一种通用供体干细胞及其制备方法与流程
本发明涉及一种干细胞领域,具体地涉及一种通用供体干细胞及其制备方法。
背景技术:
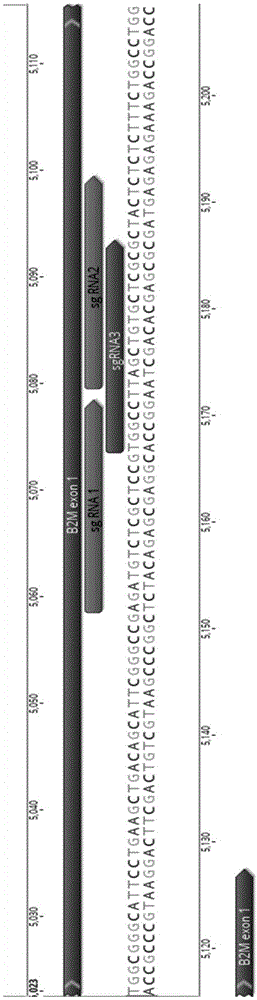
:多能干细胞具有巨大的治疗潜力。这些未分化的细胞可以产生几乎任何特化的细胞类型,作为受损组织的天然修复系统,或作为可进一步设计用于治疗疾病的新型治疗剂。科学家利用干细胞的独特性质来治疗与死亡或受损细胞相关的疾病。目前,在欧洲,每年有26000名患者接受干细胞治疗来治疗血液疾病和一些癌症,包括白血病。然而,目前人类供体是干细胞的主要来源,由于患者免疫系统的排斥而限制了治疗的成功。目前,干细胞生物学的最新进展使人们有可能考虑将患者自身细胞用作移植的无限源。不幸的是,就多能性、表观遗传状态、分化能力和基因组稳定性而言,ipsc的产生仍然是昂贵的,耗时且高度可变的过程。此外,发现在重编程和长时间培养期间发生的变化引发适应性免疫应答,导致甚至自体干细胞衍生的移植物的免疫排斥。目前已有一些重要的证据支持了hla-工程细胞将正常运作并避免移植后的异体排斥。(1)hlai类阴性或hlaii类阴性的罕见个体相对健康,表明hla阴性细胞可分化成所有必需器官。(2)缺乏主要组织相容性复合体(mhc)i类和ii类抗原(hla的鼠类等同物)的小鼠已经被广泛研究并且除了缺少cd4+和cd8+t细胞外是健康的。重要的是,移植实验已经表明,来自i型阴性小鼠供体的器官或细胞在同种异体受体(包括肝细胞,肾脏,心脏和胰岛)中存活更长时间(有时持续无限期)。这些小鼠实验表明在许多用于多能干细胞的临床环境中,hla工程化人细胞也将比同种异体细胞存活更长时间。每个人都有一套独特的人类白细胞抗原(hla)——细胞表面蛋白标志物,向免疫系统发出信号,表明他们是个体自身的细胞。在人群中,编码hla分子的基因是高度可变的——意味着每个人都有特定的hla分子条形码,这些条形码是为他们的免疫系统定制的。hla分为ⅰ类和ⅱ,在异体移植中,多种hlai类和ii类蛋白质必须与同种异体受者的组织相容性匹配。i类和ii类分子都由两部分组成。i类分子是在高变异hlai类蛋白与另一种称为β-2-微球蛋白(β-2-微球蛋白)的蛋白结合时形成的,后者是hla分子到达细胞表面所必需的。当两个高变性hlaii类分子结合在一起时,hlaii类分子到达细胞表面。这两种类型的hla分子都具有将其它蛋白质片段呈递给免疫系统的作用。所以,敲除主要组织相容性复合体mhci和mhcii(或hlai和hlaii)来降低细胞的免疫原性,以避免分化成免疫细胞后宿主对移植细胞产生排斥反应,从而实现异体移植。技术实现要素:为了克服这种免疫障碍,本发明的一方面提供一种通用供体干细胞,所述干细胞相对于野生型干细胞,mhci和mhcii的表达受调节。在本发明中,mhci和mhcii不表达是由于编码mhci和mhc的基因的转录调节因子的表达受调节。在本发明中,所述干细胞相对于野生型干细胞,还包含至少一个致耐受性因子的表达受调节。在本发明的实施方案中,所述转录调节因子的表达受调节是指表达降低。在本发明的实施方案中,所述转录调节因子的表达受调节是指表达受抑制。在本发明的实施方案中,所述转录调节因子的表达受调节是指转录调节因子缺失。在本发明的实施方案中,所述转录调节因子选自b2m、ciita、rfxank、rfx5和rfxp中的至少一种。在本发明的优选实施方案中,所述调节因子为b2m和rfxank。在本发明的实施方案中,所述致耐受性因子的表达受调节是指表达增加。在本发明的实施方案中,所述致耐受性因子抑制免疫排斥。在本发明的实施方案中,所述致耐受性因子选自hla-c、hla-e、hla-g、pd-l1、ctka-4-ig、cd47和il-35中的至少一种。在本发明的实施方案中,所述致耐受性因子为hla-e。在本发明的实施方案中,所述干细胞还包括自杀基因的表达或表达升高。在本发明的实施方案中,所述自杀基因为icaspase基因。在本发明的实施方案中,所述干细胞选自胚胎干细胞、多能干细胞、人类干细胞。本发明的另一方面提供一种制备通用供体干细胞的方法,在分离的细胞中,包括以下步骤:(1)调节mhci和mhcii的表达;(2)调节致耐受性因子的表达。在本发明的实施方案中,所述调节mhci和mhcii的表达是指降低mhci和mhcii的表达。在本发明的实施方案中,所述调节mhci和mhcii的表达是指抑制mhci和mhcii的表达。在本发明的实施方案中,所述调节mhci和mhcii的表达是指干扰mhci和mhcii的表达。在本发明的实施方案中,所述调节mhci和mhcii的表达是通过缺失编码mhci和mhcii的基因的转录调节因子来实现的。