的蛋白质。所述sstT基因为如下(m3)或(m4)或(m5)或(m6):(m3)编码区如序列表中序列11第701-1945位核苷酸所示的DNA分子;(m4)序列表中序列11所示的DNA分子;(m5)在严格条件下与(m3)或(m4)限定的DNA序列杂交且编码具有相同功能的蛋白质的DNA分子;(m6)与(m3)或(m4)限定的DNA序列具有90%以上同源性且编码具有相同功能的蛋白质的DNA分子。以上任一所述严格条件可为用0.1×SSPE(或0.1×SSC),0.1%SDS的溶液,在DNA或者RNA杂交实验中65℃下杂交并洗膜。以上任一所述出发菌更具体可为以大肠杆菌K12W3110为出发菌株,敲除如下六个基因区段得到的菌株:metA基因的开放阅读框(序列表的序列1第752-1681位核苷酸);ilvA基因的开放阅读框(序列表的序列3第638-2182位核苷酸);lysA基因的开放阅读框(序列表的序列5第639-1901位核苷酸);tdh基因的开放阅读框(序列表的序列7第753-1778位核苷酸);tdcC基因的如下区段:序列9中第701-1852位核苷酸;sstT基因的如下区段:序列11中第697-1759位核苷酸。敲除metA基因的开放阅读框具体是通过导入干扰片段Ⅰ或干扰质粒Ⅰ实现的。干扰片段Ⅰ自上游至下游依次由序列表的序列1第245-751位核苷酸所示的上游区段和序列表的序列1第1682-2154位核苷酸所示的下游区段组成。干扰质粒Ⅰ为具有干扰片段Ⅰ的重组质粒。干扰质粒Ⅰ具体可为在pKOV质粒的多克隆位点(例如SalI和NotI酶切位点之间)插入干扰片段Ⅰ得到的重组质粒。敲除ilvA基因的开放阅读框具体是通过导入干扰片段Ⅱ或干扰质粒Ⅱ实现的。干扰片段Ⅱ自上游至下游依次由序列表的序列3第140-637位核苷酸所示的上游区段和序列表的序列3第2183-2712位核苷酸所示的下游区段组成。干扰质粒Ⅱ为具有干扰片段Ⅱ的重组质粒。干扰质粒Ⅱ具体可为在pKOV质粒的多克隆位点(例如BamHI和NotI酶切位点之间)插入干扰片段Ⅱ得到的重组质粒。敲除lysA基因的开放阅读框具体是通过导入干扰片段Ⅲ或干扰质粒Ⅲ实现的。干扰片段Ⅲ自上游至下游依次由序列表的序列5第132-638位核苷酸所示的上游区段和序列表的序列5第1902-2445位核苷酸所示的下游区段组成。干扰质粒Ⅲ为具有干扰片段Ⅲ的重组质粒。干扰质粒Ⅲ具体可为在pKOV质粒的多克隆位点(例如BamHI和NotI酶切位点之间)插入干扰片段Ⅲ得到的重组质粒。敲除tdh基因的开放阅读框具体是通过导入干扰片段Ⅳ或干扰质粒Ⅳ实现的。干扰片段Ⅳ自上游至下游依次由序列表的序列7第227-752位核苷酸所示的上游区段和序列表的序列7第1779-2271位核苷酸所示的下游区段组成。干扰质粒Ⅳ为具有干扰片段Ⅳ的重组质粒。干扰质粒Ⅳ具体可为在pKOV质粒的多克隆位点(例如BamHI和NotI酶切位点之间)插入干扰片段Ⅳ得到的重组质粒。敲除“tdcC基因的如下区段:序列9中第701-1852位核苷酸”是通过导入干扰片段Ⅴ或干扰质粒Ⅴ实现的。干扰片段Ⅴ自上游至下游依次由序列表的序列9第176-700位核苷酸所示的上游区段和序列表的序列9第1853-2388位核苷酸所示的下游区段组成。干扰质粒Ⅴ为具有干扰片段Ⅴ的重组质粒。干扰质粒Ⅴ具体可为在pKOV质粒的多克隆位点(例如BamHI和NotI酶切位点之间)插入干扰片段Ⅴ得到的重组质粒。敲除“sstT基因的如下区段:序列11中第697-1759位核苷酸”是通过导入干扰片段Ⅵ或干扰质粒Ⅵ实现的。干扰片段Ⅵ自上游至下游依次由序列表的序列11第14-696位核苷酸所示的上游区段和序列表的序列11第1760-2240位核苷酸所示的下游区段组成。干扰质粒Ⅵ为具有干扰片段Ⅵ的重组质粒。干扰质粒Ⅵ具体可为在pKOV质粒的多克隆位点(例如BamHI和NotI酶切位点之间)插入干扰片段Ⅵ得到的重组质粒。本发明还保护所述重组菌丙在生产L-丙氨酸中的应用。本发明还保护所述重组菌丁在生产L-丙氨酸中的应用。应用所述重组菌生产L-丙氨酸时,采用葡萄糖作为碳源。应用所述重组菌生产L-丙氨酸时,采用发酵培养基培养所述重组菌。所述发酵培养基可以是丰富培养基,也可以是无机盐培养基。培养基包含碳源、氮源、无机离子、抗生素和其它的营养因子。作为碳源,可以使用葡萄糖、乳糖、半乳糖等糖类;也可以是甘油、甘露醇等醇类;也可以使用葡萄糖酸、柠檬酸、丁二酸等有机酸类。作为氮源,可以使用氨水、硫酸铵、磷酸铵、氯化铵等无机氮源;也可以使用玉米浆、豆粕水解液、毛发粉、酵母提取物、蛋白胨等有机氮源。无机离子包含铁、钙、镁、锰、钼、钴、铜、钾等离子中的一种或多种。其它营养因子还包括生物素、维生素B1、吡哆醛等维生素。所述发酵培养基中的碳源为葡萄糖。所述发酵培养基具体可为:葡萄糖20.0g/L、酵母粉2.0g/L、蛋白胨4g/L、硫酸铵6.0g/L、磷酸二氢钾2.0g/L、七水硫酸镁1.0g/L、甜菜碱1.0g/L、碳酸钙15.0g/L,微量元素混合液1mL/L,余量为水。微量元素混合液:FeSO4·7H2O10g/L、CaCl21.35g/L、ZnSO4·7H2O2.25g/L、MnSO4·4H2O0.5g/L、CuSO4·5H2O1g/L、(NH4)6Mo7O24·4H2O0.106g/L、Na2B4O7·10H2O0.23g/L、CoCl2·6H2O0.48g/L、35%HCl10mL/L,余量为水。所述培养条件具体可为:37℃、220rpm震荡培养12-48h。所述培养的条件具体可为:将种子液以3%的接种量接种至发酵培养基中,37℃、220rpm震荡培养12-48h。种子液的制备方法如下:将重组菌接种至液体LB培养基中,37℃、220rpm振荡培养12h,得到种子液。所述培养的过程中进行如下过程控制:培养过程中,用氨水调节反应体系的pH值使其维持在6.8-7.0;培养过程中,每隔3-4h取样一次,检测葡萄糖含量,当体系中的葡萄糖含量低于5g/L时,补加葡萄糖并使体系中的葡萄糖浓度达到10g/L。本发明提供了解除反馈阻遏的苏氨酸衰减子突变体及其应用,获得显著增强基因表达的5’-UTR突变体,应用该突变体调控丙氨酸脱氢酶表达,构建了高效生产L-丙氨酸的菌株,为改进L-丙氨酸的发酵生产提供了新途径。本发明通过翻译融合报告基因的方法验证苏氨酸衰减子的改造效果。通过融合thrA基因的5’端序列与两种报告基因lacZ和gfp的完整阅读表达框,然后测定报告蛋白LacZ的酶活和GFP荧光值,计算不同苏氨酸衰减子突变体调控下的基因表达量,验证苏氨酸衰减子突变体调控基因表达的作用。本发明提供了从5’端逐步截短苏氨酸衰减子功能序列的改造方法,筛选得到了增强基因表达的5’非翻译区(5’-UntranslatedRegion,5’-UTR)表达元件。应用本发明优化得到的5’-UTR元件调控表达丙氨酸脱氢酶基因ald,可以提高工程菌的L-丙酸氨酸产量。本发明获得高效增强基因表达的核酸序列,构建了生产L-丙氨酸的菌株,为改进L-丙氨酸的发酵生产提供了新方法。附图说明图1流式细胞仪分析不同衰减子突变体调控下的GFP表达强度。图2工程菌摇瓶发酵的L-丙氨酸产量。具体实施方式以下的实施例便于更好地理解本发明,但并不限定本发明。下述实施例中的实验方法,如无特殊说明,均为常规方法。下述实施例中所用的试验材料,如无特殊说明,均为自常规生化试剂商店购买得到的。以下实施例中的定量试验,均设置三次重复实验,结果取平均值。下述实施例中如未特别指明,实施例中所用的技术手段为本领域技术人员所熟知的常规手段和市售的常用仪器、试剂,可参见《分子克隆实验指南(第3版)》(科学出版社)、《微生物学实验(第4版)》(高等教育出版社)以及相应仪器和试剂的厂商说明书等参考。大肠杆菌K12W3110(又称E.coliK12W3110):日本技术评价研究所生物资源中心(NITEBiologicalResourceCenter,NBRC)。pKOV质粒:Addgene公司,产品目录号为25769。pACYC184质粒:NEB公司,产品目录号E4152S。pAD123质粒:Gene,1999,226(2):297-305。ONPG的全称为:邻硝基苯-β-D-吡喃半乳糖苷。枯草芽孢杆菌W168:购自美国BacillusGeneticStockCenter,货号1A308。实施例所用的各个引物序列如下(5’→3’):WY569:GCGTCGACATAGAACCCAACCGCCTGCTCA;WY570:AACGATCGACTATCACAGAAGAAACCTGATTACCTCACTACATA;WY571:TATGTAGTGAGGTAATCAGGTTTCTTCTGTGATAGTCGATCGTT;WY572:ATTGCGGCCGCCCGAAATAAAATCAGGCAACGT;WY583:CGTTAATGAAATATCGCCAG;WY584:TCGAAATCGGCCATAAAGAC。WY577:CGCGGATCCGAAAGTGTACGAAAGCCAGG;WY578:GCGCTATCAGGCATTTTTCCTATTAACCCCCCAGTTTCGA;WY579:TCGAAACTGGGGGGTTAATAGGAAAAATGCCTGATAGCGC;WY580:ATTGCGGCCGCGTGAAGCGGATCTGGCGATT;WY587:ATGGCTGTATCCGCTCGCTG;WY588:ACACCATCGATCAGCAAGGGC。WY573:CGCGGATCCGGCACGATATTTAAGCTGAC;WY574:CAACCAGCGACTAACCGCAGAACAAACTCCAGATAAGTGC;WY575:GCACTTATCTGGAGTTTGTTCTGCGGTTAGTCGCTGGTTG;WY576:ATTGCGGCCGCGCTGGCAACGCGTCATTTAA;WY585:GTAACACACACACTTCATCT;WY586:GATCCCGGATGCTGATTTAG。WY598:CGCGGATCCATACTGCGATGTGATGGGCC;WY599:AATACCAGCCCTTGTTCGTGCTCACATCCTCAGGCGATAA;WY600:TTATCGCCTGAGGATGTGAGCACGAACAAGGGCTGGTATT;WY601:ATTGCGGCCGCCGTTGCCACTTCAATCCCAC;WY602:GCTATGCCAACAACGATATG;WY603:GGTTAATACGCCGGTTGAGC。WY476:CGCGGATCCGGAACGATTGGTCTGGAAAT;WY477:GGCTTCAATCAGGTCAAGGATATCCTATCCTCAACGAATTA;WY478:TAATTCGTTGAGGATAGGATATCCTTGACCTGATTGAAGCC;WY479:ATTGCGGCCGCCGCGACGGATATTATCAATGAC;WY497:GCGCCAAAATCCAAAGTAGC;WY498:ATGTGCGCGCTGGGAAACAT。WY945:CGCGGATCCTATCTTCGCCGTGACCACTGA;WY946:ACCGAACATATTACAGGCCAGCGATCCTTTCATTGTGTTGTC;WY947:GACAACACAATGAAAGGATCGCTGGCCTGTAATATGTTCGGT;WY948:ATTGCGGCCGCCTCGCGAAGTTCCATCATCCT;WY949:CCTGTAACGAGCGTAACGACT;WY950:TATCTTCGCCGTGACCACTGA。WY914:CCCAAGCTTACAGAGTACACAACATCCATG;WY1630:CCCAAGCTTCATTAGCACCACCATTACCA;WY1629:CCCAAGCTTCAGGTAACGGTGCGGGCTGA;WY1628:CCCAAGCTTCGCGTACAGGAAACACAGAA;WY1627:CCCAAGCTTGTGCGGGCTTTTTTTTTCGA;WY913:CCCAAGCTTTCGACCAAAGGTAACGAGGT;WY1746:CATAGAACCAGAACCAGAACCCAATTGCGCCAGCGGGAAC。WY1752:CAATTGGGTTCTGGTTCTGGTTCTATGACCATGATTACGGATTCACT;WY1750:CGCGGATCCACGCGAAATACGGGCAGACA。实施例1、E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT的构建以大肠杆菌K12W3110为出发菌株,依次敲除metA基因(编码高丝氨酸琥珀酰转移酶的基因)、ilvA基因(编码苏氨酸脱氨酶的基因)、lysA基因(编码二氨基庚二酸脱羧酶的基因)、tdh基因(编码苏氨酸脱水酶的基因)、tdcC基因(编码苏氨酸吸收转运蛋白的基因)和sstT基因(编码苏氨酸吸收转运蛋白的基因),获得底盘工程菌,将其命名为E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT。1、敲除metA基因(1)以大肠杆菌K12W3110的基因组DNA为模板,采用WY569和WY570组成的引物对进行PCR扩增,得到DNA片段Ⅰ-甲(metA基因上游区域)。(2)以大肠杆菌K12W3110的基因组DNA为模板,采用WY571和WY572组成的引物对进行PCR扩增,得到DNA片段Ⅰ-乙(metA基因下游区域)。(3)将DNA片段Ⅰ-甲和DNA片段Ⅰ-乙混合后作为模板,采用WY569和WY572组成的引物对进行PCR扩增,得到DNA片段Ⅰ-丙。(4)取pKOV质粒,用限制性内切酶SalI和NotI进行双酶切,回收载体骨架(约5.6kb)。(5)取DNA片段Ⅰ-丙,用限制性内切酶SalI和NotI进行双酶切,回收酶切产物。(6)将步骤(4)得到的载体骨架和步骤(5)得到的酶切产物连接,得到重组质粒Ⅰ。根据测序结果,对重组质粒Ⅰ进行结构描述如下:在pKOV质粒的SalI和NotI酶切位点之间插入了如下特异DNA分子:自上游至下游依次由序列表的序列1第245-751位核苷酸所示的上游区段和序列表的序列1第1682-2154位核苷酸所示的下游区段组成。metA基因如序列表的序列1所示,第752-1681位核苷酸为开放阅读框(编码序列表的序列2所示的metA蛋白)。(7)将重组质粒Ⅰ导入大肠杆菌K12W3110,得到metA基因敲除的重组菌,命名为E.coliK12W3110△metA。metA基因敲除的重组菌的鉴定方法:采用WY583和WY584组成的引物对进行PCR扩增,如果得到1375bp扩增产物,初步判断为候选的目标菌;进一步通过测序验证菌株染色体上的metA基因的开放阅读框被敲除。2、敲除ilvA基因(1)以大肠杆菌K12W3110的基因组DNA为模板,采用WY577和WY578组成的引物对进行PCR扩增,得到DNA片段Ⅱ-甲(ilvA基因上游区域)。(2)以大肠杆菌K12W3110的基因组DNA为模板,采用WY579和WY580组成的引物对进行PCR扩增,得到DNA片段Ⅱ-乙(ilvA基因下游区域)。(3)将DNA片段Ⅱ-甲和DNA片段Ⅱ-乙混合后作为模板,采用WY577和WY580组成的引物对进行PCR扩增,得到DNA片段Ⅱ-丙。(4)取pKOV质粒,用限制性内切酶BamHI和NotI进行双酶切,回收载体骨架(约5.6kb)。(5)取DNA片段Ⅱ-丙,用限制性内切酶BamHI和NotI进行双酶切,回收酶切产物。(6)将步骤(4)得到的载体骨架和步骤(5)得到的酶切产物连接,得到重组质粒Ⅱ。根据测序结果,对重组质粒Ⅱ进行结构描述如下:在pKOV质粒的BamHI和NotI酶切位点之间插入了如下特异DNA分子:自上游至下游依次由序列表的序列3第140-637位核苷酸所示的上游区段和序列表的序列3第2183-2712位核苷酸所示的下游区段组成。ilvA基因如序列表的序列3所示,第638-2182位核苷酸为开放阅读框(编码序列表的序列4所示的ilvA蛋白)。(7)将重组质粒Ⅱ导入E.coliK12W3110△metA,得到ilvA基因敲除的重组菌,命名为E.coliK-12W3110△metA△ilvA。ilvA基因敲除的重组菌的鉴定方法:采用WY587和WY588组成的引物对进行PCR扩增,如果得到1344bp扩增产物,初步判断为候选的目标菌;进一步通过测序验证菌株染色体上的ilvA基因的开放阅读框被敲除。3、敲除lysA基因(1)以大肠杆菌K12W3110的基因组DNA为模板,采用WY573和WY574组成的引物对进行PCR扩增,得到DNA片段Ⅲ-甲(lysA基因上游区域)。(2)以大肠杆菌K12W3110的基因组DNA为模板,采用WY575和WY576组成的引物对进行PCR扩增,得到DNA片段Ⅲ-乙(lysA基因下游区域)。(3)将DNA片段Ⅲ-甲和DNA片段Ⅲ-乙混合后作为模板,采用WY573和WY576组成的引物对进行PCR扩增,得到DNA片段Ⅲ-丙。(4)取pKOV质粒,用限制性内切酶BamHI和NotI进行双酶切,回收载体骨架(约5.6kb)。(5)取DNA片段Ⅲ-丙,用限制性内切酶BamHI和NotI进行双酶切,回收酶切产物。(6)将步骤(4)得到的载体骨架和步骤(5)得到的酶切产物连接,得到重组质粒Ⅲ。根据测序结果,对重组质粒Ⅲ进行结构描述如下:在pKOV质粒的BamHI和NotI酶切位点之间插入了如下特异DNA分子:自上游至下游依次由序列表的序列5第132-638位核苷酸所示的上游区段和序列表的序列5第1902-2445位核苷酸所示的下游区段组成。lysA基因如序列表的序列5所示,第639-1901位核苷酸为开放阅读框(编码序列表的序列6所示的lysA蛋白)。