在本发明的实施方案中,所述缺失编码mhci和mhcii的基因的转录调节因子是通过基因敲除来实现的。在本发明的实施方案中,所述基因敲除是指转录调节因子的一对等位基因的敲除。在本发明的实施方案中,所述转录调节因子选自b2m、ciita、rfxank、rfx5和rfxp中的至少一种。在本发明的优选实施方案中,所述调节因子为b2m和rfxank。在本发明的实施方案中,所述调节致耐受性因子的表达是指增加致耐受性因子的表达。在本发明的实施方案中,所述增加致耐受性因子的表达是指插入致耐受性因子。在本发明的实施方案中,所述插入致耐受性因子是通过基因敲入的方式来实现的。在本发明的实施方案中,所述致耐受性因子选自hla-c、hla-e、hla-g、pd-l1、ctka-4-ig、cd47和il-35中的至少一种。在本发明的实施方案中,利用crisprcas9技术进行基因敲除或基因敲入。在本发明的实施方案中,所述crisprcas9技术包括向导rna和cas蛋白,所述向导rna特异性结合靶向基因的特定序列。在本发明的实施方案中,靶向b2m基因的向导rna序列如seqidno:1-3所示。在本发明的实施方案中,靶向rfxank基因的向导rna序列如seqidno:22-24所示。在本发明的实施方案中,通过将向导rna,或者编码向导rna的dna,以及编码cas蛋白的核酸,或者cas蛋白本身引入至细胞完成所述基因敲除或基因调入。在本发明的实施方案中,所述向导rna可以是crrna和tracrrna的双链rna形式,也可以是单链的rna形式。在本发明的实施方案中,所述cas蛋白为cas9蛋白。在本发明的实施方案中,所述制备通用供体干细胞的方法还包括增加自杀基因表达的步骤。在本发明的实施方案中,所述自杀基因为icaspase基因。本发明的有益效果本发明提供的通用供体干细胞具有多能性,能够分化成各种细胞,以治疗疾病,并且不会被接受者的免疫系统拒绝。附图说明图1显示了靶向b2m基因的三条sgrna的相对位置。图2显示了px458酶切图。图3显示了电转效率。图4显示了药物最佳浓度确定。图5显示了hygromycin筛选结果。图6显示了利用b2m-735f和b2m-1126r扩增的结果。图7显示了利用引物hygro-7f、hygro-890r的扩增结果。图8显示了分别用b2m的三个sgrna和donorvector共转后,hla-e的相对表达量。图9显示了b2m的三个sgrna和donorvector共转后,hygro的相对表达量。图10显示了靶向rfxank位点的三条sgrna相对位置。图11显示了rfxank的三个sgrna和donorvector共转后,电泳检测结果。图12显示了rfxank的三个sgrna和donorvector共转后,icaspase相对表达量。图13显示了rfxank的三个sgrna和donorvector共转后,puro相对表达量。图14显示了b2m-/-rfxank-/-人类间充质祖细胞(mpc)中mhc-i表达降低。图15显示了b2m-/-rfxank-/-人类间充质祖细胞(mpc)中mhc-ii表达降低。图16显示了人源化小鼠中基因组编辑的干细胞移植得到改善。具体实施方式为了使本发明所解决的技术问题、技术方案及有益效果更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。实施例以下例子在此用于示范本发明的优选实施方案。本领域内的技术人员会明白,下述例子中披露的技术代表发明人发现的可以用于实施本发明的技术,因此可以视为实施本发明的优选方案。但是本领域内的技术人员根据本说明书应该明白,这里所公开的特定实施例可以做很多修改,仍然能得到相同的或者类似的结果,而非背离本发明的精神或范围。除非另有定义,所有在此使用的技术和科学的术语,和本发明所属领域内的技术人员所通常理解的意思相同,在此公开引用及他们引用的材料都将以引用的方式被并入。那些本领域内的技术人员将意识到或者通过常规试验就能了解许多这里所描述的发明的特定实施方案的许多等同技术。这些等同将被包含在权利要求书中。实施例1hlai类工程由于hla-i是由α链和β链组成的二聚体,而所有hla-i是共用的同一β链,所以敲除掉编码β链的b2m基因就能够实现对hla-i的敲除;然而,对于一些细胞来说,敲除掉hla-i的细胞将会被nk细胞裂解。为了克服这种“缺失的自我”反应,发明人在敲除hla单链的同时敲入非多态性hla-e基因的重链从而可以抑制nk细胞的裂解。1.sgrna的设计1.1sgrna设计位置的选择根据基因名称b2m在ncbi中查找,b2m共有四个外显子,为了彻底敲除b2m,且不影响其他蛋白的表达,发明人将sgrna设计在第一个外显子上,外显子序列的寻找可以在ncbi中找出,也可以在ucsc数据库中查找,或者在geneious软件上找出。