(7)将重组质粒Ⅲ导入E.coliK-12W3110△metA△ilvA,得到lysA基因敲除的重组菌,命名为E.coliK-12W3110△metA△ilvA△lysA。lysA基因敲除的重组菌的鉴定方法:采用WY585和WY586组成的引物对进行PCR扩增,如果得到1302bp扩增产物,初步判断为候选的目标菌;进一步通过测序验证菌株染色体上的lysA基因的开放阅读框被敲除。4、敲除tdh基因(1)以大肠杆菌K12W3110的基因组DNA为模板,采用WY598和WY599组成的引物对进行PCR扩增,得到DNA片段Ⅳ-甲(tdh基因上游区域)。(2)以大肠杆菌K12W3110的基因组DNA为模板,采用WY600和WY601组成的引物对进行PCR扩增,得到DNA片段Ⅳ-乙(tdh基因下游区域)。(3)将DNA片段Ⅳ-甲和DNA片段Ⅳ-乙混合后作为模板,采用WY598和WY601组成的引物对进行PCR扩增,得到DNA片段Ⅳ-丙。(4)取pKOV质粒,用限制性内切酶BamHI和NotI进行双酶切,回收载体骨架(约5.6kb)。(5)取DNA片段Ⅳ-丙,用限制性内切酶BamHI和NotI进行双酶切,回收酶切产物。(6)将步骤(4)得到的载体骨架和步骤(5)得到的酶切产物连接,得到重组质粒Ⅳ。根据测序结果,对重组质粒Ⅳ进行结构描述如下:在pKOV质粒的BamHI和NotI酶切位点之间插入了如下特异DNA分子:自上游至下游依次由序列表的序列7第227-752位核苷酸所示的上游区段和序列表的序列7第1779-2271位核苷酸所示的下游区段组成。tdh基因如序列表的序列7所示,第753-1778位核苷酸为开放阅读框(编码序列表的序列8所示的tdh蛋白)。(7)将重组质粒Ⅳ导入E.coliK-12W3110△metA△ilvA△lysA,得到tdh基因敲除的重组菌,命名为E.coliK-12W3110△metA△ilvA△lysA△tdh。tdh基因敲除的重组菌的鉴定方法:采用WY602和WY603组成的引物对进行PCR扩增,如果得到1434bp扩增产物,初步判断为候选的目标菌;进一步通过测序验证菌株染色体上的tdh基因的开放阅读框被敲除。5、敲除tdcC基因(1)以大肠杆菌K12W3110的基因组DNA为模板,采用WY476和WY477组成的引物对进行PCR扩增,得到DNA片段Ⅴ-甲(tdcC基因上游区域)。(2)以大肠杆菌K12W3110的基因组DNA为模板,采用WY478和WY479组成的引物对进行PCR扩增,得到DNA片段Ⅴ-乙(tdcC基因下游区域)。(3)将DNA片段Ⅴ-甲和DNA片段Ⅴ-乙混合后作为模板,采用WY476和WY479组成的引物对进行PCR扩增,得到DNA片段Ⅴ-丙)。(4)取pKOV质粒,用限制性内切酶BamHI和NotI进行双酶切,回收载体骨架(约5.6kb)。(5)取DNA片段Ⅴ-丙,用限制性内切酶BamHI和NotI进行双酶切,回收酶切产物。(6)将步骤(4)得到的载体骨架和步骤(5)得到的酶切产物连接,得到重组质粒Ⅴ。根据测序结果,对重组质粒Ⅴ进行结构描述如下:在pKOV质粒的BamHI和NotI酶切位点之间插入了如下特异DNA分子:自上游至下游依次由序列表的序列9第176-700位核苷酸所示的上游区段和序列表的序列9第1853-2388位核苷酸所示的下游区段组成。tdcC基因如序列表的序列9所示,第701-2032位核苷酸为开放阅读框(编码序列表的序列10所示的tdcC蛋白)。(7)将重组质粒Ⅴ导入E.coliK-12W3110△metA△ilvA△lysA△tdh,得到tdcC基因敲除的重组菌,命名为E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC。tdcC基因敲除的重组菌的鉴定方法:采用WY497和WY498组成的引物对进行PCR扩增,如果得到1453bp扩增产物,初步判断为候选的目标菌;进一步通过测序验证菌株染色体上的tdcC基因的如下区段被敲除:序列9中第701-1852位核苷酸。6、敲除sstT基因(1)以大肠杆菌K12W3110的基因组DNA为模板,采用WY945和WY946组成的引物对进行PCR扩增,得到DNA片段Ⅵ-甲(sstT基因上游区域)。(2)以大肠杆菌K12W3110的基因组DNA为模板,采用WY947和WY948组成的引物对进行PCR扩增,得到DNA片段Ⅵ-乙(sstT基因下游区域)。(3)将DNA片段Ⅵ-甲和DNA片段Ⅵ-乙混合后作为模板,采用WY945和WY948组成的引物对进行PCR扩增,得到DNA片段Ⅵ-丙。(4)取pKOV质粒,用限制性内切酶BamHI和NotI进行双酶切,回收载体骨架(约5.6kb)。(5)取DNA片段Ⅵ-丙,用限制性内切酶BamHI和NotI进行双酶切,回收酶切产物。(6)将步骤(4)得到的载体骨架和步骤(5)得到的酶切产物连接,得到重组质粒Ⅵ。根据测序结果,对重组质粒Ⅵ进行结构描述如下:在pKOV质粒的BamHI和NotI酶切位点之间插入了如下特异DNA分子:自上游至下游依次由序列表的序列11第14-696位核苷酸所示的上游区段和序列表的序列11第1760-2240位核苷酸所示的下游区段组成。sstT基因如序列表的序列11所示,第701-1945位核苷酸为开放阅读框(编码序列表的序列12所示的sstT蛋白)。(7)将重组质粒Ⅵ导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC,得到sstT基因敲除的重组菌,命名为E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT。sstT基因敲除的重组菌的鉴定方法:采用WY949和WY950组成的引物对进行PCR扩增,如果得到1569bp扩增产物,初步判断为候选的目标菌;进一步通过测序验证菌株染色体上的sstT基因的如下区段被敲除:序列11中第697-1759位核苷酸。实施例2、衰减子突变体调控lacZ基因的表达一、构建重组质粒pACYC184-PPL1、合成序列表的序列13所示的双链DNA分子(启动子PPL)。2、以步骤1制备的双链DNA分子为模板,采用WY843和WY842组成的引物对进行PCR扩增,得到PCR扩增产物。WY843:TGCTCTAGACAATTCCGACGTCTAAGAAA;WY842:CCCAAGCTTGGTCAGTGCGTCCTGCTGAT。3、取步骤2得到的PCR扩增产物,用限制性内切酶XbaI和HindIII进行双酶切,回收酶切产物。4、取pACYC184质粒,用限制性内切酶XbaI和HindIII进行双酶切,回收载体骨架(约4.1kb)。5、将步骤3的酶切产物和步骤4的载体骨架连接,得到重组质粒pACYC184-PPL。二、构建各个重组质粒1、构建重组质粒A(1)以大肠杆菌K12W3110的基因组DNA为模板,采用WY914和WY1746组成的引物对进行PCR扩增,得到PCR扩增产物A1;以人工合成的序列表的序列15所示的双链DNA分子为模板,采用WY1752和WY1750组成的引物对进行PCR扩增,得到PCR扩增产物A2;将PCR扩增产物A1和PCR扩增产物A2混合后作为模板,采用WY914和WY1750组成的引物对进行PCR扩增,得到PCR扩增产物A3。(2)取PCR扩增产物A3,用限制性内切酶HindⅢ和BamHⅠ双酶切,回收酶切产物。(3)取重组质粒pACYC184-PPL,用限制性内切酶HindⅢ和BamHⅠ双酶切,回收载体骨架(约4.0kb)。(4)将步骤(2)的酶切产物和步骤(3)的载体骨架连接,得到重组质粒A。根据测序结果,对重组质粒A进行结构描述如下:在质粒pACYC184的XbaI和BamHⅠ酶切位点之间插入了特异DNA分子A;特异DNA分子A自上游至下游依次由如下元件组成:序列表的序列13所示的启动子PPL,限制性内切酶HindⅢ的酶切识别序列,序列表的序列14第172至606位核苷酸,连接序列“GGTTCTGGTTCTGGTTCT”,序列表的序列15所示的lacZ基因(开放阅读框为序列15中第1-3075位)。重组质粒A命名为pACYC184-PPL-thrLA-lacZ914。2、构建重组质粒B(1)以大肠杆菌K12W3110的基因组DNA为模板,采用WY1630和WY1746组成的引物对进行PCR扩增,得到PCR扩增产物B1;以人工合成的序列表的序列15所示的双链DNA分子为模板,采用WY1752和WY1750组成的引物对进行PCR扩增,得到PCR扩增产物B2;将PCR扩增产物B1和PCR扩增产物B2混合后作为模板,采用WY1630和WY1750组成的引物对进行PCR扩增,得到PCR扩增产物B3。(2)取PCR扩增产物B3,用限制性内切酶HindⅢ和BamHⅠ双酶切,回收酶切产物。(3)取重组质粒pACYC184-PPL,用限制性内切酶HindⅢ和BamHⅠ双酶切,回收载体骨架(约4.0kb)。(4)将步骤(2)的酶切产物和步骤(3)的载体骨架连接,得到重组质粒B。根据测序结果,对重组质粒B进行结构描述如下:在质粒pACYC184的XbaI和BamHⅠ酶切位点之间插入了特异DNA分子B;特异DNA分子B自上游至下游依次由如下元件组成:序列表的序列13所示的启动子PPL,限制性内切酶HindⅢ的酶切识别序列,序列表的序列14第198至606位核苷酸,连接序列“GGTTCTGGTTCTGGTTCT”,序列表的序列15所示的lacZ基因。重组质粒B命名为pACYC184-PPL-thrLA-lacZ1630。3、构建重组质粒C(1)以大肠杆菌K12W3110的基因组DNA为模板,采用WY1629和WY1746组成的引物对进行PCR扩增,得到PCR扩增产物C1;以人工合成的序列表的序列15所示的双链DNA分子为模板,采用WY1752和WY1750组成的引物对进行PCR扩增,得到PCR扩增产物C2;将PCR扩增产物C1和PCR扩增产物C2混合后作为模板,采用WY1629和WY1750组成的引物对进行PCR扩增,得到PCR扩增产物C3。(2)取PCR扩增产物C3,用限制性内切酶HindⅢ和BamHⅠ双酶切,回收酶切产物。(3)取重组质粒pACYC184-PPL,用限制性内切酶HindⅢ和BamHⅠ双酶切,回收载体骨架(约4.0kb)。(4)将步骤(2)的酶切产物和步骤(3)的载体骨架连接,得到重组质粒C。根据测序结果,对重组质粒C进行结构描述如下:在质粒pACYC184的XbaI和BamHⅠ酶切位点之间插入了特异DNA分子C;特异DNA分子C自上游至下游依次由如下元件组成:序列表的序列13所示的启动子PPL,限制性内切酶HindⅢ的酶切识别序列,序列表的序列14第236至606位核苷酸,连接序列“GGTTCTGGTTCTGGTTCT”,序列表的序列15所示的lacZ基因。重组质粒C命名为pACYC184-PPL-thrLA-lacZ1629。4、构建重组质粒D(1)以大肠杆菌K12W3110的基因组DNA为模板,采用WY1628和WY1746组成的引物对进行PCR扩增,得到PCR扩增产物D1;以人工合成的序列表的序列15所示的双链DNA分子为模板,采用WY1752和WY1750组成的引物对进行PCR扩增,得到PCR扩增产物D2;将PCR扩增产物D1和PCR扩增产物D2混合后作为模板,采用WY1628和WY1750组成的引物对进行PCR扩增,得到PCR扩增产物D3。(2)取PCR扩增产物D3,用限制性内切酶HindⅢ和BamHⅠ双酶切,回收酶切产物。(3)取重组质粒pACYC184-PPL,用限制性内切酶HindⅢ和BamHⅠ双酶切,回收载体骨架(约4.0kb)。(4)将步骤(2)的酶切产物和步骤(3)的载体骨架连接,得到重组质粒D。根据测序结果,对重组质粒D进行结构描述如下:在质粒pACYC184的XbaI和BamHⅠ酶切位点之间插入了特异DNA分子D;特异DNA分子D自上游至下游依次由如下元件组成:序列表的序列13所示的启动子PPL,限制性内切酶HindⅢ的酶切识别序列,序列表的序列14第256至606位核苷酸,连接序列“GGTTCTGGTTCTGGTTCT”,序列表的序列15所示的lacZ基因。重组质粒D命名为pACYC184-PPL-thrLA-lacZ1628。5、构建重组质粒E(1)以大肠杆菌K12W3110的基因组DNA为模板,采用WY1627和WY1746组成的引物对进行PCR扩增,得到PCR扩增产物E1;以人工合成的序列表的序列15所示的双链DNA分子为模板,采用WY1752和WY1750组成的引物对进行PCR扩增,得到PCR扩增产物E2;将PCR扩增产物E1和PCR扩增产物E2混合后作为模板,采用WY1627和WY1750组成的引物对进行PCR扩增,得到PCR扩增产物E3。(2)取PCR扩增产物E3,用限制性内切酶HindⅢ和BamHⅠ双酶切,回收酶切产物。(3)取重组质粒pACYC184-PPL,用限制性内切酶HindⅢ和BamHⅠ双酶切,回收载体骨架(约4.0kb)。(4)将步骤(2)的酶切产物和步骤(3)的载体骨架连接,得到重组质粒E。根据测序结果,对重组质粒E进行结构描述如下:在质粒pACYC184的XbaI和BamHⅠ酶切位点之间插入了特异DNA分子E;特异DNA分子E自上游至下游依次由如下元件组成:序列表的序列13所示的启动子PPL,限制性内切酶HindⅢ的酶切识别序列,序列表的序列14第294至606位核苷酸,连接序列“GGTTCTGGTTCTGGTTCT”,序列表的序列15所示的lacZ基因。重组质粒E命名为pACYC184-PPL-thrLA-lacZ1627。6、构建重组质粒F(1)以大肠杆菌K12W3110的基因组DNA为模板,采用WY913和WY1746组成的引物对进行PCR扩增,得到PCR扩增产物F1;以人工合成的序列表的序列15所示的双链DNA分子为模板,采用WY1752和WY1750组成的引物对进行PCR扩增,得到PCR扩增产物F2;将PCR扩增产物F1和PCR扩增产物F2混合后作为模板,采用WY913和WY1750组成的引物对进行PCR扩增,得到PCR扩增产物F3。(2)取PCR扩增产物F3,用限制性内切酶HindⅢ和BamHⅠ双酶切,回收酶切产物。(3)取重组质粒pACYC184-PPL,用限制性内切酶HindⅢ和BamHⅠ双酶切,回收载体骨架(约4.0kb)。(4)将步骤(2)的酶切产物和步骤(3)的载体骨架连接,得到重组质粒F。根据测序结果,对重组质粒F进行结构描述如下:在质粒pACYC184的XbaI和BamHⅠ酶切位点之间插入了特异DNA分子F;特异DNA分子F自上游至下游依次由如下元件组成:序列表的序列13所示的启动子PPL,限制性内切酶HindⅢ的酶切识别序列,序列表的序列14第310至606位核苷酸,连接序列“GGTTCTGGTTCTGGTTCT”,序列表的序列15所示的lacZ基因。重组质粒F命名为pACYC184-PPL-thrLA-lacZ913。三、构建重组菌将pACYC184-PPL-thrLA-lacZ914导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为LAC914。将pACYC184-PPL-thrLA-lacZ1630导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为LAC1630。将pACYC184-PPL-thrLA-lacZ1629导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为LAC1629。将pACYC184-PPL-thrLA-lacZ1628导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为LAC1628。将pACYC184-PPL-thrLA-lacZ1627导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为LAC1627。将pACYC184-PPL-thrLA-lacZ913导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为LAC913。将pACYC184质粒导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为LAC对照。四、β-半乳糖苷酶活性测定试验菌株为:LAC914、LAC1630、LAC1629、LAC1628、LAC1627或LAC913。1、将试验菌株接种至含34mg/L氯霉素的液体LB培养基,37℃、220rpm振荡培养12h,得到种子液。2、取步骤1得到的种子液,按照2%的接种量接种至含34mg/L氯霉素的液体2YT培养基,37℃、220rpm培养6h。3、完成步骤2后,从培养体系取样1.5ml,测定OD600nm的光密度值,1ml作为待测样本检测β-半乳糖苷酶活性。检测β-半乳糖苷酶活性的方法:(1)将1ml待测样本10000×g离心5min,收集菌体沉淀,用pH7.2的PBS缓冲液洗涤两遍,然后用Z-buffer定容至1ml并充分悬浮菌体,置于冰上备用。Z-buffer:40mMNaH2PO4、60mMNa2HPO4、10mMKCl、1mMMgSO4、50mMβ-mercaptoethanol,pH7.0。(2)完成步骤(1)后,取样0.05mL,加入0.2mL4mg/ml的ONPG水溶液和0.8mLZ-buffer并混匀,37℃静置反应并记录反应起始时间,体系呈淡黄色时加入1mL1MNa2CO3水溶液终止反应并记录反应终止时间,用紫外分光光度计测定OD420nm值。LAC对照进行上述步骤,作为紫外分光光度计测定OD420nm值的空白对照。