以后,sgrna可以设计在此基因共有的转录本上。一般的,基因特异性的sgrna模板序列位于pam(protospaceradjacentmotif)前临近序列,可以被cas9蛋白特异的识别并切割。1.2sgrna的设计目前,sgrna的设计有许多网站,最常用的是thermosgrna设计网站,和张峰sgrna设计网站http://crispr.mit.edu,发明人设计sgrna选用的是张峰实验室网站,将b2m外显子1的序列粘贴到mit张锋实验室设计sgrna的网站中,从评分较高的序列中选取了3条序列如表1,sgrna序列靶向b2m基因的位置如图1。表1靶向b2m基因的三条sgrna序列1.3sgrna引物的设计在设计好靶向b2m的sgrna后,需要将序列进行合成,由于本发明是将双链的sgrna插入到px458载体(addgene公司),所以需要合成每条sgrna的正向序列和反向序列,并在序列的5’端加上与载体匹配的bbsi的酶切位点。根据sgrna和b2m基因序列设计检测引物,设计好的引物如表2。表2插入到px458载体中的靶向b2m基因的三条sgrna的检测引物2插入基因donorvector的设计根据基因名称hla-e在ncbi中查找,并找出其cds区序列。donorvector设计:大框:需要同源臂,sa序列,t2a序列,knockin片段,bghpoly(a)signal、frt序列、ef1a、sv40poly(a)signal、抗性筛选基因、及限制性内切酶位点。sa是剪切位点,可以保证编码框对框,敲入片段后会形成不同转录本,在整个转录本转录出来,剪切产生6个转录本,总有两个会翻译正确。t2a序列:分开翻译,招募不同的转录本进行翻译。donorvector设计时两端的同源臂长度不要超出800bp,一般两端的同源臂不要超出400bp。设计donorvector时,sgrna序列中的pam序列都应换成其同义突变序列,且同义突变要改变的基因要确定其编码的是同一个氨基酸序列,这样说来改变pam序列中的碱基可以改变第一个也可以改变第二个或者第三个碱基。因为cas9在切割时切割的是pam序列后面的两个碱基,如若在donorvector序列中不将pam序列改变成其同义突变的碱基序列,sgrna切割时会将donorvector也进行切割。将设计好的需要整合的基因序列插入到puc57载体中。donorvector的合成由金斯瑞生物公司合成。3实验材料方法3.1将在b2m位点设计的sgrna2和sgrna3插入到px458载体中3.1.1将sgrna的正向链和反向链退火成双链rna(1)将sgrna引物(粉末)于3000rpm离心5min;(2)按照擎科公司要求加ddh2o溶解sgrna的正向链和反向链;(3)退火体系如下表3表3sgrna的制备组分用量(μl)sgrnaprimerf(100μmol/l)1sgrnaprimerr(100μmol/l)1t4pnkbuffer(10×)1t4pnk1ddh2o6共10(4)反应程序37℃for30min;95℃for5min;rampdownto25℃at℃min-1.(5)测定浓度之后用ddh2o1:10稀释;3.1.2线性化px458限制性内切酶为bbsi,酶切体系如表4所示;表4酶切px458组分用量(μl)px45815bbsi2buffer2.15ddh2o28共50反应条件:37℃放置4h,65℃20min;随后,按照胶回收试剂盒将酶切后的px458切胶回收,并测浓度。酶切图如图2所示。3.1.3连接用t7连接酶进行连接,连接体系如表5所示;(此时应设置阴性对照,即插入dna是ddh2o)表5t7酶连接组分用量t7buffer2×10μlpx45850ng插入dna37.5ngddh2o至20ult7ligation1μl3.1.4转化,将连接产物转入dh5a(1)取感受态细胞放置于冰浴中。(2)待感受态细胞融化后,取30μl感受态细胞到新的无菌ep管中,向感受态细胞悬液中加入10μl的连接产物,用移液器轻轻吹打混匀,冰浴30min。(3)42℃热激45s,迅速将离心管转移到冰浴中,冰上静置2-3min。(4)每个离心管中加入450μl无菌的lb培养基(不含抗生素),混匀后放置于37℃摇床,150rpm振荡培养45min使菌体复苏。(5)将复苏后的菌液3000rpm离心2min,用移液器吸弃300μl上清液,用移液器将剩余的培养基和菌吹打混匀,取出提前配好的amp培养板,然后用无菌的涂布棒将细胞均匀涂开,将平板置于37℃直到液体被吸收,倒置培养,37℃培养12-16h。(6)挑取单个克隆至5ml的amp培养基中,放置于37℃摇床中220rpm培养12-16h。(7)菌种储存:取500μl新鲜的菌液与500μl的50%的甘油1:1混匀,-80℃储存。(8)测序:取500μl菌液用u6引物测序。剩余的菌液待测序成功后小提质粒。测序结果与目标序列完全一致。3.2质粒电转与单克隆挑取3.2.1细胞处理(1)电转前24h用1umol/l的rock抑制剂处理细胞。(2)电转时用pbs清洗细胞,用200μl酶accutase处理h9细胞,37℃放置5min。(3)加入800μl10%ksr终止消化。用移液器吹打细胞,并进行计数。(4)此次实验电转体系是120μl,每个体系需要的细胞数是1.5×106。(5)计数后吸取所需要的细胞数的体积加入15ml的离心管中160g离心5min,弃上清,加入1ml的pbs吹打混匀,160×g离心5min。(6)清洗后的细胞中加入3×120μl的电转液,此次电转一个体系120μl,一个体系需要1.5×106,所以三个体系需要4.5×106。3.2.2质粒处理(1)分别电转sgrna1和donorvector2、sgrna2和donorvector2、sgrna3和donorvector1,每个体系中电转质粒总共10μg,以1:4的比例进行电转。即sgrna2μg,donorvector8μg。(7)先预混质粒,吸取120μl预混了电转液的细胞加入预混好的质粒中混匀,转入电极杯中,电转电压为600v,30m。(8)电转后用1μmol/l的rock抑制剂的m-teser培养基培养。(9)电转24h后更换新鲜的m-teser培养基(此时的培养基中不加rock抑制剂)。(10)电转48h后加入药物进行筛选,电转效率如图3。3.2.3hygromycin最佳浓度确定(1)24孔中长至70%-80%的细胞,1:3的比例传至24孔细胞培养板中进行培养,第二天换液换成含有hygro和genetine的培养基。之后每隔3天换液。一周后细胞全死的最低浓度即为最佳浓度。(2)hygromycin浓度设置依次是0,25μg/ml,50μg/ml,75μg/ml,100μg/ml,150μg/ml,200μg/ml,实验结果如图4所示。从图4中可以看出hygromycin设置的最佳浓度为75μg/ml。3.2.4筛选电转48h后,加入75ug/ml的hygromycin进行筛选,其中,筛选结果如图5。结果显示,加药前,实验组a、b、c组和对照组细胞生长状况基本一样,加药4天后,对照组的细胞基本死完,实验组细胞还有克隆。待control组全死后,实验组停止加药,待细胞长满后,传代分别做dna、rna水平分析,并储存一只细胞。3.2.5genotyping3.2.5.1待上述3.2.4步骤中的细胞长满后,分别提取基因组和rna,基因组的提取按照擎科生物公司提取试剂盒进行提取,提取后进行pcr扩增。引物序列如表6所示,pcr结果如图12所示。表6引物序列名称序列(5’-3’)seqidno:hygro-7ftgaactcaccgcgacgtctgtc12hygro-890racagtcccggctccggatc13b2m-735fgagcaggaggggtcagag14b2m-1126rtccaggtgaagcaacgtctc15表7反应体系(takara试剂盒)组分含量(μl)dna模板2b2m-735f0.5b2m-1126r0.5ddh2o10.5extaqversion12.5共25反应条件,98℃10s,58℃10s,72℃1min;30个循环。利用hygro-7f、hygro-890r扩增的退火温度为54.5℃,除此之外,体系与条件同上。利用b2m-735f和b2m-1126r扩增的结果如图6,利用引物hygro-7f、hygro-890r的扩增结果如图7。3.2.6rna水平分析表8引物序列,退火温度b2m是54℃,hygro是52℃名称序列(5’-3’)seqidno:b2m-735fgagcaggaggggtcagag14b2m-1001rtccaggtgaagcaacgtctc16b2m-999rcaggtgaagcaacgtctcc17b2m-1126rtccaggtgaagcaacgtctc15hygro-4031facagcggtcattgactggag18hygro-4131rtgctgctccatacaagccaa19hygro-4323ratttgtgtacgcccgacagt20hygro-4112fttggcttgtatggagcagca21(1)按照rna提取试剂盒提取总rna,提取后测定浓度,并取3μg进行反转录,反转录试剂盒按照thermo反转录试剂盒k1622进行反转录。