β-半乳糖苷酶酶活MillerUnit=1000×OD420nm/(OD600nm×t×V);t,反应时间(反应终止时间与反应起始时间的差值,min);V,加样体积,0.05mL。β-半乳糖苷酶活的定义为每个细胞每分钟分解1μmolONPG所需要的酶量。每个菌株测量三次,取平均值和标准差。结果见表1。不同试验菌株进行上述步骤,相应的β-半乳糖苷酶酶活具有显著差异,LAC1627的酶活水平显著高于其他各个菌株。表1试验菌株酶活(MillerUnit)LAC91447.72±3.33LAC163026.17±2.71LAC162931.20±1.17LAC162816.11±1.67LAC1627132.09±4.61LAC91322.59±4.23实施例3、衰减子突变体调控gfp基因的表达一、构建重组质粒构建如下六个重组质粒:pACYC184-PPL-thrLA-gfp914、pACYC184-PPL-thrLA-gfp1630、pACYC184-PPL-thrLA-gfp1629、pACYC184-PPL-thrLA-gfp1628、pACYC184-PPL-thrLA-gfp1627和pACYC184-PPL-thrLA-gfp913。pACYC184-PPL-thrLA-gfp914与pACYC184-PPL-thrLA-lacZ914的区别仅在于:用特异DNA分子X取代了序列表的序列15所示的lacZ基因。pACYC184-PPL-thrLA-gfp1630与pACYC184-PPL-thrLA-lacZ1630的区别仅在于:用特异DNA分子X取代了序列表的序列15所示的lacZ基因。pACYC184-PPL-thrLA-gfp1629与pACYC184-PPL-thrLA-lacZ1629的区别仅在于:用特异DNA分子X取代了序列表的序列15所示的lacZ基因。pACYC184-PPL-thrLA-gfp1628与pACYC184-PPL-thrLA-lacZ1628的区别仅在于:用特异DNA分子X取代了序列表的序列15所示的lacZ基因。pACYC184-PPL-thrLA-gfp1627与pACYC184-PPL-thrLA-lacZ1627的区别仅在于:用特异DNA分子X取代了序列表的序列15所示的lacZ基因。pACYC184-PPL-thrLA-gfp913与pACYC184-PPL-thrLA-lacZ913的区别仅在于:用特异DNA分子X取代了序列表的序列15所示的lacZ基因。特异DNA分子X为:以pAD123质粒为模板,采用WY1751和WY1748组成的引物对进行PCR扩增得到的PCR扩增产物的正数第22位核苷酸至倒数第10位核苷酸(其中具有序列表的序列16所示的gfp基因)。WY1751:TTGGGTTCTGGTTCTGGTTCTATGAGTAAAGGAGAAGAACTTTTCACT;WY1748:CGCGGATCCCTTGCATGCCTGCAGGAGAT。二、构建重组菌将pACYC184-PPL-thrLA-gfp914导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为GFP914。将pACYC184-PPL-thrLA-gfp1630导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为GFP1630。将pACYC184-PPL-thrLA-gfp1629导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为GFP1629。将pACYC184-PPL-thrLA-gfp1628导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为GFP1628。将pACYC184-PPL-thrLA-gfp1627导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为GFP1627。将pACYC184-PPL-thrLA-gfp913导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为GFP913。将pACYC184质粒导入E.coliK-12W3110△metA△ilvA△lysA△tdh△tdcC△sstT,得到重组菌,将其命名为GFP对照。三、流式细胞仪分析GFP在细胞群体中的表达试验菌株为:GFP914、GFP1630、GFP1629、GFP1628、GFP1627、GFP913或GFP对照(空白对照)。1、将试验菌株接种至含34mg/L氯霉素的液体LB培养基,37℃、220rpm振荡培养2h,离心收集菌体。2、取步骤1得到的菌体,用pH7.2的PBS缓冲液悬浮,得到OD600nm值为0.5的菌悬液。3、取步骤2得到的菌悬液,用流式细胞分析仪(FACSCalibur型,美国BD公司)计数50000个细胞,使用FlowJ软件分析实验结果。各个试验菌株相应的结果见图1和表2(50000个细胞的平均值)。图1中,菌群荧光分布曲线从右至左分别为GFP1627、GFP913、GFP914、GFP1630、GFP1629、GFP1628和GFP对照。GFP1627的荧光水平比其它菌株提高了30至1280倍。表2实施例4、制备丙氨酸一、重组质粒的构建1、合成序列表的序列13所示的双链DNA分子。2、以步骤1合成的双链DNA分子为模板,采用WY843和WY1760组成的引物对进行PCR扩增,得到PCR扩增产物。3、取步骤2得到的PCR扩增产物,用限制性内切酶XbaI和BamHI进行双酶切,回收酶切产物。4、取pACYC184质粒,用限制性内切酶XbaI和BamHI进行双酶切,回收载体骨架(约3.8kb)。5、将步骤3的酶切产物和步骤4的载体骨架连接,得到重组质粒pACYC184-PPL2。6、以枯草芽孢杆菌W168的基因组DNA为模板,采用WY1785和WY1778组成的引物对进行PCR扩增,得到PCR扩增产物。7、以枯草芽孢杆菌W168的基因组DNA为模板,采用WY1786和WY1778组成的引物对进行PCR扩增,得到PCR扩增产物。8、用限制性内切酶BamHⅠ和SphⅠ双酶切重组质粒pACYC184-PPL2,回收载体骨架(约4.2kb)。9、取步骤6得到的PCR扩增产物,用限制性内切酶BamHⅠ和SphⅠ双酶切,回收酶切产物。10、将步骤9的酶切产物和步骤8的载体骨架连接,得到重组质粒,将其命名为pACYC184-PPL-aldWT。根据测序结果,对pACYC184-PPL-aldWT进行结构描述如下:将pACYC184质粒XbaI和SphⅠ酶切位点之间插入了特异DNA分子Ⅰ;特异DNA分子Ⅰ自上游至下游依次由如下元件组成:序列表的序列13所示的启动子PPL,限制性内切酶BamHⅠ的酶切识别序列,序列表的序列17所示的双链DNA分子。11、取步骤7得到的PCR扩增产物,用限制性内切酶BamHⅠ和SphⅠ双酶切,回收酶切产物。12、将步骤11的酶切产物和步骤8的载体骨架连接,得到重组质粒,将其命名为pACYC184-PPL-ald5UTRthrA。根据测序结果,对pACYC184-PPL-ald5UTRthrA进行结构描述如下:将pACYC184质粒XbaI和SphⅠ酶切位点之间插入了特异DNA分子Ⅱ;特异DNA分子Ⅱ自上游至下游依次由如下元件组成:序列表的序列13所示的启动子PPL,限制性内切酶BamHⅠ的酶切识别序列,序列表的序列18所示的双链DNA分子。WY843:TGCTCTAGACAATTCCGACGTCTAAGAAA;WY1760:CGCGGATCCGGTCAGTGCGTCCTGCTGAT;WY1785:CGCGGATCCCACATATACAGGAGGAGACAGA;WY1786:CGCGGATCCGTGCGGGCTTTTTTTTTCGACCAAAGGTAACGAGGTAACAACCATGATCATAGGGGTTCCTAAAGA;WY1778:ACATGCATGCGTCATAATTCGTGAAATGGTCTCT。二、丙氨酸工程菌的构建将pACYC184-PPL-aldWT导入大肠杆菌K12W3110,得到重组菌,将其命名为E.coliK-12W3110/pACYC184-PPL-aldWT。将pACYC184-PPL-ald5UTRthrA导入大肠杆菌K12W3110,得到重组菌,将其命名为E.coliK-12W3110/pACYC184-PPL-ald5UTRthrA。将pACYC184质粒导入大肠杆菌K12W3110,得到重组菌,将其命名为E.coliK-12W3110/pACYC184。三、丙氨酸工程菌的摇瓶发酵试验菌株为:E.coliK-12W3110/pACYC184-PPL-aldWT、E.coliK-12W3110/pACYC184-PPL-ald5UTRthrA或E.coliK-12W3110/pACYC184。1、取试验菌株,划线接种于含34mg/L氯霉素的固体LB培养基平板,37℃静置培养12小时。2、完成步骤1后,挑取平板上的菌苔,接种至3mL液体LB培养基中,37℃、220rpm振荡培养12h,得到种子液。3、完成步骤2后,将种子液按照3%的接种量接种至30mL发酵培养基中,37℃、220rpm震荡培养。发酵培养基:葡萄糖20.0g/L、酵母粉2.0g/L、蛋白胨4g/L、硫酸铵6.0g/L、磷酸二氢钾2.0g/L、七水硫酸镁1.0g/L、甜菜碱1.0g/L、碳酸钙15.0g/L,微量元素混合液1mL/L,余量为水。微量元素混合液:FeSO4·7H2O10g/L、CaCl21.35g/L、ZnSO4·7H2O2.25g/L、MnSO4·4H2O0.5g/L、CuSO4·5H2O1g/L、(NH4)6Mo7O24·4H2O0.106g/L、Na2B4O7·10H2O0.23g/L、CoCl2·6H2O0.48g/L、35%HCl10mL/L,余量为水。培养过程中,用氨水调节反应体系的pH值使其维持在6.8-7.0。培养过程中,每隔3-4h取样一次,使用生物传感分析仪SBA-40D检测葡萄糖含量,当体系中的葡萄糖含量低于5g/L时,补加葡萄糖并使体系中的葡萄糖浓度达到10g/L。分别于培养12h和48h后取样,12000g离心2分钟,取上清液,检测L-丙氨酸浓度。培养12h和48h后,发酵上清中的L-丙氨酸浓度见图2和表3(三次重复试验的平均值±标准差)。表3培养12小时后,应用本发明筛选的5’非翻译区表达元件调控ald基因表达的工程菌E.coliK-12W3110/pACYC184-PPL-ald5UTRthrA制备L-丙氨酸比对照菌株E.coliK-12W3110/pACYC184-PPL-aldWT提高了98.6%。培养48小时后,应用本发明筛选的5’非翻译区表达元件调控ald基因表达的工程菌E.coliK-12W3110/pACYC184-PPL-ald5UTRthrA制备L-丙氨酸比对照菌株E.coliK-12W3110/pACYC184-PPL-aldWT提高了40.8%,说明本发明提供的5’非翻译区表达元件的应用可以显著提高丙氨酸的发酵产量。发酵液中L-丙氨酸含量的检测方法:高效液相法,在参考文献(氨基酸和生物资源,2000,22,59-60)中氨基酸检测方法的基础上进行优化,具体方法如下(2,4-二硝基氟苯(FDBN)柱前衍生高效液相法):取10μL上清液于2mL离心管中,加入200μL0.5MNaHCO3水溶液和100μL1%(体积比)FDBN-乙腈溶液,于60℃水浴中暗处恒温加热60min,然后冷却至室温,加入700μL0.04mol/LKH2PO4水溶液(pH=7.2±0.05,用40g/LKOH水溶液调整pH)并摇匀,静置15min,然后过滤并收集滤液。滤液用于上样,进样量为15μL。所用色谱柱为C18柱(ZORBAXEclipseXDB-C18,4.6*150mm,Agilent,USA);柱温:40℃;紫外检测波长:360nm;流动相A为0.04mol/LKH2PO4水溶液(pH=7.2±0.05,用40g/100mLKOH水溶液调整pH),流动相B为55%(体积比)乙腈水溶液,流动相总流量为1mL/min。洗脱过程:洗脱起始时刻(0min)流动相A占流动相总流量的体积份数为86%、流动相B占流动相总流量的体积份数为14%;洗脱过程分为4个阶段,每个阶段中流动相A和流动相D占流动相总流量的体积份数均为线性变化;第1阶段(从起始时刻开始共进行2min)结束时流动相A占流动相总流量的体积份数为88%、流动相B占流动相总流量的体积份数为12%,第2阶段(从第1阶段结束时刻开始共进行2min)结束时流动相A占流动相总流量的体积份数为86%、流动相B占流动相总流量的体积份数为14%,第3阶段(从第2阶段结束时刻开始共进行6min)结束时流动相A占流动相总流量的体积份数为70%、流动相B占流动相总流量的体积份数为30%,第4阶段(从第3阶段结束时刻开始共进行10min)结束时流动相A占流动相总流量的体积份数为30%、流动相B占流动相总流量的体积份数为70%。以市售L-丙氨酸为标准品制作标准曲线,计算样品的L-丙氨酸浓度。最后应说明的是:显然,上述实施例仅仅是为清楚地说明本发明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引申出的显而易见的变化或变动仍处于本发明的保护范围之中。序列表<160>19<210>1<211>2305<212>DNA<213>大肠杆菌<400>1cgttaatgaaatatcgccagttccacatccatgcgcaatcagcggtactcagtgatagtg60cggtcatggcaatgcttaagcagaaataatcgtgtcaccattggtgggtactaaacctga120agttcagcccaccgggatgagaaaaaatcgcctacgcccccacatacgccagattcagca180acggatacggtttccccaaatcgtccacctcagagcgtcccgtaaccttaaaacccacct240tcttatagaacccaaccgcctgctcattttgctcattaacgttggttgtcagttccggtg300ccatcgagagcgcatgctccaccagcacccgacctacgccgcagccgcgcacatcaggat360cgataaacagcgcatccatatgctgcccacttagcaacataaatccaaccggctgatccc420gctcattaaccgcgacccacaacggcgcttccggcaggaaggaacgaactaggtcctcca480gctcggtccgatactctgctgatagaaaatcgtgagtggcatcgacagaacgacaccaaa540tcgcaacgagttcctccccttcctcatgccgtgagcggcgaatactaataaccattttct600ctccttttagtcattcttatattctaacgtagtcttttccttgaaactttctcaccttca660acatgcaggctcgacattggcaaattttctggttatcttcagctatctggatgtctaaac720gtataagcgtatgtagtgaggtaatcaggttatgccgattcgtgtgccggacgagctacc780cgccgtcaatttcttgcgtgaagaaaacgtctttgtgatgacaacttctcgtgcgtctgg840tcaggaaattcgtccacttaaggttctgatccttaacctgatgccgaagaagattgaaac900tgaaaatcagtttctgcgcctgctttcaaactcacctttgcaggtcgatattcagctgtt960gcgcatcgattcccgtgaatcgcgcaacacgcccgcagagcatctgaacaacttctactg1020taactttgaagatattcaggatcagaactttgacggtttgattgtaactggtgcgccgct1080gggcctggtggagtttaatgatgtcgcttactggccgcagatcaaacaggtgctggagtg1140gtcgaaagatcacgtcacctcgacgctgtttgtctgctgggcggtacaggccgcgctcaa1200tatcctctacggcattcctaagcaaactcgcaccgaaaaactctctggcgtttacgagca1260tcatattctccatcctcatgcgcttctgacgcgtggctttgatgattcattcctggcacc1320gcattcgcgctatgctgactttccggcagcgttgattcgtgattacaccgatctggaaat1380tctggcagagacggaagaaggggatgcatatctgtttgccagtaaagataagcgcattgc1440ctttgtgacgggccatcccgaatatgatgcgcaaacgctggcgcaggaatttttccgcga1500tgtggaagccggactagacccggatgtaccgtataactatttcccgcacaatgatccgca1560aaatacaccgcgagcgagctggcgtagtcacggtaatttactgtttaccaactggctcaa1620ctattacgtctaccagatcacgccatacgatctacggcacatgaatccaacgctggatta1680atcttctgtgatagtcgatcgttaagcgattcagcaccttacctcaggcaccttcgggtg1740ccttttttatttccgaaacgtacctcagcaggtgaataaattttattcatattgttatca1800acaagttatcaagtatttttaattaaaatggaaattgtttttgattttgcattttaaatg1860agtagtcttagttgtgctgaacgaaaagagcacaacgatccttcgttcacagtggggaag1920ttttcggatccatgacgaggagctgcacgatgactgaacaggcaacaacaaccgatgaac1980tggctttcacaaggccgtatggcgagcaggagaagcaaattcttactgccgaagcggtag2040aatttctgactgagctggtgacgcattttacgccacaacgcaataaacttctggcagcgc2100gcattcagcagcagcaagatattgataacggaacgttgcctgattttatttcggaaacag2160cttccattcgcgatgctgattggaaaattcgcgggattcctgcggacttagaagaccgcc2220gcgtagagataactggcccggtagagcgcaagatggtgatcaacgcgctcaacgccaatg2280tgaaagtctttatggccgatttcga2305<210>2<211>309<212>PRT<213>大肠杆菌<400>2MetProIleArgValProAspGluLeuProAlaValAsnPheLeuArg151015GluGluAsnValPheValMetThrThrSerArgAlaSerGlyGlnGlu202530IleArgProLeuLysValLeuIleLeuAsnLeuMetProLysLysIle354045GluThrGluAsnGlnPheLeuArgLeuLeuSerAsnSerProLeuGln505560ValAspIleGlnLeuLeuArgIleAspSerArgGluSerArgAsnThr65707580ProAlaGluHisLeuAsnAsnPheTyrCysAsnPheGluAspIleGln859095AspGlnAsnPheAspGlyLeuIleValThrGlyAlaProLeuGlyLeu100105110ValGluPheAsnAspValAlaTyrTrpProGlnIleLysGlnValLeu115120125GluTrpSerLysAspHisValThrSerThrLeuPheValCysTrpAla130135140ValGlnAlaAlaLeuAsnIleLeuTyrGlyIleProLysGlnThrArg145150155160ThrGluLysLeuSerGlyValTyrGluHisHisIleLeuHisProHis165170175AlaLeuLeuThrArgGlyPheAspAspSerPheLeuAlaProHisSer180185190ArgTyrAlaAspPheProAlaAlaLeuIleArgAspTyrThrAspLeu195200205GluIleLeuAlaGluThrGluGluGlyAspAlaTyrLeuPheAlaSer210215220LysAspLysArgIleAlaPheValThrGlyHisProGluTyrAspAla225230235240GlnThrLeuAlaGlnGluPhePheArgAspValGluAlaGlyLeuAsp245250255ProAspValProTyrAsnTyrPheProHisAsnAspProGlnAsnThr260265270ProArgAlaSerTrpArgSerHisGlyAsnLeuLeuPheThrAsnTrp275280285LeuAsnTyrTyrValTyrGlnIleThrProTyrAspLeuArgHisMet290295300AsnProThrLeuAsp305<210>3<211>2889<212>DNA<213>大肠杆菌<400>3atggctgtatccgctcgctggaacacgcctacagcaaagacggcggcctggcggtgctct60acggtaactttgcggaaaacggctgcatcgtgaaaacggcaggcgtcgatgacagcatcc120tcaaattcaccggcccggcgaaagtgtacgaaagccaggacgatgcggtagaagcgattc180tcggcggtaaagttgtcgccggagatgtggtagtaattcgctatgaaggcccgaaaggcg240gtccggggatgcaggaaatgctctacccaaccagcttcctgaaatcaatgggtctcggca300aagcctgtgcgctgatcaccgacggtcgtttctctggtggcacctctggtctttccatcg360gccacgtctcaccggaagcggcaagcggcggcagcattggcctgattgaagatggtgacc420tgatcgctatcgacatcccgaaccgtggcattcagttacaggtaagcgatgccgaactgg480cggcgcgtcgtgaagcgcaggacgctcgaggtgacaaagcctggacgccgaaaaatcgtg540aacgtcaggtctcctttgccctgcgtgcttatgccagcctggcaaccagcgccgacaaag600gcgcggtgcgcgataaatcgaaactggggggttaataatggctgactcgcaacccctgtc660cggtgctccggaaggtgccgaatatttaagagcagtgctgcgcgcgccggtttacgaggc720ggcgcaggttacgccgctacaaaaaatggaaaaactgtcgtcgcgtcttgataacgtcat780tctggtgaagcgcgaagatcgccagccagtgcacagctttaagctgcgcggcgcatacgc840catgatggcgggcctgacggaagaacagaaagcgcacggcgtgatcactgcttctgcggg900taaccacgcgcagggcgtcgcgttttcttctgcgcggttaggcgtgaaggccctgatcgt960tatgccaaccgccaccgccgacatcaaagtcgacgcggtgcgcggcttcggcggcgaagt1020gctgctccacggcgcgaactttgatgaagcgaaagccaaagcgatcgaactgtcacagca1080gcaggggttcacctgggtgccgccgttcgaccatccgatggtgattgccgggcaaggcac1140gctggcgctggaactgctccagcaggacgcccatctcgaccgcgtatttgtgccagtcgg1200cggcggcggtctggctgctggcgtggcggtgctgatcaaacaactgatgccgcaaatcaa1260agtgatcgccgtagaagcggaagactccgcctgcctgaaagcagcgctggatgcgggtca1320tccggttgatctgccgcgcgtagggctatttgctgaaggcgtagcggtaaaacgcatcgg1380tgacgaaaccttccgtttatgccaggagtatctcgacgacatcatcaccgtcgatagcga1440tgcgatctgtgcggcgatgaaggatttattcgaagatgtgcgcgcggtggcggaaccctc1500tggcgcgctggcgctggcgggaatgaaaaaatatatcgccctgcacaacattcgcggcga1560acggctggcgcatattctttccggtgccaacgtgaacttccacggcctgcgctacgtctc1620agaacgctgcgaactgggcgaacagcgtgaagcgttgttggcggtgaccattccggaaga1680aaaaggcagcttcctcaaattctgccaactgcttggcgggcgttcggtcaccgagttcaa1740ctaccgttttgccgatgccaaaaacgcctgcatctttgtcggtgtgcgcctgagccgcgg1800cctcgaagagcgcaaagaaattttgcagatgctcaacgacggcggctacagcgtggttga1860tctctccgacgacgaaatggcgaagctacacgtgcgctatatggtcggcggacgtccatc1920gcatccgttgcaggaacgcctctacagcttcgaattcccggaatcaccgggcgcgctgct1980gcgcttcctcaacacgctgggtacgtactggaacatttctttgttccactatcgcagcca2040tggcaccgactacgggcgcgtactggcggcgttcgaacttggcgaccatgaaccggattt2100cgaaacccggctgaatgagctgggctacgattgccacgacgaaaccaataacccggcgtt2160caggttctttttggcgggttagggaaaaatgcctgatagcgcttcgcttatcaggcctac2220ccgcgcgacaacgtcatttgtggttcggcaaaatcttccagaatgcctcaattagcggct2280catgtagccgctttttctgcgcacacacgcccagctcaaacggcgttttctcatcgctgc2340gctctaaaatcatcacgcggttacgcaccggttcggggctgttttccagcaccacttccg2400gcaacaatgccacgccacagccgagtgccaccatcgataccatcgcttcatgcccgccaa2460ccgtggcgtaaatcatcgggttactgattttattgcgtcgaaaccacagttcaatgcggc2520ggcgtaccggcccctgatcggccataataaacggcaccgttgaccagtccggcttctcta2580ccgacacctgattacgcaccgggcagggcagcgcgggggcaatcagcactactgccagat2640tctccagcatcgaaaacgccactgcgccgggcaaggtttccggtttacccgcaatcgcca2700gatccgcttcaccagtgaccaccttttccatcgcatctgccgcatcaccagtagtaagtt2760taatctccaccgacgggtgttccgcgcggaagcgatccagaatcggcggcagatggctgt2820aggcagcggtcaccgagcagaagatatgtaattcgccagagagcgacggcccttgctgat2880cgatggtgt2889<210>4<211>514<212>PRT<213>大肠杆菌<400>4MetAlaAspSerGlnProLeuSerGlyAlaProGluGlyAlaGluTyr151015LeuArgAlaValLeuArgAlaProValTyrGluAlaAlaGlnValThr202530ProLeuGlnLysMetGluLysLeuSerSerArgLeuAspAsnValIle354045LeuValLysArgGluAspArgGlnProValHisSerPheLysLeuArg505560GlyAlaTyrAlaMetMetAlaGlyLeuThrGluGluGlnLysAlaHis65707580GlyValIleThrAlaSerAlaGlyAsnHisAlaGlnGlyValAlaPhe859095SerSerAlaArgLeuGlyValLysAlaLeuIleValMetProThrAla100105110ThrAlaAspIleLysValAspAlaValArgGlyPheGlyGlyGluVal115120125LeuLeuHisGlyAlaAsnPheAspGluAlaLysAlaLysAlaIleGlu130135140LeuSerGlnGlnGlnGlyPheThrTrpValProProPheAspHisPro145150155160MetValIleAlaGlyGlnGlyThrLeuAlaLeuGluLeuLeuGlnGln165170175AspAlaHisLeuAspArgValPheValProValGlyGlyGlyGlyLeu180185190AlaAlaGlyValAlaValLeuIleLysGlnLeuMetProGlnIleLys195200205ValIleAlaValGluAlaGluAspSerAlaCysLeuLysAlaAlaLeu210215220AspAlaGlyHisProValAspLeuProArgValGlyLeuPheAlaGlu225230235240GlyValAlaValLysArgIleGlyAspGluThrPheArgLeuCysGln245250255GluTyrLeuAspAspIleIleThrValAspSerAspAlaIleCysAla260265270AlaMetLysAspLeuPheGluAspValArgAlaValAlaGluProSer275280285GlyAlaLeuAlaLeuAlaGlyMetLysLysTyrIleAlaLeuHisAsn290295300IleArgGlyGluArgLeuAlaHisIleLeuSerGlyAlaAsnValAsn305310315320PheHisGlyLeuArgTyrValSerGluArgCysGluLeuGlyGluGln325330335ArgGluAlaLeuLeuAlaValThrIleProGluGluLysGlySerPhe340345350LeuLysPheCysGlnLeuLeuGlyGlyArgSerValThrGluPheAsn355360365TyrArgPheAlaAspAlaLysAsnAlaCysIlePheValGlyValArg370375380LeuSerArgGlyLeuGluGluArgLysGluIleLeuGlnMetLeuAsn385390395400AspGlyGlyTyrSerValValAspLeuSerAspAspGluMetAlaLys405410415LeuHisValArgTyrMetValGlyGlyArgProSerHisProLeuGln420425430GluArgLeuTyrSerPheGluPheProGluSerProGlyAlaLeuLeu435440445ArgPheLeuAsnThrLeuGlyThrTyrTrpAsnIleSerLeuPheHis450455460TyrArgSerHisGlyThrAspTyrGlyArgValLeuAlaAlaPheGlu465470475480LeuGlyAspHisGluProAspPheGluThrArgLeuAsnGluLeuGly485490495TyrAspCysHisAspGluThrAsnAsnProAlaPheArgPhePheLeu500505510AlaGly<210>5<211>2565<212>DNA<213>大肠杆菌<400>5gtaacacacacacttcatctaaagagagtaattcggtacgttctgttcccgcaggcgtat60ggagcgtttcagtgagtcctaaatcatgacgctgggccgagagccactcttcaagtagcg120gtgattcctggggcacgatatttaagctgacatcgggataacgtgccagaaagggttgca180ggagctgcggtaaaaaagattgcgaaaagaccggcaggcaggcaatagacagttctccct240ggcgaaactcgcgcagactttctgcggcgctgacaatgcgatccagtccgtaccaggatc300gttgcacttcttcaaacagacgcagtccttgcacggtaggatgtaatcgcccacgtacgc360gctcaaacaatttcagcccgatcaccttctcaaagcgcgcaagttcgcggctgacggttg420gctgtgaggtgtgtagcaggtgtgccgcctcagtcaggcttccggcggtcattaccgcat480gaaaaatttcaatatgacgtaagttaacggcggccattagcgctctctcgcaatccggta540atccatatcatttttgcatagactcgacataaatcgatattttttattctttttatgatg600tggcgtaatcataaaaaagcacttatctggagtttgttatgccacattcactgttcagca660ccgataccgatctcaccgccgaaaatctgctgcgtttgcccgctgaatttggctgcccgg720tgtgggtctacgatgcgcaaattattcgtcggcagattgcagcgctgaaacagtttgatg780tggtgcgctttgcacagaaagcctgttccaatattcatattttgcgcttaatgcgtgagc840agggcgtgaaagtggattccgtctcgttaggcgaaatagagcgtgcgttggcggcgggtt900acaatccgcaaacgcaccccgatgatattgtttttacggcagatgttatcgatcaggcga960cgcttgaacgcgtcagtgaattgcaaattccggtgaatgcgggttctgttgatatgctcg1020accaactgggccaggtttcgccagggcatcgggtatggctgcgcgttaatccggggtttg1080gtcacggacatagccaaaaaaccaataccggtggcgaaaacagcaagcacggtatctggt1140acaccgatctgcccgccgcactggacgtgatacaacgtcatcatctgcagctggtcggca1200ttcacatgcacattggttctggcgttgattatgcccatctggaacaggtgtgtggtgcta1260tggtgcgtcaggtcatcgaattcggtcaggatttacaggctatttctgcgggcggtgggc1320tttctgttccttatcaacagggtgaagaggcggttgataccgaacattattatggtctgt1380ggaatgccgcgcgtgagcaaatcgcccgccatttgggccaccctgtgaaactggaaattg1440aaccgggtcgcttcctggtagcgcagtctggcgtattaattactcaggtgcggagcgtca1500aacaaatggggagccgccactttgtgctggttgatgccgggttcaacgatctgatgcgcc1560cggcaatgtacggtagttaccaccatatcagtgccctggcagctgatggtcgttctctgg1620aacacgcgccaacggtggaaaccgtcgtcgccggaccgttatgtgaatcgggcgatgtct1680ttacccagcaggaagggggaaatgttgaaacccgcgccttgccggaagtgaaggcaggtg1740attatctggtactgcatgatacaggggcatatggcgcatcaatgtcatccaactacaata1800gccgtccgctgttaccagaagttctgtttgataatggtcaggcgcggttgattcgccgtc1860gccagaccatcgaagaattactggcgctggaattgctttaactgcggttagtcgctggtt1920gcatgatgacttgcctccagcgacggagttgacactgaatgacgacgtaccagcgtcgga1980ctaaagacattagtgatttccgggagagggcgattatccgccagcgccaaagccagttcg2040gcagcctgggtcgccatcgtcacgattgggtaacgcacggtggtcaggcgcggacgcaca2100tagcgtgacaccagcacatcatcaaagccaattaacgaaatctcacccggtacatcaata2160ccattatcattgagaacgcccatcgcacccgccgccattgaatcgttataacaggctacc2220gcagtgaaatttcttcctcgtcccaaaagctcggtcattgcctgttcgccgccgctttcg2280tctggttcgccaaatgtcaccagccggtcattggccgcaataccactttcagcaagggca2340tcgtaatacccttgcagacgatcttcggcgtcagaaatagagtggttagagcacagataa2400ccaatgcgggtatgaccttgctgaattaaatgacgcgttgccagccaggcaccgtaacga2460tcgtccagagcaatacaacggttttcaaagccaggcaggatacggttgatcagcaccata2520ccgggcatttgtttcattaatgaggctaaatcagcatccgggatc2565<210>6<211>420<212>PRT<213>大肠杆菌<400>6MetProHisSerLeuPheSerThrAspThrAspLeuThrAlaGluAsn151015LeuLeuArgLeuProAlaGluPheGlyCysProValTrpValTyrAsp202530AlaGlnIleIleArgArgGlnIleAlaAlaLeuLysGlnPheAspVal354045ValArgPheAlaGlnLysAlaCysSerAsnIleHisIleLeuArgLeu505560MetArgGluGlnGlyValLysValAspSerValSerLeuGlyGluIle65707580GluArgAlaLeuAlaAlaGlyTyrAsnProGlnThrHisProAspAsp859095IleValPheThrAlaAspValIleAspGlnAlaThrLeuGluArgVal100105110SerGluLeuGlnIleProValAsnAlaGlySerValAspMetLeuAsp115120125GlnLeuGlyGlnValSerProGlyHisArgValTrpLeuArgValAsn130135140ProGlyPheGlyHisGlyHisSerGlnLysThrAsnThrGlyGlyGlu145150155160AsnSerLysHisGlyIleTrpTyrThrAspLeuProAlaAlaLeuAsp165170175ValIleGlnArgHisHisLeuGlnLeuValGlyIleHisMetHisIle180185190GlySerGlyValAspTyrAlaHisLeuGluGlnValCysGlyAlaMet195200205ValArgGlnValIleGluPheGlyGlnAspLeuGlnAlaIleSerAla210215220GlyGlyGlyLeuSerValProTyrGlnGlnGlyGluGluAlaValAsp225230235240ThrGluHisTyrTyrGlyLeuTrpAsnAlaAlaArgGluGlnIleAla245250255ArgHisLeuGlyHisProValLysLeuGluIleGluProGlyArgPhe260265270LeuValAlaGlnSerGlyValLeuIleThrGlnValArgSerValLys275280285GlnMetGlySerArgHisPheValLeuValAspAlaGlyPheAsnAsp290295300LeuMetArgProAlaMetTyrGlySerTyrHisHisIleSerAlaLeu305310315320AlaAlaAspGlyArgSerLeuGluHisAlaProThrValGluThrVal325330335ValAlaGlyProLeuCysGluSerGlyAspValPheThrGlnGlnGlu340345350GlyGlyAsnValGluThrArgAlaLeuProGluValLysAlaGlyAsp355360365TyrLeuValLeuHisAspThrGlyAlaTyrGlyAlaSerMetSerSer370375380AsnTyrAsnSerArgProLeuLeuProGluValLeuPheAspAsnGly385390395400GlnAlaArgLeuIleArgArgArgGlnThrIleGluGluLeuLeuAla405410415LeuGluLeuLeu420<210>7<211>2460<212>DNA<213>大肠杆菌<400>7gctatgccaacaacgatatgcaggagctggaagcacgtctgaaagaagcgcgtgaagccg60gtgcgcgtcatgtgctgatcgccaccgatggtgtgttctcaatggacggcgtgattgcca120acctgaagggcgtttgcgatctggcagataaatatgatgccctggtgatggtagacgact180cccacgcggtcggttttgtcggtgaaaatggtcgtggttcccatgaatactgcgatgtga240tgggccgggtcgatattatcaccggtacgcttggtaaagcgctgggcggggcttctggtg300gttataccgcggcgcgcaaagaagtggttgagtggctgcgccagcgttctcgtccgtacc360tgttctccaactcgctggcaccggccattgttgccgcgtccatcaaagtactggagatgg420tcgaagcgggcagcgaactgcgtgaccgtctgtgggcgaacgcgcgtcagttccgtgagc480aaatgtcggcggcgggctttaccctggcgggagccgatcacgccattattccggtcatgc540ttggtgatgcggtagtggcgcagaaatttgcccgtgagctgcaaaaagagggcatttacg600ttaccggtttcttctatccggtcgttccgaaaggtcaggcgcgtattcgtacccagatgt660ctgcggcgcatacccctgagcaaattacgcgtgcagtagaagcatttacgcgtattggta720aacaactgggcgttatcgcctgaggatgtgagatgaaagcgttatccaaactgaaagcgg780aagagggcatctggatgaccgacgttcctgtaccggaactcgggcataacgatctgctga840ttaaaatccgtaaaacagccatctgcgggactgacgttcacatctataactgggatgagt900ggtcgcaaaaaaccatcccggtgccgatggtcgtgggccatgaatatgtcggtgaagtgg960taggtattggtcaggaagtgaaaggcttcaagatcggcgatcgcgtttctggcgaaggcc1020atatcacctgtggtcattgccgcaactgtcgtggtggtcgtacccatttgtgccgcaaca1080cgataggcgttggtgttaatcgcccgggctgctttgccgaatatctggtgatcccggcat1140tcaacgccttcaaaatccccgacaatatttccgatgacttagccgcaatttttgatccct1200tcggtaacgccgtgcataccgcgctgtcgtttgatctggtgggcgaagatgtgctggttt1260ctggtgcaggcccgattggtattatggcagcggcggtggcgaaacacgttggtgcacgca1320atgtggtgatcactgatgttaacgaataccgccttgagctggcgcgtaaaatgggtatca1380cccgtgcggttaacgtcgccaaagaaaatctcaatgacgtgatggcggagttaggcatga1440ccgaaggttttgatgtcggtctggaaatgtccggtgcgccgccagcgtttcgtaccatgc1500ttgacaccatgaatcacggcggccgtattgcgatgctgggtattccgccgtctgatatgt1560ctatcgactggaccaaagtgatctttaaaggcttgttcattaaaggtatttacggtcgtg1620agatgtttgaaacctggtacaagatggcggcgctgattcagtctggcctcgatctttcgc1680cgatcattacccatcgtttctctatcgatgatttccagaagggctttgacgctatgcgtt1740cgggccagtccgggaaagttattctgagctgggattaacacgaacaagggctggtattcc1800agcccttttatctgaggataatctgttaaatatgtaaaatcctgtcagtgtaataaagag1860ttcgtaattgtgctgatctcttatatagctgctctcattatctctctaccctgaagtgac1920tctctcacctgtaaaaataatatctcacaggcttaatagtttcttaatacaaagcctgta1980aaacgtcaggataacttcagaggtcgtcggtaatttatgatgaacagcaccaataaactt2040agtgttattattccgttatataatgcgggcgatgatttccgcacttgtatggaatcttta2100attacgcaaacctggactgctctggaaatcattattattaacgatggttcaacggataat2160tctgttgaaatagcaaagtattacgcagaaaactatccgcacgttcgtttgttgcatcag2220gcgaatgctggcgcatcggtggcgcgtaatcgtgggattgaagtggcaacgggcaaatat2280gtcgcttttgtcgatgctgacgatgaagtctatcccaccatgtacgaaacgctgatgacc2340atggcgttagaggacgacctcgacgtggcgcagtgcaacgctgactggtgttttcgtgaa2400acgggagaaacctggcaatccatccccaccgatcgccttcgctcaaccggcgtattaacc2460<210>8<211>341<212>PRT<213>大肠杆菌<400>8MetLysAlaLeuSerLysLeuLysAlaGluGluGlyIleTrpMetThr151015AspValProValProGluLeuGlyHisAsnAspLeuLeuIleLysIle202530ArgLysThrAlaIleCysGlyThrAspValHisIleTyrAsnTrpAsp354045GluTrpSerGlnLysThrIleProValProMetValValGlyHisGlu505560TyrValGlyGluValValGlyIleGlyGlnGluValLysGlyPheLys65707580IleGlyAspArgValSerGlyGluGlyHisIleThrCysGlyHisCys859095ArgAsnCysArgGlyGlyArgThrHisLeuCysArgAsnThrIleGly100105110ValGlyValAsnArgProGlyCysPheAlaGluTyrLeuValIlePro115120125AlaPheAsnAlaPheLysIleProAspAsnIleSerAspAspLeuAla130135140AlaIlePheAspProPheGlyAsnAlaValHisThrAlaLeuSerPhe145150155160AspLeuValGlyGluAspValLeuValSerGlyAlaGlyProIleGly165170175IleMetAlaAlaAlaValAlaLysHisValGlyAlaArgAsnValVal180185190IleThrAspValAsnGluTyrArgLeuGluLeuAlaArgLysMetGly195200205IleThrArgAlaValAsnValAlaLysGluAsnLeuAsnAspValMet210215220AlaGluLeuGlyMetThrGluGlyPheAspValGlyLeuGluMetSer225230235240GlyAlaProProAlaPheArgThrMetLeuAspThrMetAsnHisGly245250255GlyArgIleAlaMetLeuGlyIleProProSerAspMetSerIleAsp260265270TrpThrLysValIlePheLysGlyLeuPheIleLysGlyIleTyrGly275280285ArgGluMetPheGluThrTrpTyrLysMetAlaAlaLeuIleGlnSer290295300GlyLeuAspLeuSerProIleIleThrHisArgPheSerIleAspAsp305310315320PheGlnLysGlyPheAspAlaMetArgSerGlyGlnSerGlyLysVal325330335IleLeuSerTrpAsp340<210>9<211>2732<212>DNA<213>大肠杆菌<400>9gatgccaaaaggtgcgccaaaatccaaagtagcggcaacgtgcgactactccgcagaagt60cgttctgcatggtgataacttcaacgacactatcgctaaagtgagcgaaattgtcgaaat120ggaaggccgtatttttatcccaccttacgatgatccgaaagtgattgctggccagggaac180gattggtctggaaattatggaagatctctatgatgtcgataacgtgattgtgccaattgg240tggtggcggtttaattgctggtattgcggtggcaattaaatctattaacccgaccattcg300tgttattggcgtacagtctgaaaacgttcacggcatggcggcttctttccactccggaga360aataaccacgcaccgaactaccggcaccctggcggatggttgtgatgtctcccgcccggg420taatttaacttacgaaatcgttcgtgaattagtcgatgacatcgtgctggtcagcgaaga480cgaaatcagaaacagtatgattgccttaattcagcgcaataaagtcgtcaccgaaggcgc540aggcgctctggcatgtgctgcattattaagcggtaaattagaccaatatattcaaaacag600aaaaaccgtcagtattatttccggcggcaatatcgatctttctcgcgtctctcaaatcac660cggtttcgttgacgcttaattaattcgttgaggataggatatgagtacttcagatagcat720tgtatccagccagacaaaacaatcgtcctggcgtaaatcagataccacatggacgttagg780cttgtttggtacggcaatcggcgccggggtgctgttcttccctatccgcgcaggttttgg840cggactgatcccgattcttctgatgttggtattggcataccccatcgcgttttattgcca900ccgggcgctggcgcgtctgtgtctttctggctctaacccttccggcaacattacggaaac960ggtggaagagcattttggtaaaactggcggcgtggttatcacgttcctgtacttcttcgc1020gatttgcccactgctgtggatttatggcgttactattaccaatacctttatgacgttctg1080ggaaaaccagctcggctttgcaccgctgaatcgcggctttgtggcgctgttcctgttgct1140gctgatggctttcgtcatctggtttggtaaggatctgatggttaaagtgatgagctacct1200ggtatggccgtttatcgccagcctggtgctgatttctttgtcgctgatcccttactggaa1260ctctgcagttatcgaccaggttgacctcggttcgctgtcgttaaccggtcatgacggtat1320cctgatcactgtctggctggggatttccatcatggttttctcctttaacttctcgccaat1380cgtctcttccttcgtggtttctaagcgtgaagagtatgagaaagacttcggtcgcgactt1440caccgaacgtaaatgttcccaaatcatttctcgtgccagcatgctgatggttgcagtggt1500gatgttctttgcctttagctgcctgtttactctgtctccggccaacatggcggaagccaa1560agcgcagaatattccagtgctttcttatctggctaaccactttgcgtccatgaccggtac1620caaaacaacgttcgcgattacactggaatatgcggcttccatcatcgcactcgtggctat1680cttcaaatctttcttcggtcactatctgggaacgctggaaggtctgaatggcctggtcct1740gaagtttggttataaaggcgacaaaactaaagtgtcgctgggtaaactgaacactatcag1800catgatcttcatcatgggctccacctgggttgttgcctacgccaacccgaacatccttga1860cctgattgaagccatgggcgcaccgattatcgcatccctgctgtgcctgttgccgatgta1920tgccatccgtaaagcgccgtctctggcgaaataccgtggtcgtctggataacgtgtttgt1980taccgtgattggtctgctgaccatcctgaacatcgtatacaaactgttttaatccgtaac2040tcaggatgagaaaagagatgaatgaatttccggttgttttggttattaactgtggttcgt2100cttcgattaagttttccgtgctcgatgccagcgactgtgaagtattaatgtcaggtattg2160ccgacggtattaactcggaaaatgcattcttatccgtaaatgggggagagccagcaccgc2220tggctcaccacagctacgaaggtgcattgaaggcaattgcatttgaactggaaaaacgga2280atttaaatgacagtgtggccttaattggccaccgcatcgctcacggcggcagtattttta2340ccgagtccgccattattaccgatgaagtcattgataatatccgtcgcgtttctccactgg2400cacccctgcataattacgccaatttaagtggtattgaatcggcgcagcaattatttccgg2460gcgtaactcaggtggcggtatttgataccagtttccaccagacgatggctccggaagctt2520atttatacggcctgccgtggaaatattatgaagagttaggtgtacgccgttatggtttcc2580acggcacgtcgcaccgctatgtttcccagcgcgcacattcgctgctgaatctggcggaag2640atgactccggcctggttgtggcgcatcttggcaatggcgcgtcaatctgcgcggttcgca2700acggtcagagtgttgatacctcaatgggaatg2732<210>10<211>443<212>PRT<213>大肠杆菌<400>10MetSerThrSerAspSerIleValSerSerGlnThrLysGlnSerSer151015TrpArgLysSerAspThrThrTrpThrLeuGlyLeuPheGlyThrAla202530IleGlyAlaGlyValLeuPhePheProIleArgAlaGlyPheGlyGly354045LeuIleProIleLeuLeuMetLeuValLeuAlaTyrProIleAlaPhe505560TyrCysHisArgAlaLeuAlaArgLeuCysLeuSerGlySerAsnPro65707580SerGlyAsnIleThrGluThrValGluGluHisPheGlyLysThrGly859095GlyValValIleThrPheLeuTyrPhePheAlaIleCysProLeuLeu100105110TrpIleTyrGlyValThrIleThrAsnThrPheMetThrPheTrpGlu115120125AsnGlnLeuGlyPheAlaProLeuAsnArgGlyPheValAlaLeuPhe130135140LeuLeuLeuLeuMetAlaPheValIleTrpPheGlyLysAspLeuMet145150155160ValLysValMetSerTyrLeuValTrpProPheIleAlaSerLeuVal165170175LeuIleSerLeuSerLeuIleProTyrTrpAsnSerAlaValIleAsp180185190GlnValAspLeuGlySerLeuSerLeuThrGlyHisAspGlyIleLeu195200205IleThrValTrpLeuGlyIleSerIleMetValPheSerPheAsnPhe210215220SerProIleValSerSerPheValValSerLysArgGluGluTyrGlu225230235240LysAspPheGlyArgAspPheThrGluArgLysCysSerGlnIleIle245250255SerArgAlaSerMetLeuMetValAlaValValMetPhePheAlaPhe260265270SerCysLeuPheThrLeuSerProAlaAsnMetAlaGluAlaLysAla275280285GlnAsnIleProValLeuSerTyrLeuAlaAsnHisPheAlaSerMet290295300ThrGlyThrLysThrThrPheAlaIleThrLeuGluTyrAlaAlaSer305310315320IleIleAlaLeuValAlaIlePheLysSerPhePheGlyHisTyrLeu325330335GlyThrLeuGluGlyLeuAsnGlyLeuValLeuLysPheGlyTyrLys340345350GlyAspLysThrLysValSerLeuGlyLysLeuAsnThrIleSerMet355360365IlePheIleMetGlySerThrTrpValValAlaTyrAlaAsnProAsn370375380IleLeuAspLeuIleGluAlaMetGlyAlaProIleIleAlaSerLeu385390395400LeuCysLeuLeuProMetTyrAlaIleArgLysAlaProSerLeuAla405410415LysTyrArgGlyArgLeuAspAsnValPheValThrValIleGlyLeu420425430LeuThrIleLeuAsnIleValTyrLysLeuPhe435440<210>11<211>2645<212>DNA<213>大肠杆菌<400>11atagcattccggctatcttcgccgtgaccactgacccgttcattgtgctgacctcaaacc60tgtttgcgatcctcggcctgcgtgcgatgtatttcctgctggcgggcgtagcagagcgtt120tctcgatgctcaaatatggcctggcggtgattctggtgtttatcggtatcaagatgctga180ttgtcgacttctaccatattccaatcgccgtctcgctgggcgtggtgtttggcattctgg240tgatgacgtttattatcaacgcctgggtgaattatcggcatgataagcagcggggtggat300aatttttaatctgcctaagccgtgtaccctgtcattaacatgagcaccgttttctccctc360tcccttccagggagagggtcggggtgagggtaatttttcgcaccgatgctggcctgttcc420cctcaccctaaccctctccccaaacggggcgaggggactgaccgagtccttttttgatgt480tgtcatcagtctggaagccgcacgttggctttatttttatgtcaaagaaatgtaaccatt540aagtttcaaaatatgacctctctttaaaatccagcatttttcgcttcccgaagctgtaac600tttccttatactcgaccttgcaaacactttgttacatcctgaaagatgcgtcgacagaac660gcaccagggatgtgcgacaacacaatgaaaggatcgaaaaatgactacgcaacgttcacc720ggggctattccggcgtctggctcatggcagcctggtaaaacaaatcctggtcggccttgt780tctggggattcttctggcatggatctcaaaacccgcggcggaagctgttggtctgttagg840tactttgttcgtcggcgcactgaaagccgttgcccccatcctggtgttgatgctggtgat900ggcatctattgctaaccaccagcacgggcagaaaaccaatatccgccctattttgttcct960ctatctactgggcaccttctctgctgctctggccgcagtagtcttcagctttgccttccc1020ttctaccctgcatttatccagtagcgcgggtgatatttcgccgccgtcaggcattgtcga1080agtgatgcgcgggctggtaatgagcatggtttccaaccccatcgacgcgctgctgaaagg1140taactacatcgggattctggtgtgggcgatcggcctcggcttcgcactgcgtcacggtaa1200cgagaccaccaaaaacctggttaacgatatgtcgaatgccgttacctttatggtgaaact1260ggtcattcgcttcgcaccgattggtatttttgggctggtttcttctaccctggcaaccac1320cggtttctccacactgtggggctacgcgcaactgctggtcgtgctggttggctgtatgtt1380actggtggcgctggtggttaacccattgctggtgtggtggaaaattcgtcgtaacccgtt1440cccgctggtgctgctgtgcctgcgcgaaagcggtgtgtatgccttcttcacccgcagctc1500tgcagcgaacattccggtgaatatggcgctgtgtgaaaagctgaatctggatcgcgatac1560ctattccgtttctattccgctgggagccaccatcaatatggcgggcgcagcaatcactat1620taccgtgttgacgctggctgcggttaatacgctgggtattccggtcgatctgcccacggc1680gctgctgttgagcgtggtggcttctctgtgtgcctgtggcgcatccggcgtggcgggggg1740gtctctgctgctgatcccactggcctgtaatatgttcggtatttcgaacgatatcgccat1800gcaggtggttgccgtcggctttatcatcggcgtattgcaggactcttgcgaaaccgcgct1860gaactcttcaactgacgtgctgttcactgcggcagcttgccaggcagaagacgatcgtct1920ggcaaatagcgccctgcgtaattaattgtttaacccctttcgtctacggcggaaggggtt1980ttctcaactttaaacggatcaattccccttttctgcatccgccagaaacgaatgatattc2040aggccattcataagcagaaaactaccctcaatcatcgtgccgcctatcgaccccgcccag2100aagttgtgaatcacccagcaacacgttgaaaaccacattacgcagcgcatggtcagccct2160ttacagcagaatagcgcccaggtactgacaatcgtgccgataaccggcaatagttcgaca2220ggatgatggaacttcgcgaggccaattccgccagtcagcacaataaaaatcgccattacc2280cataagctgcgcgtgcgtaaggtaatcaatgtacgaatggcattaaggatggcactggca2340ccagcgggataggtgcccagaagaaaaaaatgtacgccaataacggcgctatagaccgaa2400agctgctttttgaagcgacgttcgtcacgattgaaaaatgttgtgataccaatcagaaag2460gcgatgacacccacgccctgggccagccaatacgcggtcatgataaatccttagcaggta2520tggaaaagcaaacggcgcttcacattatgaaacgccgttttttattaacaactcatttcg2580actttatagcgttacgccgcttttgaagatcgccagttcgcggaagtcgttacgctcgtt2640acagg2645<210>12<211>414<212>PRT<213>大肠杆菌<400>12MetThrThrGlnArgSerProGlyLeuPheArgArgLeuAlaHisGly151015SerLeuValLysGlnIleLeuValGlyLeuValLeuGlyIleLeuLeu202530AlaTrpIleSerLysProAlaAlaGluAlaValGlyLeuLeuGlyThr354045LeuPheValGlyAlaLeuLysAlaValAlaProIleLeuValLeuMet505560LeuValMetAlaSerIleAlaAsnHisGlnHisGlyGlnLysThrAsn65707580IleArgProIleLeuPheLeuTyrLeuLeuGlyThrPheSerAlaAla859095LeuAlaAlaValValPheSerPheAlaPheProSerThrLeuHisLeu100105110SerSerSerAlaGlyAspIleSerProProSerGlyIleValGluVal115120125MetArgGlyLeuValMetSerMetValSerAsnProIleAspAlaLeu130135140LeuLysGlyAsnTyrIleGlyIleLeuValTrpAlaIleGlyLeuGly145150155160PheAlaLeuArgHisGlyAsnGluThrThrLysAsnLeuValAsnAsp165170175MetSerAsnAlaValThrPheMetValLysLeuValIleArgPheAla180185190ProIleGlyIlePheGlyLeuValSerSerThrLeuAlaThrThrGly195200205PheSerThrLeuTrpGlyTyrAlaGlnLeuLeuValValLeuValGly210215220CysMetLeuLeuValAlaLeuValValAsnProLeuLeuValTrpTrp225230235240LysIleArgArgAsnProPheProLeuValLeuLeuCysLeuArgGlu245250255SerGlyValTyrAlaPhePheThrArgSerSerAlaAlaAsnIlePro260265270ValAsnMetAlaLeuCysGluLysLeuAsnLeuAspArgAspThrTyr275280285SerValSerIleProLeuGlyAlaThrIleAsnMetAlaGlyAlaAla290295300IleThrIleThrValLeuThrLeuAlaAlaValAsnThrLeuGlyIle305310315320ProValAspLeuProThrAlaLeuLeuLeuSerValValAlaSerLeu325330335CysAlaCysGlyAlaSerGlyValAlaGlyGlySerLeuLeuLeuIle340345350ProLeuAlaCysAsnMetPheGlyIleSerAsnAspIleAlaMetGln355360365ValValAlaValGlyPheIleIleGlyValLeuGlnAspSerCysGlu370375380ThrAlaLeuAsnSerSerThrAspValLeuPheThrAlaAlaAlaCys385390395400GlnAlaGluAspAspArgLeuAlaAsnSerAlaLeuArgAsn405410<210>13<211>162<212>DNA<213>人工序列<400>13caattccgacgtctaagaaaccattattatcatgacattaacctataaaaataggcgtat60cacgaggccctttcgtcttcacctcgagtccctatcagtgatagagattgacatccctat120cagtgatagagatactgagcacatcagcaggacgcactgacc162<210>14<211>5020<212>DNA<213>人工序列<400>14agcttttcattctgactgcaacgggcaatatgtctctgtgtggattaaaaaaagagtgtc60tgatagcagcttctgaactggttacctgccgtgagtaaattaaaattttattgacttagg120tcactaaatactttaaccaatataggcatagcgcacagacagataaaaattacagagtac180acaacatccatgaaacgcattagcaccaccattaccaccaccatcaccattaccacaggt240aacggtgcgggctgacgcgtacaggaaacacagaaaaaagcccgcacctgacagtgcggg300ctttttttttcgaccaaaggtaacgaggtaacaaccatgcgagtgttgaagttcggcggt360acatcagtggcaaatgcagaacgttttctgcgtgttgccgatattctggaaagcaatgcc420aggcaggggcaggtggccaccgtcctctctgcccccgccaaaatcaccaaccacctggtg480gcgatgattgaaaaaaccattagcggccaggatgctttacccaatatcagcgatgccgaa540cgtatttttgccgaacttttgacgggactcgccgccgcccagccggggttcccgctggcg600caattgaaaactttcgtcgatcaggaatttgcccaaataaaacatgtcctgcatggcatt660agtttgttggggcagtgcccggatagcatcaacgctgcgctgatttgccgtggcgagaaa720atgtcgatcgccattatggccggcgtattagaagcgcgcggtcacaacgttactgttatc780gatccggtcgaaaaactgctggcagtggggcattacctcgaatctaccgtcgatattgct840gagtccacccgccgtattgcggcaagccgcattccggctgatcacatggtgctgatggca900ggtttcaccgccggtaatgaaaaaggcgaactggtggtgcttggacgcaacggttccgac960tactctgctgcggtgctggctgcctgtttacgcgccgattgttgcgagatttggacggac1020gttgacggggtctatacctgcgacccgcgtcaggtgcccgatgcgaggttgttgaagtcg1080atgtcctaccaggaagcgatggagctttcctacttcggcgctaaagttcttcacccccgc1140accattacccccatcgcccagttccagatcccttgcctgattaaaaataccggaaatcct1200caagcaccaggtacgctcattggtgccagccgtgatgaagacgaattaccggtcaagggc1260atttccaatctgaataacatggcaatgttcagcgtttctggtccggggatgaaagggatg1320gtcggcatggcggcgcgcgtctttgcagcgatgtcacgcgcccgtatttccgtggtgctg1380attacgcaatcatcttccgaatacagcatcagtttctgcgttccacaaagcgactgtgtg1440cgagctgaacgggcaatgcaggaagagttctacctggaactgaaagaaggcttactggag1500ccgctggcagtgacggaacggctggccattatctcggtggtaggtgatggtatgcgcacc1560ttgcgtgggatctcggcgaaattctttgccgcactggcccgcgccaatatcaacattgtc1620gccattgctcagggatcttctgaacgctcaatctctgtcgtggtaaataacgatgatgcg1680accactggcgtgcgcgttactcatcagatgctgttcaataccgatcaggttatcgaagtg1740tttgtgattggcgtcggtggcgttggcggtgcgctgctggagcaactgaagcgtcagcaa1800agctggctgaagaataaacatatcgacttacgtgtctgcggtgttgccaactcgaaggct1860ctgctcaccaatgtacatggccttaatctggaaaactggcaggaagaactggcgcaagcc1920aaagagccgtttaatctcgggcgcttaattcgcctcgtgaaagaatatcatctgctgaac1980ccggtcattgttgactgcacttccagccaggcagtggcggatcaatatgccgacttcctg2040cgcgaaggtttccacgttgtcacgccgaacaaaaaggccaacacctcgtcgatggattac2100taccatcagttgcgttatgcggcggaaaaatcgcggcgtaaattcctctatgacaccaac2160gttggggctggattaccggttattgagaacctgcaaaatctgctcaatgcaggtgatgaa2220ttgatgaagttctccggcattctttctggttcgctttcttatatcttcggcaagttagac2280gaaggcatgagtttctccgaggcgaccacgctggcgcgggaaatgggttataccgaaccg2340gacccgcgagatgatctttctggtatggatgtggcgcgtaaactattgattctcgctcgt2400gaaacgggacgtgaactggagctggcggatattgaaattgaacctgtgctgcccgcagag2460tttaacgccgagggtgatgttgccgcttttatggcgaatctgtcacaactcgacgatctc2520tttgccgcgcgcgtggcgaaggcccgtgatgaaggaaaagttttgcgctatgttggcaat2580attgatgaagatggcgtctgccgcgtgaagattgccgaagtggatggtaatgatccgctg2640ttcaaagtgaaaaatggcgaaaacgccctggccttctatagccactattatcagccgctg2700ccgttggtactgcgcggatatggtgcgggcaatgacgttacagctgccggtgtctttgct2760gatctgctacgtaccctctcatggaagttaggagtctgacatggttaaagtttatgcccc2820ggcttccagtgccaatatgagcgtcgggtttgatgtgctcggggcggcggtgacacctgt2880tgatggtgcattgctcggagatgtagtcacggttgaggcggcagagacattcagtctcaa2940caacctcggacgctttgccgataagctgccgtcagaaccacgggaaaatatcgtttatca3000gtgctgggagcgtttttgccaggaactgggtaagcaaattccagtggcgatgaccctgga3060aaagaatatgccgatcggttcgggcttaggctccagtgcctgttcggtggtcgcggcgct3120gatggcgatgaatgaacactgcggcaagccgcttaatgacactcgtttgctggctttgat3180gggcgagctggaaggccgtatctccggcagcattcattacgacaacgtggcaccgtgttt3240tctcggtggtatgcagttgatgatcgaagaaaacgacatcatcagccagcaagtgccagg3300gtttgatgagtggctgtgggtgctggcgtatccggggattaaagtctcgacggcagaagc3360cagggctattttaccggcgcagtatcgccgccaggattgcattgcgcacgggcgacatct3420ggcaggcttcattcacgcctgctattcccgtcagcctgagcttgccgcgaagctgatgaa3480agatgttatcgctgaaccctaccgtgaacggttactgccaggcttccggcaggcgcggca3540ggcggtcgcggaaatcggcgcggtagcgagcggtatctccggctccggcccgaccttgtt3600cgctctgtgtgacaagccggaaaccgcccagcgcgttgccgactggttgggtaagaacta3660cctgcaaaatcaggaaggttttgttcatatttgccggctggatacggcgggcgcacgagt3720actggaaaactaaatgaaactctacaatctgaaagatcacaacgagcaggtcagctttgc3780gcaagccgtaacccaggggttgggcaaaaatcaggggctgttttttccgcacgacctgcc3840ggaattcagcctgactgaaattgatgagatgctgaagctggattttgtcacccgcagtgc3900gaagatcctctcggcgtttattggtgatgaaatcccacaggaaatcctggaagagcgcgt3960gcgcgcggcgtttgccttcccggctccggtcgccaatgttgaaagcgatgtcggttgtct4020ggaattgttccacgggccaacgctggcatttaaagatttcggcggtcgctttatggcaca4080aatgctgacccatattgcgggtgataagccagtgaccattctgaccgcgacctccggtga4140taccggagcggcagtggctcatgctttctacggtttaccgaatgtgaaagtggttatcct4200ctatccacgaggcaaaatcagtccactgcaagaaaaactgttctgtacattgggcggcaa4260tatcgaaactgttgccatcgacggcgatttcgatgcctgtcaggcgctggtgaagcaggc4320gtttgatgatgaagaactgaaagtggcgctagggttaaactcggctaactcgattaacat4380cagccgtttgctggcgcagatttgctactactttgaagctgttgcgcagctgccgcagga4440gacgcgcaaccagctggttgtctcggtgccaagcggaaacttcggcgatttgacggcggg4500tctgctggcgaagtcactcggtctgccggtgaaacgttttattgctgcgaccaacgtgaa4560cgataccgtgccacgtttcctgcacgacggtcagtggtcacccaaagcgactcaggcgac4620gttatccaacgcgatggacgtgagtcagccgaacaactggccgcgtgtggaagagttgtt4680ccgccgcaaaatctggcaactgaaagagctgggttatgcagccgtggatgatgaaaccac4740gcaacagacaatgcgtgagttaaaagaactgggctacacttcggagccgcacgctgccgt4800agcttatcgtgcgctgcgtgatcagttgaatccaggcgaatatggcttgttcctcggcac4860cgcgcatccggcgaaatttaaagagagcgtggaagcgattctcggtgaaacgttggatct4920gccaaaagagctggcagaacgtgctgatttacccttgctttcacataatctgcccgccga4980ttttgctgcgttgcgtaaattgatgatgaatcatcagtaa5020<210>15<211>3113<212>DNA<213>人工序列<400>15atgaccatgattacggattcactggccgtcgttttacaacgtcgtgactgggaaaaccct60ggcgttacccaacttaatcgccttgcagcacatccccctttcgccagctggcgtaatagc120gaagaggcccgcaccgatcgcccttcccaacagttgcgcagcctgaatggcgaatggcgc180tttgcctggtttccggcaccagaagcggtgccggaaagctggctggagtgcgatcttcct240gaggccgatactgtcgtcgtcccctcaaactggcagatgcacggttacgatgcgcccatc300tacaccaacgtgacctatcccattacggtcaatccgccgtttgttcccacggagaatccg360acgggttgttactcgctcacatttaatgttgatgaaagctggctacaggaaggccagacg420cgaattatttttgatggcgttaactcggcgtttcatctgtggtgcaacgggcgctgggtc480ggttacggccaggacagtcgtttgccgtctgaatttgacctgagcgcatttttacgcgcc540ggagaaaaccgcctcgcggtgatggtgctgcgctggagtgacggcagttatctggaagat600caggatatgtggcggatgagcggcattttccgtgacgtctcgttgctgcataaaccgact660acacaaatcagcgatttccatgttgccactcgctttaatgatgatttcagccgcgctgta720ctggaggctgaagttcagatgtgcggcgagttgcgtgactacctacgggtaacagtttct780ttatggcagggtgaaacgcaggtcgccagcggcaccgcgcctttcggcggtgaaattatc840gatgagcgtggtggttatgccgatcgcgtcacactacgtctgaacgtcgaaaacccgaaa900ctgtggagcgccgaaatcccgaatctctatcgtgcggtggttgaactgcacaccgccgac960ggcacgctgattgaagcagaagcctgcgatgtcggtttccgcgaggtgcggattgaaaat1020ggtctgctgctgctgaacggcaagccgttgctgattcgaggcgttaaccgtcacgagcat1080catcctctgcatggtcaggtcatggatgagcagacgatggtgcaggatatcctgctgatg1140aagcagaacaactttaacgccgtgcgctgttcgcattatccgaaccatccgctgtggtac1200acgctgtgcgaccgctacggcctgtatgtggtggatgaagccaatattgaaacccacggc1260atggtgccaatgaatcgtctgaccgatgatccgcgctggctaccggcgatgagcgaacgc1320gtaacgcgaatggtgcagcgcgatcgtaatcacccgagtgtgatcatctggtcgctgggg1380aatgaatcaggccacggcgctaatcacgacgcgctgtatcgctggatcaaatctgtcgat1440ccttcccgcccggtgcagtatgaaggcggcggagccgacaccacggccaccgatattatt1500tgcccgatgtacgcgcgcgtggatgaagaccagcccttcccggctgtgccgaaatggtcc1560atcaaaaaatggctttcgctacctggagagacgcgcccgctgatcctttgcgaatacgcc1620cacgcgatgggtaacagtcttggcggtttcgctaaatactggcaggcgtttcgtcagtat1680ccccgtttacagggcggcttcgtctgggactgggtggatcagtcgctgattaaatatgat1740gaaaacggcaacccgtggtcggcttacggcggtgattttggcgatacgccgaacgatcgc1800cagttctgtatgaacggtctggtctttgccgaccgcacgccgcatccagcgctgacggaa1860gcaaaacaccagcagcagtttttccagttccgtttatccgggcaaaccatcgaagtgacc1920agcgaatacctgttccgtcatagcgataacgagctcctgcactggatggtggcgctggat1980ggtaagccgctggcaagcggtgaagtgcctctggatgtcgctccacaaggtaaacagttg2040attgaactgcctgaactaccgcagccggagagcgccgggcaactctggctcacagtacgc2100gtagtgcaaccgaacgcgaccgcatggtcagaagccgggcacatcagcgcctggcagcag2160tggcgtctggcggaaaacctcagtgtgacgctccccgccgcgtcccacgccatcccgcat2220ctgaccaccagcgaaatggatttttgcatcgagctgggtaataagcgttggcaatttaac2280cgccagtcaggctttctttcacagatgtggattggcgataaaaaacaactgctgacgccg2340ctgcgcgatcagttcacccgtgcaccgctggataacgacattggcgtaagtgaagcgacc2400cgcattgaccctaacgcctgggtcgaacgctggaaggcggcgggccattaccaggccgaa2460gcagcgttgttgcagtgcacggcagatacacttgctgatgcggtgctgattacgaccgct2520cacgcgtggcagcatcaggggaaaaccttatttatcagccggaaaacctaccggattgat2580ggtagtggtcaaatggcgattaccgttgatgttgaagtggcgagcgatacaccgcatccg2640gcgcggattggcctgaactgccagctggcgcaggtagcagagcgggtaaactggctcgga2700ttagggccgcaagaaaactatcccgaccgccttactgccgcctgttttgaccgctgggat2760ctgccattgtcagacatgtataccccgtacgtcttcccgagcgaaaacggtctgcgctgc2820gggacgcgcgaattgaattatggcccacaccagtggcgcggcgacttccagttcaacatc2880agccgctacagtcaacagcaactgatggaaaccagccatcgccatctgctgcacgcggaa2940gaaggcacatggctgaatatcgacggtttccatatggggattggtggcgacgactcctgg3000agcccgtcagtatcggcggaattccagctgagcgccggtcgctaccattaccagttggtc3060tggtgtcaaaaataataataaccgggcaggccatgtctgcccgtatttcgcgt3113<210>16<211>717<212>DNA<213>人工序列<400>16atgagtaaaggagaagaacttttcactggagttgtcccaattcttgttgaattagatggt60gatgttaatgggcacaaattttctgtcagtggagagggtgaaggtgatgcaacatacgga120aaacttacccttaaatttatttgcactactggaaaactacctgttccatggccaacactt180gtcactactttcgggtatggtgttcaatgctttgcgagatacccagatcatatgaaacag240catgactttttcaagagtgccatgcccgaaggttatgtacaggaaagaactatatttttc300aaagatgacgggaactacaagacacgtgctgaagtcaagtttgaaggtgatacccttgtt360aatagaatcgagttaaaaggtattgattttaaagaagatggaaacattcttggacacaaa420ttggaatacaactataactcacacaatgtatacatcatggcagacaaacaaaagaatgga480atcaaagttaacttcaaaattagacacaacattgaagatggaagcgttcaactagcagac540cattatcaacaaaatactccaattggcgatggccctgtccttttaccagacaaccattac600ctgtccacacaatctgccctttcgaaagatcccaacgaaaagagagaccacatggtcctt660cttgagtttgtaacagctgctgggattacacatggcatggatgaactatacaaataa717<210>17<211>1242<212>DNA<213>人工序列<400>17cacatatacaggaggagacagatatgatcataggggttcctaaagagataaaaaacaatg60aaaaccgtgtcgcattaacacccgggggcgtttctcagctcatttcaaacggccaccggg120tgctggttgaaacaggcgcgggccttggaagcggatttgaaaatgaagcctatgagtcag180caggagcggaaatcattgctgatccgaagcaggtctgggacgccgaaatggtcatgaaag240taaaagaaccgctgccggaagaatatgtttattttcgcaaaggacttgtgctgtttacgt300accttcatttagcagctgagcctgagcttgcacaggccttgaaggataaaggagtaactg360ccatcgcatatgaaacggtcagtgaaggccggacattgcctcttctgacgccaatgtcag420aggttgcgggcagaatggcagcgcaaatcggcgctcaattcttagaaaagcctaaaggcg480gaaaaggcattctgcttgccggggtgcctggcgtttcccgcggaaaagtaacaattatcg540gaggaggcgttgtcgggacaaacgcggcgaaaatggctgtcggcctcggtgcagatgtga600cgatcattgacttaaacgcagaccgcttgcgccagcttgatgacatcttcggccatcaga660ttaaaacgttaatttctaatccggtcaatattgctgatgctgtggcggaagcggatctcc720tcatttgcgcggtattaattccgggtgctaaagctccgactcttgtcactgaggaaatgg780taaaacaaatgaaacccggttcagttattgttgatgtagcgatcgaccaaggcggcatcg840tcgaaactgtcgaccatatcacaacacatgatcagccaacatatgaaaaacacggggttg900tgcattatgctgtagcgaacatgccaggcgcagtccctcgtacatcaacaatcgccctga960ctaacgttactgttccatacgcgctgcaaatcgcgaacaaaggggcagtaaaagcgctcg1020cagacaatacggcactgagagcgggtttaaacaccgcaaacggacacgtgacctatgaag1080ctgtagcaagagatctaggctatgagtatgttcctgccgagaaagctttacaggatgaat1140catctgtggcgggtgcttaattcacaataagcttgcagaaagatttctgcaggctttttt1200attttttaaaaggaaaaaagagaccatttcacgaattatgac1242<210>18<211>1262<212>DNA<213>人工序列<400>18gtgcgggctttttttttcgaccaaaggtaacgaggtaacaaccatgatcataggggttcc60taaagagataaaaaacaatgaaaaccgtgtcgcattaacacccgggggcgtttctcagct120catttcaaacggccaccgggtgctggttgaaacaggcgcgggccttggaagcggatttga180aaatgaagcctatgagtcagcaggagcggaaatcattgctgatccgaagcaggtctggga240cgccgaaatggtcatgaaagtaaaagaaccgctgccggaagaatatgtttattttcgcaa300aggacttgtgctgtttacgtaccttcatttagcagctgagcctgagcttgcacaggcctt360gaaggataaaggagtaactgccatcgcatatgaaacggtcagtgaaggccggacattgcc420tcttctgacgccaatgtcagaggttgcgggcagaatggcagcgcaaatcggcgctcaatt480cttagaaaagcctaaaggcggaaaaggcattctgcttgccggggtgcctggcgtttcccg540cggaaaagtaacaattatcggaggaggcgttgtcgggacaaacgcggcgaaaatggctgt600cggcctcggtgcagatgtgacgatcattgacttaaacgcagaccgcttgcgccagcttga660tgacatcttcggccatcagattaaaacgttaatttctaatccggtcaatattgctgatgc720tgtggcggaagcggatctcctcatttgcgcggtattaattccgggtgctaaagctccgac780tcttgtcactgaggaaatggtaaaacaaatgaaacccggttcagttattgttgatgtagc840gatcgaccaaggcggcatcgtcgaaactgtcgaccatatcacaacacatgatcagccaac900atatgaaaaacacggggttgtgcattatgctgtagcgaacatgccaggcgcagtccctcg960tacatcaacaatcgccctgactaacgttactgttccatacgcgctgcaaatcgcgaacaa1020aggggcagtaaaagcgctcgcagacaatacggcactgagagcgggtttaaacaccgcaaa1080cggacacgtgacctatgaagctgtagcaagagatctaggctatgagtatgttcctgccga1140gaaagctttacaggatgaatcatctgtggcgggtgcttaattcacaataagcttgcagaa1200agatttctgcaggcttttttattttttaaaaggaaaaaagagaccatttcacgaattatg1260ac1262<210>19<211>378<212>PRT<213>人工序列<400>19MetIleIleGlyValProLysGluIleLysAsnAsnGluAsnArgVal151015AlaLeuThrProGlyGlyValSerGlnLeuIleSerAsnGlyHisArg202530ValLeuValGluThrGlyAlaGlyLeuGlySerGlyPheGluAsnGlu354045AlaTyrGluSerAlaGlyAlaGluIleIleAlaAspProLysGlnVal505560TrpAspAlaGluMetValMetLysValLysGluProLeuProGluGlu65707580TyrValTyrPheArgLysGlyLeuValLeuPheThrTyrLeuHisLeu859095AlaAlaGluProGluLeuAlaGlnAlaLeuLysAspLysGlyValThr100105110AlaIleAlaTyrGluThrValSerGluGlyArgThrLeuProLeuLeu115120125ThrProMetSerGluValAlaGlyArgMetAlaAlaGlnIleGlyAla130135140GlnPheLeuGluLysProLysGlyGlyLysGlyIleLeuLeuAlaGly145150155160ValProGlyValSerArgGlyLysValThrIleIleGlyGlyGlyVal165170175ValGlyThrAsnAlaAlaLysMetAlaValGlyLeuGlyAlaAspVal180185190ThrIleIleAspLeuAsnAlaAspArgLeuArgGlnLeuAspAspIle195200205PheGlyHisGlnIleLysThrLeuIleSerAsnProValAsnIleAla210215220AspAlaValAlaGluAlaAspLeuLeuIleCysAlaValLeuIlePro225230235240GlyAlaLysAlaProThrLeuValThrGluGluMetValLysGlnMet245250255LysProGlySerValIleValAspValAlaIleAspGlnGlyGlyIle260265270ValGluThrValAspHisIleThrThrHisAspGlnProThrTyrGlu275280285LysHisGlyValValHisTyrAlaValAlaAsnMetProGlyAlaVal290295300ProArgThrSerThrIleAlaLeuThrAsnValThrValProTyrAla305310315320LeuGlnIleAlaAsnLysGlyAlaValLysAlaLeuAlaAspAsnThr325330335AlaLeuArgAlaGlyLeuAsnThrAlaAsnGlyHisValThrTyrGlu340345350AlaValAlaArgAspLeuGlyTyrGluTyrValProAlaGluLysAla355360365LeuGlnAspGluSerSerValAlaGlyAla370375当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1