(2)将反转录后的cdna按1:10倍稀释,进行qpcr扩增,qpcr试剂选用vazymechamqsybrqpcrmastermixq311-02。(3)qpcr反应体系表9,分别对hla-e和hygro进行定量分析。结果如图8、9。表9qpcr反应体系组分用量(μl)2×chamqsybrqpcrmastermix10primer10.4primer20.450×roxreferencedye10.4h2o6.8反应程序:reps1:95℃30s;reps40:95℃10s;60℃30s实施例2hlaⅱ工程与hlai类不同,ii类蛋白缺乏可以编辑以防止表面表达的共同亚基。mhcⅱ类缺陷是由四个调节因子ciita、rfxank、rfx5和rfxp中的缺陷引起的联合免疫缺陷,其在转录水平上控制mhcⅱ的表达。该rfxank基因编码异源三聚体rfx复合物的一个亚基,其参与mhcⅱ启动子上组装几种转录因子。因此,本发明编辑mhcii类表达所需的rfxank转录因子基因的两个拷贝。具有rfxank突变的患者不在其抗原呈递细胞上表达hlaii类分子。并转入icaspase增强其安全性。靶向rfxank位点的三条sgrna相对位置如图10所示,序列分别如下:gcagaagacctcatccagac(seqidno:22)tgagcctgtgaatcctgaac(seqidno:23)agacccctgcctcagaactt(seqidno:24)表10rfxank位点三条sgrna插入到px458载体中引物序列同时设计用于检测的引物,如表11所示。表11用于检测的引物引物名称序列(5’-3’)seqidno:rfxank6636fagtttacccaccctcacagtgcaag31rfxank7766rgtgtaggaagagcattccagacaggag32rfxank7081rgcatgggcaacaagagc33根据实施例1的方法设计donorvector。根据实施例1的方法进行电转。电转48h后,用puro0.5μg/ml筛选,待正常细胞全部死后,换成正常的培养基,之后传代,1:5,分别提取dna、rna,冻存,并传代(传到mef板上进行单克隆的培养)。1、dna水平的检测引物如下表:退火温度51℃表12dna水平检测引物引物名称序列(5’-3’)seqidno:puro-4114fcaacctccccttctacgagc34rfxank-7081rgcatgggcaacaagagc33用kapa试剂盒扩增,体系如表13。表13dna水平检测体系反应条件:预变性94℃,3min;变性94℃20s,退火50℃15s,延伸51.5℃3min,30个循环;退火72℃1min。1%的胶进行琼脂糖凝胶电泳,结果如图11所示。2、rna水平检测(1)引物序列(icaspase的退火温度是52℃,puro的退火温度是54℃)表13rna水平检测引物引物名称序列(5’-3’)seqidno:icaspase1027ftgaacttctgccgtgagtcc35icaspase1172rcagcaaagccagcaccattt36icaspase1227ragagaatgaccaccacgcag37icaspase1153faaatggtgctggctttgctg38icaspase1506rgctggtcgaaggtcctcaaa39puro-3617fatgaccgagtacaagcccac40puro-3952rgaggccttccatctgttgct41puro-3933fagcaacagatggaaggcctc42puro-4133rgctcgtagaaggggaggttg43puro-3132rctcgtagaaggggaggttgc44(2)qpcr试剂选用vazymechamqsybrqpcrmastermixq311-02,结果如图12和图13所示。实施例3修饰的胚胎干细胞的分化修饰的胚胎干细胞可以分化成各种不同的细胞类型,其hla表达降低或不存在。这些细胞类型的实例包括间充质祖细胞(mpc)、低免疫原性心肌细胞、内皮细胞(ec)、巨噬细胞、肝细胞、白细胞(例如膜腺白细胞)或神经祖细胞(npc)。最初,发明人在b2m-/-和b2m-/-rfxank-/-人类es细胞中mhc-i表达降低。接着发明人检查了各种分化的细胞类型中的mhc-i表达。例如,在b2m-/-和b2m-/-rfxank-/-人类间充质祖细胞(mpc)中mhc-i和mhc-ii表达降低(图14、图15)。实施例4体内数据最后,发明人制备的细胞系包括wthues9和b2m-/-rfxank-/-hues9。wt细胞系表现出mhc-i和mhc-ii表达,b2m-/-rfxank-/-hues9细胞系不表现出mhc-i和mhc-ii表达。接着在人源化的小鼠中检测了这些细胞系,结果显示人源化小鼠中基因组编辑的干细胞的移植得到改善(图16)。在本发明提及的所有文献都在本申请中引用作为参考,就如同每一篇文献被单独引用作为参考那样。此外应理解,在阅读了本发明的上述讲授内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。序列表<110>张进<120>一种通用供体干细胞及其制备方法<130>xy-2018-1-w-011<160>44<170>siposequencelisting1.0<210>1<211>20<212>dna<213>人工序列(artificialsequence)<400>1ggccacggagcgagacatct20<210>2<211>20<212>dna<213>人工序列(artificialsequence)<400>2gagtagcgcgagcacagcta20<210>3<211>20<212>dna<213>人工序列(artificialsequence)<400>3cgcgagcacagctaaggcca20<210>4<211>25<212>dna<213>人工序列(artificialsequence)<400>4caccgggccacggagcgagacatct25<210>5<211>25<212>dna<213>人工序列(artificialsequence)<400>5aaacagatgtctcgctccgtggccc25<210>6<211>25<212>dna<213>人工序列(artificialsequence)<400>6caccggagtagcgcgagcacagcta25<210>7<211>25<212>dna<213>人工序列(artificialsequence)<400>7aaactagctgtgctcgcgctactcc25<210>8<211>25<212>dna<213>人工序列(artificialsequence)<400>8caccgcgcgagcacagctaaggcca25<210>9<211>25<212>dna<213>人工序列(artificialsequence)<400>9aaactggccttagctgtgctcgcgc25<210>10<211>27<212>dna<213>人工序列(artificialsequence)<400>10ctgagtacctactatgtgccagcccct27<210>11<211>27<212>dna<213>人工序列(artificialsequence)<400>11gaggtgctaggacatgcgaacttagcg27<210>12<211>22<212>dna<213>人工序列(artificialsequence)<400>12tgaactcaccgcgacgtctgtc22<210>13<211>19<212>dna<213>人工序列(artificialsequence)<400>13acagtcccggctccggatc19<210>14<211>18<212>dna<213>人工序列(artificialsequence)<400>14gagcaggaggggtcagag18<210>15<211>20<212>dna<213>人工序列(artificialsequence)<400>15tccaggtgaagcaacgtctc20<210>16<211>20<212>dna<213>人工序列(artificialsequence)<400>16tccaggtgaagcaacgtctc20<210>17<211>19<212>dna<213>人工序列(artificialsequence)<400>17caggtgaagcaacgtctcc19<210>18<211>20<212>dna<213>人工序列(artificialsequence)<400>18acagcggtcattgactggag20<210>19<211>20<212>dna<213>人工序列(artificialsequence)<400>19tgctgctccatacaagccaa20<210>20<211>20<212>dna<213>人工序列(artificialsequence)<400>20atttgtgtacgcccgacagt20<210>21<211>20<212>dna<213>人工序列(artificialsequence)<400>21ttggcttgtatggagcagca20<210>22<211>20<212>dna<213>人工序列(artificialsequence)<400>22gcagaagacctcatccagac20<210>23<211>20<212>dna<213>人工序列(artificialsequence)<400>23tgagcctgtgaatcctgaac20<210>24<211>20<212>dna<213>人工序列(artificialsequence)<400>24agacccctgcctcagaactt20<210>25<211>25<212>dna<213>人工序列(artificialsequence)<400>25caccggcaggctgggtaagctccat25<210>26<211>26<212>dna<213>人工序列(artificialsequence)<400>26aaacatggagcttacccagcctgccc26<210>27<211>25<212>dna<213>人工序列(artificialsequence)<400>27caccgtgagcctgtgaatcctgaac25<210>28<211>25<212>dna<213>人工序列(artificialsequence)<400>28aaacgttcaggattcacaggctcac25<210>29<211>25<212>dna<213>人工序列(artificialsequence)<400>29caccgagacccctgcctcagaactt25<210>30<211>25<212>dna<213>人工序列(artificialsequence)<400>30aaacaagttctgaggcaggggtctc25<210>31<211>25<212>dna<213>人工序列(artificialsequence)<400>31agtttacccaccctcacagtgcaag25<210>32<211>27<212>dna<213>人工序列(artificialsequence)<400>32gtgtaggaagagcattccagacaggag27<210>33<211>17<212>dna<213>人工序列(artificialsequence)<400>33gcatgggcaacaagagc17<210>34<211>20<212>dna<213>人工序列(artificialsequence)<400>34caacctccccttctacgagc20<210>35<211>20<212>dna<213>人工序列(artificialsequence)<400>35tgaacttctgccgtgagtcc20<210>36<211>20<212>dna<213>人工序列(artificialsequence)<400>36cagcaaagccagcaccattt20<210>37<211>20<212>dna<213>人工序列(artificialsequence)<400>37agagaatgaccaccacgcag20<210>38<211>20<212>dna<213>人工序列(artificialsequence)<400>38aaatggtgctggctttgctg20<210>39<211>20<212>dna<213>人工序列(artificialsequence)<400>39gctggtcgaaggtcctcaaa20<210>40<211>20<212>dna<213>人工序列(artificialsequence)<400>40atgaccgagtacaagcccac20<210>41<211>20<212>dna<213>人工序列(artificialsequence)<400>41gaggccttccatctgttgct20<210>42<211>20<212>dna<213>人工序列(artificialsequence)<400>42agcaacagatggaaggcctc20<210>43<211>20<212>dna<213>人工序列(artificialsequence)<400>43gctcgtagaaggggaggttg20<210>44<211>20<212>dna<213>人工序列(artificialsequence)<400>44ctcgtagaaggggaggttgc20当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1